HBase - Panoramica
Dal 1970, RDBMS è la soluzione per la memorizzazione dei dati e problemi legati alla manutenzione. Dopo l'avvento dei big data, le aziende hanno compreso il vantaggio di elaborare i big data e hanno iniziato a optare per soluzioni come Hadoop.
Hadoop utilizza un file system distribuito per l'archiviazione di big data e MapReduce per elaborarli. Hadoop eccelle nell'archiviazione e nell'elaborazione di enormi dati di vari formati, come arbitrari, semi o anche non strutturati.
Limitazioni di Hadoop
Hadoop può eseguire solo l'elaborazione in batch e l'accesso ai dati sarà effettuato solo in modo sequenziale. Ciò significa che si deve cercare nell'intero set di dati anche il più semplice dei lavori.
Un enorme set di dati durante l'elaborazione si traduce in un altro enorme set di dati, che dovrebbe essere elaborato in sequenza. A questo punto, è necessaria una nuova soluzione per accedere a qualsiasi punto di dati in una singola unità di tempo (accesso casuale).
Database ad accesso casuale Hadoop
Applicazioni come HBase, Cassandra, couchDB, Dynamo e MongoDB sono alcuni dei database che memorizzano enormi quantità di dati e accedono ai dati in modo casuale.
Cos'è HBase?
HBase è un database distribuito orientato alle colonne costruito sul file system Hadoop. È un progetto open source ed è scalabile orizzontalmente.
HBase è un modello di dati simile alla grande tabella di Google progettato per fornire un rapido accesso casuale a enormi quantità di dati strutturati. Sfrutta la tolleranza agli errori fornita da Hadoop File System (HDFS).
Fa parte dell'ecosistema Hadoop che fornisce accesso in lettura / scrittura casuale in tempo reale ai dati nel file system Hadoop.
È possibile memorizzare i dati in HDFS direttamente o tramite HBase. Il consumatore di dati legge / accede ai dati in HDFS in modo casuale utilizzando HBase. HBase si trova in cima al file system Hadoop e fornisce accesso in lettura e scrittura.

HBase e HDFS
| HDFS | HBase |
|---|---|
| HDFS è un file system distribuito adatto per l'archiviazione di file di grandi dimensioni. | HBase è un database costruito su HDFS. |
| HDFS non supporta ricerche rapide di record individuali. | HBase fornisce ricerche veloci per tabelle più grandi. |
| Fornisce elaborazione batch ad alta latenza; nessun concetto di elaborazione in batch. | Fornisce accesso a bassa latenza a singole righe da miliardi di record (accesso casuale). |
| Fornisce solo accesso sequenziale ai dati. | HBase utilizza internamente le tabelle hash e fornisce l'accesso casuale e memorizza i dati in file HDFS indicizzati per ricerche più veloci. |
Meccanismo di memorizzazione in HBase
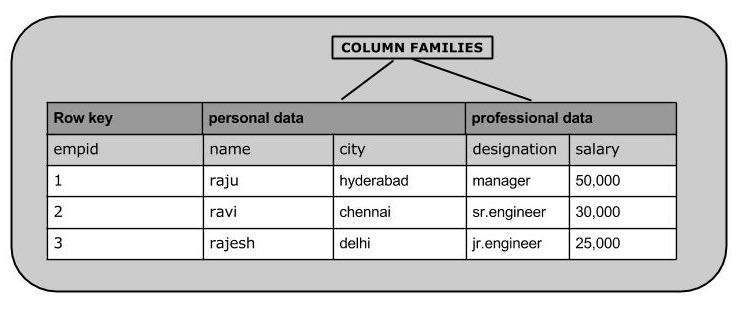
HBase è un file column-oriented databasee le tabelle in esso contenute sono ordinate per riga. Lo schema della tabella definisce solo le famiglie di colonne, che sono le coppie chiave-valore. Una tabella ha più famiglie di colonne e ciascuna famiglia di colonne può avere un numero qualsiasi di colonne. I valori delle colonne successive vengono archiviati in modo contiguo sul disco. Ogni valore di cella della tabella ha un timestamp. In breve, in un HBase:
- La tabella è una raccolta di righe.
- Row è una raccolta di famiglie di colonne.
- La famiglia di colonne è una raccolta di colonne.
- La colonna è una raccolta di coppie di valori chiave.
Di seguito è riportato uno schema di esempio di tabella in HBase.
| Rowid | Famiglia di colonne | Famiglia di colonne | Famiglia di colonne | Famiglia di colonne | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
Orientato a colonna e orientato a riga
I database orientati alle colonne sono quelli che archiviano le tabelle di dati come sezioni di colonne di dati, anziché come righe di dati. A breve, avranno famiglie di colonne.
| Database orientato alle righe | Database orientato alle colonne |
|---|---|
| È adatto per OLTP (Online Transaction Process). | È adatto per Online Analytical Processing (OLAP). |
| Tali database sono progettati per un numero limitato di righe e colonne. | I database orientati alle colonne sono progettati per tabelle di grandi dimensioni. |
L'immagine seguente mostra le famiglie di colonne in un database orientato alle colonne:
HBase e RDBMS
| HBase | RDBMS |
|---|---|
| HBase è senza schema, non ha il concetto di schema a colonne fisse; definisce solo famiglie di colonne. | Un RDBMS è governato dal suo schema, che descrive l'intera struttura delle tabelle. |
| È costruito per tavoli larghi. HBase è scalabile orizzontalmente. | È sottile e costruito per piccoli tavoli. Difficile da scalare. |
| Non ci sono transazioni in HBase. | RDBMS è transazionale. |
| Ha dati denormalizzati. | Avrà dati normalizzati. |
| È utile per dati semi-strutturati e strutturati. | È utile per i dati strutturati. |
Caratteristiche di HBase
- HBase è scalabile linearmente.
- Ha il supporto automatico dei guasti.
- Fornisce letture e scritture coerenti.
- Si integra con Hadoop, sia come sorgente che come destinazione.
- Ha una semplice API Java per il client.
- Fornisce la replica dei dati tra i cluster.
Dove utilizzare HBase
Apache HBase viene utilizzato per avere accesso in lettura / scrittura casuale e in tempo reale ai Big Data.
Ospita tabelle molto grandi in cima a cluster di hardware di base.
Apache HBase è un database non relazionale modellato sul Bigtable di Google. Bigtable agisce su Google File System, allo stesso modo Apache HBase funziona su Hadoop e HDFS.
Applicazioni di HBase
- Viene utilizzato ogni volta che è necessario scrivere applicazioni pesanti.
- HBase viene utilizzato ogni volta che è necessario fornire un accesso casuale veloce ai dati disponibili.
- Aziende come Facebook, Twitter, Yahoo e Adobe utilizzano internamente HBase.
Storia HBase
| Anno | Evento |
|---|---|
| Novembre 2006 | Google ha pubblicato il documento su BigTable. |
| Febbraio 2007 | Il prototipo iniziale di HBase è stato creato come contributo di Hadoop. |
| Ottobre 2007 | È stato rilasciato il primo HBase utilizzabile insieme a Hadoop 0.15.0. |
| Gennaio 2008 | HBase è diventato il sottoprogetto di Hadoop. |
| Ottobre 2008 | HBase 0.18.1 è stato rilasciato. |
| Gennaio 2009 | HBase 0.19.0 è stato rilasciato. |
| Settembre 2009 | HBase 0.20.0 è stato rilasciato. |
| Maggio 2010 | HBase è diventato il progetto di primo livello Apache. |