Impostazione di un progetto
In questo capitolo, comprenderemo il processo coinvolto nella creazione di un progetto per eseguire la regressione logistica in Python, in dettaglio.
Installazione di Jupyter
Useremo Jupyter, una delle piattaforme più utilizzate per l'apprendimento automatico. Se non hai Jupyter installato sul tuo computer, scaricalo da qui . Per l'installazione, puoi seguire le istruzioni sul loro sito per installare la piattaforma. Come suggerisce il sito, potresti preferire usareAnaconda Distributionche viene fornito con Python e molti pacchetti Python comunemente usati per il calcolo scientifico e la scienza dei dati. Ciò allevierà la necessità di installare questi pacchetti individualmente.
Dopo la corretta installazione di Jupyter, avvia un nuovo progetto, la schermata in questa fase apparirà come la seguente pronta per accettare il tuo codice.
Ora cambia il nome del progetto da Untitled1 to “Logistic Regression” facendo clic sul nome del titolo e modificandolo.
Innanzitutto, importeremo diversi pacchetti Python di cui avremo bisogno nel nostro codice.
Importazione di pacchetti Python
A tale scopo, digita o taglia e incolla il seguente codice nell'editor di codice:
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitIl tuo Notebook dovrebbe essere simile al seguente in questa fase:
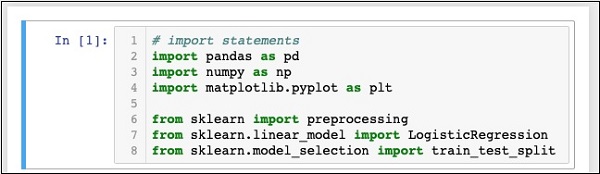
Esegui il codice facendo clic su Runpulsante. Se non vengono generati errori, hai installato correttamente Jupyter e ora sei pronto per il resto dello sviluppo.
Le prime tre istruzioni di importazione importano i pacchetti panda, numpy e matplotlib.pyplot nel nostro progetto. Le tre istruzioni successive importano i moduli specificati da sklearn.
Il nostro prossimo compito è scaricare i dati richiesti per il nostro progetto. Lo impareremo nel prossimo capitolo.