Elisir - Guida rapida
Elixir è un linguaggio dinamico e funzionale progettato per la creazione di applicazioni scalabili e gestibili. Sfrutta la VM Erlang, nota per l'esecuzione di sistemi a bassa latenza, distribuiti e con tolleranza agli errori, mentre viene utilizzata con successo anche nello sviluppo web e nel dominio del software embedded.
Elixir è un linguaggio funzionale e dinamico costruito su Erlang e Erlang VM. Erlang è un linguaggio originariamente scritto nel 1986 da Ericsson per aiutare a risolvere i problemi di telefonia come la distribuzione, la tolleranza agli errori e la concorrenza. Elixir, scritto da José Valim, estende Erlang e fornisce una sintassi più amichevole nella VM di Erlang. Lo fa mantenendo le prestazioni allo stesso livello di Erlang.
Caratteristiche di Elixir
Parliamo ora di alcune importanti caratteristiche di Elixir:
Scalability - Tutto il codice Elixir viene eseguito all'interno di processi leggeri che sono isolati e scambiano informazioni tramite messaggi.
Fault Tolerance- Elixir fornisce supervisori che descrivono come riavviare parti del sistema quando le cose vanno male, tornando a uno stato iniziale noto che è garantito per funzionare. Ciò garantisce che la tua applicazione / piattaforma non sia mai inattiva.
Functional Programming - La programmazione funzionale promuove uno stile di codifica che aiuta gli sviluppatori a scrivere codice breve, veloce e gestibile.
Build tools- Elixir viene fornito con una serie di strumenti di sviluppo. Mix è uno di questi strumenti che semplifica la creazione di progetti, la gestione di attività, l'esecuzione di test, ecc. Ha anche un proprio gestore di pacchetti - Hex.
Erlang Compatibility - Elixir viene eseguito sulla VM Erlang, offrendo agli sviluppatori l'accesso completo all'ecosistema di Erlang.
Per eseguire Elixir, devi configurarlo localmente sul tuo sistema.
Per installare Elixir, avrai prima bisogno di Erlang. Su alcune piattaforme, i pacchetti Elixir contengono Erlang.
Installazione di Elixir
Vediamo ora di capire l'installazione di Elixir in diversi sistemi operativi.
Installazione di Windows
Per installare Elixir su Windows, scarica il programma di installazione da https://repo.hex.pm/elixirwebsetup.exe e fai semplicemente clic Nextper procedere attraverso tutti i passaggi. Lo avrai sul tuo sistema locale.
Se hai problemi durante l'installazione, puoi controllare questa pagina per maggiori informazioni.
Configurazione per Mac
Se hai installato Homebrew, assicurati che sia l'ultima versione. Per l'aggiornamento, utilizzare il seguente comando:
brew updateOra installa Elixir usando il comando dato di seguito -
brew install elixirInstallazione di Ubuntu / Debian
I passaggi per installare Elixir in una configurazione Ubuntu / Debian sono i seguenti:
Aggiungi il repository Erlang Solutions -
wget https://packages.erlang-solutions.com/erlang-solutions_1.0_all.deb && sudo
dpkg -i erlang-solutions_1.0_all.deb
sudo apt-get updateInstalla la piattaforma Erlang / OTP e tutte le sue applicazioni -
sudo apt-get install esl-erlangInstalla Elixir -
sudo apt-get install elixirAltre distribuzioni Linux
Se hai un'altra distribuzione Linux, visita questa pagina per configurare l'elisir sul tuo sistema locale.
Testare l'installazione
Per testare la configurazione di Elixir sul tuo sistema, apri il tuo terminale e inserisci iex al suo interno. Si aprirà la shell elisir interattiva come la seguente:
Erlang/OTP 19 [erts-8.0] [source-6dc93c1] [64-bit]
[smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.3.1) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>Elixir è ora impostato correttamente sul tuo sistema.
Inizieremo con il consueto programma "Hello World".
Per avviare la shell interattiva Elixir, immetti il seguente comando.
iexDopo l'avvio della shell, utilizzare il IO.putsfunzione per "mettere" la stringa nell'output della console. Inserisci quanto segue nel tuo guscio di elisir:
IO.puts "Hello world"In questo tutorial, useremo la modalità script Elixir dove manterremo il codice Elixir in un file con estensione .ex. Cerchiamo ora di mantenere il codice precedente nel filetest.exfile. Nel passaggio successivo, lo eseguiremo utilizzandoelixirc-
IO.puts "Hello world"Proviamo ora a eseguire il programma sopra come segue:
$elixirc test.exIl programma di cui sopra genera il seguente risultato:
Hello WorldQui stiamo chiamando una funzione IO.putsper generare una stringa nella nostra console come output. Questa funzione può anche essere chiamata come facciamo in C, C ++, Java, ecc., Fornendo argomenti tra parentesi dopo il nome della funzione -
IO.puts("Hello world")Commenti
I commenti su una sola riga iniziano con un simbolo "#". Non ci sono commenti su più righe, ma puoi impilare più commenti. Ad esempio:
#This is a comment in ElixirFine riga
Non ci sono terminazioni di riga obbligatorie come ";" in Elisir. Tuttavia, possiamo avere più istruzioni nella stessa riga, usando ';'. Per esempio,
IO.puts("Hello"); IO.puts("World!")Il programma di cui sopra genera il seguente risultato:
Hello
World!Identificatori
Identificatori come variabili, nomi di funzioni vengono utilizzati per identificare una variabile, una funzione, ecc. In Elixir, puoi denominare i tuoi identificatori iniziando con un alfabeto minuscolo con numeri, trattini bassi e lettere maiuscole. Questa convenzione di denominazione è comunemente nota come snake_case. Ad esempio, di seguito sono riportati alcuni identificatori validi in Elixir:
var1 variable_2 one_M0r3_variableSi noti che le variabili possono anche essere denominate con un trattino basso iniziale. Un valore che non deve essere utilizzato deve essere assegnato a _ oa una variabile che inizia con il carattere di sottolineatura -
_some_random_value = 42Inoltre elixir si basa su trattini bassi per rendere le funzioni private ai moduli. Se si nomina una funzione con un trattino basso iniziale in un modulo e si importa quel modulo, questa funzione non verrà importata.
Ci sono molte altre complessità legate alla denominazione delle funzioni in Elixir di cui parleremo nei prossimi capitoli.
Parole riservate
Le seguenti parole sono riservate e non possono essere utilizzate come variabili, nomi di moduli o funzioni.
after and catch do inbits inlist nil else end
not or false fn in rescue true when xor
__MODULE__ __FILE__ __DIR__ __ENV__ __CALLER__Per utilizzare qualsiasi lingua, è necessario comprendere i tipi di dati di base supportati dalla lingua. In questo capitolo discuteremo 7 tipi di dati di base supportati dal linguaggio elisir: interi, float, booleani, atomi, stringhe, liste e tuple.
Tipi numerici
Elixir, come qualsiasi altro linguaggio di programmazione, supporta sia interi che float. Se apri la tua shell elisir e inserisci qualsiasi numero intero o float come input, restituirà il suo valore. Per esempio,
42Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
42Puoi anche definire numeri in base ottale, esadecimale e binaria.
Octal
Per definire un numero in base ottale, anteponilo a '0o'. Ad esempio, 0o52 in ottale è equivalente a 42 in decimale.
Esadecimale
Per definire un numero in base decimale, anteponilo a "0x". Ad esempio, 0xF1 in esadecimale equivale a 241 in decimale.
Binario
Per definire un numero in base binaria, anteponilo a "0b". Ad esempio, 0b1101 in binario equivale a 13 in decimale.
Elixir supporta la doppia precisione a 64 bit per i numeri in virgola mobile. E possono anche essere definiti utilizzando uno stile di esponenziazione. Ad esempio, 10145230000 può essere scritto come 1.014523e10
Atomi
Gli atomi sono costanti il cui nome è il loro valore. Possono essere creati utilizzando il simbolo del colore (:). Per esempio,
:helloBooleani
Elisir supporta true e falsecome booleani. Entrambi questi valori sono infatti associati agli atomi: true e: false rispettivamente.
stringhe
Le stringhe in Elixir vengono inserite tra virgolette doppie e sono codificate in UTF-8. Possono estendersi su più righe e contenere interpolazioni. Per definire una stringa è sufficiente inserirla tra virgolette doppie -
"Hello world"Per definire stringhe multilinea, usiamo una sintassi simile a python con virgolette triple doppie -
"""
Hello
World!
"""Impareremo le stringhe, i binari e gli elenchi di caratteri (simili alle stringhe) in modo approfondito nel capitolo sulle stringhe.
Binari
I binari sono sequenze di byte racchiusi tra << >> separati da una virgola. Per esempio,
<< 65, 68, 75>>I binari vengono utilizzati principalmente per gestire i dati relativi a bit e byte, se ne hai. Per impostazione predefinita, possono memorizzare da 0 a 255 in ogni valore. Questo limite di dimensione può essere aumentato utilizzando la funzione di dimensione che dice quanti bit sono necessari per memorizzare quel valore. Per esempio,
<<65, 255, 289::size(15)>>Liste
Elixir utilizza le parentesi quadre per specificare un elenco di valori. I valori possono essere di qualsiasi tipo. Per esempio,
[1, "Hello", :an_atom, true]Le liste sono dotate di funzioni integrate per la testa e la coda della lista denominate hd e tl che restituiscono rispettivamente la testa e la coda della lista. A volte, quando crei un elenco, restituirà un elenco di caratteri. Questo perché quando elixir vede un elenco di caratteri ASCII stampabili, lo stampa come un elenco di caratteri. Tieni presente che le stringhe e gli elenchi di caratteri non sono uguali. Discuteremo ulteriormente gli elenchi nei capitoli successivi.
Tuple
Elixir utilizza le parentesi graffe per definire le tuple. Come le liste, le tuple possono contenere qualsiasi valore.
{ 1, "Hello", :an_atom, trueQui sorge una domanda: perché fornire entrambi lists e tuplesquando funzionano entrambi allo stesso modo? Ebbene hanno diverse implementazioni.
Gli elenchi vengono effettivamente memorizzati come elenchi collegati, quindi gli inserimenti e le eliminazioni sono molto veloci negli elenchi.
Le tuple, d'altra parte, sono archiviate in blocchi di memoria contigui, il che rende l'accesso più veloce ma aggiunge un costo aggiuntivo per inserimenti e cancellazioni.
Una variabile ci fornisce una memoria con nome che i nostri programmi possono manipolare. Ogni variabile in Elixir ha un tipo specifico, che determina la dimensione e il layout della memoria della variabile; l'intervallo di valori che possono essere memorizzati all'interno di quella memoria; e l'insieme di operazioni che possono essere applicate alla variabile.
Tipi di variabili
Elixir supporta i seguenti tipi di base di variabili.
Numero intero
Questi sono usati per i numeri interi. Hanno una dimensione di 32 bit su un'architettura a 32 bit e 64 bit su un'architettura a 64 bit. I numeri interi sono sempre firmati in elisir. Se un numero intero inizia ad espandersi di dimensioni al di sopra del suo limite, elisir lo converte in un numero intero grande che occupa memoria nell'intervallo da 3 a n parole, a seconda di quale può essere contenuto in memoria.
Galleggianti
I float hanno una precisione a 64 bit in elisir. Sono anche come numeri interi in termini di memoria. Quando si definisce un float, è possibile utilizzare la notazione esponenziale.
Booleano
Possono assumere fino a 2 valori che è vero o falso.
stringhe
Le stringhe sono codificate in utf-8 in elisir. Hanno un modulo per le stringhe che fornisce molte funzionalità al programmatore per manipolare le stringhe.
Funzioni anonime / Lambda
Si tratta di funzioni che possono essere definite e assegnate a una variabile, che può quindi essere utilizzata per chiamare questa funzione.
Collezioni
Ci sono molti tipi di raccolta disponibili in Elixir. Alcuni di loro sono elenchi, tuple, mappe, binari, ecc. Questi saranno discussi nei capitoli successivi.
Dichiarazione di variabili
Una dichiarazione di variabile dice all'interprete dove e quanto creare la memoria per la variabile. Elixir non ci consente di dichiarare solo una variabile. Una variabile deve essere dichiarata e allo stesso tempo deve essere assegnato un valore. Ad esempio, per creare una variabile denominata life e assegnarle un valore 42, eseguiamo le seguenti operazioni:
life = 42Questo vincolerà la vita della variabile al valore 42. Se vogliamo riassegnare a questa variabile un nuovo valore, possiamo farlo usando la stessa sintassi di sopra, cioè,
life = "Hello world"Denominazione delle variabili
Le variabili di denominazione seguono a snake_caseconvenzione in Elixir, cioè tutte le variabili devono iniziare con una lettera minuscola, seguita da 0 o più lettere (sia maiuscole che minuscole), seguite alla fine da un "?" opzionale O '!'.
I nomi delle variabili possono anche essere avviati con un trattino basso iniziale, ma deve essere utilizzato solo quando si ignora la variabile, ovvero quella variabile non verrà utilizzata di nuovo ma è necessario assegnarla a qualcosa.
Variabili di stampa
Nella shell interattiva, le variabili verranno stampate se inserisci solo il nome della variabile. Ad esempio, se crei una variabile -
life = 42E inserisci 'vita' nella tua shell, otterrai l'output come -
42Ma se vuoi inviare una variabile alla console (quando esegui uno script esterno da un file), devi fornire la variabile come input per IO.puts funzione -
life = 42
IO.puts lifeo
life = 42
IO.puts(life)Questo ti darà il seguente output:
42Un operatore è un simbolo che dice al compilatore di eseguire specifiche manipolazioni matematiche o logiche. Ci sono MOLTI operatori forniti da elixir. Si dividono nelle seguenti categorie:
- Operatori aritmetici
- Operatori di confronto
- Operatori booleani
- Operatori vari
Operatori aritmetici
La tabella seguente mostra tutti gli operatori aritmetici supportati dal linguaggio Elixir. Assumi variabileA detiene 10 e variabile B detiene 20, quindi -
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| + | Aggiunge 2 numeri. | A + B darà 30 |
| - | Sottrae il secondo numero dal primo. | AB darà -10 |
| * | Moltiplica due numeri. | A * B darà 200 |
| / | Divide il primo numero dal secondo. Questo lancia i numeri in float e dà un risultato float | A / B darà 0,5. |
| div | Questa funzione viene utilizzata per ottenere il quoziente sulla divisione. | div (10,20) darà 0 |
| rem | Questa funzione viene utilizzata per ottenere il resto sulla divisione. | rem (A, B) darà 10 |
Operatori di confronto
Gli operatori di confronto in Elixir sono per lo più comuni a quelli forniti nella maggior parte delle altre lingue. La tabella seguente riassume gli operatori di confronto in Elixir. Assumi variabileA detiene 10 e variabile B detiene 20, quindi -
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| == | Controlla se il valore a sinistra è uguale al valore a destra (Type esegue il cast dei valori se non sono dello stesso tipo). | A == B darà falso |
| ! = | Controlla se il valore a sinistra non è uguale al valore a destra. | A! = B darà vero |
| === | Controlla se il tipo di valore a sinistra è uguale al tipo di valore a destra, se sì, controlla lo stesso per il valore. | A === B darà falso |
| ! == | Come sopra, ma controlla la disuguaglianza invece dell'uguaglianza. | A! == B darà vero |
| > | Controlla se il valore dell'operando sinistro è maggiore del valore dell'operando destro; se sì, la condizione diventa vera. | A> B darà falso |
| < | Controlla se il valore dell'operando sinistro è inferiore al valore dell'operando destro; se sì, la condizione diventa vera. | A <B darà vero |
| > = | Controlla se il valore dell'operando sinistro è maggiore o uguale al valore dell'operando destro; se sì, la condizione diventa vera. | A> = B darà falso |
| <= | Controlla se il valore dell'operando sinistro è minore o uguale al valore dell'operando destro; se sì, la condizione diventa vera. | A <= B darà vero |
Operatori logici
Elixir fornisce 6 operatori logici: and, or, not, &&, || e !. I primi tre,and or notsono operatori booleani rigorosi, il che significa che si aspettano che il loro primo argomento sia un booleano. L'argomento non booleano genererà un errore. Mentre i prossimi tre,&&, || and !non sono rigorosi, non richiedono che il primo valore sia rigorosamente booleano. Funzionano allo stesso modo delle loro controparti rigorose. Assumi variabileA è vero e variabile B detiene 20, quindi -
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| e | Verifica se entrambi i valori forniti sono veritieri, in caso affermativo restituisce il valore della seconda variabile. (Logico e). | A e B daranno 20 |
| o | Controlla se uno dei valori forniti è veritiero. Restituisce il valore vero. Altrimenti restituisce false. (Logico o). | A o B daranno vero |
| non | Operatore unario che inverte il valore di un dato input. | non A darà falso |
| && | Non rigoroso and. Funziona comeand ma non si aspetta che il primo argomento sia un booleano. | B && A darà 20 |
| || | Non rigoroso or. Funziona comeor ma non si aspetta che il primo argomento sia un booleano. | B || A dare vero |
| ! | Non rigoroso not. Funziona comenot ma non si aspetta che l'argomento sia un booleano. | ! A darà falso |
NOTE −e , o , && e || || sono operatori di cortocircuito. Ciò significa che se il primo argomento diandè falso, quindi non controllerà ulteriormente il secondo. E se il primo argomento diorè vero, quindi non controllerà il secondo. Per esempio,
false and raise("An error")
#This won't raise an error as raise function wont get executed because of short
#circuiting nature of and operatorOperatori bit per bit
Gli operatori bit per bit lavorano sui bit ed eseguono operazioni bit per bit. Elixir fornisce moduli bit per bit come parte del pacchettoBitwise, quindi per utilizzarli è necessario utilizzare il modulo bit a bit. Per usarlo, inserisci il seguente comando nella tua shell:
use BitwiseSupponiamo che A sia 5 e B sia 6 per i seguenti esempi:
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| &&& | Bitwise e l'operatore copia un bit nel risultato se esiste in entrambi gli operandi. | A &&& B darà 4 |
| ||| | Bitwise o l'operatore copia un bit nel risultato se esiste in uno degli operandi. | A ||| B darà 7 |
| >>> | L'operatore di spostamento a destra bit per bit sposta i bit del primo operando a destra del numero specificato nel secondo operando. | A >>> B darà 0 |
| <<< | L'operatore di spostamento a sinistra bit per bit sposta i bit del primo operando a sinistra del numero specificato nel secondo operando. | A <<< B darà 320 |
| ^^^ | L'operatore XOR bit per bit copia un bit nel risultato solo se è diverso su entrambi gli operandi. | A ^^^ B darà 3 |
| ~~~ | Unario bit per bit non inverte i bit sul numero dato. | ~~~ A darà -6 |
Operatori vari
Oltre agli operatori di cui sopra, Elixir fornisce anche una gamma di altri operatori simili Concatenation Operator, Match Operator, Pin Operator, Pipe Operator, String Match Operator, Code Point Operator, Capture Operator, Ternary Operator che lo rendono un linguaggio piuttosto potente.
Mostra esempi
Il pattern matching è una tecnica che Elixir eredita da Erlang. È una tecnica molto potente che ci consente di estrarre sottostrutture più semplici da strutture di dati complicate come elenchi, tuple, mappe, ecc.
Una partita ha 2 parti principali, a left e a rightlato. Il lato destro è una struttura dati di qualsiasi tipo. Il lato sinistro tenta di far corrispondere la struttura dei dati sul lato destro e associa qualsiasi variabile a sinistra alla rispettiva sottostruttura a destra. Se non viene trovata una corrispondenza, l'operatore genera un errore.
La corrispondenza più semplice è una variabile solitaria a sinistra e qualsiasi struttura dati a destra. This variable will match anything. Per esempio,
x = 12
x = "Hello"
IO.puts(x)È possibile posizionare le variabili all'interno di una struttura in modo da poter catturare una sottostruttura. Per esempio,
[var_1, _unused_var, var_2] = [{"First variable"}, 25, "Second variable" ]
IO.puts(var_1)
IO.puts(var_2)Questo memorizzerà i valori, {"First variable"}in var_1 e"Second variable"in var_2 . C'è anche uno speciale_ variabile (o variabili con prefisso '_') che funziona esattamente come le altre variabili ma dice elisir, "Make sure something is here, but I don't care exactly what it is.". Nell'esempio precedente, _unused_var era una di queste variabili.
Possiamo abbinare modelli più complicati usando questa tecnica. Perexample se vuoi scartare e ottenere un numero in una tupla che si trova all'interno di una lista che a sua volta è in una lista, puoi usare il seguente comando:
[_, [_, {a}]] = ["Random string", [:an_atom, {24}]]
IO.puts(a)Il programma di cui sopra genera il seguente risultato:
24Questo legherà a a 24. Gli altri valori vengono ignorati poiché si utilizza "_".
Nel pattern matching, se usiamo una variabile nel file right, viene utilizzato il suo valore. Se vuoi usare il valore di una variabile a sinistra, dovrai usare l'operatore pin.
Ad esempio, se hai una variabile "a" con valore 25 e desideri abbinarla a un'altra variabile "b" con valore 25, devi inserire -
a = 25
b = 25
^a = bL'ultima riga corrisponde al valore corrente di a, invece di assegnarlo, al valore di b. Se abbiamo un insieme non corrispondente del lato sinistro e destro, l'operatore di corrispondenza genera un errore. Ad esempio, se proviamo a far corrispondere una tupla con un elenco o un elenco di dimensione 2 con un elenco di dimensione 3, verrà visualizzato un errore.
Le strutture decisionali richiedono che il programmatore specifichi una o più condizioni che devono essere valutate o testate dal programma, insieme a una o più istruzioni da eseguire se la condizione è determinata truee, facoltativamente, altre istruzioni da eseguire se si determina che la condizione è false.
Di seguito è riportato il generale di una tipica struttura decisionale che si trova nella maggior parte del linguaggio di programmazione:
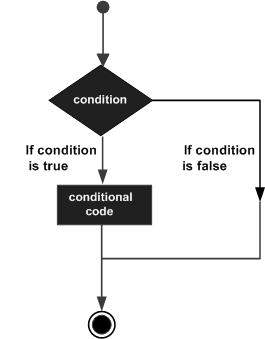
Elixir fornisce costrutti condizionali if / else come molti altri linguaggi di programmazione. Ha anche un fileconddichiarazione che chiama il primo valore vero che trova. Case è un'altra istruzione del flusso di controllo che utilizza il pattern matching per controllare il flusso del programma. Diamo uno sguardo approfondito a loro.
Elixir fornisce i seguenti tipi di dichiarazioni decisionali. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Dichiarazione e descrizione |
|---|---|
| 1 | istruzione if Un'istruzione if è costituita da un'espressione booleana seguita da do, una o più istruzioni eseguibili e infine un file endparola chiave. Il codice nell'istruzione if viene eseguito solo se la condizione booleana restituisce true. |
| 2 | if..else istruzione Un'istruzione if può essere seguita da un'istruzione else opzionale (all'interno del blocco do..end), che viene eseguita quando l'espressione booleana è falsa. |
| 3 | salvo dichiarazione Un'istruzione a meno ha lo stesso corpo di un'istruzione if. Il codice all'interno dell'istruzione a meno che venga eseguito solo quando la condizione specificata è falsa. |
| 4 | a meno che..else dichiarazione Un'istruzioneless..else ha lo stesso corpo di un'istruzione if..else. Il codice all'interno dell'istruzione a meno che venga eseguito solo quando la condizione specificata è falsa. |
| 5 | cond Un'istruzione cond viene utilizzata quando si desidera eseguire il codice sulla base di diverse condizioni. Funziona come un costrutto if ... else if ... .else in molti altri linguaggi di programmazione. |
| 6 | Astuccio L'istruzione case può essere considerata come una sostituzione dell'istruzione switch nelle lingue imperative. Case prende una variabile / letterale e applica la corrispondenza del modello ad essa con casi diversi. Se un caso corrisponde, Elixir esegue il codice associato a quel caso ed esce dall'istruzione case. |
Le stringhe in Elixir vengono inserite tra virgolette doppie e sono codificate in UTF-8. A differenza di C e C ++ in cui le stringhe predefinite sono codificate ASCII e sono possibili solo 256 caratteri diversi, UTF-8 è costituito da 1.112.064 punti di codice. Ciò significa che la codifica UTF-8 consiste di quei molti diversi caratteri possibili. Poiché le stringhe usano utf-8, possiamo anche usare simboli come: ö, ł, ecc.
Crea una stringa
Per creare una variabile stringa, è sufficiente assegnare una stringa a una variabile -
str = "Hello world"Per stamparlo sulla tua console, chiama semplicemente il file IO.puts e passagli la variabile str -
str = str = "Hello world"
IO.puts(str)Il programma di cui sopra genera il seguente risultato:
Hello WorldStringhe vuote
Puoi creare una stringa vuota usando la stringa letterale, "". Per esempio,
a = ""
if String.length(a) === 0 do
IO.puts("a is an empty string")
endIl programma di cui sopra genera il seguente risultato.
a is an empty stringInterpolazione di stringhe
L'interpolazione di stringhe è un modo per costruire un nuovo valore String da una combinazione di costanti, variabili, letterali ed espressioni includendo i loro valori all'interno di una stringa letterale. Elixir supporta l'interpolazione delle stringhe, per usare una variabile in una stringa, quando la si scrive, racchiuderla tra parentesi graffe e anteporre le parentesi graffe con un'#' cartello.
Per esempio,
x = "Apocalypse"
y = "X-men #{x}"
IO.puts(y)Questo prenderà il valore di x e lo sostituirà in y. Il codice sopra genererà il seguente risultato:
X-men ApocalypseConcatenazione di stringhe
Abbiamo già visto l'uso della concatenazione di stringhe nei capitoli precedenti. L'operatore "<>" viene utilizzato per concatenare le stringhe in Elixir. Per concatenare 2 stringhe,
x = "Dark"
y = "Knight"
z = x <> " " <> y
IO.puts(z)Il codice sopra genera il seguente risultato:
Dark KnightLunghezza della stringa
Per ottenere la lunghezza della stringa, usiamo il String.lengthfunzione. Passa la stringa come parametro e ti mostrerà la sua dimensione. Per esempio,
IO.puts(String.length("Hello"))Quando si esegue il programma sopra, produce il seguente risultato:
5Inversione di una stringa
Per invertire una stringa, passarla alla funzione String.reverse. Per esempio,
IO.puts(String.reverse("Elixir"))Il programma di cui sopra genera il seguente risultato:
rixilEConfronto tra stringhe
Per confrontare 2 stringhe, possiamo usare gli operatori == o ===. Per esempio,
var_1 = "Hello world"
var_2 = "Hello Elixir"
if var_1 === var_2 do
IO.puts("#{var_1} and #{var_2} are the same")
else
IO.puts("#{var_1} and #{var_2} are not the same")
endIl programma di cui sopra genera il seguente risultato:
Hello world and Hello elixir are not the same.Corrispondenza di stringhe
Abbiamo già visto l'uso dell'operatore di corrispondenza stringa = ~. Per verificare se una stringa corrisponde a un'espressione regolare, possiamo anche utilizzare l'operatore di corrispondenza della stringa o String.match? funzione. Per esempio,
IO.puts(String.match?("foo", ~r/foo/))
IO.puts(String.match?("bar", ~r/foo/))Il programma di cui sopra genera il seguente risultato:
true
falseLo stesso può essere ottenuto anche utilizzando l'operatore = ~. Per esempio,
IO.puts("foo" =~ ~r/foo/)Il programma di cui sopra genera il seguente risultato:
trueFunzioni stringa
Elixir supporta un gran numero di funzioni legate alle stringhe, alcune delle più utilizzate sono elencate nella tabella seguente.
| Sr.No. | Funzione e suo scopo |
|---|---|
| 1 | at(string, position) Restituisce il grafico nella posizione della stringa utf8 data. Se la posizione è maggiore della lunghezza della stringa, restituisce zero |
| 2 | capitalize(string) Converte il primo carattere della stringa data in maiuscolo e il resto in minuscolo |
| 3 | contains?(string, contents) Controlla se la stringa contiene uno dei contenuti forniti |
| 4 | downcase(string) Converte tutti i caratteri nella stringa data in minuscolo |
| 5 | ends_with?(string, suffixes) Restituisce vero se la stringa termina con uno dei suffissi forniti |
| 6 | first(string) Restituisce il primo grafema da una stringa utf8, nil se la stringa è vuota |
| 7 | last(string) Restituisce l'ultimo grafema da una stringa utf8, nil se la stringa è vuota |
| 8 | replace(subject, pattern, replacement, options \\ []) Restituisce una nuova stringa creata sostituendo le occorrenze del modello nel soggetto con la sostituzione |
| 9 | slice(string, start, len) Restituisce una sottostringa a partire dall'inizio dell'offset e di lunghezza len |
| 10 | split(string) Divide una stringa in sottostringhe in ogni occorrenza di spazio bianco Unicode con gli spazi iniziali e finali ignorati. I gruppi di spazi vengono trattati come una singola occorrenza. Le divisioni non si verificano su spazi bianchi univoci |
| 11 | upcase(string) Converte in maiuscolo tutti i caratteri nella stringa data |
Binari
Un binario è solo una sequenza di byte. I binari vengono definiti utilizzando<< >>. Per esempio:
<< 0, 1, 2, 3 >>Ovviamente questi byte possono essere organizzati in qualsiasi modo, anche in una sequenza che non li rende una stringa valida. Per esempio,
<< 239, 191, 191 >>Anche le stringhe sono binari. E l'operatore di concatenazione di stringhe<> è in realtà un operatore di concatenazione binaria:
IO.puts(<< 0, 1 >> <> << 2, 3 >>)Il codice sopra genera il seguente risultato:
<< 0, 1, 2, 3 >>Notare il carattere ł. Poiché è codificato in utf-8, questa rappresentazione di caratteri occupa 2 byte.
Poiché ogni numero rappresentato in un binario deve essere un byte, quando questo valore sale da 255, viene troncato. Per evitare ciò, usiamo il modificatore di dimensione per specificare quanti bit vogliamo che quel numero prenda. Ad esempio:
IO.puts(<< 256 >>) # truncated, it'll print << 0 >>
IO.puts(<< 256 :: size(16) >>) #Takes 16 bits/2 bytes, will print << 1, 0 >>Il programma sopra genererà il seguente risultato:
<< 0 >>
<< 1, 0 >>Possiamo anche usare il modificatore utf8, se un carattere è un punto di codice allora, verrà prodotto nell'output; altrimenti i byte -
IO.puts(<< 256 :: utf8 >>)Il programma di cui sopra genera il seguente risultato:
ĀAbbiamo anche una funzione chiamata is_binaryche controlla se una data variabile è un binario. Notare che solo le variabili memorizzate come multipli di 8 bit sono binari.
Bitstrings
Se definiamo un binario usando il modificatore di dimensione e gli passiamo un valore che non è un multiplo di 8, finiamo con una stringa di bit invece di un binario. Per esempio,
bs = << 1 :: size(1) >>
IO.puts(bs)
IO.puts(is_binary(bs))
IO.puts(is_bitstring(bs))Il programma di cui sopra genera il seguente risultato:
<< 1::size(1) >>
false
trueCiò significa quella variabile bsnon è un binario ma piuttosto una stringa di bit. Possiamo anche dire che un binario è una stringa di bit in cui il numero di bit è divisibile per 8. Il pattern matching funziona allo stesso modo su binari e stringhe di bit.
Un elenco di caratteri non è altro che un elenco di caratteri. Considera il seguente programma per capire lo stesso.
IO.puts('Hello')
IO.puts(is_list('Hello'))Il programma di cui sopra genera il seguente risultato:
Hello
trueInvece di contenere byte, un elenco di caratteri contiene i punti di codice dei caratteri tra virgolette singole. So while the double-quotes represent a string (i.e. a binary), singlequotes represent a char list (i.e. a list). Nota che IEx genererà solo punti di codice come output se uno dei caratteri è al di fuori dell'intervallo ASCII.
Gli elenchi di caratteri vengono utilizzati principalmente quando si interfaccia con Erlang, in particolare le vecchie librerie che non accettano i binari come argomenti. È possibile convertire un elenco di caratteri in una stringa e viceversa utilizzando le funzioni to_string (char_list) e to_char_list (stringa) -
IO.puts(is_list(to_char_list("hełło")))
IO.puts(is_binary(to_string ('hełło')))Il programma di cui sopra genera il seguente risultato:
true
trueNOTE - Le funzioni to_string e to_char_list sono polimorfici, cioè possono accettare più tipi di input come atomi, interi e convertirli rispettivamente in stringhe e liste di caratteri.
Elenchi (collegati)
Un elenco collegato è un elenco eterogeneo di elementi archiviati in posizioni diverse della memoria e di cui si tiene traccia utilizzando i riferimenti. Gli elenchi collegati sono strutture di dati utilizzate soprattutto nella programmazione funzionale.
Elixir utilizza le parentesi quadre per specificare un elenco di valori. I valori possono essere di qualsiasi tipo -
[1, 2, true, 3]Quando Elixir vede un elenco di numeri ASCII stampabili, Elixir lo stamperà come un elenco di caratteri (letteralmente un elenco di caratteri). Ogni volta che vedi un valore in IEx e non sei sicuro di cosa sia, puoi usare ili funzione per recuperare informazioni su di esso.
IO.puts([104, 101, 108, 108, 111])I caratteri sopra nell'elenco sono tutti stampabili. Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
helloPuoi anche definire elenchi al contrario, usando virgolette singole -
IO.puts(is_list('Hello'))Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
trueTieni presente che le rappresentazioni tra virgolette singole e doppie non sono equivalenti in Elixir in quanto sono rappresentate da tipi diversi.
Lunghezza di un elenco
Per trovare la lunghezza di una lista, usiamo la funzione di lunghezza come nel seguente programma:
IO.puts(length([1, 2, :true, "str"]))Il programma di cui sopra genera il seguente risultato:
4Concatenazione e sottrazione
Due elenchi possono essere concatenati e sottratti utilizzando il ++ e --operatori. Considera il seguente esempio per comprendere le funzioni.
IO.puts([1, 2, 3] ++ [4, 5, 6])
IO.puts([1, true, 2, false, 3, true] -- [true, false])Questo ti darà una stringa concatenata nel primo caso e una stringa sottratta nel secondo. Il programma di cui sopra genera il seguente risultato:
[1, 2, 3, 4, 5, 6]
[1, 2, 3, true]Testa e coda di una lista
La testa è il primo elemento di una lista e la coda è il resto di una lista. Possono essere recuperati con le funzionihd e tl. Assegniamo una lista a una variabile e recuperiamo la sua testa e la sua coda.
list = [1, 2, 3]
IO.puts(hd(list))
IO.puts(tl(list))Questo ci darà la testa e la coda della lista come output. Il programma di cui sopra genera il seguente risultato:
1
[2, 3]Note - Ottenere la testa o la coda di una lista vuota è un errore.
Altre funzioni di elenco
La libreria standard Elixir fornisce molte funzioni per gestire gli elenchi. Daremo un'occhiata ad alcuni di questi qui. Puoi controllare il resto qui Elenco .
| S.no. | Nome e descrizione della funzione |
|---|---|
| 1 | delete(list, item) Elimina l'elemento specificato dall'elenco. Restituisce un elenco senza l'elemento. Se l'elemento compare più di una volta nell'elenco, viene rimossa solo la prima occorrenza. |
| 2 | delete_at(list, index) Produce un nuovo elenco rimuovendo il valore in corrispondenza dell'indice specificato. Gli indici negativi indicano uno scostamento dalla fine dell'elenco. Se l'indice è fuori dai limiti, viene restituito l'elenco originale. |
| 3 | first(list) Restituisce il primo elemento in elenco o nil se l'elenco è vuoto. |
| 4 | flatten(list) Appiattisce l'elenco fornito di elenchi annidati. |
| 5 | insert_at(list, index, value) Restituisce un elenco con un valore inserito all'indice specificato. Tieni presente che l'indice è limitato alla lunghezza dell'elenco. Gli indici negativi indicano uno scostamento dalla fine dell'elenco. |
| 6 | last(list) Restituisce l'ultimo elemento della lista o nullo se la lista è vuota. |
Tuple
Le tuple sono anche strutture di dati che memorizzano una serie di altre strutture al loro interno. A differenza degli elenchi, memorizzano gli elementi in un blocco di memoria contiguo. Ciò significa che accedere a un elemento tupla per indice o ottenere la dimensione della tupla è un'operazione rapida. Gli indici iniziano da zero.
Elixir utilizza le parentesi graffe per definire le tuple. Come le liste, le tuple possono contenere qualsiasi valore -
{:ok, "hello"}Lunghezza di una tupla
Per ottenere la lunghezza di una tupla, usa tuple_size funziona come nel seguente programma -
IO.puts(tuple_size({:ok, "hello"}))Il programma di cui sopra genera il seguente risultato:
2Aggiunta di un valore
Per aggiungere un valore alla tupla, utilizzare la funzione Tuple.append -
tuple = {:ok, "Hello"}
Tuple.append(tuple, :world)Questo creerà e restituirà una nuova tupla: {: ok, "Hello",: world}
Inserimento di un valore
Per inserire un valore in una data posizione, possiamo utilizzare il Tuple.insert_at funzione o il put_elemfunzione. Considera il seguente esempio per capire lo stesso:
tuple = {:bar, :baz}
new_tuple_1 = Tuple.insert_at(tuple, 0, :foo)
new_tuple_2 = put_elem(tuple, 1, :foobar)Notare che put_elem e insert_atha restituito nuove tuple. La tupla originale memorizzata nella variabile tupla non è stata modificata perché i tipi di dati Elixir non sono modificabili. Essendo immutabile, il codice Elixir è più facile da ragionare poiché non devi mai preoccuparti se un particolare codice sta modificando la tua struttura dati.
Tuple e liste
Qual è la differenza tra liste e tuple?
Gli elenchi vengono archiviati in memoria come elenchi collegati, il che significa che ogni elemento in un elenco mantiene il proprio valore e punta all'elemento successivo fino al raggiungimento della fine dell'elenco. Chiamiamo ogni coppia di valore e puntatore una cella contro. Ciò significa che accedere alla lunghezza di una lista è un'operazione lineare: dobbiamo attraversare l'intera lista per calcolarne le dimensioni. L'aggiornamento di un elenco è veloce fintanto che stiamo anteponendo gli elementi.
Le tuple, d'altra parte, vengono archiviate in memoria in modo contiguo. Ciò significa che ottenere la dimensione della tupla o accedere a un elemento tramite indice è veloce. Tuttavia, l'aggiornamento o l'aggiunta di elementi alle tuple è costoso perché richiede la copia dell'intera tupla in memoria.
Finora, non abbiamo discusso di alcuna struttura di dati associativa, cioè strutture di dati che possono associare un certo valore (o più valori) a una chiave. Lingue diverse chiamano queste funzionalità con nomi diversi come dizionari, hash, array associativi, ecc.
In Elixir, abbiamo due principali strutture di dati associative: elenchi di parole chiave e mappe. In questo capitolo, ci concentreremo sugli elenchi di parole chiave.
In molti linguaggi di programmazione funzionale, è comune utilizzare un elenco di tuple di 2 elementi come rappresentazione di una struttura dati associativa. In Elixir, quando abbiamo un elenco di tuple e il primo elemento della tupla (cioè la chiave) è un atomo, lo chiamiamo un elenco di parole chiave. Considera il seguente esempio per capire lo stesso:
list = [{:a, 1}, {:b, 2}]Elixir supporta una sintassi speciale per la definizione di tali elenchi. Possiamo posizionare i due punti alla fine di ogni atomo e eliminare completamente le tuple. Per esempio,
list_1 = [{:a, 1}, {:b, 2}]
list_2 = [a: 1, b: 2]
IO.puts(list_1 == list_2)Il programma sopra genererà il seguente risultato:
trueEntrambi rappresentano un elenco di parole chiave. Poiché anche gli elenchi di parole chiave sono elenchi, possiamo utilizzare tutte le operazioni che abbiamo utilizzato sugli elenchi su di essi.
Per recuperare il valore associato a un atomo nell'elenco delle parole chiave, passare l'atomo come a [] dopo il nome dell'elenco -
list = [a: 1, b: 2]
IO.puts(list[:a])Il programma di cui sopra genera il seguente risultato:
1Gli elenchi di parole chiave hanno tre caratteristiche speciali:
- Le chiavi devono essere atomi.
- Le chiavi vengono ordinate, come specificato dallo sviluppatore.
- Le chiavi possono essere fornite più di una volta.
Per manipolare gli elenchi di parole chiave, Elixir fornisce il modulo Keyword . Ricorda, tuttavia, che gli elenchi di parole chiave sono semplicemente elenchi e in quanto tali forniscono le stesse caratteristiche di rendimento lineari degli elenchi. Più lungo è l'elenco, più tempo ci vorrà per trovare una chiave, per contare il numero di elementi e così via. Per questo motivo, gli elenchi di parole chiave vengono utilizzati in Elixir principalmente come opzioni. Se è necessario memorizzare molti elementi o garantire agli associati una chiave un valore massimo, è necessario utilizzare le mappe.
Accesso a una chiave
Per accedere ai valori associati a una determinata chiave, utilizziamo il Keyword.getfunzione. Restituisce il primo valore associato alla chiave data. Per ottenere tutti i valori, utilizziamo la funzione Keyword.get_values. Ad esempio:
kl = [a: 1, a: 2, b: 3]
IO.puts(Keyword.get(kl, :a))
IO.puts(Keyword.get_values(kl))Il programma sopra genererà il seguente risultato:
1
[1, 2]Inserimento di una chiave
Per aggiungere un nuovo valore, usa Keyword.put_new. Se la chiave esiste già, il suo valore rimane invariato -
kl = [a: 1, a: 2, b: 3]
kl_new = Keyword.put_new(kl, :c, 5)
IO.puts(Keyword.get(kl_new, :c))Quando il programma precedente viene eseguito, produce un nuovo elenco di parole chiave con chiave aggiuntiva, ce genera il seguente risultato:
5Eliminazione di una chiave
Se vuoi eliminare tutte le voci per una chiave, usa Keyword.delete; per eliminare solo la prima voce di una chiave, utilizzare Keyword.delete_first.
kl = [a: 1, a: 2, b: 3, c: 0]
kl = Keyword.delete_first(kl, :b)
kl = Keyword.delete(kl, :a)
IO.puts(Keyword.get(kl, :a))
IO.puts(Keyword.get(kl, :b))
IO.puts(Keyword.get(kl, :c))Questo cancellerà il primo b nell'elenco e tutti i file anella lista. Quando il programma di cui sopra viene eseguito, genererà il seguente risultato:
0Gli elenchi di parole chiave sono un modo conveniente per indirizzare i contenuti archiviati negli elenchi per chiave, ma sotto Elixir sta ancora esplorando l'elenco. Potrebbe essere adatto se hai altri piani per quell'elenco che richiedono di esaminarlo tutto, ma può essere un sovraccarico non necessario se prevedi di utilizzare le chiavi come unico approccio ai dati.
È qui che le mappe vengono in tuo soccorso. Ogni volta che hai bisogno di un archivio chiave-valore, le mappe sono la struttura dati "vai a" in Elixir.
Creazione di una mappa
Viene creata una mappa utilizzando la sintassi% {} -
map = %{:a => 1, 2 => :b}Rispetto agli elenchi di parole chiave, possiamo già vedere due differenze:
- Le mappe consentono qualsiasi valore come chiave.
- Le chiavi delle mappe non seguono alcun ordine.
Accesso a una chiave
Per accedere al valore associato a una chiave, Maps utilizza la stessa sintassi degli elenchi di parole chiave:
map = %{:a => 1, 2 => :b}
IO.puts(map[:a])
IO.puts(map[2])Quando il programma di cui sopra viene eseguito, genera il seguente risultato:
1
bInserimento di una chiave
Per inserire una chiave in una mappa, usiamo il Dict.put_new funzione che prende la mappa, la nuova chiave e il nuovo valore come argomenti -
map = %{:a => 1, 2 => :b}
new_map = Dict.put_new(map, :new_val, "value")
IO.puts(new_map[:new_val])Questo inserirà la coppia chiave-valore :new_val - "value"in una nuova mappa. Quando il programma di cui sopra viene eseguito, genera il seguente risultato:
"value"Aggiornamento di un valore
Per aggiornare un valore già presente nella mappa, puoi utilizzare la seguente sintassi:
map = %{:a => 1, 2 => :b}
new_map = %{ map | a: 25}
IO.puts(new_map[:a])Quando il programma di cui sopra viene eseguito, genera il seguente risultato:
25Pattern Matching
A differenza degli elenchi di parole chiave, le mappe sono molto utili con la corrispondenza dei pattern. Quando una mappa viene utilizzata in un modello, corrisponderà sempre a un sottoinsieme del valore dato -
%{:a => a} = %{:a => 1, 2 => :b}
IO.puts(a)Il programma di cui sopra genera il seguente risultato:
1Questo corrisponderà a con 1. E quindi, genererà l'output come1.
Come mostrato sopra, una mappa corrisponde fintanto che le chiavi nel modello esistono nella mappa data. Pertanto, una mappa vuota corrisponde a tutte le mappe.
Le variabili possono essere utilizzate durante l'accesso, la corrispondenza e l'aggiunta di chiavi della mappa -
n = 1
map = %{n => :one}
%{^n => :one} = %{1 => :one, 2 => :two, 3 => :three}Il modulo Mappa fornisce un'API molto simile al modulo Parola chiave con funzioni utili per manipolare le mappe. È possibile utilizzare funzioni comeMap.get, Map.delete, per manipolare le mappe.
Mappe con chiavi Atom
Le mappe vengono fornite con alcune proprietà interessanti. Quando tutte le chiavi in una mappa sono atomi, puoi utilizzare la sintassi della parola chiave per comodità:
map = %{:a => 1, 2 => :b}
IO.puts(map.a)Un'altra proprietà interessante delle mappe è che forniscono la propria sintassi per l'aggiornamento e l'accesso alle chiavi atom -
map = %{:a => 1, 2 => :b}
IO.puts(map.a)Il programma di cui sopra genera il seguente risultato:
1Nota che per accedere alle chiavi atom in questo modo, dovrebbe esistere o il programma non funzionerà.
In Elixir, raggruppiamo diverse funzioni in moduli. Abbiamo già utilizzato diversi moduli nei capitoli precedenti come il modulo String, il modulo Bitwise, il modulo Tuple, ecc.
Per creare i nostri moduli in Elixir, usiamo il defmodulemacro. Noi usiamo ildef macro per definire le funzioni in quel modulo -
defmodule Math do
def sum(a, b) do
a + b
end
endNelle sezioni seguenti, i nostri esempi diventeranno più lunghi in termini di dimensioni e può essere difficile digitarli tutti nella shell. Dobbiamo imparare come compilare il codice Elixir e anche come eseguire gli script Elixir.
Compilazione
È sempre conveniente scrivere moduli in file in modo che possano essere compilati e riutilizzati. Supponiamo di avere un file chiamato math.ex con il seguente contenuto:
defmodule Math do
def sum(a, b) do
a + b
end
endPossiamo compilare i file usando il comando -elixirc :
$ elixirc math.exQuesto genererà un file denominato Elixir.Math.beamcontenente il bytecode per il modulo definito. Se iniziamoiexdi nuovo, sarà disponibile la definizione del nostro modulo (ammesso che iex sia avviato nella stessa directory in cui si trova il file bytecode). Per esempio,
IO.puts(Math.sum(1, 2))Il programma sopra genererà il seguente risultato:
3Modalità con script
Oltre all'estensione del file Elixir .ex, Elixir supporta anche .exsfile per lo scripting. Elixir tratta entrambi i file esattamente allo stesso modo, l'unica differenza è nell'obiettivo..ex i file sono pensati per essere compilati mentre i file .exs sono usati per scripting. Quando vengono eseguite, entrambe le estensioni compilano e caricano i propri moduli in memoria, anche se solo.ex i file scrivono il loro bytecode su disco nel formato dei file .beam.
Ad esempio, se volessimo eseguire il file Math.sum nello stesso file, possiamo usare il .exs nel modo seguente:
Math.exs
defmodule Math do
def sum(a, b) do
a + b
end
end
IO.puts(Math.sum(1, 2))Possiamo eseguirlo usando il comando Elixir -
$ elixir math.exsIl programma sopra genererà il seguente risultato:
3Il file verrà compilato in memoria ed eseguito, stampando "3" come risultato. Non verrà creato alcun file bytecode.
Modulo Nesting
I moduli possono essere annidati in Elixir. Questa caratteristica del linguaggio ci aiuta a organizzare il nostro codice in un modo migliore. Per creare moduli annidati, usiamo la seguente sintassi:
defmodule Foo do
#Foo module code here
defmodule Bar do
#Bar module code here
end
endL'esempio sopra riportato definirà due moduli: Foo e Foo.Bar. Il secondo è accessibile comeBar dentro Foofintanto che sono nello stesso ambito lessicale. Se, in seguito, il fileBar module viene spostato al di fuori della definizione del modulo Foo, deve essere referenziato con il suo nome completo (Foo.Bar) o un alias deve essere impostato utilizzando la direttiva alias discussa nel capitolo alias.
Note- In Elixir, non è necessario definire il modulo Foo per definire il modulo Foo.Bar, poiché la lingua traduce tutti i nomi dei moduli in atomi. È possibile definire moduli annidati arbitrariamente senza definire alcun modulo nella catena. Ad esempio, puoi definireFoo.Bar.Baz senza definire Foo o Foo.Bar.
Per facilitare il riutilizzo del software, Elixir fornisce tre direttive: alias, require e import. Fornisce anche una macro chiamata use che è riassunta di seguito:
# Alias the module so it can be called as Bar instead of Foo.Bar
alias Foo.Bar, as: Bar
# Ensure the module is compiled and available (usually for macros)
require Foo
# Import functions from Foo so they can be called without the `Foo.` prefix
import Foo
# Invokes the custom code defined in Foo as an extension point
use FooVediamo ora di comprendere in dettaglio ciascuna direttiva.
alias
La direttiva alias consente di impostare alias per qualsiasi nome di modulo dato. Ad esempio, se vuoi fornire un alias'Str' al modulo String, puoi semplicemente scrivere -
alias String, as: Str
IO.puts(Str.length("Hello"))Il programma di cui sopra genera il seguente risultato:
5Viene assegnato un alias a String modulo come Str. Ora, quando chiamiamo una funzione utilizzando il letterale Str, in realtà fa riferimento aStringmodulo. Questo è molto utile quando usiamo nomi di moduli molto lunghi e vogliamo sostituire quelli con quelli più brevi nell'ambito corrente.
NOTE - Alias MUST inizia con una lettera maiuscola.
Gli alias sono validi solo all'interno di lexical scope vengono chiamati. Ad esempio, se si hanno 2 moduli in un file e si crea un alias all'interno di uno dei moduli, tale alias non sarà accessibile nel secondo modulo.
Se dai il nome di un modulo integrato, come String o Tuple, come alias a qualche altro modulo, per accedere al modulo integrato, dovrai anteporlo con "Elixir.". Per esempio,
alias List, as: String
#Now when we use String we are actually using List.
#To use the string module:
IO.puts(Elixir.String.length("Hello"))Quando il programma di cui sopra viene eseguito, genera il seguente risultato:
5richiedono
Elixir fornisce macro come meccanismo per la meta-programmazione (scrittura di codice che genera codice).
Le macro sono blocchi di codice che vengono eseguiti ed espansi al momento della compilazione. Ciò significa che, per utilizzare una macro, dobbiamo garantire che il suo modulo e la sua implementazione siano disponibili durante la compilazione. Questo viene fatto con ilrequire direttiva.
Integer.is_odd(3)Quando il programma di cui sopra viene eseguito, genererà il seguente risultato:
** (CompileError) iex:1: you must require Integer before invoking the macro Integer.is_odd/1In Elisir, Integer.is_odd è definito come un macro. Questa macro può essere utilizzata come guardia. Ciò significa che, per invocareInteger.is_odd, avremo bisogno del modulo Integer.
Utilizzare il require Integer funzione ed eseguire il programma come mostrato di seguito.
require Integer
Integer.is_odd(3)Questa volta il programma verrà eseguito e produrrà l'output come: true.
In generale, un modulo non è richiesto prima dell'uso, tranne se si desidera utilizzare le macro disponibili in quel modulo. Un tentativo di chiamare una macro che non è stata caricata genererà un errore. Si noti che, come la direttiva alias, anche require ha un ambito lessicale . Parleremo di più delle macro in un capitolo successivo.
importare
Noi usiamo il importdirettiva per accedere facilmente a funzioni o macro da altri moduli senza utilizzare il nome completo. Ad esempio, se vogliamo utilizzare l'estensioneduplicate più volte dal modulo List, possiamo semplicemente importarla.
import List, only: [duplicate: 2]In questo caso, stiamo importando solo la funzione duplicate (con lunghezza dell'elenco di argomenti 2) da List. Sebbene:only è opzionale, il suo utilizzo è consigliato per evitare di importare tutte le funzioni di un dato modulo all'interno del namespace. :except potrebbe anche essere fornito come opzione per importare tutto in un modulo tranne un elenco di funzioni.
Il import la direttiva supporta anche :macros e :functions da dare a :only. Ad esempio, per importare tutte le macro, un utente può scrivere:
import Integer, only: :macrosNota che anche l'importazione lo è Lexically scopedproprio come le direttive require e alias. Nota anche quello'import'ing a module also 'require's it.
uso
Sebbene non sia una direttiva, use è una macro strettamente correlata a requireche ti consente di utilizzare un modulo nel contesto corrente. La macro di utilizzo è spesso utilizzata dagli sviluppatori per portare funzionalità esterne nell'ambito lessicale corrente, spesso moduli. Cerchiamo di capire la direttiva sull'uso attraverso un esempio:
defmodule Example do
use Feature, option: :value
endUse è una macro che trasforma quanto sopra in -
defmodule Example do
require Feature
Feature.__using__(option: :value)
endIl use Module richiede prima il modulo e quindi chiama il file __using__macro sul modulo. Elixir ha grandi capacità di metaprogrammazione e ha macro per generare codice in fase di compilazione. La macro _ _using__ viene chiamata nell'istanza precedente e il codice viene inserito nel nostro contesto locale. Il contesto locale è il luogo in cui è stata chiamata la macro di utilizzo al momento della compilazione.
Una funzione è un insieme di istruzioni organizzate insieme per eseguire un'attività specifica. Le funzioni nella programmazione funzionano principalmente come le funzioni in matematica. Date alle funzioni un input, esse generano output in base all'input fornito.
Ci sono 2 tipi di funzioni in Elixir:
Funzione anonima
Funzioni definite utilizzando fn..end constructsono funzioni anonime. Queste funzioni sono talvolta chiamate anche lambda. Vengono utilizzati assegnandoli a nomi di variabili.
Funzione denominata
Funzioni definite utilizzando def keywordsono denominate funzioni. Queste sono funzioni native fornite in Elixir.
Funzioni anonime
Proprio come suggerisce il nome, una funzione anonima non ha nome. Questi vengono spesso passati ad altre funzioni. Per definire una funzione anonima in Elixir, abbiamo bisogno delfn e endparole chiave. All'interno di questi, possiamo definire un numero qualsiasi di parametri e corpi di funzione separati da->. Per esempio,
sum = fn (a, b) -> a + b end
IO.puts(sum.(1, 5))Quando si esegue il programma sopra, viene eseguito, genera il seguente risultato:
6Notare che queste funzioni non vengono chiamate come le funzioni denominate. Noi abbiamo un '.'tra il nome della funzione e i suoi argomenti.
Utilizzo dell'operatore di cattura
Possiamo anche definire queste funzioni usando l'operatore di cattura. Questo è un metodo più semplice per creare funzioni. Definiremo ora la funzione somma di cui sopra usando l'operatore di cattura,
sum = &(&1 + &2)
IO.puts(sum.(1, 2))Quando il programma di cui sopra viene eseguito, genera il seguente risultato:
3Nella versione abbreviata, i nostri parametri non sono denominati ma sono disponibili come & 1, & 2, & 3 e così via.
Funzioni di corrispondenza dei modelli
Il pattern matching non è limitato solo alle variabili e alle strutture di dati. Possiamo usare il pattern matching per rendere le nostre funzioni polimorfiche. Ad esempio, dichiareremo una funzione che può accettare 1 o 2 input (all'interno di una tupla) e stamparli sulla console,
handle_result = fn
{var1} -> IO.puts("#{var1} found in a tuple!")
{var_2, var_3} -> IO.puts("#{var_2} and #{var_3} found!")
end
handle_result.({"Hey people"})
handle_result.({"Hello", "World"})Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hey people found in a tuple!
Hello and World found!Funzioni denominate
Possiamo definire funzioni con nomi in modo da potervi facilmente riferire in seguito. Le funzioni denominate vengono definite all'interno di un modulo utilizzando la parola chiave def. Le funzioni denominate sono sempre definite in un modulo. Per chiamare funzioni denominate, dobbiamo fare riferimento ad esse utilizzando il nome del loro modulo.
La seguente è la sintassi per le funzioni denominate:
def function_name(argument_1, argument_2) do
#code to be executed when function is called
endDefiniamo ora la nostra funzione con nome sum all'interno del modulo Math.
defmodule Math do
def sum(a, b) do
a + b
end
end
IO.puts(Math.sum(5, 6))Quando si esegue il programma sopra, produce il seguente risultato:
11Per le funzioni di 1 riga, c'è una notazione abbreviata per definire queste funzioni, usando do:. Ad esempio:
defmodule Math do
def sum(a, b), do: a + b
end
IO.puts(Math.sum(5, 6))Quando si esegue il programma sopra, produce il seguente risultato:
11Funzioni private
Elixir ci fornisce la possibilità di definire funzioni private a cui è possibile accedere dall'interno del modulo in cui sono definite. Per definire una funzione privata, utilizzaredefp invece di def. Per esempio,
defmodule Greeter do
def hello(name), do: phrase <> name
defp phrase, do: "Hello "
end
Greeter.hello("world")Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hello worldMa se proviamo solo a chiamare esplicitamente la funzione della frase, usando il Greeter.phrase() funzione, solleverà un errore.
Argomenti predefiniti
Se vogliamo un valore predefinito per un argomento, usiamo il argument \\ value sintassi -
defmodule Greeter do
def hello(name, country \\ "en") do
phrase(country) <> name
end
defp phrase("en"), do: "Hello, "
defp phrase("es"), do: "Hola, "
end
Greeter.hello("Ayush", "en")
Greeter.hello("Ayush")
Greeter.hello("Ayush", "es")Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hello, Ayush
Hello, Ayush
Hola, AyushLa ricorsione è un metodo in cui la soluzione a un problema dipende dalle soluzioni alle istanze più piccole dello stesso problema. La maggior parte dei linguaggi di programmazione per computer supporta la ricorsione consentendo a una funzione di chiamare se stessa all'interno del testo del programma.
Idealmente le funzioni ricorsive hanno una condizione finale. Questa condizione finale, nota anche come caso di base, interrompe il rientro nella funzione e l'aggiunta di chiamate di funzione allo stack. Qui è dove si ferma la chiamata di funzione ricorsiva. Consideriamo il seguente esempio per comprendere ulteriormente la funzione ricorsiva.
defmodule Math do
def fact(res, num) do
if num === 1 do
res
else
new_res = res * num
fact(new_res, num-1)
end
end
end
IO.puts(Math.fact(1,5))Quando il programma di cui sopra viene eseguito, genera il seguente risultato:
120Quindi nella funzione sopra, Math.fact, stiamo calcolando il fattoriale di un numero. Notare che stiamo chiamando la funzione al suo interno. Vediamo ora come funziona.
Gli abbiamo fornito 1 e il numero di cui vogliamo calcolare il fattoriale. La funzione controlla se il numero è 1 o meno e restituisce res se è 1(Ending condition). In caso contrario, crea una variabile new_res e le assegna il valore del precedente res * current num. Restituisce il valore restituito dalla nostra chiamata di funzione fact (new_res, num-1) . Questo si ripete finché non otteniamo num come 1. Una volta che ciò accade, otteniamo il risultato.
Consideriamo un altro esempio, stampando ogni elemento della lista uno per uno. Per fare ciò, utilizzeremo il filehd e tl funzioni di elenchi e corrispondenza di modelli nelle funzioni -
a = ["Hey", 100, 452, :true, "People"]
defmodule ListPrint do
def print([]) do
end
def print([head | tail]) do
IO.puts(head)
print(tail)
end
end
ListPrint.print(a)La prima funzione di stampa viene chiamata quando abbiamo un elenco vuoto(ending condition). In caso contrario, verrà chiamata la seconda funzione di stampa che dividerà la lista in 2 e assegnerà il primo elemento della lista alla testata e il resto della lista alla coda. La testa viene quindi stampata e chiamiamo di nuovo la funzione di stampa con il resto della lista, cioè coda. Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hey
100
452
true
PeopleA causa dell'immutabilità, i loop in Elixir (come in qualsiasi linguaggio di programmazione funzionale) sono scritti in modo diverso dai linguaggi imperativi. Ad esempio, in un linguaggio imperativo come il C, scriverai:
for(i = 0; i < 10; i++) {
printf("%d", array[i]);
}Nell'esempio riportato sopra, stiamo mutando sia l'array che la variabile i. La mutazione non è possibile in Elixir. Invece, i linguaggi funzionali si basano sulla ricorsione: una funzione viene chiamata ricorsivamente fino a quando non viene raggiunta una condizione che interrompe l'azione ricorsiva. Nessun dato viene modificato in questo processo.
Scriviamo ora un semplice ciclo usando la ricorsione che stampa ciao n volte.
defmodule Loop do
def print_multiple_times(msg, n) when n <= 1 do
IO.puts msg
end
def print_multiple_times(msg, n) do
IO.puts msg
print_multiple_times(msg, n - 1)
end
end
Loop.print_multiple_times("Hello", 10)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hello
Hello
Hello
Hello
Hello
Hello
Hello
Hello
Hello
HelloAbbiamo utilizzato le tecniche di pattern matching della funzione e la ricorsione per implementare con successo un ciclo. Le definizioni ricorsive sono difficili da capire ma convertire i cicli in ricorsione è facile.
Elixir ci fornisce il Enum module. Questo modulo viene utilizzato per le chiamate in ciclo più iterative poiché è molto più facile da usare che cercare di capire definizioni ricorsive per le stesse. Ne discuteremo nel prossimo capitolo. Le tue definizioni ricorsive dovrebbero essere usate solo quando non trovi una soluzione usando quel modulo. Queste funzioni sono ottimizzate per la chiamata di coda e abbastanza veloci.
Un enumerabile è un oggetto che può essere enumerato. "Enumerato" significa contare i membri di un set / collezione / categoria uno per uno (di solito in ordine, di solito per nome).
Elixir fornisce il concetto di enumerabili e il modulo Enum per lavorare con loro. Le funzioni nel modulo Enum sono limitate, come dice il nome, all'enumerazione dei valori nelle strutture dati. Un esempio di una struttura dati enumerabile è una lista, una tupla, una mappa, ecc. Il modulo Enum ci fornisce poco più di 100 funzioni per gestire le enumerazioni. Discuteremo alcune importanti funzioni in questo capitolo.
Tutte queste funzioni prendono un enumerabile come primo elemento e una funzione come secondo e lavorano su di esse. Le funzioni sono descritte di seguito.
tutti?
Quando usiamo all? funzione, l'intera raccolta deve essere valutata come true altrimenti verrà restituito false. Ad esempio, per verificare se tutti gli elementi nell'elenco sono numeri dispari, allora.
res = Enum.all?([1, 2, 3, 4], fn(s) -> rem(s,2) == 1 end)
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
falseQuesto perché non tutti gli elementi di questo elenco sono dispari.
qualunque?
Come suggerisce il nome, questa funzione restituisce true se qualsiasi elemento della raccolta restituisce true. Ad esempio:
res = Enum.any?([1, 2, 3, 4], fn(s) -> rem(s,2) == 1 end)
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
truepezzo
Questa funzione divide la nostra collezione in piccoli pezzi della dimensione fornita come secondo argomento. Ad esempio:
res = Enum.chunk([1, 2, 3, 4, 5, 6], 2)
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
[[1, 2], [3, 4], [5, 6]]ogni
Potrebbe essere necessario iterare su una raccolta senza produrre un nuovo valore, in questo caso utilizziamo l'estensione each funzione -
Enum.each(["Hello", "Every", "one"], fn(s) -> IO.puts(s) end)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hello
Every
onecarta geografica
Per applicare la nostra funzione a ogni articolo e produrre una nuova collezione utilizziamo la funzione mappa. È uno dei costrutti più utili nella programmazione funzionale poiché è abbastanza espressivo e breve. Consideriamo un esempio per capirlo. Raddoppieremo i valori memorizzati in un elenco e li memorizzeremo in un nuovo elencores -
res = Enum.map([2, 5, 3, 6], fn(a) -> a*2 end)
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
[4, 10, 6, 12]ridurre
Il reducela funzione ci aiuta a ridurre il nostro enumerabile a un singolo valore. Per fare questo, forniamo un accumulatore opzionale (5 in questo esempio) da passare alla nostra funzione; se non è previsto alcun accumulatore, viene utilizzato il primo valore -
res = Enum.reduce([1, 2, 3, 4], 5, fn(x, accum) -> x + accum end)
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
15L'accumulatore è il valore iniziale passato a fn. Dalla seconda chiamata in poi il valore restituito dalla chiamata precedente viene passato come accum. Possiamo anche usare ridurre senza l'accumulatore -
res = Enum.reduce([1, 2, 3, 4], fn(x, accum) -> x + accum end)
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
10uniq
La funzione uniq rimuove i duplicati dalla nostra raccolta e restituisce solo l'insieme di elementi nella raccolta. Ad esempio:
res = Enum.uniq([1, 2, 2, 3, 3, 3, 4, 4, 4, 4])
IO.puts(res)Quando si esegue il programma sopra, produce il seguente risultato:
[1, 2, 3, 4]Valutazione desiderosa
Tutte le funzioni nel modulo Enum sono entusiaste. Molte funzioni si aspettano un enumerabile e restituiscono un elenco. Ciò significa che quando si eseguono più operazioni con Enum, ciascuna operazione genererà un elenco intermedio fino a quando non si raggiunge il risultato. Consideriamo il seguente esempio per capire questo:
odd? = &(odd? = &(rem(&1, 2) != 0)
res = 1..100_000 |> Enum.map(&(&1 * 3)) |> Enum.filter(odd?) |> Enum.sum
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
7500000000L'esempio sopra ha una pipeline di operazioni. Iniziamo con un intervallo e poi moltiplichiamo ogni elemento nell'intervallo per 3. Questa prima operazione ora creerà e restituirà un elenco con 100_000 elementi. Quindi teniamo tutti gli elementi dispari dall'elenco, generando un nuovo elenco, ora con 50_000 elementi, e quindi sommiamo tutte le voci.
Il |> il simbolo utilizzato nello snippet sopra è il pipe operator: prende semplicemente l'output dall'espressione sul lato sinistro e lo passa come primo argomento alla chiamata di funzione sul lato destro. È simile a Unix | operatore. Il suo scopo è evidenziare il flusso di dati trasformato da una serie di funzioni.
Senza il pipe operatore, il codice sembra complicato -
Enum.sum(Enum.filter(Enum.map(1..100_000, &(&1 * 3)), odd?))Abbiamo molte altre funzioni, tuttavia, solo alcune importanti sono state descritte qui.
Molte funzioni si aspettano un enumerabile e restituiscono un file listindietro. Significa che, durante l'esecuzione di più operazioni con Enum, ciascuna operazione genererà un elenco intermedio fino a raggiungere il risultato.
I flussi supportano operazioni pigre rispetto alle operazioni desiderose tramite enumerazioni. In breve,streams are lazy, composable enumerables. Ciò significa che Streams non esegue un'operazione a meno che non sia assolutamente necessario. Consideriamo un esempio per capire questo:
odd? = &(rem(&1, 2) != 0)
res = 1..100_000 |> Stream.map(&(&1 * 3)) |> Stream.filter(odd?) |> Enum.sum
IO.puts(res)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
7500000000Nell'esempio sopra riportato, 1..100_000 |> Stream.map(&(&1 * 3))restituisce un tipo di dati, un flusso effettivo, che rappresenta il calcolo della mappa nell'intervallo 1..100_000. Non ha ancora valutato questa rappresentazione. Invece di generare elenchi intermedi, i flussi creano una serie di calcoli che vengono richiamati solo quando passiamo il flusso sottostante al modulo Enum. I flussi sono utili quando si lavora con raccolte grandi, possibilmente infinite.
I flussi e le enumerazioni hanno molte funzioni in comune. I flussi forniscono principalmente le stesse funzioni fornite dal modulo Enum che ha generato gli elenchi come valori restituiti dopo aver eseguito calcoli sugli enumerabili di input. Alcuni di loro sono elencati nella tabella seguente:
| Sr.No. | Funzione e sua descrizione |
|---|---|
| 1 | chunk(enum, n, step, leftover \\ nil) Trasmette l'enumerabile in blocchi, contenenti n elementi ciascuno, in cui ogni nuovo blocco avvia gli elementi di passaggio nell'enumerabile. |
| 2 | concat(enumerables) Crea un flusso che enumera ogni enumerabile in un enumerabile. |
| 3 | each(enum, fun) Esegue la funzione data per ogni elemento. |
| 4 | filter(enum, fun) Crea un flusso che filtra gli elementi in base alla funzione data sull'enumerazione. |
| 5 | map(enum, fun) Crea un flusso che applicherà la funzione data all'enumerazione. |
| 6 | drop(enum, n) Elimina pigramente i successivi n elementi dall'enumerabile. |
Le strutture sono estensioni costruite sopra le mappe che forniscono controlli in fase di compilazione e valori predefiniti.
Definizione di strutture
Per definire una struttura, viene utilizzato il costrutto defstruct:
defmodule User do
defstruct name: "John", age: 27
endL'elenco di parole chiave utilizzato con defstruct definisce quali campi avrà la struttura insieme ai valori predefiniti. Le strutture prendono il nome del modulo in cui sono definite. Nell'esempio dato sopra, abbiamo definito una struttura chiamata Utente. Ora possiamo creare strutture utente utilizzando una sintassi simile a quella utilizzata per creare mappe -
new_john = %User{})
ayush = %User{name: "Ayush", age: 20}
megan = %User{name: "Megan"})Il codice sopra genererà tre diverse strutture con valori:
%User{age: 27, name: "John"}
%User{age: 20, name: "Ayush"}
%User{age: 27, name: "Megan"}Le strutture forniscono garanzie in fase di compilazione che solo i campi (e tutti loro) definiti tramite defstruct potranno esistere in una struttura. Quindi non puoi definire i tuoi campi dopo aver creato la struttura nel modulo.
Accesso e aggiornamento di Struct
Quando abbiamo discusso delle mappe, abbiamo mostrato come possiamo accedere e aggiornare i campi di una mappa. Le stesse tecniche (e la stessa sintassi) si applicano anche alle strutture. Ad esempio, se vogliamo aggiornare l'utente che abbiamo creato nell'esempio precedente, allora:
defmodule User do
defstruct name: "John", age: 27
end
john = %User{}
#john right now is: %User{age: 27, name: "John"}
#To access name and age of John,
IO.puts(john.name)
IO.puts(john.age)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
John
27Per aggiornare un valore in una struttura, useremo di nuovo la stessa procedura che abbiamo usato nel capitolo della mappa,
meg = %{john | name: "Meg"}Le strutture possono essere utilizzate anche nella corrispondenza dei modelli, sia per la corrispondenza sul valore di chiavi specifiche, sia per garantire che il valore corrispondente sia una struttura dello stesso tipo del valore corrispondente.
I protocolli sono un meccanismo per ottenere il polimorfismo in Elixir. Il dispacciamento su un protocollo è disponibile per qualsiasi tipo di dati fintanto che implementa il protocollo.
Consideriamo un esempio di utilizzo dei protocolli. Abbiamo usato una funzione chiamatato_stringnei capitoli precedenti per convertire da altri tipi al tipo stringa. Questo è in realtà un protocollo. Agisce in base all'input fornito senza produrre errori. Potrebbe sembrare che stiamo discutendo delle funzioni di pattern matching, ma man mano che procediamo, risulta diverso.
Considera il seguente esempio per comprendere meglio il meccanismo del protocollo.
Creiamo un protocollo che verrà visualizzato se l'input fornito è vuoto o meno. Chiameremo questo protocolloblank?.
Definizione di un protocollo
Possiamo definire un protocollo in Elixir nel modo seguente:
defprotocol Blank do
def blank?(data)
endCome puoi vedere, non abbiamo bisogno di definire un corpo per la funzione. Se hai familiarità con le interfacce in altri linguaggi di programmazione, puoi pensare a un protocollo essenzialmente come la stessa cosa.
Quindi questo protocollo dice che tutto ciò che lo implementa deve avere un'estensione empty?funzione, sebbene spetti all'implementatore come la funzione risponde. Con il protocollo definito, vediamo di capire come aggiungere un paio di implementazioni.
Attuazione di un protocollo
Poiché abbiamo definito un protocollo, ora dobbiamo dirgli come gestire i diversi input che potrebbe ottenere. Partiamo dall'esempio che avevamo preso in precedenza. Implementeremo il protocollo vuoto per elenchi, mappe e stringhe. Questo mostrerà se la cosa che abbiamo passato è vuota o no.
#Defining the protocol
defprotocol Blank do
def blank?(data)
end
#Implementing the protocol for lists
defimpl Blank, for: List do
def blank?([]), do: true
def blank?(_), do: false
end
#Implementing the protocol for strings
defimpl Blank, for: BitString do
def blank?(""), do: true
def blank?(_), do: false
end
#Implementing the protocol for maps
defimpl Blank, for: Map do
def blank?(map), do: map_size(map) == 0
end
IO.puts(Blank.blank? [])
IO.puts(Blank.blank? [:true, "Hello"])
IO.puts(Blank.blank? "")
IO.puts(Blank.blank? "Hi")Puoi implementare il tuo protocollo per tutti i tipi che desideri, qualunque cosa abbia senso per l'utilizzo del tuo protocollo. Questo è stato un caso d'uso piuttosto semplice dei protocolli. Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
true
false
true
falseNote - Se lo usi per qualsiasi tipo diverso da quelli per cui hai definito il protocollo, produrrà un errore.
File IO è parte integrante di qualsiasi linguaggio di programmazione in quanto consente al linguaggio di interagire con i file sul file system. In questo capitolo, discuteremo di due moduli: Path e File.
Il modulo Path
Il pathmodule è un modulo molto piccolo che può essere considerato come un modulo di supporto per le operazioni sul filesystem. La maggior parte delle funzioni nel modulo File si aspettano percorsi come argomenti. Più comunemente, quei percorsi saranno binari regolari. Il modulo Path fornisce servizi per lavorare con tali percorsi. È preferibile utilizzare le funzioni del modulo Path anziché manipolare i binari poiché il modulo Path si prende cura dei diversi sistemi operativi in modo trasparente. È da notare che Elixir convertirà automaticamente le barre (/) in barre rovesciate (\) su Windows durante l'esecuzione di operazioni sui file.
Consideriamo il seguente esempio per comprendere ulteriormente il modulo Path:
IO.puts(Path.join("foo", "bar"))Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
foo/barCi sono molti metodi forniti dal modulo path. Puoi dare un'occhiata ai diversi metodi qui . Questi metodi vengono utilizzati frequentemente se si eseguono molte operazioni di manipolazione dei file.
Il modulo file
Il modulo file contiene funzioni che ci consentono di aprire file come IO Device. Per impostazione predefinita, i file vengono aperti in modalità binaria, che richiede agli sviluppatori di utilizzare lo specificoIO.binread e IO.binwritefunzioni dal modulo IO. Creiamo un file chiamatonewfile e scrivere alcuni dati su di esso.
{:ok, file} = File.read("newfile", [:write])
# Pattern matching to store returned stream
IO.binwrite(file, "This will be written to the file")Se apri il file in cui abbiamo appena scritto, il contenuto verrà visualizzato nel modo seguente:
This will be written to the fileVediamo ora come utilizzare il modulo file.
Apertura di un file
Per aprire un file, possiamo utilizzare una delle seguenti 2 funzioni:
{:ok, file} = File.open("newfile")
file = File.open!("newfile")Cerchiamo ora di capire la differenza tra i file File.open funzione e il File.open!() funzione.
Il File.openla funzione restituisce sempre una tupla. Se il file viene aperto correttamente, restituisce il primo valore nella tupla come:oke il secondo valore è letterale di tipo io_device. Se viene causato un errore, restituirà una tupla con il primo valore come:error e secondo valore come motivo.
Il File.open!() la funzione d'altra parte restituirà un file io_devicese il file viene aperto con successo altrimenti verrà generato un errore. NOTA: questo è il modello seguito in tutte le funzioni del modulo file di cui parleremo.
Possiamo anche specificare le modalità in cui vogliamo aprire questo file. Per aprire un file in sola lettura e in modalità di codifica utf-8, utilizziamo il codice seguente:
file = File.open!("newfile", [:read, :utf8])Scrittura su un file
Abbiamo due modi per scrivere su file. Vediamo il primo usando la funzione di scrittura dal modulo File.
File.write("newfile", "Hello")Ma questo non dovrebbe essere usato se stai facendo più scritture sullo stesso file. Ogni volta che questa funzione viene richiamata, viene aperto un descrittore di file e viene generato un nuovo processo per scrivere nel file. Se stai facendo più scritture in un ciclo, apri il file tramiteFile.opene scrivere su di esso utilizzando i metodi nel modulo IO. Consideriamo un esempio per capire lo stesso:
#Open the file in read, write and utf8 modes.
file = File.open!("newfile_2", [:read, :utf8, :write])
#Write to this "io_device" using standard IO functions
IO.puts(file, "Random text")Puoi usare altri metodi del modulo IO come IO.write e IO.binwrite per scrivere su file aperti come io_device.
Leggere da un file
Abbiamo due modi per leggere dai file. Vediamo il primo usando la funzione di lettura dal modulo File.
IO.puts(File.read("newfile"))Quando esegui questo codice, dovresti ottenere una tupla con il primo elemento come :ok e il secondo come contenuto di newfile
Possiamo anche usare il File.read! funzione per ottenere solo il contenuto dei file restituiti.
Chiusura di un file aperto
Ogni volta che si apre un file utilizzando la funzione File.open, dopo averlo utilizzato, è necessario chiuderlo utilizzando il File.close funzione -
File.close(file)In Elixir, tutto il codice viene eseguito all'interno dei processi. I processi sono isolati l'uno dall'altro, vengono eseguiti contemporaneamente e comunicano tramite il passaggio di messaggi. I processi di Elixir non devono essere confusi con i processi del sistema operativo. I processi in Elixir sono estremamente leggeri in termini di memoria e CPU (a differenza dei thread in molti altri linguaggi di programmazione). Per questo motivo, non è raro avere decine o addirittura centinaia di migliaia di processi in esecuzione contemporaneamente.
In questo capitolo, impareremo i costrutti di base per generare nuovi processi, così come inviare e ricevere messaggi tra processi differenti.
La funzione spawn
Il modo più semplice per creare un nuovo processo è utilizzare il file spawnfunzione. Ilspawnaccetta una funzione che verrà eseguita nel nuovo processo. Ad esempio:
pid = spawn(fn -> 2 * 2 end)
Process.alive?(pid)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
falseIl valore di ritorno della funzione spawn è un PID. Questo è un identificatore univoco per il processo e quindi se esegui il codice sopra il tuo PID, sarà diverso. Come puoi vedere in questo esempio, il processo è morto quando controlliamo per vedere se è vivo. Questo perché il processo terminerà non appena avrà terminato di eseguire la funzione data.
Come già accennato, tutti i codici Elixir vengono eseguiti all'interno dei processi. Se esegui la funzione self vedrai il PID per la tua sessione corrente -
pid = self
Process.alive?(pid)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
truePassaggio del messaggio
Possiamo inviare messaggi a un processo con send e riceverli con receive. Passiamo un messaggio al processo in corso e riceviamolo sullo stesso.
send(self(), {:hello, "Hi people"})
receive do
{:hello, msg} -> IO.puts(msg)
{:another_case, msg} -> IO.puts("This one won't match!")
endQuando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hi peopleAbbiamo inviato un messaggio al processo corrente utilizzando la funzione di invio e lo abbiamo passato al PID di self. Quindi abbiamo gestito il messaggio in arrivo utilizzando ilreceive funzione.
Quando un messaggio viene inviato a un processo, il messaggio viene archiviato nel file process mailbox. Il blocco di ricezione passa attraverso la cassetta postale del processo corrente alla ricerca di un messaggio che corrisponda a uno qualsiasi dei modelli forniti. Il blocco di ricezione supporta guardie e molte clausole, come case.
Se nella cassetta postale non è presente alcun messaggio che corrisponde a nessuno dei modelli, il processo corrente attenderà fino all'arrivo di un messaggio corrispondente. È anche possibile specificare un timeout. Per esempio,
receive do
{:hello, msg} -> msg
after
1_000 -> "nothing after 1s"
endQuando il programma di cui sopra viene eseguito, produce il seguente risultato:
nothing after 1sNOTE - È possibile impostare un timeout pari a 0 quando ci si aspetta già che il messaggio sia nella casella di posta.
Collegamenti
La forma più comune di deposizione delle uova in Elixir è in realtà via spawn_linkfunzione. Prima di dare un'occhiata a un esempio con spawn_link, vediamo cosa succede quando un processo fallisce.
spawn fn -> raise "oops" endQuando il programma di cui sopra viene eseguito, produce il seguente errore:
[error] Process #PID<0.58.00> raised an exception
** (RuntimeError) oops
:erlang.apply/2Ha registrato un errore ma il processo di spawn è ancora in esecuzione. Questo perché i processi sono isolati. Se vogliamo che l'errore in un processo si propaghi a un altro, dobbiamo collegarli. Questo può essere fatto conspawn_linkfunzione. Consideriamo un esempio per capire lo stesso:
spawn_link fn -> raise "oops" endQuando il programma di cui sopra viene eseguito, produce il seguente errore:
** (EXIT from #PID<0.41.0>) an exception was raised:
** (RuntimeError) oops
:erlang.apply/2Se stai eseguendo questo file iexshell quindi la shell gestisce questo errore e non esce. Ma se esegui prima creando un file di script e poi usandoelixir <file-name>.exs, anche il processo genitore verrà interrotto a causa di questo errore.
I processi e i collegamenti svolgono un ruolo importante nella creazione di sistemi a tolleranza di errore. Nelle applicazioni Elixir, spesso colleghiamo i nostri processi a supervisori che rileveranno quando un processo muore e inizierà un nuovo processo al suo posto. Questo è possibile solo perché i processi sono isolati e non condividono nulla per impostazione predefinita. E poiché i processi sono isolati, non è possibile che un errore in un processo si blocchi o danneggi lo stato di un altro. Mentre altre lingue ci richiederanno di catturare / gestire le eccezioni; in Elixir, in realtà stiamo bene lasciando che i processi falliscano perché ci aspettiamo che i supervisori riavviino correttamente i nostri sistemi.
Stato
Se stai creando un'applicazione che richiede uno stato, ad esempio, per mantenere la configurazione dell'applicazione, o hai bisogno di analizzare un file e tenerlo in memoria, dove lo memorizzerai? La funzionalità di processo di Elixir può tornare utile quando si fanno queste cose.
Possiamo scrivere processi che ripetono all'infinito, mantengono lo stato e inviano e ricevono messaggi. Ad esempio, scriviamo un modulo che avvia nuovi processi che funzionano come un archivio di valori-chiave in un file denominatokv.exs.
defmodule KV do
def start_link do
Task.start_link(fn -> loop(%{}) end)
end
defp loop(map) do
receive do
{:get, key, caller} ->
send caller, Map.get(map, key)
loop(map)
{:put, key, value} ->
loop(Map.put(map, key, value))
end
end
endNota che il file start_link la funzione avvia un nuovo processo che esegue il file loopfunzione, iniziando con una mappa vuota. Illoopla funzione quindi attende i messaggi ed esegue l'azione appropriata per ogni messaggio. Nel caso di un file:getmessaggio, invia un messaggio al chiamante e chiama di nuovo in loop, in attesa di un nuovo messaggio. Mentre il:put il messaggio effettivamente invoca loop con una nuova versione della mappa, con la chiave e il valore dati memorizzati.
Eseguiamo ora quanto segue:
iex kv.exsOra dovresti essere nel tuo file iexconchiglia. Per testare il nostro modulo, prova quanto segue:
{:ok, pid} = KV.start_link
# pid now has the pid of our new process that is being
# used to get and store key value pairs
# Send a KV pair :hello, "Hello" to the process
send pid, {:put, :hello, "Hello"}
# Ask for the key :hello
send pid, {:get, :hello, self()}
# Print all the received messages on the current process.
flush()Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
"Hello"In questo capitolo esploreremo i sigilli, i meccanismi forniti dal linguaggio per lavorare con le rappresentazioni testuali. I sigilli iniziano con il carattere tilde (~) seguito da una lettera (che identifica il sigillo) e quindi da un delimitatore; facoltativamente, i modificatori possono essere aggiunti dopo il delimitatore finale.
Regex
Le espressioni regolari in Elisir sono sigilli. Abbiamo visto il loro utilizzo nel capitolo String. Facciamo di nuovo un esempio per vedere come possiamo usare le espressioni regolari in Elixir.
# A regular expression that matches strings which contain "foo" or
# "bar":
regex = ~r/foo|bar/
IO.puts("foo" =~ regex)
IO.puts("baz" =~ regex)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
true
falseI sigilli supportano 8 diversi delimitatori -
~r/hello/
~r|hello|
~r"hello"
~r'hello'
~r(hello)
~r[hello]
~r{hello}
~r<hello>La ragione per supportare differenti delimitatori è che differenti delimitatori possono essere più adatti a differenti sigilli. Ad esempio, l'uso delle parentesi per le espressioni regolari può essere una scelta confusa in quanto possono mescolarsi con le parentesi all'interno della regex. Tuttavia, le parentesi possono essere utili per altri sigilli, come vedremo nella prossima sezione.
Elixir supporta regex compatibili con Perl e supporta anche i modificatori. Puoi leggere di più sull'uso delle espressioni regolari qui .
Stringhe, elenchi di caratteri ed elenchi di parole
Oltre alle espressioni regolari, Elixir ha altri 3 sigilli incorporati. Diamo un'occhiata ai sigilli.
stringhe
Il sigillo ~ s viene utilizzato per generare stringhe, come le virgolette doppie. Il sigillo ~ è utile, ad esempio, quando una stringa contiene virgolette sia doppie che singole -
new_string = ~s(this is a string with "double" quotes, not 'single' ones)
IO.puts(new_string)Questo sigillo genera stringhe. Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
"this is a string with \"double\" quotes, not 'single' ones"Elenchi di caratteri
Il sigillo ~ c viene utilizzato per generare elenchi di caratteri -
new_char_list = ~c(this is a char list containing 'single quotes')
IO.puts(new_char_list)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
this is a char list containing 'single quotes'Elenchi di parole
Il sigillo ~ w viene utilizzato per generare elenchi di parole (le parole sono solo stringhe regolari). All'interno del sigillo ~ w, le parole sono separate da spazi bianchi.
new_word_list = ~w(foo bar bat)
IO.puts(new_word_list)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
foobarbatIl sigillo ~ w accetta anche il c, s e a modificatori (per elenchi di caratteri, stringhe e atomi, rispettivamente), che specificano il tipo di dati degli elementi dell'elenco risultante -
new_atom_list = ~w(foo bar bat)a
IO.puts(new_atom_list)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
[:foo, :bar, :bat]Interpolazione e fuga nei sigilli
Oltre ai sigilli minuscoli, Elixir supporta i sigilli maiuscoli per gestire i caratteri di fuga e l'interpolazione. Sebbene sia ~ s che ~ S restituiscano stringhe, il primo consente codici di escape e interpolazione mentre il secondo no. Consideriamo un esempio per capire questo:
~s(String with escape codes \x26 #{"inter" <> "polation"})
# "String with escape codes & interpolation"
~S(String without escape codes \x26 without #{interpolation})
# "String without escape codes \\x26 without \#{interpolation}"Sigilli personalizzati
Possiamo facilmente creare i nostri sigilli personalizzati. In questo esempio, creeremo un sigillo per convertire una stringa in maiuscolo.
defmodule CustomSigil do
def sigil_u(string, []), do: String.upcase(string)
end
import CustomSigil
IO.puts(~u/tutorials point/)Quando eseguiamo il codice sopra, produce il seguente risultato:
TUTORIALS POINTPer prima cosa definiamo un modulo chiamato CustomSigil e all'interno di quel modulo, abbiamo creato una funzione chiamata sigil_u. Poiché non esiste un sigillo ~ u esistente nello spazio del sigillo esistente, lo useremo. La _u indica che si desidera utilizzare u come carattere dopo la tilde. La definizione della funzione deve accettare due argomenti, un input e un elenco.
Le comprensioni delle liste sono zucchero sintattico per scorrere gli enumerabili in Elixir. In questo capitolo useremo le comprensioni per l'iterazione e la generazione.
Nozioni di base
Quando abbiamo esaminato il modulo Enum nel capitolo enumerables, ci siamo imbattuti nella funzione map.
Enum.map(1..3, &(&1 * 2))In questo esempio, passeremo una funzione come secondo argomento. Ogni elemento nell'intervallo verrà passato alla funzione, quindi verrà restituito un nuovo elenco contenente i nuovi valori.
Mappare, filtrare e trasformare sono azioni molto comuni in Elixir e quindi esiste un modo leggermente diverso per ottenere lo stesso risultato dell'esempio precedente:
for n <- 1..3, do: n * 2Quando eseguiamo il codice sopra, produce il seguente risultato:
[2, 4, 6]Il secondo esempio è una comprensione e, come probabilmente puoi vedere, è semplicemente zucchero sintattico per ciò che puoi ottenere anche se usi il Enum.mapfunzione. Tuttavia, non ci sono vantaggi reali nell'usare una comprensione su una funzione del modulo Enum in termini di prestazioni.
Le comprensioni non sono limitate agli elenchi ma possono essere utilizzate con tutti gli enumerabili.
Filtro
Puoi pensare ai filtri come a una sorta di guardia per le comprensioni. Quando viene restituito un valore filtratofalse o nilè escluso dalla lista finale. Cerchiamo di scorrere un intervallo e preoccuparci solo dei numeri pari. Useremo il fileis_even funzione dal modulo Integer per verificare se un valore è pari o meno.
import Integer
IO.puts(for x <- 1..10, is_even(x), do: x)Quando il codice sopra viene eseguito, produce il seguente risultato:
[2, 4, 6, 8, 10]Possiamo anche utilizzare più filtri nella stessa comprensione. Aggiungi un altro filtro che desideri dopo il fileis_even filtro separato da una virgola.
: in Opzione
Negli esempi precedenti, tutte le comprensioni hanno restituito elenchi come risultato. Tuttavia, il risultato di una comprensione può essere inserito in diverse strutture dati passando il:into opzione alla comprensione.
Ad esempio, a bitstring generatore può essere utilizzato con l'opzione: into per rimuovere facilmente tutti gli spazi in una stringa -
IO.puts(for <<c <- " hello world ">>, c != ?\s, into: "", do: <<c>>)Quando il codice sopra viene eseguito, produce il seguente risultato:
helloworldIl codice precedente rimuove tutti gli spazi dalla stringa utilizzando c != ?\s filter e quindi utilizzando l'opzione: into, inserisce tutti i caratteri restituiti in una stringa.
Elixir è un linguaggio tipizzato dinamicamente, quindi tutti i tipi in Elixir vengono dedotti dal runtime. Tuttavia, Elixir viene fornito con typespec, che sono una notazione usata perdeclaring custom data types and declaring typed function signatures (specifications).
Specifiche di funzione (specifiche)
Per impostazione predefinita, Elixir fornisce alcuni tipi di base, come interi o pid, e anche tipi complessi: ad esempio, il roundfunzione, che arrotonda un float al numero intero più vicino, accetta un numero come argomento (un intero o un float) e restituisce un numero intero. Nella relativa documentazione , la firma tonda dattiloscritta è scritta come:
round(number) :: integerLa descrizione sopra implica che la funzione a sinistra prende come argomento ciò che è specificato tra parentesi e restituisce ciò che è a destra di ::, cioè, Integer. Le specifiche della funzione sono scritte con l'estensione@specdirettiva, posta subito prima della definizione della funzione. La funzione round può essere scritta come -
@spec round(number) :: integer
def round(number), do: # Function implementation
...Typepec supporta anche tipi complessi, ad esempio, se desideri restituire un elenco di numeri interi, puoi utilizzare [Integer]
Tipi personalizzati
Sebbene Elixir fornisca molti utili tipi integrati, è conveniente definire tipi personalizzati quando appropriato. Questo può essere fatto quando si definiscono i moduli tramite la direttiva @type. Consideriamo un esempio per capire lo stesso:
defmodule FunnyCalculator do
@type number_with_joke :: {number, String.t}
@spec add(number, number) :: number_with_joke
def add(x, y), do: {x + y, "You need a calculator to do that?"}
@spec multiply(number, number) :: number_with_joke
def multiply(x, y), do: {x * y, "It is like addition on steroids."}
end
{result, comment} = FunnyCalculator.add(10, 20)
IO.puts(result)
IO.puts(comment)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
30
You need a calculator to do that?NOTE - I tipi personalizzati definiti tramite @type vengono esportati e disponibili all'esterno del modulo in cui sono definiti. Se si desidera mantenere privato un tipo personalizzato, è possibile utilizzare il @typep direttiva invece di @type.
I comportamenti in Elixir (e Erlang) sono un modo per separare e astrarre la parte generica di un componente (che diventa il modulo di comportamento) dalla parte specifica (che diventa il modulo di callback). I comportamenti forniscono un modo per:
- Definire un insieme di funzioni che devono essere implementate da un modulo.
- Assicurati che un modulo implementi tutte le funzioni in quell'insieme.
Se devi, puoi pensare a comportamenti come le interfacce in linguaggi orientati agli oggetti come Java: un insieme di firme di funzioni che un modulo deve implementare.
Definizione di un comportamento
Consideriamo un esempio per creare il nostro comportamento e quindi utilizzare questo comportamento generico per creare un modulo. Definiremo un comportamento che saluta le persone ciao e arrivederci in diverse lingue.
defmodule GreetBehaviour do
@callback say_hello(name :: string) :: nil
@callback say_bye(name :: string) :: nil
endIl @callbackviene utilizzata per elencare le funzioni che l'adozione dei moduli dovrà definire. Specifica inoltre il n. di argomenti, il loro tipo e i loro valori di ritorno.
Adottare un comportamento
Abbiamo definito con successo un comportamento. Ora lo adotteremo e lo implementeremo in più moduli. Creiamo due moduli che implementano questo comportamento in inglese e spagnolo.
defmodule GreetBehaviour do
@callback say_hello(name :: string) :: nil
@callback say_bye(name :: string) :: nil
end
defmodule EnglishGreet do
@behaviour GreetBehaviour
def say_hello(name), do: IO.puts("Hello " <> name)
def say_bye(name), do: IO.puts("Goodbye, " <> name)
end
defmodule SpanishGreet do
@behaviour GreetBehaviour
def say_hello(name), do: IO.puts("Hola " <> name)
def say_bye(name), do: IO.puts("Adios " <> name)
end
EnglishGreet.say_hello("Ayush")
EnglishGreet.say_bye("Ayush")
SpanishGreet.say_hello("Ayush")
SpanishGreet.say_bye("Ayush")Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Hello Ayush
Goodbye, Ayush
Hola Ayush
Adios AyushCome hai già visto, adottiamo un comportamento che utilizza il @behaviourdirettiva nel modulo. Dobbiamo definire tutte le funzioni implementate nel comportamento per tutti i moduli figli . Questo può essere più o meno considerato equivalente alle interfacce nei linguaggi OOP.
Elixir ha tre meccanismi di errore: errori, lanci ed uscite. Esploriamo ogni meccanismo in dettaglio.
Errore
Gli errori (o le eccezioni) vengono utilizzati quando si verificano cose eccezionali nel codice. Un errore di esempio può essere recuperato provando ad aggiungere un numero in una stringa -
IO.puts(1 + "Hello")Quando il programma di cui sopra viene eseguito, produce il seguente errore:
** (ArithmeticError) bad argument in arithmetic expression
:erlang.+(1, "Hello")Questo era un errore integrato di esempio.
Segnalazione di errori
Noi possiamo raiseerrori utilizzando le funzioni di sollevamento. Consideriamo un esempio per capire lo stesso:
#Runtime Error with just a message
raise "oops" # ** (RuntimeError) oopsAltri errori possono essere generati con raise / 2 passando il nome dell'errore e un elenco di argomenti di parole chiave
#Other error type with a message
raise ArgumentError, message: "invalid argument foo"Puoi anche definire i tuoi errori e sollevarli. Considera il seguente esempio:
defmodule MyError do
defexception message: "default message"
end
raise MyError # Raises error with default message
raise MyError, message: "custom message" # Raises error with custom messageSalvataggio degli errori
Non vogliamo che i nostri programmi si chiudano improvvisamente, ma piuttosto gli errori devono essere gestiti con attenzione. Per questo usiamo la gestione degli errori. Noirescue errori utilizzando il try/rescuecostruire. Consideriamo il seguente esempio per capire lo stesso:
err = try do
raise "oops"
rescue
e in RuntimeError -> e
end
IO.puts(err.message)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
oopsAbbiamo gestito gli errori nell'istruzione rescue utilizzando il pattern matching. Se non abbiamo alcun uso dell'errore e vogliamo solo usarlo a scopo di identificazione, possiamo anche usare il modulo -
err = try do
1 + "Hello"
rescue
RuntimeError -> "You've got a runtime error!"
ArithmeticError -> "You've got a Argument error!"
end
IO.puts(err)Quando si esegue il programma sopra, produce il seguente risultato:
You've got a Argument error!NOTE- La maggior parte delle funzioni nella libreria standard Elixir sono implementate due volte, una volta restituendo tuple e l'altra volta generando errori. Ad esempio, il fileFile.read e il File.read!funzioni. Il primo ha restituito una tupla se il file è stato letto correttamente e se è stato riscontrato un errore, questa tupla è stata utilizzata per fornire il motivo dell'errore. Il secondo generava un errore se si verificava un errore.
Se usiamo il primo approccio di funzione, allora dobbiamo usare il caso per il pattern che corrisponde all'errore e agire in base a quello. Nel secondo caso, utilizziamo l'approccio try rescue per il codice soggetto a errori e gestiamo gli errori di conseguenza.
Lancia
In Elixir, un valore può essere lanciato e successivamente essere catturato. Lancio e presa sono riservati alle situazioni in cui non è possibile recuperare un valore se non utilizzando lancio e ripresa.
Le istanze sono abbastanza rare nella pratica tranne quando si interfaccia con le librerie. Ad esempio, supponiamo ora che il modulo Enum non fornisse alcuna API per trovare un valore e che avessimo bisogno di trovare il primo multiplo di 13 in un elenco di numeri -
val = try do
Enum.each 20..100, fn(x) ->
if rem(x, 13) == 0, do: throw(x)
end
"Got nothing"
catch
x -> "Got #{x}"
end
IO.puts(val)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Got 26Uscita
Quando un processo muore per "cause naturali" (ad esempio, eccezioni non gestite), invia un segnale di uscita. Un processo può anche morire inviando esplicitamente un segnale di uscita. Consideriamo il seguente esempio:
spawn_link fn -> exit(1) endNell'esempio sopra, il processo collegato è morto inviando un segnale di uscita con valore 1. Notare che l'uscita può anche essere "catturata" usando try / catch. Ad esempio:
val = try do
exit "I am exiting"
catch
:exit, _ -> "not really"
end
IO.puts(val)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
not reallyDopo
A volte è necessario assicurarsi che una risorsa venga ripulita dopo un'azione che può potenzialmente generare un errore. Il costrutto try / after ti permette di farlo. Ad esempio, possiamo aprire un file e utilizzare una clausola after per chiuderlo, anche se qualcosa va storto.
{:ok, file} = File.open "sample", [:utf8, :write]
try do
IO.write file, "olá"
raise "oops, something went wrong"
after
File.close(file)
endQuando eseguiamo questo programma, ci darà un errore. Ma ilafter assicurerà che il descrittore di file venga chiuso in caso di tali eventi.
Le macro sono una delle funzionalità più avanzate e potenti di Elixir. Come per tutte le funzionalità avanzate di qualsiasi lingua, le macro dovrebbero essere utilizzate con parsimonia. Consentono di eseguire potenti trasformazioni del codice in fase di compilazione. Ora capiremo cosa sono le macro e come usarle in breve.
Citazione
Prima di iniziare a parlare di macro, diamo un'occhiata agli interni di Elixir. Un programma Elixir può essere rappresentato dalle proprie strutture dati. L'elemento costitutivo di un programma Elixir è una tupla con tre elementi. Ad esempio, la chiamata di funzione sum (1, 2, 3) è rappresentata internamente come -
{:sum, [], [1, 2, 3]}Il primo elemento è il nome della funzione, il secondo è un elenco di parole chiave contenente metadati e il terzo è l'elenco degli argomenti. Puoi ottenerlo come output nella shell iex se scrivi quanto segue:
quote do: sum(1, 2, 3)Anche gli operatori sono rappresentati come tali tuple. Anche le variabili sono rappresentate usando tali terzine, tranne per il fatto che l'ultimo elemento è un atomo, invece di una lista. Quando si citano espressioni più complesse, possiamo vedere che il codice è rappresentato in tali tuple, che sono spesso annidate l'una nell'altra in una struttura simile a un albero. Molte lingue chiamerebbero tali rappresentazioni unAbstract Syntax Tree (AST). Elixir chiama queste espressioni citate.
Unquote
Ora che possiamo recuperare la struttura interna del nostro codice, come la modifichiamo? Per iniettare nuovo codice o valori, usiamounquote. Quando deselezioniamo un'espressione, questa verrà valutata e iniettata nell'AST. Consideriamo un esempio (nella shell iex) per comprendere il concetto:
num = 25
quote do: sum(15, num)
quote do: sum(15, unquote(num))Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
{:sum, [], [15, {:num, [], Elixir}]}
{:sum, [], [15, 25]}Nell'esempio per l'espressione di virgolette, non ha sostituito automaticamente num con 25. Dobbiamo deselezionare questa variabile se vogliamo modificare l'AST.
Macro
Quindi, ora che abbiamo familiarità con citazione e non citazione, possiamo esplorare la metaprogrammazione in Elixir usando le macro.
In termini più semplici, le macro sono funzioni speciali progettate per restituire un'espressione tra virgolette che verrà inserita nel codice della nostra applicazione. Immagina che la macro venga sostituita con l'espressione tra virgolette anziché essere chiamata come una funzione. Con le macro abbiamo tutto il necessario per estendere Elixir e aggiungere dinamicamente codice alle nostre applicazioni
Cerchiamo di implementare se non come macro. Inizieremo definendo la macro utilizzando ildefmacromacro. Ricorda che la nostra macro deve restituire un'espressione tra virgolette.
defmodule OurMacro do
defmacro unless(expr, do: block) do
quote do
if !unquote(expr), do: unquote(block)
end
end
end
require OurMacro
OurMacro.unless true, do: IO.puts "True Expression"
OurMacro.unless false, do: IO.puts "False expression"Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
False expressionQuello che sta succedendo qui è che il nostro codice viene sostituito dal codice tra virgolette restituito dalla macro se non . Abbiamo rimosso le virgolette dall'espressione per valutarla nel contesto corrente e abbiamo anche rimosso il quotato dal blocco do per eseguirlo nel suo contesto. Questo esempio ci mostra la metaprogrammazione usando le macro in elisir.
Le macro possono essere utilizzate in attività molto più complesse, ma dovrebbero essere utilizzate con parsimonia. Questo perché la metaprogrammazione in generale è considerata una cattiva pratica e dovrebbe essere utilizzata solo quando necessario.
Elixir fornisce un'eccellente interoperabilità con le librerie Erlang. Parliamo brevemente di alcune biblioteche.
Il modulo binario
Il modulo Elixir String integrato gestisce i file binari con codifica UTF-8. Il modulo binario è utile quando si ha a che fare con dati binari che non sono necessariamente codificati in UTF-8. Consideriamo un esempio per comprendere ulteriormente il modulo Binary -
# UTF-8
IO.puts(String.to_char_list("Ø"))
# binary
IO.puts(:binary.bin_to_list "Ø")Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
[216]
[195, 152]L'esempio sopra mostra la differenza; il modulo String restituisce codepoint UTF-8, mentre: binary si occupa di byte di dati grezzi.
Il modulo Crypto
Il modulo di crittografia contiene funzioni di hashing, firme digitali, crittografia e altro ancora. Questo modulo non fa parte della libreria standard Erlang, ma è incluso nella distribuzione Erlang. Ciò significa che devi elencare: crypto nell'elenco delle applicazioni del tuo progetto ogni volta che lo usi. Vediamo un esempio usando il modulo crypto -
IO.puts(Base.encode16(:crypto.hash(:sha256, "Elixir")))Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
3315715A7A3AD57428298676C5AE465DADA38D951BDFAC9348A8A31E9C7401CBIl modulo Digraph
Il modulo digraph contiene funzioni per gestire i grafi diretti costruiti da vertici e archi. Dopo aver costruito il grafo, gli algoritmi presenti aiuteranno a trovare, ad esempio, il percorso più breve tra due vertici o loop nel grafico. Nota che le funzioniin :digraph alterare la struttura del grafico indirettamente come effetto collaterale, restituendo i vertici o gli spigoli aggiunti.
digraph = :digraph.new()
coords = [{0.0, 0.0}, {1.0, 0.0}, {1.0, 1.0}]
[v0, v1, v2] = (for c <- coords, do: :digraph.add_vertex(digraph, c))
:digraph.add_edge(digraph, v0, v1)
:digraph.add_edge(digraph, v1, v2)
for point <- :digraph.get_short_path(digraph, v0, v2) do
{x, y} = point
IO.puts("#{x}, #{y}")
endQuando il programma di cui sopra viene eseguito, produce il seguente risultato:
0.0, 0.0
1.0, 0.0
1.0, 1.0Il modulo matematico
Il modulo di matematica contiene operazioni matematiche comuni che coprono funzioni trigonometriche, esponenziali e logaritmiche. Consideriamo il seguente esempio per capire come funziona il modulo Math:
# Value of pi
IO.puts(:math.pi())
# Logarithm
IO.puts(:math.log(7.694785265142018e23))
# Exponentiation
IO.puts(:math.exp(55.0))
#...Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
3.141592653589793
55.0
7.694785265142018e23Il modulo della coda
La coda è una struttura di dati che implementa le code FIFO (first-in first-out) (a doppia estremità) in modo efficiente. L'esempio seguente mostra come funziona un modulo Queue:
q = :queue.new
q = :queue.in("A", q)
q = :queue.in("B", q)
{{:value, val}, q} = :queue.out(q)
IO.puts(val)
{{:value, val}, q} = :queue.out(q)
IO.puts(val)Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
A
B