Programmazione funzionale - Guida rapida
I linguaggi di programmazione funzionale sono appositamente progettati per gestire il calcolo simbolico e le applicazioni di elaborazione di elenchi. La programmazione funzionale si basa su funzioni matematiche. Alcuni dei più diffusi linguaggi di programmazione funzionale includono: Lisp, Python, Erlang, Haskell, Clojure, ecc.
I linguaggi di programmazione funzionale sono classificati in due gruppi, ovvero:
Pure Functional Languages- Questi tipi di linguaggi funzionali supportano solo i paradigmi funzionali. Ad esempio - Haskell.
Impure Functional Languages- Questi tipi di linguaggi funzionali supportano i paradigmi funzionali e la programmazione in stile imperativo. Ad esempio - LISP.
Programmazione funzionale - Caratteristiche
Le caratteristiche più importanti della programmazione funzionale sono le seguenti:
I linguaggi di programmazione funzionale sono progettati sul concetto di funzioni matematiche che utilizzano espressioni condizionali e ricorsione per eseguire calcoli.
Supporti di programmazione funzionale higher-order functions e lazy evaluation Caratteristiche.
I linguaggi di programmazione funzionale non supportano i controlli di flusso come le istruzioni loop e le istruzioni condizionali come If-Else e Switch Statements. Usano direttamente le funzioni e le chiamate funzionali.
Come l'OOP, i linguaggi di programmazione funzionale supportano concetti popolari come astrazione, incapsulamento, ereditarietà e polimorfismo.
Programmazione funzionale - Vantaggi
La programmazione funzionale offre i seguenti vantaggi:
Bugs-Free Code - La programmazione funzionale non supporta state, quindi non ci sono risultati di effetti collaterali e possiamo scrivere codici senza errori.
Efficient Parallel Programming- I linguaggi di programmazione funzionali NON hanno uno stato mutevole, quindi non ci sono problemi di cambio di stato. Si possono programmare "Funzioni" per lavorare in parallelo come "istruzioni". Tali codici supportano una facile riusabilità e testabilità.
Efficiency- I programmi funzionali sono costituiti da unità indipendenti che possono essere eseguite contemporaneamente. Di conseguenza, tali programmi sono più efficienti.
Supports Nested Functions - La programmazione funzionale supporta le funzioni annidate.
Lazy Evaluation - La programmazione funzionale supporta costrutti funzionali pigri come liste pigre, mappe pigre, ecc.
Come svantaggio, la programmazione funzionale richiede un ampio spazio di memoria. Poiché non ha uno stato, è necessario creare nuovi oggetti ogni volta per eseguire azioni.
La programmazione funzionale viene utilizzata in situazioni in cui è necessario eseguire molte operazioni diverse sullo stesso insieme di dati.
Lisp viene utilizzato per applicazioni di intelligenza artificiale come l'apprendimento automatico, l'elaborazione del linguaggio, la modellazione del parlato e della visione, ecc.
Gli interpreti Lisp incorporati aggiungono programmabilità ad alcuni sistemi come Emacs.
Programmazione funzionale vs. programmazione orientata agli oggetti
La tabella seguente evidenzia le principali differenze tra programmazione funzionale e programmazione orientata agli oggetti:
| Programmazione funzionale | OOP |
|---|---|
| Utilizza dati immutabili. | Utilizza dati mutabili. |
| Segue il modello di programmazione dichiarativo. | Segue il modello di programmazione imperativo. |
| Il focus è su: "Cosa stai facendo" | Il focus è su "Come stai" |
| Supporta la programmazione parallela | Non adatto per la programmazione parallela |
| Le sue funzioni non hanno effetti collaterali | I suoi metodi possono produrre gravi effetti collaterali. |
| Il controllo del flusso viene eseguito utilizzando chiamate di funzione e chiamate di funzione con ricorsione | Il controllo del flusso viene eseguito utilizzando cicli e istruzioni condizionali. |
| Utilizza il concetto di "ricorsione" per iterare i dati di raccolta. | Utilizza il concetto "Loop" per iterare i dati di raccolta. Ad esempio: For-each loop in Java |
| L'ordine di esecuzione delle istruzioni non è così importante. | L'ordine di esecuzione delle istruzioni è molto importante. |
| Supporta sia "Astrazione sui dati" che "Astrazione sul comportamento". | Supporta solo "Astrazione sui dati". |
Efficienza di un codice di programma
L'efficienza di un codice di programmazione è direttamente proporzionale all'efficienza algoritmica e alla velocità di esecuzione. Una buona efficienza garantisce prestazioni più elevate.
I fattori che influenzano l'efficienza di un programma includono:
- La velocità della macchina
- Velocità del compilatore
- Sistema operativo
- Scegliere il giusto linguaggio di programmazione
- La via dei dati in un programma è organizzata
- Algoritmo utilizzato per risolvere il problema
L'efficienza di un linguaggio di programmazione può essere migliorata eseguendo le seguenti attività:
Rimuovendo il codice non necessario o il codice che va all'elaborazione ridondante.
Facendo uso di memoria ottimale e archiviazione non volatile
Facendo uso di componenti riutilizzabili laddove applicabile.
Facendo uso della gestione degli errori e delle eccezioni a tutti i livelli del programma.
Creando codice di programmazione che garantisce l'integrità e la coerenza dei dati.
Sviluppando il codice del programma conforme alla logica e al flusso di progettazione.
Un codice di programmazione efficiente può ridurre il più possibile il consumo di risorse e il tempo di completamento con il minimo rischio per l'ambiente operativo.
In termini di programmazione, a functionè un blocco di istruzioni che esegue un'attività specifica. Le funzioni accettano dati, li elaborano e restituiscono un risultato. Le funzioni sono scritte principalmente per supportare il concetto di riusabilità. Una volta che una funzione è stata scritta, può essere chiamata facilmente, senza dover scrivere lo stesso codice ancora e ancora.
Linguaggi funzionali diversi utilizzano una sintassi diversa per scrivere una funzione.
Prerequisiti per la scrittura di una funzione
Prima di scrivere una funzione, un programmatore deve conoscere i seguenti punti:
Lo scopo della funzione dovrebbe essere noto al programmatore.
L'algoritmo della funzione dovrebbe essere noto al programmatore.
Le variabili di dati delle funzioni e il loro obiettivo dovrebbero essere noti al programmatore.
I dati della funzione dovrebbero essere noti al programmatore chiamato dall'utente.
Controllo del flusso di una funzione
Quando una funzione viene "chiamata", il programma "trasferisce" il controllo per eseguire la funzione e il suo "flusso di controllo" è il seguente:
Il programma raggiunge l'istruzione contenente una "chiamata di funzione".
Viene eseguita la prima riga all'interno della funzione.
Tutte le istruzioni all'interno della funzione vengono eseguite dall'alto verso il basso.
Quando la funzione viene eseguita correttamente, il controllo torna all'istruzione da cui è partita.
Tutti i dati calcolati e restituiti dalla funzione vengono utilizzati al posto della funzione nella riga di codice originale.
Sintassi di una funzione
La sintassi generale di una funzione è la seguente:
returnType functionName(type1 argument1, type2 argument2, . . . ) {
// function body
}Definizione di una funzione in C ++
Facciamo un esempio per capire come una funzione può essere definita in C ++ che è un linguaggio di programmazione orientato agli oggetti. Il codice seguente ha una funzione che aggiunge due numeri e fornisce il risultato come output.
#include <stdio.h>
int addNum(int a, int b); // function prototype
int main() {
int sum;
sum = addNum(5,6); // function call
printf("sum = %d",sum);
return 0;
}
int addNum (int a,int b) { // function definition
int result;
result = a + b;
return result; // return statement
}Produrrà il seguente output:
Sum = 11Definizione di una funzione in Erlang
Vediamo come la stessa funzione può essere definita in Erlang, che è un linguaggio di programmazione funzionale.
-module(helloworld).
-export([add/2,start/0]).
add(A,B) ->
C = A + B,
io:fwrite("~w~n",[C]).
start() ->
add(5,6).Produrrà il seguente output:
11Prototipo di funzione
Un prototipo di funzione è una dichiarazione della funzione che include il tipo restituito, il nome della funzione e l'elenco degli argomenti. È simile alla definizione di funzione senza funzione-corpo.
For Example - Alcuni linguaggi di programmazione supportano la prototipazione di funzioni e altri no.
In C ++, possiamo creare un prototipo di funzione della funzione 'sum' in questo modo:
int sum(int a, int b)Note - Linguaggi di programmazione come Python, Erlang, ecc. Non supportano la prototipazione di funzioni, dobbiamo dichiarare la funzione completa.
Qual è l'uso del prototipo di funzione?
Il prototipo della funzione viene utilizzato dal compilatore quando viene chiamata la funzione. Il compilatore lo utilizza per garantire il tipo di ritorno corretto, l'elenco degli argomenti corretto e il tipo di ritorno corretto.
Firma della funzione
Una firma di funzione è simile al prototipo di funzione in cui il numero di parametri, il tipo di dati dei parametri e l'ordine di apparizione devono essere in ordine simile. Ad esempio -
void Sum(int a, int b, int c); // function 1
void Sum(float a, float b, float c); // function 2
void Sum(float a, float b, float c); // function 3Function1 e Function2 hanno firme diverse. Function2 e Function3 hanno le stesse firme.
Note - Il sovraccarico delle funzioni e l'override delle funzioni che discuteremo nei capitoli successivi sono basati sul concetto di firme di funzione.
Il sovraccarico delle funzioni è possibile quando una classe ha più funzioni con lo stesso nome ma firme diverse.
L'override della funzione è possibile quando una funzione di una classe derivata ha lo stesso nome e firma della sua classe base.
Le funzioni sono di due tipi:
- Funzioni predefinite
- Funzioni definite dall'utente
In questo capitolo, discuteremo in dettaglio delle funzioni.
Funzioni predefinite
Queste sono le funzioni incorporate in Language per eseguire operazioni e sono memorizzate nella libreria di funzioni standard.
For Example - 'Strcat' in C ++ e 'concat' in Haskell sono usati per aggiungere le due stringhe, 'strlen' in C ++ e 'len' in Python sono usati per calcolare la lunghezza della stringa.
Programma per stampare la lunghezza della stringa in C ++
Il seguente programma mostra come stampare la lunghezza di una stringa usando C ++ -
#include <iostream>
#include <string.h>
#include <stdio.h>
using namespace std;
int main() {
char str[20] = "Hello World";
int len;
len = strlen(str);
cout<<"String length is: "<<len;
return 0;
}Produrrà il seguente output:
String length is: 11Programma per stampare la lunghezza della stringa in Python
Il seguente programma mostra come stampare la lunghezza di una stringa usando Python, che è un linguaggio di programmazione funzionale -
str = "Hello World";
print("String length is: ", len(str))Produrrà il seguente output:
('String length is: ', 11)Funzioni definite dall'utente
Le funzioni definite dall'utente sono definite dall'utente per eseguire attività specifiche. Ci sono quattro diversi modelli per definire una funzione:
- Funzioni senza argomenti e senza valore di ritorno
- Funziona senza argomenti ma con un valore di ritorno
- Funziona con argomento ma senza valore di ritorno
- Funziona con argomento e un valore di ritorno
Funzioni senza argomenti e senza valore di ritorno
Il seguente programma mostra come definire una funzione senza argomenti e senza valore di ritorno in C++ -
#include <iostream>
using namespace std;
void function1() {
cout <<"Hello World";
}
int main() {
function1();
return 0;
}Produrrà il seguente output:
Hello WorldIl seguente programma mostra come definire una funzione simile (nessun argomento e nessun valore di ritorno) in Python -
def function1():
print ("Hello World")
function1()Produrrà il seguente output:
Hello WorldFunziona senza argomenti ma con un valore di ritorno
Il seguente programma mostra come definire una funzione senza argomenti ma con un valore di ritorno in C++ -
#include <iostream>
using namespace std;
string function1() {
return("Hello World");
}
int main() {
cout<<function1();
return 0;
}Produrrà il seguente output:
Hello WorldIl seguente programma mostra come definire una funzione simile (senza argomenti ma un valore di ritorno) in Python -
def function1():
return "Hello World"
res = function1()
print(res)Produrrà il seguente output:
Hello WorldFunziona con argomento ma senza valore di ritorno
Il seguente programma mostra come definire una funzione con argomento ma nessun valore di ritorno in C++ -
#include <iostream>
using namespace std;
void function1(int x, int y) {
int c;
c = x+y;
cout<<"Sum is: "<<c;
}
int main() {
function1(4,5);
return 0;
}Produrrà il seguente output:
Sum is: 9Il seguente programma mostra come definire una funzione simile in Python -
def function1(x,y):
c = x + y
print("Sum is:",c)
function1(4,5)Produrrà il seguente output:
('Sum is:', 9)Funziona con argomento e un valore di ritorno
Il seguente programma mostra come definire una funzione in C ++ senza argomenti ma un valore di ritorno -
#include <iostream>
using namespace std;
int function1(int x, int y) {
int c;
c = x + y;
return c;
}
int main() {
int res;
res = function1(4,5);
cout<<"Sum is: "<<res;
return 0;
}Produrrà il seguente output:
Sum is: 9Il seguente programma mostra come definire una funzione simile (con argomento e valore di ritorno) in Python -
def function1(x,y):
c = x + y
return c
res = function1(4,5)
print("Sum is ",res)Produrrà il seguente output:
('Sum is ', 9)Dopo aver definito una funzione, è necessario passarvi gli argomenti per ottenere l'output desiderato. Supporta la maggior parte dei linguaggi di programmazionecall by value e call by reference metodi per passare argomenti nelle funzioni.
In questo capitolo impareremo il funzionamento della "chiamata per valore" in un linguaggio di programmazione orientato agli oggetti come C ++ e un linguaggio di programmazione funzionale come Python.
Nel metodo Call by Value, il original value cannot be changed. Quando passiamo un argomento a una funzione, viene memorizzato localmente dal parametro della funzione nella memoria dello stack. Quindi, i valori vengono modificati solo all'interno della funzione e non avrà alcun effetto all'esterno della funzione.
Chiama per valore in C ++
Il seguente programma mostra come funziona Call by Value in C ++:
#include <iostream>
using namespace std;
void swap(int a, int b) {
int temp;
temp = a;
a = b;
b = temp;
cout<<"\n"<<"value of a inside the function: "<<a;
cout<<"\n"<<"value of b inside the function: "<<b;
}
int main() {
int a = 50, b = 70;
cout<<"value of a before sending to function: "<<a;
cout<<"\n"<<"value of b before sending to function: "<<b;
swap(a, b); // passing value to function
cout<<"\n"<<"value of a after sending to function: "<<a;
cout<<"\n"<<"value of b after sending to function: "<<b;
return 0;
}Produrrà il seguente output:
value of a before sending to function: 50
value of b before sending to function: 70
value of a inside the function: 70
value of b inside the function: 50
value of a after sending to function: 50
value of b after sending to function: 70Chiama per valore in Python
Il seguente programma mostra come funziona Call by Value in Python:
def swap(a,b):
t = a;
a = b;
b = t;
print "value of a inside the function: :",a
print "value of b inside the function: ",b
# Now we can call the swap function
a = 50
b = 75
print "value of a before sending to function: ",a
print "value of b before sending to function: ",b
swap(a,b)
print "value of a after sending to function: ", a
print "value of b after sending to function: ",bProdurrà il seguente output:
value of a before sending to function: 50
value of b before sending to function: 75
value of a inside the function: : 75
value of b inside the function: 50
value of a after sending to function: 50
value of b after sending to function: 75In Call by Reference, il original value is changedperché passiamo l'indirizzo di riferimento degli argomenti. Gli argomenti effettivi e formali condividono lo stesso spazio degli indirizzi, quindi qualsiasi cambiamento di valore all'interno della funzione si riflette sia all'interno che all'esterno della funzione.
Chiamata per riferimento in C ++
Il seguente programma mostra come funziona Call by Value in C ++:
#include <iostream>
using namespace std;
void swap(int *a, int *b) {
int temp;
temp = *a;
*a = *b;
*b = temp;
cout<<"\n"<<"value of a inside the function: "<<*a;
cout<<"\n"<<"value of b inside the function: "<<*b;
}
int main() {
int a = 50, b = 75;
cout<<"\n"<<"value of a before sending to function: "<<a;
cout<<"\n"<<"value of b before sending to function: "<<b;
swap(&a, &b); // passing value to function
cout<<"\n"<<"value of a after sending to function: "<<a;
cout<<"\n"<<"value of b after sending to function: "<<b;
return 0;
}Produrrà il seguente output:
value of a before sending to function: 50
value of b before sending to function: 75
value of a inside the function: 75
value of b inside the function: 50
value of a after sending to function: 75
value of b after sending to function: 50Chiama per riferimento in Python
Il seguente programma mostra come funziona Call by Value in Python:
def swap(a,b):
t = a;
a = b;
b = t;
print "value of a inside the function: :",a
print "value of b inside the function: ",b
return(a,b)
# Now we can call swap function
a = 50
b =75
print "value of a before sending to function: ",a
print "value of b before sending to function: ",b
x = swap(a,b)
print "value of a after sending to function: ", x[0]
print "value of b after sending to function: ",x[1]Produrrà il seguente output:
value of a before sending to function: 50
value of b before sending to function: 75
value of a inside the function: 75
value of b inside the function: 50
value of a after sending to function: 75
value of b after sending to function: 50Quando abbiamo più funzioni con lo stesso nome ma parametri diversi, si dice che siano sovraccariche. Questa tecnica viene utilizzata per migliorare la leggibilità del programma.
Esistono due modi per sovraccaricare una funzione, ovvero:
- Avere un numero diverso di argomenti
- Avere diversi tipi di argomenti
Il sovraccarico delle funzioni viene normalmente eseguito quando dobbiamo eseguire una singola operazione con numero o tipi di argomenti diversi.
Sovraccarico di funzioni in C ++
L'esempio seguente mostra come viene eseguito il sovraccarico delle funzioni in C ++, che è un linguaggio di programmazione orientato agli oggetti -
#include <iostream>
using namespace std;
void addnum(int,int);
void addnum(int,int,int);
int main() {
addnum (5,5);
addnum (5,2,8);
return 0;
}
void addnum (int x, int y) {
cout<<"Integer number: "<<x+y<<endl;
}
void addnum (int x, int y, int z) {
cout<<"Float number: "<<x+y+z<<endl;
}Produrrà il seguente output:
Integer number: 10
Float number: 15Funzione sovraccarico a Erlang
L'esempio seguente mostra come eseguire il sovraccarico delle funzioni in Erlang, che è un linguaggio di programmazione funzionale -
-module(helloworld).
-export([addnum/2,addnum/3,start/0]).
addnum(X,Y) ->
Z = X+Y,
io:fwrite("~w~n",[Z]).
addnum(X,Y,Z) ->
A = X+Y+Z,
io:fwrite("~w~n",[A]).
start() ->
addnum(5,5), addnum(5,2,8).Produrrà il seguente output:
10
15Quando la classe base e la classe derivata hanno funzioni membro con esattamente lo stesso nome, lo stesso tipo restituito e lo stesso elenco di argomenti, si dice che la funzione sovrascrive.
Funzione che sovrascrive usando C ++
L'esempio seguente mostra come eseguire l'override delle funzioni in C ++, che è un linguaggio di programmazione orientato agli oggetti -
#include <iostream>
using namespace std;
class A {
public:
void display() {
cout<<"Base class";
}
};
class B:public A {
public:
void display() {
cout<<"Derived Class";
}
};
int main() {
B obj;
obj.display();
return 0;
}Produrrà il seguente output
Derived ClassFunzione che sovrascrive usando Python
L'esempio seguente mostra come eseguire l'override delle funzioni in Python, che è un linguaggio di programmazione funzionale -
class A(object):
def disp(self):
print "Base Class"
class B(A):
def disp(self):
print "Derived Class"
x = A()
y = B()
x.disp()
y.disp()Produrrà il seguente output:
Base Class
Derived ClassUna funzione che chiama se stessa è nota come funzione ricorsiva e questa tecnica è nota come ricorsione. Un'istruzione di ricorsione continua finché un'altra istruzione non la impedisce.
Ricorsione in C ++
L'esempio seguente mostra come funziona la ricorsione in C ++, che è un linguaggio di programmazione orientato agli oggetti -
#include <stdio.h>
long int fact(int n);
int main() {
int n;
printf("Enter a positive integer: ");
scanf("%d", &n);
printf("Factorial of %d = %ld", n, fact(n));
return 0;
}
long int fact(int n) {
if (n >= 1)
return n*fact(n-1);
else
return 1;
}Produrrà il seguente output
Enter a positive integer: 5
Factorial of 5 = 120Ricorsione in Python
L'esempio seguente mostra come funziona la ricorsione in Python, che è un linguaggio di programmazione funzionale -
def fact(n):
if n == 1:
return n
else:
return n* fact (n-1)
# accepts input from user
num = int(input("Enter a number: "))
# check whether number is positive or not
if num < 0:
print("Sorry, factorial does not exist for negative numbers")
else:
print("The factorial of " + str(num) + " is " + str(fact(num)))Produrrà il seguente output:
Enter a number: 6
The factorial of 6 is 720Una funzione di ordine superiore (HOF) è una funzione che segue almeno una delle seguenti condizioni:
- Assume o più funzioni come argomento
- Restituisce una funzione come risultato
HOF in PHP
L'esempio seguente mostra come scrivere una funzione di ordine superiore in PHP, che è un linguaggio di programmazione orientato agli oggetti -
<?php
$twice = function($f, $v) { return $f($f($v));
};
$f = function($v) {
return $v + 3; }; echo($twice($f, 7));Produrrà il seguente output:
13HOF in Python
L'esempio seguente mostra come scrivere una funzione di ordine superiore in Python, che è un linguaggio di programmazione orientato agli oggetti -
def twice(function):
return lambda x: function(function(x))
def f(x):
return x + 3
g = twice(f)
print g(7)Produrrà il seguente output:
13Un tipo di dati definisce il tipo di valore che un oggetto può avere e quali operazioni possono essere eseguite su di esso. Un tipo di dati deve essere dichiarato prima di essere utilizzato. Diversi linguaggi di programmazione supportano diversi tipi di dati. Per esempio,
- C supporta char, int, float, long, ecc.
- Python supporta String, List, Tuple, ecc.
In senso lato, ci sono tre tipi di tipi di dati:
Fundamental data types- Questi sono i tipi di dati predefiniti che vengono utilizzati direttamente dal programmatore per memorizzare un solo valore secondo il requisito, ad esempio, tipo intero, tipo di carattere o tipo mobile. Ad esempio: int, char, float, ecc.
Derived data types- Questi tipi di dati sono derivati utilizzando un tipo di dati integrato progettato dal programmatore per memorizzare più valori dello stesso tipo secondo i loro requisiti. Ad esempio: matrice, puntatore, funzione, elenco, ecc.
User-defined data types- Questi tipi di dati sono derivati utilizzando tipi di dati incorporati che sono racchiusi in un unico tipo di dati per memorizzare più valori dello stesso tipo o di tipo diverso o entrambi secondo il requisito. Ad esempio: Classe, Struttura, ecc.
Tipi di dati supportati da C ++
La tabella seguente elenca i tipi di dati supportati da C ++ -
| Tipo di dati | Taglia | Gamma |
|---|---|---|
| char | 1 byte | Da -128 a 127 o da 0 a 255 |
| carattere non firmato | 1 byte | Da 0 a 255 |
| firmato char | 1 byte | Da -128 a 127 |
| int | 4 byte | -2147483648 a 2147483647 |
| unsigned int | 4 byte | 0 a 4294967295 |
| firmato int | 4 byte | -2147483648 a 2147483647 |
| short int | 2 byte | Da -32768 a 32767 |
| int breve senza segno | 2 byte | Da 0 a 65.535 |
| firmato breve int | 2 byte | Da -32768 a 32767 |
| lungo int | 4 byte | -2.147.483.648 a 2.147.483.647 |
| firmato lungo int | 4 byte | -2.147.483.648 a 2.147.483.647 |
| unsigned long int | 4 byte | Da 0 a 4.294.967.295 |
| galleggiante | 4 byte | +/- 3,4e +/- 38 (~ 7 cifre) |
| Doppio | 8 byte | +/- 1.7e +/- 308 (~ 15 cifre) |
| doppio lungo | 8 byte | +/- 1.7e +/- 308 (~ 15 cifre) |
Tipi di dati supportati da Java
I seguenti tipi di dati sono supportati da Java:
| Tipo di dati | Taglia | Gamma |
|---|---|---|
| byte | 1 byte | Da -128 a 127 |
| char | 2 byte | Da 0 a 65.536 |
| corto | 2 byte | Da -32.7688 a 32.767 |
| int | 4 byte | -2.147.483.648 a 2.147.483.647 |
| lungo | 8 byte | -9.223.372.036.854.775.808 a 9.223.372.036.854.775.807 |
| galleggiante | 4 byte | -2147483648 a 2147483647 |
| Doppio | 8 byte | + 9.223 * 1018 |
| Booleano | 1 bit | Vero o falso |
Tipi di dati supportati da Erlang
In questa sezione, discuteremo i tipi di dati supportati da Erlang, che è un linguaggio di programmazione funzionale.
Numero
Erlang supporta due tipi di letterali numerici, ie integer e float. Dai un'occhiata al seguente esempio che mostra come aggiungere due valori interi:
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[5+4]).Produrrà il seguente output:
9Atomo
Un atomè una stringa il cui valore non può essere modificato. Deve iniziare con una lettera minuscola e può contenere qualsiasi carattere alfanumerico e carattere speciale. Quando un atomo contiene caratteri speciali, dovrebbe essere racchiuso tra virgolette singole ('). Dai un'occhiata al seguente esempio per capire meglio.
-module(helloworld).
-export([start/0]).
start()->
io:fwrite(monday).Produrrà il seguente output:
mondayNote- Prova a cambiare l'atomo in "Monday" con la "M" maiuscola. Il programma produrrà un errore.
Booleano
Questo tipo di dati viene utilizzato per visualizzare il risultato come entrambi true o false. Dai un'occhiata al seguente esempio. Mostra come confrontare due numeri interi.
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite(5 =< 9).Produrrà il seguente output:
trueStringa di bit
Una stringa di bit viene utilizzata per memorizzare un'area di memoria non digitata. Dai un'occhiata al seguente esempio. Mostra come convertire 2 bit di una stringa di bit in un elenco.
-module(helloworld).
-export([start/0]).
start() ->
Bin2 = <<15,25>>,
P = binary_to_list(Bin2),
io:fwrite("~w",[P]).Produrrà il seguente output:
[15,25]Tupla
Una tupla è un tipo di dati composto con un numero fisso di termini. Ogni termine di una tupla è noto comeelement. Il numero di elementi è la dimensione della tupla. L'esempio seguente mostra come definire una tupla di 5 termini e stampa la sua dimensione.
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} ,
io:fwrite("~w",[tuple_size(K)]).Produrrà il seguente output:
5Carta geografica
Una mappa è un tipo di dati composto con un numero variabile di associazioni valore-chiave. Ogni associazione valore-chiave nella mappa è nota comeassociation-pair. Ilkey e value vengono chiamate parti della coppia elements. Si dice che il numero di coppie di associazioni sia la dimensione della mappa. L'esempio seguente mostra come definire una mappa di 3 mappature e stamparne le dimensioni.
-module(helloworld).
-export([start/0]).
start() ->
Map1 = #{name => 'abc',age => 40, gender => 'M'},
io:fwrite("~w",[map_size(Map1)]).Produrrà il seguente output:
3Elenco
Un elenco è un tipo di dati composto con un numero variabile di termini. Ogni termine nell'elenco è chiamato elemento. Si dice che il numero di elementi sia la lunghezza dell'elenco. L'esempio seguente mostra come definire un elenco di 5 elementi e stamparne le dimensioni.
-module(helloworld).
-export([start/0]).
start() ->
List1 = [10,15,20,25,30] ,
io:fwrite("~w",[length(List1)]).Produrrà il seguente output:
5Note - Il tipo di dati "String" non è definito in Erlang.
Il polimorfismo, in termini di programmazione, significa riutilizzare più volte un unico codice. Più specificamente, è la capacità di un programma di elaborare gli oggetti in modo diverso a seconda del tipo di dati o della classe.
Il polimorfismo è di due tipi:
Compile-time Polymorphism - Questo tipo di polimorfismo può essere ottenuto utilizzando il sovraccarico del metodo.
Run-time Polymorphism - Questo tipo di polimorfismo può essere ottenuto utilizzando l'override del metodo e le funzioni virtuali.
Vantaggi del polimorfismo
Il polimorfismo offre i seguenti vantaggi:
Aiuta il programmatore a riutilizzare i codici, ovvero le classi una volta scritte, testate e implementate possono essere riutilizzate secondo necessità. Risparmia molto tempo.
Una singola variabile può essere utilizzata per memorizzare più tipi di dati.
Facile eseguire il debug dei codici.
Tipi di dati polimorfici
I tipi di dati polimorfici possono essere implementati utilizzando puntatori generici che memorizzano solo un indirizzo di byte, senza il tipo di dati archiviati in quell'indirizzo di memoria. Per esempio,
function1(void *p, void *q)dove p e q sono puntatori generici che possono contenere int, float (o qualsiasi altro) valore come argomento.
Funzione polimorfica in C ++
Il seguente programma mostra come utilizzare le funzioni polimorfiche in C ++, che è un linguaggio di programmazione orientato agli oggetti.
#include <iostream>
Using namespace std:
class A {
public:
void show() {
cout << "A class method is called/n";
}
};
class B:public A {
public:
void show() {
cout << "B class method is called/n";
}
};
int main() {
A x; // Base class object
B y; // Derived class object
x.show(); // A class method is called
y.show(); // B class method is called
return 0;
}Produrrà il seguente output:
A class method is called
B class method is calledFunzione polimorfica in Python
Il seguente programma mostra come utilizzare le funzioni polimorfiche in Python, che è un linguaggio di programmazione funzionale.
class A(object):
def show(self):
print "A class method is called"
class B(A):
def show(self):
print "B class method is called"
def checkmethod(clasmethod):
clasmethod.show()
AObj = A()
BObj = B()
checkmethod(AObj)
checkmethod(BObj)Produrrà il seguente output:
A class method is called
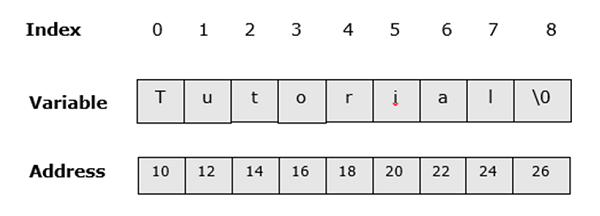
B class method is calledUN stringè un gruppo di caratteri inclusi gli spazi. Possiamo dire che è un array unidimensionale di caratteri che termina con un carattere NULL ('\ 0'). Una stringa può anche essere considerata come una classe predefinita che è supportata dalla maggior parte dei linguaggi di programmazione come C, C ++, Java, PHP, Erlang, Haskell, Lisp, ecc.
L'immagine seguente mostra come apparirà la stringa "Tutorial" nella memoria.
Crea una stringa in C ++
Il seguente programma è un esempio che mostra come creare una stringa in C ++, che è un linguaggio di programmazione orientato agli oggetti.
#include <iostream>
using namespace std;
int main () {
char greeting[20] = {'H', 'o', 'l', 'i', 'd', 'a', 'y', '\0'};
cout << "Today is: ";
cout << greeting << endl;
return 0;
}Produrrà il seguente output:
Today is: HolidayStringa in Erlang
Il seguente programma è un esempio che mostra come creare una stringa in Erlang, che è un linguaggio di programmazione funzionale.
-module(helloworld).
-export([start/0]).
start() ->
Str = "Today is: Holiday",
io:fwrite("~p~n",[Str]).Produrrà il seguente output:
"Today is: Holiday"Operazioni su stringhe in C ++
Linguaggi di programmazione diversi supportano metodi diversi sulle stringhe. La tabella seguente mostra alcuni metodi stringa predefiniti supportati da C ++.
| S.No. | Metodo e descrizione |
|---|---|
| 1 | Strcpy(s1,s2) Copia la stringa s2 nella stringa s1 |
| 2 | Strcat(s1,s2) Aggiunge la stringa s2 alla fine di s1 |
| 3 | Strlen(s1) Fornisce la lunghezza della stringa s1 |
| 4 | Strcmp(s1,s2) Restituisce 0 quando le stringhe s1 e s2 sono uguali |
| 5 | Strchr(s1,ch) Restituisce un puntatore alla prima occorrenza del carattere ch nella stringa s1 |
| 6 | Strstr(s1,s2) Restituisce un puntatore alla prima occorrenza della stringa s2 nella stringa s1 |
Il seguente programma mostra come i metodi di cui sopra possono essere utilizzati in C ++ -
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[20] = "Today is ";
char str2[20] = "Monday";
char str3[20];
int len ;
strcpy( str3, str1); // copy str1 into str3
cout << "strcpy( str3, str1) : " << str3 << endl;
strcat( str1, str2); // concatenates str1 and str2
cout << "strcat( str1, str2): " << str1 << endl;
len = strlen(str1); // String length after concatenation
cout << "strlen(str1) : " << len << endl;
return 0;
}Produrrà il seguente output:
strcpy(str3, str1) : Today is
strcat(str1, str2) : Today is Monday
strlen(str1) : 15Operazioni sulle stringhe a Erlang
La tabella seguente mostra un elenco di metodi stringa predefiniti supportati da Erlang.
| S.No. | Metodo e descrizione |
|---|---|
| 1 | len(s1) Restituisce il numero di caratteri nella stringa data. |
| 2 | equal(s1,s2) Restituisce vero quando le stringhe s1 e s2 sono uguali altrimenti restituiscono false |
| 3 | concat(s1,s2) Aggiunge la stringa s2 alla fine della stringa s1 |
| 4 | str(s1,ch) Restituisce la posizione di indice del carattere ch nella stringa s1 |
| 5 | str (s1,s2) Restituisce la posizione di indice di s2 nella stringa s1 |
| 6 | substr(s1,s2,num) Questo metodo restituisce la stringa s2 dalla stringa s1 in base alla posizione iniziale e al numero di caratteri dalla posizione iniziale |
| 7 | to_lower(s1) Questo metodo restituisce una stringa in minuscolo |
Il seguente programma mostra come utilizzare i metodi di cui sopra in Erlang.
-module(helloworld).
-import(string,[concat/2]).
-export([start/0]).
start() ->
S1 = "Today is ",
S2 = "Monday",
S3 = concat(S1,S2),
io:fwrite("~p~n",[S3]).Produrrà il seguente output:
"Today is Monday"Listè il tipo di dati più versatile disponibile nei linguaggi di programmazione funzionale utilizzato per memorizzare una raccolta di elementi di dati simili. Il concetto è simile agli array nella programmazione orientata agli oggetti. Le voci dell'elenco possono essere scritte tra parentesi quadre separate da virgole. Il modo per scrivere i dati in un elenco varia da lingua a lingua.
Programma per creare un elenco di numeri in Java
List non è un tipo di dati in Java / C / C ++, ma abbiamo modi alternativi per creare un elenco in Java, ovvero utilizzando ArrayList e LinkedList.
Il seguente esempio mostra come creare un elenco in Java. Qui stiamo usando un metodo di elenco collegato per creare un elenco di numeri.
import java.util.*;
import java.lang.*;
import java.io.*;
/* Name of the class has to be "Main" only if the class is public. */
public class HelloWorld {
public static void main (String[] args) throws java.lang.Exception {
List<String> listStrings = new LinkedList<String>();
listStrings.add("1");
listStrings.add("2");
listStrings.add("3");
listStrings.add("4");
listStrings.add("5");
System.out.println(listStrings);
}
}Produrrà il seguente output:
[1, 2, 3, 4, 5]Programma per creare un elenco di numeri in Erlang
-module(helloworld).
-export([start/0]).
start() ->
Lst = [1,2,3,4,5],
io:fwrite("~w~n",[Lst]).Produrrà il seguente output:
[1 2 3 4 5]Elenca le operazioni in Java
In questa sezione, discuteremo alcune operazioni che possono essere eseguite sugli elenchi in Java.
Aggiunta di elementi in un elenco
I metodi add (Object), add (index, Object), addAll () vengono utilizzati per aggiungere elementi in un elenco. Per esempio,
ListStrings.add(3, “three”)Rimozione di elementi da un elenco
I metodi remove (index) o removeobject () vengono utilizzati per rimuovere elementi da un elenco. Per esempio,
ListStrings.remove(3,”three”)Note - Per rimuovere tutti gli elementi dall'elenco viene utilizzato il metodo clear ().
Recupero di elementi da un elenco
Il metodo get () viene utilizzato per recuperare elementi da un elenco in una posizione specificata. I metodi getfirst () e getlast () possono essere utilizzati nella classe LinkedList. Per esempio,
String str = ListStrings.get(2)Aggiornamento di elementi in un elenco
Il metodo set (index, element) viene utilizzato per aggiornare un elemento a un indice specificato con un elemento specificato. Per esempio,
listStrings.set(2,”to”)Ordinamento degli elementi in un elenco
I metodi collection.sort () e collection.reverse () vengono utilizzati per ordinare un elenco in ordine crescente o decrescente. Per esempio,
Collection.sort(listStrings)Ricerca di elementi in un elenco
I seguenti tre metodi vengono utilizzati secondo il requisito:
Boolean contains(Object) restituisce il metodo true se l'elenco contiene l'elemento specificato, altrimenti ritorna false.
int indexOf(Object) restituisce l'indice della prima occorrenza di un elemento specificato in una lista, altrimenti restituisce -1 quando l'elemento non viene trovato.
int lastIndexOf(Object) restituisce l'indice dell'ultima occorrenza di un elemento specificato in una lista, altrimenti restituisce -1 quando l'elemento non viene trovato.
Elenco operazioni a Erlang
In questa sezione, discuteremo alcune operazioni che possono essere eseguite sugli elenchi in Erlang.
Aggiunta di due elenchi
Il metodo append (listfirst, listsecond) viene utilizzato per creare un nuovo elenco aggiungendo due elenchi. Per esempio,
append(list1,list2)Eliminazione di un elemento
Il metodo delete (element, listname) viene utilizzato per eliminare l'elemento specificato dalla lista e restituisce il nuovo elenco. Per esempio,
delete(5,list1)Eliminazione dell'ultimo elemento dalla lista
Il metodo droplast (listname) viene utilizzato per eliminare l'ultimo elemento da un elenco e restituire un nuovo elenco. Per esempio,
droplast(list1)Alla ricerca di un elemento
Il metodo member (element, listname) viene utilizzato per cercare l'elemento nell'elenco, se trovato restituisce true altrimenti restituisce false. Per esempio,
member(5,list1)Ottenere il valore massimo e minimo
I metodi max (listname) e min (listname) vengono utilizzati per trovare i valori massimo e minimo in un elenco. Per esempio,
max(list1)Ordinamento degli elementi dell'elenco
I metodi sort (listname) e reverse (listname) vengono utilizzati per ordinare un elenco in ordine crescente o decrescente. Per esempio,
sort(list1)Aggiunta di elementi dell'elenco
Il metodo sum (listname) viene utilizzato per aggiungere tutti gli elementi di una lista e restituire la loro somma. Per esempio,
sum(list1)Ordina un elenco in ordine crescente e decrescente utilizzando Java
Il seguente programma mostra come ordinare un elenco in ordine crescente e decrescente utilizzando Java:
import java.util.*;
import java.lang.*;
import java.io.*;
public class SortList {
public static void main (String[] args) throws java.lang.Exception {
List<String> list1 = new ArrayList<String>();
list1.add("5");
list1.add("3");
list1.add("1");
list1.add("4");
list1.add("2");
System.out.println("list before sorting: " + list1);
Collections.sort(list1);
System.out.println("list in ascending order: " + list1);
Collections.reverse(list1);
System.out.println("list in dsending order: " + list1);
}
}Produrrà il seguente output:
list before sorting : [5, 3, 1, 4, 2]
list in ascending order : [1, 2, 3, 4, 5]
list in dsending order : [5, 4, 3, 2, 1]Ordina un elenco in ordine crescente utilizzando Erlang
Il seguente programma mostra come ordinare un elenco in ordine crescente e decrescente utilizzando Erlang, che è un linguaggio di programmazione funzionale -
-module(helloworld).
-import(lists,[sort/1]).
-export([start/0]).
start() ->
List1 = [5,3,4,2,1],
io:fwrite("~p~n",[sort(List1)]),Produrrà il seguente output:
[1,2,3,4,5]Una tupla è un tipo di dati composto con un numero fisso di termini. Ogni termine in una tupla è noto comeelement. Il numero di elementi è la dimensione della tupla.
Programma per definire una tupla in C #
Il programma seguente mostra come definire una tupla di quattro termini e stamparli utilizzando C #, che è un linguaggio di programmazione orientato agli oggetti.
using System;
public class Test {
public static void Main() {
var t1 = Tuple.Create(1, 2, 3, new Tuple<int, int>(4, 5));
Console.WriteLine("Tuple:" + t1);
}
}Produrrà il seguente output:
Tuple :(1, 2, 3, (4, 5))Programma per definire una tupla in Erlang
Il seguente programma mostra come definire una tupla di quattro termini e stamparli usando Erlang, che è un linguaggio di programmazione funzionale.
-module(helloworld).
-export([start/0]).
start() ->
P = {1,2,3,{4,5}} ,
io:fwrite("~w",[P]).Produrrà il seguente output:
{1, 2, 3, {4, 5}}Vantaggi di Tuple
Le tuple offrono i seguenti vantaggi:
Le tuple hanno una dimensione fine in natura, cioè non possiamo aggiungere / eliminare elementi a / da una tupla.
Possiamo cercare qualsiasi elemento in una tupla.
Le tuple sono più veloci degli elenchi, perché hanno un insieme di valori costante.
Le tuple possono essere utilizzate come chiavi del dizionario, perché contengono valori immutabili come stringhe, numeri, ecc.
Tuple vs elenchi
| Tupla | Elenco |
|---|---|
| Le tuple sono immutable, cioè, non possiamo aggiornare i suoi dati. | Elenco sono mutable, cioè possiamo aggiornare i suoi dati. |
| Gli elementi in una tupla possono essere di tipo diverso. | Tutti gli elementi in un elenco sono dello stesso tipo. |
| Le tuple sono indicate da parentesi tonde attorno agli elementi. | Gli elenchi sono indicati da parentesi quadre attorno agli elementi. |
Operazioni su tuple
In questa sezione, discuteremo alcune operazioni che possono essere eseguite su una tupla.
Controlla se un valore inserito è una tupla o meno
Il metodo is_tuple(tuplevalues)viene utilizzato per determinare se un valore inserito è una tupla o meno. Ritornatrue quando un valore inserito è una tupla, altrimenti ritorna false. Per esempio,
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} , io:fwrite("~w",[is_tuple(K)]).Produrrà il seguente output:
TrueConversione di un elenco in una tupla
Il metodo list_to_tuple(listvalues)converte una lista in una tupla. Per esempio,
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[list_to_tuple([1,2,3,4,5])]).Produrrà il seguente output:
{1, 2, 3, 4, 5}Conversione di una tupla in un elenco
Il metodo tuple_to_list(tuplevalues)converte una tupla specificata nel formato elenco. Per esempio,
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[tuple_to_list({1,2,3,4,5})]).Produrrà il seguente output:
[1, 2, 3, 4, 5]Controlla la dimensione della tupla
Il metodo tuple_size(tuplename)restituisce la dimensione di una tupla. Per esempio,
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} ,
io:fwrite("~w",[tuple_size(K)]).Produrrà il seguente output:
5Un record è una struttura dati per memorizzare un numero fisso di elementi. È simile a una struttura in linguaggio C. Al momento della compilazione, le sue espressioni vengono tradotte in espressioni tuple.
Come creare un record?
La parola chiave "record" viene utilizzata per creare record specificati con il nome del record ei relativi campi. La sua sintassi è la seguente:
record(recodname, {field1, field2, . . fieldn})La sintassi per inserire i valori nel record è:
#recordname {fieldName1 = value1, fieldName2 = value2 .. fieldNamen = valuen}Programma per creare record utilizzando Erlang
Nell'esempio seguente, abbiamo creato un record di nome student avere due campi, cioè sname e sid.
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5}.Programma per creare record utilizzando C ++
L'esempio seguente mostra come creare record utilizzando C ++, che è un linguaggio di programmazione orientato agli oggetti -
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
15
};
int main() {
student S;
S.sname = "Sachin";
S.sid = 5;
return 0;
}Programma per accedere ai valori dei record utilizzando Erlang
Il seguente programma mostra come accedere ai valori dei record utilizzando Erlang, che è un linguaggio di programmazione funzionale:
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5},
io:fwrite("~p~n",[S#student.sid]),
io:fwrite("~p~n",[S#student.sname]).Produrrà il seguente output:
5
"Sachin"Programma per accedere ai valori dei record utilizzando C ++
Il seguente programma mostra come accedere ai valori dei record utilizzando C ++ -
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
};
int main() {
student S;
S.sname = "Sachin";
S.sid = 5;
cout<<S.sid<<"\n"<<S.sname;
return 0;
}Produrrà il seguente output:
5
SachinI valori del record possono essere aggiornati modificando il valore in un campo particolare e quindi assegnando quel record a un nuovo nome di variabile. Dai un'occhiata ai seguenti due esempi per capire come è fatto usando linguaggi di programmazione orientati agli oggetti e funzionali.
Programma per aggiornare i valori dei record utilizzando Erlang
Il seguente programma mostra come aggiornare i valori dei record utilizzando Erlang -
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5},
S1 = S#student{sname = "Jonny"},
io:fwrite("~p~n",[S1#student.sid]),
io:fwrite("~p~n",[S1#student.sname]).Produrrà il seguente output:
5
"Jonny"Programma per aggiornare i valori dei record utilizzando C ++
Il seguente programma mostra come aggiornare i valori dei record utilizzando C ++ -
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
};
int main() {
student S;
S.sname = "Jonny";
S.sid = 5;
cout<<S.sname<<"\n"<<S.sid;
cout<<"\n"<< "value after updating"<<"\n";
S.sid = 10;
cout<<S.sname<<"\n"<<S.sid;
return 0;
}Produrrà il seguente output:
Jonny
5
value after updating
Jonny
10Lambda calcolo è un framework sviluppato da Alonzo Church negli anni '30 per studiare i calcoli con le funzioni.
Function creation - Church ha introdotto la notazione λx.Eper denotare una funzione in cui "x" è un argomento formale e "E" è il corpo funzionale. Queste funzioni possono essere senza nomi e singoli argomenti.
Function application - Church ha usato la notazione E1.E2 per denotare l'applicazione della funzione E1 all'argomento effettivo E2. E tutte le funzioni sono su un singolo argomento.
Sintassi del Lambda Calculus
Il calcolo di Lamdba include tre diversi tipi di espressioni, ovvero
E :: = x (variabili)
| E 1 E 2 (funzione applicazione)
| λx.E (creazione della funzione)
Dove λx.E è chiamata astrazione Lambda ed E è nota come espressioni λ.
Valutazione del Lambda Calculus
Il lambda calcolo puro non ha funzioni integrate. Valutiamo la seguente espressione:
(+ (* 5 6) (* 8 3))Qui, non possiamo iniziare con "+" perché funziona solo sui numeri. Ci sono due espressioni riducibili: (* 5 6) e (* 8 3).
Possiamo prima ridurre uno dei due. Ad esempio:
(+ (* 5 6) (* 8 3))
(+ 30 (* 8 3))
(+ 30 24)
= 54Regola di β-riduzione
Abbiamo bisogno di una regola di riduzione per gestire λs
(λx . * 2 x) 4
(* 2 4)
= 8Questo si chiama β-riduzione.
Il parametro formale può essere utilizzato più volte:
(λx . + x x) 4
(+ 4 4)
= 8Quando ci sono più termini, possiamo gestirli come segue:
(λx . (λx . + (− x 1)) x 3) 9L'interno x appartiene all'interiore λ e la x esterna appartiene a quella esterna.
(λx . + (− x 1)) 9 3
+ (− 9 1) 3
+ 8 3
= 11Variabili libere e vincolate
In un'espressione, ogni aspetto di una variabile è "libero" (a λ) o "vincolato" (a λ).
β-riduzione di (λx . E) y sostituisce ogni x che si verifica gratuitamente in E con y. Ad esempio -

Riduzione alfa
La riduzione alfa è molto semplice e può essere eseguita senza modificare il significato di un'espressione lambda.
λx . (λx . x) (+ 1 x) ↔ α λx . (λy . y) (+ 1 x)Ad esempio:
(λx . (λx . + (− x 1)) x 3) 9
(λx . (λy . + (− y 1)) x 3) 9
(λy . + (− y 1)) 9 3
+ (− 9 1) 3
+ 8 3
11Teorema di Church-Rosser
Il teorema di Church-Rosser afferma quanto segue:
Se E1 ↔ E2, allora esiste una E tale che E1 → E ed E2 → E. "La riduzione in qualsiasi modo può eventualmente produrre lo stesso risultato."
Se E1 → E2 ed E2 è la forma normale, allora c'è una riduzione di ordine normale da E1 a E2. "La riduzione dell'ordine normale produrrà sempre una forma normale, se ne esiste una."
La valutazione pigra è una strategia di valutazione che mantiene la valutazione di un'espressione finché non è necessario il suo valore. Evita valutazioni ripetute.Haskell è un buon esempio di un linguaggio di programmazione così funzionale i cui fondamenti sono basati sulla valutazione pigra.
La valutazione pigra viene utilizzata nelle funzioni di mappa Unix per migliorare le loro prestazioni caricando solo le pagine richieste dal disco. Nessuna memoria verrà allocata per le pagine rimanenti.
Valutazione pigra - Vantaggi
Consente al language runtime di eliminare le sottoespressioni che non sono direttamente collegate al risultato finale dell'espressione.
Riduce la complessità temporale di un algoritmo scartando i calcoli temporanei e le condizioni.
Consente al programmatore di accedere a componenti di strutture dati fuori ordine dopo averle inizializzate, purché siano libere da dipendenze circolari.
È più adatto per caricare dati a cui si accede di rado.
Valutazione pigra - Svantaggi
Forza il language runtime a mantenere la valutazione delle sottoespressioni fino a quando non viene richiesto nel risultato finale creando thunks (oggetti ritardati).
A volte aumenta la complessità spaziale di un algoritmo.
È molto difficile trovare le sue prestazioni perché contiene thunk di espressioni prima della loro esecuzione.
Valutazione pigra usando Python
Il rangein Python segue il concetto di valutazione pigra. Risparmia il tempo di esecuzione per intervalli più ampi e non richiediamo mai tutti i valori contemporaneamente, quindi risparmia anche il consumo di memoria. Dai un'occhiata al seguente esempio.
r = range(10)
print(r)
range(0, 10)
print(r[3])Produrrà il seguente output:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
3Abbiamo bisogno di file per memorizzare l'output di un programma quando il programma termina. Utilizzando i file, possiamo accedere alle informazioni correlate utilizzando vari comandi in diverse lingue.
Ecco un elenco di alcune operazioni che possono essere eseguite su un file:
- Creazione di un nuovo file
- Apertura di un file esistente
- Lettura del contenuto del file
- Ricerca di dati su un file
- Scrittura in un nuovo file
- Aggiornamento dei contenuti a un file esistente
- Eliminazione di un file
- Chiusura di un file
Scrivere in un file
Per scrivere contenuti in un file, dobbiamo prima aprire il file richiesto. Se il file specificato non esiste, verrà creato un nuovo file.
Vediamo come scrivere contenuti in un file usando C ++.
Esempio
#include <iostream>
#include <fstream>
using namespace std;
int main () {
ofstream myfile;
myfile.open ("Tempfile.txt", ios::out);
myfile << "Writing Contents to file.\n";
cout << "Data inserted into file";
myfile.close();
return 0;
}Note -
fstream è la classe di flusso utilizzata per controllare le operazioni di lettura / scrittura dei file.
ofstream è la classe di flusso utilizzata per scrivere i contenuti nel file.
Vediamo come scrivere contenuti in un file usando Erlang, che è un linguaggio di programmazione funzionale.
-module(helloworld).
-export([start/0]).
start() ->
{ok, File1} = file:open("Tempfile.txt", [write]),
file:write(File1,"Writting contents to file"),
io:fwrite("Data inserted into file\n").Note -
Per aprire un file dobbiamo usare, open(filename,mode).
Sintassi per scrivere contenuti su file: write(filemode,file_content).
Output - Quando eseguiamo questo codice, "Scrittura del contenuto su file" verrà scritto nel file Tempfile.txt. Se il file ha un contenuto esistente, verrà sovrascritto.
Leggere da un file
Per leggere da un file, prima dobbiamo aprire il file specificato in reading mode. Se il file non esiste, il rispettivo metodo restituisce NULL.
Il seguente programma mostra come leggere il contenuto di un file in formato C++ -
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main () {
string readfile;
ifstream myfile ("Tempfile.txt",ios::in);
if (myfile.is_open()) {
while ( getline (myfile,readfile) ) {
cout << readfile << '\n';
}
myfile.close();
} else
cout << "file doesn't exist";
return 0;
}Produrrà il seguente output:
Writing contents to fileNote- In questo programma, abbiamo aperto un file di testo in modalità di lettura utilizzando "ios :: in" e poi abbiamo stampato il suo contenuto sullo schermo. Abbiamo usatowhile loop per leggere il contenuto del file riga per riga utilizzando il metodo "getline".
Il seguente programma mostra come eseguire la stessa operazione utilizzando Erlang. Qui useremo il fileread_file(filename) metodo per leggere tutti i contenuti dal file specificato.
-module(helloworld).
-export([start/0]).
start() ->
rdfile = file:read_file("Tempfile.txt"),
io:fwrite("~p~n",[rdfile]).Produrrà il seguente output:
ok, Writing contents to fileElimina un file esistente
Possiamo eliminare un file esistente utilizzando le operazioni sui file. Il seguente programma mostra come eliminare un file esistenteusing C++ -
#include <stdio.h>
int main () {
if(remove( "Tempfile.txt" ) != 0 )
perror( "File doesn’t exist, can’t delete" );
else
puts( "file deleted successfully " );
return 0;
}Produrrà il seguente output:
file deleted successfullyIl seguente programma mostra come eseguire la stessa operazione in Erlang. Qui useremo il metododelete(filename) per eliminare un file esistente.
-module(helloworld).
-export([start/0]).
start() ->
file:delete("Tempfile.txt").Output - Se il file "Tempfile.txt" esiste, verrà eliminato.
Determinazione della dimensione di un file
Il seguente programma mostra come determinare la dimensione di un file utilizzando C ++. Qui, la funzionefseek imposta l'indicatore di posizione associato allo stream su una nuova posizione, mentre ftell restituisce la posizione corrente nel flusso.
#include <stdio.h>
int main () {
FILE * checkfile;
long size;
checkfile = fopen ("Tempfile.txt","rb");
if (checkfile == NULL)
perror ("file can’t open");
else {
fseek (checkfile, 0, SEEK_END); // non-portable
size = ftell (checkfile);
fclose (checkfile);
printf ("Size of Tempfile.txt: %ld bytes.\n",size);
}
return 0;
}Output - Se il file "Tempfile.txt" esiste, mostrerà la sua dimensione in byte.
Il seguente programma mostra come eseguire la stessa operazione in Erlang. Qui useremo il metodofile_size(filename) per determinare la dimensione del file.
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w~n",[filelib:file_size("Tempfile.txt")]).Output- Se il file "Tempfile.txt" esiste, mostrerà la sua dimensione in byte. Altrimenti, verrà visualizzato "0".