Apache Spark - Programmazione di base
Spark Core è la base dell'intero progetto. Fornisce l'invio distribuito delle attività, la pianificazione e le funzionalità di I / O di base. Spark utilizza una struttura di dati fondamentale specializzata nota come RDD (Resilient Distributed Datasets) che è una raccolta logica di dati partizionati tra le macchine. Gli RDD possono essere creati in due modi; uno è fare riferimento a set di dati in sistemi di archiviazione esterni e il secondo è applicare trasformazioni (ad esempio mappa, filtro, riduttore, join) su RDD esistenti.
L'astrazione RDD viene esposta tramite un'API integrata nel linguaggio. Ciò semplifica la complessità della programmazione perché il modo in cui le applicazioni manipolano gli RDD è simile alla manipolazione delle raccolte locali di dati.
Spark Shell
Spark fornisce una shell interattiva, un potente strumento per analizzare i dati in modo interattivo. È disponibile in linguaggio Scala o Python. L'astrazione principale di Spark è una raccolta distribuita di elementi denominata Resilient Distributed Dataset (RDD). Gli RDD possono essere creati da Hadoop Input Formats (come i file HDFS) o trasformando altri RDD.
Apri Spark Shell
Il comando seguente viene utilizzato per aprire la shell Spark.
$ spark-shellCrea un semplice RDD
Creiamo un semplice RDD dal file di testo. Utilizzare il seguente comando per creare un semplice RDD.
scala> val inputfile = sc.textFile(“input.txt”)L'output per il comando precedente è
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12L'API Spark RDD ne introduce pochi Transformations e pochi Actions per manipolare RDD.
Trasformazioni RDD
Le trasformazioni RDD restituiscono il puntatore a un nuovo RDD e consentono di creare dipendenze tra RDD. Ogni RDD nella catena delle dipendenze (String of Dependencies) ha una funzione per il calcolo dei suoi dati e ha un puntatore (dipendenza) al suo RDD genitore.
Spark è pigro, quindi non verrà eseguito nulla a meno che non chiami una trasformazione o un'azione che attiverà la creazione e l'esecuzione del lavoro. Guarda il seguente frammento dell'esempio di conteggio delle parole.
Pertanto, la trasformazione RDD non è un insieme di dati ma è un passaggio in un programma (potrebbe essere l'unico passaggio) che dice a Spark come ottenere i dati e cosa farne.
Di seguito è riportato un elenco di trasformazioni RDD.
| S.No | Trasformazioni e significato |
|---|---|
| 1 | map(func) Restituisce un nuovo set di dati distribuito, formato passando ogni elemento della sorgente attraverso una funzione func. |
| 2 | filter(func) Restituisce un nuovo dataset formato selezionando quegli elementi della sorgente su cui func restituisce true. |
| 3 | flatMap(func) Simile a map, ma ogni elemento di input può essere mappato a 0 o più elementi di output (quindi func dovrebbe restituire un Seq piuttosto che un singolo elemento). |
| 4 | mapPartitions(func) Simile alla mappa, ma viene eseguito separatamente su ogni partizione (blocco) dell'RDD, quindi func deve essere di tipo Iterator <T> ⇒ Iterator <U> quando viene eseguito su un RDD di tipo T. |
| 5 | mapPartitionsWithIndex(func) Simile alla mappa delle partizioni, ma fornisce anche func con un valore intero che rappresenta l'indice della partizione, quindi func deve essere di tipo (Int, Iterator <T>) ⇒ Iterator <U> quando si esegue su un RDD di tipo T. |
| 6 | sample(withReplacement, fraction, seed) Campione a fraction dei dati, con o senza sostituzione, utilizzando un determinato seme del generatore di numeri casuali. |
| 7 | union(otherDataset) Restituisce un nuovo set di dati che contiene l'unione degli elementi nel set di dati di origine e l'argomento. |
| 8 | intersection(otherDataset) Restituisce un nuovo RDD che contiene l'intersezione di elementi nel set di dati di origine e l'argomento. |
| 9 | distinct([numTasks]) Restituisce un nuovo set di dati che contiene gli elementi distinti del set di dati di origine. |
| 10 | groupByKey([numTasks]) Quando viene chiamato su un set di dati di coppie (K, V), restituisce un set di dati di coppie (K, Iterable <V>). Note - Se stai raggruppando per eseguire un'aggregazione (come una somma o una media) su ciascuna chiave, l'utilizzo di reduceByKey o aggregateByKey produrrà prestazioni molto migliori. |
| 11 | reduceByKey(func, [numTasks]) Quando viene chiamato su un set di dati di (K, V) coppie, restituisce un set di dati di (K, V) coppie in cui i valori per ogni chiave vengono aggregati utilizzando la data ridurre la funzione func , che deve essere di tipo (V, V) ⇒ V Come in groupByKey, il numero di attività di riduzione è configurabile tramite un secondo argomento opzionale. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) Quando viene richiamato su un set di dati di coppie (K, V), restituisce un set di dati di coppie (K, U) in cui i valori di ciascuna chiave vengono aggregati utilizzando le funzioni di combinazione fornite e un valore "zero" neutro. Consente un tipo di valore aggregato diverso dal tipo di valore di input, evitando allocazioni non necessarie. Come in groupByKey, il numero di attività di riduzione è configurabile tramite un secondo argomento opzionale. |
| 13 | sortByKey([ascending], [numTasks]) Quando viene richiamato su un set di dati di coppie (K, V) in cui K implementa Ordered, restituisce un set di dati di coppie (K, V) ordinate per chiavi in ordine crescente o decrescente, come specificato nell'argomento booleano ascendente. |
| 14 | join(otherDataset, [numTasks]) Quando viene richiamato su set di dati di tipo (K, V) e (K, W), restituisce un set di dati di coppie (K, (V, W)) con tutte le coppie di elementi per ciascuna chiave. I join esterni sono supportati tramite leftOuterJoin, rightOuterJoin e fullOuterJoin. |
| 15 | cogroup(otherDataset, [numTasks]) Quando viene chiamato su set di dati di tipo (K, V) e (K, W), restituisce un set di dati di tuple (K, (Iterable <V>, Iterable <W>)). Questa operazione è anche chiamata gruppo con. |
| 16 | cartesian(otherDataset) Quando viene chiamato su set di dati di tipo T e U, restituisce un set di dati di coppie (T, U) (tutte le coppie di elementi). |
| 17 | pipe(command, [envVars]) Pipe ogni partizione dell'RDD attraverso un comando shell, ad esempio uno script Perl o bash. Gli elementi RDD vengono scritti nello stdin del processo e le righe in uscita nel relativo stdout vengono restituite come RDD di stringhe. |
| 18 | coalesce(numPartitions) Riduci il numero di partizioni nell'RDD a numPartitions. Utile per eseguire le operazioni in modo più efficiente dopo aver filtrato un set di dati di grandi dimensioni. |
| 19 | repartition(numPartitions) Rimescola i dati nell'RDD in modo casuale per creare più o meno partizioni e bilanciarle tra loro. Questo rimescola sempre tutti i dati sulla rete. |
| 20 | repartitionAndSortWithinPartitions(partitioner) Ripartiziona l'RDD in base al partizionatore specificato e, all'interno di ciascuna partizione risultante, ordina i record in base alle loro chiavi. Questo è più efficiente della chiamata alla ripartizione e quindi dell'ordinamento all'interno di ogni partizione perché può spingere l'ordinamento verso il basso nel meccanismo di riproduzione casuale. |
Azioni
La tabella seguente fornisce un elenco di azioni, che restituiscono valori.
| S.No | Azione e significato |
|---|---|
| 1 | reduce(func) Aggrega gli elementi del set di dati utilizzando una funzione func(che accetta due argomenti e ne restituisce uno). La funzione dovrebbe essere commutativa e associativa in modo che possa essere calcolata correttamente in parallelo. |
| 2 | collect() Restituisce tutti gli elementi del set di dati come array nel programma del driver. Ciò è solitamente utile dopo un filtro o un'altra operazione che restituisce un sottoinsieme di dati sufficientemente piccolo. |
| 3 | count() Restituisce il numero di elementi nel set di dati. |
| 4 | first() Restituisce il primo elemento del set di dati (simile a take (1)). |
| 5 | take(n) Restituisce un array con il primo n elementi del set di dati. |
| 6 | takeSample (withReplacement,num, [seed]) Restituisce un array con un campione casuale di num elementi del set di dati, con o senza sostituzione, eventualmente pre-specificando un seme del generatore di numeri casuali. |
| 7 | takeOrdered(n, [ordering]) Restituisce il primo n elementi dell'RDD utilizzando il loro ordine naturale o un comparatore personalizzato. |
| 8 | saveAsTextFile(path) Scrive gli elementi del set di dati come file di testo (o insieme di file di testo) in una determinata directory nel file system locale, HDFS o qualsiasi altro file system supportato da Hadoop. Spark chiama toString su ogni elemento per convertirlo in una riga di testo nel file. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Scrive gli elementi del set di dati come Hadoop SequenceFile in un determinato percorso nel file system locale, HDFS o qualsiasi altro file system supportato da Hadoop. Questo è disponibile su RDD di coppie chiave-valore che implementano l'interfaccia scrivibile di Hadoop. In Scala, è anche disponibile sui tipi convertibili in modo implicito in Writable (Spark include conversioni per tipi di base come Int, Double, String, ecc.). |
| 10 | saveAsObjectFile(path) (Java and Scala) Scrive gli elementi del set di dati in un formato semplice utilizzando la serializzazione Java, che può quindi essere caricato utilizzando SparkContext.objectFile (). |
| 11 | countByKey() Disponibile solo su RDD di tipo (K, V). Restituisce una hashmap di (K, Int) coppie con il conteggio di ogni chiave. |
| 12 | foreach(func) Esegue una funzione funcsu ogni elemento del set di dati. Questo di solito viene fatto per effetti collaterali come l'aggiornamento di un accumulatore o l'interazione con sistemi di archiviazione esterni. Note- la modifica di variabili diverse dagli accumulatori al di fuori di foreach () può comportare un comportamento indefinito. Vedere Comprensione delle chiusure per maggiori dettagli. |
Programmazione con RDD
Vediamo le implementazioni di poche trasformazioni RDD e azioni nella programmazione RDD con l'aiuto di un esempio.
Esempio
Considera un esempio di conteggio delle parole: conta ogni parola che appare in un documento. Considera il testo seguente come input e viene salvato come fileinput.txt file in una directory home.
input.txt - file di input.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Seguire la procedura indicata di seguito per eseguire l'esempio fornito.
Apri Spark-Shell
Il comando seguente viene utilizzato per aprire Spark Shell. Generalmente, spark viene creato utilizzando Scala. Pertanto, un programma Spark viene eseguito in ambiente Scala.
$ spark-shellSe la shell di Spark si apre correttamente, troverai il seguente output. Guarda l'ultima riga dell'output "Contesto Spark disponibile come sc" significa che il contenitore Spark viene creato automaticamente oggetto contesto Spark con il nomesc. Prima di iniziare il primo passaggio di un programma, è necessario creare l'oggetto SparkContext.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Crea un RDD
Innanzitutto, dobbiamo leggere il file di input utilizzando l'API Spark-Scala e creare un RDD.
Il seguente comando viene utilizzato per leggere un file da una determinata posizione. Qui, viene creato un nuovo RDD con il nome di inputfile. La stringa fornita come argomento nel metodo textFile ("") è il percorso assoluto per il nome del file di input. Tuttavia, se viene fornito solo il nome del file, significa che il file di input si trova nella posizione corrente.
scala> val inputfile = sc.textFile("input.txt")Eseguire la trasformazione del conteggio delle parole
Il nostro scopo è contare le parole in un file. Crea una mappa piatta per dividere ogni riga in parole (flatMap(line ⇒ line.split(“ ”)).
Quindi, leggi ogni parola come una chiave con un valore ‘1’ (<chiave, valore> = <parola, 1>) utilizzando la funzione mappa (map(word ⇒ (word, 1)).
Infine, riduci quelle chiavi aggiungendo valori di chiavi simili (reduceByKey(_+_)).
Il seguente comando viene utilizzato per eseguire la logica del conteggio delle parole. Dopo aver eseguito ciò, non troverai alcun output perché questa non è un'azione, questa è una trasformazione; indicare un nuovo RDD o dire a Spark cosa fare con i dati forniti)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);RDD corrente
Mentre si lavora con l'RDD, se si desidera conoscere l'RDD corrente, utilizzare il seguente comando. Ti mostrerà la descrizione dell'RDD corrente e delle sue dipendenze per il debug.
scala> counts.toDebugStringMemorizzazione nella cache delle trasformazioni
È possibile contrassegnare un RDD come persistente utilizzando i metodi persist () o cache () su di esso. La prima volta che viene calcolato in un'azione, verrà mantenuto in memoria sui nodi. Utilizzare il seguente comando per archiviare le trasformazioni intermedie in memoria.
scala> counts.cache()Applicare l'azione
L'applicazione di un'azione, come memorizzare tutte le trasformazioni, risulta in un file di testo. L'argomento String per il metodo saveAsTextFile ("") è il percorso assoluto della cartella di output. Prova il seguente comando per salvare l'output in un file di testo. Nell'esempio seguente, la cartella "output" si trova nella posizione corrente.
scala> counts.saveAsTextFile("output")Controllo dell'output
Apri un altro terminale per andare alla directory home (dove spark viene eseguito nell'altro terminale). Utilizzare i seguenti comandi per controllare la directory di output.
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSIl comando seguente viene utilizzato per visualizzare l'output da Part-00000 File.
[hadoop@localhost output]$ cat part-00000Produzione
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Il comando seguente viene utilizzato per visualizzare l'output da Part-00001 File.
[hadoop@localhost output]$ cat part-00001Produzione
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)Le Nazioni Unite persistono nell'archiviazione
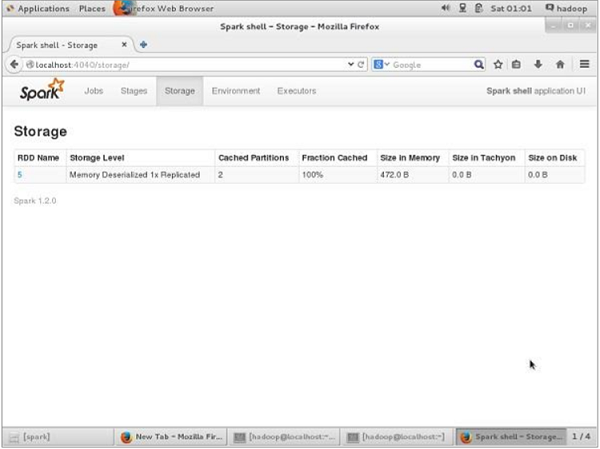
Prima della persistenza UN, se desideri visualizzare lo spazio di archiviazione utilizzato per questa applicazione, utilizza il seguente URL nel tuo browser.
http://localhost:4040Verrà visualizzata la seguente schermata, che mostra lo spazio di archiviazione utilizzato per l'applicazione, in esecuzione sulla shell Spark.

Se si desidera annullare la persistenza dello spazio di archiviazione di un determinato RDD, utilizzare il seguente comando.
Scala> counts.unpersist()Vedrai l'output come segue:
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Per verificare lo spazio di archiviazione nel browser, utilizzare il seguente URL.
http://localhost:4040/Vedrai la seguente schermata. Mostra lo spazio di archiviazione utilizzato per l'applicazione, in esecuzione sulla shell Spark.