MapReduce - Panduan Cepat
MapReduce adalah model pemrograman untuk menulis aplikasi yang dapat memproses Big Data secara paralel pada banyak node. MapReduce menyediakan kemampuan analitis untuk menganalisis data kompleks dalam jumlah besar.
Apa itu Big Data?
Big Data adalah kumpulan kumpulan data besar yang tidak dapat diproses menggunakan teknik komputasi tradisional. Misalnya, volume data yang dibutuhkan Facebook atau Youtube untuk dikumpulkan dan dikelola setiap hari, dapat termasuk dalam kategori Big Data. Namun, Big Data tidak hanya tentang skala dan volume, tetapi juga melibatkan satu atau lebih aspek berikut - Kecepatan, Variasi, Volume, dan Kompleksitas.
Mengapa MapReduce?
Sistem Perusahaan Tradisional biasanya memiliki server terpusat untuk menyimpan dan memproses data. Ilustrasi berikut menggambarkan pandangan skematis dari sistem perusahaan tradisional. Model tradisional tentunya tidak cocok untuk memproses volume besar data yang dapat diskalakan dan tidak dapat diakomodasi oleh server database standar. Selain itu, sistem terpusat menciptakan terlalu banyak hambatan saat memproses banyak file secara bersamaan.

Google memecahkan masalah kemacetan ini menggunakan algoritma yang disebut MapReduce. MapReduce membagi tugas menjadi bagian-bagian kecil dan menetapkannya ke banyak komputer. Nantinya, hasil dikumpulkan di satu tempat dan diintegrasikan untuk membentuk dataset hasil.

Bagaimana MapReduce Bekerja?
Algoritma MapReduce berisi dua tugas penting, yaitu Map dan Reduce.
Tugas Peta mengambil sekumpulan data dan mengubahnya menjadi kumpulan data lain, di mana elemen individual dipecah menjadi tupel (pasangan nilai-kunci).
Tugas Reduce mengambil output dari Map sebagai input dan menggabungkan tupel data tersebut (key-value pair) menjadi sekumpulan tupel yang lebih kecil.
Tugas pengurangan selalu dilakukan setelah pekerjaan peta.
Sekarang, mari kita cermati masing-masing fase dan coba pahami signifikansinya.
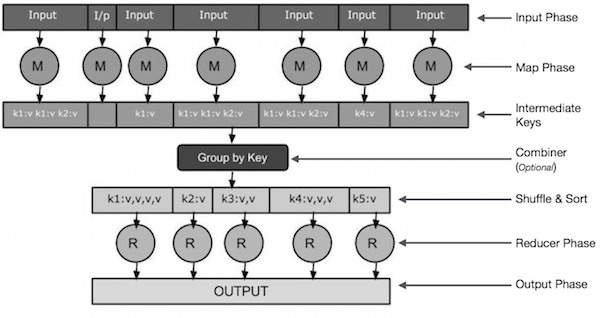
Input Phase - Di sini kita memiliki Pembaca Rekaman yang menerjemahkan setiap catatan dalam file masukan dan mengirimkan data yang diuraikan ke pembuat peta dalam bentuk pasangan nilai kunci.
Map - Peta adalah fungsi yang ditentukan pengguna, yang mengambil serangkaian pasangan nilai kunci dan memprosesnya masing-masing untuk menghasilkan nol atau lebih pasangan nilai kunci.
Intermediate Keys - Pasangan kunci-nilai yang dihasilkan oleh mapper dikenal sebagai kunci perantara.
Combiner- Penggabung adalah jenis Peredam lokal yang mengelompokkan data serupa dari fase peta ke dalam set yang dapat diidentifikasi. Ini mengambil kunci perantara dari mapper sebagai input dan menerapkan kode yang ditentukan pengguna untuk menggabungkan nilai dalam lingkup kecil satu mapper. Ini bukan bagian dari algoritma MapReduce utama; itu opsional.
Shuffle and Sort- Tugas Peredam dimulai dengan langkah Acak dan Urutkan. Ini mengunduh pasangan nilai kunci yang dikelompokkan ke mesin lokal, tempat Peredam berjalan. Pasangan nilai kunci individual diurutkan berdasarkan kunci ke dalam daftar data yang lebih besar. Daftar data mengelompokkan kunci yang setara sehingga nilainya dapat diiterasi dengan mudah dalam tugas Reducer.
Reducer- Peredam mengambil data pasangan nilai kunci yang dikelompokkan sebagai input dan menjalankan fungsi Peredam pada masing-masing data. Di sini, data dapat dikumpulkan, difilter, dan digabungkan dalam beberapa cara, dan memerlukan berbagai pemrosesan. Setelah eksekusi selesai, ini memberikan nol atau lebih pasangan nilai kunci ke langkah terakhir.
Output Phase - Dalam fase keluaran, kita memiliki pemformat keluaran yang menerjemahkan pasangan nilai kunci akhir dari fungsi Reducer dan menuliskannya ke dalam file menggunakan penulis rekaman.
Mari kita coba memahami dua tugas Map & f Reduce dengan bantuan diagram kecil -

MapReduce-Example
Mari kita ambil contoh dunia nyata untuk memahami kekuatan MapReduce. Twitter menerima sekitar 500 juta kicauan per hari, yang berarti hampir 3.000 kicauan per detik. Ilustrasi berikut menunjukkan bagaimana Tweeter mengelola tweet-nya dengan bantuan MapReduce.
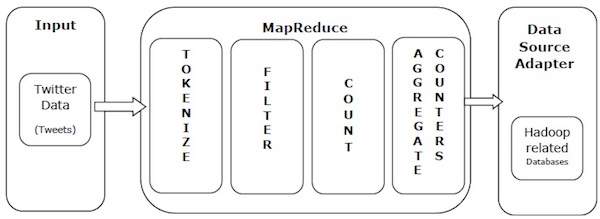
Seperti yang diperlihatkan dalam ilustrasi, algoritma MapReduce melakukan tindakan berikut -
Tokenize - Tokenize tweet ke dalam peta token dan menulisnya sebagai pasangan nilai kunci.
Filter - Memfilter kata-kata yang tidak diinginkan dari peta token dan menulis peta yang difilter sebagai pasangan nilai kunci.
Count - Menghasilkan penghitung token per kata.
Aggregate Counters - Mempersiapkan agregat nilai penghitung serupa ke dalam unit-unit kecil yang dapat dikelola.
Algoritma MapReduce berisi dua tugas penting, yaitu Map dan Reduce.
- Tugas peta dilakukan dengan menggunakan Mapper Class
- Tugas pengurangan dilakukan dengan menggunakan Kelas Peredam.
Kelas mapper mengambil masukan, membuat token, memetakan, dan mengurutkannya. Output dari kelas Mapper digunakan sebagai input oleh kelas Reducer, yang pada gilirannya mencari pasangan yang cocok dan menguranginya.

MapReduce menerapkan berbagai algoritma matematika untuk membagi tugas menjadi bagian-bagian kecil dan menetapkannya ke banyak sistem. Dalam istilah teknis, algoritma MapReduce membantu dalam mengirimkan tugas Map & Reduce ke server yang sesuai dalam sebuah cluster.
Algoritma matematika ini mungkin termasuk yang berikut -
- Sorting
- Searching
- Indexing
- TF-IDF
Penyortiran
Pengurutan adalah salah satu algoritma MapReduce dasar untuk memproses dan menganalisis data. MapReduce menerapkan algoritme pengurutan untuk secara otomatis mengurutkan pasangan nilai kunci keluaran dari mapper menurut kuncinya.
Metode pengurutan diimplementasikan di kelas mapper itu sendiri.
Dalam fase Acak dan Urutkan, setelah memberi token pada nilai di kelas mapper, file Context class (kelas yang ditentukan pengguna) mengumpulkan kunci bernilai yang cocok sebagai koleksi.
Untuk mengumpulkan pasangan nilai kunci yang serupa (kunci perantara), kelas Mapper membutuhkan bantuan RawComparator kelas untuk mengurutkan pasangan nilai kunci.
Kumpulan pasangan nilai kunci perantara untuk Peredam tertentu diurutkan secara otomatis oleh Hadoop untuk membentuk nilai kunci (K2, {V2, V2,…}) sebelum disajikan ke Peredam.
Mencari
Pencarian memainkan peran penting dalam algoritma MapReduce. Ini membantu dalam fase penggabung (opsional) dan dalam fase Peredam. Mari kita coba memahami cara kerja Penelusuran dengan bantuan sebuah contoh.
Contoh
Contoh berikut menunjukkan bagaimana MapReduce menggunakan algoritma Pencarian untuk mengetahui detail karyawan yang memperoleh gaji tertinggi dalam kumpulan data karyawan tertentu.
Mari kita asumsikan kita memiliki data karyawan dalam empat file berbeda - A, B, C, dan D. Mari kita asumsikan juga ada catatan karyawan duplikat di keempat file karena mengimpor data karyawan dari semua tabel database berulang kali. Lihat ilustrasi berikut.

The Map phasememproses setiap file masukan dan memberikan data karyawan dalam pasangan nilai kunci (<k, v>: <nama emp, gaji>). Lihat ilustrasi berikut.

The combiner phase(teknik pencarian) akan menerima masukan dari fase Peta sebagai pasangan nilai kunci dengan nama dan gaji karyawan. Dengan menggunakan teknik pencarian, penggabung akan memeriksa semua gaji karyawan untuk menemukan karyawan dengan gaji tertinggi di setiap file. Lihat cuplikan berikut.
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}Hasil yang diharapkan adalah sebagai berikut -
|
Reducer phase- Bentuk setiap file, Anda akan menemukan karyawan bergaji tertinggi. Untuk menghindari redundansi, periksa semua pasangan <k, v> dan hilangkan entri duplikat, jika ada. Algoritma yang sama digunakan di antara empat pasangan <k, v>, yang berasal dari empat file masukan. Hasil akhirnya harus sebagai berikut -
<gopal, 50000>Pengindeksan
Biasanya pengindeksan digunakan untuk menunjuk ke data tertentu dan alamatnya. Ia melakukan pengindeksan batch pada file input untuk Mapper tertentu.
Teknik pengindeksan yang biasanya digunakan di MapReduce dikenal sebagai inverted index.Mesin pencari seperti Google dan Bing menggunakan teknik pengindeksan terbalik. Mari kita coba memahami cara kerja Pengindeksan dengan bantuan contoh sederhana.
Contoh
Teks berikut adalah masukan untuk pengindeksan terbalik. Di sini T [0], T [1], dan t [2] adalah nama file dan isinya dalam tanda kutip ganda.
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"Setelah menerapkan algoritma Pengindeksan, kami mendapatkan keluaran berikut -
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}Di sini "a": {2} menyiratkan istilah "a" muncul di file T [2]. Demikian pula, "adalah": {0, 1, 2} menyiratkan istilah "adalah" muncul di file T [0], T [1], dan T [2].
TF-IDF
TF-IDF adalah algoritma pengolah teks yang merupakan kependekan dari Term Frequency - Inverse Document Frequency. Ini adalah salah satu algoritma analisis web yang umum. Di sini, istilah 'frekuensi' mengacu pada berapa kali sebuah istilah muncul dalam dokumen.
Frekuensi Jangka (TF)
Ini mengukur seberapa sering istilah tertentu muncul dalam dokumen. Ini dihitung dengan berapa kali kata muncul dalam dokumen dibagi dengan jumlah kata dalam dokumen itu.
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)Frekuensi Dokumen Terbalik (IDF)
Ini mengukur pentingnya suatu istilah. Ini dihitung dengan jumlah dokumen dalam database teks dibagi dengan jumlah dokumen di mana istilah tertentu muncul.
Saat menghitung TF, semua istilah dianggap sama pentingnya. Artinya, TF menghitung frekuensi istilah untuk kata-kata normal seperti "adalah", "a", "apa", dll. Jadi, kita perlu mengetahui istilah yang sering digunakan saat meningkatkan yang jarang, dengan menghitung yang berikut -
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).Algoritme dijelaskan di bawah ini dengan bantuan contoh kecil.
Contoh
Pertimbangkan dokumen yang berisi 1000 kata, dimana kata tersebut hivemuncul 50 kali. TF untukhive kemudian (50/1000) = 0,05.
Sekarang, anggap kita memiliki 10 juta dokumen dan kata hivemuncul di 1000 ini. Kemudian, IDF dihitung sebagai log (10.000.000 / 1.000) = 4.
Bobot TF-IDF adalah hasil kali dari jumlah ini - 0,05 × 4 = 0,20.
MapReduce hanya berfungsi pada sistem operasi rasa Linux dan dilengkapi dengan Kerangka Hadoop. Kita perlu melakukan langkah-langkah berikut untuk menginstal framework Hadoop.
Memverifikasi Instalasi JAVA
Java harus diinstal di sistem Anda sebelum menginstal Hadoop. Gunakan perintah berikut untuk memeriksa apakah Anda telah menginstal Java di sistem Anda.
$ java –versionJika Java sudah diinstal di sistem Anda, Anda akan melihat respons berikut -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Jika Anda tidak menginstal Java di sistem Anda, ikuti langkah-langkah yang diberikan di bawah ini.
Menginstal Java
Langkah 1
Unduh versi terbaru Java dari tautan berikut - tautan ini .
Setelah mengunduh, Anda dapat menemukan file tersebut jdk-7u71-linux-x64.tar.gz di folder Unduhan Anda.
Langkah 2
Gunakan perintah berikut untuk mengekstrak konten jdk-7u71-linux-x64.gz.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzLANGKAH 3
Agar Java tersedia untuk semua pengguna, Anda harus memindahkannya ke lokasi "/ usr / local /". Pergi ke root dan ketik perintah berikut -
$ su
password:
# mv jdk1.7.0_71 /usr/local/java
# exitLANGKAH 4
Untuk menyiapkan variabel PATH dan JAVA_HOME, tambahkan perintah berikut ke file ~ / .bashrc.
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/binTerapkan semua perubahan ke sistem yang sedang berjalan.
$ source ~/.bashrcLANGKAH 5
Gunakan perintah berikut untuk mengkonfigurasi alternatif Java -
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarSekarang verifikasi penginstalan menggunakan perintah java -version dari terminal.
Memverifikasi Instalasi Hadoop
Hadoop harus diinstal di sistem Anda sebelum menginstal MapReduce. Mari kita verifikasi instalasi Hadoop menggunakan perintah berikut -
$ hadoop versionJika Hadoop sudah terinstal di sistem Anda, maka Anda akan mendapatkan respons berikut -
Hadoop 2.4.1
--
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Jika Hadoop tidak diinstal pada sistem Anda, lanjutkan dengan langkah-langkah berikut.
Mendownload Hadoop
Unduh Hadoop 2.4.1 dari Apache Software Foundation dan ekstrak kontennya menggunakan perintah berikut.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitMenginstal Hadoop dalam mode Pseudo Distributed
Langkah-langkah berikut digunakan untuk menginstal Hadoop 2.4.1 dalam mode pseudo didistribusikan.
Langkah 1 - Menyiapkan Hadoop
Anda dapat menyetel variabel lingkungan Hadoop dengan menambahkan perintah berikut ke file ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binTerapkan semua perubahan ke sistem yang sedang berjalan.
$ source ~/.bashrcLangkah 2 - Konfigurasi Hadoop
Anda dapat menemukan semua file konfigurasi Hadoop di lokasi "$ HADOOP_HOME / etc / hadoop". Anda perlu membuat perubahan yang sesuai pada file konfigurasi tersebut sesuai dengan infrastruktur Hadoop Anda.
$ cd $HADOOP_HOME/etc/hadoopUntuk mengembangkan program Hadoop menggunakan Java, Anda harus mengatur ulang variabel lingkungan Java di hadoop-env.sh file dengan mengganti nilai JAVA_HOME dengan lokasi Java di sistem Anda.
export JAVA_HOME=/usr/local/javaAnda harus mengedit file berikut untuk mengkonfigurasi Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml berisi informasi berikut−
- Nomor port yang digunakan untuk instance Hadoop
- Memori dialokasikan untuk sistem file
- Batas memori untuk menyimpan data
- Ukuran buffer Baca / Tulis
Buka core-site.xml dan tambahkan properti berikut di antara tag <configuration> dan </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000 </value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml berisi informasi berikut -
- Nilai data replikasi
- Jalur namenode
- Jalur datanode sistem file lokal Anda (tempat Anda ingin menyimpan infra Hadoop)
Mari kita asumsikan data berikut.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeBuka file ini dan tambahkan properti berikut di antara tag <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - Dalam file di atas, semua nilai properti ditentukan pengguna dan Anda dapat membuat perubahan sesuai dengan infrastruktur Hadoop Anda.
benang-situs.xml
File ini digunakan untuk mengkonfigurasi benang menjadi Hadoop. Buka file yarn-site.xml dan tambahkan properti berikut di antara tag <configuration>, </configuration>.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
File ini digunakan untuk menentukan kerangka MapReduce yang kita gunakan. Secara default, Hadoop berisi template benang-situs.xml. Pertama-tama, Anda perlu menyalin file dari mapred-site.xml.template ke file mapred-site.xml menggunakan perintah berikut.
$ cp mapred-site.xml.template mapred-site.xmlBuka file mapred-site.xml dan tambahkan properti berikut di antara tag <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Memverifikasi Instalasi Hadoop
Langkah-langkah berikut digunakan untuk memverifikasi penginstalan Hadoop.
Langkah 1 - Penyiapan Node Nama
Siapkan namenode menggunakan perintah “hdfs namenode -format” sebagai berikut -
$ cd ~ $ hdfs namenode -formatHasil yang diharapkan adalah sebagai berikut -
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Langkah 2 - Memverifikasi Hadoop dfs
Jalankan perintah berikut untuk memulai sistem file Hadoop Anda.
$ start-dfs.shOutput yang diharapkan adalah sebagai berikut -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Langkah 3 - Memverifikasi Skrip Benang
Perintah berikut digunakan untuk memulai skrip benang. Menjalankan perintah ini akan memulai benang daemon Anda.
$ start-yarn.shOutput yang diharapkan adalah sebagai berikut -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outLangkah 4 - Mengakses Hadoop di Browser
Nomor port default untuk mengakses Hadoop adalah 50070. Gunakan URL berikut untuk mendapatkan layanan Hadoop di browser Anda.
http://localhost:50070/Tangkapan layar berikut menunjukkan browser Hadoop.

Langkah 5 - Verifikasi semua Aplikasi Cluster
Nomor port default untuk mengakses semua aplikasi cluster adalah 8088. Gunakan URL berikut untuk menggunakan layanan ini.
http://localhost:8088/Tangkapan layar berikut menunjukkan browser cluster Hadoop.

Dalam bab ini, kita akan melihat lebih dekat pada kelas dan metodenya yang terlibat dalam operasi pemrograman MapReduce. Kami terutama akan tetap fokus pada hal-hal berikut -
- Antarmuka Konteks Pekerjaan
- Kelas Pekerjaan
- Kelas Mapper
- Kelas Peredam
Antarmuka Konteks Pekerjaan
Antarmuka JobContext adalah antarmuka super untuk semua kelas, yang mendefinisikan pekerjaan berbeda di MapReduce. Ini memberi Anda tampilan baca-saja dari pekerjaan yang disediakan untuk tugas saat mereka sedang berjalan.
Berikut ini adalah sub-antarmuka dari antarmuka JobContext.
| S.No. | Deskripsi Subinterface |
|---|---|
| 1. | MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> Mendefinisikan konteks yang diberikan ke Mapper. |
| 2. | ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> Mendefinisikan konteks yang diteruskan ke Reducer. |
Kelas pekerjaan adalah kelas utama yang mengimplementasikan antarmuka JobContext.
Kelas Pekerjaan
Kelas Pekerjaan adalah kelas paling penting dalam API MapReduce. Ini memungkinkan pengguna untuk mengonfigurasi pekerjaan, mengirimkannya, mengontrol eksekusinya, dan menanyakan status. Metode yang ditetapkan hanya berfungsi hingga tugas dikirim, setelah itu metode tersebut akan menampilkan IllegalStateException.
Biasanya, pengguna membuat aplikasi, menjelaskan berbagai aspek pekerjaan, lalu mengirimkan pekerjaan dan memantau kemajuannya.
Berikut adalah contoh cara mengirimkan pekerjaan -
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);Konstruktor
Berikut adalah ringkasan konstruktor dari kelas Job.
| S.No | Ringkasan Konstruktor |
|---|---|
| 1 | Job() |
| 2 | Job(Konfigurasi konfigurasi) |
| 3 | Job(Konfigurasi conf, String jobName) |
Metode
Beberapa metode penting dari kelas Job adalah sebagai berikut -
| S.No | Deskripsi Metode |
|---|---|
| 1 | getJobName() Nama pekerjaan yang ditentukan pengguna. |
| 2 | getJobState() Mengembalikan status Pekerjaan saat ini. |
| 3 | isComplete() Memeriksa apakah pekerjaan telah selesai atau belum. |
| 4 | setInputFormatClass() Setel InputFormat untuk pekerjaan itu. |
| 5 | setJobName(String name) Menyetel nama pekerjaan yang ditentukan pengguna. |
| 6 | setOutputFormatClass() Mengatur Format Output untuk pekerjaan itu. |
| 7 | setMapperClass(Class) Mengatur Mapper untuk pekerjaan itu. |
| 8 | setReducerClass(Class) Mengatur Peredam untuk pekerjaan itu. |
| 9 | setPartitionerClass(Class) Mengatur Partisi untuk pekerjaan itu. |
| 10 | setCombinerClass(Class) Mengatur Pemadu untuk pekerjaan itu. |
Kelas Mapper
Kelas Mapper mendefinisikan pekerjaan Peta. Memetakan pasangan nilai kunci input ke satu set pasangan nilai kunci menengah. Peta adalah tugas individu yang mengubah catatan masukan menjadi catatan perantara. Rekaman perantara yang ditransformasikan tidak harus memiliki jenis yang sama dengan rekaman masukan. Pasangan masukan tertentu dapat dipetakan ke nol atau banyak pasangan keluaran.
metode
mapadalah metode paling menonjol dari kelas Mapper. Sintaksnya didefinisikan di bawah -
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)Metode ini dipanggil sekali untuk setiap pasangan nilai kunci dalam pemisahan input.
Kelas Peredam
Kelas Reducer mendefinisikan pekerjaan Reduce di MapReduce. Ini mengurangi sekumpulan nilai antara yang berbagi kunci menjadi sekumpulan nilai yang lebih kecil. Implementasi peredam bisa mengakses Konfigurasi untuk suatu pekerjaan melalui metode JobContext.getConfiguration (). Peredam memiliki tiga fase utama - Acak, Urutkan, dan Kurangi.
Shuffle - Reducer menyalin keluaran yang diurutkan dari setiap Pemeta menggunakan HTTP di seluruh jaringan.
Sort- Kerangka kerja menggabungkan-mengurutkan input Peredam berdasarkan kunci (karena Pemetaan berbeda mungkin memiliki keluaran kunci yang sama). Fase shuffle dan sortir terjadi secara bersamaan, yaitu saat output diambil, mereka digabungkan.
Reduce - Dalam fase ini metode reduce (Object, Iterable, Context) dipanggil untuk setiap <key, (kumpulan nilai)> dalam input yang diurutkan.
metode
reduceadalah metode paling menonjol dari kelas Reducer. Sintaksnya didefinisikan di bawah -
reduce(KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)Metode ini dipanggil sekali untuk setiap kunci pada kumpulan pasangan kunci-nilai.
MapReduce adalah kerangka kerja yang digunakan untuk menulis aplikasi guna memproses data dalam jumlah besar pada kelompok besar perangkat keras komoditas dengan cara yang andal. Bab ini memandu Anda mempelajari pengoperasian MapReduce dalam kerangka kerja Hadoop menggunakan Java.
Algoritma MapReduce
Umumnya paradigma MapReduce didasarkan pada pengiriman program pengurangan peta ke komputer di mana data aktual berada.
Selama tugas MapReduce, Hadoop mengirim tugas Map dan Reduce ke server yang sesuai di cluster.
Kerangka kerja ini mengelola semua detail penyaluran data seperti mengeluarkan tugas, memverifikasi penyelesaian tugas, dan menyalin data di sekitar cluster di antara node.
Sebagian besar komputasi terjadi pada node dengan data pada disk lokal yang mengurangi lalu lintas jaringan.
Setelah menyelesaikan tugas tertentu, cluster mengumpulkan dan mengurangi data untuk membentuk hasil yang sesuai, dan mengirimkannya kembali ke server Hadoop.

Input dan Output (Perspektif Java)
Kerangka kerja MapReduce beroperasi pada pasangan nilai-kunci, yaitu kerangka kerja memandang masukan ke pekerjaan sebagai satu set pasangan nilai-kunci dan menghasilkan satu set pasangan nilai-kunci sebagai keluaran dari pekerjaan, yang mungkin dari jenis yang berbeda.
Kelas kunci dan nilai harus dapat diserialkan oleh kerangka kerja dan karenanya, diperlukan untuk mengimplementasikan antarmuka Writable. Selain itu, kelas kunci harus mengimplementasikan antarmuka WritableComparable untuk memfasilitasi pengurutan berdasarkan kerangka kerja.
Baik format input dan output dari pekerjaan MapReduce dalam bentuk pasangan nilai-kunci -
(Masukan) <k1, v1> -> peta -> <k2, v2> -> kurangi -> <k3, v3> (Output).
| Memasukkan | Keluaran | |
|---|---|---|
| Peta | <k1, v1> | daftar (<k2, v2>) |
| Mengurangi | <k2, daftar (v2)> | daftar (<k3, v3>) |
Implementasi MapReduce
Tabel berikut menunjukkan data mengenai konsumsi listrik suatu organisasi. Tabel tersebut mencakup konsumsi listrik bulanan dan rata-rata tahunan selama lima tahun berturut-turut.
| Jan | Feb | Merusak | Apr | Mungkin | Jun | Jul | Agustus | Sep | Okt | Nov | Des | Rata-rata | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Kita perlu menulis aplikasi untuk memproses data masukan dalam tabel yang diberikan untuk menemukan tahun penggunaan maksimum, tahun penggunaan minimum, dan seterusnya. Tugas ini mudah bagi programmer dengan jumlah record yang terbatas, karena mereka hanya akan menulis logika untuk menghasilkan keluaran yang diperlukan, dan meneruskan data ke aplikasi tertulis.
Sekarang mari kita naikkan skala data masukan. Asumsikan kita harus menganalisis konsumsi listrik dari semua industri skala besar di negara bagian tertentu. Saat kami menulis aplikasi untuk memproses data massal tersebut,
Mereka akan membutuhkan banyak waktu untuk dieksekusi.
Akan ada lalu lintas jaringan yang padat saat kita memindahkan data dari sumber ke server jaringan.
Untuk mengatasi masalah ini, kami memiliki kerangka kerja MapReduce.
Memasukan data
Data di atas disimpan sebagai sample.txtdan diberikan sebagai masukan. File input terlihat seperti yang ditunjukkan di bawah ini.
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Contoh Program
Program berikut untuk data sampel menggunakan kerangka kerja MapReduce.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable, /*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()){
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}Simpan program di atas ke dalam ProcessUnits.java. Kompilasi dan eksekusi program diberikan di bawah ini.
Kompilasi dan Eksekusi Program ProcessUnits
Mari kita asumsikan bahwa kita berada di direktori home dari pengguna Hadoop (misalnya / home / hadoop).
Ikuti langkah-langkah yang diberikan di bawah ini untuk mengkompilasi dan menjalankan program di atas.
Step 1 - Gunakan perintah berikut untuk membuat direktori untuk menyimpan kelas java yang dikompilasi.
$ mkdir unitsStep 2- Unduh Hadoop-core-1.2.1.jar, yang digunakan untuk mengkompilasi dan menjalankan program MapReduce. Unduh jar dari mvnrepository.com . Mari kita asumsikan folder unduhan adalah / home / hadoop /.
Step 3 - Perintah berikut digunakan untuk mengkompilasi file ProcessUnits.java program dan membuat toples untuk program tersebut.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Step 4 - Perintah berikut digunakan untuk membuat direktori input di HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - Perintah berikut digunakan untuk menyalin file input bernama sample.txt di direktori input HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirStep 6 - Perintah berikut digunakan untuk memverifikasi file di direktori input
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Perintah berikut digunakan untuk menjalankan aplikasi Eleunit_max dengan mengambil file input dari direktori input.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirTunggu beberapa saat hingga file dieksekusi. Setelah dieksekusi, output berisi sejumlah input split, tugas Peta, tugas Peredam, dll.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=279400
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=546
HDFS: Number of bytes written=40
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2 Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=146137
Total time spent by all reduces in occupied slots (ms)=441
Total time spent by all map tasks (ms)=14613
Total time spent by all reduce tasks (ms)=44120
Total vcore-seconds taken by all map tasks=146137
Total vcore-seconds taken by all reduce tasks=44120
Total megabyte-seconds taken by all map tasks=149644288
Total megabyte-seconds taken by all reduce tasks=45178880
Map-Reduce Framework
Map input records=5
Map output records=5
Map output bytes=45
Map output materialized bytes=67
Input split bytes=208
Combine input records=5
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=6
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=948
CPU time spent (ms)=5160
Physical memory (bytes) snapshot=47749120
Virtual memory (bytes) snapshot=2899349504
Total committed heap usage (bytes)=277684224
File Output Format Counters
Bytes Written=40Step 8 - Perintah berikut digunakan untuk memverifikasi file yang dihasilkan di folder keluaran.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Perintah berikut digunakan untuk melihat keluaran dalam Part-00000mengajukan. File ini dibuat oleh HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Berikut adalah output yang dihasilkan oleh program MapReduce -
| 1981 | 34 |
| 1984 | 40 |
| 1985 | 45 |
Step 10 - Perintah berikut digunakan untuk menyalin folder output dari HDFS ke sistem file lokal.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoopPemartisi bekerja seperti kondisi dalam memproses set data masukan. Fase partisi berlangsung setelah fase Peta dan sebelum fase Mengurangi.
Jumlah pemartisi sama dengan jumlah reduksi. Itu artinya seorang pemartisi akan membagi data sesuai dengan jumlah reduksi. Oleh karena itu, data yang dikirimkan dari satu pemartisi diproses oleh satu Peredam.
Partisi
Pemartisi mempartisi pasangan nilai kunci dari keluaran Peta menengah. Ini mempartisi data menggunakan kondisi yang ditentukan pengguna, yang berfungsi seperti fungsi hash. Jumlah total partisi sama dengan jumlah tugas Peredam untuk pekerjaan itu. Mari kita ambil contoh untuk memahami cara kerja pemartisi.
Implementasi MapReduce Partitioner
Demi kenyamanan, mari kita asumsikan kita memiliki tabel kecil bernama Karyawan dengan data berikut. Kami akan menggunakan data sampel ini sebagai kumpulan data masukan kami untuk mendemonstrasikan cara kerja pemartisi.
| Indo | Nama | Usia | Jenis kelamin | Gaji |
|---|---|---|---|---|
| 1201 | gopal | 45 | Pria | 50.000 |
| 1202 | manisha | 40 | Perempuan | 50.000 |
| 1203 | khalil | 34 | Pria | 30.000 |
| 1204 | prasanth | 30 | Pria | 30.000 |
| 1205 | kiran | 20 | Pria | 40.000 |
| 1206 | laxmi | 25 | Perempuan | 35.000 |
| 1207 | bhavya | 20 | Perempuan | 15.000 |
| 1208 | reshma | 19 | Perempuan | 15.000 |
| 1209 | kranthi | 22 | Pria | 22.000 |
| 1210 | Satish | 24 | Pria | 25.000 |
| 1211 | Krishna | 25 | Pria | 25.000 |
| 1212 | Arshad | 28 | Pria | 20.000 |
| 1213 | lavanya | 18 | Perempuan | 8.000 |
Kami harus menulis aplikasi untuk memproses kumpulan data masukan untuk menemukan karyawan dengan gaji tertinggi menurut jenis kelamin di berbagai kelompok usia (misalnya, di bawah 20, antara 21 hingga 30, di atas 30).
Memasukan data
Data di atas disimpan sebagai input.txt di direktori “/ home / hadoop / hadoopPartitioner” dan diberikan sebagai masukan.
| 1201 | gopal | 45 | Pria | 50000 |
| 1202 | manisha | 40 | Perempuan | 51000 |
| 1203 | khaleel | 34 | Pria | 30000 |
| 1204 | prasanth | 30 | Pria | 31000 |
| 1205 | kiran | 20 | Pria | 40000 |
| 1206 | laxmi | 25 | Perempuan | 35000 |
| 1207 | bhavya | 20 | Perempuan | 15000 |
| 1208 | reshma | 19 | Perempuan | 14000 |
| 1209 | kranthi | 22 | Pria | 22000 |
| 1210 | Satish | 24 | Pria | 25000 |
| 1211 | Krishna | 25 | Pria | 26000 |
| 1212 | Arshad | 28 | Pria | 20000 |
| 1213 | lavanya | 18 | Perempuan | 8000 |
Berdasarkan masukan yang diberikan, berikut penjelasan algoritmik program tersebut.
Tugas Peta
Tugas peta menerima pasangan nilai kunci sebagai input sementara kita memiliki data teks dalam file teks. Input untuk tugas peta ini adalah sebagai berikut -
Input - Kuncinya adalah pola seperti "kunci khusus + nama file + nomor baris" (contoh: key = @ input1) dan nilainya adalah data di baris itu (contoh: nilai = 1201 \ t gopal \ t 45 \ t Pria \ t 50000).
Method - Pengoperasian tugas peta ini adalah sebagai berikut -
Membaca value (record data), yang datang sebagai nilai input dari daftar argumen dalam sebuah string.
Menggunakan fungsi split, pisahkan jenis kelamin dan simpan dalam variabel string.
String[] str = value.toString().split("\t", -3);
String gender=str[3];Kirim informasi gender dan data catatan value sebagai pasangan nilai kunci keluaran dari tugas peta ke partition task.
context.write(new Text(gender), new Text(value));Ulangi semua langkah di atas untuk semua catatan di file teks.
Output - Anda akan mendapatkan data jenis kelamin dan nilai data catatan sebagai pasangan nilai kunci.
Tugas Partisi
Tugas pemartisi menerima pasangan nilai kunci dari tugas peta sebagai inputnya. Partisi berarti membagi data menjadi beberapa segmen. Menurut kriteria partisi bersyarat yang diberikan, data pasangan nilai kunci yang dimasukkan dapat dibagi menjadi tiga bagian berdasarkan kriteria usia.
Input - Seluruh data dalam kumpulan pasangan nilai-kunci.
key = Nilai bidang jenis kelamin dalam catatan.
nilai = Nilai data catatan utuh dari jenis kelamin itu.
Method - Proses logika partisi berjalan sebagai berikut.
- Baca nilai bidang usia dari input key-value pair.
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);Cek nilai umur dengan ketentuan sebagai berikut.
- Usia kurang dari atau sama dengan 20 tahun
- Usia Lebih dari 20 dan Kurang dari atau sama dengan 30.
- Usia Lebih dari 30.
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}Output- Seluruh data pasangan nilai kunci tersegmentasi menjadi tiga kumpulan pasangan nilai kunci. Reducer bekerja secara individual pada setiap koleksi.
Kurangi Tugas
Jumlah tugas pemartisi sama dengan jumlah tugas peredam. Di sini kami memiliki tiga tugas pemartisi dan karenanya kami memiliki tiga tugas Reducer untuk dieksekusi.
Input - Reducer akan mengeksekusi tiga kali dengan koleksi key-value pair yang berbeda.
key = nilai bidang gender dalam catatan.
nilai = seluruh data catatan jenis kelamin itu.
Method - Logika berikut akan diterapkan pada setiap koleksi.
- Baca nilai bidang Gaji dari setiap catatan.
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.Periksa gaji dengan variabel maks. Jika str [4] adalah gaji maksimum, maka tetapkan str [4] ke max, jika tidak, lewati langkah tersebut.
if(Integer.parseInt(str[4])>max)
{
max=Integer.parseInt(str[4]);
}Ulangi Langkah 1 dan 2 untuk setiap koleksi kunci (Pria & Wanita adalah koleksi kunci). Setelah melakukan tiga langkah ini, Anda akan menemukan satu gaji maksimal dari koleksi kunci Pria dan satu gaji maksimal dari koleksi kunci Wanita.
context.write(new Text(key), new IntWritable(max));Output- Terakhir, Anda akan mendapatkan sekumpulan data pasangan nilai kunci dalam tiga koleksi kelompok usia yang berbeda. Ini berisi gaji maksimal dari koleksi Pria dan gaji maksimal dari koleksi Wanita di masing-masing kelompok umur.
Setelah menjalankan tugas Map, Partitioner, dan Reduce, tiga kumpulan data key-value pair disimpan dalam tiga file berbeda sebagai output.
Ketiga tugas tersebut diperlakukan sebagai pekerjaan MapReduce. Persyaratan dan spesifikasi berikut dari pekerjaan ini harus ditentukan dalam Konfigurasi -
- Nama Pekerjaan
- Format Input dan Output dari kunci dan nilai
- Kelas individu untuk tugas Map, Reduce, dan Partitioner
Configuration conf = getConf();
//Create Job
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
// File Input and Output paths
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
//Set Mapper class and Output format for key-value pair.
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
//Set Reducer class and Input/Output format for key-value pair.
job.setReducerClass(ReduceClass.class);
//Number of Reducer tasks.
job.setNumReduceTasks(3);
//Input and Output format for data
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);Contoh Program
Program berikut menunjukkan bagaimana mengimplementasikan pemartisi untuk kriteria yang diberikan dalam program MapReduce.
package partitionerexample;
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.util.*;
public class PartitionerExample extends Configured implements Tool
{
//Map class
public static class MapClass extends Mapper<LongWritable,Text,Text,Text>
{
public void map(LongWritable key, Text value, Context context)
{
try{
String[] str = value.toString().split("\t", -3);
String gender=str[3];
context.write(new Text(gender), new Text(value));
}
catch(Exception e)
{
System.out.println(e.getMessage());
}
}
}
//Reducer class
public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable>
{
public int max = -1;
public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException
{
max = -1;
for (Text val : values)
{
String [] str = val.toString().split("\t", -3);
if(Integer.parseInt(str[4])>max)
max=Integer.parseInt(str[4]);
}
context.write(new Text(key), new IntWritable(max));
}
}
//Partitioner class
public static class CaderPartitioner extends
Partitioner < Text, Text >
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks)
{
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
if(numReduceTasks == 0)
{
return 0;
}
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
}
}
@Override
public int run(String[] arg) throws Exception
{
Configuration conf = getConf();
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
job.setReducerClass(ReduceClass.class);
job.setNumReduceTasks(3);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
return 0;
}
public static void main(String ar[]) throws Exception
{
int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar);
System.exit(0);
}
}Simpan kode di atas sebagai PartitionerExample.javadi “/ home / hadoop / hadoopPartitioner”. Kompilasi dan eksekusi program diberikan di bawah ini.
Kompilasi dan Eksekusi
Mari kita asumsikan bahwa kita berada di direktori home dari pengguna Hadoop (misalnya, / home / hadoop).
Ikuti langkah-langkah yang diberikan di bawah ini untuk mengkompilasi dan menjalankan program di atas.
Step 1- Unduh Hadoop-core-1.2.1.jar, yang digunakan untuk mengkompilasi dan menjalankan program MapReduce. Anda dapat mengunduh jar dari mvnrepository.com .
Mari kita asumsikan folder yang diunduh adalah "/ home / hadoop / hadoopPartitioner"
Step 2 - Perintah berikut digunakan untuk menyusun program PartitionerExample.java dan membuat toples untuk program tersebut.
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .Step 3 - Gunakan perintah berikut untuk membuat direktori input di HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 4 - Gunakan perintah berikut untuk menyalin file input bernama input.txt di direktori input HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dirStep 5 - Gunakan perintah berikut untuk memverifikasi file di direktori input.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 6 - Gunakan perintah berikut untuk menjalankan aplikasi Gaji teratas dengan mengambil file input dari direktori input.
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dirTunggu beberapa saat hingga file dieksekusi. Setelah dieksekusi, output berisi sejumlah input split, tugas peta, dan tugas Reducer.
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully
15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=467
FILE: Number of bytes written=426777
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=480
HDFS: Number of bytes written=72
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=1
Launched reduce tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8212
Total time spent by all reduces in occupied slots (ms)=59858
Total time spent by all map tasks (ms)=8212
Total time spent by all reduce tasks (ms)=59858
Total vcore-seconds taken by all map tasks=8212
Total vcore-seconds taken by all reduce tasks=59858
Total megabyte-seconds taken by all map tasks=8409088
Total megabyte-seconds taken by all reduce tasks=61294592
Map-Reduce Framework
Map input records=13
Map output records=13
Map output bytes=423
Map output materialized bytes=467
Input split bytes=119
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=467
Reduce input records=13
Reduce output records=6
Spilled Records=26
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=224
CPU time spent (ms)=3690
Physical memory (bytes) snapshot=553816064
Virtual memory (bytes) snapshot=3441266688
Total committed heap usage (bytes)=334102528
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=361
File Output Format Counters
Bytes Written=72Step 7 - Gunakan perintah berikut untuk memverifikasi file yang dihasilkan di folder keluaran.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Anda akan menemukan output dalam tiga file karena Anda menggunakan tiga pemartisi dan tiga Reducer dalam program Anda.
Step 8 - Gunakan perintah berikut untuk melihat keluarannya Part-00000mengajukan. File ini dibuat oleh HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Output in Part-00000
Female 15000
Male 40000Gunakan perintah berikut untuk melihat keluarannya Part-00001 mengajukan.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001Output in Part-00001
Female 35000
Male 31000Gunakan perintah berikut untuk melihat keluarannya Part-00002 mengajukan.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002Output in Part-00002
Female 51000
Male 50000A Combiner, juga dikenal sebagai a semi-reducer, adalah kelas opsional yang beroperasi dengan menerima masukan dari kelas Peta dan kemudian meneruskan pasangan nilai kunci keluaran ke kelas Peredam.
Fungsi utama dari sebuah Combiner adalah untuk meringkas catatan keluaran peta dengan kunci yang sama. Output (kumpulan nilai-kunci) dari penggabung akan dikirim melalui jaringan ke tugas Reducer aktual sebagai input.
Penggabung
Kelas Combiner digunakan di antara kelas Map dan kelas Reduce untuk mengurangi volume transfer data antara Map dan Reduce. Biasanya, output dari tugas peta besar dan data yang ditransfer ke tugas pengurangan tinggi.
Diagram tugas MapReduce berikut memperlihatkan FASE COMBINER.
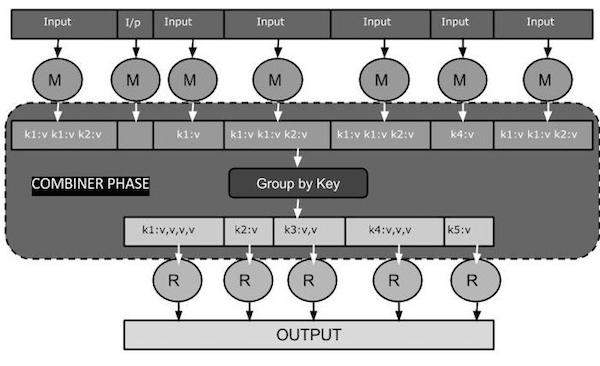
Bagaimana Combiner Bekerja?
Berikut adalah ringkasan singkat tentang cara kerja MapReduce Combiner -
Penggabung tidak memiliki antarmuka yang telah ditentukan dan harus mengimplementasikan metode reduce () antarmuka Reducer.
Penggabung beroperasi pada setiap kunci keluaran peta. Ini harus memiliki jenis nilai kunci keluaran yang sama dengan kelas Reducer.
Penggabung dapat menghasilkan informasi ringkasan dari kumpulan data besar karena menggantikan keluaran Peta asli.
Meskipun, Combiner bersifat opsional namun membantu memisahkan data menjadi beberapa grup untuk fase Reduce, yang membuatnya lebih mudah untuk diproses.
Implementasi MapReduce Combiner
Contoh berikut memberikan ide teoritis tentang penggabung. Mari kita asumsikan kita memiliki file teks input berikut bernamainput.txt untuk MapReduce.
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High PerformanceFase penting dari program MapReduce dengan Combiner dibahas di bawah ini.
Rekam Pembaca
Ini adalah fase pertama MapReduce di mana Pembaca Rekaman membaca setiap baris dari file teks masukan sebagai teks dan menghasilkan keluaran sebagai pasangan nilai kunci.
Input - Teks baris demi baris dari file input.
Output- Membentuk pasangan nilai kunci. Berikut ini adalah kumpulan pasangan kunci-nilai yang diharapkan.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Fase Peta
Fase Map mengambil masukan dari Pembaca Rekaman, memprosesnya, dan menghasilkan keluaran sebagai kumpulan pasangan nilai kunci lainnya.
Input - Pasangan nilai kunci berikut adalah input yang diambil dari Pembaca Rekaman.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Fase Map membaca setiap pasangan nilai kunci, membagi setiap kata dari nilai menggunakan StringTokenizer, memperlakukan setiap kata sebagai kunci dan jumlah kata tersebut sebagai nilai. Potongan kode berikut menunjukkan kelas Mapper dan fungsi peta.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}Output - Output yang diharapkan adalah sebagai berikut -
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Fase Penggabung
Fase Penggabung mengambil setiap pasangan nilai kunci dari fase Peta, memprosesnya, dan menghasilkan keluaran sebagai key-value collection pasangan.
Input - Pasangan nilai kunci berikut adalah input yang diambil dari fase Peta.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Fase Penggabung membaca setiap pasangan nilai kunci, menggabungkan kata-kata umum sebagai kunci dan nilai sebagai kumpulan. Biasanya, kode dan operasi untuk Combiner mirip dengan Reducer. Berikut adalah potongan kode untuk deklarasi kelas Mapper, Combiner dan Reducer.
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);Output - Output yang diharapkan adalah sebagai berikut -
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Fase Peredam
Fase Reducer mengambil setiap pasangan kumpulan nilai kunci dari fase Penggabung, memprosesnya, dan meneruskan keluaran sebagai pasangan nilai kunci. Perhatikan bahwa fungsionalitas Penggabung sama dengan Peredam.
Input - Pasangan nilai kunci berikut adalah input yang diambil dari fase Penggabung.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Fase Reducer membaca setiap pasangan nilai kunci. Berikut adalah potongan kode untuk Combiner.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}Output - Output yang diharapkan dari fase Reducer adalah sebagai berikut -
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,3>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Penulis Rekam
Ini adalah fase terakhir MapReduce di mana Record Writer menulis setiap pasangan nilai kunci dari fase Reducer dan mengirimkan output sebagai teks.
Input - Setiap pasangan nilai kunci dari fase Reducer bersama dengan format Output.
Output- Ini memberi Anda pasangan nilai kunci dalam format teks. Berikut adalah keluaran yang diharapkan.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Contoh Program
Blok kode berikut menghitung jumlah kata dalam sebuah program.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Simpan program di atas sebagai WordCount.java. Kompilasi dan eksekusi program diberikan di bawah ini.
Kompilasi dan Eksekusi
Mari kita asumsikan bahwa kita berada di direktori home pengguna Hadoop (misalnya, / home / hadoop).
Ikuti langkah-langkah yang diberikan di bawah ini untuk mengkompilasi dan menjalankan program di atas.
Step 1 - Gunakan perintah berikut untuk membuat direktori untuk menyimpan kelas java yang dikompilasi.
$ mkdir unitsStep 2- Unduh Hadoop-core-1.2.1.jar, yang digunakan untuk mengkompilasi dan menjalankan program MapReduce. Anda dapat mengunduh jar dari mvnrepository.com .
Mari kita asumsikan folder yang diunduh adalah / home / hadoop /.
Step 3 - Gunakan perintah berikut untuk mengkompilasi file WordCount.java program dan membuat toples untuk program tersebut.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java
$ jar -cvf units.jar -C units/ .Step 4 - Gunakan perintah berikut untuk membuat direktori input di HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - Gunakan perintah berikut untuk menyalin file input bernama input.txt di direktori input HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dirStep 6 - Gunakan perintah berikut untuk memverifikasi file di direktori input.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Gunakan perintah berikut untuk menjalankan aplikasi hitung kata dengan mengambil file input dari direktori input.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirTunggu beberapa saat hingga file dieksekusi. Setelah dieksekusi, output berisi sejumlah input split, tugas Peta, dan tugas Peredam.
Step 8 - Gunakan perintah berikut untuk memverifikasi file yang dihasilkan di folder keluaran.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Gunakan perintah berikut untuk melihat keluarannya Part-00000mengajukan. File ini dibuat oleh HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Berikut adalah keluaran yang dihasilkan oleh program MapReduce.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Bab ini menjelaskan administrasi Hadoop yang mencakup administrasi HDFS dan MapReduce.
Administrasi HDFS mencakup pemantauan struktur file HDFS, lokasi, dan file yang diperbarui.
Administrasi MapReduce termasuk memantau daftar aplikasi, konfigurasi node, status aplikasi, dll.
Pemantauan HDFS
HDFS (Hadoop Distributed File System) berisi direktori pengguna, file input, dan file output. Gunakan perintah MapReduce,put dan get, untuk menyimpan dan mengambil.
Setelah memulai kerangka kerja Hadoop (daemon) dengan meneruskan perintah "start-all.sh" pada "/ $ HADOOP_HOME / sbin", berikan URL berikut ke browser "http: // localhost: 50070". Anda harus melihat layar berikut di browser Anda.
Tangkapan layar berikut menunjukkan cara menelusuri HDFS.

Tangkapan layar berikut menunjukkan struktur file HDFS. Ini menunjukkan file di direktori "/ user / hadoop".

Tangkapan layar berikut menunjukkan informasi Datanode di cluster. Di sini Anda dapat menemukan satu node dengan konfigurasi dan kapasitasnya.

MapReduce Job Monitoring
Aplikasi MapReduce adalah kumpulan pekerjaan (pekerjaan Peta, Penggabung, Pemartisi, dan Kurangi pekerjaan). Adalah wajib untuk memantau dan memelihara hal-hal berikut -
- Konfigurasi datanode dimana aplikasi cocok.
- Jumlah datanoda dan resource yang digunakan per aplikasi.
Untuk memantau semua hal ini, kita harus memiliki antarmuka pengguna. Setelah memulai kerangka kerja Hadoop dengan meneruskan perintah "start-all.sh" pada "/ $ HADOOP_HOME / sbin", berikan URL berikut ke browser "http: // localhost: 8080". Anda harus melihat layar berikut di browser Anda.

Pada gambar di atas, penunjuk tangan ada di ID aplikasi. Cukup klik di atasnya untuk menemukan layar berikut di browser Anda. Ini menjelaskan hal berikut -
Pada pengguna mana aplikasi saat ini sedang berjalan
Nama aplikasi
Jenis aplikasi itu
Status saat ini, status akhir
Waktu mulai aplikasi, berlalu (waktu selesai), jika selesai pada saat pemantauan
Sejarah aplikasi ini, yaitu informasi log
Dan terakhir, informasi node, yaitu node yang berpartisipasi dalam menjalankan aplikasi.
Tangkapan layar berikut menunjukkan detail aplikasi tertentu -

Tangkapan layar berikut menjelaskan informasi node yang sedang berjalan. Di sini, tangkapan layar hanya berisi satu node. Sebuah penunjuk tangan menunjukkan alamat localhost dari node yang sedang berjalan.
