Apache Kafka - Guida rapida
Nei Big Data viene utilizzato un enorme volume di dati. Per quanto riguarda i dati, abbiamo due sfide principali: la prima è come raccogliere grandi volumi di dati e la seconda è analizzare i dati raccolti. Per superare queste sfide, è necessario un sistema di messaggistica.
Kafka è progettato per sistemi distribuiti ad alta velocità. Kafka tende a funzionare molto bene come sostituto di un broker di messaggi più tradizionale. Rispetto ad altri sistemi di messaggistica, Kafka ha un throughput migliore, partizionamento integrato, replica e tolleranza agli errori intrinseca, il che lo rende adatto per applicazioni di elaborazione di messaggi su larga scala.
Cos'è un sistema di messaggistica?
Un sistema di messaggistica è responsabile del trasferimento dei dati da un'applicazione all'altra, quindi le applicazioni possono concentrarsi sui dati, ma non preoccuparsi di come condividerli. La messaggistica distribuita si basa sul concetto di accodamento di messaggi affidabile. I messaggi vengono accodati in modo asincrono tra le applicazioni client e il sistema di messaggistica. Sono disponibili due tipi di modelli di messaggistica: uno è da punto a punto e l'altro è il sistema di messaggistica di pubblicazione-sottoscrizione (pub-sub). La maggior parte degli schemi di messaggistica seguonopub-sub.
Sistema di messaggistica punto a punto
In un sistema point-to-point, i messaggi vengono mantenuti in una coda. Uno o più consumatori possono consumare i messaggi nella coda, ma un particolare messaggio può essere utilizzato da un massimo di un solo consumatore. Una volta che un consumatore legge un messaggio nella coda, scompare da quella coda. L'esempio tipico di questo sistema è un sistema di elaborazione degli ordini, in cui ogni ordine verrà elaborato da un elaboratore di ordini, ma anche più elaboratori di ordini possono funzionare allo stesso tempo. Il diagramma seguente mostra la struttura.

Sistema di messaggistica di pubblicazione-sottoscrizione
Nel sistema di pubblicazione-sottoscrizione, i messaggi vengono mantenuti in un argomento. A differenza del sistema point-to-point, i consumatori possono iscriversi a uno o più argomenti e consumare tutti i messaggi in quell'argomento. Nel sistema Pubblica-Sottoscrivi, i produttori di messaggi sono chiamati editori e i consumatori di messaggi sono chiamati abbonati. Un esempio di vita reale è Dish TV, che pubblica diversi canali come sport, film, musica, ecc. E chiunque può iscriversi al proprio set di canali e ottenerli ogni volta che i canali a cui si è iscritti sono disponibili.

Cos'è Kafka?
Apache Kafka è un sistema di messaggistica di pubblicazione-sottoscrizione distribuito e una coda robusta in grado di gestire un volume elevato di dati e consente di passare messaggi da un endpoint a un altro. Kafka è adatto per il consumo di messaggi sia offline che online. I messaggi Kafka vengono mantenuti sul disco e replicati all'interno del cluster per prevenire la perdita di dati. Kafka si basa sul servizio di sincronizzazione ZooKeeper. Si integra molto bene con Apache Storm e Spark per l'analisi dei dati in streaming in tempo reale.
Benefici
Di seguito sono riportati alcuni vantaggi di Kafka:
Reliability - Kafka è distribuito, partizionato, replicato e con tolleranza ai guasti.
Scalability - Il sistema di messaggistica Kafka si ridimensiona facilmente senza tempi di fermo ..
Durability- Kafka utilizza il
registro di commit distribuito, il
che significa che i messaggi persistono sul disco il più velocemente possibile, quindi è durevole.Performance- Kafka ha un throughput elevato sia per la pubblicazione che per la sottoscrizione dei messaggi. Mantiene prestazioni stabili anche se vengono archiviati molti TB di messaggi.
Kafka è molto veloce e garantisce zero tempi di inattività e zero perdita di dati.
Casi d'uso
Kafka può essere utilizzato in molti casi d'uso. Alcuni di loro sono elencati di seguito:
Metrics- Kafka viene spesso utilizzato per i dati di monitoraggio operativo. Ciò comporta l'aggregazione di statistiche da applicazioni distribuite per produrre feed centralizzati di dati operativi.
Log Aggregation Solution - Kafka può essere utilizzato in un'organizzazione per raccogliere registri da più servizi e renderli disponibili in un formato standard a più consumatori.
Stream Processing- Framework popolari come Storm e Spark Streaming leggono i dati da un argomento, li elabora e scrivono i dati elaborati in un nuovo argomento dove diventano disponibili per utenti e applicazioni. La forte durabilità di Kafka è anche molto utile nel contesto dell'elaborazione del flusso.
Necessità di Kafka
Kafka è una piattaforma unificata per la gestione di tutti i feed di dati in tempo reale. Kafka supporta la consegna dei messaggi a bassa latenza e garantisce la tolleranza ai guasti in presenza di guasti della macchina. Ha la capacità di gestire un gran numero di consumatori diversi. Kafka è molto veloce, esegue 2 milioni di scritture / sec. Kafka mantiene tutti i dati sul disco, il che significa essenzialmente che tutte le scritture vanno alla cache della pagina del sistema operativo (RAM). Ciò rende molto efficiente il trasferimento dei dati dalla cache della pagina a un socket di rete.
Prima di entrare in profondità nel Kafka, è necessario conoscere le principali terminologie come argomenti, broker, produttori e consumatori. Il diagramma seguente illustra le principali terminologie e la tabella descrive in dettaglio i componenti del diagramma.
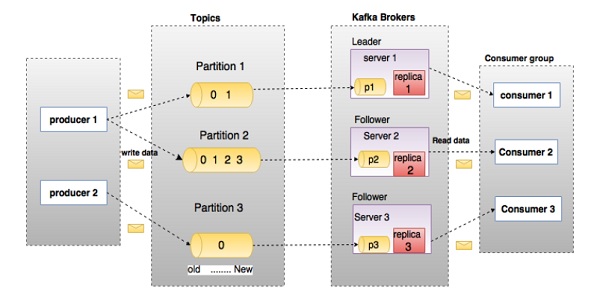
Nel diagramma sopra, un argomento è configurato in tre partizioni. La partizione 1 ha due fattori di offset 0 e 1. La partizione 2 ha quattro fattori di offset 0, 1, 2 e 3. La partizione 3 ha un fattore di offset 0. L'ID della replica è uguale all'ID del server che la ospita.
Supponiamo che se il fattore di replica dell'argomento è impostato su 3, Kafka creerà 3 repliche identiche di ciascuna partizione e le inserirà nel cluster per renderle disponibili per tutte le sue operazioni. Per bilanciare un carico nel cluster, ogni broker memorizza una o più di quelle partizioni. Più produttori e consumatori possono pubblicare e recuperare messaggi contemporaneamente.
| S.No | Componenti e descrizione |
|---|---|
| 1 | Topics Un flusso di messaggi appartenenti a una particolare categoria è chiamato argomento. I dati vengono archiviati in argomenti. Gli argomenti sono suddivisi in partizioni. Per ogni argomento, Kafka mantiene un minimo di una partizione. Ciascuna di queste partizioni contiene messaggi in una sequenza ordinata immutabile. Una partizione è implementata come un insieme di file di segmenti di uguale dimensione. |
| 2 | Partition Gli argomenti possono avere molte partizioni, quindi può gestire una quantità arbitraria di dati. |
| 3 | Partition offset Ogni messaggio partizionato ha un ID sequenza univoco chiamato |
| 4 | Replicas of partition Le repliche non sono altro che |
| 5 | Brokers
|
| 6 | Kafka Cluster Kafka ha più di un broker è chiamato cluster Kafka. Un cluster Kafka può essere espanso senza tempi di inattività. Questi cluster vengono utilizzati per gestire la persistenza e la replica dei dati dei messaggi. |
| 7 | Producers I produttori sono gli editori di messaggi su uno o più argomenti Kafka. I produttori inviano i dati ai broker Kafka. Ogni volta che un produttore pubblica un messaggio a un broker, il broker aggiunge semplicemente il messaggio all'ultimo file di segmento. In realtà, il messaggio verrà aggiunto a una partizione. Il produttore può anche inviare messaggi a una partizione di sua scelta. |
| 8 | Consumers I consumatori leggono i dati dai broker. I consumatori si iscrivono a uno o più argomenti e utilizzano i messaggi pubblicati estraendo i dati dai broker. |
| 9 | Leader
|
| 10 | Follower Il nodo che segue le istruzioni del leader è chiamato follower. Se il leader fallisce, uno dei follower diventerà automaticamente il nuovo leader. Un follower agisce come un normale consumatore, estrae i messaggi e aggiorna il proprio archivio dati. |
Dai un'occhiata alla seguente illustrazione. Mostra il diagramma a grappolo di Kafka.

La tabella seguente descrive ciascuno dei componenti mostrati nel diagramma sopra.
| S.No | Componenti e descrizione |
|---|---|
| 1 | Broker Il cluster Kafka è generalmente costituito da più broker per mantenere l'equilibrio del carico. I broker Kafka sono apolidi, quindi utilizzano ZooKeeper per mantenere lo stato del cluster. Un'istanza del broker Kafka può gestire centinaia di migliaia di letture e scritture al secondo e ogni broker può gestire TB di messaggi senza impatto sulle prestazioni. L'elezione del leader del broker Kafka può essere effettuata da ZooKeeper. |
| 2 | ZooKeeper ZooKeeper viene utilizzato per gestire e coordinare il broker Kafka. Il servizio ZooKeeper viene utilizzato principalmente per informare il produttore e il consumatore della presenza di qualsiasi nuovo broker nel sistema Kafka o di un guasto del broker nel sistema Kafka. In base alla notifica ricevuta dallo Zookeeper in merito alla presenza o al fallimento del broker, il produttore e il consumatore prendono una decisione e iniziano a coordinare il loro compito con un altro broker. |
| 3 | Producers I produttori inviano i dati ai broker. Quando il nuovo broker viene avviato, tutti i produttori lo cercano e inviano automaticamente un messaggio a quel nuovo broker. Il produttore di Kafka non attende i riconoscimenti dal broker e invia i messaggi alla velocità che il broker può gestire. |
| 4 | Consumers Poiché i broker Kafka sono senza stato, il che significa che il consumatore deve mantenere quanti messaggi sono stati consumati utilizzando l'offset della partizione. Se il consumatore riconosce un particolare messaggio di offset, implica che il consumatore ha consumato tutti i messaggi precedenti. Il consumatore invia una richiesta pull asincrona al broker per avere un buffer di byte pronto per l'uso. I consumatori possono riavvolgere o saltare a qualsiasi punto di una partizione semplicemente fornendo un valore di offset. Il valore di offset del consumatore viene notificato da ZooKeeper. |
A partire da ora, abbiamo discusso i concetti fondamentali di Kafka. Facciamo ora luce sul flusso di lavoro di Kafka.
Kafka è semplicemente una raccolta di argomenti suddivisi in una o più partizioni. Una partizione Kafka è una sequenza di messaggi ordinata linearmente, in cui ogni messaggio è identificato dal loro indice (chiamato offset). Tutti i dati in un cluster Kafka sono l'unione disgiunta di partizioni. I messaggi in arrivo vengono scritti alla fine di una partizione ei messaggi vengono letti in sequenza dai consumatori. La durabilità viene fornita replicando i messaggi a diversi broker.
Kafka fornisce sia il sistema di messaggistica pub-sub che quello basato su code in modo rapido, affidabile, persistente, con tolleranza agli errori e senza tempi di inattività. In entrambi i casi, i produttori inviano semplicemente il messaggio a un argomento e il consumatore può scegliere qualsiasi tipo di sistema di messaggistica a seconda delle proprie esigenze. Seguiamo i passaggi nella sezione successiva per capire come il consumatore può scegliere il sistema di messaggistica di sua scelta.
Flusso di lavoro della messaggistica Pub-Sub
Di seguito è riportato il flusso di lavoro passo passo della messaggistica Pub-Sub:
I produttori inviano messaggi a un argomento a intervalli regolari.
Il broker Kafka memorizza tutti i messaggi nelle partizioni configurate per quel particolare argomento. Assicura che i messaggi siano equamente condivisi tra le partizioni. Se il produttore invia due messaggi e ci sono due partizioni, Kafka memorizzerà un messaggio nella prima partizione e il secondo messaggio nella seconda partizione.
Il consumatore si abbona a un argomento specifico.
Una volta che il consumatore si iscrive a un argomento, Kafka fornirà l'offset corrente dell'argomento al consumatore e salverà anche l'offset nell'insieme Zookeeper.
Il consumatore richiederà il Kafka a intervalli regolari (come 100 Ms) per i nuovi messaggi.
Una volta che Kafka riceve i messaggi dai produttori, li inoltra ai consumatori.
Il consumatore riceverà il messaggio e lo elaborerà.
Una volta elaborati i messaggi, il consumatore invierà una conferma al broker Kafka.
Una volta che Kafka riceve un riconoscimento, modifica l'offset con il nuovo valore e lo aggiorna in Zookeeper. Poiché gli offset vengono mantenuti in Zookeeper, il consumatore può leggere correttamente il messaggio successivo anche durante gli oltraggi del server.
Questo flusso sopra si ripeterà fino a quando il consumatore interrompe la richiesta.
Il consumatore ha la possibilità di riavvolgere / saltare all'offset desiderato di un argomento in qualsiasi momento e leggere tutti i messaggi successivi.
Flusso di lavoro della messaggistica in coda / gruppo di consumatori
In un sistema di messaggistica in coda invece di un singolo consumatore, un gruppo di consumatori con lo stesso ID gruppo
si iscriverà a un argomento. In termini semplici, i consumatori che si iscrivono a un argomento con lo stesso ID gruppo
vengono considerati come un unico gruppo ei messaggi vengono condivisi tra loro. Controlliamo l'effettivo flusso di lavoro di questo sistema.
I produttori inviano messaggi a un argomento a intervalli regolari.
Kafka memorizza tutti i messaggi nelle partizioni configurate per quel particolare argomento in modo simile allo scenario precedente.
Un singolo consumatore si iscrive a un argomento specifico, presupponi
Topic-01
conGroup ID
comeGroup-1
.Interagisce Kafka con il consumatore nello stesso modo come Bar-Sub Messaging fino nuovo consumatore sottoscrive lo stesso argomento,
Topic-01
con lo stessoID gruppo
diGroup-1
.Quando arriva il nuovo consumatore, Kafka passa alla modalità di condivisione e condivide i dati tra i due consumatori. Questa condivisione continuerà fino a quando il numero di consumatori raggiungerà il numero di partizioni configurate per quel particolare argomento.
Una volta che il numero di consumatori supera il numero di partizioni, il nuovo consumatore non riceverà ulteriori messaggi fino a quando uno qualsiasi dei consumatori esistenti non annulla l'iscrizione. Questo scenario si verifica perché a ogni consumatore in Kafka verrà assegnato un minimo di una partizione e una volta assegnate tutte le partizioni ai consumatori esistenti, i nuovi consumatori dovranno attendere.
Questa funzione è anche chiamata
gruppo di consumatori
. Allo stesso modo, Kafka fornirà il meglio di entrambi i sistemi in modo molto semplice ed efficiente.
Ruolo di ZooKeeper
Una dipendenza critica di Apache Kafka è Apache Zookeeper, che è un servizio di configurazione e sincronizzazione distribuito. Zookeeper funge da interfaccia di coordinamento tra i broker Kafka e i consumatori. I server Kafka condividono le informazioni tramite un cluster Zookeeper. Kafka memorizza i metadati di base in Zookeeper come informazioni su argomenti, broker, offset dei consumatori (lettori di code) e così via.
Poiché tutte le informazioni critiche sono archiviate in Zookeeper e normalmente replica questi dati nel suo insieme, il guasto del broker / Zookeeper Kafka non influisce sullo stato del cluster Kafka. Kafka ripristinerà lo stato, una volta riavviato lo Zookeeper. Questo dà zero tempi di inattività per Kafka. L'elezione del leader tra il broker Kafka viene effettuata anche utilizzando Zookeeper in caso di fallimento del leader.
Per saperne di più su Zookeeper, fare riferimento al guardiano dello zoo
Continuiamo ulteriormente su come installare Java, ZooKeeper e Kafka sulla tua macchina nel prossimo capitolo.
Di seguito sono riportati i passaggi per l'installazione di Java sulla macchina.
Passaggio 1: verifica dell'installazione di Java
Si spera che tu abbia già installato java sulla tua macchina in questo momento, quindi devi solo verificarlo usando il seguente comando.
$ java -versionSe java è installato con successo sulla tua macchina, potresti vedere la versione di Java installato.
Passaggio 1.1: scarica JDK
Se Java non viene scaricato, scaricare l'ultima versione di JDK visitando il seguente collegamento e scaricare l'ultima versione.
http://www.oracle.com/technetwork/java/javase/downloads/index.htmlOra l'ultima versione è JDK 8u 60 e il file è "jdk-8u60-linux-x64.tar.gz". Scarica il file sulla tua macchina.
Passaggio 1.2 - Estrai file
In genere, i file scaricati vengono archiviati nella cartella dei download, verificala ed estrai il setup di tar utilizzando i seguenti comandi.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzPassaggio 1.3: passare alla directory Opt
Per rendere java disponibile a tutti gli utenti, sposta il contenuto java estratto nella cartella usr / local / java
/.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Passaggio 1.4: impostare il percorso
Per impostare il percorso e le variabili JAVA_HOME, aggiungi i seguenti comandi al file ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binOra applica tutte le modifiche al sistema in esecuzione corrente.
$ source ~/.bashrcPassaggio 1.5 - Alternative Java
Utilizzare il seguente comando per modificare le alternative Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Step 1.6 - Ora verifica java utilizzando il comando di verifica (java -version) spiegato nel passaggio 1.
Passaggio 2: installazione di ZooKeeper Framework
Passaggio 2.1 - Scarica ZooKeeper
Per installare il framework ZooKeeper sul tuo computer, visita il seguente link e scarica l'ultima versione di ZooKeeper.
http://zookeeper.apache.org/releases.htmlAl momento, l'ultima versione di ZooKeeper è la 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Passaggio 2.2: estrai il file tar
Estrai il file tar usando il seguente comando
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataPassaggio 2.3 - Crea file di configurazione
Aprire il file di configurazione denominato conf / zoo.cfg
utilizzando il comando vi “conf / zoo.cfg” e tutti i seguenti parametri da impostare come punto di partenza.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Una volta che il file di configurazione è stato salvato con successo e tornato nuovamente al terminale, è possibile avviare il server guardiano dello zoo.
Passaggio 2.4 - Avvia il server ZooKeeper
$ bin/zkServer.sh startDopo aver eseguito questo comando, riceverai una risposta come mostrato di seguito:
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDPassaggio 2.5: avviare la CLI
$ bin/zkCli.shDopo aver digitato il comando precedente, sarai connesso al server guardiano dello zoo e riceverai la risposta seguente.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Passaggio 2.6 - Arresta Zookeeper Server
Dopo aver connesso il server ed aver eseguito tutte le operazioni, puoi fermare il server zookeeper con il seguente comando:
$ bin/zkServer.sh stopOra hai installato correttamente Java e ZooKeeper sul tuo computer. Vediamo i passaggi per installare Apache Kafka.
Passaggio 3: installazione di Apache Kafka
Continuiamo con i seguenti passaggi per installare Kafka sulla tua macchina.
Passaggio 3.1 - Scarica Kafka
Per installare Kafka sulla tua macchina, fai clic sul link sottostante -
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgzOra l'ultima versione cioè, - kafka_2.11_0.9.0.0.tgz verrà scaricato sulla tua macchina.
Passaggio 3.2: estrai il file tar
Estrai il file tar utilizzando il seguente comando:
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0Ora hai scaricato l'ultima versione di Kafka sulla tua macchina.
Passaggio 3.3: avviare il server
Puoi avviare il server dando il seguente comando:
$ bin/kafka-server-start.sh config/server.propertiesDopo l'avvio del server, vedrai la risposta di seguito sullo schermo:
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….Passaggio 4: arrestare il server
Dopo aver eseguito tutte le operazioni, è possibile arrestare il server utilizzando il seguente comando:
$ bin/kafka-server-stop.sh config/server.propertiesOra che abbiamo già discusso dell'installazione di Kafka, possiamo imparare come eseguire le operazioni di base su Kafka nel prossimo capitolo.
Per prima cosa iniziamo a implementare la configurazione a singolo nodo- broker singolo
e quindi migreremo la nostra configurazione alla configurazione a nodo singolo-più broker.
Si spera che a questo punto avresti installato Java, ZooKeeper e Kafka sulla tua macchina. Prima di passare all'installazione di Kafka Cluster, devi prima avviare ZooKeeper perché Kafka Cluster usa ZooKeeper.
Avvia ZooKeeper
Apri un nuovo terminale e digita il seguente comando:
bin/zookeeper-server-start.sh config/zookeeper.propertiesPer avviare Kafka Broker, digita il seguente comando:
bin/kafka-server-start.sh config/server.propertiesDopo aver avviato Kafka Broker, digita il comando jps
sul terminale ZooKeeper e vedrai la seguente risposta:
821 QuorumPeerMain
928 Kafka
931 JpsOra puoi vedere due daemon in esecuzione sul terminale in cui QuorumPeerMain è il daemon di ZooKeeper e un altro è il daemon di Kafka.
Configurazione Single Node-Single Broker
In questa configurazione hai una singola istanza di ZooKeeper e ID broker. Di seguito sono riportati i passaggi per configurarlo:
Creating a Kafka Topic- Kafka fornisce un'utilità della riga di comando denominata kafka-topics.sh
per creare argomenti sul server. Apri un nuovo terminale e digita l'esempio seguente.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-KafkaAbbiamo appena creato un argomento denominato Hello-Kafka
con una singola partizione e un fattore di replica. L'output creato sopra sarà simile al seguente output:
Output- Argomento creato Hello-Kafka
Una volta che l'argomento è stato creato, è possibile ottenere la notifica nella finestra del terminale del broker Kafka e il registro per l'argomento creato specificato in "/ tmp / kafka-logs /" nel file config / server.properties.
Elenco degli argomenti
Per ottenere un elenco di argomenti nel server Kafka, puoi utilizzare il seguente comando:
Syntax
bin/kafka-topics.sh --list --zookeeper localhost:2181Output
Hello-KafkaPoiché abbiamo creato un argomento, elencherà solo Hello-Kafka
. Supponiamo che se crei più argomenti, otterrai i nomi degli argomenti nell'output.
Avvia Producer per inviare messaggi
Syntax
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-nameDalla sintassi precedente, sono richiesti due parametri principali per il client della riga di comando del produttore:
Broker-list- L'elenco dei broker a cui vogliamo inviare i messaggi. In questo caso abbiamo un solo broker. Il file Config / server.properties contiene l'ID della porta del broker, poiché sappiamo che il nostro broker è in ascolto sulla porta 9092, quindi puoi specificarlo direttamente.
Nome argomento: ecco un esempio per il nome dell'argomento.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-KafkaIl produttore attenderà l'input da stdin e pubblicherà nel cluster Kafka. Per impostazione predefinita, ogni nuova riga viene pubblicata come un nuovo messaggio, quindi le proprietà del produttore predefinito vengono specificate nel file config / producer.properties
. Ora puoi digitare alcune righe di messaggi nel terminale come mostrato di seguito.
Output
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first messageMy second messageAvvia consumer per ricevere messaggi
Analogamente a producer, le proprietà consumer predefinite sono specificate nel file config / consumer.proper-ties
. Apri un nuovo terminale e digita la sintassi seguente per consumare i messaggi.
Syntax
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginningExample
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginningOutput
Hello
My first message
My second messageInfine, puoi inserire messaggi dal terminale del produttore e vederli apparire nel terminale del consumatore. A partire da ora, hai un'ottima conoscenza del cluster a nodo singolo con un singolo broker. Passiamo ora alla configurazione di più broker.
Configurazione di broker a nodo singolo e multipli
Prima di passare alla configurazione del cluster di più broker, avvia il tuo server ZooKeeper.
Create Multiple Kafka Brokers- Abbiamo già un'istanza del broker Kafka in con-fig / server.properties. Ora abbiamo bisogno di più istanze di broker, quindi copia il file server.prop-erties esistente in due nuovi file di configurazione e rinominalo come server-one.properties e server-two.prop-erties. Quindi modifica entrambi i nuovi file e assegna le seguenti modifiche:
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2Start Multiple Brokers- Dopo che tutte le modifiche sono state apportate su tre server, apri tre nuovi terminali per avviare ogni broker uno per uno.
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.propertiesOra abbiamo tre diversi broker in esecuzione sulla macchina. Provalo da solo per controllare tutti i daemon digitandojps sul terminale ZooKeeper, vedrai la risposta.
Creazione di un argomento
Assegniamo il valore del fattore di replica come tre per questo argomento perché abbiamo tre diversi broker in esecuzione. Se hai due broker, il valore della replica assegnato sarà due.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic MultibrokerapplicationOutput
created topic “Multibrokerapplication”Il comando Descrivi
viene utilizzato per verificare quale broker è in ascolto sull'argomento attualmente creato come mostrato di seguito -
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cationOutput
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cation
Topic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:
Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1Dall'output di cui sopra, possiamo concludere che la prima riga fornisce un riepilogo di tutte le partizioni, mostrando il nome dell'argomento, il conteggio delle partizioni e il fattore di replica che abbiamo già scelto. Nella seconda riga, ogni nodo sarà il leader per una parte selezionata a caso delle partizioni.
Nel nostro caso, vediamo che il nostro primo broker (con broker.id 0) è il leader. Quindi Repliche: 0,2,1 significa che tutti i broker replicano l'argomento, infine Isr
è l'insieme delle repliche sincronizzate
. Ebbene, questo è il sottoinsieme delle repliche attualmente vive e raggiunto dal leader.
Avvia Producer per inviare messaggi
Questa procedura rimane la stessa della configurazione del broker singolo.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic MultibrokerapplicationOutput
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second messageAvvia consumer per ricevere messaggi
Questa procedura rimane la stessa mostrata nella configurazione del broker singolo.
Example
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion --from-beginningOutput
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second messageOperazioni sugli argomenti di base
In questo capitolo discuteremo le varie operazioni di base sugli argomenti.
Modifica di un argomento
Come hai già capito come creare un argomento in Kafka Cluster. Ora modifichiamo un argomento creato utilizzando il seguente comando
Syntax
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name
--parti-tions countExample
We have already created a topic “Hello-Kafka” with single partition count and one replica factor.
Now using “alter” command we have changed the partition count.
bin/kafka-topics.sh --zookeeper localhost:2181
--alter --topic Hello-kafka --parti-tions 2Output
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!Eliminazione di un argomento
Per eliminare un argomento, puoi utilizzare la seguente sintassi.
Syntax
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_nameExample
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafkaOutput
> Topic Hello-kafka marked for deletionNote −Questo non avrà alcun impatto se delete.topic.enable non è impostato su true
Creiamo un'applicazione per la pubblicazione e il consumo di messaggi utilizzando un client Java. Il client del produttore Kafka è costituito dalle seguenti API.
API KafkaProducer
Cerchiamo di capire il set più importante di API del produttore di Kafka in questa sezione. La parte centrale dell'API KafkaProducer
è la classe KafkaProducer
. La classe KafkaProducer fornisce un'opzione per connettere un broker Kafka nel suo costruttore con i seguenti metodi.
La classe KafkaProducer fornisce il metodo di invio per inviare messaggi in modo asincrono a un argomento. La firma di send () è la seguente
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);ProducerRecord - Il produttore gestisce un buffer di record in attesa di essere inviati.
Callback - Un callback fornito dall'utente da eseguire quando il record è stato riconosciuto dal server (null indica nessuna richiamata).
La classe KafkaProducer fornisce un metodo di svuotamento per garantire che tutti i messaggi inviati in precedenza siano stati effettivamente completati. La sintassi del metodo flush è la seguente:
public void flush()La classe KafkaProducer fornisce il metodo partitionFor, che aiuta a ottenere i metadati della partizione per un determinato argomento. Può essere utilizzato per il partizionamento personalizzato. La firma di questo metodo è la seguente:
public Map metrics()Restituisce la mappa delle metriche interne gestite dal produttore.
public void close () - La classe KafkaProducer fornisce blocchi di metodi di chiusura fino al completamento di tutte le richieste inviate in precedenza.
Producer API
La parte centrale dell'API Producer
è la classe Producer
. La classe Producer fornisce un'opzione per connettere il broker Kafka nel suo costruttore con i seguenti metodi.
La classe del produttore
La classe producer fornisce il metodo di invio a send messaggi a uno o più argomenti utilizzando le seguenti firme.
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);Esistono due tipi di produttori: Sync e Async.
La stessa configurazione API si applica anche al produttore di sincronizzazione
. La differenza tra loro è che un produttore di sincronizzazione invia i messaggi direttamente, ma invia i messaggi in background. Il produttore asincrono è preferito quando si desidera una velocità effettiva maggiore. Nelle versioni precedenti come la 0.8, un produttore asincrono non dispone di una richiamata per send () per registrare i gestori di errori. Questo è disponibile solo nella versione corrente di 0.9.
public void close ()
La classe del produttore fornisce close metodo per chiudere le connessioni del pool di produttori a tutti i broker Kafka.
Impostazioni di configurazione
Le principali impostazioni di configurazione dell'API Producer sono elencate nella tabella seguente per una migliore comprensione:
| S.No | Impostazioni di configurazione e descrizione |
|---|---|
| 1 | client.id identifica l'applicazione del produttore |
| 2 | producer.type sincronizzato o asincrono |
| 3 | acks La configurazione acks controlla che i criteri in base alle richieste del produttore siano considerati completi. |
| 4 | retries Se la richiesta del produttore non riesce, riprova automaticamente con un valore specifico. |
| 5 | bootstrap.servers elenco bootstrap di broker. |
| 6 | linger.ms se vuoi ridurre il numero di richieste puoi impostare linger.ms su qualcosa di più grande di un certo valore. |
| 7 | key.serializer Chiave per l'interfaccia del serializzatore. |
| 8 | value.serializer valore per l'interfaccia del serializzatore. |
| 9 | batch.size Dimensione buffer. |
| 10 | buffer.memory controlla la quantità totale di memoria disponibile per il produttore per il buffering. |
ProducerRecord API
ProducerRecord è una coppia chiave / valore che viene inviata al costruttore di classi Kafka cluster.ProducerRecord per la creazione di un record con coppie di partizione, chiave e valore utilizzando la seguente firma.
public ProducerRecord (string topic, int partition, k key, v value)Topic - nome dell'argomento definito dall'utente che verrà aggiunto alla registrazione.
Partition - conteggio delle partizioni
Key - La chiave che verrà inclusa nel record.
- Value - Registra i contenuti
public ProducerRecord (string topic, k key, v value)Il costruttore della classe ProducerRecord viene utilizzato per creare un record con chiavi, coppie di valori e senza partizione.
Topic - Crea un argomento per assegnare il record.
Key - chiave per la cronaca.
Value - registrare i contenuti.
public ProducerRecord (string topic, v value)La classe ProducerRecord crea un record senza partizione e chiave.
Topic - crea un argomento.
Value - registrare i contenuti.
I metodi della classe ProducerRecord sono elencati nella tabella seguente:
| S.No | Metodi di classe e descrizione |
|---|---|
| 1 | public string topic() L'argomento verrà aggiunto al record. |
| 2 | public K key() Chiave che verrà inclusa nel record. In assenza di tale chiave, qui verrà restituito null. |
| 3 | public V value() Registra i contenuti. |
| 4 | partition() Conteggio delle partizioni per il record |
Applicazione SimpleProducer
Prima di creare l'applicazione, avvia prima ZooKeeper e il broker Kafka, quindi crea il tuo argomento nel broker Kafka utilizzando il comando crea argomento. Dopodiché crea una classe java chiamata Sim-pleProducer.java
e digita la seguente codifica.
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}Compilation - L'applicazione può essere compilata utilizzando il seguente comando.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution - L'applicazione può essere eseguita utilizzando il seguente comando.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>Output
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10Semplice esempio di consumatore
A partire da ora abbiamo creato un produttore per inviare messaggi al cluster Kafka. Ora creiamo un consumatore per consumare i messaggi dal cluster Kafka. L'API KafkaConsumer viene utilizzata per consumare i messaggi dal cluster Kafka. Il costruttore della classe KafkaConsumer è definito di seguito.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)configs - Restituire una mappa delle configurazioni dei consumatori.
La classe KafkaConsumer dispone dei seguenti metodi significativi elencati nella tabella seguente.
| S.No | Metodo e descrizione |
|---|---|
| 1 | public java.util.Set<TopicPar-tition> assignment() Ottieni il set di partizioni attualmente assegnato dal consumatore. |
| 2 | public string subscription() Abbonarsi all'elenco di argomenti fornito per ottenere partizioni dinamicamente con segno. |
| 3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) Abbonarsi all'elenco di argomenti fornito per ottenere partizioni dinamicamente con segno. |
| 4 | public void unsubscribe() Annulla la sottoscrizione degli argomenti dall'elenco di partizioni fornito. |
| 5 | public void sub-scribe(java.util.List<java.lang.String> topics) Abbonarsi all'elenco di argomenti fornito per ottenere partizioni dinamicamente con segno. Se l'elenco di argomenti fornito è vuoto, viene considerato come unsubscribe (). |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) Il modello di argomento si riferisce al modello di sottoscrizione nel formato di espressione regolare e l'argomento del listener riceve le notifiche dal modello di sottoscrizione. |
| 7 | public void as-sign(java.util.List<TopicParti-tion> partitions) Assegna manualmente un elenco di partizioni al cliente. |
| 8 | poll() Recupera i dati per gli argomenti o le partizioni specificate utilizzando una delle API di sottoscrizione / assegnazione. Questo restituirà un errore, se gli argomenti non vengono sottoscritti prima del polling dei dati. |
| 9 | public void commitSync() Gli offset di commit restituiti nell'ultimo sondaggio () per tutti gli elenchi di argomenti e partizioni con sottoscrizione. La stessa operazione viene applicata a commitAsyn (). |
| 10 | public void seek(TopicPartition partition, long offset) Recupera il valore di offset corrente che il consumatore utilizzerà nel successivo metodo poll (). |
| 11 | public void resume() Riprendi le partizioni sospese. |
| 12 | public void wakeup() Sveglia il consumatore. |
API ConsumerRecord
L'API ConsumerRecord viene utilizzata per ricevere record dal cluster Kafka. Questa API è costituita da un nome di argomento, un numero di partizione da cui viene ricevuto il record e un offset che punta al record in una partizione Kafka. La classe ConsumerRecord viene utilizzata per creare un record consumer con nome argomento specifico, conteggio partizioni e coppie <chiave, valore>. Ha la seguente firma.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)Topic - Il nome dell'argomento per il record del consumatore ricevuto dal cluster Kafka.
Partition - Partizione per l'argomento.
Key - La chiave del record, se non esiste alcuna chiave verrà restituito null.
Value - Registra i contenuti.
API ConsumerRecords
L'API ConsumerRecords funge da contenitore per ConsumerRecord. Questa API viene utilizzata per mantenere l'elenco di ConsumerRecord per partizione per un particolare argomento. Il suo costruttore è definito di seguito.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)TopicPartition - Restituisce una mappa della partizione per un particolare argomento.
Records - Elenco di restituzione di ConsumerRecord.
La classe ConsumerRecords ha i seguenti metodi definiti.
| S.No | Metodi e descrizione |
|---|---|
| 1 | public int count() Il numero di record per tutti gli argomenti. |
| 2 | public Set partitions() Il set di partizioni con i dati in questo set di record (se non sono stati restituiti dati, il set è vuoto). |
| 3 | public Iterator iterator() Iterator ti consente di scorrere una raccolta, ottenendo o rimuovendo elementi. |
| 4 | public List records() Ottieni l'elenco dei record per la partizione data. |
Impostazioni di configurazione
Le impostazioni di configurazione per le impostazioni di configurazione principali dell'API client consumer sono elencate di seguito:
| S.No | Impostazioni e descrizione |
|---|---|
| 1 | bootstrap.servers Elenco bootstrap di broker. |
| 2 | group.id Assegna un singolo consumatore a un gruppo. |
| 3 | enable.auto.commit Abilita il commit automatico per gli offset se il valore è vero, altrimenti non confermato. |
| 4 | auto.commit.interval.ms Restituisce la frequenza con cui gli offset consumati aggiornati vengono scritti in ZooKeeper. |
| 5 | session.timeout.ms Indica quanti millisecondi Kafka attenderà prima che ZooKeeper risponda a una richiesta (in lettura o scrittura) prima di rinunciare e continuare a consumare messaggi. |
Applicazione SimpleConsumer
I passaggi dell'applicazione del produttore rimangono gli stessi qui. Per prima cosa, avvia il tuo broker ZooKeeper e Kafka. Quindi creare un'applicazione SimpleConsumer
con la classe java denominata SimpleCon-sumer.java
e digitare il codice seguente.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilation - L'applicazione può essere compilata utilizzando il seguente comando.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution − L'applicazione può essere eseguita utilizzando il seguente comando
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>Input- Apri la CLI del produttore e invia alcuni messaggi all'argomento. Puoi inserire l'input semplice come "Hello Consumer".
Output - Di seguito sarà l'output.
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello ConsumerIl gruppo di consumatori è un consumo multi-thread o multi-macchina degli argomenti Kafka.
Gruppo di consumatori
I consumatori possono unirsi a un gruppo utilizzando lo stesso
group.id.
Il parallelismo massimo di un gruppo è che il numero di consumatori nel gruppo ← no di partizioni.
Kafka assegna le partizioni di un argomento al consumatore in un gruppo, in modo che ogni partizione venga utilizzata esattamente da un consumatore nel gruppo.
Kafka garantisce che un messaggio venga letto solo da un singolo utente del gruppo.
I consumatori possono visualizzare il messaggio nell'ordine in cui sono stati memorizzati nel registro.
Riequilibrio di un consumatore
L'aggiunta di più processi / thread causerà il riequilibrio di Kafka. Se un consumatore o un broker non riesce a inviare heartbeat a ZooKeeper, può essere riconfigurato tramite il cluster Kafka. Durante questo riequilibrio, Kafka assegnerà le partizioni disponibili ai thread disponibili, eventualmente spostando una partizione in un altro processo.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilazione
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.javaEsecuzione
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupQui abbiamo creato un nome di gruppo di esempio come mio-gruppo
con due consumatori. Allo stesso modo, puoi creare il tuo gruppo e il numero di consumatori nel gruppo.
Ingresso
Apri la CLI del produttore e invia alcuni messaggi come:
Test consumer group 01
Test consumer group 02Output del primo processo
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01Risultato del secondo processo
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02Ora si spera che tu abbia capito SimpleConsumer e ConsumeGroup utilizzando la demo del client Java. Ora hai un'idea su come inviare e ricevere messaggi utilizzando un client Java. Continuiamo l'integrazione di Kafka con le tecnologie dei big data nel prossimo capitolo.
In questo capitolo impareremo come integrare Kafka con Apache Storm.
A proposito di Storm
Storm è stato originariamente creato da Nathan Marz e dal team di BackType. In breve tempo, Apache Storm è diventato uno standard per il sistema di elaborazione distribuito in tempo reale che consente di elaborare un enorme volume di dati. Storm è molto veloce e un benchmark lo ha registrato a oltre un milione di tuple elaborate al secondo per nodo. Apache Storm viene eseguito continuamente, consumando i dati dalle origini configurate (Spouts) e trasmette i dati alla pipeline di elaborazione (Bolt). Combinati, beccucci e bulloni creano una topologia.
Integrazione con Storm
Kafka e Storm si completano naturalmente a vicenda e la loro potente collaborazione consente analisi in streaming in tempo reale per big data in rapido movimento. L'integrazione di Kafka e Storm ha lo scopo di rendere più facile per gli sviluppatori inserire e pubblicare flussi di dati dalle topologie Storm.
Flusso concettuale
Un beccuccio è una fonte di flussi. Ad esempio, uno spout può leggere tuple da un argomento Kafka ed emetterle come flusso. Un bolt consuma flussi di input, elabora e possibilmente emette nuovi flussi. Bolts può fare qualsiasi cosa, dall'esecuzione di funzioni, al filtraggio di tuple, alle aggregazioni di streaming, ai join di streaming, alla comunicazione con i database e altro ancora. Ogni nodo in una topologia Storm viene eseguito in parallelo. Una topologia viene eseguita indefinitamente fino a quando non viene terminata. Storm riassegnerà automaticamente tutte le attività non riuscite. Inoltre, Storm garantisce che non si verificherà alcuna perdita di dati, anche se le macchine si arrestano e i messaggi vengono eliminati.
Esaminiamo in dettaglio le API di integrazione di Kafka-Storm. Esistono tre classi principali per integrare Kafka con Storm. Sono i seguenti:
BrokerHosts - ZkHosts e StaticHosts
BrokerHosts è un'interfaccia e ZkHosts e StaticHosts sono le sue due implementazioni principali. ZkHosts viene utilizzato per tenere traccia dinamicamente dei broker Kafka mantenendo i dettagli in ZooKeeper, mentre StaticHosts viene utilizzato per impostare manualmente / staticamente i broker Kafka ei relativi dettagli. ZkHosts è il modo semplice e veloce per accedere al broker Kafka.
La firma di ZkHosts è la seguente:
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)Dove brokerZkStr è l'host di ZooKeeper e brokerZkPath è il percorso di ZooKeeper per mantenere i dettagli del broker Kafka.
API KafkaConfig
Questa API viene utilizzata per definire le impostazioni di configurazione per il cluster Kafka. La firma di Kafka Con-fig è definita come segue
public KafkaConfig(BrokerHosts hosts, string topic)Hosts - I BrokerHost possono essere ZkHosts / StaticHosts.
Topic - nome dell'argomento.
API SpoutConfig
Spoutconfig è un'estensione di KafkaConfig che supporta informazioni aggiuntive su ZooKeeper.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)Hosts - BrokerHosts può essere qualsiasi implementazione dell'interfaccia BrokerHosts
Topic - nome dell'argomento.
zkRoot - Percorso radice di ZooKeeper.
id −Il beccuccio memorizza lo stato degli offset consumati in Zookeeper. L'ID dovrebbe identificare in modo univoco il tuo beccuccio.
SchemeAsMultiScheme
SchemeAsMultiScheme è un'interfaccia che determina come il ByteBuffer consumato da Kafka viene trasformato in una tupla tempesta. È derivato da MultiScheme e accetta l'implementazione della classe Scheme. Ci sono molte implementazioni della classe Scheme e una di queste è StringScheme, che analizza il byte come una semplice stringa. Controlla anche la denominazione del campo di output. La firma è definita come segue.
public SchemeAsMultiScheme(Scheme scheme)Scheme - buffer di byte consumato da kafka.
API KafkaSpout
KafkaSpout è la nostra implementazione dello spout, che si integrerà con Storm. Recupera i messaggi dall'argomento kafka e li emette nell'ecosistema Storm come tuple. KafkaSpout ottiene i dettagli di configurazione da SpoutConfig.
Di seguito è riportato un codice di esempio per creare un semplice beccuccio Kafka.
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);Creazione di bulloni
Bolt è un componente che accetta le tuple come input, elabora la tupla e produce nuove tuple come output. Bolts implementerà l'interfaccia IRichBolt. In questo programma, per eseguire le operazioni vengono utilizzate due classi di bulloni WordSplitter-Bolt e WordCounterBolt.
L'interfaccia IRichBolt ha i seguenti metodi:
Prepare- Fornisce al bolt un ambiente da eseguire. Gli esecutori eseguiranno questo metodo per inizializzare lo spout.
Execute - Elabora una singola tupla di input.
Cleanup - Chiamato quando un catenaccio sta per spegnersi.
declareOutputFields - Dichiara lo schema di output della tupla.
Creiamo SplitBolt.java, che implementa la logica per dividere una frase in parole e CountBolt.java, che implementa la logica per separare parole uniche e contare la sua occorrenza.
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Invio alla topologia
La topologia Storm è fondamentalmente una struttura Thrift. La classe TopologyBuilder fornisce metodi semplici e facili per creare topologie complesse. La classe TopologyBuilder ha metodi per impostare spout (setSpout) e per impostare bolt (setBolt). Infine, TopologyBuilder ha createTopology per creare to-pology. I metodi shuffleGrouping e fieldsGrouping aiutano a impostare il raggruppamento del flusso per spout e bolt.
Local Cluster- Ai fini di sviluppo, siamo in grado di creare un cluster locale utilizzando LocalCluster
oggetto e quindi inviare la topologia utilizzando submitTopology
metodo LocalCluster
di classe.
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}Prima di spostare la compilation, l'integrazione di Kakfa-Storm necessita della libreria java del client ZooKeeper del curatore. La versione 2.9.1 del curatore supporta la versione 0.9.5 di Apache Storm (che usiamo in questo tutorial). Scarica i file jar specificati di seguito e inseriscili nel percorso della classe java.
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
Dopo aver incluso i file delle dipendenze, compilare il programma utilizzando il seguente comando,
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.javaEsecuzione
Avvia Kafka Producer CLI (spiegato nel capitolo precedente), crea un nuovo argomento chiamato my-first-topic
e fornisci alcuni messaggi di esempio come mostrato di seguito -
hello
kafka
storm
spark
test message
another test messageOra esegui l'applicazione utilizzando il seguente comando:
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSampleL'output di esempio di questa applicazione è specificato di seguito:
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2In questo capitolo, discuteremo su come integrare Apache Kafka con Spark Streaming API.
A proposito di Spark
L'API Spark Streaming consente un'elaborazione del flusso scalabile, ad alta velocità e tolleranza agli errori di flussi di dati in tempo reale. I dati possono essere acquisiti da molte fonti come Kafka, Flume, Twitter, ecc. E possono essere elaborati utilizzando algoritmi complessi come funzioni di alto livello come map, reduce, join e window. Infine, i dati elaborati possono essere inviati a filesystem, database e dashboard live. Resilient Distributed Datasets (RDD) è una struttura dati fondamentale di Spark. È una raccolta distribuita immutabile di oggetti. Ogni set di dati in RDD è suddiviso in partizioni logiche, che possono essere calcolate su diversi nodi del cluster.
Integrazione con Spark
Kafka è una potenziale piattaforma di messaggistica e integrazione per lo streaming Spark. Kafka funge da hub centrale per flussi di dati in tempo reale e vengono elaborati utilizzando algoritmi complessi in Spark Streaming. Una volta elaborati i dati, Spark Streaming potrebbe pubblicare i risultati in un altro argomento Kafka o archiviarli in HDFS, database o dashboard. Il diagramma seguente illustra il flusso concettuale.

Ora esaminiamo in dettaglio le API di Kafka-Spark.
API SparkConf
Rappresenta la configurazione per un'applicazione Spark. Utilizzato per impostare vari parametri Spark come coppie chiave-valore.
La
classe SparkConf
ha i seguenti metodi:
set(string key, string value) - imposta la variabile di configurazione.
remove(string key) - rimuovere la chiave dalla configurazione.
setAppName(string name) - imposta il nome dell'applicazione per la tua applicazione.
get(string key) - prendi la chiave
StreamingContext API
Questo è il punto di ingresso principale per la funzionalità Spark. Un SparkContext rappresenta la connessione a un cluster Spark e può essere utilizzato per creare RDD, accumulatori e variabili di trasmissione sul cluster. La firma è definita come mostrato di seguito.
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)master - URL del cluster a cui connettersi (ad es. Mesos: // host: port, spark: // host: port, local [4]).
appName - un nome per il tuo lavoro, da visualizzare sull'interfaccia utente web del cluster
batchDuration - l'intervallo di tempo in cui i dati di streaming verranno suddivisi in batch
public StreamingContext(SparkConf conf, Duration batchDuration)Crea un StreamingContext fornendo la configurazione necessaria per un nuovo SparkContext.
conf - Parametri Spark
batchDuration - l'intervallo di tempo in cui i dati di streaming verranno suddivisi in batch
API KafkaUtils
L'API KafkaUtils viene utilizzata per connettere il cluster Kafka allo streaming Spark. Questa API ha la firma del metodo createStream significativa
definita come di seguito.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)Il metodo mostrato sopra viene utilizzato per creare un flusso di input che estrae i messaggi da Kafka Brokers.
ssc - Oggetto StreamingContext.
zkQuorum - Quorum dello Zookeeper.
groupId - L'ID gruppo per questo consumatore.
topics - restituire una mappa degli argomenti da consumare.
storageLevel - Livello di archiviazione da utilizzare per memorizzare gli oggetti ricevuti.
L'API KafkaUtils ha un altro metodo createDirectStream, che viene utilizzato per creare un flusso di input che estrae direttamente i messaggi da Kafka Brokers senza utilizzare alcun ricevitore. Questo flusso può garantire che ogni messaggio da Kafka sia incluso nelle trasformazioni esattamente una volta.
L'applicazione di esempio viene eseguita in Scala. Per compilare l'applicazione, scarica e installa sbt
, scala build tool (simile a maven). Il codice dell'applicazione principale è presentato di seguito.
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}Crea script
L'integrazione spark-kafka dipende dal barattolo di integrazione spark, spark streaming e spark Kafka. Crea un nuovo file build.sbt
e specifica i dettagli dell'applicazione e la sua dipendenza. Lo sbt
scaricherà il jar necessario durante la compilazione e il confezionamento dell'applicazione.
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"Compilazione / Confezione
Eseguire il comando seguente per compilare e creare il pacchetto del file jar dell'applicazione. Dobbiamo inviare il file jar nella console Spark per eseguire l'applicazione.
sbt packageInvio a Spark
Avvia Kafka Producer CLI (spiegato nel capitolo precedente), crea un nuovo argomento chiamato my-first-topic
e fornisci alcuni messaggi di esempio come mostrato di seguito.
Another spark test messageEseguire il comando seguente per inviare l'applicazione a Spark Console.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>L'output di esempio di questa applicazione è mostrato di seguito.
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..Analizziamo un'applicazione in tempo reale per ottenere gli ultimi feed di Twitter e i suoi hashtag. In precedenza, abbiamo visto l'integrazione di Storm e Spark con Kafka. In entrambi gli scenari, abbiamo creato un Kafka Producer (utilizzando cli) per inviare messaggi all'ecosistema Kafka. Quindi, l'integrazione di tempesta e scintilla legge i messaggi utilizzando il consumatore Kafka e lo inietta rispettivamente nell'ecosistema tempesta e scintilla. Quindi, praticamente dobbiamo creare un produttore Kafka, che dovrebbe:
- Leggere i feed di Twitter utilizzando "Twitter Streaming API",
- Elaborare i feed,
- Estrai gli hashtag e
- Mandalo a Kafka.
Una volta ricevuti
gli HashTag
da Kafka, l'integrazione di Storm / Spark riceve le informazioni e le invia all'ecosistema Storm / Spark.
Twitter Streaming API
È possibile accedere alla "Twitter Streaming API" in qualsiasi linguaggio di programmazione. “Twitter4j” è una libreria Java non ufficiale, open source, che fornisce un modulo basato su Java per accedere facilmente alla “Twitter Streaming API”. Il "twitter4j" fornisce un framework basato sull'ascoltatore per accedere ai tweet. Per accedere alla "Twitter Streaming API", dobbiamo accedere all'account sviluppatore Twitter e dovremmo ottenere quanto segueOAuth dettagli di autenticazione.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Una volta creato l'account sviluppatore, scarica i file jar "twitter4j" e inseriscili nel percorso della classe java.
La codifica completa del produttore di Twitter Kafka (KafkaTwitterProducer.java) è elencata di seguito:
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}Compilazione
Compilare l'applicazione utilizzando il seguente comando:
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.javaEsecuzione
Apri due console. Eseguire l'applicazione compilata sopra come mostrato di seguito in una console.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic foodEsegui una qualsiasi delle applicazioni Spark / Storm spiegate nel capitolo precedente in un'altra finestra. Il punto principale da notare è che l'argomento utilizzato dovrebbe essere lo stesso in entrambi i casi. In questo caso, abbiamo utilizzato "il mio primo argomento" come nome dell'argomento.
Produzione
L'output di questa applicazione dipenderà dalle parole chiave e dal feed corrente di Twitter. Di seguito è specificato un output di esempio (integrazione storm).
. . .
food : 1
foodie : 2
burger : 1
. . .Strumento Kafka contenuto in "org.apache.kafka.tools. *. Gli strumenti sono classificati in strumenti di sistema e strumenti di replica.
Strumenti di sistema
Gli strumenti di sistema possono essere eseguiti dalla riga di comando utilizzando lo script di classe di esecuzione. La sintassi è la seguente:
bin/kafka-run-class.sh package.class - - optionsAlcuni degli strumenti di sistema sono menzionati di seguito:
Kafka Migration Tool - Questo strumento viene utilizzato per migrare un broker da una versione all'altra.
Mirror Maker - Questo strumento viene utilizzato per fornire il mirroring di un cluster Kafka a un altro.
Consumer Offset Checker - Questo strumento visualizza il gruppo di consumatori, l'argomento, le partizioni, l'off-set, la dimensione del registro, il proprietario per il set di argomenti e il gruppo di consumatori specificato.
Strumento di replica
La replica di Kafka è uno strumento di progettazione di alto livello. Lo scopo dell'aggiunta di uno strumento di replica è per una maggiore durata e una maggiore disponibilità. Alcuni degli strumenti di replica sono menzionati di seguito:
Create Topic Tool - Questo crea un argomento con un numero predefinito di partizioni, fattore di replica e utilizza lo schema predefinito di Kafka per eseguire l'assegnazione delle repliche.
List Topic Tool- Questo strumento elenca le informazioni per un determinato elenco di argomenti. Se non vengono forniti argomenti nella riga di comando, lo strumento interroga Zookeeper per ottenere tutti gli argomenti ed elenca le informazioni per essi. I campi visualizzati dallo strumento sono nome argomento, partizione, leader, repliche, isr.
Add Partition Tool- Creazione di un argomento, è necessario specificare il numero di partizioni per argomento. Successivamente, potrebbero essere necessarie più partizioni per l'argomento, quando il volume dell'argomento aumenterà. Questo strumento aiuta ad aggiungere più partizioni per un argomento specifico e consente anche l'assegnazione manuale della replica delle partizioni aggiunte.
Kafka supporta molte delle migliori applicazioni industriali odierne. Forniremo una breve panoramica di alcune delle applicazioni più importanti di Kafka in questo capitolo.
Twitter è un servizio di social networking online che fornisce una piattaforma per inviare e ricevere tweet degli utenti. Gli utenti registrati possono leggere e pubblicare tweet, ma gli utenti non registrati possono solo leggere i tweet. Twitter utilizza Storm-Kafka come parte della propria infrastruttura di elaborazione dei flussi.
Apache Kafka viene utilizzato su LinkedIn per i dati del flusso di attività e le metriche operative. Il sistema di messaggistica Kafka aiuta LinkedIn con vari prodotti come LinkedIn Newsfeed, LinkedIn Today per il consumo di messaggi online e in aggiunta ai sistemi di analisi offline come Hadoop. La forte durabilità di Kafka è anche uno dei fattori chiave in relazione a LinkedIn.
Netflix
Netflix è un fornitore multinazionale americano di contenuti multimediali in streaming su Internet su richiesta. Netflix utilizza Kafka per il monitoraggio in tempo reale e l'elaborazione degli eventi.
Mozilla
Mozilla è una comunità di software libero, creata nel 1998 dai membri di Netscape. Kafka sostituirà presto una parte dell'attuale sistema di produzione Mozilla per raccogliere dati sulle prestazioni e sull'utilizzo dal browser dell'utente finale per progetti come telemetria, test pilota, ecc.
Oracolo
Oracle fornisce la connettività nativa a Kafka dal suo prodotto Enterprise Service Bus chiamato OSB (Oracle Service Bus) che consente agli sviluppatori di sfruttare le capacità di mediazione integrate di OSB per implementare pipeline di dati a fasi.