Python Web Scraping - Pendahuluan
Scraping web adalah proses otomatis mengekstraksi informasi dari web. Bab ini akan memberi Anda gambaran mendalam tentang web scraping, perbandingannya dengan web crawling, dan mengapa Anda harus memilih web scraping. Anda juga akan belajar tentang komponen dan cara kerja web scraper.
Apa itu Scraping Web?
Arti kamus dari kata 'Scrapping' menyiratkan mendapatkan sesuatu dari web. Di sini muncul dua pertanyaan: Apa yang bisa kita dapatkan dari web dan Bagaimana mendapatkannya.
Jawaban dari pertanyaan pertama adalah ‘data’. Data sangat diperlukan untuk programmer mana pun dan persyaratan dasar dari setiap proyek pemrograman adalah sejumlah besar data yang berguna.
Jawaban pertanyaan kedua agak sedikit rumit, karena banyak cara untuk mendapatkan data. Secara umum kita dapat memperoleh data dari database atau file data dan sumber lainnya. Tetapi bagaimana jika kita membutuhkan sejumlah besar data yang tersedia secara online? Salah satu cara untuk mendapatkan data semacam itu adalah dengan mencari secara manual (mengklik di browser web) dan menyimpan (menyalin-tempel ke dalam spreadsheet atau file) data yang diperlukan. Cara ini cukup melelahkan dan memakan waktu. Cara lain untuk mendapatkan data tersebut adalah dengan menggunakanweb scraping.
Web scraping, disebut juga web data mining atau web harvesting, adalah proses membangun agen yang dapat mengekstrak, mengurai, mengunduh, dan mengatur informasi berguna dari web secara otomatis. Dengan kata lain, kami dapat mengatakan bahwa alih-alih menyimpan data dari situs web secara manual, perangkat lunak pengikis web akan secara otomatis memuat dan mengekstrak data dari beberapa situs web sesuai kebutuhan kami.
Asal dari Web Scraping
Asal mula web scraping adalah screen scrapping, yang digunakan untuk mengintegrasikan aplikasi non-web atau aplikasi windows asli. Awalnya pengikisan layar digunakan sebelum penggunaan World Wide Web (WWW) secara luas, tetapi tidak dapat meningkatkan WWW diperluas. Ini membuatnya perlu untuk mengotomatiskan pendekatan pengikisan layar dan teknik yang disebut‘Web Scraping’ muncul.
Web Crawling vs Web Scraping
Istilah Web Crawling dan Scraping sering digunakan secara bergantian karena konsep dasarnya adalah mengekstrak data. Namun, mereka berbeda satu sama lain. Kita dapat memahami perbedaan mendasar dari definisi mereka.
Crawling web pada dasarnya digunakan untuk mengindeks informasi pada halaman menggunakan bot alias crawler. Itu juga disebutindexing. Di sisi lain, web scraping adalah cara otomatis untuk mengekstrak informasi menggunakan bot alias pencakar. Itu juga disebutdata extraction.
Untuk memahami perbedaan antara kedua istilah ini, mari kita lihat tabel perbandingan yang diberikan di bawah ini -
| Perayapan Web | Scraping Web |
|---|---|
| Mengacu pada mengunduh dan menyimpan konten dari sejumlah besar situs web. | Mengacu pada penggalian elemen data individu dari situs web dengan menggunakan struktur khusus situs. |
| Sebagian besar dilakukan dalam skala besar. | Dapat diimplementasikan dalam skala apapun. |
| Menghasilkan informasi umum. | Menghasilkan informasi spesifik. |
| Digunakan oleh mesin pencari utama seperti Google, Bing, Yahoo. Googlebot adalah contoh web crawler. | Informasi yang diekstrak menggunakan web scraping dapat digunakan untuk direplikasi di beberapa situs lain atau dapat digunakan untuk melakukan analisis data. Misalnya elemen data bisa berupa nama, alamat, harga dll. |
Penggunaan Web Scraping
Penggunaan dan alasan menggunakan web scraping tidak terbatas seperti penggunaan World Wide Web. Pencakar web dapat melakukan apa saja seperti memesan makanan online, memindai situs web belanja online untuk Anda dan membeli tiket pertandingan saat tersedia, dll. Seperti yang dapat dilakukan manusia. Beberapa kegunaan penting dari web scraping dibahas di sini -
E-commerce Websites - Pengikis web dapat mengumpulkan data yang secara khusus terkait dengan harga produk tertentu dari berbagai situs web e-niaga untuk perbandingan.
Content Aggregators - Scraping web digunakan secara luas oleh agregator konten seperti agregator berita dan agregator pekerjaan untuk menyediakan data terbaru kepada penggunanya.
Marketing and Sales Campaigns - Pengikis web dapat digunakan untuk mendapatkan data seperti email, nomor telepon, dll. Untuk kampanye penjualan dan pemasaran.
Search Engine Optimization (SEO) - Scraping web banyak digunakan oleh alat SEO seperti SEMRush, Majestic dll. Untuk memberi tahu bisnis bagaimana peringkat mereka untuk kata kunci pencarian yang penting bagi mereka.
Data for Machine Learning Projects - Pengambilan data untuk proyek pembelajaran mesin bergantung pada scraping web.
Data for Research - Peneliti dapat mengumpulkan data yang berguna untuk tujuan pekerjaan penelitian mereka dengan menghemat waktu mereka dengan proses otomatis ini.
Komponen Web Scraper
Scraper web terdiri dari komponen berikut -
Modul Web Crawler
Komponen pengikis web yang sangat diperlukan, modul perayap web, digunakan untuk menavigasi situs web target dengan membuat permintaan HTTP atau HTTPS ke URL. Crawler mendownload data tidak terstruktur (konten HTML) dan meneruskannya ke ekstraktor, modul berikutnya.
Alat pengambilan sari
Ekstraktor memproses konten HTML yang diambil dan mengekstrak data ke dalam format semistruktur. Ini juga disebut sebagai modul parser dan menggunakan teknik parsing yang berbeda seperti Regular expression, HTML Parsing, DOM parsing atau Artificial Intelligence untuk fungsinya.
Modul Transformasi dan Pembersihan Data
Data yang diekstrak di atas tidak cocok untuk digunakan secara siap pakai. Itu harus melewati beberapa modul pembersihan agar kita bisa menggunakannya. Metode seperti manipulasi string atau ekspresi reguler dapat digunakan untuk tujuan ini. Perhatikan bahwa ekstraksi dan transformasi juga dapat dilakukan dalam satu langkah.
Modul Penyimpanan
Setelah mengekstrak data, kami perlu menyimpannya sesuai kebutuhan kami. Modul penyimpanan akan mengeluarkan data dalam format standar yang dapat disimpan dalam database atau format JSON atau CSV.
Bekerja dari Web Scraper
Pengikis web dapat didefinisikan sebagai perangkat lunak atau skrip yang digunakan untuk mengunduh konten dari beberapa halaman web dan mengekstrak data darinya.
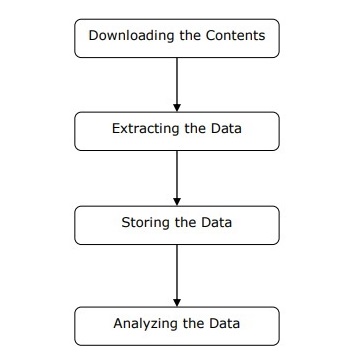
Kita dapat memahami cara kerja pengikis web dalam langkah-langkah sederhana seperti yang ditunjukkan pada diagram di atas.
Langkah 1: Mengunduh Konten dari Halaman Web
Pada langkah ini, web scraper akan mengunduh konten yang diminta dari beberapa halaman web.
Langkah 2: Mengekstrak Data
Data di situs web adalah HTML dan sebagian besar tidak terstruktur. Karenanya, pada langkah ini, web scraper akan mengurai dan mengekstrak data terstruktur dari konten yang diunduh.
Langkah 3: Menyimpan Data
Di sini, pengikis web akan menyimpan dan menyimpan data yang diekstrak dalam format apa pun seperti CSV, JSON, atau dalam database.
Langkah 4: Menganalisis Data
Setelah semua langkah tersebut berhasil dilakukan, web scraper akan menganalisis data yang diperoleh.