डेटा-केंद्रित वास्तुकला
डेटा-केंद्रित आर्किटेक्चर में, डेटा को अन्य घटकों द्वारा अक्सर केंद्रीकृत और एक्सेस किया जाता है, जो डेटा को संशोधित करता है। इस शैली का मुख्य उद्देश्य डेटा की अभिन्नता को प्राप्त करना है। डेटा-केंद्रित वास्तुकला में विभिन्न घटक होते हैं जो साझा डेटा रिपॉजिटरी के माध्यम से संवाद करते हैं। घटक एक साझा डेटा संरचना का उपयोग करते हैं और अपेक्षाकृत स्वतंत्र होते हैं, इसमें वे केवल डेटा स्टोर के माध्यम से बातचीत करते हैं।
डेटा-केंद्रित वास्तुकला का सबसे प्रसिद्ध उदाहरण एक डेटाबेस आर्किटेक्चर है, जिसमें डेटा परिभाषा प्रोटोकॉल के साथ सामान्य डेटाबेस स्कीमा बनाया जाता है - उदाहरण के लिए, संबंधित फ़ील्ड्स का एक सेट और RDBMS में डेटा प्रकार।
डेटा-केंद्रित आर्किटेक्चर का एक और उदाहरण वेब आर्किटेक्चर है जिसमें एक सामान्य डेटा स्कीमा है (यानी वेब की मेटा-संरचना) और निम्न वेब-आधारित डेटा सेवाओं के उपयोग के माध्यम से हाइपरमीडिया डेटा मॉडल और प्रक्रियाओं का संचार करता है।

अवयवों के प्रकार
घटक दो प्रकार के होते हैं -
ए central dataसंरचना या डेटा स्टोर या डेटा भंडार, जो स्थायी डेटा भंडारण प्रदान करने के लिए जिम्मेदार है। यह वर्तमान स्थिति का प्रतिनिधित्व करता है।
ए data accessor या केंद्रीय डेटा स्टोर पर काम करने वाले स्वतंत्र घटकों का एक संग्रह, संगणना करते हैं, और परिणाम वापस ला सकते हैं।
डेटा एक्सेसरों के बीच बातचीत या संचार केवल डेटा स्टोर के माध्यम से होता है। डेटा ग्राहकों के बीच संचार का एकमात्र साधन है। नियंत्रण का प्रवाह वास्तुकला को दो श्रेणियों में विभक्त करता है -
- रिपोजिटरी आर्किटेक्चर स्टाइल
- ब्लैकबोर्ड वास्तुकला शैली
रिपोजिटरी आर्किटेक्चर स्टाइल
रिपॉजिटरी आर्किटेक्चर स्टाइल में, डेटा स्टोर निष्क्रिय है और डेटा स्टोर के क्लाइंट (सॉफ़्टवेयर घटक या एजेंट) सक्रिय हैं, जो तर्क प्रवाह को नियंत्रित करते हैं। भाग लेने वाले घटक परिवर्तनों के लिए डेटा-स्टोर की जांच करते हैं।
क्लाइंट सिस्टम को कार्य करने के लिए एक अनुरोध भेजता है (उदाहरण के लिए डेटा सम्मिलित करें)।
कम्प्यूटेशनल प्रक्रियाएं स्वतंत्र हैं और आने वाले अनुरोधों से शुरू होती हैं।
यदि लेनदेन के इनपुट स्ट्रीम में लेनदेन के प्रकार निष्पादित करने के लिए प्रक्रियाओं के चयन को ट्रिगर करते हैं, तो यह पारंपरिक डेटाबेस या रिपॉजिटरी आर्किटेक्चर, या निष्क्रिय भंडार है।
यह दृष्टिकोण व्यापक रूप से DBMS, पुस्तकालय सूचना प्रणाली, CORBA में इंटरफ़ेस रिपॉजिटरी, कंपाइलर्स और CASE (कंप्यूटर एडेड सॉफ्टवेयर इंजीनियरिंग) वातावरण में उपयोग किया जाता है।

लाभ
डेटा अखंडता, बैकअप प्रदान करता है और सुविधाओं को पुनर्स्थापित करता है।
एजेंटों की स्केलेबिलिटी और पुन: प्रयोज्य प्रदान करता है क्योंकि उनके पास एक दूसरे के साथ सीधा संचार नहीं होता है।
सॉफ्टवेयर घटकों के बीच क्षणिक डेटा के ओवरहेड को कम करता है।
नुकसान
यह विफलता के लिए अधिक संवेदनशील है और डेटा प्रतिकृति या दोहराव संभव है।
डेटा स्टोर और उसके एजेंटों की डेटा संरचना के बीच उच्च निर्भरता।
डेटा संरचना में परिवर्तन ग्राहकों को अत्यधिक प्रभावित करते हैं।
डेटा का विकास मुश्किल और महंगा है।
वितरित डेटा के लिए नेटवर्क पर बढ़ते डेटा की लागत।
ब्लैकबोर्ड वास्तुकला शैली
ब्लैकबोर्ड वास्तुकला शैली में, डेटा स्टोर सक्रिय है और इसके ग्राहक निष्क्रिय हैं। इसलिए तार्किक प्रवाह डेटा स्टोर में वर्तमान डेटा स्थिति द्वारा निर्धारित किया जाता है। इसमें एक ब्लैकबोर्ड घटक होता है, जो केंद्रीय डेटा भंडार के रूप में कार्य करता है, और एक आंतरिक प्रतिनिधित्व विभिन्न कम्प्यूटेशनल तत्वों द्वारा बनाया और कार्य किया जाता है।
कई घटक जो सामान्य डेटा संरचना पर स्वतंत्र रूप से कार्य करते हैं, उन्हें ब्लैकबोर्ड में संग्रहीत किया जाता है।
इस शैली में, घटक केवल ब्लैकबोर्ड के माध्यम से बातचीत करते हैं। डेटा-स्टोर परिवर्तन होने पर डेटा-स्टोर ग्राहकों को सचेत करता है।
समाधान की वर्तमान स्थिति को ब्लैकबोर्ड में संग्रहीत किया जाता है और प्रसंस्करण ब्लैकबोर्ड की स्थिति से चालू होता है।
सिस्टम के रूप में जाना जाता सूचनाएं भेजता है trigger और डेटा में परिवर्तन होने पर क्लाइंट को डेटा।
यह दृष्टिकोण कुछ एआई अनुप्रयोगों और जटिल अनुप्रयोगों में पाया जाता है, जैसे कि भाषण मान्यता, छवि मान्यता, सुरक्षा प्रणाली, और व्यापार संसाधन प्रबंधन प्रणाली आदि।
यदि केंद्रीय डेटा संरचना की वर्तमान स्थिति निष्पादित करने के लिए प्रक्रियाओं का चयन करने का मुख्य ट्रिगर है, तो रिपॉजिटरी एक ब्लैकबोर्ड हो सकती है और यह साझा डेटा स्रोत एक सक्रिय एजेंट है।
पारंपरिक डेटाबेस सिस्टम के साथ एक बड़ा अंतर यह है कि ब्लैकबोर्ड आर्किटेक्चर में कम्प्यूटेशनल तत्वों का आह्वान ब्लैकबोर्ड की वर्तमान स्थिति से शुरू होता है, न कि बाहरी इनपुट द्वारा।
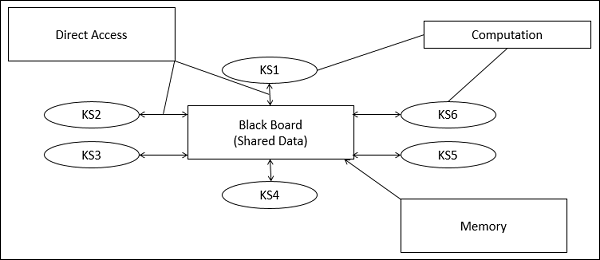
ब्लैकबोर्ड मॉडल के भाग
ब्लैकबोर्ड मॉडल आमतौर पर तीन प्रमुख भागों के साथ प्रस्तुत किया जाता है -
Knowledge Sources (KS)
ज्ञान स्रोत, के रूप में भी जाना जाता है Listeners या Subscribersअलग और स्वतंत्र इकाइयाँ हैं। वे एक समस्या के कुछ हिस्सों को हल करते हैं और आंशिक परिणामों को एकत्र करते हैं। ब्लैकबोर्ड के माध्यम से ज्ञान स्रोतों के बीच सहभागिता विशिष्ट रूप से होती है।
Blackboard Data Structure
समस्या को हल करने वाले राज्य डेटा को अनुप्रयोग-निर्भर पदानुक्रम में व्यवस्थित किया जाता है। ज्ञान के स्रोत ब्लैकबोर्ड में परिवर्तन करते हैं जो समस्या के समाधान के लिए वृद्धि का नेतृत्व करते हैं।
Control
नियंत्रण कार्यों का प्रबंधन करता है और कार्य स्थिति की जांच करता है।
लाभ
मापनीयता प्रदान करता है जो ज्ञान स्रोत को जोड़ने या अद्यतन करने के लिए आसान प्रदान करता है।
समसामयिकता प्रदान करता है जो सभी ज्ञान स्रोतों को समानांतर में काम करने की अनुमति देता है क्योंकि वे एक दूसरे से स्वतंत्र होते हैं।
परिकल्पनाओं के लिए प्रयोग का समर्थन करता है।
ज्ञान स्रोत एजेंटों के पुन: प्रयोज्य का समर्थन करता है।
नुकसान
ब्लैकबोर्ड की संरचना परिवर्तन का उसके सभी एजेंटों पर महत्वपूर्ण प्रभाव पड़ सकता है क्योंकि ब्लैकबोर्ड और ज्ञान स्रोत के बीच घनिष्ठ निर्भरता मौजूद है।
यह निर्णय करना मुश्किल हो सकता है कि तर्क को कब समाप्त किया जाए क्योंकि केवल अनुमानित समाधान की उम्मीद है।
कई एजेंटों के सिंक्रनाइज़ेशन में समस्याएं।
प्रणाली के डिजाइन और परीक्षण में प्रमुख चुनौतियां।