एसएपी हाना - त्वरित गाइड
एसएपी हाना एक एकल सूट में हाना डेटाबेस, डेटा मॉडलिंग, हाना प्रशासन और डेटा प्रावधान का एक संयोजन है। एसएपी हाना में, हाना उच्च प्रदर्शन विश्लेषणात्मक उपकरणों के लिए खड़ा है।
पूर्व एसएपी कार्यकारी, डॉ। विशाल सिक्का के अनुसार, हाना हासो न्यू आर्किटेक्चर के लिए खड़ा है। एचएएनए ने 2011 के मध्य तक रुचि विकसित की और विभिन्न भाग्य 500 कंपनियों ने इसके बाद बिजनेस वेयरहाउस की जरूरतों को बनाए रखने के विकल्प के रूप में विचार करना शुरू कर दिया।
एसएपी हाना की विशेषताएं
एसएपी हाना की मुख्य विशेषताएं नीचे दी गई हैं -
एसएपी हाना वास्तविक समय डेटा की बड़ी मात्रा को संसाधित करने के लिए सॉफ्टवेयर और हार्डवेयर नवाचार का एक संयोजन है।
वितरित प्रणाली पर्यावरण में मल्टी कोर वास्तुकला पर आधारित है।
डेटाबेस में डेटा-स्टोरेज की पंक्ति और स्तंभ प्रकार के आधार पर।
बड़े पैमाने पर वास्तविक समय डेटा को संसाधित और विश्लेषण करने के लिए मेमोरी कंप्यूटिंग इंजन (IMCE) में बड़े पैमाने पर उपयोग किया जाता है।
यह स्वामित्व की लागत को कम करता है, अनुप्रयोग प्रदर्शन को बढ़ाता है, नए अनुप्रयोगों को वास्तविक समय के वातावरण पर चलने में सक्षम बनाता है जो पहले संभव नहीं थे।
यह C ++ में लिखा गया है, यह केवल एक ऑपरेटिंग सिस्टम Suse Linux Enterprise Server 11 SP1 / 2 पर चलता है।
एसएपी हाना की आवश्यकता
आज, ज्यादातर सफल कंपनियां बाजार में बदलाव और नए अवसरों के लिए जल्दी प्रतिक्रिया देती हैं। विश्लेषक और प्रबंधकों द्वारा डेटा और सूचना का प्रभावी और कुशल उपयोग इसके लिए एक कुंजी है।
हाना नीचे दी गई सीमाओं को पार करता है -
"डेटा वॉल्यूम" में वृद्धि के कारण, कंपनियों के लिए विश्लेषण और व्यावसायिक उपयोग के लिए वास्तविक समय डेटा तक पहुंच प्रदान करना एक चुनौती है।
इसमें आईटी कंपनियों के लिए बड़े डेटा वॉल्यूम को स्टोर करने और बनाए रखने के लिए उच्च रखरखाव लागत शामिल है।
वास्तविक समय डेटा की अनुपलब्धता के कारण, विश्लेषण और प्रसंस्करण के परिणाम में देरी हो रही है।
एसएपी हाना विक्रेताओं
एसएपी ने प्रमुख आईटी हार्डवेयर विक्रेताओं जैसे आईबीएम, डेल, सिस्को आदि के साथ साझेदारी की है और एसएपी लाइसेंस प्राप्त सेवाओं और प्रौद्योगिकी के साथ इसे एसएपी हाना प्लेटफॉर्म को बेचने के लिए जोड़ा है।
कुल, 11 विक्रेता हैं जो हाना उपकरणों का निर्माण करते हैं और हाना प्रणाली की स्थापना और विन्यास के लिए ऑनसाइट समर्थन प्रदान करते हैं।
Top few Vendors include -
- IBM
- Dell
- HP
- Cisco
- Fujitsu
- लेनोवो (चीन)
- NEC
- Huawei
एसएपी द्वारा उपलब्ध कराए गए आंकड़ों के अनुसार, आईबीएम एसएपी हाना हार्डवेयर उपकरणों के प्रमुख विक्रेता में से एक है और इसकी बाजार हिस्सेदारी 50-52% है लेकिन एचएएनए ग्राहकों द्वारा किए गए एक अन्य बाजार सर्वेक्षण के अनुसार, आईबीएम की बाजार में 70% तक हिस्सेदारी है।
SAP हाना इंस्टालेशन
हाना हार्डवेयर विक्रेता हार्डवेयर, ऑपरेटिंग सिस्टम और SAP सॉफ्टवेयर उत्पाद के लिए पूर्वनिर्मित उपकरण प्रदान करते हैं।
विक्रेता एक सेटअप और हाना घटकों के विन्यास द्वारा स्थापना को अंतिम रूप देता है। इस ऑनसाइट यात्रा में डेटा सेंटर में एचएएनए प्रणाली की तैनाती, संगठन नेटवर्क से कनेक्टिविटी, एसएपी सिस्टम आईडी अनुकूलन, समाधान प्रबंधक से अपडेट, एसएपी राउटर कनेक्टिविटी, एसएसएल इनेबलमेंट और अन्य सिस्टम कॉन्फ़िगरेशन शामिल हैं।
ग्राहक / ग्राहक डेटा सोर्स सिस्टम और बीआई क्लाइंट की कनेक्टिविटी के साथ शुरू होता है। एचएएनए स्टूडियो इंस्टॉलेशन स्थानीय प्रणाली पर पूरा होता है और डेटा मॉडलिंग और प्रशासन करने के लिए एचएएनए सिस्टम को जोड़ा जाता है।
एक इन-मेमोरी डेटाबेस का मतलब है कि सोर्स सिस्टम का सारा डेटा रैम मेमोरी में स्टोर होता है। एक पारंपरिक डेटाबेस सिस्टम में, सभी डेटा हार्ड डिस्क में संग्रहीत होते हैं। एसएपी हाना इन-मेमोरी डेटाबेस में हार्ड डिस्क से रैम तक डेटा लोड करने में कोई समय बर्बाद नहीं होता है। यह सूचना प्रसंस्करण और विश्लेषण के लिए मल्टीकोर सीपीयू के लिए डेटा का तेजी से उपयोग प्रदान करता है।
इन-मेमोरी डेटाबेस की विशेषताएं
एसएपी हाना इन-मेमोरी डेटाबेस की मुख्य विशेषताएं हैं -
एसएपी हाना हाइब्रिड इन-मेमोरी डेटाबेस है।
यह पंक्ति आधारित, कॉलम आधारित और ऑब्जेक्ट ओरिएंटेड बेस टेक्नोलॉजी को जोड़ती है।
यह मल्टीकोर सीपीयू आर्किटेक्चर के साथ समानांतर प्रसंस्करण का उपयोग करता है।
परम्परागत डेटाबेस 5 मिलीसेकंड में मेमोरी डेटा पढ़ता है। SAP HANA इन-मेमोरी डेटाबेस 5 नैनोसेकंड में डेटा पढ़ता है।
इसका मतलब है, हाना डेटाबेस में मेमोरी रीड एक पारंपरिक डेटाबेस हार्ड डिस्क मेमोरी रीड की तुलना में 1 मिलियन गुना तेज है।
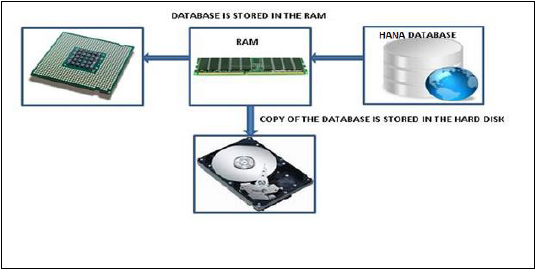
विश्लेषक वास्तविक समय में तत्काल डेटा देखना चाहते हैं और एसएपी बीडब्ल्यू सिस्टम में लोड होने तक डेटा का इंतजार नहीं करना चाहते हैं। एसएपी हाना इन-मेमोरी प्रोसेसिंग विभिन्न डेटा प्रोविजनिंग तकनीकों के उपयोग के साथ वास्तविक समय के डेटा को लोड करने की अनुमति देता है।
इन-मेमोरी डेटाबेस के लाभ
हाना डेटाबेस सबसे तेज़ डेटा-रिट्रीवल गति देने के लिए इन-मेमरी प्रोसेसिंग का लाभ उठाता है, जो उच्च-स्तरीय ऑनलाइन लेनदेन या समय पर पूर्वानुमान और योजना से जूझ रही कंपनियों को लुभा रहा है।
डिस्क-आधारित भंडारण अभी भी उद्यम मानक है और रैम की कीमत में लगातार गिरावट आ रही है, इसलिए मेमोरी-इंटेंसिव आर्किटेक्चर अंततः धीमी, यांत्रिक कताई डिस्क की जगह लेंगे और डेटा भंडारण की लागत कम करेंगे।
इन-मेमोरी कॉलम-आधारित स्टोरेज 11 बार तक डेटा संपीड़न प्रदान करता है, इस प्रकार, विशाल डेटा के संग्रहण स्थान को कम करता है।
रैम स्टोरेज सिस्टम द्वारा दी जाने वाली यह गति लाभ मल्टी-कोर सीपीयू, एक नोड में कई सीपीयू और एक वितरित वातावरण में प्रति सर्वर कई नोड्स के उपयोग से बढ़ाया जाता है।
SAP हाना स्टूडियो एक ग्रहण-आधारित उपकरण है। एसएपी हाना स्टूडियो दोनों, केंद्रीय विकास पर्यावरण और हाना प्रणाली के लिए मुख्य प्रशासन उपकरण है। अतिरिक्त विशेषताएं हैं -
यह एक क्लाइंट टूल है, जिसका उपयोग स्थानीय या दूरस्थ हाना सिस्टम तक पहुंचने के लिए किया जा सकता है।
यह HANA डेटाबेस में HANA प्रशासन, HANA सूचना मॉडलिंग और डेटा प्रावधान के लिए एक वातावरण प्रदान करता है।
SAP हाना स्टूडियो का उपयोग निम्नलिखित प्लेटफार्मों पर किया जा सकता है -
Microsoft Windows 32 और 64 बिट संस्करण: Windows XP, Windows Vista, Windows 7
SUSE लाइनेक्स एंटरप्राइज सर्वर SLES11: x86 64 बिट
मैक ओएस, हाना स्टूडियो क्लाइंट उपलब्ध नहीं है
HANA स्टूडियो की स्थापना के आधार पर, सभी सुविधाएँ उपलब्ध नहीं हो सकती हैं। स्टूडियो की स्थापना के समय, उन विशेषताओं को निर्दिष्ट करें जिन्हें आप भूमिका के अनुसार स्थापित करना चाहते हैं। हाना स्टूडियो के सबसे हाल के संस्करण पर काम करने के लिए, सॉफ़्टवेयर लाइफ साइकिल प्रबंधक का उपयोग क्लाइंट अपडेट के लिए किया जा सकता है।
SAP हाना स्टूडियो परिप्रेक्ष्य / सुविधाएँ
एसएपी हाना स्टूडियो निम्नलिखित हाना सुविधाओं पर काम करने के लिए दृष्टिकोण प्रदान करता है। आप निम्न विकल्प से हाना स्टूडियो में परिप्रेक्ष्य चुन सकते हैं -
HANA Studio → Window → Open Perspective → Other
सैप हाना स्टूडियो प्रशासन
विभिन्न प्रशासन कार्यों के लिए टूलसेट, परिवहन योग्य डिज़ाइन-टाइम रिपॉजिटरी ऑब्जेक्ट्स को छोड़कर। सामान्य समस्या निवारण उपकरण जैसे अनुरेखण, कैटलॉग ब्राउज़र और SQL कंसोल भी शामिल हैं।
एसएपी हाना स्टूडियो डेटाबेस डेवलपमेंट
यह सामग्री विकास के लिए टूलसेट प्रदान करता है। यह, विशेष रूप से, एसएपी हाना परिदृश्यों पर डेटामार्ट्स और एबीएपी को संबोधित करता है, जिसमें एसएपी हाना मूल अनुप्रयोग विकास (एक्सएस) शामिल नहीं है।
SAP हाना स्टूडियो अनुप्रयोग विकास
एसएपी हाना प्रणाली में एक छोटा वेब सर्वर होता है, जिसका उपयोग छोटे अनुप्रयोगों की मेजबानी के लिए किया जा सकता है। यह जावा और HTML में लिखे गए कोड कोड जैसे SAP HANA मूल अनुप्रयोगों को विकसित करने के लिए टूलसेट प्रदान करता है।
डिफ़ॉल्ट रूप से, सभी सुविधाएँ स्थापित हैं।
हाना डेटाबेस प्रशासन और निगरानी सुविधाओं को करने के लिए, एसएपी हाना प्रशासन कंसोल परिप्रेक्ष्य का उपयोग किया जा सकता है।
प्रशासक संपादक को कई तरीकों से पहुँचा जा सकता है -
From System View Toolbar - ओपन एडमिनिस्ट्रेशन डिफॉल्ट बटन चुनें
In System View - हाना सिस्टम या ओपन पर्सपेक्टिव पर डबल क्लिक करें
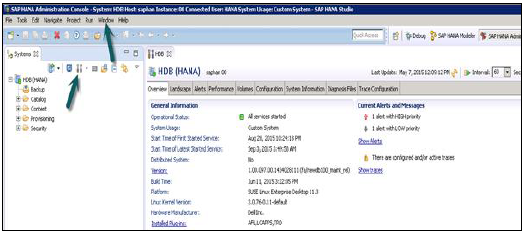
हाना स्टूडियो: प्रशासक संपादक
व्यवस्थापन दृश्य में: HANA स्टूडियो, HANA प्रणाली के विन्यास और स्वास्थ्य की जांच करने के लिए कई टैब प्रदान करता है। ओवरव्यू टैब सामान्य जानकारी जैसे, ऑपरेशनल स्टेटस, पहली और आखिरी शुरू की गई सेवा का समय, संस्करण, निर्माण तिथि और समय, प्लेटफ़ॉर्म, हार्डवेयर निर्माता, आदि बताता है।
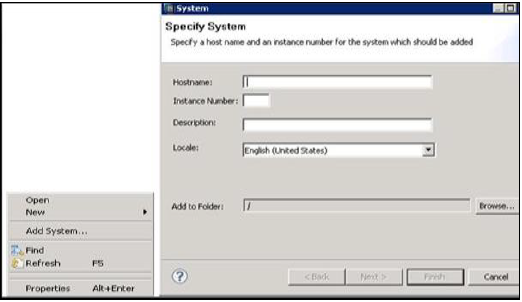
स्टूडियो में एक हाना सिस्टम जोड़ना
प्रशासन और सूचना मॉडलिंग उद्देश्य के लिए सिंगल या मल्टीपल सिस्टम को HANA स्टूडियो में जोड़ा जा सकता है। नया HANA सिस्टम जोड़ने के लिए, होस्ट नाम, उदाहरण संख्या और डेटाबेस उपयोगकर्ता नाम और पासवर्ड की आवश्यकता है।
- डेटाबेस से कनेक्ट करने के लिए पोर्ट 3615 खुला होना चाहिए
- पोर्ट 31015 की संख्या 10
- पोर्ट 30015 इंस्टेंस नं 00
- एसएसएच पोर्ट भी खोला जाना चाहिए
हाना स्टूडियो में एक सिस्टम जोड़ना
हाना स्टूडियो में एक सिस्टम जोड़ने के लिए, दिए गए चरणों का पालन करें।
नेविगेटर स्पेस में राइट क्लिक करें और ऐड सिस्टम पर क्लिक करें। HANA सिस्टम विवरण, यानी होस्ट नाम और इंस्टेंस नंबर दर्ज करें और अगला क्लिक करें।
एसएपी हाना डेटाबेस से कनेक्ट करने के लिए डेटाबेस उपयोगकर्ता नाम और पासवर्ड दर्ज करें। Next पर क्लिक करें और फिर Finish।
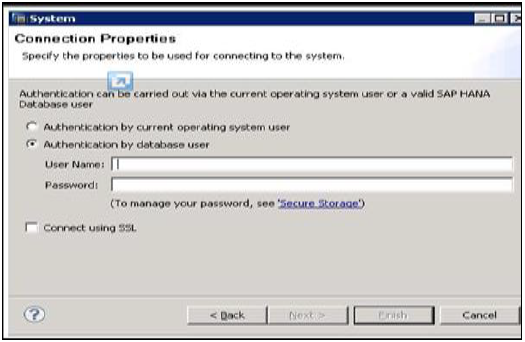
एक बार जब आप समाप्त पर क्लिक करते हैं, तो प्रशासन और मॉडलिंग उद्देश्य के लिए HANA सिस्टम को सिस्टम व्यू में जोड़ा जाएगा। प्रत्येक हाना प्रणाली में दो मुख्य उप-नोड्स, कैटलॉग और सामग्री है।
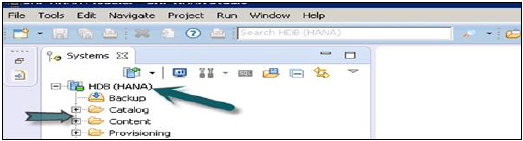
कैटलॉग और सामग्री
सूची
इसमें सभी उपलब्ध स्कीमें अर्थात सभी डेटा संरचनाएं, टेबल और डेटा, कॉलम व्यू, प्रक्रियाएं हैं जो सामग्री टैब में उपयोग की जा सकती हैं।
सामग्री
कंटेंट टैब में डिज़ाइन टाइम रिपॉजिटरी होती है, जो HANA मॉडलर के साथ बनाए गए डेटा मॉडल की सभी जानकारी रखती है। ये मॉडल संकुल में आयोजित किए जाते हैं। सामग्री नोड एक ही भौतिक डेटा पर अलग-अलग विचार प्रदान करता है।
हाना स्टूडियो में सिस्टम मॉनिटर एक नज़र में आपके सभी हाना सिस्टम का अवलोकन प्रदान करता है। सिस्टम मॉनिटर से, आप प्रशासन संपादक में एक व्यक्तिगत प्रणाली के विवरण में ड्रिल कर सकते हैं। यह प्राथमिकता के साथ संसाधन उपयोग पर डेटा डिस्क, लॉग डिस्क, ट्रेस डिस्क, अलर्ट के बारे में बताता है।
निम्नलिखित जानकारी सिस्टम मॉनिटर में उपलब्ध है -

एसएपी हाना सूचना मॉडलर; हाना डेटा मॉडलर के रूप में भी जाना जाता है हाना सिस्टम का दिल है। यह डेटाबेस तालिकाओं के शीर्ष पर मॉडलिंग दृश्य बनाने और विश्लेषण के लिए एक सार्थक रिपोर्ट बनाने के लिए व्यावसायिक तर्क को लागू करने में सक्षम बनाता है।
सूचना मॉडलर की विशेषताएं
विश्लेषण और व्यावसायिक तर्क उद्देश्य के लिए एचएएनए डेटाबेस की भौतिक तालिकाओं में संग्रहीत लेनदेन डेटा के कई विचार प्रदान करता है।
सूचनात्मक मॉडलर केवल कॉलम आधारित भंडारण तालिकाओं के लिए काम करता है।
सूचना मॉडलिंग दृश्य जावा या एचटीएमएल आधारित अनुप्रयोगों या एसएपी उपकरण जैसे एसएपी लुमिरा या विश्लेषण कार्यालय द्वारा रिपोर्टिंग उद्देश्य के लिए उपयोग किए जाते हैं।
हाना से कनेक्ट करने और रिपोर्ट बनाने के लिए एमएस एक्सेल जैसे तीसरे पक्ष के टूल का उपयोग करना संभव है।
SAP हाना मॉडलिंग दृश्य SAP हाना की वास्तविक शक्ति का फायदा उठाते हैं।
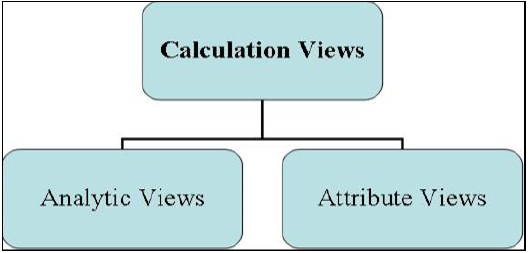
तीन प्रकार के सूचना दृश्य हैं, जिन्हें परिभाषित किया गया है -
- देखने का गुण
- विश्लेषणात्मक दृश्य
- गणना दृश्य
पंक्ति बनाम कॉलम स्टोर
SAP हाना मॉडलर दृश्य केवल स्तंभ आधारित तालिकाओं के शीर्ष पर बनाया जा सकता है। स्तंभ तालिका में डेटा संग्रहीत करना कोई नई बात नहीं है। पहले यह मान लिया गया था कि कॉलमीनर आधारित संरचना में डेटा संग्रहीत करने से मेमोरी का आकार अधिक हो जाता है और प्रदर्शन का अनुकूलन नहीं होता है।
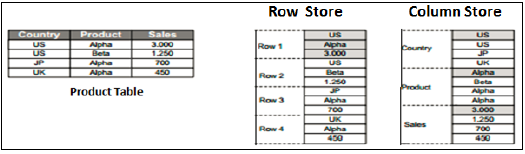
एसएपी हाना के विकास के साथ, हाना ने सूचना विचारों में स्तंभ आधारित डेटा भंडारण का उपयोग किया और रो आधारित तालिकाओं पर स्तंभ तालिकाओं के वास्तविक लाभों को प्रस्तुत किया।
कॉलम स्टोर
स्तंभ स्टोर तालिका में, डेटा लंबवत संग्रहीत होता है। तो, समान डेटा प्रकार एक साथ आते हैं जैसा कि ऊपर उदाहरण में दिखाया गया है। यह इन-मेमोरी कंप्यूटिंग इंजन की मदद से तेजी से मेमोरी रीड एंड राइट ऑपरेशन मुहैया कराता है।
एक पारंपरिक डेटाबेस में, डेटा पंक्ति आधारित संरचना में अर्थात क्षैतिज रूप से संग्रहीत किया जाता है। SAP HANA डेटा को पंक्ति और स्तंभ आधारित संरचना दोनों में संग्रहीत करता है। यह हाना डेटाबेस में प्रदर्शन अनुकूलन, लचीलापन और डेटा संपीड़न प्रदान करता है।
स्तंभकार आधारित तालिका में डेटा संग्रहीत करने के निम्नलिखित लाभ हैं -
आधार - सामग्री संकोचन
पारंपरिक रो आधारित स्टोरेज की तुलना में फास्टर पढ़ने और लिखने के लिए उपयोग को लिखते हैं
लचीलापन और समानांतर प्रसंस्करण
उच्च गति पर एकत्रीकरण और गणना करें
विभिन्न तरीकों और एल्गोरिदम हैं कि कॉलम आधारित संरचना में डेटा कैसे संग्रहीत किया जा सकता है- डिक्शनरी कंप्रेस्ड, रन लेंथ कंप्रेस्ड और कई और।
डिक्शनरी कम्प्रेस्ड में, सेल्स को टेबल में संख्याओं के रूप में संग्रहित किया जाता है और अक्षरों की तुलना में न्यूमेरल सेल को हमेशा परफॉरमेंस के अनुकूल बनाया जाता है।
संपीड़ित लंबाई में, यह गुणक प्रारूप में सेल मान के साथ गुणक को बचाता है और गुणक तालिका में दोहराव मूल्य दिखाता है।

कार्यात्मक अंतर - पंक्ति बनाम स्तंभ स्टोर
यदि कॉलम स्टेटमेंट को कुल फ़ंक्शन और गणना करना है, तो कॉलम आधारित स्टोरेज का उपयोग करना हमेशा उचित होता है। सम, काउंट, मैक्स, मिन जैसे कुलीन कार्यों को चलाने के दौरान कॉलम आधारित टेबल हमेशा बेहतर प्रदर्शन करते हैं।
पंक्ति आधारित भंडारण तब पसंद किया जाता है जब आउटपुट को पूर्ण पंक्ति में लौटना पड़ता है। नीचे दिया गया उदाहरण समझने में आसान बनाता है।

उपरोक्त उदाहरण में, बिक्री कॉलम में एक अलग फ़ंक्शन (Sum) को चलाने के लिए कहां क्लॉज के साथ, यह SQL क्वेरी चलाते समय केवल दिनांक और बिक्री कॉलम का उपयोग करेगा, इसलिए यदि यह कॉलम आधारित स्टोरेज टेबल है, तो यह डेटा के रूप में तेजी से प्रदर्शन, अनुकूलित होगा केवल दो कॉलम से आवश्यक है।
एक सरल चयन क्वेरी चलाते समय, पूर्ण पंक्ति को आउटपुट में प्रिंट करना पड़ता है, इसलिए इस परिदृश्य में पंक्ति के रूप में तालिका को संग्रहीत करना उचित है।
सूचना मॉडलिंग दृश्य
देखने का गुण
विशेषताएँ एक डेटाबेस तालिका में गैर-मापने योग्य तत्व हैं। वे मास्टर डेटा और BW की विशेषताओं के समान प्रतिनिधित्व करते हैं। विशेषता दृश्य एक डेटाबेस में आयाम हैं या मॉडलिंग में आयाम या अन्य विशेषता विचारों में शामिल होने के लिए उपयोग किया जाता है।
महत्वपूर्ण विशेषताएं हैं -
- एट्रिब्यूटिक और कैलकुलेशन व्यूज में एटिट्यूड व्यू का इस्तेमाल किया जाता है।
- विशेषता दृश्य मास्टर डेटा का प्रतिनिधित्व करते हैं।
- विश्लेषणात्मक और गणना दृश्य में आयाम तालिकाओं के आकार को फ़िल्टर करने के लिए उपयोग किया जाता है।
विश्लेषणात्मक दृश्य
विश्लेषणात्मक दृश्य डेटाबेस में तालिकाओं पर गणना और एकत्रीकरण कार्य करने के लिए एसएपी हाना की शक्ति का उपयोग करते हैं। इसमें कम से कम एक तथ्य तालिका है जिसमें आयाम तालिकाओं के माप और प्राथमिक कुंजी हैं और आयाम तालिकाओं से घिरे मास्टर डेटा होते हैं।
महत्वपूर्ण विशेषताएं हैं -
विश्लेषणात्मक विचार स्टार स्कीमा प्रश्नों को करने के लिए डिज़ाइन किए गए हैं।
विश्लेषणात्मक विचारों में मास्टर डेटा के साथ कम से कम एक तथ्य तालिका और कई आयाम टेबल होते हैं और गणना और एकत्रीकरण करते हैं
वे SAP BW में इन्फो क्यूब्स और इन्फो ऑब्जेक्ट्स के समान हैं।
एट्रिब्यूट व्यू और फैक्ट टेबल के ऊपर एनालिटिकल व्यू बनाए जा सकते हैं और बेचे गए यूनिट की संख्या, कुल कीमत, इत्यादि जैसे कैलकुलेशन करते हैं।
गणना दृश्य
गणना दृश्यों का उपयोग जटिल गणना करने के लिए विश्लेषणात्मक और गुण विचारों के शीर्ष पर किया जाता है, जो विश्लेषणात्मक दृश्यों के साथ संभव नहीं हैं। गणना दृश्य व्यापार तर्क प्रदान करने के लिए आधार स्तंभ तालिकाओं, विशेषता विचारों और विश्लेषणात्मक विचारों का एक संयोजन है।
महत्वपूर्ण विशेषताएं हैं -
गणना दृश्य को हाना मॉडलिंग सुविधा या एसक्यूएल में लिपि का उपयोग करके या तो ग्राफिकल परिभाषित किया गया है।
यह जटिल गणना करने के लिए बनाया गया है, जो अन्य विचारों के साथ संभव नहीं हैं- एसएपी हाना मॉडलर की विशेषता और विश्लेषणात्मक विचार।
एक या अधिक विशेषता वाले दृश्य और विश्लेषणात्मक विचार एक गणना दृश्य में इनबिल्ट फ़ंक्शंस की मदद से खपत किए जाते हैं, जैसे प्रोजेक्ट, यूनियन, जॉइन, रैंक।
एसएपी हाना शुरू में जावा और सी ++ में विकसित किया गया था और केवल ऑपरेटिंग सिस्टम स्यूस लिनक्स एंटरप्राइज सर्वर 11 को चलाने के लिए डिज़ाइन किया गया था। एसएपी हाना प्रणाली में कई घटक होते हैं जो हाना सिस्टम की कंप्यूटिंग शक्ति पर जोर देने के लिए जिम्मेदार होते हैं।
एसएपी हाना प्रणाली का सबसे महत्वपूर्ण घटक इंडेक्स सर्वर है, जिसमें डेटाबेस के लिए क्वेरी स्टेटमेंट को संभालने के लिए SQL / MDX प्रोसेसर होता है।
हाना प्रणाली में नाम सर्वर, प्रीप्रोसेसर सर्वर, सांख्यिकी सर्वर और एक्सएस इंजन शामिल हैं, जो छोटे वेब अनुप्रयोगों और विभिन्न घटकों को संचार और होस्ट करने के लिए उपयोग किया जाता है।

सूचकांक सर्वर
इंडेक्स सर्वर SAP HANA डेटाबेस सिस्टम का दिल है। इसमें उस डेटा को संसाधित करने के लिए वास्तविक डेटा और इंजन शामिल हैं। जब SQL या MDX को SAP HANA सिस्टम के लिए निकाल दिया जाता है, तो एक Index Server इन सभी अनुरोधों का ध्यान रखता है और उन्हें प्रोसेस करता है। सभी हाना प्रसंस्करण सूचकांक सर्वर में होता है।
सूचकांक सर्वर में हाना डेटाबेस सिस्टम में आने वाले सभी एसक्यूएल / एमडीएक्स स्टेटमेंट को संभालने के लिए डेटा इंजन होता है। इसमें Persistence Layer भी है जो HANA सिस्टम के स्थायित्व के लिए ज़िम्मेदार है और यह सुनिश्चित करता है कि सिस्टम विफलता के पुनरारंभ होने पर HANA सिस्टम को सबसे हाल की स्थिति में पुनर्स्थापित किया जाता है।
इंडेक्स सर्वर में सत्र और लेन-देन प्रबंधक भी होता है, जो लेनदेन का प्रबंधन करता है और सभी चालू और बंद लेनदेन का ट्रैक रखता है।

सूचकांक सर्वर - वास्तुकला
SQL / MDX प्रोसेसर
यह क्वेरी को चलाने के लिए जिम्मेदार डेटा इंजन के साथ SQL / MDX लेनदेन को संसाधित करने के लिए ज़िम्मेदार है। यह सभी क्वेरी अनुरोधों को विभाजित करता है और उन्हें प्रदर्शन अनुकूलन के लिए सही इंजन के लिए निर्देशित करता है।
यह भी सुनिश्चित करता है कि सभी एसक्यूएल / एमडीएक्स अनुरोध अधिकृत हैं और इन बयानों के कुशल प्रसंस्करण के लिए त्रुटि हैंडलिंग भी प्रदान करते हैं। इसमें क्वेरी निष्पादन के लिए कई इंजन और प्रोसेसर हैं -
MDX (मल्टी डाइमेंशन एक्सप्रेशन) OLAP सिस्टम के लिए क्वेरी भाषा है जैसे SQL का उपयोग रिलेशनल डेटाबेस के लिए किया जाता है। MDX इंजन प्रश्नों को संभालने के लिए जिम्मेदार है और OLAP क्यूब्स में संग्रहीत बहुआयामी डेटा में हेरफेर करता है।
नियोजन इंजन एसएपी हाना डेटाबेस के भीतर नियोजन संचालन चलाने के लिए जिम्मेदार है।
गणना इंजन बयानों के समानांतर प्रसंस्करण का समर्थन करने के लिए तार्किक निष्पादन योजना बनाने के लिए गणना मॉडल में डेटा को रूपांतरित करता है।
संग्रहीत कार्यविधि प्रोसेसर अनुकूलित प्रसंस्करण के लिए प्रक्रिया कॉल निष्पादित करता है; यह OLAP क्यूब्स को हाना अनुकूलित क्यूब्स में परिवर्तित करता है।
लेन-देन और सत्र प्रबंधन
यह सभी डेटाबेस लेनदेन को समन्वयित करने और सभी चालू और बंद लेनदेन का ट्रैक रखने के लिए जिम्मेदार है।
जब कोई लेनदेन निष्पादित या विफल हो जाता है, तो लेन-देन प्रबंधक आवश्यक कार्रवाई करने के लिए प्रासंगिक डेटा इंजन को सूचित करता है।
सत्र प्रबंधन घटक पूर्वनिर्धारित सत्र मापदंडों का उपयोग करते हुए एसएपी हाना प्रणाली के लिए सत्र और कनेक्शन को शुरू करने और प्रबंधित करने के लिए जिम्मेदार है।
दृढ़ता परत
यह हाना प्रणाली में लेनदेन के स्थायित्व और परमाणुता के लिए जिम्मेदार है। दृढ़ता परत HANA डेटाबेस के लिए आपदा वसूली प्रणाली में निर्मित प्रदान करता है।
यह सुनिश्चित करता है कि डेटाबेस को सबसे हाल की स्थिति में बहाल किया गया है और यह सुनिश्चित करता है कि सिस्टम विफलता या पुनः आरंभ होने की स्थिति में सभी लेनदेन पूर्ण या पूर्ववत हैं।
यह डेटा और लेन-देन लॉग को प्रबंधित करने के लिए भी जिम्मेदार है और इसमें डेटा बैकअप, लॉग बैकअप और एचएएनए सिस्टम के कॉन्फ़िगरेशन बैक भी हैं। बैकपॉइंट्स को सेव पॉइंट कोऑर्डिनेटर के माध्यम से डेटा वॉल्यूम में सेव पॉइंट के रूप में संग्रहित किया जाता है, जो आमतौर पर हर 5-10 मिनट में वापस लेने के लिए सेट किया जाता है।
प्रीप्रोसेसर सर्वर
एसएपी हाना प्रणाली में प्रीप्रोसेसर सर्वर का उपयोग टेक्स्ट डेटा विश्लेषण के लिए किया जाता है।
अनुक्रमणिका सर्वर पाठ डेटा का विश्लेषण करने और पाठ खोज क्षमताओं का उपयोग करने पर पाठ डेटा से जानकारी निकालने के लिए प्रीप्रोसेसर सर्वर का उपयोग करता है।
नाम सर्वर
NAME सर्वर में HANA प्रणाली के सिस्टम लैंडस्केप की जानकारी होती है। वितरित वातावरण में, प्रत्येक नोड के साथ कई सीपीयू होते हैं, जिसमें कई सीपीयू होते हैं, नाम सर्वर में एचएएनए प्रणाली की टोपोलॉजी होती है और इसमें सभी चालू घटकों के बारे में जानकारी होती है और सभी घटकों पर जानकारी फैलाई जाती है।
एसएपी हाना प्रणाली की टोपोलॉजी यहां दर्ज की गई है।
यह पुन: अनुक्रमण में समय को कम कर देता है क्योंकि यह धारण करता है कि वितरित वातावरण में कौन सा डेटा किस सर्वर पर है।
सांख्यिकीय सर्वर
यह सर्वर एचएएनए प्रणाली में सभी घटकों के स्वास्थ्य की जांच और विश्लेषण करता है। सांख्यिकीय सर्वर सिस्टम संसाधनों से संबंधित डेटा एकत्र करने, उनके आवंटन और संसाधनों की खपत और हाना प्रणाली के समग्र प्रदर्शन के लिए जिम्मेदार है।
यह हाना प्रणाली में प्रदर्शन से संबंधित मुद्दों की जांच करने और उन्हें ठीक करने के लिए विश्लेषण के उद्देश्य से सिस्टम प्रदर्शन से संबंधित ऐतिहासिक डेटा भी प्रदान करता है।
XS इंजन
XS इंजन एक्सएनए क्लाइंट की मदद से एचएएनए सिस्टम तक पहुंचने के लिए बाहरी जावा और एचटीएमएल आधारित एप्लिकेशन को मदद करता है। जैसा कि एसएपी हाना प्रणाली में एक वेब सर्वर होता है जिसका उपयोग छोटे JAVA / HTML आधारित अनुप्रयोगों की मेजबानी के लिए किया जा सकता है।
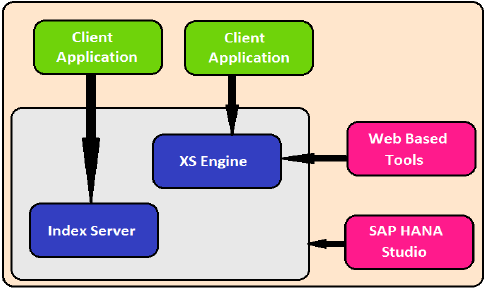
XS इंजन HTTP / HTTPS के माध्यम से उजागर क्लाइंट के लिए डेटाबेस में संग्रहीत दृढ़ता मॉडल को उपभोग मॉडल में बदल देता है।
SAP होस्ट एजेंट
एसएपी होस्ट एजेंट को उन सभी मशीनों पर स्थापित किया जाना चाहिए जो एसएपी हाना सिस्टम लैंडस्केप का हिस्सा हैं। SAP होस्ट एजेंट का उपयोग सॉफ़्टवेयर अपडेट मैनेजर SUM द्वारा वितरित वातावरण में HANA सिस्टम के सभी घटकों में स्वचालित अपडेट स्थापित करने के लिए किया जाता है।
LM संरचना
एसएपी हाना प्रणाली के एलएम संरचना में वर्तमान स्थापना विवरण के बारे में जानकारी शामिल है। इस जानकारी का उपयोग सॉफ़्टवेयर अपडेट प्रबंधक द्वारा HANA सिस्टम घटकों पर स्वचालित अपडेट स्थापित करने के लिए किया जाता है।
SAP सॉल्यूशन मैनेजर (SAP SOLMAN) डायग्नोस्टिक एजेंट
यह डायग्नोस्टिक एजेंट एसएपी हाना सिस्टम की निगरानी के लिए एसएपी समाधान प्रबंधक को सभी डेटा प्रदान करता है। यह एजेंट HANA डेटाबेस के बारे में सभी जानकारी प्रदान करता है, जिसमें डेटाबेस वर्तमान स्थिति और सामान्य जानकारी शामिल होती है।
यह हाना प्रणाली का विन्यास विवरण प्रदान करता है जब एसएपी सोलमैन एसएपी हाना प्रणाली के साथ एकीकृत होता है।
एसएपी हाना स्टूडियो रिपोजिटरी
एसएपी हाना स्टूडियो रिपॉजिटरी, एचएएनए डेवलपर्स को एचएएनए स्टूडियो के वर्तमान संस्करण को नवीनतम संस्करणों में अपडेट करने में मदद करता है। स्टूडियो रिपॉजिटरी में वह कोड होता है जो यह अपडेट करता है।
एसएपी हाना के लिए सॉफ्टवेयर अपडेट मैनेजर
SAP मार्केट प्लेस का उपयोग SAP सिस्टम के अपडेट को स्थापित करने के लिए किया जाता है। हाना प्रणाली के लिए सॉफ्टवेयर अपडेट मैनेजर एसएपी मार्केट स्थान से हाना प्रणाली का अद्यतन करने में मदद करता है।
इसका उपयोग सॉफ्टवेयर डाउनलोड, ग्राहक संदेश, एसएपी नोट्स और हाना प्रणाली के लिए लाइसेंस कुंजी का अनुरोध करने के लिए किया जाता है। उपयोगकर्ता के सिस्टम को समाप्त करने के लिए HANA स्टूडियो को वितरित करने के लिए भी इसका उपयोग किया जाता है।
एसएपी हाना मॉडलर विकल्प का उपयोग हाना डेटाबेस में स्कीमा → टेबल के शीर्ष पर सूचना दृश्य बनाने के लिए किया जाता है। ये विचार JAVA / HTML आधारित अनुप्रयोगों या SAP Lumira, Office विश्लेषण या MS Excel जैसे तीसरे पक्ष के सॉफ़्टवेयर जैसे व्यावसायिक तर्क को पूरा करने और विश्लेषण और जानकारी निकालने के उद्देश्य से रिपोर्टिंग के लिए उपयोग किए जाते हैं।
एचएएए स्टूडियो में स्कीमा के तहत कैटलॉग टैब में उपलब्ध तालिकाओं के शीर्ष पर हाना मॉडलिंग की जाती है और सभी विचारों को पैकेज के तहत सामग्री तालिका के तहत सहेजा जाता है।
आप सामग्री और नए पर राइट क्लिक करके HANA स्टूडियो में कंटेंट टैब के तहत नया पैकेज बना सकते हैं।
एक पैकेज के अंदर बनाए गए सभी मॉडलिंग दृश्य हाना स्टूडियो में एक ही पैकेज के अंतर्गत आते हैं और व्यू टाइप के अनुसार वर्गीकृत किए जाते हैं।
प्रत्येक दृश्य में आयाम और तथ्य तालिकाओं के लिए अलग-अलग संरचना होती है। डिम टेबल को मास्टर डेटा के साथ परिभाषित किया गया है और फैक्ट टेबल में डायमेंशन टेबल के लिए प्राइमरी की और बेची गई यूनिट की संख्या, औसत विलंब समय, कुल मूल्य आदि जैसे उपाय हैं।
तथ्य और आयाम तालिका
तथ्य तालिका में आयाम तालिका और उपायों के लिए प्राथमिक कुंजी हैं। वे व्यावसायिक तर्क को पूरा करने के लिए हाना व्यूज में आयाम तालिकाओं के साथ शामिल हो गए हैं।
Example of Measures - बेची गई यूनिट की संख्या, कुल मूल्य, औसत विलंब समय, आदि।
आयाम तालिका में मास्टर डेटा होता है और कुछ व्यावसायिक तर्क बनाने के लिए एक या अधिक तथ्य तालिकाओं के साथ जुड़ जाता है। आयाम तालिकाओं का उपयोग तथ्य तालिकाओं के साथ स्कीमा बनाने के लिए किया जाता है और इसे सामान्य किया जा सकता है।
Example of Dimension Table - ग्राहक, उत्पाद, आदि।
मान लीजिए कि कोई कंपनी ग्राहकों को उत्पाद बेचती है। हर बिक्री एक तथ्य है जो कंपनी के भीतर होता है और इन तथ्यों को रिकॉर्ड करने के लिए तथ्य तालिका का उपयोग किया जाता है।
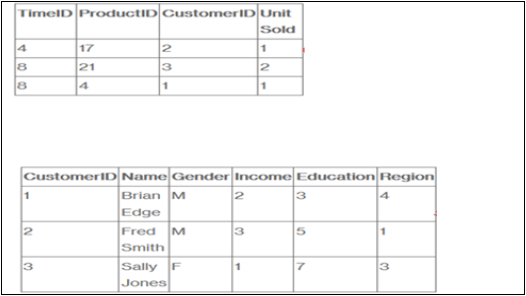
उदाहरण के लिए, तथ्य तालिका में पंक्ति 3 में इस तथ्य को दर्ज किया गया है कि ग्राहक 1 (ब्रायन) ने दिन 4 पर एक आइटम खरीदा था। और, एक पूर्ण उदाहरण में, हमारे पास एक उत्पाद तालिका और एक टाइम टेबल भी होगी ताकि हम जान सकें कि उसने क्या खरीदा है। और बिल्कुल जब।
तथ्य तालिका उन घटनाओं को सूचीबद्ध करती है जो हमारी कंपनी में होती हैं (या कम से कम वे घटनाएं जिनका हम विश्लेषण करना चाहते हैं- यूनिट यूनिट, मार्जिन, और बिक्री राजस्व की संख्या)। आयाम तालिका उन कारकों (ग्राहक, समय और उत्पाद) को सूचीबद्ध करती है जिनके द्वारा हम डेटा का विश्लेषण करना चाहते हैं।
स्कीम डेटा वेयरहाउस में तालिकाओं का तार्किक विवरण है। कुछ व्यावसायिक तर्क को पूरा करने के लिए कई तथ्य और आयाम तालिकाओं को जोड़कर स्कीमें बनाई जाती हैं।
डेटाबेस डेटा को स्टोर करने के लिए रिलेशनल मॉडल का उपयोग करता है। हालाँकि, डेटा वेयरहाउस स्कीमा का उपयोग करते हैं जो व्यावसायिक तर्क को पूरा करने के लिए आयाम और तथ्य तालिकाओं में शामिल होते हैं। डेटा वेयरहाउस में तीन प्रकार की स्कीमों का उपयोग किया जाता है -
- स्टार स्कीमा
- स्नोफ्लेक्स स्कीमा
- गैलेक्सी स्कीमा
स्टार स्कीमा
स्टार स्कीमा में, प्रत्येक आयाम एक एकल तथ्य तालिका में शामिल हो जाता है। प्रत्येक आयाम को केवल एक आयाम द्वारा दर्शाया जाता है और इसे और अधिक सामान्यीकृत नहीं किया जाता है।
आयाम तालिका में डेटा का विश्लेषण करने के लिए उपयोग की जाने वाली विशेषता का सेट होता है।
Example - नीचे दिए गए उदाहरण में, हमारे पास एक फैक्ट टेबल फैक्टसेल्स है जिसमें सभी डिम टेबल के लिए प्राथमिक कुंजी है और विश्लेषण करने के लिए यूनिट_सॉल्ड और डॉलर_ बेचे गए हैं।
हमारे पास चार डायमेंशन टेबल हैं- डिमटाइम, डिमाइटम, डिमब्रांच, डिमोकलशन
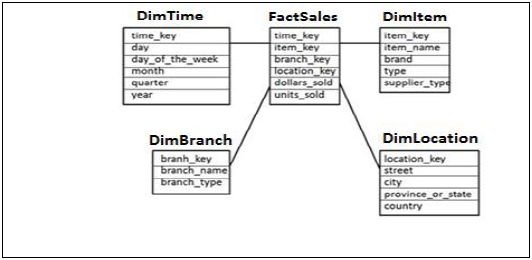
प्रत्येक आयाम तालिका फैक्ट टेबल से जुड़ी होती है क्योंकि प्रत्येक टेबल के लिए फैक्ट टेबल में प्राथमिक कुंजी होती है जिसका उपयोग दो तालिकाओं में शामिल होने के लिए किया जाता है।
तथ्य तालिका में तथ्य / माप का उपयोग विश्लेषण के उद्देश्य के साथ-साथ आयाम तालिकाओं में विशेषता के लिए किया जाता है।
स्नोफ्लेक्स स्कीमा
स्नोफ्लेक्स स्कीमा में, आयाम तालिका में से कुछ आगे हैं, सामान्यीकृत हैं और मंद तालिका एकल तथ्य तालिका से जुड़ी हैं। डेटा अतिरेक को कम करने के लिए डेटाबेस की विशेषताओं और तालिकाओं को व्यवस्थित करने के लिए सामान्यीकरण का उपयोग किया जाता है।
सामान्यीकरण में किसी भी जानकारी को खोए बिना कम निरर्थक छोटी तालिकाओं में तालिका को तोड़ना और छोटे तालिकाओं को आयाम तालिका में शामिल किया जाता है।
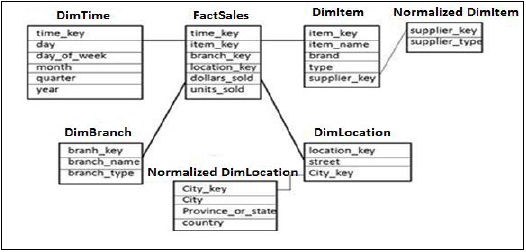
उपरोक्त उदाहरण में, DimItem और DimLocation आयाम तालिकाएँ बिना किसी जानकारी को खोए सामान्यीकृत हैं। इसे स्नोफ्लेक्स स्कीमा कहा जाता है जहां आयाम तालिकाओं को छोटी तालिकाओं के लिए सामान्यीकृत किया जाता है।
गैलेक्सी स्कीमा
गैलेक्सी स्कीमा में, कई फैक्ट टेबल और डायमेंशन टेबल हैं। प्रत्येक तथ्य तालिका विश्लेषण करने के लिए कुछ आयाम तालिकाओं और उपायों / तथ्यों की प्राथमिक कुंजी संग्रहीत करती है।
उपरोक्त उदाहरण में, फैक्ट टेबल में दो फैक्ट टेबल फैक्टलेस, फैक्टशीपिंग और कई डायमेंशन टेबल शामिल हैं। प्रत्येक फैक्ट टेबल में डिम टेबल में शामिल होने के लिए प्राथमिक कुंजी और विश्लेषण करने के लिए उपाय / तथ्य शामिल हैं।
हाना डेटाबेस में तालिकाएँ योजना के तहत कैटलॉग टैब में हाना स्टूडियो से एक्सेस की जा सकती हैं। नीचे दी गई दो विधियों का उपयोग करके नई तालिकाएँ बनाई जा सकती हैं -
- SQL संपादक का उपयोग करना
- GUI विकल्प का उपयोग करना
हाना स्टूडियो में SQL संपादक
SQL कंसोल स्कीमा नाम का चयन करके खोला जा सकता है, जिसमें सिस्टम व्यू SQL संपादक विकल्प का उपयोग करके नई तालिका बनाई जानी है या स्कीमा नाम पर राइट क्लिक करके जैसा कि नीचे दिखाया गया है -

SQL संपादक खोलने के बाद, स्कीमा नाम की पुष्टि SQL संपादक के शीर्ष पर लिखे गए नाम से की जा सकती है। SQL बनाएँ तालिका कथन का उपयोग करके नई तालिका बनाई जा सकती है -
Create column Table Test1 (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);इस एसक्यूएल स्टेटमेंट में, हमने एक कॉलम टेबल “Test1” बनाया है, जो परिभाषित डेटा प्रकार टेबल और प्राथमिक कुंजी है।
एक बार जब आप तालिका SQL क्वेरी बनाएँ, राइट साइड के शीर्ष पर Execute विकल्प पर क्लिक करें। एक बार स्टेटमेंट निष्पादित होने के बाद, हमें एक पुष्टिकरण संदेश मिलेगा जैसा कि नीचे दिए गए स्नैपशॉट में दिखाया गया है -
कथन 'स्तंभ तालिका Test1 बनाएं (ID INTEGER, NAME VARCHAR (10), PRIMARY KEY (ID))
सफलतापूर्वक 13 एमएस 761 μs (सर्वर प्रसंस्करण समय: 12 एमएस 979 μs) में निष्पादित - पंक्तियां प्रभावित: 0

निष्पादन विवरण कथन को निष्पादित करने में लगने वाले समय के बारे में भी बताता है। एक बार जब स्टेटमेंट सफलतापूर्वक निष्पादित हो जाता है, तो सिस्टम व्यू और रिफ्रेश में स्कीमा नाम के तहत टेबल टैब पर राइट क्लिक करें। नई तालिका स्कीमा नाम के तहत तालिकाओं की सूची में परिलक्षित होगी।
SQL संपादक का उपयोग करके तालिका में डेटा दर्ज करने के लिए इंसर्ट स्टेटमेंट का उपयोग किया जाता है।
Insert into TEST1 Values (1,'ABCD')
Insert into TEST1 Values (2,'EFGH');Execute पर क्लिक करें।
आप तालिका नाम पर राइट क्लिक कर सकते हैं और तालिका के डेटा प्रकार को देखने के लिए ओपन डेटा डेफिनिशन का उपयोग कर सकते हैं। तालिका सामग्री देखने के लिए डेटा पूर्वावलोकन / ओपन सामग्री खोलें।
GUI विकल्प का उपयोग करके तालिका बनाना
हाना डेटाबेस में एक तालिका बनाने का एक और तरीका है हाना स्टूडियो में GUI विकल्प का उपयोग करना।
स्कीमा के तहत टेबल टैब पर राइट क्लिक करें → 'नया टेबल' विकल्प चुनें जैसा कि नीचे दिए गए स्नैपशॉट में दिखाया गया है।
एक बार जब आप नई तालिका पर क्लिक करते हैं तो → यह तालिका नाम दर्ज करने के लिए एक विंडो खोलेगी, ड्रॉप डाउन सूची से स्कीमा नाम चुनें, ड्रॉप डाउन सूची से तालिका प्रकार परिभाषित करें: कॉलम स्टोर या पंक्ति स्टोर।
डेटा प्रकार को परिभाषित करें जैसा कि नीचे दिखाया गया है। कॉलम को + साइन पर क्लिक करके जोड़ा जा सकता है, प्राथमिक नाम को कॉलम नाम के सामने प्राथमिक कुंजी के तहत सेल पर क्लिक करके चुना जा सकता है, नॉट डिफ़ॉल्ट रूप से सक्रिय होगा।
एक बार कॉलम जुड़ जाने के बाद, Execute पर क्लिक करें।
एक बार जब आप निष्पादित करें (F8), टेबल टैब पर राइट क्लिक करें → ताज़ा करें। नई तालिका को चुने गए स्कीमा के तहत तालिकाओं की सूची में परिलक्षित किया जाएगा। नीचे सम्मिलित विकल्प का उपयोग तालिका में डेटा डालने के लिए किया जा सकता है। तालिका की सामग्री देखने के लिए कथन का चयन करें।

हाना स्टूडियो में GUI का उपयोग करके तालिका में डेटा सम्मिलित करना
आप तालिका नाम पर राइट क्लिक कर सकते हैं और तालिका के डेटा प्रकार को देखने के लिए ओपन डेटा डेफिनिशन का उपयोग कर सकते हैं। तालिका सामग्री देखने के लिए डेटा पूर्वावलोकन / ओपन सामग्री खोलें।
विचारों को बनाने के लिए एक स्कीमा से तालिकाओं का उपयोग करने के लिए हमें स्कीमा पर डिफ़ॉल्ट उपयोगकर्ता तक पहुंच प्रदान करनी चाहिए जो हाना मॉडलिंग में सभी दृश्य चलाता है। यह SQL संपादक पर जाकर और इस क्वेरी को चलाकर किया जा सकता है -
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
हाना स्टूडियो में सामग्री टैब के तहत एसएपी हाना पैकेज दिखाए जाते हैं। सभी हाना मॉडलिंग पैकेज के अंदर सहेजे गए हैं।
आप सामग्री टैब → नया → पैकेज पर राइट क्लिक करके एक नया पैकेज बना सकते हैं
आप पैकेज के नाम पर राइट क्लिक करके एक पैकेज के तहत एक उप पैकेज भी बना सकते हैं। जब हम पैकेज पर राइट क्लिक करते हैं तो हमें 7 विकल्प मिलते हैं: हम पैकेज के तहत हाना व्यू अट्रैक्शन व्यू, एनालिटिकल व्यू और कैलकुलेशन व्यू बना सकते हैं।
आप निर्णय तालिका भी बना सकते हैं, विश्लेषणात्मक विशेषाधिकार को परिभाषित कर सकते हैं और एक पैकेज में प्रक्रियाएं बना सकते हैं।
जब आप पैकेज पर राइट क्लिक करते हैं और न्यू पर क्लिक करते हैं, तो आप पैकेज में सब पैकेज भी बना सकते हैं। आपको पैकेज बनाते समय पैकेज का नाम, विवरण दर्ज करना होगा।
एसएपी हाना मॉडलिंग में विशेषता दृश्य आयाम तालिकाओं के शीर्ष पर बनाए गए हैं। उनका उपयोग आयाम तालिकाओं या अन्य विशेषता दृश्यों में शामिल होने के लिए किया जाता है। आप अन्य संकुल के अंदर पहले से मौजूद विशेषता दृश्यों से एक नया विशेषता दृश्य भी कॉपी कर सकते हैं, लेकिन यह आपको दृश्य विशेषताओं को बदलने की अनुमति नहीं देता है।
विशेषता देखें के लक्षण
हाना में विशेषता दृश्य आयाम तालिकाओं या अन्य विशेषता दृश्यों में शामिल होने के लिए उपयोग किया जाता है।
मास्टर डेटा पास करने के लिए विश्लेषण के लिए एट्रिब्यूटिकल और कैलकुलेशन व्यू में एट्रिब्यूट व्यू का उपयोग किया जाता है।
वे बीएम में विशेषताओं के समान हैं और मास्टर डेटा शामिल हैं।
विशेषता दृश्यों का उपयोग बड़े आकार के तालिकाओं में प्रदर्शन अनुकूलन के लिए किया जाता है, आप एक विशेषता दृश्य में विशेषताओं की संख्या को सीमित कर सकते हैं जो आगे रिपोर्टिंग और विश्लेषण उद्देश्य के लिए उपयोग किए जाते हैं।
विशेषता दृश्य कुछ संदर्भ देने के लिए मास्टर डेटा को मॉडल करने के लिए उपयोग किया जाता है।
एट्रीब्यूट व्यू कैसे बनाएं?
पैकेज नाम चुनें जिसके तहत आप एक एट्रीब्यूट व्यू बनाना चाहते हैं। पैकेज पर राइट क्लिक करें → नए → एट्रीब्यूट व्यू पर जाएं
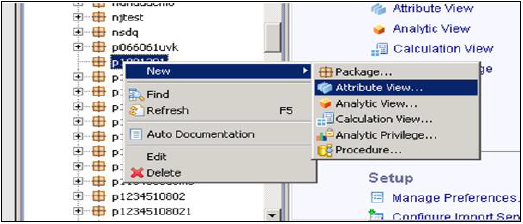
जब आप एट्रीब्यूट व्यू पर क्लिक करेंगे तो नई विंडो खुल जाएगी। नाम और विवरण दर्ज करें। ड्रॉप डाउन सूची से, देखें प्रकार और उप प्रकार चुनें। उप प्रकार में, तीन प्रकार के गुण विचार हैं - मानक, समय और व्युत्पन्न।
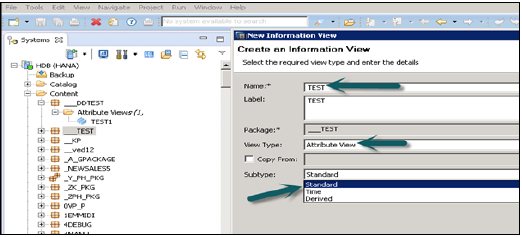
टाइम सबटाइप एट्रीब्यूट व्यू एक विशेष प्रकार का एट्रीब्यूट व्यू है जो डेटा फ़ाउंडेशन में टाइम डाइमेंशन जोड़ता है। जब आप विशेषता नाम दर्ज करते हैं, तो टाइप और सबटाइप करें और फिनिश पर क्लिक करें, यह तीन काम पैन खोल देगा -
परिदृश्य फलक जिसमें डेटा फ़ाउंडेशन और सिमेंटिक लेयर है।
विवरण फलक डेटा फ़ाउंडेशन में जोड़े गए और उनके बीच शामिल होने वाली सभी तालिकाओं की विशेषता दिखाता है।
आउटपुट फलक जहां हम रिपोर्ट में फ़िल्टर करने के लिए डिटेल पैन से विशेषताएँ जोड़ सकते हैं।
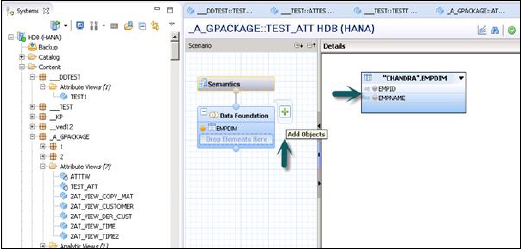
डेटा फ़ाउंडेशन के आगे लिखे '+' चिन्ह पर क्लिक करके आप डेटा फ़ाउंडेशन में ऑब्जेक्ट्स जोड़ सकते हैं। आप परिदृश्य फलक में कई आयाम तालिकाएँ और विशेषता दृश्य जोड़ सकते हैं और प्राथमिक कुंजी का उपयोग करके उनसे जुड़ सकते हैं।
जब आप डेटा फ़ाउंडेशन में ऐड ऑब्जेक्ट पर क्लिक करते हैं, तो आपको एक खोज बार मिलेगा जहां से आप डायमेंशन टेबल जोड़ सकते हैं और परिदृश्य लेन में विचार प्रस्तुत कर सकते हैं। एक बार जब टेबल्स या एट्रीब्यूट व्यूज़ को डेटा फ़ाउंडेशन में जोड़ा जाता है, तो उन्हें नीचे दिखाए गए विवरण में एक प्राथमिक कुंजी का उपयोग करके जोड़ा जा सकता है।
एक बार शामिल होने के बाद, विवरण फलक में कई विशेषताओं का चयन करें, राइट क्लिक करें और आउटपुट में जोड़ें। आउटपुट कॉलम में सभी कॉलम जोड़े जाएंगे। अब एक्टिवेट विकल्प पर क्लिक करें और आपको जॉब लॉग में एक पुष्टिकरण संदेश मिलेगा।
अब आप एट्रीब्यूट व्यू पर राइट क्लिक करके डेटा प्रीव्यू के लिए जा सकते हैं।
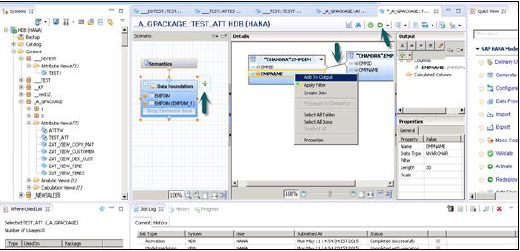
Note- जब कोई दृश्य सक्रिय नहीं होता है, तो उस पर हीरे का निशान होता है। हालाँकि, एक बार जब आप इसे सक्रिय करते हैं, तो वह हीरा गायब हो जाता है जो पुष्टि करता है कि व्यू सफलतापूर्वक सक्रिय हो गया है।
एक बार जब आप डेटा पूर्वावलोकन पर क्लिक करते हैं, तो यह उन सभी विशेषताओं को दिखाएगा जो उपलब्ध वस्तुओं के तहत आउटपुट फलक में जोड़ा गया है।
इन ऑब्जेक्ट्स को राइट क्लिक और जोड़कर या नीचे दिखाए गए ऑब्जेक्ट्स को खींचकर लेबल और वैल्यू एक्सिस में जोड़ा जा सकता है -
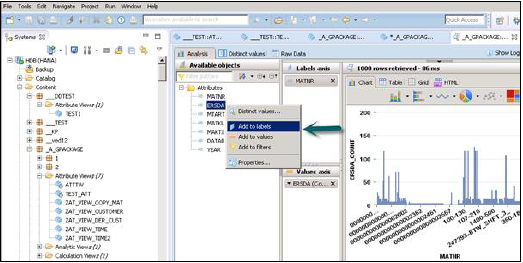
एनालिटिकल व्यू स्टार स्कीमा के रूप में होता है, जिसमें हम एक फैक्ट टेबल को कई डायमेंशन टेबल में शामिल करते हैं। विश्लेषणात्मक विचार, एसएपी हाना की वास्तविक शक्ति का उपयोग स्टार स्कीमा के रूप में तालिकाओं में शामिल होकर और स्टार स्कीमा प्रश्नों को निष्पादित करके जटिल गणना और समग्र कार्य करने के लिए करते हैं।
विश्लेषणात्मक दृश्य के लक्षण
एसएपी हाना एनालिटिक व्यू के गुण निम्नलिखित हैं -
विश्लेषणात्मक दृश्यों का उपयोग जटिल गणना और समुच्चय, गणना, न्यूनतम, अधिकतम, आदि जैसे कार्य करने के लिए किया जाता है।
एनालिटिकल व्यूज़ स्टार्ट स्कीमा क्वैश्चंस को चलाने के लिए डिज़ाइन किए गए हैं।
प्रत्येक विश्लेषणात्मक दृश्य में कई आयाम तालिकाओं से घिरी हुई एक तथ्य तालिका होती है। तथ्य तालिका में प्रत्येक मंद तालिका और उपायों के लिए प्राथमिक कुंजी होती है।
एनालिटिकल व्यूज़ SAP BW की इंफो ऑब्जेक्ट्स और इंफो सेट्स के समान हैं।
एनालिटिकल व्यू कैसे बनाएं?
पैकेज नाम चुनें जिसके तहत आप एक एनालिटिक व्यू बनाना चाहते हैं। पैकेज पर राइट क्लिक करें → नए → विश्लेषणात्मक दृश्य पर जाएं। जब आप एक विश्लेषणात्मक दृश्य पर क्लिक करते हैं, तो नई विंडो खुल जाएगी। नाम और विवरण दर्ज करें और ड्रॉप डाउन सूची से दृश्य प्रकार और समाप्त चुनें।
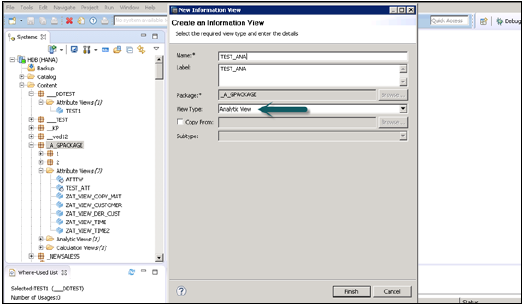
जब आप समाप्त पर क्लिक करते हैं, तो आप डेटा फ़ाउंडेशन और स्टार जॉइन विकल्प के साथ एक एनालिटिक व्यू देख सकते हैं।
डायमेंशन और फैक्ट टेबल को जोड़ने के लिए डेटा फाउंडेशन पर क्लिक करें। विशेषता दृश्य जोड़ने के लिए Star Join पर क्लिक करें।
डेटा फ़ाउंडेशन में “+” साइन का उपयोग करके डिम और फैक्ट टेबल को जोड़ें। नीचे दिए गए उदाहरण में, 3 मंद तालिकाओं को जोड़ा गया है: DIM_CUSTOMER, DIM_PRODUCT, DIM_REGION और 1 तथ्य तालिका FCT_SALES से विवरण फलक में। फैक्ट टेबल में संग्रहीत प्राथमिक कुंजी का उपयोग करके डिम टेबल को फैक्ट टेबल में शामिल करना।
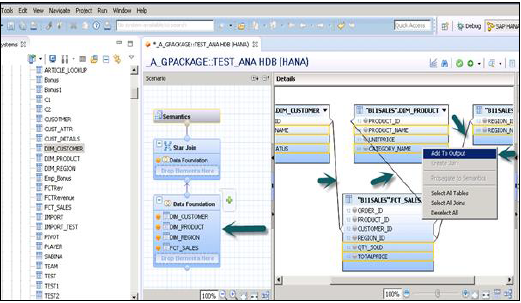
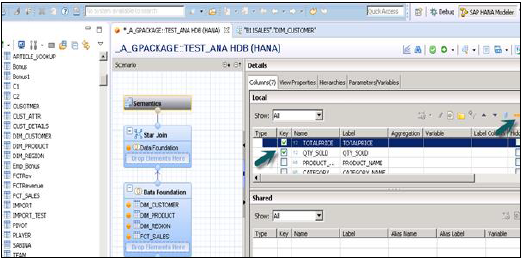
ऊपर दिखाए गए स्नैपशॉट में दिखाए गए अनुसार आउटपुट फलक में जोड़ने के लिए मंद और तथ्य तालिका से विशेषताएँ चुनें। अब तथ्य तालिका से उपायों तक, डेटा प्रकार को बदलें।
सिमेंटिक लेयर पर क्लिक करें, तथ्यों का चयन करें और उपायों पर क्लिक करें जैसा कि नीचे दिखाया गया है कि डेटाटाइप को उपायों में बदलें और व्यू को सक्रिय करें।
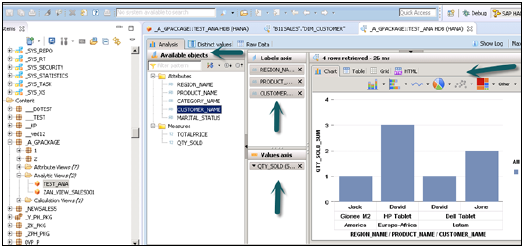
एक बार जब आप दृश्य को सक्रिय कर लेते हैं और डेटा पूर्वावलोकन पर क्लिक करते हैं, तो उपलब्ध वस्तुओं की सूची के तहत सभी विशेषताओं और उपायों को जोड़ा जाएगा। लेबल एक्सिस में गुण जोड़ें और विश्लेषण उद्देश्य के लिए मूल्य अक्ष को मापें।
विभिन्न प्रकार के चार्ट और ग्राफ़ चुनने का विकल्प है।
गणना दृश्य का उपयोग अन्य विश्लेषणात्मक, गुण और अन्य गणना विचारों और आधार स्तंभ तालिकाओं का उपभोग करने के लिए किया जाता है। इनका उपयोग जटिल गणना करने के लिए किया जाता है, जो अन्य प्रकार के दृश्यों के साथ संभव नहीं है।
गणना दृश्य के लक्षण
नीचे दिए गए गणना दृश्यों की कुछ विशेषताएं हैं -
गणना दृश्य विश्लेषणात्मक, गुण और अन्य गणना दृश्य का उपभोग करने के लिए उपयोग किया जाता है।
उनका उपयोग जटिल गणना करने के लिए किया जाता है, जो अन्य दृश्यों के साथ संभव नहीं है।
गणना दृश्य बनाने के दो तरीके हैं- SQL संपादक या आलेखीय संपादक।
बिल्ट-इन यूनियन, जॉइन, प्रोजेक्शन और एग्रीगेशन नोड्स।
गणना दृश्य कैसे बनाएं?
वह पैकेज नाम चुनें जिसके तहत आप एक गणना दृश्य बनाना चाहते हैं। पैकेज पर राइट क्लिक करें → नए → गणना दृश्य पर जाएं। जब आप गणना दृश्य पर क्लिक करेंगे, तो नई विंडो खुल जाएगी।
नाम देखें, विवरण दर्ज करें और गणना प्रकार, उप-मानक या समय के रूप में दृश्य प्रकार चुनें (यह विशेष प्रकार का दृश्य है जो समय आयाम जोड़ता है)। आप दो प्रकार की गणना दृश्य - आलेखीय और SQL स्क्रिप्ट का उपयोग कर सकते हैं।
चित्रमय गणना दृश्य
इसमें एग्रीगेशन, प्रोजेक्शन, जॉइन और यूनियन जैसे डिफॉल्ट नोड्स हैं। इसका उपयोग अन्य गुण, विश्लेषण और अन्य गणना विचारों का उपभोग करने के लिए किया जाता है।
एसक्यूएल स्क्रिप्ट आधारित गणना दृश्य
यह SQL स्क्रिप्ट्स में लिखा होता है जो SQL कमांड या हाना डिफाइन्ड फंक्शन्स पर बनाई जाती हैं।
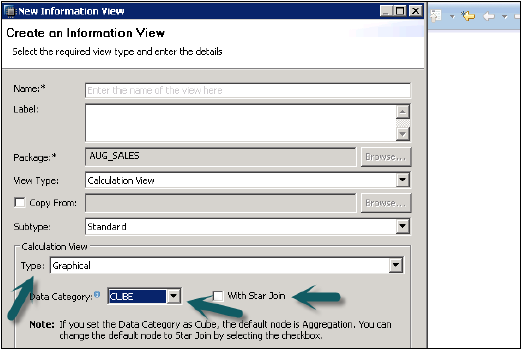
डेटा श्रेणी
घन, इस डिफ़ॉल्ट नोड में, एकत्रीकरण है। आप घन आयाम के साथ स्टार ज्वाइन चुन सकते हैं।
आयाम, इस डिफ़ॉल्ट नोड में प्रोजेक्शन है।
स्टार जॉइन के साथ गणना दृश्य
यह बेस कॉलम टेबल, अटैचमेंट व्यू या एनालिटिकल व्यू को डेटा फाउंडेशन में जोड़ने की अनुमति नहीं देता है। Star Join में उपयोग करने के लिए सभी Dimension Table को आयाम गणना के विचारों में बदलना चाहिए। सभी फैक्ट टेबल को जोड़ा जा सकता है और गणना दृश्य में डिफ़ॉल्ट नोड का उपयोग कर सकते हैं।
उदाहरण
निम्नलिखित उदाहरण से पता चलता है कि हम स्टार में शामिल होने के साथ गणना दृश्य का उपयोग कैसे कर सकते हैं -
आपके पास चार टेबल, दो डिम टेबल और दो फैक्ट टेबल हैं। आपको सभी कर्मचारियों की लिस्ट में उनकी जॉइनिंग डेट, एम्प नेम, एम्पिड, सैलरी और बोनस के साथ ढूंढना होगा।
SQL एडिटर में नीचे की स्क्रिप्ट को कॉपी और पेस्ट करें और निष्पादित करें।
Dim Tables − Empdim and Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100));
Insert into Empdim values('AA1','John');
Insert into Empdim values('BB1','Anand');
Insert into Empdim values('CC1','Jason');Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4));
Insert into Empdate values('20100101','04','2010');
Insert into Empdate values('20110101','05','2011');
Insert into Empdate values('20120101','06','2012');Fact Tables − Empfact1, Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer );
Insert into Empfact1 values('AA1','20100101',5000);
Insert into Empfact1 values('BB1','20110101',10000);
Insert into Empfact1 values('CC1','20120101',12000);Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer );
Insert into Empfact2 values ('AA1','SAP', 2000);
Insert into Empfact2 values ('BB1','Oracle', 2500);
Insert into Empfact2 values ('CC1','JAVA', 1500);अब हमें Star Join के साथ कैलकुलेशन व्यू को लागू करना है। पहले दोनों टेबल को डायमेंशन कैलकुलेशन व्यू में बदलें।
Star Join के साथ एक गणना दृश्य बनाएं। ग्राफिकल फलक में, 2 फैक्ट टेबल के लिए 2 अनुमान जोड़ें। दोनों अनुमानों को दोनों अनुमानों में जोड़ें और इन अनुमानों की विशेषताओं को आउटपुट फलक में जोड़ें।

डिफ़ॉल्ट नोड से एक जुड़ाव जोड़ें और दोनों तथ्य तालिकाओं में शामिल हों। फैक्ट के मापदंडों को आउटपुट पेन से जोड़ें।
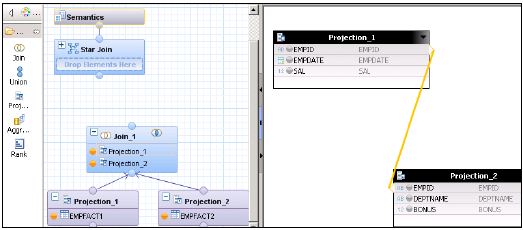
Star Join में, दोनों-Dimension गणना के विचार जोड़ें और Fact Join को Star Join में जोड़ें जैसा कि नीचे दिखाया गया है। आउटपुट फलक में पैरामीटर चुनें और दृश्य सक्रिय करें।
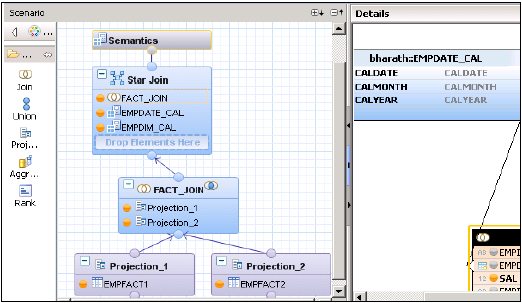
एसएपी हाना गणना दृश्य - स्टार में शामिल हों
एक बार जब दृश्य सफलतापूर्वक सक्रिय हो जाता है, तो दृश्य नाम पर राइट क्लिक करें और डेटा पूर्वावलोकन पर क्लिक करें। मूल्यों और लेबल अक्ष में विशेषताओं और उपायों को जोड़ें और विश्लेषण करें।
Star Join का उपयोग करने के लाभ
यह डिजाइन प्रक्रिया को सरल करता है। आपको विश्लेषणात्मक दृश्य और विशेषता दृश्य बनाने की आवश्यकता नहीं है और सीधे फैक्ट टेबल का उपयोग अनुमानों के रूप में किया जा सकता है।
3NF Star Join के साथ संभव है।
स्टार जॉइन के बिना गणना देखें
2 डिम टेबल पर 2 अटैचमेंट व्यू बनाएं-आउटपुट जोड़ें और दोनों के विचारों को सक्रिय करें।
फैक्ट टेबल्स पर 2 एनालिटिकल व्यूज बनाएं → एनालिटिक्स व्यू में डेटा फाउंडेशन में एट्रीब्यूट व्यूज और फैक्ट 1 / फैक्ट 2 दोनों जोड़ें।
अब एक गणना दृश्य बनाएं → आयाम (प्रोजेक्शन)। दोनों विश्लेषणात्मक दृश्यों के अनुमान बनाएँ और उनके साथ जुड़ें। इस के गुण जोड़ें आउटपुट फलक में शामिल हों। अब प्रोजेक्शन में शामिल हों और फिर से आउटपुट जोड़ें।
विश्लेषण को सफल देखें और विश्लेषण के लिए डेटा पूर्वावलोकन पर जाएं।
विश्लेषणात्मक विशेषाधिकार का उपयोग HANA सूचना विचारों पर पहुंच को सीमित करने के लिए किया जाता है। आप विश्लेषणात्मक विशेषाधिकार में एक दृश्य के विभिन्न घटक पर विभिन्न उपयोगकर्ताओं को विभिन्न प्रकार के अधिकार प्रदान कर सकते हैं।
कभी-कभी, यह आवश्यक है कि उसी दृश्य में डेटा अन्य उपयोगकर्ताओं के लिए सुलभ न हो, जिनके पास उस डेटा के लिए कोई प्रासंगिक आवश्यकता नहीं है।
उदाहरण
मान लें कि आपके पास एक विश्लेषणात्मक दृष्टिकोण है Empetetails जिसमें किसी कंपनी के कर्मचारियों के बारे में विवरण हैं- Emp नाम, Emp Id, Dept, Salary, Joining की तारीख, Emp logon, आदि। अब यदि आप नहीं चाहते हैं कि आपका रिपोर्ट डेवलपर वेतन या Emp को देखें सभी कर्मचारियों के लॉगऑन विवरण, आप एनालिटिक्स विशेषाधिकारों के विकल्प का उपयोग करके इसे छिपा सकते हैं।
विश्लेषणात्मक विशेषाधिकार केवल सूचना दृश्य में विशेषताओं पर लागू होते हैं। हम विश्लेषणात्मक विशेषाधिकारों में पहुंच को प्रतिबंधित करने के उपायों को नहीं जोड़ सकते।
विश्लेषणात्मक विशेषाधिकार का उपयोग एसएपी हाना सूचना विचारों पर पढ़ने की पहुंच को नियंत्रित करने के लिए किया जाता है।
इसलिए हम Empname, EmpId, Emp logon या Emp Dept द्वारा डेटा को प्रतिबंधित कर सकते हैं और न कि वेतन, बोनस जैसे संख्यात्मक मूल्यों द्वारा।
विश्लेषणात्मक विशेषाधिकार बनाना
पैकेज नाम पर राइट क्लिक करें और नए एनालिटिक प्रिविलेज पर जाएं या आप हाना मॉडलर क्विक लॉन्च का उपयोग करके खोल सकते हैं।
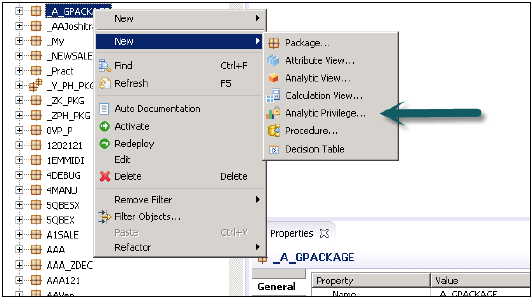
नाम और एनालिटिक्स विशेषाधिकार का विवरण → समाप्त करें दर्ज करें। नई विंडो खुलेगी।
आप नेक्स्ट बटन पर क्लिक करें और फिनिशिंग पर क्लिक करने से पहले इस विंडो में मॉडलिंग दृश्य जोड़ सकते हैं। मौजूदा एनालिटिक प्रिविलेज पैकेज को कॉपी करने का विकल्प भी है।
एक बार जब आप Add बटन पर क्लिक करते हैं, तो यह आपको सामग्री टैब के अंतर्गत सभी दृश्य दिखाएगा।
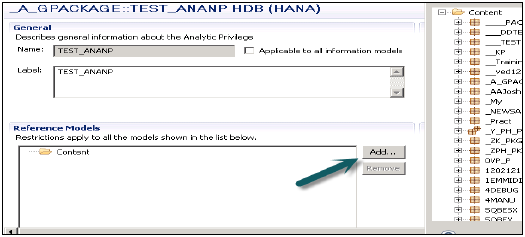
वह दृश्य चुनें जिसे आप विश्लेषणात्मक विशेषाधिकार पैकेज में जोड़ना चाहते हैं और ठीक पर क्लिक करें। चयनित दृश्य संदर्भ मॉडल के तहत जोड़े जाएंगे।
अब एनालिटिक प्रिविलेज के तहत चयनित दृश्य से विशेषताओं को जोड़ने के लिए, एसोसिएटेड एट्रीब्यूट्स रिस्ट्रिक्शन विंडो के साथ ऐड बटन पर क्लिक करें।
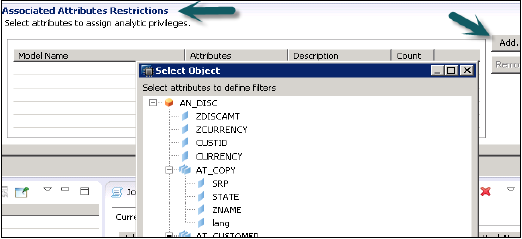
उन ऑब्जेक्ट्स को जोड़ें जिन्हें आप एनालिटिक विशेषाधिकारों में चयन वस्तु विकल्प से जोड़ना चाहते हैं और ओके पर क्लिक करें।
असाइन प्रतिबंध विकल्प में, यह आपको उन मूल्यों को जोड़ने की अनुमति देता है जिन्हें आप विशिष्ट उपयोगकर्ता से मॉडलिंग दृश्य में छिपाना चाहते हैं। आप ऑब्जेक्ट मूल्य जोड़ सकते हैं जो मॉडलिंग व्यू के डेटा पूर्वावलोकन में प्रतिबिंबित नहीं होगा।
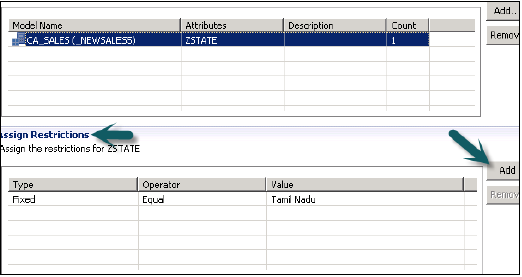
हमें शीर्ष पर ग्रीन गोल आइकन पर क्लिक करके, अब विश्लेषणात्मक विशेषाधिकार सक्रिय करना होगा। स्थिति संदेश - सफलतापूर्वक पूर्ण सफलतापूर्वक जॉब लॉग के तहत सक्रियण की पुष्टि करता है और हम इस दृश्य का उपयोग भूमिका में जोड़कर कर सकते हैं।
अब इस भूमिका को एक उपयोगकर्ता में जोड़ने के लिए, सुरक्षा टैब पर जाएं → उपयोगकर्ता → उपयोगकर्ता का चयन करें, जिस पर आप इन विश्लेषणात्मक विशेषाधिकार लागू करना चाहते हैं।
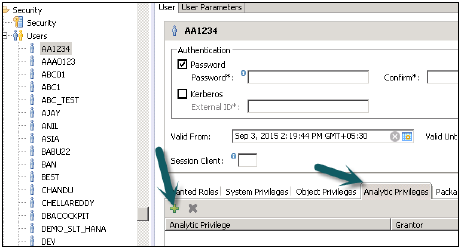
खोज विश्लेषणात्मक विशेषाधिकार आप नाम के साथ लागू करना चाहते हैं और ठीक पर क्लिक करें। उस दृश्य को विश्लेषणात्मक विशेषाधिकार के तहत उपयोगकर्ता की भूमिका में जोड़ा जाएगा।
विशिष्ट उपयोगकर्ता से विश्लेषणात्मक विशेषाधिकार को हटाने के लिए, टैब के तहत दृश्य चुनें और लाल हटाएं विकल्प का उपयोग करें। Deploy (उपयोगकर्ता प्रोफ़ाइल पर इसे लागू करने के लिए शीर्ष या F8 पर तीर का निशान) का उपयोग करें।
एसएपी हाना सूचना संगीतकार अंत उपयोगकर्ताओं के लिए डेटा सेट का विश्लेषण करने के लिए एक स्वयं सेवा मॉडलिंग वातावरण है। यह आपको कार्यपुस्तिका प्रारूप (.xls, .csv) से डेटा को हाना डेटाबेस में आयात करने और विश्लेषण के लिए मॉडलिंग विचार बनाने की अनुमति देता है।
सूचना संगीतकार हाना मॉडलर से बहुत अलग है और दोनों को अलग-अलग उपयोगकर्ताओं को लक्षित करने के लिए डिज़ाइन किया गया है। तकनीकी रूप से ध्वनि वाले लोग जो मॉडलिंग में मजबूत अनुभव रखते हैं वे हाना मॉडलर का उपयोग करते हैं। एक व्यावसायिक उपयोगकर्ता, जिसके पास कोई तकनीकी ज्ञान नहीं है, सूचना संगीतकार का उपयोग करता है। यह इंटरफ़ेस का उपयोग करने के लिए आसान के साथ सरल कार्यक्षमता प्रदान करता है।
सूचना संगीतकार की विशेषताएं
Data extraction - सूचना संगीतकार डेटा, स्वच्छ डेटा, पूर्वावलोकन डेटा निकालने और हाना डेटाबेस में भौतिक तालिका के निर्माण की प्रक्रिया को स्वचालित करने में मदद करता है।
Manipulating data - यह हमें दो ऑब्जेक्ट (भौतिक तालिकाओं, विश्लेषणात्मक दृश्य, विशेषता दृश्य और गणना दृश्य) को संयोजित करने और SAP BO उपकरण द्वारा उपभोग की जा सकने वाली सूचना दृश्य बनाने में मदद करता है जैसे SAP व्यवसाय ऑब्जेक्ट विश्लेषण, SAP व्यवसाय ऑब्जेक्ट एक्सप्लोरर और MS Excel जैसे अन्य उपकरण।
यह URL के रूप में एक केंद्रीकृत आईटी सेवा प्रदान करता है, जिसे कहीं से भी एक्सेस किया जा सकता है।
सूचना संगीतकार का उपयोग करके डेटा कैसे अपलोड करें?
यह हमें बड़ी मात्रा में डेटा (5 मिलियन सेल तक) अपलोड करने की अनुमति देता है। सूचना संगीतकार तक पहुँचने के लिए लिंक -
http://<server>:<port>/IC
एसएपी हाना सूचना संगीतकार को लॉगिन करें। आप इस टूल का उपयोग करके डेटा लोडिंग या हेरफेर कर सकते हैं।
डेटा अपलोड करने के लिए यह दो तरीकों से किया जा सकता है -
- अपलोड .xls, .csv फ़ाइल सीधे हाना डेटाबेस में
- दूसरा तरीका डेटा को क्लिपबोर्ड पर कॉपी करना और वहां से हाना डेटाबेस में कॉपी करना है।
- यह डेटा को हेडर के साथ लोड करने की अनुमति देता है।
सूचना संगीतकार में बाईं ओर, आपके पास तीन विकल्प हैं -
डेटा का स्रोत चुनें → डेटा को वर्गीकृत करें → प्रकाशित करें
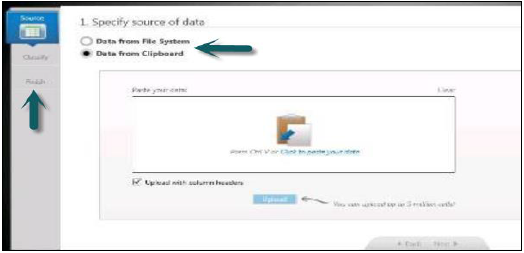
हाना डेटाबेस में डेटा प्रकाशित होने के बाद, आप तालिका का नाम नहीं बदल सकते। इस स्थिति में, आपको हाना डेटाबेस में स्कीमा से तालिका को हटाना होगा।
"SAP_IC" स्कीमा, जहाँ IC_MODELS, IC_SPREADSHEETS जैसी तालिकाएँ मौजूद हैं। एक इन तालिकाओं के तहत आईसी का उपयोग करके बनाई गई तालिकाओं का विवरण पा सकते हैं।

क्लिपबोर्ड का उपयोग करना
IC में डेटा अपलोड करने का दूसरा तरीका क्लिपबोर्ड का उपयोग है। डेटा को क्लिपबोर्ड पर कॉपी करें और सूचना संगीतकार की मदद से अपलोड करें। सूचना संगीतकार आपको डेटा का पूर्वावलोकन देखने या अस्थायी संग्रहण में डेटा का सारांश प्रदान करने की भी अनुमति देता है। इसमें डेटा सफाई की इनबिल्ट क्षमता होती है जिसका उपयोग डेटा में किसी भी असंगतता को दूर करने के लिए किया जाता है।
एक बार डेटा साफ़ हो जाने के बाद, आपको डेटा को वर्गीकृत करने की आवश्यकता होती है, चाहे वह इसके लिए जिम्मेदार हो। अपलोड किए गए डेटा के डेटा प्रकार की जांच करने के लिए IC में इनबिल्ट फीचर है।
अंतिम चरण डेटा को हाना डेटाबेस में भौतिक तालिकाओं में प्रकाशित करना है। तालिका का तकनीकी नाम और विवरण प्रदान करें और इसे IC_Tables स्कीमा के अंदर लोड किया जाएगा।
सूचना संगीतकार के साथ प्रकाशित डेटा का उपयोग करने के लिए उपयोगकर्ता भूमिकाएं
उपयोगकर्ताओं के दो सेट को IC से प्रकाशित डेटा का उपयोग करने के लिए परिभाषित किया जा सकता है।
IC_MODELER भौतिक तालिका बनाने, डेटा अपलोड करने और सूचना दृश्य बनाने के लिए है।
IC_PUBLIC उपयोगकर्ताओं को अन्य उपयोगकर्ताओं द्वारा बनाए गए सूचना विचारों को देखने की अनुमति देता है। यह भूमिका उपयोगकर्ता को IC का उपयोग करके कोई भी सूचना दृश्य अपलोड करने या बनाने की अनुमति नहीं देती है।
सूचना संगीतकार के लिए सिस्टम की आवश्यकता
Server Requirements −
कम से कम 2GB उपलब्ध RAM की आवश्यकता है।
जावा 6 (64-बिट) सर्वर पर स्थापित होना चाहिए।
सूचना संगीतकार सर्वर शारीरिक रूप से हाना सर्वर के बगल में स्थित होना चाहिए।
Client Requirements −
- सिल्वरलाइट 4 के साथ इंटरनेट एक्सप्लोरर स्थापित।
हाना एक्सपोर्ट और इम्पोर्ट विकल्प टेबल, सूचना मॉडल, लैंडस्केप को एक अलग या मौजूदा सिस्टम में जाने की अनुमति देता है। आपको सभी तालिकाओं और सूचना मॉडल को फिर से बनाने की आवश्यकता नहीं है क्योंकि आप प्रयास को कम करने के लिए बस इसे नई प्रणाली में निर्यात कर सकते हैं या मौजूदा लक्ष्य प्रणाली में आयात कर सकते हैं।
यह विकल्प शीर्ष पर फ़ाइल मेनू से या एचएएनए स्टूडियो में किसी भी तालिका या सूचना मॉडल पर राइट क्लिक करके पहुँचा जा सकता है।
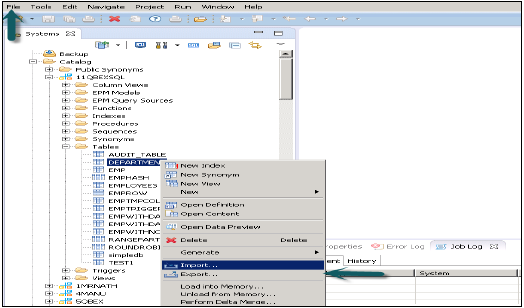
हाना स्टूडियो में एक टेबल / सूचना मॉडल का निर्यात करना
फ़ाइल मेनू पर जाएं → निर्यात → आपको नीचे दिखाए गए विकल्प दिखाई देंगे -

एसएपी हाना सामग्री के तहत निर्यात विकल्प
वितरण इकाई
डिलीवरी यूनिट एक एकल इकाई है, जिसे कई पैकेजों में मैप किया जा सकता है और इसे एकल इकाई के रूप में निर्यात किया जा सकता है ताकि डिलीवरी यूनिट को सौंपे गए सभी पैकेजों को एकल इकाई के रूप में माना जा सके।
उपयोगकर्ता इस विकल्प का उपयोग उन सभी पैकेजों को निर्यात करने के लिए कर सकते हैं जो एक डिलीवरी यूनिट और उसमें निहित संबंधित वस्तुओं को एक हाना सर्वर या स्थानीय क्लाइंट स्थान पर निर्यात करते हैं।
उपयोगकर्ता को इसका उपयोग करने से पहले डिलिवरी यूनिट बनाना चाहिए।
यह हाना मॉडलर के माध्यम से किया जा सकता है → वितरण इकाई → चयन प्रणाली और अगला → बनाएं → नाम, संस्करण, आदि जैसे विवरण भरें → ठीक है → वितरण इकाई में पैकेज जोड़ें → समाप्त करें
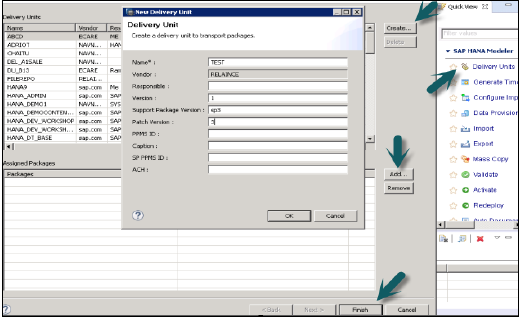
एक बार जब डिलीवरी यूनिट बनाई जाती है और पैकेज उसे सौंपे जाते हैं, तो उपयोगकर्ता निर्यात विकल्प का उपयोग करके पैकेजों की सूची देख सकता है -
फाइल → एक्सपोर्ट → डिलीवरी यूनिट → डिलीवरी यूनिट चुनें।
आप वितरण इकाई को सौंपे गए सभी पैकेजों की सूची देख सकते हैं। यह निर्यात स्थान चुनने का विकल्प देता है -
- सर्वर पर निर्यात करें
- क्लाइंट को निर्यात करें
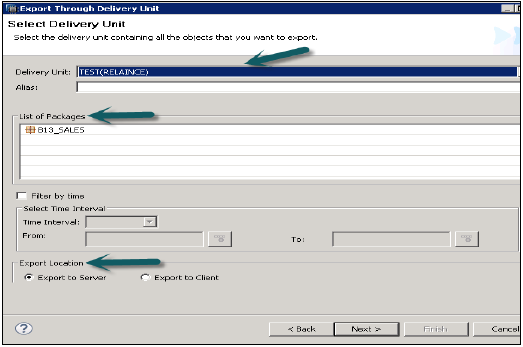
आप डिलीवरी यूनिट को या तो हाना सर्वर स्थान पर या क्लाइंट स्थान पर दिखाए अनुसार निर्यात कर सकते हैं।
उपयोगकर्ता निर्यात को "फ़िल्टर बाय टाइम" के माध्यम से प्रतिबंधित कर सकता है, जिसका अर्थ है सूचना दृश्य, जो कि निर्दिष्ट समय अंतराल के भीतर अपडेट किए गए हैं, केवल निर्यात किए जाएंगे।
वितरण इकाई और निर्यात स्थान का चयन करें और फिर अगला → समाप्त करें पर क्लिक करें। यह चयनित डिलीवरी यूनिट को निर्दिष्ट स्थान पर निर्यात करेगा।
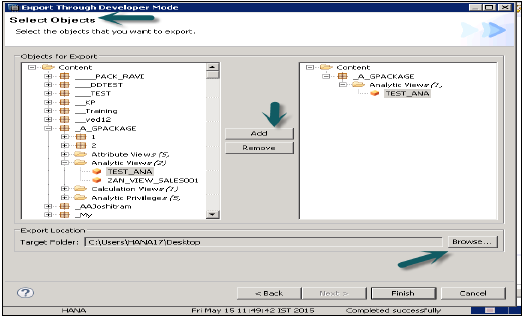
डेवलपर मोड
इस विकल्प का उपयोग व्यक्तिगत वस्तुओं को स्थानीय प्रणाली में किसी स्थान पर निर्यात करने के लिए किया जा सकता है। उपयोगकर्ता एकल सूचना दृश्य या दृश्य और संकुल के समूह का चयन कर सकते हैं और निर्यात और समाप्त के लिए स्थानीय ग्राहक स्थान का चयन कर सकते हैं।
यह नीचे स्नैपशॉट में दिखाया गया है।
समर्थन मोड
इसका उपयोग एसएपी समर्थन उद्देश्यों के लिए डेटा के साथ वस्तुओं को निर्यात करने के लिए किया जा सकता है। इसका उपयोग अनुरोध करने पर किया जा सकता है।
Example- उपयोगकर्ता एक सूचना दृश्य बनाता है, जो एक त्रुटि फेंकता है और वह हल करने में सक्षम नहीं है। उस स्थिति में, वह डेटा के साथ दृश्य को निर्यात करने के लिए इस विकल्प का उपयोग कर सकता है और डीबगिंग उद्देश्य के लिए SAP के साथ साझा कर सकता है।

Export Options under SAP HANA Studio -
Landscape - एक सिस्टम से दूसरे में लैंडस्केप एक्सपोर्ट करना।
Tables - इस विकल्प का उपयोग इसकी सामग्री के साथ तालिकाओं को निर्यात करने के लिए किया जा सकता है।
एसएपी हाना सामग्री के तहत आयात विकल्प
फ़ाइल → आयात पर जाएं, आपको नीचे दिए गए विकल्प के रूप में सभी विकल्प दिखाई देंगे।
स्थानीय फ़ाइल से डेटा
इसका उपयोग समतल फ़ाइल जैसे .xls या .csv फ़ाइल से डेटा आयात करने के लिए किया जाता है।
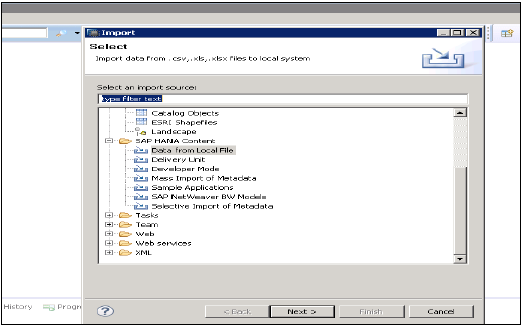
नेक्सस पर क्लिक करें → टारगेट सिस्टम चुनें → इंपोर्ट प्रॉपर्टीज को परिभाषित करें
स्थानीय प्रणाली ब्राउज़ करके स्रोत फ़ाइल का चयन करें। यदि आप शीर्ष लेख पंक्ति रखना चाहते हैं तो यह एक विकल्प भी देता है। यह मौजूदा स्कीमा के तहत एक नई तालिका बनाने का विकल्प देता है या यदि आप किसी फ़ाइल से किसी मौजूदा तालिका में डेटा आयात करना चाहते हैं।
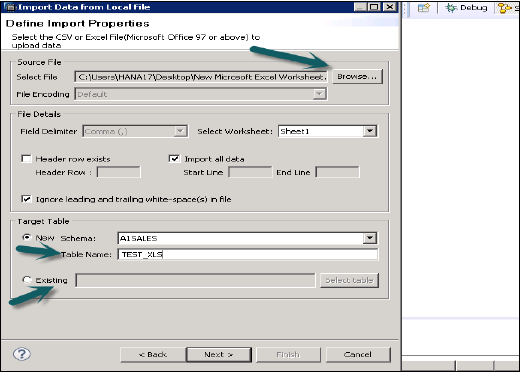
जब आप नेक्स्ट पर क्लिक करते हैं, तो यह प्राथमिक कुंजी को परिभाषित करने, डेटा प्रकार के कॉलम को बदलने, स्टोरेज प्रकार की तालिका को परिभाषित करने और साथ ही, आपको टेबल की प्रस्तावित संरचना को बदलने की अनुमति देता है।
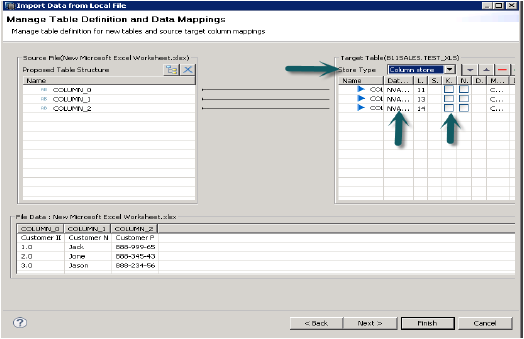
जब आप फिनिश पर क्लिक करते हैं, तो उस तालिका को स्कीमा में उल्लिखित तालिकाओं की सूची के तहत आबाद किया जाएगा। आप डेटा पूर्वावलोकन कर सकते हैं और तालिका की डेटा परिभाषा की जांच कर सकते हैं और यह .xls फ़ाइल के समान होगा।

वितरण इकाई
फ़ाइल → आयात → वितरण इकाई पर जाकर वितरण इकाई चुनें। आप एक सर्वर या स्थानीय ग्राहक से चुन सकते हैं।
आप "निष्क्रिय संस्करणों को अधिलेखित" का चयन कर सकते हैं जो आपको मौजूद वस्तुओं के किसी भी निष्क्रिय संस्करण को अधिलेखित करने की अनुमति देता है। यदि उपयोगकर्ता "ऑब्जेक्ट सक्रिय करें" का चयन करता है, तो आयात के बाद, सभी आयातित ऑब्जेक्ट डिफ़ॉल्ट रूप से सक्रिय हो जाएंगे। उपयोगकर्ता को सक्रिय रूप से आयातित विचारों के लिए सक्रियण को ट्रिगर करने की आवश्यकता नहीं है।

समाप्त पर क्लिक करें और एक बार सफलतापूर्वक पूरा होने के बाद, यह लक्ष्य प्रणाली के लिए आबाद हो जाएगा।
डेवलपर मोड
स्थानीय क्लाइंट स्थान के लिए ब्राउज़ करें जहां दृश्य निर्यात किए जाते हैं और आयात किए जाने वाले विचारों का चयन करते हैं, उपयोगकर्ता व्यक्तिगत दृश्य या दृश्य और पैकेज का समूह चुन सकता है और समाप्त पर क्लिक कर सकता है।
मेटाडेटा का द्रव्यमान आयात
फ़ाइल → आयात करें → मेटाडेटा के बड़े पैमाने पर आयात करें → अगला और स्रोत और लक्ष्य प्रणाली का चयन करें।
बड़े पैमाने पर आयात के लिए सिस्टम कॉन्फ़िगर करें और समाप्त पर क्लिक करें।
मेटाडेटा का चुनिंदा आयात
यह आपको SAP एप्लिकेशन से मेटा डेटा आयात करने के लिए तालिकाओं को चुनने और स्कीमा को लक्षित करने की अनुमति देता है।
फ़ाइल पर जाएँ → आयात → मेटाडेटा का चुनिंदा आयात → अगला
"SAP एप्लिकेशन" प्रकार का स्रोत कनेक्शन चुनें। याद रखें कि डेटा स्टोर पहले से ही SAP एप्लिकेशन प्रकार बनाया जाना चाहिए → अगला क्लिक करें
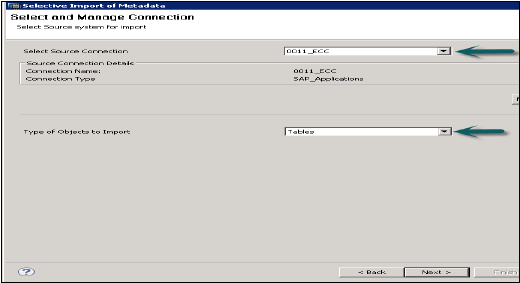
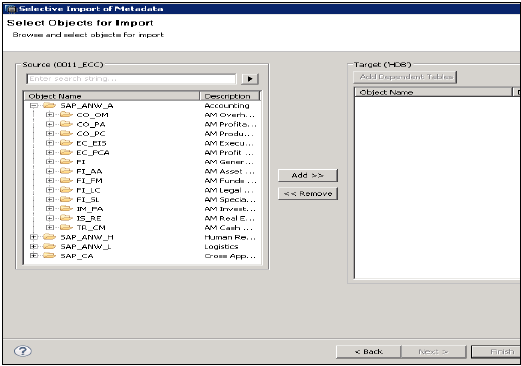
यदि आवश्यक हो, तो उन तालिकाओं का चयन करें, जिन्हें आप आयात और सत्यापित करना चाहते हैं। उसके बाद समाप्त पर क्लिक करें।
हम जानते हैं कि SAP HANA में सूचना मॉडलिंग सुविधा के उपयोग से, हम अलग-अलग सूचना दृश्य गुण, विश्लेषणात्मक दृश्य, गणना दृश्य बना सकते हैं। इन दृश्यों को एसएपी बिजनेस ऑब्जेक्ट, एसएपी लुमिरा, डिजाइन स्टूडियो, ऑफिस एनालिसिस और यहां तक कि एमएस एक्सेल जैसे थर्ड पार्टी टूल जैसे विभिन्न रिपोर्टिंग टूल्स द्वारा भी खाया जा सकता है।
ये रिपोर्टिंग उपकरण व्यवसाय प्रबंधकों, विश्लेषकों, बिक्री प्रबंधकों और वरिष्ठ प्रबंधन कर्मचारियों को व्यावसायिक परिदृश्य बनाने और कंपनी की व्यावसायिक रणनीति तय करने के लिए ऐतिहासिक जानकारी का विश्लेषण करने में सक्षम बनाते हैं।
यह अलग-अलग रिपोर्टिंग टूल द्वारा HANA मॉडलिंग के विचारों का उपभोग करने और रिपोर्ट और डैशबोर्ड बनाने की आवश्यकता उत्पन्न करता है, जो अंतिम उपयोगकर्ताओं के लिए समझना आसान है।

ज्यादातर कंपनियों में, जहां एसएपी लागू किया जाता है, हाना पर रिपोर्टिंग बीआई प्लेटफ़ॉर्म टूल के साथ की जाती है जो कि रिलेशनल और ओएलएपी कनेक्शन की मदद से एसक्यूएल और एमडीएक्स दोनों प्रश्नों का उपभोग करते हैं। बीआई उपकरण की विस्तृत विविधता है जैसे - वेब इंटेलिजेंस, क्रिस्टल रिपोर्ट, डैशबोर्ड, एक्सप्लोरर, ऑफिस एनालिसिस और कई अन्य।
रिपोर्टिंग उपकरण
वेब इंटेलिजेंस और क्रिस्टल रिपोर्ट्स सबसे आम बीआई उपकरण हैं जिनका उपयोग रिपोर्टिंग के लिए किया जाता है। WebI डेटा स्रोत से कनेक्ट करने के लिए यूनिवर्स नामक सिमेंटिक परत का उपयोग करता है और इन यूनिवर्स का उपयोग टूल में रिपोर्टिंग के लिए किया जाता है। इन यूनिवर्स को यूनिवर्स डिज़ाइन टूल UDT की मदद से या सूचना डिज़ाइन टूल IDT के साथ डिज़ाइन किया गया है। IDT मल्टीसॉर सक्षम डेटा स्रोत का समर्थन करता है। हालाँकि, UDT केवल एकल स्रोत का समर्थन करता है।
मुख्य उपकरण जो इंटरैक्टिव डैशबोर्ड- डिज़ाइन स्टूडियो और डैशबोर्ड डिज़ाइनर को डिज़ाइन करने के लिए उपयोग किए जाते हैं। डिज़ाइन स्टूडियो डैशबोर्ड डिज़ाइन करने के लिए भविष्य का उपकरण है, जो BI उपभोक्ता सेवा BICS कनेक्शन के माध्यम से HANA विचारों का उपभोग करता है। डैशबोर्ड डिज़ाइन (xc सेल्सियस) एक रिलेशनल या OLAP कनेक्शन के साथ हाना डेटाबेस में स्कीमा का उपभोग करने के लिए IDT का उपयोग करता है।
एसएपी लुमिरा में हाना डेटाबेस से सीधे डेटा को जोड़ने या लोड करने की एक इनबिल्ट सुविधा है। विज़ुअलाइज़ेशन और कहानियां बनाने के लिए हाना के दृश्यों को लुमिरा में सीधे उपभोग किया जा सकता है।
कार्यालय विश्लेषण हाना सूचना विचारों से जुड़ने के लिए एक OLAP कनेक्शन का उपयोग करता है। यह OLAP कनेक्शन CMC या IDT में बनाया जा सकता है।
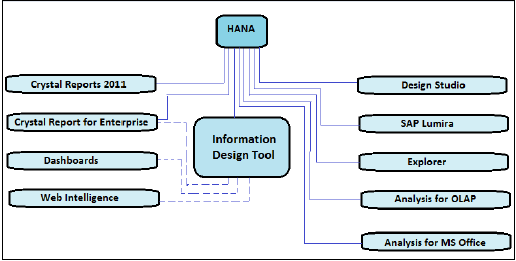
ऊपर दी गई तस्वीर में, यह ठोस रेखाओं के साथ सभी बीआई उपकरण दिखाता है, जिसे ओएलएपी कनेक्शन का उपयोग करके सीधे एसएपी हाना के साथ जोड़ा और एकीकृत किया जा सकता है। इसमें उपकरण भी दर्शाए गए हैं, जिन्हें हाना से कनेक्ट करने के लिए आईडीटी का उपयोग करके एक संबंधपरक कनेक्शन की आवश्यकता होती है जो बिंदीदार रेखाओं के साथ दिखाए जाते हैं।
संबंधपरक बनाम OLAP कनेक्शन
मूल रूप से यह विचार है कि यदि आपको किसी तालिका या पारंपरिक डेटाबेस से डेटा का उपयोग करने की आवश्यकता है तो आपका कनेक्शन एक संबंधपरक कनेक्शन होना चाहिए, लेकिन यदि आपका स्रोत एक एप्लिकेशन है और डेटा क्यूब में संग्रहीत है (जानकारी क्यूब्स, सूचना मॉडल जैसे बहुआयामी) तो आप OLAP कनेक्शन का उपयोग करें।
- एक संबंधपरक कनेक्शन केवल आईडीटी / यूडीटी में बनाया जा सकता है।
- एक OLAP IDT और CMC दोनों में बनाया जा सकता है।
ध्यान देने वाली एक और बात यह है कि एक संबंधपरक कनेक्शन हमेशा रिपोर्ट से निकाल दिया जाता है, जबकि एक OLAP कनेक्शन सामान्य रूप से MDX स्टेटमेंट बनाता है।
सूचना डिजाइन उपकरण
सूचना डिज़ाइन टूल (IDT) में, आप JDBC या ODBC ड्राइवरों का उपयोग करके SAP HANA व्यू या टेबल के लिए एक संबंधपरक कनेक्शन बना सकते हैं और इस कनेक्शन का उपयोग करके डैशबोर्ड और वेब इंटेलिजेंस जैसे क्लाइंट टूल तक पहुँच प्रदान करने के लिए एक यूनिवर्स का निर्माण कर सकते हैं जैसा कि ऊपर चित्र में दिखाया गया है।
आप JDBC या ODBC ड्राइवरों का उपयोग करके SAP HANA से सीधा संबंध बना सकते हैं।
एंटरप्राइज के लिए क्रिस्टल रिपोर्ट
एंटरप्राइज के लिए क्रिस्टल रिपोर्ट में, आप सूचना डिज़ाइन टूल का उपयोग करके बनाए गए मौजूदा संबंधपरक कनेक्शन का उपयोग करके एसएपी हाना डेटा तक पहुंच सकते हैं।
आप सूचना डिज़ाइन टूल या CMC का उपयोग करके बनाए गए OLAP कनेक्शन का उपयोग करके SAP HANA से भी जुड़ सकते हैं।
डिज़ाइन स्टूडियो
डिज़ाइन स्टूडियो सूचना विश्लेषण उपकरण या CMC में ऑफिस एनालिसिस की तरह बने मौजूदा OLAP कनेक्शन का उपयोग करके SAP HANA डेटा तक पहुँच सकता है।
डैशबोर्ड
डैशबोर्ड केवल संबंधपरक यूनिवर्स के माध्यम से एसएपी हाना से जुड़ सकता है। एसएपी हाना के शीर्ष पर डैशबोर्ड का उपयोग करने वाले ग्राहकों को डिजाइन स्टूडियो के साथ अपने नए डैशबोर्ड के निर्माण पर दृढ़ता से विचार करना चाहिए।
वेब इंटेलिजेंस
वेब इंटेलिजेंस SAP HANA से केवल रिलेशनल यूनिवर्स के माध्यम से जुड़ सकता है।
एसएपी लुमिरा
लुमिरा सीधे एसएपी हाना विश्लेषणात्मक और गणना के विचारों से जुड़ सकता है। यह रिलेशनल यूनिवर्स का उपयोग करते हुए SAP BI प्लेटफॉर्म के माध्यम से SAP HANA से भी जुड़ सकता है।
कार्यालय विश्लेषण, OLAP के लिए संस्करण
OLAP के लिए Office विश्लेषण संस्करण में, आप सेंट्रल मैनेजमेंट कंसोल या सूचना डिज़ाइन टूल में परिभाषित OLAP कनेक्शन का उपयोग करके SAP HANA से कनेक्ट कर सकते हैं।
एक्सप्लोरर
आप JDBC ड्राइवरों का उपयोग कर SAP हाना दृश्य के आधार पर एक सूचना स्थान बना सकते हैं।
CMC में OLAP कनेक्शन बनाना
हम सभी BI टूल के लिए OLAP कनेक्शन बना सकते हैं, जिसे हम विश्लेषण के लिए OLAP, एंटरप्राइज़ के लिए क्रिस्टल रिपोर्ट, डिज़ाइन स्टूडियो जैसे HANA दृश्यों के शीर्ष पर उपयोग करना चाहते हैं। आईडीटी के माध्यम से संबंधपरक कनेक्शन का उपयोग वेब इंटेलिजेंस और डैशबोर्ड को हाना डेटाबेस से जोड़ने के लिए किया जाता है।
ये कनेक्शन IDT के साथ-साथ CMC का उपयोग करके बनाया जा सकता है और दोनों कनेक्शन BO रिपोजिटरी में सहेजे गए हैं।
उपयोगकर्ता नाम और पासवर्ड के साथ सीएमसी में लॉगिन करें।
कनेक्शन की ड्रॉपडाउन सूची से, एक OLAP कनेक्शन चुनें। यह सीएमसी में पहले से निर्मित कनेक्शन भी दिखाएगा। एक नया कनेक्शन बनाने के लिए, हरे आइकन पर जाएं और इस पर क्लिक करें।
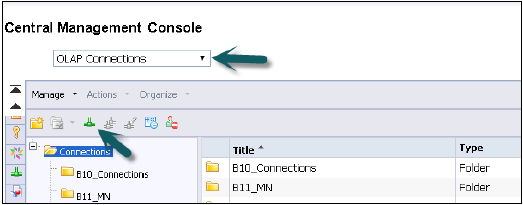
एक OLAP कनेक्शन और विवरण का नाम दर्ज करें। कई व्यक्ति, अलग-अलग BI प्लेटफ़ॉर्म टूल में, HANA के विचारों को जोड़ने के लिए, इस कनेक्शन का उपयोग कर सकते हैं।
Provider - एसएपी हाना
Server - हाना सर्वर नाम दर्ज करें
Instance - उदाहरण संख्या
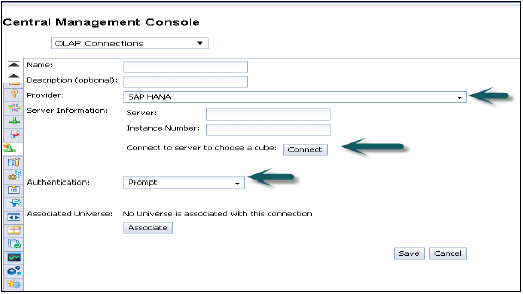
यह एक एकल घन से जुड़ने का विकल्प भी देता है (आप एकल विश्लेषणात्मक या गणना दृश्य से कनेक्ट करने के लिए भी चुन सकते हैं) या पूर्ण HANA प्रणाली से।
कनेक्ट पर क्लिक करें और उपयोगकर्ता नाम और पासवर्ड दर्ज करके मॉडलिंग दृश्य चुनें।
प्रमाणीकरण प्रकार - CMC में OLAP कनेक्शन बनाते समय तीन प्रकार के प्रमाणीकरण संभव हैं।
Predefined - यह इस कनेक्शन का उपयोग करते समय फिर से उपयोगकर्ता नाम और पासवर्ड नहीं पूछेगा।
Prompt - हर बार यह उपयोगकर्ता का नाम और पासवर्ड पूछेगा
SSO - उपयोगकर्ता
Enter user - हाना प्रणाली के लिए उपयोगकर्ता नाम और पासवर्ड और मौजूदा कनेक्शन की सूची में सहेजें और नया कनेक्शन जोड़ा जाएगा।
अब OL के लिए Office विश्लेषण जैसी रिपोर्टिंग के लिए सभी BI प्लेटफ़ॉर्म टूल खोलने के लिए BI Launchpad खोलें और यह कनेक्शन चुनने के लिए कहेगा। डिफ़ॉल्ट रूप से, यह आपको सूचना दृश्य दिखाएगा यदि आपने इस कनेक्शन को बनाते समय इसे निर्दिष्ट किया है अन्यथा नेक्स्ट पर क्लिक करें और फ़ोल्डर में जाएं → व्यूज़ (विश्लेषणात्मक या गणना दृश्य) चुनें।
SAP Lumira connectivity with HANA system
स्टार्ट प्रोग्राम से SAP Lumira खोलें, फ़ाइल मेनू पर क्लिक करें → नया → नया डेटासेट जोड़ें → SAP HANA से कनेक्ट करें → अगला

एसएपी हाना से कनेक्ट और एसएपी हाना से डाउनलोड के बीच अंतर यह है कि यह हाना सिस्टम से बीओ रिपॉजिटरी तक डेटा डाउनलोड करेगा और डेटा को रीफ्रेश करने से हाना सिस्टम में बदलाव नहीं होगा। हाना सर्वर का नाम और इंस्टेंस नंबर दर्ज करें। उपयोगकर्ता नाम और पासवर्ड दर्ज करें → कनेक्ट पर क्लिक करें।
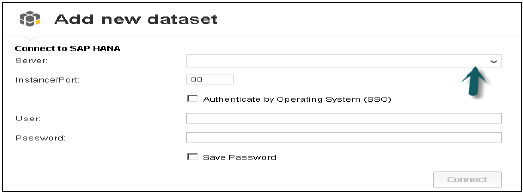
यह सभी विचारों को दिखाएगा। आप दृश्य नाम के साथ खोज कर सकते हैं → दृश्य चुनें → अगला। यह सभी उपायों और आयामों को दिखाएगा। आप चाहें तो इन विशेषताओं में से चुन सकते हैं → क्रिएट ऑप्शन पर क्लिक करें।
एसएपी लुमिरा के अंदर चार टैब हैं -
Prepare - आप डेटा देख सकते हैं और कोई कस्टम गणना कर सकते हैं।
Visualize- आप ग्राफ और चार्ट जोड़ सकते हैं। विशेषताएँ जोड़ने के लिए X अक्ष और Y अक्ष + चिन्ह पर क्लिक करें।
Compose- इस विकल्प का उपयोग विज़ुअलाइज़ेशन (कहानी) के अनुक्रम को बनाने के लिए किया जा सकता है → बोर्ड पर संख्याओं को जोड़ने के लिए बोर्ड पर क्लिक करें → create → यह बाईं ओर सभी विज़ुअलाइज़ेशन दिखाएगा। पहले विज़ुअलाइज़ेशन खींचें फिर पेज जोड़ें फिर दूसरा विज़ुअलाइज़ेशन जोड़ें।
Share- अगर इसे SAP HANA पर बनाया गया है, तो हम केवल SAP Lumira सर्वर पर प्रकाशित कर सकते हैं। अन्यथा आप SAP Lumira से SAP कम्युनिटी नेटवर्क SCN या BI प्लेटफ़ॉर्म पर भी कहानी प्रकाशित कर सकते हैं।
फ़ाइल को बाद में उपयोग करने के लिए सहेजें → फ़ाइल-सहेजें पर जाएँ → स्थानीय → सहेजें चुनें
Creating a Relational Connection in IDT to use with HANA views in WebI and Dashboard -
BI प्लेटफ़ॉर्म क्लाइंट टूल पर जाकर सूचना डिज़ाइन टूल → खोलें। New → Project Enter Project Name → समाप्त पर क्लिक करें।
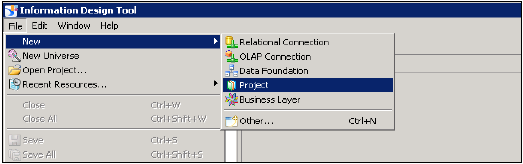
प्रोजेक्ट नाम पर राइट-क्लिक करें → नए पर जाएं → संबंधपरक कनेक्शन चुनें → कनेक्शन / संसाधन नाम दर्ज करें> अगला → HANA सिस्टम से कनेक्ट करने के लिए सूची से SAP चुनें → SAP HANA → JDBC / ODBC ड्राइवरों का चयन करें → अगला पर क्लिक करें → Enter HNA सिस्टम विवरण दर्ज करें → नेक्स्ट एंड फिनिश पर क्लिक करें।

आप इस कनेक्शन का परीक्षण कनेक्शन विकल्प पर क्लिक करके भी कर सकते हैं।
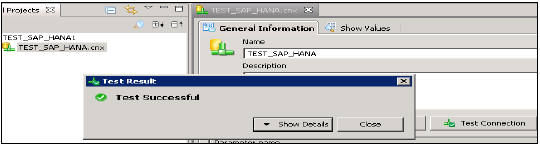
टेस्ट कनेक्शन → सफल। अगला चरण रिपोजिटरी के लिए इस संबंध को प्रकाशित करना है ताकि इसे उपयोग के लिए उपलब्ध कराया जा सके।
कनेक्शन नाम पर राइट क्लिक करें → रिपॉजिटरी से पब्लिश कनेक्शन पर क्लिक करें → बीओ रिपोजिटरी नाम और पासवर्ड दर्ज करें → कनेक्ट पर क्लिक करें → अगला → समाप्त करें + हां।
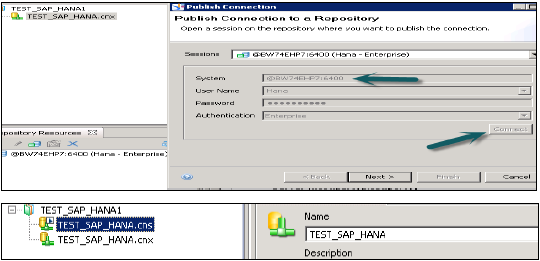
यह .cns एक्सटेंशन के साथ एक नया संबंधपरक कनेक्शन बनाएगा।
.cns - कनेक्शन प्रकार सुरक्षित रिपॉजिटरी कनेक्शन का प्रतिनिधित्व करता है जिसका उपयोग डाटा फाउंडेशन बनाने के लिए किया जाना चाहिए।
.cnx - स्थानीय असुरक्षित कनेक्शन का प्रतिनिधित्व करता है। यदि आप यूनिवर्स बनाते और प्रकाशित करते समय इस कनेक्शन का उपयोग करते हैं, तो यह आपको रिपॉजिटरी में प्रकाशित करने की अनुमति नहीं देगा।
.Cns कनेक्शन प्रकार चुनें → इस पर राइट क्लिक करें → न्यू डेटा फाउंडेशन पर क्लिक करें → डेटा फाउंडेशन का नाम लिखें → अगला → एकल स्रोत / बहु स्रोत → अगला → फिनिश पर क्लिक करें।

यह मध्य फलक में स्कीमा नाम के साथ हाना डेटाबेस में सभी तालिकाओं को दिखाएगा।
यूनिवर्स बनाने के लिए HANA डेटाबेस से मास्टर फलक तक सभी तालिकाओं को आयात करें। स्कीमा बनाने के लिए डिम तालिकाओं में प्राथमिक कुंजियों के साथ डिम और फैक्ट टेबल को मिलाएं।
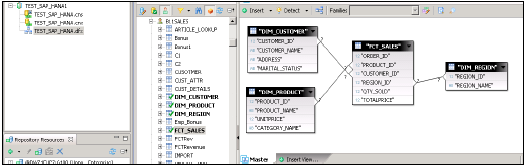
जोड़ों पर डबल क्लिक करें और कार्डिनैलिटी का पता लगाएं → पता लगाएँ → ठीक → शीर्ष पर सभी सहेजें। अब हमें डेटा एप्लिकेशन पर एक नई व्यावसायिक परत बनानी होगी, जो बीआई एप्लीकेशन टूल द्वारा खपत की जाएगी।
.Dfx पर राइट क्लिक करें और नया बिजनेस लेयर चुनें → नाम लिखें → फिनिश →। यह सभी वस्तुओं को स्वचालित रूप से दिखाएगा, मास्टर फलक → के तहत। माप के लिए आयाम बदलें (प्रकार-माप परिवर्तन आवश्यकता के अनुसार) → सभी सहेजें।
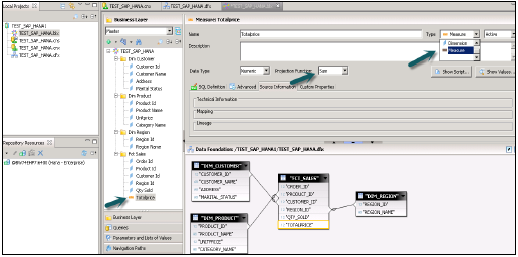
.Bfx फ़ाइल पर राइट-क्लिक करें → पब्लिश → To रिपोजिटरी पर क्लिक करें → नेक्स्ट → फिनिश पर क्लिक करें → यूनिवर्स प्रकाशित सफलतापूर्वक।
अब BI लॉन्चपैड से WebI रिपोर्ट या BI प्लेटफ़ॉर्म क्लाइंट टूल से Webi अमीर क्लाइंट → New → चयन करें Universe → TEST_SAP_HANA → OK।
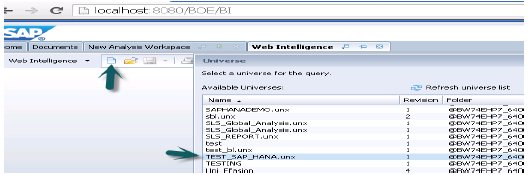
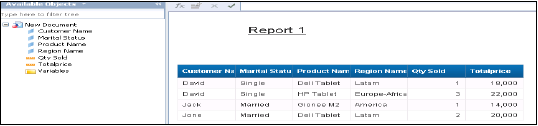
सभी ऑब्जेक्ट्स को क्वेरी पैनल में जोड़ा जाएगा। आप बाएँ फलक से विशेषताएँ और उपाय चुन सकते हैं और उन्हें परिणाम वस्तुओं में जोड़ सकते हैं। Run query SQL क्वेरी चलाएगा और आउटपुट वेबआई में रिपोर्ट के रूप में उत्पन्न होगा जैसा कि नीचे दिखाया गया है।
Microsoft Excel को कई संगठनों द्वारा सबसे आम BI रिपोर्टिंग और विश्लेषण उपकरण माना जाता है। व्यापार प्रबंधक और विश्लेषक विश्लेषण के लिए पिवट टेबल और चार्ट बनाने के लिए इसे HANA डेटाबेस से जोड़ सकते हैं।
एमएस एक्सेल को हाना से जोड़ना
Excel खोलें और अन्य स्रोतों से डेटा टैब → पर जाएं → डेटा कनेक्शन विज़ार्ड पर क्लिक करें → अन्य / उन्नत और अगला → डेटा लिंक गुणों पर क्लिक करें खुल जाएगा।
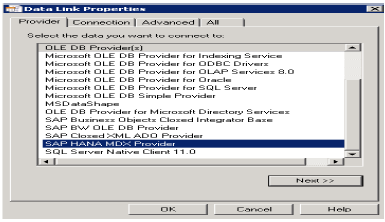
किसी भी MDX डेटा स्रोत से कनेक्ट करने के लिए इस सूची से SAP HANA MDX प्रदाता चुनें → HANA सिस्टम विवरण (सर्वर नाम, उदाहरण, उपयोगकर्ता नाम और पासवर्ड) दर्ज करें → टेस्ट कनेक्शन पर क्लिक करें → कनेक्शन सफल → ओके।
यह आपको ड्रॉप डाउन सूची के सभी पैकेजों की सूची देगा जो एचएएनए प्रणाली में उपलब्ध हैं। आप एक सूचना दृश्य चुन सकते हैं → अगला क्लिक करें → पिवट टेबल का चयन करें / अन्य → ठीक।
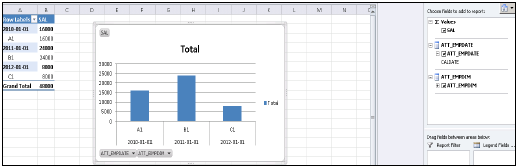
सूचना दृश्य से सभी विशेषताओं को एमएस एक्सेल में जोड़ा जाएगा। आप दिखाए गए अनुसार रिपोर्ट करने के लिए विभिन्न विशेषताओं और उपायों को चुन सकते हैं और शीर्ष पर डिज़ाइन विकल्प से पाई चार्ट और बार चार्ट जैसे विभिन्न चार्ट चुन सकते हैं।
सुरक्षा का अर्थ है कंपनी के महत्वपूर्ण डेटा को अनधिकृत पहुंच और उपयोग से बचाना, और यह सुनिश्चित करना कि कंपनी की नीति के अनुसार अनुपालन और मानकों को पूरा किया जाए। एसएपी हाना ग्राहक को विभिन्न सुरक्षा नीतियों और प्रक्रियाओं को लागू करने और कंपनी की अनुपालन आवश्यकताओं को पूरा करने में सक्षम बनाता है।
एसएपी हाना एक ही हाना प्रणाली में कई डेटाबेस का समर्थन करता है और इसे मल्टीटैनेंट डेटाबेस कंटेनर के रूप में जाना जाता है। हाना प्रणाली में एक से अधिक मल्टीटैनेंट डेटाबेस कंटेनर भी हो सकते हैं। एक मल्टीपल कंटेनर सिस्टम में हमेशा एक सिस्टम डेटाबेस और किसी भी नंबर पर मल्टीटेनेंट डेटाबेस कंटेनर होते हैं। एएन एसएपी हाना प्रणाली जो इस वातावरण में स्थापित है, एक एकल सिस्टम आईडी (एसआईडी) द्वारा पहचानी जाती है। HANA सिस्टम में डेटाबेस कंटेनरों की पहचान एक SID और डेटाबेस नाम से की जाती है। एसएपी हाना क्लाइंट, जिसे हाना स्टूडियो के रूप में जाना जाता है, विशिष्ट डेटाबेस से जुड़ता है।
SAP HANA सुरक्षा से संबंधित सभी सुविधाएँ प्रदान करता है जैसे प्रमाणीकरण, प्राधिकरण, एन्क्रिप्शन और ऑडिटिंग, और कुछ सुविधाएँ जोड़ते हैं, जो अन्य मल्टीटैनेंट डेटाबेस में समर्थित नहीं हैं।
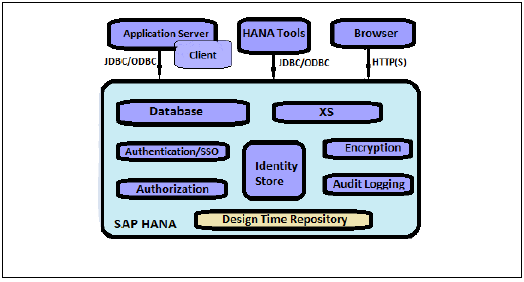
नीचे दी गई सुरक्षा संबंधित सुविधाओं की एक सूची है, जो एसएपी हाना द्वारा प्रदान की गई है -
- उपयोगकर्ता और भूमिका प्रबंधन
- प्रमाणीकरण और एस.एस.ओ.
- Authorization
- नेटवर्क में डेटा संचार का एन्क्रिप्शन
- दृढ़ता परत में डेटा का एन्क्रिप्शन
बहुराष्ट्रीय हाना डेटाबेस में अतिरिक्त विशेषताएं -
Database Isolation - इसमें ऑपरेटिंग सिस्टम तंत्र के माध्यम से क्रॉस टेनेंट हमलों को रोकना शामिल है
Configuration Change blacklist - इसमें कुछ सिस्टम प्रॉपर्टीज को टेनेंट डेटाबेस एडमिनिस्ट्रेटर द्वारा बदले जाने से रोकना शामिल है
Restricted Features - इसमें कुछ डेटाबेस सुविधाओं को अक्षम करना शामिल है जो फ़ाइल सिस्टम, नेटवर्क या अन्य संसाधनों तक सीधे पहुंच प्रदान करता है।
एसएपी हाना उपयोगकर्ता और भूमिका प्रबंधन
एसएपी हाना उपयोगकर्ता और भूमिका प्रबंधन विन्यास आपके हाना प्रणाली की वास्तुकला पर निर्भर करता है।
यदि एसएपी हाना बीआई प्लेटफ़ॉर्म टूल के साथ एकीकृत है और रिपोर्टिंग डेटाबेस के रूप में कार्य करता है, तो एंड-यूज़र और भूमिका को एप्लिकेशन सर्वर में प्रबंधित किया जाता है।
यदि अंतिम-उपयोगकर्ता सीधे एसएपी हाना डेटाबेस से जुड़ता है, तो अंत उपयोगकर्ता और प्रशासक दोनों के लिए हाना प्रणाली की डेटाबेस परत में उपयोगकर्ता और भूमिका आवश्यक है।
हर उपयोगकर्ता HANA डेटाबेस के साथ काम करना चाहता है आवश्यक आवश्यक विशेषाधिकार के साथ एक डेटाबेस उपयोगकर्ता होना चाहिए। उपयोगकर्ता की पहुंच HANA प्रणाली या तो एक तकनीकी उपयोगकर्ता या अंतिम उपयोगकर्ता हो सकती है जो एक्सेस आवश्यकता पर निर्भर करती है। सिस्टम में सफल लॉगऑन के बाद, आवश्यक ऑपरेशन करने के लिए उपयोगकर्ता का प्राधिकरण सत्यापित किया जाता है। उस ऑपरेशन को निष्पादित करना उन विशेषाधिकारों पर निर्भर करता है जो उपयोगकर्ता को दी गई हैं। इन विशेषाधिकारों को हाना सुरक्षा में भूमिकाओं का उपयोग करके दिया जा सकता है। हाना स्टूडियो, हाना डेटाबेस सिस्टम के लिए उपयोगकर्ता और भूमिकाओं को प्रबंधित करने के लिए एक शक्तिशाली उपकरण है।
उपयोगकर्ता प्रकार
उपयोगकर्ता प्रोफ़ाइल पर निर्दिष्ट सुरक्षा नीतियों और विभिन्न विशेषाधिकारों के अनुसार उपयोगकर्ता प्रकार भिन्न होते हैं। उपयोगकर्ता प्रकार एक तकनीकी डेटाबेस उपयोगकर्ता हो सकता है या अंत उपयोगकर्ता को रिपोर्टिंग उद्देश्य के लिए या डेटा हेरफेर के लिए एचएएनए सिस्टम पर पहुंच की आवश्यकता होती है।
मानक उपयोगकर्ता
मानक उपयोगकर्ता वे उपयोगकर्ता हैं जो अपने स्वयं के स्कीमा में ऑब्जेक्ट बना सकते हैं और सिस्टम इन्फ़ॉर्मेशन मॉडल में एक्सेस पढ़ सकते हैं। पब्ब्लिक भूमिका द्वारा रीड एक्सेस प्रदान किया जाता है जो हर मानक उपयोगकर्ताओं को सौंपा जाता है।
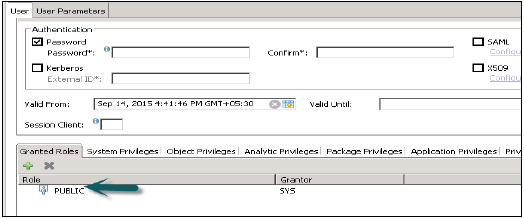
प्रतिबंधित उपयोगकर्ता
प्रतिबंधित उपयोगकर्ता वे उपयोगकर्ता हैं जो कुछ अनुप्रयोगों के साथ एचएएनए प्रणाली का उपयोग करते हैं और उनके पास एचएएन प्रणाली पर एसक्यूएल विशेषाधिकार नहीं हैं। जब ये उपयोगकर्ता बनाए जाते हैं, तो शुरू में उनकी कोई पहुँच नहीं होती है।
यदि हम प्रतिबंधित उपयोगकर्ताओं की तुलना मानक उपयोगकर्ताओं से करते हैं -
प्रतिबंधित उपयोगकर्ता HANA डेटाबेस या अपने स्वयं के स्कीमा में ऑब्जेक्ट नहीं बना सकते हैं।
डेटाबेस में किसी भी डेटा को देखने के लिए उनकी पहुंच नहीं है क्योंकि उनके पास सामान्य उपयोगकर्ताओं की तरह सामान्य सार्वजनिक भूमिका नहीं है।
वे केवल HTTP / HTTPS का उपयोग करके HANA डेटाबेस से जुड़ सकते हैं।
तकनीकी डेटाबेस उपयोगकर्ताओं का उपयोग केवल प्रशासनिक उद्देश्य के लिए किया जाता है, जैसे डेटाबेस में नई वस्तुएं बनाना, अन्य उपयोगकर्ताओं को विशेषाधिकार प्रदान करना, पैकेज, एप्लिकेशन आदि।
एसएपी हाना उपयोगकर्ता प्रशासन गतिविधियाँ
व्यावसायिक आवश्यकताओं और एचएएनए प्रणाली के विन्यास के आधार पर, विभिन्न उपयोगकर्ता गतिविधियां हैं जो उपयोगकर्ता प्रशासन उपकरण जैसे हाना स्टूडियो का उपयोग करके की जा सकती हैं।
अधिकांश सामान्य गतिविधियों में शामिल हैं -
- उपयोगकर्ता बनाएँ
- उपयोगकर्ताओं को भूमिकाएँ प्रदान करता है
- परिभाषित करें और भूमिकाएँ बनाएँ
- उपयोगकर्ताओं को हटाना
- उपयोगकर्ता पासवर्ड रीसेट करना
- कई असफल लॉगऑन प्रयासों के बाद उपयोगकर्ताओं को पुन: सक्रिय करना
- आवश्यकता पड़ने पर उपयोगकर्ताओं को निष्क्रिय करना
हाना स्टूडियो में उपयोगकर्ता कैसे बनाएं?
केवल डेटाबेस उपयोगकर्ताओं को सिस्टम विशेषाधिकार रोल ADMIN के साथ उपयोगकर्ताओं को हाना स्टूडियो में उपयोगकर्ता और भूमिकाएं बनाने की अनुमति है। हाना स्टूडियो में उपयोगकर्ता और भूमिकाएं बनाने के लिए, हाना प्रशासक कंसोल पर जाएं। आपको सिस्टम दृश्य में सुरक्षा टैब दिखाई देगा -
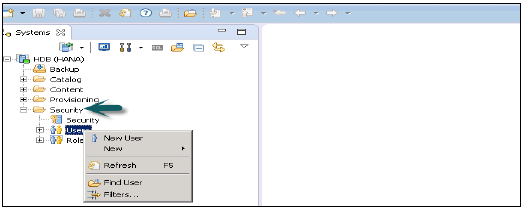
जब आप सुरक्षा टैब का विस्तार करते हैं, तो यह उपयोगकर्ता और भूमिका का विकल्प देता है। नया उपयोगकर्ता बनाने के लिए उपयोगकर्ता पर राइट क्लिक करें और नए उपयोगकर्ता पर जाएँ। नई विंडो खुल जाएगी जहां आप उपयोगकर्ता और उपयोगकर्ता मापदंडों को परिभाषित करते हैं।
उपयोगकर्ता नाम (जनादेश) दर्ज करें और प्रमाणीकरण क्षेत्र में पासवर्ड दर्ज करें। नए उपयोगकर्ता के लिए पासवर्ड सहेजते समय पासवर्ड लागू किया जाता है। आप एक प्रतिबंधित उपयोगकर्ता बनाने का विकल्प भी चुन सकते हैं।
निर्दिष्ट भूमिका नाम किसी मौजूदा उपयोगकर्ता या भूमिका के नाम के समान नहीं होना चाहिए। पासवर्ड के नियमों में एक न्यूनतम पासवर्ड की लंबाई और परिभाषा के प्रकार शामिल होते हैं (कम, ऊपरी, अंक, विशेष वर्ण) पासवर्ड का हिस्सा होना चाहिए।
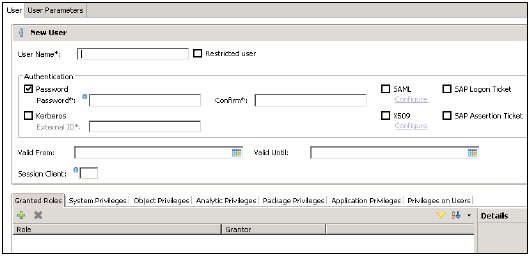
विभिन्न प्राधिकरण विधियों को SAML, X509 प्रमाणपत्र, SAP लॉगऑन टिकट, आदि जैसे कॉन्फ़िगर किया जा सकता है। डेटाबेस में उपयोगकर्ताओं को अलग-अलग तंत्र द्वारा प्रमाणित किया जा सकता है -
पासवर्ड का उपयोग करके आंतरिक प्रमाणीकरण तंत्र।
बाहरी तंत्र जैसे केर्बरोस, एसएएमएल, एसएपी लोगन टिकट, एसएपी अभिकथन टिकट या एक्स 509।
एक उपयोगकर्ता को एक बार में एक से अधिक तंत्र द्वारा प्रमाणित किया जा सकता है। हालांकि, केवल एक पासवर्ड और करबरोस के लिए एक प्रमुख नाम किसी भी एक समय में मान्य हो सकता है। एक प्रमाणीकरण तंत्र को उपयोगकर्ता को डेटाबेस उदाहरण के साथ जुड़ने और काम करने की अनुमति देने के लिए निर्दिष्ट किया जाना चाहिए।
यह उपयोगकर्ता की वैधता को परिभाषित करने का एक विकल्प भी देता है, आप तिथियों का चयन करके वैधता अंतराल का उल्लेख कर सकते हैं। वैधता विनिर्देशन एक वैकल्पिक उपयोगकर्ता पैरामीटर है।
डिफ़ॉल्ट रूप से, SAP HANA डेटाबेस के साथ दिए गए कुछ उपयोगकर्ता हैं - SYS, SYSTEM, _SYS_REPO, _SYS_STATISTICS।
एक बार ऐसा करने के बाद, अगला चरण उपयोगकर्ता प्रोफ़ाइल के लिए विशेषाधिकारों को परिभाषित करना है। उपयोगकर्ता प्रोफ़ाइल में विभिन्न प्रकार के विशेषाधिकार जोड़े जा सकते हैं।
एक उपयोगकर्ता के लिए भूमिकाएँ दी
इसका उपयोग उपयोगकर्ता प्रोफ़ाइल में इनबिल्ट SAP.HANA भूमिकाओं को जोड़ने या रोल्स टैब के तहत बनाई गई कस्टम भूमिकाओं को जोड़ने के लिए किया जाता है। कस्टम भूमिकाएँ आपको पहुँच आवश्यकता के अनुसार भूमिकाओं को परिभाषित करने की अनुमति देती हैं और आप इन भूमिकाओं को सीधे उपयोगकर्ता प्रोफ़ाइल में जोड़ सकते हैं। यह अलग-अलग एक्सेस प्रकारों के लिए हर बार उपयोगकर्ता प्रोफ़ाइल में ऑब्जेक्ट्स को याद रखने और जोड़ने की आवश्यकता को हटाता है।
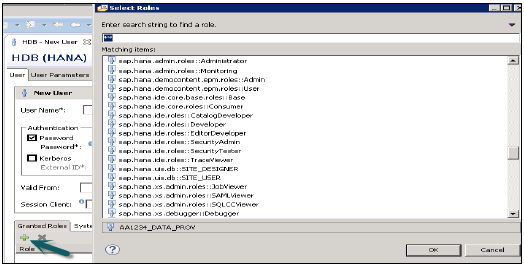
PUBLIC- यह सामान्य भूमिका है और डिफ़ॉल्ट रूप से सभी डेटाबेस उपयोगकर्ताओं को सौंपा गया है। इस भूमिका में सिस्टम दृश्य तक केवल पहुंच और कुछ प्रक्रियाओं के लिए विशेषाधिकारों को निष्पादित करना शामिल है। इन भूमिकाओं को रद्द नहीं किया जा सकता है।

मोडलिंग
इसमें SAP HANA स्टूडियो में सूचना मॉडलर का उपयोग करने के लिए आवश्यक सभी विशेषाधिकार हैं।
सिस्टम प्रिविलेज
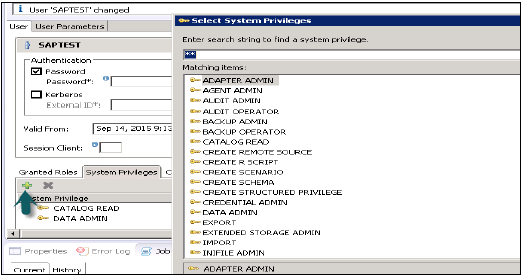
विभिन्न प्रकार के सिस्टम विशेषाधिकार हैं जिन्हें उपयोगकर्ता प्रोफ़ाइल में जोड़ा जा सकता है। उपयोगकर्ता प्रोफ़ाइल में सिस्टम विशेषाधिकारों को जोड़ने के लिए, + साइन पर क्लिक करें।
सिस्टम विशेषाधिकारों का उपयोग बैकअप / पुनर्स्थापना, उपयोगकर्ता प्रशासन, इंस्टेंस प्रारंभ और रोक आदि के लिए किया जाता है।
सामग्री व्यवस्थापक
इसमें समान भूमिकाएँ होती हैं जो कि MODELING भूमिका में होती हैं, लेकिन इसके अलावा कि इस भूमिका को इन विशेषाधिकारों को अन्य उपयोगकर्ताओं को देने की अनुमति है। इसमें आयातित वस्तुओं के साथ काम करने के लिए रिपॉजिटरी विशेषाधिकार भी हैं।
डेटा व्यवस्थापक
यह एक प्रकार का विशेषाधिकार है, जो वस्तुओं से उपयोगकर्ता प्रोफ़ाइल में डेटा जोड़ने के लिए आवश्यक है।
नीचे दिए गए सामान्य समर्थित सिस्टम विशेषाधिकार हैं -
डिबगर संलग्न करें
यह एक प्रक्रिया कॉल के डिबगिंग को अधिकृत करता है, जिसे एक अलग उपयोगकर्ता द्वारा बुलाया जाता है। इसके अतिरिक्त, संबंधित प्रक्रिया के लिए DEBUG विशेषाधिकार की आवश्यकता है।
ऑडिट व्यवस्थापक
निम्नलिखित ऑडिटिंग-संबंधित कमांड के निष्पादन को नियंत्रित करता है - क्रिएट ऑडी पॉली, ड्राप ऑडी पॉलीटी और एटर ऑडीट पॉलिक और ऑडिटिंग कॉन्फ़िगरेशन के परिवर्तन। इसके अलावा AUDIT_LOG सिस्टम दृश्य तक पहुंच की अनुमति देता है।
ऑडिट ऑपरेटर
यह निम्नलिखित कमांड के निष्पादन को अधिकृत करता है - ALTER SYSTEM CLEAR AUDIT LOG। इसके अलावा AUDIT_LOG सिस्टम दृश्य तक पहुंच की अनुमति देता है।
बैकअप व्यवस्थापक
यह बैकअप और पुनर्प्राप्ति प्रक्रियाओं को परिभाषित करने और आरंभ करने के लिए बैकअप और रिकॉर्ड आदेशों को अधिकृत करता है।
बैकअप ऑपरेटर
यह बैकअप प्रक्रिया शुरू करने के लिए BACKUP कमांड को अधिकृत करता है।
कैटलॉग पढ़ें
यह उपयोगकर्ताओं को सभी सिस्टम दृश्यों के लिए केवल-पढ़ने के लिए अनफ़िल्टर्ड करने के लिए अधिकृत करता है। आम तौर पर, इन विचारों की सामग्री को एक्सेस करने वाले उपयोगकर्ता के विशेषाधिकारों के आधार पर फ़िल्टर किया जाता है।
स्कीमा बनाएं
यह क्रिएट स्कीमा कमांड का उपयोग करके डेटाबेस स्कीमा के निर्माण को अधिकृत करता है। डिफ़ॉल्ट रूप से, प्रत्येक उपयोगकर्ता एक स्कीमा का मालिक होता है, इस विशेषाधिकार के साथ उपयोगकर्ता को अतिरिक्त स्कीमा बनाने की अनुमति होती है।
सृजित PRIVILEGE निर्मित
यह संरचित विशेषाधिकार (विश्लेषणात्मक विशेषाधिकार) के निर्माण को अधिकृत करता है। केवल एक विश्लेषणात्मक विशेषाधिकार का मालिक ही अन्य उपयोगकर्ताओं या भूमिकाओं के लिए उस विशेषाधिकार को आगे बढ़ा सकता है या रद्द कर सकता है।
क्रेडेंशियल एडमिन
यह क्रेडेंशियल कमांड्स बनाता है - क्रिएट / अलर्ट / ड्रॉड क्रेडेंशियल।
डेटा व्यवस्थापक
यह सिस्टम दृश्य में सभी डेटा को पढ़ने को अधिकृत करता है। यह एसएपी हाना डेटाबेस में किसी भी डेटा डेफिनिशन लैंग्वेज (डीडीएल) कमांड को निष्पादित करने में सक्षम बनाता है
इस विशेषाधिकार वाले उपयोगकर्ता डेटा संग्रहीत तालिकाओं का चयन या परिवर्तन नहीं कर सकते हैं, जिसके लिए उनके पास एक्सेस विशेषाधिकार नहीं हैं, लेकिन वे टेबल परिभाषाओं को छोड़ सकते हैं या संशोधित कर सकते हैं।
डेटाबेस व्यवस्थापक
यह एक डेटाबेस में डेटाबेस से संबंधित सभी आदेशों को अधिकृत करता है, जैसे कि क्रेट, ड्रोप, अल्टर, रेनैम, बेकअप, रिकोवेरी।
निर्यात
यह निर्यात तालिका आदेश के माध्यम से डेटाबेस में निर्यात गतिविधि को अधिकृत करता है।
ध्यान दें कि इस विशेषाधिकार के साथ उपयोगकर्ता को निर्यात की जाने वाली स्रोत तालिकाओं पर SELECT विशेषाधिकार की आवश्यकता होती है।
आयात
यह आयात आदेशों का उपयोग करके डेटाबेस में आयात गतिविधि को अधिकृत करता है।
ध्यान दें कि इस विशेषाधिकार के साथ उपयोगकर्ता को आयात किए जाने वाले लक्ष्य तालिकाओं पर INSERT विशेषाधिकार की आवश्यकता होती है।
इनफाइल एडमिन
यह सिस्टम सेटिंग्स को बदलने को अधिकृत करता है।
लाइसेंस व्यवस्थापक
यह SET SYSTEM LICENSE कमांड को एक नया लाइसेंस स्थापित करने के लिए अधिकृत करता है।
प्रवेश करें व्यवस्थापक
यह लॉग फ्लश तंत्र को सक्षम या अक्षम करने के लिए ALTER SYSTEM LOGGING [ON | OFF] कमांड को अधिकृत करता है।
मॉनिटर व्यवस्थापक
यह EVENT के लिए ALTER सिस्टम कमांड को अधिकृत करता है।
अनुकूलक व्यवस्थापक
यह SQL PLAN CACHE और ALTER SYSTEM UPDATE STATISTICS कमांड से संबंधित ALTER सिस्टम कमांड को अधिकृत करता है, जो क्वेरी ऑप्टिमाइज़र के व्यवहार को प्रभावित करता है।
संसाधन व्यवस्थापक
यह विशेषाधिकार सिस्टम संसाधनों से संबंधित कमांड को अधिकृत करता है। उदाहरण के लिए, ALTER SYSTEM RECLAIM DATAVOLUME और ALTER SYSTEM RESET MONITORING VIEW। यह प्रबंधन कंसोल में उपलब्ध कई कमांड को भी अधिकृत करता है।
भूमिका व्यवस्थापक
यह विशेषाधिकार क्रिएट रोल और ड्रॉप रोल आदेशों का उपयोग करके भूमिकाओं के निर्माण और विलोपन को अधिकृत करता है। यह GRANT और REVOKE आदेशों का उपयोग करके भूमिकाओं के अनुदान और निरसन को भी अधिकृत करता है।
सक्रिय भूमिकाएँ, अर्थ भूमिकाएँ जिनके निर्माता पूर्व-निर्धारित उपयोगकर्ता _SYS_REPO हैं, उन्हें न तो अन्य भूमिकाओं या उपयोगकर्ताओं को दिया जा सकता है और न ही सीधे छोड़ा जा सकता है। ROLE ADMIN विशेषाधिकार वाले उपयोगकर्ता भी ऐसा करने में सक्षम नहीं हैं। सक्रिय वस्तुओं से संबंधित प्रलेखन की जाँच करें।
सेवपॉइंट एडमिन
यह ALTER SYSTEM SAVEPOINT कमांड का उपयोग करके एक सेवपॉइंट प्रक्रिया के निष्पादन को अधिकृत करता है।
एसएपी हाना डेटाबेस के घटक नए सिस्टम विशेषाधिकार बना सकते हैं। ये विशेषाधिकार सिस्टम-विशेषाधिकार के पहले पहचानकर्ता के रूप में घटक-नाम और दूसरे पहचानकर्ता के रूप में घटक-विशेषाधिकार-नाम का उपयोग करते हैं।
ऑब्जेक्ट / SQL प्रिविलेज
ऑब्जेक्ट विशेषाधिकारों को SQL विशेषाधिकार के रूप में भी जाना जाता है। इन विशेषाधिकारों का उपयोग तालिकाओं, दृश्यों या स्कीमाओं के चयन, सम्मिलित, अद्यतन और हटाने जैसी वस्तुओं पर पहुंच की अनुमति के लिए किया जाता है।
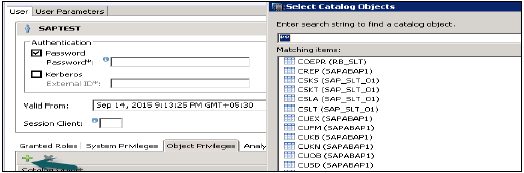
नीचे दिए गए ऑब्जेक्ट प्रिविलेज के संभावित प्रकार दिए गए हैं -
डेटाबेस ऑब्जेक्ट्स पर ऑब्जेक्ट विशेषाधिकार जो केवल रनटाइम में मौजूद हैं
गणना विचारों की तरह, भंडार में बनाई गई सक्रिय वस्तुओं पर वस्तु विशेषाधिकार
स्कीमा पर वस्तु विशेषाधिकार, सक्रिय भंडार में निर्मित वस्तुएं,
ऑब्जेक्ट / SQL विशेषाधिकार डेटाबेस ऑब्जेक्ट पर सभी DDL और DML विशेषाधिकारों का संग्रह है।
नीचे दिए गए सामान्य समर्थित वस्तु विशेषाधिकार हैं -
HANA डेटाबेस में कई डेटाबेस ऑब्जेक्ट हैं, इसलिए सभी विशेषाधिकार सभी प्रकार के डेटाबेस ऑब्जेक्ट पर लागू नहीं होते हैं।
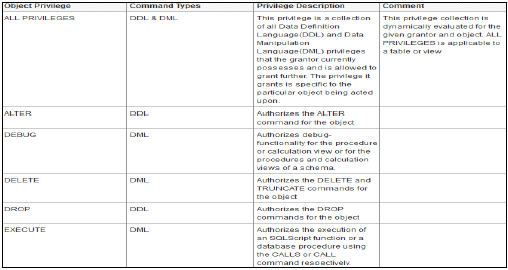
ऑब्जेक्ट विशेषाधिकार और डेटाबेस ऑब्जेक्ट पर उनकी प्रयोज्यता -
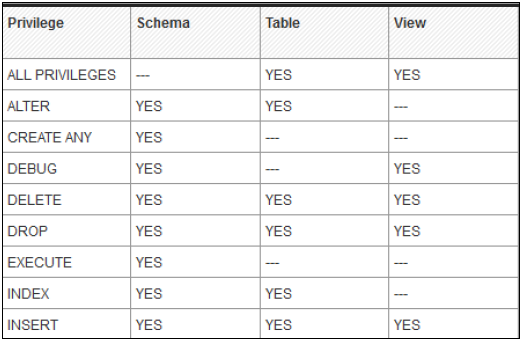
विश्लेषणात्मक विशेषाधिकार
कभी-कभी, यह आवश्यक है कि उसी दृश्य में डेटा अन्य उपयोगकर्ताओं के लिए सुलभ न हो, जिनके पास उस डेटा के लिए कोई प्रासंगिक आवश्यकता नहीं है।
विश्लेषणात्मक सूचना का उपयोग वस्तु स्तर पर हाना सूचना दृश्य तक पहुँच को सीमित करने के लिए किया जाता है। हम विश्लेषणात्मक विशेषाधिकार में पंक्ति और स्तंभ स्तर की सुरक्षा लागू कर सकते हैं।
विश्लेषणात्मक विशेषाधिकार के लिए उपयोग किया जाता है -
- विशिष्ट मूल्य सीमा के लिए पंक्ति और स्तंभ स्तर सुरक्षा का आवंटन।
- मॉडलिंग दृश्यों के लिए पंक्ति और स्तंभ स्तर की सुरक्षा का आवंटन।
पैकेज विशेषाधिकार
एसएपी हाना भंडार में, आप विशिष्ट उपयोगकर्ता के लिए या एक भूमिका के लिए पैकेज प्राधिकरण सेट कर सकते हैं। पैकेज विशेषाधिकारों का उपयोग डेटा मॉडल- विश्लेषणात्मक या गणना के विचारों या रिपॉजिटरी ऑब्जेक्ट पर पहुंच की अनुमति देने के लिए किया जाता है। सभी विशेषाधिकारों को एक रिपॉजिटरी पैकेज को सौंपा गया है जो सभी उप पैकेजों को भी सौंपा गया है। आप यह भी उल्लेख कर सकते हैं कि सौंपा गया उपयोगकर्ता प्राधिकरण अन्य उपयोगकर्ताओं को दिया जा सकता है या नहीं।
उपयोगकर्ता प्रोफ़ाइल में पैकेज विशेषाधिकार जोड़ने के चरण -
उपयोगकर्ता निर्माण के तहत हाना स्टूडियो में पैकेज विशेषाधिकार टैब पर क्लिक करें → एक या अधिक पैकेज जोड़ने के लिए + चुनें। कई संकुल का चयन करने के लिए Ctrl कुंजी का प्रयोग करें।
रिपॉजिटरी पैकेज चुनें का चयन करें, रिपॉजिटरी पैकेज का पता लगाने के लिए पैकेज नाम के सभी या भाग का उपयोग करें जिसे आप एक्सेस करना चाहते हैं।
उन एक या अधिक रिपॉजिटरी पैकेजों का चयन करें जिन्हें आप एक्सेस करने के लिए अधिकृत करना चाहते हैं, चयनित पैकेज पैकेज प्रिविलेज टैब में दिखाई देते हैं।
नीचे दिए गए अनुदान विशेषाधिकार हैं, जिनका उपयोग उपयोगकर्ता को वस्तुओं को संशोधित करने के लिए अधिकृत करने के लिए भंडार पैकेज पर किया जाता है -
REPO.READ - चयनित पैकेज और डिज़ाइन-टाइम ऑब्जेक्ट (मूल और आयातित दोनों) तक पहुंच पढ़ें
REPO.EDIT_NATIVE_OBJECTS - संकुल में वस्तुओं को संशोधित करने के लिए प्राधिकरण।
Grantable to Others - यदि आप इसके लिए 'हां' चुनते हैं, तो यह असाइन किए गए उपयोगकर्ता प्राधिकरण को अन्य उपयोगकर्ताओं को पास करने की अनुमति देता है।
आवेदन विशेषाधिकार
उपयोगकर्ता प्रोफ़ाइल में एप्लिकेशन विशेषाधिकार HANA XS एप्लिकेशन तक पहुंच के लिए प्राधिकरण को परिभाषित करने के लिए उपयोग किया जाता है। यह एक व्यक्तिगत उपयोगकर्ता या उपयोगकर्ताओं के समूह को सौंपा जा सकता है। एप्लिकेशन विशेषाधिकारों का उपयोग एक ही एप्लिकेशन को विभिन्न स्तरों तक पहुंच प्रदान करने के लिए भी किया जा सकता है जैसे डेटाबेस प्रशासकों के लिए उन्नत कार्य प्रदान करना और सामान्य उपयोगकर्ताओं के लिए केवल-पढ़ने के लिए उपयोग।
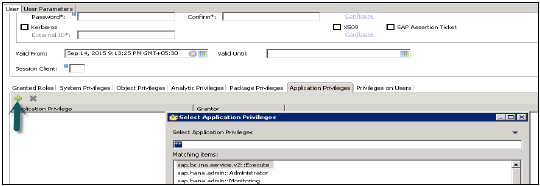
उपयोगकर्ता प्रोफ़ाइल में एप्लिकेशन विशिष्ट विशेषाधिकारों को परिभाषित करने या उपयोगकर्ताओं के समूह को जोड़ने के लिए, विशेषाधिकारों का उपयोग किया जाना चाहिए -
- एप्लिकेशन-विशेषाधिकार फ़ाइल (.xsprivileges)
- एप्लिकेशन-एक्सेस फ़ाइल (.xsaccess)
- भूमिका-परिभाषा फ़ाइल (<भूमिका नाम>। अखंड)
सभी एसएपी हाना उपयोगकर्ता जिनके पास हाना डेटाबेस तक पहुंच है, विभिन्न प्रमाणीकरण विधियों के साथ सत्यापित हैं। एसएपी हाना प्रणाली विभिन्न प्रकार के प्रमाणीकरण पद्धति का समर्थन करती है और इन सभी लॉगिन तरीकों को प्रोफ़ाइल निर्माण के समय कॉन्फ़िगर किया गया है।
नीचे SAP HANA द्वारा समर्थित प्रमाणीकरण विधियों की सूची दी गई है -
- प्रयोक्ता नाम पासवर्ड
- Kerberos
- SAML 2.0
- एसएपी लोगन टिकट
- X.509
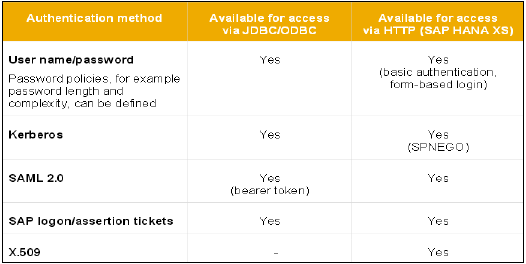
प्रयोक्ता नाम पासवर्ड
इस विधि में डेटाबेस में प्रवेश करने के लिए उपयोगकर्ता नाम और पासवर्ड दर्ज करने के लिए एक हाना उपयोगकर्ता की आवश्यकता होती है। यह उपयोगकर्ता प्रोफ़ाइल हाना स्टूडियो → सुरक्षा टैब में उपयोगकर्ता प्रबंधन के तहत बनाई गई है।
पासवर्ड पासवर्ड नीति के अनुसार होना चाहिए अर्थात पासवर्ड की लंबाई, जटिलता, निचले और ऊपरी मामले के पत्र, आदि।
आप अपने संगठन के सुरक्षा मानकों के अनुसार पासवर्ड नीति को बदल सकते हैं। कृपया ध्यान दें कि पासवर्ड नीति निष्क्रिय नहीं की जा सकती।
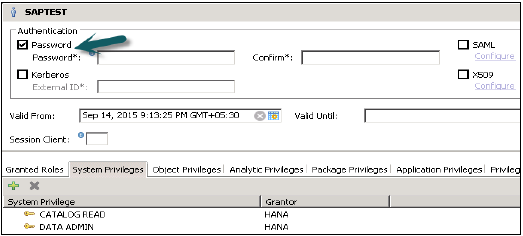
करबरोस
बाहरी प्रमाणीकरण विधि का उपयोग करके सभी उपयोगकर्ता जो HANA डेटाबेस सिस्टम से जुड़ते हैं, उनके पास भी एक डेटाबेस उपयोगकर्ता होना चाहिए। आंतरिक डेटाबेस उपयोगकर्ता के लिए बाहरी लॉगिन को मैप करना आवश्यक है।
यह विधि उपयोगकर्ताओं को नेटवर्क के माध्यम से या एसएपी व्यावसायिक वस्तुओं में फ्रंट एंड एप्लिकेशन का उपयोग करके सीधे जेडीबीसी / ओडीबीसी ड्राइवरों का उपयोग करके हाना प्रणाली को प्रमाणित करने में सक्षम बनाती है।
यह हाना एक्सएस इंजन का उपयोग करके एचएनएए विस्तारित सेवा में एचटीटीपी एक्सेस की भी अनुमति देता है। यह Kerberos प्रमाणीकरण के लिए SPENGO तंत्र का उपयोग करता है।
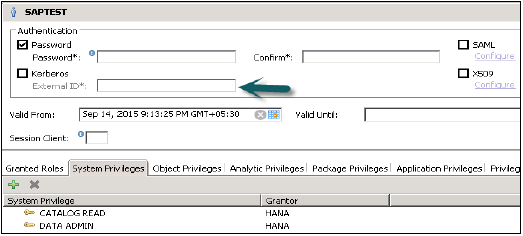
SAML
एसएएमएल का मतलब सिक्योरिटी एश्योरेंस मार्कअप लैंग्वेज है और इसका इस्तेमाल ओडीबीसी / जेबीसीबीसी क्लाइंट्स से सीधे एचएएनए सिस्टम तक पहुंचने वाले यूजर्स को प्रमाणित करने के लिए किया जा सकता है। इसका उपयोग एचएएनएएस इंजन के माध्यम से HTTP के माध्यम से आने वाले एचएएनए सिस्टम में उपयोगकर्ताओं को प्रमाणित करने के लिए भी किया जा सकता है।
SAML का उपयोग केवल प्रमाणीकरण उद्देश्य के लिए किया जाता है न कि प्राधिकरण के लिए।
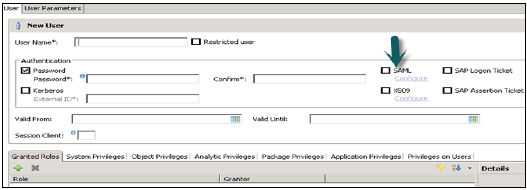
एसएपी लोगन और जोर टिकट
एसएपी लोगन / अभिकथन टिकट का उपयोग एचएएनए प्रणाली में उपयोगकर्ताओं को प्रमाणित करने के लिए किया जा सकता है। ये टिकट उपयोगकर्ताओं को SAP सिस्टम में लॉगिन करते समय जारी किए जाते हैं, जो SAP पोर्टल जैसे टिकट जारी करने के लिए कॉन्फ़िगर किया गया है, आदि SAP लॉगऑन टिकट में निर्दिष्ट उपयोगकर्ता को HANA सिस्टम में बनाया जाना चाहिए, क्योंकि यह उपयोगकर्ताओं को मैप करने के लिए समर्थन प्रदान नहीं करता है।
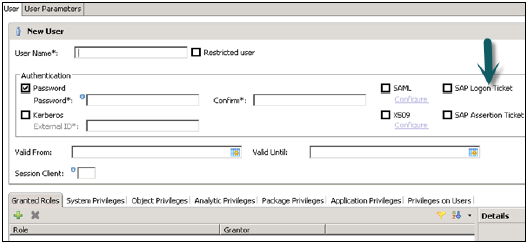
X.509 क्लाइंट सर्टिफिकेट
X.509 प्रमाणपत्र का उपयोग HANA XS इंजन से HTTP एक्सेस अनुरोध के माध्यम से HANA सिस्टम में प्रवेश करने के लिए भी किया जा सकता है। उपयोगकर्ताओं को प्रमाणित प्रमाणपत्र द्वारा प्रमाणित किया जाता है जो विश्वसनीय प्रमाणपत्र प्राधिकरण से हस्ताक्षरित हैं, जो कि एचएएनए एक्सएस सिस्टम में संग्रहीत है।
विश्वसनीय प्रमाणपत्र में उपयोगकर्ता को HANA प्रणाली में मौजूद होना चाहिए क्योंकि उपयोगकर्ता मानचित्रण के लिए कोई समर्थन नहीं है।
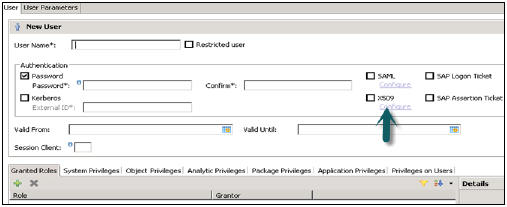
हाना सिस्टम में सिंगल साइन ऑन
एचएएनए प्रणाली पर एकल साइन को कॉन्फ़िगर किया जा सकता है, जो उपयोगकर्ताओं को क्लाइंट पर प्रारंभिक प्रमाणीकरण से एचएएनए प्रणाली में प्रवेश करने की अनुमति देता है। अलग-अलग प्रमाणीकरण विधियों और एसएसओ का उपयोग करके क्लाइंट एप्लिकेशन पर उपयोगकर्ता लॉगिन सीधे उपयोगकर्ता को हाना सिस्टम तक पहुंचने की अनुमति देता है।
एसएसओ को नीचे विन्यास विधियों पर कॉन्फ़िगर किया जा सकता है -
- SAML
- Kerberos
- HANA XS इंजन से HTTP एक्सेस के लिए X.509 क्लाइंट सर्टिफिकेट
- एसएपी लोगन / जोर टिकट
उपयोगकर्ता द्वारा HANA डेटाबेस से कनेक्ट करने और कुछ डेटाबेस ऑपरेशन करने का प्रयास करने पर प्राधिकरण की जाँच की जाती है। जब उपयोगकर्ता डेटाबेस ऑब्जेक्ट्स पर कुछ ऑपरेशन करने के लिए JDBC / ODBC या Via HTTP के माध्यम से क्लाइंट टूल्स का उपयोग करके HANA डेटाबेस से जुड़ता है, तो उपयोगकर्ता को दी जाने वाली पहुँच द्वारा संबंधित क्रिया निर्धारित की जाती है।
एक उपयोगकर्ता को दिए गए विशेषाधिकार उपयोगकर्ता प्रोफ़ाइल या उपयोगकर्ता को दी गई भूमिका पर निर्दिष्ट ऑब्जेक्ट विशेषाधिकारों द्वारा निर्धारित किए जाते हैं। प्राधिकरण दोनों एक्सेस का एक संयोजन है। जब कोई उपयोगकर्ता हाना डेटाबेस पर कुछ ऑपरेशन करने की कोशिश करता है, तो सिस्टम एक प्राधिकरण जांच करता है। जब सभी आवश्यक विशेषाधिकार मिल जाते हैं, तो सिस्टम इस चेक को रोक देता है और अनुरोधित पहुंच को अनुदान देता है।
विभिन्न प्रकार के विशेषाधिकार हैं, जो SAP HANA में उपयोग किए जाते हैं जैसा कि उपयोगकर्ता की भूमिका और प्रबंधन के तहत उल्लिखित है -
सिस्टम प्रिविलेज
वे उपयोगकर्ताओं और नियंत्रण प्रणाली की गतिविधियों के लिए सिस्टम और डेटाबेस प्राधिकरण पर लागू होते हैं। उनका उपयोग प्रशासनिक कार्यों जैसे स्कीमा, डेटा बैकअप, उपयोगकर्ता और भूमिकाएं बनाने और इत्यादि के लिए किया जाता है। सिस्टम विशेषाधिकारों का उपयोग रिपॉजिटरी संचालन करने के लिए भी किया जाता है।
ऑब्जेक्ट प्रिविलेज
वे डेटाबेस ऑपरेशंस पर लागू होते हैं और टेबल, स्कीमा आदि जैसी डेटाबेस ऑब्जेक्ट्स पर लागू होते हैं। इनका उपयोग टेबल और व्यू जैसे डेटाबेस ऑब्जेक्ट्स को मैनेज करने के लिए किया जाता है। डेटाबेस ऑब्जेक्ट्स के आधार पर अलग-अलग क्रियाएं जैसे कि Select, Execute, Alter, Drop, Delete को परिभाषित किया जा सकता है।
उनका उपयोग दूरस्थ डेटा ऑब्जेक्ट को नियंत्रित करने के लिए भी किया जाता है, जो स्मार्ट डेटा एक्सेस के माध्यम से एसएपी हाना से जुड़े होते हैं।
विश्लेषणात्मक विशेषाधिकार
वे सभी पैकेजों के अंदर डेटा के लिए लागू होते हैं जो हाना भंडार में बनाए जाते हैं। उनका उपयोग मॉडलिंग के विचारों को नियंत्रित करने के लिए किया जाता है जो कि एट्रीब्यूट व्यू, एनालिटिक व्यू और कैलकुलेशन व्यू जैसे पैकेज के अंदर बनाए जाते हैं। वे उन विशेषताओं के लिए पंक्ति और स्तंभ स्तर सुरक्षा लागू करते हैं जो हाना संकुल में मॉडलिंग दृश्य में परिभाषित हैं।
पैकेज विशेषाधिकार
वे उन पैकेजों का उपयोग करने की क्षमता और उपयोग करने के लिए लागू होते हैं जो एचएएनए डेटाबेस के भंडार में बनाए जाते हैं। पैकेज में अलग-अलग मॉडलिंग दृश्य होते हैं जैसे विशेषता, विश्लेषणात्मक और गणना के विचार और हाना रिपॉजिटरी डेटाबेस में परिभाषित विश्लेषणात्मक विशेषाधिकार भी।
आवेदन विशेषाधिकार
वे HANA XS एप्लिकेशन पर लागू होते हैं जो HTTP अनुरोध के माध्यम से HANA डेटाबेस तक पहुंचते हैं। वे हाना XS इंजन के साथ बनाए गए अनुप्रयोगों पर पहुंच को नियंत्रित करने के लिए उपयोग किए जाते हैं।
आवेदन विशेषाधिकार सीधे हाना स्टूडियो का उपयोग करके उपयोगकर्ताओं / भूमिकाओं पर लागू किया जा सकता है लेकिन यह पसंद किया जाता है कि उन्हें डिजाइन समय पर रिपॉजिटरी में बनाई गई भूमिकाओं पर लागू किया जाना चाहिए।
एसएपी हाना डेटाबेस में रिपोजिटरी प्राधिकरण
_SYS_REPO उपयोगकर्ता हाना भंडार में सभी वस्तुओं का मालिक है। इस उपयोगकर्ता को उन वस्तुओं के लिए बाहरी रूप से अधिकृत किया जाना चाहिए जिन पर रिपॉजिटरी ऑब्जेक्ट्स को HANA सिस्टम में मॉडल किया गया है। _SYS_REPO सभी वस्तुओं का स्वामी है, इसलिए इसका उपयोग केवल इन वस्तुओं पर पहुंच प्रदान करने के लिए किया जा सकता है, कोई अन्य उपयोगकर्ता _SYS_REPO उपयोगकर्ता के रूप में लॉगिन नहीं कर सकता है।
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
हाना डेटाबेस का उपयोग करने के लिए एसएपी हाना लाइसेंस प्रबंधन और कुंजियों की आवश्यकता होती है। आप हाना स्टूडियो का उपयोग करके हाना लाइसेंस कुंजी को स्थापित या हटा सकते हैं।
लाइसेंस कुंजी के प्रकार
एसएपी हाना प्रणाली दो प्रकार की लाइसेंस कुंजियों का समर्थन करती है -
Temporary License Key- जब आप हाना डेटाबेस स्थापित करते हैं तो अस्थाई लाइसेंस कुंजियाँ स्वचालित रूप से स्थापित हो जाती हैं। ये कुंजी केवल 90 दिनों के लिए मान्य हैं और आपको स्थापना के बाद इस 90 दिनों की अवधि समाप्त होने से पहले एसएपी बाजार स्थान से स्थायी लाइसेंस कुंजी का अनुरोध करना चाहिए।
Permanent License Key- स्थायी लाइसेंस कुंजियाँ केवल पूर्वनिर्धारित समाप्ति तिथि तक मान्य हैं। लाइसेंस कुंजियाँ HANA स्थापना को लक्षित करने के लिए लाइसेंस प्राप्त मेमोरी की मात्रा निर्दिष्ट करती हैं। वे एसएपी मार्केट जगह से कीज़ और रिक्वेस्ट टैब के तहत इंस्टॉल कर सकते हैं। जब एक स्थायी लाइसेंस कुंजी समाप्त हो जाती है, तो एक अस्थायी लाइसेंस कुंजी जारी की जाती है, जो केवल 28 दिनों के लिए वैध होती है। इस अवधि के दौरान, आपको एक स्थायी लाइसेंस कुंजी फिर से स्थापित करनी होगी।
हाना प्रणाली के लिए दो प्रकार की स्थायी लाइसेंस कुंजियाँ हैं -
Unenforced - यदि बिना लाइसेंस लाइसेंस कुंजी स्थापित की गई है और एचएएनए सिस्टम की खपत मेमोरी की लाइसेंस राशि से अधिक है, तो एसएपी हाना का संचालन इस मामले में प्रभावित नहीं होता है।
Enforced- यदि लागू लाइसेंस कुंजी स्थापित है और एचएएनए सिस्टम की खपत मेमोरी की लाइसेंस राशि से अधिक है, तो एचएएनए सिस्टम लॉक हो जाता है। यदि यह स्थिति होती है, तो HANA सिस्टम को पुनरारंभ करना होगा या एक नई लाइसेंस कुंजी का अनुरोध और स्थापित किया जाना चाहिए।
अलग-अलग लाइसेंस परिदृश्य हैं जिनका उपयोग सिस्टम के परिदृश्य (स्टैंडअलोन, Hana क्लाउड, BW पर HANA, आदि) के आधार पर HANA सिस्टम में किया जा सकता है और ये सभी मॉडल HANA सिस्टम इंस्टॉलेशन की मेमोरी पर आधारित नहीं हैं।
हाना के लाइसेंस गुणों की जांच कैसे करें
हाना प्रणाली पर राइट क्लिक करें → गुण → लाइसेंस
यह लाइसेंस प्रकार, प्रारंभ तिथि और समाप्ति तिथि, मेमोरी आवंटन और जानकारी (हार्डवेयर कुंजी, सिस्टम आईडी) के बारे में बताता है जो एसएपी मार्केट प्लेस के माध्यम से एक नए लाइसेंस का अनुरोध करने के लिए आवश्यक है।
लाइसेंस कुंजी स्थापित करें → ब्राउज़ करें → प्रवेश पथ, एक नई लाइसेंस कुंजी को स्थापित करने के लिए प्रयोग किया जाता है और किसी भी पुरानी समाप्ति कुंजी को हटाने के लिए डिलीट विकल्प का उपयोग किया जाता है।
लाइसेंस के तहत सभी लाइसेंस टैब उत्पाद का नाम, विवरण, हार्डवेयर कुंजी, प्रथम स्थापना समय आदि के बारे में बताता है।
एसएपी हाना ऑडिट नीति कार्यों को ऑडिट करने के लिए कहती है और यह भी शर्त है कि ऑडिटिंग के लिए प्रासंगिक होने के लिए कार्रवाई किस स्थिति में की जानी चाहिए। ऑडिट पॉलिसी यह परिभाषित करती है कि एचएएनए प्रणाली में कौन सी गतिविधियां की गई हैं और किस समय उन गतिविधियों का प्रदर्शन किया है।
एसएपी हाना डेटाबेस ऑडिटिंग सुविधा हाना सिस्टम में की गई निगरानी कार्रवाई की अनुमति देती है। इसका उपयोग करने के लिए हाना प्रणाली पर SAP HANA ऑडिट नीति को सक्रिय किया जाना चाहिए। जब कोई कार्रवाई की जाती है, तो नीति ऑडिट ट्रेल को लिखने के लिए एक ऑडिट घटना को ट्रिगर करती है। आप ऑडिट ट्रेल में ऑडिट प्रविष्टियों को भी हटा सकते हैं।
एक वितरित वातावरण में, जहां आपके पास कई डेटाबेस हैं, प्रत्येक व्यक्तिगत सिस्टम पर ऑडिट पॉलिसी को सक्षम किया जा सकता है। सिस्टम डेटाबेस के लिए, ऑडिट नीति को nameserver.ini फ़ाइल में और किरायेदार डेटाबेस के लिए परिभाषित किया गया है, इसे Global.ini फ़ाइल में परिभाषित किया गया है।
एक लेखा परीक्षा नीति को सक्रिय करना
हाना सिस्टम में ऑडिट पॉलिसी को परिभाषित करने के लिए, आपके पास सिस्टम विशेषाधिकार होना चाहिए - ऑडिट एडमिन।
हाना सिस्टम में सुरक्षा विकल्प पर जाएं → ऑडिटिंग
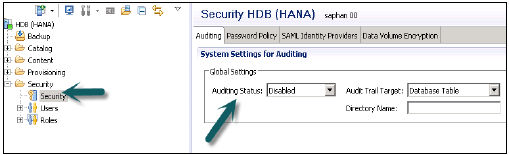
वैश्विक सेटिंग के तहत → ऑडिटिंग स्थिति को सक्षम के रूप में सेट करें।
आप ऑडिट ट्रेल लक्ष्य भी चुन सकते हैं। निम्नलिखित लेखापरीक्षा निशान लक्ष्य संभव हैं -
Syslog (डिफ़ॉल्ट) - लिनक्स ऑपरेटिंग सिस्टम का लॉगिंग सिस्टम।
Database Table - आंतरिक डेटाबेस तालिका, उपयोगकर्ता जिसके पास ऑडिट व्यवस्थापक या ऑडिट ऑपरेटर सिस्टम विशेषाधिकार है वह केवल इस तालिका पर चुनिंदा ऑपरेशन चला सकता है।
CSV text - इस प्रकार के ऑडिट ट्रेल का उपयोग केवल गैर-उत्पादन वातावरण में परीक्षण के उद्देश्य के लिए किया जाता है।
आप ऑडिट पॉलिसी क्षेत्र में एक नई ऑडिट पॉलिसी भी बना सकते हैं → नई पॉलिसी बनाएं चुनें। ऑडिट करने के लिए पॉलिसी का नाम और कार्रवाई दर्ज करें।
डिप्लॉय बटन का उपयोग करके नई नीति सहेजें। एक नई नीति स्वचालित रूप से सक्षम होती है, जब एक कार्रवाई की शर्त पूरी होती है, ऑडिट ट्रेल तालिका में एक ऑडिट प्रविष्टि बनाई जाती है। आप निष्क्रिय करने के लिए स्थिति बदलकर नीति को अक्षम कर सकते हैं या आप नीति को हटा भी सकते हैं।
एसएपी हाना प्रतिकृति स्रोत सिस्टम से एसएपी हाना डेटाबेस तक डेटा के प्रवास की अनुमति देता है। मौजूदा एसएपी प्रणाली से हाना तक डेटा स्थानांतरित करने का सरल तरीका विभिन्न डेटा प्रतिकृति तकनीकों का उपयोग करना है।
सिस्टम प्रतिकृति को कमांड लाइन के माध्यम से या हाना स्टूडियो का उपयोग करके कंसोल पर स्थापित किया जा सकता है। इस प्रक्रिया के दौरान प्राथमिक ईसीसी या लेनदेन प्रणाली ऑनलाइन रह सकती है। हाना प्रणाली में हमारे पास तीन प्रकार के डेटा प्रतिकृति तरीके हैं -
- एसएपी एलटी प्रतिकृति विधि
- ETL टूल SAP बिजनेस ऑब्जेक्ट डेटा सर्विस (BODS) विधि
- प्रत्यक्ष चिमटा कनेक्शन विधि (DXC)
एसएपी एलटी प्रतिकृति विधि
एसएपी लैंडस्केप परिवर्तन प्रतिकृति हाना प्रणाली में एक ट्रिगर आधारित डेटा प्रतिकृति विधि है। एसएपी और गैर-एसएपी स्रोतों से वास्तविक समय डेटा या शेड्यूल आधारित प्रतिकृति की नकल करने के लिए यह एक सही समाधान है। इसमें SAP LT प्रतिकृति सर्वर है, जो सभी ट्रिगर अनुरोधों का ध्यान रखता है। प्रतिकृति सर्वर को स्टैंडअलोन सर्वर के रूप में स्थापित किया जा सकता है या एसएपी एनडब्ल्यू 7.02 या इसके बाद के संस्करण के साथ किसी भी एसएपी सिस्टम पर चल सकता है।
हाना डीबी और ईसीसी लेनदेन प्रणाली के बीच एक विश्वसनीय आरएफसी कनेक्शन है, जो हाना सिस्टम वातावरण में ट्रिगर डेटा आधारित प्रतिकृति को सक्षम करता है।

एसएलटी प्रतिकृति के लाभ
एसएलटी प्रतिकृति पद्धति कई स्रोत प्रणालियों से एक एचएएनए प्रणाली और एक स्रोत प्रणाली से कई एचएएनए प्रणालियों तक डेटा प्रतिकृति की अनुमति देती है।
एसएपी एलटी ट्रिगर आधारित दृष्टिकोण का उपयोग करता है। स्रोत प्रणाली में इसका कोई औसत दर्जे का प्रदर्शन प्रभाव नहीं है।
यह हाना डेटाबेस में लोड करने से पहले डेटा परिवर्तन और फ़िल्टरिंग क्षमता भी प्रदान करता है।
यह वास्तविक समय डेटा प्रतिकृति की अनुमति देता है, एसएपी और गैर-एसएपी स्रोत प्रणालियों से केवल हाना में प्रासंगिक डेटा की नकल करता है।
यह हाना सिस्टम और हाना स्टूडियो के साथ पूरी तरह से एकीकृत है।
ईसीसी प्रणाली में एक विश्वसनीय आरएफसी कनेक्शन बनाना
अपने स्रोत SAP सिस्टम AA1 पर आप एक विश्वसनीय RFC को लक्ष्य प्रणाली BB1 की ओर सेटअप करना चाहते हैं। जब यह किया जाता है, तो इसका मतलब होगा कि जब आप AA1 पर लॉग इन होते हैं और आपके उपयोगकर्ता के पास BB1 में पर्याप्त प्राधिकरण होता है, तो आप उपयोगकर्ता और पासवर्ड को फिर से दर्ज किए बिना BB1 के लिए RFC कनेक्शन और लॉगऑन का उपयोग कर सकते हैं।
दो SAP प्रणालियों के बीच RFC विश्वसनीय / भरोसेमंद संबंध का उपयोग करना, एक विश्वसनीय प्रणाली से एक विश्वसनीय प्रणाली तक RFC, ट्रस्टिंग सिस्टम पर लॉगिंग के लिए पासवर्ड की आवश्यकता नहीं है।
SAP लॉगऑन का उपयोग करके SAP ECC सिस्टम खोलें। लेनदेन नंबर दर्ज करें sm59 → यह एक नया ट्रस्टेड RFC कनेक्शन बनाने के लिए लेनदेन नंबर है → नया कनेक्शन विज़ार्ड खोलने के लिए 3 rd आइकन पर क्लिक करें → Create पर क्लिक करें और नई विंडो खुल जाएगी।
RFC गंतव्य ECCHANA (RFC गंतव्य का नाम दर्ज करें) कनेक्शन प्रकार - 3 (ABAP सिस्टम के लिए)
तकनीकी सेटिंग पर जाएं
टारगेट होस्ट - ईसीसी सिस्टम नाम, आईपी दर्ज करें और सिस्टम नंबर दर्ज करें।
लॉगऑन और सुरक्षा टैब पर जाएं, भाषा, क्लाइंट, ईसीसी सिस्टम उपयोगकर्ता नाम और पासवर्ड दर्ज करें।
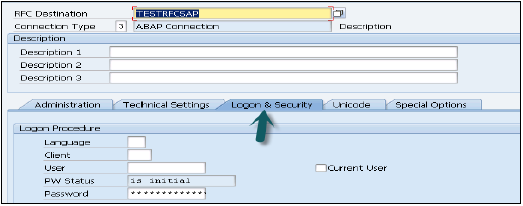
सबसे ऊपर Save ऑप्शन पर क्लिक करें।

टेस्ट कनेक्शन पर क्लिक करें और यह कनेक्शन का सफलतापूर्वक परीक्षण करेगा।
RFC कनेक्शन कॉन्फ़िगर करने के लिए
रन लेन-देन - ltr (RFC कनेक्शन कॉन्फ़िगर करने के लिए) → नया ब्राउज़र खुल जाएगा → ECC सिस्टम उपयोगकर्ता नाम और पासवर्ड और लॉगऑन दर्ज करें।

नया → नई विंडो पर क्लिक करें → विन्यास नाम दर्ज करें → अगला पर क्लिक करें → RFC गंतव्य दर्ज करें (कनेक्शन पहले बनाया गया नाम), खोज विकल्प का उपयोग करें, नाम चुनें और अगला क्लिक करें।
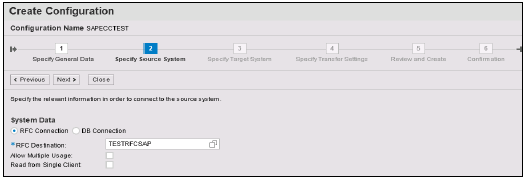
लक्ष्य प्रणाली निर्दिष्ट करें, HANA सिस्टम व्यवस्थापक उपयोगकर्ता नाम और पासवर्ड, होस्ट नाम, इंस्टेंस नंबर दर्ज करें और अगला क्लिक करें। 007 जैसी डेटा अंतरण नौकरियों की संख्या दर्ज करें (यह 000 नहीं हो सकती) → अगला → कॉन्फ़िगरेशन बनाएं।
अब इस कनेक्शन का उपयोग करने के लिए हाना स्टूडियो जाएं -
हाना स्टूडियो पर जाएं → डेटा प्रोविजनिंग पर क्लिक करें → हाना सिस्टम चुनें
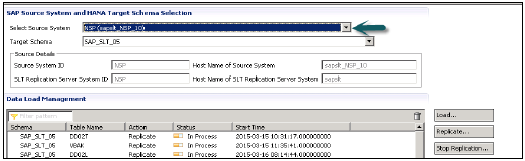
स्रोत सिस्टम (विश्वसनीय RFC कनेक्शन का नाम) का चयन करें और स्कीमा नाम को लक्षित करें जहां आप ECC सिस्टम से तालिकाओं को लोड करना चाहते हैं। उन तालिकाओं का चयन करें जिन्हें आप हाना डेटाबेस में जाना चाहते हैं → ADD → समाप्त करें।

चयनित तालिका HANA डेटाबेस के तहत चुने गए स्कीमा में चली जाएगी।
SAP हाना ETL आधारित प्रतिकृति SAP या गैर-SAP स्रोत प्रणाली से डेटा को स्थानांतरित करने के लिए SAP डेटा सेवाओं का उपयोग करता है जो साना डेटाबेस को लक्षित करता है। बीओडीएस प्रणाली एक ईटीएल उपकरण है जिसका उपयोग स्रोत प्रणाली से लक्ष्य प्रणाली में डेटा निकालने, बदलने और लोड करने के लिए किया जाता है।
यह एप्लिकेशन लेयर पर व्यावसायिक डेटा को पढ़ने में सक्षम बनाता है। आपको डेटा सेवाओं में डेटा प्रवाह को परिभाषित करने की आवश्यकता है, डेटा सेवा डिजाइनर में डेटा स्टोर में प्रतिकृति नौकरी और परिभाषित स्रोत और लक्ष्य प्रणाली को शेड्यूल करना।
SAP HANA डेटा सेवा ETL आधारित प्रतिकृति का उपयोग कैसे करें?
डेटा सेवा डिजाइनर के लिए लॉगिन (रिपॉजिटरी चुनें) → डेटा स्टोर बनाएँ
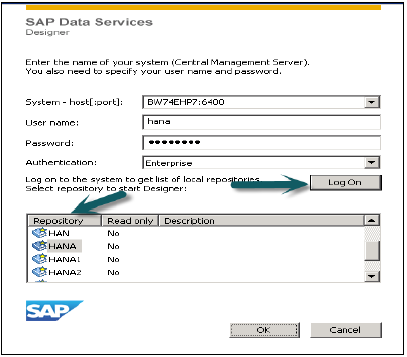
एसएपी ईसीसी प्रणाली के लिए, एसएपी एप्लिकेशन के रूप में डेटाबेस चुनें, ईसीसी सिस्टम नाम के लिए ईसीसी सर्वर नाम, उपयोगकर्ता नाम और पासवर्ड दर्ज करें, उन्नत टैब उदाहरण संख्या, ग्राहक संख्या, आदि के रूप में विवरण चुनें और आवेदन करें।
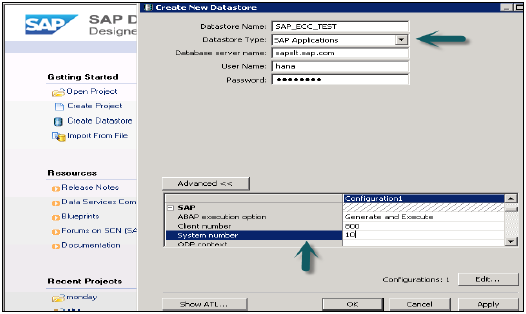
यह डेटा स्टोर स्थानीय ऑब्जेक्ट लाइब्रेरी के अंतर्गत आएगा, यदि आप इसका विस्तार करते हैं तो इसके अंदर कोई तालिका नहीं है।
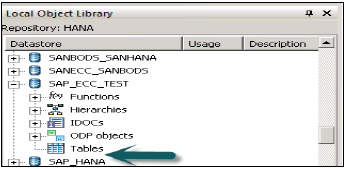
तालिका पर राइट क्लिक करें → नाम से आयात → ECC प्रणाली से आयात करने के लिए ECC तालिका दर्ज करें (ECC प्रणाली में MARA डिफ़ॉल्ट तालिका है) → आयात → अब तालिका का विस्तार करें → MARA → राइट क्लिक व्यू डेटा। यदि डेटा प्रदर्शित होता है, तो डेटा स्टोर कनेक्शन ठीक है।
अब, HANA डेटाबेस के रूप में लक्ष्य प्रणाली चुनने के लिए, एक नया डेटा स्टोर बनाएं। डेटा स्टोर बनाएं → डेटा स्टोर का नाम SAP_HANA_TEST → डेटा स्टोर प्रकार (डेटाबेस) → डेटाबेस प्रकार एसएपी हाना → डेटाबेस संस्करण हाना 1.x.
हाना सिस्टम और ओके के लिए हाना सर्वर नाम, उपयोगकर्ता नाम और पासवर्ड दर्ज करें।
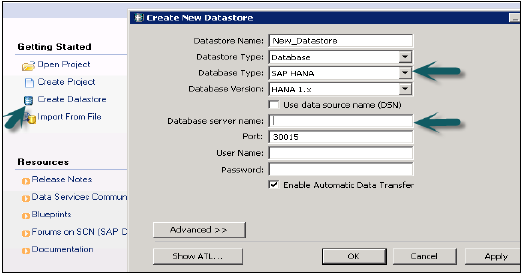
इस डेटा स्टोर को लोकल ऑब्जेक्ट लाइब्रेरी में जोड़ा जाएगा। आप तालिका जोड़ सकते हैं यदि आप स्रोत तालिका से डेटा को कुछ विशिष्ट तालिका में हाना डेटाबेस में ले जाना चाहते हैं। ध्यान दें कि लक्ष्य तालिका स्रोत तालिका के समान डेटाटाइप की होनी चाहिए।
एक प्रतिकृति नौकरी बनाना
एक नया प्रोजेक्ट बनाएं → प्रोजेक्ट का नाम लिखें → प्रोजेक्ट के नाम पर राइट क्लिक करें → न्यू बैच जॉब → जॉब का नाम डालें।
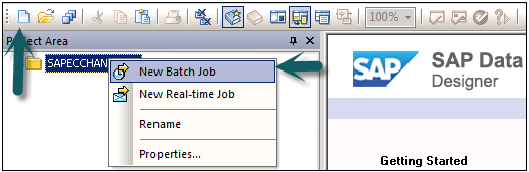
दाईं ओर टैब से, कार्य प्रवाह चुनें → कार्य प्रवाह नाम दर्ज करें → बैच कार्य के तहत इसे जोड़ने के लिए डबल क्लिक करें → डेटा प्रवाह दर्ज करें → डेटा प्रवाह नाम दर्ज करें → प्रोजेक्ट क्षेत्र में बैच जॉब के तहत इसे जोड़ने के लिए डबल क्लिक करें शीर्ष पर सभी विकल्प सहेजें।

कार्य क्षेत्र के लिए पहले डेटा स्टोर ECC (MARA) से तालिका खींचें। इसे चुनें और राइट क्लिक करें → HANA DB में समान डेटा प्रकारों के साथ नई तालिका बनाने के लिए नया → टेम्पलेट तालिका जोड़ें → तालिका नाम दर्ज करें, डेटा स्टोर ECC_HANA_TEST2 → स्वामी का नाम (स्कीमा नाम) → ठीक
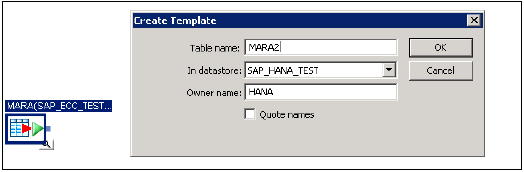
तालिका को सामने खींचें और दोनों तालिका कनेक्ट करें → सभी सहेजें। अब बैच जॉब पर जाएं → राइट क्लिक करें → एक्सक्यूट → यस → ओके
एक बार जब आप प्रतिकृति कार्य निष्पादित करते हैं, तो आपको एक पुष्टि मिलेगी कि नौकरी सफलतापूर्वक पूरी हो गई है।
हाना स्टूडियो पर जाएं → स्कीमा का विस्तार करें → टेबल → डेटा सत्यापित करें। यह एक बैच नौकरी का मैनुअल निष्पादन है।
बैच जॉब का निर्धारण
आप डेटा सेवा प्रबंधन कंसोल पर जाकर एक बैच जॉब भी शेड्यूल कर सकते हैं। डेटा सेवा प्रबंधन कंसोल में लॉगिन करें।
बाईं ओर से रिपॉजिटरी का चयन करें → 'बैच जॉब कॉन्फ़िगरेशन' टैब पर नेविगेट करें, जहां आपको नौकरियों की सूची दिखाई देगी → जिस नौकरी के लिए आप शेड्यूल करना चाहते हैं उसके खिलाफ → शेड्यूल जोड़ें पर क्लिक करें → 'शेड्यूल नाम दर्ज करें' और जैसे पैरामीटर सेट करें (जैसे) समय, तिथि, प्रतिपूर्ति आदि) उपयुक्त के रूप में और 'लागू करें' पर क्लिक करें।
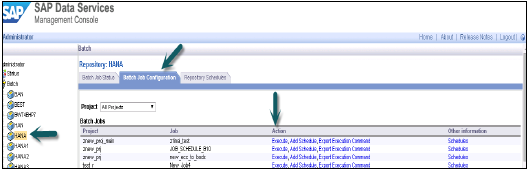
इसे हाना प्रणाली में साइबेस प्रतिकृति के रूप में भी जाना जाता है। इस प्रतिकृति विधि के मुख्य घटक Sybase प्रतिकृति एजेंट हैं, जो SAP स्रोत एप्लिकेशन सिस्टम, प्रतिकृति एजेंट और Sybase प्रतिकृति सर्वर का हिस्सा है जो SAP हाना प्रणाली में लागू किया जाना है।
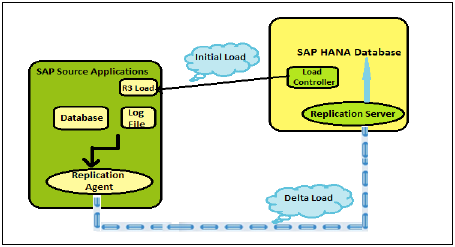
Sybase प्रतिकृति विधि में प्रारंभिक लोड लोड नियंत्रक द्वारा शुरू किया गया और SAP HANA में व्यवस्थापक द्वारा ट्रिगर किया गया। यह आर 3 लोड को हाना डेटाबेस में प्रारंभिक लोड स्थानांतरित करने के लिए सूचित करता है। स्रोत प्रणाली पर R3 लोड स्रोत प्रणाली में चयनित तालिकाओं के लिए डेटा निर्यात करता है और इस डेटा को HANA सिस्टम में R3 लोड घटकों में स्थानांतरित करता है। लक्ष्य प्रणाली पर R3 लोड SAP HANA डेटाबेस में डेटा आयात करता है।
एसएपी होस्ट एजेंट स्रोत प्रणाली और लक्ष्य प्रणाली के बीच प्रमाणीकरण का प्रबंधन करता है, जो स्रोत प्रणाली का हिस्सा है। Sybase प्रतिकृति एजेंट प्रारंभिक लोड के समय किसी भी डेटा परिवर्तन का पता लगाता है और सुनिश्चित करता है कि हर एक परिवर्तन पूरा हो गया है। जब th ere एक परिवर्तन, अद्यतन, और स्रोत प्रणाली में एक तालिका की प्रविष्टियों में हटाना है, एक तालिका लॉग बनाया जाता है। यह तालिका लॉग स्रोत सिस्टम से डेटा को HANA डेटाबेस में ले जाती है।
प्रारंभिक भार के बाद डेल्टा प्रतिकृति
डेल्टा प्रतिकृति प्रारंभिक लोड और प्रतिकृति पूरा होने के बाद वास्तविक समय में स्रोत प्रणाली में डेटा परिवर्तन को पकड़ लेती है। स्रोत प्रणाली के सभी परिवर्तनों को उपर्युक्त विधि का उपयोग करके स्रोत प्रणाली से हाना डेटाबेस पर कब्जा कर लिया गया है।
यह विधि एसएपी हाना प्रतिकृति के लिए प्रारंभिक पेशकश का हिस्सा थी, लेकिन लाइसेंसिंग के मुद्दों और जटिलता के कारण अब तैनात / समर्थित नहीं है और एसएलटी भी समान सुविधाएं प्रदान करता है।
Note - यह विधि केवल डेटा स्रोत के रूप में एसएपी ईआरपी सिस्टम और डेटाबेस के रूप में डीबी 2 का समर्थन करती है।
डायरेक्ट एक्सट्रैक्टर कनेक्शन डेटा प्रतिकृति मौजूदा निष्कर्षण, परिवर्तन और लोड तंत्र को SAP हाना के लिए एक सरल HTTP (S) कनेक्शन के माध्यम से SAP Business Suite सिस्टम में बनाया गया है। यह एक बैच-संचालित डेटा प्रतिकृति तकनीक है। इसे डेटा निष्कर्षण के लिए सीमित क्षमताओं के साथ निष्कर्षण, परिवर्तन और भार के लिए विधि माना जाता है।
डीएक्ससी एक बैच संचालित प्रक्रिया है और निश्चित अंतराल पर डीएक्ससी का उपयोग करके डेटा निष्कर्षण कई मामलों में पर्याप्त है। जब आप बैच जॉब का उदाहरण देते हैं, तो आप एक अंतराल सेट कर सकते हैं: प्रत्येक 20 मिनट और ज्यादातर मामलों में यह निश्चित समय के अंतराल पर इन बैच जॉब्स का उपयोग करके डेटा निकालने के लिए पर्याप्त है।
डीएक्ससी डेटा प्रतिकृति के लाभ
इस विधि को एसएपी हाना सिस्टम परिदृश्य में अतिरिक्त सर्वर या एप्लिकेशन की आवश्यकता नहीं है।
डीएक्ससी विधि एसएपी हाना में डेटा मॉडलिंग की जटिलता को कम कर देता है क्योंकि स्रोत सिस्टम में सभी व्यावसायिक एक्स्ट्रेक्टर लॉजिक्स लगाने के बाद डेटा हाना को भेजता है।
यह एसएपी हाना कार्यान्वयन परियोजना के लिए समय रेखाओं को गति देता है
यह एसएपी बिजनेस सूट से एसएपी हाना के लिए काफी समृद्ध डेटा प्रदान करता है
यह SAP काना के लिए एक सरल HTTP (S) कनेक्शन पर SAP बिजनेस सूट सिस्टम में निर्मित मौजूदा मालिकाना निष्कर्षण, परिवर्तन और लोड तंत्र का पुन: उपयोग करता है।
डीएक्ससी डेटा प्रतिकृति की सीमाएं
डेटा स्रोत में निष्कर्षण, परिवर्तन और भार के लिए पूर्वनिर्धारित तंत्र होना चाहिए और यदि हमें किसी को परिभाषित करने की आवश्यकता नहीं है।
इसके लिए नेट वीवर 7.0 पर आधारित बिज़नेस सूट सिस्टम की आवश्यकता होती है या कम से कम एसपी से नीचे के साथ: रिलीज़ 700 SAPKW70021 (एसपी स्टैक 19, नवंबर 2008 से)।
DXC डेटा प्रतिकृति कॉन्फ़िगर करना
Enabling XS Engine service in Configuration tab in HANA Studio- सिस्टम के हाना स्टूडियो में एडमिनिस्ट्रेटर टैब पर जाएं। कॉन्फ़िगरेशन → xsengine.ini पर जाएं और इंस्टेंस मान को 1 पर सेट करें।
Enabling ICM Web Dispatcher service in HANA Studio - कॉन्फ़िगरेशन → webdispatcher.ini पर जाएं और इंस्टेंस वैल्यू को 1 पर सेट करें।
यह हाना प्रणाली में आईसीएम वेब डिस्पैचर सेवा को सक्षम करता है। एचएएनए प्रणाली में डेटा पढ़ने और लोड करने के लिए वेब डिस्पैचर आईसीएम विधि का उपयोग करता है।
Setup SAP HANA Direct Extractor Connection- SAP हाना में DXC डिलीवरी यूनिट डाउनलोड करें। आप यूनिट को लोकेशन / usr / sap / HDB / SYS / ग्लोबल / एचडीबी / सामग्री में आयात कर सकते हैं।
एसएपी हाना कंटेंट नोड में इंपोर्ट डायलॉग का उपयोग करके यूनिट आयात करें → डीएक्ससी का उपयोग करने के लिए XS एप्लिकेशन सर्वर कॉन्फ़िगर करें → libxsdxc में application_container मान बदलें
Creating a HTTP connection in SAP BW - अब हमें लेनदेन कोड SM59 का उपयोग करके SAP BW में http कनेक्शन बनाना होगा।
Input Parameters - आरएफसी कनेक्शन, हाना होस्ट नाम और <इंस्टेंस नंबर> का नाम दर्ज करें
लॉग ऑन सिक्योरिटी टैब में, बुनियादी प्रमाणीकरण पद्धति का उपयोग करके हाना स्टूडियो में बनाए गए डीएक्ससी उपयोगकर्ता को दर्ज करें -
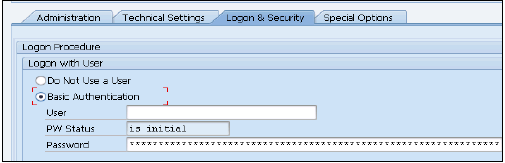
Setting up BW Parameters for HANA - लेनदेन एसई 38 का उपयोग करके बीडब्ल्यू में निम्नलिखित पैरामीटर सेट करने की आवश्यकता है। पैरामीटर सूची -
PSA_TO_HDB_DESTINATION - हमें यह उल्लेख करने की आवश्यकता है कि हमें आने वाले डेटा को स्थानांतरित करने की आवश्यकता है (कनेक्शन का नाम एसएम 59 का उपयोग करके बनाया गया है)
PSA_TO_HDB_SCHEMA - किन स्कीमों में प्रतिरूपित डेटा को असाइन करना है
PSA_TO_HDB- हाना के लिए सभी डेटा स्रोत को दोहराने के लिए अंतर्राष्ट्रीय। सिस्टम - डीएक्ससी का उपयोग करने के लिए निर्दिष्ट क्लाइंट। DATASOURCE - केवल निर्दिष्ट डेटा स्रोत के लिए उपयोग किया जाता है
PSA_TO_HDB_DATASOURCETABLE - डीएक्ससी के लिए उपयोग किए जाने वाले डेटा स्रोतों की सूची वाले तालिका का नाम देने की आवश्यकता है।
डेटा स्रोत प्रतिकृति
RSA5 का उपयोग करके ECC में डेटा स्रोत स्थापित करें।
निर्दिष्ट एप्लिकेशन घटक (डेटा स्रोत संस्करण का उपयोग करके मेटाडेटा को फिर से दोहराएं, अगर हमें 3.5 संस्करण डेटा स्रोत की आवश्यकता है, तो हमें उस माइग्रेट करने की आवश्यकता है। SAP BW में सक्रिय डेटा स्रोत। एक बार SAP BW में डेटा स्रोत सक्रिय होने के बाद यह निम्न तालिका बना देगा। परिभाषित स्कीमा में -
/ बीआईसी / ए <डेटा स्रोत> 00 - आईएमडीएसओ सक्रिय तालिका
/ BIC / A <डेटा स्रोत> 40 –IMDSO सक्रियण कतार
/ बीआईसी / ए <डेटा स्रोत> 70 - रिकॉर्ड मोड हैंडलिंग टेबल
/ बीआईसी / ए <डेटा स्रोत> 80 - अनुरोध और पैकेट आईडी जानकारी तालिका
/ BIC / A <डेटा स्रोत> A0 - टाइमस्टैम्प टेबल का अनुरोध करें
RSODSO_IMOLOG - IMDSO संबंधित तालिका। स्टोर डीएक्ससी से संबंधित सभी डेटा स्रोतों के बारे में जानकारी रखते हैं।
एक बार सक्रिय होने के बाद अब डेटा को सफलतापूर्वक टेबल / BIC / A0FI_AA_2000 में लोड किया जाता है।
SAP हाना स्टूडियो खोलें → कैटलॉग टैब के तहत स्कीमा बनाएं। <यहां शुरू करें>
डेटा तैयार करें और इसे सीएसवी प्रारूप में सहेजें। अब सिंटैक्स के साथ "ctl" एक्सटेंशन के साथ फाइल बनाएं -
---------------------------------------
import data into table Schema."Table name"
from 'file.csv'
records delimited by '\n'
fields delimited by ','
Optionally enclosed by '"'
error log 'table.err'
-----------------------------------------इस "ctl" फ़ाइल को FTP में स्थानांतरित करें और डेटा आयात करने के लिए इस फ़ाइल को निष्पादित करें -
'table.ctl' से आयात
HANA स्टूडियो → कैटलॉग → स्कीमा → टेबल्स → व्यू कंटेंट पर जाकर तालिका में डेटा की जाँच करें
MDX प्रदाता का उपयोग MS Excel को SAP HANA डेटाबेस सिस्टम से जोड़ने के लिए किया जाता है। यह ड्राइवर को एचएएनए प्रणाली को एक्सेल से जोड़ने के लिए प्रदान करता है और आगे, डेटा मॉडलिंग के लिए उपयोग किया जाता है। आप 32 बिट और 64 बिट विंडोज दोनों के लिए HANA के साथ कनेक्टिविटी के लिए Microsoft Office Excel 2010/2013 का उपयोग कर सकते हैं।
SAP HANA दोनों क्वेरी भाषाओं - SQL और MDX का समर्थन करता है। दोनों भाषाओं का उपयोग किया जा सकता है: SQL और ODBO के लिए JDBC और ODBC का उपयोग MDX प्रसंस्करण के लिए किया जाता है। Excel Pivot तालिकाएँ SAP HANA सिस्टम के डेटा को पढ़ने के लिए क्वेरी भाषा के रूप में MDX का उपयोग करती हैं। MDX को Microsoft से ODBO (OLAP DB के लिए OLE) विनिर्देशन के भाग के रूप में परिभाषित किया गया है और इसका उपयोग डेटा चयन, गणना और लेआउट के लिए किया जाता है। MDX बहुआयामी डेटा मॉडल का समर्थन करता है और रिपोर्टिंग और विश्लेषण की आवश्यकता का समर्थन करता है।
एमडीएक्स प्रदाता एसएपी और गैर एसएपी रिपोर्टिंग टूल द्वारा हाना स्टूडियो में परिभाषित सूचना विचारों की खपत को सक्षम करता है। मौजूदा भौतिक तालिकाओं और स्कीमा सूचना मॉडल के लिए डेटा नींव प्रस्तुत करते हैं।
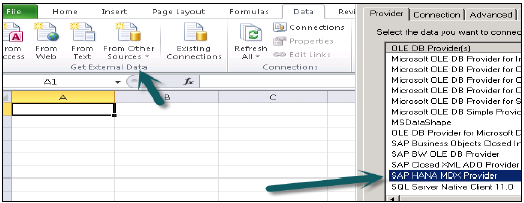
एक बार जब आप SAP HANA MDX प्रदाता को उस डेटा स्रोत की सूची से चुन लेते हैं जिसे आप कनेक्ट करना चाहते हैं, तो होस्ट नाम, उदाहरण संख्या, उपयोगकर्ता नाम और पासवर्ड जैसे HANA सिस्टम विवरण पास करें।
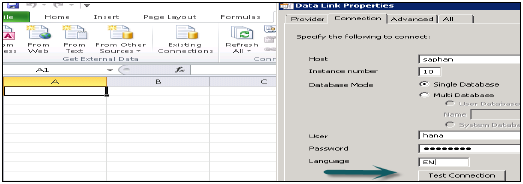
एक बार कनेक्शन सफल होने के बाद, आप पिवट टेबल उत्पन्न करने के लिए पैकेज का नाम → HANA मॉडलिंग दृश्य चुन सकते हैं।
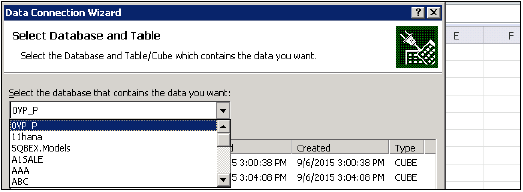
MDX कसकर HANA डेटाबेस में एकीकृत है। एचएएनए डेटाबेस के कनेक्शन और सत्र प्रबंधन, एचएएनए द्वारा निष्पादित किए जाने वाले बयानों को संभालता है। जब इन कथनों को निष्पादित किया जाता है, तो उन्हें MDX इंटरफ़ेस द्वारा पार्स किया जाता है और प्रत्येक MDX कथन के लिए एक गणना मॉडल तैयार किया जाता है। यह गणना मॉडल एक निष्पादन योजना बनाता है जो एमडीएक्स के लिए मानक परिणाम उत्पन्न करता है। ये परिणाम सीधे OLAP क्लाइंट द्वारा उपभोग किए जाते हैं।
हाना डेटाबेस के लिए एमडीएक्स कनेक्शन बनाने के लिए, हाना क्लाइंट टूल्स की आवश्यकता होती है। आप इस ग्राहक उपकरण को SAP बाज़ार स्थान से डाउनलोड कर सकते हैं। HANA क्लाइंट की स्थापना हो जाने के बाद, आप MS Excel में डेटा स्रोत की सूची में SAP HANA MDX प्रदाता का विकल्प देखेंगे।
एसएपी हाना अलर्ट मॉनिटरिंग का उपयोग सिस्टम संसाधनों और सेवाओं की स्थिति की निगरानी के लिए किया जाता है जो हाना सिस्टम में चल रहे हैं। सीपीयू उपयोग, डिस्क फुल, एफएस थ्रेशोल्ड जैसे महत्वपूर्ण अलर्ट को संभालने के लिए अलर्ट मॉनिटरिंग का उपयोग किया जाता है। एचएएनए सिस्टम का मॉनिटरिंग घटक लगातार एचएएनए डेटाबेस के सभी घटकों के स्वास्थ्य, उपयोग और प्रदर्शन के बारे में जानकारी एकत्र करता है। जब कोई घटक सेट थ्रेशोल्ड मान को भंग करता है, तो यह चेतावनी देता है।
हाना प्रणाली में उठाए गए अलर्ट की प्राथमिकता समस्या की आलोचनात्मकता को बताती है और यह घटक पर किए गए चेक पर निर्भर करती है। उदाहरण - यदि CPU उपयोग 80% है, तो कम प्राथमिकता वाला अलर्ट उठाया जाएगा। हालांकि, अगर यह 96% तक पहुंच जाता है, तो सिस्टम एक उच्च प्राथमिकता चेतावनी देगा।
सिस्टम मॉनिटर, एचएएनए सिस्टम की निगरानी करने और अपने सभी एसएपी हाना सिस्टम घटकों की उपलब्धता को सत्यापित करने का सबसे आम तरीका है। सिस्टम मॉनिटर का उपयोग एक एचएएनए प्रणाली के सभी प्रमुख घटक और सेवाओं की जांच के लिए किया जाता है।

आप प्रशासन संपादक में एक व्यक्तिगत प्रणाली के विवरण में ड्रिल कर सकते हैं। यह डेटा डिस्क, लॉग डिस्क, ट्रेस डिस्क के बारे में बताता है, प्राथमिकता के साथ संसाधन उपयोग पर अलर्ट।

प्रशासक संपादक में अलर्ट टैब का उपयोग एचएएनए प्रणाली में वर्तमान और सभी अलर्ट की जांच के लिए किया जाता है।
यह उस समय के बारे में भी बताता है जब अलर्ट उठाया जाता है, अलर्ट का वर्णन, अलर्ट की प्राथमिकता आदि।
SAP हाना निगरानी डैशबोर्ड सिस्टम के स्वास्थ्य और विन्यास के प्रमुख पहलुओं को बताता है -
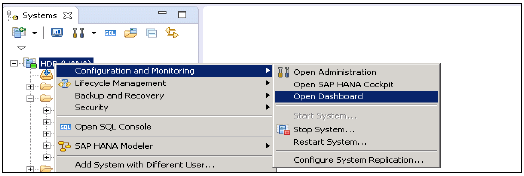
- उच्च और मध्यम प्राथमिकता वाले अलर्ट।
- मेमोरी और सीपीयू उपयोग
- डेटा बैकअप
SAP HANA डेटाबेस दृढ़ता परत सभी लेन-देन के लिए लॉग का प्रबंधन करने के लिए जिम्मेदार है जो मानक डेटा का बैकअप और सिस्टम पुनर्स्थापना फ़ंक्शन प्रदान करता है।
यह सुनिश्चित करता है कि रीस्टार्ट होने के बाद या सिस्टम क्रैश होने पर और लेन-देन पूरी तरह से या पूरी तरह से पूर्ववत किए जाने के बाद डेटाबेस को हाल ही में प्रतिबद्ध स्थिति में बहाल किया जा सकता है। एसएपी हाना पर्सिस्टेंट लेयर इंडेक्स सर्वर का हिस्सा है और इसमें हाना सिस्टम के लिए डेटा और ट्रांजेक्शन लॉग वॉल्यूम हैं और इन वॉल्यूम के लिए इन-मेमोरी डेटा को नियमित रूप से सेव किया जाता है। हाना प्रणाली में ऐसी सेवाएँ हैं जिनकी अपनी दृढ़ता है। यह अंतिम सहेजें बिंदु से सभी डेटाबेस लेनदेन के लिए सेव पॉइंट और लॉग भी प्रदान करता है।
एसएपी हाना डेटाबेस को एक निरंतर परत की आवश्यकता क्यों है?
मुख्य मेमोरी अस्थिर है इसलिए डेटा पुनरारंभ या पावर आउटेज के दौरान खो जाता है।
डेटा को स्थायी माध्यम में संग्रहीत करने की आवश्यकता है।
बैकअप और पुनर्स्थापना उपलब्ध है।
यह सुनिश्चित करता है कि डेटाबेस को फिर से शुरू करने के बाद सबसे हाल ही में प्रतिबद्ध स्थिति में बहाल किया जाता है और लेनदेन को पूरी तरह से निष्पादित या पूरी तरह से पूर्ववत किया जाता है।
डेटा और लेन-देन लॉग वॉल्यूम
डेटाबेस को हमेशा अपनी सबसे हाल की स्थिति में पुनर्स्थापित किया जा सकता है, यह सुनिश्चित करने के लिए कि डेटाबेस में डेटा में इन परिवर्तनों को नियमित रूप से डिस्क पर कॉपी किया जाता है। डेटा परिवर्तन और कुछ लेन-देन की घटनाओं से युक्त लॉग फ़ाइलों को नियमित रूप से डिस्क पर सहेजा जाता है। किसी सिस्टम के डेटा और लॉग को लॉग वॉल्यूम में संग्रहीत किया जाता है।
डेटा वॉल्यूम में SQL डेटा और पूर्व लॉग जानकारी संग्रहीत करता है और SAP हाना जानकारी मॉडलिंग डेटा भी। यह जानकारी डेटा पृष्ठों में संग्रहीत होती है, जिसे ब्लॉक कहा जाता है। इन ब्लॉकों को नियमित समय अंतराल पर डेटा वॉल्यूम के लिए लिखा जाता है, जिसे सेव पॉइंट के रूप में जाना जाता है।
लॉग वॉल्यूम डेटा परिवर्तन के बारे में जानकारी संग्रहीत करते हैं। दो लॉग पॉइंट्स के बीच होने वाले परिवर्तन को लॉग वॉल्यूम में लिखा जाता है और लॉग एंट्री कहा जाता है। लेनदेन के लिए प्रतिबद्ध होने पर उन्हें बफर लॉग करने के लिए बचाया जाता है।
Savepoints
एसएपी हाना डेटाबेस में, परिवर्तित डेटा स्वचालित रूप से मेमोरी से डिस्क पर सहेजा जाता है। इन नियमित अंतरालों को सेवपॉइंट्स कहा जाता है और डिफ़ॉल्ट रूप से वे हर पांच मिनट में होते हैं। एसएपी हाना डेटाबेस में दृढ़ता परत नियमित अंतराल पर इन बचत बिंदुओं का प्रदर्शन करती है। इस ऑपरेशन के दौरान डेटा को डिस्क में लिखा जाता है और रीडो लॉग को डिस्क पर भी सेव किया जाता है।
सेवपॉइंट से संबंधित डेटा डिस्क पर डेटा की सुसंगत स्थिति बताता है और तब तक रहता है जब तक कि अगला सेवपॉइंट ऑपरेशन पूरा नहीं हो जाता। लगातार डेटा में सभी परिवर्तनों के लिए लॉग लॉग में रीडो लॉग प्रविष्टियों को लिखा जाता है। डेटाबेस पुनरारंभ की स्थिति में, अंतिम पूर्ण सहेजे गए डेटा का डेटा डेटा वॉल्यूम, और लॉग संस्करणों में लिखी गई लॉग प्रविष्टियों को रीडओ लॉग से पढ़ा जा सकता है।
Savepoint की फ्रीक्वेंसी को Global.ini फ़ाइल द्वारा कॉन्फ़िगर किया जा सकता है। डेटाबेस के शट डाउन या सिस्टम रिस्टार्ट जैसे अन्य ऑपरेशन के द्वारा सेवपॉइंट शुरू किए जा सकते हैं। आप निचे दिए गए कमांड को क्रियान्वित करके savepoint भी चला सकते हैं -
बदल प्रणाली बचाने के लिए
लॉग वॉल्यूम में डेटा और रीडो लॉग को बचाने के लिए, आपको यह सुनिश्चित करना चाहिए कि इन पर कब्जा करने के लिए पर्याप्त डिस्क स्थान उपलब्ध है, अन्यथा सिस्टम डिस्क पूर्ण घटना जारी करेगा और डेटाबेस काम करना बंद कर देगा।
हाना प्रणाली की स्थापना के दौरान, डिफ़ॉल्ट निर्देशिकाओं को डेटा और लॉग वॉल्यूम के भंडारण स्थान के रूप में बनाया जाता है -
- /usr/sap/<SID>/SYS/global/hdb/data
- /usr/sap/<SID>/SYS/global/hdb/log
ये निर्देशिकाएँ Global.ini फ़ाइल में परिभाषित की गई हैं और इन्हें बाद के चरण में बदला जा सकता है।
ध्यान दें कि एचएएनए प्रणाली में सेव किए गए लेन-देन के प्रदर्शन पर सेव पॉइंट्स प्रभावित नहीं होते हैं। सेवपॉइंट ऑपरेशन के दौरान, लेन-देन सामान्य रूप से चलता रहता है। एचएएनए प्रणाली उचित हार्डवेयर पर चलने के साथ, सिस्टम के प्रदर्शन पर बचत के प्रभाव नगण्य है।
एसएपी हाना बैकअप और रिकवरी का उपयोग किसी भी डेटाबेस विफलता के मामले में हाना सिस्टम बैकअप और सिस्टम की रिकवरी करने के लिए किया जाता है।
अवलोकन टैब
यह वर्तमान में चल रहे डेटा बैकअप और अंतिम सफल डेटा बैकअप की स्थिति बताता है।
बैकअप अब विकल्प का उपयोग डेटा बैकअप विज़ार्ड चलाने के लिए किया जा सकता है।
कॉन्फ़िगरेशन टैब
यह बैकअप अंतराल सेटिंग्स, फ़ाइल आधारित डेटा बैकअप सेटिंग्स और लॉग आधारित डेटा बैकअप सेटिंग के बारे में बताता है।

बैकअप अंतराल सेटिंग्स
Backint सेटिंग्स डेटा के लिए थर्ड पार्टी टूल का उपयोग करने और बैकिंग एजेंट के कॉन्फ़िगरेशन के साथ बैकअप लेने का विकल्प देती है।
Backint एजेंट के लिए एक पैरामीटर फ़ाइल निर्दिष्ट करके किसी तृतीय-पक्ष बैकअप उपकरण के लिए कनेक्शन कॉन्फ़िगर करें।
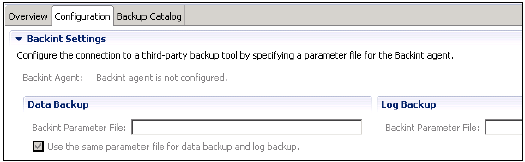
फ़ाइल और लॉग आधारित डेटा बैकअप सेटिंग्स
फ़ाइल आधारित डेटा बैकअप सेटिंग उस फ़ोल्डर को बताती है, जहां आप हाना सिस्टम पर डेटा बैकअप को सहेजना चाहते हैं। आप अपना बैकअप फ़ोल्डर बदल सकते हैं।
आप डेटा बैकअप फ़ाइलों के आकार को भी सीमित कर सकते हैं। यदि सिस्टम डेटा बैकअप इस सेट फ़ाइल आकार से अधिक है, तो यह कई फ़ाइलों में विभाजित हो जाएगा।
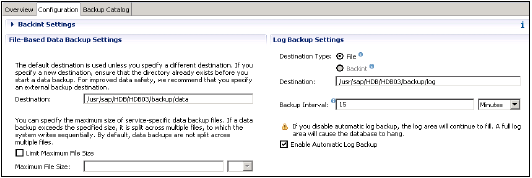
लॉग बैकअप सेटिंग्स गंतव्य फ़ोल्डर को बताएं कि आप बाहरी सर्वर पर लॉग बैकअप कैसे सहेजना चाहते हैं। आप लॉग बैकअप के लिए एक गंतव्य प्रकार चुन सकते हैं
फ़ाइल - सुनिश्चित करता है कि बैकअप स्टोर करने के लिए सिस्टम में पर्याप्त जगह है
Backint - विशेष नामित पाइप फ़ाइल सिस्टम पर मौजूद है, लेकिन डिस्क स्थान की आवश्यकता नहीं है।
आप ड्रॉप डाउन से बैकअप अंतराल चुन सकते हैं। यह समय की सबसे लंबी राशि बताता है जो नए लॉग बैकअप के लिखे जाने से पहले गुजर सकती है। बैकअप अंतराल: यह सेकंड, मिनट या घंटे में हो सकता है।
स्वचालित लॉग बैकअप विकल्प सक्षम करें: यह आपको लॉग क्षेत्र को खाली रखने में मदद करता है। यदि आप अक्षम करते हैं, तो यह लॉग क्षेत्र भरना जारी रखेगा और इसके परिणामस्वरूप डेटाबेस हैंग हो सकता है।
बैकअप विज़ार्ड खोलें - सिस्टम का बैकअप चलाने के लिए।
बैकअप सेटिंग्स को निर्दिष्ट करने के लिए बैकअप विज़ार्ड का उपयोग किया जाता है। यह बैकअप प्रकार, गंतव्य प्रकार, बैकअप गंतव्य फ़ोल्डर, बैकअप उपसर्ग, बैकअप का आकार, आदि बताता है।
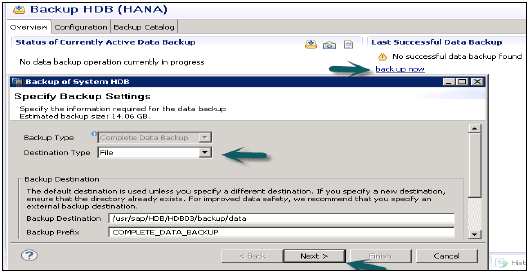
जब आप next पर क्लिक करें → बैकअप सेटिंग्स की समीक्षा करें → समाप्त करें
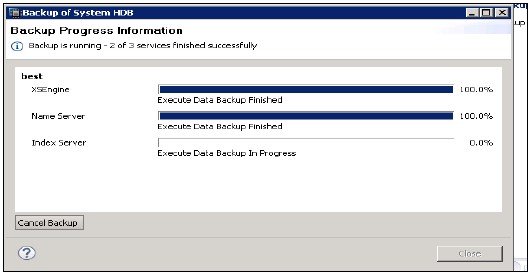
यह सिस्टम बैकअप चलाता है और प्रत्येक सर्वर के लिए बैकअप पूरा करने का समय बताता है।
हाना सिस्टम की रिकवरी
एसएपी हाना डेटाबेस को पुनर्प्राप्त करने के लिए, डेटाबेस को बंद करने की आवश्यकता है। इसलिए, पुनर्प्राप्ति के दौरान, अंतिम उपयोगकर्ता या SAP एप्लिकेशन डेटाबेस तक नहीं पहुंच सकते हैं।
निम्नलिखित स्थितियों में एसएपी हाना डेटाबेस की वसूली आवश्यक है -
डेटा क्षेत्र में एक डिस्क अनुपयोगी है या लॉग क्षेत्र में डिस्क अनुपयोगी है।
एक तार्किक त्रुटि के परिणामस्वरूप, डेटाबेस को एक विशेष समय में अपने राज्य में रीसेट करने की आवश्यकता होती है।
आप डेटाबेस की एक प्रति बनाना चाहते हैं।
हाना सिस्टम कैसे पुनर्प्राप्त करें?
हाना सिस्टम चुनें → राइट क्लिक करें → बैक एंड रिकवरी → रिकवर सिस्टम
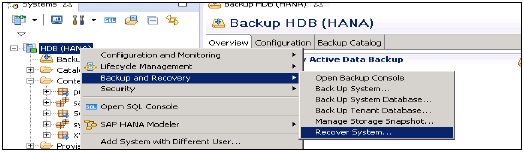
हाना सिस्टम में रिकवरी के प्रकार
Most Recent State- वर्तमान समय के लिए जितना संभव हो उतना समय डेटाबेस को पुनर्प्राप्त करने के लिए उपयोग किया जाता है। इस पुनर्प्राप्ति के लिए, डेटा बैकअप और लॉग बैकअप उपलब्ध होना आवश्यक है क्योंकि पिछले डेटा बैकअप और लॉग क्षेत्र को उपरोक्त प्रकार की वसूली करने के लिए आवश्यक है।
Point in Time- विशिष्ट समय में डेटाबेस को पुनर्प्राप्त करने के लिए उपयोग किया जाता है। इस पुनर्प्राप्ति के लिए, डेटा बैकअप और लॉग बैकअप उपलब्ध होना आवश्यक है क्योंकि पिछले डेटा बैकअप और लॉग क्षेत्र को उपरोक्त प्रकार की वसूली करने के लिए आवश्यक है
Specific Data Backup- एक निर्दिष्ट डेटा बैकअप के लिए डेटाबेस को पुनर्प्राप्त करने के लिए उपयोग किया जाता है। उपरोक्त प्रकार के पुनर्प्राप्ति विकल्प के लिए विशिष्ट डेटा बैकअप की आवश्यकता होती है।
Specific Log Position - यह पुनर्प्राप्ति प्रकार एक उन्नत विकल्प है जिसका उपयोग असाधारण मामलों में किया जा सकता है जहां पिछली वसूली विफल रही।
Note - पुनर्प्राप्ति विज़ार्ड चलाने के लिए आपके पास HANA सिस्टम पर व्यवस्थापक विशेषाधिकार होना चाहिए।
एसएपी हाना सिस्टम दोष और सॉफ्टवेयर त्रुटियों के लिए व्यापार निरंतरता और आपदा वसूली के लिए तंत्र प्रदान करता है। एचएएनए प्रणाली में उच्च उपलब्धता उन प्रथाओं के सेट को परिभाषित करती है जो डेटा केंद्रों में बिजली की विफलता, आग, बाढ़ आदि जैसी प्राकृतिक आपदाओं या किसी हार्डवेयर विफलता जैसी आपदाओं के मामले में व्यापार निरंतरता प्राप्त करने में मदद करती है।
एसएपी हाना उच्च उपलब्धता न्यूनतम व्यापार हानि के साथ आउटेज के बाद सिस्टम के संचालन को फिर से शुरू करने के लिए गलती सहिष्णुता और सिस्टम की क्षमता प्रदान करता है।
निम्न चित्र हाना प्रणाली में उच्च उपलब्धता के चरणों को दर्शाता है -
फॉल्ट के लिए पहले चरण की तैयारी की जा रही है। एक गलती का पता स्वचालित रूप से या एक प्रशासनिक कार्रवाई से लगाया जा सकता है। डेटा का बैकअप लिया जाता है और सिस्टम द्वारा स्टैंड ऑपरेशन पर ले जाता है। पुनर्प्राप्ति प्रक्रिया को कार्रवाई में रखा गया है जिसमें दोषपूर्ण प्रणाली की मरम्मत और मूल प्रणाली को पिछले कॉन्फ़िगरेशन में बहाल किया जाना शामिल है।
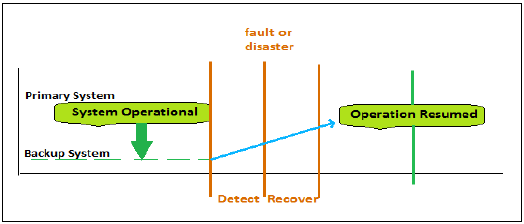
हाना प्रणाली में उच्च उपलब्धता प्राप्त करने के लिए, कुंजी अतिरिक्त घटकों का समावेश है, जो अन्य घटकों की विफलता के मामले में कार्य और उपयोग करने के लिए आवश्यक नहीं है। इसमें हार्डवेयर अतिरेक, नेटवर्क अतिरेक और डेटा केंद्र अतिरेक शामिल हैं। एसएपी हाना नीचे के रूप में हार्डवेयर और सॉफ्टवेयर अतिरेक के कई स्तर प्रदान करता है -
हाना सिस्टम हार्डवेयर अतिरेक
एसएपी हाना उपकरण विक्रेता निरर्थक हार्डवेयर आपूर्ति, सॉफ्टवेयर और नेटवर्क घटकों की कई परतों की पेशकश करते हैं, जैसे कि अनावश्यक बिजली की आपूर्ति और प्रशंसक, त्रुटि सुधारने वाली यादें, पूरी तरह से अनावश्यक नेटवर्क स्विच और राउटर, और निर्बाध विद्युत आपूर्ति (यूपीएस)। डिस्क स्टोरेज सिस्टम बिजली की विफलता की उपस्थिति में भी लेखन की गारंटी देता है और डिस्क विफलताओं से स्वचालित वसूली के लिए अतिरेक प्रदान करने के लिए स्ट्रिपिंग और मिररिंग सुविधाओं का उपयोग करता है।
एसएपी हाना सॉफ्टवेयर अतिरेक
एसएपी हाना एसएपी के लिए एसयूएसई लिनक्स एंटरप्राइज 11 पर आधारित है और इसमें सुरक्षा पूर्व-कॉन्फ़िगरेशन शामिल हैं।
एसएपी हाना सिस्टम सॉफ्टवेयर में एक वॉचडॉग फ़ंक्शन शामिल है, जो स्वचालित रूप से पता चला ठहराव (मारे गए या दुर्घटनाग्रस्त) के मामले में कॉन्फ़िगर की गई सेवाओं (इंडेक्स सर्वर, नाम सर्वर, और इसी तरह) को पुनरारंभ करता है।
SAP हाना दृढ़ता अतिरेक
एसएपी हाना न्यूनतम देरी के साथ और डेटा की हानि के बिना, सिस्टम पुनरारंभ और विफलताओं से पुनर्प्राप्ति का समर्थन करने के लिए लेनदेन लॉग, बचत और स्नैपशॉट की दृढ़ता प्रदान करता है।
हाना सिस्टम स्टैंडबाय और फेलओवर
एसएपी हाना प्रणाली में अलग-अलग स्टैंडबाय होस्ट शामिल हैं जो प्राथमिक प्रणाली की विफलता के मामले में विफलता के लिए उपयोग किए जाते हैं। यह एक आउटेज से पुनर्प्राप्ति समय को कम करके एचएएनए प्रणाली की उपलब्धता में सुधार करता है।
एसएपी हाना प्रणाली उन सभी लेनदेन को लॉग करती है जो एप्लिकेशन डेटा या डेटाबेस कैटलॉग को लॉग प्रविष्टियों में बदलते हैं और उन्हें लॉग क्षेत्र में संग्रहीत करते हैं। यह एसक्यूएल स्टेटमेंट को वापस लाने या दोहराने के लिए लॉग इन क्षेत्र में इन लॉग प्रविष्टियों का उपयोग करता है। लॉग फाइल HANA सिस्टम में उपलब्ध हैं और HNA स्टूडियो के माध्यम से डायग्नोसिस फाइल पेज पर एडमिनिस्ट्रेटर एडिटर के तहत एक्सेस की जा सकती हैं।
लॉग बैकअप प्रक्रिया के दौरान, लॉग सेगमेंट का केवल वास्तविक डेटा लॉग क्षेत्र से सेवा-विशिष्ट लॉग बैकअप फ़ाइलों या किसी तृतीय-पक्ष बैकअप उपकरण के लिए लिखा जाता है।
सिस्टम विफलता के बाद, आपको डेटाबेस को वांछित स्थिति में पुनर्स्थापित करने के लिए लॉग बैकअप से लॉग प्रविष्टियों को फिर से करना होगा।
यदि दृढ़ता के साथ एक डेटाबेस सेवा बंद हो जाती है, तो यह सुनिश्चित करना महत्वपूर्ण है कि इसे फिर से शुरू किया जाए, अन्यथा सेवा बंद होने से पहले केवल एक बिंदु तक ही वसूली संभव होगी।
लॉग बैकअप टाइमआउट कॉन्फ़िगर करना
लॉग बैकअप टाइमआउट अंतराल को निर्धारित करता है जिस पर लॉग सेगमेंट का बैकअप लिया जाता है यदि इस अंतराल में कोई कमिटमेंट हुआ है। आप SAP हाना स्टूडियो में बैकअप कंसोल का उपयोग करके लॉग बैकअप टाइमआउट को कॉन्फ़िगर कर सकते हैं -
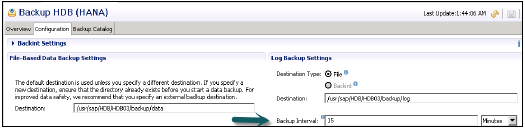
आप global.ini कॉन्फ़िगरेशन फ़ाइल में log_backup_timeout_s अंतराल भी कॉन्फ़िगर कर सकते हैं।
एसएपी हाना प्रणाली की स्थापना के बाद "फाइल" और बैकअप मोड "नोर्मल" के लिए लॉग बैकअप स्वचालित लॉग बैकअप फ़ंक्शन के लिए डिफ़ॉल्ट सेटिंग्स हैं। स्वचालित लॉग बैकअप केवल तभी काम करता है जब कम से कम एक पूर्ण डेटा बैकअप का प्रदर्शन किया गया हो।
एक बार जब पहला पूर्ण डेटा बैकअप किया जाता है, तो स्वचालित लॉग बैकअप फ़ंक्शन सक्रिय होता है। एसएपी हाना स्टूडियो का उपयोग स्वचालित लॉग बैकअप फ़ंक्शन को सक्षम / अक्षम करने के लिए किया जा सकता है। यह स्वचालित लॉग बैकअप को सक्षम रखने के लिए अनुशंसित है अन्यथा लॉग क्षेत्र भरना जारी रखेगा। एक पूर्ण लॉग क्षेत्र हाना सिस्टम में डेटाबेस फ्रीज कर सकता है।
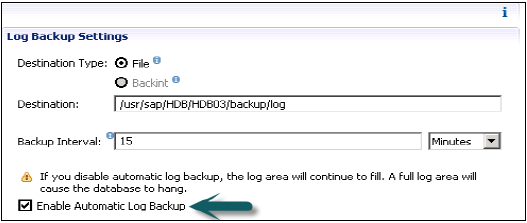
आप Global.ini कॉन्फ़िगरेशन फ़ाइल की दृढ़ता अनुभाग में enable_auto_log_backup पैरामीटर भी बदल सकते हैं।
SQL स्ट्रक्चर्ड क्वेरी लैंग्वेज के लिए है।
यह एक डेटाबेस के साथ संवाद करने के लिए एक मानकीकृत भाषा है। SQL का उपयोग डेटाबेस में डेटा को पुनः प्राप्त करने, स्टोर करने या हेरफेर करने के लिए किया जाता है।
SQL स्टेटमेंट निम्न कार्य करते हैं -
- डेटा परिभाषा और हेरफेर
- सिस्टम प्रबंधन
- सत्र प्रबंधन
- लेन - देन प्रबंधन
- स्कीमा की परिभाषा और हेरफेर
SQL एक्सटेंशन का सेट, जो डेवलपर्स को डेटाबेस में डेटा पुश करने की अनुमति देता है, कहा जाता है SQL scripts।
डेटा हेरफेर भाषा (DML)
स्कीमा ऑब्जेक्ट के भीतर डेटा के प्रबंधन के लिए डीएमएल स्टेटमेंट का उपयोग किया जाता है। कुछ उदाहरण -
SELECT - डेटाबेस से डेटा पुनः प्राप्त
INSERT - एक तालिका में डेटा डालें
UPDATE - एक टेबल के भीतर मौजूदा डेटा को अपडेट करता है
डेटा परिभाषा भाषा (DDL)
डेटाबेस संरचना या स्कीमा को परिभाषित करने के लिए DDL स्टेटमेंट का उपयोग किया जाता है। कुछ उदाहरण -
CREATE - डेटाबेस में ऑब्जेक्ट बनाने के लिए
ALTER - डेटाबेस की संरचना को बदल देता है
DROP - डेटाबेस से वस्तुओं को हटा दें
डेटा नियंत्रण भाषा (DCL)
डीसीएल बयानों के कुछ उदाहरण हैं -
GRANT - डेटाबेस के लिए उपयोगकर्ता की पहुँच विशेषाधिकार देता है
REVOKE - GRANT कमांड के साथ दिए गए एक्सेस विशेषाधिकारों को वापस ले लें
हमें SQL की आवश्यकता क्यों है?
जब हम एसएपी हाना मॉडलर में सूचना दृश्य बनाते हैं, तो हम इसे कुछ ओएलटीपी अनुप्रयोगों के शीर्ष पर बना रहे हैं। ये सभी बैक एंड में SQL पर चलते हैं। डेटाबेस केवल इस भाषा को समझता है।
एक परीक्षण करने के लिए यदि हमारी रिपोर्ट व्यावसायिक आवश्यकता को पूरा करेगी तो हमें डेटाबेस में SQL कथन चलाना होगा यदि आउटपुट आवश्यकता के अनुसार हो।
हाना गणना दृश्य दो तरह से बनाए जा सकते हैं - ग्राफिकल या एसक्यूएल स्क्रिप्ट का उपयोग करना। जब हम अधिक जटिल गणना दृश्य बनाते हैं, तो हमें प्रत्यक्ष SQL स्क्रिप्ट का उपयोग करना पड़ सकता है।
हाना स्टूडियो में SQL कंसोल कैसे खोलें?
HANA प्रणाली का चयन करें और सिस्टम दृश्य में SQL कंसोल विकल्प पर क्लिक करें। आप कैटलॉग टैब या किसी स्कीमा नाम पर राइट क्लिक करके SQL कंसोल भी खोल सकते हैं।
SAP हाना दोनों रिलेशनल और साथ ही OLAP डेटाबेस के रूप में कार्य कर सकता है। जब हम हाना पर BW का उपयोग करते हैं, तो हम BW और HANA में क्यूब्स बनाते हैं, जो रिलेशनल डेटाबेस के रूप में कार्य करते हैं और हमेशा एक SQL स्टेटमेंट का उत्पादन करते हैं। हालाँकि, जब हम OLAP कनेक्शन का उपयोग करके सीधे HANA विचारों का उपयोग करते हैं, तो यह OLAP डेटाबेस के रूप में कार्य करेगा और MDX उत्पन्न होगा।
आप SAP HANA में क्रिएट टेबल कॉलम या टेबल स्टोर बना सकते हैं। एक तालिका डेटा स्टेटमेंट क्रिएट कर या हाना स्टूडियो में ग्राफिकल विकल्प का उपयोग करके एक तालिका बनाई जा सकती है।
जब आप एक तालिका बनाते हैं, तो आपको इसके अंदर विशेषताओं को परिभाषित करने की भी आवश्यकता होती है।
SQL statement to create a table in HANA Studio SQL Console -
Create column Table TEST (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);Creating a table in HANA studio using GUI option -
जब आप एक तालिका बनाते हैं, तो आपको कॉलम और SQL डेटा प्रकारों के नामों को परिभाषित करने की आवश्यकता होती है। आयाम फ़ील्ड मान की लंबाई और इसे प्राथमिक कुंजी के रूप में परिभाषित करने के लिए कुंजी विकल्प बताता है।
एसएपी हाना एक तालिका में निम्नलिखित डेटा प्रकारों का समर्थन करता है -
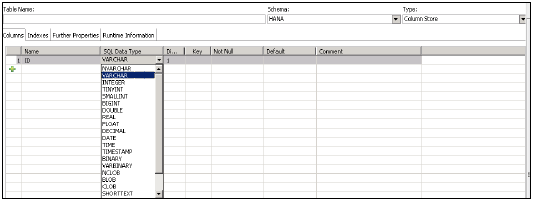
SAP HANA SQL डेटा प्रकारों की 7 श्रेणियों का समर्थन करता है और यह उस डेटा के प्रकार पर निर्भर करता है जिसे आपको किसी कॉलम में संग्रहीत करना है।
- Numeric
- वर्ण स्ट्रिंग
- Boolean
- दिनांक और समय
- Binary
- बड़ी वस्तु
- Multi-Valued
निम्न तालिका प्रत्येक श्रेणी में डेटा प्रकारों की सूची देती है -

दिनांक और समय
इन डेटा प्रकारों का उपयोग HANA डेटाबेस में एक तालिका में दिनांक और समय को संग्रहीत करने के लिए किया जाता है।
DATE- डेटा प्रकार में एक कॉलम में दिनांक मान का प्रतिनिधित्व करने के लिए वर्ष, महीने और दिन की जानकारी होती है। दिनांक डेटा प्रकार के लिए डिफ़ॉल्ट प्रारूप YYYY-MM-DD है।
TIME- डेटा प्रकार हाना डेटाबेस में एक तालिका में घंटे, मिनट और सेकंड मूल्य के होते हैं। समय डेटा प्रकार के लिए डिफ़ॉल्ट प्रारूप HH: MI: SS है।
SECOND DATE- डेटा प्रकार में हाना डेटाबेस में एक तालिका में वर्ष, महीना, दिन, घंटा, मिनट, दूसरा मूल्य होता है। सेकंड डेटा प्रकार के लिए डिफ़ॉल्ट प्रारूप YYYY-MM-DD HH: MM: SS है।
TIMESTAMP- डेटा प्रकार हाना डेटाबेस में एक तालिका में दिनांक और समय की जानकारी के होते हैं। TIMESTAMP डेटा प्रकार के लिए डिफ़ॉल्ट प्रारूप YYYY-MM-DD HH: MM: SS: FFn है, जहां FFn दूसरे के अंश का प्रतिनिधित्व करता है।
संख्यात्मक
TinyINT- स्टोर 8 बिट अहस्ताक्षरित पूर्णांक। न्यूनतम मूल्य: 0 और अधिकतम मूल्य: 255
SMALLINT- भंडार 16 बिट हस्ताक्षरित पूर्णांक। न्यूनतम मूल्य: -32,768 और अधिकतम मूल्य: 32,767
Integer- भंडार 32 बिट हस्ताक्षरित पूर्णांक। न्यूनतम मूल्य: -2,147,483,648 और अधिकतम मूल्य: 2,147,483,648
BIGINT- 64 बिट हस्ताक्षरित पूर्णांक को संग्रहीत करता है। न्यूनतम मूल्य: -9,223,372,036,854,775,808 और अधिकतम मूल्य: 9,223,372,036,854,775,808
SMALL - दशमलव और दशमलव: न्यूनतम मान: -10 ^ 38 +1 और अधिकतम मूल्य: 10 ^ 38 -1
REAL - न्यूनतम मूल्य: -3.40E + 38 और अधिकतम मूल्य: 3.40E + 38
DOUBLE- 64 बिट फ्लोटिंग पॉइंट नंबर स्टोर करता है। न्यूनतम मूल्य: -1.7976931348623157E308 और अधिकतम मूल्य: 1.79769313486231573030
बूलियन
बूलियन डेटा प्रकार बूलियन मान को संग्रहीत करता है, जो TRUE, FALSE हैं
चरित्र
Varchar - अधिकतम 8000 वर्ण।
Nvarchar - अधिकतम 4000 वर्ण
ALPHANUM- अल्फ़ान्यूमेरिक वर्णों को संग्रहीत करता है। पूर्णांक के लिए मान 1 से 127 के बीच है।
SHORTTEXT - वैरिएबल लेंथ कैरेक्टर स्ट्रिंग को स्टोर करता है जो टेक्स्ट सर्च फीचर्स और स्ट्रिंग सर्च फीचर्स को सपोर्ट करता है।
बायनरी
बाइनरी प्रकार का उपयोग बाइनरी डेटा के बाइट्स को स्टोर करने के लिए किया जाता है।
VARBINARY- बाइट्स में बाइनरी डेटा स्टोर करता है। अधिकतम पूर्णांक लंबाई 1 और 5000 के बीच है।
बड़ी वस्तु
LARGEOBJECTS का उपयोग बड़ी मात्रा में डेटा को संग्रहीत करने के लिए किया जाता है जैसे कि पाठ दस्तावेज़ और चित्र।
NCLOB - बड़े UNICODE वर्ण ऑब्जेक्ट को संग्रहीत करता है।
BLOB - बड़ी मात्रा में बाइनरी डेटा संग्रहीत करता है।
CLOB - बड़ी मात्रा में ASCII वर्ण डेटा संग्रहीत करता है।
TEXT- यह पाठ खोज सुविधाओं को सक्षम करता है। इस डेटा प्रकार को केवल स्तंभ तालिकाओं के लिए परिभाषित किया जा सकता है, पंक्ति पंक्ति तालिकाओं के लिए नहीं।
BINTEXT - पाठ खोज सुविधाओं का समर्थन करता है, लेकिन बाइनरी डेटा सम्मिलित करना संभव है।
बहु-मूल्यांकित
बहुविकल्पी डेटा प्रकारों का उपयोग समान डेटा प्रकार के साथ मूल्यों के संग्रह को संग्रहीत करने के लिए किया जाता है।
सरणी
Arrays समान डेटा प्रकार के साथ मूल्य के संग्रह को संग्रहीत करता है। उनमें शून्य मान भी हो सकते हैं।
एक ऑपरेटर एक विशेष चरित्र है जिसका उपयोग SQL स्टेटमेंट में मुख्य रूप से ऑपरेशन, जैसे कि तुलना और अंकगणितीय ऑपरेशन, करने के लिए किया जाता है। इनका उपयोग SQL क्वेरी में शर्तों को पारित करने के लिए किया जाता है।
नीचे दिए गए ऑपरेटर प्रकारों का उपयोग हाना में SQL स्टेटमेंट में किया जा सकता है -
- अंकगणितीय आपरेटर
- तुलनात्मक / रिलेशनल ऑपरेटर्स
- लॉजिकल ऑपरेटर्स
- ऑपरेटर सेट करें
अंकगणितीय आपरेटर
अंकगणितीय संचालकों को जोड़, घटाव, गुणा, भाग और प्रतिशत जैसे सरल गणना कार्य करने के लिए उपयोग किया जाता है।
| ऑपरेटर | विवरण |
|---|---|
| + | परिवर्धन - ऑपरेटर के दोनों ओर मान जोड़ता है |
| - | घटाव - बाएं हाथ के ऑपरेंड से दाहिने हाथ के ऑपरेंड को घटाते हैं |
| * | गुणन - ऑपरेटर के दोनों ओर मूल्यों को गुणा करता है |
| / | डिवीजन - दाएं हाथ के ऑपरेंड द्वारा बाएं हाथ के ऑपरेशन को विभाजित किया जाता है |
| % | मापांक - दाएं हाथ से बाएं हाथ के ऑपरेंड को बांटा जाता है और शेष को लौटाता है |
तुलना संचालक
SQL कथन में मानों की तुलना करने के लिए तुलना ऑपरेटरों का उपयोग किया जाता है।
| ऑपरेटर | विवरण |
|---|---|
| = | जाँच करता है कि दो ऑपरेंड के मान समान हैं या नहीं, यदि हाँ तो स्थिति सच हो जाती है। |
| ! = | जाँच करता है कि दो ऑपरेंड के मान समान हैं या नहीं, यदि मान बराबर नहीं हैं तो स्थिति सत्य हो जाती है। |
| <> | जाँच करता है कि दो ऑपरेंड के मान समान हैं या नहीं, यदि मान बराबर नहीं हैं तो स्थिति सत्य हो जाती है। |
| > | जाँच करता है कि क्या बाएं संकार्य का मान दाहिने संचालक के मान से अधिक है, यदि हाँ, तो स्थिति सत्य हो जाती है। |
| < | यह जाँचता है कि क्या बाएं संकार्य का मान दाहिने संचालक के मान से कम है, यदि हाँ तो स्थिति सही है। |
| > = | जाँच करता है कि क्या बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से अधिक या बराबर है, यदि हाँ तो स्थिति सच हो जाती है। |
| <= | जाँच करता है कि क्या बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से कम या बराबर है, यदि हाँ तो स्थिति सच हो जाती है। |
| ! < | जाँच करता है कि क्या बाएं संकार्य का मूल्य सही संचालक के मूल्य से कम नहीं है, यदि हाँ, तो स्थिति सत्य हो जाती है। |
| !> | जाँच करता है कि क्या बाएं संकार्य का मूल्य सही संकार्य के मूल्य से अधिक नहीं है, यदि हाँ, तो स्थिति सत्य हो जाती है। |
लॉजिकल ऑपरेटर्स
लॉजिकल ऑपरेटर्स का उपयोग SQL स्टेटमेंट में कई शर्तों को पारित करने के लिए किया जाता है या शर्तों के परिणामों में हेरफेर करने के लिए उपयोग किया जाता है।
| ऑपरेटर | विवरण |
|---|---|
| सब | सभी संचालक का उपयोग किसी मान के लिए किसी अन्य मान सेट में तुलना करने के लिए किया जाता है। |
| तथा | AND ऑपरेटर SQL स्टेटमेंट के WHERE क्लॉज में कई स्थितियों के अस्तित्व की अनुमति देता है। |
| कोई भी | किसी भी ऑपरेटर का उपयोग शर्त के अनुसार किसी भी लागू मूल्य के मूल्य की तुलना करने के लिए किया जाता है। |
| के बीच | BETWEEN ऑपरेटर का उपयोग उन मानों की खोज के लिए किया जाता है जो मानों के एक सेट के भीतर होते हैं, न्यूनतम मूल्य और अधिकतम मूल्य दिया जाता है। |
| मौजूद | EXISTS ऑपरेटर एक निर्दिष्ट तालिका में एक पंक्ति की उपस्थिति के लिए खोज करने के लिए उपयोग किया जाता है जो कुछ मानदंडों को पूरा करता है। |
| में | IN ऑपरेटर का उपयोग उन मानों की सूची की मान की तुलना करने के लिए किया जाता है जिन्हें निर्दिष्ट किया गया है। |
| पसंद | LIKE ऑपरेटर का उपयोग वाइल्डकार्ड ऑपरेटरों के उपयोग के समान मानों की तुलना करने के लिए किया जाता है। |
| नहीं | NOT ऑपरेटर उस तार्किक ऑपरेटर के अर्थ को उलट देता है जिसके साथ इसका उपयोग किया जाता है। जैसे - NOT EXISTS, NOT BETWEEN, NOT IN, etc.This is a negate operator। |
| या | OR ऑपरेटर का उपयोग SQL स्टेटमेंट के WHERE क्लॉज में कई स्थितियों की तुलना करने के लिए किया जाता है। |
| शून्य है | NULL ऑपरेटर का उपयोग NULL मान वाले मान की तुलना करने के लिए किया जाता है। |
| अद्वितीय | अद्वितीय ऑपरेटर अद्वितीयता (कोई डुप्लिकेट) के लिए एक निर्दिष्ट तालिका की हर पंक्ति को खोजता है। |
ऑपरेटर सेट करें
सेट ऑपरेटर का उपयोग दो प्रश्नों के परिणामों को एक परिणाम में संयोजित करने के लिए किया जाता है। दोनों तालिकाओं के लिए डेटा प्रकार समान होना चाहिए।
UNION- यह दो या दो से अधिक चुनिंदा कथनों के परिणामों को जोड़ता है। हालाँकि यह डुप्लिकेट पंक्तियों को समाप्त कर देगा।
UNION ALL - यह ऑपरेटर संघ के समान है लेकिन यह डुप्लिकेट पंक्तियों को भी दिखाता है।
INTERSECT- इन्टरसेक्ट ऑपरेशन का उपयोग दो SELECT स्टेटमेंट्स को मिलाने के लिए किया जाता है, और यह उन रिकॉर्ड्स को लौटाता है, जो दोनों SELECT स्टेटमेंट्स से कॉमन हैं। Intersect के मामले में, स्तंभों और डेटाटाइप की संख्या दोनों तालिकाओं में समान होनी चाहिए।
MINUS - माइनस ऑपरेशन दो चयनित बयानों के परिणाम को जोड़ता है और केवल उन परिणामों को वापस करता है, जो पहले परिणाम के सेट से संबंधित हैं और पहले के आउटपुट से दूसरे बयान में पंक्तियों को खत्म करते हैं।
एसएपी हाना डेटाबेस द्वारा प्रदान किए गए विभिन्न एसक्यूएल फ़ंक्शन हैं -
- संख्यात्मक कार्य
- स्ट्रिंग फ़ंक्शंस
- फुलटेक्स्ट फंक्शन्स
- आजीवन कार्य
- अलग कार्य
- डेटा प्रकार रूपांतरण कार्य
- विंडो फ़ंक्शंस
- श्रृंखला डेटा कार्य
- विविध कार्य
संख्यात्मक कार्य
ये SQL में inbuilt संख्यात्मक फंक्शन हैं और स्क्रिप्टिंग में उपयोग करते हैं। यह सांख्यिक वर्णों के साथ संख्यात्मक मान या स्ट्रिंग्स लेता है और संख्यात्मक मान लौटाता है।
ABS - यह एक संख्यात्मक तर्क का निरपेक्ष मान लौटाता है।
Example − SELECT ABS (-1) "abs" FROM TEST;
abs
1ACOS, ASIN, ATAN, ATAN2 (ये कार्य तर्क के त्रिकोणमितीय मान को लौटाते हैं)
BINTOHEX - यह एक बाइनरी मान को एक हेक्साडेसिमल मान में परिवर्तित करता है।
BITAND - यह पारित तर्क के बिट्स पर AND ऑपरेशन करता है।
BITCOUNT - यह एक तर्क में सेट बिट्स की संख्या की गणना करता है।
BITNOT - यह तर्क के बिट्स पर एक बिटवाइज़ नहीं ऑपरेशन करता है।
BITOR - यह पारित तर्क के बिट्स पर एक OR ऑपरेशन करता है।
BITSET - इसका उपयोग बिट्स को सेट करने के लिए <target_num> <start_bit> स्थिति से किया जाता है।
BITUNSET - इसका उपयोग <start_bit> स्थिति से बिट्स को <target_num> में सेट करने के लिए किया जाता है।
BITXOR - यह पारित तर्क के बिट्स पर XOR ऑपरेशन करता है।
CEIL - यह पहला पूर्णांक देता है जो पारित मूल्य से अधिक या बराबर है।
COS, COSH, COT ((ये फ़ंक्शन तर्क के त्रिकोणमितीय मान लौटाते हैं)
EXP - यह पारित मूल्य की शक्ति के लिए उठाए गए प्राकृतिक लॉगरिथम ई के आधार का परिणाम देता है।
FLOOR - यह सबसे बड़ा पूर्णांक देता है जो संख्यात्मक तर्क से अधिक नहीं है।
HEXTOBIN - यह एक हेक्साडेसिमल मान को एक बाइनरी मूल्य में परिवर्तित करता है।
LN - यह तर्क का स्वाभाविक लघुगणक लौटाता है।
LOG- यह पारित सकारात्मक मूल्य के एल्गोरिथ्म मूल्य को वापस करता है। आधार और लॉग मान दोनों सकारात्मक होना चाहिए।
विभिन्न अन्य संख्यात्मक कार्यों का भी उपयोग किया जा सकता है - MOD, POWER, RAND, ROUND, SIGN, SIN, SINH, SQRT, TAN, TANH, UMINUS
स्ट्रिंग फ़ंक्शंस
SQL स्क्रिप्टिंग के साथ Hana में विभिन्न SQL स्ट्रिंग फ़ंक्शन का उपयोग किया जा सकता है। सबसे आम स्ट्रिंग कार्य हैं -
ASCII - यह पास स्ट्रिंग का पूर्णांक ASCII मान लौटाता है।
CHAR - यह पारित ASCII मान से जुड़े चरित्र को लौटाता है।
CONCAT - यह कॉन्टैकटेशन ऑपरेटर है और संयुक्त पारित स्ट्रिंग्स को लौटाता है।
LCASE - यह एक स्ट्रिंग के सभी चरित्र को लोअर केस में कनवर्ट करता है।
LEFT - यह उल्लेखित मूल्य के अनुसार एक गुजर स्ट्रिंग के पहले अक्षर लौटाता है।
LENGTH - यह पारित स्ट्रिंग में वर्णों की संख्या लौटाता है।
LOCATE - यह पारित स्ट्रिंग के भीतर प्रतिस्थापन की स्थिति लौटाता है।
LOWER - यह स्ट्रिंग के सभी वर्णों को लोअरकेस में कनवर्ट करता है।
NCHAR - यह यूनिकोड वर्ण को उत्तीर्ण पूर्णांक मान के साथ लौटाता है।
REPLACE - यह खोज स्ट्रिंग की सभी घटनाओं के लिए पारित मूल स्ट्रिंग में खोज करता है और उन्हें प्रतिस्थापित स्ट्रिंग के साथ बदल देता है।
RIGHT - यह उल्लेख किए गए स्ट्रिंग का सबसे सही पारित मूल्य अक्षर देता है।
UPPER - यह उत्तीर्ण स्ट्रिंग में सभी वर्णों को अपरकेस में परिवर्तित करता है।
UCASE- यह UPPER फ़ंक्शन के समान है। यह उत्तीर्ण स्ट्रिंग में सभी वर्णों को अपरकेस में परिवर्तित करता है।
अन्य स्ट्रिंग फ़ंक्शंस जिनका उपयोग किया जा सकता है - एलपीएडी, एलटीआरआईएम, आरटीआरआईएम, स्ट्रैटोबिन, एसयूबीटीएसएबीईआर, एसयूबीटीएसबीईआर, सबस्ट्रिंग, टीआरआईएम, यूनिकोड, आरपीएडी, बंटओवर्ट्स
दिनांक समय कार्य
SQL स्क्रिप्ट में HANA में उपयोग किए जा सकने वाले विभिन्न दिनांक समय फ़ंक्शन हैं। सबसे आम दिनांक समय कार्य हैं -
CURRENT_DATE - यह वर्तमान स्थानीय प्रणाली की तारीख लौटाता है।
CURRENT_TIME - यह वर्तमान स्थानीय प्रणाली का समय लौटाता है।
CURRENT_TIMESTAMP - यह वर्तमान स्थानीय प्रणाली टाइमस्टैम्प विवरण (YYYY-MM-DD HH: MM: SS: FF) देता है।
CURRENT_UTCDATE - यह वर्तमान यूटीसी (ग्रीनविच मीन डेट) तारीख देता है।
CURRENT_UTCTIME - यह वर्तमान यूटीसी (ग्रीनविच मीन टाइम) समय देता है।
CURRENT_UTCTIMESTAMP
DAYOFMONTH - यह तर्क में पारित तारीख में दिन का पूर्णांक मान लौटाता है।
HOUR - यह तर्क में पारित समय में घंटे का पूर्णांक मान लौटाता है।
YEAR - यह पारित तिथि का वर्ष मान लौटाता है।
अन्य दिनांक समय के कार्य हैं - DAYOFYEAR, DAYNAME, DAYS_BETWEEN, EXTRACT, NANO100_BETWEEN, NEXT_DAY, अब, QUARTER, SECON_BLEETWEEN, UTCTOLOCAL, WEEKDAY, WORKDAY_B_BWEWE, ISK ADD_SECONDS, ADD_WORKDAYS
डेटा प्रकार रूपांतरण कार्य
इन फ़ंक्शन का उपयोग एक डेटा प्रकार को दूसरे में बदलने या चेक करने के लिए किया जाता है कि क्या रूपांतरण संभव है या नहीं।
SQL स्क्रिप्ट में HANA में उपयोग किए जाने वाले अधिकांश सामान्य डेटा प्रकार रूपांतरण कार्य -
CAST - यह एक प्रदत्त डेटा प्रकार में परिवर्तित अभिव्यक्ति का मूल्य देता है।
TO_ALPHANUM - यह एक पारित मूल्य को एक ALPHANUM डेटा प्रकार में परिवर्तित करता है
TO_REAL - यह एक मान को वास्तविक डेटा प्रकार में परिवर्तित करता है।
TO_TIME - यह एक टाइम टाइम स्ट्रिंग को TIME डेटा टाइप में कनवर्ट करता है।
TO_CLOB - यह एक मान को CLOB डेटा प्रकार में परिवर्तित करता है।
अन्य समान डेटा प्रकार रूपांतरण कार्य इस प्रकार हैं - TO_BIGINT, TO_BINARY, TO_BLOB, TO_DATS, TO_DECIMAL, TO_DOUBLE, TO_FIXEDCHAR, TO_INTEGER, TO_NCLOB, TO_NVARCHAR, TOZIMEMAMP, TO_TIMEMAMP, TO_TIMEMAMP, TO_TIMEMAMP, TO_TIMEMAMP, TOIZIMAMP
विभिन्न विंडोज और अन्य विविध फ़ंक्शन भी हैं जो हाना SQL स्क्रिप्ट में उपयोग किए जा सकते हैं।
Current_Schema - यह वर्तमान स्कीमा नाम युक्त स्ट्रिंग देता है।
Session_User - यह वर्तमान सत्र का उपयोगकर्ता नाम लौटाता है
मूल्यों को वापस करने के लिए एक खंड का मूल्यांकन करने के लिए एक अभिव्यक्ति का उपयोग किया जाता है। अलग-अलग SQL अभिव्यक्तियाँ हैं जिनका उपयोग HANA में किया जा सकता है -
- केस एक्सप्रेशन
- समारोह अभिव्यक्तियाँ
- अलग-अलग अभिव्यक्तियाँ
- भावों में उपशम
मामले की अभिव्यक्ति
यह एक SQL अभिव्यक्ति में कई शर्तों को पारित करने के लिए प्रयोग किया जाता है। यह SQL कथन में प्रक्रियाओं का उपयोग किए बिना IF-ELSE-THEN तर्क का उपयोग करने की अनुमति देता है।
उदाहरण
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1,
COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2,
COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;यह कथन पास की स्थिति के अनुसार पूर्णांक मान के साथ count1, count2, count3 लौटाएगा।
समारोह अभिव्यक्तियाँ
अभिव्यक्तियों में अभिव्यक्त किए जाने वाले SQL इनबिल्ट फ़ंक्शंस शामिल होते हैं।
अलग-अलग अभिव्यक्तियाँ
एग्रीगेट फ़ंक्शंस का उपयोग जटिल गणना जैसे कि सम, परसेंटेज, मिन, मैक्स, काउंट, मोड, मेडियन आदि करने के लिए किया जाता है। एग्रीगेट एक्सप्रेशन का उपयोग कई मूल्यों से एकल मान की गणना करने के लिए एग्रीगेट फ़ंक्शंस का उपयोग करता है।
Aggregate Functions- सम, गणना, न्यूनतम, अधिकतम। इन्हें माप मूल्यों (तथ्यों) पर लागू किया जाता है और यह हमेशा एक आयाम से जुड़ा होता है।
सामान्य कुल कार्यों में शामिल हैं -
- औसत ()
- गिनती ()
- ज्यादा से ज्यादा ()
- मेडियन ()
- न्यूनतम ()
- मोड ()
- सम ()
भावों में उपशम
एक अभिव्यक्ति के रूप में एक उपश्रेणी एक चयन कथन है। जब इसे एक अभिव्यक्ति में उपयोग किया जाता है, तो यह एक शून्य या एकल मान लौटाता है।
एक सबक्वेरी का उपयोग डेटा को वापस करने के लिए किया जाता है जिसका उपयोग मुख्य क्वेरी में डेटा को पुनः प्राप्त करने के लिए प्रतिबंधित करने के लिए एक शर्त के रूप में किया जाएगा।
उप-प्रकार का उपयोग SELECT, INSERT, UPDATE और DELETE कथनों के साथ किया जा सकता है जैसे ऑपरेटरों के साथ =, <,>,> =, <=, IN, BETWEEN आदि।
कुछ नियम हैं जिनका पालन करना होगा -
कोष्ठक के भीतर उप-विषयों को संलग्न किया जाना चाहिए।
सबक्लेरी का चयन खंड में केवल एक कॉलम हो सकता है, जब तक कि उसके चयनित कॉलम की तुलना करने के लिए सबक्वेरी में कई कॉलम मुख्य क्वेरी में न हों।
ORDER BY का उपयोग एक उपश्रेणी में नहीं किया जा सकता है, हालांकि मुख्य क्वेरी ORDER BY का उपयोग कर सकती है। ग्रुप BY का उपयोग एक उप-समारोह में ORDER BY के समान कार्य करने के लिए किया जा सकता है।
एक से अधिक पंक्ति में आने वाली उप-प्रक्रिया का उपयोग केवल कई मूल्य ऑपरेटरों जैसे IN ऑपरेटर के साथ किया जा सकता है।
चयन सूची में उन मूल्यों का कोई संदर्भ शामिल नहीं हो सकता है जो एक BLOB, ARRAY, CLOB या NCLOB का मूल्यांकन करते हैं।
एक सेटक्वेरी को एक सेट फ़ंक्शन में तुरंत संलग्न नहीं किया जा सकता है।
BETWEEN ऑपरेटर का उपयोग एक सबक्वेरी के साथ नहीं किया जा सकता है; हालाँकि, BETWEEN ऑपरेटर का उपयोग उपकुंजी के भीतर किया जा सकता है।
चयन कथन के साथ उपश्रेणियाँ
सबक्वेरी का उपयोग अक्सर सेलेक्ट स्टेटमेंट के साथ किया जाता है। मूल वाक्य रचना इस प्रकार है -
उदाहरण
SELECT * FROM CUSTOMERS
WHERE ID IN (SELECT ID
FROM CUSTOMERS
WHERE SALARY > 4500) ;+----+----------+-----+---------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+---------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+---------+----------+एक प्रक्रिया आपको SQL कथन को एक ब्लॉक में समूहित करने की अनुमति देती है। संग्रहीत कार्यविधियाँ अनुप्रयोगों में कुछ परिणाम प्राप्त करने के लिए उपयोग की जाती हैं। SQL कथनों का सेट और कुछ विशिष्ट कार्य करने के लिए उपयोग किए जाने वाले तर्क SQL संग्रहीत कार्यविधियों में संग्रहीत होते हैं। इन संग्रहीत प्रक्रियाओं को उस कार्य को करने के लिए अनुप्रयोगों द्वारा निष्पादित किया जाता है।
संग्रहीत कार्यविधि आउटपुट पैरामीटर (पूर्णांक या वर्ण) या कर्सर चर के रूप में डेटा वापस कर सकती है। यह चुनिंदा कथनों के सेट के परिणामस्वरूप भी हो सकता है, जिनका उपयोग अन्य संग्रहीत प्रक्रियाओं द्वारा किया जाता है।
संग्रहीत कार्यविधियाँ भी प्रदर्शन अनुकूलन के लिए उपयोग की जाती हैं क्योंकि इसमें SQL बयानों की श्रृंखला होती है और कथन के एक सेट से परिणाम निष्पादित होने वाले बयानों के अगले सेट को निर्धारित करता है। संग्रहीत कार्यविधियाँ उपयोगकर्ताओं को डेटाबेस में तालिकाओं की जटिलता और विवरण देखने के लिए रोकती हैं। चूंकि संग्रहीत प्रक्रियाओं में कुछ व्यावसायिक तर्क होते हैं, इसलिए उपयोगकर्ताओं को प्रक्रिया नाम को निष्पादित या कॉल करने की आवश्यकता होती है।
अलग-अलग वक्तव्यों को फिर से जारी रखने की आवश्यकता नहीं है लेकिन डेटाबेस प्रक्रिया को संदर्भित कर सकते हैं।
नमूना विवरण प्रक्रिया बनाने के लिए
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP")
as
begin
opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ;
end;एक अनुक्रम पूर्णांक 1, 2, 3 का एक सेट है, जो मांग पर क्रम में उत्पन्न होता है। अनुक्रम अक्सर डेटाबेस में उपयोग किए जाते हैं क्योंकि कई अनुप्रयोगों को एक अद्वितीय मूल्य वाले तालिका में प्रत्येक पंक्ति की आवश्यकता होती है, और अनुक्रम उन्हें उत्पन्न करने का एक आसान तरीका प्रदान करते हैं।
AUTO_INCREMENT कॉलम का उपयोग करना
अनुक्रम का उपयोग करने के लिए MySQL का सबसे सरल तरीका AUTO_INCREMENT के रूप में एक कॉलम को परिभाषित करना और बाकी चीजों को ध्यान में रखने के लिए MySQL पर छोड़ना है।
उदाहरण
निम्नलिखित उदाहरण देखें। यह तालिका बनाएगा और उसके बाद इस तालिका में कुछ पंक्तियाँ डालेगा जहाँ रिकॉर्ड आईडी देना आवश्यक नहीं है क्योंकि यह MySQL द्वारा स्वतः-संवर्धित है।
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO INSECT (id,name,date,origin) VALUES
-> (NULL,'housefly','2001-09-10','kitchen'),
-> (NULL,'millipede','2001-09-10','driveway'),
-> (NULL,'grasshopper','2001-09-10','front yard');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM INSECT ORDER BY id;+----+-------------+------------+------------+
| id | name | date | origin |
+----+-------------+------------+------------+
| 1 | housefly | 2001-09-10 | kitchen |
| 2 | millipede | 2001-09-10 | driveway |
| 3 | grasshopper | 2001-09-10 | front yard |
+----+-------------+------------+------------+
3 rows in set (0.00 sec)AUTO_INCREMENT मान प्राप्त करें
LAST_INSERT_ID () एक SQL फ़ंक्शन है, इसलिए आप इसे किसी भी क्लाइंट के भीतर से उपयोग कर सकते हैं जो समझता है कि SQL स्टेटमेंट कैसे जारी किया जाए। अन्यथा, PERL और PHP स्क्रिप्ट पिछले रिकॉर्ड के ऑटो-इन्क्रिमेटेड मूल्य को पुनः प्राप्त करने के लिए विशेष कार्य प्रदान करते हैं।
पर्ल उदाहरण
क्वेरी द्वारा उत्पन्न AUTO_INCREMENT मान प्राप्त करने के लिए mysql_insertid विशेषता का उपयोग करें। यह विशेषता या तो डेटाबेस हैंडल या स्टेटमेंट हैंडल के माध्यम से एक्सेस की जाती है, इस पर निर्भर करता है कि आप क्वेरी कैसे जारी करते हैं। निम्न उदाहरण इसे डेटाबेस हैंडल के माध्यम से संदर्भित करता है -
$dbh->do ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')");
my $seq = $dbh->{mysql_insertid};PHP उदाहरण
AUTO_INCREMENT मान उत्पन्न करने वाली क्वेरी जारी करने के बाद, mysql_insert_id () कॉल करके मान पुनः प्राप्त करें
mysql_query ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);एक मौजूदा अनुक्रम का नवीनीकरण
ऐसा कोई मामला हो सकता है जब आपने किसी तालिका से कई रिकॉर्ड हटा दिए हों और आप सभी रिकॉर्डों को फिर से अनुक्रमित करना चाहते हों। यह एक सरल चाल का उपयोग करके किया जा सकता है लेकिन आपको ऐसा करने में बहुत सावधानी बरतनी चाहिए अगर आपकी तालिका अन्य तालिका के साथ शामिल हो रही है।
यदि आप यह निर्धारित करते हैं कि AUTO_INCREMENT कॉलम का आकार बदलना अपरिहार्य है, तो ऐसा करने का तरीका स्तंभ को तालिका से गिराना है, फिर इसे फिर से जोड़ें। निम्नलिखित उदाहरण से पता चलता है कि इस तकनीक का उपयोग करके कीट तालिका में आईडी मूल्यों को कैसे फिर से उपयोग करना है -
mysql> ALTER TABLE INSECT DROP id;
mysql> ALTER TABLE insect
-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
-> ADD PRIMARY KEY (id);एक विशेष मूल्य पर अनुक्रम शुरू करना
डिफ़ॉल्ट रूप से, MySQL 1 से अनुक्रम शुरू करेगा, लेकिन आप तालिका निर्माण के समय किसी अन्य संख्या को भी निर्दिष्ट कर सकते हैं। निम्नलिखित उदाहरण है जहां MySQL 100 से अनुक्रम शुरू करेगा।
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);वैकल्पिक रूप से, आप तालिका बना सकते हैं और फिर ALTER TABLE के साथ प्रारंभिक अनुक्रम मान सेट कर सकते हैं।
ट्रिगर संग्रहीत प्रोग्राम हैं, जो कुछ घटनाओं के होने पर स्वचालित रूप से निष्पादित या निकाल दिए जाते हैं। ट्रिगर, वास्तव में, निम्न में से किसी भी घटना के जवाब में निष्पादित होने के लिए लिखे गए हैं -
एक डेटाबेस हेरफेर (डीएमएल) स्टेटमेंट (DELETE, INSERT या UPDATE)।
एक डेटाबेस परिभाषा (DDL) विवरण (सृजन, परिवर्तन, या ड्रॉप)।
एक डेटाबेस ऑपरेशन (SERVERERROR, LOGON, LOGOFF, STARTUP, या SHUTDOWN)।
ट्रिगर को तालिका, दृश्य, स्कीमा या डेटाबेस से परिभाषित किया जा सकता है जिसके साथ घटना जुड़ी हुई है।
ट्रिगर के लाभ
ट्रिगर को निम्नलिखित उद्देश्यों के लिए लिखा जा सकता है -
- स्वचालित रूप से कुछ व्युत्पन्न स्तंभ मान उत्पन्न करना
- संदर्भात्मक अखंडता को लागू करना
- टेबल प्रवेश पर सूचना लॉगिंग और भंडारण जानकारी
- Auditing
- तालिकाओं की तुल्यकालिक प्रतिकृति
- सुरक्षा प्राधिकरणों का निपटान
- अमान्य लेनदेन को रोकना
SQL पर्यायवाची तालिका या किसी डेटाबेस में स्कीमा ऑब्जेक्ट के लिए एक अन्य नाम है। उनका उपयोग क्लाइंट एप्लिकेशन को किसी ऑब्जेक्ट के नाम या स्थान में किए गए परिवर्तनों से बचाने के लिए किया जाता है।
पर्यायवाची उन एप्लिकेशनों को अनुमति देते हैं, जो तालिका का मालिक होने के लिए उपयोगकर्ता की परवाह किए बिना और जो डेटाबेस तालिका या ऑब्जेक्ट रखता है।
पर्यायवाची कथन का उपयोग किया जाता है एक तालिका, दृश्य, पैकेज, प्रक्रिया, वस्तुओं आदि के लिए एक पर्यायवाची बनाएं।
उदाहरण
सर्वर 1 पर स्थित efashion का एक टेबल ग्राहक है। Server2 से इसे एक्सेस करने के लिए, क्लाइंट एप्लिकेशन को Server1.efashion.Customer के रूप में नाम का उपयोग करना होगा। अब हम ग्राहक तालिका का स्थान बदल देते हैं ग्राहक आवेदन को परिवर्तन को प्रतिबिंबित करने के लिए संशोधित करना होगा।
इन्हें संबोधित करने के लिए हम Server1 पर तालिका के लिए Server2 पर ग्राहक तालिका Cust_Table का एक पर्याय बना सकते हैं। इसलिए अब क्लाइंट एप्लिकेशन को इस तालिका को संदर्भित करने के लिए सिंगल-पार्ट नाम Cust_Table का उपयोग करना होगा। अब, यदि इस तालिका का स्थान बदलता है, तो आपको तालिका के नए स्थान को इंगित करने के लिए पर्यायवाची को संशोधित करना होगा।
जैसा कि कोई भी SYNONYM कथन नहीं है, आपको पर्यायवाची Cust_Table को छोड़ना होगा और फिर समान नाम का पर्यायवाची बनाकर ग्राहक तालिका के नए स्थान के पर्याय को इंगित करना होगा।
सार्वजनिक पर्यायवाची
सार्वजनिक पर्यायवाची एक डेटाबेस में पब्लिक स्कीमा के स्वामित्व में हैं। सार्वजनिक समानार्थी शब्द डेटाबेस में सभी उपयोगकर्ताओं द्वारा संदर्भित किए जा सकते हैं। वे तालिकाओं और अन्य वस्तुओं जैसे प्रक्रियाओं और पैकेजों के लिए एप्लिकेशन के मालिक द्वारा बनाए जाते हैं ताकि एप्लिकेशन के उपयोगकर्ता ऑब्जेक्ट देख सकें।
वाक्य - विन्यास
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;PUBLIC समानार्थी बनाने के लिए, आपको दिखाए गए अनुसार PUBLIC का उपयोग करना होगा।
निजी पर्यायवाची
किसी तालिका, प्रक्रिया, दृश्य या किसी अन्य डेटाबेस ऑब्जेक्ट का सही नाम छुपाने के लिए एक डेटाबेस स्कीमा में निजी समानार्थी शब्द का उपयोग किया जाता है।
निजी समानार्थी शब्द को केवल उस स्कीमा द्वारा संदर्भित किया जा सकता है जो तालिका या ऑब्जेक्ट का मालिक है।
वाक्य - विन्यास
CREATE SYNONYM Cust_table FOR efashion.Customer;एक पर्यायवाची ड्रॉप
DROP पर्यायवाची आदेश का उपयोग कर पर्यायवाची शब्द गिराए जा सकते हैं। यदि आप एक सार्वजनिक पर्यायवाची को छोड़ रहे हैं, तो आपको कीवर्ड का उपयोग करना होगाpublic ड्रॉप स्टेटमेंट में।
वाक्य - विन्यास
DROP PUBLIC Synonym Cust_table;
DROP Synonym Cust_table;एसक्यूएल व्याख्या योजनाएं एसक्यूएल स्टेटमेंट के विवरण को उत्पन्न करने के लिए उपयोग की जाती हैं। उनका उपयोग निष्पादन योजना का मूल्यांकन करने के लिए किया जाता है जो एसएपी हाना डेटाबेस एसक्यूएल बयानों को निष्पादित करने के लिए अनुसरण करता है।
व्याख्या योजना के परिणाम मूल्यांकन के लिए EXPLAIN_PLAN_TABLE में संग्रहीत हैं। स्पष्टीकरण योजना का उपयोग करने के लिए, पास की गई SQL क्वेरी डेटा हेरफेर भाषा (DML) होनी चाहिए।
आम डीएमएल विवरण
SELECT - एक डेटाबेस से डेटा पुनः प्राप्त
INSERT - एक तालिका में डेटा डालें
UPDATE - एक टेबल के भीतर मौजूदा डेटा को अपडेट करता है
SQL स्पष्टीकरण योजनाएँ DDL और DCL SQL कथनों के साथ प्रयोग नहीं की जा सकतीं।
डेटाबेस में विस्तार से पढ़ाएं
डेटाबेस में विस्तृत PLAN_TABLE में कई कॉलम हैं। कुछ सामान्य कॉलम नाम - OPERATOR_NAME, OPERATOR_ID, PARENT_OPERATOR_ID, LEVEL और POSITION, आदि।
कोलम खोज मूल्य कॉलम इंजन ऑपरेटरों की शुरुआती स्थिति को बताता है।
ROW SEARCH मान पंक्ति इंजन ऑपरेटरों की प्रारंभिक स्थिति बताता है।
SQL क्वेरी के लिए एक विस्तृत योजना बनाएँ
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>EXPLAIN PLAN TABLE में मान देखने के लिए
SELECT Operator_Name, Operator_ID
FROM explain_plan_table
WHERE statement_name = 'statement_name';EXPLAIN PLAN TABLE में कथन हटाने के लिए
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';SQL डेटा प्रोफाइलिंग कार्य का उपयोग कई डेटा स्रोतों से डेटा को समझने और उसका विश्लेषण करने के लिए किया जाता है। इसका उपयोग डेटा वेयरहाउस में लोड होने से पहले गलत, अपूर्ण डेटा को निकालने और डेटा गुणवत्ता की समस्याओं को रोकने के लिए किया जाता है।
यहां SQL डेटा प्रोफाइलिंग कार्यों के लाभ दिए गए हैं -
यह स्रोत डेटा का अधिक प्रभावी ढंग से विश्लेषण करने में मदद करता है।
यह स्रोत डेटा को बेहतर ढंग से समझने में मदद करता है।
यह गलत, अधूरे डेटा को हटा देता है और डेटा वेयरहाउस में लोड होने से पहले डेटा की गुणवत्ता में सुधार करता है।
इसका उपयोग एक्सट्रैक्शन, ट्रांसफॉर्मेशन और लोडिंग टास्क के साथ किया जाता है।
डेटा प्रोफाइलिंग कार्य ऐसे प्रोफाइल की जाँच करता है जो डेटा स्रोत को समझने और डेटा में समस्याओं को पहचानने में मदद करता है जिसे ठीक करना होता है।
आप SQL सर्वर में संग्रहीत डेटा को प्रोफाइल करने और डेटा गुणवत्ता के साथ संभावित समस्याओं की पहचान करने के लिए इंटीग्रेशन सर्विसेज पैकेज के अंदर डेटा प्रोफाइलिंग कार्य का उपयोग कर सकते हैं।
Note - डेटा प्रोफाइलिंग टास्क केवल SQL सर्वर डेटा स्रोतों के साथ काम करता है और किसी अन्य फ़ाइल आधारित या तीसरे पक्ष के डेटा स्रोतों का समर्थन नहीं करता है।
पहुँच की आवश्यकता
एक पैकेज को चलाने के लिए डेटा प्रोफाइलिंग कार्य होता है, उपयोगकर्ता खाते को अस्थायी डेटाबेस पर क्रिएट टेबल अनुमतियों के साथ पढ़ने / लिखने की अनुमति होनी चाहिए।
डेटा प्रोफाइलर दर्शक
प्रोफाइलर व्यूअर का उपयोग प्रोफाइलर आउटपुट की समीक्षा के लिए किया जाता है। डेटा प्रोफ़ाइल व्यूअर आपको उन डेटा गुणवत्ता मुद्दों को समझने में मदद करने के लिए ड्रिलडाउन क्षमता का भी समर्थन करता है जो प्रोफ़ाइल आउटपुट में पहचाने जाते हैं। यह ड्रिल डाउन क्षमता मूल डेटा स्रोत को लाइव क्वेरी भेजती है।
डेटा रूपरेखा कार्य सेटअप और समीक्षा
डाटा प्रोफाइलिंग टास्क की स्थापना
इसमें एक पैकेज का निष्पादन शामिल है जिसमें प्रोफाइल की गणना करने के लिए डेटा प्रोफाइलिंग कार्य शामिल है। कार्य एक्सएमएल प्रारूप में आउटपुट को फ़ाइल या पैकेज चर में सहेजता है।
प्रोफाइल की समीक्षा करना
डेटा प्रोफाइल देखने के लिए, आउटपुट को फ़ाइल में भेजें और फिर डेटा प्रोफ़ाइल व्यूअर का उपयोग करें। यह दर्शक एक स्टैंड-अलोन उपयोगिता है जो वैकल्पिक ड्रिलडाउन क्षमता के साथ सारांश और विस्तार प्रारूप दोनों में प्रोफाइल आउटपुट प्रदर्शित करता है।
डेटा प्रोफाइलिंग - कॉन्फ़िगरेशन विकल्प
डेटा रूपरेखा कार्य में ये सुविधाजनक विन्यास विकल्प हैं -
वाइल्डकार्ड कॉलम
प्रोफ़ाइल अनुरोध को कॉन्फ़िगर करते समय, कार्य कॉलम नाम के स्थान पर '*' वाइल्डकार्ड स्वीकार करता है। यह कॉन्फ़िगरेशन को सरल बनाता है और अपरिचित डेटा की विशेषताओं की खोज करना आसान बनाता है। जब कार्य चलता है, तो कार्य हर कॉलम को प्रोफाइल करता है जिसमें एक उपयुक्त डेटा प्रकार होता है।
त्वरित प्रोफ़ाइल
आप कार्य को जल्दी से कॉन्फ़िगर करने के लिए क्विक प्रोफाइल का चयन कर सकते हैं। एक त्वरित प्रोफ़ाइल सभी डिफ़ॉल्ट प्रोफ़ाइल और सेटिंग्स का उपयोग करके एक तालिका या दृश्य को प्रोफाइल करता है।
डेटा प्रोफाइलिंग टास्क आठ अलग-अलग डेटा प्रोफाइल की गणना कर सकता है। इनमें से पांच प्रोफ़ाइल व्यक्तिगत कॉलम और शेष तीन विश्लेषण कर सकते हैं- कई कॉलम या स्तंभों के बीच संबंध।
डेटा प्रोफाइलिंग - टास्क आउटपुट
डेटा प्रोफाइलिंग कार्य चयनित प्रोफाइल को XML प्रारूप में संरचित करता है जो कि DataProfile.xsd स्कीमा की तरह संरचित है।
आप स्कीमा की स्थानीय प्रतिलिपि को सहेज सकते हैं और Microsoft Visual Studio या किसी अन्य स्कीमा संपादक में स्कीमा की स्थानीय प्रतिलिपि को XML संपादक में या नोटपैड जैसे पाठ संपादक में देख सकते हैं।
एचएएनए डेटाबेस के लिए एसक्यूएल स्टेटमेंट का सेट जो डेवलपर को डेटाबेस में जटिल लॉजिक पास करने की अनुमति देता है उसे एसक्यूएल स्क्रिप्ट कहते हैं। SQL स्क्रिप्ट को SQL एक्सटेंशन के संग्रह के रूप में जाना जाता है। ये एक्सटेंशन डेटा एक्सटेंशन्स, फंक्शन एक्सटेंशन्स और प्रोसीजर एक्सटेंशन हैं।
एसक्यूएल स्क्रिप्ट संग्रहीत कार्यों और प्रक्रियाओं का समर्थन करता है और यह डेटाबेस के लिए अनुप्रयोग तर्क के जटिल भागों को आगे बढ़ाने की अनुमति देता है।
SQL स्क्रिप्ट का उपयोग करने का मुख्य लाभ एसएपी हाना डेटाबेस के अंदर जटिल गणना के निष्पादन की अनुमति है। एकल क्वेरी के स्थान पर SQL स्क्रिप्ट का उपयोग करने से फ़ंक्शंस कई मानों को वापस करने में सक्षम होते हैं। जटिल SQL फ़ंक्शंस को छोटे फ़ंक्शंस में और विघटित किया जा सकता है। SQL स्क्रिप्ट नियंत्रण तर्क प्रदान करता है जो एकल SQL कथन में उपलब्ध नहीं है।
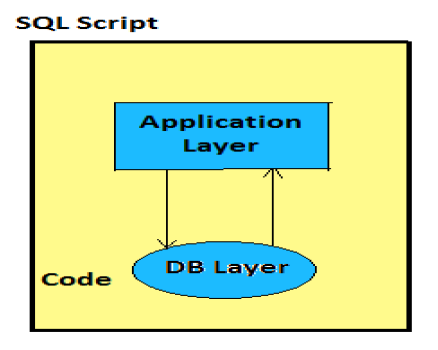
एसक्यूएल लिपियों का उपयोग एचबीए में डीबी परत पर स्क्रिप्ट निष्पादित करके प्रदर्शन अनुकूलन प्राप्त करने के लिए किया जाता है -
डेटाबेस परत पर SQL स्क्रिप्ट निष्पादित करके, यह डेटाबेस से अनुप्रयोग के लिए बड़ी मात्रा में डेटा स्थानांतरित करने की आवश्यकता को समाप्त करता है।
एचएएनए डेटाबेस के लाभ जैसे कॉलम संचालन, प्रश्नों के समानांतर प्रसंस्करण आदि प्राप्त करने के लिए गणना डेटाबेस परत पर निष्पादित की जाती है।
सूचना मॉडलर के साथ एकीकरण
सूचना मॉडलर में एसक्यूएल स्क्रिप्ट का उपयोग करते समय, नीचे दिए गए प्रक्रियाओं पर लागू किया जाता है -
- इनपुट पैरामीटर स्केलर या टेबल प्रकार के हो सकते हैं।
- आउटपुट पैरामीटर तालिका प्रकार के होने चाहिए।
- हस्ताक्षर के लिए आवश्यक तालिका प्रकार स्वचालित रूप से उत्पन्न होते हैं।
गणना दृश्य के साथ एसक्यूएल लिपियों
एसक्यूएल स्क्रिप्ट का उपयोग स्क्रिप्ट आधारित गणना विचारों को बनाने के लिए किया जाता है। मौजूदा कच्चे टेबल या कॉलम स्टोर के खिलाफ SQL स्टेटमेंट टाइप करें। आउटपुट संरचना को परिभाषित करें, दृश्य की सक्रियता संरचना के अनुसार तालिका प्रकार बनाती है।
SQL स्क्रिप्ट के साथ कैलकुलेशन व्यू कैसे बनाएं?
Launch SAP HANA studio। सामग्री नोड का विस्तार करें → एक पैकेज चुनें जहां आप नई गणना दृश्य बनाना चाहते हैं। राइट क्लिक → नेविगेशन पथ का नया गणना दृश्य अंत → नाम और विवरण प्रदान करें।
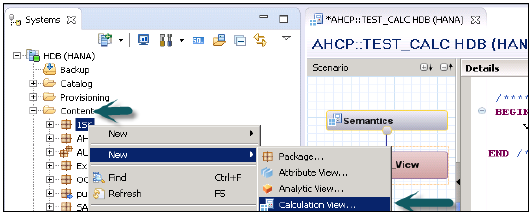
Select calculation view type → ड्रॉपडाउन सूची से, एसक्यूएल स्क्रिप्ट का चयन करें → सेट पैरामीटर केस सेंसिटिव टू ट्रू या फाल्स के आधार पर कि आपको गणना दृश्य के आउटपुट मापदंडों के लिए नामकरण सम्मेलन की आवश्यकता कैसे है → समाप्त चुनें।
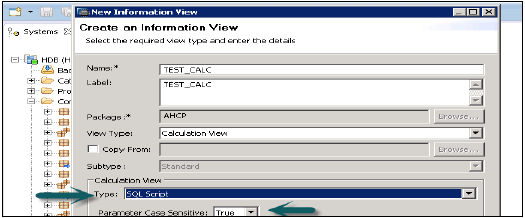
Select default schema - शब्दार्थ नोड का चयन करें → देखें गुण टैब चुनें → डिफ़ॉल्ट स्कीमा ड्रॉपडाउन सूची में, डिफ़ॉल्ट स्कीमा का चयन करें।
Choose SQL Script node in the Semantics node→ आउटपुट संरचना को परिभाषित करें। आउटपुट फलक में, लक्ष्य बनाएँ चुनें। आवश्यक आउटपुट पैरामीटर जोड़ें और इसकी लंबाई और प्रकार निर्दिष्ट करें।

स्क्रिप्ट-आधारित गणना विचारों की आउटपुट संरचना में मौजूदा जानकारी दृश्य या कैटलॉग टेबल या टेबल फ़ंक्शन का हिस्सा कई कॉलम जोड़ने के लिए -
आउटपुट फलक में, नेविगेशन पथ का प्रारंभ चुनें नया अगला नेविगेशन चरण नेविगेशन पथ के अंत से कॉलम जोड़ें → उस ऑब्जेक्ट का नाम जिसमें वह स्तंभ हैं जो आप आउटपुट में जोड़ना चाहते हैं → ड्रॉपडाउन सूची से एक या अधिक ऑब्जेक्ट का चयन करें → अगला चुनें।
स्रोत फलक में, उन स्तंभों को चुनें जिन्हें आप आउटपुट में जोड़ना चाहते हैं → आउटपुट में सेलेक्टिव कॉलम जोड़ने के लिए, फिर उन कॉलमों को चुनें और ऐड चुनें। किसी ऑब्जेक्ट के सभी कॉलम को आउटपुट में जोड़ने के लिए, फिर ऑब्जेक्ट का चयन करें और Add → Finish चुनें।
Activate the script-based calculation view- एसएपी हाना मॉडलर परिप्रेक्ष्य में - वर्तमान दृश्य को सक्रिय करने और सक्रिय करने के लिए - प्रभावित ऑब्जेक्ट के सक्रिय संस्करण मौजूद होने पर प्रभावित वस्तुओं को फिर से सक्रिय करने के लिए। अन्यथा, केवल वर्तमान दृश्य सक्रिय है।
Save and activate all - आवश्यक और प्रभावित वस्तुओं के साथ-साथ वर्तमान दृश्य को सक्रिय करने के लिए।
In the SAP HANA Development perspective- प्रोजेक्ट एक्सप्लोरर दृश्य में, आवश्यक वस्तु का चयन करें। संदर्भ मेनू में, नेविगेशन पथ का प्रारंभ का चयन करें टीम अगला नेविगेशन चरण नेविगेशन पथ के अंत को सक्रिय करें।
HANA सूचना मॉडलर में SQL स्क्रिप्टिंग का उपयोग जटिल गणना दृश्य बनाने के लिए किया जाता है, जो GUI विकल्प का उपयोग करके बनाना संभव नहीं है।