Teradata - Panduan Cepat
Apa itu Teradata?
Teradata adalah salah satu Sistem Manajemen Database Relasional yang populer. Ini terutama cocok untuk membangun aplikasi pergudangan data skala besar. Teradata mencapai ini dengan konsep paralelisme. Ini dikembangkan oleh perusahaan bernama Teradata.
Sejarah Teradata
Berikut ini adalah ringkasan singkat dari sejarah Teradata, daftar tonggak utama.
1979 - Teradata dimasukkan.
1984 - Rilis komputer database pertama DBC / 1012.
1986- Majalah Fortune menyebut Teradata sebagai 'Product of the Year'.
1999 - Database terbesar di dunia menggunakan Teradata dengan 130 Terabytes.
2002 - Teradata V2R5 dirilis dengan Partition Primary Index dan kompresi.
2006 - Peluncuran solusi Manajemen Data Master Teradata.
2008 - Teradata 13.0 dirilis dengan Active Data Warehousing.
2011 - Mengakuisisi Teradata Aster dan masuk ke Ruang Analisis Lanjutan.
2012 - Teradata 14.0 diperkenalkan.
2014 - Teradata 15.0 diperkenalkan.
Fitur Teradata
Berikut adalah beberapa fitur Teradata -
Unlimited Parallelism- Sistem database teradata didasarkan pada Arsitektur Massively Parallel Processing (MPP). Arsitektur MPP membagi beban kerja secara merata di seluruh sistem. Sistem teradata membagi tugas di antara prosesnya dan menjalankannya secara paralel untuk memastikan bahwa tugas diselesaikan dengan cepat.
Shared Nothing Architecture- Arsitektur Teradata disebut dengan Shared Nothing Architecture. Node Teradata, Pemroses Modul Akses (AMP), dan disk yang terkait dengan AMP bekerja secara independen. Mereka tidak dibagikan dengan orang lain.
Linear Scalability- Sistem teradata sangat skalabel. Mereka dapat menskalakan hingga 2048 Node. Misalnya, Anda dapat menggandakan kapasitas sistem dengan menggandakan jumlah AMP.
Connectivity - Teradata dapat terhubung ke sistem yang terpasang pada Saluran seperti Mainframe atau sistem yang terhubung ke Jaringan.
Mature Optimizer- Pengoptimal teradata adalah salah satu pengoptimal yang matang di pasar. Ini telah dirancang agar paralel sejak awal. Itu telah disempurnakan untuk setiap rilis.
SQL- Teradata mendukung SQL standar industri untuk berinteraksi dengan data yang disimpan dalam tabel. Selain itu, ia menyediakan ekstensi sendiri.
Robust Utilities - Teradata menyediakan utilitas yang kuat untuk mengimpor / mengekspor data dari / ke sistem Teradata seperti FastLoad, MultiLoad, FastExport, dan TPT.
Automatic Distribution - Teradata secara otomatis mendistribusikan data secara merata ke disk tanpa intervensi manual.
Teradata menyediakan Teradata express untuk VMWARE yang merupakan mesin virtual Teradata yang beroperasi penuh. Ini menyediakan penyimpanan hingga 1 terabyte. Teradata menyediakan VMware versi 40GB dan 1TB.
Prasyarat
Karena VM 64 bit, CPU Anda harus mendukung 64-bit.
Langkah Instalasi untuk Windows
Step 1 - Unduh versi VM yang diperlukan dari tautan, https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 - Ekstrak file dan tentukan folder target.
Step 3 - Unduh pemutar VMWare Workstation dari tautan, https://my.vmware.com/web/vmware/downloads. Ini tersedia untuk Windows dan Linux. Unduh pemutar stasiun kerja VMWARE untuk Windows.
Step 4 - Setelah pengunduhan selesai, instal perangkat lunak.
Step 5 - Setelah penginstalan selesai, jalankan klien VMWARE.
Step 6- Pilih 'Buka Mesin Virtual'. Arahkan melalui folder Teradata VMWare yang diekstrak dan pilih file dengan ekstensi .vmdk.
Step 7- Teradata VMWare ditambahkan ke klien VMWare. Pilih Teradata VMware yang ditambahkan dan klik 'Mainkan Mesin Virtual'.

Step 8 - Jika Anda mendapatkan popup tentang pembaruan perangkat lunak, Anda dapat memilih 'Ingatkan Saya Nanti'.
Step 9 - Masukkan nama pengguna sebagai root, tekan tab dan masukkan kata sandi sebagai root dan sekali lagi tekan Enter.
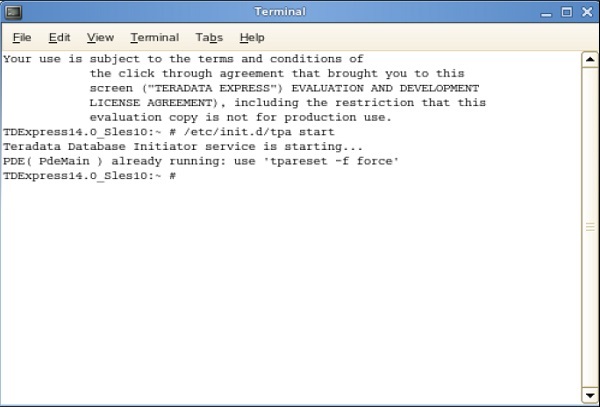
Step 10- Setelah layar berikut muncul di desktop, klik dua kali pada 'root's home'. Kemudian klik dua kali pada 'Terminal Genome'. Ini akan membuka Shell.

Step 11- Dari shell berikut, masukkan perintah /etc/init.d/tpa start. Ini akan memulai server Teradata.
Memulai BTEQ
Utilitas BTEQ digunakan untuk mengirimkan kueri SQL secara interaktif. Berikut adalah langkah-langkah untuk memulai utilitas BTEQ.
Step 1 - Masukkan perintah / sbin / ifconfig dan catat alamat IP VMWare.
Step 2- Jalankan perintah bteq. Pada prompt logon, masukkan perintah.
Logon <ipaddress> / dbc, dbc; dan masukkan Pada prompt kata sandi, masukkan kata sandi sebagai dbc;
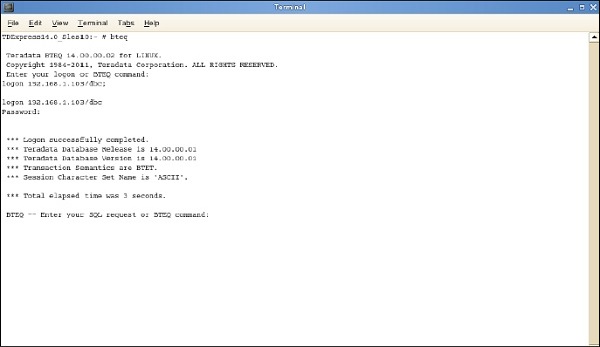
Anda dapat masuk ke sistem Teradata menggunakan BTEQ dan menjalankan kueri SQL apa pun.
Arsitektur teradata didasarkan pada arsitektur Massively Parallel Processing (MPP). Komponen utama Teradata adalah Parsing Engine, BYNET, dan Access Module Processors (AMPs). Diagram berikut menunjukkan arsitektur tingkat tinggi dari Teradata Node.
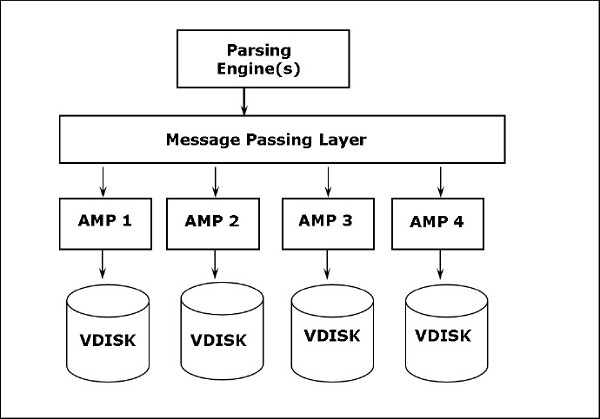
Komponen Teradata
Komponen utama Teradata adalah sebagai berikut -
Node- Ini adalah unit dasar dalam Sistem Teradata. Setiap server individu dalam sistem Teradata disebut sebagai Node. Node terdiri dari sistem operasinya sendiri, CPU, memori, salinan sendiri dari perangkat lunak RDBMS Teradata, dan ruang disk. Kabinet terdiri dari satu atau lebih Node.
Parsing Engine- Parsing Engine bertanggung jawab untuk menerima pertanyaan dari klien dan menyiapkan rencana eksekusi yang efisien. Tanggung jawab mesin parsing adalah -
Terima kueri SQL dari klien
Parse pemeriksaan kueri SQL untuk kesalahan sintaks
Periksa apakah pengguna memerlukan hak istimewa terhadap objek yang digunakan dalam kueri SQL
Periksa apakah objek yang digunakan dalam SQL benar-benar ada
Siapkan rencana eksekusi untuk mengeksekusi kueri SQL dan teruskan ke BYNET
Menerima hasil dari AMP dan mengirim ke klien
Message Passing Layer- Message Passing Layer yang disebut BYNET, adalah lapisan jaringan dalam sistem Teradata. Ini memungkinkan komunikasi antara PE dan AMP dan juga antara node. Ini menerima rencana eksekusi dari Parsing Engine dan mengirim ke AMP. Demikian pula, ini menerima hasil dari AMP dan mengirimnya ke Parsing Engine.
Access Module Processor (AMP)- AMP, disebut sebagai Prosesor Virtual (vprocs) adalah yang benar-benar menyimpan dan mengambil data. AMP menerima data dan rencana eksekusi dari Parsing Engine, melakukan semua jenis konversi data, agregasi, filter, pengurutan, dan menyimpan data dalam disk yang terkait dengannya. Catatan dari tabel didistribusikan secara merata di antara AMP dalam sistem. Setiap AMP dikaitkan dengan sekumpulan disk tempat data disimpan. Hanya AMP itu yang dapat membaca / menulis data dari disk.
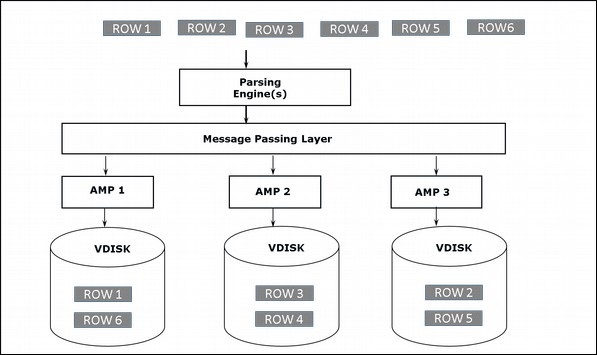
Arsitektur Penyimpanan
Ketika klien menjalankan kueri untuk menyisipkan catatan, mesin Parsing mengirimkan catatan ke BYNET. BYNET mengambil record dan mengirimkan baris tersebut ke AMP target. AMP menyimpan catatan ini di disknya. Diagram berikut menunjukkan arsitektur penyimpanan Teradata.
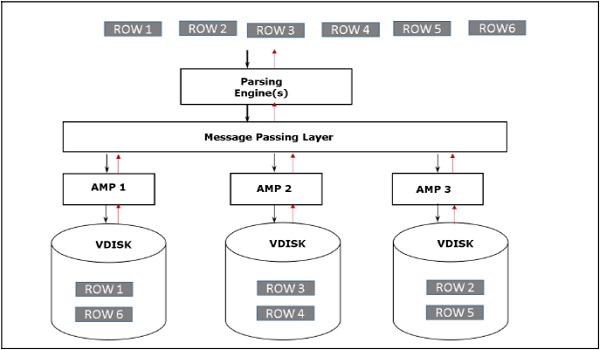
Arsitektur Retrieval
Ketika klien menjalankan kueri untuk mengambil rekaman, mesin Parsing mengirimkan permintaan ke BYNET. BYNET mengirimkan permintaan pengambilan ke AMP yang sesuai. Kemudian AMP mencari disk mereka secara paralel dan mengidentifikasi catatan yang diperlukan dan mengirimkannya ke BYNET. BYNET kemudian mengirimkan catatan ke Parsing Engine yang pada gilirannya akan dikirim ke klien. Berikut ini adalah arsitektur pengambilan Teradata.
Relational Database Management System (RDBMS) adalah perangkat lunak DBMS yang membantu untuk berinteraksi dengan database. Mereka menggunakan Structured Query Language (SQL) untuk berinteraksi dengan data yang disimpan dalam tabel.
Database
Database adalah kumpulan data yang berhubungan secara logis. Mereka diakses oleh banyak pengguna untuk tujuan berbeda. Misalnya, database penjualan berisi seluruh informasi tentang penjualan yang disimpan di banyak tabel.
Tabel
Tabel adalah unit dasar dalam RDBMS tempat data disimpan. Tabel adalah kumpulan baris dan kolom. Berikut adalah contoh tabel karyawan.
| KaryawanNo | Nama depan | Nama keluarga | Tanggal lahir |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 6/11/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 1/12/1984 |
| 103 | Peter | Paul | 1/4/1983 |
Kolom
Sebuah kolom berisi data serupa. Misalnya, kolom BirthDate di tabel Employee berisi informasi birth_date untuk semua karyawan.
| Tanggal lahir |
|---|
| 1/5/1980 |
| 6/11/1984 |
| 3/5/1983 |
| 1/12/1984 |
| 1/4/1983 |
Baris
Baris adalah salah satu contoh dari semua kolom. Misalnya, dalam tabel karyawan satu baris berisi informasi tentang satu karyawan.
| KaryawanNo | Nama depan | Nama keluarga | Tanggal lahir |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
Kunci utama
Kunci utama digunakan untuk mengidentifikasi baris dalam tabel secara unik. Tidak ada nilai duplikat yang diperbolehkan dalam kolom kunci utama dan mereka tidak dapat menerima nilai NULL. Ini adalah bidang wajib dalam tabel.
Kunci asing
Kunci asing digunakan untuk membangun hubungan antar tabel. Kunci asing dalam tabel anak didefinisikan sebagai kunci utama dalam tabel induk. Sebuah tabel dapat memiliki lebih dari satu kunci asing. Itu dapat menerima nilai duplikat dan juga nilai nol. Kunci asing adalah opsional dalam tabel.
Setiap kolom dalam tabel dikaitkan dengan tipe data. Tipe data menentukan jenis nilai apa yang akan disimpan di kolom. Teradata mendukung beberapa tipe data. Berikut adalah beberapa tipe data yang sering digunakan.
| Jenis Data | Panjang (Bytes) | Jarak nilai |
|---|---|---|
| BYTEINT | 1 | -128 hingga +127 |
| SMALLINT | 2 | -32768 hingga +32767 |
| BILANGAN BULAT | 4 | -2,147,483,648 hingga +2147,483,647 |
| BIGINT | 8 | -9,233,372,036,854,775,80 8 hingga +9,233,372,036,854,775,8 07 |
| DESIMAL | 1-16 | |
| NUMERIK | 1-16 | |
| MENGAPUNG | 8 | Format IEEE |
| ARANG | Format Tetap | 1-64,000 |
| VARCHAR | Variabel | 1-64,000 |
| TANGGAL | 4 | YYYYYMMDD |
| WAKTU | 6 atau 8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| TIMESTAMP | 10 atau 12 | YYMMDDHHMMSS.nnnnnn or YYMMDDHHMMSS.nnnnnn + HHMM |
Tabel dalam model Relasional didefinisikan sebagai kumpulan data. Mereka direpresentasikan sebagai baris dan kolom.
Jenis Tabel
Tipe Teradata mendukung tipe tabel yang berbeda.
Permanent Table - Ini adalah tabel default dan berisi data yang dimasukkan oleh pengguna dan menyimpan data secara permanen.
Volatile Table- Data yang dimasukkan ke dalam tabel volatil disimpan hanya selama sesi pengguna. Tabel dan data dihapus di akhir sesi. Tabel ini terutama digunakan untuk menyimpan data perantara selama transformasi data.
Global Temporary Table - Definisi tabel Global Temporary tetap ada tetapi data dalam tabel dihapus di akhir sesi pengguna.
Derived Table- Tabel turunan memegang hasil antara dalam kueri. Masa pakai mereka ada dalam kueri tempat mereka dibuat, digunakan, dan dijatuhkan.
Setel versus Multiset
Teradata mengklasifikasikan tabel sebagai tabel SET atau MULTISET berdasarkan bagaimana catatan duplikat ditangani. Tabel yang ditentukan sebagai tabel SET tidak menyimpan catatan duplikat, sedangkan tabel MULTISET dapat menyimpan catatan duplikat.
| Sr Tidak | Perintah & Deskripsi Tabel |
|---|---|
| 1 | Buat tabel Perintah CREATE TABLE digunakan untuk membuat tabel di Teradata. |
| 2 | Alter Table Perintah ALTER TABLE digunakan untuk menambah atau melepas kolom dari tabel yang sudah ada. |
| 3 | Meja Taruh Perintah DROP TABLE digunakan untuk menjatuhkan tabel. |
Bab ini memperkenalkan perintah SQL yang digunakan untuk memanipulasi data yang disimpan dalam tabel Teradata.
Sisipkan Rekaman
Pernyataan INSERT INTO digunakan untuk memasukkan record ke dalam tabel.
Sintaksis
Berikut ini adalah sintaks umum untuk INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);Contoh
Contoh berikut menyisipkan rekaman ke dalam tabel karyawan.
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);Setelah query di atas dimasukkan, Anda dapat menggunakan pernyataan SELECT untuk melihat record dari tabel.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartemenNo | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
Sisipkan dari Tabel Lain
Pernyataan INSERT SELECT digunakan untuk memasukkan record dari tabel lain.
Sintaksis
Berikut ini adalah sintaks umum untuk INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;Contoh
Contoh berikut menyisipkan rekaman ke dalam tabel karyawan. Buat tabel bernama Employee_Bkup dengan definisi kolom yang sama dengan tabel karyawan sebelum menjalankan kueri sisipkan berikut ini.
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;Ketika query di atas dijalankan, semua record dari tabel karyawan akan dimasukkan ke dalam tabel employee_bkup.
Aturan
Jumlah kolom yang ditentukan dalam daftar VALUES harus sesuai dengan kolom yang ditentukan dalam klausa INSERT INTO.
Nilai wajib diisi untuk kolom NOT NULL.
Jika tidak ada nilai yang ditentukan, maka NULL dimasukkan untuk bidang nullable.
Jenis data kolom yang ditentukan dalam klausa VALUES harus kompatibel dengan jenis data kolom dalam klausa INSERT.
Perbarui Rekaman
Pernyataan UPDATE digunakan untuk memperbarui catatan dari tabel.
Sintaksis
Berikut ini adalah sintaks generik untuk UPDATE.
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];Contoh
Contoh berikut memperbarui karyawan dept 03 untuk karyawan 101.
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;Pada keluaran berikut, Anda dapat melihat bahwa DepartmentNo diperbarui dari 1 menjadi 3 untuk EmployeeNo 101.
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3Aturan
Anda dapat memperbarui satu atau beberapa nilai tabel.
Jika kondisi WHERE tidak ditentukan maka semua baris tabel akan terpengaruh.
Anda dapat memperbarui tabel dengan nilai dari tabel lain.
Hapus Rekaman
DELETE FROM pernyataan digunakan untuk memperbarui catatan dari tabel.
Sintaksis
Berikut ini adalah sintaks umum untuk DELETE FROM.
DELETE FROM <tablename>
[WHERE condition];Contoh
Contoh berikut menghapus karyawan 101 dari karyawan tabel.
DELETE FROM Employee
WHERE EmployeeNo = 101;Pada output berikut, Anda dapat melihat karyawan 101 dihapus dari tabel.
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.Aturan
Anda dapat memperbarui satu atau lebih rekaman tabel.
Jika kondisi WHERE tidak ditentukan maka semua baris tabel akan dihapus.
Anda dapat memperbarui tabel dengan nilai dari tabel lain.
Pernyataan SELECT digunakan untuk mengambil record dari tabel.
Sintaksis
Berikut ini adalah sintaks dasar dari pernyataan SELECT.
SELECT
column 1, column 2, .....
FROM
tablename;Contoh
Perhatikan tabel karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartemenNo | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25/4/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21/3/2007 | 2 | 1/4/1983 |
| 104 | Alex | Stuart | 1/2/2008 | 2 | 6/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 1/12/1984 |
Berikut adalah contoh pernyataan SELECT.
SELECT EmployeeNo,FirstName,LastName
FROM Employee;Ketika kueri ini dijalankan, ia mengambil kolom EmployeeNo, FirstName, dan LastName dari tabel karyawan.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulJika Anda ingin mengambil semua kolom dari tabel, Anda dapat menggunakan perintah berikut alih-alih mencantumkan semua kolom.
SELECT * FROM Employee;Kueri di atas akan mengambil semua catatan dari tabel karyawan.
Klausul WHERE
Klausa WHERE digunakan untuk memfilter catatan yang dikembalikan oleh pernyataan SELECT. Kondisi terkait dengan klausa WHERE. Hanya, catatan yang memenuhi kondisi di klausa WHERE akan dikembalikan.
Sintaksis
Berikut ini adalah sintaks dari pernyataan SELECT dengan klausa WHERE.
SELECT * FROM tablename
WHERE[condition];Contoh
Kueri berikut mengambil rekaman dengan EmployeeNo adalah 101.
SELECT * FROM Employee
WHERE EmployeeNo = 101;Saat kueri ini dijalankan, ia mengembalikan rekaman berikut.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike JamesDIPESAN OLEH
Ketika pernyataan SELECT dijalankan, baris yang dikembalikan tidak berada dalam urutan tertentu. Klausa ORDER BY digunakan untuk mengatur catatan dalam urutan naik / turun pada kolom apa pun.
Sintaksis
Berikut adalah sintaks dari pernyataan SELECT dengan klausa ORDER BY.
SELECT * FROM tablename
ORDER BY column 1, column 2..;Contoh
Kueri berikut mengambil rekaman dari tabel karyawan dan mengurutkan hasil berdasarkan NamaDepan.
SELECT * FROM Employee
ORDER BY FirstName;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesGRUP OLEH
Klausa GROUP BY digunakan dengan pernyataan SELECT dan mengatur rekaman serupa ke dalam grup.
Sintaksis
Berikut ini adalah sintaks dari pernyataan SELECT dengan klausa GROUP BY.
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;Contoh
Contoh berikut mengelompokkan catatan menurut kolom DepartmentNo dan mengidentifikasi jumlah total dari setiap departemen.
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradata mendukung operator logis dan bersyarat berikut. Operator ini digunakan untuk melakukan perbandingan dan menggabungkan beberapa kondisi.
| Sintaksis | Berarti |
|---|---|
| > | Lebih besar dari |
| < | Kurang dari |
| >= | Lebih dari atau sama dengan |
| <= | Kurang dari atau sama dengan |
| = | Sama dengan |
| BETWEEN | Jika nilai dalam jangkauan |
| IN | Jika nilai dalam <ekspresi> |
| NOT IN | Jika nilai tidak ada dalam <ekspresi> |
| IS NULL | Jika nilainya NULL |
| IS NOT NULL | Jika nilainya NOT NULL |
| AND | Gabungkan beberapa kondisi. Mengevaluasi menjadi benar hanya jika semua ketentuan terpenuhi |
| OR | Gabungkan beberapa kondisi. Mengevaluasi menjadi benar hanya jika salah satu ketentuan terpenuhi. |
| NOT | Membalik arti dari kondisi |
ANTARA
Perintah BETWEEN digunakan untuk memeriksa apakah suatu nilai berada dalam kisaran nilai.
Contoh
Perhatikan tabel karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartemenNo | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25/4/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21/3/2007 | 2 | 1/4/1983 |
| 104 | Alex | Stuart | 1/2/2008 | 2 | 6/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 1/12/1984 |
Contoh berikut mengambil rekaman dengan nomor karyawan dalam kisaran antara 101.102 dan 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;Ketika kueri di atas dijalankan, ia mengembalikan catatan karyawan dengan no karyawan antara 101 dan 103.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterDI
Perintah IN digunakan untuk memeriksa nilai terhadap daftar nilai yang diberikan.
Contoh
Contoh berikut mengambil catatan dengan nomor karyawan di 101, 102 dan 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);Kueri di atas mengembalikan rekaman berikut.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterTIDAK MASUK
Perintah NOT IN membalikkan hasil dari perintah IN. Itu mengambil catatan dengan nilai yang tidak cocok dengan daftar yang diberikan.
Contoh
Contoh berikut mengambil record dengan nomor karyawan bukan 101, 102 dan 103.
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);Kueri di atas mengembalikan rekaman berikut.
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert JamesOperator SET menggabungkan hasil dari beberapa pernyataan SELECT. Ini mungkin terlihat mirip dengan Gabungan, tetapi gabungan menggabungkan kolom dari beberapa tabel sedangkan operator SET menggabungkan baris dari beberapa baris.
Aturan
Jumlah kolom dari setiap pernyataan SELECT harus sama.
Tipe data dari setiap SELECT harus kompatibel.
ORDER BY harus disertakan hanya dalam pernyataan SELECT terakhir.
PERSATUAN
Pernyataan UNION digunakan untuk menggabungkan hasil dari beberapa pernyataan SELECT. Ini mengabaikan duplikat.
Sintaksis
Berikut ini adalah sintaks dasar dari pernyataan UNION.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Contoh
Perhatikan tabel karyawan dan tabel gaji berikut.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartemenNo | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25/4/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21/3/2007 | 2 | 1/4/1983 |
| 104 | Alex | Stuart | 1/2/2008 | 2 | 6/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 1/12/1984 |
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Kueri UNION berikut menggabungkan nilai EmployeeNo dari tabel Employee dan Gaji.
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;Ketika kueri dijalankan, itu menghasilkan keluaran berikut.
EmployeeNo
-----------
101
102
103
104
105UNI SEMUA
Pernyataan UNION ALL mirip dengan UNION, ini menggabungkan hasil dari beberapa tabel termasuk baris duplikat.
Sintaksis
Berikut ini adalah sintaks dasar dari pernyataan UNION ALL.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Contoh
Berikut adalah contoh pernyataan UNION ALL.
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Anda dapat melihat bahwa ia juga mengembalikan duplikat.
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103MEMOTONG
Perintah INTERSECT juga digunakan untuk menggabungkan hasil dari beberapa pernyataan SELECT. Ini mengembalikan baris dari pernyataan SELECT pertama yang memiliki kecocokan yang sesuai dalam pernyataan SELECT kedua. Dengan kata lain, ini mengembalikan baris yang ada di kedua pernyataan SELECT.
Sintaksis
Berikut ini adalah sintaks dasar dari pernyataan INTERSECT.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Contoh
Berikut adalah contoh pernyataan INTERSECT. Ini mengembalikan nilai EmployeeNo yang ada di kedua tabel.
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;Saat kueri di atas dijalankan, ia mengembalikan rekaman berikut. EmployeeNo 105 dikecualikan karena tidak ada di tabel SALARY.
EmployeeNo
-----------
101
104
102
103MINUS / KECUALI
MINUS / EXCEPT perintah menggabungkan baris dari beberapa tabel dan mengembalikan baris yang ada di SELECT pertama tetapi tidak di SELECT kedua. Keduanya memberikan hasil yang sama.
Sintaksis
Berikut ini adalah sintaks dasar dari pernyataan MINUS.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Contoh
Berikut adalah contoh pernyataan MINUS.
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;Ketika kueri ini dijalankan, ia mengembalikan rekaman berikut.
EmployeeNo
-----------
105Teradata menyediakan beberapa fungsi untuk memanipulasi string. Fungsi ini kompatibel dengan standar ANSI.
| Sr Tidak | Fungsi & Deskripsi String |
|---|---|
| 1 | || Menggabungkan string menjadi satu |
| 2 | SUBSTR Mengekstrak sebagian dari string (ekstensi Teradata) |
| 3 | SUBSTRING Mengekstrak sebagian string (standar ANSI) |
| 4 | INDEX Menemukan posisi karakter dalam string (ekstensi Teradata) |
| 5 | POSITION Menemukan posisi karakter dalam string (standar ANSI) |
| 6 | TRIM Memangkas kosong dari string |
| 7 | UPPER Mengonversi string menjadi huruf besar |
| 8 | LOWER Mengonversi string menjadi huruf kecil |
Contoh
Tabel berikut mencantumkan beberapa fungsi string dengan hasilnya.
| Fungsi String | Hasil |
|---|---|
| PILIH SUBSTRING ('gudang' DARI 1 UNTUK 4) | ware |
| PILIH SUBSTR ('gudang', 1,4) | ware |
| PILIH 'data' || '' || 'gudang' | gudang data |
| PILIH ATAS ('data') | DATA |
| PILIH LEBIH RENDAH ('DATA') | data |
Bab ini membahas fungsi tanggal / waktu yang tersedia di Teradata.
Tanggal Penyimpanan
Tanggal disimpan sebagai bilangan bulat secara internal menggunakan rumus berikut.
((YEAR - 1900) * 10000) + (MONTH * 100) + DAYAnda dapat menggunakan kueri berikut ini untuk memeriksa bagaimana tanggal disimpan.
SELECT CAST(CURRENT_DATE AS INTEGER);Karena tanggal disimpan sebagai bilangan bulat, Anda dapat melakukan beberapa operasi aritmatika padanya. Teradata menyediakan fungsi untuk melakukan operasi ini.
EKSTRAK
Fungsi EXTRACT mengekstrak bagian hari, bulan dan tahun dari nilai DATE. Fungsi ini juga digunakan untuk mengekstrak jam, menit dan detik dari nilai TIME / TIMESTAMP.
Contoh
Contoh berikut memperlihatkan cara mengekstrak nilai Tahun, Bulan, Tanggal, Jam, Menit, dan detik dari nilai Tanggal dan Stempel Waktu.
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000SELANG
Teradata menyediakan fungsi INTERVAL untuk melakukan operasi aritmatika pada nilai DATE dan TIME. Ada dua jenis fungsi INTERVAL.
Interval Tahun-Bulan
- YEAR
- TAHUN KE BULAN
- MONTH
Interval Siang Hari
- DAY
- HARI KE JAM
- HARI KE MENIT
- HARI KE KEDUA
- HOUR
- JAM KE MENIT
- JAM SAMPAI KEDUA
- MINUTE
- MENIT KE KEDUA
- SECOND
Contoh
Contoh berikut menambahkan 3 tahun ke tanggal sekarang.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01Contoh berikut menambahkan 3 tahun dan 01 bulan ke tanggal sekarang.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01Contoh berikut menambahkan 01 hari, 05 jam dan 10 menit ke stempel waktu saat ini.
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradata menyediakan fungsi bawaan yang merupakan ekstensi ke SQL. Berikut ini adalah fungsi bawaan yang umum.
| Fungsi | Hasil |
|---|---|
| PILIH TANGGAL; | Tanggal -------- 16/01/01 |
| PILIH CURRENT_DATE; | Tanggal -------- 16/01/01 |
| PILIH WAKTU; | Waktu -------- 04:50:29 |
| PILIH CURRENT_TIME; | Waktu -------- 04:50:29 |
| PILIH CURRENT_TIMESTAMP; | Stempel Waktu Saat Ini (6) -------------------------------- 01-01 2016 04: 51: 06,990000 + 00: 00 |
| PILIH DATABASE; | Basis data ------------------------------ TDUSER |
Teradata mendukung fungsi agregat umum. Mereka dapat digunakan dengan pernyataan SELECT.
COUNT - Menghitung baris
SUM - Meringkas nilai dari kolom tertentu
MAX - Mengembalikan nilai besar dari kolom yang ditentukan
MIN - Mengembalikan nilai minimum dari kolom yang ditentukan
AVG - Mengembalikan nilai rata-rata dari kolom yang ditentukan
Contoh
Perhatikan Tabel Gaji berikut ini.
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 104 | 75.000 | 5.000 | 70.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 105 | 70.000 | 4.000 | 66.000 |
| 103 | 90.000 | 7.000 | 83.000 |
MENGHITUNG
Contoh berikut menghitung jumlah catatan dalam tabel Gaji.
SELECT count(*) from Salary;
Count(*)
-----------
5MAKS
Contoh berikut mengembalikan nilai gaji bersih karyawan maksimum.
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000MIN
Contoh berikut mengembalikan nilai gaji bersih karyawan minimum dari tabel Gaji.
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000AVG
Contoh berikut mengembalikan rata-rata nilai gaji bersih karyawan dari tabel.
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800JUMLAH
Contoh berikut menghitung jumlah gaji bersih karyawan dari semua catatan tabel Gaji.
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000Bab ini menjelaskan fungsi CASE dan COALESCE dari Teradata.
Ekspresi CASE
Ekspresi CASE mengevaluasi setiap baris terhadap kondisi atau klausa WHEN dan mengembalikan hasil dari kecocokan pertama. Jika tidak ada yang cocok maka hasil dari ELSE bagian dari dikembalikan.
Sintaksis
Berikut ini adalah sintaks dari ekspresi CASE.
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
ENDContoh
Perhatikan tabel Karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartemenNo | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25/4/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21/3/2007 | 2 | 1/4/1983 |
| 104 | Alex | Stuart | 1/2/2008 | 2 | 6/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 1/12/1984 |
Contoh berikut mengevaluasi kolom DepartmentNo dan mengembalikan nilai 1 jika nomor departemen adalah 1; mengembalikan 2 jika nomor departemen adalah 3; jika tidak, ia mengembalikan nilai sebagai departemen yang tidak valid.
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 ITEkspresi CASE di atas juga bisa ditulis dalam bentuk berikut yang akan menghasilkan hasil yang sama seperti di atas.
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;BERSATU
COALESCE adalah pernyataan yang mengembalikan nilai bukan-null pertama dari ekspresi tersebut. Ia mengembalikan NULL jika semua argumen ekspresi mengevaluasi ke NULL. Berikut adalah sintaksnya.
Sintaksis
COALESCE(expression 1, expression 2, ....)Contoh
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
Pernyataan NULLIF mengembalikan NULL jika argumennya sama.
Sintaksis
Berikut ini adalah sintaks dari pernyataan NULLIF.
NULLIF(expression 1, expression 2)Contoh
Contoh berikut mengembalikan NULL jika DepartmentNo sama dengan 3. Jika tidak, ia mengembalikan nilai DepartmentNo.
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;Kueri di atas mengembalikan rekaman berikut. Anda dapat melihat bahwa karyawan 105 memiliki no departemen. sebagai NULL.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2Indeks utama digunakan untuk menentukan di mana data berada di Teradata. Ini digunakan untuk menentukan AMP mana yang mendapatkan baris data. Setiap tabel di Teradata harus memiliki indeks utama yang ditentukan. Jika indeks utama tidak ditentukan, Teradata secara otomatis menetapkan indeks utama. Indeks utama menyediakan cara tercepat untuk mengakses data. Utama dapat memiliki maksimal 64 kolom.
Indeks utama ditentukan saat membuat tabel. Ada 2 jenis Indeks Utama.
- Indeks Utama Unik (UPI)
- Indeks Utama Tidak Unik (NUPI)
Indeks Utama Unik (UPI)
Jika tabel ditetapkan memiliki UPI, maka kolom yang dianggap sebagai UPI tidak boleh memiliki nilai duplikat. Jika ada nilai duplikat yang disisipkan, nilai tersebut akan ditolak.
Buat Indeks Utama Unik
Contoh berikut membuat tabel Gaji dengan kolom EmployeeNo sebagai Unique Primary Index.
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Indeks Utama Tidak Unik (NUPI)
Jika tabel ditetapkan memiliki NUPI, maka kolom yang dianggap UPI dapat menerima nilai duplikat.
Buat Indeks Utama Tidak Unik
Contoh berikut membuat tabel akun karyawan dengan kolom EmployeeNo sebagai Non Unique Primary Index. EmployeeNo didefinisikan sebagai Non Unique Primary Index karena seorang karyawan dapat memiliki banyak akun di tabel; satu untuk akun gaji dan satu lagi untuk akun reimbursement.
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);Gabung digunakan untuk menggabungkan rekaman dari lebih dari satu tabel. Tabel digabungkan berdasarkan kolom / nilai umum dari tabel ini.
Ada berbagai jenis Gabungan yang tersedia.
- Gabung Batin
- Gabung Luar Kiri
- Gabung Luar Kanan
- Gabung Luar Penuh
- Bergabung Sendiri
- Gabung Silang
- Produksi Cartesian Bergabung
GABUNG DALAM
Inner Join menggabungkan catatan dari beberapa tabel dan mengembalikan nilai yang ada di kedua tabel.
Sintaksis
Berikut ini adalah sintaks dari pernyataan INNER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Contoh
Perhatikan tabel karyawan dan tabel gaji berikut.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartemenNo | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25/4/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21/3/2007 | 2 | 1/4/1983 |
| 104 | Alex | Stuart | 1/2/2008 | 2 | 6/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 1/12/1984 |
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Kueri berikut ini menggabungkan tabel Karyawan dan tabel Gaji di kolom umum EmployeeNo. Setiap tabel diberi alias A & B dan kolom direferensikan dengan alias yang benar.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);Saat kueri di atas dijalankan, ia mengembalikan rekaman berikut. Karyawan 105 tidak disertakan dalam hasil karena tidak memiliki catatan yang cocok di tabel Gaji.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000OUTER GABUNG
LEFT OUTER JOIN dan RIGHT OUTER JOIN juga menggabungkan hasil dari beberapa tabel.
LEFT OUTER JOIN mengembalikan semua rekaman dari tabel kiri dan hanya mengembalikan rekaman yang cocok dari tabel kanan.
RIGHT OUTER JOIN mengembalikan semua rekaman dari tabel kanan dan hanya mengembalikan baris yang cocok dari tabel kiri.
FULL OUTER JOINmenggabungkan hasil dari LEFT OUTER dan RIGHT OUTER JOINS. Ini mengembalikan baris yang cocok dan tidak cocok dari tabel yang digabungkan.
Sintaksis
Berikut ini adalah sintaks dari pernyataan OUTER JOIN. Anda perlu menggunakan salah satu opsi dari LEFT OUTER JOIN, RIGHT OUTER JOIN atau FULL OUTER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Contoh
Pertimbangkan contoh berikut dari kueri LEFT OUTER JOIN. Ia mengembalikan semua catatan dari tabel Karyawan dan catatan yang cocok dari tabel Gaji.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Untuk karyawan 105, nilai NetPay adalah NULL, karena tidak memiliki catatan yang cocok dalam tabel Gaji.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?CROSS JOIN
Cross Join menggabungkan setiap baris dari tabel kiri ke setiap baris dari tabel kanan.
Sintaksis
Berikut ini adalah sintaks dari pernyataan CROSS JOIN.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Karyawan No 101 dari tabel Karyawan digabungkan dengan masing-masing dan setiap catatan dari Tabel Gaji.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000Sebuah subkueri mengembalikan rekaman dari satu tabel berdasarkan nilai dari tabel lain. Ini adalah kueri SELECT di dalam kueri lain. Kueri SELECT yang disebut sebagai kueri dalam dieksekusi terlebih dahulu dan hasilnya digunakan oleh kueri luar. Beberapa fiturnya yang menonjol adalah -
Kueri bisa memiliki beberapa subkueri dan subkueri mungkin berisi subkueri lain.
Subkueri tidak mengembalikan rekaman duplikat.
Jika subkueri hanya mengembalikan satu nilai, Anda bisa menggunakan = operator untuk menggunakannya dengan kueri luar. Jika mengembalikan beberapa nilai, Anda dapat menggunakan IN atau NOT IN.
Sintaksis
Berikut ini adalah sintaks generik subkueri.
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);Contoh
Perhatikan tabel Gaji berikut.
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Kueri berikut mengidentifikasi nomor karyawan dengan gaji tertinggi. SELECT bagian dalam melakukan fungsi agregasi untuk mengembalikan nilai NetPay maksimum dan kueri SELECT luar menggunakan nilai ini untuk mengembalikan catatan karyawan dengan nilai ini.
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);Ketika kueri ini dijalankan, itu menghasilkan keluaran berikut.
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradata mendukung tipe tabel berikut untuk menyimpan data sementara.
- Tabel Turunan
- Tabel Volatile
- Tabel Sementara Global
Tabel Turunan
Tabel turunan dibuat, digunakan, dan ditempatkan di dalam kueri. Ini digunakan untuk menyimpan hasil antara dalam kueri.
Contoh
Contoh berikut membuat tabel turunan EmpSal dengan catatan karyawan dengan gaji lebih dari 75.000.
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;Ketika kueri di atas dijalankan, ia mengembalikan karyawan dengan gaji lebih dari 75.000.
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000Tabel Volatile
Tabel volatil dibuat, digunakan, dan dijatuhkan dalam sesi pengguna. Definisi mereka tidak disimpan dalam kamus data. Mereka menyimpan data perantara dari kueri yang sering digunakan. Berikut adalah sintaksnya.
Sintaksis
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWSContoh
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
*** Table has been created.
*** Total elapsed time was 1 second.Tabel Sementara Global
Definisi tabel Global Temporary disimpan dalam kamus data dan dapat digunakan oleh banyak pengguna / sesi. Tetapi data yang dimuat ke tabel sementara global disimpan hanya selama sesi. Anda dapat membuat hingga 2000 tabel sementara global per sesi. Berikut adalah sintaksnya.
Sintaksis
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>Contoh
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
*** Table has been created.
*** Total elapsed time was 1 second.Ada tiga jenis spasi yang tersedia di Teradata.
Ruang Permanen
Ruang permanen adalah jumlah maksimum ruang yang tersedia bagi pengguna / database untuk menampung baris data. Tabel permanen, jurnal, tabel fallback dan sub-tabel indeks sekunder menggunakan spasi permanen.
Ruang permanen tidak dialokasikan sebelumnya untuk database / pengguna. Mereka hanya didefinisikan sebagai jumlah maksimum ruang yang dapat digunakan database / pengguna. Jumlah ruang permanen dibagi dengan jumlah AMP. Setiap kali per batas AMP melebihi, pesan kesalahan akan dibuat.
Spool Space
Spool space adalah ruang permanen yang tidak digunakan yang digunakan oleh sistem untuk menyimpan hasil antara kueri SQL. Pengguna tanpa ruang spool tidak dapat menjalankan kueri apa pun.
Mirip dengan ruang permanen, ruang spool menentukan jumlah maksimum ruang yang dapat digunakan pengguna. Ruang spool dibagi dengan jumlah AMP. Setiap kali per batas AMP melebihi, pengguna akan mendapatkan error ruang spool.
Temp Space
Temp space adalah ruang permanen tidak terpakai yang digunakan oleh tabel-tabel Global Temporary. Ruang temp juga dibagi dengan jumlah AMP.
Tabel hanya dapat berisi satu indeks utama. Lebih sering, Anda akan menemukan skenario di mana tabel berisi kolom lain, yang datanya sering diakses. Teradata akan melakukan pemindaian tabel lengkap untuk kueri tersebut. Indeks sekunder mengatasi masalah ini.
Indeks sekunder adalah jalur alternatif untuk mengakses data. Ada beberapa perbedaan antara indeks primer dan indeks sekunder.
Indeks sekunder tidak terlibat dalam distribusi data.
Nilai indeks sekunder disimpan dalam sub tabel. Tabel ini dibuat di semua AMP.
Indeks sekunder bersifat opsional.
Mereka dapat dibuat selama pembuatan tabel atau setelah tabel dibuat.
Mereka menempati ruang tambahan karena mereka membangun sub-tabel dan mereka juga memerlukan pemeliharaan karena sub-tabel perlu diperbarui untuk setiap baris baru.
Ada dua jenis indeks sekunder -
- Unique Secondary Index (USI)
- Indeks Sekunder Non-Unik (NUSI)
Unique Secondary Index (USI)
Indeks Sekunder Unik hanya mengizinkan nilai unik untuk kolom yang ditentukan sebagai USI. Mengakses baris oleh USI adalah operasi dua amp.
Buat Indeks Sekunder Unik
Contoh berikut membuat USI pada kolom EmployeeNo dari tabel karyawan.
CREATE UNIQUE INDEX(EmployeeNo) on employee;Non Unique Secondary Index (NUSI)
Indeks Sekunder Non-Unik memungkinkan nilai duplikat untuk kolom yang ditentukan sebagai NUSI. Mengakses baris oleh NUSI adalah operasi all-amp.
Buat Indeks Sekunder Non Unik
Contoh berikut membuat NUSI pada kolom FirstName tabel karyawan.
CREATE INDEX(FirstName) on Employee;Pengoptimal teradata hadir dengan strategi eksekusi untuk setiap kueri SQL. Strategi eksekusi ini didasarkan pada statistik yang dikumpulkan di tabel yang digunakan dalam kueri SQL. Statistik di atas tabel dikumpulkan menggunakan perintah KUMPULKAN STATISTIK. Pengoptimal membutuhkan informasi lingkungan dan demografi data untuk menghasilkan strategi eksekusi yang optimal.
Informasi Lingkungan
- Jumlah Node, AMP, dan CPU
- Jumlah memori
Demografi Data
- Jumlah baris
- Ukuran baris
- Rentang nilai dalam tabel
- Jumlah baris per nilai
- Jumlah Nulls
Ada tiga pendekatan untuk mengumpulkan statistik di atas meja.
- Pengambilan Sampel AMP Acak
- Koleksi statistik lengkap
- Menggunakan opsi SAMPEL
Mengumpulkan Statistik
KUMPULKAN STATISTIK perintah digunakan untuk mengumpulkan statistik di atas meja.
Sintaksis
Berikut ini adalah sintaks dasar untuk mengumpulkan statistik di atas meja.
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;Contoh
Contoh berikut mengumpulkan statistik pada kolom EmployeeNo dari tabel Employee.
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.Melihat Statistik
Anda dapat melihat statistik yang dikumpulkan menggunakan perintah BANTUAN STATISTIK.
Sintaksis
Berikut ini adalah sintaks untuk melihat statistik yang dikumpulkan.
HELP STATISTICS <tablename>;Contoh
Berikut adalah contoh untuk melihat statistik yang dikumpulkan pada tabel Karyawan.
HELP STATISTICS employee;Ketika query di atas dijalankan, itu menghasilkan hasil sebagai berikut.
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNoKompresi digunakan untuk mengurangi penyimpanan yang digunakan oleh tabel. Di Teradata, kompresi dapat memampatkan hingga 255 nilai berbeda termasuk NULL. Karena penyimpanan berkurang, Teradata dapat menyimpan lebih banyak catatan dalam satu blok. Ini menghasilkan waktu respons kueri yang lebih baik karena operasi I / O apa pun dapat memproses lebih banyak baris per blok. Kompresi dapat ditambahkan saat pembuatan tabel menggunakan CREATE TABLE atau setelah pembuatan tabel menggunakan perintah ALTER TABLE.
Batasan
- Hanya 255 nilai yang dapat dikompresi per kolom.
- Kolom Indeks Utama tidak dapat dikompresi.
- Tabel yang mudah menguap tidak dapat dikompresi.
Kompresi Multi-Nilai (MVC)
Tabel berikut mengompresi bidang DepatmentNo untuk nilai 1, 2, dan 3. Saat kompresi diterapkan pada kolom, nilai untuk kolom ini tidak disimpan dengan baris tersebut. Sebagai gantinya, nilai disimpan di header Tabel di setiap AMP dan hanya bit kehadiran yang ditambahkan ke baris untuk menunjukkan nilainya.
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);Kompresi Multi-Nilai dapat digunakan jika Anda memiliki kolom dalam tabel besar dengan nilai terbatas.
EXPLAIN perintah mengembalikan rencana eksekusi mesin parsing dalam bahasa Inggris. Ini dapat digunakan dengan pernyataan SQL apa pun kecuali pada perintah MENJELASKAN lainnya. Jika kueri diawali dengan perintah EXPLAIN, rencana eksekusi Mesin Parsing dikembalikan ke pengguna, bukan ke AMP.
Contoh MENJELASKAN
Perhatikan tabel Employee dengan definisi berikut.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );Beberapa contoh rencana MENJELASKAN diberikan di bawah ini.
Scan Tabel Lengkap (FTS)
Jika tidak ada kondisi yang ditentukan dalam pernyataan SELECT, maka pengoptimal dapat memilih untuk menggunakan Pemindaian Tabel Lengkap di mana setiap baris tabel diakses.
Contoh
Berikut ini adalah contoh permintaan dimana pengoptimal dapat memilih FTS.
EXPLAIN SELECT * FROM employee;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Seperti yang dapat dilihat, pengoptimal memilih untuk mengakses semua AMP dan semua baris dalam AMP.
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.Indeks Utama Unik
Jika baris diakses menggunakan Unique Primary Index, maka itu adalah salah satu operasi AMP.
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Seperti yang dapat dilihat, ini adalah pengambilan AMP tunggal dan pengoptimal menggunakan indeks utama unik untuk mengakses baris.
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Indeks Sekunder Unik
Ketika baris diakses menggunakan Indeks Sekunder Unik, itu adalah operasi dua amp.
Contoh
Perhatikan tabel Gaji dengan definisi berikut.
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Pertimbangkan pernyataan SELECT berikut.
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Seperti yang dapat dilihat, pengoptimal mengambil baris dalam operasi dua amp menggunakan indeks sekunder unik.
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Persyaratan Tambahan
Berikut adalah daftar istilah yang biasa terlihat dalam rencana MENJELASKAN.
... (Last Use) …
File spool tidak lagi diperlukan dan akan dirilis saat langkah ini selesai.
... with no residual conditions …
Semua kondisi yang berlaku telah diterapkan ke baris.
... END TRANSACTION …
Kunci transaksi dilepaskan, dan perubahan dilakukan.
... eliminating duplicate rows ...
Baris duplikat hanya ada di file spool, bukan tabel set. Melakukan operasi DISTINCT.
... by way of a traversal of index #n extracting row ids only …
File spool dibuat berisi ID Baris yang ditemukan di indeks sekunder (indeks #n)
... we do a SMS (set manipulation step) …
Menggabungkan baris menggunakan operator UNION, MINUS, atau INTERSECT.
... which is redistributed by hash code to all AMPs.
Mendistribusikan ulang data sebagai persiapan untuk bergabung.
... which is duplicated on all AMPs.
Menduplikasi data dari tabel yang lebih kecil (dalam istilah SPOOL) sebagai persiapan untuk bergabung.
... (one_AMP) or (group_AMPs)
Menunjukkan satu AMP atau subset AMP akan digunakan, bukan semua AMP.
Sebuah baris ditetapkan ke AMP tertentu berdasarkan nilai indeks utama. Teradata menggunakan algoritme hashing untuk menentukan AMP mana yang mendapatkan baris tersebut.
Berikut ini adalah diagram tingkat tinggi pada algoritma hashing.

Berikut langkah-langkah penyisipan data.
Klien mengajukan pertanyaan.
Parser menerima kueri dan meneruskan nilai PI dari rekaman ke algoritme hashing.
Algoritme hashing melakukan hash pada nilai indeks utama dan mengembalikan angka 32 bit, yang disebut Row Hash.
Bit orde tinggi dari hash baris (16 bit pertama) digunakan untuk mengidentifikasi entri peta hash. Peta hash berisi satu AMP #. Peta hash adalah serangkaian keranjang yang berisi AMP # tertentu.
BYNET mengirimkan data ke AMP yang diidentifikasi.
AMP menggunakan hash Row 32 bit untuk menemukan baris di dalam disknya.
Jika ada record dengan hash baris yang sama, maka itu akan menambah ID keunikan yaitu angka 32 bit. Untuk hash baris baru, ID keunikan ditetapkan sebagai 1 dan bertambah setiap kali rekaman dengan hash baris yang sama dimasukkan.
Kombinasi Row hash dan Uniqueness ID disebut sebagai Row ID.
ID baris mengawali setiap record di disk.
Setiap baris tabel di AMP secara logis diurutkan berdasarkan ID Barisnya.
Bagaimana Tabel Disimpan
Tabel diurutkan berdasarkan ID Barisnya (hash baris + id keunikan), lalu disimpan dalam AMP. ID baris disimpan dengan setiap baris data.
| Row Hash | ID Keunikan | KaryawanNo | Nama depan | Nama keluarga |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paul |
JOIN INDEX adalah tampilan yang terwujud. Definisinya disimpan secara permanen dan data diperbarui setiap kali tabel dasar yang dirujuk dalam indeks gabungan diperbarui. JOIN INDEX mungkin berisi satu atau lebih tabel dan juga berisi data yang telah digabungkan sebelumnya. Indeks gabungan terutama digunakan untuk meningkatkan kinerja.
Ada berbagai jenis indeks gabungan yang tersedia.
- Indeks Gabungan Tabel Tunggal (STJI)
- Multi Table Join Index (MTJI)
- Indeks Gabungan Gabungan (AJI)
Indeks Gabungan Tabel Tunggal
Indeks Gabungan Tabel Tunggal memungkinkan untuk mempartisi tabel besar berdasarkan kolom indeks utama yang berbeda dari yang dari tabel dasar.
Sintaksis
Berikut ini adalah sintaks dari JOIN INDEX.
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;Contoh
Pertimbangkan tabel Karyawan dan Gaji berikut.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Berikut adalah contoh yang membuat indeks Gabung bernama Employee_JI pada tabel Karyawan.
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);Jika pengguna mengirimkan kueri dengan klausa WHERE di EmployeeNo, sistem akan meminta tabel Karyawan menggunakan indeks utama yang unik. Jika pengguna menanyakan tabel karyawan menggunakan nama_karyawan, maka sistem dapat mengakses indeks gabungan Employee_JI menggunakan nama_karyawan. Baris indeks gabungan di-hash di kolom nama_karyawan. Jika indeks gabungan tidak ditentukan dan nama_karyawan tidak ditentukan sebagai indeks sekunder, maka sistem akan melakukan pemindaian tabel lengkap untuk mengakses baris yang memakan waktu.
Anda dapat menjalankan rencana JELASKAN berikut dan memverifikasi rencana pengoptimal. Dalam contoh berikut, Anda dapat melihat bahwa pengoptimal menggunakan Indeks Gabungan dan bukan tabel Karyawan dasar saat kueri tabel menggunakan kolom Nama_Nama.
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.Indeks Gabungan Multi Tabel
Indeks gabungan multi-tabel dibuat dengan menggabungkan lebih dari satu tabel. Indeks gabungan multi-tabel dapat digunakan untuk menyimpan kumpulan hasil dari tabel yang sering digabungkan untuk meningkatkan kinerja.
Contoh
Contoh berikut membuat JOIN INDEX bernama Employee_Salary_JI dengan menggabungkan tabel Employee dan Gaji.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);Setiap kali tabel dasar Karyawan atau Gaji diperbarui, maka indeks Gabung Employee_Salary_JI juga otomatis diperbarui. Jika Anda menjalankan kueri yang bergabung dengan tabel Karyawan dan Gaji, maka pengoptimal dapat memilih untuk mengakses data dari Employee_Salary_JI secara langsung daripada bergabung dengan tabel. JELASKAN rencana pada kueri dapat digunakan untuk memverifikasi apakah pengoptimal akan memilih tabel dasar atau Bergabung dengan indeks.
Indeks Gabungan Gabungan
Jika tabel secara konsisten digabungkan pada kolom tertentu, maka indeks gabungan gabungan dapat ditentukan pada tabel untuk meningkatkan kinerja. Salah satu batasan indeks gabungan agregat adalah bahwa ia hanya mendukung fungsi SUM dan COUNT.
Contoh
Dalam contoh berikut, Karyawan dan Gaji digabungkan untuk mengidentifikasi gaji total per Departemen.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);Tampilan adalah objek database yang dibuat oleh kueri. Tampilan dapat dibangun menggunakan satu tabel atau beberapa tabel dengan cara bergabung. Definisi mereka disimpan secara permanen dalam kamus data tetapi mereka tidak menyimpan salinan data. Data untuk tampilan dibuat secara dinamis.
Tampilan mungkin berisi subset baris tabel atau subset kolom tabel.
Buat Tampilan
Tampilan dibuat menggunakan pernyataan CREATE VIEW.
Sintaksis
Berikut adalah sintaks untuk membuat view.
CREATE/REPLACE VIEW <viewname>
AS
<select query>;Contoh
Perhatikan tabel Karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | Tanggal lahir |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 6/11/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 1/12/1984 |
| 103 | Peter | Paul | 1/4/1983 |
Contoh berikut membuat tampilan pada tabel Karyawan.
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;Menggunakan Views
Anda dapat menggunakan pernyataan SELECT biasa untuk mengambil data dari Views.
Contoh
Contoh berikut mengambil record dari Employee_View;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulMengubah Tampilan
Tampilan yang ada dapat dimodifikasi menggunakan pernyataan REPLACE VIEW.
Berikut ini adalah sintaks untuk mengubah tampilan.
REPLACE VIEW <viewname>
AS
<select query>;Contoh
Contoh berikut mengubah tampilan Employee_View untuk menambahkan kolom tambahan.
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;Tampilan Drop
Tampilan yang ada dapat dijatuhkan menggunakan pernyataan DROP VIEW.
Sintaksis
Berikut ini adalah sintaks DROP VIEW.
DROP VIEW <viewname>;Contoh
Berikut adalah contoh untuk menghilangkan tampilan Employee_View.
DROP VIEW Employee_View;Keuntungan Views
Tampilan memberikan tingkat keamanan tambahan dengan membatasi baris atau kolom tabel.
Pengguna hanya dapat diberikan akses ke tampilan, bukan tabel dasar.
Menyederhanakan penggunaan beberapa tabel dengan menggabungkannya terlebih dahulu menggunakan Views.
Makro adalah sekumpulan pernyataan SQL yang disimpan dan dijalankan dengan memanggil nama Makro. Definisi Makro disimpan di Kamus Data. Pengguna hanya membutuhkan hak istimewa EXEC untuk menjalankan Makro. Pengguna tidak memerlukan hak istimewa terpisah pada objek database yang digunakan di dalam Makro. Pernyataan makro dijalankan sebagai transaksi tunggal. Jika salah satu pernyataan SQL di Makro gagal, semua pernyataan akan dibatalkan. Makro dapat menerima parameter. Makro dapat berisi pernyataan DDL, tetapi itu harus menjadi pernyataan terakhir di Makro.
Buat Makro
Makro dibuat menggunakan pernyataan CREATE MACRO.
Sintaksis
Berikut ini adalah sintaks umum dari perintah CREATE MACRO.
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);Contoh
Perhatikan tabel Karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | Tanggal lahir |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 6/11/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 1/12/1984 |
| 103 | Peter | Paul | 1/4/1983 |
Contoh berikut membuat Makro yang disebut Get_Emp. Ini berisi pernyataan pilih untuk mengambil catatan dari tabel karyawan.
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);Menjalankan Makro
Makro dijalankan menggunakan perintah EXEC.
Sintaksis
Berikut ini adalah sintaks dari perintah EXECUTE MACRO.
EXEC <macroname>;Contoh
Contoh berikut menjalankan nama Makro Get_Emp; Ketika perintah berikut dijalankan, itu mengambil semua catatan dari tabel karyawan.
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert JamesMakro Parameter
Makro Teradata dapat menerima parameter. Dalam Makro, parameter ini direferensikan dengan; (titik koma).
Berikut adalah contoh Makro yang menerima parameter.
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);Menjalankan Makro Parameter
Makro dijalankan menggunakan perintah EXEC. Anda memerlukan hak EXEC untuk menjalankan Macro.
Sintaksis
Berikut adalah sintaks dari pernyataan EXECUTE MACRO.
EXEC <macroname>(value);Contoh
Contoh berikut menjalankan nama Makro Get_Emp; Ini menerima karyawan no sebagai parameter dan mengekstrak catatan dari tabel karyawan untuk karyawan itu.
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000Prosedur tersimpan berisi sekumpulan pernyataan SQL dan pernyataan prosedural. Mereka mungkin hanya berisi pernyataan prosedural. Definisi prosedur tersimpan disimpan dalam database dan parameter disimpan dalam tabel kamus data.
Keuntungan
Prosedur yang disimpan mengurangi beban jaringan antara klien dan server.
Memberikan keamanan yang lebih baik karena data diakses melalui prosedur yang tersimpan daripada mengaksesnya secara langsung.
Memberikan pemeliharaan yang lebih baik karena logika bisnis diuji dan disimpan di server.
Membuat Prosedur
Prosedur Tersimpan dibuat menggunakan pernyataan CREATE PROCEDURE.
Sintaksis
Berikut ini adalah sintaks umum dari pernyataan CREATE PROCEDURE.
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;Contoh
Perhatikan Tabel Gaji berikut ini.
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Contoh berikut membuat prosedur tersimpan bernama Sisipan Gaji untuk menerima nilai dan menyisipkan ke dalam Tabel Gaji.
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;Prosedur Pelaksanaan
Prosedur Tersimpan dijalankan menggunakan pernyataan CALL.
Sintaksis
Berikut ini adalah sintaks umum dari pernyataan CALL.
CALL <procedure name> [(parameter values)];Contoh
Contoh berikut memanggil prosedur tersimpan Sisipkan Gaji dan menyisipkan catatan ke Tabel Gaji.
CALL InsertSalary(105,20000,2000,18000);Setelah query di atas dijalankan, itu menghasilkan output berikut dan Anda dapat melihat baris yang disisipkan di tabel Gaji.
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
| 105 | 20.000 | 2.000 | 18.000 |
Bab ini membahas berbagai strategi JOIN yang tersedia di Teradata.
Bergabunglah dengan Metode
Teradata menggunakan metode gabungan yang berbeda untuk melakukan operasi gabungan. Beberapa metode Gabung yang umum digunakan adalah -
- Gabung Gabung
- Gabung Bersarang
- Produk Bergabung
Gabung Gabung
Metode Merge Join terjadi jika penggabungan didasarkan pada kondisi kesetaraan. Gabung Gabung mengharuskan baris penggabung berada di AMP yang sama. Baris digabungkan berdasarkan hash baris mereka. Merge Join menggunakan strategi penggabungan yang berbeda untuk membawa baris ke AMP yang sama.
Strategi # 1
Jika kolom penghubung adalah indeks utama dari tabel yang sesuai, baris penghubung sudah ada di AMP yang sama. Dalam kasus ini, tidak diperlukan distribusi.
Pertimbangkan Tabel Karyawan dan Gaji berikut.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Jika kedua tabel ini digabungkan pada kolom EmployeeNo, maka tidak ada redistribusi yang terjadi karena EmployeeNo adalah indeks utama dari kedua tabel yang akan digabungkan.
Strategi # 2
Pertimbangkan tabel Karyawan dan Departemen berikut.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );Jika kedua tabel ini digabungkan pada kolom DeparmentNo, maka baris perlu didistribusikan kembali karena DepartmentNo adalah indeks utama dalam satu tabel dan indeks non-primer di tabel lain. Dalam skenario ini, menggabungkan baris mungkin tidak berada di AMP yang sama. Dalam kasus seperti itu, Teradata dapat mendistribusikan kembali tabel karyawan di kolom DepartmentNo.
Strategi # 3
Untuk tabel Karyawan dan Departemen di atas, Teradata dapat menduplikasi tabel Departemen di semua AMP, jika ukuran tabel Departemen kecil.
Gabung Bersarang
Nested Join tidak menggunakan semua AMP. Untuk Nested Join berlangsung, salah satu syaratnya harus sama pada indeks utama unik dari satu tabel dan kemudian menggabungkan kolom ini ke indeks manapun di tabel lain.
Dalam skenario ini, sistem akan mengambil satu baris menggunakan indeks Primer Unik dari satu tabel dan menggunakan hash baris tersebut untuk mengambil rekaman yang cocok dari tabel lain. Gabung bersarang adalah metode Gabung yang paling efisien.
Produk Bergabung
Product Join membandingkan setiap baris kualifikasi dari satu tabel dengan setiap baris kualifikasi dari tabel lainnya. Penggabungan produk dapat terjadi karena beberapa faktor berikut -
- Dimana kondisinya hilang.
- Kondisi join tidak didasarkan pada kondisi kesetaraan.
- Alias tabel salah.
- Kondisi sambungan ganda.
Partitioned Primary Index (PPI) adalah mekanisme pengindeksan yang berguna dalam meningkatkan kinerja kueri tertentu. Saat baris disisipkan ke dalam tabel, baris tersebut disimpan di AMP dan disusun berdasarkan urutan hash barisnya. Ketika tabel didefinisikan dengan PPI, baris diurutkan berdasarkan nomor partisinya. Dalam setiap partisi, mereka diatur oleh hash baris mereka. Baris ditetapkan ke partisi berdasarkan ekspresi partisi yang ditentukan.
Keuntungan
Hindari pemindaian tabel penuh untuk kueri tertentu.
Hindari menggunakan indeks sekunder yang memerlukan struktur fisik tambahan dan pemeliharaan I / O tambahan.
Akses subset dari tabel besar dengan cepat.
Jatuhkan data lama dengan cepat dan tambahkan data baru.
Contoh
Pertimbangkan tabel Pesanan berikut dengan Indeks Utama di OrderNo.
| TokoNo | Nomor pesanan | Tanggal pemesanan | OrderTotal |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1.200 |
| 102 | 7503 | 2015-10-02 | 3.000 |
| 102 | 7504 | 2015-10-03 | 2.454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2.454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
Asumsikan bahwa record didistribusikan di antara AMP seperti yang ditunjukkan pada tabel berikut. Rekaman disimpan di AMP, diurutkan berdasarkan hash barisnya.
| RowHash | Nomor pesanan | Tanggal pemesanan |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | Nomor pesanan | Tanggal pemesanan |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
Jika Anda menjalankan kueri untuk mengekstrak pesanan untuk tanggal tertentu, maka pengoptimal dapat memilih untuk menggunakan Pemindaian Tabel Lengkap, kemudian semua catatan dalam AMP dapat diakses. Untuk menghindari hal ini, Anda dapat menentukan tanggal pemesanan sebagai Partitioned Primary Index. Ketika baris disisipkan ke dalam tabel pesanan, mereka dipartisi berdasarkan tanggal pemesanan. Dalam setiap partisi mereka akan diurutkan berdasarkan hash baris mereka.
Data berikut menunjukkan bagaimana record akan disimpan di AMP, jika dipartisi berdasarkan Tanggal Pemesanan. Jika kueri dijalankan untuk mengakses catatan menurut Tanggal Pemesanan, maka hanya partisi yang berisi catatan untuk pesanan tertentu yang akan diakses.
| Partisi | RowHash | Nomor pesanan | Tanggal pemesanan |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| Partisi | RowHash | Nomor pesanan | Tanggal pemesanan |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
Berikut ini adalah contoh membuat tabel dengan indeks utama partisi. PARTITION BY klausa digunakan untuk mendefinisikan partisi.
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);Dalam contoh di atas, tabel dipartisi oleh kolom OrderDate. Akan ada satu partisi terpisah untuk setiap hari.
Fungsi OLAP mirip dengan fungsi agregat kecuali bahwa fungsi agregat hanya akan mengembalikan satu nilai sedangkan fungsi OLAP akan menyediakan baris individual selain agregat.
Sintaksis
Berikut ini adalah sintaks umum fungsi OLAP.
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)Fungsi agregasi dapat berupa SUM, COUNT, MAX, MIN, AVG.
Contoh
Perhatikan tabel Gaji berikut.
| KaryawanNo | Kotor | Deduksi | Gaji bersih |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Berikut adalah contoh untuk menemukan jumlah kumulatif atau menjalankan total NetPay pada tabel Gaji. Catatan diurutkan berdasarkan EmployeeNo dan jumlah kumulatif dihitung pada kolom NetPay.
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000PANGKAT
Fungsi RANK mengurutkan rekaman berdasarkan kolom yang disediakan. Fungsi RANK juga dapat memfilter jumlah record yang dikembalikan berdasarkan ranking.
Sintaksis
Berikut ini adalah sintaks umum untuk menggunakan fungsi RANK.
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])Contoh
Perhatikan tabel Karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | JoinedDate | DepartmentID | Tanggal lahir |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25/4/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21/3/2007 | 2 | 1/4/1983 |
| 104 | Alex | Stuart | 1/2/2008 | 2 | 6/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 1/12/1984 |
Kueri berikut mengurutkan rekaman tabel karyawan berdasarkan Tanggal Bergabung dan menetapkan peringkat pada Tanggal Bergabung.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut.
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5Klausa PARTITION BY mengelompokkan data menurut kolom yang ditentukan dalam klausa PARTITION BY dan menjalankan fungsi OLAP dalam setiap grup. Berikut ini adalah contoh dari query yang menggunakan klausa PARTITION BY.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;Ketika query di atas dijalankan, itu menghasilkan keluaran sebagai berikut. Anda dapat melihat bahwa Peringkat diatur ulang untuk setiap Departemen.
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1Bab ini membahas fitur yang tersedia untuk perlindungan data di Teradata.
Jurnal Transien
Teradata menggunakan Transient Journal untuk melindungi data dari kegagalan transaksi. Setiap kali ada transaksi yang dijalankan, jurnal Transient menyimpan salinan gambar sebelumnya dari baris yang terpengaruh hingga transaksi berhasil atau berhasil dibatalkan. Kemudian, gambar sebelumnya dibuang. Jurnal transien disimpan di setiap AMP. Ini adalah proses otomatis dan tidak dapat dinonaktifkan.
Fallback
Fallback melindungi data tabel dengan menyimpan salinan kedua baris tabel di AMP lain yang disebut AMP Fallback. Jika salah satu AMP gagal, baris fallback diakses. Dengan ini, meskipun salah satu AMP gagal, datanya masih tersedia melalui AMP cadangan. Opsi fallback dapat digunakan pada pembuatan tabel atau setelah pembuatan tabel. Penggantian memastikan bahwa salinan kedua dari baris tabel selalu disimpan di AMP lain untuk melindungi data dari kegagalan AMP. Namun, fallback menempati dua kali penyimpanan dan I / O untuk Sisipkan / Hapus / Perbarui.
Diagram berikut menunjukkan bagaimana salinan fallback baris disimpan di AMP lain.
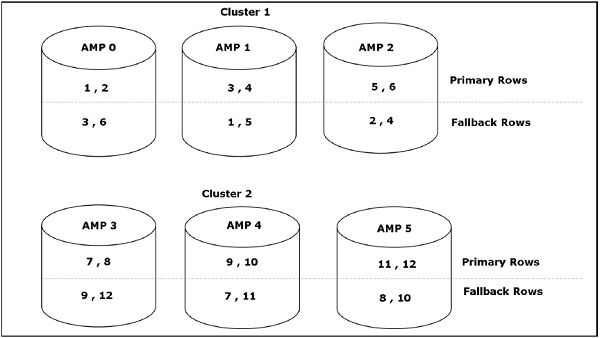
Bawah Jurnal Pemulihan AMP
Jurnal pemulihan AMP Bawah diaktifkan saat AMP gagal dan tabel dilindungi fallback. Jurnal ini melacak semua perubahan pada data AMP yang gagal. Jurnal diaktifkan di AMP yang tersisa di cluster. Ini adalah proses otomatis dan tidak dapat dinonaktifkan. Setelah AMP yang gagal ditayangkan, data dari jurnal pemulihan AMP Bawah disinkronkan dengan AMP. Setelah ini selesai, jurnal tersebut akan dibuang.
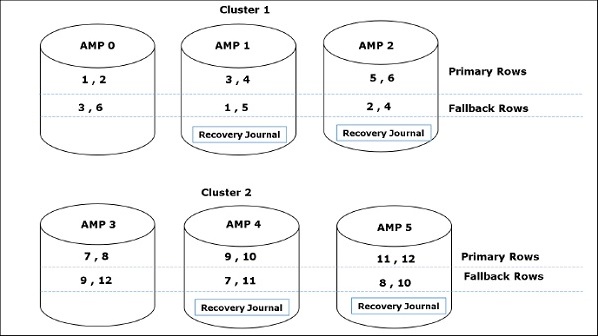
Klik
Clique adalah mekanisme yang digunakan oleh Teradata untuk melindungi data dari kegagalan Node. Sebuah klik tidak lain adalah kumpulan node Teradata yang berbagi kumpulan Disk Array yang sama. Ketika sebuah node gagal, maka vprocs dari node yang gagal akan bermigrasi ke node lain dalam klik dan terus mengakses array disk mereka.
Hot Standby Node
Hot Standby Node adalah node yang tidak berpartisipasi dalam lingkungan produksi. Jika sebuah node gagal maka vprocs dari node yang gagal akan bermigrasi ke node siaga panas. Setelah simpul yang gagal dipulihkan, itu menjadi simpul siaga panas. Node Hot Standby digunakan untuk mempertahankan kinerja jika terjadi kegagalan node.
SERANGAN
Redundant Array of Independent Disks (RAID) adalah mekanisme yang digunakan untuk melindungi data dari Kegagalan Disk. Disk Array terdiri dari sekumpulan disk yang dikelompokkan sebagai unit logis. Unit ini mungkin terlihat seperti satu unit bagi pengguna tetapi mereka mungkin tersebar di beberapa disk.
RAID 1 biasanya digunakan di Teradata. Dalam RAID 1, setiap disk dikaitkan dengan disk cermin. Setiap perubahan pada data di disk utama juga tercermin dalam salinan cermin. Jika disk utama gagal, maka data dari disk cermin dapat diakses.

Bab ini membahas berbagai strategi manajemen pengguna di Teradata.
Pengguna
Seorang pengguna dibuat menggunakan perintah CREATE USER. Di Teradata, pengguna juga mirip dengan database. Keduanya dapat diberi ruang dan berisi objek database kecuali bahwa pengguna diberi kata sandi.
Sintaksis
Berikut adalah sintaks untuk CREATE USER.
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;Saat membuat pengguna, nilai untuk nama pengguna, spasi permanen, dan Kata Sandi wajib diisi. Bidang lain bersifat opsional.
Contoh
Berikut adalah contoh untuk membuat pengguna TD01.
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;Akun
Saat membuat pengguna baru, pengguna mungkin ditugaskan ke sebuah akun. Opsi AKUN di CREATE USER digunakan untuk menetapkan akun. Seorang pengguna dapat ditetapkan ke beberapa akun.
Sintaksis
Berikut adalah sintaks untuk CREATE USER dengan opsi akun.
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountidContoh
Contoh berikut membuat pengguna TD02 dan menetapkan akun sebagai TI dan Admin.
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);Pengguna dapat menentukan id akun saat masuk ke sistem Teradata atau setelah masuk ke sistem menggunakan perintah SET SESSION.
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountidBerikan Hak Istimewa
Perintah GRANT digunakan untuk menetapkan satu atau lebih hak istimewa pada objek database ke pengguna atau database.
Sintaksis
Berikut ini adalah sintaks dari perintah GRANT.
GRANT privileges ON objectname TO username;Hak istimewa bisa SISIPKAN, PILIH, PEMBARUAN, REFERENSI.
Contoh
Berikut adalah contoh pernyataan GRANT.
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;Cabut Hak Istimewa
Perintah REVOKE menghapus hak istimewa dari pengguna atau database. Perintah REVOKE hanya dapat menghapus hak khusus.
Sintaksis
Berikut ini adalah sintaks dasar untuk perintah REVOKE.
REVOKE [ALL|privileges] ON objectname FROM username;Contoh
Berikut adalah contoh perintah REVOKE.
REVOKE INSERT,SELECT ON Employee FROM TD01;Bab ini membahas prosedur penyetelan kinerja di Teradata.
Menjelaskan
Langkah pertama dalam penyesuaian kinerja adalah penggunaan JELASKAN pada kueri Anda. JELASKAN rencana memberikan detail tentang bagaimana pengoptimal akan menjalankan kueri Anda. Dalam paket Jelaskan, periksa kata kunci seperti tingkat kepercayaan, strategi penggabungan yang digunakan, ukuran file spool, distribusi ulang, dll.
Kumpulkan Statistik
Pengoptimal menggunakan demografi Data untuk menghasilkan strategi eksekusi yang efektif. Perintah KUMPULKAN STATISTIK digunakan untuk mengumpulkan data demografi dari tabel. Pastikan statistik yang dikumpulkan di kolom adalah yang terbaru.
Kumpulkan statistik pada kolom yang digunakan dalam klausa WHERE dan pada kolom yang digunakan dalam kondisi penggabungan.
Kumpulkan statistik di kolom Indeks Utama Unik.
Kumpulkan statistik pada kolom Indeks Sekunder Non Unik. Pengoptimal akan memutuskan apakah dapat menggunakan NUSI atau Full Table Scan.
Kumpulkan statistik pada Indeks Bergabung meskipun statistik pada tabel dasar dikumpulkan.
Kumpulkan statistik pada kolom partisi.
Jenis Data
Pastikan bahwa tipe data yang tepat digunakan. Ini akan menghindari penggunaan penyimpanan yang berlebihan dari yang dibutuhkan.
Konversi
Pastikan bahwa tipe data dari kolom yang digunakan dalam kondisi gabungan kompatibel untuk menghindari konversi data eksplisit.
Menyortir
Hapus klausa ORDER BY yang tidak perlu kecuali diperlukan.
Masalah Spul Space
Error ruang spool dibuat jika kueri melebihi batas ruang spool per AMP untuk pengguna tersebut. Verifikasi rencana penjelasan dan identifikasi langkah yang menghabiskan lebih banyak ruang spool. Kueri perantara ini dapat dipisahkan dan diletakkan secara terpisah untuk membuat tabel sementara.
Indeks Utama
Pastikan bahwa Indeks Utama ditentukan dengan benar untuk tabel. Kolom indeks utama harus mendistribusikan data secara merata dan harus sering digunakan untuk mengakses data.
SET Tabel
Jika Anda mendefinisikan tabel SET, maka pengoptimal akan memeriksa apakah record tersebut duplikat untuk setiap record yang dimasukkan. Untuk menghapus kondisi pemeriksaan duplikat, Anda dapat menentukan Indeks Sekunder Unik untuk tabel.
UPDATE di Meja Besar
Memperbarui tabel besar akan memakan waktu. Alih-alih memperbarui tabel, Anda bisa menghapus rekaman dan menyisipkan rekaman dengan baris yang dimodifikasi.
Menjatuhkan Tabel Sementara
Jatuhkan tabel sementara (tabel pementasan) dan volatile jika tidak lagi diperlukan. Ini akan membebaskan ruang permanen dan ruang spool.
Tabel MULTISET
Jika Anda yakin bahwa record input tidak akan memiliki record duplikat, maka Anda dapat menentukan tabel target sebagai tabel MULTISET untuk menghindari pemeriksaan baris duplikat yang digunakan oleh tabel SET.
Utilitas FastLoad digunakan untuk memuat data ke dalam tabel kosong. Karena tidak menggunakan jurnal transien, data dapat dimuat dengan cepat. Itu tidak memuat baris duplikat bahkan jika tabel target adalah tabel MULTISET.
Keterbatasan
Tabel target tidak boleh memiliki indeks sekunder, indeks gabungan, dan referensi kunci asing.
Bagaimana FastLoad Bekerja
FastLoad dijalankan dalam dua fase.
Tahap 1
Mesin Parsing membaca catatan dari file input dan mengirim blok ke setiap AMP.
Setiap AMP menyimpan blok catatan.
Kemudian AMP mencirikan setiap catatan dan mendistribusikannya kembali ke AMP yang benar.
Di akhir Tahap 1, setiap AMP memiliki barisnya sendiri tetapi tidak dalam urutan hash baris.
Tahap 2
Fase 2 dimulai ketika FastLoad menerima pernyataan END LOADING.
Setiap AMP mengurutkan record pada hash baris dan menulisnya ke disk.
Kunci pada tabel target dilepaskan dan tabel kesalahan dijatuhkan.
Contoh
Buat file teks dengan record berikut dan beri nama file sebagai employee.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Berikut ini contoh script FastLoad untuk memuat file di atas ke dalam tabel Employee_Stg.
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;Menjalankan FastLoad Script
Setelah file input employee.txt dibuat dan skrip FastLoad dinamai EmployeeLoad.fl, Anda dapat menjalankan skrip FastLoad menggunakan perintah berikut di UNIX dan Windows.
FastLoad < EmployeeLoad.fl;Setelah perintah di atas dijalankan, script FastLoad akan berjalan dan menghasilkan log. Di log, Anda dapat melihat jumlah catatan yang diproses oleh FastLoad dan kode status.
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsPersyaratan FastLoad
Berikut adalah daftar istilah umum yang digunakan dalam skrip FastLoad.
LOGON - Masuk ke Teradata dan memulai satu atau lebih sesi.
DATABASE - Mengatur database default.
BEGIN LOADING - Mengidentifikasi tabel yang akan dimuat.
ERRORFILES - Mengidentifikasi 2 tabel kesalahan yang perlu dibuat / diperbarui.
CHECKPOINT - Mendefinisikan kapan harus mengambil pos pemeriksaan.
SET RECORD - Menentukan apakah format file input diformat, biner, teks atau tidak diformat.
DEFINE - Mendefinisikan tata letak file input.
FILE - Menentukan nama file input dan jalur.
INSERT - Menyisipkan record dari file input ke dalam tabel target.
END LOADING- Memulai fase 2 FastLoad. Mendistribusikan catatan ke dalam tabel target.
LOGOFF - Mengakhiri semua sesi dan mengakhiri FastLoad.
MultiLoad dapat memuat banyak tabel sekaligus dan juga dapat melakukan berbagai jenis tugas seperti INSERT, DELETE, UPDATE dan UPSERT. Itu dapat memuat hingga 5 tabel sekaligus dan melakukan hingga 20 operasi DML dalam sebuah skrip. Tabel target tidak diperlukan untuk MultiLoad.
MultiLoad mendukung dua mode -
- IMPORT
- DELETE
MultiLoad membutuhkan meja kerja, tabel log dan dua tabel kesalahan di samping tabel target.
Log Table - Digunakan untuk menjaga pos pemeriksaan yang diambil selama pemuatan yang akan digunakan untuk memulai kembali.
Error Tables- Tabel ini dimasukkan selama pemuatan ketika terjadi kesalahan. Tabel kesalahan pertama menyimpan kesalahan konversi sedangkan tabel kesalahan kedua menyimpan catatan duplikat.
Log Table - Mempertahankan hasil dari setiap fase MultiLoad untuk tujuan restart.
Work table- Skrip MultiLoad membuat satu meja kerja per tabel target. Meja kerja digunakan untuk menyimpan tugas-tugas DML dan data masukan.
Keterbatasan
MultiLoad memiliki beberapa batasan.
- Indeks Sekunder Unik tidak didukung pada tabel target.
- Integritas referensial tidak didukung.
- Pemicu tidak didukung.
Bagaimana MultiLoad Bekerja
Impor MultiLoad memiliki lima fase -
Phase 1 - Tahap Awal - Melakukan aktivitas pengaturan dasar.
Phase 2 - Fase Transaksi DML - Memverifikasi sintaks pernyataan DML dan membawanya ke sistem Teradata.
Phase 3 - Tahap Akuisisi - Membawa data input ke dalam tabel kerja dan mengunci tabel.
Phase 4 - Tahap Aplikasi - Menerapkan semua operasi DML.
Phase 5 - Fase Pembersihan - Melepaskan kunci meja.
Langkah-langkah yang terlibat dalam skrip MultiLoad adalah -
Step 1 - Siapkan tabel log.
Step 2 - Masuk ke Teradata.
Step 3 - Tentukan tabel Target, Work dan Error.
Step 4 - Tentukan tata letak file INPUT.
Step 5 - Tentukan kueri DML.
Step 6 - Beri nama file IMPOR.
Step 7 - Tentukan LAYOUT yang akan digunakan.
Step 8 - Mulai Load.
Step 9 - Selesaikan pemuatan dan akhiri sesi.
Contoh
Buat file teks dengan record berikut dan beri nama file sebagai employee.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Contoh berikut adalah skrip MultiLoad yang membaca catatan dari tabel karyawan dan memuat ke tabel Employee_Stg.
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;Mengeksekusi MultiLoad Script
Setelah file input employee.txt dibuat dan skrip multiload dinamai EmployeeLoad.ml, Anda dapat menjalankan skrip Multiload menggunakan perintah berikut di UNIX dan Windows.
Multiload < EmployeeLoad.ml;Utilitas FastExport digunakan untuk mengekspor data dari tabel Teradata menjadi file datar. Itu juga dapat menghasilkan data dalam format laporan. Data dapat diekstraksi dari satu atau beberapa tabel menggunakan Gabung. Karena FastExport mengekspor data dalam 64K blok, ini berguna untuk mengekstrak data dalam jumlah besar.
Contoh
Perhatikan tabel Karyawan berikut.
| KaryawanNo | Nama depan | Nama keluarga | Tanggal lahir |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 6/11/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 1/12/1984 |
| 103 | Peter | Paul | 1/4/1983 |
Berikut adalah contoh skrip FastExport. Ini mengekspor data dari tabel karyawan dan menulis ke dalam file Employeedata.txt.
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;Menjalankan FastExport Script
Setelah skrip ditulis dan dinamai sebagai employee.fx, Anda dapat menggunakan perintah berikut untuk menjalankan skrip.
fexp < employee.fxSetelah menjalankan perintah di atas, Anda akan menerima output berikut di file Employeedata.txt.
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06Ketentuan FastExport
Berikut adalah daftar istilah yang biasa digunakan dalam skrip FastExport.
LOGTABLE - Menentukan tabel log untuk tujuan restart.
LOGON - Masuk ke Teradata dan memulai satu atau lebih sesi.
DATABASE - Mengatur database default.
BEGIN EXPORT - Menunjukkan awal ekspor.
EXPORT - Menentukan file target dan format ekspor.
SELECT - Menentukan kueri pemilihan untuk mengekspor data.
END EXPORT - Menentukan akhir FastExport.
LOGOFF - Mengakhiri semua sesi dan mengakhiri FastExport.
Utilitas BTEQ adalah utilitas yang kuat di Teradata yang dapat digunakan dalam mode batch dan interaktif. Ini dapat digunakan untuk menjalankan pernyataan DDL, pernyataan DML, membuat Makro, dan prosedur tersimpan. BTEQ dapat digunakan untuk mengimpor data ke tabel Teradata dari file datar dan juga dapat digunakan untuk mengekstrak data dari tabel menjadi file atau laporan.
Persyaratan BTEQ
Berikut adalah daftar istilah yang biasa digunakan dalam skrip BTEQ.
LOGON - Digunakan untuk masuk ke sistem Teradata.
ACTIVITYCOUNT - Mengembalikan jumlah baris yang dipengaruhi oleh kueri sebelumnya.
ERRORCODE - Mengembalikan kode status dari kueri sebelumnya.
DATABASE - Mengatur database default.
LABEL - Menetapkan label ke sekumpulan perintah SQL.
RUN FILE - Menjalankan kueri yang ada dalam file.
GOTO - Mentransfer kontrol ke label.
LOGOFF - Keluar dari database dan mengakhiri semua sesi.
IMPORT - Menentukan jalur file input.
EXPORT - Menentukan jalur file keluaran dan memulai ekspor.
Contoh
Berikut ini adalah contoh skrip BTEQ.
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;Skrip di atas melakukan tugas-tugas berikut.
Masuk ke Sistem Teradata.
Mengatur Basis Data Default.
Membuat tabel yang disebut employee_bkup.
Memilih satu catatan dari tabel Karyawan untuk memeriksa apakah tabel memiliki catatan.
Menurunkan tabel employee_bkup, jika tabel kosong.
Mentransfer kontrol ke Label InsertEmployee yang menyisipkan catatan ke tabel employee_bkup
Periksa ERRORCODE untuk memastikan bahwa pernyataan tersebut berhasil, mengikuti setiap pernyataan SQL.
ACTIVITYCOUNT mengembalikan jumlah catatan yang dipilih / dipengaruhi oleh kueri SQL sebelumnya.