Lucene - Proses Pengindeksan
Proses pengindeksan adalah salah satu fungsi inti yang disediakan oleh Lucene. Diagram berikut menggambarkan proses pengindeksan dan penggunaan kelas. IndexWriter adalah komponen terpenting dan inti dari proses pengindeksan.
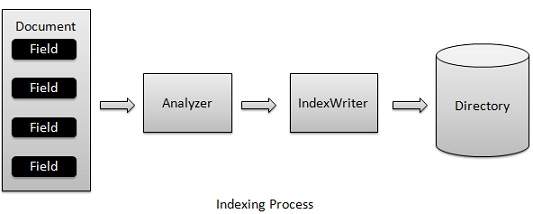
Kami menambahkan Dokumen yang berisi Bidang ke IndexWriter yang menganalisis Dokumen menggunakan Analyzer dan kemudian membuat / membuka / mengedit indeks sesuai kebutuhan dan menyimpan / memperbaruinya dalam Direktori . IndexWriter digunakan untuk memperbarui atau membuat indeks. Itu tidak digunakan untuk membaca indeks.
Sekarang kami akan menunjukkan kepada Anda proses langkah demi langkah untuk memulai dalam memahami proses pengindeksan menggunakan contoh dasar.
Buat dokumen
Buat metode untuk mendapatkan dokumen lucene dari file teks.
Buat berbagai jenis bidang yang merupakan pasangan nilai kunci yang berisi kunci sebagai nama dan nilai sebagai konten yang akan diindeks.
Setel bidang untuk dianalisis atau tidak. Dalam kasus kami, hanya konten yang akan dianalisis karena dapat berisi data seperti a, am, are, dan dll. Yang tidak diperlukan dalam operasi pencarian.
Tambahkan bidang yang baru dibuat ke objek dokumen dan kembalikan ke metode pemanggil.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}Buat Penulis Indeks
Kelas IndexWriter bertindak sebagai komponen inti yang membuat / memperbarui indeks selama proses pengindeksan. Ikuti langkah-langkah berikut untuk membuat IndexWriter -
Step 1 - Buat objek IndexWriter.
Step 2 - Buat direktori Lucene yang harus menunjuk ke lokasi di mana indeks akan disimpan.
Step 3 - Inisialisasi objek IndexWriter yang dibuat dengan direktori indeks, penganalisis standar yang memiliki informasi versi dan parameter wajib / opsional lainnya.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}Mulai Proses Pengindeksan
Program berikut menunjukkan cara memulai proses pengindeksan -
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}Contoh Aplikasi
Untuk menguji proses pengindeksan, kita perlu membuat tes aplikasi Lucene.
| Langkah | Deskripsi |
|---|---|
| 1 | Buat proyek dengan nama LuceneFirstApplication di bawah paket com.tutorialspoint.lucene seperti yang dijelaskan di Lucene - bab Aplikasi Pertama . Anda juga dapat menggunakan proyek yang dibuat di Lucene - bab Aplikasi Pertama seperti untuk bab ini untuk memahami proses pengindeksan. |
| 2 | Buat LuceneConstants.java, TextFileFilter.java dan Indexer.java seperti yang dijelaskan di Lucene - bab Aplikasi Pertama . Jaga sisa file tidak berubah. |
| 3 | Buat LuceneTester.java seperti yang disebutkan di bawah ini. |
| 4 | Bersihkan dan bangun aplikasi untuk memastikan logika bisnis berfungsi sesuai persyaratan. |
LuceneConstants.java
Kelas ini digunakan untuk menyediakan berbagai konstanta yang akan digunakan di seluruh aplikasi sampel.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Kelas ini digunakan sebagai .txt filter file.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
Kelas ini digunakan untuk mengindeks data mentah sehingga kita dapat membuatnya dapat dicari menggunakan pustaka Lucene.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}LuceneTester.java
Kelas ini digunakan untuk menguji kemampuan pengindeksan perpustakaan Lucene.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}Pembuatan Direktori Data & Indeks
Kami telah menggunakan 10 file teks dari record1.txt ke record10.txt yang berisi nama dan detail siswa lainnya dan meletakkannya di direktori E:\Lucene\Data. Uji Data . Jalur direktori indeks harus dibuat sebagaiE:\Lucene\Index. Setelah menjalankan program ini, Anda dapat melihat daftar file indeks yang dibuat di folder tersebut.
Menjalankan Program
Setelah Anda selesai dengan pembuatan sumber, data mentah, direktori data dan direktori indeks, Anda dapat melanjutkan dengan mengompilasi dan menjalankan program Anda. Untuk melakukan ini, biarkan tab file LuceneTester.Java aktif dan gunakan fileRun pilihan yang tersedia di Eclipse IDE atau gunakan Ctrl + F11 untuk mengkompilasi dan menjalankan file LuceneTesteraplikasi. Jika aplikasi Anda berjalan dengan sukses, itu akan mencetak pesan berikut di konsol Eclipse IDE -
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 msSetelah Anda menjalankan program dengan sukses, Anda akan memiliki konten berikut di index directory −