DocumentDB SQL - Guida rapida
DocumentDB è la più recente piattaforma di database di documenti NoSQL di Microsoft che viene eseguita su Azure. In questo tutorial, impareremo tutto sull'interrogazione di documenti utilizzando la versione speciale di SQL supportata da DocumentDB.
Database di documenti NoSQL
DocumentDB è il più recente database di documenti NoSQL di Microsoft, tuttavia, quando diciamo database di documenti NoSQL, cosa intendiamo precisamente per NoSQL e database di documenti?
SQL significa Structured Query Language, che è un linguaggio di query tradizionale dei database relazionali. SQL è spesso equiparato ai database relazionali.
È davvero più utile pensare a un database NoSQL come un database non relazionale, quindi NoSQL significa davvero non relazionale.
Esistono diversi tipi di database NoSQL che includono archivi di valori chiave come:
- Archiviazione tabelle di Azure
- Negozi a colonne, come Cassandra
- Database di grafici, come NEO4
- Database di documenti, come MongoDB e Azure DocumentDB
Perché la sintassi SQL?
All'inizio può sembrare strano, ma in DocumentDB, che è un database NoSQL, eseguiamo query utilizzando SQL. Come accennato in precedenza, questa è una versione speciale di SQL radicata nella semantica JSON e JavaScript.
SQL è solo un linguaggio, ma è anche un linguaggio molto popolare, ricco ed espressivo. Quindi, sembra decisamente una buona idea usare un dialetto di SQL piuttosto che inventare un modo completamente nuovo di esprimere le query che avremmo bisogno di imparare se volessi estrarre i documenti dal tuo database.
SQL è progettato per database relazionali e DocumentDB è un database di documenti non relazionali. Il team di DocumentDB ha effettivamente adattato la sintassi SQL per il mondo non relazionale dei database di documenti, e questo è ciò che si intende per rooting di SQL in JSON e JavaScript.
Il linguaggio si legge ancora come SQL familiare, ma la semantica è tutta basata su documenti JSON senza schema piuttosto che su tabelle relazionali. In DocumentDB, lavoreremo con i tipi di dati JavaScript piuttosto che con i tipi di dati SQL. Avremo familiarità con SELECT, FROM, WHERE e così via, ma i tipi JavaScript, che sono limitati a numeri e stringhe, oggetti, array, Boolean e null sono di gran lunga inferiori rispetto alla vasta gamma di tipi di dati SQL.
Allo stesso modo, le espressioni vengono valutate come espressioni JavaScript piuttosto che come una qualche forma di T-SQL. Ad esempio, in un mondo di dati denormalizzati, non abbiamo a che fare con le righe e le colonne, ma con documenti privi di schema con strutture gerarchiche che contengono array e oggetti nidificati.
Come funziona SQL?
Il team di DocumentDB ha risposto a questa domanda in diversi modi innovativi. Alcuni di loro sono elencati come segue:
Primo, supponendo che tu non abbia modificato il comportamento predefinito per indicizzare automaticamente ogni proprietà in un documento, puoi usare la notazione puntata nelle tue query per navigare un percorso verso qualsiasi proprietà, non importa quanto profondamente possa essere annidata all'interno del documento.
È inoltre possibile eseguire un join intra-documento in cui gli elementi della matrice annidati vengono uniti con il loro elemento padre all'interno di un documento in un modo molto simile al modo in cui viene eseguito un join tra due tabelle nel mondo relazionale.
Le tue query possono restituire documenti dal database così com'è, oppure puoi proiettare qualsiasi forma JSON personalizzata che desideri in base ai dati del documento che desideri.
SQL in DocumentDB supporta molti degli operatori comuni, tra cui:
Operazioni aritmetiche e bit per bit
Logica AND e OR
Uguaglianza e confronti di intervallo
Concatenazione di stringhe
Il linguaggio di query supporta anche una serie di funzioni integrate.
Il portale di Azure ha un Query Explorer che ci consente di eseguire qualsiasi query SQL sul nostro database DocumentDB. Useremo Query Explorer per dimostrare le molte diverse capacità e caratteristiche del linguaggio di query a partire dalla query più semplice possibile.
Step 1 - Apri il portale di Azure e, nel pannello del database, fai clic sul pannello Esplora query.
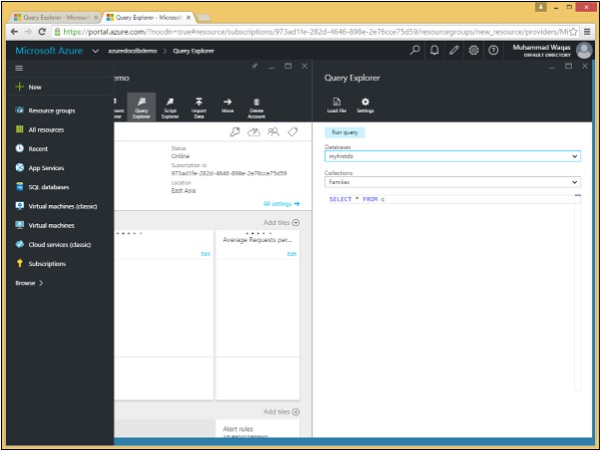
Ricorda che le query vengono eseguite nell'ambito di una raccolta, quindi Query Explorer ci consente di scegliere la raccolta in questo menu a discesa. Lo lasceremo impostato nella nostra raccolta Famiglie che contiene i tre documenti. Consideriamo questi tre documenti in questo esempio.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
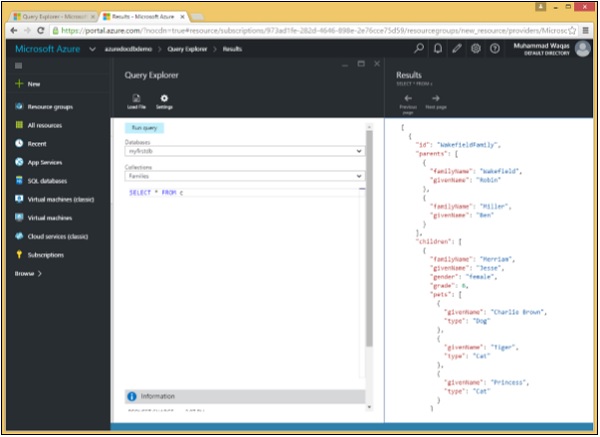
}Query Explorer si apre con questa semplice query SELECT * FROM c, che recupera semplicemente tutti i documenti dalla raccolta. Sebbene sia semplice, è comunque abbastanza diverso dalla query equivalente in un database relazionale.
Step 2- Nei database relazionali, SELECT * significa restituire tutte le colonne mentre si trova in DocumentDB. Significa che vuoi che ogni documento nel tuo risultato venga restituito esattamente come è memorizzato nel database.
Ma quando selezioni proprietà ed espressioni specifiche invece di emettere semplicemente un SELECT *, stai proiettando una nuova forma che desideri per ogni documento nel risultato.
Step 3 - Fare clic su "Esegui" per eseguire la query e aprire il pannello Risultati.

Come si può vedere, vengono recuperati WakefieldFamily, SmithFamily e AndersonFamily.
Di seguito sono riportati i tre documenti che vengono recuperati come risultato del SELECT * FROM c query.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
"givenName": "Fluffy",
"type": "Rabbit"
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Tuttavia, questi risultati includono anche le proprietà generate dal sistema che sono tutte precedute dal carattere di sottolineatura.
In questo capitolo, tratteremo la clausola FROM, che non funziona come una clausola FROM standard in SQL normale.
Le query vengono sempre eseguite nel contesto di una raccolta specifica e non possono unirsi tra i documenti all'interno della raccolta, il che ci fa chiedere perché abbiamo bisogno di una clausola FROM. In effetti, non lo facciamo, ma se non lo includiamo, non interrogheremo i documenti nella raccolta.
Lo scopo di questa clausola è specificare l'origine dati su cui deve operare la query. Comunemente l'intera raccolta è l'origine, ma è possibile specificare un sottoinsieme della raccolta. La clausola FROM <from_specification> è facoltativa a meno che l'origine non venga filtrata o proiettata in un secondo momento nella query.
Diamo di nuovo un'occhiata allo stesso esempio. Di seguito è riportato il fileAndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
Nella query precedente, "SELECT * FROM c"Indica che l'intera raccolta delle famiglie è la fonte su cui enumerare.
Documenti secondari
La sorgente può anche essere ridotta a un sottoinsieme più piccolo. Quando vogliamo recuperare solo una sottostruttura in ogni documento, la sottostruttura potrebbe quindi diventare l'origine, come mostrato nell'esempio seguente.
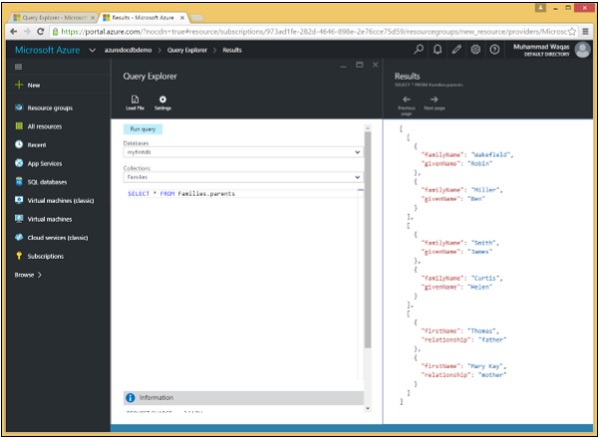
Quando eseguiamo la seguente query:
SELECT * FROM Families.parentsVerranno recuperati i seguenti documenti secondari.
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]Come risultato di questa query, possiamo vedere che vengono recuperati solo i documenti secondari principali.
In questo capitolo, tratteremo la clausola WHERE, anch'essa opzionale come la clausola FROM. Viene utilizzato per specificare una condizione durante il recupero dei dati sotto forma di documenti JSON forniti dall'origine. Qualsiasi documento JSON deve valutare le condizioni specificate come "true" per essere considerato per il risultato. Se la condizione data è soddisfatta, solo allora restituisce dati specifici sotto forma di documento (i) JSON. Possiamo usare la clausola WHERE per filtrare i record e recuperare solo i record necessari.
Considereremo gli stessi tre documenti in questo esempio. Di seguito è riportato il fileAndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un semplice esempio in cui viene utilizzata la clausola WHERE.
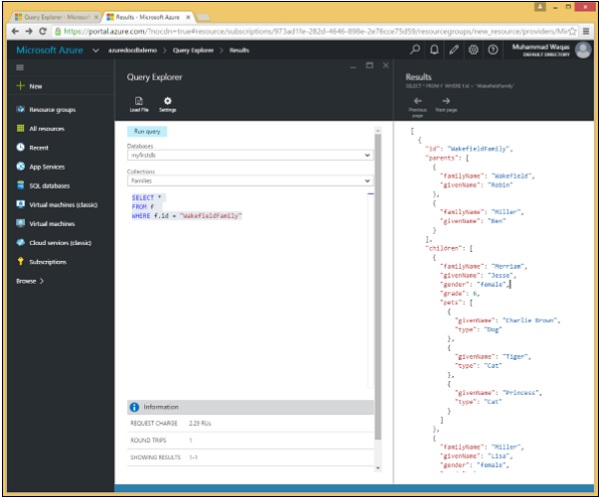
In questa query, nella clausola WHERE, viene specificata la condizione (WHERE f.id = "WakefieldFamily").
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"Quando la query precedente viene eseguita, restituirà il documento JSON completo per WakefieldFamily come mostrato nell'output seguente.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]Un operatore è una parola riservata o un carattere utilizzato principalmente in una clausola SQL WHERE per eseguire operazioni, come confronti e operazioni aritmetiche. DocumentDB SQL supporta anche una varietà di espressioni scalari. I più comunemente usati sonobinary and unary expressions.
I seguenti operatori SQL sono attualmente supportati e possono essere utilizzati nelle query.
Operatori di confronto SQL
Di seguito è riportato un elenco di tutti gli operatori di confronto disponibili nella grammatica SQL di DocumentDB.
| S.No. | Operatori e descrizione |
|---|---|
| 1 | = Controlla se i valori di due operandi sono uguali o meno. Se sì, la condizione diventa vera. |
| 2 | != Controlla se i valori di due operandi sono uguali o meno. Se i valori non sono uguali, la condizione diventa vera. |
| 3 | <> Controlla se i valori di due operandi sono uguali o meno. Se i valori non sono uguali, la condizione diventa vera. |
| 4 | > Controlla se il valore dell'operando sinistro è maggiore del valore dell'operando destro. Se sì, la condizione diventa vera. |
| 5 | < Verifica se il valore dell'operando sinistro è inferiore al valore dell'operando destro. Se sì, la condizione diventa vera. |
| 6 | >= Controlla se il valore dell'operando sinistro è maggiore o uguale al valore dell'operando destro. Se sì, la condizione diventa vera. |
| 7 | <= Controlla se il valore dell'operando sinistro è minore o uguale al valore dell'operando destro. Se sì, la condizione diventa vera. |
Operatori logici SQL
Di seguito è riportato un elenco di tutti gli operatori logici disponibili nella grammatica SQL di DocumentDB.
| S.No. | Operatori e descrizione |
|---|---|
| 1 | AND L'operatore AND consente l'esistenza di più condizioni nella clausola WHERE di un'istruzione SQL. |
| 2 | BETWEEN L'operatore BETWEEN viene utilizzato per cercare valori che sono all'interno di un insieme di valori, dato il valore minimo e il valore massimo. |
| 3 | IN L'operatore IN viene utilizzato per confrontare un valore con un elenco di valori letterali che sono stati specificati. |
| 4 | OR L'operatore OR viene utilizzato per combinare più condizioni nella clausola WHERE di un'istruzione SQL. |
| 5 | NOT L'operatore NOT inverte il significato dell'operatore logico con cui viene utilizzato. Ad esempio, NOT EXISTS, NOT BETWEEN, NOT IN, ecc. Questo è un operatore di negazione. |
Operatori aritmetici SQL
Di seguito è riportato un elenco di tutti gli operatori aritmetici disponibili nella grammatica SQL di DocumentDB.
| S.No. | Operatori e descrizione |
|---|---|
| 1 | + Addition - Aggiunge valori su entrambi i lati dell'operatore. |
| 2 | - Subtraction - Sottrae l'operando di destra dall'operando di sinistra. |
| 3 | * Multiplication - Moltiplica i valori su entrambi i lati dell'operatore. |
| 4 | / Division - Divide l'operando di sinistra per l'operando di destra. |
| 5 | % Modulus - Divide l'operando di sinistra per l'operando di destra e restituisce il resto. |
Considereremo gli stessi documenti anche in questo esempio. Di seguito è riportato il fileAndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un semplice esempio in cui viene utilizzato un operatore di confronto nella clausola WHERE.
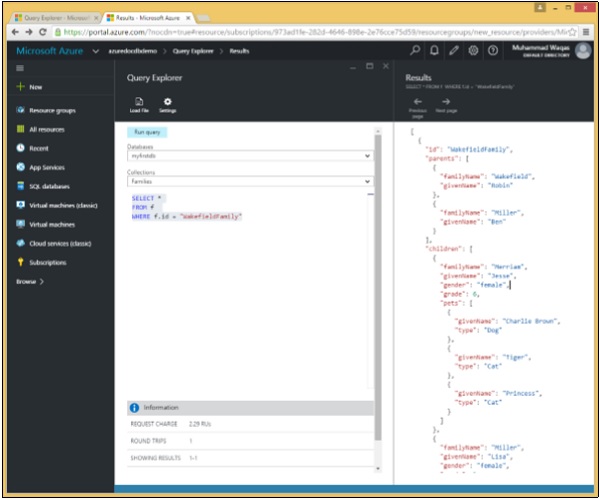
In questa query, nella clausola WHERE, viene specificata la condizione (WHERE f.id = "WakefieldFamily") e recupererà il documento il cui ID è uguale a WakefieldFamily.
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"Quando la query precedente viene eseguita, restituirà il documento JSON completo per WakefieldFamily come mostrato nell'output seguente.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]Diamo un'occhiata a un altro esempio in cui la query recupererà i dati dei bambini il cui voto è maggiore di 5.
SELECT *
FROM Families.children[0] c
WHERE (c.grade > 5)Quando la query di cui sopra viene eseguita, recupererà il seguente documento secondario come mostrato nell'output.
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]La parola chiave BETWEEN viene utilizzata per esprimere query su intervalli di valori come in SQL. BETWEEN può essere utilizzato contro stringhe o numeri. La differenza principale tra l'utilizzo di BETWEEN in DocumentDB e ANSI SQL è che è possibile esprimere query di intervallo su proprietà di tipi misti.
Ad esempio, in alcuni documenti è possibile che tu abbia "voto" come numero e in altri documenti potrebbe essere una stringa. In questi casi, un confronto tra due diversi tipi di risultati è "indefinito" e il documento verrà ignorato.
Consideriamo i tre documenti dell'esempio precedente. Di seguito è riportato il fileAndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un esempio, in cui la query restituisce tutti i documenti di famiglia in cui il voto del primo figlio è compreso tra 1-5 (entrambi inclusi).
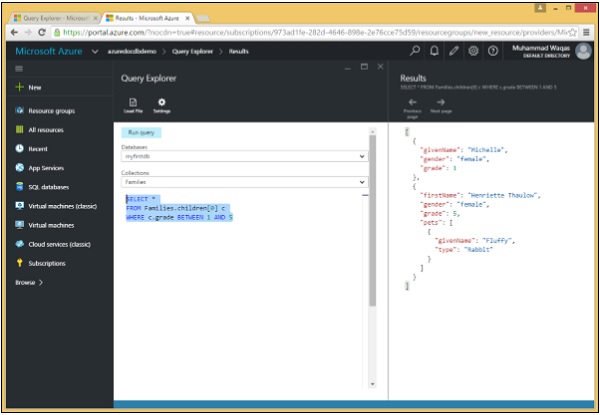
Di seguito è riportata la query in cui viene utilizzata la parola chiave BETWEEN e quindi l'operatore logico AND.
SELECT *
FROM Families.children[0] c
WHERE c.grade BETWEEN 1 AND 5Quando la query precedente viene eseguita, produce il seguente output.
[
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
]Per visualizzare i voti al di fuori dell'intervallo dell'esempio precedente, utilizzare NOT BETWEEN come mostrato nella query seguente.
SELECT *
FROM Families.children[0] c
WHERE c.grade NOT BETWEEN 1 AND 5Quando viene eseguita questa query. Produce il seguente output.
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]La parola chiave IN può essere utilizzata per verificare se un valore specificato corrisponde a qualsiasi valore in un elenco. L'operatore IN consente di specificare più valori in una clausola WHERE. IN equivale a concatenare più clausole OR.
I tre documenti simili sono considerati come fatti negli esempi precedenti. Di seguito è riportato il fileAndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un semplice esempio.
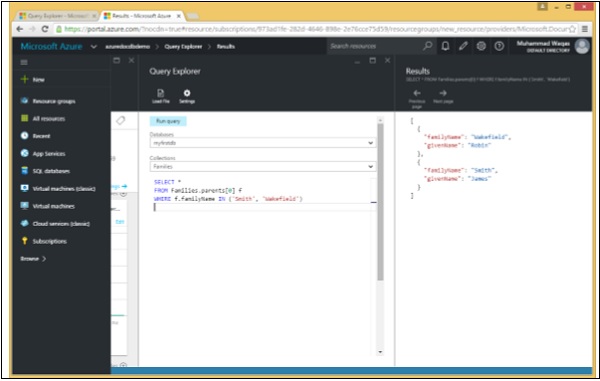
Di seguito è riportata la query che recupererà i dati il cui familyName è "Smith" o Wakefield.
SELECT *
FROM Families.parents[0] f
WHERE f.familyName IN ('Smith', 'Wakefield')Quando la query precedente viene eseguita, produce il seguente output.
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Smith",
"givenName": "James"
}
]Consideriamo un altro semplice esempio in cui verranno recuperati tutti i documenti di famiglia in cui l'id è uno di "SmithFamily" o "AndersenFamily". La seguente è la query.
SELECT *
FROM Families
WHERE Families.id IN ('SmithFamily', 'AndersenFamily')Quando la query precedente viene eseguita, produce il seguente output.
[
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Quando sai che stai restituendo un solo valore, la parola chiave VALUE può aiutarti a produrre un set di risultati più snello evitando l'overhead della creazione di un oggetto completo. La parola chiave VALUE fornisce un modo per restituire il valore JSON.
Diamo un'occhiata a un semplice esempio.
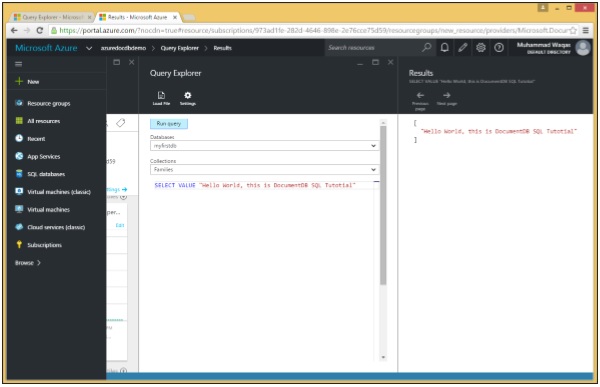
Di seguito è riportata la query con VALUE parole chiave.
SELECT VALUE "Hello World, this is DocumentDB SQL Tutorial"Quando questa query viene eseguita, restituisce lo scalare "Hello World, this is DocumentDB SQL Tutorial".
[
"Hello World, this is DocumentDB SQL Tutorial"
]In un altro esempio, consideriamo i tre documenti degli esempi precedenti.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}La seguente è la query.
SELECT VALUE f.location
FROM Families fQuando questa query viene eseguita, restituisce l'indirizzo senza l'etichetta della posizione.
[
{
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
{
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
{
"state": "WA",
"county": "King",
"city": "Seattle"
}
]Se ora specifichiamo la stessa query senza VALUE parola chiave, restituirà l'indirizzo con l'etichetta della posizione. La seguente è la domanda.
SELECT f.location
FROM Families fQuando questa query viene eseguita, produce il seguente output.
[
{
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
}
},
{
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
},
{
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
}
}
]Microsoft Azure DocumentDB supporta l'esecuzione di query sui documenti utilizzando SQL su documenti JSON. È possibile ordinare i documenti nella raccolta su numeri e stringhe utilizzando una clausola ORDER BY nella query. La clausola può includere un argomento ASC / DESC facoltativo per specificare l'ordine in cui devono essere recuperati i risultati.
Considereremo gli stessi documenti degli esempi precedenti.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un semplice esempio.
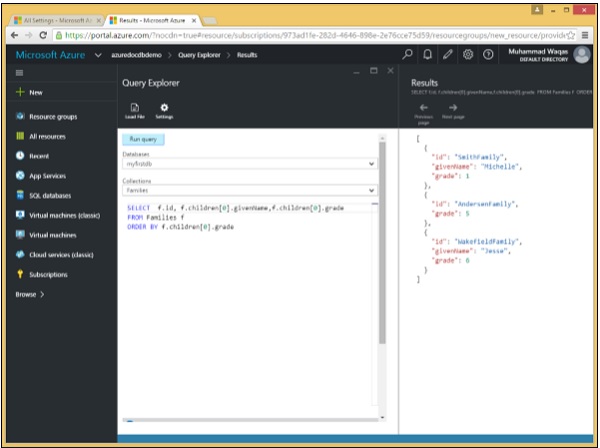
Di seguito è riportata la query che contiene la parola chiave ORDER BY.
SELECT f.id, f.children[0].givenName,f.children[0].grade
FROM Families f
ORDER BY f.children[0].gradeQuando la query precedente viene eseguita, produce il seguente output.
[
{
"id": "SmithFamily",
"givenName": "Michelle",
"grade": 1
},
{
"id": "AndersenFamily",
"grade": 5
},
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]Consideriamo un altro semplice esempio.
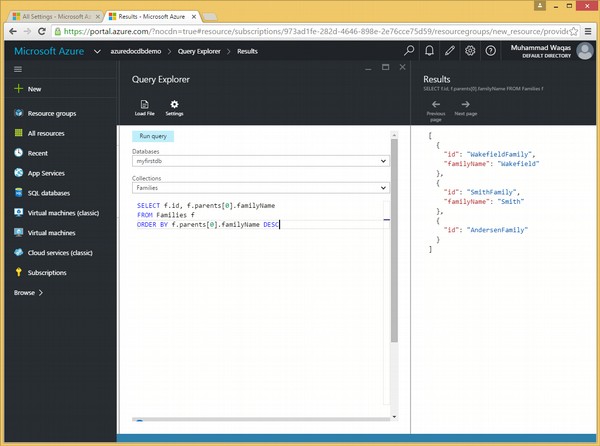
La seguente è la query che contiene la parola chiave ORDER BY e la parola chiave opzionale DESC.
SELECT f.id, f.parents[0].familyName
FROM Families f
ORDER BY f.parents[0].familyName DESCQuando la query precedente viene eseguita, produrrà il seguente output.
[
{
"id": "WakefieldFamily",
"familyName": "Wakefield"
},
{
"id": "SmithFamily",
"familyName": "Smith"
},
{
"id": "AndersenFamily"
}
]In DocumentDB SQL, Microsoft ha aggiunto un nuovo costrutto che può essere utilizzato con la parola chiave IN per fornire supporto per l'iterazione su array JSON. Il supporto per l'iterazione è fornito nella clausola FROM.
Considereremo di nuovo tre documenti simili dagli esempi precedenti.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un semplice esempio senza la parola chiave IN nella clausola FROM.
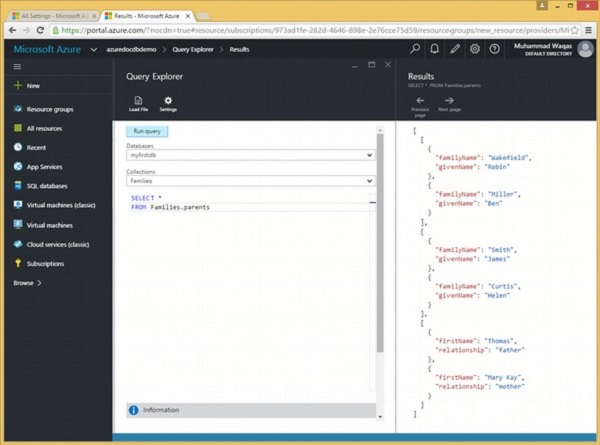
Di seguito è riportata la query che restituirà tutti i genitori dalla raccolta Famiglie.
SELECT *
FROM Families.parentsQuando la query precedente viene eseguita, produce il seguente output.
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]Come si può vedere nell'output sopra, i genitori di ciascuna famiglia vengono visualizzati in un array JSON separato.
Diamo un'occhiata allo stesso esempio, tuttavia questa volta useremo la parola chiave IN nella clausola FROM.
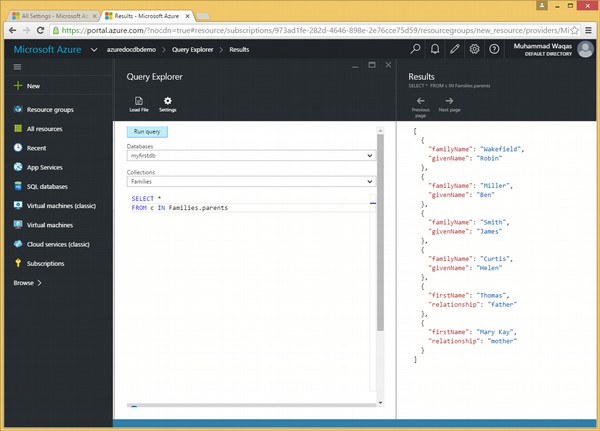
La seguente è la query che contiene la parola chiave IN.
SELECT *
FROM c IN Families.parentsQuando la query precedente viene eseguita, produce il seguente output.
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
},
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
},
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]Nell'esempio precedente, si può vedere che con l'iterazione, la query che esegue l'iterazione sui genitori nella raccolta ha un array di output diverso. Quindi, tutti i genitori di ogni famiglia vengono aggiunti in un unico array.
Nei database relazionali, la clausola Joins viene utilizzata per combinare i record di due o più tabelle in un database e la necessità di unire tra tabelle è molto importante durante la progettazione di schemi normalizzati. Poiché DocumentDB si occupa del modello di dati denormalizzato di documenti privi di schema, JOIN in DocumentDB SQL è l'equivalente logico di un "selfjoin".
Consideriamo i tre documenti come negli esempi precedenti.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un esempio per capire come funziona la clausola JOIN.
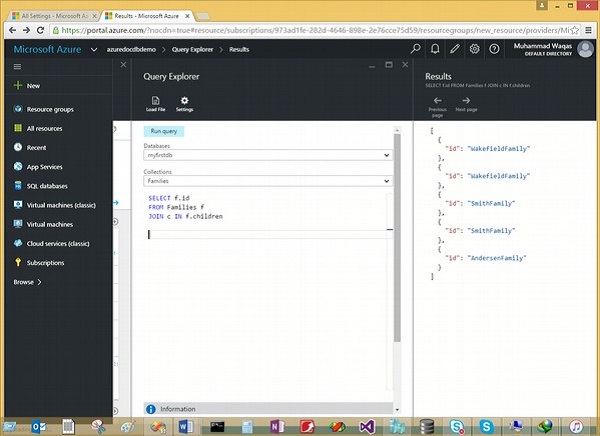
La seguente è la query che unirà la radice al documento secondario.
SELECT f.id
FROM Families f
JOIN c IN f.childrenQuando la query precedente viene eseguita, produrrà il seguente output.
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]Nell'esempio precedente, l'unione è tra la radice del documento e la radice secondaria secondaria che crea un prodotto incrociato tra due oggetti JSON. Di seguito sono riportati alcuni punti da notare:
Nella clausola FROM, la clausola JOIN è un iteratore.
I primi due documenti WakefieldFamily e SmithFamily contengono due figli, quindi il set di risultati contiene anche il prodotto incrociato che produce un oggetto separato per ogni figlio.
Il terzo documento AndersenFamily contiene un solo figlio, quindi esiste un solo oggetto corrispondente a questo documento.
Diamo un'occhiata allo stesso esempio, tuttavia questa volta recuperiamo anche il nome del bambino per una migliore comprensione della clausola JOIN.
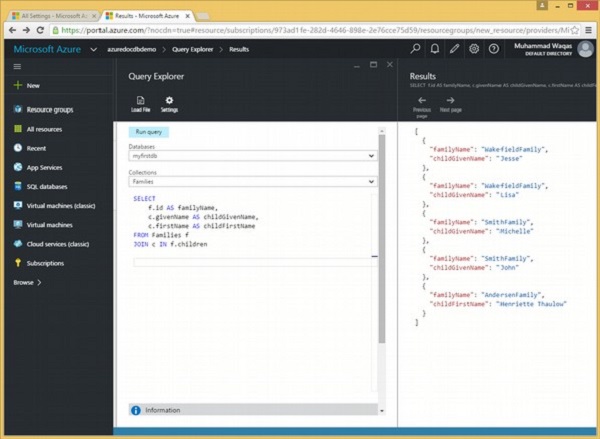
La seguente è la query che unirà la radice al documento secondario.
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenQuando la query precedente viene eseguita, produce il seguente output.
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]Nei database relazionali, gli alias SQL vengono utilizzati per rinominare temporaneamente una tabella o un'intestazione di colonna. Allo stesso modo, in DocumentDB, gli alias vengono utilizzati per rinominare temporaneamente un documento JSON, un documento secondario, un oggetto o qualsiasi campo.
La ridenominazione è una modifica temporanea e il documento effettivo non cambia. Fondamentalmente, gli alias vengono creati per rendere più leggibili i nomi dei campi / documenti. Per l'aliasing, viene utilizzata la parola chiave AS che è facoltativa.
Consideriamo tre documenti simili da quelli utilizzati negli esempi precedenti.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un esempio per discutere gli alias.
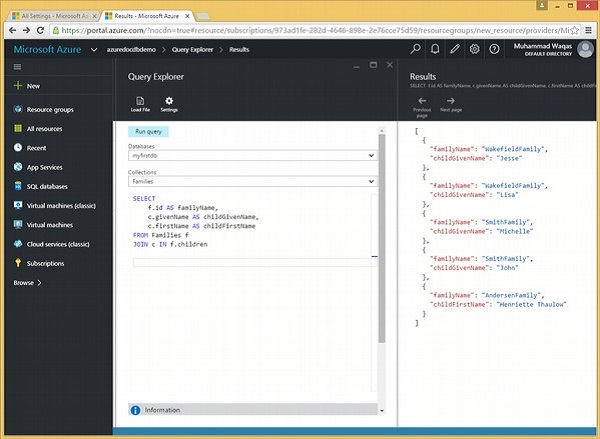
La seguente è la query che unirà la radice al documento secondario. Abbiamo alias come f.id AS familyName, c.givenName AS childGivenName e c.firstName AS childFirstName.
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenQuando la query precedente viene eseguita, produce il seguente output.
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]L'output sopra mostra che i nomi archiviati sono cambiati, ma si tratta di una modifica temporanea e i documenti originali non vengono modificati.
In DocumentDB SQL, Microsoft ha aggiunto una funzionalità chiave con l'aiuto della quale possiamo creare facilmente un array. Significa che quando eseguiamo una query, di conseguenza creerà un array di raccolte simile all'oggetto JSON come risultato della query.
Consideriamo gli stessi documenti degli esempi precedenti.
Di seguito è riportato il file AndersenFamily documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Di seguito è riportato il file SmithFamily documento.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Di seguito è riportato il file WakefieldFamily documento.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un esempio.
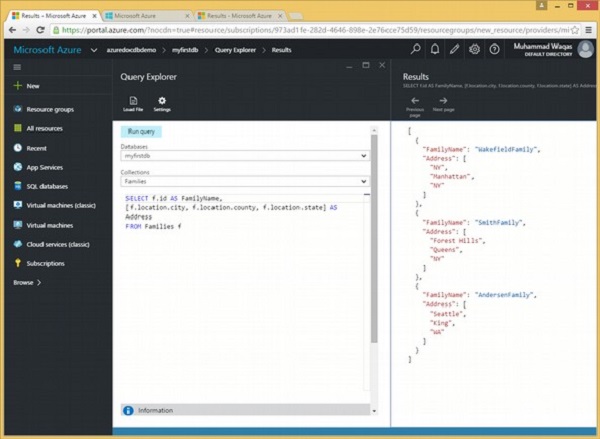
Di seguito è riportata la query che restituirà il cognome e l'indirizzo di ciascuna famiglia.
SELECT f.id AS FamilyName,
[f.location.city, f.location.county, f.location.state] AS Address
FROM Families fCome si può vedere, i campi relativi a città, provincia e stato sono racchiusi tra parentesi quadre, che creeranno un array e questo array è denominato Indirizzo. Quando la query precedente viene eseguita, produce il seguente output.
[
{
"FamilyName": "WakefieldFamily",
"Address": [
"NY",
"Manhattan",
"NY"
]
},
{
"FamilyName": "SmithFamily",
"Address": [
"Forest Hills",
"Queens",
"NY"
]
},
{
"FamilyName": "AndersenFamily",
"Address": [
"Seattle",
"King",
"WA"
]
}
]Le informazioni su città, provincia e stato vengono aggiunte nella matrice Indirizzo nell'output precedente.
In DocumentDB SQL, la clausola SELECT supporta anche espressioni scalari come costanti, espressioni aritmetiche, espressioni logiche, ecc. Normalmente, le query scalari vengono utilizzate raramente, perché in realtà non interrogano i documenti nella raccolta, ma valutano solo le espressioni. Tuttavia, è comunque utile utilizzare query di espressioni scalari per apprendere le nozioni di base, come utilizzare espressioni e modellare JSON in una query e questi concetti si applicano direttamente alle query effettive che verranno eseguite sui documenti in una raccolta.
Diamo un'occhiata a un esempio che contiene più query scalari.
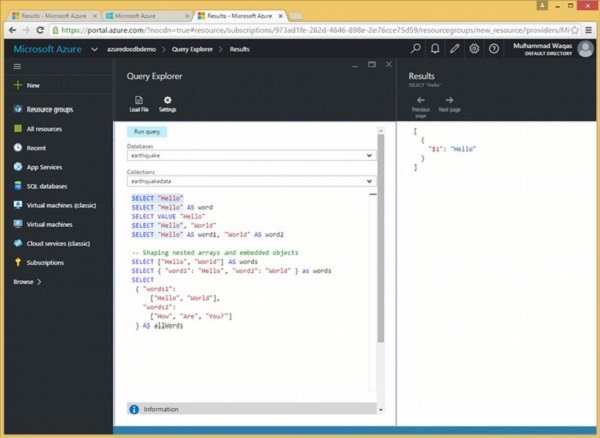
In Query Explorer, seleziona solo il testo da eseguire e fai clic su "Esegui". Eseguiamo questo primo.
SELECT "Hello"Quando la query precedente viene eseguita, produce il seguente output.
[
{
"$1": "Hello"
}
]Questo output può sembrare un po 'confuso, quindi analizziamolo.
Innanzitutto, come abbiamo visto nell'ultima demo, i risultati delle query sono sempre contenuti tra parentesi quadre perché vengono restituiti come un array JSON, anche i risultati di query di espressioni scalari come questa che restituisce un solo documento.
Abbiamo un array con un documento al suo interno e quel documento ha una singola proprietà per la singola espressione nell'istruzione SELECT.
L'istruzione SELECT non fornisce un nome per questa proprietà, quindi DocumentDB ne genera automaticamente uno utilizzando $ 1.
Questo di solito non è ciò che vogliamo, motivo per cui possiamo usare AS per creare un alias dell'espressione nella query, che imposta il nome della proprietà nel documento generato nel modo in cui vorresti che fosse, word, in questo esempio.
SELECT "Hello" AS wordQuando la query precedente viene eseguita, produce il seguente output.
[
{
"word": "Hello"
}
]Allo stesso modo, la seguente è un'altra semplice query.
SELECT ((2 + 11 % 7)-2)/3La query recupera il seguente output.
[
{
"$1": 1.3333333333333333
}
]Diamo un'occhiata a un altro esempio di modellazione di array annidati e oggetti incorporati.
SELECT
{
"words1":
["Hello", "World"],
"words2":
["How", "Are", "You?"]
} AS allWordsQuando la query precedente viene eseguita, produce il seguente output.
[
{
"allWords": {
"words1": [
"Hello",
"World"
],
"words2": [
"How",
"Are",
"You?"
]
}
}
]Nei database relazionali, una query con parametri è una query in cui vengono utilizzati segnaposto per i parametri ei valori dei parametri vengono forniti al momento dell'esecuzione. DocumentDB supporta anche query con parametri e i parametri nella query con parametri possono essere espressi con la nota notazione @. Il motivo più importante per utilizzare le query con parametri è evitare attacchi di SQL injection. Può anche fornire una gestione robusta e sfuggire all'input dell'utente.
Diamo un'occhiata a un esempio in cui utilizzeremo .Net SDK. Di seguito è riportato il codice che cancellerà la raccolta.
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine(">>> Delete Collection {0} in {1} <<<",
collectionId, _database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}",
collectionId, _database.Id);
}La costruzione di una query parametrizzata è la seguente.
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};Non stiamo codificando l'ID di raccolta, quindi questo metodo può essere utilizzato per eliminare qualsiasi raccolta. È possibile utilizzare il simbolo "@" per aggiungere un prefisso ai nomi dei parametri, in modo simile a SQL Server.
Nell'esempio precedente, stiamo eseguendo una query per una raccolta specifica per Id in cui il parametro Id è definito in questo SqlParameterCollection assegnato alla proprietà del parametro di questo SqlQuerySpec. L'SDK esegue quindi il lavoro di costruzione della stringa di query finale per DocumentDB con collectionId incorporato al suo interno. Eseguiamo la query e quindi utilizziamo il suo SelfLink per eliminare la raccolta.
Di seguito è riportata l'implementazione dell'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM
c WHERE c.id = 'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "MyCollection1");
await DeleteCollection(client, "MyCollection2");
}
}Quando il codice viene eseguito, produce il seguente output.
**** Delete Collection MyCollection1 in mydb ****
Deleted collection MyCollection1 from database myfirstdb
**** Delete Collection MyCollection2 in mydb ****
Deleted collection MyCollection2 from database myfirstdbDiamo un'occhiata a un altro esempio. Possiamo scrivere una query che prende il cognome e lo stato dell'indirizzo come parametri, quindi la esegue per vari valori di lastname e location.state in base all'input dell'utente.
SELECT *
FROM Families f
WHERE f.lastName = @lastName AND f.location.state = @addressStateQuesta richiesta può quindi essere inviata a DocumentDB come query JSON con parametri, come mostrato nel codice seguente.
{
"query": "SELECT * FROM Families f WHERE f.lastName = @lastName AND
f.location.state = @addressState",
"parameters": [
{"name": "@lastName", "value": "Wakefield"},
{"name": "@addressState", "value": "NY"},
]
}DocumentDB supporta una serie di funzioni integrate per operazioni comuni che possono essere utilizzate all'interno delle query. Ci sono un sacco di funzioni per eseguire calcoli matematici e anche funzioni di controllo del tipo che sono estremamente utili quando si lavora con schemi variabili. Queste funzioni possono verificare se una determinata proprietà esiste e se esiste se si tratta di un numero o di una stringa, di un booleano o di un oggetto.
Abbiamo anche queste utili funzioni per analizzare e manipolare le stringhe, così come diverse funzioni per lavorare con gli array che ti permettono di fare cose come concatenare gli array e testare se un array contiene un particolare elemento.
Di seguito sono riportati i diversi tipi di funzioni integrate:
| S.No. | Funzioni e descrizione integrate |
|---|---|
| 1 | Funzioni matematiche Le funzioni matematiche eseguono un calcolo, generalmente basato su valori di input forniti come argomenti, e restituiscono un valore numerico. |
| 2 | Tipo di controllo delle funzioni Le funzioni di controllo del tipo consentono di controllare il tipo di un'espressione all'interno delle query SQL. |
| 3 | Funzioni stringa Le funzioni stringa eseguono un'operazione su un valore di input stringa e restituiscono un valore stringa, numerico o booleano. |
| 4 | Funzioni array Le funzioni array eseguono un'operazione su un valore di input di array e restituiscono sotto forma di valore numerico, booleano o array. |
| 5 | Funzioni spaziali DocumentDB supporta anche le funzioni integrate di Open Geospatial Consortium (OGC) per le query geospaziali. |
In DocumentDB, usiamo effettivamente SQL per interrogare i documenti. Se stiamo sviluppando .NET, esiste anche un provider LINQ che può essere utilizzato e che può generare SQL appropriato da una query LINQ.
Tipi di dati supportati
In DocumentDB, tutti i tipi primitivi JSON sono supportati nel provider LINQ incluso con DocumentDB .NET SDK che sono i seguenti:
- Numeric
- Boolean
- String
- Null
Espressione supportata
Le seguenti espressioni scalari sono supportate nel provider LINQ incluso con DocumentDB .NET SDK.
Constant Values - Include valori costanti dei tipi di dati primitivi.
Property/Array Index Expressions - Le espressioni si riferiscono alla proprietà di un oggetto o di un elemento dell'array.
Arithmetic Expressions - Include espressioni aritmetiche comuni su valori numerici e booleani.
String Comparison Expression - Include il confronto di un valore di stringa con un valore di stringa costante.
Object/Array Creation Expression- Restituisce un oggetto di tipo valore composto o tipo anonimo o un array di tali oggetti. Questi valori possono essere annidati.
Operatori LINQ supportati
Di seguito è riportato un elenco degli operatori LINQ supportati nel provider LINQ incluso con DocumentDB .NET SDK.
Select - Le proiezioni si traducono in SQL SELECT inclusa la costruzione di oggetti.
Where- I filtri si traducono in SQL WHERE e supportano la traduzione tra &&, || e ! agli operatori SQL.
SelectMany- Consente lo svolgimento di array nella clausola SQL JOIN. Può essere utilizzato per concatenare / annidare espressioni per filtrare gli elementi dell'array.
OrderBy and OrderByDescending - Si traduce in ORDINA IN ordine crescente / decrescente.
CompareTo- Si traduce in confronti di intervallo. Comunemente utilizzato per le stringhe poiché non sono confrontabili in .NET.
Take - Si traduce in SQL TOP per limitare i risultati di una query.
Math Functions - Supporta la traduzione da Abs, Acos, Asin, Atan, Soffitto, Cos, Exp, Floor, Log, Log10, Pow, Round, Sign, Sin, Sqrt, Tan, Truncate di .NET alle funzioni integrate SQL equivalenti.
String Functions - Supporta la traduzione da Concat, Contains, EndsWith, IndexOf, Count, ToLower, TrimStart, Replace, Reverse, TrimEnd, StartsWith, SubString, ToUpper di .NET alle funzioni incorporate SQL equivalenti.
Array Functions - Supporta la traduzione da Concat, Contains e Count di .NET alle funzioni integrate SQL equivalenti.
Geospatial Extension Functions - Supporta la traduzione dai metodi stub Distance, Within, IsValid e IsValidDetailed alle funzioni incorporate SQL equivalenti.
User-Defined Extension Function - Supporta la traduzione dal metodo stub UserDefinedFunctionProvider.Invoke alla funzione definita dall'utente corrispondente.
Miscellaneous- Supporta la traduzione di coalesce e operatori condizionali. Può tradurre Contains in String CONTAINS, ARRAY_CONTAINS o SQL IN a seconda del contesto.
Diamo un'occhiata a un esempio in cui utilizzeremo .Net SDK. Di seguito sono riportati i tre documenti che prenderemo in considerazione per questo esempio.
Nuovo cliente 1
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}Nuovo cliente 2
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "678 Main Street",
"location": {
"city": "London",
"stateProvinceName": " London "
},
"postalCode": "11229",
"countryRegionName": "United Kingdom"
},
}Nuovo cliente 3
{
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "12 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}Di seguito è riportato il codice in cui eseguiamo query utilizzando LINQ. Abbiamo definito una query LINQ inq, ma non verrà eseguito finché non eseguiremo .ToList su di esso.
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == "United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} US customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}L'SDK convertirà la nostra query LINQ nella sintassi SQL per DocumentDB, generando una clausola SELECT e WHERE basata sulla nostra sintassi LINQ.
Chiamiamo le query precedenti dall'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
QueryDocumentsWithLinq(client);
}
}Quando il codice precedente viene eseguito, produce il seguente output.
**** Query Documents (LINQ) ****
Quering for US customers (LINQ)
Found 2 US customers
Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn
Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: BrooklynOggigiorno JavaScript è ovunque e non solo nei browser. DocumentDB abbraccia JavaScript come una sorta di T-SQL moderno e supporta l'esecuzione transazionale della logica JavaScript in modo nativo, direttamente all'interno del motore di database. DocumentDB fornisce un modello di programmazione per eseguire la logica dell'applicazione basata su JavaScript direttamente sulle raccolte in termini di stored procedure e trigger.
Diamo un'occhiata a un esempio in cui creiamo una semplice procedura di negozio. Di seguito sono riportati i passaggi:
Step 1 - Crea una nuova console di applicazioni.
Step 2- Aggiungi in .NET SDK da NuGet. Stiamo usando .NET SDK qui, il che significa che scriveremo del codice C # per creare, eseguire e quindi eliminare la nostra stored procedure, ma la stored procedure stessa viene scritta in JavaScript.
Step 3 - Fare clic con il pulsante destro del mouse sul progetto in Esplora soluzioni.
Step 4 - Aggiungi un nuovo file JavaScript per la stored procedure e chiamalo HelloWorldStoreProce.js
Ogni procedura memorizzata è solo una funzione JavaScript, quindi creeremo una nuova funzione e naturalmente chiameremo anche questa funzione HelloWorldStoreProce. Non importa se diamo un nome alla funzione. DocumentDB farà riferimento a questa procedura memorizzata solo tramite l'ID che forniamo quando la creiamo.
function HelloWorldStoreProce() {
var context = getContext();
var response = context.getResponse();
response.setBody('Hello, and welcome to DocumentDB!');
}Tutto ciò che la stored procedure fa è ottenere l'oggetto risposta dal contesto e chiamarlo setBodymetodo per restituire una stringa al chiamante. Nel codice C # creeremo la stored procedure, la eseguiremo e quindi la elimineremo.
Le stored procedure hanno un ambito per raccolta, quindi avremo bisogno del SelfLink della raccolta per creare la stored procedure.
Step 5 - Prima query per il myfirstdb database e poi per il MyCollection collezione.
La creazione di una stored procedure è proprio come la creazione di qualsiasi altra risorsa in DocumentDB.
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink, "SELECT * FROM
c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client.
CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client.ExecuteStoredProcedureAsync
(sproc.SelfLink); Console.WriteLine("Executed stored procedure; response = {0}", result.Response); // Delete stored procedure await client.DeleteStoredProcedureAsync(sproc.SelfLink); Console.WriteLine("Deleted stored procedure {0} ({1})", sproc.Id, sproc.ResourceId); } }
Step 6 - Prima crea un oggetto di definizione con l'ID per la nuova risorsa e poi chiama uno dei metodi Create nel file DocumentClientoggetto. Nel caso di una procedura memorizzata, la definizione include l'ID e il codice JavaScript effettivo che si desidera inviare al server.
Step 7 - Chiama File.ReadAllText per estrarre il codice della procedura memorizzata dal file JS.
Step 8 - Assegna il codice della procedura memorizzata alla proprietà body dell'oggetto definizione.
Per quanto riguarda DocumentDB, l'Id che specifichiamo qui, nella definizione, è il nome della stored procedure, indipendentemente da ciò che chiamiamo effettivamente la funzione JavaScript.
Tuttavia, quando si creano stored procedure e altri oggetti lato server, si consiglia di denominare le funzioni JavaScript e che tali nomi di funzione corrispondano all'ID che abbiamo impostato nella definizione di DocumentDB.
Step 9 - Chiama CreateStoredProcedureAsync, passando in SelfLink per il MyCollectionraccolta e la definizione della procedura memorizzata. Questo crea la stored procedure eResourceId quel DocumentDB assegnato ad esso.
Step 10 - Chiama la procedura memorizzata. ExecuteStoredProcedureAsyncaccetta un parametro di tipo impostato sul tipo di dati previsto del valore restituito dalla procedura memorizzata, che è possibile specificare semplicemente come oggetto se si desidera restituire un oggetto dinamico. Questo è un oggetto le cui proprietà verranno associate in fase di esecuzione.
In questo esempio sappiamo che la nostra stored procedure restituisce solo una stringa e quindi chiamiamo ExecuteStoredProcedureAsync<string>.
Di seguito è riportata l'implementazione completa del file Program.cs.
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBStoreProce {
class Program {
private static void Main(string[] args) {
Task.Run(async () => {
await SimpleStoredProcDemo();
}).Wait();
}
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client
.CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})", sproc
.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client
.ExecuteStoredProcedureAsync<string>(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}",
result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
}
}Quando il codice precedente viene eseguito, produce il seguente output.
Created stored procedure HelloWorldStoreProce (Ic8LAMEUVgACAAAAAAAAgA==)
Executed stored procedure; response = Hello, and welcome to DocumentDB!Come si vede nell'output sopra, la proprietà response ha "Hello e welcome to DocumentDB!" restituito dalla nostra procedura memorizzata.
DocumentDB SQL fornisce il supporto per le UDF (User-Defined Functions). Le UDF sono solo un altro tipo di funzioni JavaScript che puoi scrivere e funzionano praticamente come ti aspetteresti. È possibile creare UDF per estendere il linguaggio di query con una logica aziendale personalizzata a cui è possibile fare riferimento nelle query.
La sintassi SQL di DocumentDB è stata estesa per supportare la logica dell'applicazione personalizzata utilizzando queste UDF. È possibile registrare le UDF con DocumentDB e quindi fare riferimento come parte di una query SQL.
Consideriamo i seguenti tre documenti per questo esempio.
AndersenFamily documento è il seguente.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily documento è il seguente.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily documento è il seguente.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un esempio in cui creeremo alcune semplici UDF.
Di seguito è riportata l'implementazione di CreateUserDefinedFunctions.
private async static Task CreateUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create User Defined Functions ****");
Console.WriteLine();
await CreateUserDefinedFunction(client, "udfRegEx");
}Abbiamo un udfRegEx e in CreateUserDefinedFunction otteniamo il suo codice JavaScript dal nostro file locale. Costruiamo l'oggetto di definizione per la nuova UDF e chiamiamo CreateUserDefinedFunctionAsync con SelfLink della raccolta e l'oggetto udfDefinition come mostrato nel codice seguente.
private async static Task<UserDefinedFunction>
CreateUserDefinedFunction(DocumentClient client, string udfId) {
var udfBody = File.ReadAllText(@"..\..\Server\" + udfId + ".js");
var udfDefinition = new UserDefinedFunction {
Id = udfId,
Body = udfBody
};
var result = await client
.CreateUserDefinedFunctionAsync(_collection.SelfLink, udfDefinition);
var udf = result.Resource;
Console.WriteLine("Created user defined function {0}; RID: {1}",
udf.Id, udf.ResourceId);
return udf;
}Recuperiamo la nuova UDF dalla proprietà della risorsa del risultato e la restituiamo al chiamante. Per visualizzare l'UDF esistente, di seguito è riportata l'implementazione diViewUserDefinedFunctions. Noi chiamiamoCreateUserDefinedFunctionQuery e scorrerli come al solito.
private static void ViewUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View UDFs ****");
Console.WriteLine();
var udfs = client
.CreateUserDefinedFunctionQuery(_collection.UserDefinedFunctionsLink)
.ToList();
foreach (var udf in udfs) {
Console.WriteLine("User defined function {0}; RID: {1}", udf.Id, udf.ResourceId);
}
}DocumentDB SQL non fornisce funzioni integrate per la ricerca di sottostringhe o espressioni regolari, quindi la seguente piccola riga riempie quella lacuna che è una funzione JavaScript.
function udfRegEx(input, regex) {
return input.match(regex);
}Data la stringa di input nel primo parametro, utilizza il supporto di espressioni regolari integrato di JavaScript passando la stringa di corrispondenza del modello nel secondo parametro in.match. Possiamo eseguire una query di sottostringa per trovare tutti i negozi con la parola Andersen nel filelastName proprietà.
private static void Execute_udfRegEx(DocumentClient client) {
var sql = "SELECT c.name FROM c WHERE udf.udfRegEx(c.lastName, 'Andersen') != null";
Console.WriteLine();
Console.WriteLine("Querying for Andersen");
var documents = client.CreateDocumentQuery(_collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} Andersen:", documents.Count);
foreach (var document in documents) {
Console.WriteLine("Id: {0}, Name: {1}", document.id, document.lastName);
}
}Nota che dobbiamo qualificare ogni riferimento UDF con il prefisso udf. Abbiamo appena passato l'SQL aCreateDocumentQuerycome qualsiasi normale query. Infine, chiamiamo le query precedenti daCreateDocumentClient compito
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)){
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE
c.id = 'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'Families'").AsEnumerable().First();
await CreateUserDefinedFunctions(client);
ViewUserDefinedFunctions(client);
Execute_udfRegEx(client);
}
}Quando il codice precedente viene eseguito, produce il seguente output.
**** Create User Defined Functions ****
Created user defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
**** View UDFs ****
User defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
Querying for Andersen
Found 1 Andersen:
Id: AndersenFamily, Name: AndersenComposite Queryconsente di combinare i dati di query esistenti e quindi applicare filtri, aggregazioni e così via prima di presentare i risultati del report, che mostrano il set di dati combinato. La query composita recupera più livelli di informazioni correlate sulle query esistenti e presenta i dati combinati come un risultato di query singolo e appiattito.
Usando Composite Query, hai anche la possibilità di:
Selezionare l'opzione di eliminazione SQL per rimuovere tabelle e campi non necessari in base alle selezioni di attributi degli utenti.
Impostare le clausole ORDER BY e GROUP BY.
Imposta la clausola WHERE come filtro sul set di risultati di una query composta.
Gli operatori di cui sopra possono essere composti per formare query più potenti. Poiché DocumentDB supporta le raccolte nidificate, la composizione può essere concatenata o nidificata.
Consideriamo i seguenti documenti per questo esempio.
AndersenFamily documento è il seguente.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily documento è il seguente.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily documento è il seguente.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Diamo un'occhiata a un esempio di query concatenata.
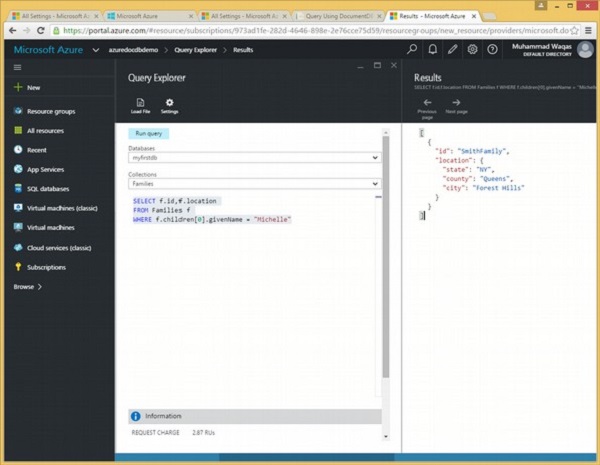
Di seguito è riportata la query che recupererà l'id e la posizione della famiglia in cui si trova il primo figlio givenName è Michelle.
SELECT f.id,f.location
FROM Families f
WHERE f.children[0].givenName = "Michelle"Quando la query precedente viene eseguita, produce il seguente output.
[
{
"id": "SmithFamily",
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
}
]Consideriamo un altro esempio di query concatenata.
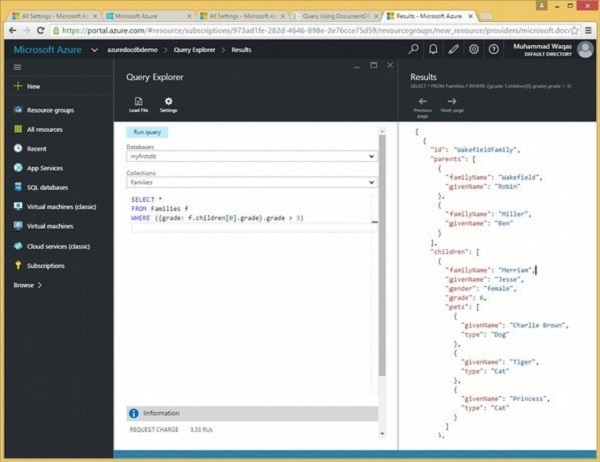
Di seguito è riportata la query che restituirà tutti i documenti in cui il primo voto del bambino è maggiore di 3.
SELECT *
FROM Families f
WHERE ({grade: f.children[0].grade}.grade > 3)Quando la query precedente viene eseguita, produce il seguente output.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Diamo un'occhiata a un file example di query annidate.
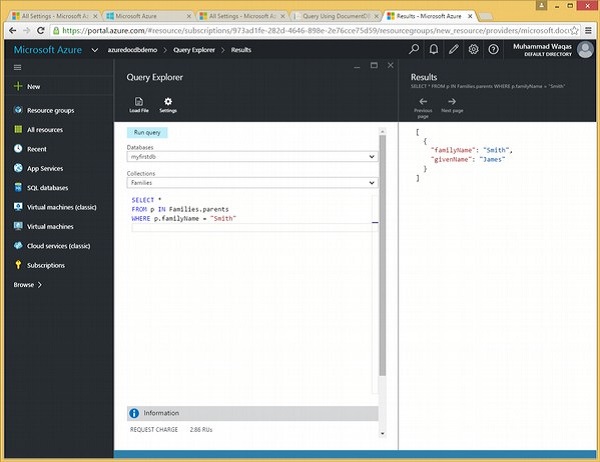
Di seguito è riportata la query che itererà tutti i genitori e quindi restituirà il documento dove familyName è Smith.
SELECT *
FROM p IN Families.parents
WHERE p.familyName = "Smith"Quando la query precedente viene eseguita, produce il seguente output.
[
{
"familyName": "Smith",
"givenName": "James"
}
]Consideriamo another example di query annidate.
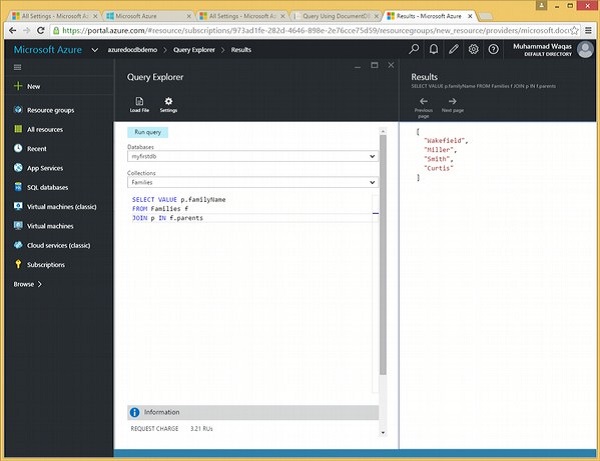
Di seguito è riportata la query che restituirà tutti i file familyName.
SELECT VALUE p.familyName
FROM Families f
JOIN p IN f.parentsQuando la query precedente viene eseguita, produce il seguente output.
[
"Wakefield",
"Miller",
"Smith",
"Curtis"
]