Hadoop - Guida rapida
"Il 90% dei dati mondiali è stato generato negli ultimi anni."
A causa dell'avvento di nuove tecnologie, dispositivi e mezzi di comunicazione come i siti di social networking, la quantità di dati prodotti dall'umanità cresce rapidamente ogni anno. La quantità di dati da noi prodotti dall'inizio del tempo fino al 2003 è stata di 5 miliardi di gigabyte. Se accumuli i dati sotto forma di dischi, potresti riempire un intero campo di calcio. Lo stesso importo è stato creato ogni due giorni in2011e ogni dieci minuti in 2013. Questo tasso sta ancora crescendo enormemente. Sebbene tutte queste informazioni prodotte siano significative e possano essere utili una volta elaborate, vengono trascurate.
Cosa sono i Big Data?
Big dataè una raccolta di grandi set di dati che non possono essere elaborati utilizzando le tecniche di calcolo tradizionali. Non è una singola tecnica o uno strumento, piuttosto è diventato un argomento completo, che coinvolge vari strumenti, tecniche e strutture.
Cosa c'è sotto i big data?
I big data riguardano i dati prodotti da diversi dispositivi e applicazioni. Di seguito sono riportati alcuni dei campi che rientrano nell'ombrello dei Big Data.
Black Box Data - È un componente di elicotteri, aeroplani e jet, ecc. Cattura le voci dell'equipaggio di volo, le registrazioni di microfoni e auricolari e le informazioni sulle prestazioni del velivolo.
Social Media Data - I social media come Facebook e Twitter contengono informazioni e visualizzazioni pubblicate da milioni di persone in tutto il mondo.
Stock Exchange Data - I dati di borsa contengono informazioni sulle decisioni di "acquisto" e "vendita" prese dai clienti su azioni di diverse società.
Power Grid Data - I dati della rete elettrica contengono le informazioni consumate da un particolare nodo rispetto a una stazione base.
Transport Data - I dati di trasporto includono modello, capacità, distanza e disponibilità di un veicolo.
Search Engine Data - I motori di ricerca recuperano molti dati da diversi database.

Pertanto, i Big Data includono un volume enorme, un'elevata velocità e una varietà estendibile di dati. I dati in esso contenuti saranno di tre tipi.
Structured data - Dati relazionali.
Semi Structured data - Dati XML.
Unstructured data - Word, PDF, testo, registri multimediali.
Vantaggi dei Big Data
Utilizzando le informazioni conservate nel social network come Facebook, le agenzie di marketing stanno imparando la risposta per le loro campagne, promozioni e altri mezzi pubblicitari.
Utilizzando le informazioni nei social media come le preferenze e la percezione del prodotto dei propri consumatori, le società di prodotti e le organizzazioni di vendita al dettaglio stanno pianificando la loro produzione.
Utilizzando i dati relativi alla precedente storia medica dei pazienti, gli ospedali forniscono un servizio migliore e rapido.
Big Data Technologies
Le tecnologie dei big data sono importanti per fornire analisi più accurate, il che può portare a un processo decisionale più concreto con conseguente maggiore efficienza operativa, riduzione dei costi e riduzione dei rischi per l'azienda.
Per sfruttare la potenza dei big data, è necessaria un'infrastruttura in grado di gestire ed elaborare enormi volumi di dati strutturati e non strutturati in tempo reale e in grado di proteggere la privacy e la sicurezza dei dati.
Esistono varie tecnologie sul mercato di diversi fornitori tra cui Amazon, IBM, Microsoft, ecc. Per gestire i big data. Analizzando le tecnologie che gestiscono i big data, esaminiamo le seguenti due classi di tecnologia:
Big Data operativi
Ciò include sistemi come MongoDB che forniscono funzionalità operative per carichi di lavoro interattivi in tempo reale in cui i dati vengono principalmente acquisiti e archiviati.
I sistemi NoSQL Big Data sono progettati per sfruttare le nuove architetture di cloud computing emerse negli ultimi dieci anni per consentire l'esecuzione di calcoli di massa in modo economico ed efficiente. Ciò rende i carichi di lavoro dei big data operativi molto più facili da gestire, più economici e più veloci da implementare.
Alcuni sistemi NoSQL possono fornire informazioni su modelli e tendenze sulla base di dati in tempo reale con una codifica minima e senza la necessità di data scientist e infrastrutture aggiuntive.
Big Data analitici
Questi includono sistemi come i sistemi di database Massively Parallel Processing (MPP) e MapReduce che forniscono capacità analitiche per analisi retrospettive e complesse che possono toccare la maggior parte o tutti i dati.
MapReduce fornisce un nuovo metodo di analisi dei dati che è complementare alle capacità fornite da SQL e un sistema basato su MapReduce che può essere scalato da singoli server a migliaia di macchine di fascia alta e bassa.
Queste due classi di tecnologia sono complementari e frequentemente utilizzate insieme.
Sistemi operativi e analitici
| Operativo | Analitico | |
|---|---|---|
| Latenza | 1 ms - 100 ms | 1 min - 100 min |
| Concorrenza | 1000 - 100.000 | 1 - 10 |
| Pattern di accesso | Scrive e legge | Legge |
| Interrogazioni | Selettivo | Non selettivo |
| Ambito dei dati | Operativo | Retrospettiva |
| Utente finale | Cliente | Data Scientist |
| Tecnologia | NoSQL | MapReduce, database MPP |
Sfide dei Big Data
Le principali sfide associate ai big data sono le seguenti:
- Acquisizione dei dati
- Curation
- Storage
- Searching
- Sharing
- Transfer
- Analysis
- Presentation
Per soddisfare le suddette sfide, le organizzazioni normalmente utilizzano i server aziendali.
Approccio tradizionale
In questo approccio, un'azienda avrà un computer per archiviare ed elaborare i big data. Ai fini della memorizzazione, i programmatori useranno l'aiuto di loro scelta di fornitori di database come Oracle, IBM, ecc. In questo approccio, l'utente interagisce con l'applicazione, che a sua volta gestisce la parte di archiviazione e analisi dei dati.
Limitazione
Questo approccio funziona bene con quelle applicazioni che elaborano dati meno voluminosi che possono essere ospitati dai server di database standard o fino al limite del processore che elabora i dati. Ma quando si tratta di gestire enormi quantità di dati scalabili, è un compito frenetico elaborare tali dati attraverso un singolo collo di bottiglia del database.
La soluzione di Google
Google ha risolto questo problema utilizzando un algoritmo chiamato MapReduce. Questo algoritmo divide l'attività in piccole parti e le assegna a molti computer e raccoglie i risultati da essi che, una volta integrati, formano il set di dati dei risultati.

Hadoop
Utilizzando la soluzione fornita da Google, Doug Cutting e il suo team ha sviluppato un progetto Open Source chiamato HADOOP.
Hadoop esegue le applicazioni utilizzando l'algoritmo MapReduce, in cui i dati vengono elaborati in parallelo con altri. In breve, Hadoop viene utilizzato per sviluppare applicazioni in grado di eseguire analisi statistiche complete su enormi quantità di dati.

Hadoop è un framework open source Apache scritto in java che consente l'elaborazione distribuita di grandi set di dati su cluster di computer utilizzando semplici modelli di programmazione. L'applicazione del framework Hadoop funziona in un ambiente che fornisce archiviazione e calcolo distribuiti tra cluster di computer. Hadoop è progettato per passare da un singolo server a migliaia di macchine, ognuna delle quali offre elaborazione e archiviazione locali.
Architettura Hadoop
Al centro, Hadoop ha due livelli principali:
- Livello di elaborazione / calcolo (MapReduce) e
- Livello di archiviazione (file system distribuito Hadoop).

Riduci mappa
MapReduce è un modello di programmazione parallela per la scrittura di applicazioni distribuite ideato da Google per l'elaborazione efficiente di grandi quantità di dati (set di dati multi-terabyte), su grandi cluster (migliaia di nodi) di hardware di base in modo affidabile e tollerante ai guasti. Il programma MapReduce viene eseguito su Hadoop, un framework open source Apache.
File system distribuito Hadoop
Hadoop Distributed File System (HDFS) è basato su Google File System (GFS) e fornisce un file system distribuito progettato per essere eseguito su hardware comune. Ha molte somiglianze con i file system distribuiti esistenti. Tuttavia, le differenze rispetto ad altri file system distribuiti sono significative. È altamente tollerante ai guasti ed è progettato per essere distribuito su hardware a basso costo. Fornisce accesso ad alta velocità di trasmissione ai dati dell'applicazione ed è adatto per applicazioni con set di dati di grandi dimensioni.
Oltre ai due componenti principali sopra menzionati, il framework Hadoop include anche i seguenti due moduli:
Hadoop Common - Si tratta di librerie e utilità Java richieste da altri moduli Hadoop.
Hadoop YARN - Questo è un framework per la pianificazione dei lavori e la gestione delle risorse del cluster.
Come funziona Hadoop?
È piuttosto costoso costruire server più grandi con configurazioni pesanti che gestiscono l'elaborazione su larga scala, ma in alternativa, puoi collegare insieme molti computer comuni con una singola CPU, come un unico sistema distribuito funzionale e praticamente, le macchine in cluster possono leggere il set di dati parallelamente e fornire un throughput molto più elevato. Inoltre, è più economico di un server di fascia alta. Quindi questo è il primo fattore motivazionale dietro l'utilizzo di Hadoop che viene eseguito su macchine in cluster ea basso costo.
Hadoop esegue il codice su un cluster di computer. Questo processo include le seguenti attività principali eseguite da Hadoop:
I dati sono inizialmente suddivisi in directory e file. I file sono divisi in blocchi di dimensioni uniformi di 128M e 64M (preferibilmente 128M).
Questi file vengono quindi distribuiti su vari nodi del cluster per un'ulteriore elaborazione.
HDFS, essendo in cima al file system locale, supervisiona l'elaborazione.
I blocchi vengono replicati per la gestione dei guasti hardware.
Verifica che il codice sia stato eseguito correttamente.
Esecuzione dell'ordinamento che avviene tra la mappa e le fasi di riduzione.
Invio dei dati ordinati a un determinato computer.
Scrittura dei log di debug per ogni lavoro.
Vantaggi di Hadoop
Il framework Hadoop consente all'utente di scrivere e testare rapidamente i sistemi distribuiti. È efficiente e distribuisce automaticamente i dati e il lavoro tra le macchine e, a sua volta, utilizza il parallelismo sottostante dei core della CPU.
Hadoop non si basa sull'hardware per fornire tolleranza agli errori e alta disponibilità (FTHA), piuttosto la libreria Hadoop stessa è stata progettata per rilevare e gestire gli errori a livello dell'applicazione.
I server possono essere aggiunti o rimossi dal cluster in modo dinamico e Hadoop continua a funzionare senza interruzioni.
Un altro grande vantaggio di Hadoop è che oltre ad essere open source, è compatibile su tutte le piattaforme poiché è basato su Java.
Hadoop è supportato dalla piattaforma GNU / Linux e dai suoi gusti. Pertanto, dobbiamo installare un sistema operativo Linux per configurare l'ambiente Hadoop. Nel caso in cui tu abbia un sistema operativo diverso da Linux, puoi installare un software Virtualbox al suo interno e avere Linux all'interno di Virtualbox.
Configurazione preinstallazione
Prima di installare Hadoop nell'ambiente Linux, è necessario configurare Linux utilizzando ssh(Secure Shell). Seguire i passaggi indicati di seguito per configurare l'ambiente Linux.
Creazione di un utente
All'inizio, si consiglia di creare un utente separato per Hadoop per isolare il file system Hadoop dal file system Unix. Seguire i passaggi indicati di seguito per creare un utente:
Aprire la radice utilizzando il comando "su".
Creare un utente dall'account root utilizzando il comando "useradd username".
Ora puoi aprire un account utente esistente utilizzando il comando "su username".
Apri il terminale Linux e digita i seguenti comandi per creare un utente.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfigurazione SSH e generazione di chiavi
L'installazione di SSH è necessaria per eseguire diverse operazioni su un cluster come l'avvio, l'arresto, le operazioni della shell del demone distribuito. Per autenticare diversi utenti di Hadoop, è necessario fornire una coppia di chiavi pubblica / privata per un utente Hadoop e condividerla con utenti diversi.
I seguenti comandi vengono utilizzati per generare una coppia di valori chiave utilizzando SSH. Copia le chiavi pubbliche da id_rsa.pub in authorized_keys e fornisci al proprietario i permessi di lettura e scrittura rispettivamente per il file authorized_keys.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysInstallazione di Java
Java è il prerequisito principale per Hadoop. Prima di tutto, dovresti verificare l'esistenza di java nel tuo sistema usando il comando "java -version". La sintassi del comando della versione Java è fornita di seguito.
$ java -versionSe tutto è in ordine, ti darà il seguente output.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se java non è installato nel tuo sistema, segui i passaggi indicati di seguito per l'installazione di java.
Passo 1
Scarica java (JDK <ultima versione> - X64.tar.gz) visitando il seguente link www.oracle.com
Poi jdk-7u71-linux-x64.tar.gz verrà scaricato nel tuo sistema.
Passo 2
Generalmente troverai il file java scaricato nella cartella Download. Verificalo ed estrai il filejdk-7u71-linux-x64.gz file utilizzando i seguenti comandi.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzPassaggio 3
Per rendere java disponibile a tutti gli utenti, è necessario spostarlo nella posizione "/ usr / local /". Apri root e digita i seguenti comandi.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitPassaggio 4
Per l'allestimento PATH e JAVA_HOME variabili, aggiungi i seguenti comandi a ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/binOra applica tutte le modifiche al sistema in esecuzione corrente.
$ source ~/.bashrcPassaggio 5
Utilizzare i seguenti comandi per configurare le alternative java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarOra verifica il comando java -version dal terminale come spiegato sopra.
Download di Hadoop
Scarica ed estrai Hadoop 2.4.1 dalla fondazione software Apache utilizzando i seguenti comandi.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitModalità operative di Hadoop
Dopo aver scaricato Hadoop, puoi utilizzare il tuo cluster Hadoop in una delle tre modalità supportate:
Local/Standalone Mode - Dopo aver scaricato Hadoop nel tuo sistema, per impostazione predefinita, è configurato in modalità standalone e può essere eseguito come un singolo processo java.
Pseudo Distributed Mode- È una simulazione distribuita su singola macchina. Ogni demone Hadoop come hdfs, filato, MapReduce ecc. Verrà eseguito come un processo Java separato. Questa modalità è utile per lo sviluppo.
Fully Distributed Mode- Questa modalità è completamente distribuita con un minimo di due o più macchine come cluster. Ci imbatteremo in questa modalità in dettaglio nei prossimi capitoli.
Installazione di Hadoop in modalità standalone
Qui discuteremo l'installazione di Hadoop 2.4.1 in modalità standalone.
Non ci sono daemon in esecuzione e tutto viene eseguito in un'unica JVM. La modalità standalone è adatta per eseguire programmi MapReduce durante lo sviluppo, poiché è facile testarli ed eseguirne il debug.
Configurazione di Hadoop
Puoi impostare le variabili d'ambiente Hadoop aggiungendo i seguenti comandi a ~/.bashrc file.
export HADOOP_HOME=/usr/local/hadoopPrima di procedere oltre, devi assicurarti che Hadoop funzioni correttamente. Basta emettere il seguente comando:
$ hadoop versionSe tutto va bene con la tua configurazione, dovresti vedere il seguente risultato:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Significa che la configurazione della modalità standalone di Hadoop funziona correttamente. Per impostazione predefinita, Hadoop è configurato per essere eseguito in modalità non distribuita su una singola macchina.
Esempio
Controlliamo un semplice esempio di Hadoop. L'installazione di Hadoop fornisce il seguente file jar MapReduce di esempio, che fornisce le funzionalità di base di MapReduce e può essere utilizzato per il calcolo, come il valore Pi, il conteggio delle parole in un determinato elenco di file, ecc.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarAbbiamo una directory di input in cui inseriremo alcuni file e il nostro requisito è di contare il numero totale di parole in quei file. Per calcolare il numero totale di parole, non è necessario scrivere il nostro MapReduce, a condizione che il file .jar contenga l'implementazione per il conteggio delle parole. Puoi provare altri esempi usando lo stesso file .jar; è sufficiente emettere i seguenti comandi per controllare i programmi funzionali MapReduce supportati dal file hadoop-mapreduce-examples-2.2.0.jar.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jarPasso 1
Crea file di contenuto temporanei nella directory di input. Puoi creare questa directory di input ovunque desideri lavorare.
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l inputFornirà i seguenti file nella directory di input:
total 24
-rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txtQuesti file sono stati copiati dalla home directory di installazione di Hadoop. Per il tuo esperimento, puoi avere set di file diversi e di grandi dimensioni.
Passo 2
Iniziamo il processo Hadoop per contare il numero totale di parole in tutti i file disponibili nella directory di input, come segue:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input outputPassaggio 3
Step-2 eseguirà l'elaborazione richiesta e salverà l'output nel file output / part-r00000, che puoi controllare usando -
$cat output/*Elencherà tutte le parole insieme ai loro conteggi totali disponibili in tutti i file disponibili nella directory di input.
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE” 1
"Not 1
"Object" 1
"Source” 1
"Work” 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
(50%) 1
(BIS), 1
(C) 1
(Don't) 1
(ECCN) 1
(INCLUDING 2
(INCLUDING, 2
.............Installazione di Hadoop in modalità pseudo distribuita
Seguire i passaggi indicati di seguito per installare Hadoop 2.4.1 in modalità pseudo distribuita.
Passaggio 1: configurazione di Hadoop
Puoi impostare le variabili d'ambiente Hadoop aggiungendo i seguenti comandi a ~/.bashrc file.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOMEOra applica tutte le modifiche al sistema in esecuzione corrente.
$ source ~/.bashrcPassaggio 2: configurazione di Hadoop
Puoi trovare tutti i file di configurazione di Hadoop nella posizione "$ HADOOP_HOME / etc / hadoop". È necessario apportare modifiche a tali file di configurazione in base alla propria infrastruttura Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPer sviluppare programmi Hadoop in java, devi reimpostare le variabili d'ambiente java in hadoop-env.sh file sostituendo JAVA_HOME value con la posizione di java nel tuo sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71Di seguito è riportato l'elenco dei file che devi modificare per configurare Hadoop.
core-site.xml
Il core-site.xml file contiene informazioni come il numero di porta utilizzato per l'istanza Hadoop, la memoria allocata per il file system, il limite di memoria per l'archiviazione dei dati e la dimensione dei buffer di lettura / scrittura.
Apri core-site.xml e aggiungi le seguenti proprietà tra i tag <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Il hdfs-site.xmlfile contiene informazioni come il valore dei dati di replica, il percorso namenode e i percorsi datanode dei file system locali. Significa il luogo in cui si desidera archiviare l'infrastruttura Hadoop.
Assumiamo i seguenti dati.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeApri questo file e aggiungi le seguenti proprietà tra i tag <configuration> </configuration> in questo file.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - Nel file sopra, tutti i valori delle proprietà sono definiti dall'utente ed è possibile apportare modifiche in base alla propria infrastruttura Hadoop.
yarn-site.xml
Questo file viene utilizzato per configurare il filato in Hadoop. Apri il file filato-site.xml e aggiungi le seguenti proprietà tra i tag <configuration>, </configuration> in questo file.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Questo file viene utilizzato per specificare quale framework MapReduce stiamo utilizzando. Per impostazione predefinita, Hadoop contiene un modello di filato-site.xml. Prima di tutto, è necessario copiare il file damapred-site.xml.template per mapred-site.xml file utilizzando il seguente comando.
$ cp mapred-site.xml.template mapred-site.xmlAperto mapred-site.xml file e aggiungi le seguenti proprietà tra i tag <configuration>, </configuration> in questo file.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verifica dell'installazione di Hadoop
I seguenti passaggi vengono utilizzati per verificare l'installazione di Hadoop.
Passaggio 1: configurazione del nodo del nome
Impostare il namenode utilizzando il comando "hdfs namenode -format" come segue.
$ cd ~
$ hdfs namenode -formatIl risultato atteso è il seguente.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Passaggio 2: verifica di Hadoop dfs
Il seguente comando viene utilizzato per avviare dfs. L'esecuzione di questo comando avvierà il tuo file system Hadoop.
$ start-dfs.shL'output previsto è il seguente:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Passaggio 3: verifica dello script del filato
Il seguente comando viene utilizzato per avviare lo script del filato. L'esecuzione di questo comando avvierà i tuoi demoni filati.
$ start-yarn.shL'output previsto come segue:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outPassaggio 4: accesso a Hadoop sul browser
Il numero di porta predefinito per accedere a Hadoop è 50070. Utilizza il seguente URL per ottenere i servizi Hadoop sul browser.
http://localhost:50070/
Passaggio 5: verifica tutte le applicazioni per il cluster
Il numero di porta predefinito per accedere a tutte le applicazioni del cluster è 8088. Utilizzare il seguente URL per visitare questo servizio.
http://localhost:8088/
Hadoop File System è stato sviluppato utilizzando un file system distribuito. Viene eseguito su hardware di base. A differenza di altri sistemi distribuiti, HDFS è altamente tollerante ai guasti e progettato utilizzando hardware a basso costo.
HDFS contiene una quantità molto grande di dati e fornisce un accesso più facile. Per archiviare dati così grandi, i file vengono archiviati su più macchine. Questi file vengono archiviati in modo ridondante per salvare il sistema da possibili perdite di dati in caso di guasto. HDFS rende anche le applicazioni disponibili per l'elaborazione parallela.
Caratteristiche di HDFS
- È adatto per lo stoccaggio e l'elaborazione distribuiti.
- Hadoop fornisce un'interfaccia di comando per interagire con HDFS.
- I server integrati di namenode e datanode aiutano gli utenti a controllare facilmente lo stato del cluster.
- Accesso in streaming ai dati del file system.
- HDFS fornisce autorizzazioni e autenticazione per i file.
Architettura HDFS
Di seguito è riportata l'architettura di un file system Hadoop.
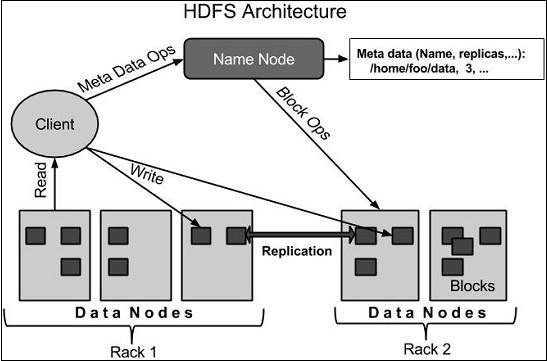
HDFS segue l'architettura master-slave e ha i seguenti elementi.
Namenode
Il namenode è l'hardware di base che contiene il sistema operativo GNU / Linux e il software namenode. È un software che può essere eseguito su hardware di base. Il sistema con namenode funge da server principale e svolge le seguenti attività:
Gestisce lo spazio dei nomi del file system.
Regola l'accesso del cliente ai file.
Esegue anche operazioni di file system come rinominare, chiudere e aprire file e directory.
Datanode
Il datanode è un hardware di base con il sistema operativo GNU / Linux e il software datanode. Per ogni nodo (hardware / sistema merceologico) in un cluster, ci sarà un codice dati. Questi nodi gestiscono l'archiviazione dei dati del loro sistema.
I codici dati eseguono operazioni di lettura / scrittura sui file system, secondo la richiesta del client.
Eseguono anche operazioni come la creazione di blocchi, l'eliminazione e la replica secondo le istruzioni del namenode.
Bloccare
Generalmente i dati dell'utente vengono archiviati nei file di HDFS. Il file in un file system verrà suddiviso in uno o più segmenti e / o archiviato in singoli nodi di dati. Questi segmenti di file sono chiamati come blocchi. In altre parole, la quantità minima di dati che HDFS può leggere o scrivere è chiamata Blocco. La dimensione predefinita del blocco è 64 MB, ma può essere aumentata in base alla necessità di modificare la configurazione HDFS.
Obiettivi di HDFS
Fault detection and recovery- Poiché HDFS include un gran numero di hardware di base, il guasto dei componenti è frequente. Pertanto, HDFS dovrebbe disporre di meccanismi per il rilevamento e il ripristino rapidi e automatici dei guasti.
Huge datasets - HDFS dovrebbe avere centinaia di nodi per cluster per gestire le applicazioni con enormi set di dati.
Hardware at data- Un'attività richiesta può essere eseguita in modo efficiente, quando il calcolo avviene vicino ai dati. Soprattutto quando sono coinvolti enormi set di dati, riduce il traffico di rete e aumenta il throughput.
Avvio di HDFS
Inizialmente è necessario formattare il file system HDFS configurato, aprire namenode (server HDFS) ed eseguire il comando seguente.
$ hadoop namenode -formatDopo aver formattato l'HDFS, avvia il file system distribuito. Il seguente comando avvierà il namenode così come i nodi di dati come cluster.
$ start-dfs.shElenco dei file in HDFS
Dopo aver caricato le informazioni nel server, possiamo trovare l'elenco dei file in una directory, lo stato di un file, utilizzando ‘ls’. Di seguito è riportata la sintassi dils che puoi passare a una directory oa un nome di file come argomento.
$ $HADOOP_HOME/bin/hadoop fs -ls <args>Inserimento di dati in HDFS
Supponiamo di avere dati nel file chiamato file.txt nel sistema locale che dovrebbe essere salvato nel file system hdfs. Seguire i passaggi indicati di seguito per inserire il file richiesto nel file system Hadoop.
Passo 1
Devi creare una directory di input.
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/inputPasso 2
Trasferisci e archivia un file di dati dai sistemi locali al file system Hadoop utilizzando il comando put.
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/inputPassaggio 3
Puoi verificare il file usando il comando ls.
$ $HADOOP_HOME/bin/hadoop fs -ls /user/inputRecupero dei dati da HDFS
Supponiamo di avere un file in HDFS chiamato outfile. Di seguito è riportata una semplice dimostrazione per recuperare il file richiesto dal file system Hadoop.
Passo 1
Inizialmente, visualizza i dati da HDFS utilizzando cat comando.
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfilePasso 2
Ottieni il file da HDFS al file system locale utilizzando get comando.
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/Arresto di HDFS
È possibile arrestare l'HDFS utilizzando il seguente comando.
$ stop-dfs.shCi sono molti altri comandi in "$HADOOP_HOME/bin/hadoop fs"di quanto mostrato qui, sebbene queste operazioni di base ti consentiranno di iniziare. L'esecuzione di ./bin/hadoop dfs senza argomenti aggiuntivi elencherà tutti i comandi che possono essere eseguiti con il sistema FsShell. Inoltre,$HADOOP_HOME/bin/hadoop fs -help commandName mostrerà un breve riepilogo dell'utilizzo per l'operazione in questione, se sei bloccato.
Di seguito è riportata una tabella di tutte le operazioni. Per i parametri vengono utilizzate le seguenti convenzioni:
"<path>" means any file or directory name.
"<path>..." means one or more file or directory names.
"<file>" means any filename.
"<src>" and "<dest>" are path names in a directed operation.
"<localSrc>" and "<localDest>" are paths as above, but on the local file system.Tutti gli altri file e nomi di percorso si riferiscono agli oggetti all'interno di HDFS.
| Suor n | Comando e descrizione |
|---|---|
| 1 | -ls <path> Elenca il contenuto della directory specificata dal percorso, mostrando i nomi, i permessi, il proprietario, le dimensioni e la data di modifica per ciascuna voce. |
| 2 | -lsr <path> Si comporta come -ls, ma visualizza in modo ricorsivo le voci in tutte le sottodirectory di path. |
| 3 | -du <path> Mostra l'utilizzo del disco, in byte, per tutti i file che corrispondono al percorso; i nomi dei file vengono riportati con il prefisso del protocollo HDFS completo. |
| 4 | -dus <path> Come -du, ma stampa un riepilogo dell'utilizzo del disco di tutti i file / directory nel percorso. |
| 5 | -mv <src><dest> Sposta il file o la directory indicata da src in dest, all'interno di HDFS. |
| 6 | -cp <src> <dest> Copia il file o la directory identificata da src in dest, all'interno di HDFS. |
| 7 | -rm <path> Rimuove il file o la directory vuota identificata dal percorso. |
| 8 | -rmr <path> Rimuove il file o la directory identificata dal percorso. Elimina in modo ricorsivo tutte le voci figlio (ad esempio, file o sottodirectory del percorso). |
| 9 | -put <localSrc> <dest> Copia il file o la directory dal file system locale identificato da localSrc a dest all'interno di DFS. |
| 10 | -copyFromLocal <localSrc> <dest> Identico al -put |
| 11 | -moveFromLocal <localSrc> <dest> Copia il file o la directory dal file system locale identificato da localSrc a dest all'interno di HDFS, quindi elimina la copia locale in caso di esito positivo. |
| 12 | -get [-crc] <src> <localDest> Copia il file o la directory in HDFS identificato da src nel percorso del file system locale identificato da localDest. |
| 13 | -getmerge <src> <localDest> Recupera tutti i file che corrispondono al percorso src in HDFS e li copia in un unico file unito nel file system locale identificato da localDest. |
| 14 | -cat <filen-ame> Visualizza il contenuto di filename su stdout. |
| 15 | -copyToLocal <src> <localDest> Identico a -get |
| 16 | -moveToLocal <src> <localDest> Funziona come -get, ma elimina la copia HDFS in caso di successo. |
| 17 | -mkdir <path> Crea una directory denominata path in HDFS. Crea tutte le directory padre nel percorso che mancano (ad esempio, mkdir -p in Linux). |
| 18 | -setrep [-R] [-w] rep <path> Imposta il fattore di replica di destinazione per i file identificati dal percorso di rep. (Il fattore di replica effettivo si sposterà verso l'obiettivo nel tempo) |
| 19 | -touchz <path> Crea un file nel percorso contenente l'ora corrente come timestamp. Non riesce se un file esiste già nel percorso, a meno che il file non sia già di dimensione 0. |
| 20 | -test -[ezd] <path> Restituisce 1 se il percorso esiste; ha lunghezza zero; o è una directory o 0 altrimenti. |
| 21 | -stat [format] <path> Stampa le informazioni sul percorso. Il formato è una stringa che accetta la dimensione del file in blocchi (% b), nome file (% n), dimensione del blocco (% o), replica (% r) e data di modifica (% y,% Y). |
| 22 | -tail [-f] <file2name> Mostra l'ultimo 1KB di file su stdout. |
| 23 | -chmod [-R] mode,mode,... <path>... Modifica i permessi dei file associati a uno o più oggetti identificati dal percorso .... Esegue le modifiche in modo ricorsivo con R. La modalità è una modalità ottale a 3 cifre, o {augo} +/- {rwxX}. Presume che non sia specificato alcun ambito e non applica una umask. |
| 24 | -chown [-R] [owner][:[group]] <path>... Imposta l'utente e / o il gruppo proprietario per i file o le directory identificati dal percorso .... Imposta il proprietario in modo ricorsivo se si specifica -R. |
| 25 | -chgrp [-R] group <path>... Imposta il gruppo proprietario per i file o le directory identificati dal percorso .... Imposta il gruppo in modo ricorsivo se si specifica -R. |
| 26 | -help <cmd-name> Restituisce le informazioni sull'utilizzo di uno dei comandi sopra elencati. È necessario omettere il carattere iniziale "-" in cmd. |
MapReduce è un framework utilizzando il quale possiamo scrivere applicazioni per elaborare enormi quantità di dati, in parallelo, su grandi cluster di hardware di base in modo affidabile.
Cos'è MapReduce?
MapReduce è una tecnica di elaborazione e un modello di programma per il calcolo distribuito basato su java. L'algoritmo MapReduce contiene due importanti attività, ovvero Map e Reduce. Map prende un set di dati e lo converte in un altro set di dati, dove i singoli elementi vengono suddivisi in tuple (coppie chiave / valore). In secondo luogo, ridurre l'attività, che prende l'output da una mappa come input e combina quelle tuple di dati in un insieme più piccolo di tuple. Come implica la sequenza del nome MapReduce, l'attività di riduzione viene sempre eseguita dopo il lavoro di mappa.
Il vantaggio principale di MapReduce è che è facile scalare l'elaborazione dei dati su più nodi di elaborazione. Nel modello MapReduce, le primitive di elaborazione dei dati sono chiamate mappatori e riduttori. La scomposizione di un'applicazione di elaborazione dati in mappatori e riduttori a volte non è banale. Tuttavia, una volta che scriviamo un'applicazione nel modulo MapReduce, ridimensionare l'applicazione per eseguirla su centinaia, migliaia o persino decine di migliaia di macchine in un cluster è semplicemente una modifica alla configurazione. Questa semplice scalabilità è ciò che ha attratto molti programmatori a utilizzare il modello MapReduce.
L'algoritmo
Generalmente il paradigma di MapReduce si basa sull'invio al computer dove risiedono i dati!
Il programma MapReduce viene eseguito in tre fasi, ovvero fase della mappa, fase casuale e fase di riduzione.
Map stage- Il compito della mappa o del mappatore consiste nell'elaborare i dati di input. Generalmente i dati di input sono sotto forma di file o directory e sono archiviati nel file system Hadoop (HDFS). Il file di input viene passato riga per riga alla funzione mapper. Il mappatore elabora i dati e crea diversi piccoli blocchi di dati.
Reduce stage - Questa fase è la combinazione di Shuffle stage e il Reducepalcoscenico. Il compito del riduttore è elaborare i dati che provengono dal mappatore. Dopo l'elaborazione, produce un nuovo set di output, che verrà archiviato nell'HDFS.
Durante un processo MapReduce, Hadoop invia le attività di mappa e riduzione ai server appropriati nel cluster.
Il framework gestisce tutti i dettagli del passaggio dei dati come l'emissione di attività, la verifica del completamento delle attività e la copia dei dati nel cluster tra i nodi.
La maggior parte dell'elaborazione avviene su nodi con dati su dischi locali che riduce il traffico di rete.
Dopo il completamento delle attività date, il cluster raccoglie e riduce i dati per formare un risultato appropriato e lo invia di nuovo al server Hadoop.

Input e output (prospettiva Java)
Il framework MapReduce opera su coppie <chiave, valore>, ovvero il framework visualizza l'input per il lavoro come un insieme di coppie <chiave, valore> e produce un insieme di coppie <chiave, valore> come output del lavoro , presumibilmente di diversi tipi.
La chiave e le classi di valore devono essere serializzate dal framework e quindi devono implementare l'interfaccia Writable. Inoltre, le classi chiave devono implementare l'interfaccia Writable-Comparable per facilitare l'ordinamento in base al framework. Tipi di input e output di aMapReduce job - (Input) <k1, v1> → map → <k2, v2> → reduce → <k3, v3> (Output).
| Ingresso | Produzione | |
|---|---|---|
| Carta geografica | <k1, v1> | elenco (<k2, v2>) |
| Ridurre | <k2, list (v2)> | elenco (<k3, v3>) |
Terminologia
PayLoad - Le applicazioni implementano le funzioni Mappa e Riduci e costituiscono il nucleo del lavoro.
Mapper - Mapper mappa le coppie chiave / valore di input su un insieme di coppie chiave / valore intermedie.
NamedNode - Nodo che gestisce Hadoop Distributed File System (HDFS).
DataNode - Nodo in cui i dati vengono presentati in anticipo prima che avvenga qualsiasi elaborazione.
MasterNode - Nodo in cui viene eseguito JobTracker e che accetta le richieste di lavoro dai client.
SlaveNode - Nodo in cui viene eseguito il programma Map and Reduce.
JobTracker - Pianifica i lavori e tiene traccia dei lavori assegnati a Task tracker.
Task Tracker - Tiene traccia dell'attività e segnala lo stato a JobTracker.
Job - Un programma è l'esecuzione di un Mapper e Reducer su un set di dati.
Task - Un'esecuzione di un Mapper o di un Reducer su una porzione di dati.
Task Attempt - Una particolare istanza di un tentativo di eseguire un'attività su uno SlaveNode.
Scenario di esempio
Di seguito sono riportati i dati relativi al consumo elettrico di un'organizzazione. Contiene il consumo elettrico mensile e la media annua dei vari anni.
| Jan | Feb | Mar | Apr | Maggio | Jun | Lug | Ago | Sep | Ott | Nov | Dic | Media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Se i dati di cui sopra vengono forniti come input, dobbiamo scrivere applicazioni per elaborarli e produrre risultati come la ricerca dell'anno di utilizzo massimo, dell'anno di utilizzo minimo e così via. Questo è un walkover per i programmatori con un numero finito di record. Scriveranno semplicemente la logica per produrre l'output richiesto e passeranno i dati all'applicazione scritta.
But, think of the data representing the electrical consumption of all the largescale industries of a particular state, since its formation.
When we write applications to process such bulk data,
They will take a lot of time to execute.
There will be a heavy network traffic when we move data from source to network server and so on.
To solve these problems, we have the MapReduce framework.
Input Data
The above data is saved as sample.txtand given as input. The input file looks as shown below.
1979 23 23 2 43 24 25 26 26 26 26 25 26 25
1980 26 27 28 28 28 30 31 31 31 30 30 30 29
1981 31 32 32 32 33 34 35 36 36 34 34 34 34
1984 39 38 39 39 39 41 42 43 40 39 38 38 40
1985 38 39 39 39 39 41 41 41 00 40 39 39 45Example Program
Given below is the program to the sample data using MapReduce framework.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits {
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()) {
lasttoken = s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > {
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxavg = 30;
int val = Integer.MIN_VALUE;
while (values.hasNext()) {
if((val = values.next().get())>maxavg) {
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception {
JobConf conf = new JobConf(ProcessUnits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}Salva il programma sopra come ProcessUnits.java. Di seguito viene spiegata la compilazione e l'esecuzione del programma.
Compilazione ed esecuzione del programma Process Units
Supponiamo di essere nella directory home di un utente Hadoop (ad esempio / home / hadoop).
Seguire i passaggi indicati di seguito per compilare ed eseguire il programma sopra.
Passo 1
Il comando seguente serve per creare una directory per memorizzare le classi java compilate.
$ mkdir unitsPasso 2
Scarica Hadoop-core-1.2.1.jar,che viene utilizzato per compilare ed eseguire il programma MapReduce. Visitare il seguente collegamento mvnrepository.com per scaricare il jar. Supponiamo che la cartella scaricata sia/home/hadoop/.
Passaggio 3
I seguenti comandi vengono utilizzati per compilare il file ProcessUnits.java programma e creando un vaso per il programma.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Passaggio 4
Il comando seguente viene utilizzato per creare una directory di input in HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirPassaggio 5
Il seguente comando viene utilizzato per copiare il file di input denominato sample.txtnella directory di input di HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirPassaggio 6
Il comando seguente viene utilizzato per verificare i file nella directory di input.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Passaggio 7
Il seguente comando viene utilizzato per eseguire l'applicazione Eleunit_max prendendo i file di input dalla directory di input.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirAttendi qualche istante finché il file non viene eseguito. Dopo l'esecuzione, come mostrato di seguito, l'output conterrà il numero di suddivisioni di input, il numero di attività di mappa, il numero di attività di riduzione, ecc.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 40Passaggio 8
Il comando seguente viene utilizzato per verificare i file risultanti nella cartella di output.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Passaggio 9
Il comando seguente viene utilizzato per visualizzare l'output in Part-00000 file. Questo file è generato da HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Di seguito è riportato l'output generato dal programma MapReduce.
1981 34
1984 40
1985 45Passaggio 10
Il comando seguente viene utilizzato per copiare la cartella di output da HDFS al file system locale per l'analisi.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoopComandi importanti
Tutti i comandi Hadoop vengono richiamati dal $HADOOP_HOME/bin/hadoopcomando. L'esecuzione dello script Hadoop senza argomenti stampa la descrizione per tutti i comandi.
Usage - hadoop [--config confdir] COMANDO
La tabella seguente elenca le opzioni disponibili e la loro descrizione.
| Sr.No. | Opzione e descrizione |
|---|---|
| 1 | namenode -format Formatta il filesystem DFS. |
| 2 | secondarynamenode Esegue il namenode secondario DFS. |
| 3 | namenode Esegue il namenode DFS. |
| 4 | datanode Esegue un codice dati DFS. |
| 5 | dfsadmin Esegue un client di amministrazione DFS. |
| 6 | mradmin Esegue un client di amministrazione Map-Reduce. |
| 7 | fsck Esegue un'utilità di controllo del file system DFS. |
| 8 | fs Esegue un client utente generico del file system. |
| 9 | balancer Esegue un'utilità di bilanciamento del cluster. |
| 10 | oiv Applica il visualizzatore fsimage offline a un'immagine fsimage. |
| 11 | fetchdt Recupera un token di delega da NameNode. |
| 12 | jobtracker Esegue il nodo MapReduce Job Tracker. |
| 13 | pipes Esegue un lavoro Pipes. |
| 14 | tasktracker Esegue un nodo MapReduce Task Tracker. |
| 15 | historyserver Esegue i server della cronologia dei lavori come daemon autonomo. |
| 16 | job Manipola i lavori MapReduce. |
| 17 | queue Ottiene informazioni su JobQueues. |
| 18 | version Stampa la versione. |
| 19 | jar <jar> Esegue un file jar. |
| 20 | distcp <srcurl> <desturl> Copia file o directory in modo ricorsivo. |
| 21 | distcp2 <srcurl> <desturl> DistCp versione 2. |
| 22 | archive -archiveName NAME -p <parent path> <src>* <dest> Crea un archivio hadoop. |
| 23 | classpath Stampa il percorso di classe necessario per ottenere il jar Hadoop e le librerie richieste. |
| 24 | daemonlog Ottieni / Imposta il livello di log per ogni daemon |
Come interagire con i lavori di MapReduce
Utilizzo - lavoro hadoop [GENERIC_OPTIONS]
Le seguenti sono le Opzioni generiche disponibili in un lavoro Hadoop.
| Sr.No. | GENERIC_OPTION e descrizione |
|---|---|
| 1 | -submit <job-file> Invia il lavoro. |
| 2 | -status <job-id> Stampa la mappa e riduce la percentuale di completamento e tutti i contatori dei lavori. |
| 3 | -counter <job-id> <group-name> <countername> Stampa il valore del contatore. |
| 4 | -kill <job-id> Uccide il lavoro. |
| 5 | -events <job-id> <fromevent-#> <#-of-events> Stampa i dettagli degli eventi ricevuti da jobtracker per l'intervallo specificato. |
| 6 | -history [all] <jobOutputDir> - history < jobOutputDir> Stampa i dettagli del lavoro, i dettagli dei suggerimenti non riusciti e terminati. Ulteriori dettagli sul lavoro come le attività riuscite e i tentativi di attività effettuati per ciascuna attività possono essere visualizzati specificando l'opzione [tutti]. |
| 7 | -list[all] Visualizza tutti i lavori. -list mostra solo i lavori che devono ancora essere completati. |
| 8 | -kill-task <task-id> Uccide il compito. Le attività terminate NON vengono conteggiate nei tentativi falliti. |
| 9 | -fail-task <task-id> Fallisce il compito. Le attività non riuscite vengono conteggiate rispetto ai tentativi falliti. |
| 10 | -set-priority <job-id> <priority> Modifica la priorità del lavoro. I valori di priorità consentiti sono VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW |
Per vedere lo stato del lavoro
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004Per vedere la cronologia del lavoro output-dir
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/outputPer uccidere il lavoro
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004Lo streaming di Hadoop è un'utilità fornita con la distribuzione di Hadoop. Questa utilità consente di creare ed eseguire lavori di mappatura / riduzione con qualsiasi eseguibile o script come mappatore e / o riduttore.
Esempio di utilizzo di Python
Per lo streaming Hadoop, stiamo considerando il problema del conteggio delle parole. Qualsiasi lavoro in Hadoop deve avere due fasi: mappatore e riduttore. Abbiamo scritto codici per il mappatore e il riduttore in script Python per eseguirlo sotto Hadoop. Si può anche scrivere lo stesso in Perl e Ruby.
Codice fase mappatore
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)Assicurati che questo file abbia il permesso di esecuzione (chmod + x / home / expert / hadoop-1.2.1 / mapper.py).
Codice fase riduttore
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)Salva i codici mappatore e riduttore in mapper.py e riduttore.py nella directory principale di Hadoop. Assicurati che questi file abbiano il permesso di esecuzione (chmod + x mapper.py e chmod + x riduttore.py). Poiché Python è sensibile all'indentazione, lo stesso codice può essere scaricato dal collegamento sottostante.
Esecuzione del programma WordCount
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1.
2.1.jar \
-input input_dirs \
-output output_dir \
-mapper <path/mapper.py \
-reducer <path/reducer.pyDove "\" viene utilizzato per la continuazione della riga per una chiara leggibilità.
Per esempio,
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.pyCome funziona lo streaming
Nell'esempio precedente, sia il mapper che il riduttore sono script Python che leggono l'input dallo standard input ed emettono l'output nell'output standard. L'utilità creerà un lavoro Mappa / Riduci, inoltrerà il lavoro a un cluster appropriato e monitorerà l'avanzamento del lavoro fino al suo completamento.
Quando viene specificato uno script per i mappatori, ogni attività del mapper avvierà lo script come processo separato quando il mapper viene inizializzato. Durante l'esecuzione dell'attività di mappatura, converte i suoi input in linee e inserisce le linee nell'input standard (STDIN) del processo. Nel frattempo, il mappatore raccoglie gli output orientati alla riga dallo standard output (STDOUT) del processo e converte ogni riga in una coppia chiave / valore, che viene raccolta come output del mappatore. Per impostazione predefinita, il prefisso di una riga fino al primo carattere di tabulazione è la chiave e il resto della riga (escluso il carattere di tabulazione) sarà il valore. Se non è presente alcun carattere di tabulazione nella riga, l'intera riga viene considerata come chiave e il valore è nullo. Tuttavia, questo può essere personalizzato, secondo una necessità.
Quando viene specificato uno script per i riduttori, ciascuna attività del riduttore avvierà lo script come processo separato, quindi il riduttore viene inizializzato. Durante l'esecuzione dell'attività del riduttore, converte le sue coppie chiave / valori di input in righe e le invia allo standard input (STDIN) del processo. Nel frattempo, il riduttore raccoglie gli output orientati alla linea dallo standard output (STDOUT) del processo, converte ogni riga in una coppia chiave / valore, che viene raccolta come output del riduttore. Per impostazione predefinita, il prefisso di una riga fino al primo carattere di tabulazione è la chiave e il resto della riga (escluso il carattere di tabulazione) è il valore. Tuttavia, questo può essere personalizzato secondo requisiti specifici.
Comandi importanti
| Parametri | Opzioni | Descrizione |
|---|---|---|
| -indirizzario di ingresso / nome-file | necessario | Posizione di input per mappatore. |
| -output nome-directory | necessario | Posizione di uscita per riduttore. |
| -mapper eseguibile o script o JavaClassName | necessario | Eseguibile del mapping. |
| -Riduttore eseguibile o script o JavaClassName | necessario | Riduttore eseguibile. |
| -file nome-file | Opzionale | Rende l'eseguibile mappatore, riduttore o combinatore disponibile localmente sui nodi di calcolo. |
| -inputformat JavaClassName | Opzionale | La classe fornita deve restituire le coppie chiave / valore della classe Text. Se non specificato, TextInputFormat viene utilizzato come impostazione predefinita. |
| -outputformat JavaClassName | Opzionale | La classe che fornisci dovrebbe prendere coppie chiave / valore della classe Text. Se non specificato, TextOutputformat viene utilizzato come impostazione predefinita. |
| -partitioner JavaClassName | Opzionale | Classe che determina a quale riduzione viene inviata una chiave. |
| -combiner streamingCommand o JavaClassName | Opzionale | Eseguibile del combinatore per l'output della mappa. |
| -cmdenv nome = valore | Opzionale | Passa la variabile di ambiente ai comandi di streaming. |
| -inputreader | Opzionale | Per compatibilità con le versioni precedenti: specifica una classe di lettore di record (invece di una classe di formato di input). |
| -verbose | Opzionale | Output dettagliato. |
| -lazyOutput | Opzionale | Crea output pigramente. Ad esempio, se il formato di output è basato su FileOutputFormat, il file di output viene creato solo alla prima chiamata a output.collect (o Context.write). |
| -numReduceTasks | Opzionale | Specifica il numero di riduttori. |
| -mapdebug | Opzionale | Script da chiamare quando l'attività della mappa fallisce. |
| -reducedebug | Opzionale | Script da chiamare quando l'attività di riduzione non riesce. |
Questo capitolo spiega la configurazione del cluster Hadoop Multi-Node in un ambiente distribuito.
Poiché non è possibile dimostrare l'intero cluster, stiamo spiegando l'ambiente del cluster Hadoop utilizzando tre sistemi (un master e due slave); di seguito sono riportati i loro indirizzi IP.
- Hadoop Master: 192.168.1.15 (hadoop-master)
- Hadoop Slave: 192.168.1.16 (hadoop-slave-1)
- Hadoop Slave: 192.168.1.17 (hadoop-slave-2)
Seguire i passaggi indicati di seguito per configurare il cluster Hadoop Multi-Node.
Installazione di Java
Java è il prerequisito principale per Hadoop. Prima di tutto, dovresti verificare l'esistenza di java nel tuo sistema usando "java -version". La sintassi del comando della versione Java è fornita di seguito.
$ java -versionSe tutto funziona bene, ti darà il seguente output.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se java non è installato nel tuo sistema, segui i passaggi indicati per l'installazione di java.
Passo 1
Scarica java (JDK <ultima versione> - X64.tar.gz) visitando il seguente link www.oracle.com
Poi jdk-7u71-linux-x64.tar.gz verrà scaricato nel tuo sistema.
Passo 2
Generalmente troverai il file java scaricato nella cartella Download. Verificalo ed estrai il filejdk-7u71-linux-x64.gz file utilizzando i seguenti comandi.
$ cd Downloads/ $ ls
jdk-7u71-Linux-x64.gz
$ tar zxf jdk-7u71-Linux-x64.gz $ ls
jdk1.7.0_71 jdk-7u71-Linux-x64.gzPassaggio 3
Per rendere java disponibile a tutti gli utenti, è necessario spostarlo nella posizione "/ usr / local /". Apri la radice e digita i seguenti comandi.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitPassaggio 4
Per l'allestimento PATH e JAVA_HOME variabili, aggiungi i seguenti comandi a ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/binOra verifica il file java -versioncomando dal terminale come spiegato sopra. Segui il processo sopra e installa java in tutti i tuoi nodi del cluster.
Creazione dell'account utente
Crea un account utente di sistema su entrambi i sistemi master e slave per utilizzare l'installazione di Hadoop.
# useradd hadoop
# passwd hadoopMappatura dei nodi
Devi modificare hosts file in /etc/ cartella su tutti i nodi, specificare l'indirizzo IP di ogni sistema seguito dai rispettivi nomi host.
# vi /etc/hosts
enter the following lines in the /etc/hosts file.
192.168.1.109 hadoop-master
192.168.1.145 hadoop-slave-1
192.168.56.1 hadoop-slave-2Configurazione dell'accesso basato su chiave
Imposta ssh in ogni nodo in modo che possano comunicare tra loro senza alcuna richiesta di password.
# su hadoop
$ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2
$ chmod 0600 ~/.ssh/authorized_keys $ exitInstallazione di Hadoop
Nel server principale, scarica e installa Hadoop utilizzando i seguenti comandi.
# mkdir /opt/hadoop
# cd /opt/hadoop/
# wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz
# tar -xzf hadoop-1.2.0.tar.gz
# mv hadoop-1.2.0 hadoop
# chown -R hadoop /opt/hadoop
# cd /opt/hadoop/hadoop/Configurazione di Hadoop
È necessario configurare il server Hadoop apportando le seguenti modifiche come indicato di seguito.
core-site.xml
Apri il core-site.xml file e modificarlo come mostrato di seguito.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>hdfs-site.xml
Apri il hdfs-site.xml file e modificarlo come mostrato di seguito.
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml
Apri il mapred-site.xml file e modificarlo come mostrato di seguito.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>hadoop-env.sh
Apri il hadoop-env.sh file e modificare JAVA_HOME, HADOOP_CONF_DIR e HADOOP_OPTS come mostrato di seguito.
Note - Imposta JAVA_HOME secondo la configurazione del tuo sistema.
export JAVA_HOME=/opt/jdk1.7.0_17
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_CONF_DIR=/opt/hadoop/hadoop/confInstallazione di Hadoop su server slave
Installa Hadoop su tutti i server slave seguendo i comandi forniti.
# su hadoop
$ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop
$ scp -r hadoop hadoop-slave-2:/opt/hadoopConfigurazione di Hadoop sul server master
Apri il server master e configuralo seguendo i comandi forniti.
# su hadoop
$ cd /opt/hadoop/hadoopConfigurazione del nodo master
$ vi etc/hadoop/masters
hadoop-masterConfigurazione del nodo slave
$ vi etc/hadoop/slaves
hadoop-slave-1
hadoop-slave-2Formato nome nodo su Hadoop Master
# su hadoop
$ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format
11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop-master/192.168.1.109
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.2.0
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473;
compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013
STARTUP_MSG: java = 1.7.0_71
************************************************************/
11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap
editlog=/opt/hadoop/hadoop/dfs/name/current/edits
………………………………………………….
………………………………………………….
………………………………………………….
11/10/14 10:58:08 INFO common.Storage: Storage directory
/opt/hadoop/hadoop/dfs/name has been successfully formatted.
11/10/14 10:58:08 INFO namenode.NameNode:
SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15
************************************************************/Avvio dei servizi Hadoop
Il comando seguente serve per avviare tutti i servizi Hadoop su Hadoop-Master.
$ cd $HADOOP_HOME/sbin
$ start-all.shAggiunta di un nuovo DataNode nel cluster Hadoop
Di seguito sono riportati i passaggi da seguire per aggiungere nuovi nodi a un cluster Hadoop.
Networking
Aggiungi nuovi nodi a un cluster Hadoop esistente con una configurazione di rete appropriata. Assumi la seguente configurazione di rete.
Per la configurazione del nuovo nodo -
IP address : 192.168.1.103
netmask : 255.255.255.0
hostname : slave3.inAggiunta di accesso utente e SSH
Aggiungi un utente
Su un nuovo nodo, aggiungi l'utente "hadoop" e imposta la password dell'utente Hadoop su "hadoop123" o qualsiasi cosa tu voglia usando i seguenti comandi.
useradd hadoop
passwd hadoopSetup Password meno connettività dal master al nuovo slave.
Eseguire quanto segue sul master
mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory
scp $HOME/.ssh/id_rsa.pub [email protected]:/home/hadoop/Eseguire quanto segue sugli slave
Accedi a hadoop. In caso contrario, accedi a hadoop user.
su hadoop ssh -X [email protected]Copia il contenuto della chiave pubblica nel file "$HOME/.ssh/authorized_keys" e quindi modificare l'autorizzazione per lo stesso eseguendo i seguenti comandi.
cd $HOME mkdir -p $HOME/.ssh
chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys
chmod 644 $HOME/.ssh/authorized_keysControlla il login ssh dalla macchina master. Ora controlla se puoi ssh al nuovo nodo senza una password dal master.
ssh [email protected] or hadoop@slave3Imposta il nome host del nuovo nodo
È possibile impostare il nome host nel file /etc/sysconfig/network
On new slave3 machine
NETWORKING = yes
HOSTNAME = slave3.inPer rendere effettive le modifiche, riavviare la macchina o eseguire il comando hostname su una nuova macchina con il rispettivo hostname (il riavvio è una buona opzione).
Sulla macchina del nodo slave3 -
hostname slave3.in
Aggiornare /etc/hosts su tutte le macchine del cluster con le seguenti righe -
192.168.1.102 slave3.in slave3Ora prova a eseguire il ping della macchina con i nomi host per verificare se si sta risolvendo su IP o meno.
Sulla nuova macchina del nodo -
ping master.inAvvia il DataNode su New Node
Avvia manualmente il demone datanode utilizzando $HADOOP_HOME/bin/hadoop-daemon.sh script. Contatterà automaticamente il master (NameNode) e si unirà al cluster. Dovremmo anche aggiungere il nuovo nodo al file conf / slaves nel server master. I comandi basati su script riconosceranno il nuovo nodo.
Accedi al nuovo nodo
su hadoop or ssh -X [email protected]Avvia HDFS su un nodo slave appena aggiunto utilizzando il comando seguente
./bin/hadoop-daemon.sh start datanodeControlla l'output del comando jps su un nuovo nodo. Sembra come segue.
$ jps
7141 DataNode
10312 JpsRimozione di un DataNode dal cluster Hadoop
Possiamo rimuovere un nodo da un cluster al volo, mentre è in esecuzione, senza alcuna perdita di dati. HDFS fornisce una funzione di disattivazione, che garantisce che la rimozione di un nodo venga eseguita in modo sicuro. Per usarlo, seguire i passaggi indicati di seguito:
Passaggio 1: accedi a master
Accedi all'utente della macchina principale su cui è installato Hadoop.
$ su hadoopPassaggio 2: modificare la configurazione del cluster
È necessario configurare un file di esclusione prima di avviare il cluster. Aggiungi una chiave denominata dfs.hosts.exclude al nostro file$HADOOP_HOME/etc/hadoop/hdfs-site.xmlfile. Il valore associato a questa chiave fornisce il percorso completo di un file nel file system locale di NameNode che contiene un elenco di macchine a cui non è consentito connettersi a HDFS.
Ad esempio, aggiungi queste righe a etc/hadoop/hdfs-site.xml file.
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value>
<description>DFS exclude</description>
</property>Passaggio 3: determinare gli host da rimuovere
Ogni macchina da disattivare deve essere aggiunta al file identificato da hdfs_exclude.txt, un nome di dominio per riga. Ciò impedirà loro di connettersi a NameNode. Contenuto di"/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt" file è mostrato di seguito, se si desidera rimuovere DataNode2.
slave2.inPassaggio 4: forzare il ricaricamento della configurazione
Esegui il comando "$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes" senza virgolette.
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodesCiò costringerà il NameNode a rileggere la sua configurazione, incluso il file "esclude" appena aggiornato. Disattiverà i nodi per un periodo di tempo, consentendo il tempo di replicare i blocchi di ciascun nodo sulle macchine che sono programmate per rimanere attive.
Sopra slave2.in, controlla l'output del comando jps. Dopo un po 'di tempo, vedrai che il processo DataNode si arresta automaticamente.
Passaggio 5: arresto dei nodi
Dopo che il processo di disattivazione è stato completato, l'hardware disattivato può essere spento in sicurezza per la manutenzione. Eseguire il comando report su dfsadmin per controllare lo stato di disattivazione. Il comando seguente descriverà lo stato del nodo di disattivazione e dei nodi connessi al cluster.
$ $HADOOP_HOME/bin/hadoop dfsadmin -reportPassaggio 6: la modifica esclude nuovamente il file
Una volta che le macchine sono state disattivate, possono essere rimosse dal file "esclude". In esecuzione"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"di nuovo leggerà il file delle eccezioni nel NameNode; consentendo ai DataNode di ricongiungersi al cluster dopo che la manutenzione è stata completata, o è necessaria di nuovo capacità aggiuntiva nel cluster, ecc.
Special Note- Se si segue il processo di cui sopra e il processo di tasktracker è ancora in esecuzione sul nodo, è necessario spegnerlo. Un modo è disconnettere la macchina come abbiamo fatto nei passaggi precedenti. Il Master riconoscerà automaticamente il processo e si dichiarerà morto. Non è necessario seguire la stessa procedura per rimuovere il tasktracker perché NON è molto cruciale rispetto al DataNode. DataNode contiene i dati che si desidera rimuovere in modo sicuro senza alcuna perdita di dati.
Il tasktracker può essere eseguito / spento al volo con il seguente comando in qualsiasi momento.
$ $HADOOP_HOME/bin/hadoop-daemon.sh stop tasktracker $HADOOP_HOME/bin/hadoop-daemon.sh start tasktracker