IMS DB - Panduan Cepat
Tinjauan Singkat
Database adalah kumpulan item data yang berkorelasi. Item data ini diatur dan disimpan dengan cara yang menyediakan akses cepat dan mudah. Basis data IMS adalah basis data hierarki di mana data disimpan pada tingkat yang berbeda dan setiap entitas bergantung pada entitas tingkat yang lebih tinggi. Elemen fisik pada sistem aplikasi yang menggunakan IMS ditunjukkan pada gambar berikut.
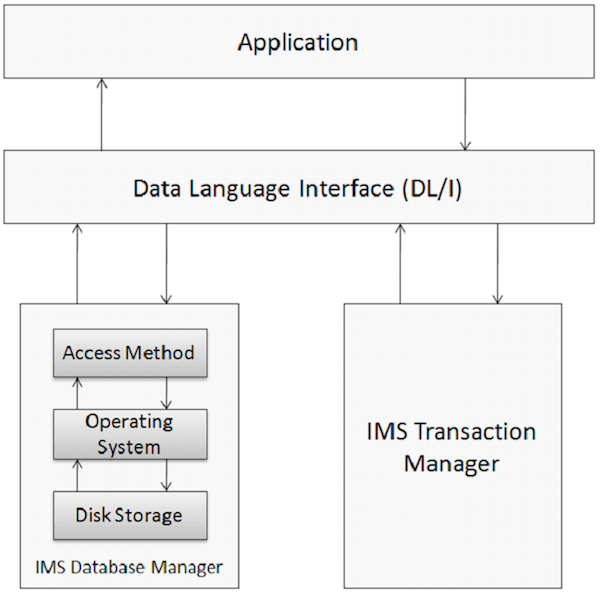
Manajemen Basis Data
Sistem Manajemen Basis Data adalah sekumpulan program aplikasi yang digunakan untuk menyimpan, mengakses, dan mengelola data dalam basis data. Sistem manajemen basis data IMS menjaga integritas dan memungkinkan pemulihan data yang cepat dengan mengaturnya sedemikian rupa sehingga mudah untuk diambil kembali. IMS mengelola sejumlah besar data perusahaan dunia dengan bantuan sistem manajemen basis datanya.
Manajer Transaksi
Fungsi manajer transaksi adalah menyediakan platform komunikasi antara database dan program aplikasi. IMS bertindak sebagai pengelola transaksi. Seorang manajer transaksi berurusan dengan pengguna akhir untuk menyimpan dan mengambil data dari database. IMS dapat menggunakan IMS DB atau DB2 sebagai database back-end untuk menyimpan data.
DL / I - Antarmuka Bahasa Data
DL / I terdiri dari program aplikasi yang memberikan akses ke data yang disimpan dalam database. IMS DB menggunakan DL / I yang berfungsi sebagai bahasa antarmuka yang digunakan programmer untuk mengakses database dalam program aplikasi. Kami akan membahas ini secara lebih rinci di bab-bab selanjutnya.
Karakteristik IMS
Poin yang perlu diperhatikan -
- IMS mendukung aplikasi dari berbagai bahasa seperti Java dan XML.
- Aplikasi dan data IMS dapat diakses melalui platform apa pun.
- Pemrosesan IMS DB sangat cepat dibandingkan dengan DB2.
Batasan IMS
Poin yang perlu diperhatikan -
- Implementasi IMS DB sangat kompleks.
- Struktur pohon yang telah ditentukan IMS mengurangi fleksibilitas.
- IMS DB sulit untuk dikelola.
Struktur Hirarki
Database IMS adalah kumpulan data yang menampung file fisik. Dalam database hierarki, tingkat paling atas berisi informasi umum tentang entitas. Saat kita melanjutkan dari tingkat atas ke tingkat bawah dalam hierarki, kita mendapatkan lebih banyak informasi tentang entitas.
Setiap level dalam hierarki berisi segmen. Dalam file standar, sulit untuk mengimplementasikan hierarki tetapi DL / I mendukung hierarki. Gambar berikut menggambarkan struktur IMS DB.
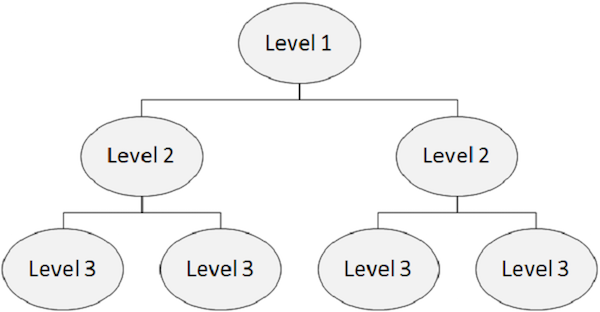
Segmen
Poin yang perlu diperhatikan -
Segmen dibuat dengan mengelompokkan data serupa.
Ini adalah unit informasi terkecil yang DL / I transfer ke dan dari program aplikasi selama operasi input-output.
Sebuah segmen dapat memiliki satu atau beberapa bidang data yang dikelompokkan bersama.
Dalam contoh berikut, segmen Siswa memiliki empat bidang data.
| Siswa | |||
|---|---|---|---|
| Nomor Gulung | Nama | Kursus | Nomor handphone |
Bidang
Poin yang perlu diperhatikan-
Bidang adalah satu bagian data dalam sebuah segmen. Misalnya, Roll Number, Name, Course, dan Mobile Number adalah satu bidang di segmen Siswa.
Segmen terdiri dari bidang terkait untuk mengumpulkan informasi dari suatu entitas.
Kolom dapat digunakan sebagai kunci untuk mengurutkan segmen.
Fields dapat digunakan sebagai kualifikasi untuk mencari informasi tentang segmen tertentu.
Jenis Segmen
Poin yang perlu diperhatikan -
Jenis Segmen adalah kategori data dalam sebuah segmen.
Database DL / I dapat memiliki 255 tipe segmen berbeda dan 15 level hierarki.
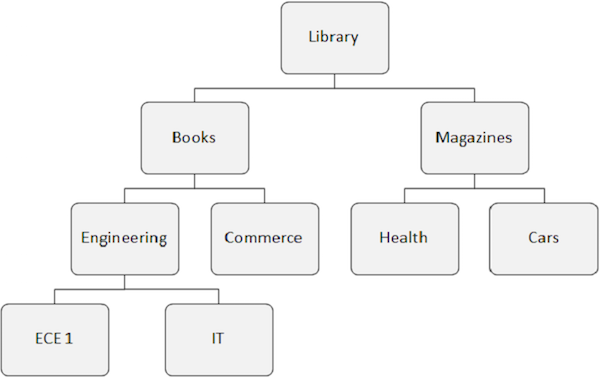
Pada gambar berikut terdapat tiga segmen yaitu Perpustakaan, Informasi Buku, dan Informasi Mahasiswa.
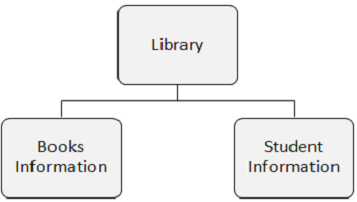
Kemunculan Segmen
Poin yang perlu diperhatikan -
Kemunculan segmen adalah segmen individu dari jenis tertentu yang berisi data pengguna. Dalam contoh di atas, Informasi Buku adalah satu jenis segmen dan ada sejumlah kemunculannya, karena dapat menyimpan informasi tentang sejumlah buku.
Dalam Basis Data IMS, hanya ada satu kejadian untuk setiap jenis segmen, tetapi bisa ada jumlah kejadian yang tidak terbatas untuk setiap jenis segmen.
Database hierarkis bekerja pada hubungan antara dua atau lebih segmen. Contoh berikut menunjukkan bagaimana segmen terkait satu sama lain dalam struktur database IMS.
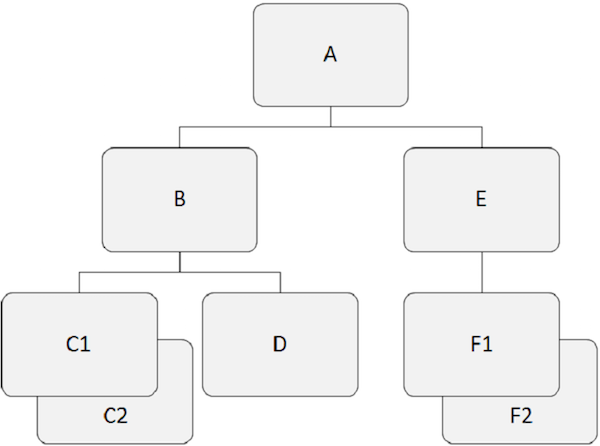
Segmen Root
Poin yang perlu diperhatikan -
Segmen yang terletak di atas hierarki disebut segmen akar.
Segmen akar adalah satu-satunya segmen di mana semua segmen dependen diakses.
Segmen akar adalah satu-satunya segmen dalam database yang tidak pernah menjadi segmen anak.
Hanya ada satu segmen root dalam struktur database IMS.
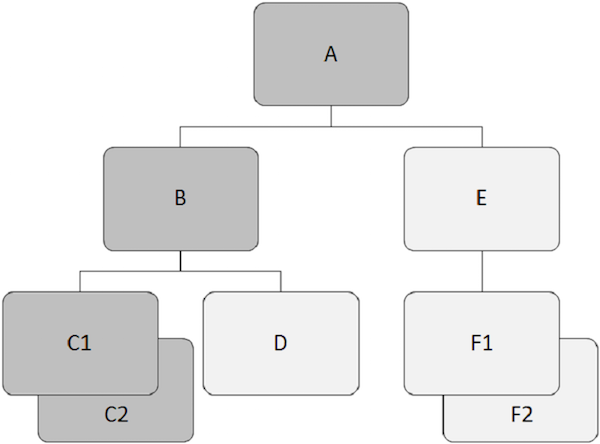
Sebagai contoh, 'A' adalah segmen akar pada contoh di atas.
Segmen Induk
Poin yang perlu diperhatikan -
Segmen induk memiliki satu atau lebih segmen bergantung tepat di bawahnya.
Sebagai contoh, 'A', 'B', dan 'E' adalah segmen induk pada contoh di atas.
Segmen Bergantung
Poin yang perlu diperhatikan -
Semua segmen selain segmen akar dikenal sebagai segmen dependen.
Segmen yang bergantung bergantung pada satu atau lebih segmen untuk menyajikan makna lengkap.
Sebagai contoh, 'B', 'C1', 'C2', 'D', 'E', 'F1' dan 'F2' adalah segmen dependen dalam contoh kami.
Segmen Anak
Poin yang perlu diperhatikan -
Segmen apa pun yang memiliki segmen tepat di atasnya dalam hierarki disebut segmen turunan.
Setiap segmen dependen dalam struktur adalah segmen anak.
Sebagai contoh, 'B', 'C1', 'C2', 'D', 'E', 'F1' dan 'F2' adalah segmen anak.
Segmen Kembar
Poin yang perlu diperhatikan -
Dua atau lebih kejadian segmen dari tipe segmen tertentu di bawah segmen induk tunggal disebut segmen kembar.
Sebagai contoh, 'C1' dan 'C2' adalah segmen kembar, begitu juga 'F1' dan 'F2' adalah.
Segmen Saudara
Poin yang perlu diperhatikan -
Segmen saudara adalah segmen dari jenis yang berbeda dan induk yang sama.
Sebagai contoh, 'B' dan 'E' adalah segmen saudara kandung. Demikian pula,'C1', 'C2', dan 'D' adalah segmen saudara kandung.
Rekaman Database
Poin yang perlu diperhatikan -
Setiap kemunculan segmen akar, ditambah semua kejadian segmen bawahan membuat satu rekaman database.
Setiap rekaman database hanya memiliki satu segmen akar tetapi mungkin memiliki sejumlah kejadian segmen.
Dalam pemrosesan file standar, record adalah unit data yang digunakan program aplikasi untuk operasi tertentu. Dalam DL / I, unit data tersebut dikenal sebagai segmen. Catatan database tunggal memiliki banyak kejadian segmen.
Jalur Basis Data
Poin yang perlu diperhatikan -
Lintasan adalah rangkaian segmen yang dimulai dari segmen akar rekaman database hingga kejadian segmen tertentu.
Jalur dalam struktur hierarki tidak harus lengkap hingga tingkat terendah. Itu tergantung pada seberapa banyak informasi yang kami butuhkan tentang suatu entitas.
Jalur harus kontinu dan kami tidak dapat melewati tingkat perantara dalam struktur.
Pada gambar berikut, rekaman anak dalam warna abu-abu tua menunjukkan jalur yang dimulai dari 'A' dan melewati 'C2'.
IMS DB menyimpan data pada level yang berbeda. Data diambil dan dimasukkan dengan mengeluarkan panggilan DL / I dari program aplikasi. Kami akan membahas tentang panggilan DL / I secara rinci di bab-bab selanjutnya. Data dapat diproses dengan dua cara berikut -
- Pemrosesan Berurutan
- Pemrosesan Acak
Pemrosesan Berurutan
Ketika segmen diambil secara berurutan dari database, DL / I mengikuti pola yang telah ditentukan sebelumnya. Mari kita pahami pemrosesan sekuensial IMS DB.
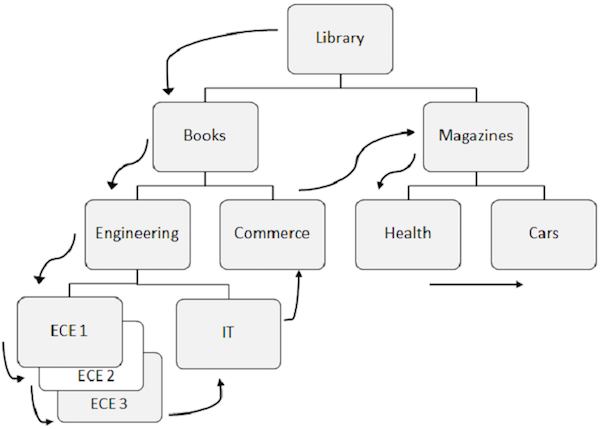
Di bawah ini adalah hal-hal yang perlu diperhatikan tentang pemrosesan berurutan -
Pola standar untuk mengakses data dalam DL / I adalah yang pertama di hierarki, lalu dari kiri ke kanan.
Segmen akar diambil terlebih dahulu, kemudian DL / I pindah ke anak kiri pertama dan turun hingga tingkat terendah. Pada tingkat terendah, itu mengambil semua kemunculan segmen kembar. Kemudian masuk ke segmen kanan.
Untuk lebih memahami, amati panah pada gambar di atas yang menunjukkan aliran untuk mengakses segmen. Perpustakaan adalah segmen akar dan alirannya dimulai dari sana dan berlanjut hingga mobil mengakses satu catatan. Proses yang sama diulangi untuk semua kejadian untuk mendapatkan semua catatan data.
Saat mengakses data, program menggunakan position dalam database yang membantu mengambil dan menyisipkan segmen.
Pemrosesan Acak
Pemrosesan acak juga dikenal sebagai pemrosesan langsung data di IMS DB. Mari kita ambil contoh untuk memahami pemrosesan acak di IMS DB -
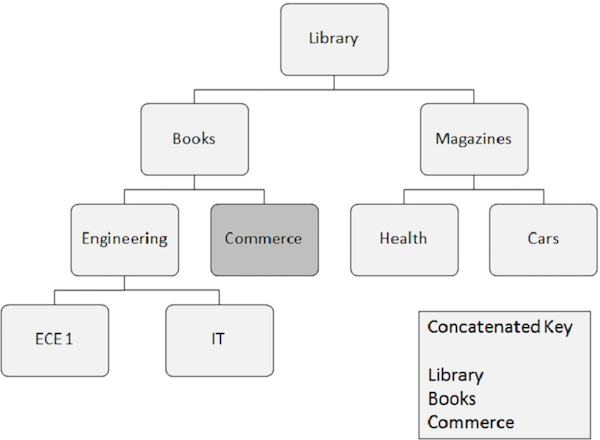
Di bawah ini adalah hal-hal yang perlu diperhatikan tentang pemrosesan acak -
Kemunculan segmen yang perlu diambil secara acak membutuhkan bidang kunci dari semua segmen yang bergantung padanya. Bidang kunci ini disediakan oleh program aplikasi.
Kunci yang digabungkan sepenuhnya mengidentifikasi jalur dari segmen akar ke segmen yang ingin Anda ambil.
Misalnya Anda ingin mengambil kemunculan segmen Niaga, maka Anda perlu menyediakan nilai bidang kunci gabungan dari segmen yang bergantung padanya, seperti Perpustakaan, Buku, dan Perdagangan.
Pemrosesan acak lebih cepat daripada pemrosesan sekuensial. Dalam skenario dunia nyata, aplikasi menggabungkan metode pemrosesan sekuensial dan acak bersama-sama untuk mencapai hasil terbaik.
Bidang Kunci
Poin yang perlu diperhatikan -
Bidang kunci juga dikenal sebagai bidang urutan.
Bidang kunci ada di dalam segmen dan digunakan untuk mengambil kemunculan segmen.
Bidang kunci mengelola kemunculan segmen dalam urutan menaik.
Di setiap segmen, hanya satu bidang yang dapat digunakan sebagai bidang kunci atau bidang urutan.
Bidang Pencarian
Seperti yang disebutkan, hanya satu bidang yang dapat digunakan sebagai bidang kunci. Jika Anda ingin mencari konten kolom segmen lain yang bukan merupakan kolom kunci, maka kolom yang digunakan untuk mengambil data disebut kolom pencarian.
Blok Kontrol IMS menentukan struktur database IMS dan akses program ke sana. Diagram berikut menunjukkan struktur blok kontrol IMS.
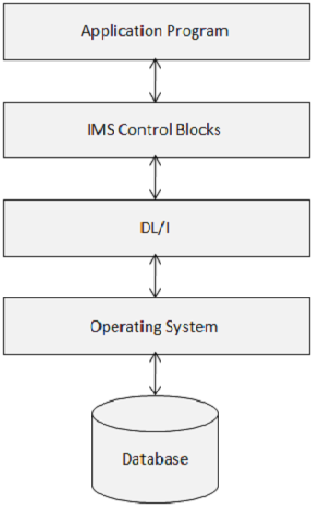
DL / I menggunakan tiga jenis Blok Kontrol berikut -
- Deskriptor Basis Data (DBD)
- Blok Spesifikasi Program (PSB)
- Blok Kontrol Akses (ACB)
Deskriptor Basis Data (DBD)
Poin yang perlu diperhatikan -
DBD menjelaskan struktur fisik lengkap dari database setelah semua segmen telah ditentukan.
Saat menginstal database DL / I, satu DBD harus dibuat karena diperlukan untuk mengakses database IMS.
Aplikasi dapat menggunakan tampilan DBD yang berbeda. Mereka disebut Struktur Data Aplikasi dan ditentukan dalam Blok Spesifikasi Program.
Administrator Database membuat DBD dengan pengkodean DBDGEN pernyataan kontrol.
DBDGEN
DBDGEN adalah Generator Deskriptor Database. Membuat blok kontrol adalah tanggung jawab Administrator Database. Semua modul beban disimpan di pustaka IMS. Pernyataan makro Bahasa Perakitan digunakan untuk membuat blok kontrol. Diberikan di bawah ini adalah contoh kode yang menunjukkan cara membuat DBD menggunakan pernyataan kontrol DBDGEN -
PRINT NOGEN
DBD NAME=LIBRARY,ACCESS=HIDAM
DATASET DD1=LIB,DEVICE=3380
SEGM NAME=LIBSEG,PARENT=0,BYTES=10
FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5
FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9
FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C
DBDGEN
FINISH
ENDMari kita pahami istilah-istilah yang digunakan dalam DBDGEN di atas -
Saat Anda menjalankan pernyataan kontrol di atas di JCL, itu menciptakan struktur fisik di mana PERPUSTAKAAN adalah segmen akar, dan BUKU dan SIHIR adalah segmen anaknya.
Pernyataan makro DBD pertama mengidentifikasi database. Di sini, kami perlu menyebutkan NAMA dan AKSES yang digunakan oleh DL / I untuk mengakses database ini.
Pernyataan makro DATASET kedua mengidentifikasi file yang berisi database.
Jenis segmen ditentukan menggunakan pernyataan makro SEGM. Kita perlu menentukan ORANG TUA dari segmen itu. Jika itu adalah segmen Root, sebutkan ORANGTUA = 0.
Tabel berikut menunjukkan parameter yang digunakan dalam pernyataan makro FIELD -
| S.No | Parameter & Deskripsi |
|---|---|
| 1 | Name Nama bidang, biasanya sepanjang 1 hingga 8 karakter |
| 2 | Bytes Panjang lapangan |
| 3 | Start Posisi lapangan dalam segmen |
| 4 | Type Jenis data lapangan |
| 5 | Type C Tipe data karakter |
| 6 | Type P Tipe data desimal yang dikemas |
| 7 | Type Z Tipe data desimal yang dikategorikan |
| 8 | Type X Tipe data heksadesimal |
| 9 | Type H Tipe data biner setengah kata |
| 10 | Type F Tipe data biner kata penuh |
Blok Spesifikasi Program (PSB)
Dasar-dasar PSB adalah sebagai berikut -
Database memiliki struktur fisik tunggal yang ditentukan oleh DBD tetapi program aplikasi yang memprosesnya dapat memiliki tampilan database yang berbeda. Tampilan ini disebut struktur data aplikasi dan ditentukan dalam PSB.
Tidak ada program yang dapat menggunakan lebih dari satu PSB dalam satu eksekusi.
Program aplikasi memiliki PSB sendiri dan program aplikasi yang memiliki persyaratan pemrosesan database serupa untuk berbagi PSB adalah hal yang umum.
PSB terdiri dari satu atau lebih blok kontrol yang disebut Program Communication Block (PCBs). PSB berisi satu PCB untuk setiap database DL / I yang akan diakses program aplikasi. Kami akan membahas lebih lanjut tentang PCB di modul mendatang.
PSBGEN harus dilakukan untuk membuat PSB untuk program tersebut.
PSBGEN
PSBGEN dikenal sebagai Generator Blok Spesifikasi Program. Contoh berikut membuat PSB menggunakan PSBGEN -
PRINT NOGEN
PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS
SENSEG NAME=LIBSEG
SENSEG NAME=BOOKSEG,PARENT=LIBSEG
SENSEG NAME=MAGSEG,PARENT=LIBSEG
PSBGEN PSBNAME=LIBPSB,LANG=COBOL
ENDMari kita pahami istilah-istilah yang digunakan dalam DBDGEN di atas -
Pernyataan makro pertama adalah Program Communication Block (PCB) yang menjelaskan Jenis database, Nama, Panjang Kunci, dan Opsi Pemrosesan.
Parameter DBDNAME pada makro PCB menentukan nama DBD. KEYLEN menentukan panjang kunci gabungan terpanjang. Program dapat memproses di database. Parameter PROCOPT menentukan opsi pemrosesan program. Misalnya, LS hanya berarti Operasi LOAD.
SENSEG dikenal sebagai Sensitivitas Tingkat Segmen. Ini mendefinisikan akses program ke bagian database dan diidentifikasi pada tingkat segmen. Program ini memiliki akses ke semua bidang dalam segmen yang sensitif. Suatu program juga dapat memiliki sensitivitas tingkat lapangan. Dalam hal ini, kami mendefinisikan nama segmen dan nama induk dari segmen tersebut.
Pernyataan makro terakhir adalah PCBGEN. PSBGEN adalah pernyataan terakhir yang mengatakan bahwa tidak ada lagi pernyataan yang harus diproses. PSBNAME mendefinisikan nama yang diberikan untuk modul PSB keluaran. Parameter LANG menentukan bahasa di mana program aplikasi ditulis, misalnya, COBOL.
Blok Kontrol Akses (ACB)
Di bawah ini adalah hal-hal yang perlu diperhatikan tentang blok kontrol akses -
Blok Kontrol Akses untuk program aplikasi menggabungkan Deskriptor Database dan Blok Spesifikasi Program ke dalam bentuk yang dapat dieksekusi.
ACBGEN dikenal sebagai Access Control Blocks Generator. Ini digunakan untuk menghasilkan ACB.
Untuk program online, kami perlu membuat ACB sebelumnya. Karenanya utilitas ACBGEN dijalankan sebelum menjalankan program aplikasi.
Untuk program batch, ACB juga dapat dibuat pada waktu eksekusi.
Program aplikasi yang mencakup panggilan DL / I tidak dapat dijalankan secara langsung. Sebaliknya, JCL diperlukan untuk memicu modul batch IMS DL / I. Modul inisialisasi batch di IMS adalah DFSRRC00. Program aplikasi dan modul DL / I dijalankan bersamaan. Diagram berikut menunjukkan struktur program aplikasi yang mencakup panggilan DL / I untuk mengakses database.
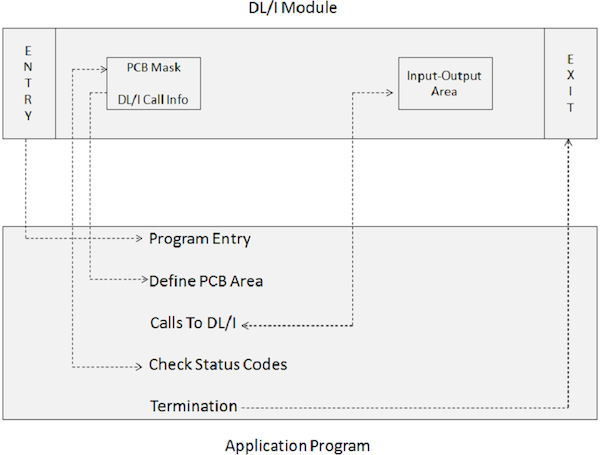
Program aplikasi berinteraksi dengan modul IMS DL / I melalui elemen program berikut -
Pernyataan ENTRY menentukan bahwa PCB digunakan oleh program.
Sebuah PCB-mask berhubungan dengan informasi yang disimpan dalam PCB yang telah dibuat sebelumnya yang menerima informasi kembali dari IMS.
Area Input-Output digunakan untuk meneruskan segmen data ke dan dari database IMS.
Panggilan ke DL / I menentukan fungsi pemrosesan seperti mengambil, menyisipkan, menghapus, mengganti, dll.
Periksa Kode Status digunakan untuk memeriksa kode kembali SQL dari opsi pemrosesan yang ditentukan untuk menginformasikan apakah operasi itu berhasil atau tidak.
Pernyataan Hentikan digunakan untuk mengakhiri pemrosesan program aplikasi yang mencakup DL / I.
Tata Letak Segmen
Sampai saat ini, kami mempelajari bahwa IMS terdiri dari segmen yang digunakan dalam bahasa pemrograman tingkat tinggi untuk mengakses data. Pertimbangkan struktur database IMS berikut dari Library yang telah kita lihat sebelumnya dan di sini kita melihat tata letak segmennya di COBOL -
01 LIBRARY-SEGMENT.
05 BOOK-ID PIC X(5).
05 ISSUE-DATE PIC X(10).
05 RETURN-DATE PIC X(10).
05 STUDENT-ID PIC A(25).
01 BOOK-SEGMENT.
05 BOOK-ID PIC X(5).
05 BOOK-NAME PIC A(30).
05 AUTHOR PIC A(25).
01 STUDENT-SEGMENT.
05 STUDENT-ID PIC X(5).
05 STUDENT-NAME PIC A(25).
05 DIVISION PIC X(10).Ikhtisar Program Aplikasi
Struktur program aplikasi IMS berbeda dengan program aplikasi Non-IMS. Program IMS tidak dapat dijalankan secara langsung; melainkan selalu disebut sebagai subrutin. Program aplikasi IMS terdiri dari Blok Spesifikasi Program untuk memberikan tampilan database IMS.
Program aplikasi dan PSB yang ditautkan ke program itu dimuat ketika kita menjalankan program aplikasi yang menyertakan modul IMS DL / I. Kemudian permintaan CALL yang dipicu oleh program aplikasi dijalankan oleh modul IMS.
Layanan IMS
Layanan IMS berikut digunakan oleh program aplikasi -
- Mengakses catatan database
- Menerbitkan perintah IMS
- Menerbitkan panggilan layanan IMS
- Panggilan pos pemeriksaan
- Sinkronkan panggilan
- Mengirim atau menerima pesan dari terminal pengguna online
Kami menyertakan panggilan DL / I di dalam program aplikasi COBOL untuk berkomunikasi dengan database IMS. Kami menggunakan pernyataan DL / I berikut dalam program COBOL untuk mengakses database -
- Pernyataan Entri
- Pernyataan Goback
- Pernyataan Panggilan
Pernyataan Entri
Ini digunakan untuk meneruskan kontrol dari DL / I ke program COBOL. Berikut adalah sintaks dari pernyataan entri -
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]Pernyataan di atas dikodekan dalam Procedure Divisiondari program COBOL. Mari kita masuk ke detail pernyataan entri di program COBOL -
Modul inisialisasi batch memicu program aplikasi dan dijalankan di bawah kendalinya.
DL / I memuat blok dan modul kontrol yang diperlukan serta program aplikasi, dan kontrol diberikan ke program aplikasi.
DLITCBL adalah singkatan dari DL/I to COBOL. Pernyataan entri digunakan untuk menentukan titik masuk dalam program.
Ketika kami memanggil sub-program di COBOL, alamatnya juga disediakan. Demikian juga, ketika DL / I memberikan kontrol ke program aplikasi, DL / I juga memberikan alamat setiap PCB yang ditentukan dalam PSB program.
Semua PCB yang digunakan dalam program aplikasi harus ditentukan di dalam Linkage Section dari program COBOL karena PCB berada di luar program aplikasi.
Definisi PCB di dalam Bagian Linkage disebut sebagai PCB Mask.
Hubungan antara topeng PCB dan PCB aktual dalam penyimpanan dibuat dengan mencantumkan PCB di pernyataan entri. Urutan daftar di pernyataan entri harus sama dengan yang muncul di PSBGEN.
Pernyataan Goback
Ini digunakan untuk meneruskan kontrol kembali ke program kontrol IMS. Berikut ini adalah sintaks dari pernyataan Goback -
GOBACKDi bawah ini adalah poin-poin mendasar yang perlu diperhatikan tentang pernyataan Goback -
GOBACK diberi kode di akhir program aplikasi. Ini mengembalikan kontrol ke DL / I dari program.
Kita tidak boleh menggunakan STOP RUN karena mengembalikan kontrol ke sistem operasi. Jika kita menggunakan STOP RUN, DL / I tidak pernah mendapat kesempatan untuk melakukan fungsi penghentiannya. Itulah sebabnya, dalam program aplikasi DL / I, pernyataan Goback digunakan.
Sebelum mengeluarkan pernyataan Goback, semua set data non-DL / I yang digunakan dalam program aplikasi COBOL harus ditutup, jika tidak program akan berhenti secara tidak normal.
Pernyataan Panggilan
Pernyataan panggilan digunakan untuk meminta layanan DL / I seperti menjalankan operasi tertentu pada database IMS. Berikut adalah sintaks dari pernyataan panggilan -
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]Sintaks di atas menunjukkan parameter yang dapat Anda gunakan dengan pernyataan panggilan. Kami akan membahas masing-masing di tabel berikut -
| S.No. | Parameter & Deskripsi |
|---|---|
| 1 | DLI Function Code Mengidentifikasi fungsi DL / I yang akan dijalankan. Argumen ini adalah nama dari empat bidang karakter yang menjelaskan operasi I / O. |
| 2 | PCB Mask Definisi PCB di dalam Bagian Linkage disebut sebagai PCB Mask. Mereka digunakan dalam pernyataan entri. Tidak ada pernyataan SELECT, ASSIGN, OPEN, atau CLOSE yang diperlukan. |
| 3 | Segment I/O Area Nama area kerja input / output. Ini adalah area program aplikasi di mana DL / I menempatkan segmen yang diminta. |
| 4 | Segment Search Arguments Ini adalah parameter opsional tergantung pada jenis panggilan yang dilakukan. Mereka digunakan untuk mencari segmen data di dalam database IMS. |
Diberikan di bawah ini adalah poin yang perlu diperhatikan tentang pernyataan Panggilan -
CBLTDLI adalah singkatan dari COBOL to DL/I. Ini adalah nama modul antarmuka yang tautannya diedit dengan modul objek program Anda.
Setelah setiap panggilan DL / I, DLI menyimpan kode status di PCB. Program dapat menggunakan kode ini untuk menentukan apakah panggilan berhasil atau gagal.
Contoh
Untuk lebih memahami COBOL, Anda dapat melalui tutorial COBOL kami di sini . Contoh berikut menunjukkan struktur program COBOL yang menggunakan database IMS dan panggilan DL / I. Kami akan membahas secara rinci masing-masing parameter yang digunakan dalam contoh di bab-bab selanjutnya.
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.Fungsi DL / I adalah parameter pertama yang digunakan dalam panggilan DL / I. Fungsi ini memberi tahu operasi mana yang akan dilakukan pada database IMS dengan panggilan IMS DL / I. Sintaks fungsi DL / I adalah sebagai berikut -
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.Sintaks ini mewakili poin-poin penting berikut -
Untuk parameter ini, kami dapat memberikan nama empat karakter apa pun sebagai bidang penyimpanan untuk menyimpan kode fungsi.
Parameter fungsi DL / I dikodekan di bagian penyimpanan kerja program COBOL.
Untuk menentukan fungsi DL / I, programmer perlu mengkodekan salah satu dari nama data level 05 seperti DLI-GU dalam panggilan DL / I, karena COBOL tidak mengizinkan kode literal pada pernyataan CALL.
Fungsi DL / I dibagi menjadi tiga kategori: Dapatkan, Perbarui, dan Fungsi lainnya. Mari kita bahas masing-masing secara rinci.
Dapatkan Fungsi
Fungsi Get mirip dengan operasi baca yang didukung oleh bahasa pemrograman apa pun. Fungsi get digunakan untuk mengambil segmen dari database IMS DL / I. Fungsi Get berikut digunakan di IMS DB -
- Menjadi Unik
- Dapatkan Berikutnya
- Dapatkan Berikutnya dalam Parent
- Dapatkan Pegangan Unik
- Bertahan Selanjutnya
- Bertahan Berikutnya dalam Orang Tua
Mari kita pertimbangkan struktur database IMS berikut untuk memahami panggilan fungsi DL / I -
Menjadi Unik
Kode 'GU' digunakan untuk fungsi Get Unique. Cara kerjanya mirip dengan pernyataan baca acak di COBOL. Ini digunakan untuk mengambil kejadian segmen tertentu berdasarkan nilai bidang. Nilai bidang dapat diberikan menggunakan argumen pencarian segmen. Sintaks dari panggilan GU adalah sebagai berikut -
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Jika Anda menjalankan pernyataan panggilan di atas dengan memberikan nilai yang sesuai untuk semua parameter dalam program COBOL, Anda dapat mengambil segmen di area I / O segmen dari database. Dalam contoh di atas, jika Anda memberikan nilai bidang Perpustakaan, Majalah, dan Kesehatan, maka Anda mendapatkan kemunculan segmen Kesehatan yang diinginkan.
Dapatkan Berikutnya
Kode 'GN' digunakan untuk fungsi Get Next. Ini bekerja mirip dengan pernyataan baca berikutnya di COBOL. Ini digunakan untuk mengambil kejadian segmen secara berurutan. Pola yang telah ditentukan untuk mengakses kejadian segmen data berada di bawah hierarki, lalu dari kiri ke kanan. Sintaks dari panggilan GN adalah sebagai berikut -
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Jika Anda menjalankan pernyataan panggilan di atas dengan memberikan nilai yang sesuai untuk semua parameter dalam program COBOL, Anda dapat mengambil kejadian segmen di area I / O segmen dari database secara berurutan. Pada contoh di atas, dimulai dengan mengakses segmen Perpustakaan, lalu segmen Buku, dan seterusnya. Kami melakukan pemanggilan GN berulang kali, hingga kami mencapai kemunculan segmen yang kami inginkan.
Dapatkan Berikutnya dalam Parent
Kode 'GNP' digunakan untuk Get Next dalam Parent. Fungsi ini digunakan untuk mengambil kejadian segmen secara berurutan di bawah segmen induk yang telah ditetapkan. Sintaks dari panggilan GNP adalah sebagai berikut -
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Dapatkan Pegangan Unik
Kode 'GHU' digunakan untuk Get Hold Unique. Fungsi tahan menentukan bahwa kita akan memperbarui segmen setelah pengambilan. Fungsi Get Hold Unique terkait dengan panggilan Get Unique. Diberikan di bawah ini adalah sintaks dari panggilan GHU -
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Bertahan Selanjutnya
Kode 'GHN' digunakan untuk Get Hold Next. Fungsi tahan menentukan bahwa kita akan memperbarui segmen setelah pengambilan. Fungsi Get Hold Next berhubungan dengan panggilan Get Next. Diberikan di bawah ini adalah sintaks dari panggilan GHN -
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Bertahan Berikutnya dalam Orang Tua
Kode 'GHNP' digunakan untuk Get Hold Next dalam Parent. Fungsi tahan menentukan bahwa kita akan memperbarui segmen setelah pengambilan. Fungsi Get Hold Next dalam Parent berhubungan dengan panggilan Get Next in Parent. Diberikan di bawah ini adalah sintaks dari panggilan GHNP -
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Perbarui Fungsi
Fungsi pemutakhiran mirip dengan operasi penulisan ulang atau penyisipan dalam bahasa pemrograman lain. Fungsi pembaruan digunakan untuk memperbarui segmen dalam database IMS DL / I. Sebelum menggunakan fungsi pembaruan, harus ada panggilan yang berhasil dengan klausa Tahan untuk terjadinya segmen. Fungsi Pembaruan berikut digunakan di IMS DB -
- Insert
- Delete
- Replace
Memasukkan
Kode 'ISRT' digunakan untuk fungsi Sisipkan. Fungsi ISRT digunakan untuk menambahkan segmen baru ke database. Ini digunakan untuk mengubah database yang ada atau memuat database baru. Diberikan di bawah ini adalah sintaks dari panggilan ISRT -
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]Menghapus
Kode 'DLET' digunakan untuk fungsi Hapus. Ini digunakan untuk menghapus segmen dari database IMS DL / I. Diberikan di bawah ini adalah sintaks dari panggilan DLET -
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]Menggantikan
Kode 'REPL' digunakan untuk Get Hold Next dalam Parent. Fungsi Replace digunakan untuk mengganti segmen dalam database IMS DL / I. Diberikan di bawah ini adalah sintaks dari panggilan REPL -
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]Fungsi Lainnya
Fungsi lain berikut ini digunakan dalam panggilan IMS DL / I -
- Checkpoint
- Restart
- PCB
Pos pemeriksaan
Kode 'CHKP' digunakan untuk fungsi Checkpoint. Ini digunakan dalam fitur pemulihan IMS. Diberikan di bawah ini adalah sintaks dari panggilan CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Mengulang kembali
Kode 'XRST' digunakan untuk fungsi Restart. Ini digunakan dalam fitur restart IMS. Diberikan di bawah ini adalah sintaks dari panggilan XRST -
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]PCB
Fungsi PCB digunakan dalam program CICS dalam database IMS DL / I. Diberikan di bawah ini adalah sintaks dari panggilan PCB -
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]Anda dapat menemukan detail selengkapnya tentang fungsi-fungsi ini di bab pemulihan.
PCB adalah singkatan dari Program Communication Block. PCB Mask adalah parameter kedua yang digunakan dalam panggilan DL / I. Itu dideklarasikan di bagian linkage. Diberikan di bawah ini adalah sintaks dari PCB Mask -
01 PCB-NAME.
05 DBD-NAME PIC X(8).
05 SEG-LEVEL PIC XX.
05 STATUS-CODE PIC XX.
05 PROC-OPTIONS PIC X(4).
05 RESERVED-DLI PIC S9(5).
05 SEG-NAME PIC X(8).
05 LENGTH-FB-KEY PIC S9(5).
05 NUMB-SENS-SEGS PIC S9(5).
05 KEY-FB-AREA PIC X(n).Berikut adalah poin-poin penting yang perlu diperhatikan -
Untuk setiap database, DL / I mempertahankan area penyimpanan yang dikenal sebagai blok komunikasi program. Ini menyimpan informasi tentang database yang diakses di dalam program aplikasi.
Pernyataan ENTRY membuat koneksi antara topeng PCB di Bagian Linkage dan PCB di dalam PSB program. Masker PCB yang digunakan dalam panggilan DL / I memberi tahu database mana yang digunakan untuk operasi.
Anda dapat menganggap ini mirip dengan menentukan nama file dalam pernyataan COBOL READ atau nama catatan dalam pernyataan tulis COBOL. Tidak ada pernyataan SELECT, ASSIGN, OPEN, atau CLOSE yang diperlukan.
Setelah setiap panggilan DL / I, DL / I menyimpan kode status di PCB dan program dapat menggunakan kode tersebut untuk menentukan apakah panggilan berhasil atau gagal.
Nama PCB
Poin yang perlu diperhatikan -
Nama PCB adalah nama area yang mengacu pada seluruh struktur bidang PCB.
Nama PCB digunakan dalam pernyataan program.
Nama PCB bukan bidang di PCB.
Nama DBD
Poin yang perlu diperhatikan -
Nama DBD berisi data karakter. Panjangnya delapan byte.
Kolom pertama di PCB adalah nama database yang sedang diproses dan memberikan nama DBD dari pustaka deskripsi database yang terkait dengan database tertentu.
Tingkat Segmen
Poin yang perlu diperhatikan -
Tingkat segmen dikenal sebagai Indikator Tingkat Hierarki Segmen. Ini berisi data karakter dan panjangnya dua byte.
Bidang tingkat segmen menyimpan tingkat segmen yang diproses. Ketika segmen berhasil diambil, nomor level dari segmen yang diambil disimpan di sini.
Bidang tingkat segmen tidak pernah memiliki nilai yang lebih besar dari 15 karena itulah jumlah maksimum tingkat yang diizinkan dalam database DL / I.
Kode status
Poin yang perlu diperhatikan -
Bidang kode status berisi dua byte data karakter.
Kode status berisi kode status DL / I.
Spasi dipindahkan ke bidang kode status saat DL / I berhasil menyelesaikan pemrosesan panggilan.
Nilai non-spasi menunjukkan bahwa panggilan tidak berhasil.
Kode status GB menunjukkan akhir file dan kode status GE menunjukkan bahwa segmen yang diminta tidak ditemukan.
Opsi Proc
Poin yang perlu diperhatikan -
Opsi Proc dikenal sebagai opsi pemrosesan yang berisi bidang data empat karakter.
Bidang Opsi Pemrosesan menunjukkan jenis pemrosesan apa yang diizinkan untuk dilakukan program pada database.
DL / I yang dipesan
Poin yang perlu diperhatikan -
DL / I yang dicadangkan dikenal sebagai area yang dicadangkan di IMS. Ini menyimpan empat byte data biner.
IMS menggunakan area ini untuk tautan internalnya sendiri yang terkait dengan program aplikasi.
Nama Segmen
Poin yang perlu diperhatikan -
Nama SEG dikenal sebagai area umpan balik nama segmen. Ini berisi 8 byte data karakter.
Nama segmen disimpan di bidang ini setelah setiap panggilan DL / I.
Panjang Kunci FB
Poin yang perlu diperhatikan -
Panjang tombol FB dikenal sebagai panjang area umpan balik kunci. Ini menyimpan empat byte data biner.
Bidang ini digunakan untuk melaporkan panjang kunci gabungan dari segmen tingkat terendah yang diproses selama panggilan sebelumnya.
Ini digunakan dengan area umpan balik utama.
Jumlah Segmen Sensitivitas
Poin yang perlu diperhatikan -
Jumlah segmen sensitivitas menyimpan data biner empat byte.
Ini menentukan tingkat sensitifitas program aplikasi. Ini mewakili hitungan jumlah segmen dalam struktur data logis.
Area Umpan Balik Utama
Poin yang perlu diperhatikan -
Panjang area umpan balik utama bervariasi dari satu PCB ke yang lain.
Ini berisi kunci gabungan terpanjang yang dapat digunakan dengan tampilan program dari database.
Setelah operasi database, DL / I mengembalikan kunci gabungan dari segmen tingkat terendah yang diproses di bidang ini, dan mengembalikan panjang kunci di area umpan balik panjang kunci.
SSA adalah singkatan dari Segment Search Arguments. SSA digunakan untuk mengidentifikasi kemunculan segmen yang sedang diakses. Ini adalah parameter opsional. Kami dapat menyertakan sejumlah SSA tergantung pada kebutuhan. Ada dua jenis SSA -
- SSA tidak memenuhi syarat
- SSA yang memenuhi syarat
SSA tidak memenuhi syarat
SSA yang tidak memenuhi syarat memberikan nama segmen yang digunakan di dalam panggilan. Diberikan di bawah ini adalah sintaks dari SSA yang tidak memenuhi syarat -
01 UNQUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X VALUE SPACE.Poin kunci dari SSA yang tidak memenuhi syarat adalah sebagai berikut -
SSA dasar yang tidak memenuhi syarat memiliki panjang 9 byte.
8 byte pertama berisi nama segmen yang digunakan untuk pemrosesan.
Byte terakhir selalu berisi spasi.
DL / I menggunakan byte terakhir untuk menentukan jenis SSA.
Untuk mengakses segmen tertentu, pindahkan nama segmen di kolom NAMA SEGMEN.
Gambar berikut menunjukkan struktur SSA yang tidak memenuhi syarat dan memenuhi syarat -
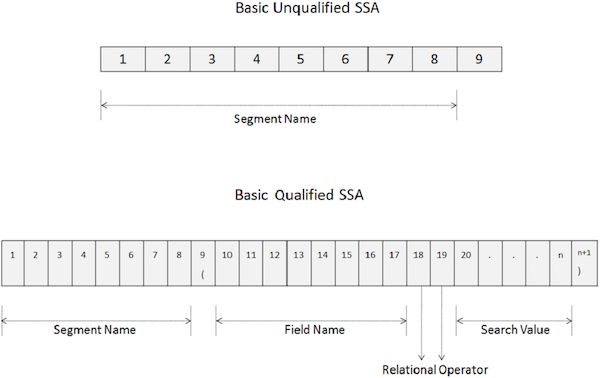
SSA yang memenuhi syarat
SSA yang Memenuhi Syarat menyediakan tipe segmen dengan kejadian database spesifik dari suatu segmen. Diberikan di bawah ini adalah sintaks dari SSA Berkualifikasi -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.Poin utama dari SSA yang memenuhi syarat adalah sebagai berikut -
8 byte pertama dari SSA yang memenuhi syarat menyimpan nama segmen yang digunakan untuk pemrosesan.
Byte kesembilan adalah tanda kurung kiri '('.
8 byte berikutnya mulai dari posisi kesepuluh menentukan nama bidang yang ingin kita cari.
Setelah nama field, dalam 18 th dan 19 th posisi, kita tentukan dua karakter kode operator relasional.
Kemudian kami menentukan nilai bidang dan di byte terakhir, ada tanda kurung kanan ')'.
Tabel berikut menunjukkan operator relasional yang digunakan dalam SSA yang Memenuhi Syarat.
| Operator Relasional | Simbol | Deskripsi |
|---|---|---|
| EQ | = | Sama |
| NE | ~ = ˜ | Tidak sama |
| GT | > | Lebih besar dari |
| GE | > = | Lebih dari atau sama |
| LT | << | Kurang dari |
| LE | <= | Kurang dari atau sama |
Kode Perintah
Kode perintah digunakan untuk meningkatkan fungsionalitas panggilan DL / I. Kode perintah mengurangi jumlah panggilan DL / I, membuat program menjadi sederhana. Selain itu, ini meningkatkan kinerja karena jumlah panggilan berkurang. Gambar berikut menunjukkan bagaimana kode perintah digunakan dalam SSA yang tidak memenuhi syarat dan memenuhi syarat -
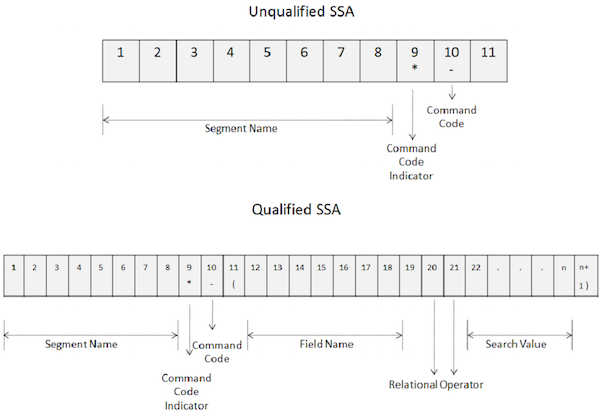
Poin utama dari kode perintah adalah sebagai berikut -
Untuk menggunakan kode perintah, tentukan tanda bintang di 9 th posisi SSA seperti yang ditunjukkan pada gambar di atas.
Kode perintah dikodekan di posisi kesepuluh.
Dari posisi ke- 10 dan seterusnya, DL / I menganggap semua karakter sebagai kode perintah hingga menemukan spasi untuk SSA yang tidak memenuhi syarat dan tanda kurung kiri untuk SSA yang memenuhi syarat.
Tabel berikut menunjukkan daftar kode perintah yang digunakan di SSA -
| Kode Perintah | Deskripsi |
|---|---|
| C | Kunci Gabungan |
| D | Path Call |
| F | Kejadian Pertama |
| L | Kejadian Terakhir |
| N | Path Call Abaikan |
| P. | Tetapkan Parentage |
| Q | Segmen Antrean |
| U | Pertahankan Posisi di level ini |
| V. | Pertahankan Posisi di level ini dan semua level di atas |
| - | Kode Perintah Null |
Kualifikasi Ganda
Poin mendasar dari beberapa kualifikasi adalah sebagai berikut -
Beberapa kualifikasi diperlukan ketika kita perlu menggunakan dua atau lebih kualifikasi atau bidang untuk perbandingan.
Kami menggunakan operator Boolean seperti AND dan OR untuk menghubungkan dua atau lebih kualifikasi.
Beberapa kualifikasi dapat digunakan saat kita ingin memproses segmen berdasarkan kisaran nilai yang memungkinkan untuk satu bidang.
Diberikan di bawah ini adalah sintaks dari Beberapa Kualifikasi -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.MUL-QUAL adalah singkatan dari MULtiple QUALIification dimana kami menyediakan operator boolean seperti AND atau OR.
Berbagai metode pengambilan data yang digunakan dalam panggilan IMS DL / I adalah sebagai berikut -
- Panggilan GU
- GN Call
- Menggunakan Kode Perintah
- Pemrosesan Ganda
Mari kita pertimbangkan struktur database IMS berikut untuk memahami panggilan fungsi pengambilan data -
Panggilan GU
Dasar-dasar panggilan GU adalah sebagai berikut -
Panggilan GU dikenal sebagai Get Unique call. Ini digunakan untuk pemrosesan acak.
Jika aplikasi tidak mengupdate database secara teratur atau jika jumlah update database kurang, maka kami menggunakan pemrosesan acak.
Panggilan GU digunakan untuk menempatkan penunjuk pada posisi tertentu untuk pengambilan sekuensial lebih lanjut.
Panggilan GU tidak tergantung pada posisi penunjuk yang ditetapkan oleh panggilan sebelumnya.
Pemrosesan panggilan GU didasarkan pada bidang kunci unik yang disediakan dalam pernyataan panggilan.
Jika kami menyediakan bidang kunci yang tidak unik, DL / I mengembalikan kejadian segmen pertama dari bidang kunci.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSAContoh di atas menunjukkan bahwa kami mengeluarkan panggilan GU dengan menyediakan satu set lengkap SSA yang memenuhi syarat. Ini mencakup semua bidang kunci mulai dari tingkat akar hingga kejadian segmen yang ingin kita ambil.
Pertimbangan Panggilan GU
Jika kami tidak menyediakan set lengkap SSA yang memenuhi syarat dalam panggilan tersebut, DL / I bekerja dengan cara berikut -
Ketika kami menggunakan SSA yang tidak memenuhi syarat dalam panggilan GU, DL / I mengakses kejadian segmen pertama dalam database yang memenuhi kriteria yang Anda tentukan.
Ketika kami mengeluarkan panggilan GU tanpa SSA, DL / I mengembalikan kejadian pertama dari segmen akar dalam database.
Jika beberapa SSA di tingkat menengah tidak disebutkan dalam panggilan, maka DL / I menggunakan posisi yang ditetapkan atau nilai default SSA yang tidak memenuhi syarat untuk segmen tersebut.
Kode Status
Tabel berikut menunjukkan kode status yang relevan setelah panggilan GU -
| S.No | Kode & Deskripsi Status |
|---|---|
| 1 | Spaces Panggilan sukses |
| 2 | GE DL / Saya tidak dapat menemukan segmen yang memenuhi kriteria yang ditentukan dalam panggilan |
GN Call
Dasar-dasar panggilan GN adalah sebagai berikut -
Panggilan GN dikenal sebagai Get Next call. Ini digunakan untuk pemrosesan sekuensial dasar.
Posisi awal penunjuk dalam database adalah sebelum segmen akar dari rekaman database pertama.
Posisi penunjuk database sebelum kejadian segmen berikutnya dalam urutan, setelah panggilan GN berhasil.
Panggilan GN dimulai melalui database dari posisi yang ditetapkan oleh panggilan sebelumnya.
Jika panggilan GN tidak memenuhi syarat, ia mengembalikan kejadian segmen berikutnya dalam database apa pun tipenya, dalam urutan hierarki.
Jika panggilan GN menyertakan SSA, DL / I hanya mengambil segmen yang memenuhi persyaratan semua SSA yang ditentukan.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSAContoh di atas menunjukkan kita mengeluarkan panggilan GN yang menyediakan posisi awal untuk membaca catatan secara berurutan. Ini mengambil kemunculan pertama dari segmen BUKU.
Kode Status
Tabel berikut menunjukkan kode status yang relevan setelah panggilan GN -
| S.No | Kode & Deskripsi Status |
|---|---|
| 1 | Spaces Panggilan sukses |
| 2 | GE DL / Saya tidak dapat menemukan segmen yang memenuhi kriteria yang ditentukan dalam panggilan. |
| 3 | GA Panggilan GN yang tidak memenuhi syarat naik satu tingkat dalam hierarki database untuk mengambil segmen. |
| 4 | GB Akhir database tercapai dan segmen tidak ditemukan. |
GK Panggilan GN yang tidak memenuhi syarat mencoba mengambil segmen dari tipe tertentu selain yang baru saja diambil tetapi tetap dalam tingkat hierarki yang sama. |
Kode Perintah
Kode perintah digunakan dengan panggilan untuk mengambil kejadian segmen. Berbagai kode perintah yang digunakan dengan panggilan dibahas di bawah ini.
Kode Perintah F.
Poin yang perlu diperhatikan -
Ketika kode perintah F ditentukan dalam panggilan, panggilan memproses kejadian pertama dari segmen tersebut.
Kode perintah F dapat digunakan ketika kita ingin memproses secara berurutan dan dapat digunakan dengan panggilan GN dan panggilan GNP.
Jika kita menentukan kode perintah F dengan panggilan GU, itu tidak memiliki arti penting, karena panggilan GU mengambil kejadian segmen pertama secara default.
Kode Perintah L.
Poin yang perlu diperhatikan -
Ketika kode perintah L ditentukan dalam panggilan, panggilan memproses kejadian terakhir dari segmen tersebut.
Kode perintah L dapat digunakan saat kita ingin memproses secara berurutan dan dapat digunakan dengan panggilan GN dan panggilan GNP.
D Kode Perintah
Poin yang perlu diperhatikan -
Kode perintah D digunakan untuk mengambil lebih dari satu kejadian segmen hanya dengan satu panggilan.
Biasanya DL / I beroperasi pada segmen level terendah yang ditentukan dalam SSA, tetapi dalam banyak kasus, kami juga menginginkan data dari level lain. Dalam kasus tersebut, kita dapat menggunakan kode perintah D.
Kode perintah D memudahkan pengambilan seluruh jalur segmen.
Kode Perintah C.
Poin yang perlu diperhatikan -
Kode perintah C digunakan untuk menggabungkan kunci.
Menggunakan operator relasional agak rumit, karena kita perlu menentukan nama bidang, operator relasional, dan nilai pencarian. Sebagai gantinya, kita dapat menggunakan kode perintah C untuk memberikan kunci yang digabungkan.
Contoh berikut menunjukkan penggunaan kode perintah C -
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSAKode Perintah P.
Poin yang perlu diperhatikan -
Ketika kami mengeluarkan panggilan GU atau GN, DL / I menetapkan induknya di segmen tingkat terendah yang diambil.
Jika kita menyertakan kode perintah P, DL / I menetapkan asal-usulnya di segmen tingkat yang lebih tinggi di jalur hierarki.
Kode Perintah U.
Poin yang perlu diperhatikan -
Ketika kode perintah U ditentukan dalam SSA yang tidak memenuhi syarat dalam panggilan GN, DL / I membatasi pencarian untuk segmen tersebut.
Kode perintah U diabaikan jika digunakan dengan SSA yang memenuhi syarat.
Kode Perintah V.
Poin yang perlu diperhatikan -
Kode perintah V bekerja mirip dengan kode perintah U, tetapi membatasi pencarian segmen pada level tertentu dan semua level di atas hierarki.
Kode perintah V diabaikan saat digunakan dengan SSA yang memenuhi syarat.
Kode Perintah Q
Poin yang perlu diperhatikan -
Kode perintah Q digunakan untuk mengantrekan atau memesan segmen untuk penggunaan eksklusif program aplikasi Anda.
Kode perintah Q digunakan dalam lingkungan interaktif di mana program lain mungkin membuat perubahan ke segmen.
Pemrosesan Ganda
Suatu program dapat memiliki banyak posisi dalam database IMS yang dikenal sebagai pemrosesan berganda. Berbagai pemrosesan dapat dilakukan dengan dua cara -
- Beberapa PCB
- Pemosisian Ganda
Beberapa PCB
Beberapa PCB dapat ditentukan untuk satu database. Jika ada beberapa PCB, maka program aplikasi dapat memiliki tampilan yang berbeda. Metode untuk mengimplementasikan banyak pemrosesan ini tidak efisien karena biaya tambahan yang dikenakan oleh PCB tambahan.
Pemosisian Ganda
Sebuah program dapat mempertahankan banyak posisi dalam database menggunakan satu PCB. Ini dicapai dengan mempertahankan posisi berbeda untuk setiap jalur hierarki. Pemosisian ganda digunakan untuk mengakses segmen dari dua jenis atau lebih secara berurutan pada saat yang bersamaan.
Metode manipulasi data berbeda yang digunakan dalam panggilan IMS DL / I adalah sebagai berikut -
- Panggilan ISRT
- Dapatkan Panggilan Tahan
- REPL Call
- DLET Call
Mari kita pertimbangkan struktur database IMS berikut untuk memahami panggilan fungsi manipulasi data -
Panggilan ISRT
Poin yang perlu diperhatikan -
Panggilan ISRT dikenal sebagai panggilan Sisipkan yang digunakan untuk menambahkan kejadian segmen ke database.
Panggilan ISRT digunakan untuk memuat database baru.
Kami mengeluarkan panggilan ISRT ketika bidang deskripsi segmen dimuat dengan data.
SSA yang tidak memenuhi syarat atau memenuhi syarat harus ditentukan dalam panggilan sehingga DL / I tahu di mana menempatkan kejadian segmen.
Kita dapat menggunakan kombinasi SSA yang tidak memenuhi syarat dan memenuhi syarat dalam panggilan tersebut. SSA yang memenuhi syarat dapat ditentukan untuk semua level di atas. Mari kita perhatikan contoh berikut -
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSAContoh di atas menunjukkan bahwa kami mengeluarkan panggilan ISRT dengan memberikan kombinasi SSA yang memenuhi syarat dan tidak memenuhi syarat.
Ketika segmen baru yang kita masukkan memiliki field kunci yang unik, maka itu ditambahkan pada posisi yang tepat. Jika bidang kunci tidak unik, maka itu ditambahkan oleh aturan yang ditentukan oleh administrator database.
Ketika kita mengeluarkan panggilan ISRT tanpa menentukan bidang kunci, maka aturan penyisipan memberi tahu tempat untuk menempatkan segmen relatif terhadap segmen kembar yang ada. Diberikan di bawah ini adalah aturan insert -
First - Jika aturannya pertama, segmen baru ditambahkan sebelum kembar yang ada.
Last - Jika aturan terakhir, segmen baru ditambahkan setelah semua kembar yang ada.
Here - Jika aturannya ada di sini, itu ditambahkan pada posisi saat ini relatif terhadap kembar yang ada, yang mungkin pertama, terakhir, atau di mana saja.
Kode Status
Tabel berikut menunjukkan kode status yang relevan setelah panggilan ISRT -
| S.No | Kode & Deskripsi Status |
|---|---|
| 1 | Spaces Panggilan sukses |
| 2 | GE Beberapa SSA digunakan dan DL / I tidak dapat memenuhi panggilan dengan jalur yang ditentukan. |
| 3 | II Coba tambahkan kejadian segmen yang sudah ada di database. |
| 4 | LB / LC LD / LE Kami mendapatkan kode status ini saat memuat pemrosesan. Dalam kebanyakan kasus, mereka menunjukkan bahwa Anda tidak menyisipkan segmen dalam urutan hierarki yang tepat. |
Dapatkan Hold Call
Poin yang perlu diperhatikan -
Ada tiga jenis panggilan Get Hold yang kami tentukan dalam panggilan DL / I:
Get Hold Unique (GHU)
Dapatkan Tahan Berikutnya (GHN)
Dapatkan Tahan Berikutnya dalam Orang Tua (GHNP)
Fungsi tahan menentukan bahwa kita akan memperbarui segmen setelah pengambilan. Jadi sebelum panggilan REPL atau DLET, panggilan tunggu yang berhasil harus dikeluarkan yang memberi tahu DL / I maksud untuk memperbarui database.
REPL Call
Poin yang perlu diperhatikan -
Setelah panggilan panggilan berhasil, kami mengeluarkan panggilan REPL untuk memperbarui kejadian segmen.
Kami tidak dapat mengubah panjang segmen menggunakan panggilan REPL.
Kami tidak dapat mengubah nilai bidang kunci menggunakan panggilan REPL.
Kami tidak dapat menggunakan SSA yang memenuhi syarat dengan panggilan REPL. Jika kami menentukan SSA yang memenuhi syarat, maka panggilan gagal.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.Contoh di atas memperbarui kejadian segmen TI menggunakan panggilan REPL. Pertama, kami mengeluarkan panggilan GHU untuk mendapatkan kejadian segmen yang ingin kami perbarui. Kemudian, kami mengeluarkan panggilan REPL untuk memperbarui nilai-nilai segmen itu.
DLET Call
Poin yang perlu diperhatikan -
Panggilan DLET bekerja dengan cara yang sama seperti panggilan REPL.
Setelah panggilan terima berhasil, kami mengeluarkan panggilan DLET untuk menghapus kejadian segmen.
Kami tidak dapat menggunakan SSA yang memenuhi syarat dengan panggilan DLET. Jika kami menentukan SSA yang memenuhi syarat, maka panggilan gagal.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.Contoh di atas menghapus kejadian segmen TI menggunakan panggilan DLET. Pertama, kami mengeluarkan panggilan GHU untuk mendapatkan kejadian segmen yang ingin kami hapus. Kemudian, kami mengeluarkan panggilan DLET untuk memperbarui nilai segmen itu.
Kode Status
Tabel berikut ini memperlihatkan kode status yang relevan setelah REPL atau panggilan DLET -
| S.No | Kode & Deskripsi Status |
|---|---|
| 1 | Spaces Panggilan sukses |
| 2 | AJ SSA yang memenuhi syarat digunakan pada panggilan REPL atau DLET. |
| 3 | DJ Program mengeluarkan panggilan ganti tanpa panggilan tunggu segera sebelum panggilan tunggu. |
| 4 | DA Program membuat perubahan ke bidang kunci segmen sebelum mengeluarkan panggilan REPL atau DLET |
Pengindeksan Sekunder digunakan saat kita ingin mengakses database tanpa menggunakan kunci gabungan lengkap atau saat kita tidak ingin menggunakan bidang utama urutan.
Segmen Penunjuk Indeks
DL / I menyimpan penunjuk ke segmen database yang diindeks dalam database terpisah. Segmen penunjuk indeks adalah satu-satunya jenis indeks sekunder. Ini terdiri dari dua bagian -
- Elemen Awalan
- Elemen Data
Elemen Awalan
Bagian awalan segmen penunjuk indeks berisi penunjuk ke Segmen Target Indeks. Segmen sasaran indeks adalah segmen yang dapat diakses dengan menggunakan indeks sekunder.
Elemen Data
Elemen data berisi nilai kunci dari segmen dalam database yang diindeks tempat indeks dibuat. Ini juga dikenal sebagai segmen sumber indeks.
Berikut adalah poin-poin penting yang perlu diperhatikan tentang Pengindeksan Sekunder -
Segmen sumber indeks dan segmen sumber sasaran tidak harus sama.
Saat kami menyiapkan indeks sekunder, secara otomatis dikelola oleh DL / I.
DBA mendefinisikan banyak indeks sekunder sesuai dengan beberapa jalur akses. Indeks sekunder ini disimpan dalam database indeks terpisah.
Kita tidak boleh membuat lebih banyak indeks sekunder, karena mereka memberlakukan overhead pemrosesan tambahan pada DL / I.
Kunci Sekunder
Poin yang perlu diperhatikan -
Bidang di segmen sumber indeks tempat pembuatan indeks sekunder disebut sebagai kunci sekunder.
Bidang apa pun dapat digunakan sebagai kunci sekunder. Ini tidak harus berupa bidang urutan segmen.
Kunci sekunder dapat berupa kombinasi dari satu kolom dalam segmen sumber indeks.
Nilai kunci sekunder tidak harus unik.
Struktur Data Sekunder
Poin yang perlu diperhatikan -
Ketika kita membangun indeks sekunder, struktur hierarki database yang terlihat juga berubah.
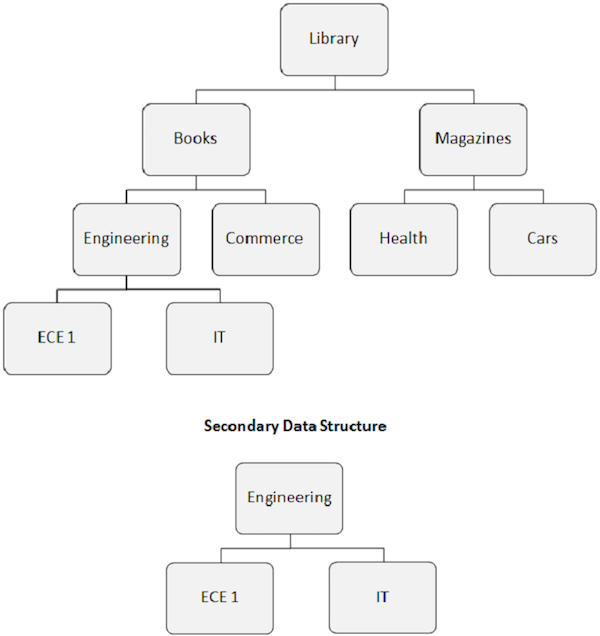
Segmen sasaran indeks menjadi segmen akar yang nyata. Seperti yang ditunjukkan pada gambar berikut, segmen Teknik menjadi segmen akar, meskipun itu bukan segmen akar.
Penataan kembali struktur basis data yang disebabkan oleh indeks sekunder ini dikenal dengan struktur data sekunder.
Struktur data sekunder tidak membuat perubahan apa pun pada struktur database fisik utama yang ada di disk. Ini hanyalah cara untuk mengubah struktur database di depan program aplikasi.
Independen DAN Operator
Poin yang perlu diperhatikan -
Jika operator AND (* atau &) digunakan dengan indeks sekunder, ini dikenal sebagai operator AND dependen.
AND (#) independen memungkinkan kita untuk menentukan kualifikasi yang tidak mungkin dilakukan dengan dependen AND.
Operator ini hanya dapat digunakan untuk indeks sekunder di mana segmen sumber indeks bergantung pada segmen sasaran indeks.
Kita dapat membuat kode SSA dengan AND independen untuk menentukan bahwa kemunculan segmen target diproses berdasarkan bidang di dua atau lebih segmen sumber dependen.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Pengurutan Renggang
Poin yang perlu diperhatikan -
Urutan renggang juga dikenal sebagai Pengindeksan Renggang. Kami dapat menghapus beberapa segmen sumber indeks dari indeks menggunakan pengurutan jarang dengan database indeks sekunder.
Pengurutan jarang digunakan untuk meningkatkan kinerja. Ketika beberapa kemunculan segmen sumber indeks tidak digunakan, kami dapat menghapusnya.
DL / I menggunakan nilai penekanan atau rutinitas penekanan atau keduanya untuk menentukan apakah segmen harus diindeks.
Jika nilai bidang urutan di segmen sumber indeks cocok dengan nilai penekanan, maka tidak ada hubungan indeks yang dibuat.
Rutin penekanan adalah program yang ditulis pengguna yang mengevaluasi segmen dan menentukan apakah harus diindeks atau tidak.
Saat pengindeksan jarang digunakan, fungsinya ditangani oleh DL / I. Kita tidak perlu membuat ketentuan khusus untuk itu dalam program aplikasi.
Persyaratan DBDGEN
Sebagaimana dibahas dalam modul sebelumnya, DBDGEN digunakan untuk membuat DBD. Saat kami membuat indeks sekunder, dua database terlibat. DBA perlu membuat dua DBD menggunakan dua DBDGEN untuk membuat hubungan antara database terindeks dan database terindeks sekunder.
Persyaratan PSBGEN
Setelah membuat indeks sekunder untuk database, DBA perlu membuat PSB. PSBGEN untuk program menentukan urutan pemrosesan yang tepat untuk database pada parameter PROCSEQ dari makro PSB. Untuk parameter PROCSEQ, DBA mengkode nama DBD untuk database indeks sekunder.
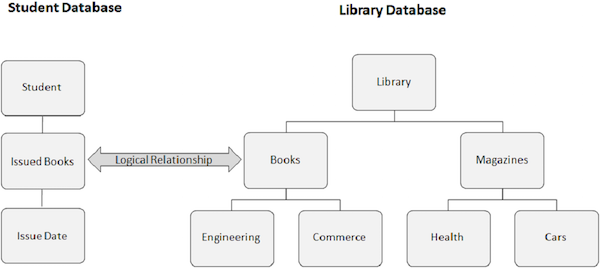
Database IMS memiliki aturan bahwa setiap jenis segmen hanya dapat memiliki satu induk. Ini membatasi kompleksitas database fisik. Banyak aplikasi DL / I memerlukan struktur kompleks yang memungkinkan segmen memiliki dua jenis segmen induk. Untuk mengatasi batasan ini, DL / I memungkinkan DBA untuk mengimplementasikan hubungan logis di mana segmen dapat memiliki induk fisik dan logis. Kita dapat membuat hubungan tambahan dalam satu database fisik. Struktur data baru setelah menerapkan hubungan logis dikenal sebagai Database Logis.
Hubungan Logis
Hubungan logis memiliki properti berikut -
Hubungan logis adalah jalur antara dua segmen yang terkait secara logis dan tidak secara fisik.
Biasanya hubungan logis dibuat antara database terpisah. Tetapi dimungkinkan untuk memiliki hubungan antara segmen dari satu database tertentu.
Gambar berikut menunjukkan dua database yang berbeda. Salah satunya adalah database Mahasiswa, dan yang lainnya adalah database Perpustakaan. Kami membuat hubungan logis antara segmen Buku yang Diterbitkan dari database Siswa dan segmen Buku dari database Perpustakaan.
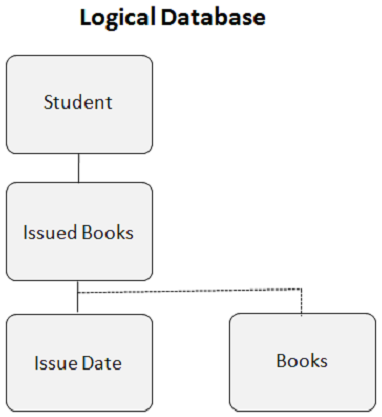
Beginilah tampilan database logis saat Anda membuat hubungan logis -
Segmen Anak Logis
Segmen anak logis adalah dasar dari hubungan logis. Ini adalah segmen data fisik tetapi untuk DL / I, tampaknya ia memiliki dua orang tua. Segmen Buku pada contoh di atas memiliki dua segmen induk. Segmen buku yang diterbitkan adalah induk logis dan segmen Perpustakaan adalah induk fisik. Satu kejadian segmen anak logis hanya memiliki satu kejadian segmen induk logis dan satu kejadian segmen induk logis dapat memiliki banyak kejadian segmen anak logis.
Kembar Logis
Kembar logis adalah kejadian dari tipe segmen anak logis yang semuanya subordinat kejadian tunggal dari tipe segmen induk logis. DL / I membuat segmen anak logis tampak mirip dengan segmen anak fisik yang sebenarnya. Ini juga dikenal sebagai segmen anak logis virtual.
Jenis Hubungan Logis
DBA membuat hubungan logis antar segmen. Untuk menerapkan hubungan logis, DBA harus menentukannya di DBDGEN untuk database fisik yang terlibat. Ada tiga jenis hubungan logis -
- Unidirectional
- Virtual dua arah
- Fisik dua arah
Searah
Koneksi logis beralih dari anak logis ke induk logis dan tidak bisa sebaliknya.
Virtual dua arah
Ini memungkinkan akses di kedua arah. Anak logis dalam struktur fisiknya dan anak logis virtual yang sesuai dapat dilihat sebagai segmen berpasangan.
Fisik dua arah
Anak logis adalah bawahan yang disimpan secara fisik untuk orang tua fisik dan logisnya. Untuk program aplikasi, itu muncul dengan cara yang sama seperti anak logis virtual dua arah.
Pertimbangan Pemrograman
Pertimbangan pemrograman untuk menggunakan database logis adalah sebagai berikut -
Panggilan DL / I untuk mengakses database tetap sama dengan database logis juga.
Blok spesifikasi program menunjukkan struktur yang kita gunakan dalam panggilan kita. Dalam beberapa kasus, kami tidak dapat mengidentifikasi bahwa kami menggunakan database logis.
Hubungan logis menambahkan dimensi baru ke pemrograman database.
Anda harus berhati-hati saat bekerja dengan database logis, karena dua database terintegrasi bersama. Jika Anda mengubah satu database, modifikasi yang sama harus tercermin di database lain.
Spesifikasi program harus menunjukkan pemrosesan apa yang diperbolehkan pada database. Jika aturan pemrosesan dilanggar, Anda mendapatkan kode status yang tidak kosong.
Segmen Gabungan
Segmen anak logis selalu dimulai dengan kunci gabungan lengkap dari induk tujuan. Ini dikenal sebagai Kunci Gabungan Induk Tujuan (DPCK). Anda harus selalu membuat kode DPCK di awal area I / O segmen untuk anak logis. Dalam database logis, segmen gabungan membuat koneksi antara segmen yang ditentukan di database fisik yang berbeda. Segmen gabungan terdiri dari dua bagian berikut -
- Segmen anak logis
- Segmen induk tujuan
Segmen anak logis terdiri dari dua bagian berikut -
- Kunci Gabungan Induk Tujuan (DPCK)
- Data pengguna anak logis

Saat kita bekerja dengan segmen bersambung selama pembaruan, dimungkinkan untuk menambah atau mengubah data di anak logis dan induk tujuan dengan satu panggilan. Ini juga bergantung pada aturan yang ditentukan DBA untuk database. Untuk menyisipkan, berikan DPCK di posisi yang benar. Untuk mengganti atau menghapus, jangan mengubah DPCK atau data bidang urutan di salah satu bagian dari segmen gabungan.
Administrator database perlu merencanakan pemulihan database jika terjadi kegagalan sistem. Kegagalan dapat dari berbagai jenis seperti crash aplikasi, kesalahan perangkat keras, kegagalan daya, dll.
Pendekatan Sederhana
Beberapa pendekatan sederhana untuk pemulihan database adalah sebagai berikut -
Buat salinan cadangan berkala dari kumpulan data penting sehingga semua transaksi yang diposting terhadap kumpulan data dipertahankan.
Jika kumpulan data rusak karena kegagalan sistem, masalah itu diperbaiki dengan memulihkan salinan cadangan. Kemudian akumulasi transaksi akan diposting kembali ke salinan cadangan untuk memperbaruinya.
Kerugian dari Pendekatan Sederhana
Kerugian dari pendekatan sederhana untuk pemulihan database adalah sebagai berikut -
Posting ulang akumulasi transaksi menghabiskan banyak waktu.
Semua aplikasi lain harus menunggu eksekusi hingga pemulihan selesai.
Pemulihan database lebih panjang daripada pemulihan file, jika hubungan indeks logis dan sekunder terlibat.
Rutinitas Penghentian yang Tidak Normal
Program DL / I lumpuh dengan cara yang berbeda dari cara program standar lumpuh karena program standar dijalankan langsung oleh sistem operasi, sedangkan program DL / I tidak. Dengan menerapkan rutinitas penghentian abnormal, sistem akan mengganggu sehingga pemulihan dapat dilakukan setelah ABnormal END (ABEND). Rutin penghentian abnormal melakukan tindakan berikut -
- Menutup semua set data
- Membatalkan semua pekerjaan yang tertunda dalam antrian
- Membuat dump penyimpanan untuk mengetahui akar penyebab ABEND
Batasan dari rutinitas ini adalah tidak memastikan apakah data yang digunakan akurat atau tidak.
DL / I Log
Ketika sebuah program aplikasi ABENDs, itu perlu untuk mengembalikan perubahan yang dilakukan oleh program aplikasi, memperbaiki kesalahan, dan menjalankan kembali program aplikasi. Untuk melakukannya, Anda harus memiliki log DL / I. Berikut adalah poin-poin penting tentang DL / I logging -
DL / I merekam semua perubahan yang dibuat oleh program aplikasi dalam file yang dikenal sebagai file log.
Ketika program aplikasi mengubah segmen, gambar sebelum dan sesudahnya dibuat oleh DL / I.
Gambar segmen ini dapat digunakan untuk memulihkan segmen, jika program aplikasi macet.
DL / I menggunakan teknik yang disebut logging depan tulis untuk merekam perubahan database. Dengan write-ahead logging, perubahan database ditulis ke dataset log sebelum ditulis ke dataset yang sebenarnya.
Karena log selalu berada di depan database, utilitas pemulihan dapat menentukan status setiap perubahan database.
Ketika program menjalankan panggilan untuk mengubah segmen database, DL / I menangani bagian loggingnya.
Pemulihan - Maju dan Mundur
Dua pendekatan pemulihan database adalah -
Forward Recovery - DL / I menggunakan file log untuk menyimpan data perubahan. Transaksi yang terakumulasi dikirim ulang menggunakan file log ini.
Backward Recovery- Pemulihan mundur juga dikenal sebagai pemulihan mundur. Catatan log untuk program dibaca mundur dan pengaruhnya dibalik dalam database. Ketika backout selesai, database berada dalam status yang sama seperti sebelum kegagalan, dengan asumsi bahwa tidak ada program aplikasi lain yang mengubah database untuk sementara.
Pos pemeriksaan
Checkpoint adalah tahapan dimana perubahan database yang dilakukan oleh program aplikasi dianggap lengkap dan akurat. Di bawah ini adalah daftar poin yang perlu diperhatikan tentang pos pemeriksaan -
Perubahan database yang dibuat sebelum checkpoint terbaru tidak dikembalikan dengan pemulihan mundur.
Perubahan database yang dicatat setelah checkpoint terbaru tidak diterapkan ke salinan gambar dari database selama pemulihan maju.
Menggunakan metode checkpoint, database dikembalikan ke kondisinya di checkpoint terbaru ketika proses pemulihan selesai.
Default untuk program batch adalah pos pemeriksaan adalah awal program.
Sebuah pos pemeriksaan dapat didirikan menggunakan panggilan pos pemeriksaan (CHKP).
Panggilan pos pemeriksaan menyebabkan catatan pos pemeriksaan ditulis di log DL / I.
Di bawah ini adalah sintaks dari panggilan CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-IDAda dua metode pos pemeriksaan -
Basic Checkpointing - Memungkinkan pemrogram untuk mengeluarkan panggilan pos pemeriksaan yang digunakan utilitas pemulihan DL / I selama pemrosesan pemulihan.
Symbolic Checkpointing- Ini adalah bentuk pemeriksaan lanjutan yang digunakan dalam kombinasi dengan fasilitas restart diperpanjang. Checkpointing simbolik dan restart diperpanjang bersama-sama membiarkan pemrogram aplikasi mengkodekan program sehingga mereka dapat melanjutkan pemrosesan pada titik tepat setelah checkpoint.