स्पार्क SQL - क्विक गाइड
उद्योग अपने डेटा सेट का विश्लेषण करने के लिए Hadoop का बड़े पैमाने पर उपयोग कर रहे हैं। कारण यह है कि Hadoop फ्रेमवर्क एक सरल प्रोग्रामिंग मॉडल (MapReduce) पर आधारित है और यह एक कंप्यूटिंग समाधान को सक्षम करता है जो स्केलेबल, लचीला, दोष-सहिष्णु और लागत प्रभावी है। यहां, प्रश्नों को चलाने और कार्यक्रम को चलाने के लिए प्रतीक्षा समय के बीच बड़े डेटासेट को संसाधित करने में गति बनाए रखना मुख्य चिंता है।
स्पैडो को अपाचे सॉफ्टवेयर फाउंडेशन द्वारा हडोप कम्प्यूट कम्प्यूटिंग सॉफ्टवेयर प्रक्रिया में तेजी लाने के लिए पेश किया गया था।
एक आम धारणा के विपरीत, Spark is not a modified version of Hadoopऔर, वास्तव में, Hadoop पर निर्भर नहीं है क्योंकि इसका अपना क्लस्टर प्रबंधन है। हाडोप स्पार्क को लागू करने के तरीकों में से एक है।
स्पार्क दो तरीकों से Hadoop का उपयोग करता है - एक है storage और दूसरा है processing। चूंकि स्पार्क की अपनी क्लस्टर प्रबंधन संगणना है, इसलिए यह केवल भंडारण उद्देश्य के लिए Hadoop का उपयोग करता है।
अपाचे स्पार्क
अपाचे स्पार्क एक लाइटनिंग-फास्ट क्लस्टर कंप्यूटिंग तकनीक है, जिसे तेज गणना के लिए डिज़ाइन किया गया है। यह Hadoop MapReduce पर आधारित है और यह MapReduce मॉडल को कुशलता से अधिक प्रकार की गणनाओं के लिए उपयोग करने के लिए विस्तारित करता है, जिसमें इंटरैक्टिव क्वेरी और स्ट्रीम प्रोसेसिंग शामिल है। स्पार्क की मुख्य विशेषता इसकी हैin-memory cluster computing जो किसी एप्लिकेशन की प्रोसेसिंग स्पीड को बढ़ाता है।
स्पार्क को कई प्रकार के वर्कलोड जैसे कि बैच एप्लिकेशन, पुनरावृत्त एल्गोरिदम, इंटरएक्टिव क्वेरी और स्ट्रीमिंग को कवर करने के लिए डिज़ाइन किया गया है। संबंधित प्रणाली में इन सभी कार्यभार का समर्थन करने के अलावा, यह अलग-अलग उपकरणों को बनाए रखने के प्रबंधन के बोझ को कम करता है।
अपाचे स्पार्क का विकास
स्पार्क होडोप की उप परियोजना में से एक है जो 2009 में माटी ज़हरिया द्वारा यूसी बर्कले के एएमपीलैब में विकसित की गई थी। यह 2010 में बीएसडी लाइसेंस के तहत ओपन सोर्ड था। यह 2013 में अपाचे सॉफ्टवेयर फाउंडेशन को दान कर दिया गया था, और अब अपाचे स्पार्क फरवरी 2014 से शीर्ष स्तर की अपाचे परियोजना बन गई है।
अपाचे स्पार्क की विशेषताएं
अपाचे स्पार्क में निम्नलिखित विशेषताएं हैं।
Speed- स्पार्क Hadoop क्लस्टर में एक एप्लिकेशन को चलाने में मदद करता है, मेमोरी में 100 गुना तेज और डिस्क पर चलने पर 10 गुना तेज। डिस्क पर रीड / राइट ऑपरेशन की संख्या कम करके यह संभव है। यह इंटरमीडिएट प्रोसेसिंग डाटा को मेमोरी में स्टोर करता है।
Supports multiple languages- स्पार्क जावा, स्काला, या पायथन में निर्मित एपीआई प्रदान करता है। इसलिए, आप विभिन्न भाषाओं में एप्लिकेशन लिख सकते हैं। स्पार्क इंटरएक्टिव क्वेरी के लिए 80 उच्च-स्तरीय ऑपरेटरों के साथ आता है।
Advanced Analytics- स्पार्क न केवल 'मैप' और 'कम' का समर्थन करता है। यह SQL क्वेरी, स्ट्रीमिंग डेटा, मशीन लर्निंग (एमएल) और ग्राफ़ एल्गोरिदम का भी समर्थन करता है।
स्पार्क बिल्ट पर बनाया गया
निम्नलिखित आरेख तीन तरीकों को दर्शाता है कि स्पार्क को Hadoop घटकों के साथ कैसे बनाया जा सकता है।
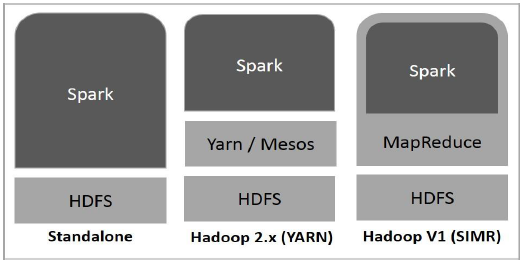
नीचे बताया गया स्पार्क तैनाती के तीन तरीके हैं।
Standalone- स्पार्क स्टैंडअलोन तैनाती का मतलब है कि स्पार्क एचडीएफएस (हडोप डिस्ट्रीब्यूटेड फाइल सिस्टम) के शीर्ष पर जगह रखता है और स्पष्ट रूप से एचडीएफएस के लिए जगह आवंटित की जाती है। यहाँ, स्पार्क और MapReduce क्लस्टर पर सभी स्पार्क नौकरियों को कवर करने के लिए कंधे से कंधा मिलाकर चलेंगे।
Hadoop Yarn- Hadoop यार्न की तैनाती का मतलब है, बस, स्पार्क यार्न पर बिना किसी पूर्व-इंस्टॉलेशन या रूट एक्सेस के आवश्यक है। यह स्पार्क को Hadoop इकोसिस्टम या Hadoop स्टैक में एकीकृत करने में मदद करता है। यह अन्य घटकों को स्टैक के शीर्ष पर चलने की अनुमति देता है।
Spark in MapReduce (SIMR)- MapReduce में स्पार्क का उपयोग स्टैंडअलोन तैनाती के अलावा स्पार्क जॉब लॉन्च करने के लिए किया जाता है। SIMR के साथ, उपयोगकर्ता स्पार्क शुरू कर सकता है और बिना किसी प्रशासनिक पहुंच के इसके शेल का उपयोग कर सकता है।
स्पार्क के घटक
निम्नलिखित दृष्टांत स्पार्क के विभिन्न घटकों को दर्शाते हैं।
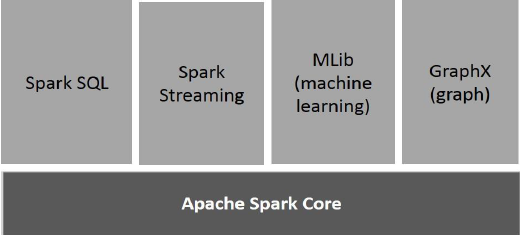
अपाचे स्पार्क कोर
स्पार्क कोर स्पार्क प्लेटफॉर्म के लिए अंतर्निहित सामान्य निष्पादन इंजन है जो अन्य सभी कार्यक्षमता पर बनाया गया है। यह बाहरी मेमोरी सिस्टम में इन-मेमोरी कंप्यूटिंग और रेफरेंसिंग डेटासेट प्रदान करता है।
स्पार्क एसक्यूएल
स्पार्क एसक्यूएल स्पार्क कोर के शीर्ष पर एक घटक है जो स्कीमाआरडीडी नामक एक नया डेटा एब्स्ट्रैक्शन पेश करता है, जो संरचित और अर्ध-संरचित डेटा के लिए समर्थन प्रदान करता है।
स्पार्क स्ट्रीमिंग
स्पार्क स्ट्रीमिंग, स्ट्रीमिंग एनालिटिक्स प्रदर्शन करने के लिए स्पार्क कोर की तीव्र शेड्यूलिंग क्षमता का लाभ उठाती है। यह मिनी-बैचों में डेटा को सम्मिलित करता है और डेटा के उन मिनी-बैचों पर आरडीडी (रेजिलिएंट डिस्ट्रीब्यूटेड डेटासेट्स) रूपांतरण करता है।
MLlib (मशीन लर्निंग लाइब्रेरी)
MLlib वितरित मेमोरी-आधारित स्पार्क वास्तुकला के कारण स्पार्क के ऊपर एक वितरित मशीन लर्निंग फ्रेमवर्क है। यह बेंचमार्क के अनुसार, एमएलबी डेवलपर्स द्वारा अल्टरनेटिंग लिस्ट स्क्वायर (एएलएस) कार्यान्वयन के खिलाफ किया जाता है। स्पार्क MLlib Hadoop डिस्क-आधारित संस्करण के रूप में नौ गुना तेज हैApache Mahout (इससे पहले कि महावत ने स्पार्क इंटरफ़ेस प्राप्त किया)।
GraphX
ग्राफएक्स स्पार्क के शीर्ष पर एक वितरित ग्राफ-प्रोसेसिंग ढांचा है। यह ग्राफ संगणना को व्यक्त करने के लिए एक एपीआई प्रदान करता है जो उपयोगकर्ता-परिभाषित रेखांकन को Pregel abstraction API का उपयोग करके मॉडल कर सकता है। यह इस अमूर्त के लिए एक अनुकूलित रनटाइम भी प्रदान करता है।
लचीला वितरित डेटासेट
रेसिलिएंट डिस्ट्रिब्यूटेड डेटसेट्स (आरडीडी) स्पार्क की एक मूलभूत डेटा संरचना है। यह वस्तुओं का एक अपरिवर्तित वितरित संग्रह है। RDD में प्रत्येक डेटासेट को तार्किक विभाजन में विभाजित किया गया है, जिसे क्लस्टर के विभिन्न नोड्स पर गणना की जा सकती है। RDD में उपयोगकर्ता-परिभाषित कक्षाओं सहित किसी भी प्रकार के पायथन, जावा या स्काला ऑब्जेक्ट शामिल हो सकते हैं।
औपचारिक रूप से, एक RDD एक केवल-पढ़ने के लिए, अभिलेखों का विभाजन संग्रह है। RDDs स्थिर भंडारण या अन्य RDDs के डेटा पर नियतात्मक संचालन के माध्यम से बनाया जा सकता है। RDD तत्वों का एक दोष-सहिष्णु संग्रह है जिसे समानांतर में संचालित किया जा सकता है।
RDDs बनाने के दो तरीके हैं - parallelizing आपके ड्राइवर प्रोग्राम में मौजूदा संग्रह, या referencing a dataset एक बाहरी भंडारण प्रणाली में, जैसे कि एक साझा फ़ाइल सिस्टम, HDFS, HBase, या Hadoop Input Format की पेशकश करने वाला कोई भी डेटा स्रोत।
स्पार्क RDD की अवधारणा का उपयोग तेज और कुशल MapReduce संचालन को प्राप्त करने के लिए करता है। चलिए पहले चर्चा करते हैं कि MapReduce के संचालन कैसे होते हैं और वे इतने कुशल क्यों नहीं हैं।
MapReduce में Data Sharing Slow है
MapReduce व्यापक रूप से एक क्लस्टर पर समानांतर, वितरित एल्गोरिदम के साथ बड़े डेटासेट को संसाधित करने और उत्पन्न करने के लिए अपनाया जाता है। यह उपयोगकर्ताओं को काम वितरण और गलती सहिष्णुता के बारे में चिंता किए बिना, उच्च-स्तरीय ऑपरेटरों के एक सेट का उपयोग करके, समानांतर संगणना लिखने की अनुमति देता है।
दुर्भाग्य से, अधिकांश वर्तमान रूपरेखाओं में, संगणनाओं के बीच डेटा का पुन: उपयोग करने का एकमात्र तरीका (Ex: दो MapReduce नौकरियों के बीच) इसे बाहरी स्थिर भंडारण प्रणाली (Ex: HDFS) में लिखना है। यद्यपि यह ढांचा क्लस्टर के कम्प्यूटेशनल संसाधनों तक पहुंचने के लिए कई सार प्रदान करता है, फिर भी उपयोगकर्ता अधिक चाहते हैं।
दोनों Iterative तथा Interactiveअनुप्रयोगों को समानांतर नौकरियों में तेजी से डेटा साझा करने की आवश्यकता होती है। के कारण MapReduce में डेटा साझाकरण धीमा हैreplication, serialization, तथा disk IO। स्टोरेज सिस्टम के बारे में, अधिकांश हडॉप एप्लिकेशन, वे HDFS पढ़ने-लिखने के संचालन में 90% से अधिक समय बिताते हैं।
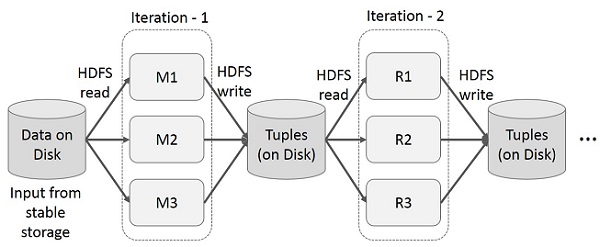
MapReduce पर Iterative ऑपरेशंस
बहु-चरण अनुप्रयोगों में कई संगणनाओं के बीच मध्यवर्ती परिणामों का पुन: उपयोग करें। निम्न चित्रण यह बताता है कि MapReduce पर पुनरावृत्त संचालन करते समय वर्तमान रूपरेखा कैसे काम करती है। यह डेटा प्रतिकृति, डिस्क I / O और क्रमांकन के कारण पर्याप्त ओवरहेड्स को उकसाता है, जिससे सिस्टम धीमा हो जाता है।
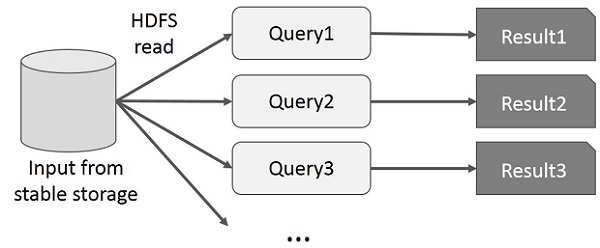
MapReduce पर इंटरएक्टिव संचालन
उपयोगकर्ता डेटा के एक ही सबसेट पर तदर्थ क्वेरी चलाता है। प्रत्येक क्वेरी स्थिर स्टोरेज पर डिस्क I / O करेगी, जो एप्लिकेशन निष्पादन समय पर हावी हो सकती है।
निम्नलिखित चित्रण यह बताता है कि MapReduce पर संवादात्मक प्रश्न करते समय वर्तमान रूपरेखा कैसे काम करती है।
स्पार्क आरडीडी का उपयोग करके डेटा शेयरिंग
के कारण MapReduce में डेटा साझाकरण धीमा है replication, serialization, तथा disk IO। Hadoop के अधिकांश एप्लिकेशन, वे HDFS पढ़ने-लिखने के संचालन में 90% से अधिक समय बिताते हैं।
इस समस्या को स्वीकार करते हुए, शोधकर्ताओं ने अपाचे स्पार्क नामक एक विशेष रूपरेखा विकसित की। चिंगारी का मुख्य विचार हैResilient Distributed Dएसेट्स (आरडीडी); यह इन-मेमोरी प्रोसेसिंग कंप्यूटेशन का समर्थन करता है। इसका मतलब है, यह नौकरियों में एक ऑब्जेक्ट के रूप में मेमोरी की स्थिति को संग्रहीत करता है और उन नौकरियों के बीच ऑब्जेक्ट को साझा करना है। नेटवर्क और डिस्क की तुलना में मेमोरी में डेटा शेयरिंग 10 से 100 गुना तेज है।
आइए अब यह पता लगाने की कोशिश करते हैं कि स्पार्क आरडीडी में पुनरावृत्ति और संवादात्मक संचालन कैसे होता है।
स्पार्क आरडीडी पर Iterative ऑपरेशन
नीचे दिया गया चित्र स्पार्क आरडीडी पर चलने वाले संचालन को दर्शाता है। यह स्थिर भंडारण (डिस्क) के बजाय एक वितरित मेमोरी में मध्यवर्ती परिणाम संग्रहीत करेगा और सिस्टम को तेज करेगा।
Note - यदि इंटरमीडिएट परिणाम (JOB की स्थिति) को संग्रहीत करने के लिए पर्याप्त रूप से वितरित मेमोरी (RAM), तो यह डिस्क पर उन परिणामों को संग्रहीत करेगा
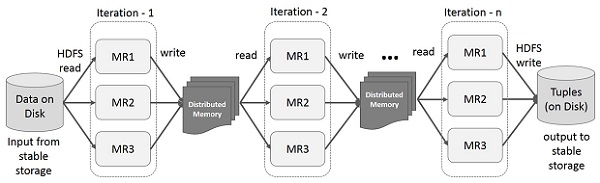
स्पार्क आरडीडी पर इंटरएक्टिव संचालन
यह चित्रण स्पार्क आरडीडी पर इंटरैक्टिव संचालन को दर्शाता है। यदि डेटा के एक ही सेट पर बार-बार अलग-अलग क्वेरीज़ रन की जाती हैं, तो बेहतर निष्पादन समय के लिए इस विशेष डेटा को मेमोरी में रखा जा सकता है।

डिफ़ॉल्ट रूप से, प्रत्येक रूपांतरित RDD को उस पर कार्रवाई चलाने पर हर बार पुनः प्राप्त किया जा सकता है। हालाँकि, आप भी कर सकते हैंpersistमेमोरी में एक RDD, जिस स्थिति में स्पार्क तत्वों को क्लस्टर पर बहुत तेज़ पहुँच के लिए रखेगा, अगली बार जब आप इसे क्वेरी करेंगे। डिस्क पर RDD को बनाए रखने के लिए समर्थन भी है, या कई नोड्स में दोहराया गया है।
स्पार्क हडोप की उप-परियोजना है। इसलिए, स्पार्क को लिनक्स आधारित प्रणाली में स्थापित करना बेहतर है। निम्न चरण दिखाते हैं कि अपाचे स्पार्क को कैसे स्थापित किया जाए।
Step1: जावा इंस्टॉलेशन को सत्यापित करना
स्पार्क को स्थापित करने में जावा इंस्टॉलेशन अनिवार्य चीजों में से एक है। जावा संस्करण को सत्यापित करने के लिए निम्न कमांड का प्रयास करें।
$java -versionयदि जावा पहले से ही आपके सिस्टम में स्थापित है, तो आपको निम्न प्रतिक्रिया देखने को मिलेगी -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)यदि आपके पास जावा आपके सिस्टम पर स्थापित नहीं है, तो अगले चरण पर आगे बढ़ने से पहले जावा स्थापित करें।
चरण 2: सत्यापन की स्थापना
स्पार्क को लागू करने के लिए आपको स्कैला भाषा चाहिए। तो आइए हम निम्नलिखित आदेश का उपयोग करके स्काला इंस्टॉलेशन को सत्यापित करते हैं।
$scala -versionयदि आपके सिस्टम पर पहले से ही Scala स्थापित है, तो आपको निम्न प्रतिक्रिया देखने को मिलेगी -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLयदि आपके पास अपने सिस्टम पर Scala स्थापित नहीं है, तो आप Scala स्थापना के लिए अगले चरण पर आगे बढ़ें।
चरण 3: स्कैला डाउनलोड करना
निम्न लिंक पर जाकर स्काला का नवीनतम संस्करण डाउनलोड करें । इस ट्यूटोरियल के लिए, हम scala-2.11.6 संस्करण का उपयोग कर रहे हैं। डाउनलोड करने के बाद, आपको डाउनलोड फ़ोल्डर में स्काला टार फाइल मिलेगी।
Step4: स्कैला स्थापित करना
स्केल स्थापित करने के लिए नीचे दिए गए चरणों का पालन करें।
स्काला टार फ़ाइल को निकालें
Scala tar फ़ाइल निकालने के लिए निम्न कमांड टाइप करें।
$ tar xvf scala-2.11.6.tgzScala सॉफ्टवेयर फ़ाइलों को स्थानांतरित करें
स्काला सॉफ़्टवेयर फ़ाइलों को संबंधित निर्देशिका में ले जाने के लिए निम्न आदेशों का उपयोग करें (/usr/local/scala)।
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitस्काला के लिए पाथ सेट करें
Scala के लिए PATH की स्थापना के लिए निम्न कमांड का उपयोग करें।
$ export PATH = $PATH:/usr/local/scala/binस्काला इंस्टालेशन का सत्यापन
स्थापना के बाद, इसे सत्यापित करना बेहतर है। Scala स्थापना को सत्यापित करने के लिए निम्न कमांड का उपयोग करें।
$scala -versionयदि आपके सिस्टम पर पहले से ही Scala स्थापित है, तो आपको निम्न प्रतिक्रिया देखने को मिलेगी -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLStep5: Apache Spark को डाउनलोड करना
निम्नलिखित लिंक पर जाकर स्पार्क का नवीनतम संस्करण डाउनलोड करें । इस ट्यूटोरियल के लिए, हम उपयोग कर रहे हैंspark-1.3.1-bin-hadoop2.6संस्करण। इसे डाउनलोड करने के बाद, आपको डाउनलोड फ़ोल्डर में स्पार्क टार फाइल मिलेगी।
Step6: स्पार्क स्थापित करना
स्पार्क स्थापित करने के लिए नीचे दिए गए चरणों का पालन करें।
स्पार्क टार निकालना
स्पार्क टार फाइल निकालने के लिए निम्न कमांड।
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzस्पार्क सॉफ़्टवेयर फ़ाइलों को ले जाना
स्पार्क सॉफ़्टवेयर फ़ाइलों को संबंधित निर्देशिका में ले जाने के लिए निम्न आदेश (/usr/local/spark)।
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitस्पार्क के लिए पर्यावरण की स्थापना
निम्नलिखित पंक्ति को ~ में जोड़ें/.bashrcफ़ाइल। इसका अर्थ है उस स्थान को जोड़ना, जहां स्पार्क सॉफ्टवेयर फ़ाइल पथ चर के लिए स्थित है।
export PATH = $PATH:/usr/local/spark/bin~ / .Bashrc फ़ाइल की सोर्सिंग के लिए निम्न कमांड का उपयोग करें।
$ source ~/.bashrcStep7: स्पार्क इंस्टॉलेशन को सत्यापित करना
स्पार्क खोल खोलने के लिए निम्नलिखित कमांड लिखिए।
$spark-shellयदि स्पार्क सफलतापूर्वक स्थापित किया गया है, तो आपको निम्न आउटपुट मिलेगा।
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>स्पार्क संरचित डेटा प्रोसेसिंग के लिए स्पार्क एसक्यूएल नामक एक प्रोग्रामिंग मॉड्यूल का परिचय देता है। यह DataFrame नामक एक प्रोग्रामिंग अमूर्तता प्रदान करता है और वितरित SQL क्वेरी इंजन के रूप में कार्य कर सकता है।
स्पार्क एसक्यूएल की विशेषताएं
स्पार्क एसक्यूएल की विशेषताएं निम्नलिखित हैं -
Integrated- सहज स्पार्क कार्यक्रमों के साथ एसक्यूएल प्रश्नों को मिलाएं। स्पार्क एसक्यूएल आपको स्पार्क में एक वितरित डेटासेट (RDD) के रूप में संरचित डेटा को पायथन, स्काला और जावा में एकीकृत एपीआई के साथ क्वेरी करने देता है। यह चुस्त एकीकरण जटिल विश्लेषणात्मक एल्गोरिदम के साथ एसक्यूएल प्रश्नों को चलाना आसान बनाता है।
Unified Data Access- विभिन्न स्रोतों से डेटा लोड और क्वेरी करें। स्कीमा-आरडीडी, अपाचे हाइव टेबल, लकड़ी की छत फ़ाइलें और JSON फ़ाइलों सहित संरचित डेटा के साथ कुशलता से काम करने के लिए एक एकल इंटरफ़ेस प्रदान करते हैं।
Hive Compatibility- मौजूदा गोदामों पर अनमॉडिफाइड हाइव क्वेरीज़ चलाएं। स्पार्क एसक्यूएल हाइव फ्रंटएंड और मेटास्टोर का पुन: उपयोग करता है, जो आपको मौजूदा हाइव डेटा, प्रश्नों और यूएएफएफ के साथ पूर्ण संगतता देता है। बस इसे हाइव के साथ स्थापित करें।
Standard Connectivity- JDBC या ODBC के माध्यम से कनेक्ट करें। स्पार्क SQL में उद्योग मानक JDBC और ODBC कनेक्टिविटी के साथ एक सर्वर मोड शामिल है।
Scalability- इंटरेक्टिव और लंबे दोनों प्रश्नों के लिए एक ही इंजन का उपयोग करें। स्पार्क SQL मध्य-क्वेरी दोष सहिष्णुता का समर्थन करने के लिए RDD मॉडल का लाभ उठाता है, जिससे इसे बड़े पैमाने पर रोजगार भी मिलता है। ऐतिहासिक डेटा के लिए एक अलग इंजन का उपयोग करने के बारे में चिंता न करें।
स्पार्क एसक्यूएल आर्किटेक्चर
निम्नलिखित दृष्टांत स्पार्क एसक्यूएल की वास्तुकला की व्याख्या करता है -
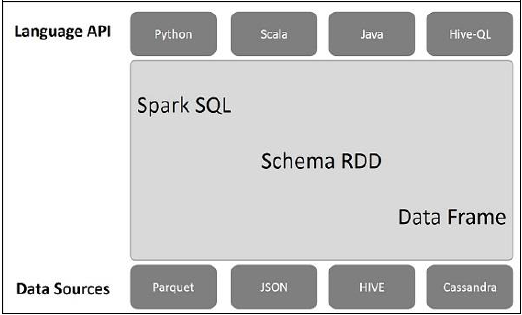
इस वास्तुकला में तीन परतें हैं, भाषा एपीआई, स्कीमा आरडीडी, और डेटा स्रोत।
Language API- स्पार्क विभिन्न भाषाओं और स्पार्क एसक्यूएल के साथ संगत है। यह इन भाषाओं द्वारा समर्थित भी है- एपीआई (अजगर, स्काला, जावा, हाइवेकेल)।
Schema RDD- स्पार्क कोर को आरडीडी नामक विशेष डेटा संरचना के साथ डिज़ाइन किया गया है। आमतौर पर, स्पार्क एसक्यूएल स्कीमा, टेबल और रिकॉर्ड पर काम करता है। इसलिए, हम स्कीमा आरडीडी को अस्थायी तालिका के रूप में उपयोग कर सकते हैं। इस स्कीमा आरडीडी को हम डेटा फ्रेम कह सकते हैं।
Data Sources- आमतौर पर स्पार्क-कोर के लिए डेटा स्रोत एक टेक्स्ट फ़ाइल, एवरो फ़ाइल आदि है। हालांकि, स्पार्क एसक्यूएल के लिए डेटा स्रोत अलग हैं। वे Parquet फ़ाइल, JSON दस्तावेज़, HIVE तालिकाओं और Cassandra डेटाबेस हैं।
हम बाद के अध्यायों में इनके बारे में अधिक चर्चा करेंगे।
डेटाफ़्रेम डेटा का एक वितरित संग्रह है, जिसे नामित कॉलम में व्यवस्थित किया जाता है। वैचारिक रूप से, यह अच्छी अनुकूलन तकनीकों के साथ संबंधपरक तालिकाओं के बराबर है।
एक DataFrame का निर्माण विभिन्न स्रोतों जैसे Hive तालिकाओं, संरचित डेटा फ़ाइलों, बाहरी डेटाबेस या मौजूदा RDBs की एक सरणी से किया जा सकता है। इस एपीआई को आधुनिक बिग डेटा और डेटा विज्ञान अनुप्रयोगों से प्रेरणा लेने के लिए डिज़ाइन किया गया थाDataFrame in R Programming तथा Pandas in Python।
DataFrame की विशेषताएं
यहाँ DataFrame की कुछ विशिष्ट विशेषताओं का एक सेट है -
एक नोड नोडल से बड़े क्लस्टर पर पेटोबाइट्स के लिए किलोबाइट्स के आकार में डेटा को संसाधित करने की क्षमता।
विभिन्न डेटा प्रारूपों (एवरो, सीएसवी, लोचदार खोज, और कैसंड्रा) और भंडारण प्रणालियों (एचडीएफएस, एचआईईवी टेबल, माइस्कल, आदि) का समर्थन करता है।
स्पार्क एसक्यूएल उत्प्रेरक उत्प्रेरक (पेड़ परिवर्तन ढांचे) के माध्यम से कला अनुकूलन और कोड पीढ़ी की स्थिति।
स्पार्क-कोर के माध्यम से सभी बिग डेटा टूल और फ्रेमवर्क के साथ आसानी से एकीकृत किया जा सकता है।
पायथन, जावा, स्काला और आर प्रोग्रामिंग के लिए एपीआई प्रदान करता है।
SQLContext
SQLContext एक वर्ग है और इसका उपयोग स्पार्क SQL की कार्यप्रणाली को शुरू करने के लिए किया जाता है। SQLContext क्लास ऑब्जेक्ट को इनिशियलाइज़ करने के लिए SparkContext क्लास ऑब्जेक्ट (sc) की आवश्यकता होती है।
स्पार्क-शेल के माध्यम से स्पार्क-कॉन्टेक्ट को आरंभ करने के लिए निम्न कमांड का उपयोग किया जाता है।
$ spark-shellडिफ़ॉल्ट रूप से, SparkContext ऑब्जेक्ट को नाम के साथ आरंभीकृत किया जाता है sc जब स्पार्क-शेल शुरू होता है।
SQLContext बनाने के लिए निम्न कमांड का उपयोग करें।
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)उदाहरण
आइए एक JSON फ़ाइल में कर्मचारी रिकॉर्ड के उदाहरण पर विचार करें employee.json। एक DataFrame (df) बनाने के लिए निम्नलिखित कमांड्स का उपयोग करें और JSON नाम का दस्तावेज़ पढ़ेंemployee.json निम्नलिखित सामग्री के साथ।
employee.json - इस फाइल को उस डायरेक्टरी में रखें जहां करंट है scala> पॉइंटर स्थित है।
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}DataFrame संचालन
DataFrame संरचित डेटा हेरफेर के लिए एक डोमेन-विशिष्ट भाषा प्रदान करता है। यहां, हम DataFrames का उपयोग करके संरचित डेटा प्रोसेसिंग के कुछ बुनियादी उदाहरणों को शामिल करते हैं।
DataFrame संचालन करने के लिए नीचे दिए गए चरणों का पालन करें -
JSON दस्तावेज़ पढ़ें
सबसे पहले, हमें JSON दस्तावेज़ पढ़ना होगा। इसके आधार पर, एक DataFrame नाम (dfs) जेनरेट करें।
JSON नाम के दस्तावेज़ को पढ़ने के लिए निम्नलिखित कमांड का उपयोग करें employee.json। डेटा को फ़ील्ड के साथ तालिका के रूप में दिखाया गया है - आईडी, नाम और आयु।
scala> val dfs = sqlContext.read.json("employee.json")Output - फ़ील्ड नामों को स्वचालित रूप से लिया जाता है employee.json।
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]डेटा दिखाएं
यदि आप DataFrame में डेटा देखना चाहते हैं, तो निम्न कमांड का उपयोग करें।
scala> dfs.show()Output - आप कर्मचारी डेटा को एक सारणीबद्ध प्रारूप में देख सकते हैं।
<console>:22, took 0.052610 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
| 23 | 1204 | javed |
| 23 | 1205 | prudvi |
+----+------+--------+PrintSchema विधि का उपयोग करें
यदि आप DataFrame की संरचना (स्कीमा) को देखना चाहते हैं, तो निम्न कमांड का उपयोग करें।
scala> dfs.printSchema()Output
root
|-- age: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)चयन विधि का उपयोग करें
लाने के लिए निम्न आदेश का उपयोग करें name-column among three columns from the DataFrame.
scala> dfs.select("name").show()Output − You can see the values of the name column.
<console>:22, took 0.044023 s
+--------+
| name |
+--------+
| satish |
| krishna|
| amith |
| javed |
| prudvi |
+--------+Use Age Filter
Use the following command for finding the employees whose age is greater than 23 (age > 23).
scala> dfs.filter(dfs("age") > 23).show()Output
<console>:22, took 0.078670 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
+----+------+--------+Use groupBy Method
Use the following command for counting the number of employees who are of the same age.
scala> dfs.groupBy("age").count().show()Output − two employees are having age 23.
<console>:22, took 5.196091 s
+----+-----+
|age |count|
+----+-----+
| 23 | 2 |
| 25 | 1 |
| 28 | 1 |
| 39 | 1 |
+----+-----+Running SQL Queries Programmatically
An SQLContext enables applications to run SQL queries programmatically while running SQL functions and returns the result as a DataFrame.
Generally, in the background, SparkSQL supports two different methods for converting existing RDDs into DataFrames −
| Sr. No | Methods & Description |
|---|---|
| 1 | Inferring the Schema using Reflection This method uses reflection to generate the schema of an RDD that contains specific types of objects. |
| 2 | Programmatically Specifying the Schema The second method for creating DataFrame is through programmatic interface that allows you to construct a schema and then apply it to an existing RDD. |
A DataFrame interface allows different DataSources to work on Spark SQL. It is a temporary table and can be operated as a normal RDD. Registering a DataFrame as a table allows you to run SQL queries over its data.
In this chapter, we will describe the general methods for loading and saving data using different Spark DataSources. Thereafter, we will discuss in detail the specific options that are available for the built-in data sources.
There are different types of data sources available in SparkSQL, some of which are listed below −
| Sr. No | Data Sources |
|---|---|
| 1 | JSON Datasets Spark SQL can automatically capture the schema of a JSON dataset and load it as a DataFrame. |
| 2 | Hive Tables Hive comes bundled with the Spark library as HiveContext, which inherits from SQLContext. |
| 3 | Parquet Files Parquet is a columnar format, supported by many data processing systems. |