Regresi Logistik dengan Python - Panduan Cepat
Regresi Logistik adalah metode statistik klasifikasi objek. Bab ini akan memberikan pengantar tentang regresi logistik dengan bantuan beberapa contoh.
Klasifikasi
Untuk memahami regresi logistik, Anda harus mengetahui arti klasifikasi. Mari kita pertimbangkan contoh berikut untuk memahami ini lebih baik -
- Seorang dokter mengklasifikasikan tumor sebagai tumor ganas atau jinak.
- Transaksi bank mungkin palsu atau asli.
Selama bertahun-tahun, manusia telah melakukan tugas-tugas semacam itu - meski rawan kesalahan. Pertanyaannya adalah dapatkah kita melatih mesin untuk melakukan tugas-tugas ini untuk kita dengan akurasi yang lebih baik?
Salah satu contoh mesin yang melakukan klasifikasi adalah email Clientdi komputer Anda yang mengklasifikasikan setiap email masuk sebagai "spam" atau "bukan spam" dan melakukannya dengan akurasi yang cukup tinggi. Teknik statistik regresi logistik telah berhasil diterapkan di klien email. Dalam hal ini, kami telah melatih mesin kami untuk memecahkan masalah klasifikasi.
Regresi Logistik hanyalah satu bagian dari pembelajaran mesin yang digunakan untuk memecahkan masalah klasifikasi biner semacam ini. Ada beberapa teknik pembelajaran mesin lain yang sudah dikembangkan dan sedang dipraktikkan untuk memecahkan jenis masalah lain.
Jika Anda telah mencatat, dalam semua contoh di atas, hasil predikasi hanya memiliki dua nilai - Ya atau Tidak. Kami menyebutnya sebagai kelas - sehingga mengatakan bahwa kita mengatakan bahwa pengklasifikasi kita mengklasifikasikan objek dalam dua kelas. Secara teknis, kita dapat mengatakan bahwa variabel hasil atau target bersifat dikotomis.
Ada masalah klasifikasi lain di mana keluaran dapat diklasifikasikan menjadi lebih dari dua kelas. Misalnya, diberi sekeranjang penuh buah-buahan, Anda diminta memisahkan buah-buahan yang berbeda jenisnya. Sekarang, keranjang itu mungkin berisi Jeruk, Apel, Mangga, dan sebagainya. Jadi ketika Anda memisahkan buah-buahan, Anda memisahkannya di lebih dari dua kelas. Ini adalah masalah klasifikasi multivariat.
Pertimbangkan bahwa bank mendekati Anda untuk mengembangkan aplikasi pembelajaran mesin yang akan membantu mereka mengidentifikasi klien potensial yang akan membuka Deposito Berjangka (juga disebut Deposit Tetap oleh beberapa bank) dengan mereka. Bank secara teratur melakukan survei melalui panggilan telepon atau formulir web untuk mengumpulkan informasi tentang calon klien. Survei ini bersifat umum dan dilakukan pada audiens yang sangat besar sehingga banyak yang mungkin tidak tertarik untuk berurusan dengan bank ini sendiri. Dari sisanya, hanya sedikit yang tertarik membuka Deposito Berjangka. Orang lain mungkin tertarik dengan fasilitas lain yang ditawarkan oleh bank. Jadi survei tidak perlu dilakukan untuk mengidentifikasi nasabah yang membuka TD. Tugas Anda adalah mengidentifikasi semua pelanggan dengan probabilitas tinggi untuk membuka TD dari data survei yang sangat besar yang akan dibagikan oleh bank kepada Anda.
Untungnya, satu jenis data seperti itu tersedia untuk umum bagi mereka yang ingin mengembangkan model pembelajaran mesin. Data ini disiapkan oleh beberapa mahasiswa di UC Irvine dengan pendanaan eksternal. Basis data tersedia sebagai bagian dariUCI Machine Learning Repositorydan digunakan secara luas oleh siswa, pendidik, dan peneliti di seluruh dunia. Datanya bisa diunduh dari sini .
Pada bab-bab berikutnya, sekarang mari kita melakukan pengembangan aplikasi menggunakan data yang sama.
Dalam bab ini, kita akan memahami proses yang terlibat dalam menyiapkan proyek untuk melakukan regresi logistik dengan Python, secara detail.
Menginstal Jupyter
Kami akan menggunakan Jupyter - salah satu platform yang paling banyak digunakan untuk pembelajaran mesin. Jika Anda belum menginstal Jupyter di mesin Anda, unduh dari sini . Untuk penginstalan, Anda dapat mengikuti petunjuk di situs mereka untuk menginstal platform. Seperti yang disarankan situs, Anda mungkin lebih suka menggunakanAnaconda Distributionyang disertakan dengan Python dan banyak paket Python yang umum digunakan untuk komputasi ilmiah dan ilmu data. Ini akan mengurangi kebutuhan untuk menginstal paket-paket ini satu per satu.
Setelah instalasi Jupyter berhasil, mulailah proyek baru, layar Anda pada tahap ini akan terlihat seperti berikut siap menerima kode Anda.
Sekarang, ubah nama proyek dari Untitled1 to “Logistic Regression” dengan mengklik nama judul dan mengeditnya.
Pertama, kami akan mengimpor beberapa paket Python yang kami perlukan dalam kode kami.
Mengimpor Paket Python
Untuk tujuan ini, ketik atau potong dan tempel kode berikut di editor kode -
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitAnda Notebook akan terlihat seperti berikut pada tahap ini -
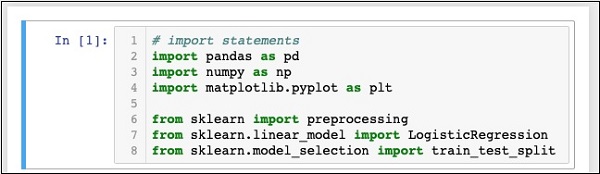
Jalankan kode dengan mengklik Runtombol. Jika tidak ada error yang dibuat, Anda telah berhasil menginstal Jupyter dan sekarang siap untuk pengembangan lainnya.
Tiga pernyataan import pertama mengimpor paket pandas, numpy dan matplotlib.pyplot dalam proyek kita. Tiga pernyataan berikutnya mengimpor modul yang ditentukan dari sklearn.
Tugas kita selanjutnya adalah mengunduh data yang diperlukan untuk proyek kita. Kita akan mempelajari ini di bab selanjutnya.
Langkah-langkah yang terlibat dalam mendapatkan data untuk melakukan regresi logistik dengan Python dibahas secara mendetail di bab ini.
Mendownload Set Data
Jika Anda belum mengunduh kumpulan data UCI yang disebutkan sebelumnya, unduh sekarang dari sini . Klik pada Folder Data. Anda akan melihat layar berikut -

Unduh file bank.zip dengan mengklik tautan yang diberikan. File zip berisi file-file berikut -

Kami akan menggunakan file bank.csv untuk pengembangan model kami. File bank-names.txt berisi deskripsi database yang Anda perlukan nanti. Bank-full.csv berisi kumpulan data yang jauh lebih besar yang dapat Anda gunakan untuk pengembangan lebih lanjut.
Di sini kami telah menyertakan file bank.csv dalam zip sumber yang dapat diunduh. File ini berisi bidang yang dipisahkan koma. Kami juga telah membuat beberapa modifikasi pada file tersebut. Disarankan agar Anda menggunakan file yang disertakan dalam zip sumber proyek untuk pembelajaran Anda.
Memuat Data
Untuk memuat data dari file csv yang baru saja Anda salin, ketik pernyataan berikut dan jalankan kodenya.
In [2]: df = pd.read_csv('bank.csv', header=0)Anda juga akan dapat memeriksa data yang dimuat dengan menjalankan pernyataan kode berikut -
IN [3]: df.head()Setelah perintah dijalankan, Anda akan melihat output berikut -
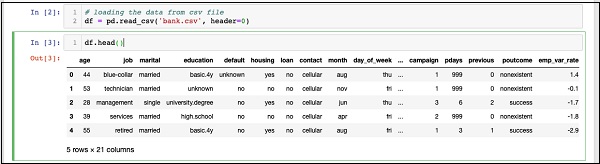
Pada dasarnya, ini telah mencetak lima baris pertama dari data yang dimuat. Perhatikan 21 kolom yang ada. Kami hanya akan menggunakan beberapa kolom dari ini untuk pengembangan model kami.
Selanjutnya, kita perlu membersihkan data. Data mungkin berisi beberapa baris denganNaN. Untuk menghilangkan baris seperti itu, gunakan perintah berikut -
IN [4]: df = df.dropna()Untungnya, bank.csv tidak berisi baris apa pun dengan NaN, jadi langkah ini tidak benar-benar diperlukan dalam kasus kami. Namun, secara umum sulit untuk menemukan baris seperti itu dalam database yang besar. Jadi selalu lebih aman menjalankan pernyataan di atas untuk membersihkan data.
Note - Anda dapat dengan mudah memeriksa ukuran data kapan saja dengan menggunakan pernyataan berikut -
IN [5]: print (df.shape)
(41188, 21)Jumlah baris dan kolom akan dicetak pada keluaran seperti yang ditunjukkan pada baris kedua di atas.
Selanjutnya yang harus dilakukan adalah memeriksa kesesuaian setiap kolom dengan model yang coba kita bangun.
Setiap kali organisasi melakukan survei, mereka mencoba mengumpulkan informasi sebanyak mungkin dari pelanggan, dengan gagasan bahwa informasi ini akan berguna bagi organisasi dengan satu atau lain cara, di lain waktu. Untuk mengatasi masalah saat ini, kita harus mengambil informasi yang secara langsung relevan dengan masalah kita.
Menampilkan Semua Bidang
Sekarang, mari kita lihat bagaimana memilih bidang data yang berguna bagi kita. Jalankan pernyataan berikut di editor kode.
In [6]: print(list(df.columns))Anda akan melihat output berikut -
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan',
'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx',
'euribor3m', 'nr_employed', 'y']Outputnya menunjukkan nama semua kolom dalam database. Kolom terakhir "y" adalah nilai Boolean yang menunjukkan apakah pelanggan ini memiliki deposito berjangka di bank. Nilai bidang ini adalah "y" atau "n". Anda dapat membaca deskripsi dan tujuan setiap kolom pada file bank-name.txt yang telah diunduh sebagai bagian dari data.
Menghilangkan Bidang yang Tidak Diinginkan
Memeriksa nama kolom, Anda akan tahu bahwa beberapa kolom tidak memiliki arti penting untuk masalah yang dihadapi. Misalnya, bidang sepertimonth, day_of_week, kampanye, dll. tidak berguna bagi kami. Kami akan menghilangkan bidang ini dari database kami. Untuk menjatuhkan kolom, kami menggunakan perintah drop seperti yang ditunjukkan di bawah ini -
In [8]: #drop columns which are not needed.
df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]],
axis = 1, inplace = True)Perintah tersebut mengatakan bahwa kolom drop nomor 0, 3, 7, 8, dan seterusnya. Untuk memastikan bahwa indeks dipilih dengan benar, gunakan pernyataan berikut -
In [7]: df.columns[9]
Out[7]: 'day_of_week'Ini mencetak nama kolom untuk indeks yang diberikan.
Setelah menjatuhkan kolom yang tidak diperlukan, periksa data dengan pernyataan kepala. Output layar ditampilkan di sini -
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1Sekarang, kami hanya memiliki bidang yang kami rasa penting untuk analisis dan prediksi data kami. PentingnyaData Scientistmulai terlihat pada langkah ini. Ilmuwan data harus memilih kolom yang sesuai untuk pembuatan model.
Misalnya, tipe jobmeskipun pada pandangan pertama mungkin tidak meyakinkan semua orang untuk dimasukkan ke dalam database, ini akan menjadi bidang yang sangat berguna. Tidak semua tipe pelanggan akan membuka TD. Orang berpenghasilan rendah mungkin tidak membuka TD, sedangkan orang berpenghasilan tinggi biasanya akan memarkir kelebihan uang mereka di TD. Jadi jenis pekerjaan menjadi sangat relevan dalam skenario ini. Demikian juga, pilihlah kolom dengan cermat yang menurut Anda akan relevan untuk analisis Anda.
Pada bab berikutnya, kami akan menyiapkan data kami untuk membangun model.
Untuk membuat pengklasifikasi, kita harus menyiapkan data dalam format yang diminta oleh modul bangunan pengklasifikasi. Kami menyiapkan data dengan melakukanOne Hot Encoding.
Pengkodean Data
Kami akan membahas secara singkat apa yang kami maksud dengan pengkodean data. Pertama, mari kita jalankan kodenya. Jalankan perintah berikut di jendela kode.
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])Seperti yang dikatakan oleh komentar, pernyataan di atas akan membuat encoding data yang panas. Mari kita lihat apa yang telah diciptakannya? Periksa data yang dibuat yang disebut“data” dengan mencetak catatan kepala di database.
In [11]: data.head()Anda akan melihat output berikut -
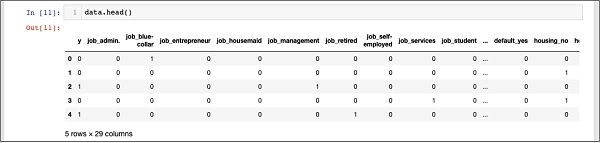
Untuk memahami data di atas, kami akan membuat daftar nama kolom dengan menjalankan data.columns perintah seperti yang ditunjukkan di bawah ini -
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')Sekarang, kami akan menjelaskan bagaimana encoding one hot dilakukan oleh get_dummiesperintah. Kolom pertama dalam database yang baru dibuat adalah kolom "y" yang menunjukkan apakah klien ini telah berlangganan TD atau tidak. Sekarang, mari kita lihat kolom yang dikodekan. Kolom pertama yang dikodekan adalah“job”. Dalam database, Anda akan menemukan bahwa kolom "pekerjaan" memiliki banyak kemungkinan nilai seperti "admin", "kerah biru", "pengusaha", dan sebagainya. Untuk setiap nilai yang mungkin, kami memiliki kolom baru yang dibuat dalam database, dengan nama kolom ditambahkan sebagai awalan.
Jadi, kami memiliki kolom yang disebut "job_admin", "job_blue-collar", dan seterusnya. Untuk setiap bidang yang dikodekan dalam database asli kami, Anda akan menemukan daftar kolom yang ditambahkan dalam database yang dibuat dengan semua kemungkinan nilai yang diambil kolom tersebut dalam database asli. Periksa dengan cermat daftar kolom untuk memahami bagaimana data dipetakan ke database baru.
Memahami Pemetaan Data
Untuk memahami data yang dihasilkan, mari kita cetak seluruh data menggunakan perintah data. Output parsial setelah menjalankan perintah ditampilkan di bawah ini.
In [13]: data
Layar di atas menunjukkan dua belas baris pertama. Jika Anda menggulir ke bawah lebih jauh, Anda akan melihat bahwa pemetaan telah selesai untuk semua baris.
Keluaran layar parsial di bagian bawah database ditampilkan di sini untuk referensi cepat Anda.
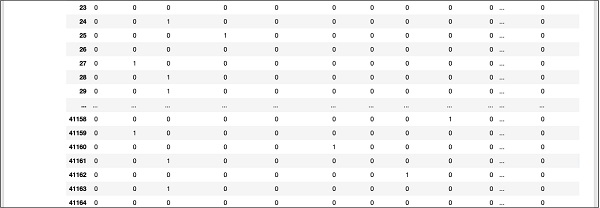
Untuk memahami data yang dipetakan, mari kita periksa baris pertama.

Dikatakan bahwa pelanggan ini belum berlangganan TD seperti yang ditunjukkan oleh nilai di kolom “y”. Ini juga menunjukkan bahwa pelanggan ini adalah pelanggan "kerah biru". Menggulir ke bawah secara horizontal, ini akan memberi tahu Anda bahwa dia memiliki "perumahan" dan tidak mengambil "pinjaman".
Setelah encoding panas ini, kita memerlukan lebih banyak pemrosesan data sebelum kita dapat mulai membangun model kita.
Menghapus "tidak diketahui"
Jika kita memeriksa kolom dalam database yang dipetakan, Anda akan menemukan adanya beberapa kolom yang diakhiri dengan "tidak diketahui". Misalnya, periksa kolom di indeks 12 dengan perintah berikut yang ditampilkan di tangkapan layar -
In [14]: data.columns[12]
Out[14]: 'job_unknown'Ini menunjukkan bahwa pekerjaan untuk pelanggan tertentu tidak diketahui. Jelas, tidak ada gunanya memasukkan kolom seperti itu dalam analisis dan pembuatan model kita. Jadi, semua kolom dengan nilai "tidak diketahui" harus dihilangkan. Ini dilakukan dengan perintah berikut -
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)Pastikan Anda menentukan nomor kolom yang benar. Jika ragu, Anda dapat memeriksa nama kolom kapan saja dengan menentukan indeksnya di perintah kolom seperti yang dijelaskan sebelumnya.
Setelah menjatuhkan kolom yang tidak diinginkan, Anda dapat memeriksa daftar kolom terakhir seperti yang ditunjukkan pada output di bawah ini -
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')Pada titik ini, data kami siap untuk pembuatan model.
Kami memiliki sekitar empat puluh satu ribu dan catatan aneh. Jika kami menggunakan seluruh data untuk pembuatan model, kami tidak akan ditinggalkan dengan data apa pun untuk pengujian. Jadi secara umum, kami membagi seluruh kumpulan data menjadi dua bagian, katakanlah 70/30 persentase. Kami menggunakan 70% data untuk pembuatan model dan sisanya untuk menguji akurasi dalam prediksi model yang kami buat. Anda dapat menggunakan rasio pemisahan yang berbeda sesuai kebutuhan Anda.
Membuat Fitur Array
Sebelum kita membagi datanya, kita pisahkan datanya menjadi dua array X dan Y. Larik X berisi semua fitur (kolom data) yang ingin kita analisis dan Larik Y adalah larik dimensi tunggal nilai boolean yang merupakan keluaran dari prediksi. Untuk memahami ini, mari kita jalankan beberapa kode.
Pertama, jalankan pernyataan Python berikut untuk membuat larik X -
In [17]: X = data.iloc[:,1:]Untuk memeriksa isi X menggunakan headuntuk mencetak beberapa catatan awal. Layar berikut menunjukkan isi dari larik X.
In [18]: X.head ()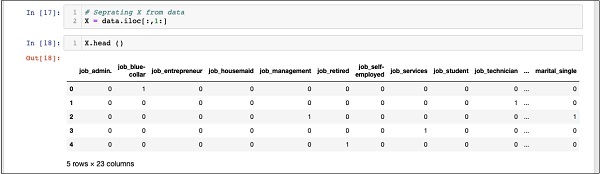
Array memiliki beberapa baris dan 23 kolom.
Selanjutnya, kita akan membuat larik keluaran yang berisi “y"Nilai.
Membuat Output Array
Untuk membuat array untuk kolom nilai yang diprediksi, gunakan pernyataan Python berikut -
In [19]: Y = data.iloc[:,0]Periksa isinya dengan menelepon head. Output layar di bawah ini menunjukkan hasil -
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64Sekarang, pisahkan data menggunakan perintah berikut -
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)Ini akan membuat empat larik yang disebut X_train, Y_train, X_test, and Y_test. Seperti sebelumnya, Anda dapat memeriksa isi dari array ini dengan menggunakan perintah head. Kita akan menggunakan array X_train dan Y_train untuk melatih model kita dan array X_test dan Y_test untuk pengujian dan validasi.
Sekarang, kami siap membuat pengklasifikasi kami. Kami akan membahasnya di bab berikutnya.
Anda tidak perlu membuat classifier dari awal. Pengklasifikasi bangunan bersifat kompleks dan membutuhkan pengetahuan tentang beberapa bidang seperti Statistik, teori probabilitas, teknik pengoptimalan, dan sebagainya. Ada beberapa pustaka yang dibuat sebelumnya yang tersedia di pasar yang memiliki implementasi pengklasifikasi yang sepenuhnya teruji dan sangat efisien. Kami akan menggunakan salah satu model yang dibuat sebelumnya darisklearn.
Pengklasifikasi sklearn
Membuat pengklasifikasi Regresi Logistik dari sklearn toolkit itu sepele dan dilakukan dalam satu pernyataan program seperti yang ditunjukkan di sini -
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)Setelah pengklasifikasi dibuat, Anda akan memasukkan data pelatihan Anda ke dalam pengklasifikasi sehingga dapat menyesuaikan parameter internalnya dan siap untuk prediksi pada data Anda di masa mendatang. Untuk menyetel pengklasifikasi, kami menjalankan pernyataan berikut -
In [23]: classifier.fit(X_train, Y_train)Pengklasifikasi sekarang siap untuk diuji. Kode berikut adalah output dari eksekusi dua pernyataan di atas -
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2', random_state=0,
solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))Sekarang, kami siap untuk menguji pengklasifikasi yang dibuat. Kami akan membahas ini di bab berikutnya.
Kita perlu menguji pengklasifikasi yang dibuat di atas sebelum menggunakannya untuk produksi. Jika pengujian menunjukkan bahwa model tidak memenuhi akurasi yang diinginkan, kita harus kembali ke proses di atas, memilih kumpulan fitur lain (kolom data), membuat model lagi, dan mengujinya. Ini akan menjadi langkah berulang sampai pengklasifikasi memenuhi persyaratan akurasi yang Anda inginkan. Jadi mari kita uji pengklasifikasi kita.
Memprediksi Data Uji
Untuk menguji pengklasifikasi, kami menggunakan data pengujian yang dihasilkan pada tahap sebelumnya. Kami menyebutnyapredict metode pada objek yang dibuat dan meneruskan X larik data uji seperti yang ditunjukkan pada perintah berikut -
In [24]: predicted_y = classifier.predict(X_test)Ini menghasilkan array dimensi tunggal untuk seluruh kumpulan data pelatihan yang memberikan prediksi untuk setiap baris dalam array X. Anda dapat memeriksa array ini dengan menggunakan perintah berikut -
In [25]: predicted_yBerikut ini adalah output dari eksekusi dua perintah di atas -
Out[25]: array([0, 0, 0, ..., 0, 0, 0])Output tersebut menunjukkan bahwa tiga pelanggan pertama dan terakhir bukanlah calon potensial untuk Term Deposit. Anda dapat memeriksa seluruh larik untuk menyortir calon pelanggan. Untuk melakukannya, gunakan cuplikan kode Python berikut -
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")Output dari menjalankan kode di atas ditunjukkan di bawah ini -

Outputnya menunjukkan indeks dari semua baris yang merupakan kandidat potensial untuk berlangganan TD. Anda sekarang dapat memberikan hasil ini kepada tim pemasaran bank yang akan mengambil detail kontak untuk setiap pelanggan di baris yang dipilih dan melanjutkan pekerjaan mereka.
Sebelum kami memasukkan model ini ke dalam produksi, kami perlu memverifikasi keakuratan prediksi.
Memverifikasi Akurasi
Untuk menguji keakuratan model, gunakan metode skor pada pengklasifikasi seperti yang ditunjukkan di bawah ini -
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))Output layar dari menjalankan perintah ini ditunjukkan di bawah ini -
Accuracy: 0.90Ini menunjukkan bahwa akurasi model kami adalah 90% yang dianggap sangat baik di sebagian besar aplikasi. Dengan demikian, tidak diperlukan penyetelan lebih lanjut. Sekarang, pelanggan kami siap untuk menjalankan kampanye berikutnya, dapatkan daftar pelanggan potensial dan kejar mereka untuk membuka TD dengan kemungkinan tingkat keberhasilan yang tinggi.
Seperti yang telah Anda lihat dari contoh di atas, menerapkan regresi logistik untuk pembelajaran mesin bukanlah tugas yang sulit. Namun, ia hadir dengan batasannya sendiri. Regresi logistik tidak akan dapat menangani fitur kategorikal dalam jumlah besar. Dalam contoh yang telah kita bahas sejauh ini, kami mengurangi sebagian besar fitur.
Namun, jika fitur ini penting dalam prediksi kami, kami akan dipaksa untuk memasukkannya, tetapi regresi logistik akan gagal memberikan akurasi yang baik. Regresi logistik juga rentan terhadap overfitting. Ini tidak dapat diterapkan pada masalah non-linier. Ini akan berkinerja buruk dengan variabel independen yang tidak berkorelasi dengan target dan berkorelasi satu sama lain. Dengan demikian, Anda harus mengevaluasi dengan cermat kesesuaian regresi logistik dengan masalah yang Anda coba selesaikan.
Ada banyak area pembelajaran mesin di mana teknik lain yang ditentukan dirancang. Untuk beberapa nama, kami memiliki algoritme seperti k-neighbourhood (kNN), Linear Regression, Support Vector Machines (SVM), Decision Trees, Naive Bayes, dan sebagainya. Sebelum menyelesaikan model tertentu, Anda harus mengevaluasi penerapan berbagai teknik ini pada masalah yang kami coba selesaikan.
Regresi Logistik adalah teknik statistik klasifikasi biner. Dalam tutorial ini, Anda telah mempelajari cara melatih mesin untuk menggunakan regresi logistik. Membuat model pembelajaran mesin, persyaratan terpenting adalah ketersediaan data. Tanpa data yang memadai dan relevan, Anda tidak bisa begitu saja membuat mesin belajar.
Setelah Anda memiliki data, tugas utama Anda berikutnya adalah membersihkan data, menghilangkan baris yang tidak diinginkan, bidang, dan memilih bidang yang sesuai untuk pengembangan model Anda. Setelah ini selesai, Anda perlu memetakan data ke dalam format yang diperlukan oleh classifier untuk pelatihannya. Dengan demikian, persiapan data adalah tugas utama dalam aplikasi pembelajaran mesin apa pun. Setelah Anda siap dengan datanya, Anda dapat memilih jenis pengklasifikasi tertentu.
Dalam tutorial ini, Anda telah mempelajari cara menggunakan pengklasifikasi regresi logistik yang disediakan di sklearnPerpustakaan. Untuk melatih pengklasifikasi, kami menggunakan sekitar 70% data untuk melatih model. Kami menggunakan sisa data untuk pengujian. Kami menguji keakuratan model. Jika ini di luar batas yang dapat diterima, kami kembali memilih kumpulan fitur baru.
Sekali lagi, ikuti seluruh proses menyiapkan data, latih model, dan uji, hingga Anda puas dengan akurasinya. Sebelum mengambil proyek pembelajaran mesin, Anda harus belajar dan memiliki eksposur ke berbagai macam teknik yang telah dikembangkan sejauh ini dan yang telah berhasil diterapkan di industri.