Data mining - Guida rapida
C'è un'enorme quantità di dati disponibili nel settore dell'informazione. Questi dati non sono utili fino a quando non vengono convertiti in informazioni utili. È necessario analizzare questa enorme quantità di dati ed estrarne informazioni utili.
L'estrazione delle informazioni non è l'unico processo che dobbiamo eseguire; il data mining coinvolge anche altri processi come la pulizia dei dati, l'integrazione dei dati, la trasformazione dei dati, il data mining, la valutazione dei modelli e la presentazione dei dati. Una volta terminati tutti questi processi, saremo in grado di utilizzare queste informazioni in molte applicazioni come rilevamento delle frodi, analisi di mercato, controllo della produzione, esplorazione scientifica, ecc.
Cos'è il data mining?
Il data mining è definito come l'estrazione di informazioni da enormi set di dati. In altre parole, possiamo dire che il data mining è la procedura per estrarre la conoscenza dai dati. Le informazioni o le conoscenze così estratte possono essere utilizzate per una qualsiasi delle seguenti applicazioni:
- Analisi di mercato
- Intercettazione di una frode
- Fidelizzazione dei clienti
- Controllo di produzione
- Esplorazione della scienza
Applicazioni di data mining
Il data mining è molto utile nei seguenti domini:
- Analisi e gestione del mercato
- Analisi aziendale e gestione dei rischi
- Intercettazione di una frode
Oltre a questi, il data mining può essere utilizzato anche nelle aree di controllo della produzione, fidelizzazione dei clienti, esplorazione scientifica, sport, astrologia e Internet Web Surf-Aid
Analisi e gestione del mercato
Di seguito sono elencati i vari campi di mercato in cui viene utilizzato il data mining:
Customer Profiling - Il data mining aiuta a determinare che tipo di persone acquistano che tipo di prodotti.
Identifying Customer Requirements- Il data mining aiuta a identificare i migliori prodotti per diversi clienti. Utilizza la previsione per trovare i fattori che possono attirare nuovi clienti.
Cross Market Analysis - Il data mining esegue associazioni / correlazioni tra le vendite di prodotti.
Target Marketing - Il data mining aiuta a trovare cluster di clienti modello che condividono le stesse caratteristiche come interessi, abitudini di spesa, reddito, ecc.
Determining Customer purchasing pattern - Il data mining aiuta a determinare il modello di acquisto dei clienti.
Providing Summary Information - Il data mining ci fornisce vari report di riepilogo multidimensionali.
Analisi aziendale e gestione dei rischi
Il data mining viene utilizzato nei seguenti campi del settore aziendale:
Finance Planning and Asset Evaluation - Comprende analisi e previsione dei flussi di cassa, analisi dei reclami contingenti per valutare le attività.
Resource Planning - Si tratta di riassumere e confrontare le risorse e la spesa.
Competition - Si tratta di monitorare i concorrenti e le direzioni del mercato.
Intercettazione di una frode
Il data mining viene utilizzato anche nei settori dei servizi di carte di credito e delle telecomunicazioni per rilevare frodi. Nelle telefonate fraudolente, aiuta a trovare la destinazione della chiamata, la durata della chiamata, l'ora del giorno o della settimana, ecc. Analizza anche i modelli che si discostano dalle norme previste.
Il data mining si occupa del tipo di modelli che possono essere estratti. Sulla base del tipo di dati da estrarre, ci sono due categorie di funzioni coinvolte nel Data Mining:
- Descriptive
- Classificazione e previsione
Funzione descrittiva
La funzione descrittiva si occupa delle proprietà generali dei dati nel database. Ecco l'elenco delle funzioni descrittive:
- Descrizione classe / concetto
- Estrazione di modelli frequenti
- Estrazione di associazioni
- Estrazione di correlazioni
- Estrazione di cluster
Descrizione classe / concetto
Classe / Concetto si riferisce ai dati da associare alle classi o ai concetti. Ad esempio, in un'azienda, le classi di articoli per la vendita includono computer e stampanti e i concetti di clienti includono chi spende e chi spende budget. Tali descrizioni di una classe o di un concetto sono chiamate descrizioni di classi / concetti. Queste descrizioni possono essere derivate nei seguenti due modi:
Data Characterization- Si riferisce al riepilogo dei dati della classe in esame. Questa classe in fase di studio è chiamata Target Class.
Data Discrimination - Si riferisce alla mappatura o classificazione di una classe con un gruppo o una classe predefinita.
Estrazione di modelli frequenti
I modelli frequenti sono quei modelli che si verificano frequentemente nei dati transazionali. Ecco l'elenco dei tipi di schemi frequenti:
Frequent Item Set - Si riferisce a un insieme di elementi che appaiono frequentemente insieme, ad esempio, latte e pane.
Frequent Subsequence - Una sequenza di schemi che si verificano frequentemente, come l'acquisto di una fotocamera, è seguita dalla scheda di memoria.
Frequent Sub Structure - Sottostruttura si riferisce a diverse forme strutturali, come grafici, alberi o reticoli, che possono essere combinati con insiemi di elementi o sottosequenze.
Estrazione dell'Associazione
Le associazioni vengono utilizzate nelle vendite al dettaglio per identificare i modelli che vengono spesso acquistati insieme. Questo processo si riferisce al processo di scoperta della relazione tra i dati e determinazione delle regole di associazione.
Ad esempio, un rivenditore genera una regola di associazione che mostra che il 70% delle volte il latte viene venduto con il pane e solo il 30% delle volte i biscotti vengono venduti con il pane.
Estrazione di correlazioni
È una sorta di analisi aggiuntiva eseguita per scoprire interessanti correlazioni statistiche tra coppie di attributo-valore associate o tra due set di elementi per analizzare se hanno effetti positivi, negativi o nulli l'uno sull'altro.
Estrazione di cluster
Cluster si riferisce a un gruppo di oggetti simili. L'analisi dei cluster si riferisce alla formazione di un gruppo di oggetti che sono molto simili tra loro ma sono molto diversi dagli oggetti in altri cluster.
Classificazione e previsione
La classificazione è il processo di ricerca di un modello che descriva le classi di dati o i concetti. Lo scopo è poter utilizzare questo modello per prevedere la classe di oggetti la cui etichetta di classe è sconosciuta. Questo modello derivato si basa sull'analisi di set di dati di addestramento. Il modello derivato può essere presentato nelle seguenti forme:
- Regole di classificazione (IF-THEN)
- Alberi decisionali
- Formule matematiche
- Reti neurali
L'elenco delle funzioni coinvolte in questi processi è il seguente:
Classification- Prevede la classe degli oggetti la cui etichetta di classe è sconosciuta. Il suo obiettivo è trovare un modello derivato che descriva e distingua classi o concetti di dati. Il modello derivato si basa sul set di analisi dei dati di addestramento, ovvero l'oggetto dati la cui etichetta di classe è ben nota.
Prediction- Viene utilizzato per prevedere i valori dei dati numerici mancanti o non disponibili piuttosto che le etichette delle classi. L'analisi di regressione viene generalmente utilizzata per la previsione. La previsione può essere utilizzata anche per identificare le tendenze di distribuzione sulla base dei dati disponibili.
Outlier Analysis - I valori anomali possono essere definiti come gli oggetti dati che non sono conformi al comportamento generale o al modello dei dati disponibili.
Evolution Analysis - L'analisi dell'evoluzione si riferisce alla descrizione e alle regolarità o tendenze del modello per oggetti il cui comportamento cambia nel tempo.
Primitive dell'attività di data mining
- Possiamo specificare un'attività di data mining sotto forma di query di data mining.
- Questa query viene immessa nel sistema.
- Una query di data mining viene definita in termini di primitive dell'attività di data mining.
Note- Queste primitive ci permettono di comunicare in modo interattivo con il sistema di data mining. Ecco l'elenco delle primitive delle attività di data mining:
- Set di dati rilevanti per l'attività da estrarre.
- Tipo di conoscenza da estrarre.
- Conoscenza di base da utilizzare nel processo di scoperta.
- Misure di interesse e soglie per la valutazione del modello.
- Rappresentazione per visualizzare i modelli scoperti.
Set di dati rilevanti per l'attività da estrarre
Questa è la porzione di database a cui l'utente è interessato. Questa parte include quanto segue:
- Attributi del database
- Dimensioni di Data Warehouse di interesse
Tipo di conoscenza da estrarre
Si riferisce al tipo di funzioni da eseguire. Queste funzioni sono:
- Characterization
- Discrimination
- Analisi di associazione e correlazione
- Classification
- Prediction
- Clustering
- Analisi anomale
- Analisi dell'evoluzione
Conoscenze di base
La conoscenza di base consente di estrarre i dati a più livelli di astrazione. Ad esempio, le gerarchie dei concetti sono una delle conoscenze di base che consentono di estrarre i dati a più livelli di astrazione.
Misure di interesse e soglie per la valutazione del modello
Viene utilizzato per valutare i modelli scoperti dal processo di scoperta della conoscenza. Esistono diverse misure interessanti per diversi tipi di conoscenza.
Rappresentazione per visualizzare i modelli scoperti
Si riferisce alla forma in cui devono essere visualizzati i modelli rilevati. Queste rappresentazioni possono includere quanto segue. -
- Rules
- Tables
- Charts
- Graphs
- Alberi decisionali
- Cubes
Il data mining non è un compito facile, poiché gli algoritmi utilizzati possono diventare molto complessi e i dati non sono sempre disponibili in un unico posto. Deve essere integrato da varie fonti di dati eterogenee. Questi fattori creano anche alcuni problemi. Qui in questo tutorial, discuteremo le principali questioni riguardanti:
- Metodologia di mining e interazione con l'utente
- Problemi di prestazione
- Problemi di diversi tipi di dati
Il diagramma seguente descrive i problemi principali.

Metodologia di mining e problemi di interazione con l'utente
Si riferisce ai seguenti tipi di problemi:
Mining different kinds of knowledge in databases- Diversi utenti possono essere interessati a diversi tipi di conoscenza. Pertanto è necessario che il data mining copra un'ampia gamma di attività di knowledge discovery.
Interactive mining of knowledge at multiple levels of abstraction - Il processo di data mining deve essere interattivo perché consente agli utenti di concentrare la ricerca di modelli, fornendo e perfezionando le richieste di data mining in base ai risultati restituiti.
Incorporation of background knowledge- Per guidare il processo di scoperta e per esprimere i modelli scoperti, è possibile utilizzare la conoscenza di base. La conoscenza di base può essere utilizzata per esprimere i modelli scoperti non solo in termini concisi ma a più livelli di astrazione.
Data mining query languages and ad hoc data mining - Il linguaggio di query del data mining che consente all'utente di descrivere attività di mining ad hoc, dovrebbe essere integrato con un linguaggio di query del data warehouse e ottimizzato per un data mining efficiente e flessibile.
Presentation and visualization of data mining results- Una volta scoperti i modelli, è necessario esprimerli in linguaggi di alto livello e rappresentazioni visive. Queste rappresentazioni dovrebbero essere facilmente comprensibili.
Handling noisy or incomplete data- I metodi di pulizia dei dati sono necessari per gestire il rumore e gli oggetti incompleti durante l'estrazione delle regolarità dei dati. Se i metodi di pulizia dei dati non sono disponibili, la precisione dei modelli rilevati sarà scarsa.
Pattern evaluation - I modelli scoperti dovrebbero essere interessanti perché rappresentano una conoscenza comune o mancano di novità.
Problemi di prestazione
Possono esserci problemi relativi alle prestazioni come segue:
Efficiency and scalability of data mining algorithms - Per estrarre efficacemente le informazioni da enormi quantità di dati nei database, l'algoritmo di data mining deve essere efficiente e scalabile.
Parallel, distributed, and incremental mining algorithms- Fattori quali l'enorme dimensione dei database, l'ampia distribuzione dei dati e la complessità dei metodi di data mining motivano lo sviluppo di algoritmi di data mining paralleli e distribuiti. Questi algoritmi dividono i dati in partizioni che vengono ulteriormente elaborate in modo parallelo. Quindi i risultati delle partizioni vengono uniti. Gli algoritmi incrementali aggiornano i database senza estrarre nuovamente i dati da zero.
Problemi di diversi tipi di dati
Handling of relational and complex types of data - Il database può contenere oggetti di dati complessi, oggetti di dati multimediali, dati spaziali, dati temporali ecc. Non è possibile per un sistema estrarre tutti questi tipi di dati.
Mining information from heterogeneous databases and global information systems- I dati sono disponibili in diverse origini dati su LAN o WAN. Queste origini dati possono essere strutturate, semi strutturate o non strutturate. Pertanto estrarre la conoscenza da loro aggiunge sfide al data mining.
Data Warehouse
Un data warehouse presenta le seguenti caratteristiche a supporto del processo decisionale della direzione:
Subject Oriented- Il data warehouse è orientato al soggetto perché ci fornisce le informazioni su un argomento piuttosto che sulle operazioni in corso dell'organizzazione. Questi soggetti possono essere prodotti, clienti, fornitori, vendite, ricavi, ecc. Il data warehouse non si concentra sulle operazioni in corso, ma piuttosto sulla modellazione e analisi dei dati per il processo decisionale.
Integrated - Il data warehouse è costruito integrando dati da fonti eterogenee come database relazionali, file flat ecc. Questa integrazione migliora l'analisi efficace dei dati.
Time Variant- I dati raccolti in un data warehouse sono identificati con un determinato periodo di tempo. I dati in un data warehouse forniscono informazioni da un punto di vista storico.
Non-volatile- Non volatile significa che i dati precedenti non vengono rimossi quando vengono aggiunti nuovi dati. Il data warehouse è tenuto separato dal database operativo, pertanto i frequenti cambiamenti nel database operativo non si riflettono nel data warehouse.
Data Warehousing
Il data warehousing è il processo di costruzione e utilizzo del data warehouse. Un data warehouse viene costruito integrando i dati da più origini eterogenee. Supporta report analitici, query strutturate e / o ad hoc e processi decisionali.
Il data warehousing implica la pulizia dei dati, l'integrazione dei dati e il consolidamento dei dati. Per integrare database eterogenei, abbiamo i seguenti due approcci:
- Approccio basato sulla query
- Approccio guidato dall'aggiornamento
Approccio basato su query
Questo è l'approccio tradizionale per integrare database eterogenei. Questo approccio viene utilizzato per creare wrapper e integratori su più database eterogenei. Questi integratori sono noti anche come mediatori.
Processo di approccio basato sulla query
Quando una query viene inviata a un lato client, un dizionario di metadati traduce la query nelle query, appropriate per il singolo sito eterogeneo coinvolto.
Ora queste query vengono mappate e inviate al Query Processor locale.
I risultati di siti eterogenei sono integrati in una serie di risposte globali.
Svantaggi
Questo approccio presenta i seguenti svantaggi:
L'approccio basato sulla query richiede processi di integrazione e filtraggio complessi.
È molto inefficiente e molto costoso per query frequenti.
Questo approccio è costoso per le query che richiedono aggregazioni.
Approccio guidato dall'aggiornamento
I sistemi di data warehouse odierni seguono un approccio guidato dall'aggiornamento piuttosto che l'approccio tradizionale discusso in precedenza. Nell'approccio basato sull'aggiornamento, le informazioni provenienti da più fonti eterogenee vengono integrate in anticipo e archiviate in un magazzino. Queste informazioni sono disponibili per query e analisi dirette.
Vantaggi
Questo approccio presenta i seguenti vantaggi:
Questo approccio fornisce prestazioni elevate.
I dati possono essere copiati, elaborati, integrati, annotati, riepilogati e ristrutturati in anticipo nel data store semantico.
L'elaborazione delle query non richiede l'interfaccia con l'elaborazione nelle origini locali.
Dal Data Warehousing (OLAP) al Data Mining (OLAM)
Online Analytical Mining si integra con Online Analytical Processing con data mining e conoscenza del mining in database multidimensionali. Ecco il diagramma che mostra l'integrazione di OLAP e OLAM -

Importanza di OLAM
OLAM è importante per i seguenti motivi:
High quality of data in data warehouses- Gli strumenti di data mining sono necessari per lavorare su dati integrati, coerenti e puliti. Questi passaggi sono molto costosi nella preelaborazione dei dati. I data warehouse costruiti da tale preelaborazione sono preziose fonti di dati di alta qualità anche per OLAP e data mining.
Available information processing infrastructure surrounding data warehouses - Infrastruttura di elaborazione delle informazioni si intende l'accesso, l'integrazione, il consolidamento e la trasformazione di più database eterogenei, strutture di servizio e di accesso al Web, reportistica e strumenti di analisi OLAP.
OLAP−based exploratory data analysis- L'analisi esplorativa dei dati è necessaria per un'efficace estrazione dei dati. OLAM fornisce funzionalità per il data mining su vari sottoinsiemi di dati ea diversi livelli di astrazione.
Online selection of data mining functions - L'integrazione di OLAP con più funzioni di data mining e il mining analitico online offre agli utenti la flessibilità di selezionare le funzioni di data mining desiderate e di scambiare dinamicamente le attività di data mining.
Estrazione dei dati
Il data mining è definito come l'estrazione di informazioni da un enorme insieme di dati. In altre parole, possiamo dire che il data mining sta estraendo la conoscenza dai dati. Queste informazioni possono essere utilizzate per una qualsiasi delle seguenti applicazioni:
- Analisi di mercato
- Intercettazione di una frode
- Fidelizzazione dei clienti
- Controllo di produzione
- Esplorazione della scienza
Motore di data mining
Il motore di data mining è molto essenziale per il sistema di data mining. Consiste in una serie di moduli funzionali che svolgono le seguenti funzioni:
- Characterization
- Analisi di associazione e correlazione
- Classification
- Prediction
- Analisi di gruppo
- Analisi anomale
- Analisi dell'evoluzione
base di conoscenza
Questa è la conoscenza del dominio. Questa conoscenza viene utilizzata per guidare la ricerca o valutare l'interesse dei modelli risultanti.
Scoperta della conoscenza
Alcune persone considerano il data mining come la scoperta della conoscenza, mentre altri considerano il data mining una fase essenziale nel processo di scoperta della conoscenza. Ecco l'elenco dei passaggi coinvolti nel processo di scoperta della conoscenza:
- Pulizia dei dati
- Integrazione dei dati
- Selezione dei dati
- Trasformazione dei dati
- Estrazione dei dati
- Valutazione del modello
- Presentazione della conoscenza
Interfaccia utente
L'interfaccia utente è il modulo del sistema di data mining che aiuta la comunicazione tra gli utenti e il sistema di data mining. L'interfaccia utente consente le seguenti funzionalità:
- Interagisci con il sistema specificando un'attività di query di data mining.
- Fornire informazioni per aiutare a focalizzare la ricerca.
- Mining basato sui risultati di data mining intermedi.
- Sfoglia schemi di database e data warehouse o strutture di dati.
- Valuta i modelli estratti.
- Visualizza i modelli in diverse forme.
Integrazione dei dati
L'integrazione dei dati è una tecnica di pre-elaborazione dei dati che unisce i dati da più origini dati eterogenee in un archivio dati coerente. L'integrazione dei dati può comportare dati incoerenti e quindi necessita di pulizia dei dati.
Pulizia dei dati
La pulizia dei dati è una tecnica che viene applicata per rimuovere i dati rumorosi e correggere le incongruenze nei dati. La pulizia dei dati comporta trasformazioni per correggere i dati errati. La pulizia dei dati viene eseguita come fase di pre-elaborazione dei dati durante la preparazione dei dati per un data warehouse.
Selezione dei dati
La selezione dei dati è il processo in cui i dati rilevanti per l'attività di analisi vengono recuperati dal database. A volte la trasformazione e il consolidamento dei dati vengono eseguiti prima del processo di selezione dei dati.
Cluster
Cluster si riferisce a un gruppo di oggetti simili. L'analisi dei cluster si riferisce alla formazione di un gruppo di oggetti che sono molto simili tra loro ma sono molto diversi dagli oggetti in altri cluster.
Trasformazione dei dati
In questa fase, i dati vengono trasformati o consolidati in moduli appropriati per il mining, eseguendo operazioni di riepilogo o aggregazione.
Cos'è la Knowledge Discovery?
Alcune persone non differenziano il data mining dalla knowledge discovery, mentre altri considerano il data mining un passaggio essenziale nel processo di knowledge discovery. Ecco l'elenco dei passaggi coinvolti nel processo di scoperta della conoscenza:
Data Cleaning - In questa fase, il rumore e i dati incoerenti vengono rimossi.
Data Integration - In questo passaggio vengono combinate più origini dati.
Data Selection - In questa fase, i dati rilevanti per l'attività di analisi vengono recuperati dal database.
Data Transformation - In questa fase, i dati vengono trasformati o consolidati in moduli appropriati per il mining eseguendo operazioni di riepilogo o aggregazione.
Data Mining - In questa fase vengono applicati metodi intelligenti per estrarre modelli di dati.
Pattern Evaluation - In questa fase vengono valutati i modelli di dati.
Knowledge Presentation - In questa fase viene rappresentata la conoscenza.
Il diagramma seguente mostra il processo di scoperta della conoscenza:

È disponibile un'ampia varietà di sistemi di data mining. I sistemi di data mining possono integrare tecniche dalle seguenti:
- Analisi dei dati spaziali
- Recupero delle informazioni
- Riconoscimento di modelli
- Analisi delle immagini
- Elaborazione del segnale
- Computer grafica
- Tecnologia web
- Business
- Bioinformatics
Classificazione del sistema di data mining
Un sistema di data mining può essere classificato secondo i seguenti criteri:
- Tecnologia database
- Statistics
- Apprendimento automatico
- Scienza dell'informazione
- Visualization
- Altre discipline

Oltre a questi, un sistema di data mining può anche essere classificato in base al tipo di (a) database estratti, (b) conoscenza estratta, (c) tecniche utilizzate e (d) applicazioni adattate.
Classificazione basata sui database estratti
Possiamo classificare un sistema di data mining in base al tipo di database estratti. Il sistema di database può essere classificato in base a diversi criteri come modelli di dati, tipi di dati, ecc. E il sistema di data mining può essere classificato di conseguenza.
Ad esempio, se classifichiamo un database in base al modello di dati, potremmo avere un sistema di mining relazionale, transazionale, relazionale a oggetti o di data warehouse.
Classificazione basata sul tipo di conoscenza estratta
Possiamo classificare un sistema di data mining in base al tipo di conoscenza estratta. Significa che il sistema di data mining è classificato sulla base di funzionalità come:
- Characterization
- Discrimination
- Analisi di associazione e correlazione
- Classification
- Prediction
- Analisi anomale
- Analisi dell'evoluzione
Classificazione basata sulle tecniche utilizzate
Possiamo classificare un sistema di data mining in base al tipo di tecniche utilizzate. Possiamo descrivere queste tecniche in base al grado di interazione dell'utente coinvolto o ai metodi di analisi impiegati.
Classificazione basata sulle applicazioni adattate
Possiamo classificare un sistema di data mining in base alle applicazioni adattate. Queste applicazioni sono le seguenti:
- Finance
- Telecommunications
- DNA
- Mercati azionari
Integrazione di un sistema di data mining con un sistema DB / DW
Se un sistema di data mining non è integrato con un database o un sistema di data warehouse, non ci sarà alcun sistema con cui comunicare. Questo schema è noto come schema di non accoppiamento. In questo schema, l'attenzione principale è sulla progettazione del data mining e sullo sviluppo di algoritmi efficienti ed efficaci per l'estrazione dei set di dati disponibili.
L'elenco degli schemi di integrazione è il seguente:
No Coupling- In questo schema, il sistema di data mining non utilizza nessuna delle funzioni del database o del data warehouse. Recupera i dati da una particolare origine e li elabora utilizzando alcuni algoritmi di data mining. Il risultato del data mining viene archiviato in un altro file.
Loose Coupling- In questo schema, il sistema di data mining può utilizzare alcune delle funzioni del database e del sistema di data warehouse. Recupera i dati dai dati respiratori gestiti da questi sistemi ed esegue il data mining su quei dati. Quindi memorizza il risultato dell'estrazione in un file o in una posizione designata in un database o in un data warehouse.
Semi−tight Coupling - In questo schema, il sistema di data mining è collegato a un database o un sistema di data warehouse e in aggiunta a ciò, nel database possono essere fornite implementazioni efficienti di alcune primitive di data mining.
Tight coupling- In questo schema di accoppiamento, il sistema di data mining è facilmente integrato nel database o nel sistema di data warehouse. Il sottosistema di data mining viene trattato come un componente funzionale di un sistema informativo.
Il Data Mining Query Language (DMQL) è stato proposto da Han, Fu, Wang, et al. per il sistema di data mining DBMiner. Il Data Mining Query Language è in realtà basato sullo Structured Query Language (SQL). I linguaggi di query di data mining possono essere progettati per supportare il data mining interattivo e ad hoc. Questo DMQL fornisce i comandi per specificare le primitive. Il DMQL può funzionare anche con database e data warehouse. DMQL può essere utilizzato per definire attività di data mining. In particolare esaminiamo come definire data warehouse e data mart in DMQL.
Sintassi per la specifica dei dati rilevanti per l'attività
Ecco la sintassi di DMQL per specificare dati rilevanti per l'attività:
use database database_name
or
use data warehouse data_warehouse_name
in relevance to att_or_dim_list
from relation(s)/cube(s) [where condition]
order by order_list
group by grouping_listSintassi per specificare il tipo di conoscenza
Qui discuteremo la sintassi per caratterizzazione, discriminazione, associazione, classificazione e previsione.
Caratterizzazione
La sintassi per la caratterizzazione è:
mine characteristics [as pattern_name]
analyze {measure(s) }La clausola di analisi specifica le misure aggregate, come count, sum o count%.
Ad esempio:
Description describing customer purchasing habits.
mine characteristics as customerPurchasing
analyze count%Discriminazione
La sintassi per la discriminazione è:
mine comparison [as {pattern_name]}
For {target_class } where {t arget_condition }
{versus {contrast_class_i }
where {contrast_condition_i}}
analyze {measure(s) }Ad esempio, un utente può definire persone che spendono molto come clienti che acquistano articoli che costano $100 or more on an average; and budget spenders as customers who purchase items at less than $100 in media. L'estrazione di descrizioni discriminanti per i clienti da ciascuna di queste categorie può essere specificata nel DMQL come:
mine comparison as purchaseGroups
for bigSpenders where avg(I.price) ≥$100 versus budgetSpenders where avg(I.price)< $100
analyze countAssociazione
La sintassi per Associazione è -
mine associations [ as {pattern_name} ]
{matching {metapattern} }Ad esempio -
mine associations as buyingHabits
matching P(X:customer,W) ^ Q(X,Y) ≥ buys(X,Z)dove X è la chiave della relazione con il cliente; P e Q sono variabili predicative; e W, Y e Z sono variabili oggetto.
Classificazione
La sintassi per la classificazione è:
mine classification [as pattern_name]
analyze classifying_attribute_or_dimensionAd esempio, per estrarre modelli, classificare la solvibilità del cliente in cui le classi sono determinate dall'attributo credit_rating e la classificazione mineraria è determinata come classifyCustomerCreditRating.
analyze credit_ratingPredizione
La sintassi per la previsione è:
mine prediction [as pattern_name]
analyze prediction_attribute_or_dimension
{set {attribute_or_dimension_i= value_i}}Sintassi per la specifica della gerarchia dei concetti
Per specificare le gerarchie dei concetti, utilizzare la seguente sintassi:
use hierarchy <hierarchy> for <attribute_or_dimension>Usiamo diverse sintassi per definire diversi tipi di gerarchie come -
-schema hierarchies
define hierarchy time_hierarchy on date as [date,month quarter,year]
-
set-grouping hierarchies
define hierarchy age_hierarchy for age on customer as
level1: {young, middle_aged, senior} < level0: all
level2: {20, ..., 39} < level1: young
level3: {40, ..., 59} < level1: middle_aged
level4: {60, ..., 89} < level1: senior
-operation-derived hierarchies
define hierarchy age_hierarchy for age on customer as
{age_category(1), ..., age_category(5)}
:= cluster(default, age, 5) < all(age)
-rule-based hierarchies
define hierarchy profit_margin_hierarchy on item as
level_1: low_profit_margin < level_0: all
if (price - cost)< $50 level_1: medium-profit_margin < level_0: all if ((price - cost) > $50) and ((price - cost) ≤ $250))
level_1: high_profit_margin < level_0: allSintassi per la specifica delle misure di interesse
Le misure e le soglie di interesse possono essere specificate dall'utente con la dichiarazione -
with <interest_measure_name> threshold = threshold_valueAd esempio -
with support threshold = 0.05
with confidence threshold = 0.7Sintassi per la presentazione del modello e le specifiche di visualizzazione
Abbiamo una sintassi che consente agli utenti di specificare la visualizzazione dei modelli rilevati in una o più forme.
display as <result_form>Ad esempio -
display as tableSpecifica completa di DMQL
In qualità di market manager di un'azienda, vorresti caratterizzare le abitudini di acquisto dei clienti che possono acquistare articoli a un prezzo non inferiore a $ 100; rispetto all'età del cliente, al tipo di articolo acquistato e al luogo in cui l'articolo è stato acquistato. Vorresti conoscere la percentuale di clienti che hanno quella caratteristica. In particolare, sei interessato solo agli acquisti effettuati in Canada e pagati con carta di credito American Express. Si desidera visualizzare le descrizioni risultanti sotto forma di tabella.
use database AllElectronics_db
use hierarchy location_hierarchy for B.address
mine characteristics as customerPurchasing
analyze count%
in relevance to C.age,I.type,I.place_made
from customer C, item I, purchase P, items_sold S, branch B
where I.item_ID = S.item_ID and P.cust_ID = C.cust_ID and
P.method_paid = "AmEx" and B.address = "Canada" and I.price ≥ 100
with noise threshold = 5%
display as tableStandardizzazione dei linguaggi di data mining
La standardizzazione dei linguaggi di data mining servirà ai seguenti scopi:
Aiuta lo sviluppo sistematico di soluzioni di data mining.
Migliora l'interoperabilità tra più sistemi e funzioni di data mining.
Promuove l'istruzione e l'apprendimento rapido.
Promuove l'uso di sistemi di data mining nell'industria e nella società.
Esistono due forme di analisi dei dati che possono essere utilizzate per estrarre modelli che descrivono classi importanti o per prevedere le tendenze future dei dati. Queste due forme sono le seguenti:
- Classification
- Prediction
I modelli di classificazione prevedono etichette di classi categoriali; ei modelli di previsione prevedono funzioni a valore continuo. Ad esempio, possiamo costruire un modello di classificazione per classificare le richieste di prestito bancario come sicure o rischiose, oppure un modello di previsione per prevedere le spese in dollari dei potenziali clienti per apparecchiature informatiche, dato il loro reddito e occupazione.
Cos'è la classificazione?
Di seguito sono riportati gli esempi di casi in cui l'attività di analisi dei dati è Classificazione:
Un addetto ai prestiti bancari desidera analizzare i dati per sapere quale cliente (richiedente prestito) è rischioso o sicuro.
Un responsabile marketing di un'azienda deve analizzare un cliente con un determinato profilo, che acquisterà un nuovo computer.
In entrambi gli esempi precedenti, viene costruito un modello o un classificatore per prevedere le etichette categoriali. Queste etichette sono rischiose o sicure per i dati della richiesta di prestito e sì o no per i dati di marketing.
Cos'è la previsione?
Di seguito sono riportati gli esempi di casi in cui l'attività di analisi dei dati è Previsione:
Supponiamo che il responsabile marketing debba prevedere quanto un determinato cliente spenderà durante una vendita presso la sua azienda. In questo esempio ci preoccupiamo di prevedere un valore numerico. Pertanto l'attività di analisi dei dati è un esempio di previsione numerica. In questo caso, verrà costruito un modello o un predittore che prevede una funzione a valore continuo o un valore ordinato.
Note - L'analisi di regressione è una metodologia statistica utilizzata più spesso per la previsione numerica.
Come funziona la classificazione?
Con l'aiuto della richiesta di prestito bancario di cui abbiamo discusso in precedenza, capiamo il funzionamento della classificazione. Il processo di classificazione dei dati comprende due passaggi:
- Creazione del classificatore o del modello
- Utilizzo del classificatore per la classificazione
Creazione del classificatore o del modello
Questa fase è la fase di apprendimento o la fase di apprendimento.
In questa fase gli algoritmi di classificazione costruiscono il classificatore.
Il classificatore è costruito dal set di addestramento composto da tuple di database e dalle etichette di classe associate.
Ogni tupla che costituisce il set di addestramento viene definita categoria o classe. Queste tuple possono anche essere indicate come punti campione, oggetto o dati.

Utilizzo del classificatore per la classificazione
In questa fase, il classificatore viene utilizzato per la classificazione. Qui i dati del test vengono utilizzati per stimare l'accuratezza delle regole di classificazione. Le regole di classificazione possono essere applicate alle nuove tuple di dati se l'accuratezza è considerata accettabile.

Problemi di classificazione e previsione
Il problema principale è preparare i dati per la classificazione e la previsione. La preparazione dei dati comporta le seguenti attività:
Data Cleaning- La pulizia dei dati comporta la rimozione del rumore e il trattamento dei valori mancanti. Il rumore viene rimosso applicando tecniche di smussatura e il problema dei valori mancanti viene risolto sostituendo un valore mancante con il valore più comune per quell'attributo.
Relevance Analysis- Il database può anche avere attributi irrilevanti. L'analisi di correlazione viene utilizzata per sapere se due attributi dati sono correlati.
Data Transformation and reduction - I dati possono essere trasformati con uno dei seguenti metodi.
Normalization- I dati vengono trasformati utilizzando la normalizzazione. La normalizzazione comporta il ridimensionamento di tutti i valori per un determinato attributo per farli rientrare in un piccolo intervallo specificato. La normalizzazione viene utilizzata quando nella fase di apprendimento vengono utilizzate le reti neurali oi metodi che coinvolgono le misurazioni.
Generalization- I dati possono anche essere trasformati generalizzandoli al concetto superiore. A questo scopo possiamo utilizzare il concetto di gerarchie.
Note - I dati possono anche essere ridotti con altri metodi come trasformazione wavelet, binning, analisi dell'istogramma e clustering.
Confronto tra metodi di classificazione e previsione
Ecco i criteri per confrontare i metodi di classificazione e previsione:
Accuracy- La precisione del classificatore si riferisce alla capacità del classificatore. Prevede correttamente l'etichetta della classe e l'accuratezza del predittore si riferisce alla capacità di un determinato predittore di indovinare il valore dell'attributo previsto per un nuovo dato.
Speed - Si riferisce al costo computazionale nella generazione e nell'utilizzo del classificatore o predittore.
Robustness - Si riferisce alla capacità del classificatore o predittore di fare previsioni corrette da dati rumorosi.
Scalability- La scalabilità si riferisce alla capacità di costruire il classificatore o predittore in modo efficiente; data una grande quantità di dati.
Interpretability - Si riferisce al grado di comprensione del classificatore o del predittore.
Un albero decisionale è una struttura che include un nodo radice, rami e nodi foglia. Ogni nodo interno denota un test su un attributo, ogni ramo denota il risultato di un test e ogni nodo foglia contiene un'etichetta di classe. Il nodo più in alto nell'albero è il nodo radice.
Il seguente albero decisionale riguarda il concetto buy_computer che indica se un cliente di un'azienda è probabile che acquisti un computer o meno. Ogni nodo interno rappresenta un test su un attributo. Ogni nodo foglia rappresenta una classe.

I vantaggi di avere un albero decisionale sono i seguenti:
- Non richiede alcuna conoscenza del dominio.
- È facile da comprendere.
- Le fasi di apprendimento e classificazione di un albero decisionale sono semplici e veloci.
Algoritmo di induzione dell'albero decisionale
Un ricercatore di macchine di nome J. Ross Quinlan nel 1980 ha sviluppato un algoritmo di albero decisionale noto come ID3 (Iterative Dichotomiser). Successivamente, ha presentato C4.5, che era il successore di ID3. ID3 e C4.5 adottano un approccio avido. In questo algoritmo, non c'è backtracking; gli alberi sono costruiti in un modo ricorsivo divide et impera dall'alto verso il basso.
Generating a decision tree form training tuples of data partition D
Algorithm : Generate_decision_tree
Input:
Data partition, D, which is a set of training tuples
and their associated class labels.
attribute_list, the set of candidate attributes.
Attribute selection method, a procedure to determine the
splitting criterion that best partitions that the data
tuples into individual classes. This criterion includes a
splitting_attribute and either a splitting point or splitting subset.
Output:
A Decision Tree
Method
create a node N;
if tuples in D are all of the same class, C then
return N as leaf node labeled with class C;
if attribute_list is empty then
return N as leaf node with labeled
with majority class in D;|| majority voting
apply attribute_selection_method(D, attribute_list)
to find the best splitting_criterion;
label node N with splitting_criterion;
if splitting_attribute is discrete-valued and
multiway splits allowed then // no restricted to binary trees
attribute_list = splitting attribute; // remove splitting attribute
for each outcome j of splitting criterion
// partition the tuples and grow subtrees for each partition
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority
class in D to node N;
else
attach the node returned by Generate
decision tree(Dj, attribute list) to node N;
end for
return N;Potatura degli alberi
La potatura degli alberi viene eseguita al fine di rimuovere le anomalie nei dati di allenamento dovute a rumore o valori anomali. Gli alberi potati sono più piccoli e meno complessi.
Approcci alla potatura degli alberi
Esistono due approcci per potare un albero:
Pre-pruning - L'albero viene potato interrompendo anticipatamente la sua costruzione.
Post-pruning - Questo approccio rimuove un sottoalbero da un albero completamente cresciuto.
Complessità dei costi
La complessità dei costi è misurata dai seguenti due parametri:
- Numero di foglie dell'albero e
- Tasso di errore dell'albero.
La classificazione bayesiana si basa sul teorema di Bayes. I classificatori bayesiani sono i classificatori statistici. I classificatori bayesiani possono prevedere le probabilità di appartenenza alla classe come la probabilità che una data tupla appartenga a una particolare classe.
Teorema di Baye
Il teorema di Bayes prende il nome da Thomas Bayes. Esistono due tipi di probabilità:
- Probabilità posteriore [P (H / X)]
- Probabilità a priori [P (H)]
dove X è la tupla di dati e H è una certa ipotesi.
Secondo il teorema di Bayes,
Rete di credenze bayesiane
Le reti di credenze bayesiane specificano distribuzioni di probabilità condizionate congiunte. Sono anche conosciuti come reti di credenze, reti bayesiane o reti probabilistiche.
Una rete di credenze consente di definire le indipendenze condizionali di classe tra sottoinsiemi di variabili.
Fornisce un modello grafico di relazione causale su cui è possibile eseguire l'apprendimento.
Possiamo usare una rete bayesiana addestrata per la classificazione.
Ci sono due componenti che definiscono una rete di credenze bayesiane:
- Grafico aciclico diretto
- Un insieme di tabelle di probabilità condizionate
Grafico aciclico diretto
- Ogni nodo in un grafo aciclico diretto rappresenta una variabile casuale.
- Queste variabili possono essere a valore discreto o continuo.
- Queste variabili possono corrispondere all'attributo effettivo fornito nei dati.
Rappresentazione grafica aciclica diretta
Il diagramma seguente mostra un grafico aciclico diretto per sei variabili booleane.

L'arco nel diagramma consente la rappresentazione della conoscenza causale. Ad esempio, il cancro del polmone è influenzato dalla storia familiare di cancro al polmone di una persona, nonché dal fatto che la persona sia o meno un fumatore. Vale la pena notare che la variabile PositiveXray è indipendente dal fatto che il paziente abbia una storia familiare di cancro ai polmoni o che il paziente sia un fumatore, dato che sappiamo che il paziente ha un cancro ai polmoni.
Tabella delle probabilità condizionate
La tabella di probabilità condizionale per i valori della variabile LungCancer (LC) che mostra ogni possibile combinazione dei valori dei suoi nodi padre, FamilyHistory (FH) e Smoker (S) è la seguente:

IF-THEN Regole
Il classificatore basato su regole fa uso di un insieme di regole IF-THEN per la classificazione. Possiamo esprimere una regola nel seguito da:
Consideriamo una regola R1,
R1: IF age = youth AND student = yes
THEN buy_computer = yesPoints to remember −
Viene chiamata la parte IF della regola rule antecedent o precondition.
Viene chiamata la parte ALLORA della regola rule consequent.
La parte antecedente la condizione consiste in uno o più test di attributi e questi test sono logicamente AND.
La parte conseguente consiste nella previsione della classe.
Note - Possiamo anche scrivere la regola R1 come segue -
R1: (age = youth) ^ (student = yes))(buys computer = yes)Se la condizione è vera per una data tupla, l'antecedente è soddisfatto.
Estrazione delle regole
Qui impareremo come costruire un classificatore basato su regole estraendo le regole IF-THEN da un albero decisionale.
Points to remember −
Per estrarre una regola da un albero decisionale:
Viene creata una regola per ogni percorso dalla radice al nodo foglia.
Per formare una regola antecedente, ogni criterio di divisione è logicamente AND.
Il nodo foglia contiene la previsione della classe, formando la regola conseguente.
Induzione di regole mediante algoritmo di copertura sequenziale
L'algoritmo di copertura sequenziale può essere utilizzato per estrarre le regole IF-THEN dai dati di addestramento. Non è necessario generare prima un albero decisionale. In questo algoritmo, ogni regola per una data classe copre molte delle tuple di quella classe.
Alcuni degli algoritmi di copertura sequenziali sono AQ, CN2 e RIPPER. Secondo la strategia generale, le regole vengono apprese una alla volta. Ogni volta che le regole vengono apprese, una tupla coperta dalla regola viene rimossa e il processo continua per il resto delle tuple. Questo perché il percorso di ciascuna foglia in un albero decisionale corrisponde a una regola.
Note - L'induzione dell'albero decisionale può essere considerata come l'apprendimento simultaneo di una serie di regole.
Quanto segue è l'algoritmo di apprendimento sequenziale in cui le regole vengono apprese per una classe alla volta. Quando si impara una regola da una classe Ci, vogliamo che la regola copra tutte le tuple solo della classe C e nessuna tupla da qualsiasi altra classe.
Algorithm: Sequential Covering
Input:
D, a data set class-labeled tuples,
Att_vals, the set of all attributes and their possible values.
Output: A Set of IF-THEN rules.
Method:
Rule_set={ }; // initial set of rules learned is empty
for each class c do
repeat
Rule = Learn_One_Rule(D, Att_valls, c);
remove tuples covered by Rule form D;
until termination condition;
Rule_set=Rule_set+Rule; // add a new rule to rule-set
end for
return Rule_Set;Regola di potatura
La regola è potata è dovuta al seguente motivo:
La valutazione della qualità viene effettuata sulla serie originale di dati di formazione. La regola può funzionare bene sui dati di addestramento ma meno sui dati successivi. Ecco perché è richiesta la regola di potatura.
La regola viene potata rimuovendo il congiunto. La regola R è ridotta, se la versione ridotta di R ha una qualità maggiore di quella valutata su un insieme indipendente di tuple.
FOIL è uno dei metodi semplici ed efficaci per la potatura a regola. Per una data regola R,
dove pos e neg è il numero di tuple positive coperte da R, rispettivamente.
Note- Questo valore aumenterà con la precisione di R sul set di potatura. Quindi, se il valore FOIL_Prune è più alto per la versione ridotta di R, allora potiamo R.
Qui discuteremo altri metodi di classificazione come algoritmi genetici, approccio insieme approssimativo e approccio insieme fuzzy.
Algoritmi genetici
L'idea di algoritmo genetico deriva dall'evoluzione naturale. Nell'algoritmo genetico, prima di tutto, viene creata la popolazione iniziale. Questa popolazione iniziale è costituita da regole generate casualmente. Possiamo rappresentare ogni regola con una stringa di bit.
Ad esempio, in un dato set di addestramento, i campioni sono descritti da due attributi booleani come A1 e A2. E questo set di addestramento contiene due classi come C1 e C2.
Possiamo codificare la regola IF A1 AND NOT A2 THEN C2 in una piccola stringa 100. In questa rappresentazione bit, i due bit più a sinistra rappresentano rispettivamente l'attributo A1 e A2.
Allo stesso modo, la regola IF NOT A1 AND NOT A2 THEN C1 può essere codificato come 001.
Note- Se l'attributo ha valori K dove K> 2, allora possiamo usare i bit K per codificare i valori dell'attributo. Anche le classi sono codificate nello stesso modo.
Punti da ricordare -
Sulla base della nozione di sopravvivenza del più adatto, si forma una nuova popolazione che consiste delle regole più adatte nella popolazione attuale e dei valori della prole di queste regole.
L'idoneità di una regola viene valutata dalla sua accuratezza di classificazione su una serie di campioni di allenamento.
Gli operatori genetici come il crossover e la mutazione vengono applicati per creare prole.
Nel crossover, la sottostringa della coppia di regole viene scambiata per formare una nuova coppia di regole.
Nella mutazione, i bit selezionati in modo casuale nella stringa di una regola vengono invertiti.
Approccio approssimativo
Possiamo usare l'approccio della serie approssimativa per scoprire relazioni strutturali all'interno di dati imprecisi e rumorosi.
Note- Questo approccio può essere applicato solo su attributi a valori discreti. Pertanto, gli attributi a valori continui devono essere discretizzati prima del loro utilizzo.
La Rough Set Theory si basa sulla definizione di classi di equivalenza all'interno dei dati di addestramento forniti. Le tuple che formano la classe di equivalenza sono indiscernibili. Significa che i campioni sono identici rispetto agli attributi che descrivono i dati.
Ci sono alcune classi nei dati del mondo reale forniti, che non possono essere distinte in termini di attributi disponibili. Possiamo usare i set approssimativi perroughly definire tali classi.
Per una data classe C, la definizione dell'insieme approssimativo è approssimata da due insiemi come segue:
Lower Approximation of C - L'approssimazione inferiore di C è costituita da tutte le tuple di dati che, in base alla conoscenza dell'attributo, sono certe di appartenere alla classe C.
Upper Approximation of C - L'approssimazione superiore di C è costituita da tutte le tuple, che in base alla conoscenza degli attributi, non possono essere descritte come non appartenenti a C.
Il diagramma seguente mostra l'approssimazione superiore e inferiore della classe C -

Approcci Fuzzy Set
La teoria degli insiemi fuzzy è anche chiamata teoria delle possibilità. Questa teoria fu proposta da Lotfi Zadeh nel 1965 come alternativa altwo-value logic e probability theory. Questa teoria ci permette di lavorare ad un alto livello di astrazione. Ci fornisce anche i mezzi per gestire misurazioni imprecise dei dati.
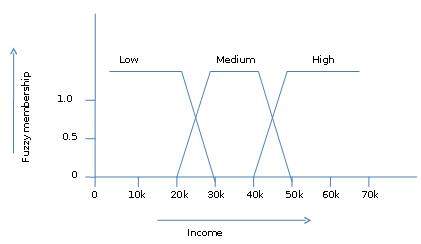
La teoria degli insiemi fuzzy ci permette anche di trattare fatti vaghi o inesatti. Ad esempio, essere un membro di una serie di redditi elevati è esatto (es. Se$50,000 is high then what about $49.000 e $ 48.000). A differenza del tradizionale set CRISP in cui l'elemento appartiene a S o al suo complemento, ma nella teoria degli insiemi fuzzy l'elemento può appartenere a più di un insieme fuzzy.
Ad esempio, il valore del reddito $ 49.000 appartiene a entrambi gli insiemi fuzzy medio e alto ma a livelli diversi. La notazione fuzzy set per questo valore di reddito è la seguente:
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96dove 'm' è la funzione di appartenenza che opera sugli insiemi fuzzy di medium_income e high_income rispettivamente. Questa notazione può essere mostrata schematicamente come segue:
Il cluster è un gruppo di oggetti che appartiene alla stessa classe. In altre parole, oggetti simili vengono raggruppati in un cluster e oggetti dissimili vengono raggruppati in un altro cluster.
Cos'è il clustering?
Il clustering è il processo di trasformazione di un gruppo di oggetti astratti in classi di oggetti simili.
Points to Remember
Un cluster di oggetti dati può essere trattato come un gruppo.
Durante l'analisi dei cluster, prima partizioniamo l'insieme di dati in gruppi in base alla somiglianza dei dati, quindi assegniamo le etichette ai gruppi.
Il vantaggio principale del clustering rispetto alla classificazione è che è adattabile ai cambiamenti e aiuta a individuare le caratteristiche utili che distinguono i diversi gruppi.
Applicazioni dell'analisi dei cluster
L'analisi di clustering è ampiamente utilizzata in molte applicazioni come la ricerca di mercato, il riconoscimento di modelli, l'analisi dei dati e l'elaborazione delle immagini.
Il clustering può anche aiutare i professionisti del marketing a scoprire gruppi distinti nella loro base di clienti. E possono caratterizzare i loro gruppi di clienti in base ai modelli di acquisto.
Nel campo della biologia, può essere utilizzato per derivare tassonomie di piante e animali, classificare geni con funzionalità simili e ottenere informazioni sulle strutture inerenti alle popolazioni.
Il raggruppamento aiuta anche nell'identificazione di aree con un uso del suolo simile in un database di osservazione della terra. Aiuta anche nell'identificazione di gruppi di case in una città in base al tipo di casa, al valore e alla posizione geografica.
Il clustering aiuta anche a classificare i documenti sul Web per l'individuazione delle informazioni.
Il clustering viene utilizzato anche nelle applicazioni di rilevamento dei valori anomali come il rilevamento di frodi con carte di credito.
In quanto funzione di data mining, l'analisi dei cluster funge da strumento per ottenere informazioni sulla distribuzione dei dati per osservare le caratteristiche di ciascun cluster.
Requisiti del clustering nel data mining
I seguenti punti fanno luce sul motivo per cui il clustering è necessario nel data mining:
Scalability - Abbiamo bisogno di algoritmi di clustering altamente scalabili per gestire database di grandi dimensioni.
Ability to deal with different kinds of attributes - Gli algoritmi dovrebbero essere in grado di essere applicati a qualsiasi tipo di dati come dati basati su intervalli (numerici), dati categoriali e binari.
Discovery of clusters with attribute shape- L'algoritmo di clustering dovrebbe essere in grado di rilevare cluster di forma arbitraria. Non dovrebbero essere limitati solo a misure di distanza che tendono a trovare ammassi sferici di piccole dimensioni.
High dimensionality - L'algoritmo di clustering non dovrebbe solo essere in grado di gestire dati a bassa dimensione, ma anche lo spazio ad alta dimensione.
Ability to deal with noisy data- I database contengono dati rumorosi, mancanti o errati. Alcuni algoritmi sono sensibili a tali dati e possono portare a cluster di scarsa qualità.
Interpretability - I risultati del raggruppamento dovrebbero essere interpretabili, comprensibili e utilizzabili.
Metodi di clustering
I metodi di clustering possono essere classificati nelle seguenti categorie:
- Metodo di partizionamento
- Metodo gerarchico
- Metodo basato sulla densità
- Metodo basato su griglia
- Metodo basato su modello
- Metodo basato su vincoli
Metodo di partizionamento
Supponiamo che ci venga fornito un database di oggetti "n" e il metodo di partizionamento costruisca la partizione "k" dei dati. Ogni partizione rappresenterà un cluster e k ≤ n. Significa che classificherà i dati in k gruppi, che soddisfano i seguenti requisiti:
Ogni gruppo contiene almeno un oggetto.
Ogni oggetto deve appartenere esattamente a un gruppo.
Points to remember −
Per un dato numero di partizioni (diciamo k), il metodo di partizionamento creerà un partizionamento iniziale.
Quindi utilizza la tecnica di rilocazione iterativa per migliorare il partizionamento spostando gli oggetti da un gruppo all'altro.
Metodi gerarchici
Questo metodo crea una scomposizione gerarchica del dato insieme di oggetti dati. Possiamo classificare i metodi gerarchici sulla base di come si forma la scomposizione gerarchica. Ci sono due approcci qui:
- Approccio agglomerativo
- Approccio divisivo
Approccio agglomerativo
Questo approccio è noto anche come approccio dal basso verso l'alto. In questo, iniziamo con ogni oggetto che forma un gruppo separato. Continua a fondere gli oggetti o i gruppi vicini tra loro. Continua così fino a quando tutti i gruppi non vengono uniti in uno o fino a quando non si verifica la condizione di terminazione.
Approccio divisivo
Questo approccio è noto anche come approccio top-down. In questo, iniziamo con tutti gli oggetti nello stesso cluster. Nell'iterazione continua, un cluster viene suddiviso in cluster più piccoli. Rimane inattivo fino a quando ogni oggetto in un cluster o la condizione di terminazione non vengono mantenuti. Questo metodo è rigido, ovvero, una volta eseguita una fusione o una divisione, non può essere annullata.
Approcci per migliorare la qualità del clustering gerarchico
Ecco i due approcci utilizzati per migliorare la qualità del clustering gerarchico:
Eseguire un'attenta analisi dei collegamenti agli oggetti in ogni partizionamento gerarchico.
Integra l'agglomerazione gerarchica utilizzando prima un algoritmo agglomerativo gerarchico per raggruppare gli oggetti in micro-cluster, quindi eseguendo il macro-clustering sui micro-cluster.
Metodo basato sulla densità
Questo metodo si basa sulla nozione di densità. L'idea di base è continuare a far crescere il cluster dato finché la densità nel vicinato supera una certa soglia, cioè, per ogni punto dati all'interno di un dato cluster, il raggio di un dato cluster deve contenere almeno un numero minimo di punti.
Metodo basato su griglia
In questo, gli oggetti insieme formano una griglia. Lo spazio dell'oggetto viene quantizzato in un numero finito di celle che formano una struttura a griglia.
Advantages
Il principale vantaggio di questo metodo è il tempo di elaborazione veloce.
Dipende solo dal numero di celle in ciascuna dimensione nello spazio quantizzato.
Metodi basati su modelli
In questo metodo, viene ipotizzato un modello per ciascun cluster per trovare la migliore corrispondenza dei dati per un dato modello. Questo metodo individua i cluster raggruppando la funzione di densità. Riflette la distribuzione spaziale dei punti dati.
Questo metodo fornisce anche un modo per determinare automaticamente il numero di cluster sulla base di statistiche standard, tenendo conto dei valori anomali o del rumore. Produce quindi metodi di clustering robusti.
Metodo basato su vincoli
In questo metodo, il clustering viene eseguito incorporando vincoli orientati all'utente o all'applicazione. Un vincolo si riferisce alle aspettative dell'utente o alle proprietà dei risultati di clustering desiderati. I vincoli ci forniscono un modo interattivo di comunicazione con il processo di clustering. I vincoli possono essere specificati dall'utente o dal requisito dell'applicazione.
I database di testo sono costituiti da un'enorme raccolta di documenti. Raccolgono queste informazioni da diverse fonti come articoli di notizie, libri, biblioteche digitali, messaggi di posta elettronica, pagine web, ecc. A causa dell'aumento della quantità di informazioni, i database di testo stanno crescendo rapidamente. In molti database di testo, i dati sono semi-strutturati.
Ad esempio, un documento può contenere alcuni campi strutturati, come titolo, autore, data_di pubblicazione, ecc. Ma insieme ai dati della struttura, il documento contiene anche componenti di testo non strutturati, come abstract e contenuti. Senza sapere cosa potrebbe esserci nei documenti, è difficile formulare query efficaci per analizzare ed estrarre informazioni utili dai dati. Gli utenti richiedono strumenti per confrontare i documenti e classificarne l'importanza e la pertinenza. Pertanto, il text mining è diventato popolare e un tema essenziale nel data mining.
Recupero delle informazioni
Il recupero delle informazioni si occupa del recupero delle informazioni da un gran numero di documenti di testo. Alcuni dei sistemi di database di solito non sono presenti nei sistemi di recupero delle informazioni perché entrambi gestiscono diversi tipi di dati. Esempi di sistemi di recupero delle informazioni includono:
- Sistema di catalogo della biblioteca online
- Sistemi di gestione dei documenti in linea
- Sistemi di ricerca web ecc.
Note- Il problema principale in un sistema di recupero delle informazioni è individuare i documenti rilevanti in una raccolta di documenti in base alla query di un utente. Questo tipo di query dell'utente è costituito da alcune parole chiave che descrivono un bisogno di informazioni.
In tali problemi di ricerca, l'utente prende l'iniziativa di estrarre le informazioni pertinenti da una raccolta. Ciò è appropriato quando l'utente ha bisogno di informazioni ad hoc, cioè una necessità a breve termine. Ma se l'utente ha una necessità di informazioni a lungo termine, il sistema di recupero può anche prendere un'iniziativa per inviare all'utente qualsiasi elemento informativo appena arrivato.
Questo tipo di accesso alle informazioni è chiamato Filtro delle informazioni. E i sistemi corrispondenti sono noti come sistemi di filtraggio o sistemi di raccomandazione.
Misure di base per il recupero del testo
Dobbiamo verificare l'accuratezza di un sistema quando recupera un numero di documenti sulla base dell'input dell'utente. Lascia che l'insieme di documenti rilevanti per una query sia indicato come {Rilevante} e l'insieme di documenti recuperati come {Recuperato}. L'insieme di documenti che sono rilevanti e recuperati può essere indicato come {Rilevante} ∩ {Recuperato}. Questo può essere mostrato sotto forma di un diagramma di Venn come segue:
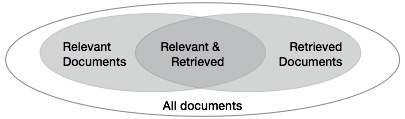
Ci sono tre misure fondamentali per valutare la qualità del recupero del testo:
- Precision
- Recall
- F-score
Precisione
La precisione è la percentuale di documenti recuperati che sono effettivamente rilevanti per la query. La precisione può essere definita come:
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|Richiamare
Il richiamo è la percentuale di documenti che sono rilevanti per la query e sono stati effettivamente recuperati. Il richiamo è definito come -
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|Punteggio F.
Il punteggio F è il compromesso comunemente usato. Il sistema di recupero delle informazioni spesso ha bisogno di un compromesso con la precisione o viceversa. Il punteggio F è definito come media armonica di richiamo o precisione come segue:
F-score = recall x precision / (recall + precision) / 2Il World Wide Web contiene enormi quantità di informazioni che forniscono una ricca fonte per il data mining.
Sfide nel web mining
Il Web pone grandi sfide per la scoperta di risorse e conoscenze sulla base delle seguenti osservazioni:
The web is too huge- La dimensione del Web è enorme e in rapido aumento. Sembra che il Web sia troppo vasto per il data warehousing e il data mining.
Complexity of Web pages- Le pagine web non hanno una struttura unificante. Sono molto complessi rispetto ai tradizionali documenti di testo. Ci sono enormi quantità di documenti nella libreria digitale del web. Queste librerie non sono disposte in base a un particolare ordine ordinato.
Web is dynamic information source- Le informazioni sul web vengono aggiornate rapidamente. I dati come notizie, mercati azionari, meteo, sport, acquisti, ecc. Vengono aggiornati regolarmente.
Diversity of user communities- La comunità di utenti sul Web è in rapida espansione. Questi utenti hanno background, interessi e scopi di utilizzo diversi. Ci sono più di 100 milioni di postazioni di lavoro connesse a Internet e ancora in rapido aumento.
Relevancy of Information - Si ritiene che una determinata persona sia generalmente interessata solo a una piccola porzione del web, mentre il resto della porzione del web contiene le informazioni che non sono rilevanti per l'utente e possono sommergere i risultati desiderati.
Struttura del layout della pagina Web di data mining
La struttura di base della pagina web è basata sul Document Object Model (DOM). La struttura DOM si riferisce a una struttura ad albero in cui il tag HTML nella pagina corrisponde a un nodo nell'albero DOM. Possiamo segmentare la pagina web utilizzando tag predefiniti in HTML. La sintassi HTML è flessibile, quindi le pagine web non seguono le specifiche W3C. Non seguire le specifiche del W3C può causare errori nella struttura ad albero DOM.
La struttura DOM è stata inizialmente introdotta per la presentazione nel browser e non per la descrizione della struttura semantica della pagina web. La struttura DOM non può identificare correttamente la relazione semantica tra le diverse parti di una pagina web.
Segmentazione della pagina basata sulla visione (VIPS)
Lo scopo di VIPS è estrarre la struttura semantica di una pagina web in base alla sua presentazione visiva.
Una tale struttura semantica corrisponde a una struttura ad albero. In questo albero ogni nodo corrisponde a un blocco.
A ogni nodo viene assegnato un valore. Questo valore è chiamato grado di coerenza. Questo valore viene assegnato per indicare il contenuto coerente nel blocco in base alla percezione visiva.
L'algoritmo VIPS estrae prima tutti i blocchi adatti dall'albero HTML DOM. Dopodiché trova i separatori tra questi blocchi.
I separatori si riferiscono alle linee orizzontali o verticali in una pagina web che si incrociano visivamente senza blocchi.
La semantica della pagina web è costruita sulla base di questi blocchi.
La figura seguente mostra la procedura dell'algoritmo VIPS -

Il data mining è ampiamente utilizzato in diverse aree. Al giorno d'oggi sono disponibili numerosi sistemi di data mining commerciali e tuttavia ci sono molte sfide in questo campo. In questo tutorial, discuteremo le applicazioni e la tendenza del data mining.
Applicazioni di data mining
Ecco l'elenco delle aree in cui il data mining è ampiamente utilizzato:
- Analisi dei dati finanziari
- Industria al dettaglio
- Industria delle telecomunicazioni
- Analisi dei dati biologici
- Altre applicazioni scientifiche
- Rilevamento delle intrusioni
Analisi dei dati finanziari
I dati finanziari nel settore bancario e finanziario sono generalmente affidabili e di alta qualità, il che facilita l'analisi sistematica dei dati e il data mining. Alcuni dei casi tipici sono i seguenti:
Progettazione e realizzazione di data warehouse per analisi dati multidimensionali e data mining.
Previsione del pagamento del prestito e analisi della politica di credito del cliente.
Classificazione e raggruppamento dei clienti per marketing mirato.
Rilevazione di riciclaggio di denaro e altri reati finanziari.
Industria al dettaglio
Il data mining ha la sua grande applicazione nel settore della vendita al dettaglio perché raccoglie grandi quantità di dati dalle vendite, dalla cronologia degli acquisti dei clienti, dal trasporto delle merci, dai consumi e dai servizi. È naturale che la quantità di dati raccolti continuerà ad espandersi rapidamente a causa della crescente facilità, disponibilità e popolarità del web.
Il data mining nel settore della vendita al dettaglio aiuta a identificare i modelli e le tendenze di acquisto dei clienti che portano a una migliore qualità del servizio clienti ea una buona fidelizzazione e soddisfazione dei clienti. Ecco l'elenco di esempi di data mining nel settore della vendita al dettaglio:
Progettazione e costruzione di data warehouse basati sui vantaggi del data mining.
Analisi multidimensionale di vendite, clienti, prodotti, tempo e regione.
Analisi dell'efficacia delle campagne di vendita.
Fidelizzazione dei clienti.
Raccomandazione del prodotto e riferimenti incrociati degli articoli.
Industria delle telecomunicazioni
Oggi l'industria delle telecomunicazioni è una delle industrie più emergenti che fornisce vari servizi come fax, cercapersone, telefono cellulare, messaggistica Internet, immagini, e-mail, trasmissione dati web, ecc. A causa dello sviluppo di nuove tecnologie informatiche e di comunicazione, il l'industria delle telecomunicazioni è in rapida espansione. Questo è il motivo per cui il data mining è diventato molto importante per aiutare e comprendere il business.
Il data mining nel settore delle telecomunicazioni aiuta a identificare i modelli di telecomunicazione, a rilevare attività fraudolente, a fare un uso migliore delle risorse e a migliorare la qualità del servizio. Ecco l'elenco degli esempi per i quali il data mining migliora i servizi di telecomunicazione:
Analisi multidimensionale dei dati di telecomunicazione.
Analisi dei modelli fraudolenti.
Identificazione di modelli insoliti.
Associazione multidimensionale e analisi di pattern sequenziali.
Servizi di telecomunicazioni mobili.
Uso di strumenti di visualizzazione nell'analisi dei dati delle telecomunicazioni.
Analisi dei dati biologici
Negli ultimi tempi, abbiamo assistito a una crescita enorme nel campo della biologia come la genomica, la proteomica, la genomica funzionale e la ricerca biomedica. Il data mining biologico è una parte molto importante della bioinformatica. Di seguito sono riportati gli aspetti in cui il data mining contribuisce all'analisi dei dati biologici:
Integrazione semantica di database genomici e proteomici eterogenei e distribuiti.
Allineamento, indicizzazione, ricerca di similarità e analisi comparativa di sequenze multiple di nucleotidi.
Scoperta di pattern strutturali e analisi di reti genetiche e percorsi proteici.
Associazione e analisi del percorso.
Strumenti di visualizzazione nell'analisi dei dati genetici.
Altre applicazioni scientifiche
Le applicazioni discusse sopra tendono a gestire set di dati relativamente piccoli e omogenei per i quali le tecniche statistiche sono appropriate. Sono state raccolte enormi quantità di dati da domini scientifici come geoscienze, astronomia, ecc. Viene generata una grande quantità di set di dati grazie alle rapide simulazioni numeriche in vari campi come la modellazione del clima e dell'ecosistema, l'ingegneria chimica, la dinamica dei fluidi, ecc. Di seguito sono riportate le applicazioni del data mining nel campo delle applicazioni scientifiche -
- Data Warehouse e preelaborazione dati.
- Estrazione basata su grafici.
- Visualizzazione e conoscenza specifica del dominio.
Rilevamento delle intrusioni
L'intrusione si riferisce a qualsiasi tipo di azione che minaccia l'integrità, la riservatezza o la disponibilità delle risorse di rete. In questo mondo di connettività, la sicurezza è diventata il problema principale. Con un maggiore utilizzo di Internet e la disponibilità di strumenti e trucchi per intromettersi e attaccare la rete, il rilevamento delle intrusioni è diventato un componente critico dell'amministrazione di rete. Di seguito è riportato l'elenco delle aree in cui è possibile applicare la tecnologia di data mining per il rilevamento delle intrusioni:
Sviluppo di algoritmi di data mining per il rilevamento delle intrusioni.
Analisi di associazione e correlazione, aggregazione per aiutare a selezionare e costruire attributi discriminanti.
Analisi dei dati di flusso.
Data mining distribuito.
Strumenti di visualizzazione e query.
Prodotti per sistemi di data mining
Esistono molti prodotti di sistema di data mining e applicazioni di data mining specifiche per dominio. I nuovi sistemi e applicazioni di data mining vengono aggiunti ai sistemi precedenti. Inoltre, si stanno compiendo sforzi per standardizzare i linguaggi di data mining.
Scegliere un sistema di data mining
La selezione di un sistema di data mining dipende dalle seguenti caratteristiche:
Data Types- Il sistema di data mining può gestire testo formattato, dati basati su record e dati relazionali. I dati potrebbero anche essere in testo ASCII, dati di database relazionali o dati di data warehouse. Pertanto, dovremmo verificare quale formato esatto può gestire il sistema di data mining.
System Issues- Dobbiamo considerare la compatibilità di un sistema di data mining con diversi sistemi operativi. Un sistema di data mining può essere eseguito su un solo sistema operativo o su più. Esistono anche sistemi di data mining che forniscono interfacce utente basate sul web e consentono dati XML come input.
Data Sources- Le origini dati si riferiscono ai formati di dati in cui funzionerà il sistema di data mining. Alcuni sistemi di data mining possono funzionare solo su file di testo ASCII mentre altri su più origini relazionali. Il sistema di data mining dovrebbe supportare anche le connessioni ODBC o OLE DB per le connessioni ODBC.
Data Mining functions and methodologies - Esistono alcuni sistemi di data mining che forniscono una sola funzione di data mining come la classificazione, mentre alcuni forniscono più funzioni di data mining come la descrizione del concetto, l'analisi OLAP basata sulla scoperta, l'estrazione di associazioni, l'analisi di linkage, l'analisi statistica, la classificazione, la previsione, il clustering, analisi anomale, ricerca di similarità, ecc.
Coupling data mining with databases or data warehouse systems- I sistemi di data mining devono essere accoppiati a un database o un sistema di data warehouse. I componenti accoppiati sono integrati in un ambiente di elaborazione delle informazioni uniforme. Ecco i tipi di accoppiamento elencati di seguito:
- Nessun accoppiamento
- Accoppiamento lasco
- Accoppiamento semi-stretto
- Accoppiamento stretto
Scalability - Ci sono due problemi di scalabilità nel data mining:
Row (Database size) Scalability- Un sistema di data mining è considerato scalabile per righe quando il numero o le righe vengono ingranditi di 10 volte. Non sono necessarie più di 10 volte per eseguire una query.
Column (Dimension) Salability - Un sistema di data mining è considerato scalabile di colonna se il tempo di esecuzione della query di mining aumenta linearmente con il numero di colonne.
Visualization Tools - La visualizzazione nel data mining può essere classificata come segue:
- Visualizzazione dati
- Visualizzazione dei risultati di mining
- Visualizzazione del processo di mining
- Data mining visuale
Data Mining query language and graphical user interface- Un'interfaccia utente grafica di facile utilizzo è importante per promuovere il data mining interattivo e guidato dall'utente. A differenza dei sistemi di database relazionali, i sistemi di data mining non condividono il linguaggio di query di data mining sottostante.
Tendenze nel data mining
I concetti di data mining sono ancora in evoluzione e qui ci sono le ultime tendenze che possiamo vedere in questo campo:
Esplorazione dell'applicazione.
Metodi di data mining scalabili e interattivi.
Integrazione del data mining con sistemi di database, sistemi di data warehouse e sistemi di database web.
Standardizzazione del linguaggio delle query di data mining.
Data mining visuale.
Nuovi metodi per estrarre tipi di dati complessi.
Data mining biologico.
Data mining e ingegneria del software.
Web mining.
Data mining distribuito.
Data mining in tempo reale.
Data mining multi database.
Protezione della privacy e sicurezza delle informazioni nel data mining.
Fondamenti teorici del data mining
Le basi teoriche del data mining includono i seguenti concetti:
Data Reduction- L'idea di base di questa teoria è di ridurre la rappresentazione dei dati che scambia l'accuratezza con la velocità in risposta alla necessità di ottenere risposte rapide e approssimative a query su database molto grandi. Alcune delle tecniche di riduzione dei dati sono le seguenti:
Scomposizione di un valore singolo
Wavelets
Regression
Modelli logaritmici
Histograms
Clustering
Sampling
Costruzione di alberi indice
Data Compression - L'idea di base di questa teoria è quella di comprimere i dati forniti codificando nei termini di quanto segue:
Bits
Regole dell'Associazione
Alberi decisionali
Clusters
Pattern Discovery- L'idea di base di questa teoria è scoprire i modelli che si verificano in un database. Di seguito sono riportate le aree che contribuiscono a questa teoria:
Apprendimento automatico
Rete neurale
Associazione mineraria
Corrispondenza sequenziale di modelli
Clustering
Probability Theory- Questa teoria si basa sulla teoria statistica. L'idea di base alla base di questa teoria è scoprire distribuzioni di probabilità congiunte di variabili casuali.
Probability Theory - Secondo questa teoria, il data mining trova i modelli che sono interessanti solo nella misura in cui possono essere utilizzati nel processo decisionale di alcune imprese.
Microeconomic View- Secondo questa teoria, uno schema di database è costituito da dati e modelli che vengono memorizzati in un database. Pertanto, il data mining è il compito di eseguire l'induzione sui database.
Inductive databases- Oltre alle tecniche orientate al database, sono disponibili tecniche statistiche per l'analisi dei dati. Queste tecniche possono essere applicate anche a dati scientifici e dati provenienti dalle scienze economiche e sociali.
Data mining statistico
Alcune delle tecniche di data mining statistico sono le seguenti:
Regression- I metodi di regressione vengono utilizzati per prevedere il valore della variabile di risposta da una o più variabili predittore in cui le variabili sono numeriche. Di seguito sono elencate le forme di regressione:
Linear
Multiple
Weighted
Polynomial
Nonparametric
Robust
Generalized Linear Models - Il modello lineare generalizzato include:
Regressione logistica
Regressione di Poisson
La generalizzazione del modello consente di correlare una variabile di risposta categoriale a un insieme di variabili predittori in modo simile alla modellazione della variabile di risposta numerica utilizzando la regressione lineare.
Analysis of Variance - Questa tecnica analizza -
Dati sperimentali per due o più popolazioni descritte da una variabile di risposta numerica.
Una o più variabili categoriali (fattori).
Mixed-effect Models- Questi modelli vengono utilizzati per analizzare i dati raggruppati. Questi modelli descrivono la relazione tra una variabile di risposta e alcune covariate nei dati raggruppati in base a uno o più fattori.
Factor Analysis- L'analisi fattoriale viene utilizzata per prevedere una variabile di risposta categoriale. Questo metodo presuppone che le variabili indipendenti seguano una distribuzione normale multivariata.
Time Series Analysis - Di seguito sono riportati i metodi per analizzare i dati di serie temporali -
Metodi di regressione automatica.
Modellazione ARIMA (AutoRegressive Integrated Moving Average) univariata.
Modellazione di serie temporali a memoria lunga.
Data mining visuale
Visual Data Mining utilizza tecniche di visualizzazione dei dati e / o della conoscenza per scoprire la conoscenza implicita da set di dati di grandi dimensioni. Il data mining visivo può essere visto come un'integrazione delle seguenti discipline:
Visualizzazione dati
Estrazione dei dati
Il data mining visivo è strettamente correlato a quanto segue:
Computer grafica
Sistemi multimediali
Interazione umano-computer
Riconoscimento di modelli
Elaborazione ad alte prestazioni
Generalmente la visualizzazione e il data mining dei dati possono essere integrati nei seguenti modi:
Data Visualization - I dati in un database o in un data warehouse possono essere visualizzati in diversi moduli visivi elencati di seguito -
Boxplots
Cubi 3-D
Grafici di distribuzione dei dati
Curves
Surfaces
Collega grafici ecc.
Data Mining Result Visualization- La visualizzazione dei risultati del data mining è la presentazione dei risultati del data mining in forma visiva. Queste forme visive potrebbero essere trame sparse, boxplot, ecc.
Data Mining Process Visualization- La visualizzazione del processo di data mining presenta i diversi processi di data mining. Consente agli utenti di vedere come vengono estratti i dati. Consente inoltre agli utenti di vedere da quale database o data warehouse i dati vengono puliti, integrati, preelaborati ed estratti.
Data mining audio
Il data mining audio fa uso di segnali audio per indicare i modelli di dati o le caratteristiche dei risultati del data mining. Trasformando i modelli in suoni e riflessioni, possiamo ascoltare toni e melodie, invece di guardare immagini, per identificare qualcosa di interessante.
Data mining e filtraggio collaborativo
I consumatori oggi si imbattono in una varietà di beni e servizi durante gli acquisti. Durante le transazioni con i clienti in tempo reale, un sistema di raccomandazione aiuta il consumatore fornendo consigli sui prodotti. L'approccio di filtraggio collaborativo viene generalmente utilizzato per consigliare i prodotti ai clienti. Questi consigli si basano sulle opinioni di altri clienti.