Apache Flink - Architettura
Apache Flink funziona sull'architettura Kappa. L'architettura Kappa ha un unico processore - stream, che tratta tutti gli input come stream e il motore di streaming elabora i dati in tempo reale. I dati batch nell'architettura kappa sono un caso speciale di streaming.
Il diagramma seguente mostra il file Apache Flink Architecture.
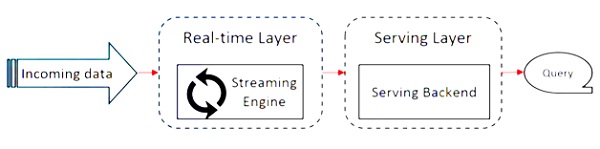
L'idea chiave nell'architettura Kappa è gestire i dati sia batch che in tempo reale attraverso un singolo motore di elaborazione del flusso.
La maggior parte dei framework per big data funziona su architettura Lambda, che ha processori separati per batch e dati in streaming. Nell'architettura Lambda, hai codebase separati per le viste batch e stream. Per eseguire query e ottenere il risultato, le basi di codice devono essere unite. Non mantenere basi di codice / viste separate e unirle è un problema, ma l'architettura Kappa risolve questo problema poiché ha una sola vista: in tempo reale, quindi non è richiesta la fusione della base di codice.
Ciò non significa che l'architettura Kappa sostituisca l'architettura Lambda, dipende completamente dal caso d'uso e dall'applicazione che decide quale architettura sarebbe preferibile.
Il diagramma seguente mostra l'architettura di esecuzione del lavoro di Apache Flink.

Programma
È un pezzo di codice, che viene eseguito su Flink Cluster.
Cliente
È responsabile di prendere il codice (programma) e costruire il grafico del flusso di dati del lavoro, quindi passarlo a JobManager. Recupera anche i risultati del lavoro.
JobManager
Dopo aver ricevuto il grafico del flusso di dati del lavoro dal client, è responsabile della creazione del grafico di esecuzione. Assegna il lavoro ai TaskManager nel cluster e supervisiona l'esecuzione del lavoro.
TaskManager
È responsabile dell'esecuzione di tutte le attività assegnate da JobManager. Tutti i TaskManager eseguono le attività nei rispettivi slot separati nel parallelismo specificato. È responsabile dell'invio dello stato delle attività a JobManager.
Caratteristiche di Apache Flink
Le caratteristiche di Apache Flink sono le seguenti:
Ha un processore di streaming, che può eseguire sia programmi in batch che in streaming.
Può elaborare i dati a una velocità fulminea.
API disponibili in Java, Scala e Python.
Fornisce API per tutte le operazioni comuni, che è molto facile da usare per i programmatori.
Elabora i dati a bassa latenza (nanosecondi) e velocità effettiva elevata.
È tollerante agli errori. Se un nodo, un'applicazione o un hardware si guasta, non influisce sul cluster.
Può integrarsi facilmente con Apache Hadoop, Apache MapReduce, Apache Spark, HBase e altri strumenti per big data.
La gestione in memoria può essere personalizzata per una migliore elaborazione.
È altamente scalabile e può scalare fino a migliaia di nodi in un cluster.
Il windowing è molto flessibile in Apache Flink.
Fornisce librerie di elaborazione di grafici, apprendimento automatico e elaborazione di eventi complessi.