Pemrosesan Bahasa Alami - Panduan Cepat
Bahasa adalah metode komunikasi yang dengannya kita dapat berbicara, membaca, dan menulis. Misalnya, kami berpikir, kami membuat keputusan, rencana dan lebih banyak lagi dalam bahasa alami; tepatnya, dengan kata-kata. Namun, pertanyaan besar yang menghadang kita di era AI ini adalah apakah kita dapat berkomunikasi dengan cara yang sama dengan komputer. Dengan kata lain, dapatkah manusia berkomunikasi dengan komputer dalam bahasa aslinya? Merupakan tantangan bagi kami untuk mengembangkan aplikasi NLP karena komputer membutuhkan data terstruktur, tetapi ucapan manusia tidak terstruktur dan seringkali bersifat ambigu.
Dalam pengertian ini, dapat dikatakan bahwa Natural Language Processing (NLP) adalah sub-bidang Ilmu Komputer khususnya Artificial Intelligence (AI) yang berkepentingan untuk memungkinkan komputer memahami dan memproses bahasa manusia. Secara teknis, tugas utama NLP adalah memprogram komputer untuk menganalisis dan memproses data bahasa alami dalam jumlah besar.
Sejarah NLP
Kami telah membagi sejarah NLP menjadi empat fase. Fase memiliki perhatian dan gaya yang berbeda.
Fase Pertama (Fase Terjemahan Mesin) - Akhir 1940-an hingga akhir 1960-an
Pekerjaan yang dilakukan dalam fase ini difokuskan terutama pada terjemahan mesin (MT). Fase ini merupakan periode antusiasme dan optimisme.
Sekarang mari kita lihat semua yang dimiliki fase pertama di dalamnya -
Penelitian tentang NLP dimulai pada awal 1950-an setelah investigasi Booth & Richens dan memorandum Weaver tentang terjemahan mesin pada tahun 1949.
1954 adalah tahun ketika percobaan terbatas pada terjemahan otomatis dari bahasa Rusia ke bahasa Inggris didemonstrasikan dalam percobaan Georgetown-IBM.
Pada tahun yang sama, penerbitan jurnal MT (Machine Translation) dimulai.
Konferensi internasional pertama tentang Terjemahan Mesin (MT) diadakan pada tahun 1952 dan yang kedua diadakan pada tahun 1956.
Pada tahun 1961, karya yang dipresentasikan dalam Teddington International Conference on Machine Translation of Languages and Applied Language analysis adalah titik puncak dari fase ini.
Fase Kedua (Fase yang Dipengaruhi AI) - Akhir 1960-an hingga akhir 1970-an
Dalam fase ini, pekerjaan yang dilakukan sebagian besar terkait dengan pengetahuan dunia dan perannya dalam konstruksi dan manipulasi representasi makna. Itu sebabnya, fase ini disebut juga fase rasa AI.
Fase itu ada di dalamnya, sebagai berikut -
Pada awal 1961, pekerjaan dimulai pada masalah menangani dan membangun data atau basis pengetahuan. Pekerjaan ini dipengaruhi oleh AI.
Pada tahun yang sama juga dikembangkan sistem tanya jawab BASEBALL. Masukan ke sistem ini dibatasi dan pemrosesan bahasa yang terlibat sederhana.
Sistem yang jauh lebih maju dijelaskan dalam Minsky (1968). Sistem ini, jika dibandingkan dengan sistem penjawab pertanyaan BASEBALL, diakui dan disediakan untuk kebutuhan inferensi pada basis pengetahuan dalam menafsirkan dan menanggapi masukan bahasa.
Fase Ketiga (Fase Grammatico-logis) - Akhir 1970-an hingga akhir 1980-an
Fase ini dapat digambarkan sebagai fase tata bahasa-logis. Karena kegagalan pembangunan sistem praktis pada fase terakhir, para peneliti beralih ke penggunaan logika untuk representasi pengetahuan dan penalaran dalam AI.
Fase ketiga memiliki yang berikut di dalamnya -
Pendekatan gramatika-logis, menjelang akhir dekade, membantu kami dengan pemroses kalimat tujuan umum yang kuat seperti Mesin Bahasa Inti SRI dan Teori Representasi Wacana, yang menawarkan sarana untuk menangani wacana yang lebih luas.
Dalam fase ini kami mendapatkan beberapa sumber daya & alat praktis seperti parser, misalnya Alvey Natural Language Tools bersama dengan sistem yang lebih operasional dan komersial, misalnya untuk kueri database.
Karya tentang leksikon pada tahun 1980-an juga menunjukkan arah pendekatan gramatika-logis.
Fase Keempat (Fase Leksikal & Corpus) - Tahun 1990-an
Kami dapat menggambarkan ini sebagai fase leksikal & korpus. Fase memiliki pendekatan leksikalisasi tata bahasa yang muncul pada akhir 1980-an dan menjadi pengaruh yang meningkat. Ada revolusi dalam pemrosesan bahasa alami dalam dekade ini dengan pengenalan algoritme pembelajaran mesin untuk pemrosesan bahasa.
Studi Bahasa Manusia
Bahasa adalah komponen penting bagi kehidupan manusia dan juga aspek paling mendasar dari perilaku kita. Kita dapat mengalaminya terutama dalam dua bentuk - tertulis dan lisan. Dalam bentuk tertulis, itu adalah cara untuk meneruskan pengetahuan kita dari satu generasi ke generasi berikutnya. Dalam bentuk lisan, itu adalah media utama bagi manusia untuk berkoordinasi satu sama lain dalam perilaku sehari-hari mereka. Bahasa dipelajari dalam berbagai disiplin ilmu. Setiap disiplin ilmu dilengkapi dengan masalah dan solusi untuk mengatasinya.
Pertimbangkan tabel berikut untuk memahami ini -
| Disiplin | Masalah | Alat |
|---|---|---|
Ahli bahasa |
Bagaimana frase dan kalimat dapat dibentuk dengan kata-kata? Apa yang membatasi kemungkinan arti sebuah kalimat? |
Intuisi tentang kemapanan dan makna. Model matematika struktur. Misalnya semantik teori model, teori bahasa formal. |
Psikolinguis |
Bagaimana manusia dapat mengidentifikasi struktur kalimat? Bagaimana arti kata-kata dapat diidentifikasi? Kapan pemahaman terjadi? |
Teknik eksperimental terutama untuk mengukur kinerja manusia. Analisis statistik pengamatan. |
Filsuf |
Bagaimana kata dan kalimat mendapatkan maknanya? Bagaimana objek diidentifikasi oleh kata-kata? Apa artinya |
Argumentasi bahasa alami dengan menggunakan intuisi. Model matematika seperti logika dan teori model. |
Ahli Bahasa Komputasi |
Bagaimana kita bisa mengidentifikasi struktur kalimat Bagaimana pengetahuan dan penalaran dapat dimodelkan? Bagaimana kita bisa menggunakan bahasa untuk menyelesaikan tugas tertentu? |
Algoritma Struktur data Model formal representasi dan penalaran. Teknik AI seperti metode pencarian & representasi. |
Ambiguitas dan Ketidakpastian dalam Bahasa
Ambiguitas, umumnya digunakan dalam pemrosesan bahasa alami, dapat disebut sebagai kemampuan untuk dipahami dengan lebih dari satu cara. Secara sederhana, kita dapat mengatakan bahwa ambiguitas adalah kemampuan untuk dipahami dengan lebih dari satu cara. Bahasa alami sangat ambigu. NLP memiliki jenis ambiguitas berikut -
Ambiguitas Leksikal
Ambiguitas dari satu kata disebut ambiguitas leksikal. Misalnya memperlakukan katasilver sebagai kata benda, kata sifat, atau kata kerja.
Ambiguitas Sintaksis
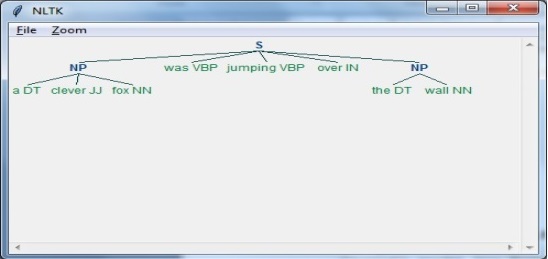
Jenis ambiguitas ini terjadi ketika kalimat diuraikan dengan cara yang berbeda. Misalnya kalimat “Pria melihat gadis dengan teleskop”. Tidaklah jelas apakah pria itu melihat gadis itu membawa teleskop atau dia melihatnya melalui teleskopnya.
Ambiguitas Semantik
Jenis ambiguitas ini terjadi ketika arti kata-kata itu sendiri dapat disalahartikan. Dengan kata lain, ambiguitas semantik terjadi ketika sebuah kalimat mengandung kata atau frase yang ambigu. Sebagai contoh, kalimat “Mobil menabrak tiang saat sedang melaju” memiliki ambiguitas semantik karena interpretasinya dapat berupa “Mobil, saat bergerak, menabrak tiang” dan “Mobil menabrak tiang saat tiang itu bergerak”.
Ambiguitas Anaforis
Jenis ambiguitas ini muncul karena penggunaan entitas anaphora dalam wacana. Misalnya, kuda berlari ke atas bukit. Itu sangat curam. Segera lelah. Di sini, referensi anaforis dari "itu" dalam dua situasi menyebabkan ambiguitas.
Ambiguitas pragmatis
Jenis ambiguitas seperti itu mengacu pada situasi di mana konteks frasa memberinya banyak interpretasi. Dengan kata sederhana, kita dapat mengatakan bahwa ambiguitas pragmatis muncul ketika pernyataannya tidak spesifik. Misalnya, kalimat “Aku juga menyukaimu” dapat memiliki banyak interpretasi seperti aku menyukaimu (sama seperti kamu seperti aku), aku menyukaimu (seperti orang lain dosis).
Tahapan NLP
Diagram berikut menunjukkan tahapan atau langkah logis dalam pemrosesan bahasa alami -
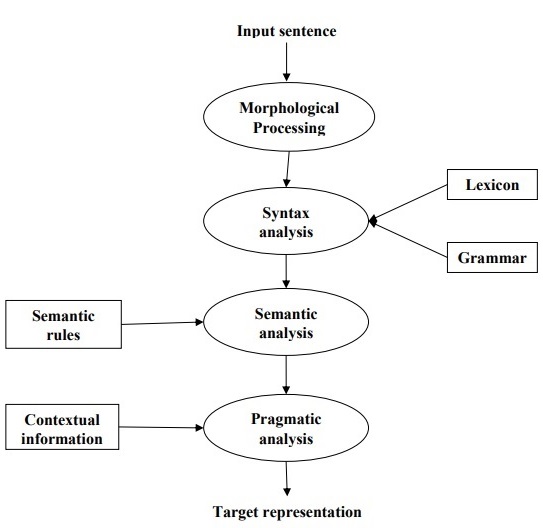
Pengolahan Morfologi
Ini adalah fase pertama NLP. Tujuan dari fase ini adalah untuk memecah potongan input bahasa menjadi kumpulan token yang sesuai dengan paragraf, kalimat, dan kata. Misalnya, kata suka“uneasy” dapat dipecah menjadi dua token sub-kata sebagai “un-easy”.
Analisis Sintaks
Ini adalah fase kedua dari NLP. Tujuan dari fase ini ada dua: untuk memeriksa apakah sebuah kalimat terbentuk dengan baik atau tidak dan untuk memecahnya menjadi struktur yang menunjukkan hubungan sintaksis antara kata-kata yang berbeda. Misalnya kalimat like“The school goes to the boy” akan ditolak oleh syntax analyzer atau parser.
Analisis Semantik
Ini adalah fase ketiga dari NLP. Tujuan dari fase ini adalah untuk menggambar makna yang tepat, atau Anda dapat mengucapkan makna kamus dari teks. Teks tersebut diperiksa kebermaknaannya. Misalnya, penganalisis semantik akan menolak kalimat seperti "Es krim panas".
Analisis Pragmatis
Ini adalah fase keempat dari NLP. Analisis pragmatis hanya menyesuaikan objek / peristiwa aktual, yang ada dalam konteks tertentu dengan referensi objek yang diperoleh selama fase terakhir (analisis semantik). Misalnya, kalimat "Taruh pisang di keranjang di rak" dapat memiliki dua interpretasi semantik dan penganalisis pragmatis akan memilih di antara dua kemungkinan ini.
Pada bab ini, kita akan belajar tentang sumber daya linguistik dalam Natural Language Processing.
Corpus
Korpus adalah sekumpulan teks besar dan terstruktur yang dapat dibaca mesin yang telah diproduksi dalam pengaturan komunikatif alami. Jamaknya adalah corpora. Mereka dapat diturunkan dengan berbagai cara seperti teks yang aslinya elektronik, transkrip bahasa lisan dan pengenalan karakter optik, dll.
Elemen Desain Corpus
Bahasa tidak terbatas tetapi ukuran korpus harus terbatas. Agar korpus berukuran terbatas, kita perlu mengambil sampel dan secara proporsional menyertakan berbagai jenis teks untuk memastikan desain korpus yang baik.
Sekarang mari kita belajar tentang beberapa elemen penting untuk desain corpus -
Keterwakilan Corpus
Keterwakilan adalah ciri khas dari desain korpus. Definisi berikut dari dua peneliti hebat - Leech dan Biber, akan membantu kita memahami keterwakilan korpus -
According to Leech (1991), “Korpus dianggap mewakili ragam bahasa yang semestinya diwakili jika temuan berdasarkan isinya dapat digeneralisasikan ke ragam bahasa tersebut”.
According to Biber (1993), “Keterwakilan mengacu pada sejauh mana sampel mencakup berbagai variabilitas dalam suatu populasi”.
Dengan cara ini, kita dapat menyimpulkan bahwa keterwakilan korpus ditentukan oleh dua faktor berikut:
Balance - Kisaran genre termasuk dalam korpus
Sampling - Bagaimana potongan untuk setiap genre dipilih.
Corpus Balance
Elemen lain yang sangat penting dari desain korpus adalah keseimbangan korpus - rentang genre yang termasuk dalam korpus. Kita telah mempelajari bahwa keterwakilan korpus umum bergantung pada seberapa seimbang korpus tersebut. Korpus yang seimbang mencakup berbagai kategori teks, yang seharusnya mewakili bahasa tersebut. Kami tidak memiliki ukuran ilmiah yang dapat diandalkan untuk keseimbangan tetapi estimasi dan intuisi terbaik bekerja dalam masalah ini. Dengan kata lain, kita dapat mengatakan bahwa saldo yang diterima ditentukan oleh tujuan penggunaannya saja.
Contoh
Elemen penting lainnya dari desain korpus adalah pengambilan sampel. Keterwakilan dan keseimbangan korpus sangat erat kaitannya dengan pengambilan sampel. Itulah mengapa kita dapat mengatakan bahwa pengambilan sampel tidak dapat dihindari dalam pembentukan korpus.
Berdasarkan Biber(1993), “Beberapa pertimbangan pertama dalam membangun korpus berkaitan dengan desain keseluruhan: misalnya, jenis teks yang dimasukkan, jumlah teks, pemilihan teks tertentu, pemilihan sampel teks dari dalam teks, dan panjang teks sampel. Masing-masing melibatkan pengambilan sampel, baik disadari atau tidak. "
Saat mendapatkan sampel yang representatif, kita perlu mempertimbangkan hal-hal berikut -
Sampling unit- Ini mengacu pada unit yang membutuhkan sampel. Misalnya, untuk teks tertulis, unit sampling dapat berupa surat kabar, jurnal, atau buku.
Sampling frame - Daftar al unit sampling disebut kerangka sampling.
Population- Ini dapat disebut sebagai perakitan semua unit pengambilan sampel. Ini didefinisikan dalam istilah produksi bahasa, penerimaan bahasa atau bahasa sebagai produk.
Ukuran Corpus
Elemen penting lainnya dari desain korpus adalah ukurannya. Berapa besar korpusnya? Tidak ada jawaban khusus untuk pertanyaan ini. Ukuran korpus tergantung pada tujuan yang dimaksudkan serta pada beberapa pertimbangan praktis sebagai berikut -
Jenis pertanyaan yang diantisipasi dari pengguna.
Metodologi yang digunakan oleh pengguna untuk mempelajari data.
Ketersediaan sumber data.
Dengan kemajuan teknologi, ukuran korpus juga meningkat. Tabel perbandingan berikut akan membantu Anda memahami cara kerja ukuran korpus -
| Tahun | Nama Corpus | Ukuran (dalam kata-kata) |
|---|---|---|
| 1960-an - 70-an | Coklat dan LOB | 1 Juta kata |
| 1980-an | Korpora Birmingham | 20 Juta kata |
| 1990-an | Korpus Nasional Inggris | 100 Juta kata |
| Awal 21 st abad | Bank of English corpus | 650 Juta kata |
Pada bagian selanjutnya, kita akan melihat beberapa contoh korpus.
TreeBank Corpus
Ini dapat didefinisikan sebagai korpus teks yang diurai secara linguistik yang menganotasi struktur kalimat sintaksis atau semantik. Geoffrey Leech menciptakan istilah 'treebank', yang menyatakan bahwa cara paling umum untuk merepresentasikan analisis tata bahasa adalah dengan menggunakan struktur pohon. Umumnya, Treebanks dibuat di bagian atas korpus, yang telah diberi anotasi dengan tag part-of-speech.
Jenis-jenis TreeBank Corpus
Treebank semantik dan sintaksis adalah dua jenis Treebank yang paling umum dalam linguistik. Sekarang mari kita pelajari lebih lanjut tentang jenis ini -
Treebanks Semantik
Treebank ini menggunakan representasi formal dari struktur semantik kalimat. Mereka bervariasi dalam kedalaman representasi semantik mereka. Perintah Robot Treebank, Geoquery, Groningen Meaning Bank, RoboCup Corpus adalah beberapa contoh dari Semantic Treebanks.
Treebanks Sintaks
Berlawanan dengan Treebank semantik, masukan ke sistem Treebank Sintaksis adalah ekspresi bahasa formal yang diperoleh dari konversi data Treebank yang diurai. Keluaran dari sistem tersebut adalah representasi makna berbasis logika predikat. Berbagai Treebank sintaksis dalam berbagai bahasa telah dibuat sejauh ini. Sebagai contoh,Penn Arabic Treebank, Columbia Arabic Treebank adalah Treebanks sintaksis yang dibuat dalam bahasa Arab. Sininca Treebank sintaksis dibuat dalam bahasa Cina. Lucy, Susane dan BLLIP WSJ korpus sintaksis dibuat dalam bahasa Inggris.
Aplikasi TreeBank Corpus
Berikut adalah beberapa aplikasi TreeBanks -
Dalam Linguistik Komputasi
Jika kita berbicara tentang Linguistik Komputasi maka penggunaan terbaik TreeBanks adalah untuk merekayasa sistem pemrosesan bahasa alami yang canggih seperti tagger part-of-speech, parser, penganalisis semantik, dan sistem terjemahan mesin.
Dalam Corpus Linguistics
Dalam kasus linguistik Corpus, penggunaan terbaik Treebanks adalah untuk mempelajari fenomena sintaksis.
Dalam Linguistik Teoritis dan Psikolinguistik
Penggunaan terbaik Treebanks dalam teori dan psikolinguistik adalah bukti interaksi.
PropBank Corpus
PropBank lebih khusus disebut “Bank Proposisi” adalah korpus, yang dianotasi dengan proposisi verbal dan argumennya. Korpus adalah sumber daya berorientasi kata kerja; anotasi di sini lebih dekat hubungannya dengan tingkat sintaksis. Martha Palmer et al., Departemen Linguistik, University of Colorado Boulder mengembangkannya. Kita dapat menggunakan istilah PropBank sebagai kata benda umum yang mengacu pada korpus mana pun yang telah dijelaskan dengan proposisi dan argumennya.
Dalam Natural Language Processing (NLP), proyek PropBank telah memainkan peran yang sangat signifikan. Ini membantu dalam pelabelan peran semantik.
VerbNet (VN)
VerbNet (VN) adalah sumber leksikal yang tidak bergantung pada domain hierarki dan terbesar yang ada dalam bahasa Inggris yang menggabungkan informasi semantik dan sintaksis tentang isinya. VN adalah leksikon kata kerja dengan cakupan luas yang memiliki pemetaan ke sumber leksikal lain seperti WordNet, Xtag, dan FrameNet. Ini diatur ke dalam kelas kata kerja yang memperluas kelas Levin dengan perbaikan dan penambahan subkelas untuk mencapai koherensi sintaksis dan semantik di antara anggota kelas.
Setiap kelas VerbNet (VN) berisi -
Satu set deskripsi sintaksis atau bingkai sintaksis
Untuk menggambarkan realisasi permukaan yang mungkin dari struktur argumen untuk konstruksi seperti transitif, intransitif, frase preposisi, resultatif, dan sekumpulan besar pergantian diatesis.
Seperangkat deskripsi semantik seperti animasi, manusia, organisasi
Untuk membatasi, jenis peran tematik yang diizinkan oleh argumen, dan pembatasan lebih lanjut dapat diberlakukan. Ini akan membantu dalam menunjukkan sifat sintaksis dari konstituen yang mungkin terkait dengan peran tematik.
WordNet
WordNet, dibuat oleh Princeton adalah database leksikal untuk bahasa Inggris. Ini adalah bagian dari korpus NLTK. Di WordNet, kata benda, kata kerja, kata sifat, dan kata keterangan dikelompokkan ke dalam kumpulan sinonim kognitif yang disebutSynsets. Semua synset dihubungkan dengan bantuan hubungan konseptual-semantik dan leksikal. Strukturnya membuatnya sangat berguna untuk pemrosesan bahasa alami (NLP).
Dalam sistem informasi, WordNet digunakan untuk berbagai tujuan seperti disambiguasi arti kata, pencarian informasi, klasifikasi teks otomatis, dan terjemahan mesin. Salah satu kegunaan WordNet yang paling penting adalah untuk mengetahui kesamaan antar kata. Untuk tugas ini, berbagai algoritma telah diimplementasikan di berbagai paket seperti Kesamaan di Perl, NLTK dengan Python dan ADW di Java.
Dalam bab ini, kita akan memahami analisis tingkat dunia dalam Pemrosesan Bahasa Alami.
Ekspresi Reguler
Ekspresi reguler (RE) adalah bahasa untuk menentukan string pencarian teks. RE membantu kita mencocokkan atau menemukan string atau kumpulan string lain, menggunakan sintaks khusus yang disimpan dalam pola. Ekspresi reguler digunakan untuk mencari teks di UNIX dan MS WORD dengan cara yang identik. Kami memiliki berbagai mesin pencari yang menggunakan sejumlah fitur RE.
Properti Ekspresi Reguler
Berikut ini adalah beberapa sifat penting RE -
Ahli matematika Amerika Stephen Cole Kleene memformalkan bahasa Ekspresi Reguler.
RE adalah rumus dalam bahasa khusus, yang dapat digunakan untuk menentukan kelas string sederhana, rangkaian simbol. Dengan kata lain, kita dapat mengatakan bahwa RE adalah notasi aljabar untuk mengkarakterisasi sekumpulan string.
Ekspresi reguler membutuhkan dua hal, satu adalah pola yang ingin kita cari dan yang lainnya adalah kumpulan teks yang perlu kita cari.
Secara matematis, Ekspresi Reguler dapat didefinisikan sebagai berikut -
ε adalah Ekspresi Reguler, yang menunjukkan bahwa bahasa tersebut memiliki string kosong.
φ adalah Ekspresi Reguler yang menunjukkan bahwa ini adalah bahasa kosong.
Jika X dan Y adalah Ekspresi Reguler, lalu
X, Y
X.Y(Concatenation of XY)
X+Y (Union of X and Y)
X*, Y* (Kleen Closure of X and Y)
juga ekspresi reguler.
Jika sebuah string diturunkan dari aturan di atas maka itu juga akan menjadi ekspresi reguler.
Contoh Ekspresi Reguler
Tabel berikut menunjukkan beberapa contoh Ekspresi Reguler -
| Ekspresi Reguler | Set Reguler |
|---|---|
| (0 + 10 *) | {0, 1, 10, 100, 1000, 10000,…} |
| (0 * 10 *) | {1, 01, 10, 010, 0010,…} |
| (0 + ε) (1 + ε) | {ε, 0, 1, 01} |
| (a + b) * | Ini akan menjadi himpunan string a dan b dengan panjang berapa pun yang juga termasuk string nol yaitu {ε, a, b, aa, ab, bb, ba, aaa …….} |
| (a + b) * abb | Itu akan menjadi set string a dan b yang diakhiri dengan string abb yaitu {abb, aabb, babb, aaabb, ababb, ………… ..} |
| (11) * | Ini akan ditetapkan terdiri dari bilangan genap 1 yang juga menyertakan string kosong yaitu {ε, 11, 1111, 111111, ……….} |
| (aa) * (bb) * b | Ini akan menjadi himpunan string yang terdiri dari bilangan genap a diikuti dengan bilangan ganjil yaitu {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, ………… ..} |
| (aa + ab + ba + bb) * | Ini akan menjadi string a dan b dengan panjang genap yang dapat diperoleh dengan menggabungkan kombinasi string aa, ab, ba dan bb termasuk null yaitu {aa, ab, ba, bb, aaab, aaba, …………. .} |
Set Reguler & Properti Mereka
Ini dapat didefinisikan sebagai himpunan yang mewakili nilai ekspresi reguler dan terdiri dari properti tertentu.
Properti set reguler
Jika kita melakukan penyatuan dua set reguler maka set yang dihasilkan juga akan menjadi regula.
Jika kita melakukan perpotongan dua himpunan beraturan maka himpunan yang dihasilkan juga akan beraturan.
Jika kita melakukan komplemen pada set reguler, maka set yang dihasilkan juga akan biasa.
Jika kita melakukan perbedaan dua set biasa, maka set yang dihasilkan juga akan biasa.
Jika kita melakukan pembalikan himpunan biasa, maka himpunan yang dihasilkan juga akan beraturan.
Jika kita mengambil closure dari set biasa, maka set yang dihasilkan juga akan jadi regular.
Jika kita melakukan penggabungan dua set reguler, maka set yang dihasilkan juga akan menjadi reguler.
Automata Negara Hingga
Istilah automata, yang berasal dari kata Yunani "αὐτόματα" yang berarti "bertindak sendiri", adalah bentuk jamak dari otomat yang dapat didefinisikan sebagai perangkat komputasi gerak sendiri abstrak yang mengikuti urutan operasi yang telah ditentukan secara otomatis.
Sebuah robot yang memiliki jumlah negara yang terbatas disebut Finite Automaton (FA) atau Finite State automata (FSA).
Secara matematis, sebuah robot dapat diwakili oleh 5-tupel (Q, Σ, δ, q0, F), di mana -
Q adalah himpunan keadaan yang terbatas.
Σ adalah seperangkat simbol yang terbatas, disebut alfabet robot.
δ adalah fungsi transisi
q0 adalah status awal dari mana input diproses (q0 ∈ Q).
F adalah himpunan keadaan akhir dari Q (F ⊆ Q).
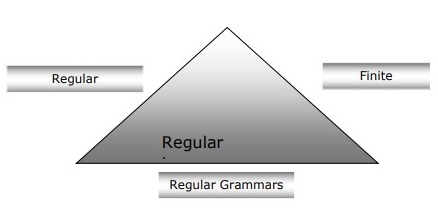
Hubungan antara Finite Automata, Tata Bahasa Reguler dan Ekspresi Reguler
Poin berikut akan memberi kita pandangan yang jelas tentang hubungan antara automata hingga, tata bahasa reguler dan ekspresi reguler -
Seperti yang kita ketahui bahwa automata keadaan hingga adalah fondasi teoritis dari pekerjaan komputasi dan ekspresi reguler adalah salah satu cara untuk menggambarkannya.
Kita dapat mengatakan bahwa ekspresi reguler apa pun dapat diterapkan sebagai FSA dan FSA apa pun dapat dijelaskan dengan ekspresi reguler.
Di sisi lain, ekspresi reguler adalah cara untuk mencirikan jenis bahasa yang disebut bahasa reguler. Oleh karena itu, kami dapat mengatakan bahwa bahasa reguler dapat dijelaskan dengan bantuan FSA dan ekspresi reguler.
Tata bahasa reguler, tata bahasa formal yang dapat berupa reguler kanan atau reguler kiri, adalah cara lain untuk menandai bahasa reguler.
Diagram berikut menunjukkan bahwa automata hingga, ekspresi reguler, dan tata bahasa reguler adalah cara yang setara untuk mendeskripsikan bahasa reguler.
Jenis Otomatisasi Keadaan Hingga (FSA)
Otomatisasi keadaan hingga terdiri dari dua jenis. Mari kita lihat apa saja tipenya.
Otomatisasi Hingga Deterministik (DFA)
Ini dapat didefinisikan sebagai jenis otomatisasi terbatas dimana, untuk setiap simbol masukan kita dapat menentukan keadaan mesin akan bergerak. Ini memiliki jumlah status yang terbatas, itulah sebabnya mesin disebut Deterministic Finite Automaton (DFA).
Secara matematis, DFA dapat diwakili oleh 5-tupel (Q, Σ, δ, q0, F), di mana -
Q adalah himpunan keadaan yang terbatas.
Σ adalah seperangkat simbol yang terbatas, disebut alfabet robot.
δ adalah fungsi transisi dimana δ: Q × Σ → Q.
q0 adalah status awal dari mana input diproses (q0 ∈ Q).
F adalah himpunan keadaan akhir dari Q (F ⊆ Q).
Sedangkan secara grafis, DFA dapat diwakili oleh diagraph yang disebut diagram keadaan dimana -
Negara bagian diwakili oleh vertices.
Transisi ditunjukkan dengan label arcs.
Keadaan awal diwakili oleh empty incoming arc.
Keadaan akhir diwakili oleh double circle.
Contoh DFA
Misalkan DFA menjadi
Q = {a, b, c},
Σ = {0, 1},
q 0 = {a},
F = {c},
Fungsi transisi δ ditunjukkan pada tabel sebagai berikut -
| Kondisi saat ini | Status Berikutnya untuk Input 0 | Status Berikutnya untuk Input 1 |
|---|---|---|
| SEBUAH | Sebuah | B |
| B | b | SEBUAH |
| C | c | C |
Representasi grafis dari DFA ini adalah sebagai berikut -

Otomatisasi Hingga Non-deterministik (NDFA)
Ini dapat didefinisikan sebagai jenis otomatisasi terbatas di mana untuk setiap simbol input kita tidak dapat menentukan status ke mana mesin akan bergerak, yaitu mesin dapat berpindah ke kombinasi status apa pun. Ini memiliki jumlah status yang terbatas, itulah sebabnya mesin ini disebut Non-deterministic Finite Automation (NDFA).
Secara matematis, NDFA dapat direpresentasikan dengan 5-tuple (Q, Σ, δ, q0, F), dimana -
Q adalah himpunan keadaan yang terbatas.
Σ adalah seperangkat simbol yang terbatas, disebut alfabet robot.
δ: -adalah fungsi transisi di mana δ: Q × Σ → 2 Q .
q0: -adalah status awal dari mana input diproses (q0 ∈ Q).
F: -adalah himpunan keadaan akhir / keadaan Q (F ⊆ Q).
Sedangkan secara grafis (sama seperti DFA), NDFA dapat diwakili oleh diagraph yang disebut state diagrams dimana -
Negara bagian diwakili oleh vertices.
Transisi ditunjukkan dengan label arcs.
Keadaan awal diwakili oleh empty incoming arc.
Keadaan akhir diwakili oleh ganda circle.
Contoh NDFA
Misalkan NDFA menjadi
Q = {a, b, c},
Σ = {0, 1},
q 0 = {a},
F = {c},
Fungsi transisi δ ditunjukkan pada tabel sebagai berikut -
| Kondisi saat ini | Status Berikutnya untuk Input 0 | Status Berikutnya untuk Input 1 |
|---|---|---|
| SEBUAH | a, b | B |
| B | C | a, c |
| C | b, c | C |
Representasi grafis NDFA ini adalah sebagai berikut -

Penguraian Morfologis
Istilah penguraian morfologis berkaitan dengan penguraian morfem. Kita dapat mendefinisikan penguraian morfologis sebagai masalah mengenali bahwa sebuah kata dipecah menjadi unit-unit bermakna yang lebih kecil yang disebut morfem yang menghasilkan semacam struktur linguistik untuknya. Misalnya, kita bisa membagi kata rubah menjadi dua, rubah dan -es . Kita dapat melihat bahwa kata rubah , terdiri dari dua morfem, satu adalah rubah dan lainnya adalah -es .
Dalam arti lain, kita dapat mengatakan bahwa morfologi adalah studi tentang -
Pembentukan kata-kata.
Asal kata.
Bentuk tata bahasa dari kata-kata.
Penggunaan prefiks dan sufiks dalam pembentukan kata.
Bagaimana part-of-speech (PoS) suatu bahasa terbentuk.
Jenis Morfem
Morfem, unit pembawa makna terkecil, dapat dibagi menjadi dua jenis -
Stems
Susunan kata
Batang
Ini adalah unit makna inti dari sebuah kata. Kita juga bisa mengatakan bahwa itu adalah akar kata. Misalnya, dalam kata rubah, batangnya adalah rubah.
Affixes- Seperti namanya, kata tersebut menambahkan beberapa arti tambahan dan fungsi tata bahasa pada kata. Misalnya, pada kata foxes, imbuhannya adalah - es.
Selanjutnya, imbuhan juga dapat dibagi menjadi empat jenis berikut -
Prefixes- Seperti namanya, awalan mendahului batang. Misalnya, pada kata unbuckle, un adalah awalannya.
Suffixes- Seperti namanya, akhiran mengikuti batang. Misalnya, dalam kata kucing, -s adalah sufiks.
Infixes- Sesuai namanya, infiks disisipkan di dalam batang. Misalnya, kata cupful, bisa dijadikan jamak sebagai cupful dengan menggunakan -s sebagai infiks.
Circumfixes- Mereka mendahului dan mengikuti batangnya. Ada sangat sedikit contoh pengunaan dalam bahasa Inggris. Contoh yang sangat umum adalah 'A-ing' di mana kita dapat menggunakan -A sebelum dan -ing mengikuti batang.
Susunan kata
Urutan kata akan ditentukan dengan penguraian morfologis. Sekarang mari kita lihat persyaratan untuk membangun parser morfologi -
Kamus
Persyaratan pertama untuk membangun pengurai morfologi adalah leksikon, yang mencakup daftar batang dan imbuhan beserta informasi dasar tentangnya. Misalnya, informasi seperti apakah stemnya adalah nomina stem atau verba stem, dll.
Morfotaktik
Ini pada dasarnya adalah model pemesanan morfem. Dalam pengertian lain, model menjelaskan kelas morfem mana yang dapat mengikuti kelas morfem lain di dalam sebuah kata. Misalnya, fakta morfotaksisnya adalah bahwa morfem jamak bahasa Inggris selalu mengikuti kata benda, bukan sebelumnya.
Aturan ortografi
Aturan ejaan ini digunakan untuk memodelkan perubahan yang terjadi dalam sebuah kata. Misalnya, aturan untuk mengubah y menjadi ie dalam kata seperti city + s = cities bukan citys.
Analisis sintaksis atau parsing atau analisis sintaks adalah tahap ketiga dari NLP. Tujuan dari fase ini adalah untuk menggambar makna yang tepat, atau Anda dapat mengucapkan makna kamus dari teks. Analisis sintaksis memeriksa teks untuk kemaknaan yang dibandingkan dengan aturan tata bahasa formal. Misalnya, kalimat seperti "es krim panas" akan ditolak oleh penganalisis semantik.
Dalam pengertian ini, analisis atau penguraian sintaksis dapat didefinisikan sebagai proses menganalisis string simbol dalam bahasa alami yang sesuai dengan aturan tata bahasa formal. Asal kata‘parsing’ berasal dari kata Latin ‘pars’ yang berarti ‘part’.
Konsep Parser
Ini digunakan untuk mengimplementasikan tugas parsing. Ini dapat didefinisikan sebagai komponen perangkat lunak yang dirancang untuk mengambil data masukan (teks) dan memberikan representasi struktural dari masukan setelah memeriksa sintaks yang benar sesuai tata bahasa formal. Itu juga membangun struktur data umumnya dalam bentuk pohon parse atau pohon sintaks abstrak atau struktur hierarki lainnya.

Peran utama parse meliputi -
Untuk melaporkan kesalahan sintaks.
Untuk memulihkan dari kesalahan yang biasa terjadi sehingga pemrosesan sisa program dapat dilanjutkan.
Untuk membuat pohon parse.
Untuk membuat tabel simbol.
Untuk menghasilkan representasi menengah (IR).
Jenis Parsing
Derivation membagi parsing menjadi dua jenis berikut -
Parsing Top-down
Parsing Bottom-up
Parsing Top-down
Dalam penguraian semacam ini, pengurai mulai membangun pohon parse dari simbol awal dan kemudian mencoba mengubah simbol awal menjadi input. Bentuk parsing topdown yang paling umum menggunakan prosedur rekursif untuk memproses input. Kerugian utama dari penguraian keturunan rekursif adalah penguraian mundur.
Parsing Bottom-up
Dalam penguraian jenis ini, pengurai dimulai dengan simbol input dan mencoba untuk membangun pohon pengurai hingga simbol awal.
Konsep Derivasi
Untuk mendapatkan string input, kita membutuhkan urutan aturan produksi. Derivasi adalah seperangkat aturan produksi. Selama penguraian, kita perlu memutuskan non-terminal, yang akan diganti bersama dengan memutuskan aturan produksi dengan bantuan yang non-terminal akan diganti.
Jenis Derivasi
Pada bagian ini, kita akan belajar tentang dua jenis turunan, yang dapat digunakan untuk memutuskan non-terminal mana yang akan diganti dengan aturan produksi -
Penurunan paling kiri
Dalam derivasi paling kiri, bentuk sentensial dari suatu input dipindai dan diganti dari kiri ke kanan. Bentuk sentensial dalam hal ini disebut bentuk sentensial kiri.
Penurunan Paling Kanan
Dalam derivasi paling kiri, bentuk sentensial dari suatu input dipindai dan diganti dari kanan ke kiri. Bentuk sentensial dalam hal ini disebut bentuk sentensial-kanan.
Konsep Parse Tree
Ini dapat didefinisikan sebagai penggambaran grafis dari suatu derivasi. Simbol awal penurunan berfungsi sebagai akar dari pohon parse. Di setiap pohon parse, simpul daun adalah terminal dan simpul interior adalah non-terminal. Properti parse tree adalah in-order traversal akan menghasilkan string input asli.
Konsep Tata Bahasa
Tata bahasa sangat penting dan penting untuk menggambarkan struktur sintaksis program yang terbentuk dengan baik. Dalam pengertian sastra, mereka menunjukkan aturan sintaksis untuk percakapan dalam bahasa alami. Linguistik telah berusaha untuk mendefinisikan tata bahasa sejak dimulainya bahasa alami seperti Inggris, Hindi, dll.
Teori bahasa formal juga dapat diterapkan di bidang Ilmu Komputer terutama dalam bahasa pemrograman dan struktur data. Misalnya, dalam bahasa 'C', aturan tata bahasa yang tepat menyatakan bagaimana fungsi dibuat dari daftar dan pernyataan.
Model matematika tata bahasa diberikan oleh Noam Chomsky pada tahun 1956, yang efektif untuk menulis bahasa komputer.
Secara matematis, tata bahasa G dapat secara formal ditulis sebagai 4-tupel (N, T, S, P) di mana -
N atau VN = kumpulan simbol non-terminal, yaitu variabel.
T atau ∑ = set simbol terminal.
S = Simbol start dimana S ∈ N
Pmenunjukkan aturan Produksi untuk Terminal serta Non-terminal. Ini memiliki bentuk α → β, di mana α dan β adalah string pada V N ∪ ∑ dan setidaknya satu simbol α dimiliki oleh V N
Struktur Frasa atau Tata Bahasa Konstituensi
Tata bahasa struktur frasa yang diperkenalkan oleh Noam Chomsky didasarkan pada relasi konstituensi. Itulah mengapa disebut juga tata bahasa konstituensi. Ini berlawanan dengan tata bahasa ketergantungan.
Contoh
Sebelum memberikan contoh tata bahasa daerah pemilihan, perlu diketahui pokok-pokok bahasan tentang tata bahasa daerah pemilihan dan hubungan daerah pemilihan.
Semua kerangka terkait melihat struktur kalimat dalam kaitannya dengan hubungan konstituensi.
Relasi konstituensi diturunkan dari pembagian subjek-predikat bahasa Latin serta tata bahasa Yunani.
Struktur klausa dasar dipahami dalam istilah noun phrase NP dan verb phrase VP.
Kita bisa menulis kalimatnya “This tree is illustrating the constituency relation” sebagai berikut -

Ketergantungan Tata Bahasa
Ini berlawanan dengan tata bahasa konstituensi dan berdasarkan pada hubungan ketergantungan. Itu diperkenalkan oleh Lucien Tesniere. Tata bahasa ketergantungan (Dependency grammar / DG) berlawanan dengan tata bahasa daerah pemilihan karena tidak memiliki simpul frase.
Contoh
Sebelum memberikan contoh tata bahasa Dependensi, kita perlu mengetahui poin-poin mendasar tentang Tata bahasa Dependensi dan relasi Dependensi.
Dalam DG, unit linguistik, yaitu kata-kata dihubungkan satu sama lain melalui tautan langsung.
Kata kerja menjadi pusat dari struktur klausa.
Setiap unit sintaksis lainnya terhubung ke kata kerja dalam kaitannya dengan tautan terarah. Unit sintaksis ini disebutdependencies.
Kita bisa menulis kalimatnya “This tree is illustrating the dependency relation” sebagai berikut;

Pohon parse yang menggunakan tata bahasa Konstituensi disebut pohon parse berbasis konstituensi; dan pohon parse yang menggunakan tata bahasa dependensi disebut pohon parse berbasis dependensi.
Tata Bahasa Bebas Konteks
Tata bahasa bebas konteks, juga disebut CFG, adalah notasi untuk mendeskripsikan bahasa dan superset dari tata bahasa Reguler. Hal tersebut dapat dilihat pada diagram berikut -

Definisi CFG
CFG terdiri dari seperangkat aturan tata bahasa yang terbatas dengan empat komponen berikut -
Set Non-terminal
Ini dilambangkan dengan V. Non-terminal adalah variabel sintaksis yang menunjukkan himpunan string, yang selanjutnya membantu mendefinisikan bahasa, yang dihasilkan oleh tata bahasa.
Set Terminal
Ini juga disebut token dan didefinisikan oleh Σ. String dibentuk dengan simbol dasar terminal.
Set Produksi
Ini dilambangkan dengan P. Himpunan mendefinisikan bagaimana terminal dan non-terminal dapat digabungkan. Setiap produksi (P) terdiri dari non-terminal, panah, dan terminal (urutan terminal). Non-terminal disebut sisi kiri produksi dan terminal disebut sisi kanan produksi.
Mulai Simbol
Produksi dimulai dari simbol awal. Ini dilambangkan dengan simbol S. Simbol non-terminal selalu ditunjuk sebagai simbol awal.
Tujuan dari analisis semantik adalah untuk menggambarkan arti yang tepat, atau Anda dapat mengatakan arti kamus dari teks. Pekerjaan penganalisis semantik adalah memeriksa makna teks.
Kita sudah mengetahui bahwa analisis leksikal juga berkaitan dengan pengertian dari kata-kata, lalu bagaimana analisis semantik berbeda dengan analisis leksikal? Analisis leksikal didasarkan pada token yang lebih kecil tetapi di sisi lain, analisis semantik berfokus pada potongan yang lebih besar. Itulah mengapa analisis semantik dapat dibagi menjadi dua bagian berikut -
Mempelajari arti kata individu
Ini adalah bagian pertama dari analisis semantik di mana studi tentang arti kata-kata dilakukan. Bagian ini disebut semantik leksikal.
Mempelajari kombinasi kata-kata individu
Pada bagian kedua, setiap kata akan digabungkan untuk memberikan makna dalam kalimat.
Tugas terpenting dari analisis semantik adalah mendapatkan makna kalimat yang tepat. Misalnya menganalisis kalimat“Ram is great.”Dalam kalimat ini, pembicara berbicara tentang Lord Ram atau tentang seseorang yang bernama Ram. Itulah mengapa tugas penganalisis semantik untuk mendapatkan arti yang tepat dari kalimat itu penting.
Elemen Analisis Semantik
Berikut adalah beberapa elemen penting dari analisis semantik -
Hyponymy
Ini dapat didefinisikan sebagai hubungan antara istilah umum dan contoh dari istilah umum itu. Di sini istilah generik disebut hypernym dan contoh-contohnya disebut hiponim. Misalnya, kata color adalah hypernym dan warna biru, kuning, dll. Adalah hiponim.
Kehomoniman
Ini dapat didefinisikan sebagai kata-kata yang memiliki ejaan yang sama atau bentuk yang sama tetapi memiliki arti yang berbeda dan tidak berhubungan. Misalnya, kata “Bat” adalah kata homonymy karena kelelawar bisa menjadi alat untuk memukul bola atau kelelawar juga merupakan mamalia terbang nokturnal.
Hal berarti banyak
Polisemi adalah kata Yunani, yang berarti "banyak tanda". Ini adalah kata atau frase dengan arti yang berbeda tetapi berhubungan. Dengan kata lain, kita dapat mengatakan bahwa polisemi memiliki ejaan yang sama tetapi memiliki arti yang berbeda dan terkait. Misalnya, kata "bank" adalah kata polisemi yang memiliki arti sebagai berikut -
Lembaga keuangan.
Bangunan tempat lembaga semacam itu berada.
Sinonim dari "mengandalkan".
Perbedaan antara Polisemi dan Homonimi
Kata polysemy dan homonymy memiliki sintaks atau ejaan yang sama. Perbedaan utama di antara mereka adalah bahwa dalam polisemi, arti kata-kata itu terkait tetapi dalam homonimi, arti kata-kata itu tidak terkait. Misalnya, jika kita berbicara tentang kata yang sama “Bank”, kita dapat menulis artinya 'lembaga keuangan' atau 'tepi sungai'. Dalam hal itu akan menjadi contoh homonim karena maknanya tidak berhubungan satu sama lain.
Kesinoniman
Ini adalah hubungan antara dua item leksikal yang memiliki bentuk berbeda tetapi mengungkapkan makna yang sama atau dekat. Contohnya adalah 'penulis / penulis', 'nasib / takdir'.
Antonimi
Ini adalah hubungan antara dua item leksikal yang memiliki kesimetrian antara komponen semantik relatif terhadap sumbu. Ruang lingkup antonimi adalah sebagai berikut -
Application of property or not - Contohnya adalah 'hidup / mati', 'kepastian / ketidaksertaan'
Application of scalable property - Contohnya adalah 'kaya / miskin', 'panas / dingin'
Application of a usage - Contohnya adalah 'ayah / anak', 'bulan / matahari'.
Representasi Arti
Analisis semantik menciptakan representasi makna kalimat. Namun sebelum masuk ke konsep dan pendekatan terkait representasi makna, kita perlu memahami blok bangunan sistem semantik.
Blok Bangunan Sistem Semantik
Dalam representasi kata atau representasi dari arti kata-kata, blok bangunan berikut memainkan peran penting -
Entities- Ini mewakili individu seperti orang tertentu, lokasi dll. Misalnya, Haryana. India, Ram semuanya adalah entitas.
Concepts - Ini mewakili kategori umum individu seperti orang, kota, dll.
Relations- Ini mewakili hubungan antara entitas dan konsep. Misalnya, Ram adalah seseorang.
Predicates- Ini mewakili struktur kata kerja. Misalnya, peran semantik dan tata bahasa kasus adalah contoh predikat.
Sekarang, kita dapat memahami bahwa representasi makna menunjukkan bagaimana menyusun blok bangunan sistem semantik. Dengan kata lain, ini menunjukkan bagaimana menggabungkan entitas, konsep, relasi, dan predikat untuk menggambarkan suatu situasi. Ini juga memungkinkan penalaran tentang dunia semantik.
Pendekatan untuk Representasi Arti
Analisis semantik menggunakan pendekatan berikut untuk representasi makna -
Logika predikat urutan pertama (FOPL)
Jaring Semantik
Frames
Ketergantungan konseptual (CD)
Arsitektur berbasis aturan
Tata Bahasa Kasus
Grafik Konseptual
Kebutuhan Representasi Arti
Pertanyaan yang muncul di sini adalah mengapa kita membutuhkan representasi makna? Berikut ini adalah alasan yang sama -
Menghubungkan unsur linguistik dengan unsur non-linguistik
Alasan pertama adalah bahwa dengan bantuan representasi makna, keterkaitan unsur-unsur linguistik dengan unsur-unsur non-linguistik dapat dilakukan.
Mewakili keragaman pada tingkat leksikal
Dengan bantuan representasi makna, bentuk-bentuk kanonik yang tidak ambigu dapat direpresentasikan di tingkat leksikal.
Bisa digunakan untuk penalaran
Representasi makna dapat digunakan sebagai alasan untuk memverifikasi apa yang benar di dunia serta untuk menyimpulkan pengetahuan dari representasi semantik.
Semantik Leksikal
Bagian pertama dari analisis semantik, mempelajari arti dari setiap kata disebut semantik leksikal. Ini termasuk kata, sub-kata, imbuhan (sub-unit), kata majemuk dan frase juga. Semua kata, sub-kata, dll. Secara kolektif disebut item leksikal. Dengan kata lain, kita dapat mengatakan bahwa semantik leksikal adalah hubungan antara item leksikal, makna kalimat dan sintaks kalimat.
Berikut adalah langkah-langkah yang terlibat dalam semantik leksikal -
Klasifikasi item leksikal seperti kata, sub-kata, imbuhan, dll dilakukan dalam semantik leksikal.
Penguraian item leksikal seperti kata, sub-kata, imbuhan, dll. Dilakukan dalam semantik leksikal.
Perbedaan serta persamaan antara berbagai struktur semantik leksikal juga dianalisis.
Kami memahami bahwa kata-kata memiliki arti yang berbeda berdasarkan konteks penggunaannya dalam kalimat. Jika kita berbicara tentang bahasa manusia, maka bahasa itu juga ambigu karena banyak kata dapat diartikan dengan berbagai cara tergantung pada konteks kemunculannya.
Disambiguasi arti kata, dalam pemrosesan bahasa alami (NLP), dapat diartikan sebagai kemampuan untuk menentukan arti kata mana yang diaktifkan dengan penggunaan kata dalam konteks tertentu. Ambiguitas leksikal, sintaksis atau semantik, adalah salah satu masalah pertama yang dihadapi setiap sistem NLP. Pemberi tag Part-of-speech (POS) dengan tingkat akurasi tinggi dapat menyelesaikan ambiguitas sintaksis Word. Di sisi lain, masalah dalam menyelesaikan ambiguitas semantik disebut WSD (word sense disambiguation). Menyelesaikan ambiguitas semantik lebih sulit daripada menyelesaikan ambiguitas sintaksis.
Misalnya, perhatikan dua contoh arti berbeda yang ada untuk kata tersebut “bass” -
Saya bisa mendengar suara bass.
Dia suka makan bass panggang.
Terjadinya kata bassdengan jelas menunjukkan arti yang berbeda. Dalam kalimat pertama, artinyafrequency dan kedua, artinya fish. Oleh karena itu, jika disambigasikan oleh WSD maka makna yang benar untuk kalimat di atas dapat diberikan sebagai berikut -
Saya bisa mendengar suara bass / frekuensi.
Dia suka makan bass / ikan bakar.
Evaluasi WSD
Evaluasi WSD membutuhkan dua masukan berikut -
Sebuah kamus
Masukan pertama untuk evaluasi WSD adalah kamus, yang digunakan untuk menentukan indra yang akan disambigasikan.
Uji Corpus
Input lain yang dibutuhkan oleh WSD adalah korpus tes beranotasi tinggi yang memiliki target atau indra yang benar. Korpora uji dapat terdiri dari dua jenis & minsu;
Lexical sample - Corpora jenis ini digunakan dalam sistem, di mana diperlukan untuk menghilangkan sedikit contoh kata.
All-words - Corpora semacam ini digunakan dalam sistem, yang diharapkan dapat menghilangkan ambiguitas semua kata dalam sebuah running text.
Pendekatan dan Metode untuk Word Sense Disambiguation (WSD)
Pendekatan dan metode untuk WSD diklasifikasikan menurut sumber pengetahuan yang digunakan dalam disambiguasi kata.
Sekarang mari kita lihat empat metode konvensional untuk WSD -
Metode Berbasis Kamus atau Pengetahuan
Seperti namanya, untuk disambiguasi, metode ini terutama mengandalkan kamus, harta karun, dan basis pengetahuan leksikal. Mereka tidak menggunakan bukti corpora untuk disambiguasi. Metode Lesk adalah metode berbasis kamus mani yang diperkenalkan oleh Michael Lesk pada tahun 1986. Definisi Lesk, yang mendasari algoritma Lesk“measure overlap between sense definitions for all words in context”. Namun, pada tahun 2000, Kilgarriff dan Rosensweig memberikan definisi Lesk yang disederhanakan sebagai“measure overlap between sense definitions of word and current context”, yang selanjutnya berarti mengidentifikasi arti yang benar untuk satu kata pada satu waktu. Di sini konteks saat ini adalah sekumpulan kata-kata di sekitar kalimat atau paragraf.
Metode yang Diawasi
Untuk menghilangkan keraguan, metode pembelajaran mesin menggunakan corpora beranotasi pengertian untuk dilatih. Metode-metode ini mengasumsikan bahwa konteks dapat memberikan cukup bukti dengan sendirinya untuk menghilangkan pengertiannya. Dalam metode ini, kata pengetahuan dan nalar dianggap tidak perlu. Konteks direpresentasikan sebagai sekumpulan "fitur" dari kata-kata. Ini termasuk informasi tentang kata-kata di sekitarnya juga. Mendukung mesin vektor dan pembelajaran berbasis memori adalah pendekatan pembelajaran terawasi yang paling berhasil untuk WSD. Metode ini mengandalkan sejumlah besar korpora yang diberi tag indra secara manual, yang pembuatannya sangat mahal.
Metode Semi-supervisi
Karena kurangnya korpus pelatihan, sebagian besar algoritma disambiguasi arti kata menggunakan metode pembelajaran semi-supervised. Itu karena metode semi-supervised menggunakan data berlabel maupun tidak berlabel. Metode ini memerlukan teks beranotasi dalam jumlah sangat kecil dan teks polos tanpa anotasi dalam jumlah besar. Teknik yang digunakan metode semisupervised adalah bootstrap dari data seed.
Metode Tanpa Pengawasan
Metode ini mengasumsikan bahwa indra yang serupa terjadi dalam konteks yang serupa. Itulah mengapa indra dapat diinduksi dari teks dengan mengelompokkan kemunculan kata dengan menggunakan beberapa ukuran kesamaan konteks. Tugas ini disebut induksi atau diskriminasi pengertian kata. Metode tanpa pengawasan memiliki potensi besar untuk mengatasi kemacetan akuisisi pengetahuan karena tidak bergantung pada upaya manual.
Aplikasi Word Sense Disambiguation (WSD)
Word sense disambiguation (WSD) diterapkan di hampir setiap aplikasi teknologi bahasa.
Sekarang mari kita lihat cakupan WSD -
Mesin penerjemah
Terjemahan mesin atau MT adalah aplikasi WSD yang paling jelas. Di MT, pilihan leksikal untuk kata-kata yang memiliki terjemahan berbeda untuk pengertian yang berbeda, dilakukan oleh WSD. Indra di MT direpresentasikan sebagai kata-kata dalam bahasa target. Sebagian besar sistem terjemahan mesin tidak menggunakan modul WSD eksplisit.
Pengambilan Informasi (IR)
Pengambilan informasi (IR) dapat didefinisikan sebagai program perangkat lunak yang berhubungan dengan organisasi, penyimpanan, pengambilan dan evaluasi informasi dari repositori dokumen terutama informasi tekstual. Sistem pada dasarnya membantu pengguna dalam menemukan informasi yang mereka butuhkan tetapi tidak secara eksplisit mengembalikan jawaban dari pertanyaan. WSD digunakan untuk menyelesaikan ambiguitas kueri yang diberikan ke sistem IR. Seperti halnya MT, sistem IR saat ini tidak secara eksplisit menggunakan modul WSD dan mereka mengandalkan konsep bahwa pengguna akan mengetikkan konteks yang cukup dalam kueri untuk hanya mengambil dokumen yang relevan.
Penambangan Teks dan Ekstraksi Informasi (IE)
Di sebagian besar aplikasi, WSD diperlukan untuk melakukan analisis teks yang akurat. Misalnya, WSD membantu sistem pengumpulan cerdas untuk menandai kata-kata yang benar. Misalnya, sistem intelijen medis mungkin perlu menandai "obat-obatan terlarang" daripada "obat-obatan medis"
Leksikografi
WSD dan leksikografi dapat bekerja sama dalam satu lingkaran karena leksikografi modern berbasis korpus. Dengan leksikografi, WSD memberikan pengelompokan pengertian empiris yang kasar serta indikator kontekstual yang signifikan secara statistik.
Kesulitan dalam Word Sense Disambiguation (WSD)
Berikut adalah beberapa kesulitan yang dihadapi oleh word sense disambiguation (WSD) -
Perbedaan antar kamus
Masalah utama dari WSD adalah menentukan arti kata tersebut karena pengertian yang berbeda dapat sangat erat terkait. Bahkan kamus dan tesaurus yang berbeda dapat memberikan pembagian kata yang berbeda ke dalam pengertian.
Algoritme berbeda untuk aplikasi berbeda
Masalah lain dari WSD adalah bahwa algoritma yang sama sekali berbeda mungkin diperlukan untuk aplikasi yang berbeda. Misalnya, dalam terjemahan mesin, ia mengambil bentuk pemilihan kata target; dan dalam pencarian informasi, inventaris pengertian tidak diperlukan.
Varians antar hakim
Masalah lain dari WSD adalah bahwa sistem WSD umumnya diuji dengan mendapatkan hasil pada suatu tugas dibandingkan dengan tugas manusia. Ini disebut masalah varians interjudge.
Kebijaksanaan pengertian kata
Kesulitan lain dalam WSD adalah kata-kata tidak dapat dengan mudah dibagi menjadi sub-arti tersendiri.
Masalah tersulit dari AI adalah mengolah bahasa alami oleh komputer atau dengan kata lain pemrosesan bahasa alami merupakan masalah tersulit dalam kecerdasan buatan. Jika kita berbicara tentang masalah utama dalam NLP, maka salah satu masalah utama dalam NLP adalah pemrosesan wacana - membangun teori dan model tentang bagaimana ucapan-ucapan saling menempel membentukcoherent discourse. Sebenarnya, bahasa tersebut selalu terdiri dari kumpulan kalimat yang berurutan, terstruktur dan koheren daripada kalimat yang terisolasi dan tidak terkait seperti film. Kelompok kalimat yang koheren ini disebut sebagai wacana.
Konsep Koherensi
Koherensi dan struktur wacana saling berhubungan dalam banyak hal. Koherensi, bersama dengan properti teks yang baik, digunakan untuk mengevaluasi kualitas keluaran sistem pembangkitan bahasa alami. Pertanyaan yang muncul di sini adalah apa yang dimaksud dengan teks yang koheren? Misalkan kita mengumpulkan satu kalimat dari setiap halaman koran, apakah itu akan menjadi wacana? Tentu saja tidak. Itu karena kalimat-kalimat ini tidak menunjukkan koherensi. Wacana yang koheren harus memiliki properti berikut -
Hubungan koherensi antar ucapan
Wacana tersebut akan koheren jika memiliki hubungan yang bermakna di antara ucapannya. Properti ini disebut hubungan koherensi. Misalnya, semacam penjelasan harus ada untuk membenarkan hubungan antara ucapan.
Hubungan antar entitas
Properti lain yang membuat wacana koheren adalah harus ada jenis hubungan tertentu dengan entitas. Koherensi semacam itu disebut koherensi berbasis entitas.
Struktur wacana
Sebuah pertanyaan penting tentang wacana adalah seperti apa struktur wacana itu. Jawaban atas pertanyaan ini bergantung pada segmentasi yang kita terapkan pada wacana. Segmentasi wacana dapat didefinisikan sebagai penentu jenis struktur wacana besar. Melakukan segmentasi wacana memang cukup sulit, tetapi sangat penting untuk dilakukaninformation retrieval, text summarization and information extraction jenis aplikasi.
Algoritma untuk Segmentasi Wacana
Pada bagian ini, kita akan mempelajari tentang algoritma untuk segmentasi wacana. Algoritme dijelaskan di bawah -
Segmentasi Wacana Tanpa Pengawasan
Kelas segmentasi wacana tanpa pengawasan sering direpresentasikan sebagai segmentasi linier. Kita dapat memahami tugas segmentasi linier dengan bantuan sebuah contoh. Dalam contoh, ada tugas untuk membagi teks menjadi unit multi-paragraf; unit mewakili bagian dari teks asli. Algoritma ini bergantung pada kohesi yang dapat didefinisikan sebagai penggunaan perangkat linguistik tertentu untuk mengikat unit tekstual bersama. Di sisi lain, kohesi leksikon adalah kohesi yang ditunjukkan oleh hubungan antara dua kata atau lebih dalam dua unit seperti penggunaan sinonim.
Segmentasi Wacana yang Dibimbing
Metode sebelumnya tidak memiliki batas segmen berlabel tangan. Di sisi lain, segmentasi wacana yang diawasi perlu memiliki data pelatihan berlabel batas. Sangat mudah untuk mendapatkan yang sama. Dalam segmentasi wacana terbimbing, penanda wacana atau kata-kata isyarat memainkan peran penting. Penanda wacana atau kata isyarat adalah kata atau frase yang berfungsi untuk memberi sinyal pada struktur wacana. Penanda wacana ini khusus domain.
Koherensi Teks
Pengulangan leksikal adalah cara untuk menemukan struktur dalam suatu wacana, tetapi tidak memenuhi syarat untuk menjadi wacana yang koheren. Untuk mencapai wacana yang koheren, kita harus fokus pada hubungan koherensi secara spesifik. Seperti kita ketahui bahwa hubungan koherensi mendefinisikan kemungkinan hubungan antara ujaran dalam sebuah wacana. Hebb telah mengusulkan hubungan semacam itu sebagai berikut -
Kami mengambil dua istilah S0 dan S1 untuk mewakili arti dari dua kalimat terkait -
Hasil
Ini menyimpulkan bahwa negara ditegaskan dengan istilah S0 dapat menyebabkan negara ditegaskan oleh S1. Sebagai contoh, dua pernyataan menunjukkan hasil hubungan: Ram terjebak dalam api. Kulitnya terbakar.
Penjelasan
Ini menyimpulkan bahwa negara ditegaskan oleh S1 dapat menyebabkan negara ditegaskan oleh S0. Misalnya, dua pernyataan menunjukkan hubungannya - Rama bertengkar dengan teman Shyam. Dia mabuk.
Paralel
Ini menyimpulkan p (a1, a2,…) dari pernyataan S0 dan p (b1, b2,…) dari pernyataan S1. Di sini ai dan bi serupa untuk semua i. Misalnya, dua pernyataan sejajar - Mobil buronan Ram. Shyam menginginkan uang.
Elaborasi
Ini menyimpulkan proposisi P yang sama dari kedua pernyataan - S0 dan S1Misalnya, dua pernyataan menunjukkan elaborasi relasi: Ram berasal dari Chandigarh. Shyam berasal dari Kerala.
Kesempatan
Itu terjadi ketika perubahan keadaan dapat disimpulkan dari pernyataan S0, keadaan akhir yang dapat disimpulkan S1dan sebaliknya. Misalnya, dua pernyataan menunjukkan peristiwa hubungan: Ram mengambil bukunya. Dia memberikannya pada Shyam.
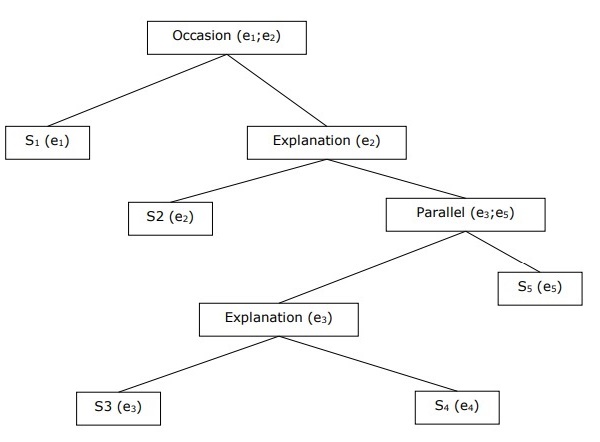
Membangun Struktur Wacana Hirarkis
Koherensi seluruh wacana juga dapat dipertimbangkan oleh struktur hierarki antara hubungan koherensi. Misalnya, bagian berikut dapat direpresentasikan sebagai struktur hierarki -
S1 - Ram pergi ke bank untuk menyetor uang.
S2 - Dia kemudian naik kereta ke toko kain Shyam.
S3 - Dia ingin membeli beberapa pakaian.
S4 - Dia tidak punya baju baru untuk pesta.
S5 - Dia juga ingin berbicara dengan Shyam tentang kesehatannya
Resolusi Referensi
Interpretasi kalimat dari setiap wacana adalah tugas penting lainnya dan untuk mencapai ini kita perlu mengetahui siapa atau entitas apa yang dibicarakan. Di sini, referensi interpretasi adalah elemen kuncinya.Referencedapat didefinisikan sebagai ekspresi linguistik untuk menunjukkan suatu entitas atau individu. Misalnya, di bagian ini, Ram , manajer bank ABC , melihat nya teman Shyam di toko. Dia pergi menemuinya, ekspresi linguistik seperti Ram, His, He adalah referensi.
Pada catatan yang sama, reference resolution dapat didefinisikan sebagai tugas untuk menentukan entitas apa yang dirujuk oleh ekspresi linguistik.
Terminologi yang Digunakan dalam Resolusi Referensi
Kami menggunakan terminologi berikut dalam resolusi referensi -
Referring expression- Ekspresi bahasa alami yang digunakan untuk melakukan referensi disebut ekspresi rujukan. Misalnya, bagian yang digunakan di atas adalah ungkapan pengarah.
Referent- Ini adalah entitas yang dirujuk. Misalnya, dalam contoh terakhir yang diberikan Ram adalah referensi.
Corefer- Ketika dua ekspresi digunakan untuk merujuk ke entitas yang sama, mereka disebut corefers. Sebagai contoh,Ram dan he adalah orang inti.
Antecedent- Istilah memiliki lisensi untuk menggunakan istilah lain. Sebagai contoh,Ram adalah anteseden referensi he.
Anaphora & Anaphoric- Ini dapat didefinisikan sebagai referensi ke entitas yang sebelumnya telah dimasukkan ke dalam kalimat. Dan, ekspresi pengarah disebut anaphoric.
Discourse model - Model yang memuat representasi dari entitas yang dirujuk dalam wacana dan hubungan yang mereka jalani.
Jenis Ekspresi Pengacu
Sekarang mari kita lihat berbagai jenis ekspresi pengarah. Lima jenis ekspresi pengarah dijelaskan di bawah ini -
Frase Kata Benda Tidak Terbatas
Referensi semacam itu mewakili entitas yang baru bagi pendengar dalam konteks wacana. Misalnya - dalam kalimat Ram suatu hari pergi untuk membawakannya makanan - beberapa adalah referensi yang tidak terbatas.
Frasa Kata Benda Pasti
Berlawanan dengan di atas, jenis referensi semacam itu mewakili entitas yang tidak baru atau dapat diidentifikasi oleh pendengar ke dalam konteks wacana. Misalnya, dalam kalimat - saya biasa membaca The Times of India - The Times of India adalah referensi yang pasti.
Kata ganti
Ini adalah bentuk referensi yang pasti. Misalnya, Ram tertawa sekeras yang dia bisa. Katahe mewakili ekspresi merujuk kata ganti.
Demonstratif
Ini menunjukkan dan berperilaku berbeda dari kata ganti pasti sederhana. Misalnya, ini dan itu adalah kata ganti demonstratif.
Nama
Ini adalah jenis ekspresi pengarah yang paling sederhana. Ini bisa menjadi nama seseorang, organisasi dan lokasi juga. Misalnya, dalam contoh di atas, Ram adalah ekspresi wasit nama.
Referensi Resolusi Tugas
Dua tugas resolusi referensi dijelaskan di bawah ini.
Resolusi Coreference
Ini adalah tugas menemukan ekspresi rujukan dalam teks yang merujuk ke entitas yang sama. Dengan kata sederhana, ini adalah tugas untuk menemukan ekspresi inti. Satu set ekspresi coreferring disebut rantai coreference. Misalnya - He, Chief Manager dan His - ini adalah ekspresi acuan di bagian pertama yang diberikan sebagai contoh.
Batasan pada Resolusi Coreference
Dalam bahasa Inggris, masalah utama dari resolusi inti adalah kata ganti itu. Alasan di balik ini adalah karena kata ganti memiliki banyak kegunaan. Misalnya, itu bisa merujuk seperti dia dan dia. Kata ganti itu juga mengacu pada hal-hal yang tidak mengacu pada hal-hal tertentu. Misalnya, sedang hujan. Ini sangat bagus.
Resolusi Anaphora Pronominal
Berbeda dengan resolusi coreference, resolusi anaphora pronominal dapat didefinisikan sebagai tugas menemukan anteseden untuk satu kata ganti. Misalnya, kata ganti adalah his dan tugas dari resolusi pronominal anaphora adalah menemukan kata Ram karena Ram adalah antesedennya.
Pemberian tag adalah sejenis klasifikasi yang dapat didefinisikan sebagai penetapan otomatis deskripsi ke token. Di sini deskriptor disebut tag, yang mungkin mewakili salah satu bagian-of-speech, informasi semantik, dan seterusnya.
Sekarang, jika kita berbicara tentang penandaan Part-of-Speech (PoS), maka itu dapat didefinisikan sebagai proses penugasan salah satu bagian ucapan ke kata tertentu. Ini umumnya disebut penandaan POS. Dengan kata sederhana, kita dapat mengatakan bahwa penandaan POS adalah tugas memberi label pada setiap kata dalam kalimat dengan bagian ucapan yang sesuai. Kita sudah tahu bahwa parts of speech mencakup kata benda, kata kerja, kata keterangan, kata sifat, kata ganti, konjungsi, dan subkategorinya.
Sebagian besar penandaan POS termasuk dalam penandaan Rule Base POS, penandaan POS Stochastic, dan penandaan berbasis Transformasi.
Pemberian Tag POS berbasis aturan
Salah satu teknik penandaan tertua adalah penandaan POS berbasis aturan. Pemberi tag berbasis aturan menggunakan kamus atau leksikon untuk mendapatkan kemungkinan tag untuk menandai setiap kata. Jika kata tersebut memiliki lebih dari satu kemungkinan tag, maka pemberi tag berbasis aturan menggunakan aturan yang ditulis tangan untuk mengidentifikasi tag yang benar. Disambiguasi juga dapat dilakukan dalam penandaan berbasis aturan dengan menganalisis fitur linguistik dari sebuah kata bersama dengan kata-kata sebelumnya dan kata-kata berikutnya. Misalnya, jika kata sebelumnya dari sebuah kata adalah artikel maka kata tersebut haruslah kata benda.
Seperti namanya, semua jenis informasi dalam penandaan POS berbasis aturan dikodekan dalam bentuk aturan. Aturan ini bisa berupa -
Aturan pola konteks
Atau, sebagai ekspresi reguler yang dikompilasi menjadi automata keadaan-hingga, berpotongan dengan representasi kalimat yang ambigu secara leksikal.
Kita juga dapat memahami penandaan POS berbasis aturan dengan arsitektur dua tahapnya -
First stage - Pada tahap pertama, menggunakan kamus untuk menetapkan setiap kata daftar potensi part-of-speech.
Second stage - Pada tahap kedua, ia menggunakan daftar besar aturan disambiguasi tulisan tangan untuk mengurutkan daftar menjadi satu bagian ucapan untuk setiap kata.
Properti Penandaan POS Berbasis Aturan
Pemberi tag POS berbasis aturan memiliki properti berikut -
Pemberi tag ini adalah pemberi tag berdasarkan pengetahuan.
Aturan dalam penandaan POS berbasis aturan dibuat secara manual.
Informasi tersebut dikodekan dalam bentuk aturan.
Kami memiliki sejumlah aturan terbatas sekitar 1000.
Pemulusan dan pemodelan bahasa didefinisikan secara eksplisit dalam tagger berbasis aturan.
Penandaan POS Stochastic
Teknik penandaan lainnya adalah Stochastic POS Tagging. Sekarang, pertanyaan yang muncul di sini adalah model mana yang bisa menjadi stokastik. Model yang menyertakan frekuensi atau probabilitas (statistik) bisa disebut stokastik. Sejumlah pendekatan berbeda untuk masalah penandaan part-of-speech dapat disebut sebagai penandaan stokastik.
Stochastic tagger paling sederhana menerapkan pendekatan berikut untuk penandaan POS -
Pendekatan Frekuensi Kata
Dalam pendekatan ini, stochastic taggers menguraikan kata-kata tersebut berdasarkan probabilitas bahwa sebuah kata muncul dengan tag tertentu. Kita juga dapat mengatakan bahwa tag yang paling sering ditemukan dengan kata dalam set pelatihan adalah tag yang ditetapkan untuk contoh kata yang ambigu. Masalah utama dengan pendekatan ini adalah mungkin menghasilkan urutan tag yang tidak dapat diterima.
Probabilitas Urutan Tag
Ini adalah pendekatan lain dari pemberian tag stokastik, di mana pemberi tag menghitung kemungkinan terjadinya urutan tag tertentu. Ini juga disebut pendekatan n-gram. Disebut demikian karena tag terbaik untuk kata tertentu ditentukan oleh probabilitas kemunculannya dengan n tag sebelumnya.
Sifat Stochastic POST Tagging
Stochastic POS taggers memiliki properti berikut -
Pemberian tag POS ini didasarkan pada kemungkinan terjadinya tag.
Ini membutuhkan korpus pelatihan
Tidak ada kemungkinan untuk kata-kata yang tidak ada dalam korpus.
Ini menggunakan korpus pengujian yang berbeda (selain korpus pelatihan).
Ini adalah penandaan POS paling sederhana karena memilih tag yang paling sering dikaitkan dengan kata dalam korpus pelatihan.
Penandaan Berbasis Transformasi
Penandaan berbasis transformasi juga disebut penandaan Brill. Ini adalah contoh dari pembelajaran berbasis transformasi (TBL), yang merupakan algoritma berbasis aturan untuk penandaan otomatis POS ke teks yang diberikan. TBL, memungkinkan kita memiliki pengetahuan linguistik dalam bentuk yang dapat dibaca, mengubah satu keadaan ke keadaan lain dengan menggunakan aturan transformasi.
Ini menarik inspirasi dari kedua tagger yang dijelaskan sebelumnya - berbasis aturan dan stokastik. Jika kita melihat kesamaan antara rule-based dan tranformation tagger, maka seperti rule-based, hal ini juga berdasarkan pada rules yang menentukan tag apa yang perlu diberikan ke kata apa. Di sisi lain, jika kita melihat kemiripan antara tagger stokastik dan transformasi maka seperti stokastik, itu adalah teknik pembelajaran mesin di mana aturan secara otomatis diinduksi dari data.
Cara Kerja Transformation Based Learning (TBL)
Untuk memahami cara kerja dan konsep tagger berbasis transformasi, kita perlu memahami cara kerja pembelajaran berbasis transformasi. Pertimbangkan langkah-langkah berikut untuk memahami cara kerja TBL -
Start with the solution - TBL biasanya dimulai dengan beberapa solusi untuk masalah dan bekerja dalam beberapa siklus.
Most beneficial transformation chosen - Dalam setiap siklus, TBL akan memilih transformasi yang paling menguntungkan.
Apply to the problem - Transformasi yang dipilih pada langkah terakhir akan diterapkan ke masalah.
Algoritme akan berhenti ketika transformasi yang dipilih pada langkah 2 tidak akan menambah nilai lebih atau tidak ada lagi transformasi untuk dipilih. Jenis pembelajaran seperti ini paling cocok untuk tugas klasifikasi.
Keuntungan Pembelajaran Berbasis Transformasi (TBL)
Keunggulan TBL adalah sebagai berikut -
Kami mempelajari sekumpulan kecil aturan sederhana dan aturan ini cukup untuk pemberian tag.
Pengembangan serta debugging sangat mudah di TBL karena aturan yang dipelajari mudah dipahami.
Kompleksitas dalam penandaan berkurang karena di TBL ada jalinan aturan yang dipelajari mesin dan yang dibuat oleh manusia.
Pemberi tag berbasis transformasi jauh lebih cepat daripada penanda model Markov.
Kekurangan Pembelajaran Berbasis Transformasi (TBL)
Kerugian dari TBL adalah sebagai berikut -
Pembelajaran berbasis transformasi (TBL) tidak memberikan probabilitas tag.
Di TBL waktu pelatihan sangat lama terutama pada perusahaan besar.
Penandaan POS Hidden Markov Model (HMM)
Sebelum mendalami penandaan POS HMM, kita harus memahami konsep Hidden Markov Model (HMM).
Model Markov Tersembunyi
Model HMM dapat didefinisikan sebagai model stokastik tertanam ganda, di mana proses stokastik yang mendasarinya tersembunyi. Proses stokastik tersembunyi ini hanya dapat diamati melalui sekumpulan proses stokastik lainnya yang menghasilkan urutan pengamatan.
Contoh
Misalnya, urutan percobaan melempar koin tersembunyi dilakukan dan kita hanya melihat urutan pengamatan yang terdiri dari kepala dan ekor. Rincian sebenarnya dari proses tersebut - berapa banyak koin yang digunakan, urutan pemilihannya - disembunyikan dari kami. Dengan mengamati urutan head dan tails ini, kita dapat membangun beberapa HMM untuk menjelaskan urutannya. Berikut adalah salah satu bentuk Model Markov Tersembunyi untuk masalah ini -

Kami berasumsi bahwa ada dua negara bagian di HMM dan masing-masing negara bagian tersebut sesuai dengan pemilihan koin bias yang berbeda. Matriks berikut memberikan probabilitas transisi status -
$$A = \begin{bmatrix}a11 & a12 \\a21 & a22 \end{bmatrix}$$
Sini,
aij = probabilitas transisi dari satu keadaan ke keadaan lain dari i ke j.
a11 + a12= 1 dan 21 + a 22 = 1
P1 = probabilitas kepala koin pertama, yaitu bias koin pertama.
P2 = probabilitas kepala koin kedua, yaitu bias koin kedua.
Kami juga dapat membuat model HMM dengan asumsi ada 3 koin atau lebih.
Dengan cara ini, kita dapat mengkarakterisasi HMM dengan elemen berikut -
N, banyaknya state dalam model (dalam contoh di atas N = 2, hanya dua state).
M, jumlah pengamatan berbeda yang dapat muncul dengan setiap status pada contoh di atas M = 2, yaitu, H atau T).
A, distribusi probabilitas transisi status - matriks A dalam contoh di atas.
P, distribusi probabilitas simbol yang dapat diamati di setiap status (dalam contoh kita P1 dan P2).
I, distribusi keadaan awal.
Penggunaan HMM untuk Penandaan POS
Proses penandaan POS adalah proses menemukan urutan tag yang paling mungkin menghasilkan urutan kata tertentu. Kita dapat memodelkan proses POS ini dengan menggunakan Hidden Markov Model (HMM), dimanatags adalah hidden states yang menghasilkan observable output, yaitu, words.
Secara matematis, dalam penandaan POS, kami selalu tertarik untuk menemukan urutan tag (C) yang memaksimalkan -
P (C|W)
Dimana,
C = C 1 , C 2 , C 3 ... C T
W = W 1 , W 2 , W 3 , W T
Di sisi lain, faktanya adalah kita membutuhkan banyak data statistik untuk memperkirakan secara wajar urutan semacam itu. Namun, untuk menyederhanakan masalah, kita dapat menerapkan beberapa transformasi matematis beserta beberapa asumsi.
Penggunaan HMM untuk melakukan penandaan POS adalah kasus khusus gangguan Bayesian. Oleh karena itu, kita akan mulai dengan mengulang masalah menggunakan aturan Bayes, yang mengatakan bahwa probabilitas bersyarat yang disebutkan di atas sama dengan -
(PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT)) / PROB (W1,..., WT)
Kita dapat menghilangkan penyebut dalam semua kasus ini karena kita tertarik untuk menemukan barisan C yang memaksimalkan nilai di atas. Ini tidak akan mempengaruhi jawaban kita. Sekarang, masalah kita berkurang menjadi menemukan urutan C yang memaksimalkan -
PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT) (1)
Bahkan setelah mengurangi masalah pada ekspresi di atas, itu akan membutuhkan data dalam jumlah besar. Kita dapat membuat asumsi independensi yang masuk akal tentang dua kemungkinan pada ekspresi di atas untuk mengatasi masalah.
Asumsi Pertama
Probabilitas suatu tag tergantung pada tag sebelumnya (model bigram) atau dua sebelumnya (model trigram) atau tag n sebelumnya (model n-gram) yang secara matematis dapat dijelaskan sebagai berikut -
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-n+1…Ci-1) (n-gram model)
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-1) (bigram model)
Awal kalimat dapat dihitung dengan mengasumsikan probabilitas awal untuk setiap tag.
PROB (C1|C0) = PROB initial (C1)
Asumsi Kedua
Probabilitas kedua dalam persamaan (1) di atas dapat didekati dengan mengasumsikan bahwa sebuah kata muncul dalam kategori yang tidak bergantung pada kata-kata dalam kategori sebelumnya atau selanjutnya yang dapat dijelaskan secara matematis sebagai berikut -
PROB (W1,..., WT | C1,..., CT) = Πi=1..T PROB (Wi|Ci)
Sekarang, berdasarkan dua asumsi di atas, tujuan kita berkurang menjadi menemukan urutan C yang memaksimalkan
Πi=1...T PROB(Ci|Ci-1) * PROB(Wi|Ci)
Sekarang pertanyaan yang muncul di sini adalah mengubah masalah ke bentuk di atas sangat membantu kami. Jawabannya adalah - ya, benar. Jika kita memiliki korpus bertanda besar, maka dua probabilitas dalam rumus di atas dapat dihitung sebagai -
PROB (Ci=VERB|Ci-1=NOUN) = (# of instances where Verb follows Noun) / (# of instances where Noun appears) (2)
PROB (Wi|Ci) = (# of instances where Wi appears in Ci) /(# of instances where Ci appears) (3)
Dalam bab ini, kita akan membahas permulaan bahasa alami dalam Pengolahan Bahasa Alami. Untuk memulainya, pertama-tama mari kita pahami apa itu Tata Bahasa Bahasa Alami.
Tata Bahasa Bahasa Alami
Untuk linguistik, bahasa adalah sekelompok tanda vokal yang berubah-ubah. Kita dapat mengatakan bahwa bahasa itu kreatif, diatur oleh aturan, bawaan serta universal pada saat yang bersamaan. Di sisi lain, secara manusiawi juga. Sifat bahasa berbeda untuk orang yang berbeda. Ada banyak kesalahpahaman tentang sifat bahasa tersebut. Itulah mengapa sangat penting untuk memahami arti dari istilah ambigu tersebut‘grammar’. Dalam linguistik, istilah tata bahasa dapat didefinisikan sebagai aturan atau prinsip dengan bantuan bahasa mana yang berfungsi. Dalam arti luas, kita dapat membagi tata bahasa dalam dua kategori -
Tata Bahasa Deskriptif
Seperangkat aturan, di mana linguistik dan tata bahasa merumuskan tata bahasa pembicara disebut tata bahasa deskriptif.
Tata Bahasa Perspektif
Ini adalah pengertian tata bahasa yang sangat berbeda, yang berusaha mempertahankan standar kebenaran dalam bahasa tersebut. Kategori ini tidak ada hubungannya dengan cara kerja bahasa yang sebenarnya.
Komponen Bahasa
Bahasa studi dibagi menjadi komponen yang saling terkait, yang konvensional serta divisi investigasi linguistik yang sewenang-wenang. Penjelasan dari komponen tersebut adalah sebagai berikut -
Fonologi
Komponen bahasa pertama adalah fonologi. Ini adalah studi tentang suara ucapan dari bahasa tertentu. Asal usul kata tersebut dapat ditelusuri ke bahasa Yunani, di mana 'telepon' berarti suara atau suara. Fonetik, subdivisi fonologi adalah studi tentang suara ucapan bahasa manusia dari perspektif produksi, persepsi, atau sifat fisiknya. IPA (International Phonetic Alphabet) adalah alat yang merepresentasikan suara manusia secara teratur saat mempelajari fonologi. Dalam IPA, setiap simbol tertulis mewakili satu dan hanya satu suara ucapan dan sebaliknya.
Fonem
Ini dapat didefinisikan sebagai salah satu unit suara yang membedakan satu kata dari kata lain dalam suatu bahasa. Dalam linguistik, fonem ditulis di antara garis miring. Misalnya fonem/k/ terjadi pada kata-kata seperti kit, skit.
Morfologi
Ini adalah komponen bahasa kedua. Ini adalah studi tentang struktur dan klasifikasi kata-kata dalam bahasa tertentu. Asal kata tersebut berasal dari bahasa Yunani, dimana kata 'morphe' berarti 'bentuk'. Morfologi mempertimbangkan prinsip-prinsip pembentukan kata-kata dalam suatu bahasa. Dengan kata lain, bagaimana suara bergabung menjadi unit yang bermakna seperti prefiks, sufiks, dan akar. Ini juga mempertimbangkan bagaimana kata-kata dapat dikelompokkan menjadi bagian-bagian pidato.
Lexeme
Dalam linguistik, unit abstrak dari analisis morfologi yang berhubungan dengan sekumpulan bentuk yang diambil oleh satu kata disebut lexeme. Cara penggunaan leksem dalam sebuah kalimat ditentukan oleh kategori tata bahasanya. Lexeme dapat berupa kata individu atau multi kata. Misalnya, kata bicara adalah contoh dari kata leksem individu, yang mungkin memiliki banyak varian tata bahasa seperti berbicara, berbicara dan berbicara. Leksem multiword dapat terdiri dari lebih dari satu kata ortografik. Misalnya, speak up, pull through, dll. Adalah contoh leksem multiword.
Sintaksis
Ini adalah komponen bahasa ketiga. Ini adalah studi tentang urutan dan pengaturan kata-kata menjadi unit yang lebih besar. Kata itu dapat ditelusuri ke bahasa Yunani, di mana kata suntassein berarti 'menertibkan'. Ini mempelajari jenis kalimat dan strukturnya, klausa, frasa.
Semantik
Ini adalah komponen bahasa keempat. Ini adalah studi tentang bagaimana makna disampaikan. Makna bisa terkait dengan dunia luar atau bisa terkait dengan tata bahasa kalimat. Kata tersebut dapat ditelusuri ke bahasa Yunani, di mana kata semainein berarti 'menandakan', 'menunjukkan', 'memberi isyarat'.
Pragmatis
Ini adalah komponen bahasa kelima. Ini adalah studi tentang fungsi bahasa dan penggunaannya dalam konteks. Asal usul kata tersebut dapat ditelusuri ke bahasa Yunani di mana kata 'pragma' berarti 'perbuatan', 'perselingkuhan'.
Kategori Tata Bahasa
Kategori tata bahasa dapat didefinisikan sebagai kelas unit atau fitur dalam tata bahasa suatu bahasa. Unit-unit ini adalah blok bangunan bahasa dan berbagi sekumpulan karakteristik yang sama. Kategori tata bahasa juga disebut fitur tata bahasa.
Daftar kategori tata bahasa dijelaskan di bawah ini -
Jumlah
Ini adalah kategori tata bahasa yang paling sederhana. Kami memiliki dua istilah yang terkait dengan kategori ini −singular dan jamak. Singular adalah konsep 'satu' sedangkan, jamak adalah konsep 'lebih dari satu'. Misalnya, anjing / anjing, ini / ini.
Jenis kelamin
Gender gramatikal diekspresikan oleh variasi dalam kata ganti orang dan orang ketiga. Contoh gramatikal jenis kelamin adalah tunggal - he, she, it; bentuk orang pertama dan kedua - saya, kami dan Anda; bentuk jamak orang ketiga, mereka adalah jenis kelamin umum atau jenis kelamin netral.
Orang
Kategori tata bahasa sederhana lainnya adalah orang. Di bawah ini, tiga istilah berikut diakui -
1st person - Orang yang berbicara dikenali sebagai orang pertama.
2nd person - Orang yang menjadi pendengar atau yang diajak bicara diakui sebagai orang ke-2.
3rd person - Orang atau hal yang kita bicarakan dikenali sebagai orang ketiga.
Kasus
Ini adalah salah satu kategori tata bahasa yang paling sulit. Ini dapat didefinisikan sebagai indikasi fungsi frase kata benda (NP) atau hubungan frase kata benda dengan kata kerja atau dengan frase kata benda lain dalam kalimat. Kami memiliki tiga kasus berikut yang diekspresikan dalam kata ganti pribadi dan interogatif -
Nominative case- Ini adalah fungsi subjek. Misalnya, saya, kami, Anda, dia, dia, itu, mereka dan siapa yang nominatif.
Genitive case- Ini adalah fungsi pemilik. Misalnya my / mine, our / ours, his, her / hers, its, their / theirs, yang genitive.
Objective case- Ini adalah fungsi objek. Misalnya, saya, kami, Anda, dia, dia, mereka, yang objektif.
Gelar
Kategori tata bahasa ini terkait dengan kata sifat dan kata keterangan. Ini memiliki tiga istilah berikut -
Positive degree- Ini mengungkapkan kualitas. Misalnya, besar, cepat, indah adalah derajat positif.
Comparative degree- Ini mengungkapkan derajat atau intensitas kualitas yang lebih besar dalam salah satu dari dua item. Misalnya, lebih besar, lebih cepat, lebih indah adalah derajat komparatif.
Superlative degree- Ini mengungkapkan derajat atau intensitas kualitas terbesar dalam salah satu dari tiga item atau lebih. Misalnya, derajat terbesar, tercepat, terindah adalah derajat superlatif.
Kepastian dan Ketidakpastian
Kedua konsep ini sangat sederhana. Kepastian seperti yang kita ketahui mewakili suatu acuan, yang dikenal, dikenal atau dikenali oleh pembicara atau pendengar. Di sisi lain, ketidaktentuan mewakili rujukan yang tidak diketahui, atau tidak dikenal. Konsep tersebut dapat dipahami dalam kejadian bersamaan dari artikel dengan kata benda -
definite article- itu
indefinite article- a / an
Tegang
Kategori gramatikal ini terkait dengan kata kerja dan dapat didefinisikan sebagai indikasi linguistik waktu suatu tindakan. Suatu tegang membentuk suatu hubungan karena ini menunjukkan waktu suatu peristiwa sehubungan dengan saat berbicara. Secara umum, ini adalah dari tiga jenis berikut -
Present tense- Mewakili terjadinya suatu tindakan di saat sekarang. Misalnya, Ram bekerja keras.
Past tense- Mewakili terjadinya suatu tindakan sebelum momen sekarang. Misalnya, hujan.
Future tense- Mewakili terjadinya suatu tindakan setelah momen saat ini. Misalnya, akan turun hujan.
Aspek
Kategori tata bahasa ini dapat didefinisikan sebagai pandangan yang diambil dari suatu peristiwa. Ini bisa dari jenis berikut -
Perfective aspect- Tampilan diambil secara keseluruhan dan lengkap dalam aspek. Misalnya simple past tense sepertiyesterday I met my friend, dalam bahasa Inggris adalah kesempurnaan dalam aspek karena memandang acara tersebut secara lengkap dan utuh.
Imperfective aspect- Tampilan dianggap berkelanjutan dan tidak lengkap dalam aspeknya. Misalnya, present participle tense sepertiI am working on this problem, dalam bahasa Inggris tidak sempurna dalam aspek karena memandang acara tersebut tidak lengkap dan berkelanjutan.
Suasana hati
Kategori gramatikal ini agak sulit untuk didefinisikan tetapi secara sederhana dapat dinyatakan sebagai indikasi dari sikap pembicara terhadap apa yang dia bicarakan. Ini juga merupakan fitur tata bahasa dari kata kerja. Ini berbeda dari tenses gramatikal dan aspek gramatikal. Contoh mood adalah indicative, interrogative, imperative, injunctive, subjunctive, potential, optative, gerunds dan participles.
Persetujuan
Itu juga disebut kerukunan. Itu terjadi ketika sebuah kata berubah dari bergantung pada kata lain yang terkait dengannya. Dengan kata lain, ini melibatkan membuat nilai dari beberapa kategori tata bahasa sesuai antara kata-kata atau bagian dari pidato yang berbeda. Berikut adalah kesepakatan berdasarkan kategori tata bahasa lainnya -
Agreement based on Person- Ini adalah kesepakatan antara subjek dan kata kerja. Misalnya, kita selalu menggunakan "Saya" dan "Dia", tetapi tidak pernah menggunakan "Dia" dan "Saya adalah".
Agreement based on Number- Kesepakatan ini antara subjek dan kata kerja. Dalam hal ini, ada bentuk verba khusus untuk orang pertama tunggal, orang kedua jamak dan seterusnya. Misalnya, orang pertama tunggal: Saya sungguh, orang kedua jamak: Kami benar-benar, orang ketiga tunggal: Anak laki-laki menyanyi, orang ketiga jamak: Anak laki-laki bernyanyi.
Agreement based on Gender- Dalam bahasa Inggris, ada kesepakatan dalam gender antara kata ganti dan anteseden. Misalnya, Dia mencapai tujuannya. Kapal mencapai tujuannya.
Agreement based on Case- Perjanjian semacam ini bukanlah fitur bahasa Inggris yang signifikan. Misalnya, siapa yang lebih dulu - dia atau saudara perempuannya?
Sintaks Bahasa Lisan
Tata bahasa Inggris tertulis dan lisan memiliki banyak ciri umum tetapi seiring dengan itu, mereka juga berbeda dalam beberapa aspek. Fitur berikut membedakan antara tata bahasa Inggris lisan dan tulisan -
Disfluencies dan Repair
Fitur mencolok ini membuat tata bahasa Inggris lisan dan tulisan berbeda satu sama lain. Ini secara individu dikenal sebagai fenomena disfluencies dan secara kolektif sebagai fenomena perbaikan. Disfluensi termasuk penggunaan berikut -
Fillers words- Terkadang di sela-sela kalimat, kami menggunakan beberapa kata pengisi. Mereka disebut pengisi jeda pengisi. Contoh dari kata-kata seperti itu adalah uh dan um.
Reparandum and repair- Segmen kata yang berulang di antara kalimat disebut reparandum. Di segmen yang sama, kata yang diubah disebut perbaikan. Pertimbangkan contoh berikut untuk memahami ini -
Does ABC airlines offer any one-way flights uh one-way fares for 5000 rupees?
Pada kalimat di atas, penerbangan satu arah merupakan reparadum dan penerbangan satu arah adalah perbaikan.
Mulai ulang
Setelah pengisi jeda, restart terjadi. Misalnya, pada kalimat di atas, restart terjadi ketika pembicara mulai bertanya tentang penerbangan satu arah kemudian berhenti, perbaiki sendiri dengan jeda pengisi dan kemudian memulai kembali menanyakan tentang tarif satu arah.
Fragmen Kata
Terkadang kita mengucapkan kalimat dengan potongan kata yang lebih kecil. Sebagai contoh,wwha-what is the time? Di sini kata-katanya w-wha adalah fragmen kata.
Pengambilan informasi (IR) dapat didefinisikan sebagai program perangkat lunak yang berhubungan dengan organisasi, penyimpanan, pengambilan dan evaluasi informasi dari repositori dokumen terutama informasi tekstual. Sistem membantu pengguna dalam menemukan informasi yang mereka butuhkan tetapi tidak secara eksplisit mengembalikan jawaban dari pertanyaan. Ini menginformasikan keberadaan dan lokasi dokumen yang mungkin terdiri dari informasi yang diperlukan. Dokumen yang memenuhi kebutuhan pengguna disebut dokumen yang relevan. Sistem IR yang sempurna hanya akan mengambil dokumen yang relevan.
Dengan bantuan diagram berikut, kita dapat memahami proses pengambilan informasi (IR) -

Jelas dari diagram di atas bahwa pengguna yang membutuhkan informasi harus merumuskan permintaan dalam bentuk query dalam bahasa alami. Kemudian sistem IR akan merespon dengan mengambil output yang relevan, berupa dokumen, tentang informasi yang dibutuhkan.
Masalah Klasik dalam Sistem Information Retrieval (IR)
Tujuan utama penelitian IR adalah mengembangkan model untuk mengambil informasi dari repositori dokumen. Di sini, kita akan membahas masalah klasik bernamaad-hoc retrieval problem, terkait dengan sistem IR.
Dalam pengambilan ad-hoc, pengguna harus memasukkan kueri dalam bahasa alami yang menjelaskan informasi yang diperlukan. Kemudian sistem IR akan mengembalikan dokumen yang diperlukan terkait dengan informasi yang diinginkan. Misalnya, kita mencari sesuatu di Internet dan memberikan beberapa halaman persis yang relevan sesuai kebutuhan kita, tetapi mungkin ada beberapa halaman yang tidak relevan juga. Hal ini karena masalah pengambilan ad-hoc.
Aspek Pengambilan Ad-hoc
Berikut adalah beberapa aspek pengambilan ad-hoc yang dibahas dalam penelitian IR -
Bagaimana pengguna dengan bantuan umpan balik relevansi dapat meningkatkan formulasi asli dari sebuah kueri?
Bagaimana menerapkan penggabungan database, yaitu bagaimana hasil dari database teks yang berbeda dapat digabungkan menjadi satu kumpulan hasil?
Bagaimana cara menangani sebagian data yang rusak? Model mana yang cocok untuk hal yang sama?
Model Pengambilan Informasi (IR)
Secara matematis, model digunakan di banyak bidang ilmiah yang bertujuan untuk memahami beberapa fenomena di dunia nyata. Model pencarian informasi memprediksi dan menjelaskan apa yang akan ditemukan pengguna dalam relevansinya dengan kueri yang diberikan. Model IR pada dasarnya adalah pola yang mendefinisikan aspek prosedur pengambilan yang disebutkan di atas dan terdiri dari:
Model untuk dokumen.
Sebuah model untuk query.
Fungsi pencocokan yang membandingkan kueri dengan dokumen.
Secara matematis, model pengambilan terdiri dari -
D - Representasi untuk dokumen.
R - Representasi untuk pertanyaan.
F - Kerangka pemodelan untuk D, Q bersama dengan hubungan di antara mereka.
R (q,di)- Fungsi kesamaan yang memesan dokumen sehubungan dengan kueri. Ini juga disebut peringkat.
Jenis Model Information Retrieval (IR)
Model model informasi (IR) dapat diklasifikasikan ke dalam tiga model berikut -
Model IR Klasik
Ini adalah model IR yang paling sederhana dan mudah diimplementasikan. Model ini didasarkan pada pengetahuan matematika yang mudah dikenali dan dipahami dengan baik. Boolean, Vektor dan Probabilistik adalah tiga model IR klasik.
Model IR Non-Klasik
Ini sangat berlawanan dengan model IR klasik. Model IR semacam itu didasarkan pada prinsip selain kesamaan, probabilitas, operasi Boolean. Model logika informasi, model teori situasi dan model interaksi adalah contoh model IR non klasik.
Model IR Alternatif
Ini adalah peningkatan model IR klasik yang menggunakan beberapa teknik tertentu dari beberapa bidang lain. Model cluster, model fuzzy dan model latent semantic indexing (LSI) adalah contoh model IR alternatif.
Fitur desain sistem temu kembali informasi (IR)
Sekarang mari kita belajar tentang fitur desain sistem IR -
Indeks Terbalik
Struktur data primer dari sebagian besar sistem IR berbentuk indeks terbalik. Kita dapat mendefinisikan indeks terbalik sebagai struktur data yang mencantumkan, untuk setiap kata, semua dokumen yang memuatnya dan frekuensi kemunculan dalam dokumen. Ini memudahkan untuk mencari 'hits' dari kata kueri.
Hentikan Penghapusan Kata
Kata-kata berhenti adalah kata-kata berfrekuensi tinggi yang dianggap tidak mungkin berguna untuk pencarian. Mereka memiliki bobot semantik yang lebih sedikit. Semua jenis kata seperti itu ada dalam daftar yang disebut daftar berhenti. Misalnya, artikel "a", "an", "the" dan preposisi seperti "in", "of", "for", "at", dll. Adalah contoh kata berhenti. Ukuran indeks terbalik dapat dikurangi secara signifikan dengan daftar berhenti. Sesuai hukum Zipf, daftar berhenti yang mencakup beberapa lusin kata mengurangi ukuran indeks terbalik hampir setengahnya. Di sisi lain, terkadang penghapusan kata berhenti dapat menyebabkan penghapusan istilah yang berguna untuk pencarian. Misalnya, jika kita menghilangkan alfabet "A" dari "Vitamin A" maka itu tidak ada artinya.
Stemming
Stemming, bentuk sederhana dari analisis morfologi, adalah proses heuristik mengekstraksi bentuk dasar kata dengan memotong ujung kata. Misalnya, kata tertawa, tertawa, tertawa akan berasal dari akar kata tertawa.
Di bagian selanjutnya, kami akan membahas tentang beberapa model IR yang penting dan berguna.
Model Boolean
Ini adalah model pengambilan informasi (IR) tertua. Model ini didasarkan pada teori himpunan dan aljabar Boolean, di mana dokumen adalah himpunan istilah dan kueri adalah ekspresi Boolean pada istilah. Model Boolean dapat didefinisikan sebagai -
D- Seperangkat kata, yaitu istilah pengindeksan yang ada dalam dokumen. Di sini, setiap suku ada (1) atau tidak ada (0).
Q - Ekspresi Boolean, di mana istilah adalah istilah indeks dan operator adalah produk logika - DAN, jumlah logis - ATAU dan perbedaan logis - BUKAN
F - Aljabar Boolean atas kumpulan istilah serta kumpulan dokumen
Jika kita berbicara tentang umpan balik relevansi, maka dalam model IR Boolean, prediksi relevansi dapat didefinisikan sebagai berikut -
R - Dokumen diprediksi relevan dengan ekspresi kueri jika dan hanya jika memenuhi ekspresi kueri seperti -
((˅) ˄ ˄ ˜ ℎ)
Kami dapat menjelaskan model ini dengan istilah kueri sebagai definisi yang tidak ambigu dari sekumpulan dokumen.
Misalnya, istilah kueri “economic” mendefinisikan kumpulan dokumen yang diindeks dengan istilah “economic”.
Sekarang, apa hasil setelah menggabungkan istilah dengan Boolean AND Operator? Ini akan menentukan kumpulan dokumen yang lebih kecil dari atau sama dengan kumpulan dokumen dari salah satu istilah tunggal. Misalnya, kueri dengan istilah“social” dan “economic”akan menghasilkan kumpulan dokumen dari dokumen yang diindeks dengan kedua istilah tersebut. Dengan kata lain, kumpulan dokumen dengan perpotongan dari kedua kumpulan.
Sekarang, apa hasil setelah menggabungkan suku-suku dengan operator Boolean OR? Ini akan menentukan kumpulan dokumen yang lebih besar atau sama dengan kumpulan dokumen dari salah satu istilah tunggal. Misalnya, kueri dengan istilah“social” atau “economic” akan menghasilkan kumpulan dokumen dokumen yang diindeks dengan istilah yang baik “social” atau “economic”. Dengan kata lain, dokumen ditetapkan dengan penyatuan kedua set.
Keuntungan dari Mode Boolean
Keuntungan dari model Boolean adalah sebagai berikut -
Model paling sederhana, yang didasarkan pada set.
Mudah dipahami dan diterapkan.
Ini hanya mengambil kecocokan persis
Ini memberi pengguna rasa kendali atas sistem.
Kekurangan Model Boolean
Kerugian dari model Boolean adalah sebagai berikut -
Fungsi kesamaan model adalah Boolean. Karenanya, tidak akan ada kecocokan parsial. Ini bisa mengganggu pengguna.
Dalam model ini, penggunaan operator Boolean memiliki pengaruh yang jauh lebih besar daripada kata kritis.
Bahasa kueri ekspresif, tetapi juga rumit.
Tidak ada peringkat untuk dokumen yang diambil.
Model Ruang Vektor
Karena kelemahan model Boolean di atas, Gerard Salton dan rekannya menyarankan model, yang didasarkan pada kriteria kesamaan Luhn. Kriteria kesamaan yang dirumuskan oleh Luhn menyatakan, "semakin banyak dua representasi yang disetujui dalam elemen tertentu dan distribusinya, semakin tinggi kemungkinan representasi informasi serupa."
Pertimbangkan poin penting berikut untuk memahami lebih lanjut tentang Model Ruang Vektor -
Representasi indeks (dokumen) dan kueri dianggap sebagai vektor yang disematkan dalam ruang Euclidean berdimensi tinggi.
Ukuran kesamaan vektor dokumen dengan vektor query biasanya merupakan cosinus dari sudut di antara mereka.
Rumus Pengukuran Kesamaan Cosine
Cosine adalah produk titik yang dinormalisasi, yang dapat dihitung dengan bantuan rumus berikut -
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
Representasi Ruang Vektor dengan Query dan Dokumen
Kueri dan dokumen diwakili oleh ruang vektor dua dimensi. Istilahnya adalahcar dan insurance. Ada satu kueri dan tiga dokumen dalam ruang vektor.

Dokumen peringkat teratas dalam menanggapi istilah mobil dan asuransi adalah dokumen tersebut d2 karena sudut antara q dan d2adalah yang terkecil. Alasan di balik ini adalah bahwa baik konsep mobil maupun asuransi menonjol di d 2 dan karenanya memiliki bobot yang tinggi. Di sisi lain,d1 dan d3 juga menyebutkan kedua istilah tersebut tetapi dalam setiap kasus, salah satunya bukan istilah yang sangat penting dalam dokumen.
Pembobotan Jangka
Bobot term berarti bobot pada istilah dalam ruang vektor. Semakin tinggi bobot suku, semakin besar dampak suku pada cosinus. Lebih banyak bobot harus diberikan ke istilah yang lebih penting dalam model. Sekarang pertanyaan yang muncul di sini adalah bagaimana kita bisa membuat model ini.
Salah satu cara untuk melakukannya adalah dengan menghitung kata-kata dalam dokumen sebagai bobot istilahnya. Namun, menurut Anda apakah itu akan menjadi metode yang efektif?
Metode lain, yang lebih efektif, adalah dengan menggunakan term frequency (tfij), document frequency (dfi) dan collection frequency (cfi).
Frekuensi Jangka (tf ij )
Ini dapat didefinisikan sebagai jumlah kemunculan wi di dj. Informasi yang ditangkap oleh term frekuensi adalah seberapa menonjol sebuah kata dalam dokumen yang diberikan atau dengan kata lain kita dapat mengatakan bahwa semakin tinggi term frekuensi semakin banyak kata tersebut yang menjadi deskripsi yang baik dari isi dokumen tersebut.
Frekuensi Dokumen (df i )
Ini dapat didefinisikan sebagai jumlah total dokumen dalam koleksi tempat w i terjadi. Ini adalah indikator keinformatifan. Kata-kata yang difokuskan secara semantik akan muncul beberapa kali dalam dokumen, tidak seperti kata-kata yang tidak fokus secara semantik.
Frekuensi Pengumpulan (cf i )
Ini dapat didefinisikan sebagai jumlah total kemunculan wi dalam koleksi.
Secara matematis, $df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
Bentuk Pembobotan Frekuensi Dokumen
Sekarang mari kita belajar tentang berbagai bentuk pembobotan frekuensi dokumen. Formulir dijelaskan di bawah ini -
Faktor Frekuensi Jangka
Ini juga diklasifikasikan sebagai faktor frekuensi istilah, yang berarti jika istilah t sering muncul di dokumen lalu kueri yang berisi tharus mengambil dokumen itu. Kita bisa menggabungkan kataterm frequency (tfij) dan document frequency (dfi) menjadi satu bobot sebagai berikut -
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
Di sini N adalah jumlah dokumen.
Frekuensi Dokumen Terbalik (idf)
Ini adalah bentuk lain dari pembobotan frekuensi dokumen dan sering disebut pembobotan idf atau pembobotan frekuensi dokumen terbalik. Poin penting dari pembobotan idf adalah bahwa kelangkaan istilah di seluruh koleksi adalah ukuran kepentingan dan kepentingannya berbanding terbalik dengan frekuensi kemunculannya.
Secara matematis,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
Sini,
N = dokumen dalam koleksi
n t = dokumen yang mengandung term t
Peningkatan Permintaan Pengguna
Tujuan utama dari sistem pengambilan informasi harus keakuratan - untuk menghasilkan dokumen yang relevan sesuai kebutuhan pengguna. Namun, pertanyaan yang muncul di sini adalah bagaimana kami dapat meningkatkan keluaran dengan meningkatkan gaya pembentukan kueri pengguna. Tentu saja, keluaran dari sistem IR apa pun bergantung pada kueri pengguna dan kueri yang diformat dengan baik akan menghasilkan hasil yang lebih akurat. Pengguna dapat meningkatkan permintaannya dengan bantuanrelevance feedback, aspek penting dari model IR apa pun.
Relevansi Umpan Balik
Umpan balik relevansi mengambil keluaran yang awalnya dikembalikan dari kueri yang diberikan. Output awal ini dapat digunakan untuk mengumpulkan informasi pengguna dan untuk mengetahui apakah output tersebut relevan untuk melakukan kueri baru atau tidak. Umpan balik dapat diklasifikasikan sebagai berikut -
Umpan Balik Eksplisit
Ini dapat didefinisikan sebagai umpan balik yang diperoleh dari penilai relevansi. Penilai ini juga akan menunjukkan relevansi dokumen yang diambil dari kueri. Untuk meningkatkan kinerja pengambilan kueri, informasi umpan balik relevansi perlu diinterpolasi dengan kueri asli.
Penilai atau pengguna lain dari sistem dapat menunjukkan relevansi secara eksplisit dengan menggunakan sistem relevansi berikut -
Binary relevance system - Sistem umpan balik relevansi ini menunjukkan bahwa dokumen relevan (1) atau tidak relevan (0) untuk kueri tertentu.
Graded relevance system- Sistem umpan balik relevansi bertingkat menunjukkan relevansi dokumen, untuk kueri tertentu, berdasarkan penilaian dengan menggunakan angka, huruf, atau deskripsi. Deskripsi bisa seperti "tidak relevan", "agak relevan", "sangat relevan", atau "relevan".
Umpan Balik Implisit
Itu adalah umpan balik yang disimpulkan dari perilaku pengguna. Perilaku tersebut mencakup durasi waktu yang dihabiskan pengguna untuk melihat dokumen, dokumen mana yang dipilih untuk dilihat dan mana yang tidak, penjelajahan halaman dan tindakan menggulir, dll. Salah satu contoh terbaik dari umpan balik implisit adalahdwell time, yang merupakan ukuran berapa banyak waktu yang dihabiskan pengguna untuk melihat halaman yang ditautkan dalam hasil penelusuran.
Umpan Balik Semu
Ini juga disebut Umpan balik buta. Ini memberikan metode untuk analisis lokal otomatis. Bagian manual dari umpan balik relevansi diotomatiskan dengan bantuan umpan balik relevansi semu sehingga pengguna mendapatkan kinerja pengambilan yang lebih baik tanpa interaksi yang diperpanjang. Keuntungan utama dari sistem umpan balik ini adalah tidak memerlukan penilai seperti dalam sistem umpan balik relevansi eksplisit.
Pertimbangkan langkah-langkah berikut untuk menerapkan umpan balik ini -
Step 1- Pertama, hasil yang dikembalikan oleh permintaan awal harus dianggap sebagai hasil yang relevan. Kisaran hasil yang relevan harus berada di 10-50 hasil teratas.
Step 2 - Sekarang, pilih 20-30 term teratas dari dokumen yang menggunakan bobot misalnya term frequency (tf) -inverse document frequency (idf).
Step 3- Tambahkan istilah ini ke kueri dan cocok dengan dokumen yang dikembalikan. Kemudian kembalikan dokumen yang paling relevan.
Natural Language Processing (NLP) adalah teknologi baru yang menghasilkan berbagai bentuk AI yang kita lihat di masa sekarang dan penggunaannya untuk menciptakan antarmuka yang mulus dan interaktif antara manusia dan mesin akan terus menjadi prioritas utama untuk hari ini dan masa depan. aplikasi kognitif yang semakin meningkat. Di sini, kita akan membahas tentang beberapa aplikasi NLP yang sangat berguna.
Mesin penerjemah
Terjemahan mesin (MT), proses menerjemahkan satu bahasa sumber atau teks ke bahasa lain, adalah salah satu aplikasi terpenting NLP. Kami dapat memahami proses penerjemahan mesin dengan bantuan diagram alur berikut -
Jenis Sistem Terjemahan Mesin
Ada berbagai jenis sistem terjemahan mesin. Mari kita lihat apa saja jenis-jenisnya.
Sistem MT Bilingual
Sistem MT dwibahasa menghasilkan terjemahan antara dua bahasa tertentu.
Sistem MT Multibahasa
Sistem MT multibahasa menghasilkan terjemahan antara pasangan bahasa apa pun. Mereka mungkin bersifat uni-directional atau bi-directional.
Pendekatan Terjemahan Mesin (MT)
Sekarang mari kita belajar tentang pendekatan penting untuk Terjemahan Mesin. Pendekatan ke MT adalah sebagai berikut -
Pendekatan MT Langsung
Ini kurang populer tetapi pendekatan MT tertua. Sistem yang menggunakan pendekatan ini mampu menerjemahkan SL (bahasa sumber) langsung ke TL (bahasa target). Sistem seperti itu bersifat bi-bahasa dan satu arah.
Pendekatan Interlingua
Sistem yang menggunakan pendekatan Interlingua menerjemahkan SL ke bahasa perantara yang disebut Interlingua (IL) dan kemudian menerjemahkan IL ke TL. Pendekatan Interlingua dapat dipahami dengan bantuan piramida MT berikut -

Pendekatan Transfer
Ada tiga tahap yang terlibat dengan pendekatan ini.
Pada tahap pertama, teks bahasa sumber (SL) diubah menjadi representasi berorientasi SL yang abstrak.
Pada tahap kedua, representasi berorientasi SL diubah menjadi representasi berorientasi bahasa target (TL) yang setara.
Pada tahap ketiga, teks terakhir dibuat.
Pendekatan Empiris MT
Ini adalah pendekatan yang muncul untuk MT. Pada dasarnya, ini menggunakan sejumlah besar data mentah dalam bentuk korpora paralel. Data mentah terdiri dari teks dan terjemahannya. Teknik terjemahan mesin berbasis analog, berbasis contoh, berbasis memori menggunakan pendekatan MT empiris.
Memerangi Spam
Salah satu masalah paling umum saat ini adalah email yang tidak diinginkan. Ini membuat filter Spam semakin penting karena ini adalah garis pertahanan pertama melawan masalah ini.
Sistem pemfilteran spam dapat dikembangkan dengan menggunakan fungsionalitas NLP dengan mempertimbangkan masalah utama positif palsu dan negatif palsu.
Model NLP yang ada untuk pemfilteran spam
Berikut adalah beberapa model NLP yang ada untuk pemfilteran spam -
Pemodelan N-gram
Model N-Gram adalah potongan karakter N dari string yang lebih panjang. Dalam model ini, N-gram dengan beberapa panjang berbeda digunakan secara bersamaan dalam memproses dan mendeteksi email spam.
Word Stemming
Spammer, pembuat email spam, biasanya mengubah satu atau lebih karakter kata-kata yang menyerang dalam spam mereka sehingga mereka dapat melanggar filter spam berbasis konten. Itulah mengapa kami dapat mengatakan bahwa filter berbasis konten tidak berguna jika mereka tidak dapat memahami arti kata atau frasa dalam email. Untuk menghilangkan masalah tersebut dalam pemfilteran spam, teknik stemming kata berbasis aturan, yang dapat mencocokkan kata-kata yang mirip dan terdengar mirip, dikembangkan.
Klasifikasi Bayesian
Ini sekarang telah menjadi teknologi yang banyak digunakan untuk penyaringan spam. Insiden kata-kata dalam email diukur terhadap kemunculannya yang khas dalam database pesan email yang tidak diminta (spam) dan sah (ham) dalam teknik statistik.
Peringkasan Otomatis
Di era digital ini, yang paling berharga adalah data, atau bisa dikatakan informasi. Namun, apakah kita benar-benar mendapatkan informasi yang berguna serta jumlah informasi yang dibutuhkan? Jawabannya adalah 'TIDAK' karena informasi terlalu banyak dan akses kita ke pengetahuan dan informasi jauh melebihi kemampuan kita untuk memahaminya. Kami sangat membutuhkan peringkasan teks dan informasi otomatis karena banjir informasi melalui internet tidak akan berhenti.
Peringkasan teks dapat didefinisikan sebagai teknik untuk membuat ringkasan pendek dan akurat dari dokumen teks yang lebih panjang. Peringkasan teks otomatis akan membantu kami dengan informasi yang relevan dalam waktu yang lebih singkat. Pemrosesan bahasa alami (NLP) memainkan peran penting dalam mengembangkan ringkasan teks otomatis.
Menjawab pertanyaan
Aplikasi utama lain dari pemrosesan bahasa alami (NLP) adalah menjawab pertanyaan. Mesin pencari meletakkan informasi dunia di ujung jari kita, tetapi mereka masih kekurangan dalam menjawab pertanyaan yang diposting oleh manusia dalam bahasa aslinya. Kami memiliki perusahaan teknologi besar seperti Google yang juga bekerja ke arah ini.
Menjawab pertanyaan adalah disiplin Ilmu Komputer dalam bidang AI dan NLP. Ini berfokus pada membangun sistem yang secara otomatis menjawab pertanyaan yang dikirim oleh manusia dalam bahasa alami mereka. Sistem komputer yang memahami bahasa alami memiliki kemampuan sistem program untuk menerjemahkan kalimat yang ditulis oleh manusia menjadi representasi internal sehingga dapat dihasilkan jawaban yang valid oleh sistem. Jawaban yang tepat dapat dihasilkan dengan melakukan analisis sintaks dan semantik pertanyaan. Lexical gap, ambiguity dan multilingualism menjadi beberapa tantangan bagi NLP dalam membangun sistem penjawab pertanyaan yang baik.
Analisis Sentimen
Aplikasi penting lainnya dari pemrosesan bahasa alami (NLP) adalah analisis sentimen. Seperti namanya, analisis sentimen digunakan untuk mengidentifikasi sentimen di antara beberapa postingan. Ini juga digunakan untuk mengidentifikasi sentimen di mana emosi tidak diekspresikan secara eksplisit. Perusahaan menggunakan analisis sentimen, aplikasi pemrosesan bahasa alami (NLP) untuk mengidentifikasi opini dan sentimen pelanggan mereka secara online. Ini akan membantu perusahaan untuk memahami apa yang pelanggan pikirkan tentang produk dan layanan. Perusahaan dapat menilai reputasi keseluruhan mereka dari posting pelanggan dengan bantuan analisis sentimen. Dengan cara ini, kami dapat mengatakan bahwa selain menentukan polaritas sederhana, analisis sentimen memahami sentimen dalam konteks untuk membantu kami lebih memahami apa yang ada di balik opini yang diungkapkan.
Pada bab ini, kita akan belajar tentang pemrosesan bahasa menggunakan Python.
Fitur berikut membuat Python berbeda dari bahasa lain -
Python is interpreted - Kita tidak perlu mengkompilasi program Python kita sebelum menjalankannya karena interpreter memproses Python saat runtime.
Interactive - Kami dapat langsung berinteraksi dengan penerjemah untuk menulis program Python kami.
Object-oriented - Python bersifat berorientasi objek dan membuat bahasa ini lebih mudah untuk menulis program karena dengan bantuan teknik pemrograman ini merangkum kode di dalam objek.
Beginner can easily learn - Python juga disebut bahasa pemula karena sangat mudah dipahami, dan mendukung pengembangan berbagai macam aplikasi.
Prasyarat
Versi terbaru Python 3 yang dirilis adalah Python 3.7.1 tersedia untuk Windows, Mac OS dan sebagian besar versi Linux OS.
Untuk windows, kita bisa masuk ke link www.python.org/downloads/windows/ untuk mendownload dan menginstal Python.
For MAC OS, we can use the link www.python.org/downloads/mac-osx/.
In case of Linux, different flavors of Linux use different package managers for installation of new packages.
For example, to install Python 3 on Ubuntu Linux, we can use the following command from terminal −
$sudo apt-get install python3-minimalTo study more about Python programming, read Python 3 basic tutorial – Python 3
Getting Started with NLTK
We will be using Python library NLTK (Natural Language Toolkit) for doing text analysis in English Language. The Natural language toolkit (NLTK) is a collection of Python libraries designed especially for identifying and tag parts of speech found in the text of natural language like English.
Installing NLTK
Before starting to use NLTK, we need to install it. With the help of following command, we can install it in our Python environment −
pip install nltkIf we are using Anaconda, then a Conda package for NLTK can be built by using the following command −
conda install -c anaconda nltkDownloading NLTK’s Data
After installing NLTK, another important task is to download its preset text repositories so that it can be easily used. However, before that we need to import NLTK the way we import any other Python module. The following command will help us in importing NLTK −
import nltkNow, download NLTK data with the help of the following command −
nltk.download()It will take some time to install all available packages of NLTK.
Other Necessary Packages
Some other Python packages like gensim and pattern are also very necessary for text analysis as well as building natural language processing applications by using NLTK. the packages can be installed as shown below −
gensim
gensim is a robust semantic modeling library which can be used for many applications. We can install it by following command −
pip install gensimpattern
It can be used to make gensim package work properly. The following command helps in installing pattern −
pip install patternTokenization
Tokenization may be defined as the Process of breaking the given text, into smaller units called tokens. Words, numbers or punctuation marks can be tokens. It may also be called word segmentation.
Example
Input − Bed and chair are types of furniture.

We have different packages for tokenization provided by NLTK. We can use these packages based on our requirements. The packages and the details of their installation are as follows −
sent_tokenize package
This package can be used to divide the input text into sentences. We can import it by using the following command −
from nltk.tokenize import sent_tokenizeword_tokenize package
This package can be used to divide the input text into words. We can import it by using the following command −
from nltk.tokenize import word_tokenizeWordPunctTokenizer package
This package can be used to divide the input text into words and punctuation marks. We can import it by using the following command −
from nltk.tokenize import WordPuncttokenizerStemming
Due to grammatical reasons, language includes lots of variations. Variations in the sense that the language, English as well as other languages too, have different forms of a word. For example, the words like democracy, democratic, and democratization. For machine learning projects, it is very important for machines to understand that these different words, like above, have the same base form. That is why it is very useful to extract the base forms of the words while analyzing the text.
Stemming is a heuristic process that helps in extracting the base forms of the words by chopping of their ends.
The different packages for stemming provided by NLTK module are as follows −
PorterStemmer package
Porter’s algorithm is used by this stemming package to extract the base form of the words. With the help of the following command, we can import this package −
from nltk.stem.porter import PorterStemmerFor example, ‘write’ would be the output of the word ‘writing’ given as the input to this stemmer.
LancasterStemmer package
Lancaster’s algorithm is used by this stemming package to extract the base form of the words. With the help of following command, we can import this package −
from nltk.stem.lancaster import LancasterStemmerFor example, ‘writ’ would be the output of the word ‘writing’ given as the input to this stemmer.
SnowballStemmer package
Snowball’s algorithm is used by this stemming package to extract the base form of the words. With the help of following command, we can import this package −
from nltk.stem.snowball import SnowballStemmerFor example, ‘write’ would be the output of the word ‘writing’ given as the input to this stemmer.
Lemmatization
It is another way to extract the base form of words, normally aiming to remove inflectional endings by using vocabulary and morphological analysis. After lemmatization, the base form of any word is called lemma.
NLTK module provides the following package for lemmatization −
WordNetLemmatizer package
This package will extract the base form of the word depending upon whether it is used as a noun or as a verb. The following command can be used to import this package −
from nltk.stem import WordNetLemmatizerCounting POS Tags–Chunking
The identification of parts of speech (POS) and short phrases can be done with the help of chunking. It is one of the important processes in natural language processing. As we are aware about the process of tokenization for the creation of tokens, chunking actually is to do the labeling of those tokens. In other words, we can say that we can get the structure of the sentence with the help of chunking process.
Example
In the following example, we will implement Noun-Phrase chunking, a category of chunking which will find the noun phrase chunks in the sentence, by using NLTK Python module.
Consider the following steps to implement noun-phrase chunking −
Step 1: Chunk grammar definition
In this step, we need to define the grammar for chunking. It would consist of the rules, which we need to follow.
Step 2: Chunk parser creation
Next, we need to create a chunk parser. It would parse the grammar and give the output.
Step 3: The Output
In this step, we will get the output in a tree format.
Running the NLP Script
Start by importing the the NLTK package −
import nltkNow, we need to define the sentence.
Here,
DT is the determinant
VBP is the verb
JJ is the adjective
IN is the preposition
NN is the noun
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Next, the grammar should be given in the form of regular expression.
grammar = "NP:{<DT>?<JJ>*<NN>}"Now, we need to define a parser for parsing the grammar.
parser_chunking = nltk.RegexpParser(grammar)Now, the parser will parse the sentence as follows −
parser_chunking.parse(sentence)Next, the output will be in the variable as follows:-
Output = parser_chunking.parse(sentence)Now, the following code will help you draw your output in the form of a tree.
output.draw()