AI con Python - Riconoscimento vocale
In questo capitolo impareremo il riconoscimento vocale usando l'AI con Python.
La parola è il mezzo più basilare della comunicazione umana adulta. L'obiettivo fondamentale dell'elaborazione del parlato è fornire un'interazione tra un essere umano e una macchina.
Il sistema di elaborazione vocale ha principalmente tre compiti:
First, riconoscimento vocale che consente alla macchina di catturare le parole, le frasi e le frasi che pronunciamo
Second, elaborazione del linguaggio naturale per consentire alla macchina di capire cosa parliamo e
Third, sintesi vocale per consentire alla macchina di parlare.
Questo capitolo si concentra su speech recognition, il processo di comprensione delle parole pronunciate dagli esseri umani. Ricorda che i segnali vocali vengono catturati con l'aiuto di un microfono e quindi devono essere compresi dal sistema.
Costruire un riconoscimento vocale
Il riconoscimento vocale o riconoscimento vocale automatico (ASR) è al centro dell'attenzione per i progetti di intelligenza artificiale come la robotica. Senza ASR, non è possibile immaginare un robot cognitivo che interagisce con un essere umano. Tuttavia, non è abbastanza facile creare un riconoscimento vocale.
Difficoltà nello sviluppo di un sistema di riconoscimento vocale
Lo sviluppo di un sistema di riconoscimento vocale di alta qualità è davvero un problema difficile. La difficoltà della tecnologia di riconoscimento vocale può essere ampiamente caratterizzata lungo una serie di dimensioni come discusso di seguito:
Size of the vocabulary- La dimensione del vocabolario influisce sulla facilità di sviluppo di un ASR. Considera le seguenti dimensioni del vocabolario per una migliore comprensione.
Un vocabolario di piccole dimensioni è composto da 2-100 parole, ad esempio, come in un sistema di menu vocale
Un vocabolario di medie dimensioni è composto da diverse centinaia di migliaia di parole, ad esempio, come in un'attività di recupero del database
Un vocabolario di grandi dimensioni è composto da diverse decine di migliaia di parole, come in un'attività di dettatura generale.
Channel characteristics- Anche la qualità del canale è una dimensione importante. Ad esempio, il parlato umano contiene una larghezza di banda elevata con una gamma di frequenze completa, mentre un discorso telefonico è costituito da una larghezza di banda ridotta con un intervallo di frequenze limitato. Nota che è più difficile in quest'ultimo.
Speaking mode- La facilità di sviluppo di un ASR dipende anche dalla modalità di parlato, ovvero se il discorso è in modalità parola isolata, modalità parola connessa o in modalità vocale continua. Nota che un discorso continuo è più difficile da riconoscere.
Speaking style- Un discorso letto può essere in uno stile formale o spontaneo e colloquiale con uno stile casual. Quest'ultimo è più difficile da riconoscere.
Speaker dependency- Il parlato può essere dipendente dal parlante, adattivo dal parlante o indipendente dal parlante. Un altoparlante indipendente è il più difficile da costruire.
Type of noise- Il rumore è un altro fattore da considerare durante lo sviluppo di un ASR. Il rapporto segnale / rumore può essere in vari intervalli, a seconda dell'ambiente acustico che osserva meno rispetto a più rumore di fondo -
Se il rapporto segnale / rumore è maggiore di 30 dB, viene considerato come gamma alta
Se il rapporto segnale / rumore è compreso tra 30 dB e 10 dB, viene considerato come SNR medio
Se il rapporto segnale / rumore è inferiore a 10 dB, viene considerato come gamma bassa
Microphone characteristics- La qualità del microfono può essere buona, media o inferiore alla media. Inoltre, la distanza tra la bocca e il microfono può variare. Questi fattori dovrebbero essere considerati anche per i sistemi di riconoscimento.
Notare che, maggiore è la dimensione del vocabolario, più difficile è eseguire il riconoscimento.
Ad esempio, anche il tipo di rumore di fondo come il rumore stazionario, non umano, il parlato di sottofondo e la diafonia di altri oratori contribuisce alla difficoltà del problema.
Nonostante queste difficoltà, i ricercatori hanno lavorato molto su vari aspetti del discorso come la comprensione del segnale vocale, l'oratore e l'identificazione degli accenti.
Dovrai seguire i passaggi indicati di seguito per creare un riconoscimento vocale:
Visualizzazione dei segnali audio - Leggere da un file e lavorarci sopra
Questo è il primo passo nella costruzione di un sistema di riconoscimento vocale in quanto fornisce una comprensione di come è strutturato un segnale audio. Alcuni passaggi comuni che possono essere seguiti per lavorare con i segnali audio sono i seguenti:
Registrazione
Quando devi leggere il segnale audio da un file, registralo inizialmente usando un microfono.
Campionamento
Quando si registra con il microfono, i segnali vengono memorizzati in una forma digitalizzata. Ma per lavorarci sopra, la macchina ne ha bisogno nella forma numerica discreta. Quindi, dovremmo eseguire il campionamento a una certa frequenza e convertire il segnale nella forma numerica discreta. La scelta dell'alta frequenza per il campionamento implica che quando gli esseri umani ascoltano il segnale, lo percepiscono come un segnale audio continuo.
Esempio
L'esempio seguente mostra un approccio graduale per analizzare un segnale audio, utilizzando Python, che è memorizzato in un file. La frequenza di questo segnale audio è 44.100 HZ.
Importa i pacchetti necessari come mostrato qui -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileOra leggi il file audio memorizzato. Restituirà due valori: la frequenza di campionamento e il segnale audio. Fornisci il percorso del file audio in cui è memorizzato, come mostrato qui -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Visualizza i parametri come la frequenza di campionamento del segnale audio, il tipo di dati del segnale e la sua durata, utilizzando i comandi mostrati -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Questo passaggio comporta la normalizzazione del segnale come mostrato di seguito:
audio_signal = audio_signal / np.power(2, 15)In questa fase, stiamo estraendo i primi 100 valori da questo segnale da visualizzare. Utilizzare i seguenti comandi per questo scopo:
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)Ora, visualizza il segnale utilizzando i comandi riportati di seguito:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()Sarai in grado di vedere un grafico di output e i dati estratti per il segnale audio sopra come mostrato nell'immagine qui

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsCaratterizzazione del segnale audio: trasformazione nel dominio della frequenza
La caratterizzazione di un segnale audio implica la conversione del segnale nel dominio del tempo nel dominio della frequenza e la comprensione delle sue componenti di frequenza, tramite. Questo è un passaggio importante perché fornisce molte informazioni sul segnale. È possibile utilizzare uno strumento matematico come la trasformata di Fourier per eseguire questa trasformazione.
Esempio
L'esempio seguente mostra, passo dopo passo, come caratterizzare il segnale, utilizzando Python, che è memorizzato in un file. Nota che qui stiamo usando lo strumento matematico della Trasformata di Fourier per convertirlo nel dominio della frequenza.
Importa i pacchetti necessari, come mostrato qui -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileOra leggi il file audio memorizzato. Restituirà due valori: la frequenza di campionamento e il segnale audio. Fornisci il percorso del file audio in cui è memorizzato come mostrato nel comando qui -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")In questo passaggio, verranno visualizzati i parametri come la frequenza di campionamento del segnale audio, il tipo di dati del segnale e la sua durata, utilizzando i comandi riportati di seguito -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')In questo passaggio, dobbiamo normalizzare il segnale, come mostrato nel seguente comando:
audio_signal = audio_signal / np.power(2, 15)Questo passaggio comporta l'estrazione della lunghezza e della metà della lunghezza del segnale. Utilizzare i seguenti comandi per questo scopo:
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)Ora, dobbiamo applicare strumenti matematici per la trasformazione nel dominio della frequenza. Qui stiamo usando la trasformata di Fourier.
signal_frequency = np.fft.fft(audio_signal)Ora, fai la normalizzazione del segnale nel dominio della frequenza e quadralo -
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2Quindi, estrai la lunghezza e metà lunghezza del segnale trasformato in frequenza -
len_fts = len(signal_frequency)Si noti che il segnale trasformato di Fourier deve essere regolato sia per i casi pari che per quelli dispari.
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2Ora, estrai la potenza in decibal (dB) -
signal_power = 10 * np.log10(signal_frequency)Regola la frequenza in kHz per l'asse X -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0Ora, visualizza la caratterizzazione del segnale come segue:
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()Puoi osservare il grafico di output del codice sopra come mostrato nell'immagine qui sotto -

Generazione di segnale audio monotono
I due passaggi che hai visto fino ad ora sono importanti per conoscere i segnali. Ora, questo passaggio sarà utile se desideri generare il segnale audio con alcuni parametri predefiniti. Nota che questo passaggio salverà il segnale audio in un file di output.
Esempio
Nell'esempio seguente, genereremo un segnale monotono, utilizzando Python, che verrà memorizzato in un file. Per questo, dovrai seguire i seguenti passaggi:
Importa i pacchetti necessari come mostrato -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeFornisci il file in cui salvare il file di output
output_file = 'audio_signal_generated.wav'Ora, specifica i parametri di tua scelta, come mostrato -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piIn questo passaggio, possiamo generare il segnale audio, come mostrato -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Ora salva il file audio nel file di output -
write(output_file, frequency_sampling, signal_scaled)Estrai i primi 100 valori per il nostro grafico, come mostrato -
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Ora, visualizza il segnale audio generato come segue:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
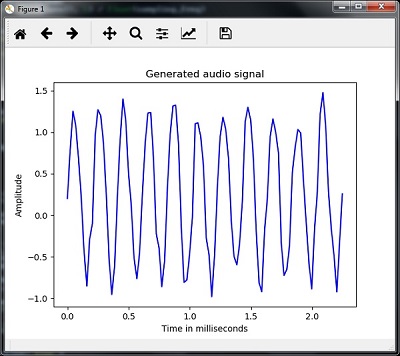
plt.title('Generated audio signal')
plt.show()Puoi osservare la trama come mostrato nella figura qui riportata -
Feature Extraction from Speech
Questo è il passo più importante nella costruzione di un riconoscimento vocale perché dopo aver convertito il segnale vocale nel dominio della frequenza, dobbiamo convertirlo nella forma utilizzabile di vettore di caratteristiche. A tale scopo possiamo utilizzare diverse tecniche di estrazione delle caratteristiche come MFCC, PLP, PLP-RASTA ecc.
Esempio
Nel seguente esempio, estrarremo le caratteristiche dal segnale, passo dopo passo, usando Python, usando la tecnica MFCC.
Importa i pacchetti necessari, come mostrato qui -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankOra leggi il file audio memorizzato. Restituirà due valori: la frequenza di campionamento e il segnale audio. Fornisci il percorso del file audio in cui è memorizzato.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Nota che qui stiamo prendendo i primi 15000 campioni per l'analisi.
audio_signal = audio_signal[:15000]Utilizza le tecniche MFCC ed esegui il seguente comando per estrarre le funzionalità MFCC:
features_mfcc = mfcc(audio_signal, frequency_sampling)Ora, stampa i parametri MFCC, come mostrato -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Ora traccia e visualizza le funzionalità MFCC utilizzando i comandi forniti di seguito:
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')In questo passaggio, lavoriamo con le funzionalità del banco di filtri come mostrato:
Estrai le caratteristiche del banco di filtri -
filterbank_features = logfbank(audio_signal, frequency_sampling)Ora, stampa i parametri del banco di filtri.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Ora traccia e visualizza le funzionalità del filterbank.
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
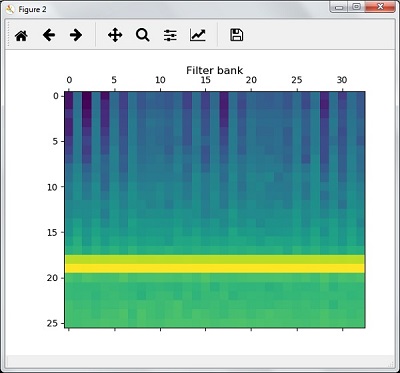
plt.title('Filter bank')
plt.show()Come risultato dei passaggi precedenti, è possibile osservare i seguenti output: Figure1 per MFCC e Figure2 per Filter Bank

Riconoscimento delle parole pronunciate
Il riconoscimento vocale significa che quando gli esseri umani parlano, una macchina lo capisce. Qui stiamo usando l'API di Google Speech in Python per realizzarlo. Dobbiamo installare i seguenti pacchetti per questo:
Pyaudio - Può essere installato utilizzando pip install Pyaudio comando.
SpeechRecognition - Questo pacchetto può essere installato utilizzando pip install SpeechRecognition.
Google-Speech-API - Può essere installato utilizzando il comando pip install google-api-python-client.
Esempio
Osservare il seguente esempio per comprendere il riconoscimento delle parole pronunciate:
Importa i pacchetti necessari come mostrato -
import speech_recognition as srCrea un oggetto come mostrato di seguito -
recording = sr.Recognizer()Ora il Microphone() il modulo prenderà la voce come input -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Ora l'API di Google riconoscerà la voce e fornirà l'output.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Puoi vedere il seguente output:
Please Say Something:
You said:Ad esempio, se hai detto tutorialspoint.com, quindi il sistema lo riconosce correttamente come segue:
tutorialspoint.com