Mahout - Pengelompokan
Clustering adalah prosedur untuk mengatur elemen atau item dari suatu koleksi ke dalam kelompok berdasarkan kesamaan antar item. Misalnya, aplikasi yang terkait dengan penerbitan berita online mengelompokkan artikel beritanya menggunakan clustering.
Aplikasi Clustering
Clustering secara luas digunakan di banyak aplikasi seperti riset pasar, pengenalan pola, analisis data, dan pemrosesan gambar.
Pengelompokan dapat membantu pemasar menemukan grup yang berbeda dalam basis pelanggan mereka. Dan mereka dapat mengkarakterisasi kelompok pelanggan mereka berdasarkan pola pembelian.
Di bidang biologi, ini dapat digunakan untuk memperoleh taksonomi tumbuhan dan hewan, mengkategorikan gen dengan fungsi serupa dan mendapatkan wawasan tentang struktur yang melekat dalam populasi.
Pengelompokan membantu dalam mengidentifikasi area penggunaan lahan serupa dalam database observasi bumi.
Pengelompokan juga membantu dalam mengklasifikasikan dokumen di web untuk penemuan informasi.
Clustering digunakan dalam aplikasi deteksi outlier seperti deteksi penipuan kartu kredit.
Sebagai fungsi data mining, Cluster Analysis berfungsi sebagai alat untuk mendapatkan wawasan tentang distribusi data untuk mengamati karakteristik setiap cluster.
Menggunakan Mahout, kita dapat mengelompokkan sekumpulan data tertentu. Langkah-langkah yang diperlukan adalah sebagai berikut:
Algorithm Anda perlu memilih algoritme pengelompokan yang sesuai untuk mengelompokkan elemen kluster.
Similarity and Dissimilarity Anda perlu memiliki aturan untuk memverifikasi kesamaan antara elemen yang baru ditemukan dan elemen dalam grup.
Stopping Condition Kondisi penghentian diperlukan untuk menentukan titik di mana tidak diperlukan pengelompokan.
Prosedur Pengelompokan
Untuk mengelompokkan data yang diberikan, Anda perlu -
Mulai server Hadoop. Buat direktori yang diperlukan untuk menyimpan file di Sistem File Hadoop. (Buat direktori untuk file input, file urutan, dan output berkerumun jika ada kanopi).
Salin file input ke sistem File Hadoop dari sistem file Unix.
Siapkan file sequence dari input data.
Jalankan salah satu algoritme pengelompokan yang tersedia.
Dapatkan data berkerumun.
Memulai Hadoop
Mahout bekerja dengan Hadoop, oleh karena itu pastikan server Hadoop aktif dan berjalan.
$ cd HADOOP_HOME/bin
$ start-all.shMempersiapkan Direktori File Input
Buat direktori di sistem file Hadoop untuk menyimpan file input, file urutan, dan data berkerumun menggunakan perintah berikut:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
$ hadoop fs -p mkdir /mahout_seqAnda dapat memverifikasi apakah direktori dibuat menggunakan antarmuka web hadoop di URL berikut - http://localhost:50070/
Ini memberi Anda output seperti yang ditunjukkan di bawah ini:
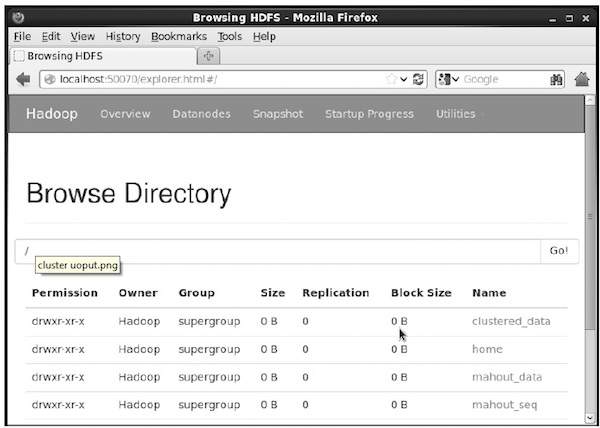
Menyalin File Input ke HDFS
Sekarang, salin file data masukan dari sistem file Linux ke direktori mahout_data di Sistem File Hadoop seperti yang ditunjukkan di bawah ini. Asumsikan file input Anda adalah mydata.txt dan itu ada di direktori / home / Hadoop / data /.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/Mempersiapkan File Urutan
Mahout memberi Anda utilitas untuk mengubah file input yang diberikan menjadi format file urutan. Utilitas ini membutuhkan dua parameter.
- Direktori file masukan tempat data asli berada.
- Direktori file keluaran tempat penyimpanan data berkerumun.
Diberikan di bawah ini adalah prompt bantuan mahout seqdirectory utilitas.
Step 1:Jelajahi direktori utama Mahout. Anda bisa mendapatkan bantuan utilitas seperti yang ditunjukkan di bawah ini:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryBuat file urutan menggunakan utilitas menggunakan sintaks berikut:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/Algoritma Pengelompokan
Mahout mendukung dua algoritma utama untuk pengelompokan yaitu:
- Pengelompokan kanopi
- Pengelompokan K-means
Pengelompokan Kanopi
Pengelompokan kanopi adalah teknik sederhana dan cepat yang digunakan oleh Mahout untuk tujuan pengelompokan. Objek akan diperlakukan sebagai titik di ruang biasa. Teknik ini sering digunakan sebagai langkah awal pada teknik clustering lain seperti k-means clustering. Anda dapat menjalankan pekerjaan Canopy menggunakan sintaks berikut:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>Pekerjaan kanopi membutuhkan direktori file masukan dengan file urutan dan direktori keluaran tempat penyimpanan data berkerumun.
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30Anda akan mendapatkan data berkerumun yang dihasilkan di direktori keluaran yang diberikan.
Pengelompokan K-means
Pengelompokan K-means adalah algoritme pengelompokan yang penting. K dalam algoritme pengelompokan k-means mewakili jumlah kluster tempat data akan dibagi. Misalnya, nilai k yang ditentukan untuk algoritme ini dipilih sebagai 3, algoritme akan membagi data menjadi 3 cluster.
Setiap objek akan direpresentasikan sebagai vektor di ruang angkasa. Awalnya k poin akan dipilih oleh algoritma secara acak dan diperlakukan sebagai pusat, setiap objek yang paling dekat dengan setiap pusat dikelompokkan. Ada beberapa algoritma untuk pengukuran jarak dan pengguna harus memilih salah satu yang diperlukan.
Creating Vector Files
Berbeda dengan algoritma Canopy, algoritma k-means membutuhkan file vektor sebagai input, oleh karena itu Anda harus membuat file vektor.
Untuk menghasilkan file vektor dari format file sequence, Mahout menyediakan seq2parse utilitas.
Diberikan di bawah ini adalah beberapa opsi seq2parseutilitas. Buat file vektor menggunakan opsi ini.
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Setelah membuat vektor, lanjutkan dengan algoritma k-means. Sintaks untuk menjalankan pekerjaan k-means adalah sebagai berikut:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>Pekerjaan clustering K-means membutuhkan direktori vektor input, direktori cluster output, pengukuran jarak, jumlah iterasi maksimum yang akan dilakukan, dan nilai integer yang mewakili jumlah cluster tempat data input akan dibagi.