Apache Tajo - Panduan Cepat
Sistem Gudang Data Terdistribusi
Gudang data adalah database relasional yang dirancang untuk kueri dan analisis daripada untuk pemrosesan transaksi. Ini adalah kumpulan data yang berorientasi pada subjek, terintegrasi, varian waktu, dan non-volatil. Data ini membantu analis untuk mengambil keputusan yang tepat dalam sebuah organisasi tetapi volume data relasional meningkat dari hari ke hari.
Untuk mengatasi tantangan tersebut, sistem gudang data terdistribusi membagikan data di beberapa repositori data untuk tujuan Online Analytical Processing (OLAP). Setiap gudang data mungkin milik satu atau lebih organisasi. Ia melakukan load balancing dan skalabilitas. Metadata direplikasi dan didistribusikan secara terpusat.
Apache Tajo adalah sistem gudang data terdistribusi yang menggunakan Hadoop Distributed File System (HDFS) sebagai lapisan penyimpanan dan memiliki mesin eksekusi kuerinya sendiri, bukan kerangka kerja MapReduce.
Ringkasan SQL di Hadoop
Hadoop adalah kerangka kerja sumber terbuka yang memungkinkan untuk menyimpan dan memproses data besar dalam lingkungan terdistribusi. Ini sangat cepat dan kuat. Namun, Hadoop memiliki kemampuan kueri yang terbatas sehingga kinerjanya dapat dibuat lebih baik lagi dengan bantuan SQL di Hadoop. Ini memungkinkan pengguna untuk berinteraksi dengan Hadoop melalui perintah SQL yang mudah.
Beberapa contoh SQL pada aplikasi Hadoop adalah Hive, Impala, Drill, Presto, Spark, HAWQ dan Apache Tajo.
Apa itu Apache Tajo
Apache Tajo adalah kerangka kerja pemrosesan data relasional dan terdistribusi. Ini dirancang untuk latensi rendah dan analisis kueri ad-hoc yang skalabel.
Tajo mendukung SQL standar dan berbagai format data. Sebagian besar kueri Tajo dapat dijalankan tanpa modifikasi apa pun.
Tajo punya fault-tolerance melalui mekanisme restart untuk tugas-tugas yang gagal dan mesin penulisan ulang kueri yang dapat diperluas.
Tajo melakukan yang diperlukan ETL (Extract Transform and Load process)operasi untuk meringkas kumpulan data besar yang disimpan di HDFS. Ini adalah pilihan alternatif untuk Sarang / Babi.
Versi terbaru Tajo memiliki konektivitas yang lebih baik ke program Java dan database pihak ketiga seperti Oracle dan PostGreSQL.
Fitur Apache Tajo
Apache Tajo memiliki beberapa fitur berikut -
- Skalabilitas unggul dan kinerja yang dioptimalkan
- Latensi rendah
- Fungsi yang ditentukan pengguna
- Kerangka kerja pemrosesan penyimpanan baris / kolom.
- Kompatibilitas dengan HiveQL dan Hive MetaStore
- Aliran data sederhana dan perawatan mudah.
Manfaat Apache Tajo
Apache Tajo menawarkan keuntungan berikut -
- Mudah digunakan
- Arsitektur yang disederhanakan
- Pengoptimalan kueri berbasis biaya
- Rencana eksekusi kueri vektor
- Pengiriman cepat
- Mekanisme I / O sederhana dan mendukung berbagai jenis penyimpanan.
- Toleransi kesalahan
Kasus Penggunaan Apache Tajo
Berikut adalah beberapa kasus penggunaan Apache Tajo -
Penyimpanan dan analisis data
Perusahaan SK Telecom Korea menjalankan Tajo terhadap data senilai 1,7 terabyte dan menemukan bahwa itu dapat menyelesaikan kueri dengan kecepatan lebih tinggi daripada Hive atau Impala.
Penemuan data
Layanan streaming musik Korea Melon menggunakan Tajo untuk pemrosesan analitik. Tajo menjalankan tugas ETL (proses ekstraksi-transformasi-pemuatan) 1,5 hingga 10 kali lebih cepat dari Hive.
Analisis log
Bluehole Studio, sebuah perusahaan yang berbasis di Korea mengembangkan TERA - sebuah game online fantasi multipemain. Perusahaan menggunakan Tajo untuk analisis log permainan dan menemukan penyebab utama gangguan kualitas layanan.
Format Penyimpanan dan Data
Apache Tajo mendukung format data berikut -
- JSON
- File teks (CSV)
- Parquet
- File Urutan
- AVRO
- Penyangga Protokol
- Apache Orc
Tajo mendukung format penyimpanan berikut -
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
Ilustrasi berikut menggambarkan arsitektur Apache Tajo.

Tabel berikut menjelaskan setiap komponen secara rinci.
| S.No. | Deskripsi komponen |
|---|---|
| 1 | Client Client mengirimkan pernyataan SQL ke Tajo Master untuk mendapatkan hasilnya. |
| 2 | Master Master adalah daemon utama. Ini bertanggung jawab untuk perencanaan permintaan dan koordinator untuk pekerja. |
| 3 | Catalog server Menjaga tabel dan deskripsi indeks. Itu tertanam dalam daemon Master. Server katalog menggunakan Apache Derby sebagai lapisan penyimpanan dan terhubung melalui klien JDBC. |
| 4 | Worker Node master memberikan tugas ke node pekerja. TajoWorker memproses data. Dengan meningkatnya jumlah TajoWorkers, kapasitas pemrosesan juga meningkat secara linier. |
| 5 | Query Master Master Tajo menetapkan kueri ke Master Kueri. Query Master bertanggung jawab untuk mengontrol rencana eksekusi terdistribusi. Ini meluncurkan TaskRunner dan menjadwalkan tugas ke TaskRunner. Peran utama Query Master adalah untuk memantau tugas yang sedang berjalan dan melaporkannya ke Master node. |
| 6 | Node Managers Mengelola sumber daya node pekerja. Ini memutuskan untuk mengalokasikan permintaan ke node. |
| 7 | TaskRunner Bertindak sebagai mesin eksekusi kueri lokal. Ini digunakan untuk menjalankan dan memantau proses kueri. TaskRunner memproses satu tugas dalam satu waktu. Ini memiliki tiga atribut utama berikut -
|
| 8 | Query Executor Ini digunakan untuk mengeksekusi kueri. |
| 9 | Storage service Menghubungkan penyimpanan data pokok ke Tajo. |
Alur Kerja
Tajo menggunakan Hadoop Distributed File System (HDFS) sebagai lapisan penyimpanan dan memiliki mesin eksekusi kuerinya sendiri, bukan kerangka kerja MapReduce. Cluster Tajo terdiri dari satu node master dan sejumlah pekerja di seluruh node cluster.
Master terutama bertanggung jawab untuk perencanaan permintaan dan koordinator untuk pekerja. Master membagi kueri menjadi tugas-tugas kecil dan menugaskan kepada pekerja. Setiap pekerja memiliki mesin kueri lokal yang menjalankan grafik asiklik terarah dari operator fisik.
Selain itu, Tajo dapat mengontrol aliran data terdistribusi dengan lebih fleksibel daripada MapReduce dan mendukung teknik pengindeksan.
Antarmuka Tajo berbasis web memiliki kemampuan berikut -
- Pilihan untuk menemukan bagaimana permintaan yang diajukan direncanakan
- Pilihan untuk menemukan bagaimana kueri didistribusikan ke seluruh node
- Pilihan untuk memeriksa status cluster dan node
Untuk menginstal Apache Tajo, Anda harus memiliki perangkat lunak berikut di sistem Anda -
- Hadoop versi 2.3 atau yang lebih baru
- Java versi 1.7 atau lebih tinggi
- Linux atau Mac OS
Mari kita lanjutkan dengan langkah-langkah berikut untuk menginstal Tajo.
Memverifikasi instalasi Java
Mudah-mudahan, Anda telah menginstal Java versi 8 di komputer Anda. Sekarang, Anda hanya perlu melanjutkan dengan memverifikasinya.
Untuk memverifikasi, gunakan perintah berikut -
$ java -versionJika Java berhasil diinstal pada mesin Anda, Anda dapat melihat versi Java yang diinstal saat ini. Jika Java tidak diinstal ikuti langkah-langkah ini untuk menginstal Java 8 di komputer Anda.
Unduh JDK
Unduh versi terbaru JDK dengan mengunjungi tautan berikut dan kemudian, unduh versi terbaru.
https://www.oracle.com
Versi terbaru adalah JDK 8u 92 dan file tersebut adalah “jdk-8u92-linux-x64.tar.gz”. Silakan unduh file di mesin Anda. Setelah ini, ekstrak file dan pindahkan ke direktori tertentu. Sekarang, atur alternatif Java. Terakhir, Java diinstal di mesin Anda.
Memverifikasi Instalasi Hadoop
Anda sudah menginstal Hadoopdi sistem Anda. Sekarang, verifikasi menggunakan perintah berikut -
$ hadoop versionJika semua baik-baik saja dengan penyiapan Anda, maka Anda dapat melihat versi Hadoop. Jika Hadoop tidak diinstal, unduh dan instal Hadoop dengan mengunjungi tautan berikut -https://www.apache.org
Instalasi Apache Tajo
Apache Tajo menyediakan dua mode eksekusi - mode lokal dan mode terdistribusi penuh. Setelah memverifikasi instalasi Java dan Hadoop, lanjutkan dengan langkah-langkah berikut untuk menginstal cluster Tajo di komputer Anda. Instance Tajo mode lokal memerlukan konfigurasi yang sangat mudah.
Unduh versi terbaru Tajo dengan mengunjungi tautan berikut - https://www.apache.org/dyn/closer.cgi/tajo
Sekarang Anda dapat mengunduh file tersebut “tajo-0.11.3.tar.gz” dari mesin Anda.
Ekstrak File Tar
Ekstrak file tar dengan menggunakan perintah berikut -
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Tetapkan Variabel Lingkungan
Tambahkan perubahan berikut ke “conf/tajo-env.sh” mengajukan
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Di sini, Anda harus menentukan jalur Hadoop dan Java ke “tajo-env.sh”mengajukan. Setelah perubahan dilakukan, simpan file dan keluar dari terminal.
Mulai Tajo Server
Untuk meluncurkan server Tajo, jalankan perintah berikut -
$ bin/start-tajo.shAnda akan menerima tanggapan yang serupa dengan berikut -
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Sekarang, ketik perintah “jps” untuk melihat daemon yang sedang berjalan.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterLuncurkan Tajo Shell (Tsql)
Untuk meluncurkan klien shell Tajo, gunakan perintah berikut -
$ bin/tsqlAnda akan menerima output berikut -
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Keluar dari Tajo Shell
Jalankan perintah berikut untuk keluar dari Tsql -
default> \q
bye!Di sini, defaultnya mengacu pada katalog di Tajo.
UI web
Ketik URL berikut untuk meluncurkan UI web Tajo - http://localhost:26080/
Anda sekarang akan melihat layar berikut yang mirip dengan opsi ExecuteQuery.

Hentikan Tajo
Untuk menghentikan server Tajo, gunakan perintah berikut -
$ bin/stop-tajo.shAnda akan mendapatkan tanggapan berikut -
localhost: stopping worker
stopping masterKonfigurasi Tajo didasarkan pada sistem konfigurasi Hadoop. Bab ini menjelaskan pengaturan konfigurasi Tajo secara rinci.
Pengaturan dasar
Tajo menggunakan dua file konfigurasi berikut -
- catalog-site.xml - konfigurasi untuk server katalog.
- tajo-site.xml - konfigurasi untuk modul Tajo lainnya.
Konfigurasi Mode Terdistribusi
Setup mode terdistribusi berjalan di Hadoop Distributed File System (HDFS). Mari ikuti langkah-langkah untuk mengonfigurasi pengaturan mode terdistribusi Tajo.
tajo-site.xml
File ini tersedia @ /path/to/tajo/confdirektori dan bertindak sebagai konfigurasi untuk modul Tajo lainnya. Untuk mengakses Tajo dalam mode terdistribusi, terapkan perubahan berikut ke“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Konfigurasi Master Node
Tajo menggunakan HDFS sebagai jenis penyimpanan utama. Konfigurasinya adalah sebagai berikut dan harus ditambahkan ke“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Konfigurasi Katalog
Jika Anda ingin menyesuaikan layanan katalog, salin $path/to/Tajo/conf/catalogsite.xml.template untuk $path/to/Tajo/conf/catalog-site.xml dan tambahkan salah satu konfigurasi berikut sesuai kebutuhan.
Misalnya, jika Anda menggunakan “Hive catalog store” untuk mengakses Tajo, maka konfigurasinya harus seperti berikut -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Jika Anda perlu menyimpan MySQL katalog, lalu terapkan perubahan berikut -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>Demikian pula, Anda dapat mendaftarkan katalog yang didukung Tajo lainnya di file konfigurasi.
Konfigurasi Pekerja
Secara default, TajoWorker menyimpan data sementara di sistem file lokal. Ini didefinisikan dalam file "tajo-site.xml" sebagai berikut -
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Untuk meningkatkan kapasitas menjalankan tugas dari setiap resource pekerja, pilih konfigurasi berikut -
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Untuk membuat pekerja Tajo berjalan dalam mode khusus, pilih konfigurasi berikut -
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>Pada bab ini, kita akan memahami perintah Tajo Shell secara detail.
Untuk menjalankan perintah shell Tajo, Anda perlu memulai server Tajo dan shell Tajo menggunakan perintah berikut -
Mulai server
$ bin/start-tajo.shMulai Shell
$ bin/tsqlPerintah di atas sekarang siap untuk dieksekusi.
Perintah Meta
Sekarang mari kita bahas Meta Commands. Perintah meta tsql dimulai dengan garis miring terbalik(‘\’).
Perintah Bantuan
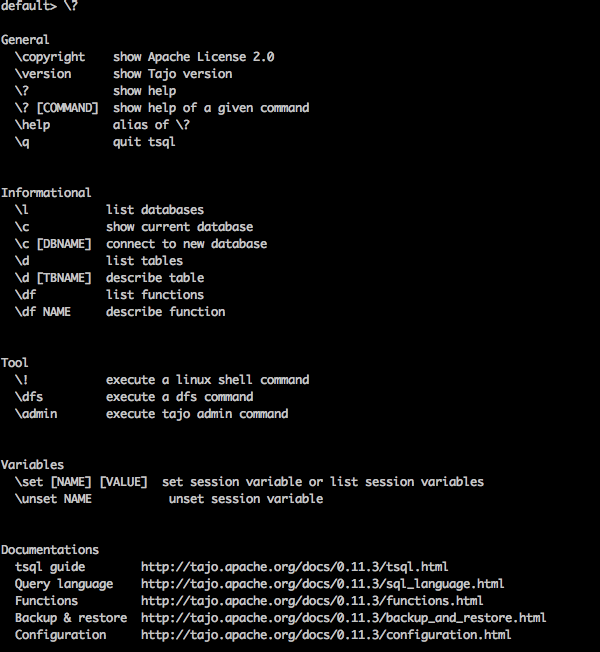
“\?” Perintah digunakan untuk menampilkan opsi bantuan.
Query
default> \?Result
Di atas \?Perintah mencantumkan semua opsi penggunaan dasar di Tajo. Anda akan menerima output berikut -
Daftar Database
Untuk mencantumkan semua database di Tajo, gunakan perintah berikut -
Query
default> \lResult
Anda akan menerima output berikut -
information_schema
defaultSaat ini, kami belum membuat database apa pun sehingga ini menunjukkan dua database Tajo yang dibangun.
Database Saat Ini
\c opsi digunakan untuk menampilkan nama database saat ini.
Query
default> \cResult
Anda sekarang terhubung ke database "default" sebagai "username" pengguna.
Buat daftar Fungsi Bawaan
Untuk mencantumkan semua fungsi bawaan, ketikkan kueri sebagai berikut -
Query
default> \dfResult
Anda akan menerima output berikut -

Jelaskan Fungsi
\df function name - Kueri ini mengembalikan deskripsi lengkap dari fungsi yang diberikan.
Query
default> \df sqrtResult
Anda akan menerima output berikut -

Keluar dari Terminal
Untuk keluar dari terminal, ketikkan kueri berikut -
Query
default> \qResult
Anda akan menerima output berikut -
bye!Perintah Admin
Tajo shell menyediakan \admin opsi untuk mencantumkan semua fitur admin.
Query
default> \adminResult
Anda akan menerima output berikut -

Info Cluster
Untuk menampilkan informasi cluster di Tajo, gunakan kueri berikut ini
Query
default> \admin -clusterResult
Anda akan menerima output berikut -

Tunjukkan master
Kueri berikut menampilkan informasi master saat ini.
Query
default> \admin -showmastersResult
localhostDemikian pula, Anda dapat mencoba perintah admin lainnya.
Variabel Sesi
Klien Tajo terhubung ke Master melalui id sesi unik. Sesi ini berlangsung sampai klien terputus atau kedaluwarsa.
Perintah berikut digunakan untuk membuat daftar semua variabel sesi.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'Itu \set key val akan mengatur variabel sesi bernama key dengan nilai val. Sebagai contoh,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Di sini, Anda dapat menetapkan kunci dan nilai di \setperintah. Jika Anda perlu mengembalikan perubahan, gunakan\unset perintah.
Untuk mengeksekusi kueri di shell Tajo, buka terminal Anda dan pindah ke direktori yang diinstal Tajo dan kemudian ketik perintah berikut -
$ bin/tsqlAnda sekarang akan melihat respons seperti yang ditunjukkan pada program berikut -
default>Anda sekarang dapat menjalankan kueri Anda. Jika tidak, Anda dapat menjalankan kueri Anda melalui aplikasi konsol web ke URL berikut -http://localhost:26080/
Tipe Data Primitif
Apache Tajo mendukung daftar tipe data primitif berikut -
| S.No. | Tipe & Deskripsi Data |
|---|---|
| 1 | integer Digunakan untuk menyimpan nilai integer dengan penyimpanan 4 byte. |
| 2 | tinyint Nilai integer kecil adalah 1 byte |
| 3 | smallint Digunakan untuk menyimpan nilai bilangan bulat ukuran kecil 2 byte. |
| 4 | bigint Nilai integer rentang besar memiliki penyimpanan 8 byte. |
| 5 | boolean Menampilkan benar / salah. |
| 6 | real Digunakan untuk menyimpan nilai nyata. Ukurannya 4 byte. |
| 7 | float Nilai presisi floating point yang memiliki ruang penyimpanan 4 atau 8 byte. |
| 8 | double Nilai presisi titik ganda disimpan dalam 8 byte. |
| 9 | char[(n)] Nilai karakter. |
| 10 | varchar[(n)] Data non-Unicode dengan panjang variabel. |
| 11 | number Nilai desimal. |
| 12 | binary Nilai biner. |
| 13 | date Tanggal kalender (tahun, bulan, hari). Example - DATE '2016-08-22' |
| 14 | time Waktu dalam sehari (jam, menit, detik, milidetik) tanpa zona waktu. Nilai jenis ini diurai dan dirender dalam zona waktu sesi. |
| 15 | timezone Waktu dalam hari (jam, menit, detik, milidetik) dengan zona waktu. Nilai jenis ini dirender menggunakan zona waktu dari nilai. Example - TIME '01: 02: 03.456 Asia / kolkata ' |
| 16 | timestamp Instan dalam waktu yang mencakup tanggal dan waktu tanpa zona waktu. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Teks Unicode dengan panjang variabel. |
Operator berikut digunakan di Tajo untuk melakukan operasi yang diinginkan.
| S.No. | Operator & Deskripsi |
|---|---|
| 1 | Operator aritmatika Presto mendukung operator aritmatika seperti +, -, *, /,%. |
| 2 | Operator relasional <,>, <=,> =, =, <> |
| 3 | Operator logika DAN, ATAU, TIDAK |
| 4 | Operator string '||' operator melakukan penggabungan string. |
| 5 | Operator jangkauan Operator jarak digunakan untuk menguji nilai dalam kisaran tertentu. Tajo mendukung BETWEEN, IS NULL, IS NOT NULL operator. |
Sampai sekarang, Anda tahu cara menjalankan kueri dasar sederhana di Tajo. Dalam beberapa bab berikutnya, kita akan membahas fungsi SQL berikut -
- Fungsi Matematika
- Fungsi String
- Fungsi DateTime
- Fungsi JSON
Fungsi matematika beroperasi pada rumus matematika. Tabel berikut menjelaskan daftar fungsi secara rinci.
| S.No. | Deskripsi fungsi |
|---|---|
| 1 | abs (x) Mengembalikan nilai absolut dari x. |
| 2 | cbrt (x) Mengembalikan akar pangkat tiga dari x. |
| 3 | langit-langit (x) Mengembalikan nilai x yang dibulatkan ke atas ke bilangan bulat terdekat. |
| 4 | lantai (x) Mengembalikan nilai x yang dibulatkan ke bawah ke bilangan bulat terdekat. |
| 5 | pi () Mengembalikan nilai pi. Hasil akan dikembalikan sebagai nilai ganda. |
| 6 | radian (x) mengubah sudut x dalam radian derajat. |
| 7 | derajat (x) Mengembalikan nilai derajat untuk x. |
| 8 | pow (x, p) Mengembalikan pangkat nilai'p 'ke nilai x. |
| 9 | div (x, y) Mengembalikan hasil pembagian untuk dua nilai bilangan bulat x, y yang ditentukan. |
| 10 | exp (x) Mengembalikan bilangan Euler e pangkat dari angka. |
| 11 | sqrt (x) Mengembalikan akar kuadrat dari x. |
| 12 | tanda (x) Mengembalikan fungsi signum dari x, yaitu -
|
| 13 | mod (n, m) Mengembalikan modulus (sisa) dari n dibagi dengan m. |
| 14 | bulat (x) Mengembalikan nilai dibulatkan untuk x. |
| 15 | cos (x) Mengembalikan nilai kosinus (x). |
| 16 | asin (x) Mengembalikan nilai sinus terbalik (x). |
| 17 | acos (x) Mengembalikan nilai kosinus terbalik (x). |
| 18 | atan (x) Mengembalikan nilai tangen terbalik (x). |
| 19 | atan2 (y, x) Mengembalikan nilai tangen terbalik (y / x). |
Fungsi Tipe Data
Tabel berikut mencantumkan fungsi tipe data yang tersedia di Apache Tajo.
| S.No. | Deskripsi fungsi |
|---|---|
| 1 | to_bin (x) Mengembalikan representasi biner dari integer. |
| 2 | to_char (int, teks) Mengonversi bilangan bulat menjadi string. |
| 3 | to_hex (x) Mengonversi nilai x menjadi heksadesimal. |
Tabel berikut mencantumkan fungsi string di Tajo.
| S.No. | Deskripsi fungsi |
|---|---|
| 1 | concat (string1, ..., stringN) Gabungkan string yang diberikan. |
| 2 | panjang (string) Mengembalikan panjang string yang diberikan. |
| 3 | lebih rendah (string) Mengembalikan format huruf kecil untuk string. |
| 4 | atas (string) Mengembalikan format huruf besar untuk string yang diberikan. |
| 5 | ascii (teks string) Mengembalikan kode ASCII dari karakter pertama teks. |
| 6 | bit_length (teks string) Mengembalikan jumlah bit dalam sebuah string. |
| 7 | char_length (teks string) Mengembalikan jumlah karakter dalam string. |
| 8 | octet_length (teks string) Menampilkan jumlah byte dalam sebuah string. |
| 9 | intisari (teks masukan, teks metode) Menghitung Digesthash string. Di sini, metode arg kedua mengacu pada metode hash. |
| 10 | initcap (teks string) Mengonversi huruf pertama dari setiap kata menjadi huruf besar. |
| 11 | md5 (teks string) Menghitung MD5 hash string. |
| 12 | kiri (teks string, ukuran int) Mengembalikan n karakter pertama dalam string. |
| 13 | kanan (teks string, ukuran int) Mengembalikan n karakter terakhir dalam string. |
| 14 | cari (teks sumber, teks target, indeks_mulai) Mengembalikan lokasi substring yang ditentukan. |
| 15 | strposb (teks sumber, teks target) Mengembalikan lokasi biner dari substring yang ditentukan. |
| 16 | substr (teks sumber, indeks awal, panjang) Mengembalikan substring untuk panjang yang ditentukan. |
| 17 | trim (teks string [, teks karakter]) Menghapus karakter (spasi secara default) dari awal / akhir / kedua ujung string. |
| 18 | split_part (teks string, teks pembatas, bidang int) Memisahkan string pada pembatas dan mengembalikan bidang yang diberikan (dihitung dari satu). |
| 19 | regexp_replace (teks string, teks pola, teks pengganti) Mengganti substring yang cocok dengan pola ekspresi reguler tertentu. |
| 20 | mundur (string) Operasi terbalik dilakukan untuk string. |
Apache Tajo mendukung fungsi DateTime berikut.
| S.No. | Deskripsi fungsi |
|---|---|
| 1 | add_days (tanggal tanggal atau stempel waktu, int hari Tanggal pengembalian ditambahkan dengan nilai hari yang ditentukan. |
| 2 | add_months (tanggal tanggal atau stempel waktu, int bulan) Tanggal pengembalian ditambahkan dengan nilai bulan tertentu. |
| 3 | tanggal sekarang() Mengembalikan tanggal hari ini. |
| 4 | waktu saat ini() Mengembalikan waktu hari ini. |
| 5 | ekstrak (abad dari tanggal / cap waktu) Mengekstrak abad dari parameter yang diberikan. |
| 6 | ekstrak (hari dari tanggal / cap waktu) Ekstrak hari dari parameter tertentu. |
| 7 | ekstrak (dekade dari tanggal / cap waktu) Ekstrak dekade dari parameter yang diberikan. |
| 8 | ekstrak (tanggal hari dow / cap waktu) Ekstrak hari dalam seminggu dari parameter yang diberikan. |
| 9 | ekstrak (doy from date / timestamp) Ekstrak hari dalam setahun dari parameter yang diberikan. |
| 10 | pilih ekstrak (jam dari stempel waktu) Ekstrak jam dari parameter tertentu. |
| 11 | pilih ekstrak (isodow dari timestamp) Ekstrak hari dalam seminggu dari parameter yang diberikan. Ini identik dengan dow kecuali hari Minggu. Ini cocok dengan penomoran hari ISO 8601 dalam seminggu. |
| 12 | pilih ekstrak (isoyear from date) Ekstrak tahun ISO dari tanggal yang ditentukan. Tahun ISO mungkin berbeda dari tahun Gregorian. |
| 13 | ekstrak (mikrodetik dari waktu) Ekstrak mikrodetik dari parameter yang diberikan. Bidang detik, termasuk bagian pecahan, dikalikan dengan 1.000.000; |
| 14 | ekstrak (milenium dari cap waktu) Mengekstrak milenium dari parameter yang diberikan. Satu milenium sama dengan 1000 tahun. Karenanya, milenium ketiga dimulai 1 Januari 2001. |
| 15 | ekstrak (milidetik dari waktu) Ekstrak milidetik dari parameter yang diberikan. |
| 16 | ekstrak (menit dari cap waktu) Ekstrak menit dari parameter yang diberikan. |
| 17 | ekstrak (seperempat dari cap waktu) Ekstrak kuartal tahun ini (1 - 4) dari parameter yang diberikan. |
| 18 | date_part (teks bidang, tanggal sumber atau stempel waktu atau waktu) Mengekstrak bidang tanggal dari teks. |
| 19 | sekarang() Mengembalikan stempel waktu saat ini. |
| 20 | to_char (stempel waktu, format teks) Mengonversi stempel waktu menjadi teks. |
| 21 | to_date (teks src, format teks) Mengonversi teks menjadi tanggal. |
| 22 | to_timestamp (teks src, format teks) Mengonversi teks menjadi stempel waktu. |
Fungsi JSON tercantum dalam tabel berikut -
| S.No. | Deskripsi fungsi |
|---|---|
| 1 | json_extract_path_text (js pada teks, teks json_path) Mengekstrak string JSON dari string JSON berdasarkan jalur json yang ditentukan. |
| 2 | json_array_get (teks json_array, indeks int4) Mengembalikan elemen pada indeks yang ditentukan ke dalam larik JSON. |
| 3 | json_array_contains (teks array json_, nilai apa saja) Tentukan apakah nilai yang diberikan ada dalam larik JSON. |
| 4 | json_array_length (teks sinar json_ar) Mengembalikan panjang larik json. |
Bagian ini menjelaskan perintah Tajo DDL. Tajo memiliki database bawaan bernamadefault.
Buat Pernyataan Database
Create Databaseadalah pernyataan yang digunakan untuk membuat database di Tajo. Sintaks untuk pernyataan ini adalah sebagai berikut -
CREATE DATABASE [IF NOT EXISTS] <database_name>Pertanyaan
default> default> create database if not exists test;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
OKDatabase adalah namespace di Tajo. Database bisa berisi beberapa tabel dengan nama yang unik.
Tunjukkan Database Saat Ini
Untuk memeriksa nama database saat ini, jalankan perintah berikut -
Pertanyaan
default> \cHasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
You are now connected to database "default" as user “user1".
default>Hubungkan ke Database
Sampai sekarang, Anda telah membuat database bernama "test". Sintaks berikut digunakan untuk menghubungkan database "test".
\c <database name>Pertanyaan
default> \c testHasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
You are now connected to database "test" as user “user1”.
test>Anda sekarang dapat melihat perubahan prompt dari database default ke database pengujian.
Jatuhkan Database
Untuk menjatuhkan database, gunakan sintaks berikut -
DROP DATABASE <database-name>Pertanyaan
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
OKTabel adalah tampilan logis dari satu sumber data. Ini terdiri dari skema logis, partisi, URL, dan berbagai properti. Tabel Tajo dapat berupa direktori dalam HDFS, satu file, satu tabel HBase, atau tabel RDBMS.
Tajo mendukung dua jenis tabel berikut -
- tabel eksternal
- tabel internal
Tabel Eksternal
Tabel eksternal membutuhkan properti lokasi saat tabel dibuat. Misalnya, jika data Anda sudah ada sebagai file Teks / JSON atau tabel HBase, Anda dapat mendaftarkannya sebagai tabel eksternal Tajo.
Kueri berikut adalah contoh pembuatan tabel eksternal.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Sini,
External keyword- Ini digunakan untuk membuat tabel eksternal. Ini membantu membuat tabel di lokasi yang ditentukan.
Sampel mengacu pada nama tabel.
Location- Ini adalah direktori untuk HDFS, Amazon S3, HBase atau sistem file lokal. Untuk menetapkan properti lokasi untuk direktori, gunakan contoh URI di bawah ini -
HDFS - hdfs: // localhost: port / path / ke / tabel
Amazon S3 - s3: // nama-keranjang / tabel
local file system - file: /// jalur / ke / tabel
Openstack Swift - swift: // nama-ember / tabel
Properti Tabel
Tabel eksternal memiliki properti berikut -
TimeZone - Pengguna dapat menentukan zona waktu untuk membaca atau menulis tabel.
Compression format- Digunakan untuk membuat ukuran data menjadi kompak. Misalnya, file teks / json menggunakancompression.codec Properti.
Tabel Internal
Tabel internal juga disebut Managed Table. Itu dibuat di lokasi fisik yang telah ditentukan sebelumnya yang disebut Tablespace.
Sintaksis
create table table1(col1 int,col2 text);Secara default, Tajo menggunakan "tajo.warehouse.directory" yang terletak di "conf / tajo-site.xml". Untuk menetapkan lokasi baru untuk tabel, Anda dapat menggunakan konfigurasi Tablespace.
Tablespace
Tablespace digunakan untuk menentukan lokasi dalam sistem penyimpanan. Ini hanya didukung untuk tabel internal. Anda dapat mengakses tablespaces dengan namanya. Setiap tablespace dapat menggunakan jenis penyimpanan yang berbeda. Jika Anda tidak menentukan tablespaces, Tajo menggunakan tablespace default di direktori root.
Konfigurasi Tablespace
Kamu punya “conf/tajo-site.xml.template”di Tajo. Salin file dan ganti namanya menjadi“storagesite.json”. File ini akan bertindak sebagai konfigurasi untuk Tablespaces. Format data Tajo menggunakan konfigurasi berikut -
Konfigurasi HDFS
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Konfigurasi HBase
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Konfigurasi File Teks
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Pembuatan Tablespace
Catatan tabel internal Tajo hanya dapat diakses dari tabel lain. Anda dapat mengkonfigurasinya dengan tablespace.
Sintaksis
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Sini,
IF NOT EXISTS - Ini menghindari kesalahan jika tabel yang sama belum dibuat.
TABLESPACE - Klausul ini digunakan untuk menetapkan nama tablespace.
Storage type - Data Tajo mendukung format seperti teks, JSON, HBase, Parquet, Sequencefile dan ORC.
AS select statement - Pilih catatan dari tabel lain.
Konfigurasi Tablespace
Mulai layanan Hadoop Anda dan buka file “conf/storage-site.json”, lalu tambahkan perubahan berikut -
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Di sini, Tajo akan mengacu pada data dari lokasi HDFS dan space1adalah nama tablespace. Jika Anda tidak memulai layanan Hadoop, Anda tidak dapat mendaftarkan tablespace.
Pertanyaan
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;Kueri di atas membuat tabel bernama "table1" dan "space1" mengacu pada nama tablespace.
Format data
Tajo mendukung format data. Mari kita bahas setiap format satu per satu secara mendetail.
Teks
File teks biasa nilai yang dipisahkan karakter mewakili kumpulan data tabel yang terdiri dari baris dan kolom. Setiap baris adalah baris teks biasa.
Membuat Tabel
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Sini, “customers.csv” file mengacu pada file nilai dipisahkan koma yang terletak di direktori instalasi Tajo.
Untuk membuat tabel internal menggunakan format teks, gunakan query berikut -
default> create table customer(id int,name text,address text,age int) using text;Dalam query di atas, Anda belum menetapkan tablespace apa pun sehingga itu akan mengambil tablespace default Tajo.
Properti
Format file teks memiliki properti berikut -
text.delimiter- Ini adalah karakter pembatas. Default-nya adalah '|'.
compression.codec- Ini adalah format kompresi. Secara default, ini dinonaktifkan. Anda dapat mengubah pengaturan menggunakan algoritma yang ditentukan.
timezone - Meja yang digunakan untuk membaca atau menulis.
text.error-tolerance.max-num - Jumlah maksimum tingkat toleransi.
text.skip.headerlines - Jumlah baris header per dilewati.
text.serde - Ini adalah properti serialisasi.
JSON
Apache Tajo mendukung format JSON untuk meminta data. Tajo memperlakukan objek JSON sebagai data SQL. Satu objek sama dengan satu baris dalam tabel Tajo. Mari pertimbangkan "array.json" sebagai berikut -
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}Setelah Anda membuat file ini, beralihlah ke Tajo shell dan ketik kueri berikut untuk membuat tabel menggunakan format JSON.
Pertanyaan
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Ingatlah selalu bahwa data file harus sesuai dengan skema tabel. Jika tidak, Anda bisa menghilangkan nama kolom dan menggunakan * yang tidak memerlukan daftar kolom.
Untuk membuat tabel internal, gunakan query berikut -
default> create table sample (num1 int,num2 text,num3 float) using json;Parket
Parket adalah format penyimpanan berbentuk kolom. Tajo menggunakan format Parket untuk akses yang mudah, cepat dan efisien.
Pembuatan tabel
Query berikut adalah contoh pembuatan tabel -
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Format file parket memiliki properti berikut -
parquet.block.size - ukuran grup baris yang di-buffer dalam memori.
parquet.page.size - Ukuran halaman untuk kompresi.
parquet.compression - Algoritma kompresi yang digunakan untuk mengompres halaman.
parquet.enable.dictionary - Nilai boolean adalah untuk mengaktifkan / menonaktifkan pengkodean kamus.
RCFile
RCFile adalah File Kolom Rekam. Ini terdiri dari pasangan kunci / nilai biner.
Pembuatan tabel
Query berikut adalah contoh pembuatan tabel -
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile memiliki properti berikut -
rcfile.serde - kelas deserializer khusus.
compression.codec - algoritma kompresi.
rcfile.null - Karakter NULL.
SequenceFile
SequenceFile adalah format file dasar di Hadoop yang terdiri dari pasangan kunci / nilai.
Pembuatan tabel
Query berikut adalah contoh pembuatan tabel -
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;File urutan ini memiliki kompatibilitas Hive. Ini dapat ditulis di Hive sebagai,
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) adalah format penyimpanan kolom dari Hive.
Pembuatan tabel
Query berikut adalah contoh pembuatan tabel -
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;Format ORC memiliki properti berikut -
orc.max.merge.distance - File ORC dibaca, itu menyatu ketika jaraknya lebih rendah.
orc.stripe.size - Ini adalah ukuran setiap garis.
orc.buffer.size - Standarnya adalah 256KB.
orc.rowindex.stride - Ini adalah langkah indeks ORC dalam jumlah baris.
Di bab sebelumnya, Anda telah memahami cara membuat tabel di Tajo. Bab ini menjelaskan tentang pernyataan SQL di Tajo.
Buat Pernyataan Tabel
Sebelum pindah ke membuat tabel, buat file teks "students.csv" di jalur direktori instalasi Tajo sebagai berikut -
students.csv
| Indo | Nama | Alamat | Usia | Tanda |
|---|---|---|---|---|
| 1 | Adam | 23 Jalan Baru | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Mendongkrak | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
Setelah file dibuat, pindah ke terminal dan mulai server Tajo dan shell satu per satu.
Buat Database
Buat database baru menggunakan perintah berikut -
Pertanyaan
default> create database sampledb;
OKHubungkan ke database "sampledb" yang sekarang dibuat.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Kemudian, buat tabel di "sampledb" seperti berikut -
Pertanyaan
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
OKDi sini, tabel eksternal dibuat. Sekarang, Anda hanya perlu memasukkan lokasi file. Jika Anda harus menetapkan tabel dari hdfs, gunakan hdfs sebagai ganti file.
Selanjutnya, “students.csv”file berisi nilai yang dipisahkan koma. Itutext.delimiter bidang diberikan dengan ','.
Anda sekarang telah berhasil membuat "mytable" di "sampledb".
Tunjukkan Tabel
Untuk memperlihatkan tabel di Tajo, gunakan kueri berikut ini.
Pertanyaan
sampledb> \d
mytable
sampledb> \d mytableHasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4Tabel daftar
Untuk mengambil semua record dalam tabel, ketikkan query berikut -
Pertanyaan
sampledb> select * from mytable;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.

Sisipkan Pernyataan Tabel
Tajo menggunakan sintaks berikut untuk menyisipkan rekaman dalam tabel.
Sintaksis
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Pernyataan insert Tajo mirip dengan INSERT INTO SELECT pernyataan SQL.
Pertanyaan
Mari buat tabel untuk menimpa data tabel dari tabel yang sudah ada.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dHasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
mytable
testSisipkan Rekaman
Untuk menyisipkan record dalam tabel "test", ketik query berikut.
Pertanyaan
sampledb> insert overwrite into test select * from mytable;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
Progress: 100%, response time: 0.518 secDi sini, catatan "mytable" menimpa tabel "test". Jika Anda tidak ingin membuat tabel "test", maka langsung tetapkan lokasi jalur fisik seperti yang disebutkan dalam opsi alternatif untuk menyisipkan kueri.
Ambil catatan
Gunakan query berikut untuk mendaftar semua record di tabel "test" -
Pertanyaan
sampledb> select * from test;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.

Pernyataan ini digunakan untuk menambah, menghapus, atau mengubah kolom dari tabel yang sudah ada.
Untuk mengganti nama tabel gunakan sintaks berikut -
Alter table table1 RENAME TO table2;Pertanyaan
sampledb> alter table test rename to students;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
OKUntuk memeriksa nama tabel yang diubah, gunakan kueri berikut ini.
sampledb> \d
mytable
studentsSekarang tabel “test” diubah menjadi tabel “siswa”.
Tambahkan Kolom
Untuk menyisipkan kolom baru di tabel "siswa", ketik sintaks berikut -
Alter table <table_name> ADD COLUMN <column_name> <data_type>Pertanyaan
sampledb> alter table students add column grade text;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
OKTetapkan Properti
Properti ini digunakan untuk mengubah properti tabel.
Pertanyaan
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKDi sini, tipe kompresi dan properti codec ditetapkan.
Untuk mengubah properti pembatas teks, gunakan yang berikut ini -
Pertanyaan
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKHasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTHasil di atas menunjukkan bahwa properti tabel diubah menggunakan properti "SET".
Pilih Pernyataan
Pernyataan SELECT digunakan untuk memilih data dari database.
Sintaks untuk pernyataan Select adalah sebagai berikut -
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Dimana Klausul
Klausa Di mana digunakan untuk memfilter rekaman dari tabel.
Pertanyaan
sampledb> select * from mytable where id > 5;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
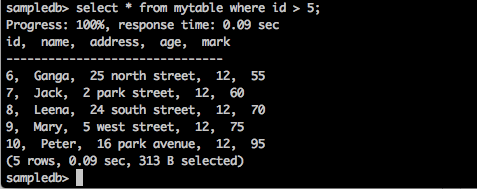
Kueri mengembalikan rekaman siswa yang idnya lebih besar dari 5.
Pertanyaan
sampledb> select * from mytable where name = ‘Peter’;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Hasilnya hanya menyaring catatan Peter.
Klausul Berbeda
Kolom tabel mungkin berisi nilai duplikat. Kata kunci DISTINCT dapat digunakan untuk mengembalikan hanya nilai yang berbeda (berbeda).
Sintaksis
SELECT DISTINCT column1,column2 FROM table_name;Pertanyaan
sampledb> select distinct age from mytable;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12Kueri mengembalikan usia siswa yang berbeda dari mytable.
Kelompok Menurut Klausul
Klausa GROUP BY digunakan berkolaborasi dengan pernyataan SELECT untuk menyusun data identik ke dalam grup.
Sintaksis
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Pertanyaan
select age,sum(mark) as sumofmarks from mytable group by age;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
age, sumofmarks
-------------------------------
13, 145
12, 610Di sini, kolom "tabel saya" memiliki dua jenis usia - 12 dan 13. Sekarang kueri mengelompokkan catatan menurut usia dan menghasilkan jumlah nilai untuk usia siswa yang sesuai.
Memiliki Klausul
Klausa HAVING memungkinkan Anda menentukan kondisi yang memfilter hasil grup yang muncul di hasil akhir. Klausa WHERE menempatkan kondisi pada kolom yang dipilih, sedangkan klausa HAVING menempatkan kondisi pada grup yang dibuat oleh klausa GROUP BY.
Sintaksis
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Pertanyaan
sampledb> select age from mytable group by age having sum(mark) > 200;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
age
-------------------------------
12Kueri mengelompokkan rekaman berdasarkan usia dan mengembalikan usia saat jumlah hasil kondisi (tanda)> 200.
Urutkan Berdasarkan Klausul
Klausa ORDER BY digunakan untuk mengurutkan data dalam urutan naik atau turun, berdasarkan satu atau beberapa kolom. Database Tajo mengurutkan hasil kueri dalam urutan menaik secara default.
Sintaksis
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Pertanyaan
sampledb> select * from mytable where mark > 60 order by name desc;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.

Kueri mengembalikan nama siswa tersebut dalam urutan menurun yang nilainya lebih dari 60.
Buat Pernyataan Indeks
Pernyataan CREATE INDEX digunakan untuk membuat indeks dalam tabel. Indeks digunakan untuk pengambilan data dengan cepat. Versi saat ini mendukung indeks hanya untuk format TEXT biasa yang disimpan di HDFS.
Sintaksis
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Pertanyaan
create index student_index on mytable(id);Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
id
———————————————Untuk melihat indeks yang ditetapkan untuk kolom tersebut, ketikkan kueri berikut ini.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Di sini, metode TWO_LEVEL_BIN_TREE digunakan secara default di Tajo.
Pernyataan Drop Table
Pernyataan Drop Table digunakan untuk menjatuhkan tabel dari database.
Sintaksis
drop table table name;Pertanyaan
sampledb> drop table mytable;Untuk memeriksa apakah tabel telah dihapus dari tabel, ketikkan kueri berikut ini.
sampledb> \d mytable;Hasil
Kueri di atas akan menghasilkan hasil sebagai berikut.
ERROR: relation 'mytable' does not existAnda juga dapat memeriksa kueri menggunakan perintah “\ d” untuk mencantumkan tabel Tajo yang tersedia.
Bab ini menjelaskan fungsi agregat dan jendela secara rinci.
Fungsi Agregasi
Fungsi agregat menghasilkan satu hasil dari sekumpulan nilai input. Tabel berikut menjelaskan daftar fungsi agregat secara rinci.
| S.No. | Deskripsi fungsi |
|---|---|
| 1 | AVG (exp) Rata-rata kolom dari semua catatan di sumber data. |
| 2 | CORR (ekspresi1, ekspresi2) Mengembalikan koefisien korelasi antara sekumpulan pasangan bilangan. |
| 3 | MENGHITUNG() Mengembalikan baris angka. |
| 4 | MAX (ekspresi) Mengembalikan nilai terbesar dari kolom yang dipilih. |
| 5 | MIN (ekspresi) Mengembalikan nilai terkecil dari kolom yang dipilih. |
| 6 | SUM (ekspresi) Mengembalikan jumlah kolom yang ditentukan. |
| 7 | LAST_VALUE (ekspresi) Mengembalikan nilai terakhir dari kolom yang ditentukan. |
Fungsi Jendela
Fungsi Window dijalankan pada satu set baris dan mengembalikan satu nilai untuk setiap baris dari query. Jendela istilah memiliki arti kumpulan baris untuk fungsi tersebut.
Fungsi Window dalam query, mendefinisikan jendela menggunakan klausa OVER ().
Itu OVER() klausa memiliki kemampuan berikut -
- Mendefinisikan partisi jendela untuk membentuk kelompok baris. (PARTITION BY klausa)
- Mengurutkan baris dalam sebuah partisi. (ORDER BY klausa)
Tabel berikut menjelaskan fungsi jendela secara rinci.
| Fungsi | Jenis pengembalian | Deskripsi |
|---|---|---|
| pangkat() | int | Mengembalikan peringkat dari baris saat ini dengan celah. |
| row_num () | int | Mengembalikan baris saat ini dalam partisi, dihitung dari 1. |
| prospek (nilai [, bilangan bulat offset [, default apa pun]]) | Sama seperti tipe masukan | Mengembalikan nilai yang dievaluasi pada baris yang merupakan baris offset setelah baris saat ini dalam partisi. Jika tidak ada baris seperti itu, nilai default akan dikembalikan. |
| lag (nilai [, offset integer [, default any]]) | Sama seperti tipe masukan | Mengembalikan nilai yang dievaluasi pada baris yang merupakan baris offset sebelum baris saat ini dalam partisi. |
| first_value (nilai) | Sama seperti tipe masukan | Mengembalikan nilai pertama dari baris masukan. |
| last_value (nilai) | Sama seperti tipe masukan | Mengembalikan nilai terakhir dari baris masukan. |
Bab ini menjelaskan tentang Kueri penting berikut.
- Predicates
- Explain
- Join
Mari kita lanjutkan dan lakukan kueri.
Predikat
Predikat adalah ekspresi yang digunakan untuk mengevaluasi nilai benar / salah dan TIDAK DIKETAHUI. Predikat digunakan dalam kondisi pencarian klausa WHERE dan klausa HAVING serta konstruksi lain yang memerlukan nilai Boolean.
DI predikat
Menentukan apakah nilai ekspresi yang akan diuji cocok dengan nilai apa pun di subkueri atau daftar. Subquery adalah pernyataan SELECT biasa yang memiliki kumpulan hasil dari satu kolom dan satu atau lebih baris. Kolom ini atau semua ekspresi dalam daftar harus memiliki tipe data yang sama dengan ekspresi yang akan diuji.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueKueri mengembalikan rekaman dari mytable untuk siswa id 2,3 dan 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueKueri di atas mengembalikan rekaman dari mytable dimana siswa tidak berada di 2,3 dan 4.
Seperti Predikat
Predikat LIKE membandingkan string yang ditentukan dalam ekspresi pertama untuk menghitung nilai string, yang dirujuk sebagai nilai untuk diuji, dengan pola yang ditentukan dalam ekspresi kedua untuk menghitung nilai string.
Polanya mungkin berisi kombinasi karakter pengganti seperti -
Simbol garis bawah (_), yang dapat digunakan sebagai pengganti karakter tunggal apa pun dalam nilai untuk diuji.
Tanda persen (%), yang menggantikan string apa pun yang tidak memiliki karakter atau lebih dalam nilai yang akan diuji.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Kueri mengembalikan catatan dari mytable siswa yang namanya dimulai dengan 'A'.
Query
select * from mytable where name like ‘_a%';Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Kueri mengembalikan rekaman dari mytable dari siswa yang namanya dimulai dengan 'a' sebagai karakter kedua.
Menggunakan Nilai NULL dalam Kondisi Pencarian
Mari kita sekarang memahami bagaimana menggunakan Nilai NULL dalam kondisi pencarian.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Di sini, hasilnya benar sehingga mengembalikan semua nama dari tabel.
Query
Sekarang mari kita periksa query dengan kondisi NULL.
default> select name from mytable where name is null;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Menjelaskan
Explaindigunakan untuk mendapatkan rencana eksekusi kueri. Ini menunjukkan eksekusi rencana logis dan global dari sebuah pernyataan.
Kueri Rencana Logis
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Kueri di atas akan menghasilkan hasil sebagai berikut.

Hasil kueri menunjukkan format rencana logis untuk tabel yang diberikan. Rencana Logis mengembalikan tiga hasil berikut -
- Daftar target
- Skema keluar
- Dalam skema
Kueri Rencana Global
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Kueri di atas akan menghasilkan hasil sebagai berikut.

Di sini, rencana Global menunjukkan ID blok eksekusi, urutan eksekusi dan informasinya.
Bergabung
Gabungan SQL digunakan untuk menggabungkan baris dari dua atau lebih tabel. Berikut ini adalah jenis-jenis SQL Joins -
- Bergabung batin
- {KIRI | KANAN | FULL} OUTER GABUNG
- Bergabung silang
- Bergabung sendiri
- Gabungan alami
Pertimbangkan dua tabel berikut untuk melakukan operasi penggabungan.
Tabel1 - Pelanggan
| Indo | Nama | Alamat | Usia |
|---|---|---|---|
| 1 | Pelanggan 1 | 23 Old Street | 21 |
| 2 | Pelanggan 2 | 12 Jalan Baru | 23 |
| 3 | Pelanggan 3 | 10 Express Avenue | 22 |
| 4 | Pelanggan 4 | 15 Express Avenue | 22 |
| 5 | Pelanggan 5 | 20 Garden Street | 33 |
| 6 | Pelanggan 6 | 21 North Street | 25 |
Tabel2 - pesanan_pelanggan
| Indo | Id pemesanan | Id Emp |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Sekarang mari kita lanjutkan dan lakukan operasi gabungan SQL pada dua tabel di atas.
Gabung Batin
Gabungan dalam memilih semua baris dari kedua tabel saat ada kecocokan antara kolom di kedua tabel.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Kueri cocok dengan lima baris dari kedua tabel. Oleh karena itu, ia mengembalikan usia baris yang cocok dari tabel pertama.
Gabung Luar Kiri
Gabungan luar kiri mempertahankan semua baris dari tabel "kiri", terlepas dari apakah ada baris yang cocok dengan tabel "kanan" atau tidak.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Di sini, left outer join mengembalikan baris kolom nama dari tabel pelanggan (kiri) dan kolom kosong yang cocok dengan baris dari tabel customer_order (kanan).
Gabung Luar Kanan
Gabungan kanan luar mempertahankan semua baris dari tabel "kanan", terlepas dari apakah ada baris yang cocok pada tabel "kiri".
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Di sini, Gabung Luar Kanan mengembalikan baris kosong dari tabel customer_order (kanan) dan kolom nama cocok dengan baris dari tabel pelanggan.
Gabung Luar Penuh
Gabungan Luar Penuh mempertahankan semua baris dari tabel kiri dan kanan.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.

Kueri mengembalikan semua baris yang cocok dan tidak cocok dari tabel pelanggan dan tabel customer_order.
Gabung Silang
Ini mengembalikan produk Cartesian dari kumpulan rekaman dari dua atau lebih tabel yang digabungkan.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
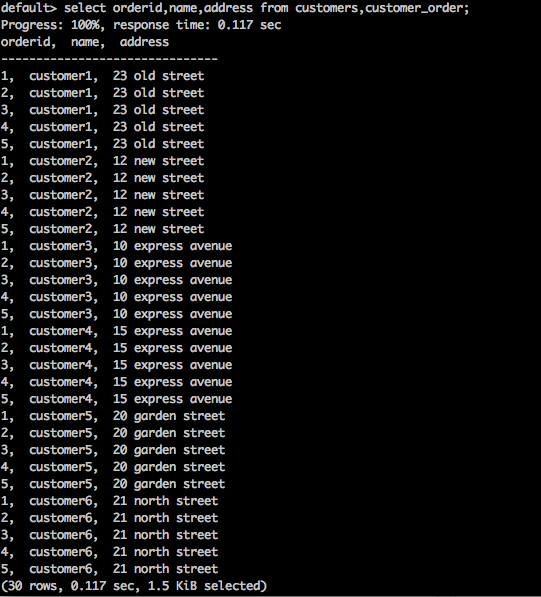
Kueri di atas mengembalikan produk Cartesian dari tabel.
Bergabung Alami
A Natural Join tidak menggunakan operator perbandingan apa pun. Ini tidak menggabungkan seperti yang dilakukan produk Cartesian. Kita dapat melakukan Gabung Alami hanya jika ada setidaknya satu atribut umum yang ada di antara kedua relasi.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.

Di sini, ada satu id kolom umum yang ada di antara dua tabel. Menggunakan kolom umum itu, fileNatural Join menggabungkan kedua tabel.
Bergabung Sendiri
SQL SELF JOIN digunakan untuk menggabungkan tabel ke tabel itu sendiri seolah-olah tabel adalah dua tabel, untuk sementara mengganti nama setidaknya satu tabel dalam pernyataan SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Kueri di atas akan menghasilkan hasil sebagai berikut.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Kueri menggabungkan tabel pelanggan ke dirinya sendiri.
Tajo mendukung berbagai format penyimpanan. Untuk mendaftarkan konfigurasi plugin penyimpanan, Anda harus menambahkan perubahan ke file konfigurasi "storage-site.json".
storage-site.json
Strukturnya didefinisikan sebagai berikut -
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Setiap instance penyimpanan diidentifikasi oleh URI.
Penangan Penyimpanan PostgreSQL
Tajo mendukung penangan penyimpanan PostgreSQL. Ini memungkinkan kueri pengguna untuk mengakses objek database di PostgreSQL. Ini adalah penangan penyimpanan default di Tajo sehingga Anda dapat dengan mudah mengkonfigurasinya.
konfigurasi
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Sini, “database1” mengacu kepada postgreSQL database yang dipetakan ke database “sampledb” di Tajo.
Apache Tajo mendukung integrasi HBase. Ini memungkinkan kami untuk mengakses tabel HBase di Tajo. HBase adalah database berorientasi kolom terdistribusi yang dibangun di atas sistem file Hadoop. Ini adalah bagian dari ekosistem Hadoop yang menyediakan akses baca / tulis waktu nyata acak ke data di Sistem File Hadoop. Langkah-langkah berikut diperlukan untuk mengkonfigurasi integrasi HBase.
Tetapkan Variabel Lingkungan
Tambahkan perubahan berikut ke file "conf / tajo-env.sh".
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseSetelah Anda memasukkan jalur HBase, Tajo akan mengatur file perpustakaan HBase ke jalur kelas.
Buat Tabel Eksternal
Buat tabel eksternal menggunakan sintaks berikut -
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;Untuk mengakses tabel HBase, Anda harus mengkonfigurasi lokasi tablespace.
Sini,
Table- Tetapkan nama tabel asal hbase. Jika ingin membuat tabel eksternal, tabel tersebut harus ada di HBase.
Columns- Key mengacu pada kunci baris HBase. Jumlah entri kolom harus sama dengan jumlah kolom tabel Tajo.
hbase.zookeeper.quorum - Tetapkan alamat kuorum penjaga kebun binatang.
hbase.zookeeper.property.clientPort - Atur port klien penjaga kebun binatang.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Di sini, bidang jalur Lokasi menyetel id port klien penjaga kebun binatang. Jika Anda tidak menyetel porta, Tajo akan merujuk properti file hbase-site.xml.
Buat Tabel di HBase
Anda dapat memulai shell interaktif HBase menggunakan perintah "hbase shell" seperti yang ditunjukkan pada kueri berikut.
Query
/bin/hbase shellResult
Kueri di atas akan menghasilkan hasil sebagai berikut.
hbase(main):001:0>Langkah-langkah untuk Menanyakan HBase
Untuk menanyakan HBase, Anda harus menyelesaikan langkah-langkah berikut -
Step 1 - Pipa perintah berikut ke shell HBase untuk membuat tabel "tutorial".
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Sekarang, jalankan perintah berikut di shell hbase untuk memuat data ke dalam tabel.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Sekarang, kembali ke shell Tajo dan jalankan perintah berikut untuk melihat metadata tabel -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Untuk mengambil hasil dari tabel, gunakan query berikut -
Query
default> select * from studentsResult
Kueri di atas akan mengambil hasil berikut -
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo mendukung HiveCatalogStore untuk berintegrasi dengan Apache Hive. Integrasi ini memungkinkan Tajo mengakses tabel di Apache Hive.
Tetapkan Variabel Lingkungan
Tambahkan perubahan berikut ke file "conf / tajo-env.sh".
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveSetelah Anda memasukkan jalur Hive, Tajo akan mengatur file perpustakaan Hive ke jalur kelas.
Konfigurasi Katalog
Tambahkan perubahan berikut ke file "conf / catalog-site.xml".
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>Setelah HiveCatalogStore dikonfigurasi, Anda dapat mengakses tabel Hive di Tajo.
Swift adalah penyimpanan objek / blob yang terdistribusi dan konsisten. Swift menawarkan perangkat lunak penyimpanan awan sehingga Anda dapat menyimpan dan mengambil banyak data dengan API sederhana. Tajo mendukung integrasi Swift.
Berikut ini adalah prasyarat Integrasi Swift -
- Swift
- Hadoop
Core-site.xml
Tambahkan perubahan berikut ke file hadoop "core-site.xml" -
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Ini akan digunakan untuk Hadoop untuk mengakses objek Swift. Setelah Anda membuat semua perubahan, pindah ke direktori Tajo untuk menyetel variabel lingkungan Swift.
conf / tajo-env.h
Buka file konfigurasi Tajo dan tambahkan setel variabel lingkungan sebagai berikut -
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarSekarang, Tajo akan dapat melakukan kueri data menggunakan Swift.
Buat tabel
Mari buat tabel eksternal untuk mengakses objek Swift di Tajo sebagai berikut -
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';Setelah tabel dibuat, Anda dapat menjalankan kueri SQL.
Apache Tajo menyediakan antarmuka JDBC untuk menghubungkan dan menjalankan kueri. Kita dapat menggunakan antarmuka JDBC yang sama untuk menghubungkan Tajo dari aplikasi berbasis Java kita. Sekarang mari kita memahami cara menghubungkan Tajo dan menjalankan perintah di aplikasi Java contoh kita menggunakan antarmuka JDBC di bagian ini.
Unduh JDBC Driver
Unduh driver JDBC dengan mengunjungi tautan berikut - http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Sekarang, file "tajo-jdbc-0.11.3.jar" telah didownload di komputer Anda.
Atur Jalur Kelas
Untuk menggunakan driver JDBC dalam program Anda, setel jalur kelas sebagai berikut -
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHHubungkan ke Tajo
Apache Tajo menyediakan driver JDBC sebagai file jar tunggal dan tersedia @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
String koneksi untuk menghubungkan Apache Tajo adalah dalam format berikut -
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseSini,
host - Nama host dari TajoMaster.
port- Nomor port yang didengarkan server. Nomor port default adalah 26002.
database- Nama database. Nama database default adalah default.
Aplikasi Java
Mari kita sekarang memahami aplikasi Java.
Pengodean
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Aplikasi dapat dikompilasi dan dijalankan menggunakan perintah berikut.
Kompilasi
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaEksekusi
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleHasil
Perintah di atas akan menghasilkan hasil sebagai berikut -
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo mendukung fungsi yang ditentukan pengguna / kustom (UDF). Fungsi kustom dapat dibuat dengan python.
Fungsi khusus hanyalah fungsi python biasa dengan dekorator “@output_type(<tajo sql datatype>)” sebagai berikut -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;Skrip python dengan UDF dapat didaftarkan dengan menambahkan konfigurasi di bawah ini di “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>Setelah skrip terdaftar, mulai ulang cluster dan UDF akan tersedia tepat di kueri SQL sebagai berikut -
select sum_py(10, 10) as pyfn;Apache Tajo juga mendukung fungsi agregat yang ditentukan pengguna tetapi tidak mendukung fungsi jendela yang ditentukan pengguna.