LISP - Guida rapida
John McCarthy ha inventato LISP nel 1958, poco dopo lo sviluppo di FORTRAN. È stato implementato per la prima volta da Steve Russell su un computer IBM 704.
È particolarmente adatto per i programmi di Intelligenza Artificiale, poiché elabora efficacemente le informazioni simboliche.
Common Lisp è nato, durante gli anni '80 e '90, nel tentativo di unificare il lavoro di diversi gruppi di implementazione che erano successori di Maclisp, come ZetaLisp e NIL (New Implementation of Lisp) ecc.
Serve come linguaggio comune, che può essere facilmente esteso per un'implementazione specifica.
I programmi scritti in Common LISP non dipendono dalle caratteristiche specifiche della macchina, come la lunghezza delle parole, ecc.
Caratteristiche di Common LISP
È indipendente dalla macchina
Utilizza una metodologia di progettazione iterativa e una facile estensibilità.
Permette l'aggiornamento dinamico dei programmi.
Fornisce debug di alto livello.
Fornisce una programmazione avanzata orientata agli oggetti.
Fornisce un comodo sistema macro.
Fornisce tipi di dati ad ampio raggio come oggetti, strutture, elenchi, vettori, array regolabili, tabelle hash e simboli.
È basato sull'espressione.
Fornisce un sistema di condizioni orientato agli oggetti.
Fornisce una libreria I / O completa.
Fornisce ampie strutture di controllo.
Applicazioni integrate in LISP
Grandi applicazioni di successo costruite in Lisp.
Emacs
G2
AutoCad
Igor Engraver
Yahoo Store
Configurazione dell'ambiente locale
Se sei ancora disposto a configurare il tuo ambiente per il linguaggio di programmazione Lisp, hai bisogno dei seguenti due software disponibili sul tuo computer, (a) Text Editor e (b) The Lisp Executer.
Editor di testo
Questo verrà utilizzato per digitare il tuo programma. Esempi di pochi editor includono Blocco note di Windows, comando OS Edit, Brief, Epsilon, EMACS e vim o vi.
Il nome e la versione dell'editor di testo possono variare a seconda dei sistemi operativi. Ad esempio, il Blocco note verrà utilizzato su Windows e vim o vi possono essere utilizzati su Windows e Linux o UNIX.
I file che crei con il tuo editor sono chiamati file sorgente e contengono il codice sorgente del programma. I file sorgente per i programmi Lisp sono generalmente denominati con l'estensione ".lisp".
Prima di iniziare la programmazione, assicurati di disporre di un editor di testo e di avere esperienza sufficiente per scrivere un programma per computer, salvarlo in un file e infine eseguirlo.
Il Lisp Executer
Il codice sorgente scritto nel file sorgente è la sorgente leggibile dall'uomo per il tuo programma. Deve essere "eseguito", per trasformarsi in linguaggio macchina in modo che la tua CPU possa effettivamente eseguire il programma secondo le istruzioni fornite.
Questo linguaggio di programmazione Lisp verrà utilizzato per eseguire il codice sorgente nel programma eseguibile finale. Presumo che tu abbia una conoscenza di base di un linguaggio di programmazione.
CLISP è il compilatore multi-architettura GNU Common LISP utilizzato per configurare LISP in Windows. La versione per Windows emula un ambiente unix usando MingW sotto Windows. Il programma di installazione si occupa di questo e aggiunge automaticamente clisp alla variabile PATH di Windows.
È possibile ottenere l'ultimo CLISP per Windows da qui - https://sourceforge.net/projects/clisp/files/latest/download
Per impostazione predefinita, crea un collegamento nel menu Start per l'interprete riga per riga.
Come utilizzare CLISP
Durante l'installazione, clisp viene automaticamente aggiunto alla variabile PATH se selezioni l'opzione (CONSIGLIATO) Ciò significa che puoi semplicemente aprire una nuova finestra del prompt dei comandi e digitare "clisp" per far apparire il compilatore.
Per eseguire un file * .lisp o * .lsp, usa semplicemente -
clisp hello.lispLe espressioni LISP sono chiamate espressioni simboliche o s-espressioni. Le s-espressioni sono composte da tre oggetti validi, atomi, liste e stringhe.
Qualsiasi espressione s è un programma valido.
I programmi LISP vengono eseguiti su un file interpreter o come compiled code.
L'interprete controlla il codice sorgente in un ciclo ripetuto, chiamato anche ciclo di lettura-valutazione-stampa (REPL). Legge il codice del programma, lo valuta e stampa i valori restituiti dal programma.
Un semplice programma
Scriviamo un'espressione s per trovare la somma dei tre numeri 7, 9 e 11. Per fare ciò, possiamo digitare al prompt dell'interprete.
(+ 7 9 11)LISP restituisce il risultato -
27Se desideri eseguire lo stesso programma di un codice compilato, crea un file di codice sorgente LISP denominato myprog.lisp e digita il codice seguente.
(write (+ 7 9 11))Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
27LISP utilizza la notazione del prefisso
Potresti aver notato che LISP utilizza prefix notation.
Nel programma sopra il simbolo + funziona come il nome della funzione per il processo di somma dei numeri.
Nella notazione del prefisso, gli operatori vengono scritti prima dei loro operandi. Ad esempio, l'espressione,
a * ( b + c ) / dsarà scritto come -
(/ (* a (+ b c) ) d)Facciamo un altro esempio, scriviamo il codice per convertire la temperatura Fahrenheit di 60 o F nella scala centigrado -
L'espressione matematica per questa conversione sarà:
(60 * 9 / 5) + 32Crea un file di codice sorgente denominato main.lisp e digita il codice seguente.
(write(+ (* (/ 9 5) 60) 32))Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
140Valutazione dei programmi LISP
La valutazione dei programmi LISP ha due parti:
Traduzione del testo del programma in oggetti Lisp da un programma di lettura
Implementazione della semantica del linguaggio in termini di questi oggetti da parte di un programma di valutazione
Il processo di valutazione prevede i seguenti passaggi:
Il lettore traduce le stringhe di caratteri in oggetti LISP o s-expressions.
Il valutatore definisce la sintassi di Lisp formsche sono costruiti da s-espressioni. Questo secondo livello di valutazione definisce una sintassi che determina quales-expressions sono moduli LISP.
Il valutatore funziona come una funzione che accetta una forma LISP valida come argomento e restituisce un valore. Questo è il motivo per cui mettiamo l'espressione LISP tra parentesi, perché stiamo inviando l'intera espressione / modulo al valutatore come argomenti.
Il programma "Hello World"
Imparare un nuovo linguaggio di programmazione non decolla davvero finché non impari a salutare il mondo intero in quella lingua, giusto!
Quindi, crea un nuovo file di codice sorgente denominato main.lisp e digita il seguente codice al suo interno.
(write-line "Hello World")
(write-line "I am at 'Tutorials Point'! Learning LISP")Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
Hello World
I am at 'Tutorials Point'! Learning LISPElementi fondamentali di base in LISP
I programmi LISP sono costituiti da tre elementi costitutivi di base:
- atom
- list
- string
Un atomè un numero o una stringa di caratteri contigui. Include numeri e caratteri speciali.
Di seguito sono riportati esempi di alcuni atomi validi:
hello-from-tutorials-point
name
123008907
*hello*
Block#221
abc123UN list è una sequenza di atomi e / o altri elenchi racchiusi tra parentesi.
Di seguito sono riportati alcuni esempi di elenchi validi:
( i am a list)
(a ( a b c) d e fgh)
(father tom ( susan bill joe))
(sun mon tue wed thur fri sat)
( )UN string è un gruppo di caratteri racchiuso tra virgolette doppie.
Di seguito sono riportati alcuni esempi di alcune stringhe valide:
" I am a string"
"a ba c d efg #$%^&!"
"Please enter the following details :"
"Hello from 'Tutorials Point'! "Aggiunta di commenti
Il simbolo del punto e virgola (;) viene utilizzato per indicare una riga di commento.
Per esempio,
(write-line "Hello World") ; greet the world
; tell them your whereabouts
(write-line "I am at 'Tutorials Point'! Learning LISP")Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
Hello World
I am at 'Tutorials Point'! Learning LISPAlcuni punti importanti prima di passare a Next
Di seguito sono riportati alcuni dei punti importanti da notare:
Le operazioni numeriche di base in LISP sono +, -, * e /
LISP rappresenta una chiamata di funzione f (x) come (fx), ad esempio cos (45) è scritto come cos 45
Le espressioni LISP non fanno distinzione tra maiuscole e minuscole, cos 45 o COS 45 sono uguali.
LISP cerca di valutare tutto, inclusi gli argomenti di una funzione. Solo tre tipi di elementi sono costanti e restituiscono sempre il proprio valore
Numbers
La lettera t, che sta per logico vero.
Il valore nil, che sta per falso logico, così come un elenco vuoto.
Poco di più sui moduli LISP
Nel capitolo precedente, abbiamo accennato al fatto che il processo di valutazione del codice LISP richiede i seguenti passaggi.
Il lettore traduce le stringhe di caratteri in oggetti LISP o s-expressions.
Il valutatore definisce la sintassi di Lisp formsche sono costruiti da s-espressioni. Questo secondo livello di valutazione definisce una sintassi che determina quali espressioni s sono forme LISP.
Ora, un modulo LISP potrebbe essere.
- Un atomo
- Un elenco vuoto o non
- Qualsiasi elenco che ha un simbolo come primo elemento
Il valutatore funziona come una funzione che accetta una forma LISP valida come argomento e restituisce un valore. Questo è il motivo per cui inseriamo l'estensioneLISP expression in parenthesis, perché stiamo inviando l'intera espressione / modulo al valutatore come argomenti.
Convenzioni di denominazione in LISP
Il nome oi simboli possono essere costituiti da un numero qualsiasi di caratteri alfanumerici diversi da spazi bianchi, parentesi aperte e chiuse, virgolette doppie e singole, barra rovesciata, virgola, due punti, punto e virgola e barra verticale. Per utilizzare questi caratteri in un nome, è necessario utilizzare il carattere di escape (\).
Un nome può avere cifre ma non interamente composto da cifre, perché in tal caso verrebbe letto come un numero. Allo stesso modo un nome può avere punti, ma non può essere composto interamente da punti.
Uso delle virgolette singole
LISP valuta tutto, inclusi gli argomenti della funzione e i membri dell'elenco.
A volte, dobbiamo prendere gli atomi o le liste letteralmente e non vogliamo che vengano valutati o trattati come chiamate di funzione.
Per fare ciò, dobbiamo far precedere l'atomo o l'elenco con una virgoletta singola.
Il seguente esempio lo dimostra.
Crea un file denominato main.lisp e digita il seguente codice al suo interno.
(write-line "single quote used, it inhibits evaluation")
(write '(* 2 3))
(write-line " ")
(write-line "single quote not used, so expression evaluated")
(write (* 2 3))Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
single quote used, it inhibits evaluation
(* 2 3)
single quote not used, so expression evaluated
6In LISP, le variabili non vengono digitate, ma gli oggetti dati lo sono.
I tipi di dati LISP possono essere classificati come.
Scalar types - ad esempio, tipi di numeri, caratteri, simboli ecc.
Data structures - ad esempio, elenchi, vettori, vettori di bit e stringhe.
Qualsiasi variabile può prendere qualsiasi oggetto LISP come valore, a meno che tu non l'abbia dichiarato esplicitamente.
Sebbene non sia necessario specificare un tipo di dati per una variabile LISP, tuttavia, aiuta in certe espansioni di loop, nelle dichiarazioni di metodi e in alcune altre situazioni che discuteremo nei capitoli successivi.
I tipi di dati sono organizzati in una gerarchia. Un tipo di dati è un insieme di oggetti LISP e molti oggetti possono appartenere a uno di questi set.
Il typep predicato viene utilizzato per determinare se un oggetto appartiene a un tipo specifico.
Il type-of funzione restituisce il tipo di dati di un dato oggetto.
Specificatori di tipo in LISP
Gli identificatori di tipo sono simboli definiti dal sistema per i tipi di dati.
| Vettore | fixnum | pacchetto | stringa semplice |
| atomo | galleggiante | nome del percorso | vettore semplice |
| bignum | funzione | stato casuale | galleggiante singolo |
| po | tabella hash | rapporto | carattere standard |
| bit-vettore | numero intero | razionale | ruscello |
| personaggio | parola chiave | leggibile | corda |
| [Comune] | elenco | sequenza | [string-char] |
| funzione compilata | galleggiante lungo | galleggiante corto | simbolo |
| complesso | nulla | byte con segno | t |
| contro | nullo | array semplice | byte senza segno |
| doppio galleggiante | numero | vettore di bit semplice | vettore |
Oltre a questi tipi definiti dal sistema, è possibile creare i propri tipi di dati. Quando un tipo di struttura viene definito utilizzandodefstruct funzione, il nome del tipo di struttura diventa un simbolo di tipo valido.
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq x 10)
(setq y 34.567)
(setq ch nil)
(setq n 123.78)
(setq bg 11.0e+4)
(setq r 124/2)
(print x)
(print y)
(print n)
(print ch)
(print bg)
(print r)Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
10
34.567
123.78
NIL
110000.0
62Esempio 2
Successivamente controlliamo i tipi di variabili utilizzate nell'esempio precedente. Crea un nuovo file di codice sorgente denominato main. lisp e digita il codice seguente.
(defvar x 10)
(defvar y 34.567)
(defvar ch nil)
(defvar n 123.78)
(defvar bg 11.0e+4)
(defvar r 124/2)
(print (type-of x))
(print (type-of y))
(print (type-of n))
(print (type-of ch))
(print (type-of bg))
(print (type-of r))Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
(INTEGER 0 281474976710655)
SINGLE-FLOAT
SINGLE-FLOAT
NULL
SINGLE-FLOAT
(INTEGER 0 281474976710655)Le macro consentono di estendere la sintassi del LISP standard.
Tecnicamente, una macro è una funzione che accetta un'espressione s come argomenti e restituisce un modulo LISP, che viene quindi valutato.
Definizione di una macro
In LISP, una macro denominata viene definita utilizzando un'altra macro denominata defmacro. La sintassi per la definizione di una macro è:
(defmacro macro-name (parameter-list))
"Optional documentation string."
body-formLa definizione della macro consiste nel nome della macro, un elenco di parametri, una stringa di documentazione opzionale e un corpo di espressioni Lisp che definiscono il lavoro che deve essere eseguito dalla macro.
Esempio
Scriviamo una semplice macro chiamata setTo10, che prenderà un numero e ne imposterà il valore a 10.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defmacro setTo10(num)
(setq num 10)(print num))
(setq x 25)
(print x)
(setTo10 x)Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
25
10In LISP, ogni variabile è rappresentata da un symbol. Il nome della variabile è il nome del simbolo e viene memorizzato nella cella di memorizzazione del simbolo.
Variabili globali
Le variabili globali hanno valori permanenti in tutto il sistema LISP e rimangono in vigore fino a quando non viene specificato un nuovo valore.
Le variabili globali vengono generalmente dichiarate utilizzando l'estensione defvar costruire.
Per esempio
(defvar x 234)
(write x)Quando si fa clic sul pulsante Esegui o si digita Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è
234Poiché non esiste una dichiarazione di tipo per le variabili in LISP, si specifica direttamente un valore per un simbolo con l'estensione setq costruire.
Per esempio
->(setq x 10)L'espressione sopra assegna il valore 10 alla variabile x. Puoi fare riferimento alla variabile usando il simbolo stesso come espressione.
Il symbol-value la funzione permette di estrarre il valore memorizzato nel luogo di memorizzazione del simbolo.
Per esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq x 10)
(setq y 20)
(format t "x = ~2d y = ~2d ~%" x y)
(setq x 100)
(setq y 200)
(format t "x = ~2d y = ~2d" x y)Quando si fa clic sul pulsante Esegui o si digita Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è.
x = 10 y = 20
x = 100 y = 200Variabili locali
Le variabili locali sono definite all'interno di una determinata procedura. Anche i parametri denominati come argomenti all'interno di una definizione di funzione sono variabili locali. Le variabili locali sono accessibili solo all'interno della rispettiva funzione.
Come le variabili globali, anche le variabili locali possono essere create utilizzando il setq costruire.
Ci sono altri due costrutti: let e prog per creare variabili locali.
Il costrutto let ha la seguente sintassi.
(let ((var1 val1) (var2 val2).. (varn valn))<s-expressions>)Dove var1, var2, ..varn sono nomi di variabili e val1, val2, .. valn sono i valori iniziali assegnati alle rispettive variabili.
quando letviene eseguita, a ciascuna variabile viene assegnato il rispettivo valore e infine viene valutata l' espressione s . Viene restituito il valore dell'ultima espressione valutata.
Se non includi un valore iniziale per una variabile, viene assegnato a nil.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(let ((x 'a) (y 'b)(z 'c))
(format t "x = ~a y = ~a z = ~a" x y z))Quando si fa clic sul pulsante Esegui o si digita Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è.
x = A y = B z = CIl prog Il costrutto ha anche l'elenco delle variabili locali come primo argomento, seguito dal corpo del file prog, e qualsiasi numero di espressioni s.
Il prog funzione esegue l'elenco di s-espressioni in sequenza e restituisce nil a meno che non incontri una chiamata di funzione denominata return. Quindi l'argomento del return la funzione viene valutata e restituita.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(prog ((x '(a b c))(y '(1 2 3))(z '(p q 10)))
(format t "x = ~a y = ~a z = ~a" x y z))Quando si fa clic sul pulsante Esegui o si digita Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è.
x = (A B C) y = (1 2 3) z = (P Q 10)In LISP, le costanti sono variabili che non cambiano mai i propri valori durante l'esecuzione del programma. Le costanti vengono dichiarate utilizzando ildefconstant costruire.
Esempio
L'esempio seguente mostra la dichiarazione di una costante globale PI e l'utilizzo successivo di questo valore all'interno di una funzione denominata area-circle che calcola l'area di un cerchio.
Il defun viene utilizzato per definire una funzione, lo esamineremo in Functions capitolo.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defconstant PI 3.141592)
(defun area-circle(rad)
(terpri)
(format t "Radius: ~5f" rad)
(format t "~%Area: ~10f" (* PI rad rad)))
(area-circle 10)Quando si fa clic sul pulsante Esegui o si digita Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è.
Radius: 10.0
Area: 314.1592Un operatore è un simbolo che dice al compilatore di eseguire specifiche manipolazioni matematiche o logiche. LISP consente numerose operazioni sui dati, supportate da varie funzioni, macro e altri costrutti.
Le operazioni consentite sui dati potrebbero essere classificate come:
- Operazioni aritmetiche
- Operazioni di confronto
- Operazioni logiche
- Operazioni bit per bit
Operazioni aritmetiche
La tabella seguente mostra tutti gli operatori aritmetici supportati da LISP. Assumi variabileA detiene 10 e variabile B tiene 20 quindi -
Show Examples
| Operatore | Descrizione | Esempio |
|---|---|---|
| + | Aggiunge due operandi | (+ AB) darà 30 |
| - | Sottrae il secondo operando dal primo | (- AB) darà -10 |
| * | Moltiplica entrambi gli operandi | (* AB) darà 200 |
| / | Divide il numeratore per il de-numeratore | (/ BA) darà 2 |
| mod, rem | Operatore modulo e resto di dopo una divisione intera | (mod BA) darà 0 |
| incf | L'operatore Incrementa aumenta il valore intero in base al secondo argomento specificato | (incf A 3) darà 13 |
| decf | L'operatore Decrementa diminuisce il valore intero del secondo argomento specificato | (decf A 4) darà 9 |
Operazioni di confronto
La tabella seguente mostra tutti gli operatori relazionali supportati da LISP che confronta i numeri. Tuttavia, a differenza degli operatori relazionali in altre lingue, gli operatori di confronto LISP possono richiedere più di due operandi e funzionano solo sui numeri.
Assumi variabile A detiene 10 e variabile B detiene 20, quindi -
Show Examples
| Operatore | Descrizione | Esempio |
|---|---|---|
| = | Controlla se i valori degli operandi sono tutti uguali o meno, in caso affermativo la condizione diventa vera. | (= AB) non è vero. |
| / = | Controlla se i valori degli operandi sono tutti diversi o meno, se i valori non sono uguali la condizione diventa vera. | (/ = AB) è vero. |
| > | Controlla se i valori degli operandi stanno diminuendo in modo monotono. | (> AB) non è vero. |
| < | Controlla se i valori degli operandi aumentano in modo monotono. | (<AB) è vero. |
| > = | Controlla se il valore di qualsiasi operando sinistro è maggiore o uguale al valore dell'operando destro successivo, in caso affermativo la condizione diventa vera. | (> = AB) non è vero. |
| <= | Controlla se il valore di un qualsiasi operando sinistro è minore o uguale al valore del suo operando destro, in caso affermativo la condizione diventa vera. | (<= AB) è vero. |
| max | Confronta due o più argomenti e restituisce il valore massimo. | (max AB) restituisce 20 |
| min | Confronta due o più argomenti e restituisce il valore minimo. | (min AB) restituisce 10 |
Operazioni logiche su valori booleani
Common LISP fornisce tre operatori logici: and, or, e notche opera su valori booleani. AssumereA ha valore nullo e B ha valore 5, quindi -
Show Examples
| Operatore | Descrizione | Esempio |
|---|---|---|
| e | Richiede un numero qualsiasi di argomenti. Gli argomenti vengono valutati da sinistra a destra. Se tutti gli argomenti restituiscono un valore diverso da zero, viene restituito il valore dell'ultimo argomento. In caso contrario, viene restituito zero. | (e AB) restituirà NIL. |
| o | Richiede un numero qualsiasi di argomenti. Gli argomenti vengono valutati da sinistra a destra finché non si valuta un valore diverso da zero, in tal caso viene restituito il valore dell'argomento, altrimenti restituiscenil. | (o AB) restituirà 5. |
| non | Richiede un argomento e restituisce t se l'argomento restituisce nil. | (non A) restituirà T. |
Operazioni bit per bit sui numeri
Gli operatori bit per bit lavorano sui bit ed eseguono operazioni bit per bit. Le tabelle di verità per le operazioni bit per bit and, or e xor sono le seguenti:
Show Examples
| p | q | pe q | p o q | p xo q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Assume if A = 60; and B = 13; now in binary format they will be as follows:
A = 0011 1100
B = 0000 1101
-----------------
A and B = 0000 1100
A or B = 0011 1101
A xor B = 0011 0001
not A = 1100 0011Gli operatori bit per bit supportati da LISP sono elencati nella tabella seguente. Assumi variabileA detiene 60 e variabile B tiene 13, quindi -
| Operatore | Descrizione | Esempio |
|---|---|---|
| logand | Ciò restituisce l'AND logico bit-saggio dei suoi argomenti. Se non viene fornito alcun argomento, il risultato è -1, che è un'identità per questa operazione. | (logand ab)) darà 12 |
| logior | Restituisce l'OR logico bit-saggio INCLUSIVE dei suoi argomenti. Se non viene fornito alcun argomento, il risultato è zero, che è un'identità per questa operazione. | (logior ab) darà 61 |
| logxor | Ciò restituisce l'OR ESCLUSIVO logico bit per bit dei suoi argomenti. Se non viene fornito alcun argomento, il risultato è zero, che è un'identità per questa operazione. | (logxor ab) darà 49 |
| lognor | Questo restituisce il bit per bit NON dei suoi argomenti. Se non viene fornito alcun argomento, il risultato è -1, che è un'identità per questa operazione. | (lognor ab) darà -62, |
| logeqv | Ciò restituisce l'EQUIVALENZA logica bit per bit (nota anche come esclusivo né) dei suoi argomenti. Se non viene fornito alcun argomento, il risultato è -1, che è un'identità per questa operazione. | (logeqv ab) darà -50 |
Le strutture decisionali richiedono che il programmatore specifichi una o più condizioni che devono essere valutate o testate dal programma, insieme a una o più istruzioni da eseguire se la condizione è determinata essere vera e, facoltativamente, altre istruzioni da eseguire se la condizione è determinato a essere falso.
Di seguito è riportata la forma generale di una tipica struttura decisionale presente nella maggior parte dei linguaggi di programmazione:
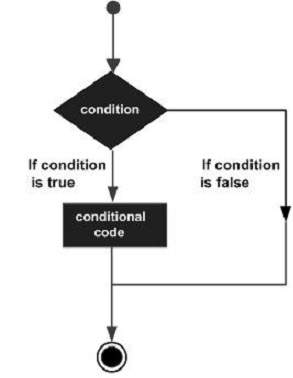
LISP fornisce i seguenti tipi di costrutti decisionali. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Costruisci e descrizione |
|---|---|
| 1 | cond Questo costrutto viene utilizzato per il controllo di più clausole test-action. Può essere paragonato alle istruzioni if annidate in altri linguaggi di programmazione. |
| 2 | Se Il costrutto if ha varie forme. Nella forma più semplice è seguito da una clausola di test, un'azione di test e alcune altre azioni conseguenti. Se la clausola di test restituisce true, l'azione di test viene eseguita altrimenti, viene valutata la clausola conseguente. |
| 3 | quando Nella forma più semplice è seguito da una clausola di test e da un'azione di test. Se la clausola di test restituisce true, l'azione di test viene eseguita altrimenti, viene valutata la clausola conseguente. |
| 4 | Astuccio Questo costrutto implementa più clausole test-action come il costrutto cond. Tuttavia, valuta una forma chiave e consente più clausole di azione in base alla valutazione di quella forma chiave. |
Potrebbe esserci una situazione in cui è necessario eseguire un blocco di numeri di codice di volte. Un'istruzione loop ci consente di eseguire un'istruzione o un gruppo di istruzioni più volte e la seguente è la forma generale di un'istruzione loop nella maggior parte dei linguaggi di programmazione.
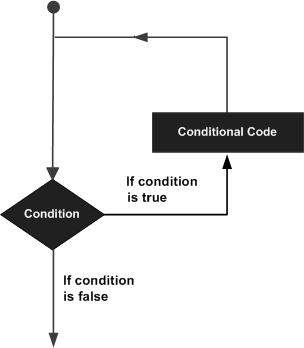
LISP fornisce i seguenti tipi di costrutti per gestire i requisiti di loop. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Costruisci e descrizione |
|---|---|
| 1 | ciclo continuo Il loopcostrutto è la forma più semplice di iterazione fornita da LISP. Nella sua forma più semplice, consente di eseguire ripetutamente alcune istruzioni finché non trova un filereturn dichiarazione. |
| 2 | loop per Il costrutto loop for ti consente di implementare un'iterazione simile al ciclo for, come più comune in altri linguaggi. |
| 3 | fare Il costrutto do viene utilizzato anche per eseguire l'iterazione utilizzando LISP. Fornisce una forma strutturata di iterazione. |
| 4 | dotimes Il costrutto dotimes consente il ciclo per un numero fisso di iterazioni. |
| 5 | dolista Il costrutto dolist consente l'iterazione attraverso ogni elemento di un elenco. |
Uscita con grazia da un blocco
Il block e return-from consente di uscire con grazia da qualsiasi blocco annidato in caso di errore.
Il blockLa funzione consente di creare un blocco denominato con un corpo composto da zero o più istruzioni. La sintassi è -
(block block-name(
...
...
))Il return-from la funzione accetta un nome di blocco e un valore di ritorno opzionale (il valore predefinito è nullo).
Il seguente esempio lo dimostra:
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il seguente codice in esso -
(defun demo-function (flag)
(print 'entering-outer-block)
(block outer-block
(print 'entering-inner-block)
(print (block inner-block
(if flag
(return-from outer-block 3)
(return-from inner-block 5)
)
(print 'This-wil--not-be-printed))
)
(print 'left-inner-block)
(print 'leaving-outer-block)
t)
)
(demo-function t)
(terpri)
(demo-function nil)Quando fai clic sul pulsante Esegui o digiti Ctrl + E, LISP lo esegue immediatamente e il risultato restituito è -
ENTERING-OUTER-BLOCK
ENTERING-INNER-BLOCK
ENTERING-OUTER-BLOCK
ENTERING-INNER-BLOCK
5
LEFT-INNER-BLOCK
LEAVING-OUTER-BLOCKUna funzione è un gruppo di istruzioni che insieme eseguono un'attività.
Puoi dividere il tuo codice in funzioni separate. Come suddividere il codice tra le diverse funzioni dipende da te, ma logicamente la divisione di solito è in modo che ciascuna funzione svolga un compito specifico.
Definizione di funzioni in LISP
La macro denominata defunviene utilizzato per definire le funzioni. Ildefun la macro ha bisogno di tre argomenti:
- Nome della funzione
- Parametri della funzione
- Corpo della funzione
La sintassi per defun è -
(defun name (parameter-list) "Optional documentation string." body)Illustriamo il concetto con semplici esempi.
Esempio 1
Scriviamo una funzione chiamata averagenum che stamperà la media di quattro numeri. Invieremo questi numeri come parametri.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun averagenum (n1 n2 n3 n4)
(/ ( + n1 n2 n3 n4) 4)
)
(write(averagenum 10 20 30 40))Quando esegui il codice, restituisce il seguente risultato:
25Esempio 2
Definiamo e chiamiamo una funzione che calcola l'area di un cerchio quando il raggio del cerchio è dato come argomento.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun area-circle(rad)
"Calculates area of a circle with given radius"
(terpri)
(format t "Radius: ~5f" rad)
(format t "~%Area: ~10f" (* 3.141592 rad rad))
)
(area-circle 10)Quando esegui il codice, restituisce il seguente risultato:
Radius: 10.0
Area: 314.1592Si prega di notare che -
È possibile fornire un elenco vuoto come parametri, il che significa che la funzione non accetta argomenti, l'elenco è vuoto, scritto come ().
LISP consente anche argomenti opzionali, multipli e basati su parole chiave.
La stringa di documentazione descrive lo scopo della funzione. È associato al nome della funzione e può essere ottenuto utilizzando ildocumentation funzione.
Il corpo della funzione può essere costituito da un numero qualsiasi di espressioni Lisp.
Il valore dell'ultima espressione nel corpo viene restituito come valore della funzione.
È inoltre possibile restituire un valore dalla funzione utilizzando il return-from operatore speciale.
Cerchiamo di discutere i concetti di cui sopra in breve. Fare clic sui seguenti collegamenti per trovare i dettagli -
Parametri opzionali
Parametri di riposo
Parametri delle parole chiave
Restituzione di valori da una funzione
Funzioni Lambda
Funzioni di mappatura
I predicati sono funzioni che testano i loro argomenti per alcune condizioni specifiche e restituiscono zero se la condizione è falsa o un valore diverso da zero se la condizione è vera.
La tabella seguente mostra alcuni dei predicati più comunemente usati:
| Sr.No. | Predicato e descrizione |
|---|---|
| 1 | atom Accetta un argomento e restituisce t se l'argomento è un atomo o nullo in caso contrario. |
| 2 | equal Richiede due argomenti e restituisce t se sono strutturalmente uguali o nil altrimenti. |
| 3 | eq Richiede due argomenti e restituisce t se sono gli stessi oggetti identici, condividono la stessa posizione di memoria o nil altrimenti. |
| 4 | eql Richiede due argomenti e restituisce t se gli argomenti sono eq, o se sono numeri dello stesso tipo con lo stesso valore, o se sono oggetti carattere che rappresentano lo stesso carattere, o nil altrimenti. |
| 5 | evenp Accetta un argomento numerico e restituisce t se l'argomento è un numero pari o nil in caso contrario. |
| 6 | oddp Accetta un argomento numerico e restituisce t se l'argomento è un numero dispari o nil in caso contrario. |
| 7 | zerop Accetta un argomento numerico e restituisce t se l'argomento è zero o nil in caso contrario. |
| 8 | null Richiede un argomento e restituisce t se l'argomento restituisce zero, altrimenti ritorna nil. |
| 9 | listp Richiede un argomento e restituisce t se l'argomento restituisce una lista altrimenti ritorna nil. |
| 10 | greaterp Richiede uno o più argomenti e restituisce t se c'è un solo argomento o gli argomenti sono successivamente più grandi da sinistra a destra, o nil in caso contrario. |
| 11 | lessp Richiede uno o più argomenti e restituisce t se c'è un solo argomento o gli argomenti sono successivamente più piccoli da sinistra a destra, o nil in caso contrario. |
| 12 | numberp Richiede un argomento e restituisce t se l'argomento è un numero o nil in caso contrario. |
| 13 | symbolp Richiede un argomento e restituisce t se l'argomento è un simbolo altrimenti ritorna nil. |
| 14 | integerp Richiede un argomento e restituisce t se l'argomento è un numero intero altrimenti restituisce nil. |
| 15 | rationalp Richiede un argomento e restituisce t se l'argomento è un numero razionale, un rapporto o un numero, altrimenti restituisce nil. |
| 16 | floatp Richiede un argomento e restituisce t se l'argomento è un numero in virgola mobile altrimenti restituisce nil. |
| 17 | realp Richiede un argomento e restituisce t se l'argomento è un numero reale altrimenti restituisce nil. |
| 18 | complexp Richiede un argomento e restituisce t se l'argomento è un numero complesso altrimenti restituisce nil. |
| 19 | characterp Richiede un argomento e restituisce t se l'argomento è un carattere altrimenti ritorna nil. |
| 20 | stringp Richiede un argomento e restituisce t se l'argomento è un oggetto stringa altrimenti restituisce nil. |
| 21 | arrayp Richiede un argomento e restituisce t se l'argomento è un oggetto array, altrimenti restituisce nil. |
| 22 | packagep Richiede un argomento e restituisce t se l'argomento è un pacchetto altrimenti ritorna nil. |
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (atom 'abcd))
(terpri)
(write (equal 'a 'b))
(terpri)
(write (evenp 10))
(terpri)
(write (evenp 7 ))
(terpri)
(write (oddp 7 ))
(terpri)
(write (zerop 0.0000000001))
(terpri)
(write (eq 3 3.0 ))
(terpri)
(write (equal 3 3.0 ))
(terpri)
(write (null nil ))Quando esegui il codice, restituisce il seguente risultato:
T
NIL
T
NIL
T
NIL
NIL
NIL
TEsempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun factorial (num)
(cond ((zerop num) 1)
(t ( * num (factorial (- num 1))))
)
)
(setq n 6)
(format t "~% Factorial ~d is: ~d" n (factorial n))Quando esegui il codice, restituisce il seguente risultato:
Factorial 6 is: 720Common Lisp definisce diversi tipi di numeri. Ilnumber il tipo di dati include vari tipi di numeri supportati da LISP.
I tipi di numero supportati da LISP sono:
- Integers
- Ratios
- Numeri in virgola mobile
- Numeri complessi
Il diagramma seguente mostra la gerarchia dei numeri e vari tipi di dati numerici disponibili in LISP -
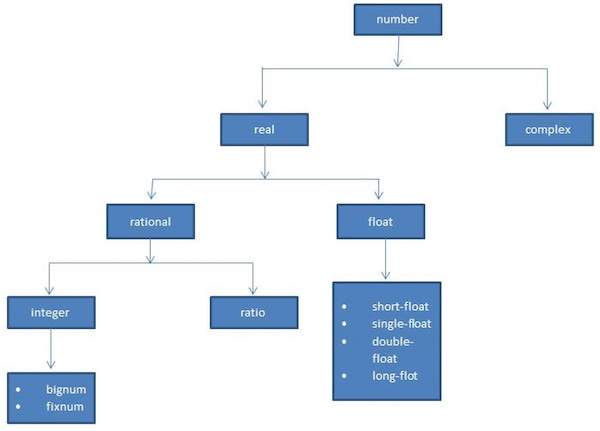
Vari tipi numerici in LISP
La tabella seguente descrive i vari tipi di dati numerici disponibili in LISP -
| Sr.No. | Tipo di dati e descrizione |
|---|---|
| 1 | fixnum Questo tipo di dati rappresenta numeri interi che non sono troppo grandi e per lo più nell'intervallo da -215 a 215-1 (dipende dalla macchina) |
| 2 | bignum Questi sono numeri molto grandi con dimensioni limitate dalla quantità di memoria allocata per LISP, non sono numeri fissi. |
| 3 | ratio Rappresenta il rapporto tra due numeri nella forma numeratore / denominatore. La funzione / produce sempre il risultato in rapporti, quando i suoi argomenti sono numeri interi. |
| 4 | float Rappresenta numeri non interi. Esistono quattro tipi di dati in virgola mobile con precisione crescente. |
| 5 | complex Rappresenta numeri complessi, indicati con #c. Le parti reale e immaginaria potrebbero essere numeri sia razionali che in virgola mobile. |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (/ 1 2))
(terpri)
(write ( + (/ 1 2) (/ 3 4)))
(terpri)
(write ( + #c( 1 2) #c( 3 -4)))Quando esegui il codice, restituisce il seguente risultato:
1/2
5/4
#C(4 -2)Funzioni numeriche
La tabella seguente descrive alcune funzioni numeriche di uso comune:
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | +, -, *, / Rispettive operazioni aritmetiche |
| 2 | sin, cos, tan, acos, asin, atan Rispettive funzioni trigonometriche. |
| 3 | sinh, cosh, tanh, acosh, asinh, atanh Rispettive funzioni iperboliche. |
| 4 | exp Funzione di esponenziazione. Calcola e x |
| 5 | expt Funzione di esponenziazione, prende sia base che potenza. |
| 6 | sqrt Calcola la radice quadrata di un numero. |
| 7 | log Funzione logaritmica. Se viene fornito un parametro, calcola il suo logaritmo naturale, altrimenti il secondo parametro viene utilizzato come base. |
| 8 | conjugate Calcola il complesso coniugato di un numero. In caso di numero reale, restituisce il numero stesso. |
| 9 | abs Restituisce il valore assoluto (o grandezza) di un numero. |
| 10 | gcd Calcola il massimo comune divisore dei numeri dati. |
| 11 | lcm Calcola il minimo comune multiplo dei numeri dati. |
| 12 | isqrt Fornisce il numero intero più grande minore o uguale alla radice quadrata esatta di un dato numero naturale. |
| 13 | floor, ceiling, truncate, round Tutte queste funzioni accettano due argomenti come un numero e restituiscono il quoziente; floor restituisce il numero intero più grande che non è maggiore del rapporto, ceiling sceglie il numero intero più piccolo che è maggiore del rapporto, truncate sceglie il numero intero dello stesso segno come rapporto con il valore assoluto più grande che è inferiore al valore assoluto di rapporto, e round sceglie un numero intero più vicino al rapporto. |
| 14 | ffloor, fceiling, ftruncate, fround Fa come sopra, ma restituisce il quoziente come numero in virgola mobile. |
| 15 | mod, rem Restituisce il resto in un'operazione di divisione. |
| 16 | float Converte un numero reale in un numero in virgola mobile. |
| 17 | rational, rationalize Converte un numero reale in un numero razionale. |
| 18 | numerator, denominator Restituisce le rispettive parti di un numero razionale. |
| 19 | realpart, imagpart Restituisce la parte reale e immaginaria di un numero complesso. |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (/ 45 78))
(terpri)
(write (floor 45 78))
(terpri)
(write (/ 3456 75))
(terpri)
(write (floor 3456 75))
(terpri)
(write (ceiling 3456 75))
(terpri)
(write (truncate 3456 75))
(terpri)
(write (round 3456 75))
(terpri)
(write (ffloor 3456 75))
(terpri)
(write (fceiling 3456 75))
(terpri)
(write (ftruncate 3456 75))
(terpri)
(write (fround 3456 75))
(terpri)
(write (mod 3456 75))
(terpri)
(setq c (complex 6 7))
(write c)
(terpri)
(write (complex 5 -9))
(terpri)
(write (realpart c))
(terpri)
(write (imagpart c))Quando esegui il codice, restituisce il seguente risultato:
15/26
0
1152/25
46
47
46
46
46.0
47.0
46.0
46.0
6
#C(6 7)
#C(5 -9)
6
7In LISP, i caratteri sono rappresentati come oggetti dati di tipo character.
Puoi indicare un oggetto carattere che precede # \ prima del carattere stesso. Ad esempio, # \ a indica il carattere a.
Lo spazio e altri caratteri speciali possono essere indicati facendo precedere # \ prima del nome del carattere. Ad esempio, # \ SPACE rappresenta il carattere spazio.
Il seguente esempio lo dimostra:
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write 'a)
(terpri)
(write #\a)
(terpri)
(write-char #\a)
(terpri)
(write-char 'a)Quando esegui il codice, restituisce il seguente risultato:
A
#\a
a
*** - WRITE-CHAR: argument A is not a characterPersonaggi speciali
Common LISP consente di utilizzare i seguenti caratteri speciali nel codice. Sono chiamati i caratteri semi-standard.
- #\Backspace
- #\Tab
- #\Linefeed
- #\Page
- #\Return
- #\Rubout
Funzioni di confronto dei caratteri
Le funzioni e gli operatori di confronto numerico, come, <e> non funzionano sui caratteri. Common LISP fornisce altri due set di funzioni per confrontare i caratteri nel codice.
Un set fa distinzione tra maiuscole e minuscole e l'altro.
La tabella seguente fornisce le funzioni:
| Funzioni sensibili al maiuscolo / minuscolo | Funzioni senza distinzione tra maiuscole e minuscole | Descrizione |
|---|---|---|
| char = | char-equal | Controlla se i valori degli operandi sono tutti uguali o meno, in caso affermativo la condizione diventa vera. |
| char / = | char-not-equal | Controlla se i valori degli operandi sono tutti diversi o meno, se i valori non sono uguali la condizione diventa vera. |
| char < | char-lessp | Controlla se i valori degli operandi stanno diminuendo in modo monotono. |
| char> | carattere maggiore p | Controlla se i valori degli operandi aumentano in modo monotono. |
| char <= | char-not-greaterp | Controlla se il valore di qualsiasi operando sinistro è maggiore o uguale al valore dell'operando destro successivo, in caso affermativo la condizione diventa vera. |
| char> = | char-not-lessp | Controlla se il valore di un qualsiasi operando sinistro è minore o uguale al valore del suo operando destro, in caso affermativo la condizione diventa vera. |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
; case-sensitive comparison
(write (char= #\a #\b))
(terpri)
(write (char= #\a #\a))
(terpri)
(write (char= #\a #\A))
(terpri)
;case-insensitive comparision
(write (char-equal #\a #\A))
(terpri)
(write (char-equal #\a #\b))
(terpri)
(write (char-lessp #\a #\b #\c))
(terpri)
(write (char-greaterp #\a #\b #\c))Quando esegui il codice, restituisce il seguente risultato:
NIL
T
NIL
T
NIL
T
NILLISP consente di definire array a dimensione singola o multipla utilizzando l'estensione make-arrayfunzione. Un array può memorizzare qualsiasi oggetto LISP come suoi elementi.
Tutti gli array sono costituiti da posizioni di memoria contigue. L'indirizzo più basso corrisponde al primo elemento e l'indirizzo più alto all'ultimo elemento.
Il numero di dimensioni di un array è chiamato il suo rango.
In LISP, un elemento della matrice è specificato da una sequenza di indici interi non negativi. La lunghezza della sequenza deve essere uguale al rango dell'array. L'indicizzazione inizia da zero.
Ad esempio, per creare un array con 10 celle, denominato my-array, possiamo scrivere -
(setf my-array (make-array '(10)))La funzione aref permette di accedere al contenuto delle celle. Richiede due argomenti, il nome dell'array e il valore dell'indice.
Ad esempio, per accedere al contenuto della decima cella, scriviamo:
(aref my-array 9)Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (setf my-array (make-array '(10))))
(terpri)
(setf (aref my-array 0) 25)
(setf (aref my-array 1) 23)
(setf (aref my-array 2) 45)
(setf (aref my-array 3) 10)
(setf (aref my-array 4) 20)
(setf (aref my-array 5) 17)
(setf (aref my-array 6) 25)
(setf (aref my-array 7) 19)
(setf (aref my-array 8) 67)
(setf (aref my-array 9) 30)
(write my-array)Quando esegui il codice, restituisce il seguente risultato:
#(NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL)
#(25 23 45 10 20 17 25 19 67 30)Esempio 2
Creiamo un array 3 per 3.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setf x (make-array '(3 3)
:initial-contents '((0 1 2 ) (3 4 5) (6 7 8)))
)
(write x)Quando esegui il codice, restituisce il seguente risultato:
#2A((0 1 2) (3 4 5) (6 7 8))Esempio 3
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq a (make-array '(4 3)))
(dotimes (i 4)
(dotimes (j 3)
(setf (aref a i j) (list i 'x j '= (* i j)))
)
)
(dotimes (i 4)
(dotimes (j 3)
(print (aref a i j))
)
)Quando esegui il codice, restituisce il seguente risultato:
(0 X 0 = 0)
(0 X 1 = 0)
(0 X 2 = 0)
(1 X 0 = 0)
(1 X 1 = 1)
(1 X 2 = 2)
(2 X 0 = 0)
(2 X 1 = 2)
(2 X 2 = 4)
(3 X 0 = 0)
(3 X 1 = 3)
(3 X 2 = 6)Sintassi completa per la funzione make-array
La funzione make-array accetta molti altri argomenti. Esaminiamo la sintassi completa di questa funzione:
make-array dimensions :element-type :initial-element :initial-contents :adjustable :fill-pointer :displaced-to :displaced-index-offsetA parte l' argomento delle dimensioni , tutti gli altri argomenti sono parole chiave. La tabella seguente fornisce una breve descrizione degli argomenti.
| Sr.No. | Argomento e descrizione |
|---|---|
| 1 | dimensions Fornisce le dimensioni dell'array. È un numero per un array unidimensionale e un elenco per un array multidimensionale. |
| 2 | :element-type È l'identificatore del tipo, il valore predefinito è T, ovvero qualsiasi tipo |
| 3 | :initial-element Valore degli elementi iniziali. Creerà un array con tutti gli elementi inizializzati su un valore particolare. |
| 4 | :initial-content Contenuto iniziale come oggetto. |
| 5 | :adjustable Aiuta a creare un vettore ridimensionabile (o regolabile) la cui memoria sottostante può essere ridimensionata. L'argomento è un valore booleano che indica se l'array è regolabile o meno, il valore predefinito è NIL. |
| 6 | :fill-pointer Tiene traccia del numero di elementi effettivamente memorizzati in un vettore ridimensionabile. |
| 7 | :displaced-to Aiuta a creare un array spostato o un array condiviso che condivide i suoi contenuti con l'array specificato. Entrambi gli array dovrebbero avere lo stesso tipo di elemento. L'opzione: displaced-to non può essere utilizzata con l'opzione: initial-element o: initial-contents. Il valore predefinito di questo argomento è nil. |
| 8 | :displaced-index-offset Fornisce l'offset dell'indice dell'array condiviso creato. |
Esempio 4
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array 4 :displaced-to myarray :displaced-index-offset 2))
(write myarray)
(terpri)
(write array2)Quando esegui il codice, restituisce il seguente risultato:
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9)))
#(C 1 2 3)Se l'array spostato è bidimensionale -
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array '(3 2) :displaced-to myarray :displaced-index-offset 2))
(write myarray)
(terpri)
(write array2)Quando esegui il codice, restituisce il seguente risultato:
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9)))
#2A((C 1) (2 3) (D E))Cambiamo l'offset dell'indice spostato su 5 -
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array '(3 2) :displaced-to myarray :displaced-index-offset 5))
(write myarray)
(terpri)
(write array2)Quando esegui il codice, restituisce il seguente risultato:
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9)))
#2A((3 D) (E F) (4 5))Esempio 5
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
;a one dimensional array with 5 elements,
;initail value 5
(write (make-array 5 :initial-element 5))
(terpri)
;two dimensional array, with initial element a
(write (make-array '(2 3) :initial-element 'a))
(terpri)
;an array of capacity 14, but fill pointer 5, is 5
(write(length (make-array 14 :fill-pointer 5)))
(terpri)
;however its length is 14
(write (array-dimensions (make-array 14 :fill-pointer 5)))
(terpri)
; a bit array with all initial elements set to 1
(write(make-array 10 :element-type 'bit :initial-element 1))
(terpri)
; a character array with all initial elements set to a
; is a string actually
(write(make-array 10 :element-type 'character :initial-element #\a))
(terpri)
; a two dimensional array with initial values a
(setq myarray (make-array '(2 2) :initial-element 'a :adjustable t))
(write myarray)
(terpri)
;readjusting the array
(adjust-array myarray '(1 3) :initial-element 'b)
(write myarray)Quando esegui il codice, restituisce il seguente risultato:
#(5 5 5 5 5)
#2A((A A A) (A A A))
5
(14)
#*1111111111
"aaaaaaaaaa"
#2A((A A) (A A))
#2A((A A B))Le stringhe in Common Lisp sono vettori, cioè array di caratteri unidimensionali.
I valori letterali stringa sono racchiusi tra virgolette doppie. Qualsiasi carattere supportato dal set di caratteri può essere racchiuso tra virgolette doppie per formare una stringa, tranne il carattere virgolette doppie (") e il carattere di escape (\). Tuttavia, è possibile includerli facendo l'escape con una barra rovesciata (\).
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write-line "Hello World")
(write-line "Welcome to Tutorials Point")
;escaping the double quote character
(write-line "Welcome to \"Tutorials Point\"")Quando esegui il codice, restituisce il seguente risultato:
Hello World
Welcome to Tutorials Point
Welcome to "Tutorials Point"Funzioni di confronto tra stringhe
Le funzioni e gli operatori di confronto numerico, come, <e> non funzionano sulle stringhe. Common LISP fornisce altri due set di funzioni per confrontare le stringhe nel codice. Un set fa distinzione tra maiuscole e minuscole e l'altro.
La tabella seguente fornisce le funzioni:
| Funzioni sensibili al maiuscolo / minuscolo | Funzioni senza distinzione tra maiuscole e minuscole | Descrizione |
|---|---|---|
| stringa = | stringa uguale | Controlla se i valori degli operandi sono tutti uguali o meno, in caso affermativo la condizione diventa vera. |
| stringa / = | stringa non uguale | Controlla se i valori degli operandi sono tutti diversi o meno, se i valori non sono uguali la condizione diventa vera. |
| stringa < | string-lessp | Controlla se i valori degli operandi stanno diminuendo in modo monotono. |
| stringa> | stringa-maggiore p | Controlla se i valori degli operandi aumentano in modo monotono. |
| stringa <= | stringa non maggiore p | Controlla se il valore di qualsiasi operando sinistro è maggiore o uguale al valore dell'operando destro successivo, in caso affermativo la condizione diventa vera. |
| stringa> = | string-not-lessp | Controlla se il valore di un qualsiasi operando sinistro è minore o uguale al valore del suo operando destro, in caso affermativo la condizione diventa vera. |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
; case-sensitive comparison
(write (string= "this is test" "This is test"))
(terpri)
(write (string> "this is test" "This is test"))
(terpri)
(write (string< "this is test" "This is test"))
(terpri)
;case-insensitive comparision
(write (string-equal "this is test" "This is test"))
(terpri)
(write (string-greaterp "this is test" "This is test"))
(terpri)
(write (string-lessp "this is test" "This is test"))
(terpri)
;checking non-equal
(write (string/= "this is test" "this is Test"))
(terpri)
(write (string-not-equal "this is test" "This is test"))
(terpri)
(write (string/= "lisp" "lisping"))
(terpri)
(write (string/= "decent" "decency"))Quando esegui il codice, restituisce il seguente risultato:
NIL
0
NIL
T
NIL
NIL
8
NIL
4
5Funzioni di controllo dei casi
La tabella seguente descrive le funzioni di controllo del caso:
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | string-upcase Converte la stringa in maiuscolo |
| 2 | string-downcase Converte la stringa in minuscolo |
| 3 | string-capitalize Rende in maiuscolo ogni parola della stringa |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write-line (string-upcase "a big hello from tutorials point"))
(write-line (string-capitalize "a big hello from tutorials point"))Quando esegui il codice, restituisce il seguente risultato:
A BIG HELLO FROM TUTORIALS POINT
A Big Hello From Tutorials PointCorde da taglio
La tabella seguente descrive le funzioni di trimming delle stringhe:
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | string-trim Prende una stringa di caratteri come primo argomento e una stringa come secondo argomento e restituisce una sottostringa in cui tutti i caratteri che si trovano nel primo argomento vengono rimossi dalla stringa dell'argomento. |
| 2 | String-left-trim Prende una stringa di caratteri come primo argomento e una stringa come secondo argomento e restituisce una sottostringa in cui tutti i caratteri che si trovano nel primo argomento vengono rimossi dall'inizio della stringa dell'argomento. |
| 3 | String-right-trim Prende uno o più caratteri stringa come primo argomento e una stringa come secondo argomento e restituisce una sottostringa in cui tutti i caratteri che si trovano nel primo argomento vengono rimossi dalla fine della stringa dell'argomento. |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write-line (string-trim " " " a big hello from tutorials point "))
(write-line (string-left-trim " " " a big hello from tutorials point "))
(write-line (string-right-trim " " " a big hello from tutorials point "))
(write-line (string-trim " a" " a big hello from tutorials point "))Quando esegui il codice, restituisce il seguente risultato:
a big hello from tutorials point
a big hello from tutorials point
a big hello from tutorials point
big hello from tutorials pointAltre funzioni di stringa
Le stringhe in LISP sono array e quindi anche sequenze. Tratteremo questi tipi di dati nei prossimi tutorial. Tutte le funzioni applicabili ad array e sequenze si applicano anche alle stringhe. Tuttavia, dimostreremo alcune funzioni di uso comune utilizzando vari esempi.
Calcolo della lunghezza
Il length funzione calcola la lunghezza di una stringa.
Estrazione della sottostringa
Il subseq restituisce una sottostringa (poiché anche una stringa è una sequenza) che inizia da un particolare indice e continua fino a un particolare indice finale o alla fine della stringa.
Accesso a un carattere in una stringa
Il char la funzione consente di accedere ai singoli caratteri di una stringa.
Example
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (length "Hello World"))
(terpri)
(write-line (subseq "Hello World" 6))
(write (char "Hello World" 6))Quando esegui il codice, restituisce il seguente risultato:
11
World
#\WOrdinamento e unione di stringhe
Il sortla funzione consente di ordinare una stringa. Accetta una sequenza (vettore o stringa) e un predicato a due argomenti e restituisce una versione ordinata della sequenza.
Il merge funzione prende due sequenze e un predicato e restituisce una sequenza prodotta dalla fusione delle due sequenze, in base al predicato.
Example
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
;sorting the strings
(write (sort (vector "Amal" "Akbar" "Anthony") #'string<))
(terpri)
;merging the strings
(write (merge 'vector (vector "Rishi" "Zara" "Priyanka")
(vector "Anju" "Anuj" "Avni") #'string<))Quando esegui il codice, restituisce il seguente risultato:
#("Akbar" "Amal" "Anthony")
#("Anju" "Anuj" "Avni" "Rishi" "Zara" "Priyanka")Inversione di una stringa
Il reverse funzione inverte una stringa.
Ad esempio, crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write-line (reverse "Are we not drawn onward, we few, drawn onward to new era"))Quando esegui il codice, restituisce il seguente risultato:
are wen ot drawno nward ,wef ew ,drawno nward ton ew erAConcatenazione di stringhe
La funzione concatenate concatena due stringhe. Questa è una funzione di sequenza generica e devi fornire il tipo di risultato come primo argomento.
Ad esempio, crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write-line (concatenate 'string "Are we not drawn onward, " "we few, drawn onward to new era"))Quando esegui il codice, restituisce il seguente risultato:
Are we not drawn onward, we few, drawn onward to new eraLa sequenza è un tipo di dati astratto in LISP. I vettori e gli elenchi sono i due sottotipi concreti di questo tipo di dati. Tutte le funzionalità definite sul tipo di dati di sequenza vengono effettivamente applicate su tutti i vettori e tipi di lista.
In questa sezione, discuteremo delle funzioni più comunemente usate sulle sequenze.
Prima di iniziare con vari modi di manipolare le sequenze (cioè vettori ed elenchi), diamo uno sguardo all'elenco di tutte le funzioni disponibili.
Creazione di una sequenza
La funzione make-sequence consente di creare una sequenza di qualsiasi tipo. La sintassi per questa funzione è:
make-sequence sqtype sqsize &key :initial-elementCrea una sequenza di tipo sqtype e di lunghezza sqsize.
Facoltativamente, puoi specificare un valore utilizzando l' argomento : initial-element , quindi ciascuno degli elementi verrà inizializzato su questo valore.
Ad esempio, crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (make-sequence '(vector float)
10
:initial-element 1.0))Quando esegui il codice, restituisce il seguente risultato:
#(1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0)Funzioni generiche sulle sequenze
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | elt Consente l'accesso a singoli elementi tramite un indice intero. |
| 2 | length Restituisce la lunghezza di una sequenza. |
| 3 | subseq Restituisce una sottosequenza estraendo la sottosequenza a partire da un particolare indice e continuando fino a un particolare indice finale o alla fine della sequenza. |
| 4 | copy-seq Restituisce una sequenza che contiene gli stessi elementi del suo argomento. |
| 5 | fill Viene utilizzato per impostare più elementi di una sequenza su un singolo valore. |
| 6 | replace Richiede due sequenze e la prima sequenza di argomenti viene modificata in modo distruttivo copiandovi gli elementi successivi dalla seconda sequenza di argomenti. |
| 7 | count Prende un elemento e una sequenza e restituisce il numero di volte in cui l'elemento appare nella sequenza. |
| 8 | reverse Restituisce una sequenza contenente gli stessi elementi dell'argomento ma in ordine inverso. |
| 9 | nreverse Restituisce la stessa sequenza contenente gli stessi elementi della sequenza ma in ordine inverso. |
| 10 | concatenate Crea una nuova sequenza contenente la concatenazione di un numero qualsiasi di sequenze. |
| 11 | position Prende un elemento e una sequenza e restituisce l'indice dell'elemento nella sequenza o nullo. |
| 12 | find Ci vuole un oggetto e una sequenza. Trova l'elemento nella sequenza e lo restituisce, se non lo trova restituisce zero. |
| 13 | sort Accetta una sequenza e un predicato a due argomenti e restituisce una versione ordinata della sequenza. |
| 14 | merge Richiede due sequenze e un predicato e restituisce una sequenza prodotta dalla fusione delle due sequenze, in base al predicato. |
| 15 | map Accetta una funzione con n argomenti e n sequenze e restituisce una nuova sequenza contenente il risultato dell'applicazione della funzione agli elementi successivi delle sequenze. |
| 16 | some Prende un predicato come argomento e itera sulla sequenza di argomenti e restituisce il primo valore non NIL restituito dal predicato o restituisce false se il predicato non è mai soddisfatto. |
| 17 | every Prende un predicato come argomento e itera sulla sequenza di argomenti, termina, restituendo falso, non appena il predicato fallisce. Se il predicato è sempre soddisfatto, restituisce vero. |
| 18 | notany Prende un predicato come argomento e ripete la sequenza di argomenti e restituisce false non appena il predicato è soddisfatto o vero se non lo è mai. |
| 19 | notevery Accetta un predicato come argomento e ripete la sequenza di argomenti e restituisce true non appena il predicato fallisce o false se il predicato è sempre soddisfatto. |
| 20 | reduce Mappa su una singola sequenza, applicando una funzione a due argomenti prima ai primi due elementi della sequenza e poi al valore restituito dalla funzione e ai successivi elementi della sequenza. |
| 21 | search Cerca una sequenza per individuare uno o più elementi che soddisfano un test. |
| 22 | remove Prende un elemento e una sequenza e restituisce la sequenza con le istanze dell'elemento rimosse. |
| 23 | delete Questo prende anche un elemento e una sequenza e restituisce una sequenza dello stesso tipo della sequenza di argomenti che ha gli stessi elementi tranne l'elemento. |
| 24 | substitute Prende un nuovo elemento, un elemento esistente e una sequenza e restituisce una sequenza con istanze dell'elemento esistente sostituite con il nuovo elemento. |
| 25 | nsubstitute Prende un nuovo elemento, un elemento esistente e una sequenza e restituisce la stessa sequenza con istanze dell'elemento esistente sostituite con il nuovo elemento. |
| 26 | mismatch Richiede due sequenze e restituisce l'indice della prima coppia di elementi non corrispondenti. |
Argomenti delle parole chiave della funzione sequenza standard
| Discussione | Senso | Valore predefinito |
|---|---|---|
| :test | È una funzione a due argomenti utilizzata per confrontare l'elemento (o il valore estratto da: funzione chiave) con l'elemento. | EQL |
| :chiave | Funzione con un argomento per estrarre il valore della chiave dall'effettivo elemento della sequenza. NIL significa usa l'elemento così com'è. | NULLA |
| :inizio | Indice iniziale (compreso) della sottosequenza. | 0 |
| :fine | Indice finale (esclusivo) della sottosequenza. NIL indica la fine della sequenza. | NULLA |
| : dalla fine | Se vero, la sequenza verrà percorsa in ordine inverso, dalla fine all'inizio. | NULLA |
| :contare | Numero che indica il numero di elementi da rimuovere o sostituire o NIL per indicare tutti (solo RIMUOVI e SOSTITUISCI). | NULLA |
Abbiamo appena discusso di varie funzioni e parole chiave che vengono usate come argomenti in queste funzioni che lavorano sulle sequenze. Nelle prossime sezioni vedremo come utilizzare queste funzioni utilizzando esempi.
Trovare la lunghezza e l'elemento
Il length la funzione restituisce la lunghezza di una sequenza e il elt consente di accedere ai singoli elementi utilizzando un indice intero.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq x (vector 'a 'b 'c 'd 'e))
(write (length x))
(terpri)
(write (elt x 3))Quando esegui il codice, restituisce il seguente risultato:
5
DModifica delle sequenze
Alcune funzioni di sequenza consentono di iterare attraverso la sequenza ed eseguire alcune operazioni come la ricerca, la rimozione, il conteggio o il filtraggio di elementi specifici senza scrivere loop espliciti.
Il seguente esempio lo dimostra:
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (count 7 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (remove 5 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (delete 5 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (substitute 10 7 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (find 7 '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (position 5 '(1 5 6 7 8 9 2 7 3 4 5)))Quando esegui il codice, restituisce il seguente risultato:
2
(1 6 7 8 9 2 7 3 4)
(1 6 7 8 9 2 7 3 4)
(1 5 6 10 8 9 2 10 3 4 5)
7
1Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (delete-if #'oddp '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (delete-if #'evenp '(1 5 6 7 8 9 2 7 3 4 5)))
(terpri)
(write (remove-if #'evenp '(1 5 6 7 8 9 2 7 3 4 5) :count 1 :from-end t))
(terpri)
(setq x (vector 'a 'b 'c 'd 'e 'f 'g))
(fill x 'p :start 1 :end 4)
(write x)Quando esegui il codice, restituisce il seguente risultato:
(6 8 2 4)
(1 5 7 9 7 3 5)
(1 5 6 7 8 9 2 7 3 5)
#(A P P P E F G)Ordinamento e unione di sequenze
Le funzioni di ordinamento accettano una sequenza e un predicato a due argomenti e restituiscono una versione ordinata della sequenza.
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (sort '(2 4 7 3 9 1 5 4 6 3 8) #'<))
(terpri)
(write (sort '(2 4 7 3 9 1 5 4 6 3 8) #'>))
(terpri)Quando esegui il codice, restituisce il seguente risultato:
(1 2 3 3 4 4 5 6 7 8 9)
(9 8 7 6 5 4 4 3 3 2 1)Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (merge 'vector #(1 3 5) #(2 4 6) #'<))
(terpri)
(write (merge 'list #(1 3 5) #(2 4 6) #'<))
(terpri)Quando esegui il codice, restituisce il seguente risultato:
#(1 2 3 4 5 6)
(1 2 3 4 5 6)Predicati di sequenza
Le funzioni every, some, notany e notevery sono chiamate predicati di sequenza.
Queste funzioni eseguono l'iterazione su sequenze e testano il predicato booleano.
Tutte queste funzioni accettano un predicato come primo argomento e gli argomenti rimanenti sono sequenze.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (every #'evenp #(2 4 6 8 10)))
(terpri)
(write (some #'evenp #(2 4 6 8 10 13 14)))
(terpri)
(write (every #'evenp #(2 4 6 8 10 13 14)))
(terpri)
(write (notany #'evenp #(2 4 6 8 10)))
(terpri)
(write (notevery #'evenp #(2 4 6 8 10 13 14)))
(terpri)Quando esegui il codice, restituisce il seguente risultato:
T
T
NIL
NIL
TSequenze di mappatura
Abbiamo già discusso le funzioni di mappatura. Allo stesso modo ilmap funzione consente di applicare una funzione agli elementi successivi di una o più sequenze.
Il map funzione accetta una funzione con n argomenti e n sequenze e restituisce una nuova sequenza dopo aver applicato la funzione agli elementi successivi delle sequenze.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (map 'vector #'* #(2 3 4 5) #(3 5 4 8)))Quando esegui il codice, restituisce il seguente risultato:
#(6 15 16 40)Gli elenchi erano stati la struttura di dati composita più importante e primaria nel LISP tradizionale. Il Common LISP di oggi fornisce altre strutture di dati come, vettore, tabella hash, classi o strutture.
Le liste sono singole liste collegate. In LISP, gli elenchi sono costruiti come una catena di una semplice struttura di record denominatacons collegati insieme.
I contro Record Structure
UN cons è una struttura di record contenente due componenti denominati car e il cdr.
Le celle contro o contro sono oggetti sono coppie di valori che vengono creati utilizzando la funzione cons.
Il consla funzione accetta due argomenti e restituisce una nuova cella contro contenente i due valori. Questi valori possono essere riferimenti a qualsiasi tipo di oggetto.
Se il secondo valore non è nullo o un'altra cella contro, i valori vengono stampati come una coppia punteggiata racchiusa tra parentesi.
I due valori in una cella contro sono chiamati car e il cdr. Il car viene utilizzata per accedere al primo valore e al file cdr viene utilizzata per accedere al secondo valore.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (cons 1 2))
(terpri)
(write (cons 'a 'b))
(terpri)
(write (cons 1 nil))
(terpri)
(write (cons 1 (cons 2 nil)))
(terpri)
(write (cons 1 (cons 2 (cons 3 nil))))
(terpri)
(write (cons 'a (cons 'b (cons 'c nil))))
(terpri)
(write ( car (cons 'a (cons 'b (cons 'c nil)))))
(terpri)
(write ( cdr (cons 'a (cons 'b (cons 'c nil)))))Quando esegui il codice, restituisce il seguente risultato:
(1 . 2)
(A . B)
(1)
(1 2)
(1 2 3)
(A B C)
A
(B C)L'esempio sopra mostra come le strutture contro potrebbero essere utilizzate per creare un singolo elenco collegato, ad esempio, l'elenco (ABC) è costituito da tre celle contro collegate tra loro dai loro CDR .
Diagrammaticamente, potrebbe essere espresso come -
Elenchi in LISP
Sebbene le celle contro possano essere utilizzate per creare elenchi, tuttavia, costruendo un elenco da file nidificati consle chiamate di funzione non possono essere la soluzione migliore. Illist è piuttosto usata per creare liste in LISP.
La funzione lista può accettare un numero qualsiasi di argomenti e poiché è una funzione, valuta i suoi argomenti.
Il first e restle funzioni danno il primo elemento e la parte restante di una lista. I seguenti esempi dimostrano i concetti.
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (list 1 2))
(terpri)
(write (list 'a 'b))
(terpri)
(write (list 1 nil))
(terpri)
(write (list 1 2 3))
(terpri)
(write (list 'a 'b 'c))
(terpri)
(write (list 3 4 'a (car '(b . c)) (* 4 -2)))
(terpri)
(write (list (list 'a 'b) (list 'c 'd 'e)))Quando esegui il codice, restituisce il seguente risultato:
(1 2)
(A B)
(1 NIL)
(1 2 3)
(A B C)
(3 4 A B -8)
((A B) (C D E))Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun my-library (title author rating availability)
(list :title title :author author :rating rating :availabilty availability)
)
(write (getf (my-library "Hunger Game" "Collins" 9 t) :title))Quando esegui il codice, restituisce il seguente risultato:
"Hunger Game"Elenca le funzioni di manipolazione
La tabella seguente fornisce alcune funzioni di manipolazione degli elenchi di uso comune.
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | car Accetta una lista come argomento e restituisce il suo primo elemento. |
| 2 | cdr Accetta una lista come argomento e restituisce una lista senza il primo elemento |
| 3 | cons Prende due argomenti, un elemento e una lista e restituisce una lista con l'elemento inserito al primo posto. |
| 4 | list Accetta un numero qualsiasi di argomenti e restituisce un elenco con gli argomenti come elementi membri dell'elenco. |
| 5 | append Unisce due o più elenchi in uno. |
| 6 | last Prende un elenco e restituisce un elenco contenente l'ultimo elemento. |
| 7 | member Richiede due argomenti di cui il secondo deve essere un elenco, se il primo argomento è un membro del secondo argomento, quindi restituisce il resto dell'elenco a partire dal primo argomento. |
| 8 | reverse Prende un elenco e restituisce un elenco con gli elementi in alto in ordine inverso. |
Si noti che tutte le funzioni di sequenza sono applicabili agli elenchi.
Esempio 3
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (car '(a b c d e f)))
(terpri)
(write (cdr '(a b c d e f)))
(terpri)
(write (cons 'a '(b c)))
(terpri)
(write (list 'a '(b c) '(e f)))
(terpri)
(write (append '(b c) '(e f) '(p q) '() '(g)))
(terpri)
(write (last '(a b c d (e f))))
(terpri)
(write (reverse '(a b c d (e f))))Quando esegui il codice, restituisce il seguente risultato:
A
(B C D E F)
(A B C)
(A (B C) (E F))
(B C E F P Q G)
((E F))
((E F) D C B A)Concatenazione di funzioni auto e cdr
Il car e cdr funzioni e la loro combinazione consente di estrarre qualsiasi elemento / membro particolare di una lista.
Tuttavia, le sequenze di funzioni car e cdr potrebbero essere abbreviate concatenando la lettera a per car e d per cdr all'interno delle lettere c e r.
Ad esempio possiamo scrivere cadadr per abbreviare la sequenza delle chiamate di funzione: car cdr car cdr.
Quindi, (cadadr '(a (cd) (efg))) restituirà d
Esempio 4
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (cadadr '(a (c d) (e f g))))
(terpri)
(write (caar (list (list 'a 'b) 'c)))
(terpri)
(write (cadr (list (list 1 2) (list 3 4))))
(terpri)Quando esegui il codice, restituisce il seguente risultato:
D
A
(3 4)In LISP, un simbolo è un nome che rappresenta oggetti dati e, cosa interessante, è anche un oggetto dati.
Ciò che rende speciali i simboli è che hanno un componente chiamato property list, o plist.
Elenchi di proprietà
LISP consente di assegnare proprietà ai simboli. Ad esempio, diamo un oggetto "persona". Vorremmo che questo oggetto "persona" avesse proprietà come nome, sesso, altezza, peso, indirizzo, professione ecc. Una proprietà è come il nome di un attributo.
Un elenco di proprietà viene implementato come un elenco con un numero pari (possibilmente zero) di elementi. Ciascuna coppia di elementi nell'elenco costituisce una voce; il primo elemento è ilindicator, e il secondo è il value.
Quando viene creato un simbolo, il suo elenco di proprietà è inizialmente vuoto. Le proprietà vengono create utilizzandoget All'interno di una setf modulo.
Ad esempio, le seguenti istruzioni ci consentono di assegnare proprietà titolo, autore ed editore, e rispettivi valori, a un oggetto denominato (simbolo) "libro".
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (setf (get 'books'title) '(Gone with the Wind)))
(terpri)
(write (setf (get 'books 'author) '(Margaret Michel)))
(terpri)
(write (setf (get 'books 'publisher) '(Warner Books)))Quando esegui il codice, restituisce il seguente risultato:
(GONE WITH THE WIND)
(MARGARET MICHEL)
(WARNER BOOKS)Diverse funzioni di elenco delle proprietà consentono di assegnare proprietà nonché di recuperare, sostituire o rimuovere le proprietà di un simbolo.
Il getrestituisce l'elenco delle proprietà del simbolo per un dato indicatore. Ha la seguente sintassi:
get symbol indicator &optional defaultIl getla funzione cerca l'elenco delle proprietà del simbolo dato per l'indicatore specificato, se trovato restituisce il valore corrispondente; altrimenti viene restituito default (o nil, se non viene specificato un valore predefinito).
Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setf (get 'books 'title) '(Gone with the Wind))
(setf (get 'books 'author) '(Margaret Micheal))
(setf (get 'books 'publisher) '(Warner Books))
(write (get 'books 'title))
(terpri)
(write (get 'books 'author))
(terpri)
(write (get 'books 'publisher))Quando esegui il codice, restituisce il seguente risultato:
(GONE WITH THE WIND)
(MARGARET MICHEAL)
(WARNER BOOKS)Il symbol-plist la funzione ti permette di vedere tutte le proprietà di un simbolo.
Esempio 3
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setf (get 'annie 'age) 43)
(setf (get 'annie 'job) 'accountant)
(setf (get 'annie 'sex) 'female)
(setf (get 'annie 'children) 3)
(terpri)
(write (symbol-plist 'annie))Quando esegui il codice, restituisce il seguente risultato:
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT AGE 43)Il remprop la funzione rimuove la proprietà specificata da un simbolo.
Esempio 4
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setf (get 'annie 'age) 43)
(setf (get 'annie 'job) 'accountant)
(setf (get 'annie 'sex) 'female)
(setf (get 'annie 'children) 3)
(terpri)
(write (symbol-plist 'annie))
(remprop 'annie 'age)
(terpri)
(write (symbol-plist 'annie))Quando esegui il codice, restituisce il seguente risultato:
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT AGE 43)
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT)I vettori sono array unidimensionali, quindi un sottotipo di array. I vettori e gli elenchi sono chiamati collettivamente sequenze. Pertanto, tutte le funzioni generiche di sequenza e le funzioni array di cui abbiamo discusso finora, funzionano sui vettori.
Creazione di vettori
La funzione vettoriale consente di creare vettori di dimensioni fisse con valori specifici. Accetta un numero qualsiasi di argomenti e restituisce un vettore contenente tali argomenti.
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setf v1 (vector 1 2 3 4 5))
(setf v2 #(a b c d e))
(setf v3 (vector 'p 'q 'r 's 't))
(write v1)
(terpri)
(write v2)
(terpri)
(write v3)Quando esegui il codice, restituisce il seguente risultato:
#(1 2 3 4 5)
#(A B C D E)
#(P Q R S T)Si noti che LISP utilizza la sintassi # (...) come notazione letterale per i vettori. È possibile utilizzare questa sintassi # (...) per creare e includere vettori letterali nel codice.
Tuttavia, questi sono vettori letterali, quindi la loro modifica non è definita in LISP. Pertanto, per la programmazione, dovresti sempre usare ilvector funzione, o la funzione più generale make-array per creare vettori che intendi modificare.
Il make-arrayfunzione è il modo più generico per creare un vettore. È possibile accedere agli elementi vettoriali utilizzando ilaref funzione.
Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq a (make-array 5 :initial-element 0))
(setq b (make-array 5 :initial-element 2))
(dotimes (i 5)
(setf (aref a i) i))
(write a)
(terpri)
(write b)
(terpri)Quando esegui il codice, restituisce il seguente risultato:
#(0 1 2 3 4)
#(2 2 2 2 2)Riempi puntatore
Il make-array consente di creare un vettore ridimensionabile.
Il fill-pointerL'argomento della funzione tiene traccia del numero di elementi effettivamente memorizzati nel vettore. È l'indice della posizione successiva da riempire quando aggiungi un elemento al vettore.
Il vector-pushla funzione consente di aggiungere un elemento alla fine di un vettore ridimensionabile. Aumenta il puntatore di riempimento di 1.
Il vector-pop restituisce l'elemento inserito più di recente e riduce il puntatore di riempimento di 1.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq a (make-array 5 :fill-pointer 0))
(write a)
(vector-push 'a a)
(vector-push 'b a)
(vector-push 'c a)
(terpri)
(write a)
(terpri)
(vector-push 'd a)
(vector-push 'e a)
;this will not be entered as the vector limit is 5
(vector-push 'f a)
(write a)
(terpri)
(vector-pop a)
(vector-pop a)
(vector-pop a)
(write a)Quando esegui il codice, restituisce il seguente risultato:
#()
#(A B C)
#(A B C D E)
#(A B)Essendo i vettori sequenze, tutte le funzioni di sequenza sono applicabili ai vettori. Consultare il capitolo sulle sequenze, per le funzioni vettoriali.
Common Lisp non fornisce un tipo di dati impostato. Tuttavia, fornisce una serie di funzioni che consentono di eseguire le operazioni impostate su un elenco.
È possibile aggiungere, rimuovere e cercare elementi in un elenco, in base a vari criteri. Puoi anche eseguire varie operazioni sugli insiemi come: unione, intersezione e differenza tra insiemi.
Implementazione di insiemi in LISP
I set, come gli elenchi, sono generalmente implementati in termini di celle contro. Tuttavia, proprio per questo motivo, le operazioni sugli insiemi diventano sempre meno efficienti quanto più grandi diventano gli insiemi.
Il adjoinla funzione ti permette di costruire un set. Prende un elemento e una lista che rappresentano un set e restituisce un elenco che rappresenta il set contenente l'elemento e tutti gli elementi nel set originale.
Il adjoinla funzione prima cerca l'elemento nell'elenco dato, se viene trovato, quindi restituisce l'elenco originale; altrimenti crea una nuova cella contro con il suocar come l'articolo e cdr puntando all'elenco originale e restituisce questo nuovo elenco.
Il adjoin funzione richiede anche :key e :testargomenti delle parole chiave. Questi argomenti vengono utilizzati per verificare se l'elemento è presente nell'elenco originale.
Poiché la funzione adiacente non modifica l'elenco originale, per apportare una modifica nell'elenco stesso, è necessario assegnare il valore restituito da adiacente all'elenco originale oppure, è possibile utilizzare la macro pushnew per aggiungere un elemento al set.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
; creating myset as an empty list
(defparameter *myset* ())
(adjoin 1 *myset*)
(adjoin 2 *myset*)
; adjoin did not change the original set
;so it remains same
(write *myset*)
(terpri)
(setf *myset* (adjoin 1 *myset*))
(setf *myset* (adjoin 2 *myset*))
;now the original set is changed
(write *myset*)
(terpri)
;adding an existing value
(pushnew 2 *myset*)
;no duplicate allowed
(write *myset*)
(terpri)
;pushing a new value
(pushnew 3 *myset*)
(write *myset*)
(terpri)Quando esegui il codice, restituisce il seguente risultato:
NIL
(2 1)
(2 1)
(3 2 1)Controllo dell'iscrizione
Il gruppo di funzioni membro consente di verificare se un elemento è membro di un insieme o meno.
Le seguenti sono le sintassi di queste funzioni:
member item list &key :test :test-not :key
member-if predicate list &key :key
member-if-not predicate list &key :keyQueste funzioni cercano nell'elenco dato un dato elemento che soddisfa il test. Se non viene trovato alcun elemento di questo tipo, la funzione restituiscenil. In caso contrario, viene restituita la coda dell'elenco con l'elemento come primo elemento.
La ricerca viene eseguita solo al livello superiore.
Queste funzioni potrebbero essere utilizzate come predicati.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(write (member 'zara '(ayan abdul zara riyan nuha)))
(terpri)
(write (member-if #'evenp '(3 7 2 5/3 'a)))
(terpri)
(write (member-if-not #'numberp '(3 7 2 5/3 'a 'b 'c)))Quando esegui il codice, restituisce il seguente risultato:
(ZARA RIYAN NUHA)
(2 5/3 'A)
('A 'B 'C)Set Union
Il gruppo di funzioni union consente di eseguire l'unione di set su due elenchi forniti come argomenti a queste funzioni sulla base di un test.
Le seguenti sono le sintassi di queste funzioni:
union list1 list2 &key :test :test-not :key
nunion list1 list2 &key :test :test-not :keyIl unionla funzione prende due liste e restituisce una nuova lista contenente tutti gli elementi presenti in una delle liste. Se sono presenti duplicazioni, nell'elenco restituito viene conservata solo una copia del membro.
Il nunion la funzione esegue la stessa operazione ma può distruggere gli elenchi di argomenti.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq set1 (union '(a b c) '(c d e)))
(setq set2 (union '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (union '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)Quando esegui il codice, restituisce il seguente risultato:
(A B C D E)
(#(F H) #(5 6 7) #(A B) #(G H))
(#(A B) #(5 6 7) #(F H) #(5 6 7) #(A B) #(G H))Notare che
La funzione union non funziona come previsto senza :test-not #'mismatchargomenti per un elenco di tre vettori. Questo perché gli elenchi sono composti da celle contro e sebbene i valori sembrino uguali a noi apparentemente, il filecdrparte delle celle non corrisponde, quindi non sono esattamente le stesse dell'interprete / compilatore LISP. Questo è il motivo; l'implementazione di grandi insiemi non è consigliata utilizzando le liste. Funziona bene per piccoli set però.
Imposta intersezione
Il gruppo di funzioni di intersezione consente di eseguire l'intersezione su due elenchi forniti come argomenti a queste funzioni sulla base di un test.
Le seguenti sono le sintassi di queste funzioni:
intersection list1 list2 &key :test :test-not :key
nintersection list1 list2 &key :test :test-not :keyQueste funzioni prendono due liste e restituiscono una nuova lista contenente tutti gli elementi presenti in entrambe le liste di argomenti. Se uno degli elenchi contiene voci duplicate, le voci ridondanti possono o non possono essere visualizzate nel risultato.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq set1 (intersection '(a b c) '(c d e)))
(setq set2 (intersection '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (intersection '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)Quando esegui il codice, restituisce il seguente risultato:
(C)
(#(A B) #(5 6 7))
NILLa funzione di intersezione è la versione distruttiva dell'intersezione, cioè può distruggere gli elenchi originali.
Imposta differenza
Il gruppo di funzioni set-differenza consente di eseguire set-differenza su due elenchi forniti come argomenti a queste funzioni sulla base di un test.
Le seguenti sono le sintassi di queste funzioni:
set-difference list1 list2 &key :test :test-not :key
nset-difference list1 list2 &key :test :test-not :keyLa funzione di differenza di insiemi restituisce un elenco di elementi del primo elenco che non compaiono nel secondo elenco.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq set1 (set-difference '(a b c) '(c d e)))
(setq set2 (set-difference '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (set-difference '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)Quando esegui il codice, restituisce il seguente risultato:
(A B)
(#(F H))
(#(A B) #(5 6 7) #(F H))È possibile creare strutture di dati ad albero dalle celle contro, come elenchi di elenchi.
Per implementare le strutture ad albero, dovrai progettare funzionalità che attraversino le celle contro, in un ordine specifico, ad esempio, pre-ordine, in-ordine e post-ordine per alberi binari.
Albero come elenco di elenchi
Consideriamo una struttura ad albero composta da celle contro che formano il seguente elenco di elenchi:
((1 2) (3 4) (5 6)).
Diagrammaticamente, potrebbe essere espresso come -
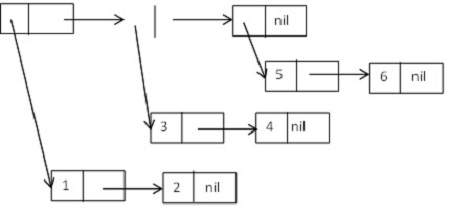
Funzioni ad albero in LISP
Sebbene per lo più dovrai scrivere le tue funzionalità ad albero secondo le tue esigenze specifiche, LISP fornisce alcune funzioni ad albero che puoi usare.
Oltre a tutte le funzioni di elenco, le seguenti funzioni funzionano soprattutto sulle strutture ad albero:
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | copy-tree x e vecp opzionale Restituisce una copia dell'albero delle celle contro x. Copia ricorsivamente sia la direzione dell'auto che quella del CDR. Se x non è una cella contro, la funzione restituisce semplicemente x invariata. Se l'argomento opzionale vecp è vero, questa funzione copia i vettori (ricorsivamente) e le celle contro. |
| 2 | tree-equal xy & key: test: test-not: key Confronta due alberi di celle contro. Se x e y sono entrambe celle contro, le loro auto e cdr vengono confrontate ricorsivamente. Se né x né y è una cella contro, vengono confrontati da eql o in base al test specificato. La funzione: key, se specificata, viene applicata agli elementi di entrambi gli alberi. |
| 3 | subst nuovo vecchio albero e chiave: test: test-not: chiave Sostituisce le occorrenze di un dato elemento vecchio con un nuovo elemento, nell'albero , che è un albero di celle contro. |
| 4 | nsubst nuovo vecchio albero e chiave: test: test-not: chiave Funziona come subst, ma distrugge l'albero originale. |
| 5 | sublis albero elenco e chiave: test: non test: chiave Funziona come subst, solo che ci vuole una lista un'associazione alist di coppie vecchi-nuovi. Ogni elemento dell'albero (dopo aver applicato la funzione: chiave, se presente), viene confrontato con le auto di lista; se corrisponde, viene sostituito dal corrispondente cdr. |
| 6 | nsublis albero elenco e chiave: test: non test: chiave Funziona come sublis, ma una versione distruttiva. |
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq lst (list '(1 2) '(3 4) '(5 6)))
(setq mylst (copy-list lst))
(setq tr (copy-tree lst))
(write lst)
(terpri)
(write mylst)
(terpri)
(write tr)Quando esegui il codice, restituisce il seguente risultato:
((1 2) (3 4) (5 6))
((1 2) (3 4) (5 6))
((1 2) (3 4) (5 6))Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq tr '((1 2 (3 4 5) ((7 8) (7 8 9)))))
(write tr)
(setq trs (subst 7 1 tr))
(terpri)
(write trs)Quando esegui il codice, restituisce il seguente risultato:
((1 2 (3 4 5) ((7 8) (7 8 9))))
((7 2 (3 4 5) ((7 8) (7 8 9))))Costruisci il tuo albero
Proviamo a costruire il nostro albero, utilizzando le funzioni di lista disponibili in LISP.
Per prima cosa creiamo un nuovo nodo che contenga alcuni dati
(defun make-tree (item)
"it creates a new node with item."
(cons (cons item nil) nil)
)Quindi aggiungiamo un nodo figlio all'albero: ci vorranno due nodi dell'albero e aggiungeremo il secondo albero come figlio del primo.
(defun add-child (tree child)
(setf (car tree) (append (car tree) child))
tree)Questa funzione restituirà al primo figlio un dato albero - prenderà un nodo albero e restituirà il primo figlio di quel nodo, o nullo, se questo nodo non ha alcun nodo figlio.
(defun first-child (tree)
(if (null tree)
nil
(cdr (car tree))
)
)Questa funzione restituirà il fratello successivo di un dato nodo: prende un nodo albero come argomento e restituisce un riferimento al nodo fratello successivo, o nil, se il nodo non ne ha.
(defun next-sibling (tree)
(cdr tree)
)Infine abbiamo bisogno di una funzione per restituire le informazioni in un nodo -
(defun data (tree)
(car (car tree))
)Esempio
Questo esempio utilizza le funzionalità di cui sopra:
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun make-tree (item)
"it creates a new node with item."
(cons (cons item nil) nil)
)
(defun first-child (tree)
(if (null tree)
nil
(cdr (car tree))
)
)
(defun next-sibling (tree)
(cdr tree)
)
(defun data (tree)
(car (car tree))
)
(defun add-child (tree child)
(setf (car tree) (append (car tree) child))
tree
)
(setq tr '((1 2 (3 4 5) ((7 8) (7 8 9)))))
(setq mytree (make-tree 10))
(write (data mytree))
(terpri)
(write (first-child tr))
(terpri)
(setq newtree (add-child tr mytree))
(terpri)
(write newtree)Quando esegui il codice, restituisce il seguente risultato:
10
(2 (3 4 5) ((7 8) (7 8 9)))
((1 2 (3 4 5) ((7 8) (7 8 9)) (10)))La struttura dati della tabella hash rappresenta una raccolta di file key-and-valuecoppie organizzate in base al codice hash della chiave. Usa la chiave per accedere agli elementi nella raccolta.
Una tabella hash viene utilizzata quando è necessario accedere agli elementi utilizzando una chiave ed è possibile identificare un valore chiave utile. Ogni elemento nella tabella hash ha una coppia chiave / valore. La chiave viene utilizzata per accedere agli elementi della collezione.
Creazione di una tabella hash in LISP
In Common LISP, la tabella hash è una raccolta generica. È possibile utilizzare oggetti arbitrari come chiave o indici.
Quando memorizzi un valore in una tabella hash, crei una coppia chiave-valore e la memorizzi sotto quella chiave. Successivamente è possibile recuperare il valore dalla tabella hash utilizzando la stessa chiave. Ogni chiave è mappata a un singolo valore, sebbene sia possibile memorizzare un nuovo valore in una chiave.
Le tabelle hash, in LISP, potrebbero essere classificate in tre tipi, in base al modo in cui le chiavi potrebbero essere confrontate: eq, eql o uguale. Se la tabella hash è sottoposta ad hashing su oggetti LISP, le chiavi vengono confrontate con eq o eql. Se la tabella hash ha hash sulla struttura ad albero, verrà confrontata usando uguale.
Il make-hash-tableviene utilizzata per creare una tabella hash. La sintassi per questa funzione è:
make-hash-table &key :test :size :rehash-size :rehash-thresholdDove -
Il key l'argomento fornisce la chiave.
Il :testL'argomento determina il modo in cui le chiavi vengono confrontate: dovrebbe avere uno dei tre valori # 'eq, #' eql o # 'uguale o uno dei tre simboli eq, eql o uguale. Se non specificato, viene assunto eql.
Il :sizeL'argomento imposta la dimensione iniziale della tabella hash. Dovrebbe essere un numero intero maggiore di zero.
Il :rehash-sizeL'argomento specifica di quanto aumentare la dimensione della tabella hash quando diventa piena. Può essere un numero intero maggiore di zero, che è il numero di voci da aggiungere, oppure può essere un numero a virgola mobile maggiore di 1, che è il rapporto tra la nuova dimensione e la vecchia dimensione. Il valore predefinito per questo argomento dipende dall'implementazione.
Il :rehash-thresholdL'argomento specifica quanto può essere piena la tabella hash prima di dover crescere. Può essere un numero intero maggiore di zero e minore di: rehash-size (nel qual caso verrà ridimensionato ogni volta che la tabella viene ingrandita), oppure può essere un numero a virgola mobile compreso tra zero e 1. Il valore predefinito per questo l'argomento dipende dall'implementazione.
Puoi anche chiamare la funzione make-hash-table senza argomenti.
Recupero di elementi da e aggiunta di elementi nella tabella hash
Il gethashla funzione recupera un elemento dalla tabella hash cercando la sua chiave. Se non trova la chiave, restituisce zero.
Ha la seguente sintassi:
gethash key hash-table &optional defaultdove -
chiave: è la chiave associata
tabella hash: è la tabella hash in cui eseguire la ricerca
default: è il valore da restituire, se la voce non viene trovata, che è nullo, se non specificato.
Il gethash la funzione restituisce effettivamente due valori, il secondo è un valore del predicato che è vero se è stata trovata una voce e falso se non è stata trovata alcuna voce.
Per aggiungere un elemento alla tabella hash, puoi utilizzare il file setf funzione insieme a gethash funzione.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq empList (make-hash-table))
(setf (gethash '001 empList) '(Charlie Brown))
(setf (gethash '002 empList) '(Freddie Seal))
(write (gethash '001 empList))
(terpri)
(write (gethash '002 empList))Quando esegui il codice, restituisce il seguente risultato:
(CHARLIE BROWN)
(FREDDIE SEAL)Rimozione di una voce
Il remhashLa funzione rimuove qualsiasi voce per una chiave specifica nella tabella hash. Questo è un predicato vero se c'era una voce o falso se non c'era.
La sintassi per questa funzione è:
remhash key hash-tableEsempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq empList (make-hash-table))
(setf (gethash '001 empList) '(Charlie Brown))
(setf (gethash '002 empList) '(Freddie Seal))
(setf (gethash '003 empList) '(Mark Mongoose))
(write (gethash '001 empList))
(terpri)
(write (gethash '002 empList))
(terpri)
(write (gethash '003 empList))
(remhash '003 empList)
(terpri)
(write (gethash '003 empList))Quando esegui il codice, restituisce il seguente risultato:
(CHARLIE BROWN)
(FREDDIE SEAL)
(MARK MONGOOSE)
NILLa funzione maphash
Il maphash funzione consente di applicare una funzione specificata a ciascuna coppia chiave-valore su una tabella hash.
Richiede due argomenti: la funzione e una tabella hash e richiama la funzione una volta per ogni coppia chiave / valore nella tabella hash.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(setq empList (make-hash-table))
(setf (gethash '001 empList) '(Charlie Brown))
(setf (gethash '002 empList) '(Freddie Seal))
(setf (gethash '003 empList) '(Mark Mongoose))
(maphash #'(lambda (k v) (format t "~a => ~a~%" k v)) empList)Quando esegui il codice, restituisce il seguente risultato:
3 => (MARK MONGOOSE)
2 => (FREDDIE SEAL)
1 => (CHARLIE BROWN)Common LISP fornisce numerose funzioni di input-output. Abbiamo già utilizzato la funzione di formattazione e la funzione di stampa per l'output. In questa sezione, esamineremo alcune delle funzioni di input-output più comunemente utilizzate fornite in LISP.
Funzioni di input
La tabella seguente fornisce le funzioni di input più comunemente utilizzate di LISP:
| Sr.No. | Descrizione della funzione |
|---|---|
| 1 | read& opzionale input-stream eof-error-p eof-value ricorsivo-p Legge la rappresentazione stampata di un oggetto Lisp dal flusso di input, costruisce un oggetto Lisp corrispondente e restituisce l'oggetto. |
| 2 | read-preserving-whitespace& opzionale in-stream eof-error-p eof-value recursive-p Viene utilizzato in alcune situazioni specializzate in cui è desiderabile determinare con precisione quale carattere ha terminato il token esteso. |
| 3 | read-line& opzionale input-stream eof-error-p eof-value ricorsivo-p Si legge in una riga di testo terminata da una nuova riga. |
| 4 | read-char& opzionale input-stream eof-error-p eof-value ricorsivo-p Prende un carattere da input-stream e lo restituisce come oggetto carattere. |
| 5 | unread-char carattere e flusso di input opzionale Mette il carattere letto più di recente dal flusso di input, sulla parte anteriore del flusso di input. |
| 6 | peek-char& opzionale peek-type input-stream eof-error-p eof-value recursive-p Restituisce il carattere successivo da leggere dal flusso di input, senza rimuoverlo effettivamente dal flusso di input. |
| 7 | listen& flusso di input opzionale Il predicato listen è vero se c'è un carattere immediatamente disponibile da input-stream, ed è falso in caso contrario. |
| 8 | read-char-no-hang& opzionale input-stream eof-error-p eof-value ricorsivo-p È simile a read-char, ma se non ottiene un carattere, non attende un carattere, ma restituisce immediatamente zero. |
| 9 | clear-input& flusso di input opzionale Cancella qualsiasi input bufferizzato associato a input-stream. |
| 10 | read-from-string stringa e opzionale eof-error-p eof-valore e chiave: inizio: fine: conserva-spazi bianchi Prende i caratteri della stringa in successione e costruisce un oggetto LISP e restituisce l'oggetto. Restituisce anche l'indice del primo carattere della stringa non letta, o la lunghezza della stringa (o, lunghezza +1), a seconda dei casi. |
| 11 | parse-integer stringa e chiave: inizio: fine: radix: junk-consentita Esamina la sottostringa della stringa delimitata da: start e: end (impostazione predefinita all'inizio e alla fine della stringa). Salta i caratteri di spazio bianco e quindi tenta di analizzare un numero intero. |
| 12 | read-byte binary-input-stream e opzionale eof-error-p eof-value Legge un byte dal flusso di input binario e lo restituisce sotto forma di numero intero. |
Lettura dell'input dalla tastiera
Il readviene utilizzata per ricevere input dalla tastiera. Potrebbe non essere necessario alcun argomento.
Ad esempio, considera lo snippet di codice:
(write ( + 15.0 (read)))Supponiamo che l'utente inserisca 10.2 dall'ingresso STDIN, ritorna,
25.2La funzione read legge i caratteri da un flusso di input e li interpreta analizzandoli come rappresentazioni di oggetti Lisp.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il seguente codice in esso -
; the function AreaOfCircle
; calculates area of a circle
; when the radius is input from keyboard
(defun AreaOfCircle()
(terpri)
(princ "Enter Radius: ")
(setq radius (read))
(setq area (* 3.1416 radius radius))
(princ "Area: ")
(write area))
(AreaOfCircle)Quando esegui il codice, restituisce il seguente risultato:
Enter Radius: 5 (STDIN Input)
Area: 78.53999Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(with-input-from-string (stream "Welcome to Tutorials Point!")
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (read-char stream))
(print (peek-char nil stream nil 'the-end))
(values)
)Quando esegui il codice, restituisce il seguente risultato:
#\W
#\e
#\l
#\c
#\o
#\m
#\e
#\Space
#\t
#\o
#\SpaceLe funzioni di output
Tutte le funzioni di output in LISP accettano un argomento opzionale chiamato output-stream, dove viene inviato l'output. Se non è menzionato o è nullo, output-stream utilizza per impostazione predefinita il valore della variabile * standard-output *.
La tabella seguente fornisce le funzioni di output più comunemente utilizzate di LISP:
| Sr.No. | Funzione e descrizione |
|---|---|
| 1 | write oggetto e chiave: stream: escape: radix: base: circle: pretty: level: length: case: gensym: array write oggetto e chiave: stream: escape: radix: base: circle: pretty: level: length: case: gensym: array: readably: right-margin: miser-width: lines: pprint-dispatch Entrambi scrivono l'oggetto nel flusso di output specificato da: stream, il cui valore predefinito è * standard-output *. Gli altri valori vengono impostati per impostazione predefinita sulle variabili globali corrispondenti impostate per la stampa. |
| 2 | prin1 oggetto e flusso di output opzionale print oggetto e flusso di output opzionale pprint oggetto e flusso di output opzionale princ oggetto e flusso di output opzionale Tutte queste funzioni restituiscono la rappresentazione stampata dell'oggetto in output-stream . Tuttavia, ci sono le seguenti differenze:
|
| 3 | write-to-string oggetto e chiave : escape: radix: base: circle: pretty: level: length: case: gensym: array write-to-string oggetto e chiave: escape: radix: base: circle: pretty: level: length: case: gensym: array: readably: right-margin: miser-width: lines: pprint-dispatch prin1-to-string oggetto princ-to-string oggetto L'oggetto viene stampato in modo efficace ei caratteri di output vengono trasformati in una stringa, che viene restituita. |
| 4 | write-char carattere e flusso di output opzionale Emette il carattere nel flusso di output e restituisce il carattere. |
| 5 | write-string stringa e flusso di output facoltativo e chiave: inizio: fine Scrive i caratteri della sottostringa di stringa specificata nel flusso di output. |
| 6 | write-line stringa e flusso di output facoltativo e chiave: inizio: fine Funziona allo stesso modo di write-string, ma in seguito restituisce una nuova riga. |
| 7 | terpri& flusso di output opzionale Emette una nuova riga in output-stream. |
| 8 | fresh-line& flusso di output opzionale emette una nuova riga solo se il flusso non è già all'inizio di una riga. |
| 9 | finish-output& flusso di output opzionale force-output& flusso di output opzionale clear-output& flusso di output opzionale
|
| 10 | write-byte flusso di output binario intero Scrive un byte, il valore dell'intero. |
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
; this program inputs a numbers and doubles it
(defun DoubleNumber()
(terpri)
(princ "Enter Number : ")
(setq n1 (read))
(setq doubled (* 2.0 n1))
(princ "The Number: ")
(write n1)
(terpri)
(princ "The Number Doubled: ")
(write doubled)
)
(DoubleNumber)Quando esegui il codice, restituisce il seguente risultato:
Enter Number : 3456.78 (STDIN Input)
The Number: 3456.78
The Number Doubled: 6913.56Output formattato
La funzione formatviene utilizzato per produrre testo ben formattato. Ha la seguente sintassi:
format destination control-string &rest argumentsdove,
- la destinazione è lo standard output
- stringa di controllo contiene i caratteri da visualizzare e la direttiva di stampa.
UN format directive consiste in una tilde (~), parametri di prefisso opzionali separati da virgole, modificatori opzionali di due punti (:) e segno (@) e un singolo carattere che indica che tipo di direttiva si tratta.
I parametri del prefisso sono generalmente numeri interi, annotati come numeri decimali con segno facoltativo.
La tabella seguente fornisce una breve descrizione delle direttive comunemente utilizzate:
| Sr.No. | Direttiva e descrizione |
|---|---|
| 1 | ~A È seguito da argomenti ASCII. |
| 2 | ~S È seguito da espressioni S. |
| 3 | ~D Per argomenti decimali. |
| 4 | ~B Per argomenti binari. |
| 5 | ~O Per argomenti ottali. |
| 6 | ~X Per argomenti esadecimali. |
| 7 | ~C Per argomenti di carattere. |
| 8 | ~F Per argomenti a virgola mobile in formato fisso. |
| 9 | ~E Argomenti in virgola mobile esponenziale. |
| 10 | ~$ Dollaro e argomenti in virgola mobile. |
| 11 | ~% Viene stampata una nuova riga. |
| 12 | ~* L'argomento successivo viene ignorato. |
| 13 | ~? Indiretto. L'argomento successivo deve essere una stringa e quello dopo un elenco. |
Esempio
Riscriviamo il programma calcolando l'area di un cerchio -
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun AreaOfCircle()
(terpri)
(princ "Enter Radius: ")
(setq radius (read))
(setq area (* 3.1416 radius radius))
(format t "Radius: = ~F~% Area = ~F" radius area)
)
(AreaOfCircle)Quando esegui il codice, restituisce il seguente risultato:
Enter Radius: 10.234 (STDIN Input)
Radius: = 10.234
Area = 329.03473Abbiamo discusso di come l'input e l'output standard vengono gestiti da LISP comune. Tutte queste funzioni funzionano anche per leggere e scrivere in file di testo e binari. L'unica differenza è che in questo caso il flusso che usiamo non è input o output standard, ma un flusso creato per lo scopo specifico di scrivere o leggere da file.
In questo capitolo vedremo come LISP può creare, aprire, chiudere file di testo o binari per la loro memorizzazione dei dati.
Un file rappresenta una sequenza di byte, non importa se si tratta di un file di testo o di un file binario. Questo capitolo ti guiderà attraverso importanti funzioni / macro per la gestione dei file.
Apertura di file
Puoi usare il file openfunzione per creare un nuovo file o per aprire un file esistente. È la funzione più semplice per aprire un file. in ogni caso, ilwith-open-file di solito è più conveniente e più comunemente usato, come vedremo più avanti in questa sezione.
Quando un file viene aperto, viene costruito un oggetto stream per rappresentarlo nell'ambiente LISP. Tutte le operazioni sul flusso sono sostanzialmente equivalenti alle operazioni sul file.
Sintassi per open la funzione è -
open filename &key :direction :element-type :if-exists :if-does-not-exist :external-formatdove,
L' argomento filename è il nome del file da aprire o creare.
Gli argomenti della parola chiave specificano il tipo di flusso e le modalità di gestione degli errori.
Il :direction la parola chiave specifica se il flusso deve gestire input, output o entrambi, assume i seguenti valori:
: input - per flussi di input (valore predefinito)
: output - per flussi di output
: io - per flussi bidirezionali
: probe - per controllare solo l'esistenza di un file; il flusso viene aperto e quindi chiuso.
Il :element-type specifica il tipo di unità di transazione per il flusso.
Il :if-existsargomento specifica l'azione da intraprendere se la direzione: è: output o: io e un file con il nome specificato esiste già. Se la direzione è: input o: probe, questo argomento viene ignorato. Prende i seguenti valori:
: errore - segnala un errore.
: new-version - crea un nuovo file con lo stesso nome ma con un numero di versione maggiore.
: rename - rinomina il file esistente.
: rinomina ed elimina: rinomina il file esistente e quindi lo elimina.
: append - aggiunge al file esistente.
: supersede - sostituisce il file esistente.
nil - non crea un file o anche un flusso restituisce semplicemente nil per indicare un errore.
Il :if-does-not-existargomento specifica l'azione da intraprendere se un file con il nome specificato non esiste già. Prende i seguenti valori:
: errore - segnala un errore.
: create - crea un file vuoto con il nome specificato e quindi lo utilizza.
nil - non crea un file o anche un flusso, ma restituisce semplicemente nil per indicare un errore.
Il :external-format argomento specifica uno schema riconosciuto dall'implementazione per rappresentare i caratteri nei file.
Ad esempio, puoi aprire un file denominato myfile.txt archiviato nella cartella / tmp come -
(open "/tmp/myfile.txt")Scrittura e lettura da file
Il with-open-fileconsente la lettura o la scrittura in un file, utilizzando la variabile stream associata alla transazione di lettura / scrittura. Una volta terminato il lavoro, chiude automaticamente il file. È estremamente comodo da usare.
Ha la seguente sintassi:
with-open-file (stream filename {options}*)
{declaration}* {form}*nomefile è il nome del file da aprire; può essere una stringa, un percorso o un flusso.
Le opzioni sono le stesse degli argomenti della parola chiave per la funzione open.
Esempio 1
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(with-open-file (stream "/tmp/myfile.txt" :direction :output)
(format stream "Welcome to Tutorials Point!")
(terpri stream)
(format stream "This is a tutorials database")
(terpri stream)
(format stream "Submit your Tutorials, White Papers and Articles into our Tutorials Directory.")
)Si noti che tutte le funzioni di input-output discusse nel capitolo precedente, come, terpri e format, funzionano per la scrittura nel file che abbiamo creato qui.
Quando si esegue il codice, non viene restituito nulla; tuttavia, i nostri dati vengono scritti nel file. Il:direction :output le parole chiave ci consentono di farlo.
Tuttavia, possiamo leggere da questo file utilizzando il read-line funzione.
Esempio 2
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(let ((in (open "/tmp/myfile.txt" :if-does-not-exist nil)))
(when in
(loop for line = (read-line in nil)
while line do (format t "~a~%" line))
(close in)
)
)Quando esegui il codice, restituisce il seguente risultato:
Welcome to Tutorials Point!
This is a tutorials database
Submit your Tutorials, White Papers and Articles into our Tutorials Directory.File di chiusura
Il close la funzione chiude un flusso.
Le strutture sono uno dei tipi di dati definiti dall'utente, che consente di combinare elementi di dati di diversi tipi.
Le strutture vengono utilizzate per rappresentare un record. Supponi di voler tenere traccia dei tuoi libri in una biblioteca. Potresti voler monitorare i seguenti attributi di ogni libro:
- Title
- Author
- Subject
- ID libro
Definizione di una struttura
Il defstructmacro in LISP consente di definire una struttura di record astratta. Ildefstruct L'istruzione definisce un nuovo tipo di dati, con più di un membro per il programma.
Per discutere il formato del file defstructmacro, scriviamo la definizione della struttura del Libro. Potremmo definire la struttura del libro come:
(defstruct book
title
author
subject
book-id
)notare che
La dichiarazione di cui sopra crea una struttura a libro con quattro named components. Quindi ogni libro creato sarà un oggetto di questa struttura.
Definisce quattro funzioni denominate titolo-libro, autore-libro, soggetto-libro e ID-libro-libro, che richiederanno un argomento, una struttura del libro e restituiranno i campi titolo, autore, soggetto e ID libro del libro oggetto. Queste funzioni sono chiamateaccess functions.
Il libro dei simboli diventa un tipo di dati e puoi verificarlo utilizzando il typep predicato.
Ci sarà anche una funzione implicita denominata book-p, che è un predicato e sarà vero se il suo argomento è un libro ed è falso altrimenti.
Un'altra funzione implicita denominata make-book verrà creato, che è un file constructor, che, quando invocato, creerà una struttura dati con quattro componenti, adatta per l'utilizzo con le funzioni di accesso.
Il #S syntax si riferisce a una struttura e puoi usarla per leggere o stampare istanze di un libro.
Viene definita anche una funzione implicita denominata copy-book di un argomento. Prende un oggetto libro e crea un altro oggetto libro, che è una copia del primo. Questa funzione è chiamatacopier function.
Puoi usare setf per alterare i componenti di un libro, per esempio
(setf (book-book-id book3) 100)Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defstruct book
title
author
subject
book-id
)
( setq book1 (make-book :title "C Programming"
:author "Nuha Ali"
:subject "C-Programming Tutorial"
:book-id "478")
)
( setq book2 (make-book :title "Telecom Billing"
:author "Zara Ali"
:subject "C-Programming Tutorial"
:book-id "501")
)
(write book1)
(terpri)
(write book2)
(setq book3( copy-book book1))
(setf (book-book-id book3) 100)
(terpri)
(write book3)Quando esegui il codice, restituisce il seguente risultato:
#S(BOOK :TITLE "C Programming" :AUTHOR "Nuha Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID "478")
#S(BOOK :TITLE "Telecom Billing" :AUTHOR "Zara Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID "501")
#S(BOOK :TITLE "C Programming" :AUTHOR "Nuha Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID 100)In termini generali di linguaggi di programmazione, un pacchetto è progettato per fornire un modo per mantenere un insieme di nomi separato da un altro. I simboli dichiarati in un pacchetto non entreranno in conflitto con gli stessi simboli dichiarati in un altro. In questo modo i pacchetti riducono i conflitti di denominazione tra moduli di codice indipendenti.
Il lettore LISP mantiene una tabella di tutti i simboli che ha trovato. Quando trova una nuova sequenza di caratteri, crea un nuovo simbolo e lo memorizza nella tabella dei simboli. Questa tabella è chiamata pacchetto.
Il pacchetto corrente è indicato dalla variabile speciale * pacchetto *.
Ci sono due pacchetti predefiniti in LISP:
common-lisp - contiene simboli per tutte le funzioni e variabili definite.
common-lisp-user- utilizza il pacchetto common-lisp e tutti gli altri pacchetti con strumenti di modifica e debug; si chiama in breve cl-user
Funzioni del pacchetto in LISP
La tabella seguente fornisce le funzioni usate più comunemente per creare, usare e manipolare i pacchetti:
| Sr.No. | Funzione e descrizione |
|---|---|
| 1 | make-package nome-pacchetto e chiave: soprannomi: usa Crea e restituisce un nuovo pacchetto con il nome del pacchetto specificato. |
| 2 | in-package nome-pacchetto e chiave: soprannomi: usa Rende il pacchetto attuale. |
| 3 | in-package nome Questa macro fa sì che * pacchetto * venga impostato sul pacchetto denominato nome, che deve essere un simbolo o una stringa. |
| 4 | find-package nome Cerca un pacchetto. Viene restituito il pacchetto con quel nome o nickname; se tale pacchetto non esiste, find-package restituisce nil. |
| 5 | rename-package pacchetto nuovo-nome e nuovi-soprannomi opzionali rinomina un pacchetto. |
| 6 | list-all-packages Questa funzione restituisce un elenco di tutti i pacchetti attualmente esistenti nel sistema Lisp. |
| 7 | delete-package pacchetto Elimina un pacchetto. |
Creazione di un pacchetto LISP
Il defpackageviene utilizzata per creare un pacchetto definito dall'utente. Ha la seguente sintassi:
(defpackage :package-name
(:use :common-lisp ...)
(:export :symbol1 :symbol2 ...)
)Dove,
nome-pacchetto è il nome del pacchetto.
La parola chiave: use specifica i pacchetti di cui ha bisogno questo pacchetto, cioè i pacchetti che definiscono le funzioni usate dal codice in questo pacchetto.
La parola chiave: export specifica i simboli esterni in questo pacchetto.
Il make-packageviene utilizzata anche per creare un pacchetto. La sintassi per questa funzione è:
make-package package-name &key :nicknames :usegli argomenti e le parole chiave hanno lo stesso significato di prima.
Utilizzo di un pacchetto
Dopo aver creato un pacchetto, è possibile utilizzare il codice in questo pacchetto, rendendolo il pacchetto corrente. Ilin-package macro rende un pacchetto corrente nell'ambiente.
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(make-package :tom)
(make-package :dick)
(make-package :harry)
(in-package tom)
(defun hello ()
(write-line "Hello! This is Tom's Tutorials Point")
)
(hello)
(in-package dick)
(defun hello ()
(write-line "Hello! This is Dick's Tutorials Point")
)
(hello)
(in-package harry)
(defun hello ()
(write-line "Hello! This is Harry's Tutorials Point")
)
(hello)
(in-package tom)
(hello)
(in-package dick)
(hello)
(in-package harry)
(hello)Quando esegui il codice, restituisce il seguente risultato:
Hello! This is Tom's Tutorials Point
Hello! This is Dick's Tutorials Point
Hello! This is Harry's Tutorials PointEliminazione di un pacchetto
Il delete-packagemacro consente di eliminare un pacchetto. Il seguente esempio lo dimostra:
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(make-package :tom)
(make-package :dick)
(make-package :harry)
(in-package tom)
(defun hello ()
(write-line "Hello! This is Tom's Tutorials Point")
)
(in-package dick)
(defun hello ()
(write-line "Hello! This is Dick's Tutorials Point")
)
(in-package harry)
(defun hello ()
(write-line "Hello! This is Harry's Tutorials Point")
)
(in-package tom)
(hello)
(in-package dick)
(hello)
(in-package harry)
(hello)
(delete-package tom)
(in-package tom)
(hello)Quando esegui il codice, restituisce il seguente risultato:
Hello! This is Tom's Tutorials Point
Hello! This is Dick's Tutorials Point
Hello! This is Harry's Tutorials Point
*** - EVAL: variable TOM has no valueNella terminologia Common LISP, le eccezioni sono chiamate condizioni.
In effetti, le condizioni sono più generali delle eccezioni nei linguaggi di programmazione tradizionali, perché a condition rappresenta qualsiasi occorrenza, errore o meno, che potrebbe influenzare vari livelli dello stack di chiamate di funzione.
Il meccanismo di gestione delle condizioni in LISP gestisce tali situazioni in modo tale che le condizioni vengano utilizzate per segnalare un avviso (ad esempio stampando un avviso) mentre il codice di livello superiore sullo stack di chiamate può continuare il suo lavoro.
Il sistema di gestione delle condizioni in LISP ha tre parti:
- Segnalazione di una condizione
- Gestire la condizione
- Riavvia il processo
Gestione di una condizione
Facciamo un esempio della gestione di una condizione derivante dalla condizione di divisione per zero, per spiegare i concetti qui.
È necessario eseguire i seguenti passaggi per gestire una condizione:
Define the Condition - "Una condizione è un oggetto la cui classe indica la natura generale della condizione ei cui dati di istanza contengono informazioni sui dettagli delle circostanze particolari che portano alla segnalazione della condizione".
La macro di definizione delle condizioni viene utilizzata per definire una condizione, che ha la seguente sintassi:
(define-condition condition-name (error) ((text :initarg :text :reader text)) )I nuovi oggetti condizione vengono creati con la macro MAKE-CONDITION, che inizializza gli slot della nuova condizione in base al file :initargs discussione.
Nel nostro esempio, il codice seguente definisce la condizione:
(define-condition on-division-by-zero (error) ((message :initarg :message :reader message)) )Writing the Handlers- un condition handler è un codice utilizzato per gestire la condizione segnalata su di esso. È generalmente scritto in una delle funzioni di livello superiore che chiamano la funzione di errore. Quando viene segnalata una condizione, il meccanismo di segnalazione cerca un gestore appropriato in base alla classe della condizione.
Ogni gestore è composto da:
- Identificatore di tipo, che indica il tipo di condizione che può gestire
- Una funzione che accetta un singolo argomento, la condizione
Quando viene segnalata una condizione, il meccanismo di segnalazione trova il gestore stabilito più di recente compatibile con il tipo di condizione e chiama la sua funzione.
La macro handler-casestabilisce un gestore delle condizioni. La forma base di un caso del gestore -
(handler-case expression error-clause*)Dove, ogni clausola di errore ha la forma -
condition-type ([var]) code)Restarting Phase
Questo è il codice che ripristina effettivamente il programma dagli errori e i gestori di condizioni possono quindi gestire una condizione invocando un riavvio appropriato. Il codice di riavvio si trova generalmente nelle funzioni di livello medio o basso e i gestori delle condizioni sono posizionati nei livelli superiori dell'applicazione.
Il handler-bindmacro consente di fornire una funzione di riavvio e consente di continuare alle funzioni di livello inferiore senza srotolare lo stack di chiamate di funzione. In altre parole, il flusso di controllo sarà ancora nella funzione di livello inferiore.
La forma base di handler-bind è il seguente -
(handler-bind (binding*) form*)Dove ogni associazione è un elenco di quanto segue:
- un tipo di condizione
- una funzione gestore di un argomento
Il invoke-restart macro trova e richiama la funzione di riavvio associata più di recente con il nome specificato come argomento.
Puoi avere più riavvii.
Esempio
In questo esempio, dimostriamo i concetti precedenti scrivendo una funzione denominata funzione-divisione, che creerà una condizione di errore se l'argomento divisore è zero. Abbiamo tre funzioni anonime che forniscono tre modi per uscirne: restituendo un valore 1, inviando un divisore 2 e ricalcolando o restituendo 1.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(define-condition on-division-by-zero (error)
((message :initarg :message :reader message))
)
(defun handle-infinity ()
(restart-case
(let ((result 0))
(setf result (division-function 10 0))
(format t "Value: ~a~%" result)
)
(just-continue () nil)
)
)
(defun division-function (value1 value2)
(restart-case
(if (/= value2 0)
(/ value1 value2)
(error 'on-division-by-zero :message "denominator is zero")
)
(return-zero () 0)
(return-value (r) r)
(recalc-using (d) (division-function value1 d))
)
)
(defun high-level-code ()
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'return-zero)
)
)
(handle-infinity)
)
)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'return-value 1)
)
)
)
(handle-infinity)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'recalc-using 2)
)
)
)
(handle-infinity)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'just-continue)
)
)
)
(handle-infinity)
)
(format t "Done."))Quando esegui il codice, restituisce il seguente risultato:
error signaled: denominator is zero
Value: 1
error signaled: denominator is zero
Value: 5
error signaled: denominator is zero
Done.Oltre al 'Sistema delle condizioni', come discusso sopra, Common LISP fornisce anche varie funzioni che possono essere chiamate per segnalare un errore. La gestione di un errore, quando segnalato, dipende tuttavia dall'implementazione.
Funzioni di segnalazione errori in LISP
La tabella seguente fornisce le funzioni di uso comune che segnalano avvisi, interruzioni, errori non irreversibili e fatali.
Il programma utente specifica un messaggio di errore (una stringa). Le funzioni elaborano questo messaggio e possono / non possono visualizzarlo all'utente.
I messaggi di errore dovrebbero essere costruiti applicando il format funzione, non dovrebbe contenere un carattere di nuova riga né all'inizio né alla fine e non è necessario indicare errori, poiché il sistema LISP si prenderà cura di questi secondo il suo stile preferito.
| Sr.No. | Funzione e descrizione |
|---|---|
| 1 | error formato-stringa e rest args Segnala un errore fatale. È impossibile continuare da questo tipo di errore; quindi l'errore non tornerà mai al suo chiamante. |
| 2 | cerror continue-stringa-formato stringa-formato-errore e rest args Segnala un errore ed entra nel debugger. Tuttavia, consente di continuare il programma dal debugger dopo aver risolto l'errore. |
| 3 | warn formato-stringa e rest args stampa un messaggio di errore ma normalmente non entra nel debugger |
| 4 | break& stringa di formato opzionale & rest args Stampa il messaggio e accede direttamente al debugger, senza consentire alcuna possibilità di intercettazione da parte delle strutture di gestione degli errori programmate |
Esempio
In questo esempio, la funzione fattoriale calcola fattoriale di un numero; tuttavia, se l'argomento è negativo, genera una condizione di errore.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defun factorial (x)
(cond ((or (not (typep x 'integer)) (minusp x))
(error "~S is a negative number." x))
((zerop x) 1)
(t (* x (factorial (- x 1))))
)
)
(write(factorial 5))
(terpri)
(write(factorial -1))Quando esegui il codice, restituisce il seguente risultato:
120
*** - -1 is a negative number.Il LISP comune ha preceduto il progresso della programmazione orientata agli oggetti di due decenni. Tuttavia, l'orientamento agli oggetti è stato incorporato in una fase successiva.
Definizione di classi
Il defclassmacro permette di creare classi definite dall'utente. Stabilisce una classe come tipo di dati. Ha la seguente sintassi:
(defclass class-name (superclass-name*)
(slot-description*)
class-option*))Gli slot sono variabili che memorizzano dati o campi.
Una descrizione dello slot ha la forma (slot-name slot-option *), dove ogni opzione è una parola chiave seguita da un nome, un'espressione e altre opzioni. Le opzioni di slot più comunemente utilizzate sono:
:accessor nome-funzione
:initform espressione
:initarg simbolo
Ad esempio, definiamo una classe Box, con tre slot di lunghezza, larghezza e altezza.
(defclass Box ()
(length
breadth
height)
)Fornire accesso e controllo di lettura / scrittura a uno slot
A meno che gli slot non abbiano valori a cui è possibile accedere, leggere o scrivere, le classi sono piuttosto inutili.
Puoi specificare accessorsper ogni slot quando si definisce una classe. Ad esempio, prendi la nostra classe Box -
(defclass Box ()
((length :accessor length)
(breadth :accessor breadth)
(height :accessor height)
)
)Puoi anche specificare separato accessor nomi per leggere e scrivere uno slot.
(defclass Box ()
((length :reader get-length :writer set-length)
(breadth :reader get-breadth :writer set-breadth)
(height :reader get-height :writer set-height)
)
)Creazione di istanze di una classe
La funzione generica make-instance crea e restituisce una nuova istanza di una classe.
Ha la seguente sintassi:
(make-instance class {initarg value}*)Esempio
Creiamo una classe Box, con tre slot, lunghezza, larghezza e altezza. Useremo tre funzioni di accesso agli slot per impostare i valori in questi campi.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
)
)
(setf item (make-instance 'box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
(format t "Length of the Box is ~d~%" (box-length item))
(format t "Breadth of the Box is ~d~%" (box-breadth item))
(format t "Height of the Box is ~d~%" (box-height item))Quando esegui il codice, restituisce il seguente risultato:
Length of the Box is 10
Breadth of the Box is 10
Height of the Box is 5Definizione di un metodo di classe
Il defmethodmacro ti permette di definire un metodo all'interno della classe. L'esempio seguente estende la nostra classe Box per includere un metodo denominato volume.
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
(volume :reader volume)
)
)
; method calculating volume
(defmethod volume ((object box))
(* (box-length object) (box-breadth object)(box-height object))
)
;setting the values
(setf item (make-instance 'box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
; displaying values
(format t "Length of the Box is ~d~%" (box-length item))
(format t "Breadth of the Box is ~d~%" (box-breadth item))
(format t "Height of the Box is ~d~%" (box-height item))
(format t "Volume of the Box is ~d~%" (volume item))Quando esegui il codice, restituisce il seguente risultato:
Length of the Box is 10
Breadth of the Box is 10
Height of the Box is 5
Volume of the Box is 500Eredità
LISP consente di definire un oggetto in termini di un altro oggetto. Questo è chiamatoinheritance.È possibile creare una classe derivata aggiungendo funzionalità nuove o diverse. La classe derivata eredita le funzionalità della classe genitore.
Il seguente esempio spiega questo:
Esempio
Crea un nuovo file di codice sorgente denominato main.lisp e digita il codice seguente al suo interno.
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
(volume :reader volume)
)
)
; method calculating volume
(defmethod volume ((object box))
(* (box-length object) (box-breadth object)(box-height object))
)
;wooden-box class inherits the box class
(defclass wooden-box (box)
((price :accessor box-price)))
;setting the values
(setf item (make-instance 'wooden-box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
(setf (box-price item) 1000)
; displaying values
(format t "Length of the Wooden Box is ~d~%" (box-length item))
(format t "Breadth of the Wooden Box is ~d~%" (box-breadth item))
(format t "Height of the Wooden Box is ~d~%" (box-height item))
(format t "Volume of the Wooden Box is ~d~%" (volume item))
(format t "Price of the Wooden Box is ~d~%" (box-price item))Quando esegui il codice, restituisce il seguente risultato:
Length of the Wooden Box is 10
Breadth of the Wooden Box is 10
Height of the Wooden Box is 5
Volume of the Wooden Box is 500
Price of the Wooden Box is 1000