स्किकिट जानें - वेक्टर मशीनों का समर्थन करें
यह अध्याय मशीन लर्निंग विधि से सपोर्ट वेक्टर मशीन (SVM) के रूप में जाना जाता है।
परिचय
समर्थन वेक्टर मशीनें (SVM) वर्गीकरण, प्रतिगमन और आउटलेर्स की पहचान के लिए उपयोग की जाने वाली शक्तिशाली अभी तक लचीली पर्यवेक्षित मशीन शिक्षण विधियाँ हैं। एसवीएम उच्च आयामी स्थानों में बहुत कुशल हैं और आमतौर पर वर्गीकरण की समस्याओं में उपयोग किया जाता है। SVM लोकप्रिय और मेमोरी कुशल हैं क्योंकि वे निर्णय फ़ंक्शन में प्रशिक्षण बिंदुओं के सबसेट का उपयोग करते हैं।
एसवीएम का मुख्य लक्ष्य ए को खोजने के लिए डेटासेट को कक्षाओं की संख्या में विभाजित करना है maximum marginal hyperplane (MMH) जो निम्नलिखित दो चरणों में किया जा सकता है -
सपोर्ट वेक्टर मशीनें सबसे पहले हाइपरप्लेन को पुन: उत्पन्न करती हैं जो कक्षाओं को सबसे अच्छे तरीके से अलग करती हैं।
उसके बाद यह हाइपरप्लेन का चयन करेगा जो कक्षाओं को सही ढंग से अलग करता है।
एसवीएम में कुछ महत्वपूर्ण अवधारणाएं इस प्रकार हैं -
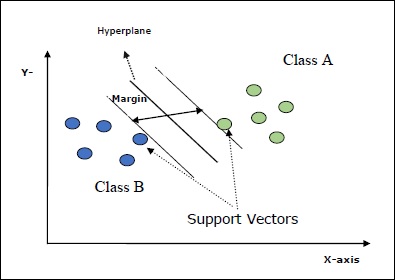
Support Vectors-उन्हें परिभाषित किया जा सकता है कि वे डैटपॉइंट के रूप में हैं जो हाइपरप्लेन के सबसे करीब हैं। सपोर्ट वैक्टर अलग लाइन तय करने में मदद करते हैं।
Hyperplane - निर्णय विमान या अंतरिक्ष जो विभिन्न वर्गों वाली वस्तुओं के सेट को विभाजित करता है।
Margin - विभिन्न वर्गों के कोठरी डेटा बिंदुओं पर दो लाइनों के बीच के अंतर को मार्जिन कहा जाता है।
निम्नलिखित आरेख आपको इन एसवीएम अवधारणाओं के बारे में जानकारी देंगे -
एसवीएम इन स्किट-लर्न दोनों इनपुट के रूप में विरल और घने नमूना वैक्टर का समर्थन करता है।
एसवीएम का वर्गीकरण
स्किकिट-लर्न अर्थात् तीन कक्षाएं प्रदान करता है SVC, NuSVC तथा LinearSVC जो बहु-स्तरीय वर्गीकरण का प्रदर्शन कर सकता है।
एसवीसी
यह सी-सपोर्ट वेक्टर वर्गीकरण है जिसके कार्यान्वयन पर आधारित है libsvm। स्किकिट-लर्न द्वारा उपयोग किया जाने वाला मॉड्यूल हैsklearn.svm.SVC। यह वर्ग एक-बनाम-एक योजना के अनुसार मल्टीक्लास समर्थन को संभालता है।
मापदंडों
अनुसरण तालिका में उपयोग किए गए पैरामीटर शामिल हैं sklearn.svm.SVC वर्ग -
| अनु क्रमांक | पैरामीटर और विवरण |
|---|---|
| 1 | C - फ्लोट, वैकल्पिक, डिफ़ॉल्ट = 1.0 यह त्रुटि शब्द का पेनल्टी पैरामीटर है। |
| 2 | kernel - स्ट्रिंग, वैकल्पिक, डिफ़ॉल्ट = 'आरबीएफ' यह पैरामीटर एल्गोरिथ्म में उपयोग किए जाने वाले कर्नेल के प्रकार को निर्दिष्ट करता है। हम किसी एक को चुन सकते हैं,‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’। कर्नेल का डिफ़ॉल्ट मान होगा‘rbf’। |
| 3 | degree - int, वैकल्पिक, डिफ़ॉल्ट = 3 यह 'पॉली' कर्नेल फ़ंक्शन की डिग्री का प्रतिनिधित्व करता है और अन्य सभी कर्नेल द्वारा अनदेखा किया जाएगा। |
| 4 | gamma - {'स्केल', 'ऑटो'} या फ्लोट, यह कर्नेल 'आरबीएफ', 'पॉली' और 'सिग्मॉइड' के लिए कर्नेल गुणांक है। |
| 5 | optinal default - = 'पैमाना' यदि आप डिफॉल्ट यानी गामा = 'स्केल' चुनते हैं तो एसवीसी द्वारा उपयोग किए जाने वाले गामा का मूल्य 1 / (_)। ()) है। दूसरी ओर, यदि गामा = 'ऑटो', यह 1 / _ का उपयोग करता है। |
| 6 | coef0 - फ्लोट, वैकल्पिक, डिफ़ॉल्ट = 0.0 कर्नेल फ़ंक्शन में एक स्वतंत्र शब्द जो केवल 'पॉली' और 'सिग्मॉइड' में महत्वपूर्ण है। |
| 7 | tol - फ्लोट, वैकल्पिक, डिफ़ॉल्ट = 1.e-3 यह पैरामीटर पुनरावृत्तियों के लिए स्टॉपिंग मानदंड का प्रतिनिधित्व करता है। |
| 8 | shrinking - बूलियन, वैकल्पिक, डिफ़ॉल्ट = सच यह पैरामीटर दर्शाता है कि क्या हम सिकुड़ते हुए उपयोग करना चाहते हैं या नहीं। |
| 9 | verbose - बूलियन, डिफ़ॉल्ट: गलत यह वर्बोज़ आउटपुट को सक्षम या अक्षम करता है। इसका डिफ़ॉल्ट मान गलत है। |
| 10 | probability - बूलियन, वैकल्पिक, डिफ़ॉल्ट = सच यह पैरामीटर संभाव्यता अनुमानों को सक्षम या अक्षम करता है। डिफ़ॉल्ट मान गलत है, लेकिन इसे हम फिट होने से पहले सक्षम होना चाहिए। |
| 1 1 | max_iter - int, वैकल्पिक, डिफ़ॉल्ट = -1 जैसा कि नाम से पता चलता है, यह सॉल्वर के भीतर अधिकतम पुनरावृत्तियों का प्रतिनिधित्व करता है। मान -1 का अर्थ है कि पुनरावृत्तियों की संख्या की कोई सीमा नहीं है। |
| 12 | cache_size - फ्लोट, वैकल्पिक यह पैरामीटर कर्नेल कैश का आकार निर्दिष्ट करेगा। मान MB (MegaBytes) में होगा। |
| 13 | random_state - int, randomState उदाहरण या कोई नहीं, वैकल्पिक, डिफ़ॉल्ट = कोई नहीं यह पैरामीटर उत्पन्न छद्म यादृच्छिक संख्या के बीज का प्रतिनिधित्व करता है जिसका उपयोग डेटा को फेरबदल करते समय किया जाता है। अनुवर्ती विकल्प हैं -
|
| 14 | class_weight - {तानाशाह, 'संतुलित'}, वैकल्पिक यह पैरामीटर SVC के लिए वर्ग J से _] [] parameter के पैरामीटर C को सेट करेगा। यदि हम डिफ़ॉल्ट विकल्प का उपयोग करते हैं, तो इसका मतलब है कि सभी वर्गों का वजन एक होना चाहिए। दूसरी ओर, यदि आप चुनते हैंclass_weight:balanced, यह स्वचालित रूप से वजन को समायोजित करने के लिए y के मूल्यों का उपयोग करेगा। |
| 15 | decision_function_shape - ovo ',' ovr ', default =' ovr ' यह पैरामीटर तय करेगा कि एल्गोरिथम वापस आएगा या नहीं ‘ovr’ (एक-बनाम-बाकी) सभी अन्य सहपाठियों, या मूल के रूप में आकार का निर्णय कार्य ovo(एक-बनाम-एक) libsvm का निर्णय कार्य। |
| 16 | break_ties - बूलियन, वैकल्पिक, डिफ़ॉल्ट = गलत True - निर्णय निर्णय के विश्वास मूल्यों के अनुसार संबंध टूट जाएगा False - भविष्यवाणी बंधे वर्गों के बीच पहली कक्षा को लौटा देगी। |
गुण
अनुसरण तालिका में उपयोग की जाने वाली विशेषताएँ शामिल हैं sklearn.svm.SVC वर्ग -
| अनु क्रमांक | विशेषताएँ और विवरण |
|---|---|
| 1 | support_ - सरणी-जैसा, आकार = [n_SV] यह समर्थन वैक्टर के सूचकांक लौटाता है। |
| 2 | support_vectors_ - सरणी-जैसा, आकार = [n_SV, n_features] यह सपोर्ट वैक्टर लौटाता है। |
| 3 | n_support_ - सरणी-जैसा, dtype = int32, shape = [n_class] यह प्रत्येक वर्ग के लिए समर्थन वैक्टर की संख्या का प्रतिनिधित्व करता है। |
| 4 | dual_coef_ - सरणी, आकार = [n_class-1, n_SV] ये निर्णय समारोह में समर्थन वैक्टर के गुणांक हैं। |
| 5 | coef_ - सरणी, आकार = [n_class * (n_class-1) / 2, n_features] यह विशेषता, केवल रैखिक कर्नेल के मामले में उपलब्ध है, सुविधाओं को सौंपा गया वजन प्रदान करता है। |
| 6 | intercept_ - सरणी, आकार = [n_class * (n_class-1) / 2] यह निर्णय समारोह में स्वतंत्र शब्द (स्थिर) का प्रतिनिधित्व करता है। |
| 7 | fit_status_ - इंट यदि यह सही ढंग से फिट है तो आउटपुट 0 होगा। यदि यह गलत तरीके से फिट किया गया है तो आउटपुट 1 होगा। |
| 8 | classes_ आकार की सरणी = [n_classes] यह कक्षाओं के लेबल देता है। |
Implementation Example
अन्य क्लासिफायर की तरह, SVC को भी दो सरणियों के साथ फिट किया जाना है -
एक सरणी Xप्रशिक्षण के नमूने पकड़े। यह आकार [n_samples, n_features] का है।
एक सरणी Yप्रशिक्षण के नमूनों के लिए लक्ष्य मानों अर्थात कक्षा के लेबल को धारण करना। यह आकार [n_samples] का है।
पायथन लिपि का उपयोग करता है sklearn.svm.SVC वर्ग -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
अब, एक बार फिट होने के बाद, हम पायथन लिपि की मदद से वेट वेक्टर प्राप्त कर सकते हैं -
SVCClf.coef_Output
array([[0.5, 0.5]])Example
इसी प्रकार, हम अन्य विशेषताओं का मूल्य निम्नानुसार प्राप्त कर सकते हैं -
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC परमाणु सहायता वेक्टर वर्गीकरण है। यह स्किकिट-लर्न द्वारा प्रदान की गई एक और क्लास है जो मल्टी-क्लास वर्गीकरण का प्रदर्शन कर सकती है। यह SVC की तरह है लेकिन NuSVC मापदंडों के कुछ अलग सेटों को स्वीकार करता है। SVC से भिन्न पैरामीटर निम्नानुसार है -
nu - फ्लोट, वैकल्पिक, डिफ़ॉल्ट = 0.5
यह प्रशिक्षण त्रुटियों के अंश पर एक ऊपरी बाउंड और समर्थन वैक्टर के अंश के निचले हिस्से का प्रतिनिधित्व करता है। इसका मान (o, 1] के अंतराल में होना चाहिए।
बाकी पैरामीटर और विशेषताएँ SVC के समान हैं।
कार्यान्वयन उदाहरण
हम उसी उदाहरण का उपयोग करके लागू कर सकते हैं sklearn.svm.NuSVC वर्ग भी।
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)उत्पादन
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)हम बाकी विशेषताओं के आउटपुट प्राप्त कर सकते हैं जैसा कि SVC के मामले में किया गया था।
LinearSVC
यह रैखिक समर्थन वेक्टर वर्गीकरण है। यह SVC कर्नेल = 'रैखिक' होने के समान है। उनके बीच अंतर यह है किLinearSVC एसवीसी में लागू होने के दौरान कामेच्छा के मामले में लागू किया जाता है libsvm। यही कारण हैLinearSVCदंड और नुकसान कार्यों की पसंद में अधिक लचीलापन है। यह बड़ी संख्या में नमूनों की तुलना में बेहतर है।
अगर हम इसके मापदंडों और विशेषताओं के बारे में बात करते हैं तो यह समर्थन नहीं करता है ‘kernel’ क्योंकि इसे रेखीय माना जाता है और इसमें कुछ विशेषताओं का भी अभाव है support_, support_vectors_, n_support_, fit_status_ तथा, dual_coef_।
हालाँकि, यह समर्थन करता है penalty तथा loss पैरामीटर निम्नानुसार हैं -
penalty − string, L1 or L2(default = ‘L2’)
यह पैरामीटर दंड (नियमितीकरण) में उपयोग किए जाने वाले मानदंड (L1 या L2) को निर्दिष्ट करने के लिए उपयोग किया जाता है।
loss − string, hinge, squared_hinge (default = squared_hinge)
यह नुकसान फ़ंक्शन का प्रतिनिधित्व करता है जहां 'काज' मानक SVM नुकसान है और 'squared_hinge' काज हानि का वर्ग है।
कार्यान्वयन उदाहरण
पायथन लिपि का उपयोग करता है sklearn.svm.LinearSVC वर्ग -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)उत्पादन
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)उदाहरण
अब, एक बार फिट होने के बाद, मॉडल नए मूल्यों की भविष्यवाणी कर सकता है -
LSVCClf.predict([[0,0,0,0]])उत्पादन
[1]उदाहरण
उपरोक्त उदाहरण के लिए, हम पायथन लिपि की मदद से वेट वेक्टर प्राप्त कर सकते हैं -
LSVCClf.coef_उत्पादन
[[0. 0. 0.91214955 0.22630686]]उदाहरण
इसी प्रकार, हम निम्नलिखित लिपि की मदद से अवरोधन का मूल्य प्राप्त कर सकते हैं -
LSVCClf.intercept_उत्पादन
[0.26860518]एसवीएम के साथ प्रतिगमन
जैसा कि पहले चर्चा की गई है, एसवीएम का उपयोग वर्गीकरण और प्रतिगमन समस्याओं दोनों के लिए किया जाता है। समर्थन वेक्टर वर्गीकरण (एसवीसी) के स्किकिट-लर्न की विधि को प्रतिगमन समस्याओं को हल करने के लिए भी बढ़ाया जा सकता है। उस विस्तारित विधि को सपोर्ट वेक्टर रिग्रेशन (SVR) कहा जाता है।
एसवीएम और एसवीआर के बीच बुनियादी समानता
SVC द्वारा बनाया गया मॉडल केवल प्रशिक्षण डेटा के सबसेट पर निर्भर करता है। क्यों? क्योंकि मॉडल के निर्माण के लिए लागत फ़ंक्शन प्रशिक्षण डेटा बिंदुओं के बारे में परवाह नहीं करता है जो मार्जिन के बाहर स्थित हैं।
जबकि, SVR (सपोर्ट वेक्टर रिग्रेशन) द्वारा निर्मित मॉडल भी केवल प्रशिक्षण डेटा के सबसेट पर निर्भर करता है। क्यों? क्योंकि मॉडल के निर्माण के लिए लागत फ़ंक्शन मॉडल की भविष्यवाणी के करीब किसी भी प्रशिक्षण डेटा बिंदुओं को अनदेखा करता है।
स्किकिट-लर्न अर्थात् तीन कक्षाएं प्रदान करता है SVR, NuSVR and LinearSVR एसवीआर के तीन अलग-अलग कार्यान्वयन के रूप में।
SVR
यह एप्सिलॉन-सपोर्ट वेक्टर रिग्रेशन है, जिसके कार्यान्वयन पर आधारित है libsvm। के विपरीत हैSVC मॉडल में दो मुक्त पैरामीटर हैं ‘C’ तथा ‘epsilon’।
epsilon - फ्लोट, वैकल्पिक, डिफ़ॉल्ट = 0.1
यह एप्सिलॉन-एसवीआर मॉडल में एप्सिलॉन का प्रतिनिधित्व करता है, और एप्सिलॉन-ट्यूब को निर्दिष्ट करता है, जिसके भीतर प्रशिक्षण हानि फ़ंक्शन में कोई जुर्माना नहीं जुड़ा होता है, जो वास्तविक मूल्य से दूरी एप्सिलॉन के भीतर अनुमानित अंकों के साथ होता है।
बाकी पैरामीटर और विशेषताएँ समान हैं जैसा कि हमने उपयोग किया था SVC।
कार्यान्वयन उदाहरण
पायथन लिपि का उपयोग करता है sklearn.svm.SVR वर्ग -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)उत्पादन
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)उदाहरण
अब, एक बार फिट होने के बाद, हम पायथन लिपि की मदद से वेट वेक्टर प्राप्त कर सकते हैं -
SVRReg.coef_उत्पादन
array([[0.4, 0.4]])उदाहरण
इसी प्रकार, हम अन्य विशेषताओं का मूल्य निम्नानुसार प्राप्त कर सकते हैं -
SVRReg.predict([[1,1]])उत्पादन
array([1.1])इसी तरह, हम अन्य विशेषताओं के मूल्यों को भी प्राप्त कर सकते हैं।
NuSVR
NuSVR परमाणु समर्थन वेक्टर प्रतिगमन है। यह NuSVC की तरह है, लेकिन NuSVR एक पैरामीटर का उपयोग करता हैnuसमर्थन वैक्टर की संख्या को नियंत्रित करने के लिए। और इसके अलावा, जहां NuSVC के विपरीत हैnu सी पैरामीटर को बदल दिया गया, यहां यह बदल जाता है epsilon।
कार्यान्वयन उदाहरण
पायथन लिपि का उपयोग करता है sklearn.svm.SVR वर्ग -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)उत्पादन
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)उदाहरण
अब, एक बार फिट होने के बाद, हम पायथन लिपि की मदद से वेट वेक्टर प्राप्त कर सकते हैं -
NuSVRReg.coef_उत्पादन
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)इसी तरह, हम अन्य विशेषताओं का भी मूल्य प्राप्त कर सकते हैं।
LinearSVR
यह रैखिक समर्थन वेक्टर प्रतिगमन है। यह SVR कर्नेल = 'रैखिक' होने के समान है। उनके बीच अंतर यह है किLinearSVR के संदर्भ में लागू किया गया liblinear, जबकि SVC में लागू किया गया libsvm। यही कारण हैLinearSVRदंड और नुकसान कार्यों की पसंद में अधिक लचीलापन है। यह बड़ी संख्या में नमूनों की तुलना में बेहतर है।
अगर हम इसके मापदंडों और विशेषताओं के बारे में बात करते हैं तो यह समर्थन नहीं करता है ‘kernel’ क्योंकि इसे रेखीय माना जाता है और इसमें कुछ विशेषताओं का भी अभाव है support_, support_vectors_, n_support_, fit_status_ तथा, dual_coef_।
हालाँकि, यह 'नुकसान' मापदंडों का समर्थन करता है -
loss - स्ट्रिंग, वैकल्पिक, डिफ़ॉल्ट = 'epsilon_insensitive'
यह हानि फ़ंक्शन का प्रतिनिधित्व करता है जहां epsilon_insensitive नुकसान L1 नुकसान है और चुकता epsilon-असंवेदनशील नुकसान L2 नुकसान है।
कार्यान्वयन उदाहरण
पायथन लिपि का उपयोग करता है sklearn.svm.LinearSVR वर्ग -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)उत्पादन
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)उदाहरण
अब, एक बार फिट होने के बाद, मॉडल नए मूल्यों की भविष्यवाणी कर सकता है -
LSRReg.predict([[0,0,0,0]])उत्पादन
array([-0.01041416])उदाहरण
उपरोक्त उदाहरण के लिए, हम पायथन लिपि की मदद से वेट वेक्टर प्राप्त कर सकते हैं -
LSRReg.coef_उत्पादन
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])उदाहरण
इसी प्रकार, हम निम्नलिखित लिपि की मदद से अवरोधन का मूल्य प्राप्त कर सकते हैं -
LSRReg.intercept_उत्पादन
array([-0.01041416])