DocumentDB - Guida rapida
In questo capitolo, discuteremo brevemente i principali concetti su NoSQL e database di documenti. Avremo anche una rapida panoramica di DocumentDB.
Database di documenti NoSQL
DocumentDB è il più recente database di documenti NoSQL di Microsoft, quindi quando dici database di documenti NoSQL, cosa si intende precisamente per NoSQL e database di documenti?
SQL significa Structured Query Language, che è il tradizionale linguaggio di query dei database relazionali. SQL è spesso equiparato ai database relazionali.
È davvero più utile pensare a un database NoSQL come un database non relazionale, quindi NoSQL significa davvero non relazionale.
Esistono diversi tipi di database NoSQL che includono archivi di valori chiave come:
- Archiviazione tabelle di Azure.
- Negozi a colonne come Cassandra.
- Database di grafici come NEO4.
- Database di documenti come MongoDB e Azure DocumentDB.
Azure DocumentDB
Microsoft ha lanciato ufficialmente Azure DocumentDB l'8 aprile ° 2015, e certamente può essere caratterizzato come un tipico database di documenti NoSQL. È estremamente scalabile e funziona con documenti JSON senza schema.
DocumentDB è un vero servizio di database di documenti NoSQL privo di schemi progettato per le moderne applicazioni mobili e web.
Offre inoltre letture e scritture costantemente veloci, flessibilità dello schema e capacità di scalare facilmente un database su e giù su richiesta.
Non presuppone né richiede alcuno schema per i documenti JSON che indicizza.
DocumentDB indicizza automaticamente ogni proprietà in un documento non appena il documento viene aggiunto al database.
DocumentDB consente complesse query ad-hoc utilizzando un linguaggio SQL e ogni documento è immediatamente interrogabile nel momento in cui viene creato ed è possibile cercare su qualsiasi proprietà ovunque all'interno della gerarchia del documento.
DocumentDB - Prezzi
DocumentDB viene fatturato in base al numero di raccolte contenute in un account di database. Ogni account può avere uno o più database e ogni database può avere un numero virtualmente illimitato di raccolte, sebbene vi sia una quota predefinita iniziale di 100. Questa quota può essere revocata contattando il supporto di Azure.
Una raccolta non è solo un'unità di scala, ma anche un'unità di costo, quindi in DocumentDB paghi per raccolta, che ha una capacità di archiviazione fino a 10 GB.
Come minimo, avrai bisogno di una raccolta S1 per archiviare i documenti in un database che costerà circa $ 25 al mese, che viene addebitato sulla tua sottoscrizione di Azure.
Man mano che le dimensioni del database aumentano e superano i 10 GB, sarà necessario acquistare un'altra raccolta per contenere i dati aggiuntivi.
Ogni raccolta S1 ti darà 250 unità di richiesta al secondo e, se ciò non bastasse, puoi ridimensionare la raccolta fino a un S2 e ottenere 1000 unità di richiesta al secondo per circa $ 50 al mese.
Puoi anche trasformarlo fino a un S3 e pagare circa $ 100 al mese.
DocumentDB si distingue per alcune funzionalità davvero uniche. Azure DocumentDB offre le funzionalità e i vantaggi chiave seguenti.
Schema gratuito
In un database relazionale, ogni tabella ha uno schema che definisce le colonne e i tipi di dati a cui deve conformarsi ogni riga della tabella.
Al contrario, un database di documenti non ha uno schema definito e ogni documento può essere strutturato in modo diverso.
Sintassi SQL
DocumentDB consente query complesse ad-hoc utilizzando il linguaggio SQL e ogni documento è immediatamente interrogabile nel momento in cui viene creato. Puoi cercare in qualsiasi proprietà ovunque all'interno della gerarchia del documento.
Consistenza sintonizzabile
Fornisce alcuni livelli di coerenza granulari e ben definiti, che consentono di fare ottimi compromessi tra coerenza, disponibilità e latenza.
È possibile scegliere tra quattro livelli di coerenza ben definiti per ottenere un compromesso ottimale tra coerenza e prestazioni. Per le query e le operazioni di lettura, DocumentDB offre quattro distinti livelli di coerenza:
- Strong
- Bounded-staleness
- Session
- Eventual
Scala elastica
La scalabilità è il nome del gioco con NoSQL e DocumentDB lo offre. DocumentDB ha già dimostrato la sua portata.
I principali servizi come Office OneNote e Xbox sono già supportati da DocumentDB con database contenenti decine di terabyte di documenti JSON, oltre un milione di utenti attivi e che operano in modo coerente con una disponibilità del 99,95%.
Puoi scalare in modo elastico DocumentDB con prestazioni prevedibili creando più unità man mano che la tua applicazione cresce.
Completamente gestito
DocumentDB è disponibile come piattaforma basata su cloud completamente gestita come servizio in esecuzione su Azure.
Non c'è semplicemente nulla da installare o gestire.
Non ci sono server, cavi, sistemi operativi o aggiornamenti da gestire, né repliche da configurare.
Microsoft fa tutto ciò che funziona e mantiene il servizio in esecuzione.
In pochi minuti, puoi iniziare a lavorare con DocumentDB usando solo un browser e una sottoscrizione di Azure.
Microsoft fornisce una versione gratuita di Visual Studio che contiene anche SQL Server e può essere scaricata da https://www.visualstudio.com
Installazione
Step 1- Una volta completato il download, esegui il programma di installazione. Verrà visualizzata la seguente finestra di dialogo.

Step 2 - Fare clic sul pulsante Installa e inizierà il processo di installazione.
Step 3 - Una volta completato con successo il processo di installazione, vedrai la seguente finestra di dialogo.
Step 4 - Chiudi questa finestra di dialogo e riavvia il computer se necessario.
Step 5- Ora apri Visual Studio dal menu di avvio che aprirà la finestra di dialogo sottostante. Ci vorrà del tempo per la prima volta solo per la preparazione.

Una volta fatto tutto, vedrai la finestra principale di Visual Studio.

Step 6 - Creiamo un nuovo progetto da File → Nuovo → Progetto.
Step 7 - Seleziona Applicazione console, inserisci DocumentDBDemo nel campo Nome e fai clic sul pulsante OK.
Step 8 - In Esplora soluzioni, fare clic con il pulsante destro del mouse sul progetto.
Step 9 - Selezionare Gestisci pacchetti NuGet che aprirà la finestra seguente in Visual Studio e nella casella di input Cerca in linea, cercare DocumentDB Client Library.
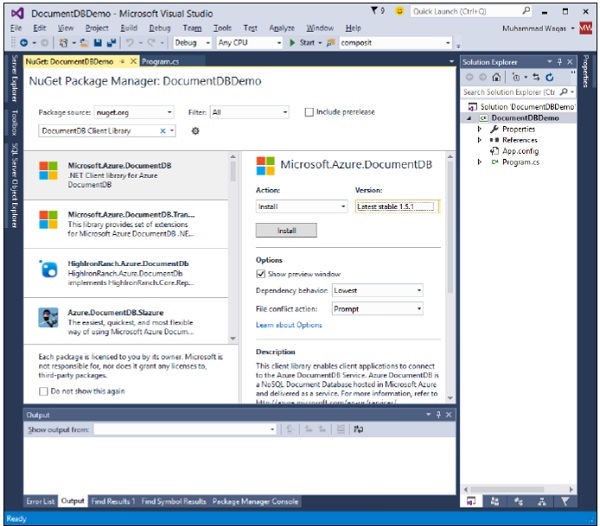
Step 10 - Installa l'ultima versione facendo clic sul pulsante di installazione.

Step 11- Fare clic su "Accetto". Al termine dell'installazione vedrai il messaggio nella finestra di output.
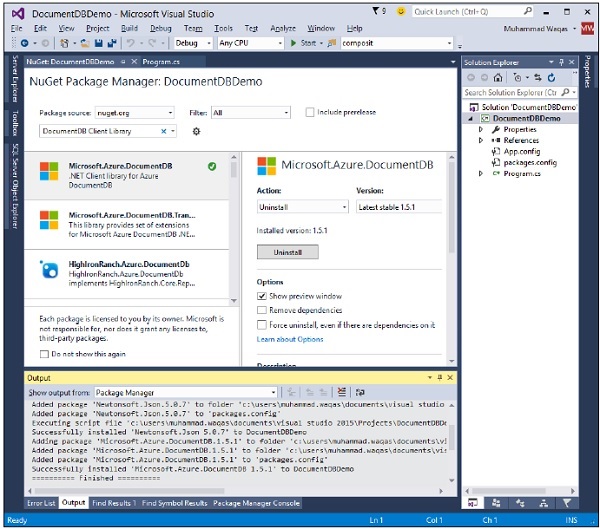
Ora sei pronto per avviare la tua applicazione.
Per utilizzare Microsoft Azure DocumentDB, è necessario creare un account DocumentDB. In questo capitolo creeremo un account DocumentDB usando il portale di Azure.
Step 1 - Accedi all'online https://portal.azure.com se hai già una sottoscrizione di Azure altrimenti devi prima accedere.
Vedrai la dashboard principale. È completamente personalizzabile in modo da poter disporre queste tessere come preferisci, ridimensionarle, aggiungere e rimuovere tessere per cose che usi frequentemente o che non fai più.
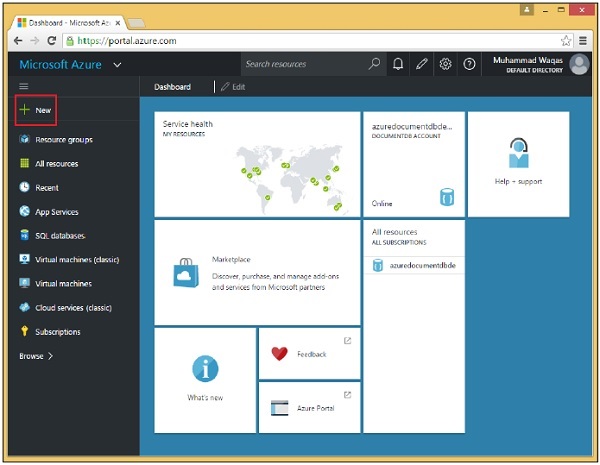
Step 2 - Seleziona l'opzione "Nuovo" nella parte superiore sinistra della pagina.
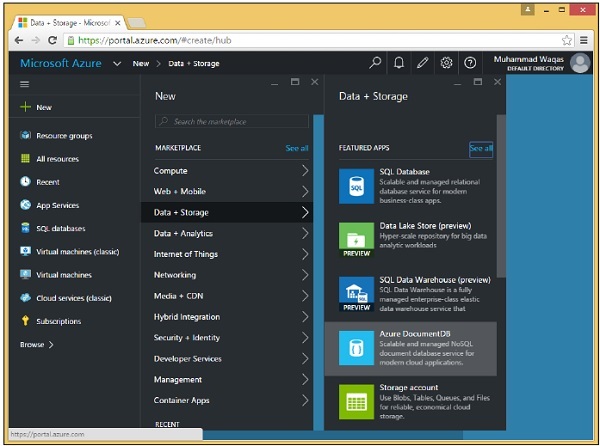
Step 3 - Ora seleziona Dati + Archiviazione> Opzione Azure DocumentDB e vedrai la seguente sezione Nuovo account DocumentDB.
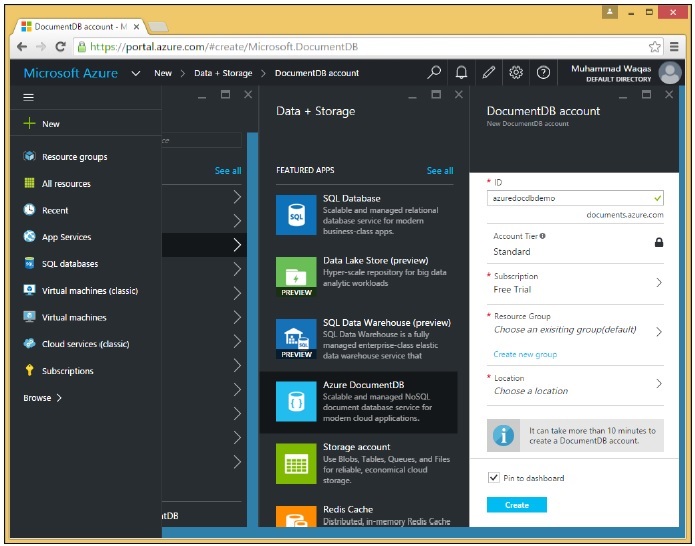
Dobbiamo trovare un nome (ID) univoco globale, che combinato con .documents.azure.com sia l'endpoint indirizzabile pubblicamente al nostro account DocumentDB. È possibile accedere a tutti i database che creiamo sotto tale account tramite Internet utilizzando questo endpoint.
Step 4 - Chiamiamolo azuredocdbdemo e fai clic su Resource Group → new_resource.
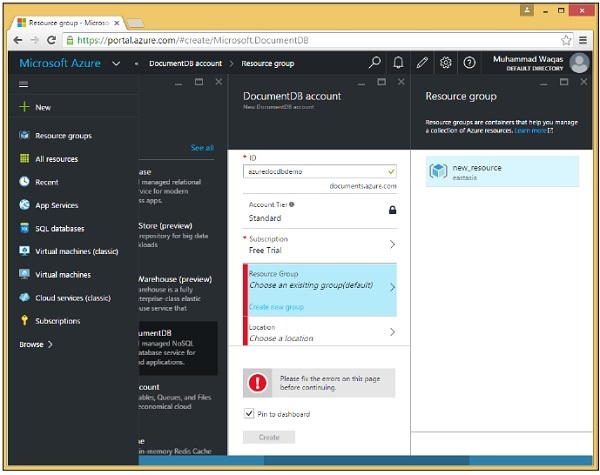
Step 5- Scegli la posizione, ovvero il data center Microsoft in cui desideri ospitare questo account. Seleziona la località e scegli la tua regione.
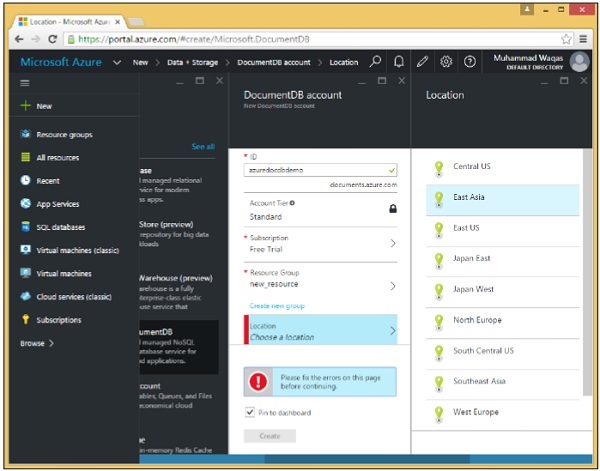
Step 6 - Seleziona la casella di controllo Aggiungi alla dashboard e vai avanti e fai clic sul pulsante Crea.
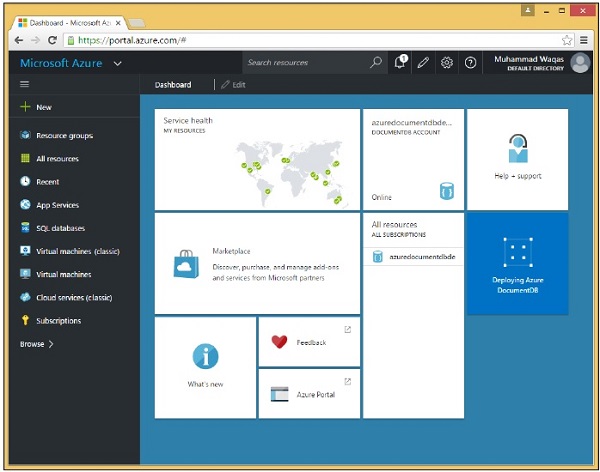
Puoi vedere che il riquadro è già stato aggiunto alla dashboard e ci informa che l'account è in fase di creazione. In realtà possono essere necessari alcuni minuti per configurare le cose per un nuovo account mentre DocumentDB alloca l'endpoint, effettua il provisioning delle repliche ed esegue altre operazioni in background.
Una volta terminato, vedrai la dashboard.
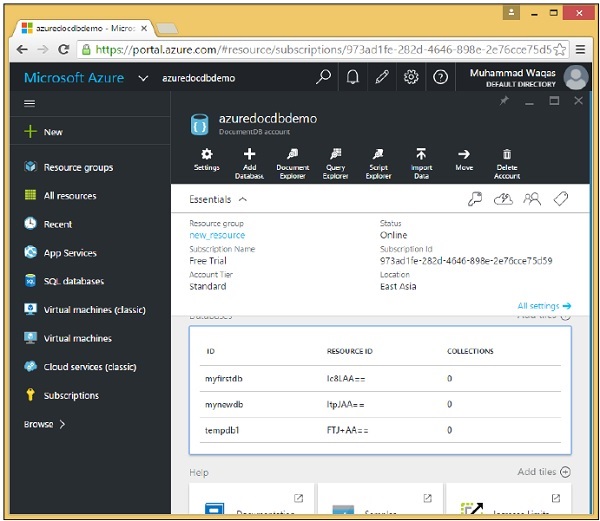
Step 7 - Ora fai clic sull'account DocumentDB creato e vedrai una schermata dettagliata come l'immagine seguente.
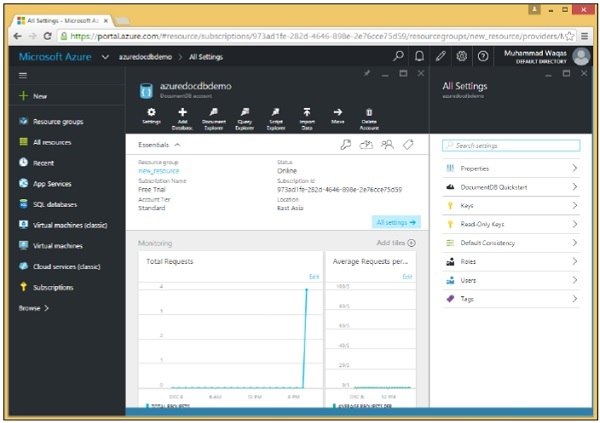
Quando inizi a programmare con DocumentDB, il primo passo è connettersi. Quindi per connetterti al tuo account DocumentDB avrai bisogno di due cose;
- Endpoint
- Chiave di autorizzazione
Endpoint
L'endpoint è l'URL del tuo account DocumentDB ed è costruito combinando il nome dell'account DocumentDB con .documents.azure.com. Andiamo alla dashboard.
Ora, fai clic sull'account DocumentDB creato. Vedrai i dettagli come mostrato nell'immagine seguente.
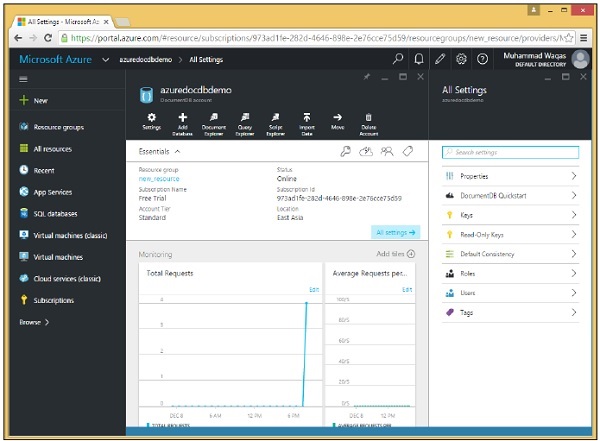
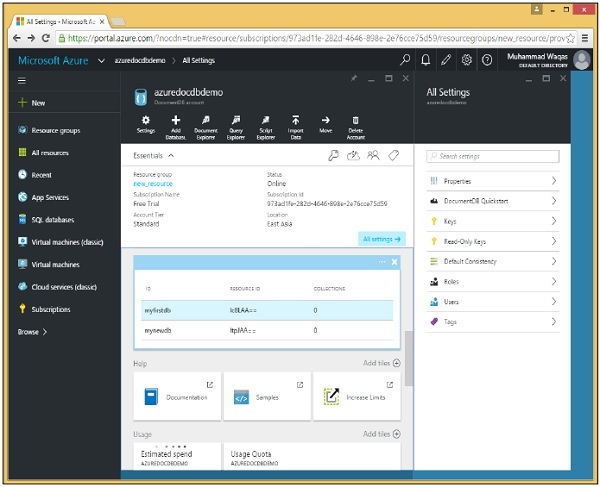
Quando selezioni l'opzione "Chiavi", verranno visualizzate informazioni aggiuntive come mostrato nell'immagine seguente. Vedrai anche l'URL del tuo account DocumentDB, che puoi utilizzare come endpoint.
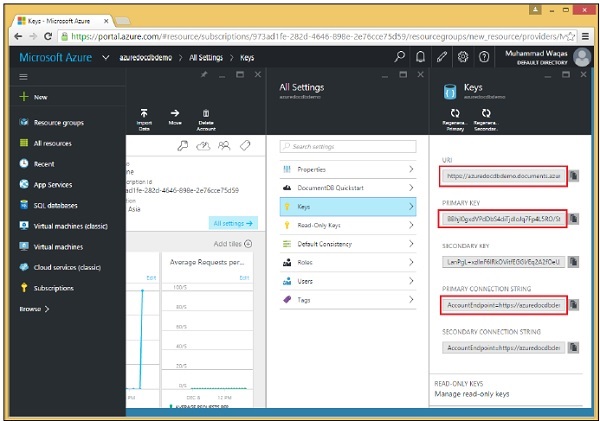
Chiave di autorizzazione
La chiave di autorizzazione contiene le tue credenziali e ci sono due tipi di chiavi. La chiave principale consente l'accesso completo a tutte le risorse all'interno dell'account, mentre i token delle risorse consentono un accesso limitato a risorse specifiche.
Chiavi principali
Non c'è niente che non puoi fare con una chiave principale. Puoi spazzare via l'intero database, se lo desideri, utilizzando la chiave principale.
Per questo motivo, sicuramente non vuoi condividere la chiave principale o distribuirla agli ambienti client. Come misura di sicurezza aggiuntiva, è una buona idea cambiarla frequentemente.
In realtà ci sono due chiavi principali per ogni account di database, la primaria e la secondaria come evidenziato nello screenshot sopra.
Token di risorse
Puoi anche utilizzare token risorsa invece di una chiave principale.
Le connessioni basate sui token di risorse possono accedere solo alle risorse specificate dai token e non ad altre risorse.
I token di risorsa si basano sulle autorizzazioni dell'utente, quindi prima crei uno o più utenti e questi vengono definiti a livello di database.
Si creano una o più autorizzazioni per ogni utente, in base alle risorse a cui si desidera consentire a ciascun utente di accedere.
Ogni autorizzazione genera un token di risorsa che consente l'accesso in sola lettura o completo a una determinata risorsa e che può essere qualsiasi risorsa utente all'interno del database.
Andiamo all'applicazione console creata nel capitolo 3.
Step 1 - Aggiungere i seguenti riferimenti nel file Program.cs.
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;Step 2- Ora aggiungi l'URL dell'endpoint e la chiave di autorizzazione. In questo esempio useremo la chiave primaria come chiave di autorizzazione.
Tieni presente che nel tuo caso sia l'URL dell'endpoint che la chiave di autorizzazione dovrebbero essere diversi.
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";Step 3 - Crea una nuova istanza di DocumentClient in un'attività asincrona chiamata CreateDocumentClient e crea un'istanza del nuovo DocumentClient.
Step 4 - Chiama la tua attività asincrona dal tuo metodo Main.
Di seguito è riportato il file Program.cs completo finora.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;
namespace DocumentDBDemo {
class Program {
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey = "BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/
StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
static void Main(string[] args) {
try {
CreateDocumentClient().Wait();
} catch (Exception e) {
Exception baseException = e.GetBaseException();
Console.WriteLine("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
Console.ReadKey();
}
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey);
}
}
}In questo capitolo abbiamo imparato come connetterci a un account DocumentDB e creare un'istanza della classe DocumentClient.
In questo capitolo impareremo come creare un database. Per usare Microsoft Azure DocumentDB, è necessario disporre di un account DocumentDB, un database, una raccolta e documenti. Abbiamo già un account DocumentDB, ora per creare il database abbiamo due opzioni:
- Portale Microsoft Azure o
- .Net SDK
Creare un database per DocumentDB utilizzando il portale di Microsoft Azure
Per creare un database utilizzando il portale, di seguito sono riportati i passaggi.
Step 1 - Accedi al portale di Azure e vedrai il dashboard.
Step 2 - Ora fai clic sull'account DocumentDB creato e vedrai i dettagli come mostrato nello screenshot seguente.

Step 3 - Seleziona l'opzione Aggiungi database e fornisci l'ID per il tuo database.
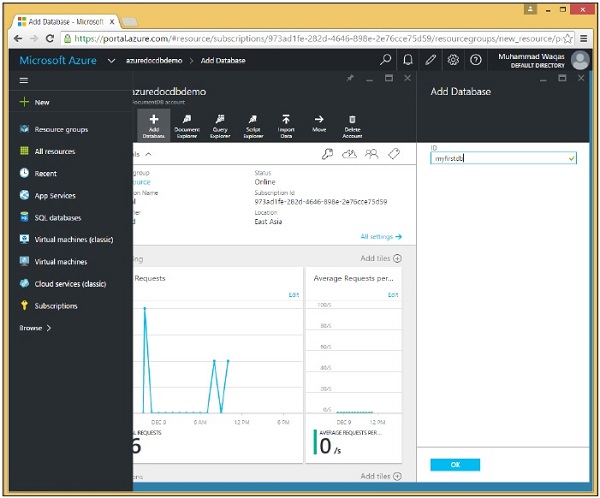
Step 4 - Fare clic su OK.
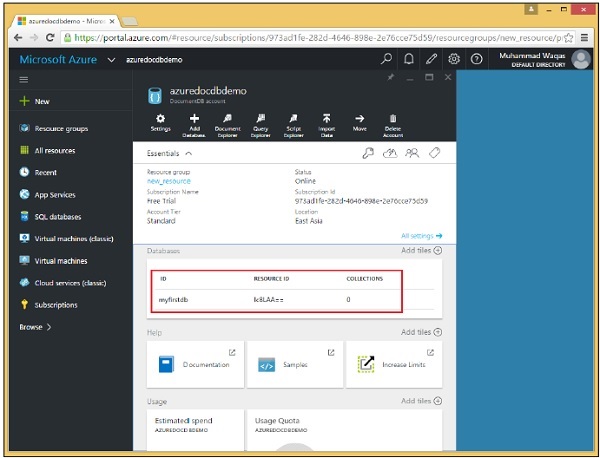
Puoi vedere che il database è stato aggiunto. Al momento, non ha raccolte, ma possiamo aggiungere raccolte in seguito, che sono i contenitori che memorizzeranno i nostri documenti JSON. Notare che ha sia un ID che un ID risorsa.
Creare un database per DocumentDB utilizzando .Net SDK
Per creare un database utilizzando .Net SDK, di seguito sono riportati i passaggi.
Step 1 - Apri l'applicazione console in Visual Studio dall'ultimo capitolo.
Step 2- Crea il nuovo database creando un nuovo oggetto database. Per creare un nuovo database, dobbiamo solo assegnare la proprietà Id, che stiamo impostando su "mynewdb" in un'attività CreateDatabase.
private async static Task CreateDatabase(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("******** Create Database *******");
var databaseDefinition = new Database { Id = "mynewdb" };
var result = await client.CreateDatabaseAsync(databaseDefinition);
var database = result.Resource;
Console.WriteLine(" Database Id: {0}; Rid: {1}", database.Id, database.ResourceId);
Console.WriteLine("******** Database Created *******");
}Step 3- Ora passa questo databaseDefinition a CreateDatabaseAsync e ottieni un risultato con una proprietà Resource. Tutti i metodi di creazione dell'oggetto restituiscono una proprietà Resource che descrive l'elemento che è stato creato, che in questo caso è un database.
Otteniamo il nuovo oggetto di database dalla proprietà Resource e viene visualizzato sulla console insieme all'ID risorsa che DocumentDB gli ha assegnato.
Step 4 - Ora chiama l'attività CreateDatabase dall'attività CreateDocumentClient dopo l'istanza di DocumentClient.
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
await CreateDatabase(client);
}Di seguito è riportato il file Program.cs completo finora.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;
namespace DocumentDBDemo {
class Program {
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey = "BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/
StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
static void Main(string[] args) {
try {
CreateDocumentClient().Wait();
} catch (Exception e) {
Exception baseException = e.GetBaseException();
Console.WriteLine("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
Console.ReadKey();
}
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
await CreateDatabase(client);
}
}
private async static Task CreateDatabase(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("******** Create Database *******");
var databaseDefinition = new Database { Id = "mynewdb" };
var result = await client.CreateDatabaseAsync(databaseDefinition);
var database = result.Resource;
Console.WriteLine(" Database Id: {0}; Rid: {1}", database.Id, database.ResourceId);
Console.WriteLine("******** Database Created *******");
}
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output che contiene gli ID database e risorse.
******** Create Database *******
Database Id: mynewdb; Rid: ltpJAA==
******** Database Created *******Finora, abbiamo creato due database nel nostro account DocumentDB, il primo viene creato utilizzando il portale di Azure mentre il secondo database viene creato utilizzando .Net SDK. Ora per visualizzare questi database, puoi usare il portale di Azure.
Vai al tuo account DocumentDB sul portale di Azure e ora vedrai due database.
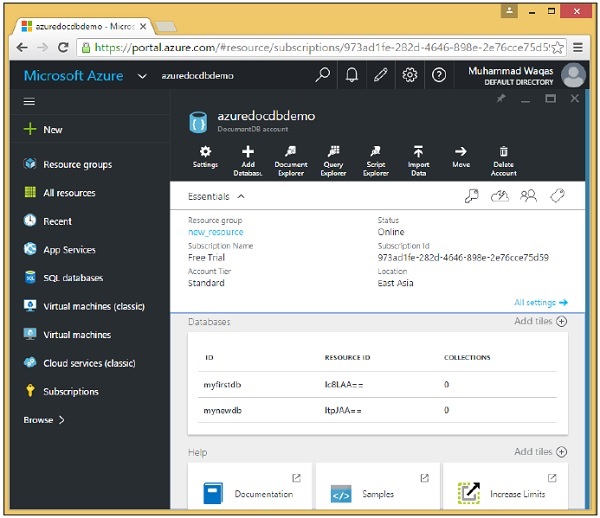
È inoltre possibile visualizzare o elencare i database dal codice utilizzando .Net SDK. Di seguito sono riportati i passaggi coinvolti.
Step 1 - Emetti una query di database senza parametri che restituisce un elenco completo, ma puoi anche passare una query per cercare un database specifico o database specifici.
private static void GetDatabases(DocumentClient client) {
Console.WriteLine();
Console.WriteLine();
Console.WriteLine("******** Get Databases List ********");
var databases = client.CreateDatabaseQuery().ToList();
foreach (var database in databases) {
Console.WriteLine(" Database Id: {0}; Rid: {1}", database.Id, database.ResourceId);
}
Console.WriteLine();
Console.WriteLine("Total databases: {0}", databases.Count);
}Vedrai che esistono molti di questi metodi CreateQuery per individuare raccolte, documenti, utenti e altre risorse. Questi metodi non eseguono effettivamente la query, definiscono semplicemente la query e restituiscono un oggetto iterabile.
È la chiamata a ToList () che esegue effettivamente la query, itera i risultati e li restituisce in un elenco.
Step 2 - Chiama il metodo GetDatabases dall'attività CreateDocumentClient dopo l'istanza di DocumentClient.
Step 3 - È inoltre necessario commentare l'attività CreateDatabase o modificare l'ID del database, altrimenti verrà visualizzato un messaggio di errore relativo all'esistenza del database.
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
//await CreateDatabase(client);
GetDatabases(client);
}Di seguito è riportato il file Program.cs completo finora.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;
namespace DocumentDBDemo {
class Program {
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey = "BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/
StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
static void Main(string[] args) {
try {
CreateDocumentClient().Wait();
} catch (Exception e) {
Exception baseException = e.GetBaseException();
Console.WriteLine("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
Console.ReadKey();
}
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
await CreateDatabase(client);
GetDatabases(client);
}
}
private async static Task CreateDatabase(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("******** Create Database *******");
var databaseDefinition = new Database { Id = "mynewdb" };
var result = await client.CreateDatabaseAsync(databaseDefinition);
var database = result.Resource;
Console.WriteLine(" Database Id: {0}; Rid: {1}", database.Id, database.ResourceId);
Console.WriteLine("******** Database Created *******");
}
private static void GetDatabases(DocumentClient client) {
Console.WriteLine();
Console.WriteLine();
Console.WriteLine("******** Get Databases List ********");
var databases = client.CreateDatabaseQuery().ToList();
foreach (var database in databases) {
Console.WriteLine(" Database Id: {0}; Rid: {1}",
database.Id, database.ResourceId);
}
Console.WriteLine();
Console.WriteLine("Total databases: {0}", databases.Count);
}
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output che contiene gli ID database e risorse di entrambi i database. Alla fine vedrai anche il numero totale di database.
******** Get Databases List ********
Database Id: myfirstdb; Rid: Ic8LAA==
Database Id: mynewdb; Rid: ltpJAA==
Total databases: 2È possibile eliminare uno o più database dal portale oltre che dal codice utilizzando .Net SDK. Qui discuteremo, in modo graduale, come rilasciare un database in DocumentDB.
Step 1- Vai al tuo account DocumentDB nel portale di Azure. Ai fini della demo, ho aggiunto altri due database come mostrato nello screenshot seguente.
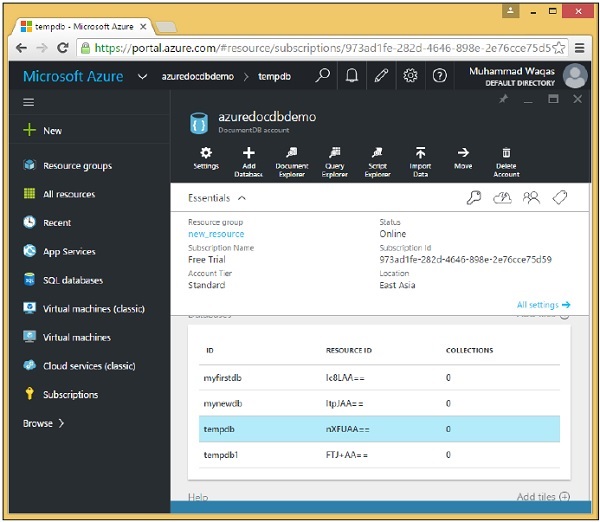
Step 2- Per eliminare qualsiasi database, è necessario fare clic su quel database. Selezioniamo tempdb, vedrai la pagina seguente, seleziona l'opzione 'Elimina database'.
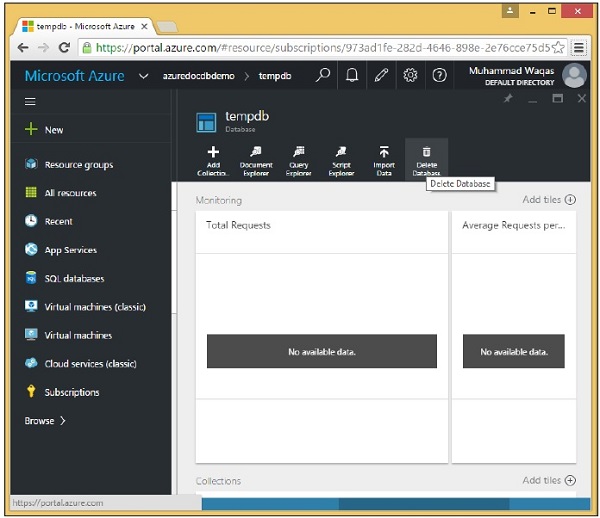
Step 3 - Verrà visualizzato il messaggio di conferma, ora fare clic sul pulsante "Sì".
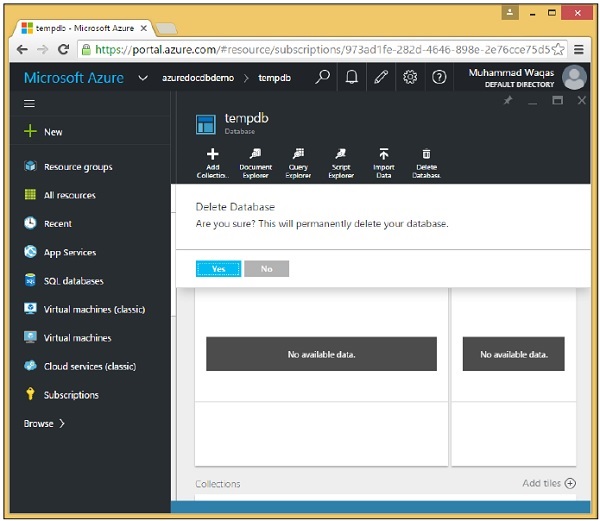
Vedrai che tempdb non è più disponibile nella tua dashboard.
È inoltre possibile eliminare i database dal codice utilizzando .Net SDK. Di seguito sono riportati i passaggi.
Step 1 - Eliminiamo il database specificando l'ID del database che vogliamo eliminare, ma abbiamo bisogno del suo SelfLink.
Step 2 - Stiamo chiamando CreateDatabaseQuery come prima, ma questa volta stiamo effettivamente fornendo una query per restituire solo un database con l'ID tempdb1.
private async static Task DeleteDatabase(DocumentClient client) {
Console.WriteLine("******** Delete Database ********");
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'tempdb1'")
.AsEnumerable()
.First();
await client.DeleteDatabaseAsync(database.SelfLink);
}Step 3- Questa volta, possiamo chiamare AsEnumerable invece di ToList () perché in realtà non abbiamo bisogno di un oggetto elenco. Aspettandosi solo il risultato, è sufficiente chiamare AsEnumerable in modo da poter ottenere il primo oggetto di database restituito dalla query con First (). Questo è l'oggetto database per tempdb1 e ha un SelfLink che possiamo usare per chiamare DeleteDatabaseAsync che elimina il database.
Step 4 - È inoltre necessario chiamare l'attività DeleteDatabase dall'attività CreateDocumentClient dopo l'istanza di DocumentClient.
Step 5 - Per visualizzare l'elenco dei database dopo aver eliminato il database specificato, richiamiamo nuovamente il metodo GetDatabases.
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
//await CreateDatabase(client);
GetDatabases(client);
await DeleteDatabase(client);
GetDatabases(client);
}Di seguito è riportato il file Program.cs completo finora.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;
namespace DocumentDBDemo {
class Program {
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey = "BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/
StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
static void Main(string[] args) {
try {
CreateDocumentClient().Wait();
} catch (Exception e) {
Exception baseException = e.GetBaseException();
Console.WriteLine("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
Console.ReadKey();
}
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
//await CreateDatabase(client);
GetDatabases(client);
await DeleteDatabase(client);
GetDatabases(client);
}
}
private async static Task CreateDatabase(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("******** Create Database *******");
var databaseDefinition = new Database { Id = "mynewdb" };
var result = await client.CreateDatabaseAsync(databaseDefinition);
var database = result.Resource;
Console.WriteLine(" Database Id: {0}; Rid: {1}",
database.Id, database.ResourceId);
Console.WriteLine("******** Database Created *******");
}
private static void GetDatabases(DocumentClient client) {
Console.WriteLine();
Console.WriteLine();
Console.WriteLine("******** Get Databases List ********");
var databases = client.CreateDatabaseQuery().ToList();
foreach (var database in databases) {
Console.WriteLine(" Database Id: {0}; Rid: {1}", database.Id,
database.ResourceId);
}
Console.WriteLine();
Console.WriteLine("Total databases: {0}", databases.Count);
}
private async static Task DeleteDatabase(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("******** Delete Database ********");
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'tempdb1'")
.AsEnumerable()
.First();
await client.DeleteDatabaseAsync(database.SelfLink);
}
}
}Quando il codice precedente viene compilato ed eseguito, si riceverà il seguente output che contiene gli ID database e risorse dei tre database e il numero totale di database.
******** Get Databases List ********
Database Id: myfirstdb; Rid: Ic8LAA==
Database Id: mynewdb; Rid: ltpJAA==
Database Id: tempdb1; Rid: 06JjAA==
Total databases: 3
******** Delete Database ********
******** Get Databases List ********
Database Id: myfirstdb; Rid: Ic8LAA==
Database Id: mynewdb; Rid: ltpJAA==
Total databases: 2Dopo aver eliminato il database, vedrai anche alla fine che nell'account DocumentDB sono rimasti solo due database.
In questo capitolo impareremo come creare una raccolta. È simile alla creazione di un database. È possibile creare una raccolta dal portale o dal codice utilizzando .Net SDK.
Step 1 - Vai alla dashboard principale nel portale di Azure.
Step 2 - Seleziona myfirstdb dall'elenco dei database.
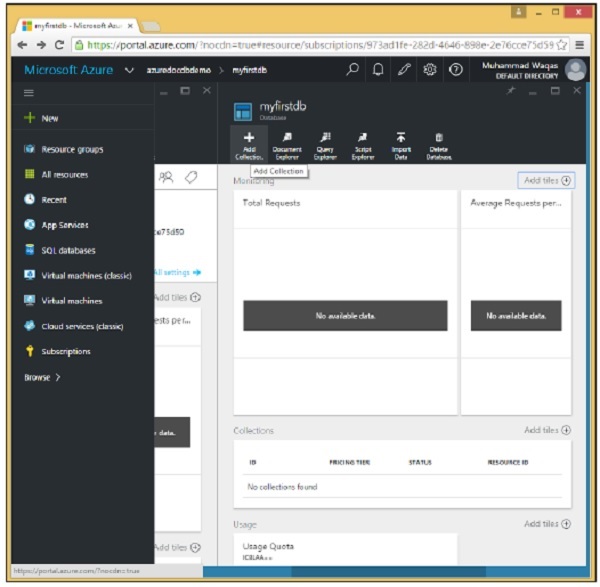
Step 3- Fare clic sull'opzione "Aggiungi raccolta" e specificare l'ID per la raccolta. Seleziona il livello di prezzo per un'opzione diversa.
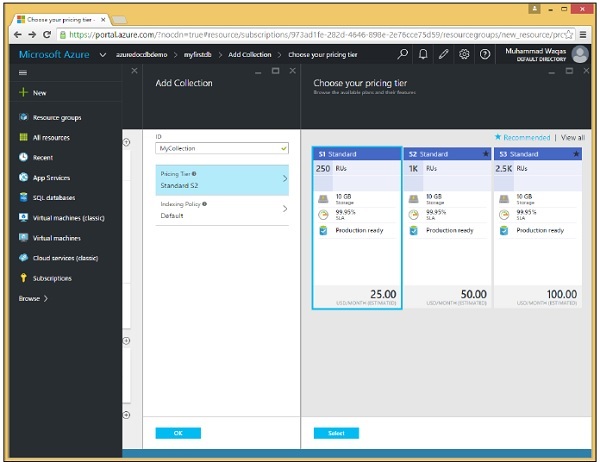
Step 4 - Selezionare S1 Standard e fare clic su Seleziona → pulsante OK.
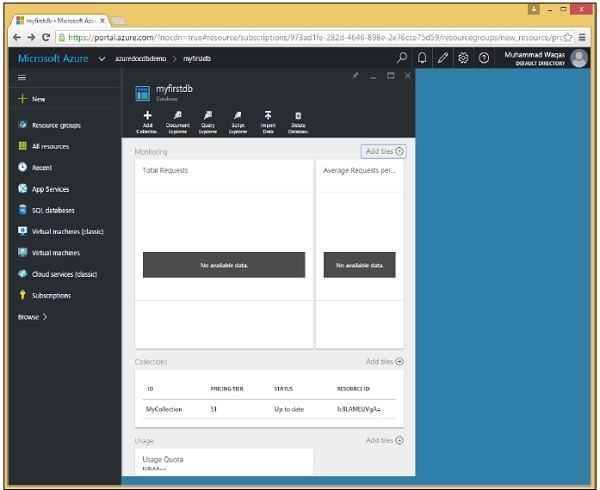
Come puoi vedere, MyCollection viene aggiunto al myfirstdb.
È inoltre possibile creare una raccolta dal codice utilizzando .Net SDK. Diamo un'occhiata ai seguenti passaggi per aggiungere raccolte dal codice.
Step 1 - Apri l'applicazione Console in Visual Studio.
Step 2 - Per creare una raccolta, recuperare prima il database myfirstdb tramite il suo ID nell'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
await CreateCollection(client, "MyCollection1");
await CreateCollection(client, "MyCollection2", "S2");
}
}Di seguito è riportata l'implementazione per l'attività CreateCollection.
private async static Task CreateCollection(DocumentClient client, string collectionId,
string offerType = "S1") {
Console.WriteLine();
Console.WriteLine("**** Create Collection {0} in {1} ****", collectionId, database.Id);
var collectionDefinition = new DocumentCollection { Id = collectionId };
var options = new RequestOptions { OfferType = offerType };
var result = await client.CreateDocumentCollectionAsync(database.SelfLink,
collectionDefinition, options);
var collection = result.Resource;
Console.WriteLine("Created new collection");
ViewCollection(collection);
}Creiamo un nuovo oggetto DocumentCollection che definisce la nuova raccolta con l'ID desiderato per il metodo CreateDocumentCollectionAsync che accetta anche un parametro di opzioni che stiamo usando qui per impostare il livello di prestazioni della nuova raccolta, che chiamiamo offerType.
Il valore predefinito è S1 e poiché non abbiamo passato un offerType, per MyCollection1, quindi questa sarà una raccolta S1 e per MyCollection2 abbiamo superato S2 che rende questo un S2 come mostrato sopra.
Di seguito è riportata l'implementazione del metodo ViewCollection.
private static void ViewCollection(DocumentCollection collection) {
Console.WriteLine("Collection ID: {0} ", collection.Id);
Console.WriteLine("Resource ID: {0} ", collection.ResourceId);
Console.WriteLine("Self Link: {0} ", collection.SelfLink);
Console.WriteLine("Documents Link: {0} ", collection.DocumentsLink);
Console.WriteLine("UDFs Link: {0} ", collection.UserDefinedFunctionsLink);
Console.WriteLine(" StoredProcs Link: {0} ", collection.StoredProceduresLink);
Console.WriteLine("Triggers Link: {0} ", collection.TriggersLink);
Console.WriteLine("Timestamp: {0} ", collection.Timestamp);
}Di seguito è riportata l'implementazione completa del file program.cs per le raccolte.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;
namespace DocumentDBDemo {
class Program {
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey = "BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/
StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
private static Database database;
static void Main(string[] args) {
try {
CreateDocumentClient().Wait();
} catch (Exception e) {
Exception baseException = e.GetBaseException();
Console.WriteLine("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
Console.ReadKey();
}
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
await CreateCollection(client, "MyCollection1");
await CreateCollection(client, "MyCollection2", "S2");
//await CreateDatabase(client);
//GetDatabases(client);
//await DeleteDatabase(client);
//GetDatabases(client);
}
}
private async static Task CreateCollection(DocumentClient client,
string collectionId, string offerType = "S1") {
Console.WriteLine();
Console.WriteLine("**** Create Collection {0} in {1} ****", collectionId,
database.Id);
var collectionDefinition = new DocumentCollection { Id = collectionId };
var options = new RequestOptions { OfferType = offerType };
var result = await
client.CreateDocumentCollectionAsync(database.SelfLink,
collectionDefinition, options);
var collection = result.Resource;
Console.WriteLine("Created new collection");
ViewCollection(collection);
}
private static void ViewCollection(DocumentCollection collection) {
Console.WriteLine("Collection ID: {0} ", collection.Id);
Console.WriteLine("Resource ID: {0} ", collection.ResourceId);
Console.WriteLine("Self Link: {0} ", collection.SelfLink);
Console.WriteLine("Documents Link: {0} ", collection.DocumentsLink);
Console.WriteLine("UDFs Link: {0} ", collection.UserDefinedFunctionsLink);
Console.WriteLine("StoredProcs Link: {0} ", collection.StoredProceduresLink);
Console.WriteLine("Triggers Link: {0} ", collection.TriggersLink);
Console.WriteLine("Timestamp: {0} ", collection.Timestamp);
}
}
}Quando il codice sopra viene compilato ed eseguito, riceverai il seguente output che contiene tutte le informazioni relative alla raccolta.
**** Create Collection MyCollection1 in myfirstdb ****
Created new collection
Collection ID: MyCollection1
Resource ID: Ic8LAPPvnAA=
Self Link: dbs/Ic8LAA==/colls/Ic8LAPPvnAA=/
Documents Link: dbs/Ic8LAA==/colls/Ic8LAPPvnAA=/docs/
UDFs Link: dbs/Ic8LAA==/colls/Ic8LAPPvnAA=/udfs/
StoredProcs Link: dbs/Ic8LAA==/colls/Ic8LAPPvnAA=/sprocs/
Triggers Link: dbs/Ic8LAA==/colls/Ic8LAPPvnAA=/triggers/
Timestamp: 12/10/2015 4:55:36 PM
**** Create Collection MyCollection2 in myfirstdb ****
Created new collection
Collection ID: MyCollection2
Resource ID: Ic8LAKGHDwE=
Self Link: dbs/Ic8LAA==/colls/Ic8LAKGHDwE=/
Documents Link: dbs/Ic8LAA==/colls/Ic8LAKGHDwE=/docs/
UDFs Link: dbs/Ic8LAA==/colls/Ic8LAKGHDwE=/udfs/
StoredProcs Link: dbs/Ic8LAA==/colls/Ic8LAKGHDwE=/sprocs/
Triggers Link: dbs/Ic8LAA==/colls/Ic8LAKGHDwE=/triggers/
Timestamp: 12/10/2015 4:55:38 PMPer eliminare la raccolta o le raccolte è possibile eseguire la stessa operazione dal portale e dal codice utilizzando .Net SDK.
Step 1- Vai al tuo account DocumentDB nel portale di Azure. Ai fini della demo, ho aggiunto altre due raccolte come mostrato nello screenshot seguente.
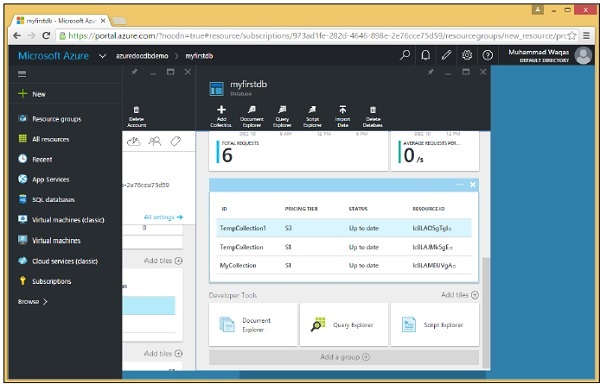
Step 2- Per eliminare qualsiasi raccolta, è necessario fare clic su quella raccolta. Selezioniamo TempCollection1. Vedrai la pagina seguente, seleziona l'opzione "Elimina raccolta".
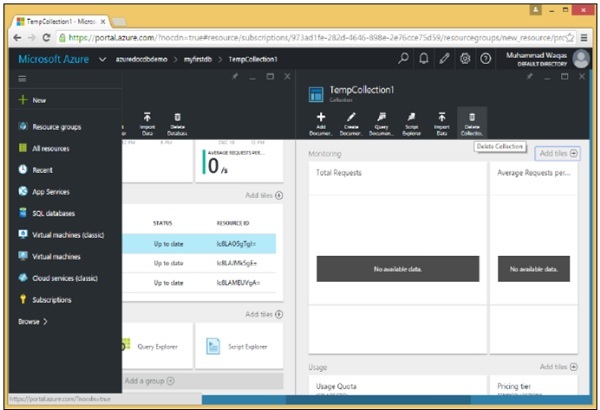
Step 3- Verrà visualizzato il messaggio di conferma. Ora fai clic sul pulsante "Sì".
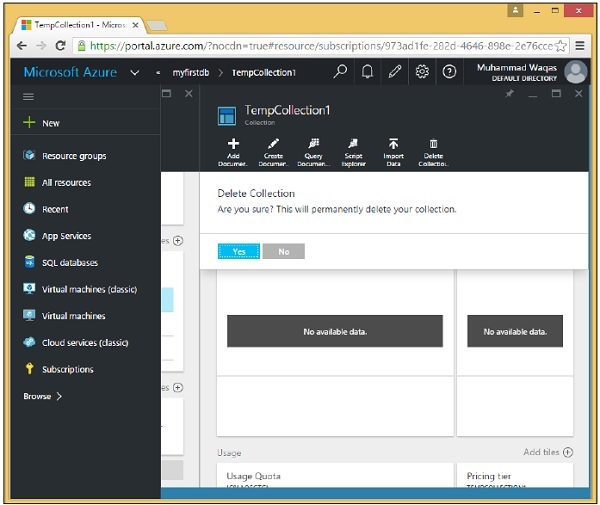
Vedrai che TempCollection1 non è più disponibile sulla tua dashboard.
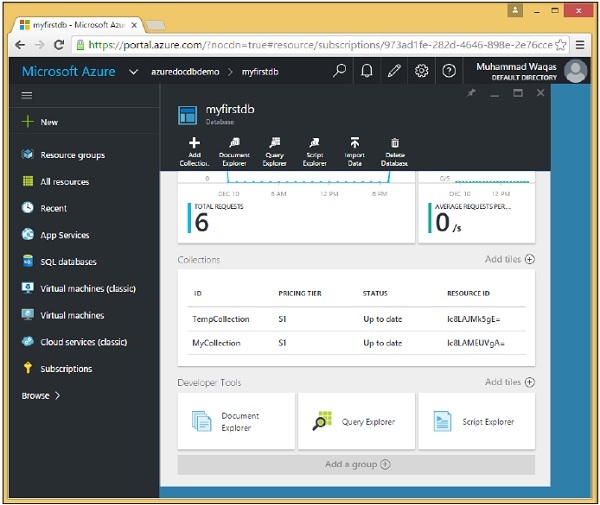
È inoltre possibile eliminare raccolte dal codice utilizzando .Net SDK. Per fare ciò, di seguito sono riportati i passaggi seguenti.
Step 1 - Eliminiamo la raccolta specificando l'ID della raccolta che vogliamo eliminare.
È il solito modello di interrogazione da parte dell'ID per ottenere i collegamenti automatici necessari per eliminare una risorsa.
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine("**** Delete Collection {0} in {1} ****", collectionId, database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection {
new SqlParameter {
Name = "@id", Value = collectionId
}
}
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}", collectionId,
database.Id);
}Qui vediamo il modo preferito di costruire una query con parametri. Non stiamo codificando l'ID di raccolta, quindi questo metodo può essere utilizzato per eliminare qualsiasi raccolta. Stiamo interrogando per una raccolta specifica per Id in cui il parametro Id è definito in questo SqlParameterCollection assegnato alla proprietà del parametro di questo SqlQuerySpec.
Quindi l'SDK esegue il lavoro di costruzione della stringa di query finale per DocumentDB con collectionId incorporato al suo interno.
Step 2 - Eseguire la query e quindi utilizzare il suo SelfLink per eliminare la raccolta dall'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "TempCollection");
}
}Di seguito è riportata l'implementazione completa del file Program.cs.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using Newtonsoft.Json;
namespace DocumentDBDemo {
class Program {
private const string EndpointUrl = "https://azuredocdbdemo.documents.azure.com:443/";
private const string AuthorizationKey = "BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/
StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
private static Database database;
static void Main(string[] args) {
try {
CreateDocumentClient().Wait();
} catch (Exception e) {
Exception baseException = e.GetBaseException();
Console.WriteLine("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
Console.ReadKey();
}
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "TempCollection");
//await CreateCollection(client, "MyCollection1");
//await CreateCollection(client, "MyCollection2", "S2");
////await CreateDatabase(client);
//GetDatabases(client);
//await DeleteDatabase(client);
//GetDatabases(client);
}
}
private async static Task CreateCollection(DocumentClient client,
string collectionId, string offerType = "S1") {
Console.WriteLine();
Console.WriteLine("**** Create Collection {0} in {1} ****", collectionId,
database.Id);
var collectionDefinition = new DocumentCollection { Id = collectionId };
var options = new RequestOptions { OfferType = offerType };
var result = await client.CreateDocumentCollectionAsync(database.SelfLink,
collectionDefinition, options);
var collection = result.Resource;
Console.WriteLine("Created new collection");
ViewCollection(collection);
}
private static void ViewCollection(DocumentCollection collection) {
Console.WriteLine("Collection ID: {0} ", collection.Id);
Console.WriteLine("Resource ID: {0} ", collection.ResourceId);
Console.WriteLine("Self Link: {0} ", collection.SelfLink);
Console.WriteLine("Documents Link: {0} ", collection.DocumentsLink);
Console.WriteLine("UDFs Link: {0} ", collection.UserDefinedFunctionsLink);
Console.WriteLine("StoredProcs Link: {0} ", collection.StoredProceduresLink);
Console.WriteLine("Triggers Link: {0} ", collection.TriggersLink);
Console.WriteLine("Timestamp: {0} ", collection.Timestamp);
}
private async static Task DeleteCollection(DocumentClient client,
string collectionId) {
Console.WriteLine();
Console.WriteLine("**** Delete Collection {0} in {1} ****", collectionId,
database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id", Parameters = new
SqlParameterCollection {
new SqlParameter {
Name = "@id", Value = collectionId
}
}
};
DocumentCollection collection = client.CreateDocumentCollectionQuery
(database.SelfLink, query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}", collectionId,
database.Id);
}
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Delete Collection TempCollection in myfirstdb ****
Deleted collection TempCollection from database myfirstdbIn questo capitolo lavoreremo con i documenti effettivi di una raccolta. È possibile creare documenti usando il portale di Azure o .Net SDK.
Creazione di documenti con il portale di Azure
Diamo un'occhiata ai seguenti passaggi per aggiungere un documento alla tua raccolta.
Step 1 - Aggiungi una nuova raccolta Famiglie del piano tariffario S1 in myfirstdb.
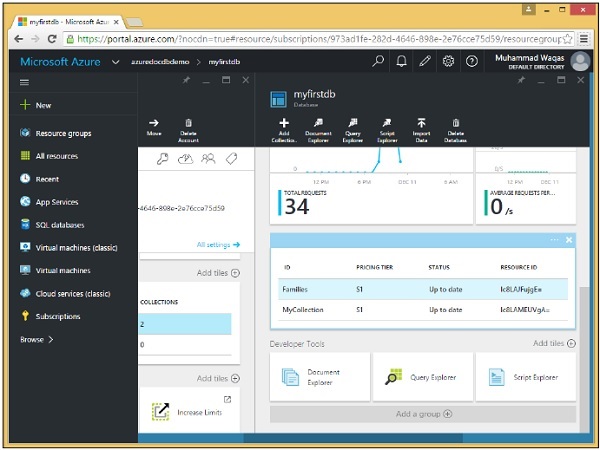
Step 2 - Seleziona la raccolta Famiglie e fai clic sull'opzione Crea documento per aprire il pannello Nuovo documento.
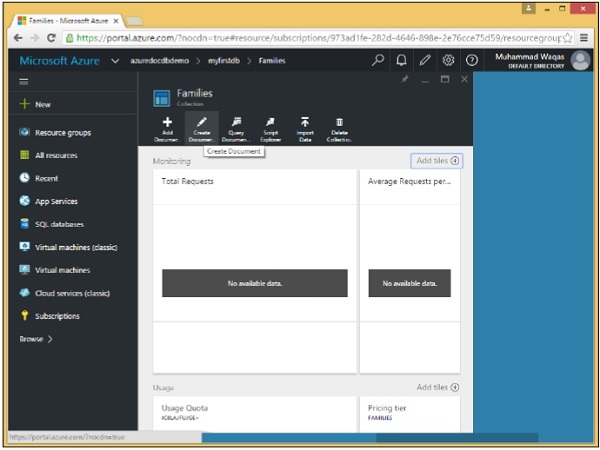
Questo è solo un semplice editor di testo che ti consente di digitare qualsiasi JSON per un nuovo documento.
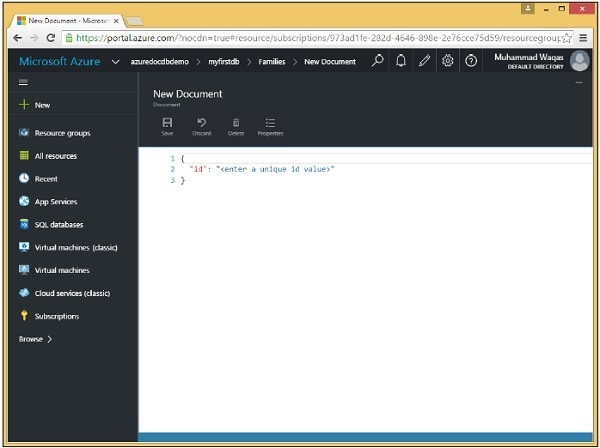
Step 3 - Poiché si tratta di immissione di dati grezzi, inseriamo il nostro primo documento.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle"},
"isRegistered": true
}Quando si accede al documento sopra, verrà visualizzata la seguente schermata.
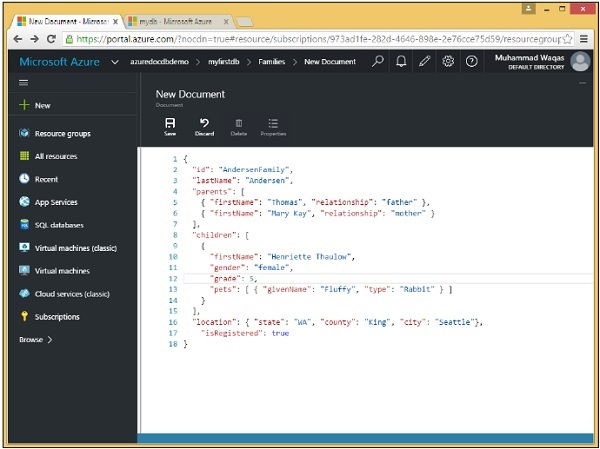
Notare che abbiamo fornito un ID per il documento. Il valore id è sempre obbligatorio e deve essere univoco in tutti gli altri documenti nella stessa raccolta. Quando lo lasci fuori, DocumentDB ne genererà automaticamente uno per te utilizzando un GUID o un identificatore univoco globale.
L'id è sempre una stringa e non può essere un numero, una data, un valore booleano o un altro oggetto e non può essere più lungo di 255 caratteri.
Notare anche la struttura gerarchica del documento che ha alcune proprietà di primo livello come l'id richiesto, nonché lastName e isRegistered, ma ha anche proprietà nidificate.
Ad esempio, la proprietà genitori viene fornita come matrice JSON come indicato dalle parentesi quadre. Abbiamo anche un altro array per i bambini, anche se c'è un solo figlio nell'array in questo esempio.
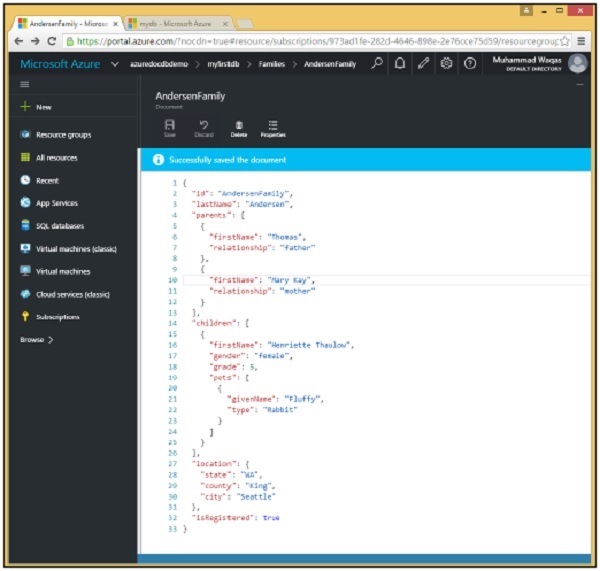
Step 4 - Fare clic sul pulsante "Salva" per salvare il documento e abbiamo creato il nostro primo documento.
Come puoi vedere, al nostro JSON è stata applicata una formattazione carina, che suddivide ogni proprietà sulla propria riga indentata con uno spazio bianco per trasmettere il livello di nidificazione di ciascuna proprietà.
Il portale include un Document Explorer, quindi usiamolo ora per recuperare il documento che abbiamo appena creato.
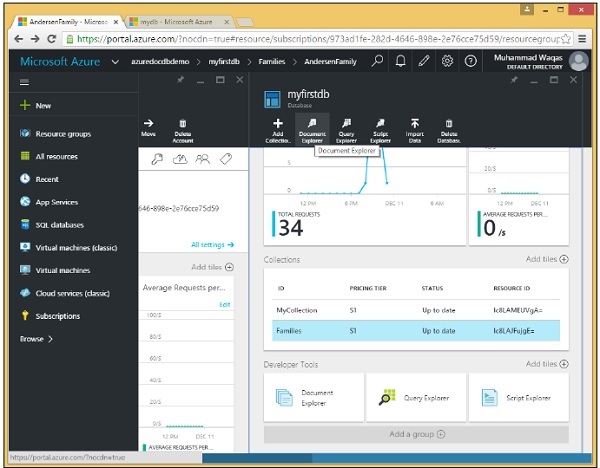
Step 5- Scegli un database e qualsiasi raccolta all'interno del database per visualizzare i documenti in quella raccolta. Al momento abbiamo un solo database chiamato myfirstdb con una raccolta chiamata Famiglie, entrambe preselezionate qui nei menu a discesa.
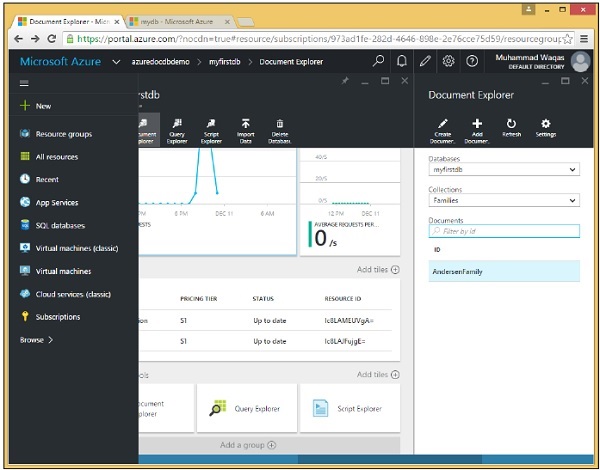
Per impostazione predefinita, Document Explorer visualizza un elenco non filtrato di documenti all'interno della raccolta, ma puoi anche cercare qualsiasi documento specifico per ID o più documenti in base a una ricerca con caratteri jolly di un ID parziale.
Finora abbiamo un solo documento nella nostra raccolta e vediamo il suo ID nella schermata seguente, AndersonFamily.
Step 6 - Fare clic sull'ID per visualizzare il documento.
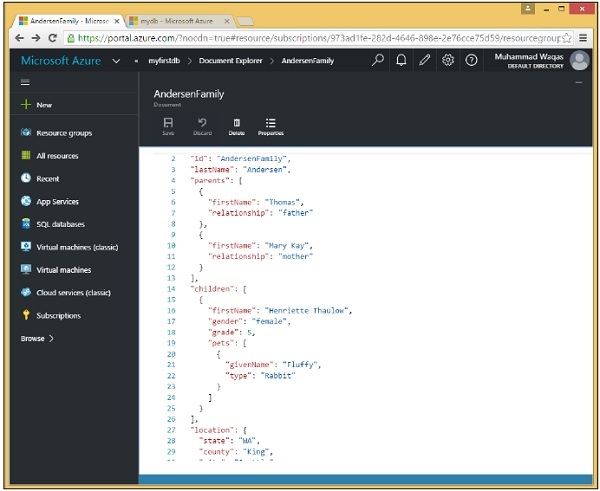
Creazione di documenti con .NET SDK
Come sai che i documenti sono solo un altro tipo di risorsa e hai già acquisito familiarità con come trattare le risorse utilizzando l'SDK.
L'unica grande differenza tra i documenti e le altre risorse è che, ovviamente, sono privi di schemi.
Quindi ci sono molte opzioni. Naturalmente, puoi lavorare solo con grafici a oggetti JSON o anche stringhe non elaborate di testo JSON, ma puoi anche utilizzare oggetti dinamici che ti consentono di collegarti a proprietà in fase di esecuzione senza definire una classe in fase di compilazione.
È inoltre possibile lavorare con oggetti C # reali, o entità come vengono chiamate, che potrebbero essere le classi del dominio aziendale.
Cominciamo a creare documenti usando .Net SDK. Di seguito sono riportati i passaggi.
Step 1 - Istanziare DocumentClient, quindi interrogheremo il database myfirstdb e quindi interrogheremo la raccolta MyCollection, che memorizziamo in questa raccolta di variabili private in modo che sia accessibile in tutta la classe.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
await CreateDocuments(client);
}
}Step 2 - Crea alcuni documenti nell'attività CreateDocuments.
private async static Task CreateDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents ****");
Console.WriteLine();
dynamic document1Definition = new {
name = "New Customer 1", address = new {
addressType = "Main Office",
addressLine1 = "123 Main Street",
location = new {
city = "Brooklyn", stateProvinceName = "New York"
}, postalCode = "11229", countryRegionName = "United States"
},
};
Document document1 = await CreateDocument(client, document1Definition);
Console.WriteLine("Created document {0} from dynamic object", document1.Id);
Console.WriteLine();
}Il primo documento verrà generato da questo oggetto dinamico. Potrebbe sembrare JSON, ma ovviamente non lo è. Questo è codice C # e stiamo creando un vero oggetto .NET, ma non esiste una definizione di classe. Le proprietà vengono invece dedotte dal modo in cui viene inizializzato l'oggetto.
Si noti che non abbiamo fornito una proprietà Id per questo documento.
Ora diamo uno sguardo a CreateDocument. Sembra lo stesso modello che abbiamo visto per la creazione di database e raccolte.
private async static Task<Document> CreateDocument(DocumentClient client,
object documentObject) {
var result = await client.CreateDocumentAsync(collection.SelfLink, documentObject);
var document = result.Resource;
Console.WriteLine("Created new document: {0}\r\n{1}", document.Id, document);
return result;
}Step 3- Questa volta chiamiamo CreateDocumentAsync specificando il SelfLink della raccolta a cui vogliamo aggiungere il documento. Riceviamo una risposta con una proprietà della risorsa che, in questo caso, rappresenta il nuovo documento con le sue proprietà generate dal sistema.
L'oggetto Document è una classe definita nell'SDK che eredita dalla risorsa e quindi ha tutte le proprietà comuni della risorsa, ma include anche le proprietà dinamiche che definiscono il documento senza schema stesso.
private async static Task CreateDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents ****");
Console.WriteLine();
dynamic document1Definition = new {
name = "New Customer 1", address = new {
addressType = "Main Office",
addressLine1 = "123 Main Street",
location = new {
city = "Brooklyn", stateProvinceName = "New York"
}, postalCode = "11229", countryRegionName = "United States"
},
};
Document document1 = await CreateDocument(client, document1Definition);
Console.WriteLine("Created document {0} from dynamic object", document1.Id);
Console.WriteLine();
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Create Documents ****
Created new document: 34e9873a-94c8-4720-9146-d63fb7840fad {
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn", "stateProvinceName": "New York"
},
"postalCode": "11229", "countryRegionName": "United States"
},
"id": "34e9873a-94c8-4720-9146-d63fb7840fad",
"_rid": "Ic8LAMEUVgACAAAAAAAAAA==",
"_ts": 1449812756,
"_self": "dbs/Ic8LAA==/colls/Ic8LAMEUVgA=/docs/Ic8LAMEUVgACAAAAAAAAAA==/",
"_etag": "\"00001000-0000-0000-0000-566a63140000\"",
"_attachments": "attachments/"
}
Created document 34e9873a-94c8-4720-9146-d63fb7840fad from dynamic objectCome puoi vedere, non abbiamo fornito un ID, tuttavia DocumentDB lo ha generato per noi per il nuovo documento.
In DocumentDB, usiamo effettivamente SQL per eseguire query per i documenti, quindi questo capitolo è interamente dedicato alle query utilizzando la speciale sintassi SQL in DocumentDB. Anche se si esegue lo sviluppo .NET, esiste anche un provider LINQ che può essere utilizzato e che può generare SQL appropriato da una query LINQ.
Interrogazione del documento utilizzando il portale
Il portale di Azure ha un Query Explorer che consente di eseguire qualsiasi query SQL sul database DocumentDB.
Useremo Query Explorer per dimostrare le molte diverse capacità e caratteristiche del linguaggio di query a partire dalla query più semplice possibile.
Step 1 - Nel pannello del database, fare clic per aprire il pannello Query Explorer.
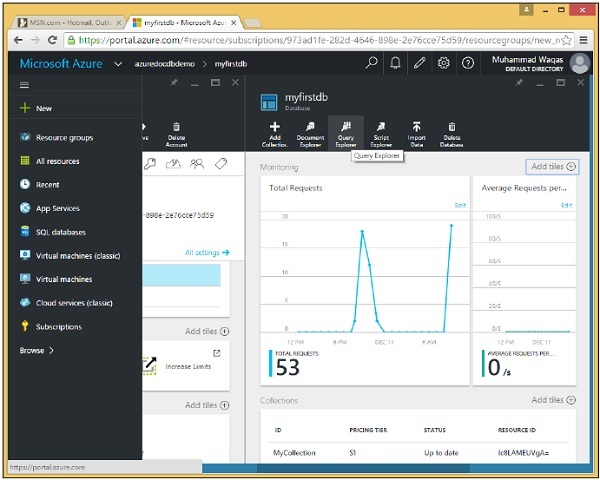
Ricorda che le query vengono eseguite nell'ambito di una raccolta, quindi Query Explorer ti consente di scegliere la raccolta in questo menu a discesa.
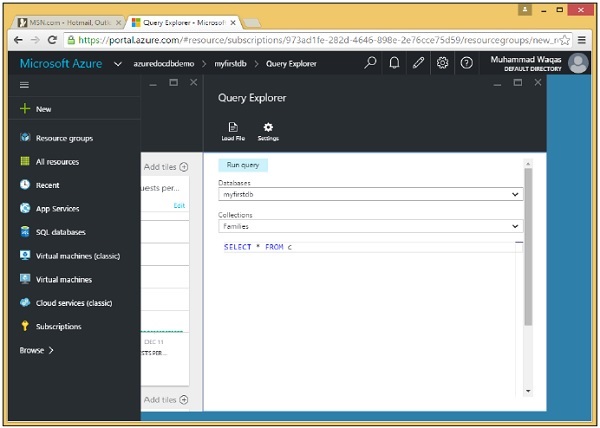
Step 2 - Seleziona la raccolta Famiglie creata in precedenza utilizzando il portale.
Query Explorer si apre con questa semplice query SELECT * FROM c, che recupera semplicemente tutti i documenti dalla raccolta.
Step 3- Esegui questa query facendo clic sul pulsante "Esegui query". Quindi vedrai che il documento completo viene recuperato nel pannello Risultati.

Interrogazione del documento utilizzando .Net SDK
Di seguito sono riportati i passaggi per eseguire alcune query sui documenti utilizzando .Net SDK.
In questo esempio, vogliamo eseguire una query per i documenti appena creati che abbiamo appena aggiunto.
Step 1 - Chiama CreateDocumentQuery, passando la raccolta su cui eseguire la query tramite il suo SelfLink e il testo della query.
private async static Task QueryDocumentsWithPaging(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (paged results) ****");
Console.WriteLine();
Console.WriteLine("Quering for all documents");
var sql = "SELECT * FROM c";
var query = client.CreateDocumentQuery(collection.SelfLink, sql).AsDocumentQuery();
while (query.HasMoreResults) {
var documents = await query.ExecuteNextAsync();
foreach (var document in documents) {
Console.WriteLine(" Id: {0}; Name: {1};", document.id, document.name);
}
}
Console.WriteLine();
}Questa query restituisce anche tutti i documenti dell'intera raccolta, ma non stiamo chiamando .ToList su CreateDocumentQuery come prima, che emetterebbe tutte le richieste necessarie per estrarre tutti i risultati in una riga di codice.
Step 2 - Invece, chiama AsDocumentQuery e questo metodo restituisce un oggetto query con una proprietà HasMoreResults.
Step 3 - Se HasMoreResults è true, chiama ExecuteNextAsync per ottenere il blocco successivo e quindi eseguire il dump di tutti i contenuti di quel blocco.
Step 4- Puoi anche eseguire query utilizzando LINQ anziché SQL, se preferisci. Qui abbiamo definito una query LINQ in q, ma non verrà eseguita finché non eseguiremo .ToList su di essa.
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == " United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} UK customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}L'SDK convertirà la nostra query LINQ nella sintassi SQL per DocumentDB, generando una clausola SELECT e WHERE basata sulla nostra sintassi LINQ
Step 5 - Ora chiama le query precedenti dall'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
//await CreateDocuments(client);
await QueryDocumentsWithPaging(client);
QueryDocumentsWithLinq(client);
}
}Quando il codice precedente viene eseguito, riceverai il seguente output.
**** Query Documents (paged results) ****
Quering for all documents
Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1;
Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1;
**** Query Documents (LINQ) ****
Quering for US customers (LINQ)
Found 2 UK customers
Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn
Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: BrooklynIn questo capitolo impareremo come aggiornare i documenti. Utilizzando il portale di Azure, è possibile aggiornare facilmente il documento aprendo il documento in Esplora documenti e aggiornandolo nell'editor come un file di testo.
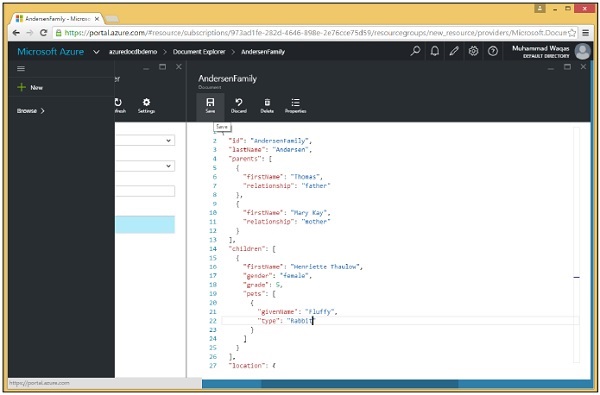
Fare clic sul pulsante "Salva". Ora, quando è necessario modificare un documento utilizzando .Net SDK, è sufficiente sostituirlo. Non è necessario eliminarlo e ricrearlo, il che oltre a essere noioso, cambierebbe anche l'id della risorsa, cosa che non vorresti fare quando stai solo modificando un documento. Di seguito sono riportati i passaggi seguenti per aggiornare il documento utilizzando .Net SDK.
Diamo un'occhiata alla seguente attività ReplaceDocuments in cui interrogheremo i documenti in cui la proprietà isNew è vera, ma non ne otterremo nessuno perché non ce ne sono. Quindi, modifichiamo i documenti che abbiamo aggiunto in precedenza, quelli i cui nomi iniziano con Nuovo cliente.
Step 1 - Aggiungere la proprietà isNew a questi documenti e impostarne il valore su true.
private async static Task ReplaceDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine(">>> Replace Documents <<<");
Console.WriteLine();
Console.WriteLine("Quering for documents with 'isNew' flag");
var sql = "SELECT * FROM c WHERE c.isNew = true";
var documents = client.CreateDocumentQuery(collection.SelfLink, sql).ToList();
Console.WriteLine("Documents with 'isNew' flag: {0} ", documents.Count);
Console.WriteLine();
Console.WriteLine("Quering for documents to be updated");
sql = "SELECT * FROM c WHERE STARTSWITH(c.name, 'New Customer') = true";
documents = client.CreateDocumentQuery(collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} documents to be updated", documents.Count);
foreach (var document in documents) {
document.isNew = true;
var result = await client.ReplaceDocumentAsync(document._self, document);
var updatedDocument = result.Resource;
Console.WriteLine("Updated document 'isNew' flag: {0}", updatedDocument.isNew);
}
Console.WriteLine();
Console.WriteLine("Quering for documents with 'isNew' flag");
sql = "SELECT * FROM c WHERE c.isNew = true";
documents = client.CreateDocumentQuery(collection.SelfLink, sql).ToList();
Console.WriteLine("Documents with 'isNew' flag: {0}: ", documents.Count);
Console.WriteLine();
}Step 2 - Ottieni i documenti da aggiornare utilizzando la stessa query STARTSWITH e che ci dà i documenti, che stiamo recuperando qui come oggetti dinamici.
Step 3 - Allega la proprietà isNew e impostala su true per ogni documento.
Step 4 - Chiama ReplaceDocumentAsync, passando il SelfLink del documento, insieme al documento aggiornato.
Ora, solo per dimostrare che ha funzionato, eseguire una query per i documenti in cui isNew è uguale a true. Chiamiamo le query precedenti dall'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
//await CreateDocuments(client);
//QueryDocumentsWithSql(client);
//await QueryDocumentsWithPaging(client);
//QueryDocumentsWithLinq(client);
await ReplaceDocuments(client);
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Replace Documents ****
Quering for documents with 'isNew' flag
Documents with 'isNew' flag: 0
Quering for documents to be updated
Found 2 documents to be updated
Updated document ‘isNew’ flag: True
Updated document ‘isNew’ flag: True
Quering for documents with 'isNew' flag
Documents with 'isNew' flag: 2In questo capitolo impareremo come eliminare un documento dal tuo account DocumentDB. Utilizzando il portale di Azure, è possibile eliminare facilmente qualsiasi documento aprendo il documento in Document Explorer e facendo clic sull'opzione "Elimina".
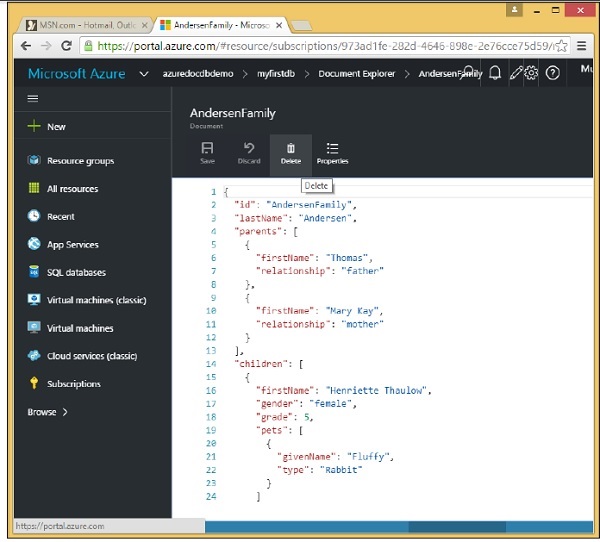
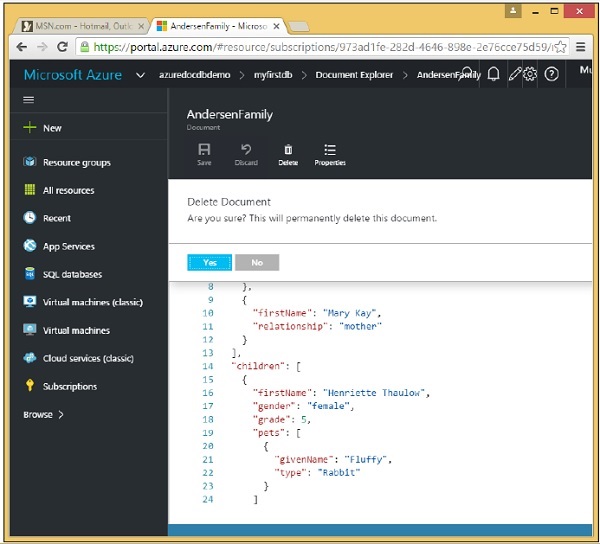
Verrà visualizzato il messaggio di conferma. Ora premi il pulsante Sì e vedrai che il documento non è più disponibile nel tuo account DocumentDB.
Ora, quando vuoi eliminare un documento utilizzando .Net SDK.
Step 1- È lo stesso modello che abbiamo visto prima in cui interrogheremo prima per ottenere i SelfLink di ogni nuovo documento. Non usiamo SELECT * qui, che restituirebbe i documenti nella loro interezza, cosa che non ci serve.
Step 2 - Invece stiamo solo selezionando i SelfLink in un elenco e quindi chiamiamo DeleteDocumentAsync per ogni SelfLink, uno alla volta, per eliminare i documenti dalla raccolta.
private async static Task DeleteDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine(">>> Delete Documents <<<");
Console.WriteLine();
Console.WriteLine("Quering for documents to be deleted");
var sql =
"SELECT VALUE c._self FROM c WHERE STARTSWITH(c.name, 'New Customer') = true";
var documentLinks =
client.CreateDocumentQuery<string>(collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} documents to be deleted", documentLinks.Count);
foreach (var documentLink in documentLinks) {
await client.DeleteDocumentAsync(documentLink);
}
Console.WriteLine("Deleted {0} new customer documents", documentLinks.Count);
Console.WriteLine();
}Step 3 - Ora chiamiamo il precedente DeleteDocuments dall'attività CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
await DeleteDocuments(client);
}
}Quando il codice precedente viene eseguito, riceverai il seguente output.
***** Delete Documents *****
Quering for documents to be deleted
Found 2 documents to be deleted
Deleted 2 new customer documentsSebbene i database senza schema, come DocumentDB, rendano estremamente facile accettare le modifiche al modello di dati, dovresti comunque dedicare un po 'di tempo a pensare ai tuoi dati.
Hai molte opzioni. Naturalmente, puoi lavorare solo con grafici a oggetti JSON o anche stringhe non elaborate di testo JSON, ma puoi anche utilizzare oggetti dinamici che ti consentono di collegarti a proprietà in fase di esecuzione senza definire una classe in fase di compilazione.
È inoltre possibile lavorare con oggetti C # reali, o entità come vengono chiamate, che potrebbero essere le classi del dominio aziendale.
Relazioni
Diamo un'occhiata alla struttura gerarchica del documento. Ha alcune proprietà di primo livello come l'id richiesto, lastName e isRegistered, ma ha anche proprietà nidificate.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle"},
"isRegistered": true
}Ad esempio, la proprietà genitori viene fornita come matrice JSON come indicato dalle parentesi quadre.
Abbiamo anche un altro array per i bambini, anche se c'è un solo figlio nell'array in questo esempio. Quindi è così che modellate l'equivalente delle relazioni uno-a-molti all'interno di un documento.
Si utilizzano semplicemente array in cui ogni elemento dell'array potrebbe essere un valore semplice o un altro oggetto complesso, anche un altro array.
Quindi una famiglia può avere più genitori e più figli e se guardi gli oggetti figlio, hanno la proprietà di un animale domestico che è essa stessa un array annidato per una relazione uno-molti tra bambini e animali domestici.
Per la proprietà location, stiamo combinando tre proprietà correlate, lo stato, la contea e la città in un oggetto.
Incorporare un oggetto in questo modo piuttosto che incorporare un array di oggetti è simile ad avere una relazione uno a uno tra due righe in tabelle separate in un database relazionale.
Incorporamento dei dati
Quando inizi a modellare i dati in un archivio di documenti, come DocumentDB, prova a trattare le tue entità come documenti autonomi rappresentati in JSON. Quando lavoriamo con database relazionali, normalizziamo sempre i dati.
La normalizzazione dei dati in genere comporta l'acquisizione di un'entità, come un cliente, e la scomposizione in parti di dati discrete, come dettagli di contatto e indirizzi.
Per leggere un cliente, con tutti i suoi dettagli di contatto e indirizzi, è necessario utilizzare JOINS per aggregare efficacemente i dati in fase di esecuzione.
Ora diamo un'occhiata a come modellare gli stessi dati di un'entità indipendente in un database di documenti.
{
"id": "1",
"firstName": "Mark",
"lastName": "Upston",
"addresses": [
{
"line1": "232 Main Street",
"line2": "Unit 1",
"city": "Brooklyn",
"state": "NY",
"zip": 11229
}
],
"contactDetails": [
{"email": "[email protected]"},
{"phone": "+1 356 545-86455", "extension": 5555}
]
}Come puoi vedere, abbiamo denormalizzato il record del cliente in cui tutte le informazioni del cliente sono incorporate in un unico documento JSON.
In NoSQL abbiamo uno schema gratuito, quindi puoi aggiungere anche i dettagli di contatto e gli indirizzi in diversi formati. In NoSQL, puoi recuperare un record del cliente dal database in una singola operazione di lettura. Allo stesso modo, anche l'aggiornamento di un record è una singola operazione di scrittura.
Di seguito sono riportati i passaggi per creare documenti utilizzando .Net SDK.
Step 1- Istanziare DocumentClient. Quindi interrogheremo il database myfirstdb e interrogheremo anche la raccolta MyCollection, che memorizziamo in questa raccolta di variabili private in modo che sia accessibile in tutta la classe.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
await CreateDocuments(client);
}
}Step 2 - Crea alcuni documenti nell'attività CreateDocuments.
private async static Task CreateDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents ****");
Console.WriteLine();
dynamic document1Definition = new {
name = "New Customer 1", address = new {
addressType = "Main Office",
addressLine1 = "123 Main Street",
location = new {
city = "Brooklyn", stateProvinceName = "New York"
},
postalCode = "11229", countryRegionName = "United States"
},
};
Document document1 = await CreateDocument(client, document1Definition);
Console.WriteLine("Created document {0} from dynamic object", document1.Id);
Console.WriteLine();
}Il primo documento verrà generato da questo oggetto dinamico. Potrebbe sembrare JSON, ma ovviamente non lo è. Questo è codice C # e stiamo creando un vero oggetto .NET, ma non esiste una definizione di classe. Invece le proprietà vengono dedotte dal modo in cui l'oggetto viene inizializzato. Puoi anche notare che non abbiamo fornito una proprietà Id per questo documento.
Step 3 - Ora diamo un'occhiata al CreateDocument e sembra lo stesso modello che abbiamo visto per la creazione di database e raccolte.
private async static Task<Document> CreateDocument(DocumentClient client,
object documentObject) {
var result = await client.CreateDocumentAsync(collection.SelfLink, documentObject);
var document = result.Resource;
Console.WriteLine("Created new document: {0}\r\n{1}", document.Id, document);
return result;
}Step 4- Questa volta chiamiamo CreateDocumentAsync specificando il SelfLink della raccolta a cui vogliamo aggiungere il documento. Riceviamo una risposta con una proprietà della risorsa che, in questo caso, rappresenta il nuovo documento con le sue proprietà generate dal sistema.
Nella seguente attività CreateDocuments, abbiamo creato tre documenti.
Nel primo documento, l'oggetto Document è una classe definita nell'SDK che eredita dalla risorsa e quindi ha tutte le proprietà comuni delle risorse, ma include anche le proprietà dinamiche che definiscono il documento senza schema stesso.
private async static Task CreateDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents ****");
Console.WriteLine();
dynamic document1Definition = new {
name = "New Customer 1", address = new {
addressType = "Main Office",
addressLine1 = "123 Main Street",
location = new {
city = "Brooklyn", stateProvinceName = "New York"
},
postalCode = "11229",
countryRegionName = "United States"
},
};
Document document1 = await CreateDocument(client, document1Definition);
Console.WriteLine("Created document {0} from dynamic object", document1.Id);
Console.WriteLine();
var document2Definition = @" {
""name"": ""New Customer 2"",
""address"": {
""addressType"": ""Main Office"",
""addressLine1"": ""123 Main Street"",
""location"": {
""city"": ""Brooklyn"", ""stateProvinceName"": ""New York""
},
""postalCode"": ""11229"",
""countryRegionName"": ""United States""
}
}";
Document document2 = await CreateDocument(client, document2Definition);
Console.WriteLine("Created document {0} from JSON string", document2.Id);
Console.WriteLine();
var document3Definition = new Customer {
Name = "New Customer 3",
Address = new Address {
AddressType = "Main Office",
AddressLine1 = "123 Main Street",
Location = new Location {
City = "Brooklyn", StateProvinceName = "New York"
},
PostalCode = "11229",
CountryRegionName = "United States"
},
};
Document document3 = await CreateDocument(client, document3Definition);
Console.WriteLine("Created document {0} from typed object", document3.Id);
Console.WriteLine();
}Questo secondo documento funziona solo con una stringa JSON non elaborata. Ora entriamo in un overload per CreateDocument che utilizza JavaScriptSerializer per de-serializzare la stringa in un oggetto, che poi passa allo stesso metodo CreateDocument che abbiamo usato per creare il primo documento.
Nel terzo documento abbiamo utilizzato l'oggetto C # Customer definito nella nostra applicazione.
Diamo un'occhiata a questo cliente, ha una proprietà Id e address in cui l'indirizzo è un oggetto nidificato con le sue proprietà inclusa la posizione, che è ancora un altro oggetto nidificato.
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBDemo {
public class Customer {
[JsonProperty(PropertyName = "id")]
public string Id { get; set; }
// Must be nullable, unless generating unique values for new customers on client
[JsonProperty(PropertyName = "name")]
public string Name { get; set; }
[JsonProperty(PropertyName = "address")]
public Address Address { get; set; }
}
public class Address {
[JsonProperty(PropertyName = "addressType")]
public string AddressType { get; set; }
[JsonProperty(PropertyName = "addressLine1")]
public string AddressLine1 { get; set; }
[JsonProperty(PropertyName = "location")]
public Location Location { get; set; }
[JsonProperty(PropertyName = "postalCode")]
public string PostalCode { get; set; }
[JsonProperty(PropertyName = "countryRegionName")]
public string CountryRegionName { get; set; }
}
public class Location {
[JsonProperty(PropertyName = "city")]
public string City { get; set; }
[JsonProperty(PropertyName = "stateProvinceName")]
public string StateProvinceName { get; set; }
}
}Disponiamo anche di attributi di proprietà JSON perché vogliamo mantenere le convenzioni appropriate su entrambi i lati del recinto.
Quindi creo semplicemente il mio oggetto Nuovo cliente insieme ai suoi oggetti figlio nidificati e chiamo di nuovo in CreateDocument. Sebbene il nostro oggetto cliente abbia una proprietà Id, non abbiamo fornito un valore per esso e quindi DocumentDB ne ha generato uno basato sul GUID, proprio come ha fatto per i due documenti precedenti.
Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Create Documents ****
Created new document: 575882f0-236c-4c3d-81b9-d27780206b2c
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
"id": "575882f0-236c-4c3d-81b9-d27780206b2c",
"_rid": "kV5oANVXnwDGPgAAAAAAAA==",
"_ts": 1450037545,
"_self": "dbs/kV5oAA==/colls/kV5oANVXnwA=/docs/kV5oANVXnwDGPgAAAAAAAA==/",
"_etag": "\"00006fce-0000-0000-0000-566dd1290000\"",
"_attachments": "attachments/"
}
Created document 575882f0-236c-4c3d-81b9-d27780206b2c from dynamic object
Created new document: 8d7ad239-2148-4fab-901b-17a85d331056
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
"id": "8d7ad239-2148-4fab-901b-17a85d331056",
"_rid": "kV5oANVXnwDHPgAAAAAAAA==",
"_ts": 1450037545,
"_self": "dbs/kV5oAA==/colls/kV5oANVXnwA=/docs/kV5oANVXnwDHPgAAAAAAAA==/",
"_etag": "\"000070ce-0000-0000-0000-566dd1290000\"",
"_attachments": "attachments/"
}
Created document 8d7ad239-2148-4fab-901b-17a85d331056 from JSON string
Created new document: 49f399a8-80c9-4844-ac28-cd1dee689968
{
"id": "49f399a8-80c9-4844-ac28-cd1dee689968",
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
"_rid": "kV5oANVXnwDIPgAAAAAAAA==",
"_ts": 1450037546,
"_self": "dbs/kV5oAA==/colls/kV5oANVXnwA=/docs/kV5oANVXnwDIPgAAAAAAAA==/",
"_etag": "\"000071ce-0000-0000-0000-566dd12a0000\"",
"_attachments": "attachments/"
}
Created document 49f399a8-80c9-4844-ac28-cd1dee689968 from typed objectJSON o JavaScript Object Notation è uno standard aperto basato su testo leggero progettato per lo scambio di dati leggibili dall'uomo e anche facile da analizzare e generare per le macchine. JSON è il cuore di DocumentDB. Trasmettiamo JSON via cavo, memorizziamo JSON come JSON e indicizziamo l'albero JSON consentendo query sul documento JSON completo.
Il formato JSON supporta i seguenti tipi di dati:
| S.No. | Tipo e descrizione |
|---|---|
| 1 | Number Formato a virgola mobile a doppia precisione in JavaScript |
| 2 | String Unicode con virgolette doppie con escape della barra rovesciata |
| 3 | Boolean Vero o falso |
| 4 | Array Una sequenza ordinata di valori |
| 5 | Value Può essere una stringa, un numero, vero o falso, null, ecc. |
| 6 | Object Una raccolta non ordinata di coppie chiave: valore |
| 7 | Whitespace Può essere utilizzato tra qualsiasi coppia di gettoni |
| 8 | Null Vuoto |
Diamo un'occhiata a un semplice esempio di tipo DateTime. Aggiungi la data di nascita alla classe del cliente.
public class Customer {
[JsonProperty(PropertyName = "id")]
public string Id { get; set; }
// Must be nullable, unless generating unique values for new customers on client
[JsonProperty(PropertyName = "name")]
public string Name { get; set; }
[JsonProperty(PropertyName = "address")]
public Address Address { get; set; }
[JsonProperty(PropertyName = "birthDate")]
public DateTime BirthDate { get; set; }
}Possiamo archiviare, recuperare ed eseguire query utilizzando DateTime come mostrato nel codice seguente.
private async static Task CreateDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents ****");
Console.WriteLine();
var document3Definition = new Customer {
Id = "1001",
Name = "Luke Andrew",
Address = new Address {
AddressType = "Main Office",
AddressLine1 = "123 Main Street",
Location = new Location {
City = "Brooklyn",
StateProvinceName = "New York"
},
PostalCode = "11229",
CountryRegionName = "United States"
},
BirthDate = DateTime.Parse(DateTime.Today.ToString()),
};
Document document3 = await CreateDocument(client, document3Definition);
Console.WriteLine("Created document {0} from typed object", document3.Id);
Console.WriteLine();
}Quando il codice sopra viene compilato ed eseguito e il documento viene creato, vedrai che la data di nascita è stata aggiunta ora.
**** Create Documents ****
Created new document: 1001
{
"id": "1001",
"name": "Luke Andrew",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
"birthDate": "2015-12-14T00:00:00",
"_rid": "Ic8LAMEUVgAKAAAAAAAAAA==",
"_ts": 1450113676,
"_self": "dbs/Ic8LAA==/colls/Ic8LAMEUVgA=/docs/Ic8LAMEUVgAKAAAAAAAAAA==/",
"_etag": "\"00002d00-0000-0000-0000-566efa8c0000\"",
"_attachments": "attachments/"
}
Created document 1001 from typed objectMicrosoft ha recentemente aggiunto una serie di miglioramenti su come eseguire query in Azure DocumentDB, come la parola chiave TOP per la grammatica SQL, che ha reso le query più veloci e consumano meno risorse, aumentato i limiti per gli operatori di query e aggiunto il supporto per operatori LINQ aggiuntivi in .NET SDK.
Diamo un'occhiata a un semplice esempio in cui recupereremo solo i primi due record. Se si dispone di più record e si desidera recuperarne solo alcuni, è possibile utilizzare la parola chiave Top. In questo esempio, abbiamo molti record di terremoti.

Ora vogliamo mostrare solo i primi due record
Step 1 - Vai a Query Explorer ed esegui questa query.
SELECT * FROM c
WHERE c.magnitude > 2.5Vedrai che ha recuperato quattro record perché non abbiamo ancora specificato la parola chiave TOP.
Step 2- Ora usa la parola chiave TOP con la stessa query. Qui abbiamo specificato la parola chiave TOP e "2" significa che vogliamo solo due record.
SELECT TOP 2 * FROM c
WHERE c.magnitude > 2.5Step 3 - Ora esegui questa query e vedrai che vengono recuperati solo due record.
Allo stesso modo, puoi utilizzare la parola chiave TOP nel codice utilizzando .Net SDK. Di seguito è riportata l'implementazione.
private async static Task QueryDocumentsWithPaging(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (paged results) ****");
Console.WriteLine();
Console.WriteLine("Quering for all documents");
var sql = "SELECT TOP 3 * FROM c";
var query = client
.CreateDocumentQuery(collection.SelfLink, sql)
.AsDocumentQuery();
while (query.HasMoreResults) {
var documents = await query.ExecuteNextAsync();
foreach (var document in documents) {
Console.WriteLine(" PublicId: {0}; Magnitude: {1};", document.publicid,
document.magnitude);
}
}
Console.WriteLine();
}Di seguito è riportata l'attività CreateDocumentClient in cui vengono istanziate il database DocumentClient e il database dei terremoti.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'earthquakedata'").AsEnumerable().First();
await QueryDocumentsWithPaging(client);
}
}Quando il codice precedente viene compilato ed eseguito, vedrai che vengono recuperati solo tre record.
**** Query Documents (paged results) ****
Quering for all documents
PublicId: 2015p947400; Magnitude: 2.515176918;
PublicId: 2015p947373; Magnitude: 1.506774108;
PublicId: 2015p947329; Magnitude: 1.593394461;Microsoft Azure DocumentDB supporta l'esecuzione di query sui documenti utilizzando SQL su documenti JSON. È possibile ordinare i documenti nella raccolta su numeri e stringhe utilizzando una clausola ORDER BY nella query. La clausola può includere un argomento ASC / DESC facoltativo per specificare l'ordine in cui devono essere recuperati i risultati.
Diamo un'occhiata al seguente esempio in cui abbiamo un documento JSON.
{
"id": "Food Menu",
"description": "Grapes, red or green (European type, such as Thompson seedless), raw",
"tags": [
{
"name": "grapes"
},
{
"name": "red or green (european type"
},
{
"name": "such as thompson seedless)"
},
{
"name": "raw"
}
],
"foodGroup": "Fruits and Fruit Juices",
"servings": [
{
"amount": 1,
"description": "cup",
"weightInGrams": 151
},
{
"amount": 10,
"description": "grapes",
"weightInGrams": 49
},
{
"amount": 1,
"description": "NLEA serving",
"weightInGrams": 126
}
]
}Di seguito è riportata la query SQL per ordinare il risultato in ordine decrescente.
SELECT f.description, f.foodGroup,
f.servings[2].description AS servingDescription,
f.servings[2].weightInGrams AS servingWeight
FROM f
ORDER BY f.servings[2].weightInGrams DESCQuando viene eseguita la query precedente, riceverai il seguente output.
[
{
"description": "Grapes, red or green (European type, such as Thompson
seedless), raw",
"foodGroup": "Fruits and Fruit Juices",
"servingDescription": "NLEA serving",
"servingWeight": 126
}
]Per impostazione predefinita, DocumentDB indicizza automaticamente ogni proprietà in un documento non appena il documento viene aggiunto al database. Tuttavia, puoi assumere il controllo e ottimizzare i tuoi criteri di indicizzazione che riducono il sovraccarico di archiviazione ed elaborazione quando sono presenti documenti e / o proprietà specifici che non devono mai essere indicizzati.
Il criterio di indicizzazione predefinito che indica a DocumentDB di indicizzare automaticamente ogni proprietà è adatto a molti scenari comuni. Ma puoi anche implementare una policy personalizzata che eserciti un controllo preciso su ciò che viene indicizzato e cosa no e altre funzionalità per quanto riguarda l'indicizzazione.
DocumentDB supporta i seguenti tipi di indicizzazione:
- Hash
- Range
Hash
L'indice hash consente una query efficiente per l'uguaglianza, ovvero durante la ricerca di documenti in cui una data proprietà è uguale a un valore esatto, piuttosto che corrispondere a un intervallo di valori come minore di, maggiore di o compreso tra.
È possibile eseguire query di intervallo con un indice hash, ma DocumentDB non sarà in grado di utilizzare l'indice hash per trovare i documenti corrispondenti e dovrà invece eseguire la scansione sequenziale di ogni documento per determinare se deve essere selezionato dalla query di intervallo.
Non sarai in grado di ordinare i tuoi documenti con una clausola ORDER BY su una proprietà che ha solo un indice hash.
Gamma
Indice di intervallo definito per la proprietà, DocumentDB consente di eseguire query in modo efficiente per i documenti rispetto a un intervallo di valori. Consente inoltre di ordinare i risultati della query su quella proprietà, utilizzando ORDER BY.
DocumentDB consente di definire sia un hash che un indice di intervallo su una o tutte le proprietà, il che consente query efficienti su uguaglianza e intervallo, nonché ORDER BY.
Politica di indicizzazione
Ogni raccolta ha una politica di indicizzazione che determina quali tipi di indici vengono utilizzati per numeri e stringhe in ogni proprietà di ogni documento.
Puoi anche controllare se i documenti devono essere indicizzati automaticamente quando vengono aggiunti alla raccolta.
L'indicizzazione automatica è abilitata per impostazione predefinita, ma è possibile ignorare tale comportamento quando si aggiunge un documento, dicendo a DocumentDB di non indicizzare quel particolare documento.
È possibile disabilitare l'indicizzazione automatica in modo che, per impostazione predefinita, i documenti non vengano indicizzati quando vengono aggiunti alla raccolta. Allo stesso modo, puoi sovrascriverlo a livello di documento e istruire DocumentDB a indicizzare un particolare documento quando lo aggiungi alla raccolta. Questo è noto come indicizzazione manuale.
Includi / escludi indicizzazione
Un criterio di indicizzazione può anche definire il percorso oi percorsi da includere o escludere dall'indice. Ciò è utile se sai che ci sono alcune parti di un documento su cui non interroghi mai e certe parti che fai.
In questi casi, puoi ridurre il sovraccarico di indicizzazione dicendo a DocumentDB di indicizzare solo quelle parti particolari di ogni documento aggiunto alla raccolta.
Indicizzazione automatica
Diamo un'occhiata a un semplice esempio di indicizzazione automatica.
Step 1 - Per prima cosa creiamo una raccolta chiamata autoindicizzazione e senza fornire esplicitamente una politica, questa raccolta utilizza la politica di indicizzazione predefinita, il che significa che l'indicizzazione automatica è abilitata su questa raccolta.
Qui stiamo usando il routing basato sull'ID per l'auto-collegamento del database, quindi non abbiamo bisogno di conoscere il suo ID risorsa o interrogarlo prima di creare la raccolta. Possiamo semplicemente usare l'ID del database, che è mydb.
Step 2 - Adesso creiamo due documenti, entrambi con il cognome Upston.
private async static Task AutomaticIndexing(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Override Automatic Indexing ****");
// Create collection with automatic indexing
var collectionDefinition = new DocumentCollection {
Id = "autoindexing"
};
var collection = await client.CreateDocumentCollectionAsync("dbs/mydb",
collectionDefinition);
// Add a document (indexed)
dynamic indexedDocumentDefinition = new {
id = "MARK",
firstName = "Mark",
lastName = "Upston",
addressLine = "123 Main Street",
city = "Brooklyn",
state = "New York",
zip = "11229",
};
Document indexedDocument = await client
.CreateDocumentAsync("dbs/mydb/colls/autoindexing", indexedDocumentDefinition);
// Add another document (request no indexing)
dynamic unindexedDocumentDefinition = new {
id = "JANE",
firstName = "Jane",
lastName = "Upston",
addressLine = "123 Main Street",
city = "Brooklyn",
state = "New York",
zip = "11229",
};
Document unindexedDocument = await client
.CreateDocumentAsync("dbs/mydb/colls/autoindexing", unindexedDocumentDefinition,
new RequestOptions { IndexingDirective = IndexingDirective.Exclude });
//Unindexed document won't get returned when querying on non-ID (or selflink) property
var doeDocs = client.CreateDocumentQuery("dbs/mydb/colls/autoindexing", "SELECT *
FROM c WHERE c.lastName = 'Doe'").ToList();
Console.WriteLine("Documents WHERE lastName = 'Doe': {0}", doeDocs.Count);
// Unindexed document will get returned when using no WHERE clause
var allDocs = client.CreateDocumentQuery("dbs/mydb/colls/autoindexing",
"SELECT * FROM c").ToList();
Console.WriteLine("All documents: {0}", allDocs.Count);
// Unindexed document will get returned when querying by ID (or self-link) property
Document janeDoc = client.CreateDocumentQuery("dbs/mydb/colls/autoindexing",
"SELECT * FROM c WHERE c.id = 'JANE'").AsEnumerable().FirstOrDefault();
Console.WriteLine("Unindexed document self-link: {0}", janeDoc.SelfLink);
// Delete the collection
await client.DeleteDocumentCollectionAsync("dbs/mydb/colls/autoindexing");
}Questo primo, per Mark Upston, viene aggiunto alla raccolta e viene quindi immediatamente indicizzato automaticamente in base alla politica di indicizzazione predefinita.
Ma quando viene aggiunto il secondo documento per Mark Upston, abbiamo passato le opzioni di richiesta con IndexingDirective.Exclude che indica esplicitamente a DocumentDB di non indicizzare questo documento, nonostante la politica di indicizzazione della raccolta.
Abbiamo diversi tipi di query per entrambi i documenti alla fine.
Step 3 - Chiamiamo l'attività AutomaticIndexing da CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
await AutomaticIndexing(client);
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Override Automatic Indexing ****
Documents WHERE lastName = 'Upston': 1
All documents: 2
Unindexed document self-link: dbs/kV5oAA==/colls/kV5oAOEkfQA=/docs/kV5oAOEkfQACA
AAAAAAAAA==/Come puoi vedere, abbiamo due di questi documenti, ma la query restituisce solo quello per Mark perché quello per Mark non è indicizzato. Se interroghiamo di nuovo, senza una clausola WHERE per recuperare tutti i documenti nella raccolta, allora otteniamo un set di risultati con entrambi i documenti e questo perché i documenti non indicizzati vengono sempre restituiti da query che non hanno clausola WHERE.
Possiamo anche recuperare documenti non indicizzati tramite il loro ID o collegamento automatico. Quindi, quando interroghiamo il documento di Mark tramite il suo ID, MARK, vediamo che DocumentDB restituisce il documento anche se non è indicizzato nella raccolta.
Indicizzazione manuale
Diamo uno sguardo a un semplice esempio di indicizzazione manuale sovrascrivendo l'indicizzazione automatica.
Step 1- Per prima cosa creeremo una raccolta chiamataindicizzazione manuale e sovrascriveremo la politica predefinita disabilitando esplicitamente l'indicizzazione automatica. Ciò significa che, a meno che non venga richiesto diversamente, i nuovi documenti aggiunti a questa raccolta non verranno indicizzati.
private async static Task ManualIndexing(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Manual Indexing ****");
// Create collection with manual indexing
var collectionDefinition = new DocumentCollection {
Id = "manualindexing",
IndexingPolicy = new IndexingPolicy {
Automatic = false,
},
};
var collection = await client.CreateDocumentCollectionAsync("dbs/mydb",
collectionDefinition);
// Add a document (unindexed)
dynamic unindexedDocumentDefinition = new {
id = "MARK",
firstName = "Mark",
lastName = "Doe",
addressLine = "123 Main Street",
city = "Brooklyn",
state = "New York",
zip = "11229",
};
Document unindexedDocument = await client
.CreateDocumentAsync("dbs/mydb/colls/manualindexing", unindexedDocumentDefinition);
// Add another document (request indexing)
dynamic indexedDocumentDefinition = new {
id = "JANE",
firstName = "Jane",
lastName = "Doe",
addressLine = "123 Main Street",
city = "Brooklyn",
state = "New York",
zip = "11229",
};
Document indexedDocument = await client.CreateDocumentAsync
("dbs/mydb/colls/manualindexing", indexedDocumentDefinition, new RequestOptions {
IndexingDirective = IndexingDirective.Include });
//Unindexed document won't get returned when querying on non-ID (or selflink) property
var doeDocs = client.CreateDocumentQuery("dbs/mydb/colls/manualindexing",
"SELECT * FROM c WHERE c.lastName = 'Doe'").ToList();
Console.WriteLine("Documents WHERE lastName = 'Doe': {0}", doeDocs.Count);
// Unindexed document will get returned when using no WHERE clause
var allDocs = client.CreateDocumentQuery("dbs/mydb/colls/manualindexing",
"SELECT * FROM c").ToList();
Console.WriteLine("All documents: {0}", allDocs.Count);
// Unindexed document will get returned when querying by ID (or self-link) property
Document markDoc = client
.CreateDocumentQuery("dbs/mydb/colls/manualindexing",
"SELECT * FROM c WHERE c.id = 'MARK'")
.AsEnumerable().FirstOrDefault();
Console.WriteLine("Unindexed document self-link: {0}", markDoc.SelfLink);
await client.DeleteDocumentCollectionAsync("dbs/mydb/colls/manualindexing");
}Step 2- Ora creeremo di nuovo gli stessi due documenti di prima. Questa volta non forniremo alcuna opzione di richiesta speciale per il documento di Mark, a causa della politica di indicizzazione della raccolta, questo documento non verrà indicizzato.
Step 3 - Ora, quando aggiungiamo il secondo documento per Mark, usiamo RequestOptions con IndexingDirective.Include per dire a DocumentDB che dovrebbe indicizzare questo documento, il che sovrascrive la politica di indicizzazione della raccolta che dice che non dovrebbe.
Abbiamo diversi tipi di query per entrambi i documenti alla fine.
Step 4 - Chiamiamo l'attività ManualIndexing da CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
await ManualIndexing(client);
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Manual Indexing ****
Documents WHERE lastName = 'Upston': 1
All documents: 2
Unindexed document self-link: dbs/kV5oAA==/colls/kV5oANHJPgE=/docs/kV5oANHJPgEBA
AAAAAAAAA==/Anche in questo caso, la query restituisce solo uno dei due documenti, ma questa volta restituisce Jane Doe, di cui abbiamo richiesto esplicitamente l'indicizzazione. Ma ancora una volta, come prima, una query senza una clausola WHERE recupera tutti i documenti nella raccolta, incluso il documento non indicizzato per Mark. Possiamo anche interrogare il documento non indicizzato tramite il suo ID, che DocumentDB restituisce anche se non è indicizzato.
Microsoft ha aggiunto geospatial support, che consente di memorizzare i dati sulla posizione nei documenti ed eseguire calcoli spaziali per la distanza e le intersezioni tra punti e poligoni.
I dati spaziali descrivono la posizione e la forma degli oggetti nello spazio.
In genere, può essere utilizzato per rappresentare la posizione di una persona, un luogo di interesse o il confine di una città o di un lago.
I casi d'uso comuni spesso comportano query di prossimità. Ad esempio, "trova tutte le università vicine alla mia posizione attuale".
UN Pointdenota una singola posizione nello spazio che rappresenta la posizione esatta, ad esempio l'indirizzo stradale di una particolare università. Un punto è rappresentato in DocumentDB usando la sua coppia di coordinate (longitudine e latitudine). Di seguito è riportato un esempio di punto JSON.
{
"type":"Point",
"coordinates":[ 28.3, -10.7 ]
}Diamo un'occhiata a un semplice esempio che contiene l'ubicazione di un'università.
{
"id":"case-university",
"name":"CASE: Center For Advanced Studies In Engineering",
"city":"Islamabad",
"location": {
"type":"Point",
"coordinates":[ 33.7194136, -73.0964862 ]
}
}Per recuperare il nome dell'università in base alla posizione, puoi utilizzare la seguente query.
SELECT c.name FROM c
WHERE c.id = "case-university" AND ST_ISVALID({
"type":"Point",
"coordinates":[ 33.7194136, -73.0964862 ]})Quando viene eseguita la query di cui sopra, riceverai il seguente output.
[
{
"name": "CASE: Center For Advanced Studies In Engineering"
}
]Crea documento con dati geospaziali in .NET
Puoi creare un documento con dati geospaziali, diamo un'occhiata a un semplice esempio in cui viene creato un documento universitario.
private async static Task CreateDocuments(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents ****");
Console.WriteLine();
var uniDocument = new UniversityProfile {
Id = "nust",
Name = "National University of Sciences and Technology",
City = "Islamabad",
Loc = new Point(33.6455715, 72.9903447)
};
Document document = await CreateDocument(client, uniDocument);
Console.WriteLine("Created document {0} from typed object", document.Id);
Console.WriteLine();
}Di seguito è riportata l'implementazione per la classe UniversityProfile.
public class UniversityProfile {
[JsonProperty(PropertyName = "id")]
public string Id { get; set; }
[JsonProperty("name")]
public string Name { get; set; }
[JsonProperty("city")]
public string City { get; set; }
[JsonProperty("location")]
public Point Loc { get; set; }
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** Create Documents ****
Created new document: nust
{
"id": "nust",
"name": "National University of Sciences and Technology",
"city": "Islamabad",
"location": {
"type": "Point",
"coordinates": [
33.6455715,
72.9903447
]
},
"_rid": "Ic8LAMEUVgANAAAAAAAAAA==",
"_ts": 1450200910,
"_self": "dbs/Ic8LAA==/colls/Ic8LAMEUVgA=/docs/Ic8LAMEUVgANAAAAAAAAAA==/",
"_etag": "\"00004100-0000-0000-0000-56704f4e0000\"",
"_attachments": "attachments/"
}
Created document nust from typed objectQuando il database inizia a crescere oltre i 10 GB, puoi ridimensionare semplicemente creando nuove raccolte e quindi diffondendo o partizionando i dati su un numero sempre maggiore di raccolte.
Prima o poi una singola raccolta, che ha una capacità di 10 GB, non sarà sufficiente per contenere il database. Ora 10 GB potrebbero non sembrare un numero molto elevato, ma ricorda che stiamo archiviando documenti JSON, che è solo testo normale e puoi adattare molti documenti di testo normale in 10 GB, anche se si considera il sovraccarico di archiviazione per gli indici.
Lo storage non è l'unica preoccupazione quando si parla di scalabilità. La velocità effettiva massima disponibile su una raccolta è di duemila unità di richiesta al secondo ottenute con una raccolta S3. Pertanto, se è necessaria una velocità effettiva maggiore, sarà anche necessario eseguire la scalabilità orizzontale partizionando con più raccolte. Viene anche chiamato il partizionamento con scalabilità orizzontalehorizontal partitioning.
Esistono molti approcci che possono essere usati per il partizionamento dei dati con Azure DocumentDB. Di seguito sono riportate le strategie più comuni:
- Partizionamento spillover
- Partizionamento dell'intervallo
- Partizionamento di ricerca
- Partizionamento hash
Partizionamento spillover
Il partizionamento spillover è la strategia più semplice perché non esiste una chiave di partizione. Spesso è una buona scelta iniziare quando non sei sicuro di molte cose. Potresti non sapere se avrai mai bisogno di scalare oltre una singola raccolta o quante raccolte potresti dover aggiungere o quanto velocemente potresti dover aggiungerle.
Il partizionamento spillover inizia con una singola raccolta e non è presente alcuna chiave di partizione.
La raccolta inizia a crescere e poi cresce ancora, e poi ancora di più, fino a quando non inizi ad avvicinarti al limite di 10 GB.
Quando si raggiunge la capacità del 90%, si passa a una nuova raccolta e si inizia a utilizzarla per nuovi documenti.
Una volta che il tuo database si ridimensiona a un numero maggiore di raccolte, probabilmente vorrai passare a una strategia basata su una chiave di partizione.
Quando lo fai, dovrai ribilanciare i tuoi dati spostando i documenti in raccolte diverse in base alla strategia a cui stai migrando.
Partizionamento dell'intervallo
Una delle strategie più comuni è il partizionamento dell'intervallo. Con questo approccio si determina l'intervallo di valori in cui potrebbe rientrare la chiave di partizione di un documento e si indirizza il documento a una raccolta corrispondente a tale intervallo.
Le date vengono utilizzate molto in genere con questa strategia in cui si crea una raccolta per contenere documenti che rientrano nell'intervallo di date definito. Quando si definiscono intervalli sufficientemente piccoli, in cui si è certi che nessuna raccolta supererà mai il limite di 10 GB. Ad esempio, potrebbe esserci uno scenario in cui una singola raccolta può ragionevolmente gestire i documenti per un intero mese.
Può anche accadere che la maggior parte degli utenti stia interrogando i dati correnti, che sarebbero dati per questo mese o forse il mese scorso, ma gli utenti raramente cercano dati molto più vecchi. Quindi inizi a giugno con una raccolta S3, che è la raccolta più costosa che puoi acquistare e offre la migliore produttività possibile.
A luglio acquisti un'altra raccolta S3 per archiviare i dati di luglio e riduci i dati di giugno a una raccolta S2 meno costosa. Poi ad agosto, ottieni un'altra collezione S3 e riduci luglio a S2 e giugno fino a S1. Va, mese dopo mese, dove si mantengono sempre i dati correnti disponibili per un throughput elevato e i dati meno recenti vengono tenuti disponibili a throughput inferiori.
Finché la query fornisce una chiave di partizione, verrà interrogata solo la raccolta che deve essere interrogata e non tutte le raccolte nel database come accade con il partizionamento spillover.
Partizionamento di ricerca
Con il partizionamento di ricerca è possibile definire una mappa delle partizioni che instrada i documenti a raccolte specifiche in base alla loro chiave di partizione. Ad esempio, potresti partizionare per regione.
Archivia tutti i documenti statunitensi in una raccolta, tutti i documenti europei in un'altra raccolta e tutti i documenti di qualsiasi altra regione in una terza raccolta.
Usa questa mappa delle partizioni e un risolutore di partizioni di ricerca può capire in quale raccolta creare un documento e quali raccolte interrogare, in base alla chiave di partizione, che è la proprietà della regione contenuta in ogni documento.
Partizionamento hash
Nel partizionamento hash, le partizioni vengono assegnate in base al valore di una funzione hash, consentendo di distribuire uniformemente richieste e dati su un numero di partizioni.
Viene comunemente utilizzato per partizionare i dati prodotti o consumati da un gran numero di client distinti ed è utile per archiviare profili utente, elementi di catalogo, ecc.
Diamo un'occhiata a un semplice esempio di partizionamento di intervalli utilizzando RangePartitionResolver fornito da .NET SDK.
Step 1- Crea un nuovo DocumentClient e creeremo due raccolte nell'attività CreateCollections. Uno conterrà i documenti per gli utenti che hanno ID utente che iniziano da A a M e l'altro per gli ID utente da N a Z.
private static async Task CreateCollections(DocumentClient client) {
await client.CreateDocumentCollectionAsync(“dbs/myfirstdb”, new DocumentCollection {
Id = “CollectionAM” });
await client.CreateDocumentCollectionAsync(“dbs/myfirstdb”, new DocumentCollection {
Id = “CollectionNZ” });
}Step 2 - Registra il risolutore di intervalli per il database.
Step 3- Crea un nuovo RangePartitionResolver <string>, che è il tipo di dati della nostra chiave di partizione. Il costruttore accetta due parametri, il nome della proprietà della chiave di partizione e un dizionario che è la mappa di partizioni o mappa di partizione, che è solo un elenco degli intervalli e delle raccolte corrispondenti che stiamo predefinendo per il risolutore.
private static void RegisterRangeResolver(DocumentClient client) {
//Note: \uffff is the largest UTF8 value, so M\ufff includes all strings that start with M.
var resolver = new RangePartitionResolver<string>(
"userId", new Dictionary<Range<string>, string>() {
{ new Range<string>("A", "M\uffff"), "dbs/myfirstdb/colls/CollectionAM" },
{ new Range<string>("N", "Z\uffff"), "dbs/myfirstdb/colls/CollectionNZ" },
});
client.PartitionResolvers["dbs/myfirstdb"] = resolver;
}È necessario codificare il valore UTF-8 più grande possibile qui. Oppure il primo intervallo non corrisponderebbe su nessuna M eccetto quella singola M, e allo stesso modo per Z nel secondo intervallo. Quindi, puoi semplicemente pensare a questo valore codificato qui come un carattere jolly per la corrispondenza sulla chiave di partizione.
Step 4- Dopo aver creato il resolver, registrarlo per il database con il DocumentClient corrente. Per farlo basta assegnarlo alla proprietà del dizionario di PartitionResolver.
Creeremo e interrogheremo i documenti sul database, non una raccolta come fai normalmente, il risolutore utilizzerà questa mappa per instradare le richieste alle raccolte appropriate.
Ora creiamo alcuni documenti. Prima ne creeremo uno per userId Kirk, e poi uno per Spock.
private static async Task CreateDocumentsAcrossPartitions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create Documents Across Partitions ****");
var kirkDocument = await client.CreateDocumentAsync("dbs/myfirstdb", new { userId =
"Kirk", title = "Captain" });
Console.WriteLine("Document 1: {0}", kirkDocument.Resource.SelfLink);
var spockDocument = await client.CreateDocumentAsync("dbs/myfirstdb", new { userId =
"Spock", title = "Science Officer" });
Console.WriteLine("Document 2: {0}", spockDocument.Resource.SelfLink);
}Il primo parametro qui è un collegamento automatico al database, non una raccolta specifica. Questo non è possibile senza un risolutore di partizioni, ma con uno funziona perfettamente.
Entrambi i documenti sono stati salvati nel database myfirstdb, ma sappiamo che Kirk viene archiviato nella raccolta da A a M e Spock viene archiviato nella raccolta da N a Z, se il nostro RangePartitionResolver funziona correttamente.
Chiamiamoli dall'attività CreateDocumentClient come mostrato nel codice seguente.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
await CreateCollections(client);
RegisterRangeResolver(client);
await CreateDocumentsAcrossPartitions(client);
}
}Quando il codice precedente viene eseguito, riceverai il seguente output.
**** Create Documents Across Partitions ****
Document 1: dbs/Ic8LAA==/colls/Ic8LAO2DxAA=/docs/Ic8LAO2DxAABAAAAAAAAAA==/
Document 2: dbs/Ic8LAA==/colls/Ic8LAP12QAE=/docs/Ic8LAP12QAEBAAAAAAAAAA==/Come si è visto, i collegamenti automatici dei due documenti hanno ID risorsa diversi perché esistono in due raccolte separate.
Con lo strumento di migrazione dei dati di DocumentDB, è possibile migrare facilmente i dati in DocumentDB. Lo strumento di migrazione dei dati di DocumentDB è un'utilità gratuita e open source che puoi scaricare dall'Area download Microsofthttps://www.microsoft.com/
Lo strumento di migrazione supporta molte origini dati, alcune delle quali sono elencate di seguito:
- server SQL
- File JSON
- File flat di valori separati da virgola (CSV)
- MongoDB
- Archiviazione tabelle di Azure
- Amazon DynamoDB
- HBase e anche altri database DocumentDB
Dopo aver scaricato lo strumento di migrazione dei dati di DocumentDB, estrai il file zip.
Puoi vedere due eseguibili in questa cartella come mostrato nello screenshot seguente.
In primo luogo, c'è dt.exe, che è la versione console con un'interfaccia a riga di comando, e poi c'è dtui.exe, che è la versione desktop con un'interfaccia utente grafica.
Lanciamo la versione GUI.
Puoi vedere la pagina di benvenuto. Fare clic su "Avanti" per la pagina Informazioni sulla fonte.
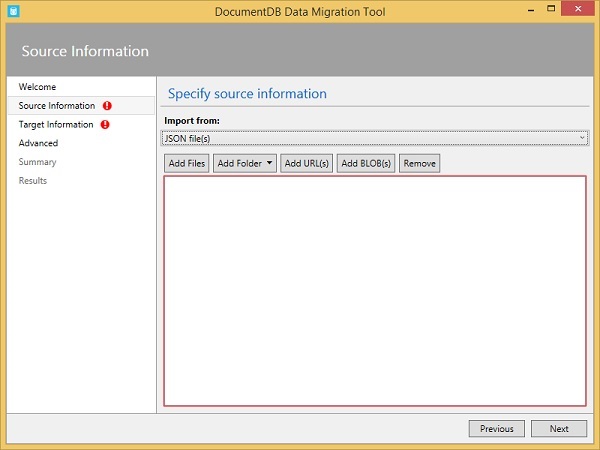
Qui è dove configuri la tua origine dati e puoi vedere le molte scelte supportate dal menu a discesa.
Quando si effettua una selezione, il resto della pagina Informazioni sulla fonte cambia di conseguenza.
È molto facile importare dati in DocumentDB utilizzando lo strumento di migrazione dei dati di DocumentDB. Ti consigliamo di esercitare gli esempi precedenti e di utilizzare anche gli altri file di dati.
DocumentDB fornisce i concetti per controllare l'accesso alle risorse di DocumentDB. L'accesso alle risorse di DocumentDB è regolato da un token di chiave master o da un token di risorsa. Le connessioni basate sui token di risorse possono accedere solo alle risorse specificate dai token e non ad altre risorse. I token delle risorse si basano sulle autorizzazioni dell'utente.
Innanzitutto si creano uno o più utenti e questi vengono definiti a livello di database.
Quindi crei una o più autorizzazioni per ogni utente, in base alle risorse a cui desideri consentire l'accesso a ciascun utente.
Ogni autorizzazione genera un token di risorsa che consente l'accesso in sola lettura o completo a una determinata risorsa e che può essere qualsiasi risorsa utente all'interno del database.
Gli utenti vengono definiti a livello di database e le autorizzazioni sono definite per ogni utente.
Gli utenti e le autorizzazioni si applicano a tutte le raccolte nel database.
Diamo un'occhiata a un semplice esempio in cui impareremo come definire utenti e permessi per ottenere una sicurezza granulare in DocumentDB.
Inizieremo con un nuovo DocumentClient e interrogheremo il database myfirstdb.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
var alice = await CreateUser(client, "Alice");
var tom = await CreateUser(client, "Tom");
}
}Di seguito è riportata l'implementazione per CreateUser.
private async static Task<User> CreateUser(DocumentClient client, string userId) {
Console.WriteLine();
Console.WriteLine("**** Create User {0} in {1} ****", userId, database.Id);
var userDefinition = new User { Id = userId };
var result = await client.CreateUserAsync(database.SelfLink, userDefinition);
var user = result.Resource;
Console.WriteLine("Created new user");
ViewUser(user);
return user;
}Step 1- Creiamo due utenti, Alice e Tom come qualsiasi risorsa che creiamo, costruiamo un oggetto di definizione con l'ID desiderato e chiamiamo il metodo create e in questo caso chiamiamo CreateUserAsync con SelfLink del database e userDefinition. Otteniamo il risultato dalla cui proprietà della risorsa otteniamo l'oggetto utente appena creato.
Ora per vedere questi due nuovi utenti nel database.
private static void ViewUsers(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View Users in {0} ****", database.Id);
var users = client.CreateUserQuery(database.UsersLink).ToList();
var i = 0;
foreach (var user in users) {
i++;
Console.WriteLine();
Console.WriteLine("User #{0}", i);
ViewUser(user);
}
Console.WriteLine();
Console.WriteLine("Total users in database {0}: {1}", database.Id, users.Count);
}
private static void ViewUser(User user) {
Console.WriteLine("User ID: {0} ", user.Id);
Console.WriteLine("Resource ID: {0} ", user.ResourceId);
Console.WriteLine("Self Link: {0} ", user.SelfLink);
Console.WriteLine("Permissions Link: {0} ", user.PermissionsLink);
Console.WriteLine("Timestamp: {0} ", user.Timestamp);
}Step 2- Chiama CreateUserQuery, contro UsersLink del database per recuperare un elenco di tutti gli utenti. Quindi scorrerli e visualizzare le loro proprietà.
Ora dobbiamo prima crearli. Quindi diciamo che volevamo consentire ad Alice i permessi di lettura / scrittura per la raccolta MyCollection, ma Tom può solo leggere i documenti nella raccolta.
await CreatePermission(client, alice, "Alice Collection Access", PermissionMode.All,
collection);
await CreatePermission(client, tom, "Tom Collection Access", PermissionMode.Read,
collection);Step 3- Crea un'autorizzazione su una risorsa che è la raccolta MyCollection, quindi abbiamo bisogno di ottenere quella risorsa un SelfLink.
Step 4 - Quindi crea un Permission.All su questa raccolta per Alice e un Permission.Read su questa raccolta per Tom.
Di seguito è riportata l'implementazione per CreatePermission.
private async static Task CreatePermission(DocumentClient client, User user,
string permId, PermissionMode permissionMode, string resourceLink) {
Console.WriteLine();
Console.WriteLine("**** Create Permission {0} for {1} ****", permId, user.Id);
var permDefinition = new Permission {
Id = permId,
PermissionMode = permissionMode,
ResourceLink = resourceLink
};
var result = await client.CreatePermissionAsync(user.SelfLink, permDefinition);
var perm = result.Resource;
Console.WriteLine("Created new permission");
ViewPermission(perm);
}Come dovresti ormai aspettarti, lo facciamo creando un oggetto di definizione per la nuova autorizzazione, che include un Id e un permissionMode, che è Permission.All o Permission.Read, e il SelfLink della risorsa che viene protetta dal permesso.
Step 5 - Chiama CreatePermissionAsync e ottieni l'autorizzazione creata dalla proprietà della risorsa nel risultato.
Per visualizzare l'autorizzazione creata, di seguito è riportata l'implementazione di ViewPermissions.
private static void ViewPermissions(DocumentClient client, User user) {
Console.WriteLine();
Console.WriteLine("**** View Permissions for {0} ****", user.Id);
var perms = client.CreatePermissionQuery(user.PermissionsLink).ToList();
var i = 0;
foreach (var perm in perms) {
i++;
Console.WriteLine();
Console.WriteLine("Permission #{0}", i);
ViewPermission(perm);
}
Console.WriteLine();
Console.WriteLine("Total permissions for {0}: {1}", user.Id, perms.Count);
}
private static void ViewPermission(Permission perm) {
Console.WriteLine("Permission ID: {0} ", perm.Id);
Console.WriteLine("Resource ID: {0} ", perm.ResourceId);
Console.WriteLine("Permission Mode: {0} ", perm.PermissionMode);
Console.WriteLine("Token: {0} ", perm.Token);
Console.WriteLine("Timestamp: {0} ", perm.Timestamp);
}Questa volta, è una query di autorizzazione sul collegamento delle autorizzazioni dell'utente e viene semplicemente elencata ogni autorizzazione restituita per l'utente.
Eliminiamo i permessi di Alice e Tom.
await DeletePermission(client, alice, "Alice Collection Access");
await DeletePermission(client, tom, "Tom Collection Access");Di seguito è riportata l'implementazione per DeletePermission.
private async static Task DeletePermission(DocumentClient client, User user,
string permId) {
Console.WriteLine();
Console.WriteLine("**** Delete Permission {0} from {1} ****", permId, user.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection {
new SqlParameter { Name = "@id", Value = permId }
}
};
Permission perm = client.CreatePermissionQuery(user.PermissionsLink, query)
.AsEnumerable().First();
await client.DeletePermissionAsync(perm.SelfLink);
Console.WriteLine("Deleted permission {0} from user {1}", permId, user.Id);
}Step 6 - Per eliminare le autorizzazioni, eseguire una query in base all'ID autorizzazione per ottenere SelfLink, quindi utilizzare SelfLink per eliminare l'autorizzazione.
Successivamente, eliminiamo gli utenti stessi. Eliminiamo entrambi gli utenti.
await DeleteUser(client, "Alice");
await DeleteUser(client, "Tom");Di seguito è riportata l'implementazione per DeleteUser.
private async static Task DeleteUser(DocumentClient client, string userId) {
Console.WriteLine();
Console.WriteLine("**** Delete User {0} in {1} ****", userId, database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection {
new SqlParameter { Name = "@id", Value = userId }
}
};
User user = client.CreateUserQuery(database.SelfLink, query).AsEnumerable().First();
await client.DeleteUserAsync(user.SelfLink);
Console.WriteLine("Deleted user {0} from database {1}", userId, database.Id);
}Step 7 - Prima query per ottenere il suo SelfLink e poi chiama DeleteUserAsync per eliminare il suo oggetto utente.
Di seguito è riportata l'implementazione dell'attività CreateDocumentClient in cui chiamiamo tutte le attività precedenti.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
ViewUsers(client);
var alice = await CreateUser(client, "Alice");
var tom = await CreateUser(client, "Tom");
ViewUsers(client);
ViewPermissions(client, alice);
ViewPermissions(client, tom);
string collectionLink = client.CreateDocumentCollectionQuery(database.SelfLink,
"SELECT VALUE c._self FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable().First().Value;
await CreatePermission(client, alice, "Alice Collection Access", PermissionMode.All,
collectionLink);
await CreatePermission(client, tom, "Tom Collection Access", PermissionMode.Read,
collectionLink);
ViewPermissions(client, alice);
ViewPermissions(client, tom);
await DeletePermission(client, alice, "Alice Collection Access");
await DeletePermission(client, tom, "Tom Collection Access");
await DeleteUser(client, "Alice");
await DeleteUser(client, "Tom");
}
}Quando il codice precedente viene compilato ed eseguito, riceverai il seguente output.
**** View Users in myfirstdb ****
Total users in database myfirstdb: 0
**** Create User Alice in myfirstdb ****
Created new user
User ID: Alice
Resource ID: kV5oAC56NwA=
Self Link: dbs/kV5oAA==/users/kV5oAC56NwA=/
Permissions Link: dbs/kV5oAA==/users/kV5oAC56NwA=/permissions/
Timestamp: 12/17/2015 5:44:19 PM
**** Create User Tom in myfirstdb ****
Created new user
User ID: Tom
Resource ID: kV5oAALxKgA=
Self Link: dbs/kV5oAA==/users/kV5oAALxKgA=/
Permissions Link: dbs/kV5oAA==/users/kV5oAALxKgA=/permissions/
Timestamp: 12/17/2015 5:44:21 PM
**** View Users in myfirstdb ****
User #1
User ID: Tom
Resource ID: kV5oAALxKgA=
Self Link: dbs/kV5oAA==/users/kV5oAALxKgA=/
Permissions Link: dbs/kV5oAA==/users/kV5oAALxKgA=/permissions/
Timestamp: 12/17/2015 5:44:21 PM
User #2
User ID: Alice
Resource ID: kV5oAC56NwA=
Self Link: dbs/kV5oAA==/users/kV5oAC56NwA=/
Permissions Link: dbs/kV5oAA==/users/kV5oAC56NwA=/permissions/
Timestamp: 12/17/2015 5:44:19 PM
Total users in database myfirstdb: 2
**** View Permissions for Alice ****
Total permissions for Alice: 0
**** View Permissions for Tom ****
Total permissions for Tom: 0
**** Create Permission Alice Collection Access for Alice ****
Created new permission
Permission ID: Alice Collection Access
Resource ID: kV5oAC56NwDON1RduEoCAA==
Permission Mode: All
Token: type=resource&ver=1&sig=zB6hfvvleC0oGGbq5cc67w==;Zt3Lx
Ol14h8pd6/tyF1h62zbZKk9VwEIATIldw4ZyipQGW951kirueAKdeb3MxzQ7eCvDfvp7Y/ZxFpnip/D G
JYcPyim5cf+dgLvos6fUuiKSFSul7uEKqp5JmJqUCyAvD7w+qt1Qr1PmrJDyAIgbZDBFWGe2VT9FaBH o
PYwrLjRlnH0AxfbrR+T/UpWMSSHtLB8JvNFZNSH8hRjmQupuTSxCTYEC89bZ/pS6fNmNg8=;
Timestamp: 12/17/2015 5:44:28 PM
**** Create Permission Tom Collection Access for Tom ****
Created new permission
Permission ID: Tom Collection Access
Resource ID: kV5oAALxKgCMai3JKWdfAA==
Permission Mode: Read
Token: type=resource&ver=1&sig=ieBHKeyi6EY9ZOovDpe76w==;92gwq
V4AxKaCJ2dLS02VnJiig/5AEbPcfo1xvOjR10uK3a3FUMFULgsaK8nzxdz6hLVCIKUj6hvMOTOSN8Lt 7
i30mVqzpzCfe7JO3TYSJEI9D0/5HbMIEgaNJiCu0JPPwsjVecTytiLN56FHPguoQZ7WmUAhVTA0IMP6 p
jQpLDgJ43ZaG4Zv3qWJiO689balD+egwiU2b7RICH4j6R66UVye+GPxq/gjzqbHwx79t54=;
Timestamp: 12/17/2015 5:44:30 PM
**** View Permissions for Alice ****
Permission #1
Permission ID: Alice Collection Access
Resource ID: kV5oAC56NwDON1RduEoCAA==
Permission Mode: All
Token: type=resource&ver=1&sig=BSzz/VNe9j4IPJ9M31Mf4Q==;Tcq/B
X50njB1vmANZ/4aHj/3xNkghaqh1OfV95JMi6j4v7fkU+gyWe3mJasO3MJcoop9ixmVnB+RKOhFaSxE l
P37SaGuIIik7GAWS+dcEBWglMefc95L2YkeNuZsjmmW5b+a8ELCUg7N45MKbpzkp5BrmmGVJ7h4Z4pf D
rdmehYLuxSPLkr9ndbOOrD8E3bux6TgXCsgYQscpIlJHSKCKHUHfXWBP2Y1LV2zpJmRjis=;
Timestamp: 12/17/2015 5:44:28 PM
Total permissions for Alice: 1
**** View Permissions for Tom ****
Permission #1
Permission ID: Tom Collection Access
Resource ID: kV5oAALxKgCMai3JKWdfAA==
Permission Mode: Read
Token: type=resource&ver=1&sig=NPkWNJp1mAkCASE8KdR6PA==;ur/G2
V+fDamBmzECux000VnF5i28f8WRbPwEPxD1DMpFPqYcu45wlDyzT5A5gBr3/R3qqYkEVn8bU+een6Gl j
L6vXzIwsZfL12u/1hW4mJT2as2PWH3eadry6Q/zRXHAxV8m+YuxSzlZPjBFyJ4Oi30mrTXbBAEafZhA 5
yvbHkpLmQkLCERy40FbIFOzG87ypljREpwWTKC/z8RSrsjITjAlfD/hVDoOyNJwX3HRaz4=;
Timestamp: 12/17/2015 5:44:30 PM
Total permissions for Tom: 1
**** Delete Permission Alice Collection Access from Alice ****
Deleted permission Alice Collection Access from user Alice
**** Delete Permission Tom Collection Access from Tom ****
Deleted permission Tom Collection Access from user Tom
**** Delete User Alice in myfirstdb ****
Deleted user Alice from database myfirstdb
**** Delete User Tom in myfirstdb ****
Deleted user Tom from database myfirstdbIn questo capitolo impareremo come visualizzare i dati memorizzati in DocumentDB. Microsoft ha fornito lo strumento Power BI Desktop che trasforma i dati in immagini ricche. Consente inoltre di recuperare i dati da varie origini dati, unire e trasformare i dati, creare report e visualizzazioni potenti e pubblicare i report in Power BI.
Nell'ultima versione di Power BI Desktop, Microsoft ha aggiunto il supporto anche per DocumentDB in cui ora puoi connetterti al tuo account DocumentDB. Puoi scaricare questo strumento dal link,https://powerbi.microsoft.com
Diamo un'occhiata a un esempio in cui visualizzeremo i dati dei terremoti importati nell'ultimo capitolo.
Step 1 - Una volta scaricato lo strumento, avvia il desktop di Power BI.
Step 2 - Fare clic sull'opzione "Ottieni dati" che si trova nella scheda Home nel gruppo Dati esterni e visualizzerà la pagina Ottieni dati.
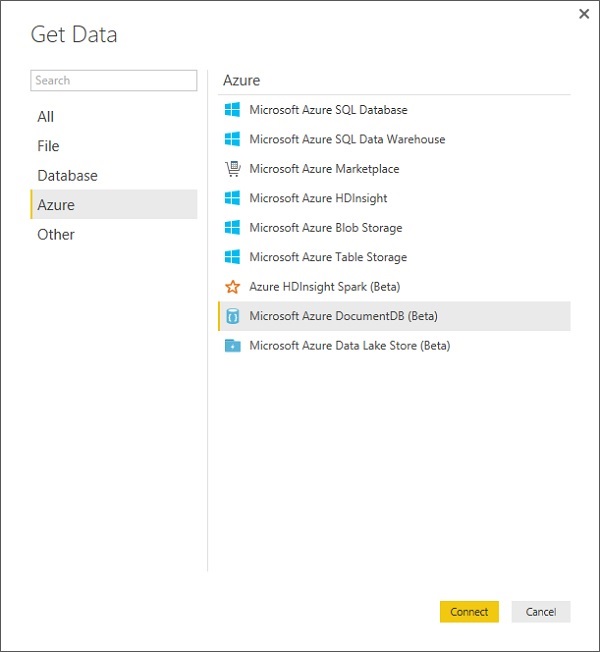
Step 3 - Seleziona l'opzione Microsoft Azure DocumentDB (Beta) e fai clic sul pulsante "Connetti".
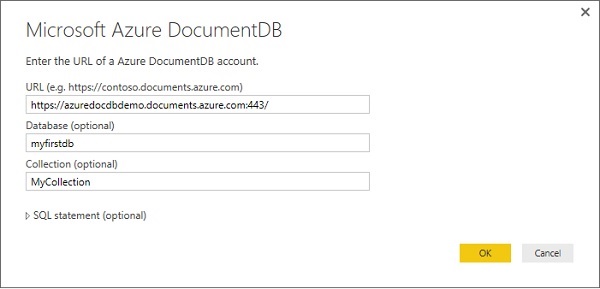
Step 4 - Immettere l'URL del proprio account Azure DocumentDB, database e raccolta da cui si desidera visualizzare i dati e premere Ok.
Se ti connetti a questo endpoint per la prima volta, ti verrà richiesta la chiave dell'account.
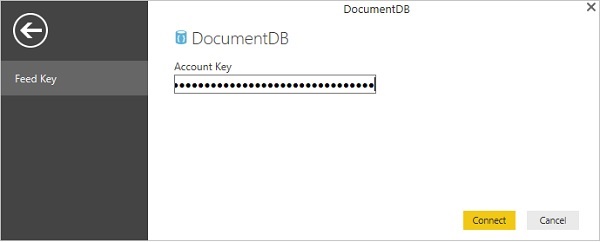
Step 5 - Immettere la chiave dell'account (chiave primaria) che è univoca per ogni account DocumentDB disponibile nel portale di Azure, quindi fare clic su Connetti.
Quando l'account è connesso correttamente, recupererà i dati dal database specificato. Il riquadro Anteprima mostra un elenco di elementi record, un documento è rappresentato come un tipo di record in Power BI.
Step 6 - Fare clic sul pulsante "Modifica" che avvierà l'editor di query.
Step 7 - Nell'editor di query di Power BI, dovresti vedere una colonna Documento nel riquadro centrale, fare clic sull'espansore sul lato destro dell'intestazione della colonna Documento e selezionare le colonne che si desidera visualizzare.
Come puoi vedere, abbiamo la latitudine e la longitudine come colonne separate ma visualizziamo i dati sotto forma di coordinate di latitudine e longitudine.
Step 8 - Per farlo, fai clic sulla scheda "Aggiungi colonna".
Step 9 - Seleziona Aggiungi colonna personalizzata che visualizzerà la pagina seguente.
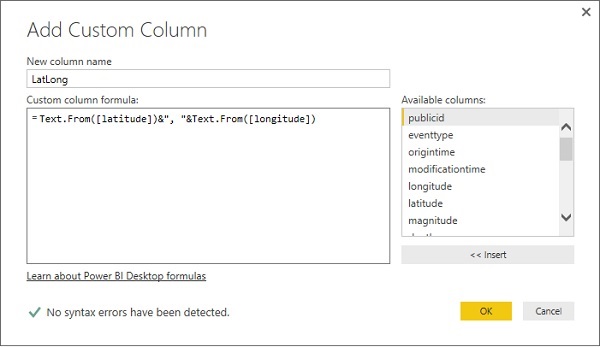
Step 10- Specifica il nuovo nome della colonna, diciamo LatLong e anche la formula che combinerà la latitudine e la longitudine in una colonna separata da una virgola. Di seguito è la formula.
Text.From([latitude])&", "&Text.From([longitude])Step 11 - Fare clic su OK per continuare e vedrai che la nuova colonna viene aggiunta.
Step 12 - Vai alla scheda Home e fai clic sull'opzione "Chiudi e applica".
Step 13- È possibile creare report trascinando e rilasciando i campi nell'area di disegno Report. Puoi vedere a destra che ci sono due riquadri: un riquadro Visualizzazioni e l'altro è il riquadro Campi.
Creiamo una vista mappa che mostri la posizione di ogni terremoto.
Step 14 - Trascina il tipo di visualizzazione della mappa dal riquadro Visualizzazioni.
Step 15- Ora, trascina e rilascia il campo LatLong dal riquadro Campi alla proprietà Posizione nel riquadro Visualizzazioni. Quindi, trascina e rilascia il campo di grandezza nella proprietà Valori.
Step 16 - Trascina e rilascia il campo di profondità sulla proprietà Saturazione colore.
Ora vedrai la visuale Mappa che mostra una serie di bolle che indicano la posizione di ogni terremoto.