Microsoft Cognitive Toolkit - Panduan Cepat
Di bab ini, kita akan mempelajari apa itu CNTK, fitur-fiturnya, perbedaan antara versi 1.0 dan 2.0 dan hal-hal penting dari versi 2.7.
Apa itu Microsoft Cognitive Toolkit (CNTK)?
Microsoft Cognitive Toolkit (CNTK), sebelumnya dikenal sebagai Computational Network Toolkit, adalah toolkit kelas komersial yang gratis, mudah digunakan, bersumber terbuka, dan memungkinkan kita melatih algoritma pembelajaran mendalam untuk belajar seperti otak manusia. Ini memungkinkan kami untuk membuat beberapa sistem pembelajaran dalam yang populer sepertifeed-forward neural network time series prediction systems and Convolutional neural network (CNN) image classifiers.
Untuk performa optimal, fungsi kerangka kerjanya ditulis dalam C ++. Meskipun kita dapat memanggil fungsinya menggunakan C ++, tetapi pendekatan yang paling umum digunakan untuk hal yang sama adalah dengan menggunakan program Python.
Fitur CNTK
Berikut adalah beberapa fitur dan kapabilitas yang ditawarkan di versi terbaru Microsoft CNTK:
Komponen bawaan
CNTK memiliki komponen bawaan yang sangat dioptimalkan yang dapat menangani data multi-dimensi yang padat atau jarang dari Python, C ++ atau BrainScript.
Kita dapat mengimplementasikan CNN, FNN, RNN, Batch Normalization dan Sequence-to-Sequence dengan perhatian.
Ini memberi kita fungsionalitas untuk menambahkan komponen inti yang ditentukan pengguna baru pada GPU dari Python.
Ini juga menyediakan penyetelan hyperparameter otomatis.
Kami dapat mengimplementasikan pembelajaran Reinforcement, Generative Adversarial Networks (GANs), Supervised serta unsupervised learning.
Untuk kumpulan data yang sangat besar, CNTK memiliki pembaca terintegrasi yang dioptimalkan.
Penggunaan sumber daya secara efisien
CNTK memberi kita paralelisme dengan akurasi tinggi pada beberapa GPU / mesin melalui SGD 1-bit.
Untuk menyesuaikan model terbesar dalam memori GPU, ini menyediakan berbagi memori dan metode bawaan lainnya.
Ekspresikan jaringan kami sendiri dengan mudah
CNTK memiliki API lengkap untuk menentukan jaringan Anda sendiri, pelajar, pembaca, pelatihan dan evaluasi dari Python, C ++, dan BrainScript.
Menggunakan CNTK, kita dapat dengan mudah mengevaluasi model dengan Python, C ++, C # atau BrainScript.
Ini menyediakan API tingkat tinggi maupun tingkat rendah.
Berdasarkan data kami, secara otomatis dapat membentuk inferensi.
Ini memiliki loop Simbolis Recurrent Neural Network (RNN) yang sepenuhnya dioptimalkan.
Mengukur kinerja model
CNTK menyediakan berbagai komponen untuk mengukur performa jaringan neural yang Anda buat.
Menghasilkan data log dari model Anda dan pengoptimal terkait, yang dapat kita gunakan untuk memantau proses pelatihan.
Versi 1.0 vs Versi 2.0
Tabel berikut membandingkan CNTK Versi 1.0 dan 2.0:
| Versi 1.0 | Versi 2.0 |
|---|---|
| Itu dirilis pada 2016. | Ini adalah penulisan ulang yang signifikan dari Versi 1.0 dan dirilis pada Juni 2017. |
| Itu menggunakan bahasa scripting berpemilik yang disebut BrainScript. | Fungsi kerangka kerjanya bisa dipanggil menggunakan C ++, Python. Kami dapat dengan mudah memuat modul kami di C # atau Java. BrainScript juga didukung oleh Versi 2.0. |
| Ini berjalan di sistem Windows dan Linux tetapi tidak langsung di Mac OS. | Ini juga berjalan pada sistem Windows (Win 8.1, Win 10, Server 2012 R2 dan lebih baru) dan Linux tetapi tidak langsung di Mac OS. |
Sorotan Penting Versi 2.7
Version 2.7adalah versi rilis utama terakhir dari Microsoft Cognitive Toolkit. Ini memiliki dukungan penuh untuk ONNX 1.4.1. Berikut adalah beberapa sorotan penting dari versi CNTK yang terakhir dirilis ini.
Dukungan penuh untuk ONNX 1.4.1.
Dukungan untuk CUDA 10 untuk sistem Windows dan Linux.
Ini mendukung loop Recurrent Neural Networks (RNN) lanjutan dalam ekspor ONNX.
Itu dapat mengekspor lebih dari model 2GB dalam format ONNX.
Mendukung FP16 dalam aksi pelatihan bahasa skrip BrainScript.
Di sini, kita akan mengerti tentang instalasi CNTK di Windows dan Linux. Selain itu, bab ini menjelaskan cara menginstal paket CNTK, langkah-langkah untuk menginstal Anaconda, file CNTK, struktur direktori, dan organisasi perpustakaan CNTK.
Prasyarat
Untuk menginstal CNTK, kita harus menginstal Python di komputer kita. Anda bisa pergi ke linkhttps://www.python.org/downloads/dan pilih versi terbaru untuk OS Anda, yaitu Windows dan Linux / Unix. Untuk tutorial dasar tentang Python, Anda dapat merujuk ke tautannyahttps://www.tutorialspoint.com/python3/index.htm.

CNTK didukung untuk Windows serta Linux sehingga kita akan membahas keduanya.
Menginstal di Windows
Untuk menjalankan CNTK di Windows, kami akan menggunakan Anaconda versiondari Python. Kita tahu bahwa Anaconda adalah redistribusi Python. Ini termasuk paket tambahan sepertiScipy danScikit-learn yang digunakan oleh CNTK untuk melakukan berbagai kalkulasi berguna.
Jadi, pertama-tama mari kita lihat langkah-langkah untuk menginstal Anaconda di mesin Anda -
Step 1−Pertama unduh file setup dari situs publik https://www.anaconda.com/distribution/.
Step 2 - Setelah Anda mengunduh file penyiapan, mulai penginstalan dan ikuti petunjuk dari tautan https://docs.anaconda.com/anaconda/install/.
Step 3- Setelah terinstal, Anaconda juga akan menginstal beberapa utilitas lain, yang secara otomatis akan menyertakan semua executable Anaconda di variabel PATH komputer Anda. Kita dapat mengelola lingkungan Python kita dari prompt ini, dapat menginstal paket dan menjalankan skrip Python.
Menginstal paket CNTK
Setelah instalasi Anaconda selesai, Anda dapat menggunakan cara yang paling umum untuk menginstal paket CNTK melalui pip yang dapat dieksekusi dengan menggunakan perintah berikut -
pip install cntkAda berbagai metode lain untuk menginstal Cognitive Toolkit di komputer Anda. Microsoft memiliki kumpulan dokumentasi rapi yang menjelaskan metode instalasi lainnya secara rinci. Silakan ikuti tautannyahttps://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine.
Menginstal di Linux
Pemasangan CNTK di Linux sedikit berbeda dengan pemasangannya di Windows. Di sini, untuk Linux kita akan menggunakan Anaconda untuk menginstal CNTK, tetapi alih-alih penginstal grafis untuk Anaconda, kita akan menggunakan penginstal berbasis terminal di Linux. Meskipun, penginstal akan bekerja dengan hampir semua distribusi Linux, kami membatasi deskripsi pada Ubuntu.
Jadi, pertama-tama mari kita lihat langkah-langkah untuk menginstal Anaconda di mesin Anda -
Langkah-langkah untuk menginstal Anaconda
Step 1- Sebelum memasang Anaconda, pastikan bahwa sistem sudah diperbarui sepenuhnya. Untuk memeriksanya, pertama-tama jalankan dua perintah berikut di dalam terminal -
sudo apt update
sudo apt upgradeStep 2 - Setelah komputer diperbarui, dapatkan URL dari situs web publik https://www.anaconda.com/distribution/ untuk file instalasi Anaconda terbaru.
Step 3 - Setelah URL disalin, buka jendela terminal dan jalankan perintah berikut -
wget -0 anaconda-installer.sh url SHAPE \* MERGEFORMAT
y
f
x
| }Ganti url placeholder dengan URL yang disalin dari situs web Anaconda.
Step 4 - Selanjutnya, dengan bantuan perintah berikut, kita dapat menginstal Anaconda -
sh ./anaconda-installer.shPerintah di atas akan diinstal secara default Anaconda3 di dalam direktori home kami.
Menginstal paket CNTK
Setelah instalasi Anaconda selesai, Anda dapat menggunakan cara yang paling umum untuk menginstal paket CNTK melalui pip yang dapat dieksekusi dengan menggunakan perintah berikut -
pip install cntkMemeriksa file CNTK & struktur direktori
Setelah CNTK diinstal sebagai paket Python, kita dapat memeriksa file dan struktur direktorinya. Ini diC:\Users\

Memverifikasi instalasi CNTK
Setelah CNTK diinstal sebagai paket Python, Anda harus memverifikasi bahwa CNTK telah diinstal dengan benar. Dari shell perintah Anaconda, mulai penerjemah Python dengan memasukkanipython. Lalu, impor CNTK dengan memasukkan perintah berikut.
import cntk as cSetelah diimpor, periksa versinya dengan bantuan perintah berikut -
print(c.__version__)Penerjemah akan merespons dengan versi CNTK yang diinstal. Jika tidak merespons, berarti ada masalah dengan penginstalan.
Organisasi perpustakaan CNTK
CNTK, paket python secara teknis, diatur menjadi 13 sub-paket tingkat tinggi dan 8 sub-paket yang lebih kecil. Tabel berikut terdiri dari 10 paket yang paling sering digunakan:
| Sr Tidak | Nama & Deskripsi Paket |
|---|---|
| 1 | cntk.io Berisi fungsi untuk membaca data. Misalnya: next_minibatch () |
| 2 | cntk.layers Berisi fungsi tingkat tinggi untuk membuat jaringan neural. Misalnya: Dense () |
| 3 | cntk.learners Berisi fungsi untuk pelatihan. Misalnya: sgd () |
| 4 | cntk.losses Berisi fungsi untuk mengukur kesalahan pelatihan. Misalnya: squared_error () |
| 5 | cntk.metrics Berisi fungsi untuk mengukur kesalahan model. Misalnya: classificatoin_error |
| 6 | cntk.ops Berisi fungsi tingkat rendah untuk membuat jaringan neural. Contoh: tanh () |
| 7 | cntk.random Berisi fungsi untuk menghasilkan bilangan acak. Misalnya: normal () |
| 8 | cntk.train Berisi fungsi pelatihan. Misalnya: train_minibatch () |
| 9 | cntk.initializer Berisi penginisialisasi parameter model. Misalnya: normal () dan uniform () |
| 10 | cntk.variables Berisi konstruksi tingkat rendah. Misalnya: Parameter () dan Variable () |
Microsoft Cognitive Toolkit menawarkan dua versi build yang berbeda yaitu hanya CPU dan hanya GPU.
CPU hanya membangun versi
Versi build hanya CPU dari CNTK menggunakan Intel MKLML yang dioptimalkan, di mana MKLML adalah bagian dari MKL (Math Kernel Library) dan dirilis dengan Intel MKL-DNN sebagai versi Intel MKL untuk MKL-DNN yang dihentikan.
GPU hanya versi build
Di sisi lain, versi build khusus GPU dari CNTK menggunakan pustaka NVIDIA yang sangat dioptimalkan seperti CUB dan cuDNN. Ini mendukung pelatihan terdistribusi di beberapa GPU dan banyak mesin. Untuk pelatihan yang lebih cepat terdistribusi di CNTK, versi pembuatan GPU juga menyertakan -
SGD terkuantisasi 1-bit yang dikembangkan MSR.
Algoritme pelatihan paralel SGD blok-momentum.
Mengaktifkan GPU dengan CNTK di Windows
Di bagian sebelumnya, kami melihat cara menginstal versi dasar CNTK untuk digunakan dengan CPU. Sekarang mari kita bahas bagaimana kita dapat menginstal CNTK untuk digunakan dengan GPU. Namun, sebelum mendalami lebih dalam, Anda harus terlebih dahulu memiliki kartu grafis yang didukung.
Saat ini, CNTK mendukung kartu grafis NVIDIA dengan setidaknya dukungan CUDA 3.0. Untuk memastikannya, Anda bisa mengecek dihttps://developer.nvidia.com/cuda-gpus apakah GPU Anda mendukung CUDA.
Jadi, mari kita lihat langkah-langkah untuk mengaktifkan GPU dengan CNTK di OS Windows -
Step 1 - Bergantung pada kartu grafis yang Anda gunakan, pertama-tama Anda harus memiliki driver GeForce atau Quadro terbaru untuk kartu grafis Anda.
Step 2 - Setelah Anda mengunduh driver, Anda perlu menginstal CUDA toolkit Versi 9.0 untuk Windows dari situs web NVIDIA https://developer.nvidia.com/cuda-90-download-archive?target_os=Windows&target_arch=x86_64. Setelah menginstal, jalankan penginstal dan ikuti petunjuknya.
Step 3 - Selanjutnya, Anda perlu menginstal binari cuDNN dari situs NVIDIA https://developer.nvidia.com/rdp/form/cudnn-download-survey. Dengan versi CUDA 9.0, cuDNN 7.4.1 bekerja dengan baik. Pada dasarnya, cuDNN adalah lapisan di atas CUDA yang digunakan oleh CNTK.
Step 4 - Setelah mengunduh binari cuDNN, Anda perlu mengekstrak file zip ke folder root dari instalasi toolkit CUDA Anda.
Step 5- Ini adalah langkah terakhir yang akan mengaktifkan penggunaan GPU di dalam CNTK. Jalankan perintah berikut di dalam prompt Anaconda di OS Windows -
pip install cntk-gpuMengaktifkan GPU dengan CNTK di Linux
Mari kita lihat bagaimana kita dapat mengaktifkan GPU dengan CNTK di OS Linux -
Mendownload toolkit CUDA
Pertama, Anda perlu menginstal toolkit CUDA dari situs web NVIDIA https://developer.nvidia.com/cuda-90-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1604&target_type = runfilelocal .
Menjalankan penginstal
Sekarang, setelah Anda memiliki binari pada disk, jalankan penginstal dengan membuka terminal dan menjalankan perintah berikut dan instruksi di layar -
sh cuda_9.0.176_384.81_linux-runUbah skrip profil Bash
Setelah menginstal toolkit CUDA di mesin Linux Anda, Anda perlu memodifikasi skrip profil BASH. Untuk ini, pertama buka file $ HOME / .bashrc di editor teks. Sekarang, di akhir skrip, sertakan baris berikut -
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
InstallingMenginstal pustaka cuDNN
Akhirnya kita perlu menginstal binari cuDNN. Ini dapat diunduh dari situs web NVIDIAhttps://developer.nvidia.com/rdp/form/cudnn-download-survey. Dengan versi CUDA 9.0, cuDNN 7.4.1 bekerja dengan baik. Pada dasarnya, cuDNN adalah lapisan di atas CUDA yang digunakan oleh CNTK.
Setelah mengunduh versi untuk Linux, ekstrak ke /usr/local/cuda-9.0 folder dengan menggunakan perintah berikut -
tar xvzf -C /usr/local/cuda-9.0/ cudnn-9.0-linux-x64-v7.4.1.5.tgzUbah jalur ke nama file sesuai kebutuhan.
Pada bab ini, kita akan mempelajari secara detail tentang sekuens di CNTK dan klasifikasinya.
Tensor
Konsep kerja CNTK adalah tensor. Pada dasarnya, input, output, dan parameter CNTK diatur sebagaitensors, yang sering dianggap sebagai matriks umum. Setiap tensor memiliki arank -
Tensor peringkat 0 adalah skalar.
Tensor peringkat 1 adalah vektor.
Tensor rank 2 adalah amatrix.
Di sini, dimensi yang berbeda ini disebut axes.
Sumbu statis dan sumbu Dinamis
Sesuai dengan namanya, sumbu statik memiliki panjang yang sama sepanjang hidup jaringan. Di sisi lain, panjang sumbu dinamis dapat bervariasi dari satu contoh ke contoh lainnya. Faktanya, panjangnya biasanya tidak diketahui sebelum setiap minibatch disajikan.
Sumbu dinamis seperti sumbu statis karena sumbu dinamis juga menentukan pengelompokan angka yang ada dalam tensor.
Contoh
Untuk lebih jelasnya, mari kita lihat bagaimana sebuah minibatch klip video pendek direpresentasikan di CNTK. Misalkan resolusi klip video adalah 640 * 480. Dan, juga klip diambil dalam warna yang biasanya dikodekan dengan tiga saluran. Ini lebih lanjut berarti minibatch kami memiliki yang berikut -
3 sumbu statis dengan panjang masing-masing 640, 480 dan 3.
Dua sumbu dinamis; panjang video dan sumbu minibatch.
Artinya, jika sebuah minibatch memiliki 16 video yang masing-masing berukuran 240 frame, akan direpresentasikan sebagai 16*240*3*640*480 tensor.
Bekerja dengan urutan di CNTK
Mari kita pahami urutan di CNTK dengan terlebih dahulu mempelajari tentang Jaringan Memori Jangka Pendek.
Jaringan Memori Jangka Pendek (LSTM)

Jaringan memori jangka pendek (LSTM) diperkenalkan oleh Hochreiter & Schmidhuber. Ini memecahkan masalah mendapatkan lapisan berulang dasar untuk mengingat banyak hal untuk waktu yang lama. Arsitektur LSTM diberikan di atas dalam diagram. Seperti yang bisa kita lihat, ia memiliki neuron masukan, sel memori, dan neuron keluaran. Untuk mengatasi masalah gradien yang menghilang, jaringan memori jangka panjang menggunakan sel memori eksplisit (menyimpan nilai sebelumnya) dan gerbang berikut -
Forget gate- Sesuai dengan namanya, ini memberitahu sel memori untuk melupakan nilai sebelumnya. Sel memori menyimpan nilai-nilai sampai gerbang yaitu 'gerbang lupa' memberitahu untuk melupakannya.
Input gate - Seperti namanya, itu menambahkan barang baru ke sel.
Output gate - Seperti namanya, gerbang keluaran memutuskan kapan harus melewati vektor dari sel ke keadaan tersembunyi berikutnya.
Sangat mudah untuk bekerja dengan urutan di CNTK. Mari kita lihat dengan bantuan contoh berikut -
import sys
import os
from cntk import Trainer, Axis
from cntk.io import MinibatchSource, CTFDeserializer, StreamDef, StreamDefs,\
INFINITELY_REPEAT
from cntk.learners import sgd, learning_parameter_schedule_per_sample
from cntk import input_variable, cross_entropy_with_softmax, \
classification_error, sequence
from cntk.logging import ProgressPrinter
from cntk.layers import Sequential, Embedding, Recurrence, LSTM, Dense
def create_reader(path, is_training, input_dim, label_dim):
return MinibatchSource(CTFDeserializer(path, StreamDefs(
features=StreamDef(field='x', shape=input_dim, is_sparse=True),
labels=StreamDef(field='y', shape=label_dim, is_sparse=False)
)), randomize=is_training,
max_sweeps=INFINITELY_REPEAT if is_training else 1)
def LSTM_sequence_classifier_net(input, num_output_classes, embedding_dim,
LSTM_dim, cell_dim):
lstm_classifier = Sequential([Embedding(embedding_dim),
Recurrence(LSTM(LSTM_dim, cell_dim)),
sequence.last,
Dense(num_output_classes)])
return lstm_classifier(input)
def train_sequence_classifier():
input_dim = 2000
cell_dim = 25
hidden_dim = 25
embedding_dim = 50
num_output_classes = 5
features = sequence.input_variable(shape=input_dim, is_sparse=True)
label = input_variable(num_output_classes)
classifier_output = LSTM_sequence_classifier_net(
features, num_output_classes, embedding_dim, hidden_dim, cell_dim)
ce = cross_entropy_with_softmax(classifier_output, label)
pe = classification_error(classifier_output, label)
rel_path = ("../../../Tests/EndToEndTests/Text/" +
"SequenceClassification/Data/Train.ctf")
path = os.path.join(os.path.dirname(os.path.abspath(__file__)), rel_path)
reader = create_reader(path, True, input_dim, num_output_classes)
input_map = {
features: reader.streams.features,
label: reader.streams.labels
}
lr_per_sample = learning_parameter_schedule_per_sample(0.0005)
progress_printer = ProgressPrinter(0)
trainer = Trainer(classifier_output, (ce, pe),
sgd(classifier_output.parameters, lr=lr_per_sample),progress_printer)
minibatch_size = 200
for i in range(255):
mb = reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(mb)
evaluation_average = float(trainer.previous_minibatch_evaluation_average)
loss_average = float(trainer.previous_minibatch_loss_average)
return evaluation_average, loss_average
if __name__ == '__main__':
error, _ = train_sequence_classifier()
print(" error: %f" % error)average since average since examples
loss last metric last
------------------------------------------------------
1.61 1.61 0.886 0.886 44
1.61 1.6 0.714 0.629 133
1.6 1.59 0.56 0.448 316
1.57 1.55 0.479 0.41 682
1.53 1.5 0.464 0.449 1379
1.46 1.4 0.453 0.441 2813
1.37 1.28 0.45 0.447 5679
1.3 1.23 0.448 0.447 11365
error: 0.333333Penjelasan rinci dari program di atas akan dibahas di bagian selanjutnya, terutama ketika kita akan membangun jaringan Neural Berulang.
Bab ini membahas tentang membangun model regresi logistik di CNTK.
Dasar-dasar model Regresi Logistik
Regresi Logistik, salah satu teknik ML yang paling sederhana, merupakan teknik khusus untuk klasifikasi biner. Dengan kata lain, untuk membuat model prediksi dalam situasi di mana nilai variabel untuk diprediksi dapat menjadi salah satu dari dua nilai kategorikal. Salah satu contoh Regresi Logistik yang paling sederhana adalah memprediksi apakah orang tersebut laki-laki atau perempuan, berdasarkan usia, suara, rambut, dan sebagainya.
Contoh
Mari kita pahami konsep Regresi Logistik secara matematis dengan bantuan contoh lain -
Misalkan, kita ingin memprediksi kelayakan kredit suatu aplikasi pinjaman; 0 berarti menolak, dan 1 berarti menyetujui, berdasarkan pemohondebt , income dan credit rating. Kami mewakili hutang dengan X1, pendapatan dengan X2 dan peringkat kredit dengan X3.
Dalam Regresi Logistik, kami menentukan nilai bobot, yang diwakili oleh w, untuk setiap fitur dan satu nilai bias, diwakili oleh b.
Sekarang misalkan,
X1 = 3.0
X2 = -2.0
X3 = 1.0Dan misalkan kita menentukan bobot dan bias sebagai berikut -
W1 = 0.65, W2 = 1.75, W3 = 2.05 and b = 0.33Sekarang, untuk memprediksi kelas, kita perlu menerapkan rumus berikut -
Z = (X1*W1)+(X2*W2)+(X3+W3)+b
i.e. Z = (3.0)*(0.65) + (-2.0)*(1.75) + (1.0)*(2.05) + 0.33
= 0.83Selanjutnya, kita perlu menghitung P = 1.0/(1.0 + exp(-Z)). Di sini, fungsi exp () adalah bilangan Euler.
P = 1.0/(1.0 + exp(-0.83)
= 0.6963Nilai P dapat diartikan sebagai probabilitas kelas tersebut adalah 1. Jika P <0,5 maka prediksinya adalah kelas = 0, sedangkan prediksi (P> = 0,5) adalah kelas = 1.
Untuk menentukan nilai bobot dan bias, kita harus mendapatkan sekumpulan data latih yang memiliki nilai prediksi masukan yang diketahui dan nilai label kelas yang benar. Setelah itu, kita bisa menggunakan algoritma, umumnya Gradient Descent, untuk mencari nilai bobot dan bias.
Contoh implementasi model LR
Untuk model LR ini, kita akan menggunakan kumpulan data berikut -
1.0, 2.0, 0
3.0, 4.0, 0
5.0, 2.0, 0
6.0, 3.0, 0
8.0, 1.0, 0
9.0, 2.0, 0
1.0, 4.0, 1
2.0, 5.0, 1
4.0, 6.0, 1
6.0, 5.0, 1
7.0, 3.0, 1
8.0, 5.0, 1Untuk memulai implementasi model LR ini di CNTK, pertama-tama kita perlu mengimpor paket berikut -
import numpy as np
import cntk as CProgram ini disusun dengan fungsi main () sebagai berikut -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")Sekarang, kita perlu memuat data pelatihan ke dalam memori sebagai berikut -
data_file = ".\\dataLRmodel.txt"
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)Sekarang, kita akan membuat program pelatihan yang membuat model regresi logistik yang kompatibel dengan data pelatihan -
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = pSekarang, kita perlu membuat Lerner dan pelatih sebagai berikut -
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000Pelatihan Model LR
Setelah kita membuat model LR, selanjutnya sekarang saatnya untuk memulai proses pelatihan -
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)Sekarang, dengan bantuan kode berikut, kita dapat mencetak bobot dan bias model -
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
print("")
if __name__ == "__main__":
main()Melatih model Regresi Logistik - Contoh lengkap
import numpy as np
import cntk as C
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = p
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
if __name__ == "__main__":
main()Keluaran
Using CNTK version = 2.7
1000 cross entropy error on curr item = 0.1941
2000 cross entropy error on curr item = 0.1746
3000 cross entropy error on curr item = 0.0563
Model weights:
[-0.2049]
[0.9666]]
Model bias:
[-2.2846]Prediksi menggunakan Model LR terlatih
Setelah model LR dilatih, kita dapat menggunakannya untuk prediksi sebagai berikut -
Pertama-tama, program evaluasi kami mengimpor paket numpy dan memuat data pelatihan ke dalam matriks fitur dan matriks label kelas dengan cara yang sama seperti program pelatihan yang kami terapkan di atas -
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)Selanjutnya, saatnya untuk mengatur nilai bobot dan bias yang ditentukan oleh program pelatihan kita -
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2Selanjutnya program evaluasi kami akan menghitung probabilitas regresi logistik dengan berjalan melalui setiap item pelatihan sebagai berikut -
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))Sekarang mari kita tunjukkan bagaimana melakukan prediksi -
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")Program evaluasi prediksi lengkap
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")
if __name__ == "__main__":
main()Keluaran
Mengatur bobot dan nilai bias.
Item pred_prob pred_label act_label result
0 0.3640 0 0 correct
1 0.7254 1 0 WRONG
2 0.2019 0 0 correct
3 0.3562 0 0 correct
4 0.0493 0 0 correct
5 0.1005 0 0 correct
6 0.7892 1 1 correct
7 0.8564 1 1 correct
8 0.9654 1 1 correct
9 0.7587 1 1 correct
10 0.3040 0 1 WRONG
11 0.7129 1 1 correct
Predicting class for age, education =
[9.5 4.5]
Predicting p = 0.526487952
Predicting class = 1Bab ini membahas konsep Neural Network yang berkaitan dengan CNTK.
Seperti yang kita ketahui, beberapa lapisan neuron digunakan untuk membuat jaringan saraf. Tetapi, muncul pertanyaan bahwa di CNTK bagaimana kita bisa memodelkan lapisan NN? Ini dapat dilakukan dengan bantuan fungsi lapisan yang ditentukan dalam modul lapisan.
Fungsi lapisan
Sebenarnya, di CNTK, bekerja dengan lapisan memiliki nuansa pemrograman fungsional yang berbeda. Fungsi lapisan terlihat seperti fungsi biasa dan menghasilkan fungsi matematika dengan serangkaian parameter yang telah ditentukan. Mari kita lihat bagaimana kita dapat membuat tipe lapisan paling dasar, Dense, dengan bantuan fungsi lapisan.
Contoh
Dengan bantuan langkah-langkah dasar berikut, kita dapat membuat jenis lapisan paling dasar -
Step 1 - Pertama, kita perlu mengimpor fungsi Dense layer dari paket layer CNTK.
from cntk.layers import DenseStep 2 - Selanjutnya dari paket root CNTK, kita perlu mengimpor fungsi input_variable.
from cntk import input_variableStep 3- Sekarang, kita perlu membuat variabel input baru menggunakan fungsi input_variable. Kami juga perlu memberikan ukurannya.
feature = input_variable(100)Step 4 - Terakhir, kita akan membuat layer baru menggunakan fungsi Dense bersamaan dengan memberikan jumlah neuron yang kita inginkan.
layer = Dense(40)(feature)Sekarang, kita dapat menjalankan fungsi Dense layer yang telah dikonfigurasi untuk menghubungkan layer Dense ke input.
Contoh implementasi lengkap
from cntk.layers import Dense
from cntk import input_variable
feature= input_variable(100)
layer = Dense(40)(feature)Menyesuaikan lapisan
Seperti yang telah kita lihat, CNTK memberi kita satu set default yang cukup bagus untuk membangun NN. Berdasarkanactivationfungsi dan pengaturan lain yang kami pilih, perilaku serta kinerja NN berbeda. Ini adalah algoritma stemming yang sangat berguna. Itulah alasannya, sebaiknya kita memahami apa yang bisa kita konfigurasi.
Langkah-langkah untuk mengonfigurasi lapisan Padat
Setiap lapisan di NN memiliki opsi konfigurasi unik dan ketika kita berbicara tentang lapisan Dense, kita harus mengikuti pengaturan penting berikut ini -
shape - Seperti namanya, ini mendefinisikan bentuk keluaran dari lapisan yang selanjutnya menentukan jumlah neuron di lapisan itu.
activation - Ini mendefinisikan fungsi aktivasi lapisan itu, sehingga dapat mengubah data masukan.
init- Ini mendefinisikan fungsi inisialisasi lapisan itu. Ini akan menginisialisasi parameter lapisan saat kita mulai melatih NN.
Mari kita lihat langkah-langkah dengan bantuan yang dapat kita konfigurasikan Dense lapisan -
Step1 - Pertama, kita perlu mengimpor file Dense fungsi lapisan dari paket lapisan CNTK.
from cntk.layers import DenseStep2 - Selanjutnya dari paket operasi CNTK, kita perlu mengimpor file sigmoid operator. Ini akan digunakan untuk mengkonfigurasi sebagai fungsi aktivasi.
from cntk.ops import sigmoidStep3 - Sekarang, dari paket penginisialisasi, kita perlu mengimpor file glorot_uniform penginisialisasi.
from cntk.initializer import glorot_uniformStep4 - Terakhir, kita akan membuat layer baru dengan menggunakan fungsi Dense bersama dengan memberikan jumlah neuron sebagai argumen pertama. Juga, sediakansigmoid operator sebagai activation fungsi dan glorot_uniform sebagai init berfungsi untuk lapisan.
layer = Dense(50, activation = sigmoid, init = glorot_uniform)Contoh implementasi lengkap -
from cntk.layers import Dense
from cntk.ops import sigmoid
from cntk.initializer import glorot_uniform
layer = Dense(50, activation = sigmoid, init = glorot_uniform)Mengoptimalkan parameter
Hingga saat ini, kita telah melihat bagaimana membuat struktur NN dan bagaimana mengkonfigurasi berbagai pengaturan. Di sini, kita akan melihat, bagaimana kita dapat mengoptimalkan parameter NN. Dengan bantuan kombinasi dua komponen yaitulearners dan trainers, kita dapat mengoptimalkan parameter NN.
komponen pelatih
Komponen pertama yang digunakan untuk mengoptimalkan parameter NN adalah trainerkomponen. Ini pada dasarnya mengimplementasikan proses propagasi mundur. Jika kita berbicara tentang kerjanya, ia melewatkan data melalui NN untuk mendapatkan prediksi.
Setelah itu, ia menggunakan komponen lain yang disebut pelajar untuk mendapatkan nilai baru untuk parameter di NN. Setelah memperoleh nilai baru, ia menerapkan nilai baru ini dan mengulangi proses sampai kriteria keluar terpenuhi.
komponen pelajar
Komponen kedua yang digunakan untuk mengoptimalkan parameter NN adalah learner komponen, yang pada dasarnya bertanggung jawab untuk melakukan algoritma penurunan gradien.
Peserta didik termasuk dalam perpustakaan CNTK
Berikut adalah daftar dari beberapa pembelajar menarik yang termasuk dalam perpustakaan CNTK -
Stochastic Gradient Descent (SGD) - Peserta ini mewakili penurunan gradien stokastik dasar, tanpa tambahan apa pun.
Momentum Stochastic Gradient Descent (MomentumSGD) - Dengan SGD, pembelajar ini memanfaatkan momentum untuk mengatasi masalah maxima lokal.
RMSProp - Pelajar ini, untuk mengontrol laju penurunan, menggunakan laju pembelajaran yang menurun.
Adam - Pelajar ini, untuk mengurangi laju penurunan dari waktu ke waktu, menggunakan momentum yang membusuk.
Adagrad - Pelajar ini, untuk fitur yang sering dan jarang muncul, menggunakan kecepatan pembelajaran yang berbeda.
CNTK - Membuat Jaringan Neural Pertama
Bab ini akan menguraikan tentang cara membuat jaringan saraf di CNTK.
Bangun struktur jaringan
Untuk menerapkan konsep CNTK untuk membangun NN pertama kita, kita akan menggunakan NN untuk mengklasifikasikan jenis bunga iris berdasarkan sifat fisik lebar dan panjang sepal, serta lebar dan panjang kelopak. Dataset yang akan kita gunakan adalah dataset iris yang menggambarkan sifat fisik dari berbagai varietas bunga iris -
- Panjang sepal
- Lebar sepal
- Panjang kelopak
- Lebar kelopak
- Kelasnya yaitu iris setosa atau iris versicolor atau iris virginica
Di sini, kita akan membangun NN biasa yang disebut NN feedforward. Mari kita lihat langkah-langkah implementasi untuk membangun struktur NN -
Step 1 - Pertama, kami akan mengimpor komponen yang diperlukan seperti jenis lapisan kami, fungsi aktivasi, dan fungsi yang memungkinkan kami untuk menentukan variabel input untuk NN kami, dari perpustakaan CNTK.
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, reluStep 2- Setelah itu, kami akan membuat model kami menggunakan fungsi sekuensial. Setelah dibuat, kita akan memberinya makan dengan lapisan yang kita inginkan. Di sini, kita akan membuat dua layer berbeda di NN kita; satu dengan empat neuron dan satu lagi dengan tiga neuron.
model = Sequential([Dense(4, activation=relu), Dense(3, activation=log_sogtmax)])Step 3- Terakhir, untuk mengkompilasi NN, kita akan mengikat jaringan ke variabel input. Ini memiliki lapisan masukan dengan empat neuron dan lapisan keluaran dengan tiga neuron.
feature= input_variable(4)
z = model(feature)Menerapkan fungsi aktivasi
Ada banyak fungsi aktivasi untuk dipilih dan memilih fungsi aktivasi yang tepat pasti akan membuat perbedaan besar pada seberapa baik model pembelajaran mendalam kita akan bekerja.
Pada lapisan keluaran
Memilih file activation Fungsi pada lapisan keluaran akan tergantung pada jenis masalah yang akan kita selesaikan dengan model kita.
Untuk masalah regresi, kita harus menggunakan file linear activation function pada lapisan keluaran.
Untuk masalah klasifikasi biner, kita harus menggunakan file sigmoid activation function pada lapisan keluaran.
Untuk masalah klasifikasi kelas jamak, kita harus menggunakan file softmax activation function pada lapisan keluaran.
Di sini, kita akan membuat model untuk memprediksi salah satu dari tiga kelas. Artinya kita perlu menggunakansoftmax activation function di lapisan keluaran.
Di lapisan tersembunyi
Memilih file activation Fungsi pada lapisan tersembunyi memerlukan beberapa eksperimen untuk memantau kinerja guna melihat fungsi aktivasi mana yang bekerja dengan baik.
Dalam masalah klasifikasi, kita perlu memprediksi probabilitas suatu sampel termasuk dalam kelas tertentu. Itu sebabnya kami membutuhkan fileactivation functionyang memberi kita nilai probabilistik. Untuk mencapai tujuan ini,sigmoid activation function dapat membantu kami.
Salah satu masalah utama yang terkait dengan fungsi sigmoid adalah masalah gradien menghilang. Untuk mengatasi masalah seperti itu, kita bisa menggunakanReLU activation function yang menutupi semua nilai negatif menjadi nol dan berfungsi sebagai filter penerusan untuk nilai positif.
Memilih fungsi kerugian
Setelah kita memiliki struktur untuk model NN kita, kita harus mengoptimalkannya. Untuk mengoptimalkan kita membutuhkan aloss function. Tidak sepertiactivation functions, kami memiliki lebih sedikit fungsi kerugian untuk dipilih. Namun, memilih fungsi kerugian akan bergantung pada jenis masalah yang akan kita selesaikan dengan model kita.
Misalnya, dalam masalah klasifikasi, kita harus menggunakan fungsi kerugian yang dapat mengukur perbedaan antara kelas yang diprediksi dan kelas yang sebenarnya.
fungsi kerugian
Untuk masalah klasifikasi, kita akan menyelesaikannya dengan model NN kita, categorical cross entropyfungsi kerugian adalah kandidat terbaik. Di CNTK, ini diimplementasikan sebagaicross_entropy_with_softmax yang dapat diimpor dari cntk.losses paket, sebagai berikut-
label= input_variable(3)
loss = cross_entropy_with_softmax(z, label)Metrik
Dengan memiliki struktur untuk model NN kami dan fungsi kerugian untuk diterapkan, kami memiliki semua bahan untuk mulai membuat resep untuk mengoptimalkan model pembelajaran mendalam kami. Namun, sebelum mendalami hal ini, kita harus belajar tentang metrik.
cntk.metricsCNTK memiliki paket bernama cntk.metricsdari mana kita dapat mengimpor metrik yang akan kita gunakan. Saat kami membangun model klasifikasi, kami akan menggunakanclassification_error matriks yang akan menghasilkan angka antara 0 dan 1. Angka antara 0 dan 1 menunjukkan persentase sampel yang diprediksi dengan benar -
Pertama, kita perlu mengimpor metrik dari cntk.metrics paket -
from cntk.metrics import classification_error
error_rate = classification_error(z, label)Fungsi di atas sebenarnya membutuhkan keluaran NN dan label yang diharapkan sebagai masukan.
CNTK - Melatih Jaringan Neural
Di sini, kita akan memahami tentang pelatihan Jaringan Saraf di CNTK.
Melatih model di CNTK
Di bagian sebelumnya, kami telah mendefinisikan semua komponen untuk model pembelajaran mendalam. Sekarang saatnya melatihnya. Seperti yang telah kita bahas sebelumnya, kita bisa melatih model NN di CNTK menggunakan kombinasilearner dan trainer.
Memilih pelajar dan menyiapkan pelatihan
Pada bagian ini, kami akan mendefinisikan file learner. CNTK menyediakan beberapalearnersuntuk memilih dari. Untuk model kami, yang ditentukan di bagian sebelumnya, kami akan menggunakanStochastic Gradient Descent (SGD) learner.
Untuk melatih jaringan saraf, mari kita konfigurasikan learner dan trainer dengan bantuan langkah-langkah berikut -
Step 1 - Pertama, kita perlu mengimpor sgd fungsi dari cntk.lerners paket.
from cntk.learners import sgdStep 2 - Selanjutnya, kita perlu mengimpor Trainer fungsi dari cntk.trainpaket .trainer.
from cntk.train.trainer import TrainerStep 3 - Sekarang, kita perlu membuat file learner. Itu dapat dibuat dengan memohonsgd berfungsi bersama dengan memberikan parameter model dan nilai untuk kecepatan pembelajaran.
learner = sgd(z.parametrs, 0.01)Step 4 - Akhirnya, kita perlu menginisialisasi trainer. Ini harus disediakan jaringan, kombinasi dariloss dan metric Bersama dengan learner.
trainer = Trainer(z, (loss, error_rate), [learner])Kecepatan pembelajaran yang mengontrol kecepatan pengoptimalan harus berjumlah kecil antara 0,1 hingga 0,001.
Memilih pelajar dan menyiapkan pelatihan - Contoh lengkap
from cntk.learners import sgd
from cntk.train.trainer import Trainer
learner = sgd(z.parametrs, 0.01)
trainer = Trainer(z, (loss, error_rate), [learner])Memasukkan data ke dalam pelatih
Setelah kami memilih dan mengonfigurasi pelatih, sekarang saatnya memuat kumpulan data. Kami telah menyimpaniris set data sebagai.CSV file dan kami akan menggunakan paket data wrangling bernama pandas untuk memuat set data.
Langkah-langkah untuk memuat set data dari file .CSV
Step 1 - Pertama, kita perlu mengimpor file pandas paket.
from import pandas as pdStep 2 - Sekarang, kita perlu memanggil fungsi bernama read_csv berfungsi untuk memuat file .csv dari disk.
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, index_col=False)Setelah kami memuat dataset, kami perlu membaginya menjadi satu set fitur dan label.
Langkah-langkah untuk membagi dataset menjadi fitur dan label
Step 1- Pertama, kita perlu memilih semua baris dan empat kolom pertama dari dataset. Itu bisa dilakukan dengan menggunakaniloc fungsi.
x = df_source.iloc[:, :4].valuesStep 2- Selanjutnya kita perlu memilih kolom spesies dari dataset iris. Kami akan menggunakan properti nilai untuk mengakses yang mendasarinyanumpy Himpunan.
x = df_source[‘species’].valuesLangkah-langkah untuk menyandikan kolom spesies ke representasi vektor numerik
Seperti yang kita bahas sebelumnya, model kita didasarkan pada klasifikasi, itu membutuhkan nilai input numerik. Oleh karena itu, di sini kita perlu menyandikan kolom spesies ke representasi vektor numerik. Mari kita lihat langkah-langkah untuk melakukannya -
Step 1- Pertama, kita perlu membuat ekspresi daftar untuk mengulang semua elemen dalam array. Kemudian lakukan pencarian di kamus label_mapping untuk setiap nilai.
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 2- Selanjutnya, konversikan nilai numerik yang dikonversi ini ke vektor enkode one-hot. Kami akan menggunakanone_hot berfungsi sebagai berikut -
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultStep 3 - Akhirnya, kita perlu mengubah daftar yang diubah ini menjadi numpy Himpunan.
y = np.array([one_hot(label_mapping[v], 3) for v in y])Langkah-langkah untuk mendeteksi overfitting
Situasinya, saat model Anda mengingat sampel tetapi tidak dapat menyimpulkan aturan dari sampel pelatihan, terjadi overfitting. Dengan bantuan langkah-langkah berikut, kami dapat mendeteksi overfitting pada model kami -
Step 1 - Pertama, dari sklearn paket, impor train_test_split fungsi dari model_selection modul.
from sklearn.model_selection import train_test_splitStep 2 - Selanjutnya, kita perlu memanggil fungsi train_test_split dengan fitur x dan label y sebagai berikut -
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2,
stratify=y)Kami menentukan test_size 0,2 untuk menyisihkan 20% dari total data.
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Langkah-langkah untuk memasukkan set pelatihan dan set validasi ke model kita
Step 1 - Untuk melatih model kita, pertama, kita akan memanggil train_minibatchmetode. Kemudian berikan kamus yang memetakan data masukan ke variabel masukan yang telah kita gunakan untuk mendefinisikan NN dan fungsi kerugian yang terkait.
trainer.train_minibatch({ features: X_train, label: y_train})Step 2 - Selanjutnya, telepon train_minibatch dengan menggunakan for loop berikut -
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))Memasukkan data ke pelatih - Contoh lengkap
from import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, index_col=False)
x = df_source.iloc[:, :4].values
x = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
y = np.array([one_hot(label_mapping[v], 3) for v in y])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2, stratify=y)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
trainer.train_minibatch({ features: X_train, label: y_train})
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))Mengukur kinerja NN
Untuk mengoptimalkan model NN kami, setiap kali kami meneruskan data melalui pelatih, ini mengukur kinerja model melalui metrik yang kami konfigurasikan untuk pelatih. Pengukuran performansi model NN selama pelatihan dilakukan pada data pelatihan. Namun di sisi lain, untuk analisis lengkap performa model, kami juga perlu menggunakan data pengujian.
Jadi, untuk mengukur kinerja model menggunakan data uji, kita dapat memanggil test_minibatch metode di trainer sebagai berikut -
trainer.test_minibatch({ features: X_test, label: y_test})Membuat prediksi dengan NN
Setelah Anda melatih model deep learning, hal terpenting adalah membuat prediksi menggunakan model tersebut. Untuk membuat prediksi dari NN terlatih di atas, kita dapat mengikuti langkah-langkah yang diberikan-
Step 1 - Pertama, kita perlu memilih item acak dari set pengujian menggunakan fungsi berikut -
np.random.choiceStep 2 - Selanjutnya, kita perlu memilih data sampel dari set pengujian dengan menggunakan sample_index.
Step 3 - Sekarang, untuk mengubah keluaran numerik ke NN menjadi label sebenarnya, buat pemetaan terbalik.
Step 4 - Sekarang, gunakan yang dipilih sampledata. Buat prediksi dengan memanggil NN z sebagai fungsi.
Step 5- Sekarang, setelah Anda mendapatkan output yang diprediksi, ambil indeks neuron yang memiliki nilai tertinggi sebagai nilai prediksi. Itu bisa dilakukan dengan menggunakannp.argmax fungsi dari numpy paket.
Step 6 - Terakhir, ubah nilai indeks menjadi label sebenarnya dengan menggunakan inverted_mapping.
Membuat prediksi dengan NN - Contoh lengkap
sample_index = np.random.choice(X_test.shape[0])
sample = X_test[sample_index]
inverted_mapping = {
1:’Iris-setosa’,
2:’Iris-versicolor’,
3:’Iris-virginica’
}
prediction = z(sample)
predicted_label = inverted_mapping[np.argmax(prediction)]
print(predicted_label)Keluaran
Setelah melatih model deep learning di atas dan menjalankannya, Anda akan mendapatkan output berikut -
Iris-versicolorCNTK - Dalam Memori dan Set Data Besar
Pada bab ini, kita akan belajar tentang bagaimana bekerja dengan dalam memori dan dataset besar di CNTK.
Pelatihan dengan set data memori kecil
Saat kita berbicara tentang memasukkan data ke pelatih CNTK, ada banyak cara, tetapi itu akan tergantung pada ukuran kumpulan data dan format data. Kumpulan data bisa dalam memori kecil atau kumpulan data besar.
Di bagian ini, kita akan bekerja dengan set data dalam memori. Untuk ini, kami akan menggunakan dua kerangka kerja berikut -
- Numpy
- Pandas
Menggunakan array Numpy
Di sini, kami akan bekerja dengan kumpulan data yang dibuat secara acak berbasis numpy di CNTK. Dalam contoh ini, kita akan mensimulasikan data untuk masalah klasifikasi biner. Misalkan, kita memiliki sekumpulan observasi dengan 4 fitur dan ingin memprediksi dua kemungkinan label dengan model deep learning kita.
Contoh Implementasi
Untuk ini, pertama-tama kita harus membuat satu set label yang berisi representasi vektor one-hot dari label, yang ingin kita prediksi. Itu dapat dilakukan dengan bantuan langkah-langkah berikut -
Step 1 - Impor numpy paket sebagai berikut -
import numpy as np
num_samples = 20000Step 2 - Selanjutnya, buat pemetaan label dengan menggunakan np.eye berfungsi sebagai berikut -
label_mapping = np.eye(2)Step 3 - Sekarang dengan menggunakan np.random.choice fungsi, kumpulkan 20.000 sampel acak sebagai berikut -
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)Step 4 - Sekarang akhirnya dengan menggunakan fungsi np.random.random, buat larik nilai floating point acak sebagai berikut -
x = np.random.random(size=(num_samples, 4)).astype(np.float32)Setelah, kami menghasilkan array nilai floating-point acak, kami perlu mengubahnya menjadi angka floating point 32-bit sehingga dapat dicocokkan dengan format yang diharapkan oleh CNTK. Mari ikuti langkah-langkah di bawah ini untuk melakukan ini -
Step 5 - Impor fungsi lapisan Dense dan Sequential dari modul cntk.layers sebagai berikut -
from cntk.layers import Dense, SequentialStep 6- Sekarang, kita perlu mengimpor fungsi aktivasi untuk lapisan di jaringan. Mari kita imporsigmoid sebagai fungsi aktivasi -
from cntk import input_variable, default_options
from cntk.ops import sigmoidStep 7- Sekarang, kita perlu mengimpor fungsi kerugian untuk melatih jaringan. Mari kita imporbinary_cross_entropy sebagai fungsi kerugian -
from cntk.losses import binary_cross_entropyStep 8- Selanjutnya, kita perlu menentukan opsi default untuk jaringan. Di sini, kami akan menyediakansigmoidfungsi aktivasi sebagai pengaturan default. Juga, buat model dengan menggunakan fungsi Sequential layer sebagai berikut -
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])Step 9 - Selanjutnya, inisialisasi input_variable dengan 4 fitur masukan yang berfungsi sebagai masukan untuk jaringan.
features = input_variable(4)Step 10 - Sekarang, untuk melengkapinya, kita perlu menghubungkan variabel fitur ke NN.
z = model(features)Jadi, sekarang kita memiliki NN, dengan bantuan langkah-langkah berikut, mari kita latih menggunakan dataset dalam memori -
Step 11 - Untuk melatih NN ini, pertama-tama kita perlu mengimpor pelajar dari cntk.learnersmodul. Kami akan mengimporsgd pelajar sebagai berikut -
from cntk.learners import sgdStep 12 - Seiring dengan impor itu ProgressPrinter dari cntk.logging modul juga.
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 13 - Selanjutnya, tentukan variabel input baru untuk label sebagai berikut -
labels = input_variable(2)Step 14 - Untuk melatih model NN, selanjutnya, kita perlu mendefinisikan kerugian menggunakan binary_cross_entropyfungsi. Juga, berikan model z dan variabel label.
loss = binary_cross_entropy(z, labels)Step 15 - Selanjutnya, inisialisasi sgd pelajar sebagai berikut -
learner = sgd(z.parameters, lr=0.1)Step 16- Terakhir, panggil metode kereta pada fungsi kerugian. Selain itu, berikan juga data masukan, yaitusgd pelajar dan progress_printer.−
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])Contoh implementasi lengkap
import numpy as np
num_samples = 20000
label_mapping = np.eye(2)
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)
x = np.random.random(size=(num_samples, 4)).astype(np.float32)
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid
from cntk.losses import binary_cross_entropy
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])
features = input_variable(4)
z = model(features)
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(2)
loss = binary_cross_entropy(z, labels)
learner = sgd(z.parameters, lr=0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])Keluaran
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.52 1.52 0 0 32
1.51 1.51 0 0 96
1.48 1.46 0 0 224
1.45 1.42 0 0 480
1.42 1.4 0 0 992
1.41 1.39 0 0 2016
1.4 1.39 0 0 4064
1.39 1.39 0 0 8160
1.39 1.39 0 0 16352Menggunakan Pandas DataFrames
Array numpy sangat terbatas dalam apa yang dapat dimuatnya dan salah satu cara paling dasar untuk menyimpan data. Misalnya, array n-dimensi dapat berisi data dari satu tipe data. Namun di sisi lain, untuk banyak kasus di dunia nyata, kita memerlukan pustaka yang dapat menangani lebih dari satu tipe data dalam satu set data.
Salah satu pustaka Python yang disebut Pandas membuatnya lebih mudah untuk bekerja dengan kumpulan data semacam itu. Ini memperkenalkan konsep DataFrame (DF) dan memungkinkan kita memuat kumpulan data dari disk yang disimpan dalam berbagai format sebagai DF. Misalnya, kita dapat membaca DF yang disimpan sebagai CSV, JSON, Excel, dll.
Anda dapat mempelajari pustaka Python Pandas lebih detail di https://www.tutorialspoint.com/python_pandas/index.htm.
Contoh Implementasi
Dalam contoh ini, kita akan menggunakan contoh pengklasifikasian tiga kemungkinan spesies bunga iris berdasarkan empat properti. Kami juga telah membuat model pembelajaran mendalam ini di bagian sebelumnya. Modelnya adalah sebagai berikut -
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)Model di atas berisi satu lapisan tersembunyi dan lapisan keluaran dengan tiga neuron untuk mencocokkan jumlah kelas yang dapat kita prediksi.
Selanjutnya, kita akan menggunakan train metode dan lossberfungsi untuk melatih jaringan. Untuk ini, pertama-tama kita harus memuat dan memproses terlebih dahulu dataset iris, sehingga cocok dengan tata letak dan format data yang diharapkan untuk NN. Itu dapat dilakukan dengan bantuan langkah-langkah berikut -
Step 1 - Impor numpy dan Pandas paket sebagai berikut -
import numpy as np
import pandas as pdStep 2 - Selanjutnya, gunakan read_csv berfungsi untuk memuat dataset ke dalam memori -
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 - Sekarang, kita perlu membuat kamus yang akan memetakan label dalam dataset dengan representasi numerik yang sesuai.
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 4 - Sekarang, dengan menggunakan iloc pengindeks di DataFrame, pilih empat kolom pertama sebagai berikut -
x = df_source.iloc[:, :4].valuesStep 5−Selanjutnya, kita perlu memilih kolom spesies sebagai label untuk dataset. Itu dapat dilakukan sebagai berikut -
y = df_source[‘species’].valuesStep 6 - Sekarang, kita perlu memetakan label dalam dataset, yang bisa dilakukan dengan menggunakan label_mapping. Juga, gunakanone_hot encoding untuk mengubahnya menjadi array encoding one-hot.
y = np.array([one_hot(label_mapping[v], 3) for v in y])Step 7 - Selanjutnya, untuk menggunakan fitur dan label yang dipetakan dengan CNTK, kita perlu mengonversinya menjadi float -
x= x.astype(np.float32)
y= y.astype(np.float32)Seperti yang kita ketahui, label disimpan dalam dataset sebagai string dan CNTK tidak dapat bekerja dengan string ini. Oleh karena itu, diperlukan vektor enkode one-hot yang mewakili label. Untuk ini, kita dapat mendefinisikan fungsi katakanone_hot sebagai berikut -
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return resultSekarang, kita memiliki numpy array dalam format yang benar, dengan bantuan langkah-langkah berikut kita dapat menggunakannya untuk melatih model kita -
Step 8- Pertama, kita perlu mengimpor fungsi kerugian untuk melatih jaringan. Mari kita imporbinary_cross_entropy_with_softmax sebagai fungsi kerugian -
from cntk.losses import binary_cross_entropy_with_softmaxStep 9 - Untuk melatih NN ini, kami juga perlu mengimpor pelajar dari cntk.learnersmodul. Kami akan mengimporsgd pelajar sebagai berikut -
from cntk.learners import sgdStep 10 - Seiring dengan impor itu ProgressPrinter dari cntk.logging modul juga.
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 11 - Selanjutnya, tentukan variabel input baru untuk label sebagai berikut -
labels = input_variable(3)Step 12 - Untuk melatih model NN, selanjutnya, kita perlu mendefinisikan kerugian menggunakan binary_cross_entropy_with_softmaxfungsi. Berikan juga model z dan variabel label.
loss = binary_cross_entropy_with_softmax (z, labels)Step 13 - Selanjutnya, inisialisasi sgd pelajar sebagai berikut -
learner = sgd(z.parameters, 0.1)Step 14- Terakhir, panggil metode kereta pada fungsi kerugian. Selain itu, berikan juga data masukan, yaitusgd pelajar dan progress_printer.
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=
[progress_writer],minibatch_size=16,max_epochs=5)Contoh implementasi lengkap
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)
import numpy as np
import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
x = df_source.iloc[:, :4].values
y = df_source[‘species’].values
y = np.array([one_hot(label_mapping[v], 3) for v in y])
x= x.astype(np.float32)
y= y.astype(np.float32)
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return result
from cntk.losses import binary_cross_entropy_with_softmax
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(3)
loss = binary_cross_entropy_with_softmax (z, labels)
learner = sgd(z.parameters, 0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer],minibatch_size=16,max_epochs=5)Keluaran
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.1 1.1 0 0 16
0.835 0.704 0 0 32
1.993 1.11 0 0 48
1.14 1.14 0 0 112
[………]Pelatihan dengan set data besar
Di bagian sebelumnya, kami bekerja dengan set data dalam memori kecil menggunakan Numpy dan pandas, tetapi tidak semua set data berukuran sangat kecil. Khususnya dataset yang berisi gambar, video, sampel suara berukuran besar.MinibatchSourceadalah sebuah komponen, yang dapat memuat data dalam potongan-potongan, disediakan oleh CNTK untuk bekerja dengan kumpulan data yang besar. Beberapa fiturMinibatchSource komponennya adalah sebagai berikut -
MinibatchSource dapat mencegah NN overfitting dengan secara otomatis mengacak sampel yang dibaca dari sumber data.
Ini memiliki pipeline transformasi built-in yang dapat digunakan untuk menambah data.
Ini memuat data pada thread latar belakang yang terpisah dari proses pelatihan.
Pada bagian berikut, kita akan mengeksplorasi bagaimana menggunakan sumber minibatch dengan data di luar memori untuk bekerja dengan kumpulan data yang besar. Kami juga akan mengeksplorasi, bagaimana kami dapat menggunakannya untuk memberi makan untuk pelatihan NN.
Membuat instance MinibatchSource
Di bagian sebelumnya, kami telah menggunakan contoh bunga iris dan bekerja dengan dataset kecil dalam memori menggunakan Pandas DataFrames. Di sini, kami akan mengganti kode yang menggunakan data dari pandas DF denganMinibatchSource. Pertama, kita perlu membuat instanceMinibatchSource dengan bantuan langkah-langkah berikut -
Contoh Implementasi
Step 1 - Pertama, dari cntk.io modul impor komponen untuk minibatchsource sebagai berikut -
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 - Sekarang, dengan menggunakan StreamDef kelas, buat definisi aliran untuk label.
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 3 - Selanjutnya, buat untuk membaca fitur yang diajukan dari file input, buat instance lain dari StreamDef sebagai berikut.
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 4 - Sekarang, kita perlu menyediakan iris.ctf file sebagai input dan menginisialisasi file deserializer sebagai berikut -
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=
label_stream, features=features_stream)Step 5 - Akhirnya, kita perlu membuat instance minisourceBatch dengan menggunakan deserializer sebagai berikut -
Minibatch_source = MinibatchSource(deserializer, randomize=True)Membuat instance MinibatchSource - Contoh implementasi lengkap
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True)Membuat file MCTF
Seperti yang Anda lihat di atas, kami mengambil data dari file 'iris.ctf'. Ini memiliki format file yang disebut CNTK Text Format (CTF). File CTF wajib dibuat untuk mendapatkan data untuk fileMinibatchSourceMisalnya kita buat di atas. Mari kita lihat bagaimana kita bisa membuat file CTF.
Contoh Implementasi
Step 1 - Pertama, kita perlu mengimpor paket pandas dan numpy sebagai berikut -
import pandas as pd
import numpy as npStep 2- Selanjutnya kita perlu memuat file data kita, yaitu iris.csv ke dalam memori. Kemudian, simpan didf_source variabel.
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 - Sekarang, dengan menggunakan ilocpengindeks sebagai fitur, ambil konten dari empat kolom pertama. Selain itu, gunakan data dari kolom spesies sebagai berikut -
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].valuesStep 4- Selanjutnya, kita perlu membuat pemetaan antara nama label dan representasi numeriknya. Itu bisa dilakukan dengan membuatlabel_mapping sebagai berikut -
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 5 - Sekarang, ubah label menjadi sekumpulan vektor yang dikodekan one-hot sebagai berikut -
labels = [one_hot(label_mapping[v], 3) for v in labels]Sekarang, seperti yang kita lakukan sebelumnya, buat fungsi utilitas bernama one_hotuntuk menyandikan label. Itu dapat dilakukan sebagai berikut -
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultKarena, kami telah memuat dan memproses data sebelumnya, inilah waktunya untuk menyimpannya di disk dalam format file CTF. Kita dapat melakukannya dengan bantuan kode Python berikut -
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))Membuat file MCTF - Contoh implementasi lengkap
import pandas as pd
import numpy as np
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
labels = [one_hot(label_mapping[v], 3) for v in labels]
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))Memberi makan data
Setelah Anda membuat MinibatchSource,Misalnya, kita perlu melatihnya. Kita bisa menggunakan logika pelatihan yang sama seperti yang digunakan saat kita bekerja dengan set data dalam memori yang kecil. Di sini, kami akan menggunakanMinibatchSource contoh sebagai input untuk metode kereta pada fungsi kerugian sebagai berikut -
Contoh Implementasi
Step 1 - Untuk mencatat keluaran sesi pelatihan, impor ProgressPrinter dari cntk.logging modul sebagai berikut -
from cntk.logging import ProgressPrinterStep 2 - Selanjutnya, untuk menyiapkan sesi pelatihan, impor file trainer dan training_session dari cntk.train modul sebagai berikut -
from cntk.train import Trainer,Step 3 - Sekarang, kita perlu mendefinisikan beberapa set konstanta seperti minibatch_size, samples_per_epoch dan num_epochs sebagai berikut -
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30Step 4 - Selanjutnya, untuk mengetahui CNTK cara membaca data selama pelatihan, kita perlu mendefinisikan pemetaan antara variabel input untuk jaringan dan aliran di sumber minibatch.
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}Step 5 - Selanjutnya, untuk mencatat keluaran dari proses pelatihan, lakukan inisialisasi progress_printer variabel dengan baru ProgressPrinter Misalnya sebagai berikut -
progress_writer = ProgressPrinter(0)Step 6 - Akhirnya, kita perlu memanggil metode kereta pada kerugian sebagai berikut -
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)Memberi makan data - Contoh implementasi lengkap
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}
progress_writer = ProgressPrinter(0)
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)Keluaran
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.21 1.21 0 0 32
1.15 0.12 0 0 96
[………]CNTK - Mengukur Kinerja
Bab ini akan menjelaskan bagaimana mengukur kinerja model di CNKT.
Strategi untuk memvalidasi kinerja model
Setelah membuat model ML, kami biasa melatihnya menggunakan sekumpulan sampel data. Karena pelatihan ini, model ML kami mempelajari dan memperoleh beberapa aturan umum. Performa model ML penting saat kami memasukkan sampel baru, yaitu sampel yang berbeda dari yang diberikan pada saat pelatihan, ke model. Model berperilaku berbeda dalam kasus tersebut. Mungkin lebih buruk dalam membuat prediksi yang baik pada sampel baru tersebut.
Tetapi model harus bekerja dengan baik untuk sampel baru juga karena dalam lingkungan produksi kita akan mendapatkan masukan yang berbeda dari pada kita menggunakan data sampel untuk tujuan pelatihan. Itulah alasannya, kita harus memvalidasi model ML dengan menggunakan sekumpulan sampel yang berbeda dari sampel yang kita gunakan untuk tujuan pelatihan. Di sini, kita akan membahas dua teknik berbeda untuk membuat dataset untuk memvalidasi NN.
Dataset hold-out
Ini adalah salah satu metode termudah untuk membuat set data untuk memvalidasi NN. Seperti namanya, dalam metode ini kami akan menahan satu set sampel dari pelatihan (katakanlah 20%) dan menggunakannya untuk menguji performa model ML kami. Diagram berikut menunjukkan rasio antara sampel pelatihan dan validasi -

Model set data hold-out memastikan bahwa kami memiliki cukup data untuk melatih model ML kami dan pada saat yang sama kami akan memiliki jumlah sampel yang wajar untuk mendapatkan pengukuran performa model yang baik.
Untuk menyertakan set pelatihan dan set pengujian, praktik yang baik adalah memilih sampel acak dari set data utama. Ini memastikan distribusi yang merata antara pelatihan dan set pengujian.
Berikut ini adalah contoh di mana kami memproduksi dataset hold-out sendiri dengan menggunakan train_test_split fungsi dari scikit-learn Perpustakaan.
Contoh
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)Keluaran
Predictions: ['versicolor', 'virginica']Saat menggunakan CNTK, kita perlu mengacak urutan dataset kita setiap kali kita melatih model kita karena -
Algoritme pembelajaran mendalam sangat dipengaruhi oleh generator angka acak.
Urutan kami memberikan sampel ke NN selama pelatihan sangat memengaruhi kinerjanya.
Kelemahan utama dari penggunaan teknik dataset hold-out adalah teknik ini tidak dapat diandalkan karena terkadang kami mendapatkan hasil yang sangat baik tetapi terkadang, kami mendapatkan hasil yang buruk.
Validasi K-fold cross
Untuk membuat model ML kita lebih andal, ada teknik yang disebut validasi K-fold cross. Pada dasarnya teknik validasi K-fold cross sama dengan teknik sebelumnya, namun diulangi beberapa kali-biasanya sekitar 5 hingga 10 kali. Diagram berikut mewakili konsepnya -

Cara kerja validasi K-fold cross
Cara kerja validasi K-fold cross dapat dipahami dengan bantuan langkah-langkah berikut -
Step 1- Seperti pada teknik dataset Hand-out, pada teknik validasi K-fold cross, pertama-tama kita perlu membagi dataset menjadi set pelatihan dan pengujian. Idealnya, rasionya adalah 80-20, yaitu 80% set pelatihan dan 20% set tes.
Step 2 - Selanjutnya, kita perlu melatih model kita menggunakan set pelatihan.
Step 3−Akhirnya, kami akan menggunakan set pengujian untuk mengukur kinerja model kami. Satu-satunya perbedaan antara teknik dataset Hold-out dan teknik validasi k-cross adalah bahwa proses di atas biasanya diulangi selama 5 hingga 10 kali dan pada akhirnya rata-rata dihitung untuk semua metrik kinerja. Rata-rata itu akan menjadi metrik kinerja akhir.
Mari kita lihat contoh dengan kumpulan data kecil -
Contoh
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))Keluaran
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ]
train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7]
train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4]
train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8]
train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]Seperti yang kita lihat, karena menggunakan pelatihan yang lebih realistis dan skenario pengujian, teknik validasi silang k-fold memberi kita pengukuran kinerja yang jauh lebih stabil tetapi, pada sisi negatifnya, dibutuhkan banyak waktu saat memvalidasi model pembelajaran yang mendalam.
CNTK tidak mendukung validasi k-cross, oleh karena itu kita perlu menulis skrip kita sendiri untuk melakukannya.
Mendeteksi underfitting dan overfitting
Baik kita menggunakan dataset Hand-out atau teknik k-fold cross-validation, kita akan menemukan bahwa output untuk metrik akan berbeda untuk dataset yang digunakan untuk pelatihan dan dataset yang digunakan untuk validasi.
Mendeteksi overfitting
Fenomena yang disebut overfitting adalah situasi di mana model ML kita memodelkan data pelatihan dengan sangat baik, tetapi gagal berfungsi dengan baik pada data pengujian, yaitu tidak dapat memprediksi data pengujian.
Hal ini terjadi jika model ML mempelajari pola dan gangguan tertentu dari data pelatihan sedemikian rupa, sehingga berdampak negatif pada kemampuan model untuk menggeneralisasi dari data pelatihan ke data baru, yaitu data yang tidak terlihat. Di sini, noise adalah informasi yang tidak relevan atau keacakan dalam kumpulan data.
Berikut adalah dua cara dengan bantuan yang kami dapat mendeteksi cuaca model kami overfit atau tidak -
Model overfit akan bekerja dengan baik pada sampel yang sama yang kita gunakan untuk pelatihan, tetapi akan sangat buruk pada sampel baru, yaitu sampel yang berbeda dari pelatihan.
Model overfit selama validasi jika metrik pada set pengujian lebih rendah dari metrik yang sama, yang kami gunakan pada set pelatihan kami.
Mendeteksi underfitting
Situasi lain yang dapat muncul dalam ML kami adalah underfitting. Ini adalah situasi di mana, model ML kami tidak membuat model data pelatihan dengan baik dan gagal memprediksi keluaran yang berguna. Saat kita mulai melatih epoch pertama, model kita akan underfitting, tetapi underfitnya akan berkurang seiring kemajuan pelatihan.
Salah satu cara untuk mendeteksi, apakah model kita underfit atau tidak adalah dengan melihat metrik set pelatihan dan set pengujian. Model kita akan kurang fit jika metrik pada set pengujian lebih tinggi dari metrik pada set pelatihan.
CNTK - Klasifikasi Jaringan Neural
Pada bab ini, kita akan mempelajari bagaimana mengklasifikasikan jaringan syaraf tiruan dengan menggunakan CNTK.
pengantar
Klasifikasi dapat didefinisikan sebagai proses untuk memprediksi label keluaran kategorial atau tanggapan untuk data masukan yang diberikan. Keluaran yang dikategorikan, yang akan didasarkan pada apa yang telah dipelajari model dalam fase pelatihan, dapat berbentuk seperti "Hitam" atau "Putih" atau "spam" atau "tidak ada spam".
Di sisi lain, secara matematis, ini adalah tugas untuk memperkirakan fungsi pemetaan, katakanlah f dari variabel input katakan X ke variabel output katakan Y.
Contoh klasik dari masalah klasifikasi adalah deteksi spam di email. Jelas bahwa hanya ada dua kategori keluaran, "spam" dan "tidak ada spam".
Untuk menerapkan klasifikasi seperti itu, pertama-tama kita perlu melakukan pelatihan pengklasifikasi di mana email "spam" dan "tidak ada spam" akan digunakan sebagai data pelatihan. Setelah pengklasifikasi berhasil dilatih, pengklasifikasi dapat digunakan untuk mendeteksi email yang tidak dikenal.
Di sini, kita akan membuat 4-5-3 NN menggunakan dataset bunga iris yang memiliki:
Node 4-masukan (satu untuk setiap nilai prediktor).
5 node pemrosesan tersembunyi.
Node 3-output (karena ada tiga kemungkinan spesies dalam dataset iris).
Memuat Set Data
Kami akan menggunakan dataset bunga iris, dari mana kami ingin mengklasifikasikan spesies bunga iris berdasarkan sifat fisik lebar dan panjang sepal, dan lebar dan panjang kelopak. Dataset menggambarkan sifat fisik berbagai varietas bunga iris -
Panjang sepal
Lebar sepal
Panjang kelopak
Lebar kelopak
Kelasnya yaitu iris setosa atau iris versicolor atau iris virginica
Kita punya iris.CSVfile yang kami gunakan sebelumnya di bab-bab sebelumnya juga. Itu dapat dimuat dengan bantuanPandasPerpustakaan. Namun, sebelum menggunakannya atau memuatnya untuk pengklasifikasi kita, kita perlu menyiapkan file training dan test, agar dapat digunakan dengan mudah dengan CNTK.
Mempersiapkan file pelatihan & pengujian
Dataset Iris adalah salah satu set data paling populer untuk proyek ML. Ini memiliki 150 item data dan data mentah terlihat sebagai berikut -
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
…
7.0 3.2 4.7 1.4 versicolor
6.4 3.2 4.5 1.5 versicolor
…
6.3 3.3 6.0 2.5 virginica
5.8 2.7 5.1 1.9 virginicaSeperti yang dikisahkan sebelumnya, empat nilai pertama pada setiap baris menggambarkan sifat fisik varietas yang berbeda, yaitu panjang sepal, lebar sepal, panjang kelopak, lebar kelopak bunga iris.
Tapi, kita harus mengkonversi datanya dalam format yang mudah digunakan oleh CNTK dan formatnya adalah file .ctf (kita juga membuat satu iris.ctf di bagian sebelumnya). Ini akan terlihat seperti berikut -
|attribs 5.1 3.5 1.4 0.2|species 1 0 0
|attribs 4.9 3.0 1.4 0.2|species 1 0 0
…
|attribs 7.0 3.2 4.7 1.4|species 0 1 0
|attribs 6.4 3.2 4.5 1.5|species 0 1 0
…
|attribs 6.3 3.3 6.0 2.5|species 0 0 1
|attribs 5.8 2.7 5.1 1.9|species 0 0 1Pada data di atas, tag | attribs menandai awal dari nilai fitur dan | spesies menandai nilai label kelas. Kita juga bisa menggunakan nama tag lain sesuai keinginan kita, bahkan kita bisa menambahkan ID item juga. Misalnya, lihat data berikut -
|ID 001 |attribs 5.1 3.5 1.4 0.2|species 1 0 0 |#setosa
|ID 002 |attribs 4.9 3.0 1.4 0.2|species 1 0 0 |#setosa
…
|ID 051 |attribs 7.0 3.2 4.7 1.4|species 0 1 0 |#versicolor
|ID 052 |attribs 6.4 3.2 4.5 1.5|species 0 1 0 |#versicolor
…Ada total 150 item data dalam dataset iris dan untuk contoh ini, kita akan menggunakan 80-20 aturan dataset hold-out yaitu 80% (120 item) item data untuk tujuan pelatihan dan sisa 20% (30 item) item data untuk pengujian tujuan.
Membangun model Klasifikasi
Pertama, kita perlu memproses file data dalam format CNTK dan untuk itu kita akan menggunakan fungsi helper bernama create_reader sebagai berikut -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcSekarang, kita perlu menyetel argumen arsitektur untuk NN kita dan juga menyediakan lokasi file data. Itu dapat dilakukan dengan bantuan kode python berikut -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)Sekarang, dengan bantuan baris kode berikut, program kami akan membuat NN yang tidak terlatih -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)Sekarang, setelah kita membuat model ganda yang tidak terlatih, kita perlu menyiapkan objek algoritme Pelajar dan kemudian menggunakannya untuk membuat objek pelatihan Trainer. Kami akan menggunakan pelajar SGD dancross_entropy_with_softmax fungsi kerugian -
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])Kode algoritma pembelajaran sebagai berikut -
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])Sekarang, setelah kita selesai dengan objek Trainer, kita perlu membuat fungsi pembaca untuk membaca data pelatihan−
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }Sekarang saatnya melatih model NN kita−
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))Setelah selesai dengan pelatihan, mari kita evaluasi model menggunakan item data pengujian -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)Setelah mengevaluasi keakuratan model NN terlatih kami, kami akan menggunakannya untuk membuat prediksi pada data yang tidak terlihat -
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[6.4, 3.2, 4.5, 1.5]], dtype=np.float32)
print("\nPredicting Iris species for input features: ")
print(unknown[0]) pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])Model Klasifikasi Lengkap
Import numpy as np
Import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])
if __name__== ”__main__”:
main()Keluaran
Using CNTK version = 2.7
batch 0: mean loss = 1.0986, mean accuracy = 40.00%
batch 500: mean loss = 0.6677, mean accuracy = 80.00%
batch 1000: mean loss = 0.5332, mean accuracy = 70.00%
batch 1500: mean loss = 0.2408, mean accuracy = 100.00%
Evaluating test data
Classification accuracy = 94.58%
Predicting species for input features:
[7.0 3.2 4.7 1.4]
Prediction probabilities:
[0.0847 0.736 0.113]Menyimpan model terlatih
Dataset Iris ini hanya memiliki 150 item data, oleh karena itu hanya perlu beberapa detik untuk melatih model pengklasifikasi NN, tetapi pelatihan pada set data besar yang memiliki ratusan atau ribu item data dapat memakan waktu berjam-jam atau bahkan berhari-hari.
Kita dapat menyimpan model kita sehingga kita tidak perlu menyimpannya dari awal. Dengan bantuan kode Python berikut, kita dapat menyimpan NN terlatih kita -
nn_classifier = “.\\neuralclassifier.model” #provide the name of the file
model.save(nn_classifier, format=C.ModelFormat.CNTKv2)Berikut adalah argumen dari save() fungsi yang digunakan di atas -
Nama file adalah argumen pertama dari save()fungsi. Itu juga dapat ditulis bersama dengan jalur file.
Parameter lainnya adalah format parameter yang memiliki nilai default C.ModelFormat.CNTKv2.
Memuat model terlatih
Setelah Anda menyimpan model terlatih, sangat mudah untuk memuat model itu. Kami hanya perlu menggunakanload ()fungsi. Mari kita periksa dalam contoh berikut -
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralclassifier.model”)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])Manfaat model tersimpan adalah, setelah Anda memuat model yang disimpan, model tersebut dapat digunakan persis seperti model yang baru saja dilatih.
CNTK - Klasifikasi Biner Jaringan Neural
Mari kita pahami, apa itu klasifikasi biner jaringan saraf menggunakan CNTK, pada bab ini.
Klasifikasi biner menggunakan NN seperti klasifikasi kelas jamak, satu-satunya hal adalah hanya ada dua node keluaran, bukan tiga atau lebih. Disini kita akan melakukan klasifikasi biner menggunakan neural network dengan menggunakan dua teknik yaitu teknik one-node dan two-node. Teknik satu simpul lebih umum daripada teknik dua simpul.
Memuat Set Data
Untuk menerapkan kedua teknik ini menggunakan NN, kami akan menggunakan set data uang kertas. Dataset dapat diunduh dari UCI Machine Learning Repository yang tersedia dihttps://archive.ics.uci.edu/ml/datasets/banknote+authentication.
Untuk contoh kita, kita akan menggunakan 50 item data otentik yang memiliki kelas pemalsuan = 0, dan 50 item palsu pertama yang memiliki kelas pemalsuan = 1.
Mempersiapkan file pelatihan & pengujian
Ada 1372 item data dalam dataset lengkap. Dataset mentah terlihat sebagai berikut -
3.6216, 8.6661, -2.8076, -0.44699, 0
4.5459, 8.1674, -2.4586, -1.4621, 0
…
-1.3971, 3.3191, -1.3927, -1.9948, 1
0.39012, -0.14279, -0.031994, 0.35084, 1Sekarang, pertama-tama kita perlu mengonversi data mentah ini menjadi format CNTK dua node, yang akan menjadi sebagai berikut -
|stats 3.62160000 8.66610000 -2.80730000 -0.44699000 |forgery 0 1 |# authentic
|stats 4.54590000 8.16740000 -2.45860000 -1.46210000 |forgery 0 1 |# authentic
. . .
|stats -1.39710000 3.31910000 -1.39270000 -1.99480000 |forgery 1 0 |# fake
|stats 0.39012000 -0.14279000 -0.03199400 0.35084000 |forgery 1 0 |# fakeAnda dapat menggunakan program python berikut untuk membuat data format CNTK dari data mentah -
fin = open(".\\...", "r") #provide the location of saved dataset text file.
for line in fin:
line = line.strip()
tokens = line.split(",")
if tokens[4] == "0":
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 0 1 |# authentic" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
else:
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 1 0 |# fake" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
fin.close()Model Klasifikasi biner dua node
Ada sedikit perbedaan antara klasifikasi dua simpul dan klasifikasi kelas jamak. Di sini pertama-tama kita perlu memproses file data dalam format CNTK dan untuk itu kita akan menggunakan fungsi helper bernamacreate_reader sebagai berikut -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcSekarang, kita perlu menyetel argumen arsitektur untuk NN kita dan juga menyediakan lokasi file data. Itu dapat dilakukan dengan bantuan kode python berikut -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test fileSekarang, dengan bantuan baris kode berikut, program kami akan membuat NN yang tidak terlatih -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)Sekarang, setelah kita membuat model ganda yang tidak terlatih, kita perlu menyiapkan objek algoritme Pelajar dan kemudian menggunakannya untuk membuat objek pelatihan Trainer. Kami akan menggunakan SGD pelajar dan fungsi kehilangan cross_entropy_with_softmax -
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])Sekarang, setelah kita selesai dengan objek Trainer, kita perlu membuat fungsi pembaca untuk membaca data pelatihan -
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }Sekarang, saatnya melatih model NN kita -
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))Setelah pelatihan selesai, mari kita evaluasi model menggunakan item data uji -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)Setelah mengevaluasi keakuratan model NN terlatih kami, kami akan menggunakannya untuk membuat prediksi pada data yang tidak terlihat -
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)Model Klasifikasi Dua Node Lengkap
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
withC.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()Keluaran
Using CNTK version = 2.7
batch 0: mean loss = 0.6928, accuracy = 80.00%
batch 50: mean loss = 0.6877, accuracy = 70.00%
batch 100: mean loss = 0.6432, accuracy = 80.00%
batch 150: mean loss = 0.4978, accuracy = 80.00%
batch 200: mean loss = 0.4551, accuracy = 90.00%
batch 250: mean loss = 0.3755, accuracy = 90.00%
batch 300: mean loss = 0.2295, accuracy = 100.00%
batch 350: mean loss = 0.1542, accuracy = 100.00%
batch 400: mean loss = 0.1581, accuracy = 100.00%
batch 450: mean loss = 0.1499, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.58%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probabilities are:
[0.7847 0.2536]
Prediction: fakeModel Klasifikasi biner satu node
Program implementasi hampir seperti yang telah kami lakukan di atas untuk klasifikasi dua node. Perubahan utama adalah ketika menggunakan teknik klasifikasi dua node.
Kita bisa menggunakan fungsi klasifikasi_error () bawaan CNTK, tetapi dalam kasus klasifikasi satu simpul CNTK tidak mendukung fungsi klasifikasi_error (). Itulah alasan kita perlu mengimplementasikan fungsi yang ditentukan program sebagai berikut -
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)Dengan perubahan itu, mari kita lihat contoh klasifikasi satu node lengkap -
Model Klasifikasi satu node lengkap
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = oLayer
tr_loss = C.cross_entropy_with_softmax(model, Y)
max_iter = 1000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(model.parameters, learn_rate)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = {X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 100 == 0:
mcee=trainer.previous_minibatch_loss_average
ca = class_acc(curr_batch, X,Y, model)
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, ca))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map)
acc = class_acc(all_test, X,Y, model)
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval({X:unknown})
print("Prediction probability: ")
print(“%0.4f” % pred_prob[0,0])
if pred_prob[0,0] < 0.5:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()Keluaran
Using CNTK version = 2.7
batch 0: mean loss = 0.6936, accuracy = 10.00%
batch 100: mean loss = 0.6882, accuracy = 70.00%
batch 200: mean loss = 0.6597, accuracy = 50.00%
batch 300: mean loss = 0.5298, accuracy = 70.00%
batch 400: mean loss = 0.4090, accuracy = 100.00%
batch 500: mean loss = 0.3790, accuracy = 90.00%
batch 600: mean loss = 0.1852, accuracy = 100.00%
batch 700: mean loss = 0.1135, accuracy = 100.00%
batch 800: mean loss = 0.1285, accuracy = 100.00%
batch 900: mean loss = 0.1054, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.00%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probability:
0.8846
Prediction: fakeCNTK - Regresi Jaringan Neural
Bab ini akan membantu Anda memahami regresi jaringan saraf yang berkaitan dengan CNTK.
pengantar
Seperti yang kita ketahui bahwa untuk memprediksi nilai numerik dari satu atau lebih variabel prediktor, kita menggunakan regresi. Mari kita ambil contoh untuk memprediksi nilai median sebuah rumah, misalnya salah satu dari 100 kota. Untuk melakukannya, kami memiliki data yang mencakup -
Statistik kejahatan untuk setiap kota.
Usia rumah di setiap kota.
Ukuran jarak dari setiap kota ke lokasi utama.
Rasio siswa-guru di setiap kota.
Statistik demografis rasial untuk setiap kota.
Nilai rumah median di setiap kota.
Berdasarkan lima variabel prediktor ini, kami ingin memprediksi nilai median rumah. Dan untuk ini kita dapat membuat model regresi linier sepanjang garis -
Y = a0+a1(crime)+a2(house-age)+(a3)(distance)+(a4)(ratio)+(a5)(racial)Dalam persamaan di atas -
Y adalah nilai median yang diprediksi
a0 adalah konstanta dan
a1 sampai a5 semuanya adalah konstanta yang terkait dengan lima prediktor yang kita bahas di atas.
Kami juga memiliki pendekatan alternatif untuk menggunakan jaringan saraf. Ini akan membuat model prediksi yang lebih akurat.
Di sini, kami akan membuat model regresi jaringan saraf dengan menggunakan CNTK.
Memuat Set Data
Untuk mengimplementasikan regresi Neural Network menggunakan CNTK, kita akan menggunakan dataset nilai house area Boston. Dataset dapat diunduh dari UCI Machine Learning Repository yang tersedia dihttps://archive.ics.uci.edu/ml/machine-learning-databases/housing/. Dataset ini memiliki total 14 variabel dan 506 instance.
Tapi, untuk program implementasi kami, kami akan menggunakan enam dari 14 variabel dan 100 contoh. Dari 6, 5 sebagai prediktor dan satu sebagai nilai untuk memprediksi. Dari 100 contoh, kami akan menggunakan 80 untuk pelatihan dan 20 untuk tujuan pengujian. Nilai yang ingin kita prediksi adalah median harga rumah di suatu kota. Mari kita lihat lima prediktor yang akan kita gunakan -
Crime per capita in the town - Kami berharap nilai yang lebih kecil dikaitkan dengan prediktor ini.
Proportion of owner - unit yang ditempati yang dibangun sebelum 1940 - Kami mengharapkan nilai yang lebih kecil dikaitkan dengan prediktor ini karena nilai yang lebih besar berarti rumah yang lebih tua.
Weighed distance of the town to five Boston employment centers.
Area school pupil-to-teacher ratio.
An indirect metric of the proportion of black residents in the town.
Mempersiapkan file pelatihan & pengujian
Seperti yang kita lakukan sebelumnya, pertama-tama kita perlu mengubah data mentah menjadi format CNTK. Kami akan menggunakan 80 item data pertama untuk tujuan pelatihan, jadi format CNTK tab-delimited adalah sebagai berikut -
|predictors 1.612820 96.90 3.76 21.00 248.31 |medval 13.50
|predictors 0.064170 68.20 3.36 19.20 396.90 |medval 18.90
|predictors 0.097440 61.40 3.38 19.20 377.56 |medval 20.00
. . .20 item berikutnya, juga diubah menjadi format CNTK, akan digunakan untuk tujuan pengujian.
Menyusun model Regresi
Pertama, kita perlu memproses file data dalam format CNTK dan untuk itu, kita akan menggunakan fungsi helper bernama create_reader sebagai berikut -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcSelanjutnya, kita perlu membuat fungsi pembantu yang menerima objek batch mini CNTK dan menghitung metrik akurasi khusus.
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)Sekarang, kita perlu menyetel argumen arsitektur untuk NN kita dan juga menyediakan lokasi file data. Itu dapat dilakukan dengan bantuan kode python berikut -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)Sekarang, dengan bantuan baris kode berikut, program kami akan membuat NN yang tidak terlatih -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)Sekarang, setelah kita membuat model ganda yang tidak terlatih, kita perlu menyiapkan objek algoritma Pelajar. Kami akan menggunakan pelajar SGD dansquared_error fungsi kerugian -
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch=C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])Sekarang, setelah kita selesai dengan objek algoritma Pembelajaran, kita perlu membuat fungsi pembaca untuk membaca data pelatihan -
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }Sekarang, saatnya melatih model NN kita -
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))Setelah kita selesai dengan pelatihan, mari kita evaluasi model menggunakan item data uji -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)Setelah mengevaluasi keakuratan model NN terlatih kami, kami akan menggunakannya untuk membuat prediksi pada data yang tidak terlihat -
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])Model Regresi Lengkap
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch = C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
if __name__== ”__main__”:
main()Keluaran
Using CNTK version = 2.7
batch 0: mean squared error = 385.6727, accuracy = 0.00%
batch 300: mean squared error = 41.6229, accuracy = 20.00%
batch 600: mean squared error = 28.7667, accuracy = 40.00%
batch 900: mean squared error = 48.6435, accuracy = 40.00%
batch 1200: mean squared error = 77.9562, accuracy = 80.00%
batch 1500: mean squared error = 7.8342, accuracy = 60.00%
batch 1800: mean squared error = 47.7062, accuracy = 60.00%
batch 2100: mean squared error = 40.5068, accuracy = 40.00%
batch 2400: mean squared error = 46.5023, accuracy = 40.00%
batch 2700: mean squared error = 15.6235, accuracy = 60.00%
Evaluating test data
Prediction accuracy = 64.00%
Predicting median home value for feature/predictor values:
[0.09 50. 4.5 17. 350.]
Predicted value is:
$21.02(x1000)Menyimpan model terlatih
Dataset nilai Boston Home ini hanya memiliki 506 item data (di antaranya kami hanya menggugat 100). Karenanya, hanya perlu beberapa detik untuk melatih model regressor NN, tetapi pelatihan pada kumpulan data besar yang memiliki ratusan atau ribu item data dapat memakan waktu berjam-jam atau bahkan berhari-hari.
Kita dapat menyimpan model kita, sehingga kita tidak perlu menyimpannya dari awal. Dengan bantuan kode Python berikut, kita dapat menyimpan NN terlatih kita -
nn_regressor = “.\\neuralregressor.model” #provide the name of the file
model.save(nn_regressor, format=C.ModelFormat.CNTKv2)Berikut adalah argumen dari fungsi save () yang digunakan di atas -
Nama file adalah argumen pertama dari save()fungsi. Itu juga dapat ditulis bersama dengan jalur file.
Parameter lainnya adalah format parameter yang memiliki nilai default C.ModelFormat.CNTKv2.
Memuat model terlatih
Setelah Anda menyimpan model terlatih, sangat mudah untuk memuat model itu. Kita hanya perlu menggunakan fungsi load (). Mari kita periksa dalam contoh berikut -
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralregressor.model”)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting area median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])Manfaat model yang disimpan adalah setelah Anda memuat model yang disimpan, model tersebut dapat digunakan persis seperti jika model tersebut baru saja dilatih.
CNTK - Model Klasifikasi
Bab ini akan membantu Anda untuk memahami bagaimana mengukur kinerja model klasifikasi di CNTK. Mari kita mulai dengan matriks kebingungan.
Matriks kebingungan
Confusion matrix - tabel dengan output yang diprediksi versus output yang diharapkan adalah cara termudah untuk mengukur kinerja masalah klasifikasi, di mana outputnya dapat berupa dua atau lebih jenis kelas.
Untuk memahami cara kerjanya, kami akan membuat matriks kebingungan untuk model klasifikasi biner yang memprediksi, apakah transaksi kartu kredit itu normal atau penipuan. Ini ditunjukkan sebagai berikut -
| Penipuan yang sebenarnya | Sebenarnya normal | |
|---|---|---|
| Predicted fraud |
Benar-benar positif |
Positif palsu |
| Predicted normal |
Negatif palsu |
Negatif benar |
Seperti yang dapat kita lihat, contoh matriks kebingungan di atas berisi 2 kolom, satu untuk penipuan kelas dan lainnya untuk kelas normal. Dengan cara yang sama kita memiliki 2 baris, satu ditambahkan untuk penipuan kelas dan lainnya ditambahkan untuk kelas normal. Berikut penjelasan istilah-istilah yang berhubungan dengan matriks konfusi -
True Positives - Ketika kelas aktual & kelas prediksi dari titik data adalah 1.
True Negatives - Ketika kelas aktual & kelas prediksi dari titik data adalah 0.
False Positives - Ketika kelas titik data aktual adalah 0 & kelas prediksi titik data adalah 1.
False Negatives - Ketika kelas titik data aktual adalah 1 & kelas titik data yang diprediksi adalah 0.
Mari kita lihat, bagaimana kita dapat menghitung jumlah hal yang berbeda dari matriks kebingungan -
Accuracy- Ini adalah jumlah prediksi benar yang dibuat oleh model klasifikasi ML kami. Itu dapat dihitung dengan bantuan rumus berikut -
Precision−Ini memberitahu kita berapa banyak sampel yang diprediksi dengan benar dari semua sampel yang kita prediksi. Itu dapat dihitung dengan bantuan rumus berikut -
Recall or Sensitivity- Perolehan adalah jumlah positif yang dikembalikan oleh model klasifikasi ML kami. Dengan kata lain, ini memberi tahu kita berapa banyak kasus penipuan dalam kumpulan data yang sebenarnya terdeteksi oleh model. Itu dapat dihitung dengan bantuan rumus berikut -
Specificity- Kebalikan dari penarikan, ini memberikan jumlah negatif yang dikembalikan oleh model klasifikasi ML kami. Itu dapat dihitung dengan bantuan rumus berikut -




F-ukuran
Kita dapat menggunakan F-measure sebagai alternatif dari matriks Confusion. Alasan utama di balik ini, kami tidak dapat memaksimalkan Recall dan Precision pada saat yang bersamaan. Ada hubungan yang sangat kuat antara metrik ini dan itu dapat dipahami dengan bantuan contoh berikut -
Misalkan, kita ingin menggunakan model DL untuk mengklasifikasikan sampel sel sebagai kanker atau normal. Di sini, untuk mencapai presisi maksimum, kita perlu mengurangi jumlah prediksi menjadi 1. Meskipun, ini bisa memberi kita presisi mencapai sekitar 100 persen, tetapi daya ingat akan menjadi sangat rendah.
Di sisi lain, jika ingin mendapatkan ingatan yang maksimal, kita perlu membuat prediksi sebanyak mungkin. Meskipun, ini dapat memberi kita daya ingat sekitar 100 persen, tetapi presisi akan menjadi sangat rendah.
Dalam praktiknya, kita perlu menemukan cara menyeimbangkan antara presisi dan perolehan. Metrik F-measure memungkinkan kita melakukannya, karena metrik ini mengekspresikan rata-rata harmonis antara presisi dan perolehan.

Rumus ini disebut ukuran F1, di mana suku tambahan yang disebut B diatur ke 1 untuk mendapatkan rasio presisi dan perolehan yang sama. Untuk menekankan recall, kita dapat mengatur faktor B ke 2. Sebaliknya, untuk menekankan presisi, kita dapat mengatur faktor B menjadi 0,5.
Menggunakan CNTK untuk mengukur kinerja klasifikasi
Pada bagian sebelumnya kita telah membuat model klasifikasi menggunakan dataset bunga iris. Di sini, kita akan mengukur kinerjanya dengan menggunakan matriks konfusi dan metrik F-measure.
Membuat matriks Kebingungan
Kami sudah membuat model, sehingga kami dapat memulai proses validasi, yang meliputi confusion matrix, pada saat yang sama. Pertama, kita akan membuat matriks kebingungan dengan bantuan fileconfusion_matrix fungsi dari scikit-learn. Untuk ini, kami memerlukan label nyata untuk sampel uji kami dan label prediksi untuk sampel uji yang sama.
Mari kita hitung matriks konfusi dengan menggunakan kode python berikut -
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)Keluaran
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]Kita juga dapat menggunakan fungsi peta panas untuk memvisualisasikan matriks kebingungan sebagai berikut -
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()
Kami juga harus memiliki satu nomor kinerja, yang dapat kami gunakan untuk membandingkan model. Untuk ini, kita perlu menghitung kesalahan klasifikasi dengan menggunakanclassification_error fungsi, dari paket metrik di CNTK seperti yang dilakukan saat membuat model klasifikasi.
Sekarang untuk menghitung kesalahan klasifikasi, jalankan metode pengujian pada fungsi kerugian dengan kumpulan data. Setelah itu, CNTK akan mengambil sampel yang kita berikan sebagai masukan untuk fungsi ini dan membuat prediksi berdasarkan fitur masukan X_test.
loss.test([X_test, y_test])Keluaran
{'metric': 0.36666666666, 'samples': 30}Menerapkan F-Measures
Untuk mengimplementasikan F-Measures, CNTK juga menyertakan fungsi yang disebut fmeasures. Kita bisa menggunakan fungsi ini, sambil melatih NN dengan mengganti selcntk.metrics.classification_error, dengan panggilan ke cntk.losses.fmeasure saat mendefinisikan fungsi pabrik kriteria sebagai berikut -
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metricSetelah menggunakan fungsi cntk.losses.fmeasure, kita akan mendapatkan output yang berbeda untuk file loss.test pemanggilan metode diberikan sebagai berikut -
loss.test([X_test, y_test])Keluaran
{'metric': 0.83101488749, 'samples': 30}CNTK - Model Regresi
Di sini, kita akan mempelajari tentang mengukur kinerja yang berkaitan dengan model regresi.
Dasar-dasar memvalidasi model regresi
Seperti yang kita ketahui bahwa model regresi berbeda dengan model klasifikasi, dalam artian tidak ada ukuran biner benar atau salah untuk sampel individu. Dalam model regresi, kami ingin mengukur seberapa dekat prediksi tersebut dengan nilai sebenarnya. Semakin dekat nilai prediksi dengan keluaran yang diharapkan, semakin baik performa model.
Di sini, kita akan mengukur kinerja NN yang digunakan untuk regresi menggunakan fungsi tingkat kesalahan yang berbeda.
Menghitung margin kesalahan
Seperti yang telah dibahas sebelumnya, saat memvalidasi model regresi, kami tidak dapat mengatakan apakah prediksi itu benar atau salah. Kami ingin prediksi kami sedekat mungkin dengan nilai sebenarnya. Namun, margin kesalahan kecil dapat diterima di sini.
Rumus untuk menghitung margin kesalahan adalah sebagai berikut -

Sini,
Predicted value = ditunjukkan y dengan topi
Real value = diprediksi oleh y
Pertama, kita perlu menghitung jarak antara prediksi dan nilai sebenarnya. Kemudian, untuk mendapatkan tingkat kesalahan keseluruhan, kita perlu menjumlahkan jarak kuadrat ini dan menghitung rata-ratanya. Ini disebutmean squared fungsi kesalahan.
Tetapi, jika kita menginginkan figur kinerja yang menyatakan margin kesalahan, kita memerlukan rumus yang menyatakan kesalahan absolut. Rumus untukmean absolute fungsi kesalahan adalah sebagai berikut -

Rumus di atas mengambil jarak absolut antara prediksi dan nilai sebenarnya.
Menggunakan CNTK untuk mengukur kinerja regresi
Di sini, kita akan melihat bagaimana menggunakan metrik yang berbeda, yang kita diskusikan dalam kombinasi dengan CNTK. Kami akan menggunakan model regresi, yang memprediksi mil per galon untuk mobil menggunakan langkah-langkah yang diberikan di bawah ini.
Langkah-langkah implementasi−
Step 1 - Pertama, kita perlu mengimpor komponen yang dibutuhkan dari cntk paket sebagai berikut -
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import reluStep 2 - Selanjutnya, kita perlu mendefinisikan fungsi aktivasi default menggunakan default_optionsfungsi. Kemudian, buat set layer Sequential baru dan sediakan dua layer Dense dengan masing-masing 64 neuron. Kemudian, kami menambahkan lapisan Dense tambahan (yang akan bertindak sebagai lapisan keluaran) ke set lapisan Sequential dan memberikan 1 neuron tanpa aktivasi sebagai berikut -
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])Step 3- Setelah jaringan dibuat, kita perlu membuat fitur masukan. Kita perlu memastikan bahwa, itu memiliki bentuk yang sama dengan fitur yang akan kita gunakan untuk pelatihan.
features = input_variable(X.shape[1])Step 4 - Sekarang, kita perlu membuat yang lain input_variable dengan ukuran 1. Ini akan digunakan untuk menyimpan nilai yang diharapkan untuk NN.
target = input_variable(1)
z = model(features)Sekarang, kita perlu melatih model dan untuk melakukannya, kita akan membagi dataset dan melakukan preprocessing menggunakan langkah-langkah implementasi berikut -
Step 5−Pertama, impor StandardScaler dari sklearn.preprocessing untuk mendapatkan nilai antara -1 dan +1. Ini akan membantu kita melawan masalah gradien yang meledak di NN.
from sklearn.preprocessing import StandardScalarStep 6 - Selanjutnya, impor train_test_split dari sklearn.model_selection sebagai berikut−
from sklearn.model_selection import train_test_splitStep 7 - Jatuhkan mpg kolom dari dataset dengan menggunakan dropmetode. Terakhir, pisahkan kumpulan data menjadi kumpulan pelatihan dan validasi menggunakantrain_test_split berfungsi sebagai berikut -
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Step 8 - Sekarang, kita perlu membuat input_variable lain dengan ukuran 1. Ini akan digunakan untuk menyimpan nilai yang diharapkan untuk NN.
target = input_variable(1)
z = model(features)Kami telah membagi dan memproses data, sekarang kami perlu melatih NN. Seperti yang dilakukan di bagian sebelumnya saat membuat model regresi, kita perlu menentukan kombinasi kerugian danmetric berfungsi untuk melatih model.
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metricSekarang, mari kita lihat cara menggunakan model yang terlatih. Untuk model kita, kita akan menggunakan criterion_factory sebagai kombinasi kerugian dan metrik.
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)Contoh implementasi lengkap
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import relu
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])
features = input_variable(X.shape[1])
target = input_variable(1)
z = model(features)
from sklearn.preprocessing import StandardScalar
from sklearn.model_selection import train_test_split
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
target = input_variable(1)
z = model(features)
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metric
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)Keluaran
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.001
690 690 24.9 24.9 16
654 636 24.1 23.7 48
[………]Untuk memvalidasi model regresi kita, kita perlu memastikan bahwa, model tersebut menangani data baru seperti halnya dengan data pelatihan. Untuk ini, kita perlu memanggiltest metode aktif loss dan metric kombinasi dengan data uji sebagai berikut -
loss.test([X_test, y_test])Keluaran-
{'metric': 1.89679785619, 'samples': 79}CNTK - Set Data Kehabisan Memori
Dalam bab ini, cara mengukur kinerja set data yang kehabisan memori akan dijelaskan.
Pada bagian sebelumnya, kita telah membahas tentang berbagai metode untuk memvalidasi kinerja NN kita, tetapi metode yang telah kita diskusikan, adalah metode yang berhubungan dengan dataset yang sesuai dengan memori.
Di sini, muncul pertanyaan bagaimana dengan dataset out-of-memory, karena dalam skenario produksi, kita membutuhkan banyak data untuk dilatih. NN. Di bagian ini, kita akan membahas bagaimana mengukur kinerja saat bekerja dengan sumber minibatch dan loop minibatch manual.
Sumber tangkapan mini
Saat bekerja dengan set data out-of-memory, yaitu sumber minibatch, kami memerlukan pengaturan yang sedikit berbeda untuk loss, serta metrik, daripada pengaturan yang kami gunakan saat bekerja dengan dataset kecil yaitu dataset dalam memori. Pertama, kita akan melihat cara menyiapkan cara untuk memasukkan data ke trainer model NN.
Berikut adalah langkah-langkah implementasinya−
Step 1 - Pertama, dari cntk.Modul io mengimpor komponen untuk membuat sumber minibatch sebagai berikut−
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 - Selanjutnya, buat fungsi baru bernama say create_datasource. Fungsi ini akan memiliki dua parameter yaitu nama file dan batas, dengan nilai defaultINFINITELY_REPEAT.
def create_datasource(filename, limit =INFINITELY_REPEAT)Step 3 - Sekarang, di dalam fungsinya, dengan menggunakan StreamDefclass crate definisi aliran untuk label yang membaca dari bidang label yang memiliki tiga fitur. Kami juga perlu mengaturis_sparse untuk False sebagai berikut-
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 4 - Selanjutnya, buat untuk membaca fitur yang diajukan dari file input, buat instance lain dari StreamDef sebagai berikut.
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 5 - Sekarang, inisialisasi CTFDeserializerkelas contoh. Tentukan nama file dan aliran yang perlu kita deserialisasi sebagai berikut -
deserializer = CTFDeserializer(filename, StreamDefs(labels=
label_stream, features=features_stream)Step 6 - Selanjutnya kita perlu membuat instance minisourceBatch dengan menggunakan deserializer sebagai berikut -
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_sourceStep 7- Terakhir, kami perlu menyediakan sumber pelatihan dan pengujian, yang juga kami buat di bagian sebelumnya. Kami menggunakan dataset bunga iris.
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)Setelah Anda membuat MinibatchSourceMisalnya, kita perlu melatihnya. Kita bisa menggunakan logika pelatihan yang sama, seperti yang digunakan saat kita bekerja dengan set data dalam memori yang kecil. Di sini, kami akan menggunakanMinibatchSource Misalnya, sebagai masukan untuk metode kereta pada fungsi kerugian sebagai berikut -
Berikut adalah langkah-langkah implementasinya−
Step 1 - Untuk mencatat keluaran sesi pelatihan, impor file ProgressPrinter dari cntk.logging modul sebagai berikut -
from cntk.logging import ProgressPrinterStep 2 - Selanjutnya, untuk menyiapkan sesi pelatihan, impor file trainer dan training_session dari cntk.train modul sebagai berikut-
from cntk.train import Trainer, training_sessionStep 3 - Sekarang, kita perlu mendefinisikan beberapa set konstanta seperti minibatch_size, samples_per_epoch dan num_epochs sebagai berikut-
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochsStep 4 - Selanjutnya, untuk mengetahui cara membaca data selama pelatihan di CNTK, kita perlu mendefinisikan pemetaan antara variabel input untuk jaringan dan aliran di sumber minibatch.
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}Step 5 - Selanjutnya untuk mencatat keluaran dari proses pelatihan, inisialisasi progress_printer variabel dengan baru ProgressPrintercontoh. Juga, lakukan inisialisasitrainer dan menyediakannya dengan model sebagai berikut-
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labelsStep 6 - Akhirnya, untuk memulai proses pelatihan, kita perlu memanggil training_session berfungsi sebagai berikut -
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()Setelah kami melatih model, kami dapat menambahkan validasi ke penyiapan ini dengan menggunakan file TestConfig objek dan menetapkannya ke test_config argumen kata kunci dari train_session fungsi.
Berikut adalah langkah-langkah implementasinya−
Step 1 - Pertama, kita perlu mengimpor file TestConfig kelas dari modul cntk.train sebagai berikut-
from cntk.train import TestConfigStep 2 - Sekarang, kita perlu membuat instance baru dari TestConfig dengan test_source sebagai masukan−
Test_config = TestConfig(test_source)Contoh Lengkap
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
def create_datasource(filename, limit =INFINITELY_REPEAT)
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_source
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochs
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labels
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()
from cntk.train import TestConfig
Test_config = TestConfig(test_source)Keluaran
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.57 1.57 0.214 0.214 16
1.38 1.28 0.264 0.289 48
[………]
Finished Evaluation [1]: Minibatch[1-1]:metric = 69.65*30;Loop minibatch manual
Seperti yang kita lihat di atas, mudah untuk mengukur performa model NN kita selama dan setelah pelatihan, dengan menggunakan metrik saat melatih dengan API reguler di CNTK. Namun, di sisi lain, banyak hal tidak akan semudah itu saat bekerja dengan loop minibatch manual.
Di sini, kami menggunakan model yang diberikan di bawah ini dengan 4 input dan 3 output dari dataset Iris Flower, yang juga dibuat di bagian sebelumnya-
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)Selanjutnya, kerugian untuk model didefinisikan sebagai kombinasi dari fungsi kerugian lintas entropi, dan metrik pengukuran F seperti yang digunakan di bagian sebelumnya. Kami akan menggunakancriterion_factory utilitas, untuk membuat ini sebagai objek fungsi CNTK seperti yang ditunjukkan di bawah-
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}Sekarang, karena kita telah mendefinisikan fungsi kerugian, kita akan melihat bagaimana kita dapat menggunakannya di pelatih, untuk menyiapkan sesi pelatihan manual.
Berikut langkah-langkah implementasinya -
Step 1 - Pertama, kita perlu mengimpor paket yang dibutuhkan seperti numpy dan pandas untuk memuat dan memproses data sebelumnya.
import pandas as pd
import numpy as npStep 2 - Selanjutnya, untuk mencatat informasi selama pelatihan, impor file ProgressPrinter kelas sebagai berikut-
from cntk.logging import ProgressPrinterStep 3 - Kemudian, kita perlu mengimpor modul pelatih dari modul cntk.train sebagai berikut -
from cntk.train import TrainerStep 4 - Selanjutnya, buat instance baru dari ProgressPrinter sebagai berikut -
progress_writer = ProgressPrinter(0)Step 5 - Sekarang, kita perlu menginisialisasi pelatih dengan parameter kerugian, pelajar dan progress_writer sebagai berikut -
trainer = Trainer(z, loss, learner, progress_writer)Step 6−Selanjutnya, untuk melatih model, kita akan membuat sebuah loop yang akan mengulang dataset tiga puluh kali. Ini akan menjadi loop pelatihan luar.
for _ in range(0,30):Step 7- Sekarang, kita perlu memuat data dari disk menggunakan panda. Kemudian, untuk memuat dataset dimini-batches, mengatur chunksize argumen kata kunci ke 16.
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)Step 8 - Sekarang, buat pelatihan dalam untuk perulangan untuk mengulang setiap mini-batches.
for df_batch in input_data:Step 9 - Sekarang di dalam loop ini, baca empat kolom pertama menggunakan iloc pengindeks, sebagai features untuk melatih dan mengubahnya menjadi float32 -
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)Step 10 - Sekarang, baca kolom terakhir sebagai label asal latihan, sebagai berikut -
label_values = df_batch.iloc[:,-1]Step 11 - Selanjutnya, kita akan menggunakan vektor one-hot untuk mengubah string label menjadi presentasi numeriknya sebagai berikut -
label_values = label_values.map(lambda x: label_mapping[x])Step 12- Setelah itu, lakukan presentasi numerik pada label. Selanjutnya, konversikan ke array numpy, sehingga lebih mudah untuk bekerja dengannya sebagai berikut -
label_values = label_values.valuesStep 13 - Sekarang, kita perlu membuat array numpy baru yang memiliki jumlah baris yang sama dengan nilai label yang telah kita konversi.
encoded_labels = np.zeros((label_values.shape[0], 3))Step 14 - Sekarang, untuk membuat label berenkode one-hot, pilih kolom berdasarkan nilai label numerik.
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.Step 15 - Akhirnya, kita perlu memanggil train_minibatch metode pada pelatih dan memberikan fitur dan label yang diproses untuk minibatch.
trainer.train_minibatch({features: feature_values, labels: encoded_labels})Contoh Lengkap
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
import pandas as pd
import numpy as np
from cntk.logging import ProgressPrinter
from cntk.train import Trainer
progress_writer = ProgressPrinter(0)
trainer = Trainer(z, loss, learner, progress_writer)
for _ in range(0,30):
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]),
label_values] = 1.
trainer.train_minibatch({features: feature_values, labels: encoded_labels})Keluaran
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]Pada keluaran di atas, kita mendapatkan keluaran untuk kerugian dan metrik selama pelatihan. Itu karena kami menggabungkan metrik dan kerugian dalam objek fungsi dan menggunakan printer kemajuan dalam konfigurasi pelatih.
Sekarang, untuk mengevaluasi kinerja model, kita perlu melakukan tugas yang sama seperti melatih model, tetapi kali ini, kita perlu menggunakan Evaluatorcontoh untuk menguji model. Ini ditunjukkan dalam kode Python berikut-
from cntk import Evaluator
evaluator = Evaluator(loss.outputs[1], [progress_writer])
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.
evaluator.test_minibatch({ features: feature_values, labels:
encoded_labels})
evaluator.summarize_test_progress()Sekarang, kita akan mendapatkan keluaran seperti berikut-
Keluaran
Finished Evaluation [1]: Minibatch[1-11]:metric = 74.62*143;CNTK - Memantau Model
Pada bab ini, kita akan memahami cara memantau model di CNTK.
pengantar
Di bagian sebelumnya, kami telah melakukan beberapa validasi pada model NN kami. Tapi, apakah itu juga perlu dan mungkin untuk memantau model kita selama pelatihan?
Ya, sudah kami gunakan ProgressWriterkelas untuk memantau model kami dan ada banyak cara lain untuk melakukannya. Sebelum membahas lebih dalam, pertama-tama mari kita lihat cara kerja pemantauan di CNTK dan bagaimana kita dapat menggunakannya untuk mendeteksi masalah dalam model NN kita.
Callback di CNTK
Sebenarnya, selama pelatihan dan validasi, CNTK memungkinkan kita menentukan callback di beberapa tempat di API. Pertama, mari kita lihat lebih dekat kapan CNTK memanggil callback.
Kapan CNTK meminta panggilan balik?
CNTK akan memanggil callback pada momen set pelatihan dan pengujian when−
Minibatch selesai.
Sapuan penuh atas kumpulan data diselesaikan selama pelatihan.
Sebuah minibatch pengujian selesai.
Sapuan penuh atas kumpulan data diselesaikan selama pengujian.
Menentukan panggilan balik
Saat bekerja dengan CNTK, kita dapat menentukan callback di beberapa tempat di API. Misalnya-
Kapan call train pada fungsi loss?
Di sini, ketika kita memanggil train pada fungsi kerugian, kita bisa menetapkan satu set callback melalui argumen callback sebagai berikut−
training_summary=loss.train((x_train,y_train),
parameter_learners=[learner],
callbacks=[progress_writer]),
minibatch_size=16, max_epochs=15)Saat bekerja dengan sumber minibatch atau menggunakan loop minibatch manual−
Dalam hal ini, kita dapat menentukan callback untuk tujuan pemantauan saat membuat file Trainer sebagai berikut-
from cntk.logging import ProgressPrinter
callbacks = [
ProgressPrinter(0)
]
Trainer = Trainer(z, (loss, metric), learner, [callbacks])Berbagai alat pemantauan
Mari kita pelajari tentang alat pemantauan yang berbeda.
ProgressPrinter
Saat membaca tutorial ini, Anda akan menemukannya ProgressPrintersebagai alat pemantauan yang paling banyak digunakan. Beberapa karakteristikProgressPrinter alat pemantau adalah-
ProgressPrinterclass menerapkan logging berbasis konsol dasar untuk memantau model kami. Itu bisa masuk ke disk yang kita inginkan.
Sangat berguna saat bekerja dalam skenario pelatihan terdistribusi.
Ini juga sangat berguna saat bekerja dalam skenario di mana kita tidak dapat masuk ke konsol untuk melihat keluaran dari program Python kita.
Dengan bantuan kode berikut, kita dapat membuat sebuah instance ProgressPrinter-
ProgressPrinter(0, log_to_file=’test.txt’)Kita akan mendapatkan hasil yang telah kita lihat di bagian sebelumnya−
Test.txt
CNTKCommandTrainInfo: train : 300
CNTKCommandTrainInfo: CNTKNoMoreCommands_Total : 300
CNTKCommandTrainBegin: train
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]TensorBoard
Salah satu kelemahan menggunakan ProgressPrinter adalah, kami tidak bisa mendapatkan gambaran yang baik tentang bagaimana kerugian dan kemajuan metrik dari waktu ke waktu sulit. TensorBoardProgressWriter adalah alternatif yang bagus untuk kelas ProgressPrinter di CNTK.
Sebelum menggunakannya, kita perlu menginstalnya terlebih dahulu dengan bantuan perintah berikut -
pip install tensorboardSekarang, untuk menggunakan TensorBoard, kita perlu menyiapkan TensorBoardProgressWriter dalam kode pelatihan kami sebagai berikut-
import time
from cntk.logging import TensorBoardProgressWriter
tensorbrd_writer = TensorBoardProgressWriter(log_dir=’logs/{}’.format(time.time()),freq=1,model=z)Ini adalah praktik yang baik untuk memanggil metode tutup TensorBoardProgressWriter Misalnya setelah selesai dengan pelatihan NNmodel.
Kita dapat memvisualisasikan TensorBoard mencatat data dengan bantuan perintah berikut -
Tensorboard –logdir logsCNTK - Jaringan Neural Konvolusional
Dalam bab ini, mari kita pelajari cara membangun Jaringan Neural Konvolusional (CNN) di CNTK.
pengantar
Jaringan saraf konvolusional (CNN) juga terdiri dari neuron, yang memiliki bobot dan bias yang dapat dipelajari. Itulah mengapa dengan cara ini, mereka seperti jaringan saraf biasa (NN).
Jika kita mengingat cara kerja NN biasa, setiap neuron menerima satu atau lebih masukan, mengambil jumlah tertimbang dan melewati fungsi aktivasi untuk menghasilkan keluaran akhir. Di sini, muncul pertanyaan bahwa jika CNN dan NN biasa memiliki begitu banyak kesamaan, lalu apa yang membuat kedua jaringan ini berbeda satu sama lain?
Apa yang membuat mereka berbeda adalah perlakuan terhadap data masukan dan jenis lapisan? Struktur data masukan diabaikan dalam NN biasa dan semua data diubah menjadi larik 1-D sebelum memasukkannya ke dalam jaringan.
Namun, arsitektur Convolutional Neural Network dapat mempertimbangkan struktur 2D gambar, memprosesnya, dan memungkinkannya mengekstrak properti yang khusus untuk gambar. Selain itu, CNN memiliki keuntungan karena memiliki satu atau lebih lapisan Konvolusional dan lapisan penggabungan, yang merupakan blok penyusun utama CNN.
Lapisan ini diikuti oleh satu atau lebih lapisan yang terhubung sepenuhnya seperti pada NN multilayer standar. Jadi, kita dapat menganggap CNN, sebagai kasus khusus dari jaringan yang terhubung sepenuhnya.
Arsitektur Convolutional Neural Network (CNN)
Arsitektur CNN pada dasarnya adalah daftar lapisan yang mengubah 3 dimensi, yaitu lebar, tinggi dan kedalaman volume gambar menjadi volume keluaran 3 dimensi. Satu hal penting yang perlu diperhatikan di sini adalah bahwa, setiap neuron di lapisan saat ini terhubung ke patch kecil keluaran dari lapisan sebelumnya, yang seperti melapisi filter N * N pada gambar masukan.
Ini menggunakan filter M, yang pada dasarnya adalah ekstraktor fitur yang mengekstrak fitur seperti tepi, sudut, dan sebagainya. Berikut adalah lapisannya [INPUT-CONV-RELU-POOL-FC] yang digunakan untuk membangun jaringan saraf konvolusional (CNN) -
INPUT- Sesuai dengan namanya, layer ini menyimpan nilai piksel mentah. Nilai piksel mentah berarti data gambar apa adanya. Contoh, INPUT [64 × 64 × 3] adalah gambar RGB 3 saluran dengan lebar-64, tinggi-64 dan kedalaman-3.
CONV- Lapisan ini adalah salah satu blok penyusun CNN karena sebagian besar komputasi dilakukan di lapisan ini. Contoh - jika kita menggunakan 6 filter pada INPUT yang disebutkan di atas [64 × 64 × 3], ini mungkin menghasilkan volume [64 × 64 × 6].
RELU−Juga disebut lapisan unit linier tersearah, yang menerapkan fungsi aktivasi ke keluaran dari lapisan sebelumnya. Dengan cara lain, non-linearitas akan ditambahkan ke jaringan oleh RELU.
POOL- Lapisan ini, yaitu lapisan Pooling adalah salah satu blok penyusun CNN lainnya. Tugas utama lapisan ini adalah pengambilan sampel, yang berarti ia beroperasi secara independen pada setiap potongan masukan dan mengubah ukurannya secara spasial.
FC- Ini disebut lapisan Sepenuhnya Terhubung atau lebih khusus lagi lapisan keluaran. Ini digunakan untuk menghitung skor kelas keluaran dan keluaran yang dihasilkan adalah volume dengan ukuran 1 * 1 * L dimana L adalah angka yang sesuai dengan skor kelas.
Diagram di bawah ini mewakili arsitektur khas CNNs−

Membuat struktur CNN
Kami telah melihat arsitektur dan dasar-dasar CNN, sekarang kami akan membangun jaringan konvolusional menggunakan CNTK. Di sini, pertama-tama kita akan melihat bagaimana menyusun struktur CNN dan kemudian kita akan melihat bagaimana melatih parameternya.
Akhirnya kita akan melihat, bagaimana kita dapat meningkatkan jaringan saraf dengan mengubah strukturnya dengan berbagai pengaturan lapisan yang berbeda. Kami akan menggunakan dataset gambar MNIST.
Jadi, pertama-tama mari buat struktur CNN. Umumnya, ketika kita membangun CNN untuk mengenali pola dalam gambar, kita melakukan hal berikut-
Kami menggunakan kombinasi lapisan konvolusi dan penggabungan.
Satu atau lebih lapisan tersembunyi di ujung jaringan.
Akhirnya, kami menyelesaikan jaringan dengan lapisan softmax untuk tujuan klasifikasi.
Dengan bantuan langkah-langkah berikut, kita dapat membangun struktur jaringan−
Step 1- Pertama, kita perlu mengimpor lapisan yang diperlukan untuk CNN.
from cntk.layers import Convolution2D, Sequential, Dense, MaxPoolingStep 2- Selanjutnya, kita perlu mengimpor fungsi aktivasi untuk CNN.
from cntk.ops import log_softmax, reluStep 3- Setelah itu untuk menginisialisasi lapisan konvolusional nanti, kita perlu mengimpor file glorot_uniform_initializer sebagai berikut-
from cntk.initializer import glorot_uniformStep 4- Selanjutnya, untuk membuat variabel input, impor file input_variablefungsi. Dan impordefault_option fungsi, untuk membuat konfigurasi NN sedikit lebih mudah.
from cntk import input_variable, default_optionsStep 5- Sekarang untuk menyimpan gambar masukan, buat yang baru input_variable. Ini akan berisi tiga saluran yaitu merah, hijau dan biru. Ini akan memiliki ukuran 28 kali 28 piksel.
features = input_variable((3,28,28))Step 6−Selanjutnya, kita perlu membuat yang lain input_variable untuk menyimpan label yang akan diprediksi.
labels = input_variable(10)Step 7- Sekarang, kita perlu membuat file default_optionuntuk NN. Dan, kita perlu menggunakanglorot_uniform sebagai fungsi inisialisasi.
with default_options(initialization=glorot_uniform, activation=relu):Step 8- Selanjutnya, untuk mengatur struktur NN, kita perlu membuat yang baru Sequential set lapisan.
Step 9- Sekarang kita perlu menambahkan Convolutional2D lapisan dengan a filter_shape dari 5 dan a strides pengaturan 1, dalam Sequentialset lapisan. Selain itu, aktifkan pengisi, sehingga gambar dilengkapi bantalan untuk mempertahankan dimensi aslinya.
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),Step 10- Sekarang saatnya menambahkan file MaxPooling lapisan dengan filter_shape dari 2, dan a strides pengaturan 2 untuk memampatkan gambar menjadi setengah.
MaxPooling(filter_shape=(2,2), strides=(2,2)),Step 11- Sekarang, seperti yang kita lakukan di langkah 9, kita perlu menambahkan yang lain Convolutional2D lapisan dengan a filter_shape dari 5 dan a stridespengaturan 1, gunakan 16 filter. Selain itu, aktifkan pengisi, sehingga ukuran gambar yang dihasilkan oleh lapisan penggabungan sebelumnya harus dipertahankan.
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),Step 12- Sekarang, seperti yang kita lakukan pada langkah 10, tambahkan lagi MaxPooling lapisan dengan a filter_shape dari 3 dan a strides pengaturan 3 untuk mengurangi gambar menjadi sepertiga.
MaxPooling(filter_shape=(3,3), strides=(3,3)),Step 13- Terakhir, tambahkan lapisan Dense dengan sepuluh neuron untuk 10 kemungkinan kelas, jaringan dapat memprediksi. Untuk mengubah jaringan menjadi model klasifikasi, gunakan alog_siftmax fungsi aktivasi.
Dense(10, activation=log_softmax)
])Contoh Lengkap untuk membuat struktur CNN
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)Melatih CNN dengan gambar
Karena kita telah membuat struktur jaringan, inilah waktunya untuk melatih jaringan. Tetapi sebelum memulai pelatihan jaringan kita, kita perlu menyiapkan sumber minibatch, karena melatih NN yang bekerja dengan gambar membutuhkan lebih banyak memori, daripada kebanyakan komputer.
Kami telah membuat sumber minibatch di bagian sebelumnya. Berikut adalah kode Python untuk mengatur dua sumber minibatch -
Seperti yang kita miliki create_datasource fungsi, sekarang kita dapat membuat dua sumber data terpisah (pelatihan dan pengujian) untuk melatih model.
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)Sekarang, setelah kami menyiapkan gambar, kami dapat memulai pelatihan NN kami. Seperti yang kita lakukan di bagian sebelumnya, kita bisa menggunakan metode train pada fungsi kerugian untuk memulai pelatihan. Berikut adalah kode untuk ini -
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)Dengan bantuan kode sebelumnya, kami telah menyiapkan loss dan pelajar untuk NN. Kode berikut akan melatih dan memvalidasi NN−
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])Contoh Implementasi Lengkap
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])Keluaran
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.2
142 142 0.922 0.922 64
1.35e+06 1.51e+07 0.896 0.883 192
[………]Transformasi gambar
Seperti yang telah kita lihat, sulit untuk melatih NN yang digunakan untuk pengenalan gambar dan, mereka juga membutuhkan banyak data untuk dilatih. Satu masalah lagi adalah, mereka cenderung menyesuaikan gambar yang digunakan selama pelatihan. Mari kita lihat dengan sebuah contoh, saat kita memiliki foto wajah dalam posisi tegak, model kita akan kesulitan mengenali wajah yang diputar ke arah lain.
Untuk mengatasi masalah tersebut, kita dapat menggunakan augmentasi gambar dan CNTK mendukung transformasi tertentu, saat membuat sumber minibatch untuk gambar. Kita dapat menggunakan beberapa transformasi sebagai berikut-
Kami dapat secara acak memotong gambar yang digunakan untuk pelatihan hanya dengan beberapa baris kode.
Kita juga bisa menggunakan skala dan warna.
Mari kita lihat dengan bantuan kode Python berikut, bagaimana kita dapat mengubah daftar transformasi dengan memasukkan transformasi pemangkasan dalam fungsi yang digunakan untuk membuat sumber minibatch sebelumnya.
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)Dengan bantuan kode di atas, kita dapat meningkatkan fungsi untuk menyertakan sekumpulan transformasi gambar, sehingga ketika akan dilatih kita dapat melakukan crop gambar secara acak, sehingga kita mendapatkan lebih banyak variasi gambar.
CNTK - Jaringan Neural Berulang
Sekarang, mari kita pahami cara membuat Jaringan Neural Berulang (RNN) di CNTK.
pengantar
Kami belajar cara mengklasifikasikan gambar dengan jaringan saraf, dan ini adalah salah satu pekerjaan ikonik dalam pembelajaran mendalam. Tapi, area lain di mana neural network unggul dan banyak penelitian terjadi adalah Recurrent Neural Networks (RNN). Di sini, kita akan mengetahui apa itu RNN dan bagaimana RNN dapat digunakan dalam skenario di mana kita perlu menangani data deret waktu.
Apa itu Jaringan Neural Berulang?
Jaringan saraf berulang (RNN) dapat didefinisikan sebagai jenis khusus NN yang mampu melakukan penalaran dari waktu ke waktu. RNN terutama digunakan dalam skenario, di mana kita perlu menangani nilai yang berubah dari waktu ke waktu, yaitu data deret waktu. Untuk memahaminya dengan cara yang lebih baik, mari kita bandingkan kecil antara jaringan saraf biasa dan jaringan saraf berulang -
Seperti yang kita ketahui bahwa, dalam jaringan neural biasa, kita hanya dapat memberikan satu masukan. Ini membatasi untuk menghasilkan hanya satu prediksi. Sebagai contoh, kami dapat melakukan pekerjaan menerjemahkan teks dengan menggunakan jaringan saraf biasa.
Di sisi lain, dalam jaringan neural berulang, kami dapat memberikan urutan sampel yang menghasilkan satu prediksi. Dengan kata lain, dengan menggunakan RNN kita dapat memprediksi urutan keluaran berdasarkan urutan masukan. Misalnya, ada beberapa eksperimen yang berhasil dengan RNN dalam tugas penerjemahan.
Penggunaan Jaringan Neural Berulang
RNN dapat digunakan dengan beberapa cara. Beberapa di antaranya adalah sebagai berikut -
Memprediksi satu keluaran
Sebelum mendalami langkah-langkahnya, bahwa bagaimana RNN dapat memprediksi keluaran tunggal berdasarkan suatu urutan, mari kita lihat bagaimana RNN dasar terlihat-

Seperti yang kita bisa pada diagram di atas, RNN berisi koneksi loopback ke input dan kapan pun, kami memberi makan urutan nilai itu akan memproses setiap elemen dalam urutan sebagai langkah waktu.
Selain itu, karena koneksi loopback, RNN dapat menggabungkan output yang dihasilkan dengan input untuk elemen berikutnya dalam urutan tersebut. Dengan cara ini, RNN akan membangun memori di seluruh urutan yang dapat digunakan untuk membuat prediksi.
Untuk membuat prediksi dengan RNN, kita dapat melakukan langkah-langkah berikut-
Pertama, untuk membuat keadaan awal tersembunyi, kita perlu memberi makan elemen pertama dari urutan masukan.
Setelah itu, untuk menghasilkan hidden state yang diperbarui, kita perlu mengambil hidden state awal dan menggabungkannya dengan elemen kedua dalam urutan masukan.
Akhirnya, untuk menghasilkan keadaan tersembunyi terakhir dan memprediksi keluaran untuk RNN, kita perlu mengambil elemen terakhir dalam urutan masukan.
Dengan cara ini, dengan bantuan koneksi loopback ini, kami dapat mengajarkan RNN untuk mengenali pola yang terjadi seiring waktu.
Memprediksi urutan
Model dasar, yang dibahas di atas, dari RNN dapat diperluas ke kasus penggunaan lain juga. Misalnya, kita dapat menggunakannya untuk memprediksi urutan nilai berdasarkan satu input. Dalam skenario ini, untuk membuat prediksi dengan RNN kita dapat melakukan langkah-langkah berikut -
Pertama, untuk membuat keadaan awal tersembunyi dan memprediksi elemen pertama dalam urutan keluaran, kita perlu memasukkan sampel masukan ke dalam jaringan saraf.
Setelah itu, untuk menghasilkan keadaan tersembunyi yang diperbarui dan elemen kedua dalam urutan keluaran, kita perlu menggabungkan keadaan tersembunyi awal dengan sampel yang sama.
Terakhir, untuk memperbarui status tersembunyi sekali lagi dan memprediksi elemen akhir dalam urutan keluaran, kami memberi makan sampel di lain waktu.
Memprediksi urutan
Seperti yang telah kita lihat bagaimana memprediksi nilai tunggal berdasarkan urutan dan bagaimana memprediksi urutan berdasarkan nilai tunggal. Sekarang mari kita lihat bagaimana kita bisa memprediksi urutan urutan. Dalam skenario ini, untuk membuat prediksi dengan RNN kita dapat melakukan langkah-langkah berikut -
Pertama, untuk membuat keadaan awal tersembunyi dan memprediksi elemen pertama dalam urutan keluaran, kita perlu mengambil elemen pertama dalam urutan masukan.
Setelah itu, untuk memperbarui keadaan tersembunyi dan memprediksi elemen kedua dalam urutan keluaran, kita perlu mengambil keadaan awal tersembunyi.
Akhirnya, untuk memprediksi elemen terakhir dalam urutan keluaran, kita perlu mengambil status tersembunyi yang diperbarui dan elemen terakhir dalam urutan masukan.
Bekerja dari RNN
Untuk memahami cara kerja jaringan saraf berulang (RNN), pertama-tama kita perlu memahami cara kerja lapisan berulang dalam jaringan. Jadi pertama-tama mari kita bahas bagaimana e dapat memprediksi output dengan lapisan berulang standar.
Memprediksi keluaran dengan lapisan RNN standar
Seperti yang telah kita bahas sebelumnya, juga bahwa lapisan dasar di RNN sangat berbeda dari lapisan biasa di jaringan saraf. Pada bagian sebelumnya, kami juga mendemonstrasikan dalam diagram arsitektur dasar RNN. Untuk memperbarui keadaan tersembunyi untuk urutan langkah demi langkah pertama kali kita dapat menggunakan rumus berikut -

Dalam persamaan di atas, kami menghitung keadaan tersembunyi baru dengan menghitung perkalian titik antara keadaan tersembunyi awal dan satu set bobot.
Sekarang untuk langkah berikutnya, status tersembunyi untuk langkah waktu saat ini digunakan sebagai status awal tersembunyi untuk langkah waktu berikutnya dalam urutan. Itu sebabnya, untuk memperbarui keadaan tersembunyi untuk langkah kedua kalinya, kita dapat mengulangi penghitungan yang dilakukan pada langkah pertama kali sebagai berikut -
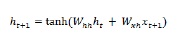
Selanjutnya, kita dapat mengulangi proses memperbarui keadaan tersembunyi untuk langkah ketiga dan terakhir secara berurutan seperti di bawah ini -

Dan ketika kita telah memproses semua langkah di atas secara berurutan, kita dapat menghitung hasilnya sebagai berikut -

Untuk rumus di atas, kami telah menggunakan set bobot ketiga dan status tersembunyi dari langkah waktu terakhir.
Unit Berulang Lanjutan
Masalah utama dengan lapisan berulang dasar adalah masalah gradien lenyap dan karena itu tidak begitu baik dalam mempelajari korelasi jangka panjang. Dengan kata sederhana, lapisan berulang dasar tidak menangani urutan panjang dengan baik. Itulah alasan beberapa jenis lapisan berulang lainnya yang jauh lebih cocok untuk bekerja dengan urutan yang lebih panjang adalah sebagai berikut -
Memori Jangka Panjang-Pendek (LSTM)

Jaringan memori jangka pendek (LSTM) diperkenalkan oleh Hochreiter & Schmidhuber. Ini memecahkan masalah mendapatkan lapisan berulang dasar untuk mengingat banyak hal untuk waktu yang lama. Arsitektur LSTM diberikan di atas dalam diagram. Seperti yang bisa kita lihat, ia memiliki neuron masukan, sel memori, dan neuron keluaran. Untuk mengatasi masalah gradien yang menghilang, jaringan memori jangka panjang menggunakan sel memori eksplisit (menyimpan nilai sebelumnya) dan gerbang berikut -
Forget gate- Seperti namanya, ini memberitahu sel memori untuk melupakan nilai sebelumnya. Sel memori menyimpan nilai sampai gerbang yaitu 'gerbang lupa' memberitahu untuk melupakannya.
Input gate- Seperti namanya, itu menambahkan barang baru ke sel.
Output gate- Seperti namanya, gerbang keluaran memutuskan kapan harus melewati vektor dari sel ke keadaan tersembunyi berikutnya.
Gated Recurrent Units (GRUs)

Gradient recurrent units(GRU) adalah variasi kecil dari jaringan LSTM. Ini memiliki satu gerbang lebih sedikit dan kabel sedikit berbeda dari LSTM. Arsitekturnya ditunjukkan pada diagram di atas. Ia memiliki neuron masukan, sel memori yang terjaga keamanannya, dan neuron keluaran. Jaringan Gated Recurrent Units memiliki dua gerbang berikut -
Update gate- Ini menentukan dua hal berikut-
Berapa banyak informasi yang harus disimpan dari keadaan terakhir?
Berapa banyak informasi yang harus dimasukkan dari lapisan sebelumnya?
Reset gate- Fungsionalitas reset gate sangat mirip dengan fungsi lupa gate dari jaringan LSTM. Satu-satunya perbedaan adalah lokasinya yang sedikit berbeda.
Berbeda dengan jaringan memori jangka panjang, jaringan Gated Recurrent Unit sedikit lebih cepat dan lebih mudah dijalankan.
Membuat struktur RNN
Sebelum kita dapat memulai, membuat prediksi tentang keluaran dari salah satu sumber data kita, pertama-tama kita perlu membuat RNN dan membuat RNN sama seperti yang kita lakukan pada jaringan neural biasa di bagian sebelumnya. Berikut adalah kode untuk membangun satu−
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10Mempertaruhkan banyak lapisan
Kami juga dapat menumpuk beberapa lapisan berulang di CNTK. Sebagai contoh, kita dapat menggunakan kombinasi layer− berikut
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)Seperti yang dapat kita lihat pada kode di atas, kita memiliki dua cara berikut di mana kita dapat memodelkan RNN di CNTK -
Pertama, jika kita hanya menginginkan hasil akhir dari lapisan berulang, kita dapat menggunakan Fold lapisan dalam kombinasi dengan lapisan berulang, seperti GRU, LSTM, atau bahkan RNNStep.
Kedua, sebagai alternatif, kita juga bisa menggunakan file Recurrence blok.
Melatih RNN dengan data deret waktu
Setelah kita membangun model, mari kita lihat bagaimana kita bisa melatih RNN di CNTK -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)Sekarang untuk memuat data ke dalam proses pelatihan, kita harus melakukan deserialisasi urutan dari sekumpulan file CTF. Kode berikut memilikicreate_datasource function, yang merupakan fungsi utilitas yang berguna untuk membuat sumber data pelatihan dan pengujian.
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.Sekarang, karena kita telah menyiapkan sumber data, model, dan fungsi kerugian, kita dapat memulai proses pelatihan. Ini sangat mirip seperti yang kita lakukan di bagian sebelumnya dengan jaringan saraf dasar.
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)Kami akan mendapatkan hasil yang serupa sebagai berikut -
Keluaran-
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]Memvalidasi model
Sebenarnya melakukan rediksi dengan RNN sangat mirip dengan membuat prediksi dengan model CNK lainnya. Satu-satunya perbedaan adalah, kita perlu memberikan urutan daripada sampel tunggal.
Sekarang, karena RNN kita akhirnya selesai dengan pelatihan, kita dapat memvalidasi model dengan mengujinya menggunakan beberapa urutan sampel sebagai berikut -
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZEKeluaran-
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)