TIKA - एक्सएमएल दस्तावेज़ निकालना
नीचे एक XML दस्तावेज़ से सामग्री और मेटाडेटा निकालने का कार्यक्रम दिया गया है -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}उपरोक्त कोड को इस प्रकार सेव करें XmlParse.java, और निम्न कमांड का उपयोग करके कमांड प्रॉम्प्ट से इसे संकलित करें -
javac XmlParse.java
java XmlParseनीचे दिया गया example.xml फ़ाइल का स्नैपशॉट है
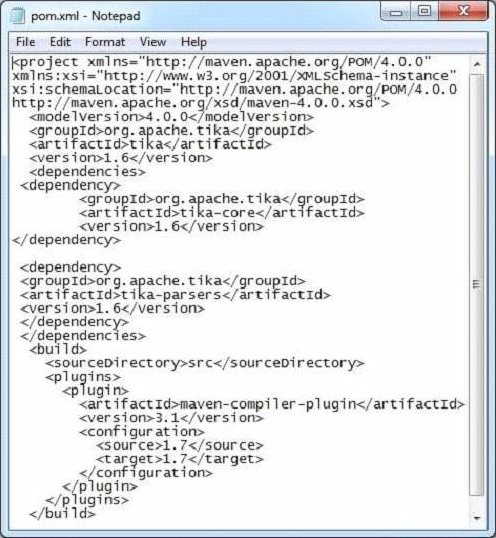
इस दस्तावेज़ में निम्नलिखित गुण हैं -

यदि आप उपरोक्त कार्यक्रम निष्पादित करते हैं, तो यह आपको निम्नलिखित आउटपुट देगा -
Output -
Contents of the document:
4.0.0
org.apache.tika
tika
1.6
org.apache.tika
tika-core
1.6
org.apache.tika
tika-parsers
1.6
src
maven-compiler-plugin
3.1
1.7
1.7
Metadata of the document:
Content-Type: application/xml