Beautiful Soup - Guida rapida
Nel mondo di oggi, abbiamo tonnellate di dati / informazioni non strutturati (principalmente dati web) disponibili gratuitamente. A volte i dati disponibili gratuitamente sono facili da leggere e talvolta no. Indipendentemente dalla disponibilità dei dati, il web scraping è uno strumento molto utile per trasformare i dati non strutturati in dati strutturati più facili da leggere e analizzare. In altre parole, un modo per raccogliere, organizzare e analizzare questa enorme quantità di dati è attraverso il web scraping. Cerchiamo quindi prima di capire cos'è il web-scraping.
Che cos'è il web scraping?
Lo scraping è semplicemente un processo di estrazione (con vari mezzi), copia e screening dei dati.
Quando eseguiamo lo scraping o l'estrazione di dati o feed dal Web (come da pagine Web o siti Web), si parla di web-scraping.
Quindi, il web scraping, noto anche come estrazione di dati web o raccolta web, è l'estrazione di dati dal web. In breve, il web scraping fornisce agli sviluppatori un modo per raccogliere e analizzare i dati da Internet.
Perché il web scraping?
Il web scraping fornisce uno degli ottimi strumenti per automatizzare la maggior parte delle cose che un essere umano fa durante la navigazione. Lo scraping del web viene utilizzato in un'azienda in diversi modi:
Dati per la ricerca
L'analista intelligente (come un ricercatore o un giornalista) utilizza il web scrapper invece di raccogliere e pulire manualmente i dati dai siti web.
Prezzi dei prodotti e confronto di popolarità
Attualmente ci sono un paio di servizi che utilizzano web scrapper per raccogliere dati da numerosi siti online e utilizzarli per confrontare popolarità e prezzi dei prodotti.
Monitoraggio SEO
Esistono numerosi strumenti SEO come Ahrefs, Seobility, SEMrush, ecc., Che vengono utilizzati per l'analisi competitiva e per estrarre dati dai siti Web dei tuoi clienti.
Motori di ricerca
Ci sono alcune grandi aziende IT la cui attività dipende esclusivamente dal web scraping.
Vendite e marketing
I dati raccolti attraverso il web scraping possono essere utilizzati dai marketer per analizzare nicchie e concorrenti diversi o dallo specialista delle vendite per la vendita di servizi di content marketing o promozione sui social media.
Perché Python per Web Scraping?
Python è uno dei linguaggi più popolari per il web scraping in quanto può gestire molto facilmente la maggior parte delle attività correlate alla scansione web.
Di seguito sono riportati alcuni punti sul perché scegliere Python per il web scraping:
Facilità d'uso
Poiché la maggior parte degli sviluppatori concorda sul fatto che python è molto facile da codificare. Non è necessario utilizzare parentesi graffe "{}" o punto e virgola ";" ovunque, il che lo rende più leggibile e facile da usare durante lo sviluppo di web scrapers.
Enorme supporto per le biblioteche
Python fornisce un vasto set di librerie per requisiti diversi, quindi è appropriato per il web scraping, la visualizzazione dei dati, l'apprendimento automatico, ecc.
Sintassi facilmente spiegabile
Python è un linguaggio di programmazione molto leggibile poiché la sintassi di Python è facile da capire. Python è molto espressivo e l'indentazione del codice aiuta gli utenti a differenziare diversi blocchi o scoop nel codice.
Linguaggio tipizzato dinamicamente
Python è un linguaggio tipizzato dinamicamente, il che significa che i dati assegnati a una variabile dicono, che tipo di variabile è. Risparmia molto tempo e rende il lavoro più veloce.
Enorme comunità
La comunità di Python è enorme e ti aiuta ovunque ti trovi mentre scrivi codice.
Introduzione a Beautiful Soup
The Beautiful Soup è una libreria di python che prende il nome da una poesia di Lewis Carroll con lo stesso nome in "Le avventure di Alice nel paese delle meraviglie". Beautiful Soup è un pacchetto Python e come suggerisce il nome, analizza i dati indesiderati e aiuta a organizzare e formattare i dati web disordinati correggendo l'HTML errato e presentandoci in strutture XML facilmente attraversabili.
In breve, Beautiful Soup è un pacchetto python che ci permette di estrarre dati da documenti HTML e XML.
Poiché BeautifulSoup non è una libreria Python standard, dobbiamo prima installarla. Installeremo la libreria BeautifulSoup 4 (nota anche come BS4), che è l'ultima.
Per isolare il nostro ambiente di lavoro in modo da non disturbare la configurazione esistente, creiamo prima un ambiente virtuale.
Creazione di un ambiente virtuale (opzionale)
Un ambiente virtuale ci consente di creare una copia di lavoro isolata di Python per un progetto specifico senza influire sulla configurazione esterna.
Il modo migliore per installare qualsiasi macchina con pacchetti Python è usare pip, tuttavia, se pip non è già installato (puoi controllarlo usando - "pip –version" nel tuo comando o prompt della shell), puoi installare dando il comando seguente -
Ambiente Linux
$sudo apt-get install python-pipAmbiente Windows
Per installare pip in Windows, procedi come segue:
Scarica get-pip.py da https://bootstrap.pypa.io/get-pip.py o da GitHub al tuo computer.
Apri il prompt dei comandi e vai alla cartella contenente il file get-pip.py.
Esegui il seguente comando:
>python get-pip.pyEcco fatto, pip è ora installato nel tuo computer Windows.
Puoi verificare il tuo pip installato eseguendo il comando seguente:
>pip --version
pip 19.2.3 from c:\users\yadur\appdata\local\programs\python\python37\lib\site-packages\pip (python 3.7)Installazione dell'ambiente virtuale
Esegui il comando seguente nel prompt dei comandi -
>pip install virtualenvDopo l'esecuzione, vedrai lo screenshot qui sotto:

Il comando seguente creerà un ambiente virtuale ("myEnv") nella directory corrente -
>virtualenv myEnvImmagine dello schermo

Per attivare il tuo ambiente virtuale, esegui il seguente comando:
>myEnv\Scripts\activate
Nello screenshot qui sopra, puoi vedere che abbiamo "myEnv" come prefisso che ci dice che siamo nell'ambiente virtuale "myEnv".
Per uscire dall'ambiente virtuale, esegui Disattiva.
(myEnv) C:\Users\yadur>deactivate
C:\Users\yadur>Dato che il nostro ambiente virtuale è pronto, ora installiamo beautifulsoup.
Installazione di BeautifulSoup
Poiché BeautifulSoup non è una libreria standard, è necessario installarla. Useremo il pacchetto BeautifulSoup 4 (noto come bs4).
Macchina Linux
Per installare bs4 su Debian o Ubuntu Linux utilizzando il gestore dei pacchetti di sistema, esegui il comando seguente:
$sudo apt-get install python-bs4 (for python 2.x)
$sudo apt-get install python3-bs4 (for python 3.x)È possibile installare bs4 utilizzando easy_install o pip (nel caso in cui si riscontrino problemi nell'installazione utilizzando System Packager).
$easy_install beautifulsoup4
$pip install beautifulsoup4(Potrebbe essere necessario utilizzare easy_install3 o pip3 rispettivamente se stai usando python3)
Macchina Windows
Installare beautifulsoup4 in Windows è molto semplice, soprattutto se hai pip già installato.
>pip install beautifulsoup4
Quindi ora beautifulsoup4 è installato nella nostra macchina. Parliamo di alcuni problemi riscontrati dopo l'installazione.
Problemi dopo l'installazione
Sulla macchina Windows potresti incontrare, errore di versione errata installata principalmente attraverso:
errore: ImportError “No module named HTMLParser”, quindi devi eseguire la versione python 2 del codice in Python 3.
errore: ImportError “No module named html.parser” errore, quindi è necessario eseguire la versione Python 3 del codice in Python 2.
Il modo migliore per uscire da queste due situazioni è reinstallare di nuovo BeautifulSoup, rimuovendo completamente l'installazione esistente.
Se ottieni il file SyntaxError “Invalid syntax” sulla riga ROOT_TAG_NAME = u '[document]', quindi devi convertire il codice python 2 in python 3, semplicemente installando il pacchetto -
$ python3 setup.py installo eseguendo manualmente lo script di conversione da 2 a 3 di python nella directory bs4 -
$ 2to3-3.2 -w bs4Installazione di un parser
Per impostazione predefinita, Beautiful Soup supporta il parser HTML incluso nella libreria standard di Python, tuttavia supporta anche molti parser Python esterni di terze parti come il parser lxml o il parser html5lib.
Per installare il parser lxml o html5lib, usa il comando -
Macchina Linux
$apt-get install python-lxml
$apt-get insall python-html5libMacchina Windows
$pip install lxml
$pip install html5lib
In generale, gli utenti utilizzano lxml per la velocità e si consiglia di utilizzare il parser lxml o html5lib se si utilizza una versione precedente di python 2 (prima della versione 2.7.3) o python 3 (prima della 3.2.2) come il parser HTML integrato di python è non molto bravo a gestire la versione precedente.
Esecuzione di bella zuppa
È ora di provare il nostro pacchetto Beautiful Soup in una delle pagine html (prendendo la pagina web - https://www.tutorialspoint.com/index.htm, puoi scegliere qualsiasi altra pagina web che desideri) ed estrarre alcune informazioni da essa.
Nel codice sottostante, stiamo cercando di estrarre il titolo dalla pagina web -
from bs4 import BeautifulSoup
import requests
url = "https://www.tutorialspoint.com/index.htm"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
print(soup.title)Produzione
<title>H2O, Colab, Theano, Flutter, KNime, Mean.js, Weka, Solidity, Org.Json, AWS QuickSight, JSON.Simple, Jackson Annotations, Passay, Boon, MuleSoft, Nagios, Matplotlib, Java NIO, PyTorch, SLF4J, Parallax Scrolling, Java Cryptography</title>Un'attività comune è estrarre tutti gli URL all'interno di una pagina web. Per questo dobbiamo solo aggiungere la riga di codice sottostante -
for link in soup.find_all('a'):
print(link.get('href'))Produzione
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/about/about_careers.htm
https://www.tutorialspoint.com/questions/index.php
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/codingground.htm
https://www.tutorialspoint.com/current_affairs.htm
https://www.tutorialspoint.com/upsc_ias_exams.htm
https://www.tutorialspoint.com/tutor_connect/index.php
https://www.tutorialspoint.com/whiteboard.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/tutorialslibrary.htm
https://www.tutorialspoint.com/videotutorials/index.php
https://store.tutorialspoint.com
https://www.tutorialspoint.com/gate_exams_tutorials.htm
https://www.tutorialspoint.com/html_online_training/index.asp
https://www.tutorialspoint.com/css_online_training/index.asp
https://www.tutorialspoint.com/3d_animation_online_training/index.asp
https://www.tutorialspoint.com/swift_4_online_training/index.asp
https://www.tutorialspoint.com/blockchain_online_training/index.asp
https://www.tutorialspoint.com/reactjs_online_training/index.asp
https://www.tutorix.com
https://www.tutorialspoint.com/videotutorials/top-courses.php
https://www.tutorialspoint.com/the_full_stack_web_development/index.asp
….
….
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/free_web_graphics.htm
https://www.tutorialspoint.com/online_file_conversion.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/free_online_whiteboard.htm
http://www.tutorialspoint.com
https://www.facebook.com/tutorialspointindia
https://plus.google.com/u/0/+tutorialspoint
http://www.twitter.com/tutorialspoint
http://www.linkedin.com/company/tutorialspoint
https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg
https://www.tutorialspoint.com/index.htm
/about/about_privacy.htm#cookies
/about/faq.htm
/about/about_helping.htm
/about/contact_us.htmAllo stesso modo, possiamo estrarre informazioni utili usando beautifulsoup4.
Ora capiamo di più sulla "zuppa" nell'esempio sopra.
Nell'esempio di codice precedente, analizziamo il documento tramite un bellissimo costruttore utilizzando un metodo stringa. Un altro modo è passare il documento attraverso il filehandle aperto.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Innanzitutto il documento viene convertito in Unicode e le entità HTML vengono convertite in caratteri Unicode: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Produzione
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>BeautifulSoup quindi analizza i dati utilizzando un parser HTML o gli si dice esplicitamente di analizzare utilizzando un parser XML.
Struttura ad albero HTML
Prima di esaminare i diversi componenti di una pagina HTML, dobbiamo prima comprendere la struttura ad albero HTML.
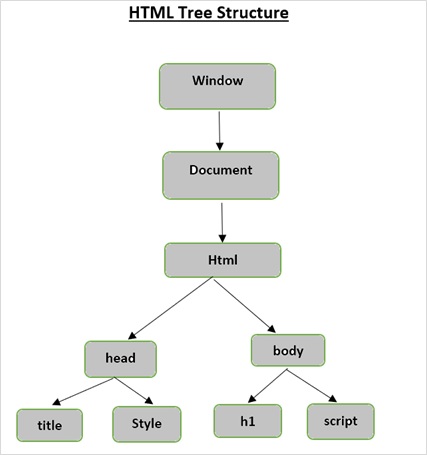
L'elemento radice nell'albero del documento è l'html, che può avere genitori, figli e fratelli e questo determina dalla sua posizione nella struttura ad albero. Per spostarsi tra elementi HTML, attributi e testo, è necessario spostarsi tra i nodi nella struttura ad albero.
Supponiamo che la pagina web sia come mostrato di seguito:
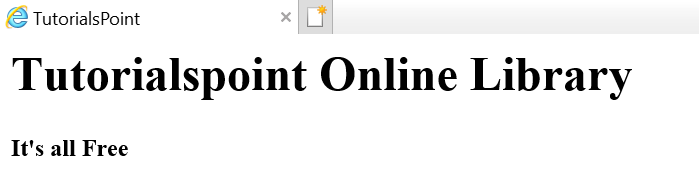
Che si traduce in un documento html come segue:
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>Il che significa semplicemente, per il documento html sopra, abbiamo una struttura ad albero html come segue:
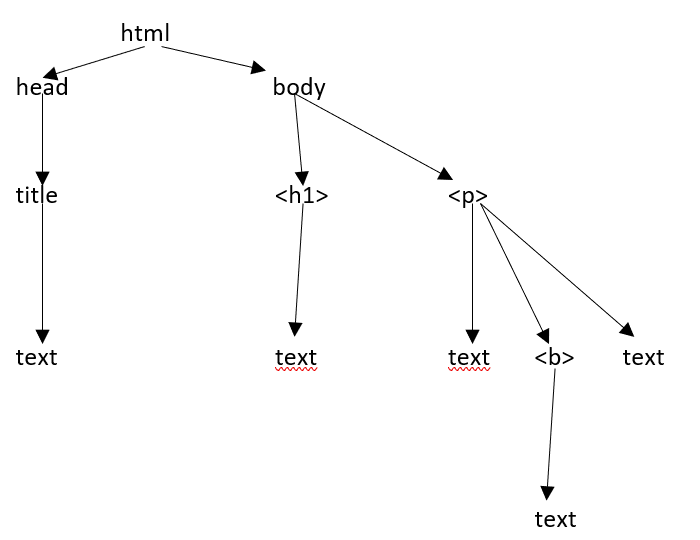
Quando abbiamo passato un documento o una stringa html a un costruttore di beautifulsoup, beautifulsoup converte fondamentalmente una pagina html complessa in diversi oggetti Python. Di seguito discuteremo quattro tipi principali di oggetti:
Tag
NavigableString
BeautifulSoup
Comments
Oggetti tag
Un tag HTML viene utilizzato per definire vari tipi di contenuto. Un oggetto tag in BeautifulSoup corrisponde a un tag HTML o XML nella pagina o nel documento effettivo.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>')
>>> tag = soup.html
>>> type(tag)
<class 'bs4.element.Tag'>I tag contengono molti attributi e metodi e due importanti caratteristiche di un tag sono il nome e gli attributi.
Nome (tag.name)
Ogni tag contiene un nome ed è possibile accedervi tramite ".name" come suffisso. tag.name restituirà il tipo di tag che è.
>>> tag.name
'html'Tuttavia, se cambiamo il nome del tag, lo stesso si rifletterà nel markup HTML generato da BeautifulSoup.
>>> tag.name = "Strong"
>>> tag
<Strong><body><b class="boldest">TutorialsPoint</b></body></Strong>
>>> tag.name
'Strong'Attributi (tag.attrs)
Un oggetto tag può avere un numero qualsiasi di attributi. Il tag <b class = "boldest"> ha un attributo "class" il cui valore è "boldest". Tutto ciò che NON è tag, è fondamentalmente un attributo e deve contenere un valore. Puoi accedere agli attributi sia accedendo alle chiavi (come l'accesso a "class" nell'esempio sopra) o accedendo direttamente tramite ".attrs"
>>> tutorialsP = BeautifulSoup("<div class='tutorialsP'></div>",'lxml')
>>> tag2 = tutorialsP.div
>>> tag2['class']
['tutorialsP']Possiamo apportare tutti i tipi di modifiche agli attributi del nostro tag (aggiungi / rimuovi / modifica).
>>> tag2['class'] = 'Online-Learning'
>>> tag2['style'] = '2007'
>>>
>>> tag2
<div class="Online-Learning" style="2007"></div>
>>> del tag2['style']
>>> tag2
<div class="Online-Learning"></div>
>>> del tag['class']
>>> tag
<b SecondAttribute="2">TutorialsPoint</b>
>>>
>>> del tag['SecondAttribute']
>>> tag
</b>
>>> tag2['class']
'Online-Learning'
>>> tag2['style']
KeyError: 'style'Attributi multivalore
Alcuni degli attributi HTML5 possono avere più valori. Il più comunemente usato è l'attributo di classe che può avere più valori CSS. Altri includono "rel", "rev", "headers", "accesskey" e "accept-charset". Gli attributi multivalore in una bella zuppa sono mostrati come elenco.
>>> from bs4 import BeautifulSoup
>>>
>>> css_soup = BeautifulSoup('<p class="body"></p>')
>>> css_soup.p['class']
['body']
>>>
>>> css_soup = BeautifulSoup('<p class="body bold"></p>')
>>> css_soup.p['class']
['body', 'bold']Tuttavia, se un attributo contiene più di un valore ma non è un attributo multivalore da nessuna versione dello standard HTML, una bella zuppa lascerà l'attributo da solo -
>>> id_soup = BeautifulSoup('<p id="body bold"></p>')
>>> id_soup.p['id']
'body bold'
>>> type(id_soup.p['id'])
<class 'str'>È possibile consolidare più valori di attributo se si trasforma un tag in una stringa.
>>> rel_soup = BeautifulSoup("<p> tutorialspoint Main <a rel='Index'> Page</a></p>")
>>> rel_soup.a['rel']
['Index']
>>> rel_soup.a['rel'] = ['Index', ' Online Library, Its all Free']
>>> print(rel_soup.p)
<p> tutorialspoint Main <a rel="Index Online Library, Its all Free"> Page</a></p>Usando 'get_attribute_list', ottieni un valore che è sempre un elenco, una stringa, indipendentemente dal fatto che sia multivalore o meno.
id_soup.p.get_attribute_list(‘id’)Tuttavia, se analizzi il documento come "xml", non ci sono attributi multivalore -
>>> xml_soup = BeautifulSoup('<p class="body bold"></p>', 'xml')
>>> xml_soup.p['class']
'body bold'NavigableString
L'oggetto navigablestring viene utilizzato per rappresentare il contenuto di un tag. Per accedere ai contenuti, utilizzare ".string" con tag.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>>
>>> soup.string
'Hello, Tutorialspoint!'
>>> type(soup.string)
>Puoi sostituire la stringa con un'altra stringa ma non puoi modificare la stringa esistente.
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> soup.string.replace_with("Online Learning!")
'Hello, Tutorialspoint!'
>>> soup.string
'Online Learning!'
>>> soup
<html><body><h2 id="message">Online Learning!</h2></body></html>BeautifulSoup
BeautifulSoup è l'oggetto creato quando proviamo a raschiare una risorsa web. Quindi, è il documento completo che stiamo cercando di raschiare. Il più delle volte viene trattato come oggetto tag.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> type(soup)
<class 'bs4.BeautifulSoup'>
>>> soup.name
'[document]'Commenti
L'oggetto commento illustra la parte commento del documento Web. È solo un tipo speciale di NavigableString.
>>> soup = BeautifulSoup('<p><!-- Everything inside it is COMMENTS --></p>')
>>> comment = soup.p.string
>>> type(comment)
<class 'bs4.element.Comment'>
>>> type(comment)
<class 'bs4.element.Comment'>
>>> print(soup.p.prettify())
<p>
<!-- Everything inside it is COMMENTS -->
</p>Oggetti NavigableString
Gli oggetti della stringa di navigazione vengono utilizzati per rappresentare il testo all'interno dei tag, piuttosto che i tag stessi.
In questo capitolo, discuteremo della navigazione per tag.
Di seguito è riportato il nostro documento html -
>>> html_doc = """
<html><head><title>Tutorials Point</title></head>
<body>
<p class="title"><b>The Biggest Online Tutorials Library, It's all Free</b></p>
<p class="prog">Top 5 most used Programming Languages are:
<a href="https://www.tutorialspoint.com/java/java_overview.htm" class="prog" id="link1">Java</a>,
<a href="https://www.tutorialspoint.com/cprogramming/index.htm" class="prog" id="link2">C</a>,
<a href="https://www.tutorialspoint.com/python/index.htm" class="prog" id="link3">Python</a>,
<a href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" class="prog" id="link4">JavaScript</a> and
<a href="https://www.tutorialspoint.com/ruby/index.htm" class="prog" id="link5">C</a>;
as per online survey.</p>
<p class="prog">Programming Languages</p>
"""
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_doc, 'html.parser')
>>>Sulla base del documento sopra, proveremo a spostarci da una parte all'altra del documento.
Scendendo
Una delle parti importanti dell'elemento in qualsiasi parte di documento HTML sono i tag, che possono contenere altri tag / stringhe (figli dei tag). Beautiful Soup offre diversi modi per navigare e iterare sui figli dei tag.
Navigare utilizzando i nomi dei tag
Il modo più semplice per cercare un albero di analisi è cercare il tag in base al nome. Se vuoi il tag <head>, usa soup.head -
>>> soup.head
<head>&t;title>Tutorials Point</title></head>
>>> soup.title
<title>Tutorials Point</title>Per ottenere un tag specifico (come il primo tag <b>) nel tag <body>.
>>> soup.body.b
<b>The Biggest Online Tutorials Library, It's all Free</b>L'uso di un nome di tag come attributo ti darà solo il primo tag con quel nome -
>>> soup.a
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>Per ottenere tutti gli attributi del tag, puoi utilizzare il metodo find_all () -
>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>]>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>].contenuti e .bambini
Possiamo cercare i figli del tag in un elenco in base al suo contenuto.
>>> head_tag = soup.head
>>> head_tag
<head><title>Tutorials Point</title></head>
>>> Htag = soup.head
>>> Htag
<head><title>Tutorials Point</title></head>
>>>
>>> Htag.contents
[<title>Tutorials Point</title>
>>>
>>> Ttag = head_tag.contents[0]
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.contents
['Tutorials Point']L'oggetto BeautifulSoup stesso ha figli. In questo caso, il tag <html> è il figlio dell'oggetto BeautifulSoup -
>>> len(soup.contents)
2
>>> soup.contents[1].name
'html'Una stringa non ha .contents, perché non può contenere nulla -
>>> text = Ttag.contents[0]
>>> text.contents
self.__class__.__name__, attr))
AttributeError: 'NavigableString' object has no attribute 'contents'Invece di ottenerli come un elenco, usa il generatore .children per accedere ai figli del tag -
>>> for child in Ttag.children:
print(child)
Tutorials Point.descendants
L'attributo .descendants ti consente di iterare su tutti i figli di un tag, in modo ricorsivo -
i suoi figli diretti e i figli dei suoi figli diretti e così via -
>>> for child in Htag.descendants:
print(child)
<title>Tutorials Point</title>
Tutorials PointIl tag <head> ha un solo figlio, ma ha due discendenti: il tag <title> e il tag <title> figlio. L'oggetto beautifulsoup ha un solo figlio diretto (il tag <html>), ma ha molti discendenti -
>>> len(list(soup.children))
2
>>> len(list(soup.descendants))
33.corda
Se il tag ha un solo elemento secondario e tale elemento secondario è una NavigableString, l'elemento secondario viene reso disponibile come .string -
>>> Ttag.string
'Tutorials Point'Se l'unico tag secondario di un tag è un altro tag e quel tag ha una stringa .string, si considera che il tag principale abbia la stessa .string del tag secondario:
>>> Htag.contents
[<title>Tutorials Point</title>]
>>>
>>> Htag.string
'Tutorials Point'Tuttavia, se un tag contiene più di una cosa, non è chiaro a cosa dovrebbe riferirsi .string, quindi .string è definito su Nessuno -
>>> print(soup.html.string)
None.strings e stripped_strings
Se c'è più di una cosa all'interno di un tag, puoi comunque guardare solo le stringhe. Usa il generatore di stringhe -
>>> for string in soup.strings:
print(repr(string))
'\n'
'Tutorials Point'
'\n'
'\n'
"The Biggest Online Tutorials Library, It's all Free"
'\n'
'Top 5 most used Programming Languages are: \n'
'Java'
',\n'
'C'
',\n'
'Python'
',\n'
'JavaScript'
' and\n'
'C'
';\n \nas per online survey.'
'\n'
'Programming Languages'
'\n'Per rimuovere spazi bianchi extra, usa il generatore di .stripped_strings -
>>> for string in soup.stripped_strings:
print(repr(string))
'Tutorials Point'
"The Biggest Online Tutorials Library, It's all Free"
'Top 5 most used Programming Languages are:'
'Java'
','
'C'
','
'Python'
','
'JavaScript'
'and'
'C'
';\n \nas per online survey.'
'Programming Languages'Salendo
In un'analogia con l '"albero genealogico", ogni tag e ogni stringa ha un genitore: il tag che lo contiene:
.genitore
Per accedere all'elemento padre dell'elemento, utilizza l'attributo .parent.
>>> Ttag = soup.title
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.parent
<head>title>Tutorials Point</title></head>Nel nostro html_doc, la stessa stringa del titolo ha un genitore: il tag <title> che lo contiene -
>>> Ttag.string.parent
<title>Tutorials Point</title>Il genitore di un tag di primo livello come <html> è l'oggetto Beautifulsoup stesso -
>>> htmltag = soup.html
>>> type(htmltag.parent)
<class 'bs4.BeautifulSoup'>Il .parent di un oggetto Beautifulsoup è definito come Nessuno -
>>> print(soup.parent)
None.parents
Per iterare su tutti gli elementi principali, utilizza l'attributo .parents.
>>> link = soup.a
>>> link
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
>>>
>>> for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
[document]Andando di traverso
Di seguito è riportato un semplice documento:
>>> sibling_soup = BeautifulSoup("<a><b>TutorialsPoint</b><c><strong>The Biggest Online Tutorials Library, It's all Free</strong></b></a>")
>>> print(sibling_soup.prettify())
<html>
<body>
<a>
<b>
TutorialsPoint
</b>
<c>
<strong>
The Biggest Online Tutorials Library, It's all Free
</strong>
</c>
</a>
</body>
</html>Nel documento precedente, i tag <b> e <c> sono allo stesso livello e sono entrambi figli dello stesso tag. Entrambi i tag <b> e <c> sono fratelli.
.next_sibling e .previous_sibling
Usa .next_sibling e .previous_sibling per navigare tra gli elementi della pagina che si trovano sullo stesso livello dell'albero di analisi:
>>> sibling_soup.b.next_sibling
<c><strong>The Biggest Online Tutorials Library, It's all Free</strong></c>
>>>
>>> sibling_soup.c.previous_sibling
<b>TutorialsPoint</b>Il tag <b> ha un .next_sibling ma non .previous_sibling, poiché non c'è nulla prima del tag <b> sullo stesso livello dell'albero, lo stesso caso è con il tag <c>.
>>> print(sibling_soup.b.previous_sibling)
None
>>> print(sibling_soup.c.next_sibling)
NoneLe due stringhe non sono fratelli, poiché non hanno lo stesso genitore.
>>> sibling_soup.b.string
'TutorialsPoint'
>>>
>>> print(sibling_soup.b.string.next_sibling)
None.next_siblings e .previous_siblings
Per scorrere i fratelli di un tag, usa .next_siblings e .previous_siblings.
>>> for sibling in soup.a.next_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
>a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>
' and\n'
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm"
id="link5">C</a>
';\n \nas per online survey.'
>>> for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
'Top 5 most used Programming Languages are: \n'Andando avanti e indietro
Ora torniamo alle prime due righe nel nostro precedente esempio "html_doc":
&t;html><head><title>Tutorials Point</title></head>
<body>
<h4 class="tagLine"><b>The Biggest Online Tutorials Library, It's all Free</b></h4>Un parser HTML prende la stringa di caratteri sopra e la trasforma in una serie di eventi come "apri un tag <html>", "apri un tag <head>", "apri il tag <title>", "aggiungi una stringa", "Chiudi il tag </title>", "chiudi il tag </head>", "apri un tag <h4>" e così via. BeautifulSoup offre diversi metodi per ricostruire l'analisi iniziale del documento.
.next_element e .previous_element
L'attributo .next_element di un tag o di una stringa punta a tutto ciò che è stato analizzato immediatamente dopo. A volte sembra simile a .next_sibling, tuttavia non è completamente lo stesso. Di seguito è riportato il tag <a> finale nel nostro documento di esempio "html_doc".
>>> last_a_tag = soup.find("a", id="link5")
>>> last_a_tag
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>
>>> last_a_tag.next_sibling
';\n \nas per online survey.'Tuttavia l'elemento .next_ di quel tag <a>, la cosa che è stata analizzata immediatamente dopo il tag <a>, non è il resto di quella frase: è la parola "C":
>>> last_a_tag.next_element
'C'Il comportamento sopra è dovuto al fatto che nel markup originale, la lettera "C" appariva prima di quel punto e virgola. Il parser ha rilevato un tag <a>, poi la lettera "C", quindi il tag di chiusura </a>, quindi il punto e virgola e il resto della frase. Il punto e virgola si trova allo stesso livello del tag <a>, ma prima è stata rilevata la lettera "C".
L'attributo .previous_element è l'esatto opposto di .next_element. Indica qualsiasi elemento è stato analizzato immediatamente prima di questo.
>>> last_a_tag.previous_element
' and\n'
>>>
>>> last_a_tag.previous_element.next_element
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>.next_elements e .previous_elements
Usiamo questi iteratori per spostarci avanti e indietro su un elemento.
>>> for element in last_a_tag.next_e lements:
print(repr(element))
'C'
';\n \nas per online survey.'
'\n'
<p class="prog">Programming Languages</p>
'Programming Languages'
'\n'Esistono molti metodi Beautifulsoup, che ci consentono di cercare un albero di analisi. I due metodi più comuni e utilizzati sono find () e find_all ().
Prima di parlare di find () e find_all (), vediamo alcuni esempi di diversi filtri che puoi passare a questi metodi.
Tipi di filtri
Abbiamo diversi filtri che possiamo passare a questi metodi e la comprensione di questi filtri è fondamentale poiché questi filtri vengono utilizzati più e più volte, attraverso l'API di ricerca. Possiamo utilizzare questi filtri in base al nome del tag, ai suoi attributi, al testo di una stringa o a un misto di questi.
Una stringa
Uno dei tipi più semplici di filtro è una stringa. Passando una stringa al metodo di ricerca, Beautifulsoup eseguirà una corrispondenza con quella stringa esatta.
Il codice sottostante troverà tutti i tag <p> nel documento -
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>> markup.find_all('p')
[<p>Top Three</p>, <p></p>, <p><b>Java, Python, Cplusplus</b></p>]Espressione regolare
Puoi trovare tutti i tag che iniziano con una data stringa / tag. Prima di ciò dobbiamo importare il modulo re per utilizzare l'espressione regolare.
>>> import re
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>>
>>> markup.find_all(re.compile('^p'))
[<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>]Elenco
Puoi passare più tag da trovare fornendo un elenco. Il codice sottostante trova tutti i tag <b> e <pre> -
>>> markup.find_all(['pre', 'b'])
[<pre>Programming Languages are:</pre>, <b>Java, Python, Cplusplus</b>]Vero
True restituirà tutti i tag che può trovare, ma nessuna stringa da sola -
>>> markup.find_all(True)
[<html><body><p>Top Three</p><p></p><pre>Programming Languages are:</pre>
<p><b>Java, Python, Cplusplus</b> </p> </body></html>,
<body><p>Top Three</p><p></p><pre> Programming Languages are:</pre><p><b>Java, Python, Cplusplus</b></p>
</body>,
<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>, <b>Java, Python, Cplusplus</b>]Per restituire solo i tag dalla zuppa di cui sopra -
>>> for tag in markup.find_all(True):
(tag.name)
'html'
'body'
'p'
'p'
'pre'
'p'
'b'trova tutto()
Puoi utilizzare find_all per estrarre tutte le occorrenze di un particolare tag dalla risposta della pagina come:
Sintassi
find_all(name, attrs, recursive, string, limit, **kwargs)Cerchiamo di estrarre alcuni dati interessanti da IMDB- "I film più votati" di tutti i tempi.
>>> url="https://www.imdb.com/chart/top/?ref_=nv_mv_250"
>>> content = requests.get(url)
>>> soup = BeautifulSoup(content.text, 'html.parser')
#Extract title Page
>>> print(soup.find('title'))
<title>IMDb Top 250 - IMDb</title>
#Extracting main heading
>>> for heading in soup.find_all('h1'):
print(heading.text)
Top Rated Movies
#Extracting sub-heading
>>> for heading in soup.find_all('h3'):
print(heading.text)
IMDb Charts
You Have Seen
IMDb Charts
Top India Charts
Top Rated Movies by Genre
Recently ViewedDall'alto, possiamo vedere find_all ci darà tutti gli elementi che corrispondono ai criteri di ricerca che definiamo. Tutti i filtri che possiamo usare con find_all () possono essere usati con find () e anche altri metodi di ricerca come find_parents () o find_siblings ().
trova()
Abbiamo visto sopra, find_all () è usato per scansionare l'intero documento per trovare tutti i contenuti ma qualcosa, il requisito è trovare un solo risultato. Se sai che il documento contiene solo un tag <body>, è una perdita di tempo cercare l'intero documento. Un modo è chiamare find_all () con limit = 1 ogni volta oppure possiamo usare il metodo find () per fare lo stesso -
Sintassi
find(name, attrs, recursive, string, **kwargs)Quindi di seguito due metodi diversi danno lo stesso risultato:
>>> soup.find_all('title',limit=1)
[<title>IMDb Top 250 - IMDb</title>]
>>>
>>> soup.find('title')
<title>IMDb Top 250 - IMDb</title>Negli output sopra, possiamo vedere che il metodo find_all () restituisce una lista contenente un singolo elemento mentre il metodo find () restituisce un singolo risultato.
Un'altra differenza tra il metodo find () e find_all () è:
>>> soup.find_all('h2')
[]
>>>
>>> soup.find('h2')Se il metodo soup.find_all () non riesce a trovare nulla, restituisce un elenco vuoto mentre find () restituisce None.
find_parents () e find_parent ()
A differenza dei metodi find_all () e find () che attraversano l'albero, guardando i discendenti dei tag, i metodi find_parents () e find_parents () fanno il contrario, attraversano l'albero verso l'alto e guardano i genitori di un tag (o di una stringa).
Sintassi
find_parents(name, attrs, string, limit, **kwargs)
find_parent(name, attrs, string, **kwargs)
>>> a_string = soup.find(string="The Godfather")
>>> a_string
'The Godfather'
>>> a_string.find_parents('a')
[<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>]
>>> a_string.find_parent('a')
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
>>> a_string.find_parent('tr')
<tr>
<td class="posterColumn">
<span data-value="2" name="rk"></span>
<span data-value="9.149038526210072" name="ir"></span>
<span data-value="6.93792E10" name="us"></span>
<span data-value="1485540" name="nv"></span>
<span data-value="-1.850961473789928" name="ur"></span>
<a href="/title/tt0068646/"> <img alt="The Godfather" height="67" src="https://m.media-amazon.com/images/M/MV5BM2MyNjYxNmUtYTAwNi00MTYxLWJmNWYtYzZlODY3ZTk3OTFlXkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR1,0,45,67_AL_.jpg" width="45"/>
</a> </td>
<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>
<td class="ratingColumn imdbRating">
<strong title="9.1 based on 1,485,540 user ratings">9.1</strong>
</td>
<td class="ratingColumn">
<div class="seen-widget seen-widget-tt0068646 pending" data-titleid="tt0068646">
<div class="boundary">
<div class="popover">
<span class="delete"> </span><ol><li>1<li>2<li>3<li>4<li>5<li>6<li>7<li>8<li>9<li>10</li>0</li></li></li></li&td;</li></li></li></li></li></ol> </div>
</div>
<div class="inline">
<div class="pending"></div>
<div class="unseeable">NOT YET RELEASED</div>
<div class="unseen"> </div>
<div class="rating"></div>
<div class="seen">Seen</div>
</div>
</div>
</td>
<td class="watchlistColumn">
<div class="wlb_ribbon" data-recordmetrics="true" data-tconst="tt0068646"></div>
</td>
</tr>
>>>
>>> a_string.find_parents('td')
[<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>]Esistono altri otto metodi simili:
find_next_siblings(name, attrs, string, limit, **kwargs)
find_next_sibling(name, attrs, string, **kwargs)
find_previous_siblings(name, attrs, string, limit, **kwargs)
find_previous_sibling(name, attrs, string, **kwargs)
find_all_next(name, attrs, string, limit, **kwargs)
find_next(name, attrs, string, **kwargs)
find_all_previous(name, attrs, string, limit, **kwargs)
find_previous(name, attrs, string, **kwargs)Dove,
find_next_siblings() e find_next_sibling() i metodi itereranno su tutti i fratelli dell'elemento che vengono dopo quello corrente.
find_previous_siblings() e find_previous_sibling() metodi itereranno su tutti i fratelli che vengono prima dell'elemento corrente.
find_all_next() e find_next() i metodi itereranno su tutti i tag e le stringhe che vengono dopo l'elemento corrente.
find_all_previous e find_previous() i metodi itereranno su tutti i tag e le stringhe che precedono l'elemento corrente.
Selettori CSS
La libreria BeautifulSoup per supportare i selettori CSS più comunemente usati. Puoi cercare elementi usando i selettori CSS con l'aiuto del metodo select ().
Ecco alcuni esempi:
>>> soup.select('title')
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>>
>>> soup.select("p:nth-of-type(1)")
[<p>The Top Rated Movie list only includes theatrical features.</p>, <p> class="imdb-footer__copyright _2-iNNCFskmr4l2OFN2DRsf">© 1990- by IMDb.com, Inc.</p>]
>>> len(soup.select("p:nth-of-type(1)"))
2
>>> len(soup.select("a"))
609
>>> len(soup.select("p"))
2
>>> soup.select("html head title")
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>> soup.select("head > title")
[<title>IMDb Top 250 - IMDb</title>]
#print HTML code of the tenth li elemnet
>>> soup.select("li:nth-of-type(10)")
[<li class="subnav_item_main">
<a href="/search/title?genres=film_noir&sort=user_rating,desc&title_type=feature&num_votes=25000,">Film-Noir
</a> </li>]Uno degli aspetti importanti di BeautifulSoup è la ricerca nell'albero di analisi e ti consente di apportare modifiche al documento Web in base alle tue esigenze. Possiamo apportare modifiche alle proprietà del tag usando i suoi attributi, come il metodo .name, .string o .append (). Ti permette di aggiungere nuovi tag e stringhe a un tag esistente con l'aiuto dei metodi .new_string () e .new_tag (). Esistono anche altri metodi, come .insert (), .insert_before () o .insert_after () per apportare varie modifiche al documento HTML o XML.
Modifica dei nomi e degli attributi dei tag
Dopo aver creato la zuppa, è facile apportare modifiche come rinominare il tag, apportare modifiche ai suoi attributi, aggiungere nuovi attributi ed eliminare attributi.
>>> soup = BeautifulSoup('<b class="bolder">Very Bold</b>')
>>> tag = soup.bLa modifica e l'aggiunta di nuovi attributi sono le seguenti:
>>> tag.name = 'Blockquote'
>>> tag['class'] = 'Bolder'
>>> tag['id'] = 1.1
>>> tag
<Blockquote class="Bolder" id="1.1">Very Bold</Blockquote>L'eliminazione degli attributi è la seguente:
>>> del tag['class']
>>> tag
<Blockquote id="1.1">Very Bold</Blockquote>
>>> del tag['id']
>>> tag
<Blockquote>Very Bold</Blockquote>Modifica .string
Puoi facilmente modificare l'attributo .string del tag -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner>/i<</a>'
>>> Bsoup = BeautifulSoup(markup)
>>> tag = Bsoup.a
>>> tag.string = "My Favourite spot."
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">My Favourite spot.</a>Dall'alto, possiamo vedere se il tag contiene altri tag, questi e tutto il loro contenuto saranno sostituiti da nuovi dati.
aggiungere()
L'aggiunta di nuovi dati / contenuti a un tag esistente avviene utilizzando il metodo tag.append (). È molto simile al metodo append () nell'elenco Python.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i></a>'
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.a.append(" Really Liked it")
>>> Bsoup
<html><body><a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i> Really Liked it</a></body></html>
>>> Bsoup.a.contents
['Must for every ', <i>Learner</i>, ' Really Liked it']NavigableString () e .new_tag ()
Nel caso in cui si desideri aggiungere una stringa a un documento, è possibile farlo facilmente utilizzando il costruttore append () o NavigableString () -
>>> soup = BeautifulSoup("<b></b>")
>>> tag = soup.b
>>> tag.append("Start")
>>>
>>> new_string = NavigableString(" Your")
>>> tag.append(new_string)
>>> tag
<b>Start Your</b>
>>> tag.contents
['Start', ' Your']Note: Se trovi qualche errore di nome durante l'accesso alla funzione NavigableString (), come segue -
NameError: il nome "NavigableString" non è definito
Basta importare la directory NavigableString dal pacchetto bs4 -
>>> from bs4 import NavigableStringPossiamo risolvere l'errore di cui sopra.
Puoi aggiungere commenti ai tuoi tag esistenti o puoi aggiungere qualche altra sottoclasse di NavigableString, basta chiamare il costruttore.
>>> from bs4 import Comment
>>> adding_comment = Comment("Always Learn something Good!")
>>> tag.append(adding_comment)
>>> tag
<b>Start Your<!--Always Learn something Good!--></b>
>>> tag.contents
['Start', ' Your', 'Always Learn something Good!']L'aggiunta di un tag completamente nuovo (senza aggiunta a un tag esistente) può essere eseguita utilizzando il metodo integrato Beautifulsoup, BeautifulSoup.new_tag () -
>>> soup = BeautifulSoup("<b></b>")
>>> Otag = soup.b
>>>
>>> Newtag = soup.new_tag("a", href="https://www.tutorialspoint.com")
>>> Otag.append(Newtag)
>>> Otag
<b><a href="https://www.tutorialspoint.com"></a></b>È richiesto solo il primo argomento, il nome del tag.
inserire()
Simile al metodo .insert () nell'elenco python, tag.insert () inserirà un nuovo elemento, tuttavia, a differenza di tag.append (), il nuovo elemento non va necessariamente alla fine del contenuto del suo genitore. Un nuovo elemento può essere aggiunto in qualsiasi posizione.
>>> markup = '<a href="https://www.djangoproject.com/community/">Django Official website <i>Huge Community base</i></a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>>
>>> tag.insert(1, "Love this framework ")
>>> tag
<a href="https://www.djangoproject.com/community/">Django Official website Love this framework <i>Huge Community base</i></a>
>>> tag.contents
['Django Official website ', 'Love this framework ', <i>Huge Community base</i
>]
>>>insert_before () e insert_after ()
Per inserire un tag o una stringa appena prima di qualcosa nell'albero di analisi, usiamo insert_before () -
>>> soup = BeautifulSoup("Brave")
>>> tag = soup.new_tag("i")
>>> tag.string = "Be"
>>>
>>> soup.b.string.insert_before(tag)
>>> soup.b
<b><i>Be</i>Brave</b>Allo stesso modo per inserire un tag o una stringa subito dopo qualcosa nell'albero di analisi, utilizzare insert_after ().
>>> soup.b.i.insert_after(soup.new_string(" Always "))
>>> soup.b
<b><i>Be</i> Always Brave</b>
>>> soup.b.contents
[<i>Be</i>, ' Always ', 'Brave']chiaro()
Per rimuovere il contenuto di un tag, usa tag.clear () -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical&lr;/i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> tag.clear()
>>> tag
<a href="https://www.tutorialspoint.com/index.htm"></a>estratto()
Per rimuovere un tag o stringhe dall'albero, utilizzare PageElement.extract ().
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i&gr;technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> i_tag = soup.i.extract()
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>
>>> i_tag
<i>technical & Non-technical</i>
>>>
>>> print(i_tag.parent)
Nonedecomporsi()
Il tag.decompose () rimuove un tag dall'albero e cancella tutto il suo contenuto.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> soup.i.decompose()
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>Sostituirlo con()
Come suggerisce il nome, la funzione pageElement.replace_with () sostituirà il vecchio tag o stringa con il nuovo tag o stringa nell'albero -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Complete Python <i>Material</i></a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> new_tag = soup.new_tag("Official_site")
>>> new_tag.string = "https://www.python.org/"
>>> a_tag.i.replace_with(new_tag)
<i>Material</i>
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">Complete Python <Official_site>https://www.python.org/</Official_site></a>Nell'output sopra, hai notato che replace_with () restituisce il tag o la stringa che è stata sostituita (come "Material" nel nostro caso), quindi puoi esaminarla o aggiungerla di nuovo a un'altra parte dell'albero.
avvolgere ()
Il pageElement.wrap () racchiude un elemento nel tag specificato e restituisce un nuovo wrapper -
>>> soup = BeautifulSoup("<p>tutorialspoint.com</p>")
>>> soup.p.string.wrap(soup.new_tag("b"))
<b>tutorialspoint.com</b>
>>>
>>> soup.p.wrap(soup.new_tag("Div"))
<Div><p><b>tutorialspoint.com</b></p></Div>scartare()
Il tag.unwrap () è esattamente l'opposto di wrap () e sostituisce un tag con qualunque cosa all'interno di quel tag.
>>> soup = BeautifulSoup('<a href="https://www.tutorialspoint.com/">I liked <i>tutorialspoint</i></a>')
>>> a_tag = soup.a
>>>
>>> a_tag.i.unwrap()
<i></i>
>>> a_tag
<a href="https://www.tutorialspoint.com/">I liked tutorialspoint</a>Dall'alto, hai notato che come replace_with (), unfrap () restituisce il tag che è stato sostituito.
Di seguito è riportato un altro esempio di scartare () per capirlo meglio:
>>> soup = BeautifulSoup("<p>I <strong>AM</strong> a <i>text</i>.</p>")
>>> soup.i.unwrap()
<i></i>
>>> soup
<html><body><p>I <strong>AM</strong> a text.</p></body></html>Unrap () è utile per rimuovere il markup.
Tutti i documenti HTML o XML sono scritti in una codifica specifica come ASCII o UTF-8. Tuttavia, quando carichi quel documento HTML / XML in BeautifulSoup, è stato convertito in Unicode.
>>> markup = "<p>I will display £</p>"
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.p
<p>I will display £</p>
>>> Bsoup.p.string
'I will display £'Il comportamento sopra è dovuto al fatto che BeautifulSoup utilizza internamente la sotto-libreria chiamata Unicode, Dammit per rilevare la codifica di un documento e quindi convertirla in Unicode.
Tuttavia, non sempre, Unicode, Dammit indovina correttamente. Poiché il documento viene cercato byte per byte per indovinare la codifica, ci vuole molto tempo. Puoi risparmiare tempo ed evitare errori, se conosci già la codifica passandola al costruttore BeautifulSoup come from_encoding.
Di seguito è riportato un esempio in cui BeautifulSoup identifica erroneamente un documento ISO-8859-8 come ISO-8859-7 -
>>> markup = b"<h1>\xed\xe5\xec\xf9</h1>"
>>> soup = BeautifulSoup(markup)
>>> soup.h1
<h1>νεμω</h1>
>>> soup.original_encoding
'ISO-8859-7'
>>>Per risolvere il problema precedente, passalo a BeautifulSoup usando from_encoding -
>>> soup = BeautifulSoup(markup, from_encoding="iso-8859-8")
>>> soup.h1
<h1>ולש </h1>
>>> soup.original_encoding
'iso-8859-8'
>>>Un'altra nuova funzionalità aggiunta da BeautifulSoup 4.4.0 è exclude_encoding. Può essere usato, quando non conosci la codifica corretta ma sei sicuro che Unicode, Dammit sta mostrando un risultato sbagliato.
>>> soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])Codifica dell'output
L'output di BeautifulSoup è un documento UTF-8, indipendentemente dal documento inserito in BeautifulSoup. Di seguito un documento, dove i caratteri polacchi sono presenti nel formato ISO-8859-2.
html_markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</BODY>
</HTML>
"""
>>> soup = BeautifulSoup(html_markup)
>>> print(soup.prettify())
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</body>
</html>Nell'esempio sopra, se noti, il tag <meta> è stato riscritto per riflettere il documento generato da BeautifulSoup ora è in formato UTF-8.
Se non vuoi l'output generato in UTF-8, puoi assegnare la codifica desiderata in prettify ().
>>> print(soup.prettify("latin-1"))
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'Nell'esempio sopra, abbiamo codificato il documento completo, tuttavia puoi codificare, qualsiasi elemento particolare nella zuppa come se fosse una stringa Python -
>>> soup.p.encode("latin-1")
b'<p>0My first paragraph.</p>'
>>> soup.h1.encode("latin-1")
b'<h1>My First Heading</h1>'Tutti i caratteri che non possono essere rappresentati nella codifica scelta verranno convertiti in riferimenti numerici di entità XML. Di seguito è riportato uno di questi esempi:
>>> markup = u"<b>\N{SNOWMAN}</b>"
>>> snowman_soup = BeautifulSoup(markup)
>>> tag = snowman_soup.b
>>> print(tag.encode("utf-8"))
b'<b>\xe2\x98\x83</b>'Se provi a codificare quanto sopra in "latin-1" o "ascii", verrà generato "☃", indicando che non c'è alcuna rappresentazione per quello.
>>> print (tag.encode("latin-1"))
b'<b>☃</b>'
>>> print (tag.encode("ascii"))
b'<b>☃</b>'Unicode, dannazione
Unicode, Dammit viene utilizzato principalmente quando il documento in arrivo è in formato sconosciuto (principalmente lingua straniera) e vogliamo codificare in un formato noto (Unicode) e inoltre non abbiamo bisogno di Beautifulsoup per fare tutto questo.
Il punto di partenza di qualsiasi progetto BeautifulSoup è l'oggetto BeautifulSoup. Un oggetto BeautifulSoup rappresenta il documento HTML / XML di input utilizzato per la sua creazione.
Possiamo passare una stringa o un oggetto simile a un file per Beautiful Soup, dove i file (oggetti) sono memorizzati localmente nella nostra macchina o in una pagina web.
Gli oggetti BeautifulSoup più comuni sono:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Confronto di oggetti per l'uguaglianza
Come per la bella zuppa, due oggetti stringa o tag navigabili sono uguali se rappresentano lo stesso markup HTML / XML.
Vediamo ora l'esempio seguente, in cui i due tag <b> sono trattati come uguali, anche se risiedono in parti diverse dell'albero degli oggetti, perché entrambi hanno l'aspetto di "<b> Java </b>".
>>> markup = "<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>"
>>> soup = BeautifulSoup(markup, "html.parser")
>>> first_b, second_b = soup.find_all('b')
>>> print(first_b == second_b)
True
>>> print(first_b.previous_element == second_b.previous_element)
FalseTuttavia, per verificare se le due variabili si riferiscono agli stessi oggetti, è possibile utilizzare quanto segue -
>>> print(first_b is second_b)
FalseCopia di oggetti Beautiful Soup
Per creare una copia di qualsiasi tag o NavigableString, usa la funzione copy.copy (), proprio come sotto -
>>> import copy
>>> p_copy = copy.copy(soup.p)
>>> print(p_copy)
<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>
>>>Sebbene le due copie (quella originale e quella copiata) contengano lo stesso markup, le due non rappresentano lo stesso oggetto -
>>> print(soup.p == p_copy)
True
>>>
>>> print(soup.p is p_copy)
False
>>>L'unica vera differenza è che la copia è completamente staccata dall'albero degli oggetti Beautiful Soup originale, proprio come se su di essa fosse stato chiamato extract ().
>>> print(p_copy.parent)
NoneIl comportamento di cui sopra è dovuto a due diversi oggetti tag che non possono occupare lo stesso spazio contemporaneamente.
Esistono più situazioni in cui desideri estrarre tipi specifici di informazioni (solo tag <a>) utilizzando Beautifulsoup4. La classe SoupStrainer in Beautifulsoup ti consente di analizzare solo una parte specifica di un documento in arrivo.
Un modo è creare un SoupStrainer e passarlo al costruttore Beautifulsoup4 come argomento parse_only.
SoupStrainer
Un SoupStrainer dice a BeautifulSoup quali parti vengono estratte e l'albero di analisi consiste solo di questi elementi. Se restringi le informazioni richieste a una parte specifica dell'HTML, i risultati della ricerca verranno accelerati.
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)Le righe di codice sopra analizzeranno solo i titoli di un sito di prodotto, che potrebbe trovarsi all'interno di un campo tag.
Allo stesso modo, come sopra, possiamo usare altri oggetti soupStrainer, per analizzare informazioni specifiche da un tag HTML. Di seguito sono riportati alcuni esempi:
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings =SoupStrainer(string=is_short_string)Gestione degli errori
Esistono due tipi principali di errori che devono essere gestiti in BeautifulSoup. Questi due errori non provengono dal tuo script ma dalla struttura dello snippet perché l'API BeautifulSoup genera un errore.
I due errori principali sono i seguenti:
AttributeError
È causato quando la notazione del punto non trova un tag di pari livello nel tag HTML corrente. Ad esempio, potresti aver riscontrato questo errore, a causa della mancanza del "tag di ancoraggio", cost-key genererà un errore mentre attraversa e richiede un tag di ancoraggio.
KeyError
Questo errore si verifica se manca l'attributo del tag HTML richiesto. Ad esempio, se non abbiamo l'attributo data-pid in uno snippet, la chiave pid genererà un errore di chiave.
Per evitare i due errori sopra elencati durante l'analisi di un risultato, tale risultato verrà ignorato per assicurarsi che uno snippet non valido non venga inserito nei database -
except(AttributeError, KeyError) as er:
passdiagnosticare()
Ogni volta che troviamo difficoltà nel capire cosa fa BeautifulSoup al nostro documento o HTML, passalo semplicemente alla funzione diagnostic (). Passando il file del documento alla funzione diagnostic (), possiamo mostrare come l'elenco dei diversi parser gestisce il documento.
Di seguito è riportato un esempio per dimostrare l'uso della funzione diagnostic ():
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)Produzione
Errore di analisi
Esistono due tipi principali di errori di analisi. Potresti ottenere un'eccezione come HTMLParseError, quando inserisci il tuo documento in BeautifulSoup. Potresti anche ottenere un risultato imprevisto, dove l'albero di analisi BeautifulSoup ha un aspetto molto diverso dal risultato atteso dal documento di analisi.
Nessuno degli errori di analisi è causato da BeautifulSoup. È a causa del parser esterno che utilizziamo (html5lib, lxml) poiché BeautifulSoup non contiene alcun codice del parser. Un modo per risolvere l'errore di analisi precedente è utilizzare un altro parser.
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
passIl parser HTML integrato in Python causa due errori di analisi più comuni, HTMLParser.HTMLParserError: tag di inizio non valido e HTMLParser.HTMLParserError: tag di fine non valido e per risolvere questo problema, è utilizzare principalmente un altro parser: lxml o html5lib.
Un altro tipo comune di comportamento imprevisto è che non riesci a trovare un tag che sai essere nel documento. Tuttavia, quando si esegue find_all () restituisce [] o find () restituisce None.
Ciò può essere dovuto al parser HTML integrato in Python a volte salta i tag che non comprende.
Errore del parser XML
Per impostazione predefinita, il pacchetto BeautifulSoup analizza i documenti come HTML, tuttavia, è molto facile da usare e gestisce XML mal formato in modo molto elegante utilizzando beautifulsoup4.
Per analizzare il documento come XML, devi avere un parser lxml e devi solo passare "xml" come secondo argomento al costruttore Beautifulsoup -
soup = BeautifulSoup(markup, "lxml-xml")o
soup = BeautifulSoup(markup, "xml")Un errore di analisi XML comune è:
AttributeError: 'NoneType' object has no attribute 'attrib'Ciò potrebbe accadere nel caso in cui qualche elemento sia mancante o non definito durante l'utilizzo della funzione find () o findall ().
Altri errori di analisi
Di seguito sono riportati alcuni degli altri errori di analisi di cui parleremo in questa sezione:
Problema ambientale
Oltre agli errori di analisi sopra menzionati, potresti riscontrare altri problemi di analisi come problemi ambientali in cui lo script potrebbe funzionare in un sistema operativo ma non in un altro sistema operativo o potrebbe funzionare in un ambiente virtuale ma non in un altro ambiente virtuale o potrebbe non funzionare fuori dall'ambiente virtuale. Tutti questi problemi possono essere dovuti al fatto che i due ambienti hanno diverse librerie di parser disponibili.
Si consiglia di conoscere o controllare il parser predefinito nell'ambiente di lavoro corrente. È possibile controllare il parser predefinito corrente disponibile per l'ambiente di lavoro corrente oppure passare esplicitamente la libreria parser richiesta come secondi argomenti al costruttore BeautifulSoup.
Case-insensitive
Poiché i tag e gli attributi HTML non fanno distinzione tra maiuscole e minuscole, tutti e tre i parser HTML convertono i nomi di tag e attributi in lettere minuscole. Tuttavia, se si desidera conservare tag e attributi con lettere maiuscole o minuscole, è meglio analizzare il documento come XML.
UnicodeEncodeError
Esaminiamo il segmento di codice seguente:
soup = BeautifulSoup(response, "html.parser")
print (soup)Produzione
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'Il problema sopra potrebbe essere dovuto a due situazioni principali. Potresti provare a stampare un carattere Unicode che la tua console non sa come visualizzare. Secondo, stai provando a scrivere su un file e passi un carattere Unicode che non è supportato dalla tua codifica predefinita.
Un modo per risolvere il problema di cui sopra è codificare il testo / carattere della risposta prima di preparare la zuppa per ottenere il risultato desiderato, come segue:
responseTxt = response.text.encode('UTF-8')KeyError: [attr]
È causato dall'accesso al tag ['attr'] quando il tag in questione non definisce l'attributo attr. Gli errori più comuni sono: "KeyError: 'href'" e "KeyError: 'class'". Usa tag.get ('attr') se non sei sicuro che attr sia definito.
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback actionAttributeError
Potresti incontrare AttributeError come segue:
AttributeError: 'list' object has no attribute 'find_all'L'errore precedente si verifica principalmente perché ti aspettavi che find_all () restituisse un singolo tag o stringa. Tuttavia, soup.find_all restituisce un elenco di elementi Python.
Tutto quello che devi fare è scorrere l'elenco e catturare i dati da quegli elementi.