Apache Flink - Arsitektur
Apache Flink bekerja pada arsitektur Kappa. Arsitektur Kappa memiliki prosesor tunggal - aliran, yang memperlakukan semua input sebagai aliran dan mesin streaming memproses data secara real-time. Data batch dalam arsitektur kappa adalah kasus khusus streaming.
Diagram berikut menunjukkan Apache Flink Architecture.
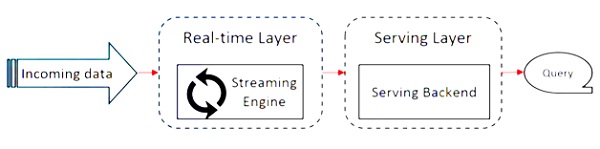
Ide utama dalam arsitektur Kappa adalah menangani data batch dan real-time melalui mesin pemroses aliran tunggal.
Sebagian besar kerangka data besar berfungsi pada arsitektur Lambda, yang memiliki prosesor terpisah untuk data batch dan streaming. Dalam arsitektur Lambda, Anda memiliki basis kode terpisah untuk tampilan batch dan aliran. Untuk membuat kueri dan mendapatkan hasil, basis kode perlu digabungkan. Tidak memelihara basis kode / tampilan yang terpisah dan menggabungkannya merupakan hal yang sulit, tetapi arsitektur Kappa menyelesaikan masalah ini karena hanya memiliki satu tampilan - waktu nyata, sehingga penggabungan basis kode tidak diperlukan.
Itu tidak berarti arsitektur Kappa menggantikan arsitektur Lambda, itu sepenuhnya bergantung pada kasus penggunaan dan aplikasi yang memutuskan arsitektur mana yang lebih disukai.
Diagram berikut menunjukkan arsitektur eksekusi tugas Apache Flink.

Program
Ini adalah bagian dari kode, yang Anda jalankan di Flink Cluster.
Klien
Ini bertanggung jawab untuk mengambil kode (program) dan membuat grafik aliran data pekerjaan, lalu meneruskannya ke JobManager. Itu juga mengambil hasil Pekerjaan.
JobManager
Setelah menerima Grafik Aliran Data Pekerjaan dari Klien, ini bertanggung jawab untuk membuat grafik eksekusi. Ini menetapkan pekerjaan ke TaskManagers di cluster dan mengawasi pelaksanaan pekerjaan.
Pengelola tugas
Ini bertanggung jawab untuk menjalankan semua tugas yang telah ditetapkan oleh JobManager. Semua TaskManager menjalankan tugas di slotnya yang terpisah dalam paralelisme yang ditentukan. Ini bertanggung jawab untuk mengirim status tugas ke JobManager.
Fitur Apache Flink
Fitur-fitur Apache Flink adalah sebagai berikut -
Ini memiliki prosesor streaming, yang dapat menjalankan program batch dan streaming.
Itu dapat memproses data dengan kecepatan kilat.
API tersedia di Java, Scala, dan Python.
Menyediakan API untuk semua operasi umum, yang sangat mudah digunakan oleh pemrogram.
Memproses data dalam latensi rendah (nanodetik) dan throughput tinggi.
Toleransi kesalahannya. Jika node, aplikasi atau perangkat keras gagal, itu tidak mempengaruhi cluster.
Dapat dengan mudah diintegrasikan dengan Apache Hadoop, Apache MapReduce, Apache Spark, HBase, dan alat data besar lainnya.
Manajemen dalam memori dapat disesuaikan untuk komputasi yang lebih baik.
Ini sangat skalabel dan dapat menskalakan hingga ribuan node dalam sebuah cluster.
Windowing sangat fleksibel di Apache Flink.
Menyediakan pustaka Pemrosesan Grafik, Pembelajaran Mesin, Pemrosesan Acara Kompleks.