Apache Kafka - Panduan Cepat
Di Big Data, volume data yang sangat besar digunakan. Terkait data, ada dua tantangan utama, tantangan pertama adalah bagaimana mengumpulkan data dalam jumlah besar dan tantangan kedua adalah menganalisis data yang dikumpulkan. Untuk mengatasi tantangan tersebut, Anda harus membutuhkan sistem pesan.
Kafka dirancang untuk sistem throughput tinggi terdistribusi. Kafka cenderung bekerja dengan sangat baik sebagai pengganti broker pesan yang lebih tradisional. Dibandingkan dengan sistem perpesanan lain, Kafka memiliki throughput yang lebih baik, partisi bawaan, replikasi, dan toleransi kesalahan yang melekat, yang membuatnya cocok untuk aplikasi pemrosesan pesan berskala besar.
Apa itu Sistem Pesan?
Sistem Pesan bertanggung jawab untuk mentransfer data dari satu aplikasi ke aplikasi lainnya, sehingga aplikasi dapat fokus pada data, tetapi tidak khawatir tentang cara membagikannya. Pesan terdistribusi didasarkan pada konsep antrian pesan yang andal. Pesan antri secara asinkron antara aplikasi klien dan sistem perpesanan. Tersedia dua jenis pola perpesanan - yang satu mengarah ke titik dan yang lainnya adalah sistem perpesanan publish-subscribe (pub-sub). Sebagian besar pola pesan mengikutipub-sub.
Point to Point Messaging System
Dalam sistem point-to-point, pesan disimpan dalam antrian. Satu atau lebih konsumen dapat menggunakan pesan dalam antrian, tetapi pesan tertentu hanya dapat dikonsumsi oleh satu konsumen. Setelah konsumen membaca pesan di antrean, pesan tersebut menghilang dari antrean itu. Contoh tipikal dari sistem ini adalah Sistem Pemrosesan Pesanan, di mana setiap pesanan akan diproses oleh satu Pemroses Pesanan, tetapi Pemroses Pesanan Ganda dapat bekerja juga pada saat yang sama. Diagram berikut menggambarkan strukturnya.

Terbitkan-Berlangganan Sistem Pesan
Dalam sistem terbitkan-langganan, pesan disimpan dalam satu topik. Tidak seperti sistem point-to-point, konsumen dapat berlangganan satu atau lebih topik dan mengkonsumsi semua pesan dalam topik itu. Dalam sistem Publish-Subscribe, produsen pesan disebut penerbit dan konsumen pesan disebut pelanggan. Contoh kehidupan nyata adalah Dish TV, yang menerbitkan saluran berbeda seperti olahraga, film, musik, dll., Dan siapa pun dapat berlangganan ke saluran mereka sendiri dan mendapatkannya setiap kali saluran langganan mereka tersedia.

Apa Kafka?
Apache Kafka adalah sistem perpesanan terbitkan-langganan terdistribusi dan antrean yang kuat yang dapat menangani data dalam jumlah besar dan memungkinkan Anda untuk meneruskan pesan dari satu titik akhir ke titik akhir lainnya. Kafka cocok untuk konsumsi pesan offline dan online. Pesan Kafka disimpan di disk dan direplikasi di dalam cluster untuk mencegah kehilangan data. Kafka dibangun di atas layanan sinkronisasi Zookeeper. Ini terintegrasi dengan sangat baik dengan Apache Storm dan Spark untuk analisis data streaming waktu nyata.
Manfaat
Berikut adalah beberapa manfaat Kafka -
Reliability - Kafka didistribusikan, dipartisi, direplikasi dan toleransi kesalahan.
Scalability - Sistem pesan Kafka dapat diskalakan dengan mudah tanpa waktu henti ..
Durability- Kafka menggunakan
log komit Terdistribusi
yang berarti pesan tetap ada di disk secepat mungkin, sehingga tahan lama ..Performance- Kafka memiliki throughput tinggi untuk menerbitkan dan berlangganan pesan. Ini mempertahankan kinerja yang stabil bahkan banyak TB pesan disimpan.
Kafka sangat cepat dan menjamin nol waktu henti dan tidak ada kehilangan data.
Gunakan Kasus
Kafka dapat digunakan di banyak Kasus Penggunaan. Beberapa dari mereka tercantum di bawah -
Metrics- Kafka sering digunakan untuk data monitoring operasional. Ini melibatkan statistik agregat dari aplikasi terdistribusi untuk menghasilkan umpan data operasional terpusat.
Log Aggregation Solution - Kafka dapat digunakan di seluruh organisasi untuk mengumpulkan log dari berbagai layanan dan membuatnya tersedia dalam format standar untuk beberapa konsumen.
Stream Processing- Kerangka kerja populer seperti Storm dan Spark Streaming membaca data dari suatu topik, memprosesnya, dan menulis data yang diproses ke topik baru yang akan tersedia untuk pengguna dan aplikasi. Daya tahan Kafka yang kuat juga sangat berguna dalam konteks pemrosesan aliran.
Kebutuhan Kafka
Kafka adalah platform terpadu untuk menangani semua data feed waktu nyata. Kafka mendukung pengiriman pesan berlatensi rendah dan memberikan jaminan untuk toleransi kesalahan jika terjadi kegagalan mesin. Ia memiliki kemampuan untuk menangani sejumlah besar konsumen yang beragam. Kafka sangat cepat, melakukan 2 juta tulis / detik. Kafka menyimpan semua data ke disk, yang pada dasarnya berarti bahwa semua penulisan masuk ke cache halaman OS (RAM). Ini membuatnya sangat efisien untuk mentransfer data dari cache halaman ke soket jaringan.
Sebelum masuk jauh ke dalam Kafka, Anda harus mengetahui terminologi utama seperti topik, perantara, produsen, dan konsumen. Diagram berikut mengilustrasikan terminologi utama dan tabel menjelaskan komponen diagram secara rinci.
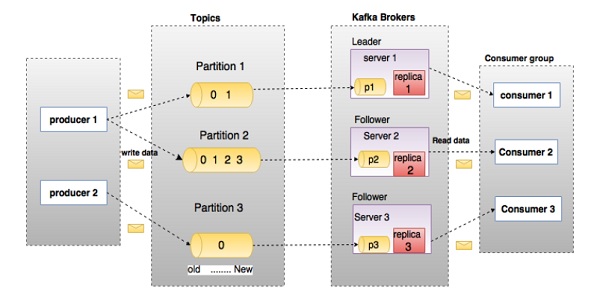
Pada diagram di atas, sebuah topik dikonfigurasikan menjadi tiga partisi. Partisi 1 memiliki dua faktor offset 0 dan 1. Partisi 2 memiliki empat faktor offset 0, 1, 2, dan 3. Partisi 3 memiliki satu faktor offset 0. Id replika sama dengan id server yang menghostingnya.
Asumsikan, jika faktor replikasi topik diatur ke 3, maka Kafka akan membuat 3 replika identik dari setiap partisi dan menempatkannya di cluster agar tersedia untuk semua operasinya. Untuk menyeimbangkan beban dalam cluster, setiap broker menyimpan satu atau lebih partisi tersebut. Beberapa produsen dan konsumen dapat menerbitkan dan mengambil pesan pada saat yang bersamaan.
| S.No | Komponen dan Deskripsi |
|---|---|
| 1 | Topics Aliran pesan yang termasuk dalam kategori tertentu disebut topik. Data disimpan dalam topik. Topik dibagi menjadi beberapa partisi. Untuk setiap topik, Kafka menyimpan mini-mum dari satu partisi. Setiap partisi tersebut berisi pesan dalam urutan yang tidak dapat diubah. Partisi diimplementasikan sebagai sekumpulan file segmen dengan ukuran yang sama. |
| 2 | Partition Topik mungkin memiliki banyak partisi, sehingga dapat menangani jumlah data yang berubah-ubah. |
| 3 | Partition offset Setiap pesan yang dipartisi memiliki id urutan unik yang disebut sebagai |
| 4 | Replicas of partition Replika hanyalah |
| 5 | Brokers
|
| 6 | Kafka Cluster Kafka yang memiliki lebih dari satu broker disebut cluster Kafka. Cluster Kafka dapat diperluas tanpa waktu henti. Kluster ini digunakan untuk mengelola persistensi dan replikasi data pesan. |
| 7 | Producers Produser adalah penerbit pesan untuk satu atau lebih topik Kafka. Produsen mengirim data ke broker Kafka. Setiap kali produsen mempublikasikan pesan ke broker, broker hanya menambahkan pesan tersebut ke file segmen terakhir. Sebenarnya, pesan tersebut akan ditambahkan ke partisi. Produser juga dapat mengirim pesan ke partisi pilihan mereka. |
| 8 | Consumers Konsumen membaca data dari broker. Konsumen berlangganan satu atau lebih topik dan mengkonsumsi pesan yang diterbitkan dengan menarik data dari broker. |
| 9 | Leader
|
| 10 | Follower Node yang mengikuti instruksi pemimpin disebut sebagai pengikut. Jika pemimpin gagal, salah satu pengikut otomatis akan menjadi pemimpin baru. Pengikut bertindak sebagai konsumen biasa, menarik pesan dan memperbarui penyimpanan datanya sendiri. |
Perhatikan ilustrasi berikut. Ini menunjukkan diagram cluster Kafka.

Tabel berikut menjelaskan masing-masing komponen yang ditunjukkan pada diagram di atas.
| S.No | Komponen dan Deskripsi |
|---|---|
| 1 | Broker Cluster Kafka biasanya terdiri dari beberapa broker untuk menjaga keseimbangan beban. Broker Kafka tidak memiliki kewarganegaraan, jadi mereka menggunakan Zookeeper untuk mempertahankan status cluster mereka. Satu contoh broker Kafka dapat menangani ratusan ribu pembacaan dan penulisan per detik dan setiap bro-ker dapat menangani TB pesan tanpa dampak kinerja. Pemilihan pemimpin broker Kafka dapat dilakukan oleh ZooKeeper. |
| 2 | ZooKeeper ZooKeeper digunakan untuk mengelola dan mengkoordinasikan broker Kafka. Layanan Zookeeper terutama digunakan untuk memberi tahu produsen dan konsumen tentang keberadaan broker baru dalam sistem Kafka atau kegagalan broker dalam sistem Kafka. Sesuai dengan notifikasi yang diterima oleh Zookeeper mengenai ada atau tidaknya broker maka pro-ducer dan konsumen mengambil keputusan dan mulai mengkoordinasikan tugas mereka dengan beberapa broker lain. |
| 3 | Producers Produsen mendorong data ke broker. Ketika broker baru dimulai, semua produsen mencarinya dan secara otomatis mengirim pesan ke broker baru tersebut. Produser Kafka tidak menunggu pengakuan dari broker dan mengirim pesan secepat yang bisa ditangani broker. |
| 4 | Consumers Karena broker Kafka tidak memiliki kewarganegaraan, yang berarti konsumen harus menjaga berapa banyak pesan yang telah dikonsumsi dengan menggunakan offset partisi. Jika konsumen mengakui pesan tertentu offset, itu menyiratkan bahwa konsumen telah mengkonsumsi semua pesan sebelumnya. Konsumen mengeluarkan permintaan tarik asinkron ke broker agar memiliki buffer byte yang siap digunakan. Konsumen dapat memundurkan atau melompat ke titik mana pun dalam partisi hanya dengan memberikan nilai offset. Nilai offset konsumen diberitahukan oleh ZooKeeper. |
Sampai sekarang, kami membahas konsep inti Kafka. Mari kita sekarang menyoroti alur kerja Kafka.
Kafka hanyalah kumpulan topik yang dibagi menjadi satu atau lebih partisi. Partisi Kafka adalah urutan pesan yang diurutkan secara linier, di mana setiap pesan diidentifikasi oleh indeksnya (disebut sebagai offset). Semua data dalam cluster Kafka adalah gabungan partisi yang terputus-putus. Pesan masuk ditulis di akhir partisi dan pesan dibaca secara berurutan oleh konsumen. Daya tahan disediakan dengan mereplikasi pesan ke broker yang berbeda.
Kafka menyediakan sistem pesan berbasis pub-sub dan antrian dengan cara yang cepat, andal, bertahan, toleransi kesalahan, dan tanpa waktu henti. Dalam kedua kasus tersebut, produsen cukup mengirim pesan ke suatu topik dan konsumen dapat memilih salah satu jenis sistem pesan tergantung pada kebutuhan mereka. Mari kita ikuti langkah-langkah di bagian selanjutnya untuk memahami bagaimana konsumen dapat memilih sistem pesan pilihan mereka.
Alur Kerja Perpesanan Pub-Sub
Berikut adalah langkah alur kerja bijak dari Pesan Pub-Sub -
Produser mengirim pesan ke suatu topik secara berkala.
Broker Kafka menyimpan semua pesan di partisi yang dikonfigurasi untuk topik tertentu itu. Ini memastikan pesan dibagikan secara merata antar partisi. Jika produser mengirim dua pesan dan ada dua partisi, Kafka akan menyimpan satu pesan di partisi pertama dan pesan kedua di partisi kedua.
Konsumen berlangganan topik tertentu.
Setelah konsumen berlangganan ke suatu topik, Kafka akan memberikan offset topik tersebut kepada konsumen dan juga menyimpan offset dalam ansambel Zookeeper.
Konsumen akan meminta Kafka dalam interval reguler (seperti 100 Ms) untuk pesan baru.
Setelah Kafka menerima pesan dari produsen, pesan tersebut diteruskan ke konsumen.
Konsumen akan menerima pesan tersebut dan memprosesnya.
Setelah pesan diproses, konsumen akan mengirimkan pemberitahuan ke broker Kafka.
Setelah Kafka menerima pengakuan, itu mengubah offset ke nilai baru dan memperbaruinya di Zookeeper. Karena offset dipertahankan di Zookeeper, konsumen dapat membaca pesan berikutnya dengan benar bahkan selama gangguan server.
Alur di atas ini akan berulang sampai konsumen menghentikan permintaan.
Konsumen memiliki opsi untuk mundur / melompat ke offset topik yang diinginkan kapan saja dan membaca semua pesan berikutnya.
Alur Kerja Pesan Antrian / Grup Konsumen
Dalam sistem pesan antrian alih-alih satu konsumen, sekelompok konsumen yang memiliki ID Grup yang
sama akan berlangganan ke suatu topik. Secara sederhana, konsumen yang berlangganan topik dengan ID Grup yang
sama dianggap sebagai satu grup dan pesan dibagikan di antara mereka. Mari kita periksa alur kerja sebenarnya dari sistem ini.
Produser mengirim pesan ke suatu topik dalam interval yang teratur.
Kafka menyimpan semua pesan di partisi yang dikonfigurasi untuk topik tertentu yang mirip dengan skenario sebelumnya.
Seorang konsumen berlangganan ke topik tertentu, anggap
Topik-01
denganID
Grup
sebagaiGrup-1
.Kafka berinteraksi dengan konsumen dengan cara yang sama seperti Pub-Sub Messaging hingga konsumen baru berlangganan topik yang sama,
Topik-01
denganID Grup yang
sama denganGrup-1
.Begitu konsumen baru tiba, Kafka mengalihkan operasinya ke mode berbagi dan berbagi data antara dua konsumen. Berbagi ini akan berlanjut hingga jumlah konsumen mencapai jumlah partisi yang dikonfigurasi untuk topik tertentu tersebut.
Setelah jumlah konsumen melebihi jumlah partisi, konsumen baru tidak akan menerima pesan lebih lanjut sampai salah satu konsumen yang ada berhenti berlangganan. Skenario ini muncul karena setiap konsumen di Kafka akan diberikan minimal satu partisi dan setelah semua partisi ditetapkan ke konsumen yang ada, konsumen baru harus menunggu.
Fitur ini juga disebut sebagai
Grup Konsumen
. Dengan cara yang sama, Kafka akan memberikan yang terbaik dari kedua sistem dengan cara yang sangat sederhana dan efisien.
Peran ZooKeeper
Ketergantungan kritis Apache Kafka adalah Apache Zookeeper, yang merupakan layanan konfigurasi dan sinkronisasi terdistribusi. Zookeeper berfungsi sebagai antarmuka koordinasi antara broker Kafka dan konsumen. Server Kafka berbagi informasi melalui cluster Zookeeper. Kafka menyimpan metadata dasar di Zookeeper seperti informasi tentang topik, pialang, offset konsumen (pembaca antrian), dan sebagainya.
Karena semua informasi penting disimpan di Zookeeper dan biasanya mereplikasi data ini di seluruh ansambelnya, kegagalan broker Kafka / Zookeeper tidak memengaruhi status cluster Kafka. Kafka akan memulihkan keadaan, setelah Zookeeper dimulai ulang. Ini memberikan nol waktu henti untuk Kafka. Pemilihan pemimpin antara broker Kafka juga dilakukan dengan menggunakan Zookeeper jika terjadi kegagalan pemimpin.
Untuk mempelajari lebih lanjut tentang Zookeeper, silakan merujuk penjaga kebun binatang
Mari kita lanjutkan lebih jauh tentang cara menginstal Java, Zookeeper, dan Kafka di komputer Anda di bab berikutnya.
Berikut adalah langkah-langkah untuk menginstal Java di komputer Anda.
Langkah 1 - Memverifikasi Instalasi Java
Semoga Anda sudah menginstal java di mesin Anda sekarang, jadi Anda cukup memverifikasinya menggunakan perintah berikut.
$ java -versionJika java berhasil diinstal di komputer Anda, Anda dapat melihat versi Java yang diinstal.
Langkah 1.1 - Unduh JDK
Jika Java belum diunduh, silakan unduh versi terbaru JDK dengan mengunjungi tautan berikut dan unduh versi terbaru.
http://www.oracle.com/technetwork/java/javase/downloads/index.htmlSekarang versi terbaru adalah JDK 8u 60 dan file tersebut adalah "jdk-8u60-linux-x64.tar.gz". Silakan unduh file di mesin Anda.
Langkah 1.2 - Ekstrak File
Umumnya, file yang sedang diunduh disimpan dalam folder unduhan, verifikasi dan ekstrak pengaturan tar menggunakan perintah berikut.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzLangkah 1.3 - Pindah ke Direktori Opt
Agar java tersedia untuk semua pengguna, pindahkan konten java yang telah diekstrak ke folder usr / local / java
/.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Langkah 1.4 - Tetapkan jalur
Untuk mengatur path dan variabel JAVA_HOME, tambahkan perintah berikut ke file ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binSekarang terapkan semua perubahan ke dalam sistem yang sedang berjalan.
$ source ~/.bashrcLangkah 1.5 - Alternatif Java
Gunakan perintah berikut untuk mengubah Alternatif Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Step 1.6 - Sekarang verifikasi java menggunakan perintah verifikasi (java -version) yang dijelaskan pada Langkah 1.
Langkah 2 - Instalasi Kerangka ZooKeeper
Langkah 2.1 - Unduh ZooKeeper
Untuk memasang kerangka kerja Zookeeper di komputer Anda, kunjungi tautan berikut dan unduh versi terbaru Zookeeper.
http://zookeeper.apache.org/releases.htmlSaat ini, versi terbaru dari ZooKeeper adalah 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Langkah 2.2 - Ekstrak file tar
Ekstrak file tar menggunakan perintah berikut
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataLangkah 2.3 - Buat File Konfigurasi
Buka File Konfigurasi dengan nama conf / zoo.cfg
menggunakan perintah vi "conf / zoo.cfg" dan semua parameter berikut untuk ditetapkan sebagai titik awal.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Setelah file konfigurasi berhasil disimpan dan kembali ke terminal lagi, Anda dapat menjalankan server penjaga kebun binatang.
Langkah 2.4 - Mulai Server ZooKeeper
$ bin/zkServer.sh startSetelah menjalankan perintah ini, Anda akan mendapatkan respons seperti yang ditunjukkan di bawah ini -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDLangkah 2.5 - Mulai CLI
$ bin/zkCli.shSetelah mengetik perintah di atas, Anda akan terhubung ke server zookeeper dan akan mendapatkan respons di bawah ini.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Langkah 2.6 - Hentikan Zookeeper Server
Setelah menghubungkan server dan melakukan semua operasi, Anda dapat menghentikan server penjaga kebun binatang dengan perintah berikut -
$ bin/zkServer.sh stopSekarang Anda telah berhasil menginstal Java dan Zookeeper di komputer Anda. Mari kita lihat langkah-langkah untuk menginstal Apache Kafka.
Langkah 3 - Instalasi Apache Kafka
Mari kita lanjutkan dengan langkah-langkah berikut untuk menginstal Kafka di komputer Anda.
Langkah 3.1 - Unduh Kafka
Untuk menginstal Kafka di mesin Anda, klik tautan di bawah ini -
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgzSekarang versi terbaru yaitu, - kafka_2.11_0.9.0.0.tgz akan diunduh ke komputer Anda.
Langkah 3.2 - Ekstrak file tar
Ekstrak file tar menggunakan perintah berikut -
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0Sekarang Anda telah mengunduh Kafka versi terbaru di komputer Anda.
Langkah 3.3 - Mulai Server
Anda dapat memulai server dengan memberikan perintah berikut -
$ bin/kafka-server-start.sh config/server.propertiesSetelah server dimulai, Anda akan melihat respons di bawah ini di layar Anda -
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….Langkah 4 - Hentikan Server
Setelah melakukan semua operasi, Anda dapat menghentikan server menggunakan perintah berikut -
$ bin/kafka-server-stop.sh config/server.propertiesSekarang kita telah membahas instalasi Kafka, kita dapat mempelajari bagaimana melakukan operasi dasar pada Kafka di bab berikutnya.
Pertama mari kita mulai menerapkan konfigurasi pialang simpul-tunggal
dan kita kemudian akan memigrasi pengaturan kita ke konfigurasi pialang simpul-banyak.
Mudah-mudahan Anda sudah menginstal Java, Zookeeper dan Kafka di komputer Anda sekarang. Sebelum pindah ke Penyiapan Klaster Kafka, pertama-tama Anda perlu memulai Penjaga Kebun karena Kluster Kafka menggunakan Penjaga Kebun.
Mulai ZooKeeper
Buka terminal baru dan ketik perintah berikut -
bin/zookeeper-server-start.sh config/zookeeper.propertiesUntuk memulai Kafka Broker, ketik perintah berikut -
bin/kafka-server-start.sh config/server.propertiesSetelah memulai Kafka Broker, ketik perintah jps
di terminal Zookeeper dan Anda akan melihat respon berikut -
821 QuorumPeerMain
928 Kafka
931 JpsSekarang Anda dapat melihat dua daemon berjalan di terminal di mana QuorumPeerMain adalah daemon Zookeeper dan satu lagi adalah daemon Kafka.
Konfigurasi Broker Node-Single Tunggal
Dalam konfigurasi ini Anda memiliki satu instance Zookeeper dan broker id. Berikut adalah langkah-langkah untuk mengkonfigurasinya -
Creating a Kafka Topic- Kafka menyediakan utilitas baris perintah bernama kafka-topics.sh
untuk membuat topik di server. Buka terminal baru dan ketik contoh di bawah ini.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-KafkaKami baru saja membuat topik bernama Hello-Kafka
dengan satu partisi dan satu faktor replika. Output yang dibuat di atas akan mirip dengan output berikut -
Output- Topik yang dibuat Hello-Kafka
Setelah topik dibuat, Anda bisa mendapatkan notifikasi di jendela terminal Kafka broker dan log untuk topik yang dibuat ditentukan di "/ tmp / kafka-logs /" di file config / server.properties.
Daftar Topik
Untuk mendapatkan daftar topik di server Kafka, Anda dapat menggunakan perintah berikut -
Syntax
bin/kafka-topics.sh --list --zookeeper localhost:2181Output
Hello-KafkaKarena kita telah membuat topik, itu hanya akan mencantumkan Hello-Kafka
. Misalkan, jika Anda membuat lebih dari satu topik, Anda akan mendapatkan nama topik di output.
Mulai Produser untuk Mengirim Pesan
Syntax
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-nameDari sintaks di atas, dua parameter utama diperlukan untuk klien baris perintah produser -
Broker-list- Daftar pialang yang ingin kami kirimi pesan. Dalam hal ini kami hanya memiliki satu broker. File Config / server.properties berisi id port broker, karena kami tahu broker kami mendengarkan pada port 9092, jadi Anda dapat menentukannya secara langsung.
Nama topik - Berikut adalah contoh nama topik.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-KafkaProduser akan menunggu masukan dari stdin dan mempublikasikan ke cluster Kafka. Secara default, setiap baris baru diterbitkan sebagai pesan baru, kemudian properti produsen default ditentukan dalam file config / producer.properties
. Sekarang Anda dapat mengetik beberapa baris pesan di terminal seperti yang ditunjukkan di bawah ini.
Output
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first messageMy second messageMulai Konsumen Menerima Pesan
Mirip dengan produsen, properti konsumen default ditentukan dalam file config / consumer.proper-ties
. Buka terminal baru dan ketik sintaks di bawah ini untuk menggunakan pesan.
Syntax
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginningExample
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginningOutput
Hello
My first message
My second messageTerakhir, Anda dapat memasukkan pesan dari terminal produsen dan melihatnya muncul di terminal konsumen. Sampai sekarang, Anda memiliki pemahaman yang sangat baik tentang cluster node tunggal dengan satu broker. Sekarang mari kita beralih ke konfigurasi beberapa broker.
Konfigurasi Single Node-Multiple Brokers
Sebelum melanjutkan ke pengaturan cluster beberapa broker, pertama-tama mulai server Zookeeper Anda.
Create Multiple Kafka Brokers- Kami memiliki satu contoh broker Kafka yang sudah ada di con-fig / server.properties. Sekarang kita memerlukan beberapa contoh broker, jadi salin file server.prop-erties yang ada ke dalam dua file konfigurasi baru dan ubah namanya menjadi server-one.properties dan server-two.prop-erties. Kemudian edit kedua file baru dan tetapkan perubahan berikut -
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2Start Multiple Brokers- Setelah semua perubahan dilakukan pada tiga server, buka tiga terminal baru untuk memulai setiap broker satu per satu.
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.propertiesSekarang kami memiliki tiga broker berbeda yang berjalan di mesin. Cobalah sendiri untuk memeriksa semua daemon dengan mengetikjps di terminal ZooKeeper, maka Anda akan melihat tanggapannya.
Membuat Topik
Mari kita tetapkan nilai faktor replikasi sebagai tiga untuk topik ini karena kita memiliki tiga broker berbeda yang berjalan. Jika Anda memiliki dua broker, maka nilai replika yang ditetapkan adalah dua.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic MultibrokerapplicationOutput
created topic “Multibrokerapplication”The Jelaskan
Perintah ini digunakan untuk memeriksa broker mendengarkan pada topik dibuat saat ini seperti gambar di bawah -
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cationOutput
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cation
Topic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:
Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1Dari output di atas, kita dapat menyimpulkan bahwa baris pertama memberikan ringkasan dari semua partisi, yang menunjukkan nama topik, jumlah partisi dan faktor replikasi yang telah kita pilih. Di baris kedua, setiap node akan menjadi pemimpin untuk bagian partisi yang dipilih secara acak.
Dalam kasus kami, kami melihat bahwa broker pertama kami (dengan broker.id 0) adalah pemimpinnya. Kemudian Replika: 0,2,1 berarti bahwa semua broker mereplikasi topik tersebut, akhirnya Isr
adalah kumpulan replika yang tidak sinkron
. Nah, ini adalah bagian dari replika yang saat ini hidup dan ditangkap oleh pemimpinnya.
Mulai Produser untuk Mengirim Pesan
Prosedur ini tetap sama seperti pada pengaturan broker tunggal.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic MultibrokerapplicationOutput
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second messageMulai Konsumen Menerima Pesan
Prosedur ini tetap sama seperti yang ditunjukkan dalam pengaturan broker tunggal.
Example
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion --from-beginningOutput
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second messageOperasi Topik Dasar
Dalam bab ini kita akan membahas berbagai operasi topik dasar.
Mengubah Topik
Seperti yang Anda sudah mengerti cara membuat topik di Kafka Cluster. Sekarang mari kita ubah topik yang dibuat menggunakan perintah berikut
Syntax
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name
--parti-tions countExample
We have already created a topic “Hello-Kafka” with single partition count and one replica factor.
Now using “alter” command we have changed the partition count.
bin/kafka-topics.sh --zookeeper localhost:2181
--alter --topic Hello-kafka --parti-tions 2Output
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!Menghapus Topik
Untuk menghapus topik, Anda dapat menggunakan sintaks berikut.
Syntax
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_nameExample
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafkaOutput
> Topic Hello-kafka marked for deletionNote −Ini tidak akan berdampak jika delete.topic.enable tidak disetel ke true
Mari kita buat aplikasi untuk menerbitkan dan menggunakan pesan menggunakan klien Java. Klien produser Kafka terdiri dari API berikut.
API KafkaProducer
Mari kita pahami kumpulan API produsen Kafka yang paling penting di bagian ini. Bagian sentral dari KafkaProducer API adalah kelas KafkaProducer
. Kelas KafkaProducer menyediakan opsi untuk menghubungkan broker Kafka dalam konstruktornya dengan metode berikut.
Kelas KafkaProducer menyediakan metode kirim untuk mengirim pesan secara asinkron ke suatu topik. Tanda tangan send () adalah sebagai berikut
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);ProducerRecord - Produser mengelola penyangga rekaman yang menunggu untuk dikirim.
Callback - Callback yang disediakan pengguna untuk dieksekusi ketika record telah diakui oleh server (null menunjukkan tidak ada callback).
Kelas KafkaProducer menyediakan metode flush untuk memastikan semua pesan yang dikirim sebelumnya telah benar-benar diselesaikan. Sintaks dari metode flush adalah sebagai berikut -
public void flush()Kelas KafkaProducer menyediakan metode partitionFor, yang membantu mendapatkan metadata partisi untuk topik tertentu. Ini dapat digunakan untuk partisi kustom. Tanda tangan metode ini adalah sebagai berikut -
public Map metrics()Ini mengembalikan peta metrik internal yang dikelola oleh produsen.
public void close () - kelas KafkaProducer menyediakan blok metode dekat sampai semua permintaan yang dikirim sebelumnya selesai.
API Produsen
Bagian utama dari API Produser
adalah kelas Produser
. Kelas produser menyediakan opsi untuk menghubungkan broker Kafka dalam konstruktornya dengan metode berikut.
Kelas Produser
Kelas produser menyediakan metode kirim ke send pesan ke satu atau beberapa topik menggunakan tanda tangan berikut.
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);Ada dua jenis produsen - Sync dan Async.
Konfigurasi API yang sama juga berlaku untuk produsen sinkronisasi
. Perbedaan di antara keduanya adalah produsen sinkronisasi mengirim pesan secara langsung, tetapi mengirim pesan di latar belakang. Produser asinkron lebih disukai jika Anda menginginkan throughput yang lebih tinggi. Dalam rilis sebelumnya seperti 0.8, produser asinkron tidak memiliki callback untuk send () untuk mendaftarkan penangan kesalahan. Ini hanya tersedia di rilis saat ini 0,9.
public void close ()
Kelas produser menyediakan close metode untuk menutup koneksi kumpulan produsen ke semua Kafka bro-kers.
Pengaturan konfigurasi
Pengaturan konfigurasi utama Producer API tercantum dalam tabel berikut untuk pemahaman yang lebih baik -
| S.No | Pengaturan dan Deskripsi Konfigurasi |
|---|---|
| 1 | client.id mengidentifikasi aplikasi produsen |
| 2 | producer.type baik sinkronisasi atau asinkron |
| 3 | acks Konfigurasi acks mengontrol kriteria berdasarkan permintaan produsen yang dianggap lengkap. |
| 4 | retries Jika permintaan produsen gagal, maka secara otomatis coba lagi dengan nilai tertentu. |
| 5 | bootstrap.servers daftar bootstrap pialang. |
| 6 | linger.ms jika Anda ingin mengurangi jumlah permintaan, Anda dapat mengatur linger.ms menjadi sesuatu yang lebih besar dari nilai tertentu. |
| 7 | key.serializer Kunci untuk antarmuka serializer. |
| 8 | value.serializer nilai untuk antarmuka serializer. |
| 9 | batch.size Ukuran buffer. |
| 10 | buffer.memory mengontrol jumlah total memori yang tersedia bagi produsen untuk buff-ering. |
ProducerRecord API
ProducerRecord adalah pasangan kunci / nilai yang dikirim ke kluster Kafka. Konstruktor kelas ProducerRecord untuk membuat rekaman dengan pasangan partisi, kunci dan nilai menggunakan tanda tangan berikut.
public ProducerRecord (string topic, int partition, k key, v value)Topic - nama topik yang ditentukan pengguna yang akan ditambahkan ke rekaman.
Partition - jumlah partisi
Key - Kunci yang akan dimasukkan ke dalam rekaman.
- Value - Rekam isinya
public ProducerRecord (string topic, k key, v value)Konstruktor kelas ProducerRecord digunakan untuk membuat record dengan kunci, pasangan nilai dan tanpa partisi.
Topic - Buat topik untuk menetapkan catatan.
Key - kunci catatan.
Value - merekam konten.
public ProducerRecord (string topic, v value)Kelas ProducerRecord membuat record tanpa partisi dan kunci.
Topic - buat topik.
Value - merekam konten.
Metode kelas ProducerRecord tercantum dalam tabel berikut -
| S.No | Metode dan Deskripsi Kelas |
|---|---|
| 1 | public string topic() Topik akan ditambahkan ke rekaman. |
| 2 | public K key() Kunci yang akan dimasukkan dalam catatan. Jika tidak ada kunci seperti itu, nol akan diaktifkan kembali di sini. |
| 3 | public V value() Rekam isinya. |
| 4 | partition() Hitungan partisi untuk catatan |
Aplikasi SimpleProducer
Sebelum membuat aplikasi, pertama mulai Zookeeper dan broker Kafka kemudian buat topik Anda sendiri di broker Kafka menggunakan perintah buat topik. Setelah itu buat kelas java bernama Sim-pleProducer.java
dan ketikkan koding berikut.
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}Compilation - Aplikasi dapat dikompilasi menggunakan perintah berikut.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution - Aplikasi dapat dijalankan menggunakan perintah berikut.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>Output
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10Contoh Konsumen Sederhana
Sampai sekarang kami telah membuat produser untuk mengirim pesan ke cluster Kafka. Sekarang mari kita buat konsumen untuk mengkonsumsi pesan dari cluster Kafka. KafkaConsumer API digunakan untuk menggunakan pesan dari cluster Kafka. Konstruktor kelas KafkaConsumer didefinisikan di bawah ini.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)configs - Kembalikan peta konfigurasi konsumen.
Kelas KafkaConsumer memiliki metode signifikan berikut yang didaftar di dalam tabel di bawah.
| S.No | Metode dan Deskripsi |
|---|---|
| 1 | public java.util.Set<TopicPar-tition> assignment() Dapatkan sekumpulan partisi yang saat ini ditetapkan oleh konsumen. |
| 2 | public string subscription() Berlangganan ke daftar topik yang diberikan untuk mendapatkan partisi yang ditandatangani secara dinamis. |
| 3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) Berlangganan ke daftar topik yang diberikan untuk mendapatkan partisi yang ditandatangani secara dinamis. |
| 4 | public void unsubscribe() Berhenti berlangganan topik dari daftar partisi yang diberikan. |
| 5 | public void sub-scribe(java.util.List<java.lang.String> topics) Berlangganan ke daftar topik yang diberikan untuk mendapatkan partisi yang ditandatangani secara dinamis. Jika daftar topik yang diberikan kosong, itu diperlakukan sama dengan unsubscribe (). |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) Pola argumen mengacu pada pola berlangganan dalam format ekspresi reguler dan argumen pendengar mendapat pemberitahuan dari pola berlangganan. |
| 7 | public void as-sign(java.util.List<TopicParti-tion> partitions) Tetapkan daftar partisi ke pelanggan secara manual. |
| 8 | poll() Ambil data untuk topik atau partisi yang ditentukan menggunakan salah satu API langganan / penetapan. Ini akan mengembalikan kesalahan, jika topik tidak berlangganan sebelum pengumpulan data. |
| 9 | public void commitSync() Offset komit yang dikembalikan pada jajak pendapat terakhir () untuk semua daftar topik dan partisi yang dibuat sub-juru tulis. Operasi yang sama diterapkan ke commitAsyn (). |
| 10 | public void seek(TopicPartition partition, long offset) Ambil nilai offset saat ini yang akan digunakan konsumen pada metode poll () berikutnya. |
| 11 | public void resume() Lanjutkan partisi yang dijeda. |
| 12 | public void wakeup() Bangunkan konsumen. |
ConsumerRecord API
API ConsumerRecord digunakan untuk menerima catatan dari kluster Kafka. API ini terdiri dari nama topik, nomor partisi, dari mana record diterima dan offset yang menunjuk ke record di partisi Kafka. Kelas ConsumerRecord digunakan untuk membuat catatan konsumen dengan nama topik tertentu, jumlah partisi, dan pasangan <kunci, nilai>. Ini memiliki tanda tangan berikut.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)Topic - Nama topik untuk catatan konsumen yang diterima dari cluster Kafka.
Partition - Partisi untuk topik.
Key - Kunci rekaman, jika tidak ada kunci, null akan dikembalikan.
Value - Rekam isinya.
API ConsumerRecords
ConsumerRecords API bertindak sebagai wadah untuk ConsumerRecord. API ini digunakan untuk menyimpan daftar ConsumerRecord per partisi untuk topik tertentu. Pembuatnya ditentukan di bawah ini.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)TopicPartition - Kembalikan peta partisi untuk topik tertentu.
Records - Kembali daftar ConsumerRecord.
Kelas ConsumerRecords memiliki metode berikut yang ditentukan.
| S.No | Metode dan Deskripsi |
|---|---|
| 1 | public int count() Jumlah rekaman untuk semua topik. |
| 2 | public Set partitions() Kumpulan partisi dengan data dalam kumpulan record ini (jika tidak ada data yang dikembalikan maka kumpulan tersebut kosong). |
| 3 | public Iterator iterator() Iterator memungkinkan Anda untuk menggilir koleksi, mendapatkan atau memindahkan kembali elemen. |
| 4 | public List records() Dapatkan daftar catatan untuk partisi yang diberikan. |
Pengaturan konfigurasi
Pengaturan konfigurasi untuk pengaturan konfigurasi utama API klien konsumen tercantum di bawah ini -
| S.No | Pengaturan dan Deskripsi |
|---|---|
| 1 | bootstrap.servers Daftar pialang bootstrap. |
| 2 | group.id Menetapkan konsumen individu ke grup. |
| 3 | enable.auto.commit Aktifkan komit otomatis untuk offset jika nilainya benar, jika tidak, tidak dilakukan. |
| 4 | auto.commit.interval.ms Kembalikan seberapa sering offset yang dikonsumsi yang diperbarui dituliskan ke ZooKeeper. |
| 5 | session.timeout.ms Menunjukkan berapa milidetik Kafka akan menunggu ZooKeeper menanggapi permintaan (baca atau tulis) sebelum menyerah dan terus menggunakan pesan. |
Aplikasi SimpleConsumer
Langkah-langkah aplikasi produsen tetap sama di sini. Pertama, mulai pialang ZooKeeper dan Kafka Anda. Kemudian buat aplikasi SimpleConsumer
dengan kelas java bernama SimpleCon-sumer.java
dan ketikkan kode berikut.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilation - Aplikasi dapat dikompilasi menggunakan perintah berikut.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution − Aplikasi dapat dijalankan dengan menggunakan perintah berikut
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>Input- Buka CLI produser dan kirim beberapa pesan ke topik. Anda dapat menempatkan input smple sebagai 'Halo Konsumen'.
Output - Berikut akan menjadi outputnya.
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello ConsumerKelompok konsumen adalah konsumsi multi-threaded atau multi-mesin dari topik Kafka.
Grup Konsumen
Konsumen dapat bergabung dalam grup dengan menggunakan
group.id yang
sama.
Paralelisme maksimum grup adalah jumlah konsumen dalam grup ← jumlah partisi.
Kafka menetapkan partisi topik ke konsumen dalam grup, sehingga setiap partisi dikonsumsi oleh satu konsumen dalam grup.
Kafka menjamin bahwa sebuah pesan hanya akan dibaca oleh satu konsumen dalam grup.
Konsumen dapat melihat pesan tersebut sesuai urutan penyimpanannya di log.
Re-balancing Konsumen
Menambahkan lebih banyak proses / utas akan menyebabkan Kafka menyeimbangkan kembali. Jika ada konsumen atau broker yang gagal mengirim detak jantung ke Zookeeper, maka detak jantung dapat dikonfigurasi ulang melalui klaster Kafka. Selama penyeimbangan ulang ini, Kafka akan menetapkan partisi yang tersedia ke utas yang tersedia, kemungkinan memindahkan partisi ke proses lain.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Kompilasi
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.javaEksekusi
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupDi sini kami telah membuat nama grup sampel sebagai grup-saya
dengan dua konsumen. Demikian pula, Anda dapat membuat grup dan jumlah konsumen di grup.
Memasukkan
Buka produser CLI dan kirim beberapa pesan seperti -
Test consumer group 01
Test consumer group 02Output dari Proses Pertama
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01Output dari Proses Kedua
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02Sekarang semoga Anda memahami SimpleConsumer dan ConsumeGroup dengan menggunakan demo klien Java. Sekarang Anda memiliki ide tentang cara mengirim dan menerima pesan menggunakan klien Java. Mari kita lanjutkan integrasi Kafka dengan teknologi data besar di bab berikutnya.
Pada bab ini, kita akan belajar bagaimana mengintegrasikan Kafka dengan Apache Storm.
Tentang Storm
Storm awalnya dibuat oleh Nathan Marz dan tim di BackType. Dalam waktu singkat, Apache Storm menjadi standar untuk sistem pemrosesan waktu nyata terdistribusi yang memungkinkan Anda memproses data dalam jumlah besar. Storm sangat cepat dan patokan mencatatnya di lebih dari satu juta tupel yang diproses per detik per node. Apache Storm berjalan terus-menerus, mengonsumsi data dari sumber yang dikonfigurasi (Spout) dan meneruskan data ke pipa pemrosesan (Bolts). Gabungan, Cerat, dan Baut membuat Topologi.
Integrasi dengan Storm
Kafka dan Storm secara alami saling melengkapi, dan kerja sama mereka yang kuat memungkinkan analisis streaming waktu nyata untuk data besar yang bergerak cepat. Integrasi Kafka dan Storm memudahkan pengembang untuk menyerap dan memublikasikan aliran data dari topologi Storm.
Aliran konseptual
Cerat adalah sumber aliran. Misalnya, cerat dapat membaca tupel dari Topik Kafka dan memancarkannya sebagai aliran. Sebuah baut mengkonsumsi aliran input, memproses dan mungkin memancarkan aliran baru. Bolts dapat melakukan apa saja mulai dari menjalankan fungsi, memfilter tupel, melakukan agregasi streaming, streaming bergabung, berbicara dengan database, dan banyak lagi. Setiap node dalam topologi Storm dijalankan secara paralel. Sebuah topologi berjalan tanpa batas waktu sampai Anda menghentikannya. Storm secara otomatis akan menetapkan ulang tugas yang gagal. Selain itu, Storm menjamin bahwa tidak akan ada kehilangan data, bahkan jika mesin mati dan pesan dijatuhkan.
Mari kita lihat API integrasi Kafka-Storm secara detail. Ada tiga kelas utama untuk mengintegrasikan Kafka dengan Storm. Mereka adalah sebagai berikut -
BrokerHosts - ZkHosts & StaticHosts
BrokerHosts adalah sebuah antarmuka dan ZkHosts dan StaticHosts adalah dua implementasi utamanya. ZkHosts digunakan untuk melacak broker Kafka secara dinamis dengan menjaga detail di ZooKeeper, sedangkan StaticHosts digunakan untuk mengatur broker Kafka secara manual / statis dan detailnya. ZkHosts adalah cara sederhana dan cepat untuk mengakses broker Kafka.
Tanda tangan ZkHosts adalah sebagai berikut -
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)Dimana brokerZkStr adalah host Zkeeper dan brokerZkPath adalah jalur ZooKeeper untuk menjaga detail broker Kafka.
API KafkaConfig
API ini digunakan untuk menentukan pengaturan konfigurasi untuk cluster Kafka. Tanda tangan Kafka Con-fig didefinisikan sebagai berikut
public KafkaConfig(BrokerHosts hosts, string topic)Hosts - BrokerHosts dapat berupa ZkHosts / StaticHosts.
Topic - nama topik.
SpoutConfig API
Spoutconfig adalah perpanjangan dari KafkaConfig yang mendukung informasi tambahan ZooKeeper.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)Hosts - BrokerHosts dapat berupa implementasi antarmuka BrokerHosts apa pun
Topic - nama topik.
zkRoot - Jalur root ZooKeeper.
id −Cerat menyimpan keadaan offset yang dikonsumsi di Zookeeper. Id harus mengidentifikasi cerat Anda secara unik.
SchemeAsMultiScheme
SchemeAsMultiScheme adalah antarmuka yang menentukan bagaimana ByteBuffer yang dikonsumsi dari Kafka diubah menjadi tupel badai. Ini berasal dari MultiScheme dan menerima implementasi kelas Skema. Ada banyak implementasi kelas Scheme dan salah satu implementasi tersebut adalah StringScheme, yang mem-parsing byte sebagai string sederhana. Ini juga mengontrol penamaan bidang output Anda. Tanda tangan tersebut didefinisikan sebagai berikut.
public SchemeAsMultiScheme(Scheme scheme)Scheme - buffer byte yang dikonsumsi dari kafka.
API KafkaSpout
KafkaSpout adalah implementasi cerat kami, yang akan terintegrasi dengan Storm. Ini mengambil pesan dari topik kafka dan memancarkannya ke ekosistem Storm sebagai tuple. KafkaSpout mendapatkan detail konfigurasi dari SpoutConfig.
Di bawah ini adalah contoh kode untuk membuat cerat Kafka sederhana.
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);Pembuatan Baut
Bolt merupakan komponen yang mengambil tupel sebagai masukan, memproses tupel, dan menghasilkan tupel baru sebagai keluaran. Baut akan mengimplementasikan antarmuka IRichBolt. Dalam program ini, dua kelas baut WordSplitter-Bolt dan WordCounterBolt digunakan untuk menjalankan operasi.
Antarmuka IRichBolt memiliki metode berikut -
Prepare- Melengkapi baut dengan lingkungan untuk dieksekusi. Pelaksana akan menjalankan metode ini untuk menginisialisasi cerat.
Execute - Memproses satu tupel input.
Cleanup - Dipanggil saat baut akan mati.
declareOutputFields - Mendeklarasikan skema keluaran tupel.
Mari kita buat SplitBolt.java, yang mengimplementasikan logika untuk membagi kalimat menjadi kata-kata dan CountBolt.java, yang mengimplementasikan logika untuk memisahkan kata-kata unik dan menghitung kemunculannya.
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Mengirimkan ke Topologi
Topologi Storm pada dasarnya adalah struktur Hemat. Kelas TopologyBuilder menyediakan metode sederhana dan mudah untuk membuat topologi yang kompleks. Kelas TopologyBuilder memiliki metode untuk menyetel cerat (setSpout) dan untuk menyetel baut (setBolt). Terakhir, TopologyBuilder memiliki createTopology untuk membuat to-pology. shuffleGrouping and fieldsGrouping method membantu mengatur pengelompokan aliran untuk cerat dan baut.
Local Cluster- Untuk tujuan pembangunan, kita dapat membuat cluster lokal menggunakan LocalCluster
objek dan kemudian menyerahkan topologi menggunakan submitTopology
metode LocalCluster
kelas.
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}Sebelum memindahkan kompilasi, integrasi Kakfa-Storm membutuhkan perpustakaan java klien kurator ZooKeeper. Kurator versi 2.9.1 mendukung Apache Storm versi 0.9.5 (yang kami gunakan dalam tutorial ini). Unduh file jar yang ditentukan di bawah ini dan letakkan di jalur kelas java.
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
Setelah memasukkan file dependensi, kompilasi program menggunakan perintah berikut,
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.javaEksekusi
Mulai Kafka Producer CLI (dijelaskan di bab sebelumnya), buat topik baru bernama my-first-topic
dan berikan beberapa contoh pesan seperti yang ditunjukkan di bawah ini -
hello
kafka
storm
spark
test message
another test messageSekarang jalankan aplikasi menggunakan perintah berikut -
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSampleContoh keluaran dari aplikasi ini ditentukan di bawah -
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2Pada bab ini, kita akan membahas tentang bagaimana mengintegrasikan Apache Kafka dengan API Streaming Spark.
Tentang Spark
Spark Streaming API memungkinkan pemrosesan streaming data langsung yang dapat diskalakan, throughput tinggi, dan toleran terhadap kesalahan. Data dapat diserap dari banyak sumber seperti Kafka, Flume, Twitter, dll., Dan dapat diproses menggunakan algoritme kompleks seperti fungsi tingkat tinggi seperti peta, pengurangan, penggabungan, dan jendela. Terakhir, data yang diproses dapat dikirim ke sistem file, database, dan papan dasbor langsung. Set Data Terdistribusi Tangguh (RDD) adalah struktur data fundamental dari Spark. Ini adalah kumpulan objek terdistribusi yang tidak dapat diubah. Setiap set data di RDD dibagi menjadi partisi logis, yang dapat dihitung pada node cluster yang berbeda.
Integrasi dengan Spark
Kafka adalah platform perpesanan dan integrasi potensial untuk streaming Spark. Kafka bertindak sebagai hub pusat untuk aliran data real-time dan diproses menggunakan algoritme kompleks di Spark Streaming. Setelah data diproses, Spark Streaming dapat mempublikasikan hasil ke dalam topik Kafka lain atau menyimpan di HDFS, database atau dasbor. Diagram berikut menggambarkan aliran konseptual.

Sekarang, mari kita lihat API Kafka-Spark secara detail.
SparkConf API
Ini mewakili konfigurasi untuk aplikasi Spark. Digunakan untuk mengatur berbagai parameter Spark sebagai pasangan nilai-kunci.
Kelas SparkConf
memiliki metode berikut -
set(string key, string value) - mengatur variabel konfigurasi.
remove(string key) - hapus kunci dari konfigurasi.
setAppName(string name) - atur nama aplikasi untuk aplikasi Anda.
get(string key) - ambil kunci
API StreamingContext
Ini adalah titik masuk utama untuk fungsionalitas Spark. SparkContext merepresentasikan koneksi ke cluster Spark, dan dapat digunakan untuk membuat RDD, akumulator, dan variabel siaran di cluster. Tanda tangan didefinisikan seperti yang ditunjukkan di bawah ini.
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)master - URL cluster yang akan disambungkan (misalnya mesos: // host: port, spark: // host: port, local [4]).
appName - nama untuk pekerjaan Anda, untuk ditampilkan di UI web cluster
batchDuration - interval waktu di mana data streaming akan dibagi menjadi beberapa batch
public StreamingContext(SparkConf conf, Duration batchDuration)Buat StreamingContext dengan menyediakan konfigurasi yang diperlukan untuk SparkContext baru.
conf - Parameter percikan
batchDuration - interval waktu di mana data streaming akan dibagi menjadi beberapa batch
KafkaUtils API
KafkaUtils API digunakan untuk menghubungkan cluster Kafka ke streaming Spark. API ini memiliki tanda tangan createStream
metode signifikan yang ditentukan seperti di bawah ini.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)Metode yang ditunjukkan di atas digunakan untuk membuat aliran input yang menarik pesan dari Broker Kafka.
ssc - Objek StreamingContext.
zkQuorum - Kuorum penjaga kebun binatang.
groupId - ID grup untuk konsumen ini.
topics - mengembalikan peta topik untuk dikonsumsi.
storageLevel - Tingkat penyimpanan yang digunakan untuk menyimpan objek yang diterima.
KafkaUtils API memiliki metode lain createDirectStream, yang digunakan untuk membuat aliran input yang secara langsung menarik pesan dari Kafka Brokers tanpa menggunakan penerima apa pun. Aliran ini dapat menjamin bahwa setiap pesan dari Kafka disertakan dalam transformasi tepat satu kali.
Aplikasi sampel dilakukan di Scala. Untuk mengkompilasi aplikasi, silahkan download dan install sbt
, scala build tool (mirip dengan maven). Kode aplikasi utama disajikan di bawah ini.
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}Build Script
Integrasi spark-kafka bergantung pada percikan, streaming percikan, dan percikan Kafka integrasi jar. Buat file baru build.sbt
dan tentukan detail aplikasi dan ketergantungannya. The sbt
akan men-download jar diperlukan saat kompilasi dan kemasan aplikasi.
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"Kompilasi / Pengemasan
Jalankan perintah berikut untuk mengompilasi dan mengemas file jar aplikasi. Kita perlu mengirimkan file jar ke konsol percikan untuk menjalankan aplikasi.
sbt packageMengirimkan ke Spark
Mulai CLI Produser Kafka (dijelaskan di bab sebelumnya), buat topik baru bernama my-first-topic
dan berikan beberapa contoh pesan seperti yang ditunjukkan di bawah ini.
Another spark test messageJalankan perintah berikut untuk mengirimkan aplikasi ke konsol percikan.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>Output sampel dari aplikasi ini ditampilkan di bawah ini.
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..Mari kita analisis aplikasi waktu nyata untuk mendapatkan feed twitter terbaru dan tagar-nya. Sebelumnya, kita telah melihat integrasi Storm dan Spark dengan Kafka. Dalam kedua skenario, kami membuat Produsen Kafka (menggunakan cli) untuk mengirim pesan ke ekosistem Kafka. Kemudian, badai dan percikan api membaca pesan dengan menggunakan konsumen Kafka dan memasukkannya ke dalam badai dan memicu ekosistem masing-masing. Jadi, secara praktis kita perlu membuat Produser Kafka, yang harus -
- Baca feed twitter menggunakan "Twitter Streaming API",
- Proses feed,
- Ekstrak HashTag dan
- Kirimkan ke Kafka.
Setelah HashTag
diterima oleh Kafka, integrasi Storm / Spark menerima informasi dan mengirimkannya ke ekosistem Storm / Spark.
API Streaming Twitter
"Twitter Streaming API" dapat diakses dalam bahasa pemrograman apa pun. "Twitter4j" adalah open source, pustaka Java tidak resmi, yang menyediakan modul berbasis Java untuk mengakses "Twitter Streaming API" dengan mudah. "Twitter4j" menyediakan kerangka kerja berbasis pendengar untuk mengakses tweet. Untuk mengakses "Twitter Streaming API", kita perlu masuk ke akun pengembang Twitter dan mendapatkan yang berikut iniOAuth detail otentikasi.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Setelah akun pengembang dibuat, unduh file jar “twitter4j” dan letakkan di jalur kelas java.
Pengodean produser Kafka Twitter Lengkap (KafkaTwitterProducer.java) tercantum di bawah -
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}Kompilasi
Kompilasi aplikasi menggunakan perintah berikut -
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.javaEksekusi
Buka dua konsol. Jalankan aplikasi yang dikompilasi di atas seperti yang ditunjukkan di bawah ini dalam satu konsol.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic foodJalankan salah satu aplikasi Spark / Storm yang dijelaskan di bab sebelumnya di win-dow lain. Hal utama yang perlu diperhatikan adalah bahwa topik yang digunakan harus sama dalam kedua kasus tersebut. Di sini, kami telah menggunakan "topik-pertama-saya" sebagai nama topik.
Keluaran
Output dari aplikasi ini akan tergantung pada kata kunci dan feed twitter saat ini. Keluaran sampel ditentukan di bawah ini (integrasi badai).
. . .
food : 1
foodie : 2
burger : 1
. . .Kafka Tool dikemas dalam “org.apache.kafka.tools. *. Alat dikategorikan ke dalam alat sistem dan alat replikasi.
Alat Sistem
Alat sistem dapat dijalankan dari baris perintah menggunakan skrip run class. Sintaksnya adalah sebagai berikut -
bin/kafka-run-class.sh package.class - - optionsBeberapa alat sistem disebutkan di bawah -
Kafka Migration Tool - Alat ini digunakan untuk memigrasi broker dari satu versi ke versi lainnya.
Mirror Maker - Alat ini digunakan untuk memberikan mirroring dari satu cluster Kafka ke cluster lainnya.
Consumer Offset Checker - Alat ini menampilkan Grup Konsumen, Topik, Partisi, Off-set, logSize, Pemilik untuk kumpulan Topik dan Grup Konsumen tertentu.
Alat Replikasi
Replikasi Kafka adalah alat desain tingkat tinggi. Tujuan penambahan alat replikasi adalah untuk ketahanan yang lebih kuat dan ketersediaan yang lebih tinggi. Beberapa alat replikasi disebutkan di bawah -
Create Topic Tool - Ini membuat topik dengan jumlah partisi default, faktor replikasi dan menggunakan skema default Kafka untuk melakukan tugas replika.
List Topic Tool- Alat ini mencantumkan informasi untuk daftar topik tertentu. Jika tidak ada topik yang disediakan di baris perintah, alat meminta Zookeeper untuk mendapatkan semua topik dan mencantumkan informasinya. Bidang yang ditampilkan alat adalah nama topik, partisi, pemimpin, replika, isr.
Add Partition Tool- Pembuatan topik, jumlah partisi untuk topik harus ditentukan. Nanti, lebih banyak partisi mungkin diperlukan untuk topik tersebut, ketika volume topik akan meningkat. Alat ini membantu menambahkan lebih banyak partisi untuk topik tertentu dan juga memungkinkan penugasan replika manual dari partisi yang ditambahkan.
Kafka mendukung banyak aplikasi industri terbaik saat ini. Kami akan memberikan gambaran singkat tentang beberapa aplikasi Kafka yang paling terkenal di bab ini.
Indonesia
Twitter adalah layanan jejaring sosial online yang menyediakan platform untuk mengirim dan menerima tweet pengguna. Pengguna terdaftar dapat membaca dan memposting tweet, tetapi pengguna yang tidak terdaftar hanya dapat membaca tweet. Twitter menggunakan Storm-Kafka sebagai bagian dari infrastruktur pemrosesan streaming mereka.
Apache Kafka digunakan di LinkedIn untuk data aliran aktivitas dan metrik operasional. Sistem pesan Kafka membantu LinkedIn dengan berbagai produk seperti LinkedIn Newsfeed, LinkedIn Today untuk konsumsi pesan online dan sebagai tambahan untuk sistem analitik offline seperti Hadoop. Daya tahan Kafka yang kuat juga merupakan salah satu faktor kunci yang berhubungan dengan LinkedIn.
Netflix
Netflix adalah penyedia media streaming Internet on-demand multinasional Amerika. Netflix menggunakan Kafka untuk pemantauan waktu nyata dan pemrosesan acara.
Mozilla
Mozilla adalah komunitas perangkat lunak bebas, dibuat pada tahun 1998 oleh anggota Netscape. Kafka akan segera menggantikan bagian dari sistem produksi Mozilla saat ini untuk mengumpulkan data kinerja dan penggunaan dari browser pengguna akhir untuk proyek seperti Telemetri, Uji Coba, dll.
Peramal
Oracle menyediakan konektivitas asli ke Kafka dari produk Enterprise Service Bus-nya yang disebut OSB (Oracle Service Bus) yang memungkinkan pengembang memanfaatkan kemampuan mediasi bawaan OSB untuk mengimplementasikan pipeline data bertahap.