Assemblaggio - Guida rapida
Cos'è il linguaggio Assembly?
Ogni personal computer dispone di un microprocessore che gestisce le attività aritmetiche, logiche e di controllo del computer.
Ogni famiglia di processori ha il proprio set di istruzioni per gestire varie operazioni come ricevere input dalla tastiera, visualizzare informazioni sullo schermo ed eseguire vari altri lavori. Questi set di istruzioni sono chiamati "istruzioni in linguaggio macchina".
Un processore comprende solo le istruzioni in linguaggio macchina, che sono stringhe di 1 e 0. Tuttavia, il linguaggio macchina è troppo oscuro e complesso per essere utilizzato nello sviluppo del software. Quindi, il linguaggio assembly di basso livello è progettato per una specifica famiglia di processori che rappresenta varie istruzioni in codice simbolico e in una forma più comprensibile.
Vantaggi del linguaggio assembly
Avere una comprensione del linguaggio assembly rende consapevoli di:
- In che modo i programmi si interfacciano con OS, processore e BIOS;
- Come vengono rappresentati i dati nella memoria e in altri dispositivi esterni;
- Come il processore accede ed esegue le istruzioni;
- Modalità di accesso e trattamento dei dati da parte delle istruzioni;
- Come un programma accede ai dispositivi esterni.
Altri vantaggi dell'utilizzo del linguaggio assembly sono:
Richiede meno memoria e tempo di esecuzione;
Consente lavori complessi specifici dell'hardware in un modo più semplice;
È adatto per lavori con tempi critici;
È più adatto per scrivere routine di servizio di interrupt e altri programmi residenti in memoria.
Caratteristiche di base dell'hardware del PC
L'hardware interno principale di un PC è costituito da processore, memoria e registri. I registri sono componenti del processore che contengono dati e indirizzo. Per eseguire un programma, il sistema lo copia dal dispositivo esterno alla memoria interna. Il processore esegue le istruzioni del programma.
L'unità fondamentale di archiviazione del computer è un po '; potrebbe essere ON (1) o OFF (0) e un gruppo di 8 bit correlati crea un byte sulla maggior parte dei computer moderni.
Quindi, il bit di parità viene utilizzato per rendere dispari il numero di bit in un byte. Se la parità è pari, il sistema presume che si sia verificato un errore di parità (sebbene raro), che potrebbe essere stato causato da un guasto hardware o da un disturbo elettrico.
Il processore supporta le seguenti dimensioni di dati:
- Word: un elemento di dati a 2 byte
- Doubleword: un elemento di dati a 4 byte (32 bit)
- Quadword: un elemento di dati a 8 byte (64 bit)
- Paragrafo: un'area di 16 byte (128 bit)
- Kilobyte: 1024 byte
- Megabyte: 1.048.576 byte
Sistema di numeri binari
Ogni sistema numerico utilizza la notazione posizionale, ovvero ogni posizione in cui è scritta una cifra ha un valore posizionale diverso. Ogni posizione è la potenza della base, che è 2 per il sistema di numeri binari, e queste potenze iniziano da 0 e aumentano di 1.
La tabella seguente mostra i valori posizionali per un numero binario a 8 bit, dove tutti i bit sono impostati su ON.
| Valore in bit | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Valore di posizione come potenza di base 2 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| Numero di bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Il valore di un numero binario si basa sulla presenza di 1 bit e sul loro valore di posizione. Quindi, il valore di un dato numero binario è -
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
che è uguale a 2 8-1 .
Sistema numerico esadecimale
Il sistema numerico esadecimale utilizza la base 16. Le cifre in questo sistema vanno da 0 a 15. Per convenzione, le lettere dalla A alla F vengono utilizzate per rappresentare le cifre esadecimali corrispondenti ai valori decimali da 10 a 15.
I numeri esadecimali nell'informatica vengono utilizzati per abbreviare lunghe rappresentazioni binarie. Fondamentalmente, il sistema numerico esadecimale rappresenta un dato binario dividendo ogni byte a metà ed esprimendo il valore di ogni mezzo byte. La tabella seguente fornisce gli equivalenti decimali, binari ed esadecimali:
| Numero decimale | Rappresentazione binaria | Rappresentazione esadecimale |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | UN |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
Per convertire un numero binario nel suo equivalente esadecimale, suddividilo in gruppi di 4 gruppi consecutivi ciascuno, a partire da destra, e scrivi quei gruppi sulle cifre corrispondenti del numero esadecimale.
Example - Il numero binario 1000 1100 1101 0001 è equivalente a esadecimale - 8CD1
Per convertire un numero esadecimale in binario, scrivi semplicemente ogni cifra esadecimale nel suo equivalente binario a 4 cifre.
Example - Il numero esadecimale FAD8 è equivalente a binario - 1111 1010 1101 1000
Aritmetica binaria
La tabella seguente illustra quattro semplici regole per l'addizione binaria:
| (io) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| = 0 | = 1 | = 10 | = 11 |
Le regole (iii) e (iv) mostrano un riporto di 1 bit nella posizione successiva a sinistra.
Example
| Decimale | Binario |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Un valore binario negativo è espresso in two's complement notation. Secondo questa regola, convertire un numero binario nel suo valore negativo significa invertire i suoi valori di bit e aggiungere 1 .
Example
| Numero 53 | 00110101 |
| Inverti i bit | 11001010 |
| Aggiungi 1 | 0000000 1 |
| Numero -53 | 11001011 |
Per sottrarre un valore da un altro, converti il numero da sottrarre nel formato del complemento a due e aggiungi i numeri .
Example
Sottrai 42 da 53
| Numero 53 | 00110101 |
| Numero 42 | 00101010 |
| Invertire i bit di 42 | 11010101 |
| Aggiungi 1 | 0000000 1 |
| Numero -42 | 11010110 |
| 53-42 = 11 | 00001011 |
L'overflow dell'ultimo bit viene perso.
Indirizzamento dei dati in memoria
Il processo attraverso il quale il processore controlla l'esecuzione delle istruzioni è denominato fetch-decode-execute cycle o il execution cycle. Consiste di tre passaggi continui:
- Recupero dell'istruzione dalla memoria
- Decodificare o identificare l'istruzione
- Esecuzione dell'istruzione
Il processore può accedere a uno o più byte di memoria alla volta. Consideriamo un numero esadecimale 0725H. Questo numero richiederà due byte di memoria. Il byte di ordine superiore o il byte più significativo è 07 e il byte di ordine inferiore è 25.
Il processore memorizza i dati in una sequenza di byte inversa, ovvero un byte di ordine inferiore viene memorizzato in un indirizzo di memoria bassa e un byte di ordine elevato nell'indirizzo di memoria alta. Quindi, se il processore porta il valore 0725H dal registro alla memoria, trasferirà prima 25 all'indirizzo di memoria inferiore e 07 al successivo indirizzo di memoria.
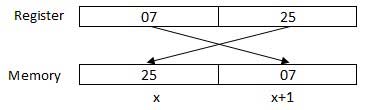
x: indirizzo di memoria
Quando il processore ottiene i dati numerici dalla memoria per registrarli, inverte nuovamente i byte. Esistono due tipi di indirizzi di memoria:
Indirizzo assoluto: un riferimento diretto a una posizione specifica.
Indirizzo segmento (o offset) - indirizzo iniziale di un segmento di memoria con il valore di offset.
Configurazione dell'ambiente locale
Il linguaggio assembly dipende dal set di istruzioni e dall'architettura del processore. In questo tutorial, ci concentriamo sui processori Intel-32 come Pentium. Per seguire questo tutorial, avrai bisogno di:
- Un PC IBM o qualsiasi computer compatibile equivalente
- Una copia del sistema operativo Linux
- Una copia del programma assembler NASM
Ci sono molti buoni programmi assembler, come:
- Microsoft Assembler (MASM)
- Borland Turbo Assembler (TASM)
- L'assemblatore GNU (GAS)
Useremo l'assembler NASM, così com'è -
- Gratuito. Puoi scaricarlo da varie fonti web.
- Ben documentato e riceverai molte informazioni in rete.
- Può essere utilizzato sia su Linux che su Windows.
Installazione di NASM
Se si seleziona "Strumenti di sviluppo" durante l'installazione di Linux, è possibile che NASM venga installato insieme al sistema operativo Linux e non è necessario scaricarlo e installarlo separatamente. Per verificare se hai già installato NASM, segui i seguenti passaggi:
Apri un terminale Linux.
genere whereis nasm e premere INVIO.
Se è già installato, appare una riga come nasm: / usr / bin / nasm . Altrimenti, vedrai solo nasm:, quindi dovrai installare NASM.
Per installare NASM, eseguire i seguenti passaggi:
Controllare il sito Web dell'assemblatore di rete (NASM) per la versione più recente.
Scarica l'archivio sorgente Linux
nasm-X.XX.ta.gz, dove siX.XXtrova il numero di versione NASM nell'archivio.Decomprimere l'archivio in una directory che crea una sottodirectory
nasm-X. XX.cd
nasm-X.XXe digita./configure. Questo script di shell troverà il miglior compilatore C da usare e configurerà i Makefile di conseguenza.genere make per costruire i binari nasm e ndisasm.
genere make install installare nasm e ndisasm in / usr / local / bin e installare le pagine man.
Questo dovrebbe installare NASM sul tuo sistema. In alternativa, puoi usare una distribuzione RPM per Fedora Linux. Questa versione è più semplice da installare, basta fare doppio clic sul file RPM.
Un programma di montaggio può essere suddiviso in tre sezioni:
Il data sezione,
Il bss sezione e
Il text sezione.
La sezione dati
Il dataviene utilizzata per dichiarare dati o costanti inizializzati. Questi dati non cambiano in fase di esecuzione. In questa sezione è possibile dichiarare vari valori di costanti, nomi di file o dimensioni del buffer, ecc.
La sintassi per la dichiarazione della sezione dati è:
section.dataLa sezione bss
Il bssè usata per dichiarare le variabili. La sintassi per dichiarare la sezione bss è:
section.bssLa sezione di testo
Il textviene utilizzata per mantenere il codice effettivo. Questa sezione deve iniziare con la dichiarazioneglobal _start, che indica al kernel dove inizia l'esecuzione del programma.
La sintassi per dichiarare la sezione di testo è:
section.text
global _start
_start:Commenti
Il commento in linguaggio assembly inizia con un punto e virgola (;). Può contenere qualsiasi carattere stampabile incluso lo spazio vuoto. Può apparire su una riga da solo, come -
; This program displays a message on screeno, sulla stessa linea insieme a un'istruzione, come -
add eax, ebx ; adds ebx to eaxDichiarazioni in lingua dell'Assemblea
I programmi in linguaggio assembly sono costituiti da tre tipi di istruzioni:
- Istruzioni o istruzioni eseguibili,
- Direttive o pseudo-operazioni dell'assemblatore e
- Macros.
Il executable instructions o semplicemente instructionsdite al processore cosa fare. Ogni istruzione consiste in un fileoperation code(codice operativo). Ogni istruzione eseguibile genera un'istruzione in linguaggio macchina.
Il assembler directives o pseudo-opsracconta all'assemblatore i vari aspetti del processo di assemblaggio. Questi non sono eseguibili e non generano istruzioni in linguaggio macchina.
Macros sono fondamentalmente un meccanismo di sostituzione del testo.
Sintassi delle dichiarazioni in linguaggio assembly
Le istruzioni in linguaggio assembly vengono immesse una istruzione per riga. Ogni affermazione segue il seguente formato:
[label] mnemonic [operands] [;comment]I campi tra parentesi quadre sono facoltativi. Un'istruzione di base ha due parti, la prima è il nome dell'istruzione (o lo mnemonico), che deve essere eseguita, e la seconda sono gli operandi oi parametri del comando.
Di seguito sono riportati alcuni esempi di dichiarazioni tipiche del linguaggio assembly:
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL registerIl programma Hello World in Assemblea
Il codice del linguaggio assembly seguente mostra la stringa "Hello World" sullo schermo:
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the stringQuando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Hello, world!Compilazione e collegamento di un programma di assemblaggio in NASM
Assicurati di aver impostato il percorso di nasm e ldbinari nella variabile d'ambiente PATH. Ora, segui i seguenti passaggi per compilare e collegare il programma sopra:
Digita il codice sopra utilizzando un editor di testo e salvalo come hello.asm.
Assicurati di essere nella stessa directory in cui hai salvato hello.asm.
Per assemblare il programma, digitare nasm -f elf hello.asm
In caso di errore, in questa fase ti verrà chiesto di farlo. Altrimenti, un file oggetto del programma denominatohello.o sarà creato.
Per collegare il file oggetto e creare un file eseguibile denominato hello, digitare ld -m elf_i386 -s -o hello hello.o
Eseguire il programma digitando ./hello
Se hai fatto tutto correttamente, verrà visualizzato "Hello, world!" sullo schermo.
Abbiamo già discusso le tre sezioni di un programma di assemblea. Queste sezioni rappresentano anche vari segmenti di memoria.
È interessante notare che se sostituisci la parola chiave della sezione con segmento, otterrai lo stesso risultato. Prova il codice seguente:
segment .text ;code segment
global _start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear stringQuando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Hello, world!Segmenti di memoria
Un modello di memoria segmentata divide la memoria di sistema in gruppi di segmenti indipendenti referenziati da puntatori situati nei registri di segmento. Ogni segmento viene utilizzato per contenere un tipo specifico di dati. Un segmento viene utilizzato per contenere i codici di istruzione, un altro segmento memorizza gli elementi di dati e un terzo segmento conserva lo stack del programma.
Alla luce della discussione sopra, possiamo specificare vari segmenti di memoria come:
Data segment - È rappresentato da .data sezione e il .bss. La sezione .data viene utilizzata per dichiarare la regione di memoria, in cui sono memorizzati gli elementi di dati per il programma. Questa sezione non può essere espansa dopo che gli elementi di dati sono stati dichiarati e rimane statica in tutto il programma.
La sezione .bss è anche una sezione di memoria statica che contiene i buffer per i dati da dichiarare successivamente nel programma. Questa memoria buffer è riempita con zero.
Code segment - È rappresentato da .textsezione. Definisce un'area della memoria che memorizza i codici delle istruzioni. Anche questa è un'area fissa.
Stack - Questo segmento contiene i valori dei dati passati a funzioni e procedure all'interno del programma.
Le operazioni del processore riguardano principalmente l'elaborazione dei dati. Questi dati possono essere archiviati in memoria e da lì accedervi. Tuttavia, la lettura e l'archiviazione dei dati nella memoria rallenta il processore, poiché implica processi complicati di invio della richiesta di dati attraverso il bus di controllo e nell'unità di archiviazione della memoria e il trasferimento dei dati attraverso lo stesso canale.
Per velocizzare le operazioni del processore, il processore include alcune posizioni di archiviazione della memoria interna, chiamate registers.
I registri memorizzano elementi di dati per l'elaborazione senza dover accedere alla memoria. Un numero limitato di registri è integrato nel chip del processore.
Registri del processore
Ci sono dieci registri del processore a 32 bit e sei a 16 bit nell'architettura IA-32. I registri sono raggruppati in tre categorie:
- Registri generali,
- Registri di controllo e
- Registri di segmento.
I registri generali sono ulteriormente suddivisi nei seguenti gruppi:
- Registri di dati,
- Pointer registra e
- Registri indice.
Registri dati
Quattro registri dati a 32 bit vengono utilizzati per operazioni aritmetiche, logiche e di altro tipo. Questi registri a 32 bit possono essere utilizzati in tre modi:
Come registri dati completi a 32 bit: EAX, EBX, ECX, EDX.
Le metà inferiori dei registri a 32 bit possono essere utilizzate come quattro registri di dati a 16 bit: AX, BX, CX e DX.
Le metà inferiore e superiore dei quattro registri a 16 bit summenzionati possono essere utilizzate come otto registri di dati a 8 bit: AH, AL, BH, BL, CH, CL, DH e DL.

Alcuni di questi registri di dati hanno un uso specifico nelle operazioni aritmetiche.
AX is the primary accumulator; viene utilizzato in input / output e nella maggior parte delle istruzioni aritmetiche. Ad esempio, nell'operazione di moltiplicazione, un operando viene memorizzato nel registro EAX o AX o AL in base alla dimensione dell'operando.
BX is known as the base register, in quanto potrebbe essere utilizzato nell'indirizzamento indicizzato.
CX is known as the count register, poiché ECX, i registri CX memorizzano il conteggio dei loop in operazioni iterative.
DX is known as the data register. Viene anche utilizzato nelle operazioni di input / output. Viene anche utilizzato con il registro AX insieme a DX per operazioni di moltiplicazione e divisione che coinvolgono valori elevati.
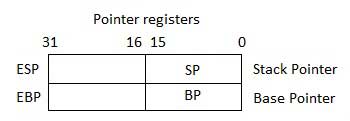
Registri puntatore
I registri del puntatore sono i registri EIP, ESP ed EBP a 32 bit e le corrispondenti porzioni destre a 16 bit IP, SP e BP. Esistono tre categorie di registri di puntatori:
Instruction Pointer (IP)- Il registro IP a 16 bit memorizza l'indirizzo di offset della successiva istruzione da eseguire. IP in associazione con il registro CS (come CS: IP) fornisce l'indirizzo completo dell'istruzione corrente nel segmento di codice.
Stack Pointer (SP)- Il registro SP a 16 bit fornisce il valore di offset all'interno dello stack del programma. SP in associazione con il registro SS (SS: SP) si riferisce alla posizione corrente dei dati o dell'indirizzo all'interno dello stack del programma.
Base Pointer (BP)- Il registro BP a 16 bit aiuta principalmente a fare riferimento alle variabili dei parametri passate a una subroutine. L'indirizzo nel registro SS viene combinato con l'offset in BP per ottenere la posizione del parametro. BP può anche essere combinato con DI e SI come registro di base per indirizzamenti speciali.
Registri indice
I registri di indice a 32 bit, ESI e EDI e le loro parti a destra a 16 bit. SI e DI, vengono utilizzati per l'indirizzamento indicizzato e talvolta utilizzati in aggiunta e sottrazione. Esistono due serie di puntatori di indice:
Source Index (SI) - Viene utilizzato come indice di origine per le operazioni sulle stringhe.
Destination Index (DI) - Viene utilizzato come indice di destinazione per le operazioni sulle stringhe.

Registri di controllo
Il registro del puntatore dell'istruzione a 32 bit e il registro dei flag a 32 bit combinati sono considerati come registri di controllo.
Molte istruzioni implicano confronti e calcoli matematici e cambiano lo stato dei flag e alcune altre istruzioni condizionali testano il valore di questi flag di stato per portare il flusso di controllo in un'altra posizione.
I bit flag comuni sono:
Overflow Flag (OF) - Indica l'overflow di un bit di ordine elevato (bit più a sinistra) di dati dopo un'operazione aritmetica con segno.
Direction Flag (DF)- Determina la direzione sinistra o destra per lo spostamento o il confronto dei dati della stringa. Quando il valore DF è 0, l'operazione di stringa assume la direzione da sinistra a destra e quando il valore è impostato su 1, l'operazione di stringa assume la direzione da destra a sinistra.
Interrupt Flag (IF)- Determina se gli interrupt esterni come l'inserimento da tastiera, ecc. Devono essere ignorati o elaborati. Disabilita l'interrupt esterno quando il valore è 0 e abilita gli interrupt quando è impostato a 1.
Trap Flag (TF)- Permette di impostare il funzionamento del processore in modalità single-step. Il programma DEBUG che abbiamo usato imposta il flag trap, quindi possiamo eseguire l'esecuzione un'istruzione alla volta.
Sign Flag (SF)- Mostra il segno del risultato di un'operazione aritmetica. Questo flag è impostato in base al segno di un elemento di dati che segue l'operazione aritmetica. Il segno è indicato dall'ordine superiore del bit più a sinistra. Un risultato positivo cancella il valore di SF a 0 e un risultato negativo lo imposta a 1.
Zero Flag (ZF)- Indica il risultato di un'operazione aritmetica o di confronto. Un risultato diverso da zero cancella il flag zero a 0 e un risultato zero lo imposta a 1.
Auxiliary Carry Flag (AF)- Contiene il riporto dal bit 3 al bit 4 a seguito di un'operazione aritmetica; utilizzato per aritmetica specializzata. L'AF viene impostato quando un'operazione aritmetica a 1 byte provoca un trasferimento dal bit 3 al bit 4.
Parity Flag (PF)- Indica il numero totale di 1 bit nel risultato ottenuto da un'operazione aritmetica. Un numero pari di 1 bit cancella il flag di parità a 0 e un numero dispari di 1 bit imposta il flag di parità a 1.
Carry Flag (CF)- Contiene il riporto di 0 o 1 da un bit di ordine elevato (più a sinistra) dopo un'operazione aritmetica. Memorizza anche il contenuto dell'ultimo bit di un'operazione di spostamento o rotazione .
La tabella seguente indica la posizione dei bit flag nel registro Flags a 16 bit:
| Bandiera: | O | D | io | T | S | Z | UN | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit no: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Registri di segmento
I segmenti sono aree specifiche definite in un programma per contenere dati, codice e stack. Ci sono tre segmenti principali:
Code Segment- Contiene tutte le istruzioni da eseguire. Un registro del segmento di codice a 16 bit o un registro CS memorizza l'indirizzo iniziale del segmento di codice.
Data Segment- Contiene dati, costanti e aree di lavoro. Un registro del segmento di dati a 16 bit o un registro DS memorizza l'indirizzo iniziale del segmento di dati.
Stack Segment- Contiene dati e indirizzi di ritorno di procedure o subroutine. È implementato come una struttura di dati "stack". Il registro Stack Segment o il registro SS memorizza l'indirizzo iniziale dello stack.
Oltre ai registri DS, CS e SS, ci sono altri registri di segmento extra - ES (segmento extra), FS e GS, che forniscono segmenti aggiuntivi per la memorizzazione dei dati.
Nella programmazione in assembly, un programma deve accedere alle posizioni di memoria. Tutte le posizioni di memoria all'interno di un segmento sono relative all'indirizzo iniziale del segmento. Un segmento inizia in un indirizzo uniformemente divisibile per 16 o esadecimale 10. Quindi, la cifra esadecimale più a destra in tutti questi indirizzi di memoria è 0, che generalmente non è memorizzata nei registri del segmento.
I registri del segmento memorizzano gli indirizzi iniziali di un segmento. Per ottenere la posizione esatta dei dati o dell'istruzione all'interno di un segmento, è necessario un valore di offset (o spostamento). Per fare riferimento a qualsiasi posizione di memoria in un segmento, il processore combina l'indirizzo del segmento nel registro del segmento con il valore di offset della posizione.
Esempio
Guarda il seguente semplice programma per comprendere l'uso dei registri nella programmazione in assembly. Questo programma visualizza 9 stelle sullo schermo insieme a un semplice messaggio:
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Displaying 9 stars
*********Le chiamate di sistema sono API per l'interfaccia tra lo spazio utente e lo spazio kernel. Abbiamo già utilizzato le chiamate di sistema. sys_write e sys_exit, rispettivamente per scrivere sullo schermo e uscire dal programma.
Chiamate di sistema Linux
È possibile utilizzare le chiamate di sistema Linux nei programmi assembly. È necessario eseguire i seguenti passaggi per utilizzare le chiamate di sistema Linux nel programma:
- Metti il numero di chiamata di sistema nel registro EAX.
- Memorizza gli argomenti della chiamata di sistema nei registri EBX, ECX, ecc.
- Chiama il relativo interrupt (80h).
- Il risultato viene solitamente restituito nel registro EAX.
Ci sono sei registri che memorizzano gli argomenti della chiamata di sistema utilizzata. Questi sono EBX, ECX, EDX, ESI, EDI e EBP. Questi registri accettano gli argomenti consecutivi, a partire dal registro EBX. Se sono presenti più di sei argomenti, la posizione di memoria del primo argomento viene memorizzata nel registro EBX.
Il seguente frammento di codice mostra l'uso della chiamata di sistema sys_exit -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernelIl seguente frammento di codice mostra l'uso della chiamata di sistema sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernelTutte le chiamate di sistema sono elencate in /usr/include/asm/unistd.h , insieme ai loro numeri (il valore da inserire in EAX prima di chiamare int 80h).
La tabella seguente mostra alcune delle chiamate di sistema utilizzate in questo tutorial:
| % eax | Nome | % ebx | % ecx | % edx | % esx | % edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | unsigned int | char * | size_t | - | - |
| 4 | sys_write | unsigned int | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | unsigned int | - | - | - | - |
Esempio
L'esempio seguente legge un numero dalla tastiera e lo visualizza sullo schermo:
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80hQuando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Please enter a number:
1234
You have entered:1234La maggior parte delle istruzioni in linguaggio assembly richiede l'elaborazione degli operandi. Un indirizzo operando fornisce la posizione in cui vengono memorizzati i dati da elaborare. Alcune istruzioni non richiedono un operando, mentre altre possono richiedere uno, due o tre operandi.
Quando un'istruzione richiede due operandi, il primo operando è generalmente la destinazione, che contiene dati in un registro o posizione di memoria e il secondo operando è la sorgente. La sorgente contiene i dati da consegnare (indirizzamento immediato) o l'indirizzo (in registro o in memoria) dei dati. In genere, i dati di origine rimangono inalterati dopo l'operazione.
Le tre modalità di indirizzamento di base sono:
- Registrare l'indirizzamento
- Indirizzamento immediato
- Indirizzamento della memoria
Registra indirizzamento
In questa modalità di indirizzamento, un registro contiene l'operando. A seconda dell'istruzione, il registro può essere il primo operando, il secondo operando o entrambi.
Per esempio,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registersPoiché l'elaborazione dei dati tra i registri non coinvolge la memoria, fornisce un'elaborazione più rapida dei dati.
Indirizzamento immediato
Un operando immediato ha un valore costante o un'espressione. Quando un'istruzione con due operandi utilizza l'indirizzamento immediato, il primo operando può essere un registro o una posizione di memoria e il secondo operando è una costante immediata. Il primo operando definisce la lunghezza dei dati.
Per esempio,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AXIndirizzamento diretto alla memoria
Quando gli operandi sono specificati in modalità di indirizzamento della memoria, è richiesto l'accesso diretto alla memoria principale, solitamente al segmento di dati. Questo modo di affrontare si traduce in un'elaborazione più lenta dei dati. Per individuare la posizione esatta dei dati in memoria, abbiamo bisogno dell'indirizzo iniziale del segmento, che si trova in genere nel registro DS e un valore di offset. Questo valore di offset viene anche chiamatoeffective address.
Nella modalità di indirizzamento diretto, il valore di offset viene specificato direttamente come parte dell'istruzione, solitamente indicato dal nome della variabile. L'assemblatore calcola il valore di offset e mantiene una tabella dei simboli, che memorizza i valori di offset di tutte le variabili utilizzate nel programma.
Nell'indirizzamento diretto della memoria, uno degli operandi si riferisce a una posizione di memoria e l'altro operando fa riferimento a un registro.
Per esempio,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to registerIndirizzamento con offset diretto
Questa modalità di indirizzamento utilizza gli operatori aritmetici per modificare un indirizzo. Ad esempio, guarda le seguenti definizioni che definiscono tabelle di dati:
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of wordsLe seguenti operazioni accedono ai dati dalle tabelle in memoria nei registri:
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLEIndirizzamento indiretto della memoria
Questa modalità di indirizzamento utilizza la capacità del computer di Segment: Offset addressing. In genere, a questo scopo vengono utilizzati i registri di base EBX, EBP (o BX, BP) e i registri indice (DI, SI), codificati tra parentesi quadre per i riferimenti di memoria.
L'indirizzamento indiretto viene generalmente utilizzato per variabili contenenti diversi elementi come array. L'indirizzo iniziale dell'array è memorizzato, ad esempio, nel registro EBX.
Il frammento di codice seguente mostra come accedere a diversi elementi della variabile.
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123L'istruzione MOV
Abbiamo già utilizzato l'istruzione MOV utilizzata per spostare i dati da uno spazio di archiviazione a un altro. L'istruzione MOV accetta due operandi.
Sintassi
La sintassi dell'istruzione MOV è:
MOV destination, sourceL'istruzione MOV può avere una delle seguenti cinque forme:
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerSi prega di notare che -
- Entrambi gli operandi nell'operazione MOV dovrebbero avere la stessa dimensione
- Il valore dell'operando di origine rimane invariato
L'istruzione MOV a volte causa ambiguità. Ad esempio, guarda le dichiarazioni:
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110Non è chiaro se si desidera spostare un equivalente in byte o un equivalente in parola del numero 110. In questi casi, è consigliabile utilizzare un type specifier.
La tabella seguente mostra alcuni degli specificatori di tipo comuni:
| Identificatore di tipo | Byte indirizzati |
|---|---|
| BYTE | 1 |
| PAROLA | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
Esempio
Il seguente programma illustra alcuni dei concetti discussi sopra. Memorizza un nome "Zara Ali" nella sezione dati della memoria, quindi cambia il suo valore in un altro nome "Nuha Ali" a livello di programmazione e visualizza entrambi i nomi.
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali 'Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Zara Ali Nuha AliNASM fornisce vari define directivesper riservare lo spazio di archiviazione per le variabili. La direttiva define assembler viene utilizzata per l'allocazione dello spazio di archiviazione. Può essere utilizzato per riservare e inizializzare uno o più byte.
Allocazione dello spazio di archiviazione per i dati inizializzati
La sintassi per l'istruzione di allocazione della memoria per i dati inizializzati è:
[variable-name] define-directive initial-value [,initial-value]...Dove, nome-variabile è l'identificativo per ogni spazio di archiviazione. L'assembler associa un valore di offset per ogni nome di variabile definito nel segmento di dati.
Esistono cinque forme di base della direttiva define:
| Direttiva | Scopo | Spazio di archiviazione |
|---|---|---|
| DB | Definisci byte | alloca 1 byte |
| DW | Definisci la parola | alloca 2 byte |
| DD | Definisci Doubleword | alloca 4 byte |
| DQ | Definisci Quadword | alloca 8 byte |
| DT | Definisci dieci byte | alloca 10 byte |
Di seguito sono riportati alcuni esempi di utilizzo delle direttive di definizione:
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456Si prega di notare che -
Ogni byte di carattere viene memorizzato come valore ASCII in esadecimale.
Ogni valore decimale viene convertito automaticamente nel suo equivalente binario a 16 bit e memorizzato come numero esadecimale.
Il processore utilizza l'ordinamento dei byte little-endian.
I numeri negativi vengono convertiti nella sua rappresentazione in complemento a 2.
I numeri in virgola mobile brevi e lunghi vengono rappresentati utilizzando rispettivamente 32 o 64 bit.
Il seguente programma mostra l'uso della direttiva define -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
yAllocazione dello spazio di archiviazione per i dati non inizializzati
Le direttive sulla riserva vengono utilizzate per riservare spazio ai dati non inizializzati. Le direttive di riserva accettano un singolo operando che specifica il numero di unità di spazio da riservare. Ogni direttiva di definizione ha una direttiva di riserva correlata.
Esistono cinque forme di base della direttiva sulla riserva:
| Direttiva | Scopo |
|---|---|
| RESB | Prenota un byte |
| RESW | Prenota una parola |
| RESD | Prenota una Doubleword |
| RESQ | Prenota un Quadword |
| RIPOSO | Riserva dieci byte |
Definizioni multiple
È possibile avere più istruzioni di definizione dei dati in un programma. Ad esempio:
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15HL'assembler alloca memoria contigua per più definizioni di variabili.
Inizializzazioni multiple
La direttiva TIMES consente più inizializzazioni con lo stesso valore. Ad esempio, un array denominato contrassegni di dimensione 9 può essere definito e inizializzato a zero utilizzando la seguente istruzione:
marks TIMES 9 DW 0La direttiva TIMES è utile per definire array e tabelle. Il seguente programma visualizza 9 asterischi sullo schermo:
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
*********Esistono diverse direttive fornite da NASM che definiscono le costanti. Abbiamo già utilizzato la direttiva EQU nei capitoli precedenti. Discuteremo in particolare tre direttive:
- EQU
- %assign
- %define
La direttiva EQU
Il EQUviene utilizzata per definire le costanti. La sintassi della direttiva EQU è la seguente:
CONSTANT_NAME EQU expressionPer esempio,
TOTAL_STUDENTS equ 50È quindi possibile utilizzare questo valore costante nel codice, ad esempio:
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTSL'operando di un'istruzione EQU può essere un'espressione -
LENGTH equ 20
WIDTH equ 10
AREA equ length * widthIl segmento di codice precedente definirà AREA come 200.
Esempio
Il seguente esempio illustra l'uso della direttiva EQU:
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Hello, programmers!
Welcome to the world of,
Linux assembly programming!La direttiva% assign
Il %assignLa direttiva può essere utilizzata per definire costanti numeriche come la direttiva EQU. Questa direttiva consente la ridefinizione. Ad esempio, puoi definire la costante TOTALE come -
%assign TOTAL 10Più avanti nel codice, puoi ridefinirlo come:
%assign TOTAL 20Questa direttiva fa distinzione tra maiuscole e minuscole.
La% definisce la direttiva
Il %definela direttiva consente di definire costanti sia numeriche che stringa. Questa direttiva è simile alla #define in C. Ad esempio, puoi definire la costante PTR come -
%define PTR [EBP+4]Il codice sopra sostituisce PTR con [EBP + 4].
Questa direttiva consente anche la ridefinizione e distingue tra maiuscole e minuscole.
L'istruzione INC
L'istruzione INC viene utilizzata per incrementare un operando di uno. Funziona su un singolo operando che può essere in un registro o in memoria.
Sintassi
L'istruzione INC ha la seguente sintassi:
INC destinationLa destinazione dell'operando potrebbe essere un operando a 8 bit, 16 bit o 32 bit.
Esempio
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variableL'istruzione DEC
L'istruzione DEC viene utilizzata per decrementare un operando di uno. Funziona su un singolo operando che può essere in un registro o in memoria.
Sintassi
L'istruzione DEC ha la seguente sintassi:
DEC destinationLa destinazione dell'operando potrebbe essere un operando a 8 bit, 16 bit o 32 bit.
Esempio
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]Le istruzioni ADD e SUB
Le istruzioni ADD e SUB vengono utilizzate per eseguire semplici addizioni / sottrazioni di dati binari in dimensioni di byte, parola e doppia parola, ovvero per aggiungere o sottrarre operandi a 8 bit, 16 bit o 32 bit, rispettivamente.
Sintassi
Le istruzioni ADD e SUB hanno la seguente sintassi:
ADD/SUB destination, sourceL'istruzione ADD / SUB può avvenire tra -
- Registrati per registrarti
- Memoria da registrare
- Registrati in memoria
- Registrati a dati costanti
- Memoria a dati costanti
Tuttavia, come altre istruzioni, le operazioni da memoria a memoria non sono possibili utilizzando le istruzioni ADD / SUB. Un'operazione ADD o SUB imposta o cancella i flag di overflow e carry.
Esempio
Il seguente esempio chiederà due cifre all'utente, memorizzerà le cifre rispettivamente nel registro EAX ed EBX, aggiungerà i valori, memorizzerà il risultato in una posizione di memoria " res " e infine visualizzerà il risultato.
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The sum is:
7L'istruzione MUL / IMUL
Sono disponibili due istruzioni per moltiplicare i dati binari. L'istruzione MUL (Multiply) gestisce i dati senza segno e l'IMUL (Integer Multiply) gestisce i dati con segno. Entrambe le istruzioni influenzano il flag Carry e Overflow.
Sintassi
La sintassi per le istruzioni MUL / IMUL è la seguente:
MUL/IMUL multiplierIl moltiplicando in entrambi i casi sarà in un accumulatore, a seconda della dimensione del moltiplicando e del moltiplicatore e anche il prodotto generato viene memorizzato in due registri a seconda della dimensione degli operandi. La sezione seguente spiega le istruzioni MUL con tre diversi casi:
| Sr.No. | Scenari |
|---|---|
| 1 | When two bytes are multiplied − Il moltiplicando si trova nel registro AL e il moltiplicatore è un byte nella memoria o in un altro registro. Il prodotto è in AX. Gli 8 bit di ordine superiore del prodotto vengono memorizzati in AH e gli 8 bit di ordine inferiore vengono memorizzati in AL.

|
| 2 | When two one-word values are multiplied − Il moltiplicando dovrebbe essere nel registro AX e il moltiplicatore è una parola in memoria o un altro registro. Ad esempio, per un'istruzione come MUL DX, è necessario memorizzare il moltiplicatore in DX e il moltiplicando in AX. Il prodotto risultante è una doppia parola, che richiederà due registri. La parte di ordine superiore (più a sinistra) viene memorizzata in DX e la parte di ordine inferiore (più a destra) viene archiviata in AX.

|
| 3 | When two doubleword values are multiplied − Quando due valori di doppia parola vengono moltiplicati, il moltiplicando dovrebbe essere in EAX e il moltiplicatore è un valore di doppia parola archiviato in memoria o in un altro registro. Il prodotto generato viene memorizzato nei registri EDX: EAX, ovvero i 32 bit di ordine alto vengono memorizzati nel registro EDX ei 32 bit di ordine basso vengono memorizzati nel registro EAX.

|
Esempio
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DLEsempio
L'esempio seguente moltiplica 3 per 2 e visualizza il risultato:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The result is:
6Le istruzioni DIV / IDIV
L'operazione di divisione genera due elementi: a quotient e a remainder. In caso di moltiplicazione, l'overflow non si verifica perché vengono utilizzati registri a doppia lunghezza per mantenere il prodotto. Tuttavia, in caso di divisione, potrebbe verificarsi un trabocco. Il processore genera un interrupt se si verifica un overflow.
L'istruzione DIV (Divide) viene utilizzata per i dati senza segno e IDIV (Integer Divide) viene utilizzata per i dati con segno.
Sintassi
Il formato per l'istruzione DIV / IDIV -
DIV/IDIV divisorIl dividendo è in un accumulatore. Entrambe le istruzioni possono funzionare con operandi a 8 bit, 16 bit o 32 bit. L'operazione influisce su tutti e sei i flag di stato. La sezione seguente spiega tre casi di divisione con diverse dimensioni di operandi:
| Sr.No. | Scenari |
|---|---|
| 1 | When the divisor is 1 byte − Si presume che il dividendo sia nel registro AX (16 bit). Dopo la divisione, il quoziente va al registro AL e il resto va al registro AH.

|
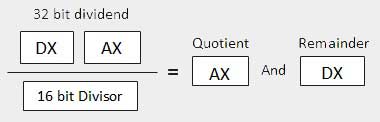
| 2 | When the divisor is 1 word − Si presume che il dividendo sia lungo 32 bit e nei registri DX: AX. I 16 bit di ordine superiore sono in DX e i 16 bit di ordine inferiore sono in AX. Dopo la divisione, il quoziente di 16 bit va al registro AX e il resto di 16 bit va al registro DX.
|
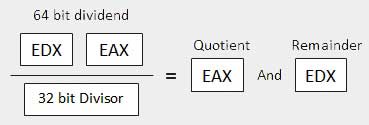
| 3 | When the divisor is doubleword − Si presume che il dividendo sia lungo 64 bit e nei registri EDX: EAX. I 32 bit di ordine superiore sono in EDX ei 32 bit di ordine inferiore sono in EAX. Dopo la divisione, il quoziente a 32 bit va al registro EAX e il resto a 32 bit va al registro EDX.
|
Esempio
L'esempio seguente divide 8 per 2. Il file dividend 8 è memorizzato nel file 16-bit AX register e il divisor 2 è memorizzato nel file 8-bit BL register.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The result is:
4Il set di istruzioni del processore fornisce le istruzioni AND, OR, XOR, TEST e NOT Boolean logica, che verifica, imposta e cancella i bit in base alle necessità del programma.
Il formato per queste istruzioni -
| Sr.No. | Istruzioni | Formato |
|---|---|---|
| 1 | E | AND operando1, operando2 |
| 2 | O | OR operando1, operando2 |
| 3 | XOR | Operando 1 XOR, operando 2 |
| 4 | TEST | TEST operando1, operando2 |
| 5 | NON | NON operando 1 |
Il primo operando in tutti i casi potrebbe essere in registro o in memoria. Il secondo operando può essere nel registro / memoria o in un valore immediato (costante). Tuttavia, le operazioni da memoria a memoria non sono possibili. Queste istruzioni confrontano o abbinano i bit degli operandi e impostano i flag CF, OF, PF, SF e ZF.
L'istruzione AND
L'istruzione AND viene utilizzata per supportare le espressioni logiche eseguendo l'operazione AND bit per bit. L'operazione AND bit per bit restituisce 1, se i bit corrispondenti di entrambi gli operandi sono 1, altrimenti restituisce 0. Ad esempio:
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001L'operazione AND può essere utilizzata per cancellare uno o più bit. Ad esempio, si supponga che il registro BL contenga 0011 1010. Se è necessario azzerare i bit di ordine elevato, si AND con 0FH.
AND BL, 0FH ; This sets BL to 0000 1010Facciamo un altro esempio. Se vuoi controllare se un dato numero è pari o dispari, un semplice test sarebbe controllare il bit meno significativo del numero. Se questo è 1, il numero è dispari, altrimenti il numero è pari.
Supponendo che il numero sia nel registro AL, possiamo scrivere -
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBERIl seguente programma lo illustra:
Esempio
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msgQuando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Even Number!Cambia il valore nel registro dell'ascia con una cifra dispari, come -
mov ax, 9h ; getting 9 in the axIl programma visualizzerà:
Odd Number!Allo stesso modo per cancellare l'intero registro puoi farlo AND con 00H.
L'istruzione OR
L'istruzione OR viene utilizzata per supportare l'espressione logica eseguendo un'operazione OR bit per bit. L'operatore OR bit per bit restituisce 1, se i bit corrispondenti di uno o entrambi gli operandi sono uno. Restituisce 0, se entrambi i bit sono zero.
Per esempio,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111L'operazione OR può essere utilizzata per impostare uno o più bit. Ad esempio, supponiamo che il registro AL contenga 0011 1010, è necessario impostare i quattro bit di ordine inferiore, è possibile OR con un valore 0000 1111, cioè FH.
OR BL, 0FH ; This sets BL to 0011 1111Esempio
L'esempio seguente mostra l'istruzione OR. Memorizziamo rispettivamente il valore 5 e 3 nei registri AL e BL, quindi l'istruzione,
OR AL, BLdovrebbe memorizzare 7 nel registro AL -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
7L'istruzione XOR
L'istruzione XOR implementa l'operazione XOR bit per bit. L'operazione XOR imposta il bit risultante a 1, se e solo se i bit degli operandi sono diversi. Se i bit degli operandi sono gli stessi (entrambi 0 o entrambi 1), il bit risultante viene azzerato.
Per esempio,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110XORing un operando con se stesso cambia l'operando in 0. Viene utilizzato per cancellare un registro.
XOR EAX, EAXL'istruzione TEST
L'istruzione TEST funziona come l'operazione AND, ma a differenza dell'istruzione AND, non cambia il primo operando. Quindi, se abbiamo bisogno di controllare se un numero in un registro è pari o dispari, possiamo farlo anche usando l'istruzione TEST senza cambiare il numero originale.
TEST AL, 01H
JZ EVEN_NUMBERL'istruzione NOT
L'istruzione NOT implementa l'operazione NOT bit per bit. L'operazione NOT inverte i bit in un operando. L'operando potrebbe essere in un registro o in memoria.
Per esempio,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100L'esecuzione condizionale in linguaggio assembly viene eseguita da diverse istruzioni di loop e ramificazione. Queste istruzioni possono modificare il flusso di controllo in un programma. L'esecuzione condizionale viene osservata in due scenari:
| Sr.No. | Istruzioni condizionali |
|---|---|
| 1 | Unconditional jump Questa operazione viene eseguita dall'istruzione JMP. L'esecuzione condizionale spesso implica il trasferimento del controllo all'indirizzo di un'istruzione che non segue l'istruzione in esecuzione. Il trasferimento del controllo può essere in avanti, per eseguire una nuova serie di istruzioni o all'indietro, per rieseguire gli stessi passaggi. |
| 2 | Conditional jump Ciò viene eseguito da una serie di istruzioni di salto j <condizione> a seconda della condizione. Le istruzioni condizionali trasferiscono il controllo interrompendo il flusso sequenziale e lo fanno modificando il valore di offset in IP. |
Discutiamo l'istruzione CMP prima di discutere le istruzioni condizionali.
Istruzioni CMP
L'istruzione CMP confronta due operandi. Viene generalmente utilizzato nell'esecuzione condizionale. Questa istruzione sostanzialmente sottrae un operando dall'altro per confrontare se gli operandi sono uguali o meno. Non disturba la destinazione o gli operandi di origine. Viene utilizzato insieme all'istruzione di salto condizionale per il processo decisionale.
Sintassi
CMP destination, sourceCMP confronta due campi di dati numerici. L'operando di destinazione potrebbe essere nel registro o in memoria. L'operando sorgente potrebbe essere un dato, un registro o una memoria costanti (immediati).
Esempio
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...CMP viene spesso utilizzato per confrontare se un valore del contatore ha raggiunto il numero di volte in cui è necessario eseguire un ciclo. Considera la seguente condizione tipica:
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1Salto incondizionato
Come accennato in precedenza, ciò viene eseguito dall'istruzione JMP. L'esecuzione condizionale spesso implica il trasferimento del controllo all'indirizzo di un'istruzione che non segue l'istruzione in esecuzione. Il trasferimento del controllo può essere in avanti, per eseguire una nuova serie di istruzioni o all'indietro, per rieseguire gli stessi passaggi.
Sintassi
L'istruzione JMP fornisce un nome di etichetta in cui il flusso di controllo viene trasferito immediatamente. La sintassi dell'istruzione JMP è:
JMP labelEsempio
Il seguente frammento di codice illustra l'istruzione JMP:
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statementsSalto condizionale
Se una determinata condizione è soddisfatta nel salto condizionale, il flusso di controllo viene trasferito a un'istruzione di destinazione. Esistono numerose istruzioni di salto condizionale a seconda delle condizioni e dei dati.
Di seguito sono riportate le istruzioni di salto condizionale utilizzate sui dati con segno utilizzati per le operazioni aritmetiche:
| Istruzioni | Descrizione | Bandiere testate |
|---|---|---|
| JE / JZ | Salta uguale o Salta zero | ZF |
| JNE / JNZ | Salta non uguale o Salta diverso da zero | ZF |
| JG / JNLE | Salta maggiore o Salta non inferiore / uguale | OF, SF, ZF |
| JGE / JNL | Salta maggiore / uguale o Salta non inferiore | OF, SF |
| JL / JNGE | Salta di meno o Salta non maggiore / uguale | OF, SF |
| JLE / JNG | Salta di meno / uguale o non maggiore | OF, SF, ZF |
Di seguito sono riportate le istruzioni di salto condizionale utilizzate sui dati senza segno utilizzati per le operazioni logiche:
| Istruzioni | Descrizione | Bandiere testate |
|---|---|---|
| JE / JZ | Salta uguale o Salta zero | ZF |
| JNE / JNZ | Salta non uguale o Salta diverso da zero | ZF |
| JA / JNBE | Salta sopra o Salta non sotto / uguale | CF, ZF |
| JAE / JNB | Salta sopra / uguale o Salta non sotto | CF |
| JB / JNAE | Salta sotto o non salta sopra / uguale | CF |
| JBE / JNA | Salta sotto / uguale o Salta non sopra | AF, CF |
Le seguenti istruzioni di salto condizionale hanno usi speciali e controllano il valore dei flag -
| Istruzioni | Descrizione | Bandiere testate |
|---|---|---|
| JXCZ | Salta se CX è zero | nessuna |
| JC | Salta se trasporta | CF |
| JNC | Salta se non lo porti | CF |
| JO | Salta in caso di overflow | DI |
| JNO | Salta se non c'è overflow | DI |
| JP / JPE | Salta parità o Salta parità pari | PF |
| JNP / JPO | Salta senza parità o Salta parità dispari | PF |
| JS | Segno di salto (valore negativo) | SF |
| JNS | Jump No Sign (valore positivo) | SF |
La sintassi per il set di istruzioni J <condizione> -
Esempio,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...Esempio
Il seguente programma visualizza la più grande delle tre variabili. Le variabili sono variabili a due cifre. Le tre variabili num1, num2 e num3 hanno rispettivamente i valori 47, 22 e 31 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The largest digit is:
47L'istruzione JMP può essere utilizzata per implementare i loop. Ad esempio, il seguente frammento di codice può essere utilizzato per eseguire 10 volte il corpo del ciclo.
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1Il set di istruzioni del processore, tuttavia, include un gruppo di istruzioni di ciclo per l'implementazione dell'iterazione. L'istruzione LOOP di base ha la seguente sintassi:
LOOP labelDove, etichetta è l'etichetta di destinazione che identifica l'istruzione di destinazione come nelle istruzioni di salto. L'istruzione LOOP presuppone che il fileECX register contains the loop count. Quando viene eseguita l'istruzione di ciclo, il registro ECX viene decrementato e il controllo salta all'etichetta di destinazione, finché il valore del registro ECX, cioè il contatore raggiunge il valore zero.
Lo snippet di codice sopra potrebbe essere scritto come:
mov ECX,10
l1:
<loop body>
loop l1Esempio
Il seguente programma stampa il numero da 1 a 9 sullo schermo:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
123456789:I dati numerici sono generalmente rappresentati nel sistema binario. Le istruzioni aritmetiche operano su dati binari. Quando i numeri vengono visualizzati sullo schermo o immessi dalla tastiera, sono in formato ASCII.
Finora, abbiamo convertito questi dati di input in formato ASCII in binario per calcoli aritmetici e abbiamo riconvertito il risultato in binario. Il codice seguente mostra questo:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The sum is:
7Tali conversioni, tuttavia, hanno un sovraccarico e la programmazione in linguaggio assembly consente di elaborare i numeri in modo più efficiente, in forma binaria. I numeri decimali possono essere rappresentati in due forme:
- Modulo ASCII
- BCD o formato decimale con codice binario
Rappresentazione ASCII
Nella rappresentazione ASCII, i numeri decimali vengono memorizzati come stringhe di caratteri ASCII. Ad esempio, il valore decimale 1234 viene memorizzato come -
31 32 33 34HDove 31H è il valore ASCII per 1, 32H è il valore ASCII per 2 e così via. Sono disponibili quattro istruzioni per l'elaborazione dei numeri nella rappresentazione ASCII:
AAA - Regolazione ASCII dopo l'aggiunta
AAS - Regolazione ASCII dopo la sottrazione
AAM - Regolazione ASCII dopo la moltiplicazione
AAD - Regolazione ASCII prima della divisione
Queste istruzioni non accettano operandi e presuppongono che l'operando richiesto sia nel registro AL.
L'esempio seguente utilizza l'istruzione AAS per dimostrare il concetto:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The Result is:
6Rappresentanza BCD
Esistono due tipi di rappresentazione BCD:
- Rappresentazione BCD decompressa
- Rappresentazione BCD imballata
Nella rappresentazione BCD decompressa, ogni byte memorizza l'equivalente binario di una cifra decimale. Ad esempio, il numero 1234 viene memorizzato come -
01 02 03 04HCi sono due istruzioni per elaborare questi numeri:
AAM - Regolazione ASCII dopo la moltiplicazione
AAD - Regolazione ASCII prima della divisione
Le quattro istruzioni di regolazione ASCII, AAA, AAS, AAM e AAD, possono essere utilizzate anche con la rappresentazione BCD decompressa. Nella rappresentazione BCD compressa, ogni cifra viene memorizzata utilizzando quattro bit. Due cifre decimali vengono compresse in un byte. Ad esempio, il numero 1234 viene memorizzato come -
12 34HCi sono due istruzioni per elaborare questi numeri:
DAA - Regolazione dei decimali dopo l'aggiunta
DAS - Regolazione decimale dopo la sottrazione
Non è disponibile alcun supporto per la moltiplicazione e la divisione nella rappresentazione BCD compressa.
Esempio
Il seguente programma somma due numeri decimali a 5 cifre e visualizza la somma. Utilizza i concetti di cui sopra -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' 'Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The Sum is:
35801Abbiamo già utilizzato stringhe di lunghezza variabile nei nostri esempi precedenti. Le stringhe di lunghezza variabile possono avere tanti caratteri quanti sono necessari. Generalmente, specifichiamo la lunghezza della stringa in uno dei due modi:
- Memorizzazione esplicita della lunghezza della stringa
- Usando un personaggio sentinella
È possibile memorizzare la lunghezza della stringa in modo esplicito utilizzando il simbolo $ location counter che rappresenta il valore corrente del contatore di posizione. Nell'esempio seguente:
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string$ punta al byte dopo l'ultimo carattere della variabile stringa msg . Perciò,$-msgdà la lunghezza della stringa. Possiamo anche scrivere
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear stringIn alternativa, è possibile memorizzare stringhe con un carattere sentinella finale per delimitare una stringa invece di memorizzare esplicitamente la lunghezza della stringa. Il carattere sentinella dovrebbe essere un carattere speciale che non compare all'interno di una stringa.
Ad esempio:
message DB 'I am loving it!', 0Istruzioni per le stringhe
Ciascuna istruzione stringa può richiedere un operando di origine, un operando di destinazione o entrambi. Per i segmenti a 32 bit, le istruzioni stringa utilizzano i registri ESI e EDI per puntare rispettivamente agli operandi di origine e di destinazione.
Per i segmenti a 16 bit, tuttavia, i registri SI e DI vengono utilizzati per puntare rispettivamente alla sorgente e alla destinazione.
Sono disponibili cinque istruzioni di base per l'elaborazione delle stringhe. Sono -
MOVS - Questa istruzione sposta 1 byte, parola o doppia parola di dati dalla posizione di memoria a un'altra.
LODS- Questa istruzione viene caricata dalla memoria. Se l'operando è di un byte, viene caricato nel registro AL, se l'operando è una parola, viene caricato nel registro AX e una doppia parola viene caricata nel registro EAX.
STOS - Questa istruzione memorizza i dati dal registro (AL, AX o EAX) alla memoria.
CMPS- Questa istruzione confronta due elementi di dati in memoria. I dati possono essere di dimensioni in byte, parola o doppia parola.
SCAS - Questa istruzione confronta il contenuto di un registro (AL, AX o EAX) con il contenuto di un elemento in memoria.
Ciascuna delle istruzioni precedenti ha una versione di byte, parola e doppia parola e le istruzioni di stringa possono essere ripetute utilizzando un prefisso di ripetizione.
Queste istruzioni utilizzano la coppia di registri ES: DI e DS: SI, dove i registri DI e SI contengono indirizzi di offset validi che si riferiscono a byte archiviati in memoria. SI è normalmente associato a DS (segmento dati) e DI è sempre associato a ES (segmento extra).
I registri DS: SI (o ESI) ed ES: DI (o EDI) puntano rispettivamente agli operandi di origine e di destinazione. Si presume che l'operando di origine sia in DS: SI (o ESI) e l'operando di destinazione in ES: DI (o EDI) in memoria.
Per gli indirizzi a 16 bit, vengono utilizzati i registri SI e DI, mentre per gli indirizzi a 32 bit vengono utilizzati i registri ESI e EDI.
La tabella seguente fornisce varie versioni delle istruzioni di stringa e lo spazio presunto degli operandi.
| Istruzioni di base | Operandi in | Byte Operation | Operazione con le parole | Operazione a doppia parola |
|---|---|---|---|---|
| MOVS | ES: DI, DS: SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS: SI | LODSB | LODSW | LODSD |
| STOS | ES: DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS: SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES: DI, AX | SCASB | SCASW | SCASD |
Prefissi di ripetizione
Il prefisso REP, se impostato prima di un'istruzione stringa, ad esempio - REP MOVSB, provoca la ripetizione dell'istruzione in base a un contatore posto nel registro CX. REP esegue l'istruzione, diminuisce CX di 1 e controlla se CX è zero. Ripete l'elaborazione dell'istruzione fino a quando CX è zero.
Il Flag di direzione (DF) determina la direzione dell'operazione.
- Utilizzare CLD (Clear Direction Flag, DF = 0) per eseguire l'operazione da sinistra a destra.
- Utilizzare STD (Set Direction Flag, DF = 1) per eseguire l'operazione da destra a sinistra.
Il prefisso REP ha anche le seguenti varianti:
REP: È la ripetizione incondizionata. Ripete l'operazione fino a quando CX è zero.
REPE o REPZ: è una ripetizione condizionale. Ripete l'operazione mentre il flag di zero indica uguale / zero. Si ferma quando ZF indica non uguale / zero o quando CX è zero.
REPNE o REPNZ: è anche una ripetizione condizionale. Ripete l'operazione mentre il flag di zero indica non uguale / zero. Si ferma quando ZF indica uguale / zero o quando CX viene decrementato a zero.
Abbiamo già discusso che le direttive di definizione dei dati all'assembler vengono utilizzate per allocare memoria per le variabili. La variabile potrebbe anche essere inizializzata con un valore specifico. Il valore inizializzato può essere specificato in formato esadecimale, decimale o binario.
Ad esempio, possiamo definire una variabile parola "mesi" in uno dei seguenti modi:
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110BLe direttive di definizione dei dati possono essere utilizzate anche per definire una matrice unidimensionale. Definiamo una matrice unidimensionale di numeri.
NUMBERS DW 34, 45, 56, 67, 75, 89La definizione precedente dichiara una matrice di sei parole, ciascuna inizializzata con i numeri 34, 45, 56, 67, 75, 89. Questo alloca 2x6 = 12 byte di spazio di memoria consecutivo. L'indirizzo simbolico del primo numero sarà NUMERI e quello del secondo numero sarà NUMERI + 2 e così via.
Facciamo un altro esempio. È possibile definire un array denominato inventario di dimensione 8 e inizializzare tutti i valori con zero, come -
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0Che può essere abbreviato come -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0La direttiva TIMES può essere utilizzata anche per più inizializzazioni con lo stesso valore. Utilizzando TIMES, l'array INVENTORY può essere definito come:
INVENTORY TIMES 8 DW 0Esempio
Il seguente esempio dimostra i concetti di cui sopra definendo un array di 3 elementi x, che memorizza tre valori: 2, 3 e 4. Aggiunge i valori nell'array e visualizza la somma 9 -
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
9Le procedure o le subroutine sono molto importanti nel linguaggio assembly, poiché i programmi in linguaggio assembly tendono ad essere di grandi dimensioni. Le procedure sono identificate da un nome. Dopo questo nome, viene descritto il corpo della procedura che esegue un lavoro ben definito. La fine della procedura è indicata da una dichiarazione di reso.
Sintassi
Di seguito è riportata la sintassi per definire una procedura:
proc_name:
procedure body
...
retLa procedura viene chiamata da un'altra funzione utilizzando l'istruzione CALL. L'istruzione CALL dovrebbe avere il nome della procedura chiamata come argomento come mostrato di seguito -
CALL proc_nameLa procedura chiamata restituisce il controllo alla procedura chiamante utilizzando l'istruzione RET.
Esempio
Scriviamo una procedura molto semplice denominata sum che aggiunge le variabili memorizzate nel registro ECX ed EDX e restituisce la somma nel registro EAX -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
The sum is:
9Stack struttura dati
Uno stack è una struttura di dati simile a un array nella memoria in cui i dati possono essere archiviati e rimossi da una posizione denominata "cima" dello stack. I dati che devono essere archiviati vengono "inseriti" nello stack e i dati da recuperare vengono "estratti" dallo stack. Stack è una struttura dati LIFO, cioè i dati memorizzati per primi vengono recuperati per ultimi.
Il linguaggio Assembly fornisce due istruzioni per le operazioni sullo stack: PUSH e POP. Queste istruzioni hanno sintassi come -
PUSH operand
POP address/registerLo spazio di memoria riservato nel segmento dello stack viene utilizzato per l'implementazione dello stack. I registri SS e ESP (o SP) vengono utilizzati per implementare lo stack. La parte superiore dello stack, che punta all'ultimo elemento di dati inserito nello stack, è indicata dal registro SS: ESP, dove il registro SS punta all'inizio del segmento dello stack e SP (o ESP) fornisce l'offset in il segmento dello stack.
L'implementazione dello stack ha le seguenti caratteristiche:
Solo words o doublewords potrebbe essere salvato nello stack, non in un byte.
Lo stack cresce nella direzione opposta, cioè verso l'indirizzo di memoria inferiore
La parte superiore della pila punta all'ultimo elemento inserito nella pila; punta al byte inferiore dell'ultima parola inserita.
Come abbiamo discusso sulla memorizzazione dei valori dei registri nello stack prima di usarli per qualche uso; può essere fatto in questo modo:
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP BX
POP AXEsempio
Il seguente programma visualizza l'intero set di caratteri ASCII. Il programma principale chiama una procedura denominata display , che visualizza il set di caratteri ASCII.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...Una procedura ricorsiva è quella che chiama se stessa. Esistono due tipi di ricorsione: diretta e indiretta. Nella ricorsione diretta, la procedura chiama se stessa e nella ricorsione indiretta, la prima procedura chiama una seconda procedura, che a sua volta chiama la prima procedura.
La ricorsione potrebbe essere osservata in numerosi algoritmi matematici. Si consideri ad esempio il caso del calcolo del fattoriale di un numero. Il fattoriale di un numero è dato dall'equazione -
Fact (n) = n * fact (n-1) for n > 0Ad esempio: fattoriale di 5 è 1 x 2 x 3 x 4 x 5 = 5 x fattoriale di 4 e questo può essere un buon esempio per mostrare una procedura ricorsiva. Ogni algoritmo ricorsivo deve avere una condizione finale, cioè la chiamata ricorsiva del programma dovrebbe essere interrotta quando una condizione è soddisfatta. Nel caso dell'algoritmo fattoriale, la condizione finale viene raggiunta quando n è 0.
Il seguente programma mostra come il fattoriale n è implementato in linguaggio assembly. Per mantenere il programma semplice, calcoleremo il fattoriale 3.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Factorial 3 is:
6La scrittura di una macro è un altro modo per garantire la programmazione modulare in linguaggio assembly.
Una macro è una sequenza di istruzioni, assegnata da un nome e può essere utilizzata ovunque nel programma.
In NASM, le macro sono definite con %macro e %endmacro direttive.
La macro inizia con la direttiva% macro e termina con la direttiva% endmacro.
La sintassi per la definizione di macro -
%macro macro_name number_of_params
<macro body>
%endmacroDove, number_of_params specifica i parametri del numero, macro_name specifica il nome della macro.
La macro viene richiamata utilizzando il nome della macro insieme ai parametri necessari. Quando è necessario utilizzare una sequenza di istruzioni molte volte in un programma, è possibile inserire tali istruzioni in una macro e utilizzarla invece di scrivere le istruzioni tutto il tempo.
Ad esempio, un'esigenza molto comune per i programmi è scrivere una stringa di caratteri sullo schermo. Per visualizzare una stringa di caratteri, è necessaria la seguente sequenza di istruzioni:
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernelNell'esempio precedente di visualizzazione di una stringa di caratteri, i registri EAX, EBX, ECX ed EDX sono stati utilizzati dalla chiamata di funzione INT 80H. Quindi, ogni volta che è necessario visualizzare sullo schermo, è necessario salvare questi registri sullo stack, richiamare INT 80H e quindi ripristinare il valore originale dei registri dallo stack. Quindi, potrebbe essere utile scrivere due macro per salvare e ripristinare i dati.
Abbiamo osservato che alcune istruzioni come IMUL, IDIV, INT, ecc. Richiedono che alcune informazioni siano memorizzate in alcuni registri particolari e che restituiscano anche valori in alcuni registri specifici. Se il programma stava già utilizzando quei registri per conservare i dati importanti, i dati esistenti da questi registri dovrebbero essere salvati nello stack e ripristinati dopo che l'istruzione è stata eseguita.
Esempio
L'esempio seguente mostra la definizione e l'utilizzo delle macro:
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Hello, programmers!
Welcome to the world of,
Linux assembly programming!Il sistema considera tutti i dati di input o output come flusso di byte. Sono disponibili tre flussi di file standard:
- Input standard (stdin),
- Output standard (stdout) e
- Errore standard (stderr).
Descrittore del file
UN file descriptorè un numero intero a 16 bit assegnato a un file come ID file. Quando viene creato un nuovo file o viene aperto un file esistente, il descrittore di file viene utilizzato per accedere al file.
Descrittore di file dei flussi di file standard - stdin, stdout e stderr sono rispettivamente 0, 1 e 2.
Puntatore file
UN file pointerspecifica la posizione per una successiva operazione di lettura / scrittura nel file in termini di byte. Ogni file è considerato come una sequenza di byte. Ogni file aperto è associato a un puntatore al file che specifica un offset in byte, relativo all'inizio del file. Quando un file viene aperto, il puntatore del file viene impostato su zero.
Chiamate di sistema per la gestione dei file
La tabella seguente descrive brevemente le chiamate di sistema relative alla gestione dei file:
| % eax | Nome | % ebx | % ecx | % edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | unsigned int | char * | size_t |
| 4 | sys_write | unsigned int | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | unsigned int | - | - |
| 8 | sys_creat | const char * | int | - |
| 19 | sys_lseek | unsigned int | off_t | unsigned int |
I passaggi necessari per utilizzare le chiamate di sistema sono gli stessi, come abbiamo discusso in precedenza:
- Metti il numero di chiamata di sistema nel registro EAX.
- Memorizza gli argomenti della chiamata di sistema nei registri EBX, ECX, ecc.
- Chiama il relativo interrupt (80h).
- Il risultato viene solitamente restituito nel registro EAX.
Creazione e apertura di un file
Per creare e aprire un file, eseguire le seguenti attività:
- Metti la chiamata di sistema sys_creat () numero 8, nel registro EAX.
- Metti il nome del file nel registro EBX.
- Metti i permessi del file nel registro ECX.
La chiamata di sistema restituisce il descrittore del file creato nel registro EAX, in caso di errore, il codice di errore è nel registro EAX.
Apertura di un file esistente
Per aprire un file esistente, eseguire le seguenti attività:
- Metti la chiamata di sistema sys_open () numero 5, nel registro EAX.
- Metti il nome del file nel registro EBX.
- Metti la modalità di accesso ai file nel registro ECX.
- Metti i permessi del file nel registro EDX.
La chiamata di sistema restituisce il descrittore del file creato nel registro EAX, in caso di errore, il codice di errore è nel registro EAX.
Tra le modalità di accesso ai file, le più comunemente utilizzate sono: sola lettura (0), sola scrittura (1) e lettura-scrittura (2).
Leggere da un file
Per leggere da un file, eseguire le seguenti attività:
Metti la chiamata di sistema sys_read () numero 3, nel registro EAX.
Metti il descrittore di file nel registro EBX.
Posiziona il puntatore al buffer di input nel registro ECX.
Metti la dimensione del buffer, cioè il numero di byte da leggere, nel registro EDX.
La chiamata di sistema restituisce il numero di byte letti nel registro EAX, in caso di errore, il codice di errore è nel registro EAX.
Scrittura su un file
Per scrivere su un file, eseguire le seguenti attività:
Metti la chiamata di sistema sys_write () numero 4, nel registro EAX.
Metti il descrittore di file nel registro EBX.
Posiziona il puntatore al buffer di output nel registro ECX.
Inserite la dimensione del buffer, cioè il numero di byte da scrivere, nel registro EDX.
La chiamata di sistema restituisce il numero effettivo di byte scritti nel registro EAX, in caso di errore, il codice di errore è nel registro EAX.
Chiusura di un file
Per chiudere un file, eseguire le seguenti attività:
- Metti la chiamata di sistema sys_close () numero 6, nel registro EAX.
- Metti il descrittore di file nel registro EBX.
La chiamata di sistema restituisce, in caso di errore, il codice di errore nel registro EAX.
Aggiornamento di un file
Per aggiornare un file, eseguire le seguenti attività:
- Metti la chiamata di sistema sys_lseek () numero 19, nel registro EAX.
- Metti il descrittore di file nel registro EBX.
- Metti il valore di offset nel registro ECX.
- Mettere la posizione di riferimento per l'offset nel registro EDX.
La posizione di riferimento potrebbe essere:
- Inizio del file - valore 0
- Posizione attuale - valore 1
- Fine del file - valore 2
La chiamata di sistema restituisce, in caso di errore, il codice di errore nel registro EAX.
Esempio
Il seguente programma crea e apre un file denominato myfile.txt e scrive un testo "Welcome to Tutorials Point" in questo file. Successivamente, il programma legge dal file e memorizza i dati in un buffer denominato info . Infine, visualizza il testo come memorizzato in info .
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Written to file
Welcome to Tutorials PointIl sys_brk()la chiamata di sistema è fornita dal kernel, per allocare la memoria senza la necessità di spostarla in seguito. Questa chiamata alloca la memoria proprio dietro l'immagine dell'applicazione nella memoria. Questa funzione di sistema consente di impostare l'indirizzo più alto disponibile nella sezione dati.
Questa chiamata di sistema accetta un parametro, che è l'indirizzo di memoria più alto che deve essere impostato. Questo valore è memorizzato nel registro EBX.
In caso di errore, sys_brk () restituisce -1 o restituisce il codice di errore negativo stesso. L'esempio seguente mostra l'allocazione dinamica della memoria.
Esempio
Il seguente programma alloca 16kb di memoria usando la chiamata di sistema sys_brk () -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msgQuando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
Allocated 16 kb of memory!