Node.js - Guida rapida
Cos'è Node.js?
Node.js è una piattaforma lato server costruita sul motore JavaScript di Google Chrome (motore V8). Node.js è stato sviluppato da Ryan Dahl nel 2009 e la sua ultima versione è la v0.10.36. La definizione di Node.js fornita dalla sua documentazione ufficiale è la seguente:
Node.js è una piattaforma basata sul runtime JavaScript di Chrome per creare facilmente applicazioni di rete veloci e scalabili. Node.js utilizza un modello di I / O non bloccante basato sugli eventi che lo rende leggero ed efficiente, perfetto per applicazioni in tempo reale ad alta intensità di dati che vengono eseguite su dispositivi distribuiti.
Node.js è un ambiente di runtime multipiattaforma open source per lo sviluppo di applicazioni lato server e di rete. Le applicazioni Node.js sono scritte in JavaScript e possono essere eseguite all'interno del runtime Node.js su OS X, Microsoft Windows e Linux.
Node.js fornisce anche una ricca libreria di vari moduli JavaScript che semplifica notevolmente lo sviluppo di applicazioni web utilizzando Node.js.
Node.js = Runtime Environment + JavaScript LibraryCaratteristiche di Node.js
Di seguito sono riportate alcune delle caratteristiche importanti che rendono Node.js la prima scelta degli architetti del software.
Asynchronous and Event Driven- Tutte le API della libreria Node.js sono asincrone, ovvero non bloccanti. Significa essenzialmente che un server basato su Node.js non attende mai che un'API restituisca dati. Il server passa all'API successiva dopo averla chiamata e un meccanismo di notifica di Events of Node.js aiuta il server a ottenere una risposta dalla chiamata API precedente.
Very Fast - Essendo costruita sul motore JavaScript V8 di Google Chrome, la libreria Node.js è molto veloce nell'esecuzione del codice.
Single Threaded but Highly Scalable- Node.js utilizza un modello a thread singolo con loop di eventi. Il meccanismo degli eventi aiuta il server a rispondere in modo non bloccante e rende il server altamente scalabile rispetto ai server tradizionali che creano thread limitati per gestire le richieste. Node.js utilizza un singolo programma a thread e lo stesso programma può fornire un servizio a un numero molto maggiore di richieste rispetto ai server tradizionali come Apache HTTP Server.
No Buffering- Le applicazioni Node.js non bufferizzano mai i dati. Queste applicazioni generano semplicemente i dati in blocchi.
License- Node.js è rilasciato con la licenza MIT .
Chi utilizza Node.js?
Di seguito è riportato il collegamento sul wiki di github contenente un elenco esaustivo di progetti, applicazioni e aziende che utilizzano Node.js. Questo elenco include eBay, General Electric, GoDaddy, Microsoft, PayPal, Uber, Wikipins, Yahoo! E Yammer per citarne alcuni.
Progetti, applicazioni e aziende che utilizzano Node
Concetti
Il diagramma seguente illustra alcune parti importanti di Node.js che discuteremo in dettaglio nei capitoli successivi.
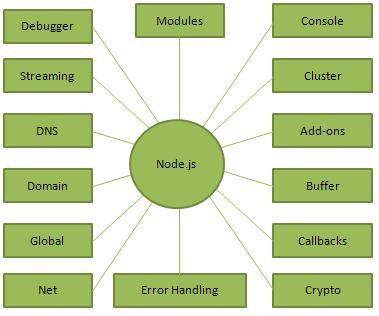
Dove utilizzare Node.js?
Di seguito sono riportate le aree in cui Node.js si sta dimostrando un perfetto partner tecnologico.
- Applicazioni associate a I / O
- Applicazioni per lo streaming di dati
- Applicazioni in tempo reale ad alta intensità di dati (DIRT)
- Applicazioni basate su API JSON
- Applicazioni a pagina singola
Dove non usare Node.js?
Non è consigliabile utilizzare Node.js per applicazioni ad alta intensità di CPU.
Provalo Opzione online
Non hai davvero bisogno di configurare il tuo ambiente per iniziare a imparare Node.js. La ragione è molto semplice, abbiamo già configurato l'ambiente Node.js online, in modo che tu possa eseguire tutti gli esempi disponibili online e imparare attraverso la pratica. Sentiti libero di modificare qualsiasi esempio e controlla i risultati con diverse opzioni.
Prova il seguente esempio usando il Live Demo opzione disponibile nell'angolo in alto a destra della casella del codice di esempio sottostante (sul nostro sito Web) -
/* Hello World! program in Node.js */ console.log("Hello World!");Per la maggior parte degli esempi forniti in questo tutorial, troverai un'opzione Provalo, quindi usala e goditi il tuo apprendimento.
Configurazione dell'ambiente locale
Se sei ancora disposto a configurare il tuo ambiente per Node.js, hai bisogno dei seguenti due software disponibili sul tuo computer, (a) Text Editor e (b) Gli installabili binari di Node.js.
Editor di testo
Questo verrà utilizzato per digitare il tuo programma. Esempi di pochi editor includono Blocco note di Windows, comando OS Edit, Brief, Epsilon, EMACS e vim o vi.
Il nome e la versione dell'editor di testo possono variare a seconda dei sistemi operativi. Ad esempio, il Blocco note verrà utilizzato su Windows e vim o vi possono essere utilizzati su Windows e Linux o UNIX.
I file che crei con il tuo editor sono chiamati file sorgente e contengono il codice sorgente del programma. I file sorgente per i programmi Node.js sono generalmente denominati con l'estensione ".js".
Prima di iniziare la programmazione, assicurati di disporre di un editor di testo e di avere esperienza sufficiente per scrivere un programma per computer, salvarlo in un file e infine eseguirlo.
Il Node.js Runtime
Il codice sorgente scritto nel file sorgente è semplicemente javascript. L'interprete Node.js verrà utilizzato per interpretare ed eseguire il codice javascript.
La distribuzione Node.js viene fornita come binario installabile per i sistemi operativi SunOS, Linux, Mac OS X e Windows con architetture di processore x86 a 32 bit (386) e 64 bit (amd64).
La sezione seguente ti guida su come installare la distribuzione binaria Node.js su vari sistemi operativi.
Scarica l'archivio Node.js.
Scarica l'ultima versione del file di archivio installabile Node.js da Node.js Downloads . Al momento della stesura di questo tutorial, di seguito sono riportate le versioni disponibili su diversi sistemi operativi.
| OS | Nome dell'archivio |
|---|---|
| finestre | node-v6.3.1-x64.msi |
| Linux | node-v6.3.1-linux-x86.tar.gz |
| Mac | node-v6.3.1-darwin-x86.tar.gz |
| SunOS | node-v6.3.1-sunos-x86.tar.gz |
Installazione su UNIX / Linux / Mac OS X e SunOS
In base all'architettura del tuo sistema operativo, scarica ed estrai l'archivio node-v6.3.1-osname.tar.gz in / tmp, quindi sposta infine i file estratti nella directory / usr / local / nodejs. Per esempio:
$ cd /tmp $ wget http://nodejs.org/dist/v6.3.1/node-v6.3.1-linux-x64.tar.gz
$ tar xvfz node-v6.3.1-linux-x64.tar.gz $ mkdir -p /usr/local/nodejs
$ mv node-v6.3.1-linux-x64/* /usr/local/nodejsAggiungi / usr / local / nodejs / bin alla variabile d'ambiente PATH.
| OS | Produzione |
|---|---|
| Linux | export PATH = $ PATH: / usr / local / nodejs / bin |
| Mac | export PATH = $ PATH: / usr / local / nodejs / bin |
| FreeBSD | export PATH = $ PATH: / usr / local / nodejs / bin |
Installazione su Windows
Usa il file MSI e segui le istruzioni per installare Node.js. Per impostazione predefinita, il programma di installazione utilizza la distribuzione Node.js in C: \ Programmi \ nodejs. Il programma di installazione dovrebbe impostare la directory C: \ Program Files \ nodejs \ bin nella variabile di ambiente PATH della finestra. Riavvia tutti i prompt dei comandi aperti per rendere effettive le modifiche.
Verifica installazione: esecuzione di un file
Crea un file js denominato main.js sulla tua macchina (Windows o Linux) con il seguente codice.
/* Hello, World! program in node.js */
console.log("Hello, World!")Ora esegui il file main.js usando l'interprete Node.js per vedere il risultato -
$ node main.jsSe tutto va bene con la tua installazione, questo dovrebbe produrre il seguente risultato:
Hello, World!Prima di creare un vero e proprio "Hello, World!" applicazione utilizzando Node.js, vediamo i componenti di un'applicazione Node.js. Un'applicazione Node.js è costituita dai seguenti tre componenti importanti:
Import required modules - Usiamo il file require direttiva per caricare i moduli Node.js.
Create server - Un server che ascolterà le richieste del client simile a Apache HTTP Server.
Read request and return response - Il server creato in un passaggio precedente leggerà la richiesta HTTP fatta dal client che può essere un browser o una console e restituirà la risposta.
Creazione dell'applicazione Node.js.
Passaggio 1: importare il modulo richiesto
Noi usiamo il require direttiva per caricare il modulo http e memorizzare l'istanza HTTP restituita in una variabile http come segue:
var http = require("http");Passaggio 2: creare un server
Usiamo l'istanza http creata e chiamiamo http.createServer() metodo per creare un'istanza del server e quindi la colleghiamo alla porta 8081 utilizzando il listenmetodo associato all'istanza del server. Passa una funzione con i parametri richiesta e risposta. Scrivi l'implementazione di esempio per restituire sempre "Hello World".
http.createServer(function (request, response) {
// Send the HTTP header
// HTTP Status: 200 : OK
// Content Type: text/plain
response.writeHead(200, {'Content-Type': 'text/plain'});
// Send the response body as "Hello World"
response.end('Hello World\n');
}).listen(8081);
// Console will print the message
console.log('Server running at http://127.0.0.1:8081/');Il codice sopra è sufficiente per creare un server HTTP che ascolta, cioè attende una richiesta sulla porta 8081 sulla macchina locale.
Passaggio 3: test di richiesta e risposta
Mettiamo insieme i passaggi 1 e 2 in un file chiamato main.js e avvia il nostro server HTTP come mostrato di seguito -
var http = require("http");
http.createServer(function (request, response) {
// Send the HTTP header
// HTTP Status: 200 : OK
// Content Type: text/plain
response.writeHead(200, {'Content-Type': 'text/plain'});
// Send the response body as "Hello World"
response.end('Hello World\n');
}).listen(8081);
// Console will print the message
console.log('Server running at http://127.0.0.1:8081/');Ora esegui main.js per avviare il server come segue:
$ node main.jsVerifica l'output. Il server è stato avviato.
Server running at http://127.0.0.1:8081/Effettua una richiesta al server Node.js
Apri http://127.0.0.1:8081/ in qualsiasi browser e osserva il seguente risultato.
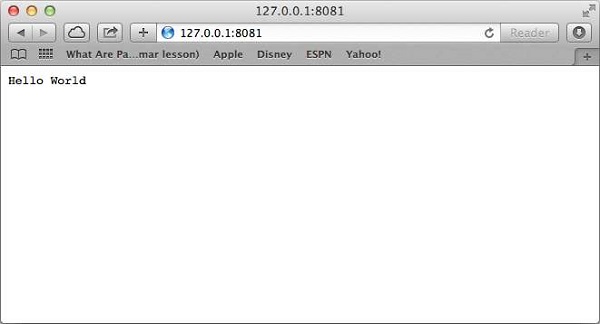
Congratulazioni, hai il tuo primo server HTTP attivo e funzionante che risponde a tutte le richieste HTTP sulla porta 8081.
REPL sta per Read Eval Print Loop e rappresenta un ambiente informatico come una console Windows o una shell Unix / Linux in cui viene immesso un comando e il sistema risponde con un output in modalità interattiva. Node.js oNodeviene fornito in bundle con un ambiente REPL. Svolge le seguenti attività:
Read - Legge l'input dell'utente, analizza l'input nella struttura dati JavaScript e lo archivia in memoria.
Eval - Prende e valuta la struttura dei dati.
Print - Stampa il risultato.
Loop - Ripete il comando precedente finché l'utente non preme ctrl-c due volte.
La funzionalità REPL di Node è molto utile per sperimentare codici Node.js e per eseguire il debug dei codici JavaScript.
Terminale REPL in linea
Per semplificare il tuo apprendimento, abbiamo creato un ambiente REPL Node.js online di facile utilizzo, in cui puoi esercitarti con la sintassi Node.js - Avvia Node.js REPL Terminal
Avvio di REPL
REPL può essere avviato semplicemente eseguendo node su shell / console senza argomenti come segue.
$ nodeVedrai il prompt dei comandi REPL> dove puoi digitare qualsiasi comando Node.js -
$ node
>Espressione semplice
Proviamo una semplice matematica al prompt dei comandi REPL di Node.js -
$ node
> 1 + 3
4
> 1 + ( 2 * 3 ) - 4
3
>Usa variabili
È possibile utilizzare variabili per memorizzare valori e stampare in seguito come qualsiasi script convenzionale. Sevarla parola chiave non viene utilizzata, quindi il valore viene memorizzato nella variabile e stampato. Mentre sevarviene utilizzata la parola chiave, quindi il valore viene memorizzato ma non stampato. È possibile stampare variabili utilizzandoconsole.log().
$ node
> x = 10
10
> var y = 10
undefined
> x + y
20
> console.log("Hello World")
Hello World
undefinedEspressione multilinea
Il nodo REPL supporta espressioni su più righe simili a JavaScript. Controlliamo il seguente ciclo di do-while in azione:
$ node
> var x = 0
undefined
> do {
... x++;
... console.log("x: " + x);
... }
while ( x < 5 );
x: 1
x: 2
x: 3
x: 4
x: 5
undefined
>...viene automaticamente quando si preme Invio dopo la parentesi di apertura. Node controlla automaticamente la continuità delle espressioni.
Sottolineatura variabile
Puoi usare il trattino basso (_) per ottenere l'ultimo risultato -
$ node
> var x = 10
undefined
> var y = 20
undefined
> x + y
30
> var sum = _
undefined
> console.log(sum)
30
undefined
>Comandi REPL
ctrl + c - termina il comando corrente.
ctrl + c twice - terminare il nodo REPL.
ctrl + d - terminare il nodo REPL.
Up/Down Keys - vedere la cronologia dei comandi e modificare i comandi precedenti.
tab Keys - elenco dei comandi correnti.
.help - elenco di tutti i comandi.
.break - uscita dall'espressione multilinea.
.clear - uscita dall'espressione multilinea.
.save filename - salva la sessione REPL del nodo corrente in un file.
.load filename - carica il contenuto del file nella sessione REPL del nodo corrente.
Arresto di REPL
Come accennato in precedenza, dovrai usare ctrl-c twice per uscire da Node.js REPL.
$ node
>
(^C again to quit)
>Node Package Manager (NPM) fornisce due funzionalità principali:
Repository online per pacchetti / moduli node.js che sono ricercabili su search.nodejs.org
Utilità della riga di comando per installare i pacchetti Node.js, eseguire la gestione delle versioni e la gestione delle dipendenze dei pacchetti Node.js.
NPM viene fornito in bundle con gli installabili Node.js dopo la versione v0.6.3. Per verificare lo stesso, apri la console e digita il seguente comando e guarda il risultato:
$ npm --version
2.7.1Se stai utilizzando una vecchia versione di NPM, è abbastanza facile aggiornarla all'ultima versione. Usa semplicemente il seguente comando da root:
$ sudo npm install npm -g
/usr/bin/npm -> /usr/lib/node_modules/npm/bin/npm-cli.js
[email protected] /usr/lib/node_modules/npmInstallazione di moduli tramite NPM
C'è una semplice sintassi per installare qualsiasi modulo Node.js -
$ npm install <Module Name>Ad esempio, di seguito è riportato il comando per installare un famoso modulo framework web Node.js chiamato express -
$ npm install expressOra puoi usare questo modulo nel tuo file js come segue:
var express = require('express');Installazione globale e locale
Per impostazione predefinita, NPM installa qualsiasi dipendenza in modalità locale. Qui la modalità locale si riferisce all'installazione del pacchetto nella directory node_modules che si trova nella cartella in cui è presente l'applicazione Node. I pacchetti distribuiti localmente sono accessibili tramite il metodo require (). Ad esempio, quando abbiamo installato il modulo express, ha creato la directory node_modules nella directory corrente in cui è installato il modulo express.
$ ls -l
total 0
drwxr-xr-x 3 root root 20 Mar 17 02:23 node_modulesIn alternativa, puoi usare npm ls comando per elencare tutti i moduli installati localmente.
I pacchetti / dipendenze installati a livello globale vengono archiviati nella directory di sistema. Tali dipendenze possono essere utilizzate nella funzione CLI (Command Line Interface) di qualsiasi node.js ma non possono essere importate utilizzando require () direttamente nell'applicazione Node. Ora proviamo a installare il modulo express usando l'installazione globale.
$ npm install express -gQuesto produrrà un risultato simile ma il modulo verrà installato globalmente. Qui, la prima riga mostra la versione del modulo e la posizione in cui viene installato.
[email protected] /usr/lib/node_modules/express
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected] ([email protected])
├── [email protected] ([email protected])
├── [email protected] ([email protected])
├── [email protected] ([email protected], [email protected])
├── [email protected] ([email protected], [email protected], [email protected])
├── [email protected] ([email protected])
├── [email protected] ([email protected], [email protected])
└── [email protected] ([email protected], [email protected])È possibile utilizzare il seguente comando per controllare tutti i moduli installati a livello globale:
$ npm ls -gUtilizzando package.json
package.json è presente nella directory root di qualsiasi applicazione / modulo Node e viene utilizzato per definire le proprietà di un pacchetto. Apriamo package.json del pacchetto express presente innode_modules/express/
{
"name": "express",
"description": "Fast, unopinionated, minimalist web framework",
"version": "4.11.2",
"author": {
"name": "TJ Holowaychuk",
"email": "[email protected]"
},
"contributors": [{
"name": "Aaron Heckmann",
"email": "[email protected]"
},
{
"name": "Ciaran Jessup",
"email": "[email protected]"
},
{
"name": "Douglas Christopher Wilson",
"email": "[email protected]"
},
{
"name": "Guillermo Rauch",
"email": "[email protected]"
},
{
"name": "Jonathan Ong",
"email": "[email protected]"
},
{
"name": "Roman Shtylman",
"email": "[email protected]"
},
{
"name": "Young Jae Sim",
"email": "[email protected]"
} ],
"license": "MIT", "repository": {
"type": "git",
"url": "https://github.com/strongloop/express"
},
"homepage": "https://expressjs.com/", "keywords": [
"express",
"framework",
"sinatra",
"web",
"rest",
"restful",
"router",
"app",
"api"
],
"dependencies": {
"accepts": "~1.2.3",
"content-disposition": "0.5.0",
"cookie-signature": "1.0.5",
"debug": "~2.1.1",
"depd": "~1.0.0",
"escape-html": "1.0.1",
"etag": "~1.5.1",
"finalhandler": "0.3.3",
"fresh": "0.2.4",
"media-typer": "0.3.0",
"methods": "~1.1.1",
"on-finished": "~2.2.0",
"parseurl": "~1.3.0",
"path-to-regexp": "0.1.3",
"proxy-addr": "~1.0.6",
"qs": "2.3.3",
"range-parser": "~1.0.2",
"send": "0.11.1",
"serve-static": "~1.8.1",
"type-is": "~1.5.6",
"vary": "~1.0.0",
"cookie": "0.1.2",
"merge-descriptors": "0.0.2",
"utils-merge": "1.0.0"
},
"devDependencies": {
"after": "0.8.1",
"ejs": "2.1.4",
"istanbul": "0.3.5",
"marked": "0.3.3",
"mocha": "~2.1.0",
"should": "~4.6.2",
"supertest": "~0.15.0",
"hjs": "~0.0.6",
"body-parser": "~1.11.0",
"connect-redis": "~2.2.0",
"cookie-parser": "~1.3.3",
"express-session": "~1.10.2",
"jade": "~1.9.1",
"method-override": "~2.3.1",
"morgan": "~1.5.1",
"multiparty": "~4.1.1",
"vhost": "~3.0.0"
},
"engines": {
"node": ">= 0.10.0"
},
"files": [
"LICENSE",
"History.md",
"Readme.md",
"index.js",
"lib/"
],
"scripts": {
"test": "mocha --require test/support/env
--reporter spec --bail --check-leaks test/ test/acceptance/",
"test-cov": "istanbul cover node_modules/mocha/bin/_mocha
-- --require test/support/env --reporter dot --check-leaks test/ test/acceptance/",
"test-tap": "mocha --require test/support/env
--reporter tap --check-leaks test/ test/acceptance/",
"test-travis": "istanbul cover node_modules/mocha/bin/_mocha
--report lcovonly -- --require test/support/env
--reporter spec --check-leaks test/ test/acceptance/"
},
"gitHead": "63ab25579bda70b4927a179b580a9c580b6c7ada",
"bugs": {
"url": "https://github.com/strongloop/express/issues"
},
"_id": "[email protected]",
"_shasum": "8df3d5a9ac848585f00a0777601823faecd3b148",
"_from": "express@*",
"_npmVersion": "1.4.28",
"_npmUser": {
"name": "dougwilson",
"email": "[email protected]"
},
"maintainers": [{
"name": "tjholowaychuk",
"email": "[email protected]"
},
{
"name": "jongleberry",
"email": "[email protected]"
},
{
"name": "shtylman",
"email": "[email protected]"
},
{
"name": "dougwilson",
"email": "[email protected]"
},
{
"name": "aredridel",
"email": "[email protected]"
},
{
"name": "strongloop",
"email": "[email protected]"
},
{
"name": "rfeng",
"email": "[email protected]"
}],
"dist": {
"shasum": "8df3d5a9ac848585f00a0777601823faecd3b148",
"tarball": "https://registry.npmjs.org/express/-/express-4.11.2.tgz"
},
"directories": {},
"_resolved": "https://registry.npmjs.org/express/-/express-4.11.2.tgz",
"readme": "ERROR: No README data found!"
}Attributi di Package.json
name - nome del pacchetto
version - versione del pacchetto
description - descrizione del pacchetto
homepage - homepage del pacchetto
author - autore del pacchetto
contributors - nome dei contributori al pacchetto
dependencies- elenco delle dipendenze. NPM installa automaticamente tutte le dipendenze qui menzionate nella cartella node_module del pacchetto.
repository - tipo di repository e URL del pacchetto
main - punto di ingresso del pacchetto
keywords - parole chiave
Disinstallazione di un modulo
Utilizzare il seguente comando per disinstallare un modulo Node.js.
$ npm uninstall expressUna volta che NPM disinstalla il pacchetto, puoi verificarlo guardando il contenuto della directory / node_modules / o digita il seguente comando:
$ npm lsAggiornamento di un modulo
Aggiorna package.json e modifica la versione della dipendenza da aggiornare ed esegui il seguente comando.
$ npm update expressCerca un modulo
Cerca un nome di pacchetto utilizzando NPM.
$ npm search expressCrea un modulo
La creazione di un modulo richiede la generazione di package.json. Generiamo package.json utilizzando NPM, che genererà lo scheletro di base di package.json.
$ npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sane defaults.
See 'npm help json' for definitive documentation on these fields
and exactly what they do.
Use 'npm install <pkg> --save' afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
name: (webmaster)Dovrai fornire tutte le informazioni richieste sul tuo modulo. Puoi chiedere aiuto al file package.json sopra menzionato per comprendere il significato delle varie informazioni richieste. Una volta generato package.json, utilizzare il seguente comando per registrarsi al sito del repository NPM utilizzando un indirizzo e-mail valido.
$ npm adduser
Username: mcmohd
Password:
Email: (this IS public) [email protected]È giunto il momento di pubblicare il tuo modulo -
$ npm publishSe tutto va bene con il tuo modulo, allora sarà pubblicato nel repository e sarà accessibile per l'installazione utilizzando NPM come qualsiasi altro modulo Node.js.
Cos'è la richiamata?
Il callback è un equivalente asincrono per una funzione. Una funzione di callback viene chiamata al completamento di una determinata attività. Node fa un uso massiccio di callback. Tutte le API di Node sono scritte in modo tale da supportare i callback.
Ad esempio, una funzione per leggere un file può iniziare a leggere il file e restituire immediatamente il controllo all'ambiente di esecuzione in modo che l'istruzione successiva possa essere eseguita. Una volta completato l'I / O del file, chiamerà la funzione di callback mentre passa la funzione di callback, il contenuto del file come parametro. Quindi non c'è blocco o attesa per File I / O. Ciò rende Node.js altamente scalabile, in quanto può elaborare un numero elevato di richieste senza attendere che nessuna funzione restituisca risultati.
Esempio di codice di blocco
Crea un file di testo denominato input.txt con il seguente contenuto -
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Crea un file js denominato main.js con il seguente codice -
var fs = require("fs");
var data = fs.readFileSync('input.txt');
console.log(data.toString());
console.log("Program Ended");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!
Program EndedEsempio di codice non bloccante
Crea un file di testo denominato input.txt con il seguente contenuto.
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Aggiorna main.js per avere il seguente codice:
var fs = require("fs");
fs.readFile('input.txt', function (err, data) {
if (err) return console.error(err);
console.log(data.toString());
});
console.log("Program Ended");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Program Ended
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Questi due esempi spiegano il concetto di blocco e non blocco delle chiamate.
Il primo esempio mostra che il programma si blocca fino a quando non legge il file e solo dopo continua a terminare il programma.
Il secondo esempio mostra che il programma non attende la lettura del file e procede a stampare "Program Ended" e contemporaneamente il programma senza blocco continua a leggere il file.
Pertanto, un programma di blocco viene eseguito molto in sequenza. Dal punto di vista della programmazione è più facile implementare la logica ma i programmi non bloccanti non vengono eseguiti in sequenza. Nel caso in cui un programma necessiti di utilizzare qualsiasi dato per essere elaborato, dovrebbe essere mantenuto all'interno dello stesso blocco per renderlo sequenziale.
Node.js è un'applicazione a thread singolo, ma può supportare la concorrenza tramite il concetto di event e callbacks. Ogni API di Node.js è asincrona ed essendo a thread singolo, usanoasync function callsper mantenere la concorrenza. Il nodo utilizza il pattern dell'osservatore. Il thread del nodo mantiene un ciclo di eventi e ogni volta che un'attività viene completata, attiva l'evento corrispondente che segnala l'esecuzione della funzione listener di eventi.
Programmazione guidata dagli eventi
Node.js utilizza molto gli eventi ed è anche uno dei motivi per cui Node.js è piuttosto veloce rispetto ad altre tecnologie simili. Non appena Node avvia il suo server, avvia semplicemente le sue variabili, dichiara le funzioni e quindi attende semplicemente che si verifichi l'evento.
In un'applicazione basata sugli eventi, generalmente è presente un ciclo principale che ascolta gli eventi e quindi attiva una funzione di callback quando viene rilevato uno di questi eventi.
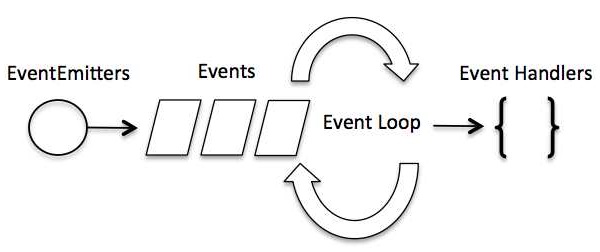
Sebbene gli eventi siano abbastanza simili ai callback, la differenza sta nel fatto che le funzioni di callback vengono chiamate quando una funzione asincrona restituisce il suo risultato, mentre la gestione degli eventi funziona sul pattern dell'osservatore. Le funzioni che ascoltano gli eventi agiscono comeObservers. Ogni volta che un evento viene generato, la sua funzione listener inizia l'esecuzione. Node.js ha più eventi integrati disponibili tramite il modulo eventi e la classe EventEmitter che vengono utilizzati per associare eventi e ascoltatori di eventi come segue:
// Import events module
var events = require('events');
// Create an eventEmitter object
var eventEmitter = new events.EventEmitter();Di seguito è riportata la sintassi per associare un gestore di eventi a un evento:
// Bind event and event handler as follows
eventEmitter.on('eventName', eventHandler);Possiamo attivare un evento a livello di codice come segue:
// Fire an event
eventEmitter.emit('eventName');Esempio
Crea un file js denominato main.js con il codice seguente:
// Import events module
var events = require('events');
// Create an eventEmitter object
var eventEmitter = new events.EventEmitter();
// Create an event handler as follows
var connectHandler = function connected() {
console.log('connection succesful.');
// Fire the data_received event
eventEmitter.emit('data_received');
}
// Bind the connection event with the handler
eventEmitter.on('connection', connectHandler);
// Bind the data_received event with the anonymous function
eventEmitter.on('data_received', function() {
console.log('data received succesfully.');
});
// Fire the connection event
eventEmitter.emit('connection');
console.log("Program Ended.");Ora proviamo a eseguire il programma sopra e controlliamo il suo output -
$ node main.jsIT dovrebbe produrre il seguente risultato:
connection successful.
data received successfully.
Program Ended.Come funzionano le applicazioni dei nodi?
Nell'applicazione nodo, qualsiasi funzione asincrona accetta un callback come ultimo parametro e una funzione di callback accetta un errore come primo parametro. Rivisitiamo di nuovo l'esempio precedente. Crea un file di testo denominato input.txt con il seguente contenuto.
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Crea un file js denominato main.js con il seguente codice:
var fs = require("fs");
fs.readFile('input.txt', function (err, data) {
if (err) {
console.log(err.stack);
return;
}
console.log(data.toString());
});
console.log("Program Ended");Qui fs.readFile () è una funzione asincrona il cui scopo è leggere un file. Se si verifica un errore durante l'operazione di lettura, il fileerr object conterrà l'errore corrispondente, altrimenti i dati conterranno il contenuto del file. readFile passa err e dati alla funzione di callback dopo che l'operazione di lettura è stata completata, che alla fine stampa il contenuto.
Program Ended
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Molti oggetti in un nodo emettono eventi, ad esempio un net.Server emette un evento ogni volta che un peer si collega ad esso, un fs.readStream emette un evento quando il file viene aperto. Tutti gli oggetti che emettono eventi sono le istanze di events.EventEmitter.
EventEmitter Class
Come abbiamo visto nella sezione precedente, la classe EventEmitter si trova nel modulo events. È accessibile tramite il codice seguente:
// Import events module
var events = require('events');
// Create an eventEmitter object
var eventEmitter = new events.EventEmitter();Quando un'istanza EventEmitter affronta un errore, emette un evento di "errore". Quando viene aggiunto un nuovo listener, viene generato l'evento "newListener" e quando un listener viene rimosso, viene generato l'evento "removeListener".
EventEmitter fornisce più proprietà come on e emit. on viene utilizzata per associare una funzione all'evento e emit viene utilizzato per attivare un evento.
Metodi
| Sr.No. | Metodo e descrizione |
|---|---|
| 1 | addListener(event, listener) Aggiunge un listener alla fine dell'array listener per l'evento specificato. Non vengono effettuati controlli per vedere se l'ascoltatore è già stato aggiunto. Più chiamate che passano la stessa combinazione di evento e listener comporteranno l'aggiunta più volte del listener. Restituisce l'emettitore, quindi le chiamate possono essere concatenate. |
| 2 | on(event, listener) Aggiunge un listener alla fine dell'array listener per l'evento specificato. Non vengono effettuati controlli per vedere se l'ascoltatore è già stato aggiunto. Più chiamate che passano la stessa combinazione di evento e listener comporteranno l'aggiunta più volte del listener. Restituisce l'emettitore, quindi le chiamate possono essere concatenate. |
| 3 | once(event, listener) Aggiunge un ascoltatore occasionale all'evento. Questo listener viene richiamato solo la volta successiva in cui viene generato l'evento, dopodiché viene rimosso. Restituisce l'emettitore, quindi le chiamate possono essere concatenate. |
| 4 | removeListener(event, listener) Rimuove un listener dall'array listener per l'evento specificato. Caution −Modifica gli indici dell'array nell'array listener dietro l'ascoltatore. removeListener rimuoverà al massimo un'istanza di un listener dall'array listener. Se un singolo listener è stato aggiunto più volte all'array listener per l'evento specificato, removeListener deve essere chiamato più volte per rimuovere ogni istanza. Restituisce l'emettitore, quindi le chiamate possono essere concatenate. |
| 5 | removeAllListeners([event]) Rimuove tutti i listener o quelli dell'evento specificato. Non è una buona idea rimuovere i listener che sono stati aggiunti altrove nel codice, specialmente quando si trova su un emettitore che non hai creato (es. Socket o flussi di file). Restituisce l'emettitore, quindi le chiamate possono essere concatenate. |
| 6 | setMaxListeners(n) Per impostazione predefinita, EventEmitters stamperà un avviso se vengono aggiunti più di 10 listener per un particolare evento. Questa è un'utile impostazione predefinita che aiuta a trovare perdite di memoria. Ovviamente non tutti gli Emettitori dovrebbero essere limitati a 10. Questa funzione permette di aumentarlo. Impostare a zero per illimitato. |
| 7 | listeners(event) Restituisce un array di listener per l'evento specificato. |
| 8 | emit(event, [arg1], [arg2], [...]) Esegui ciascuno degli ascoltatori in ordine con gli argomenti forniti. Restituisce vero se l'evento aveva ascoltatori, falso in caso contrario. |
Metodi di classe
| Sr.No. | Metodo e descrizione |
|---|---|
| 1 | listenerCount(emitter, event) Restituisce il numero di listener per un determinato evento. |
Eventi
| Sr.No. | Eventi e descrizione |
|---|---|
| 1 | newListener
Questo evento viene emesso ogni volta che viene aggiunto un listener. Quando questo evento viene attivato, il listener potrebbe non essere stato ancora aggiunto all'array di listener per l'evento. |
| 2 | removeListener
Questo evento viene emesso ogni volta che qualcuno rimuove un ascoltatore. Quando questo evento viene attivato, il listener potrebbe non essere stato ancora rimosso dall'array di listener per l'evento. |
Esempio
Crea un file js denominato main.js con il seguente codice Node.js:
var events = require('events');
var eventEmitter = new events.EventEmitter();
// listener #1
var listner1 = function listner1() {
console.log('listner1 executed.');
}
// listener #2
var listner2 = function listner2() {
console.log('listner2 executed.');
}
// Bind the connection event with the listner1 function
eventEmitter.addListener('connection', listner1);
// Bind the connection event with the listner2 function
eventEmitter.on('connection', listner2);
var eventListeners = require('events').EventEmitter.listenerCount
(eventEmitter,'connection');
console.log(eventListeners + " Listner(s) listening to connection event");
// Fire the connection event
eventEmitter.emit('connection');
// Remove the binding of listner1 function
eventEmitter.removeListener('connection', listner1);
console.log("Listner1 will not listen now.");
// Fire the connection event
eventEmitter.emit('connection');
eventListeners = require('events').EventEmitter.listenerCount(eventEmitter,'connection');
console.log(eventListeners + " Listner(s) listening to connection event");
console.log("Program Ended.");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
2 Listner(s) listening to connection event
listner1 executed.
listner2 executed.
Listner1 will not listen now.
listner2 executed.
1 Listner(s) listening to connection event
Program Ended.Pure JavaScript è compatibile con Unicode, ma non lo è per i dati binari. Durante la gestione dei flussi TCP o del file system, è necessario gestire i flussi di ottetti. Il nodo fornisce la classe Buffer che fornisce istanze per memorizzare dati grezzi simili a un array di numeri interi ma corrisponde a un'allocazione di memoria non elaborata all'esterno dell'heap V8.
La classe buffer è una classe globale a cui è possibile accedere in un'applicazione senza importare il modulo buffer.
Creazione di buffer
Node Buffer può essere costruito in molti modi.
Metodo 1
Di seguito è riportata la sintassi per creare un Buffer non iniziato di 10 ottetti -
var buf = new Buffer(10);Metodo 2
Di seguito è riportata la sintassi per creare un buffer da un dato array:
var buf = new Buffer([10, 20, 30, 40, 50]);Metodo 3
Di seguito è riportata la sintassi per creare un buffer da una determinata stringa e facoltativamente tipo di codifica:
var buf = new Buffer("Simply Easy Learning", "utf-8");Sebbene "utf8" sia la codifica predefinita, puoi utilizzare una qualsiasi delle seguenti codifiche "ascii", "utf8", "utf16le", "ucs2", "base64" o "hex".
Scrittura su buffer
Sintassi
Di seguito è riportata la sintassi del metodo per scrivere in un buffer del nodo:
buf.write(string[, offset][, length][, encoding])Parametri
Ecco la descrizione dei parametri utilizzati:
string - Questa è la stringa di dati da scrivere nel buffer.
offset- Questo è l'indice del buffer da cui iniziare a scrivere. Il valore predefinito è 0.
length- Questo è il numero di byte da scrivere. Il valore predefinito è buffer.length.
encoding- Codifica da utilizzare. "utf8" è la codifica predefinita.
Valore di ritorno
Questo metodo restituisce il numero di ottetti scritti. Se non c'è abbastanza spazio nel buffer per contenere l'intera stringa, scriverà una parte della stringa.
Esempio
buf = new Buffer(256);
len = buf.write("Simply Easy Learning");
console.log("Octets written : "+ len);Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
Octets written : 20Lettura dai buffer
Sintassi
Di seguito è riportata la sintassi del metodo per leggere i dati da un buffer del nodo:
buf.toString([encoding][, start][, end])Parametri
Ecco la descrizione dei parametri utilizzati:
encoding- Codifica da utilizzare. "utf8" è la codifica predefinita.
start - Inizio indice per iniziare a leggere, il valore predefinito è 0.
end - Fine indice per terminare la lettura, il valore predefinito è buffer completo.
Valore di ritorno
Questo metodo decodifica e restituisce una stringa dai dati del buffer codificati utilizzando la codifica del set di caratteri specificata.
Esempio
buf = new Buffer(26);
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log( buf.toString('ascii')); // outputs: abcdefghijklmnopqrstuvwxyz
console.log( buf.toString('ascii',0,5)); // outputs: abcde
console.log( buf.toString('utf8',0,5)); // outputs: abcde
console.log( buf.toString(undefined,0,5)); // encoding defaults to 'utf8', outputs abcdeQuando il programma di cui sopra viene eseguito, produce il seguente risultato:
abcdefghijklmnopqrstuvwxyz
abcde
abcde
abcdeConverti Buffer in JSON
Sintassi
Di seguito è riportata la sintassi del metodo per convertire un buffer del nodo in un oggetto JSON:
buf.toJSON()Valore di ritorno
Questo metodo restituisce una rappresentazione JSON dell'istanza Buffer.
Esempio
var buf = new Buffer('Simply Easy Learning');
var json = buf.toJSON(buf);
console.log(json);Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
{ type: 'Buffer',
data:
[
83,
105,
109,
112,
108,
121,
32,
69,
97,
115,
121,
32,
76,
101,
97,
114,
110,
105,
110,
103
]
}Buffer concatenati
Sintassi
Di seguito è riportata la sintassi del metodo per concatenare i buffer del nodo a un singolo buffer del nodo:
Buffer.concat(list[, totalLength])Parametri
Ecco la descrizione dei parametri utilizzati:
list - Elenco array di oggetti Buffer da concatenare.
totalLength - Questa è la lunghezza totale dei buffer quando concatenati.
Valore di ritorno
Questo metodo restituisce un'istanza di Buffer.
Esempio
var buffer1 = new Buffer('TutorialsPoint ');
var buffer2 = new Buffer('Simply Easy Learning');
var buffer3 = Buffer.concat([buffer1,buffer2]);
console.log("buffer3 content: " + buffer3.toString());Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
buffer3 content: TutorialsPoint Simply Easy LearningConfronta i buffer
Sintassi
Di seguito è riportata la sintassi del metodo per confrontare due buffer del nodo:
buf.compare(otherBuffer);Parametri
Ecco la descrizione dei parametri utilizzati:
otherBuffer - Questo è l'altro buffer che verrà confrontato con buf
Valore di ritorno
Restituisce un numero che indica se viene prima o dopo o è uguale all'altroBuffer nell'ordinamento.
Esempio
var buffer1 = new Buffer('ABC');
var buffer2 = new Buffer('ABCD');
var result = buffer1.compare(buffer2);
if(result < 0) {
console.log(buffer1 +" comes before " + buffer2);
} else if(result === 0) {
console.log(buffer1 +" is same as " + buffer2);
} else {
console.log(buffer1 +" comes after " + buffer2);
}Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
ABC comes before ABCDBuffer di copia
Sintassi
Di seguito è riportata la sintassi del metodo per copiare un buffer del nodo:
buf.copy(targetBuffer[, targetStart][, sourceStart][, sourceEnd])Parametri
Ecco la descrizione dei parametri utilizzati:
targetBuffer - Oggetto buffer in cui verrà copiato il buffer.
targetStart - Numero, opzionale, predefinito: 0
sourceStart - Numero, opzionale, predefinito: 0
sourceEnd - Numero, opzionale, predefinito: buffer.length
Valore di ritorno
Nessun valore restituito. Copia i dati da una regione di questo buffer a una regione nel buffer di destinazione anche se la regione di memoria di destinazione si sovrappone all'origine. Se non è definito, i parametri targetStart e sourceStart vengono impostati per impostazione predefinita su 0, mentre sourceEnd è predefinito su buffer.length.
Esempio
var buffer1 = new Buffer('ABC');
//copy a buffer
var buffer2 = new Buffer(3);
buffer1.copy(buffer2);
console.log("buffer2 content: " + buffer2.toString());Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
buffer2 content: ABCSlice Buffer
Sintassi
Di seguito è riportata la sintassi del metodo per ottenere un buffer secondario di un buffer del nodo:
buf.slice([start][, end])Parametri
Ecco la descrizione dei parametri utilizzati:
start - Numero, opzionale, predefinito: 0
end - Numero, opzionale, predefinito: buffer.length
Valore di ritorno
Restituisce un nuovo buffer che fa riferimento alla stessa memoria di quello vecchio, ma sfalsato e ritagliato dagli indici di inizio (valore predefinito 0) e fine (valore predefinito buffer.length). Gli indici negativi iniziano dalla fine del buffer.
Esempio
var buffer1 = new Buffer('TutorialsPoint');
//slicing a buffer
var buffer2 = buffer1.slice(0,9);
console.log("buffer2 content: " + buffer2.toString());Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
buffer2 content: TutorialsLunghezza buffer
Sintassi
Di seguito è riportata la sintassi del metodo per ottenere una dimensione di un buffer del nodo in byte:
buf.length;Valore di ritorno
Restituisce la dimensione di un buffer in byte.
Esempio
var buffer = new Buffer('TutorialsPoint');
//length of the buffer
console.log("buffer length: " + buffer.length);Quando il programma di cui sopra viene eseguito, produce il seguente risultato:
buffer length: 14Riferimento ai metodi
| Sr.No. | Metodo e descrizione |
|---|---|
| 1 | new Buffer(size) Alloca un nuovo buffer di ottetti di dimensione. Notare che la dimensione non deve essere superiore a kMaxLength. Altrimenti, qui verrà lanciato un RangeError. |
| 2 | new Buffer(buffer) Copia i dati del buffer passati in una nuova istanza Buffer. |
| 3 | new Buffer(str[, encoding]) Alloca un nuovo buffer contenente il dato str. la codifica predefinita è "utf8". |
| 4 | buf.length Restituisce la dimensione del buffer in byte. Nota che questa non è necessariamente la dimensione dei contenuti. la lunghezza si riferisce alla quantità di memoria allocata per l'oggetto buffer. Non cambia quando il contenuto del buffer viene modificato. |
| 5 | buf.write(string[, offset][, length][, encoding]) Scrive una stringa nel buffer all'offset utilizzando la codifica data. offset predefinito a 0, codifica predefinito a "utf8". length è il numero di byte da scrivere. Restituisce il numero di ottetti scritti. |
| 6 | buf.writeUIntLE(value, offset, byteLength[, noAssert]) Scrive un valore nel buffer all'offset e byteLength specificati. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Il valore predefinito è false. |
| 7 | buf.writeUIntBE(value, offset, byteLength[, noAssert]) Scrive un valore nel buffer all'offset e byteLength specificati. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Il valore predefinito è false. |
| 8 | buf.writeIntLE(value, offset, byteLength[, noAssert]) Scrive un valore nel buffer all'offset e byteLength specificati. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Il valore predefinito è false. |
| 9 | buf.writeIntBE(value, offset, byteLength[, noAssert]) Scrive un valore nel buffer all'offset e byteLength specificati. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Il valore predefinito è false. |
| 10 | buf.readUIntLE(offset, byteLength[, noAssert]) Una versione generalizzata di tutti i metodi di lettura numerica. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 11 | buf.readUIntBE(offset, byteLength[, noAssert]) Una versione generalizzata di tutti i metodi di lettura numerica. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 12 | buf.readIntLE(offset, byteLength[, noAssert]) Una versione generalizzata di tutti i metodi di lettura numerica. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 13 | buf.readIntBE(offset, byteLength[, noAssert]) Una versione generalizzata di tutti i metodi di lettura numerica. Supporta fino a 48 bit di precisione. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 14 | buf.toString([encoding][, start][, end]) Decodifica e restituisce una stringa dai dati del buffer codificati utilizzando la codifica del set di caratteri specificata. |
| 15 | buf.toJSON() Restituisce una rappresentazione JSON dell'istanza Buffer. JSON.stringify chiama implicitamente questa funzione quando stringe un'istanza Buffer. |
| 16 | buf[index] Ottieni e imposta l'ottetto su index. I valori si riferiscono a singoli byte, quindi l'intervallo consentito è compreso tra 0x00 e 0xFF hex o 0 e 255. |
| 17 | buf.equals(otherBuffer) Restituisce un valore booleano se questo buffer e l'altro buffer hanno gli stessi byte. |
| 18 | buf.compare(otherBuffer) Restituisce un numero che indica se questo buffer viene prima o dopo o è uguale all'altroBuffer nell'ordinamento. |
| 19 | buf.copy(targetBuffer[, targetStart][, sourceStart][, sourceEnd]) Copia i dati da una regione di questo buffer a una regione nel buffer di destinazione anche se la regione di memoria di destinazione si sovrappone all'origine. Se non è definito, i parametri targetStart e sourceStart vengono impostati per impostazione predefinita su 0, mentre sourceEnd è predefinito su buffer.length. |
| 20 | buf.slice([start][, end]) Restituisce un nuovo buffer che fa riferimento alla stessa memoria del vecchio, ma sfalsato e ritagliato dagli indici di inizio (valore predefinito 0) e fine (valore predefinito buffer.length). Gli indici negativi iniziano dalla fine del buffer. |
| 21 | buf.readUInt8(offset[, noAssert]) Legge un numero intero a 8 bit senza segno dal buffer all'offset specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 22 | buf.readUInt16LE(offset[, noAssert]) Legge un intero senza segno a 16 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 23 | buf.readUInt16BE(offset[, noAssert]) Legge un intero senza segno a 16 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 24 | buf.readUInt32LE(offset[, noAssert]) Legge un intero senza segno a 32 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 25 | buf.readUInt32BE(offset[, noAssert]) Legge un intero senza segno a 32 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 26 | buf.readInt8(offset[, noAssert]) Legge un intero a 8 bit con segno dal buffer all'offset specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 27 | buf.readInt16LE(offset[, noAssert]) Legge un intero con segno a 16 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 28 | buf.readInt16BE(offset[, noAssert]) Legge un intero con segno a 16 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 29 | buf.readInt32LE(offset[, noAssert]) Legge un intero con segno a 32 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 30 | buf.readInt32BE(offset[, noAssert]) Legge un intero con segno a 32 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 31 | buf.readFloatLE(offset[, noAssert]) Legge un float a 32 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 32 | buf.readFloatBE(offset[, noAssert]) Legge un float a 32 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 33 | buf.readDoubleLE(offset[, noAssert]) Legge un double a 64 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 34 | buf.readDoubleBE(offset[, noAssert]) Legge un double a 64 bit dal buffer all'offset specificato con il formato endian specificato. Impostare noAssert su true per saltare la convalida dell'offset. Significa che l'offset potrebbe essere oltre la fine del buffer. Il valore predefinito è false. |
| 35 | buf.writeUInt8(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato. Si noti che il valore deve essere un numero intero a 8 bit senza segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 36 | buf.writeUInt16LE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Notare che il valore deve essere un numero intero a 16 bit senza segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della correttezza. Il valore predefinito è false. |
| 37 | buf.writeUInt16BE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Notare che il valore deve essere un numero intero a 16 bit senza segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 38 | buf.writeUInt32LE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Notare che il valore deve essere un numero intero a 32 bit senza segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 39 | buf.writeUInt32BE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Notare che il valore deve essere un numero intero a 32 bit senza segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 40 | buf.writeInt8(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Si noti che il valore deve essere un numero intero a 8 bit con segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 41 | buf.writeInt16LE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Si noti che il valore deve essere un numero intero a 16 bit con segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 42 | buf.writeInt16BE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Si noti che il valore deve essere un numero intero a 16 bit con segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 43 | buf.writeInt32LE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Si noti che il valore deve essere un intero a 32 bit con segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 44 | buf.writeInt32BE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Si noti che il valore deve essere un intero a 32 bit con segno valido. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della correttezza. Il valore predefinito è false. |
| 45 | buf.writeFloatLE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Notare che il valore deve essere un float valido a 32 bit. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 46 | buf.writeFloatBE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Nota, il valore deve essere un float valido a 32 bit. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 47 | buf.writeDoubleLE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Nota, il valore deve essere un double valido a 64 bit. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 48 | buf.writeDoubleBE(value, offset[, noAssert]) Scrive un valore nel buffer all'offset specificato con il formato endian specificato. Nota, il valore deve essere un double valido a 64 bit. Impostare noAssert su true per saltare la convalida del valore e dell'offset. Significa che il valore potrebbe essere troppo grande per la funzione specifica e l'offset potrebbe essere oltre la fine del buffer, causando l'eliminazione silenziosa dei valori. Non dovrebbe essere utilizzato a meno che non si sia certi della sua correttezza. Il valore predefinito è false. |
| 49 | buf.fill(value[, offset][, end]) Riempie il buffer con il valore specificato. Se l'offset (il valore predefinito è 0) e la fine (il valore predefinito è buffer.length) non vengono forniti, riempirà l'intero buffer. |
Metodi di classe
| Sr.No. | Metodo e descrizione |
|---|---|
| 1 | Buffer.isEncoding(encoding) Restituisce true se la codifica è un argomento di codifica valido, false in caso contrario. |
| 2 | Buffer.isBuffer(obj) Verifica se obj è un Buffer. |
| 3 | Buffer.byteLength(string[, encoding]) Fornisce la lunghezza in byte effettiva di una stringa. la codifica predefinita è "utf8". Non è uguale a String.prototype.length, poiché String.prototype.length restituisce il numero di caratteri in una stringa. |
| 4 | Buffer.concat(list[, totalLength]) Restituisce un buffer che è il risultato della concatenazione di tutti i buffer nell'elenco. |
| 5 | Buffer.compare(buf1, buf2) Lo stesso di buf1.compare (buf2). Utile per ordinare un array di buffer. |
Cosa sono gli stream?
I flussi sono oggetti che consentono di leggere dati da un'origine o scrivere dati in una destinazione in modo continuo. In Node.js, ci sono quattro tipi di stream:
Readable - Stream che viene utilizzato per l'operazione di lettura.
Writable - Flusso utilizzato per operazioni di scrittura.
Duplex - Stream che può essere utilizzato sia per operazioni di lettura che per operazioni di scrittura.
Transform - Un tipo di flusso duplex in cui l'output viene calcolato in base all'input.
Ogni tipo di Stream è un file EventEmitteristanza e genera diversi eventi in diverse istanze di volte. Ad esempio, alcuni degli eventi comunemente usati sono:
data - Questo evento viene generato quando sono disponibili dati per la lettura.
end - Questo evento viene generato quando non ci sono più dati da leggere.
error - Questo evento viene generato quando si verifica un errore durante la ricezione o la scrittura dei dati.
finish - Questo evento viene generato quando tutti i dati sono stati scaricati nel sistema sottostante.
Questo tutorial fornisce una comprensione di base delle operazioni comunemente utilizzate su Streams.
Lettura da un flusso
Crea un file di testo denominato input.txt con il seguente contenuto:
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Crea un file js denominato main.js con il codice seguente:
var fs = require("fs");
var data = '';
// Create a readable stream
var readerStream = fs.createReadStream('input.txt');
// Set the encoding to be utf8.
readerStream.setEncoding('UTF8');
// Handle stream events --> data, end, and error
readerStream.on('data', function(chunk) {
data += chunk;
});
readerStream.on('end',function() {
console.log(data);
});
readerStream.on('error', function(err) {
console.log(err.stack);
});
console.log("Program Ended");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Program Ended
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Scrivere in un flusso
Crea un file js denominato main.js con il codice seguente:
var fs = require("fs");
var data = 'Simply Easy Learning';
// Create a writable stream
var writerStream = fs.createWriteStream('output.txt');
// Write the data to stream with encoding to be utf8
writerStream.write(data,'UTF8');
// Mark the end of file
writerStream.end();
// Handle stream events --> finish, and error
writerStream.on('finish', function() {
console.log("Write completed.");
});
writerStream.on('error', function(err) {
console.log(err.stack);
});
console.log("Program Ended");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Program Ended
Write completed.Ora apri output.txt creato nella tua directory corrente; dovrebbe contenere quanto segue:
Simply Easy LearningPiping dei flussi
Il piping è un meccanismo in cui forniamo l'output di un flusso come input per un altro flusso. Viene normalmente utilizzato per ottenere dati da un flusso e per passare l'output di tale flusso a un altro flusso. Non ci sono limiti alle operazioni di tubazioni. Ora mostreremo un esempio di piping per leggere da un file e scriverlo su un altro file.
Crea un file js denominato main.js con il codice seguente:
var fs = require("fs");
// Create a readable stream
var readerStream = fs.createReadStream('input.txt');
// Create a writable stream
var writerStream = fs.createWriteStream('output.txt');
// Pipe the read and write operations
// read input.txt and write data to output.txt
readerStream.pipe(writerStream);
console.log("Program Ended");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Program EndedApri output.txt creato nella directory corrente; dovrebbe contenere quanto segue:
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Concatenamento dei flussi
Il concatenamento è un meccanismo per connettere l'output di un flusso a un altro flusso e creare una catena di più operazioni di flusso. Viene normalmente utilizzato con operazioni di tubazioni. Ora useremo piping e chaining per prima comprimere un file e poi decomprimerlo.
Crea un file js denominato main.js con il codice seguente:
var fs = require("fs");
var zlib = require('zlib');
// Compress the file input.txt to input.txt.gz
fs.createReadStream('input.txt')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('input.txt.gz'));
console.log("File Compressed.");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
File Compressed.Scoprirai che input.txt è stato compresso e ha creato un file input.txt.gz nella directory corrente. Ora proviamo a decomprimere lo stesso file usando il seguente codice:
var fs = require("fs");
var zlib = require('zlib');
// Decompress the file input.txt.gz to input.txt
fs.createReadStream('input.txt.gz')
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream('input.txt'));
console.log("File Decompressed.");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
File Decompressed.Il nodo implementa l'I / O di file utilizzando semplici wrapper attorno alle funzioni POSIX standard. Il modulo Node File System (fs) può essere importato utilizzando la seguente sintassi:
var fs = require("fs")Sincrono vs Asincrono
Ogni metodo nel modulo fs ha forme sincrone e asincrone. I metodi asincroni accettano l'ultimo parametro come callback della funzione di completamento e il primo parametro della funzione callback come errore. È preferibile utilizzare un metodo asincrono invece di un metodo sincrono, poiché il primo non blocca mai un programma durante la sua esecuzione, mentre il secondo lo fa.
Esempio
Crea un file di testo denominato input.txt con il seguente contenuto -
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Creiamo un file js denominato main.js con il seguente codice -
var fs = require("fs");
// Asynchronous read
fs.readFile('input.txt', function (err, data) {
if (err) {
return console.error(err);
}
console.log("Asynchronous read: " + data.toString());
});
// Synchronous read
var data = fs.readFileSync('input.txt');
console.log("Synchronous read: " + data.toString());
console.log("Program Ended");Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Synchronous read: Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!
Program Ended
Asynchronous read: Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Le sezioni seguenti di questo capitolo forniscono una serie di buoni esempi sui principali metodi di I / O di file.
Apri un file
Sintassi
Di seguito è riportata la sintassi del metodo per aprire un file in modalità asincrona:
fs.open(path, flags[, mode], callback)Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questa è la stringa con il nome del file incluso il percorso.
flags- I flag indicano il comportamento del file da aprire. Tutti i valori possibili sono stati menzionati di seguito.
mode- Imposta la modalità del file (permessi e sticky bits), ma solo se il file è stato creato. Il valore predefinito è 0666, leggibile e scrivibile.
callback - Questa è la funzione di callback che ottiene due argomenti (err, fd).
Bandiere
I flag per le operazioni di lettura / scrittura sono:
| Sr.No. | Bandiera e descrizione |
|---|---|
| 1 | r Apri file per la lettura. Si verifica un'eccezione se il file non esiste. |
| 2 | r+ Apri file in lettura e scrittura. Si verifica un'eccezione se il file non esiste. |
| 3 | rs Apri file per la lettura in modalità sincrona. |
| 4 | rs+ Apri il file per la lettura e la scrittura, chiedendo al sistema operativo di aprirlo in modo sincrono. Vedere le note per "rs" sull'utilizzo di questo con cautela. |
| 5 | w Apri file per la scrittura. Il file viene creato (se non esiste) o troncato (se esiste). |
| 6 | wx Come "w" ma fallisce se il percorso esiste. |
| 7 | w+ Apri file in lettura e scrittura. Il file viene creato (se non esiste) o troncato (se esiste). |
| 8 | wx+ Come 'w +' ma fallisce se il percorso esiste. |
| 9 | a Apri file da aggiungere. Il file viene creato se non esiste. |
| 10 | ax Come "a" ma fallisce se il percorso esiste. |
| 11 | a+ Apri file per leggere e aggiungere. Il file viene creato se non esiste. |
| 12 | ax+ Come "a +" ma fallisce se il percorso esiste. |
Esempio
Creiamo un file js denominato main.js con il seguente codice per aprire un file input.txt per la lettura e la scrittura.
var fs = require("fs");
// Asynchronous - Opening File
console.log("Going to open file!");
fs.open('input.txt', 'r+', function(err, fd) {
if (err) {
return console.error(err);
}
console.log("File opened successfully!");
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to open file!
File opened successfully!Ottieni informazioni sul file
Sintassi
Di seguito è riportata la sintassi del metodo per ottenere le informazioni su un file:
fs.stat(path, callback)Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questa è la stringa con il nome del file incluso il percorso.
callback - Questa è la funzione di callback che ottiene due argomenti (err, stats) dove stats è un oggetto di tipo fs.Stats che è stampato sotto nell'esempio.
Oltre agli attributi importanti che sono stampati di seguito nell'esempio, sono disponibili diversi metodi utili in fs.Statsclasse che può essere utilizzata per controllare il tipo di file. Questi metodi sono riportati nella tabella seguente.
| Sr.No. | Metodo e descrizione |
|---|---|
| 1 | stats.isFile() Restituisce vero se il tipo di file di un file semplice. |
| 2 | stats.isDirectory() Restituisce vero se il tipo di file di una directory. |
| 3 | stats.isBlockDevice() Restituisce vero se il tipo di file di un dispositivo a blocchi. |
| 4 | stats.isCharacterDevice() Restituisce vero se il tipo di file di un dispositivo a caratteri. |
| 5 | stats.isSymbolicLink() Restituisce vero se il tipo di file di un collegamento simbolico. |
| 6 | stats.isFIFO() Restituisce vero se il tipo di file di un FIFO. |
| 7 | stats.isSocket() Restituisce vero se il tipo di file di asocket. |
Esempio
Creiamo un file js denominato main.js con il seguente codice -
var fs = require("fs");
console.log("Going to get file info!");
fs.stat('input.txt', function (err, stats) {
if (err) {
return console.error(err);
}
console.log(stats);
console.log("Got file info successfully!");
// Check file type
console.log("isFile ? " + stats.isFile());
console.log("isDirectory ? " + stats.isDirectory());
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to get file info!
{
dev: 1792,
mode: 33188,
nlink: 1,
uid: 48,
gid: 48,
rdev: 0,
blksize: 4096,
ino: 4318127,
size: 97,
blocks: 8,
atime: Sun Mar 22 2015 13:40:00 GMT-0500 (CDT),
mtime: Sun Mar 22 2015 13:40:57 GMT-0500 (CDT),
ctime: Sun Mar 22 2015 13:40:57 GMT-0500 (CDT)
}
Got file info successfully!
isFile ? true
isDirectory ? falseScrivere un file
Sintassi
Di seguito è riportata la sintassi di uno dei metodi per scrivere in un file:
fs.writeFile(filename, data[, options], callback)Questo metodo sovrascriverà il file se il file esiste già. Se vuoi scrivere in un file esistente, dovresti usare un altro metodo disponibile.
Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questa è la stringa con il nome del file incluso il percorso.
data - Questa è la stringa o il buffer da scrivere nel file.
options- Il terzo parametro è un oggetto che conterrà {encoding, mode, flag}. Per impostazione predefinita. la codifica è utf8, la modalità è il valore ottale 0666 e il flag è 'w'
callback - Questa è la funzione di callback che ottiene un singolo parametro err che restituisce un errore in caso di errore di scrittura.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
console.log("Going to write into existing file");
fs.writeFile('input.txt', 'Simply Easy Learning!', function(err) {
if (err) {
return console.error(err);
}
console.log("Data written successfully!");
console.log("Let's read newly written data");
fs.readFile('input.txt', function (err, data) {
if (err) {
return console.error(err);
}
console.log("Asynchronous read: " + data.toString());
});
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to write into existing file
Data written successfully!
Let's read newly written data
Asynchronous read: Simply Easy Learning!Leggere un file
Sintassi
Di seguito è riportata la sintassi di uno dei metodi per leggere da un file:
fs.read(fd, buffer, offset, length, position, callback)Questo metodo utilizzerà il descrittore di file per leggere il file. Se si desidera leggere il file direttamente utilizzando il nome del file, è necessario utilizzare un altro metodo disponibile.
Parametri
Ecco la descrizione dei parametri utilizzati:
fd - Questo è il descrittore di file restituito da fs.open ().
buffer - Questo è il buffer in cui verranno scritti i dati.
offset - Questo è l'offset nel buffer da cui iniziare a scrivere.
length - Questo è un numero intero che specifica il numero di byte da leggere.
position- Questo è un numero intero che specifica da dove iniziare la lettura nel file. Se la posizione è nulla, i dati verranno letti dalla posizione del file corrente.
callback - Questa è la funzione di callback che ottiene i tre argomenti, (err, bytesRead, buffer).
Esempio
Creiamo un file js denominato main.js con il seguente codice -
var fs = require("fs");
var buf = new Buffer(1024);
console.log("Going to open an existing file");
fs.open('input.txt', 'r+', function(err, fd) {
if (err) {
return console.error(err);
}
console.log("File opened successfully!");
console.log("Going to read the file");
fs.read(fd, buf, 0, buf.length, 0, function(err, bytes){
if (err){
console.log(err);
}
console.log(bytes + " bytes read");
// Print only read bytes to avoid junk.
if(bytes > 0){
console.log(buf.slice(0, bytes).toString());
}
});
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to open an existing file
File opened successfully!
Going to read the file
97 bytes read
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!Chiusura di un file
Sintassi
Di seguito è riportata la sintassi per chiudere un file aperto:
fs.close(fd, callback)Parametri
Ecco la descrizione dei parametri utilizzati:
fd - Questo è il descrittore di file restituito dal metodo file fs.open ().
callback - Questa è la funzione di callback. Nessun argomento diverso da una possibile eccezione viene dato al callback di completamento.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
var buf = new Buffer(1024);
console.log("Going to open an existing file");
fs.open('input.txt', 'r+', function(err, fd) {
if (err) {
return console.error(err);
}
console.log("File opened successfully!");
console.log("Going to read the file");
fs.read(fd, buf, 0, buf.length, 0, function(err, bytes) {
if (err) {
console.log(err);
}
// Print only read bytes to avoid junk.
if(bytes > 0) {
console.log(buf.slice(0, bytes).toString());
}
// Close the opened file.
fs.close(fd, function(err) {
if (err) {
console.log(err);
}
console.log("File closed successfully.");
});
});
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to open an existing file
File opened successfully!
Going to read the file
Tutorials Point is giving self learning content
to teach the world in simple and easy way!!!!!
File closed successfully.Troncare un file
Sintassi
Di seguito è riportata la sintassi del metodo per troncare un file aperto:
fs.ftruncate(fd, len, callback)Parametri
Ecco la descrizione dei parametri utilizzati:
fd - Questo è il descrittore di file restituito da fs.open ().
len - Questa è la lunghezza del file dopo la quale il file verrà troncato.
callback - Questa è la funzione di callback. Nessun argomento diverso da una possibile eccezione viene dato al callback di completamento.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
var buf = new Buffer(1024);
console.log("Going to open an existing file");
fs.open('input.txt', 'r+', function(err, fd) {
if (err) {
return console.error(err);
}
console.log("File opened successfully!");
console.log("Going to truncate the file after 10 bytes");
// Truncate the opened file.
fs.ftruncate(fd, 10, function(err) {
if (err) {
console.log(err);
}
console.log("File truncated successfully.");
console.log("Going to read the same file");
fs.read(fd, buf, 0, buf.length, 0, function(err, bytes){
if (err) {
console.log(err);
}
// Print only read bytes to avoid junk.
if(bytes > 0) {
console.log(buf.slice(0, bytes).toString());
}
// Close the opened file.
fs.close(fd, function(err) {
if (err) {
console.log(err);
}
console.log("File closed successfully.");
});
});
});
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to open an existing file
File opened successfully!
Going to truncate the file after 10 bytes
File truncated successfully.
Going to read the same file
Tutorials
File closed successfully.Elimina un file
Sintassi
Di seguito è riportata la sintassi del metodo per eliminare un file:
fs.unlink(path, callback)Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questo è il nome del file incluso il percorso.
callback - Questa è la funzione di callback. Nessun argomento diverso da una possibile eccezione viene dato al callback di completamento.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
console.log("Going to delete an existing file");
fs.unlink('input.txt', function(err) {
if (err) {
return console.error(err);
}
console.log("File deleted successfully!");
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to delete an existing file
File deleted successfully!Crea una directory
Sintassi
Di seguito è riportata la sintassi del metodo per creare una directory:
fs.mkdir(path[, mode], callback)Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questo è il nome della directory incluso il percorso.
mode- Questa è l'autorizzazione della directory da impostare. Il valore predefinito è 0777.
callback - Questa è la funzione di callback. Nessun argomento diverso da una possibile eccezione viene dato al callback di completamento.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
console.log("Going to create directory /tmp/test");
fs.mkdir('/tmp/test',function(err) {
if (err) {
return console.error(err);
}
console.log("Directory created successfully!");
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to create directory /tmp/test
Directory created successfully!Leggere una directory
Sintassi
Di seguito è riportata la sintassi del metodo per leggere una directory:
fs.readdir(path, callback)Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questo è il nome della directory incluso il percorso.
callback- Questa è la funzione di callback che ottiene due argomenti (err, files) dove files è un array dei nomi dei file nella directory escluso '.' e '..'.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
console.log("Going to read directory /tmp");
fs.readdir("/tmp/",function(err, files) {
if (err) {
return console.error(err);
}
files.forEach( function (file) {
console.log( file );
});
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to read directory /tmp
ccmzx99o.out
ccyCSbkF.out
employee.ser
hsperfdata_apache
test
test.txtRimuovi una directory
Sintassi
Di seguito è riportata la sintassi del metodo per rimuovere una directory:
fs.rmdir(path, callback)Parametri
Ecco la descrizione dei parametri utilizzati:
path - Questo è il nome della directory incluso il percorso.
callback - Questa è la funzione di callback. Nessun argomento diverso da una possibile eccezione viene dato al callback di completamento.
Esempio
Creiamo un file js denominato main.js avente il seguente codice -
var fs = require("fs");
console.log("Going to delete directory /tmp/test");
fs.rmdir("/tmp/test",function(err) {
if (err) {
return console.error(err);
}
console.log("Going to read directory /tmp");
fs.readdir("/tmp/",function(err, files) {
if (err) {
return console.error(err);
}
files.forEach( function (file) {
console.log( file );
});
});
});Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output.
Going to read directory /tmp
ccmzx99o.out
ccyCSbkF.out
employee.ser
hsperfdata_apache
test.txtRiferimento ai metodi
| Suor n | Metodo e descrizione |
|---|---|
| 1 | fs.rename(oldPath, newPath, callback) Rename asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 2 | fs.ftruncate(fd, len, callback) Ftruncate () asincrono. Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 3 | fs.ftruncateSync(fd, len) Ftruncate sincrono (). |
| 4 | fs.truncate(path, len, callback) Truncate asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 5 | fs.truncateSync(path, len) Truncate sincrono (). |
| 6 | fs.chown(path, uid, gid, callback) Chown asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 7 | fs.chownSync(path, uid, gid) Chown sincrono (). |
| 8 | fs.fchown(fd, uid, gid, callback) Fchown asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 9 | fs.fchownSync(fd, uid, gid) Fchown sincrono (). |
| 10 | fs.lchown(path, uid, gid, callback) Lchown asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 11 | fs.lchownSync(path, uid, gid) Lchown sincrono (). |
| 12 | fs.chmod(path, mode, callback) Chmod asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 13 | fs.chmodSync(path, mode) Chmod sincrono (). |
| 14 | fs.fchmod(fd, mode, callback) Fchmod asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 15 | fs.fchmodSync(fd, mode) Fchmod sincrono (). |
| 16 | fs.lchmod(path, mode, callback) Lchmod asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. Disponibile solo su Mac OS X. |
| 17 | fs.lchmodSync(path, mode) Lchmod sincrono (). |
| 18 | fs.stat(path, callback) Stat asincrona (). Il callback ottiene due argomenti (err, stats) dove stats è un oggetto fs.Stats. |
| 19 | fs.lstat(path, callback) Lstat asincrono (). Il callback ottiene due argomenti (err, stats) dove stats è un oggetto fs.Stats. lstat () è identico a stat (), tranne per il fatto che se path è un collegamento simbolico, allora il collegamento stesso è stat-ed, non il file a cui si riferisce. |
| 20 | fs.fstat(fd, callback) Fstat asincrono (). Il callback ottiene due argomenti (err, stats) dove stats è un oggetto fs.Stats. fstat () è identico a stat (), tranne per il fatto che il file da modificare è specificato dal descrittore di file fd. |
| 21 | fs.statSync(path) Stat sincrono (). Restituisce un'istanza di fs.Stats. |
| 22 | fs.lstatSync(path) Lstat () sincrono. Restituisce un'istanza di fs.Stats. |
| 23 | fs.fstatSync(fd) Fstat sincrono (). Restituisce un'istanza di fs.Stats. |
| 24 | fs.link(srcpath, dstpath, callback) Collegamento asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 25 | fs.linkSync(srcpath, dstpath) Collegamento sincrono (). |
| 26 | fs.symlink(srcpath, dstpath[, type], callback) Symlink asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. L'argomento tipo può essere impostato su "dir", "file" o "junction" (l'impostazione predefinita è "file") ed è disponibile solo su Windows (ignorato su altre piattaforme). Si noti che i punti di giunzione di Windows richiedono che il percorso di destinazione sia assoluto. Quando si utilizza "junction", l'argomento di destinazione verrà automaticamente normalizzato al percorso assoluto. |
| 27 | fs.symlinkSync(srcpath, dstpath[, type]) Symlink sincrono (). |
| 28 | fs.readlink(path, callback) Readlink asincrono (). Il callback ottiene due argomenti (err, linkString). |
| 29 | fs.realpath(path[, cache], callback) Realpath () asincrono. Il callback ottiene due argomenti (err, resolvedPath). Può utilizzare process.cwd per risolvere i percorsi relativi. cache è un oggetto letterale di percorsi mappati che può essere utilizzato per forzare una risoluzione di percorso specifica o evitare chiamate fs.stat aggiuntive per percorsi reali noti. |
| 30 | fs.realpathSync(path[, cache]) Realpath () sincrono. Restituisce il percorso risolto. |
| 31 | fs.unlink(path, callback) Unlink asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 32 | fs.unlinkSync(path) Unlink sincrono (). |
| 33 | fs.rmdir(path, callback) Rmdir asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 34 | fs.rmdirSync(path) Rmdir sincrono (). |
| 35 | fs.mkdir(path[, mode], callback) Mkdir asincrono (2). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. la modalità predefinita è 0777. |
| 36 | fs.mkdirSync(path[, mode]) Mkdir sincrono (). |
| 37 | fs.readdir(path, callback) Readdir asincrono (3). Legge il contenuto di una directory. Il callback ottiene due argomenti (err, files) dove files è un array dei nomi dei file nella directory escluso '.' e '..'. |
| 38 | fs.readdirSync(path) Readdir sincrono (). Restituisce un array di nomi di file escluso "." e '..'. |
| 39 | fs.close(fd, callback) Chiusura asincrona (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 40 | fs.closeSync(fd) Chiusura sincrona (). |
| 41 | fs.open(path, flags[, mode], callback) File asincrono aperto. |
| 42 | fs.openSync(path, flags[, mode]) Versione sincrona di fs.open (). |
| 43 | fs.utimes(path, atime, mtime, callback)
|
| 44 | fs.utimesSync(path, atime, mtime) Modificare i timestamp del file a cui fa riferimento il percorso fornito. |
| 45 | fs.futimes(fd, atime, mtime, callback)
|
| 46 | fs.futimesSync(fd, atime, mtime) Modificare i timestamp di un file a cui fa riferimento il descrittore di file fornito. |
| 47 | fs.fsync(fd, callback) Fsync asincrono. Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. |
| 48 | fs.fsyncSync(fd) Fsync sincrono. |
| 49 | fs.write(fd, buffer, offset, length[, position], callback) Scrive il buffer nel file specificato da fd. |
| 50 | fs.write(fd, data[, position[, encoding]], callback) Scrive i dati nel file specificato da fd. Se i dati non sono un'istanza Buffer, il valore verrà convertito in una stringa. |
| 51 | fs.writeSync(fd, buffer, offset, length[, position]) Versioni sincrone di fs.write (). Restituisce il numero di byte scritti. |
| 52 | fs.writeSync(fd, data[, position[, encoding]]) Versioni sincrone di fs.write (). Restituisce il numero di byte scritti. |
| 53 | fs.read(fd, buffer, offset, length, position, callback) Legge i dati dal file specificato da fd. |
| 54 | fs.readSync(fd, buffer, offset, length, position) Versione sincrona di fs.read. Restituisce il numero di byteRead. |
| 55 | fs.readFile(filename[, options], callback) Legge in modo asincrono l'intero contenuto di un file. |
| 56 | fs.readFileSync(filename[, options]) Versione sincrona di fs.readFile. Restituisce il contenuto del nome del file. |
| 57 | fs.writeFile(filename, data[, options], callback) Scrive in modo asincrono i dati in un file, sostituendolo se esiste già. i dati possono essere una stringa o un buffer. |
| 58 | fs.writeFileSync(filename, data[, options]) La versione sincrona di fs.writeFile. |
| 59 | fs.appendFile(filename, data[, options], callback) Accoda in modo asincrono i dati a un file, creando il file se non esiste. i dati possono essere una stringa o un buffer. |
| 60 | fs.appendFileSync(filename, data[, options]) La versione sincrona di fs.appendFile. |
| 61 | fs.watchFile(filename[, options], listener) Guarda i cambiamenti sul nome del file. Il listener di callback verrà chiamato ogni volta che si accede al file. |
| 62 | fs.unwatchFile(filename[, listener]) Smetti di guardare le modifiche al nome del file. Se listener è specificato, viene rimosso solo quel particolare listener. Altrimenti, tutti i listener vengono rimossi e hai effettivamente smesso di guardare il nome del file. |
| 63 | fs.watch(filename[, options][, listener]) Controlla le modifiche al nome del file, dove il nome del file è un file o una directory. L'oggetto restituito è un fs.FSWatcher. |
| 64 | fs.exists(path, callback) Verifica se il percorso specificato esiste o meno controllando con il file system. Quindi chiama l'argomento callback con true o false. |
| 65 | fs.existsSync(path) Esiste la versione sincrona di fs. |
| 66 | fs.access(path[, mode], callback) Verifica le autorizzazioni di un utente per il file specificato dal percorso. mode è un numero intero opzionale che specifica i controlli di accessibilità da eseguire. |
| 67 | fs.accessSync(path[, mode]) Versione sincrona di fs.access. Viene generato se qualsiasi controllo di accessibilità fallisce e non fa nulla altrimenti. |
| 68 | fs.createReadStream(path[, options]) Restituisce un nuovo oggetto ReadStream. |
| 69 | fs.createWriteStream(path[, options]) Restituisce un nuovo oggetto WriteStream. |
| 70 | fs.symlink(srcpath, dstpath[, type], callback) Symlink asincrono (). Nessun argomento diverso da una possibile eccezione viene fornito al callback di completamento. L'argomento tipo può essere impostato su "dir", "file" o "junction" (l'impostazione predefinita è "file") ed è disponibile solo su Windows (ignorato su altre piattaforme). Si noti che i punti di giunzione di Windows richiedono che il percorso di destinazione sia assoluto. Quando si utilizza "junction", l'argomento di destinazione verrà automaticamente normalizzato al percorso assoluto. |
Gli oggetti globali Node.js sono di natura globale e sono disponibili in tutti i moduli. Non abbiamo bisogno di includere questi oggetti nella nostra applicazione, piuttosto possiamo usarli direttamente. Questi oggetti sono moduli, funzioni, stringhe e l'oggetto stesso come spiegato di seguito.
__nome del file
Il __filenamerappresenta il nome del file del codice in esecuzione. Questo è il percorso assoluto risolto di questo file di codice. Per un programma principale, questo non è necessariamente lo stesso nome file utilizzato nella riga di comando. Il valore all'interno di un modulo è il percorso di quel file di modulo.
Esempio
Crea un file js denominato main.js con il codice seguente:
// Let's try to print the value of __filename
console.log( __filename );Ora esegui main.js per vedere il risultato -
$ node main.jsIn base alla posizione del programma, stamperà il nome del file principale come segue:
/web/com/1427091028_21099/main.js__dirname
Il __dirname rappresenta il nome della directory in cui risiede lo script attualmente in esecuzione.
Esempio
Crea un file js denominato main.js con il codice seguente:
// Let's try to print the value of __dirname
console.log( __dirname );Ora esegui main.js per vedere il risultato -
$ node main.jsIn base alla posizione del programma, stamperà il nome della directory corrente come segue:
/web/com/1427091028_21099setTimeout (cb, ms)
Il setTimeout(cb, ms)La funzione globale viene utilizzata per eseguire il callback cb dopo almeno ms millisecondi. Il ritardo effettivo dipende da fattori esterni come la granularità del timer del sistema operativo e il carico del sistema. Un timer non può durare più di 24,8 giorni.
Questa funzione restituisce un valore opaco che rappresenta il timer che può essere utilizzato per azzerare il timer.
Esempio
Crea un file js denominato main.js con il codice seguente:
function printHello() {
console.log( "Hello, World!");
}
// Now call above function after 2 seconds
setTimeout(printHello, 2000);Ora esegui main.js per vedere il risultato -
$ node main.jsVerificare che l'output venga stampato dopo un po 'di ritardo.
Hello, World!clearTimeout (t)
Il clearTimeout(t)La funzione globale viene utilizzata per arrestare un timer precedentemente creato con setTimeout (). Quit è il timer restituito dalla funzione setTimeout ().
Esempio
Crea un file js denominato main.js con il codice seguente:
function printHello() {
console.log( "Hello, World!");
}
// Now call above function after 2 seconds
var t = setTimeout(printHello, 2000);
// Now clear the timer
clearTimeout(t);Ora esegui main.js per vedere il risultato -
$ node main.jsVerifica l'output in cui non troverai nulla stampato.
setInterval (cb, ms)
Il setInterval(cb, ms)La funzione globale viene utilizzata per eseguire il callback cb ripetutamente dopo almeno ms millisecondi. Il ritardo effettivo dipende da fattori esterni come la granularità del timer del sistema operativo e il carico del sistema. Un timer non può durare più di 24,8 giorni.
Questa funzione restituisce un valore opaco che rappresenta il timer che può essere utilizzato per cancellare il timer utilizzando la funzione clearInterval(t).
Esempio
Crea un file js denominato main.js con il codice seguente:
function printHello() {
console.log( "Hello, World!");
}
// Now call above function after 2 seconds
setInterval(printHello, 2000);Ora esegui main.js per vedere il risultato -
$ node main.jsIl programma precedente eseguirà printHello () ogni 2 secondi. A causa della limitazione del sistema.
Oggetti globali
La tabella seguente fornisce un elenco di altri oggetti che utilizziamo frequentemente nelle nostre applicazioni. Per maggiori dettagli, puoi fare riferimento alla documentazione ufficiale.
| Sr.No. | Nome e descrizione del modulo |
|---|---|
| 1 | Console Utilizzato per stampare informazioni su stdout e stderr. |
| 2 | Process Utilizzato per ottenere informazioni sul processo corrente. Fornisce più eventi relativi alle attività di processo. |
Sono disponibili diversi moduli di utilità nella libreria dei moduli Node.js. Questi moduli sono molto comuni e vengono utilizzati frequentemente durante lo sviluppo di qualsiasi applicazione basata su Node.
| Sr.No. | Nome e descrizione del modulo |
|---|---|
| 1 | Modulo OS Fornisce funzioni di utilità di base relative al sistema operativo. |
| 2 | Modulo Path Fornisce utilità per la gestione e la trasformazione dei percorsi dei file. |
| 3 | Modulo Net Fornisce sia server che client come flussi. Funziona come un wrapper di rete. |
| 4 | Modulo DNS Fornisce funzioni per eseguire la ricerca DNS effettiva e per utilizzare le funzionalità di risoluzione dei nomi del sistema operativo sottostante. |
| 5 | Modulo di dominio Fornisce modi per gestire più operazioni di I / O diverse come un unico gruppo. |
Cos'è un Web Server?
Un server Web è un'applicazione software che gestisce le richieste HTTP inviate dal client HTTP, come i browser Web, e restituisce le pagine Web in risposta ai client. I server Web di solito forniscono documenti html insieme a immagini, fogli di stile e script.
La maggior parte dei server Web supporta script lato server, utilizzando linguaggi di scripting o reindirizzando l'attività a un server delle applicazioni che recupera i dati da un database ed esegue una logica complessa, quindi invia un risultato al client HTTP tramite il server Web.
Il server Web Apache è uno dei server Web più comunemente utilizzati. È un progetto open source.
Architettura dell'applicazione Web
Un'applicazione Web è generalmente suddivisa in quattro livelli:

Client - Questo livello è costituito da browser Web, browser mobili o applicazioni che possono effettuare richieste HTTP al server Web.
Server - Questo livello ha il server Web che può intercettare le richieste fatte dai client e passare loro la risposta.
Business- Questo livello contiene il server delle applicazioni utilizzato dal server Web per eseguire l'elaborazione richiesta. Questo livello interagisce con il livello dati tramite il database o alcuni programmi esterni.
Data - Questo livello contiene i database o qualsiasi altra fonte di dati.
Creazione di un server Web utilizzando Node
Node.js fornisce un file httpmodulo che può essere utilizzato per creare un client HTTP di un server. Di seguito è riportata la struttura minima del server HTTP che ascolta sulla porta 8081.
Crea un file js denominato server.js -
File: server.js
var http = require('http');
var fs = require('fs');
var url = require('url');
// Create a server
http.createServer( function (request, response) {
// Parse the request containing file name
var pathname = url.parse(request.url).pathname;
// Print the name of the file for which request is made.
console.log("Request for " + pathname + " received.");
// Read the requested file content from file system
fs.readFile(pathname.substr(1), function (err, data) {
if (err) {
console.log(err);
// HTTP Status: 404 : NOT FOUND
// Content Type: text/plain
response.writeHead(404, {'Content-Type': 'text/html'});
} else {
//Page found
// HTTP Status: 200 : OK
// Content Type: text/plain
response.writeHead(200, {'Content-Type': 'text/html'});
// Write the content of the file to response body
response.write(data.toString());
}
// Send the response body
response.end();
});
}).listen(8081);
// Console will print the message
console.log('Server running at http://127.0.0.1:8081/');Quindi creiamo il seguente file html denominato index.htm nella stessa directory in cui hai creato server.js.
File: index.htm
<html>
<head>
<title>Sample Page</title>
</head>
<body>
Hello World!
</body>
</html>Ora eseguiamo server.js per vedere il risultato -
$ node server.jsVerifica l'output.
Server running at http://127.0.0.1:8081/Fai una richiesta al server Node.js.
Apri http://127.0.0.1:8081/index.htm in qualsiasi browser per vedere il seguente risultato.

Verificare l'output alla fine del server.
Server running at http://127.0.0.1:8081/
Request for /index.htm received.Creazione di client Web utilizzando Node
È possibile creare un client Web utilizzando httpmodulo. Controlliamo il seguente esempio.
Crea un file js denominato client.js -
File: client.js
var http = require('http');
// Options to be used by request
var options = {
host: 'localhost',
port: '8081',
path: '/index.htm'
};
// Callback function is used to deal with response
var callback = function(response) {
// Continuously update stream with data
var body = '';
response.on('data', function(data) {
body += data;
});
response.on('end', function() {
// Data received completely.
console.log(body);
});
}
// Make a request to the server
var req = http.request(options, callback);
req.end();Ora esegui client.js da un terminale di comando diverso da server.js per vedere il risultato -
$ node client.jsVerifica l'output.
<html>
<head>
<title>Sample Page</title>
</head>
<body>
Hello World!
</body>
</html>Verificare l'output alla fine del server.
Server running at http://127.0.0.1:8081/
Request for /index.htm received.Panoramica di Express
Express è un framework per applicazioni web Node.js minimale e flessibile che fornisce un robusto set di funzionalità per sviluppare applicazioni web e mobili. Facilita il rapido sviluppo di applicazioni Web basate su nodi. Di seguito sono riportate alcune delle funzionalità principali di Express Framework:
Consente di impostare middleware per rispondere alle richieste HTTP.
Definisce una tabella di routing che viene utilizzata per eseguire diverse azioni in base al metodo HTTP e all'URL.
Consente il rendering dinamico delle pagine HTML in base al passaggio di argomenti ai modelli.
Installazione di Express
Innanzitutto, installa il framework Express a livello globale utilizzando NPM in modo che possa essere utilizzato per creare un'applicazione Web utilizzando il terminale del nodo.
$ npm install express --saveIl comando precedente salva l'installazione localmente nel file node_modulesdirectory e crea una directory express all'interno di node_modules. Dovresti installare i seguenti importanti moduli insieme a express -
body-parser - Questo è un middleware node.js per la gestione dei dati di moduli codificati in JSON, Raw, Text e URL.
cookie-parser - Analizza l'intestazione dei cookie e popola i req.cookies con un oggetto codificato dai nomi dei cookie.
multer - Questo è un middleware node.js per la gestione di multipart / form-data.
$ npm install body-parser --save
$ npm install cookie-parser --save $ npm install multer --saveCiao esempio mondo
Di seguito è riportata un'app Express molto semplice che avvia un server e ascolta sulla porta 8081 per la connessione. Questa app risponde conHello World!per richieste alla homepage. Per ogni altro percorso, risponderà con a404 Not Found.
var express = require('express');
var app = express();
app.get('/', function (req, res) {
res.send('Hello World');
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Salva il codice sopra in un file denominato server.js ed eseguilo con il seguente comando.
$ node server.jsVedrai il seguente output:
Example app listening at http://0.0.0.0:8081Apri http://127.0.0.1:8081/ in qualsiasi browser per vedere il seguente risultato.
Richiedere risposta
L'applicazione Express utilizza una funzione di callback i cui parametri sono request e response oggetti.
app.get('/', function (req, res) {
// --
})Oggetto richiesta: l'oggetto richiesta rappresenta la richiesta HTTP e dispone di proprietà per la stringa di query della richiesta, i parametri, il corpo, le intestazioni HTTP e così via.
Oggetto risposta: l'oggetto risposta rappresenta la risposta HTTP che un'app Express invia quando riceve una richiesta HTTP.
Puoi stampare req e res oggetti che forniscono molte informazioni relative alla richiesta e alla risposta HTTP inclusi cookie, sessioni, URL, ecc.
Routing di base
Abbiamo visto un'applicazione di base che serve la richiesta HTTP per la homepage. Il routing si riferisce alla determinazione del modo in cui un'applicazione risponde a una richiesta client a un particolare endpoint, che è un URI (o percorso) e un metodo di richiesta HTTP specifico (GET, POST e così via).
Estenderemo il nostro programma Hello World per gestire più tipi di richieste HTTP.
var express = require('express');
var app = express();
// This responds with "Hello World" on the homepage
app.get('/', function (req, res) {
console.log("Got a GET request for the homepage");
res.send('Hello GET');
})
// This responds a POST request for the homepage
app.post('/', function (req, res) {
console.log("Got a POST request for the homepage");
res.send('Hello POST');
})
// This responds a DELETE request for the /del_user page.
app.delete('/del_user', function (req, res) {
console.log("Got a DELETE request for /del_user");
res.send('Hello DELETE');
})
// This responds a GET request for the /list_user page.
app.get('/list_user', function (req, res) {
console.log("Got a GET request for /list_user");
res.send('Page Listing');
})
// This responds a GET request for abcd, abxcd, ab123cd, and so on
app.get('/ab*cd', function(req, res) {
console.log("Got a GET request for /ab*cd");
res.send('Page Pattern Match');
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Salva il codice sopra in un file denominato server.js ed eseguilo con il seguente comando.
$ node server.jsVedrai il seguente output:
Example app listening at http://0.0.0.0:8081Ora puoi provare diverse richieste su http://127.0.0.1:8081 per vedere l'output generato da server.js. Di seguito sono riportate alcune schermate che mostrano risposte diverse per URL diversi.
Schermata che mostra di nuovo http://127.0.0.1:8081/list_user
Schermata che mostra di nuovo http://127.0.0.1:8081/abcd
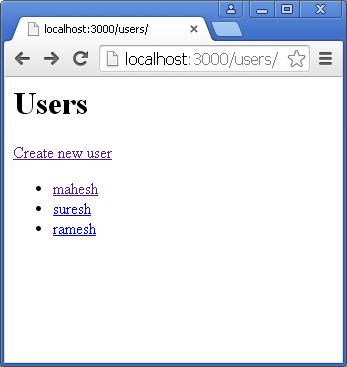
Schermata che mostra di nuovo http://127.0.0.1:8081/abcdefg
Pubblicazione di file statici
Express fornisce un middleware integrato express.static per servire file statici, come immagini, CSS, JavaScript, ecc.
Devi semplicemente passare il nome della directory in cui conservi le tue risorse statiche, al file express.staticmiddleware per iniziare a servire i file direttamente. Ad esempio, se mantieni le immagini, i file CSS e JavaScript in una directory denominata public, puoi farlo:
app.use(express.static('public'));Conserveremo alcune immagini in formato public/images sottodirectory come segue -
node_modules
server.js
public/
public/images
public/images/logo.pngModifichiamo l'app "Hello Word" per aggiungere la funzionalità per gestire i file statici.
var express = require('express');
var app = express();
app.use(express.static('public'));
app.get('/', function (req, res) {
res.send('Hello World');
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Salva il codice sopra in un file denominato server.js ed eseguilo con il seguente comando.
$ node server.jsOra apri http://127.0.0.1:8081/images/logo.png in qualsiasi browser e guarda il seguente risultato.
Metodo GET
Ecco un semplice esempio che passa due valori utilizzando il metodo HTML FORM GET. Useremoprocess_get router all'interno di server.js per gestire questo input.
<html>
<body>
<form action = "http://127.0.0.1:8081/process_get" method = "GET">
First Name: <input type = "text" name = "first_name"> <br>
Last Name: <input type = "text" name = "last_name">
<input type = "submit" value = "Submit">
</form>
</body>
</html>Salviamo il codice sopra in index.htm e modifichiamo server.js per gestire le richieste della home page e l'input inviato dal modulo HTML.
var express = require('express');
var app = express();
app.use(express.static('public'));
app.get('/index.htm', function (req, res) {
res.sendFile( __dirname + "/" + "index.htm" );
})
app.get('/process_get', function (req, res) {
// Prepare output in JSON format
response = {
first_name:req.query.first_name,
last_name:req.query.last_name
};
console.log(response);
res.end(JSON.stringify(response));
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})L'accesso al documento HTML utilizzando http://127.0.0.1:8081/index.htm genererà il seguente modulo:
Ora puoi inserire il nome e il cognome e quindi fare clic sul pulsante Invia per vedere il risultato e dovrebbe restituire il seguente risultato:
{"first_name":"John","last_name":"Paul"}Metodo POST
Ecco un semplice esempio che passa due valori utilizzando il metodo HTML FORM POST. Useremoprocess_get router all'interno di server.js per gestire questo input.
<html>
<body>
<form action = "http://127.0.0.1:8081/process_post" method = "POST">
First Name: <input type = "text" name = "first_name"> <br>
Last Name: <input type = "text" name = "last_name">
<input type = "submit" value = "Submit">
</form>
</body>
</html>Salviamo il codice sopra in index.htm e modifichiamo server.js per gestire le richieste della home page e l'input inviato dal modulo HTML.
var express = require('express');
var app = express();
var bodyParser = require('body-parser');
// Create application/x-www-form-urlencoded parser
var urlencodedParser = bodyParser.urlencoded({ extended: false })
app.use(express.static('public'));
app.get('/index.htm', function (req, res) {
res.sendFile( __dirname + "/" + "index.htm" );
})
app.post('/process_post', urlencodedParser, function (req, res) {
// Prepare output in JSON format
response = {
first_name:req.body.first_name,
last_name:req.body.last_name
};
console.log(response);
res.end(JSON.stringify(response));
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})L'accesso al documento HTML utilizzando http://127.0.0.1:8081/index.htm genererà il seguente modulo:
Ora puoi inserire il nome e il cognome e quindi fare clic sul pulsante di invio per vedere il seguente risultato:
{"first_name":"John","last_name":"Paul"}Upload di file
Il seguente codice HTML crea un modulo di caricamento file. Questo modulo ha l'attributo del metodo impostato suPOST e l'attributo enctype è impostato su multipart/form-data
<html>
<head>
<title>File Uploading Form</title>
</head>
<body>
<h3>File Upload:</h3>
Select a file to upload: <br />
<form action = "http://127.0.0.1:8081/file_upload" method = "POST"
enctype = "multipart/form-data">
<input type="file" name="file" size="50" />
<br />
<input type = "submit" value = "Upload File" />
</form>
</body>
</html>Salviamo il codice sopra in index.htm e modifichiamo server.js per gestire le richieste della home page e il caricamento dei file.
var express = require('express');
var app = express();
var fs = require("fs");
var bodyParser = require('body-parser');
var multer = require('multer');
app.use(express.static('public'));
app.use(bodyParser.urlencoded({ extended: false }));
app.use(multer({ dest: '/tmp/'}));
app.get('/index.htm', function (req, res) {
res.sendFile( __dirname + "/" + "index.htm" );
})
app.post('/file_upload', function (req, res) {
console.log(req.files.file.name);
console.log(req.files.file.path);
console.log(req.files.file.type);
var file = __dirname + "/" + req.files.file.name;
fs.readFile( req.files.file.path, function (err, data) {
fs.writeFile(file, data, function (err) {
if( err ) {
console.log( err );
} else {
response = {
message:'File uploaded successfully',
filename:req.files.file.name
};
}
console.log( response );
res.end( JSON.stringify( response ) );
});
});
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})L'accesso al documento HTML utilizzando http://127.0.0.1:8081/index.htm genererà il seguente modulo:
File Upload:
Select a file to upload:
NOTE: This is just dummy form and would not work, but it must work at your server.Gestione dei cookie
È possibile inviare cookie a un server Node.js che può gestirli utilizzando la seguente opzione middleware. Di seguito è riportato un semplice esempio per stampare tutti i cookie inviati dal cliente.
var express = require('express')
var cookieParser = require('cookie-parser')
var app = express()
app.use(cookieParser())
app.get('/', function(req, res) {
console.log("Cookies: ", req.cookies)
})
app.listen(8081)Cos'è l'architettura REST?
REST sta per REpresentational State Transfer. REST è un'architettura basata su standard web e utilizza il protocollo HTTP. Ruota intorno a una risorsa in cui ogni componente è una risorsa e una risorsa è accessibile da un'interfaccia comune utilizzando metodi standard HTTP. REST è stato introdotto per la prima volta da Roy Fielding nel 2000.
Un server REST fornisce semplicemente l'accesso alle risorse e il client REST accede e modifica le risorse utilizzando il protocollo HTTP. Qui ogni risorsa è identificata da URI / ID globali. REST utilizza varie rappresentazioni per rappresentare una risorsa come testo, JSON, XML ma JSON è la più popolare.
Metodi HTTP
I seguenti quattro metodi HTTP sono comunemente usati nell'architettura basata su REST.
GET - Viene utilizzato per fornire un accesso di sola lettura a una risorsa.
PUT - Viene utilizzato per creare una nuova risorsa.
DELETE - Viene utilizzato per rimuovere una risorsa.
POST - Viene utilizzato per aggiornare una risorsa esistente o creare una nuova risorsa.
Servizi Web RESTful
Un servizio Web è una raccolta di protocolli aperti e standard utilizzati per lo scambio di dati tra applicazioni o sistemi. Le applicazioni software scritte in vari linguaggi di programmazione e in esecuzione su varie piattaforme possono utilizzare i servizi web per scambiare dati su reti di computer come Internet in un modo simile alla comunicazione tra processi su un singolo computer. Questa interoperabilità (ad esempio, comunicazione tra Java e Python o applicazioni Windows e Linux) è dovuta all'uso di standard aperti.
I servizi Web basati sull'architettura REST sono noti come servizi Web RESTful. Questi servizi web utilizzano metodi HTTP per implementare il concetto di architettura REST. Un servizio Web RESTful di solito definisce un URI, Uniform Resource Identifier un servizio, che fornisce la rappresentazione delle risorse come JSON e un insieme di metodi HTTP.
Creazione di RESTful per una libreria
Considera che abbiamo un database di utenti basato su JSON con i seguenti utenti in un file users.json:
{
"user1" : {
"name" : "mahesh",
"password" : "password1",
"profession" : "teacher",
"id": 1
},
"user2" : {
"name" : "suresh",
"password" : "password2",
"profession" : "librarian",
"id": 2
},
"user3" : {
"name" : "ramesh",
"password" : "password3",
"profession" : "clerk",
"id": 3
}
}Sulla base di queste informazioni forniremo le seguenti API RESTful.
| Sr.No. | URI | Metodo HTTP | POST corpo | Risultato |
|---|---|---|---|---|
| 1 | listUsers | OTTENERE | vuoto | Mostra l'elenco di tutti gli utenti. |
| 2 | Aggiungi utente | INVIARE | Stringa JSON | Aggiungi i dettagli del nuovo utente. |
| 3 | deleteUser | ELIMINA | Stringa JSON | Elimina un utente esistente. |
| 4 | : id | OTTENERE | vuoto | Mostra i dettagli di un utente. |
Sto mantenendo la maggior parte della parte di tutti gli esempi sotto forma di hard coding supponendo che tu sappia già come passare valori dal front-end usando Ajax o semplici dati di form e come elaborarli usando express Request oggetto.
Elenca utenti
Implementiamo la nostra prima API RESTful listUsers utilizzando il codice seguente in un file server.js -
server.js
var express = require('express');
var app = express();
var fs = require("fs");
app.get('/listUsers', function (req, res) {
fs.readFile( __dirname + "/" + "users.json", 'utf8', function (err, data) {
console.log( data );
res.end( data );
});
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Ora prova ad accedere all'API definita utilizzando l' URL: http://127.0.0.1:8081/listUsers e il metodo HTTP: GET sulla macchina locale utilizzando qualsiasi client REST. Questo dovrebbe produrre il seguente risultato:
È possibile modificare l'indirizzo IP specificato quando si inserirà la soluzione nell'ambiente di produzione.
{
"user1" : {
"name" : "mahesh",
"password" : "password1",
"profession" : "teacher",
"id": 1
},
"user2" : {
"name" : "suresh",
"password" : "password2",
"profession" : "librarian",
"id": 2
},
"user3" : {
"name" : "ramesh",
"password" : "password3",
"profession" : "clerk",
"id": 3
}
}Aggiungi utente
La seguente API ti mostrerà come aggiungere un nuovo utente nell'elenco. Di seguito è riportato il dettaglio del nuovo utente:
user = {
"user4" : {
"name" : "mohit",
"password" : "password4",
"profession" : "teacher",
"id": 4
}
}Puoi accettare lo stesso input sotto forma di JSON usando la chiamata Ajax ma per il punto di vista dell'insegnamento, lo stiamo rendendo hard coded qui. Di seguito è riportato il fileaddUser API per un nuovo utente nel database -
server.js
var express = require('express');
var app = express();
var fs = require("fs");
var user = {
"user4" : {
"name" : "mohit",
"password" : "password4",
"profession" : "teacher",
"id": 4
}
}
app.post('/addUser', function (req, res) {
// First read existing users.
fs.readFile( __dirname + "/" + "users.json", 'utf8', function (err, data) {
data = JSON.parse( data );
data["user4"] = user["user4"];
console.log( data );
res.end( JSON.stringify(data));
});
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Ora prova ad accedere all'API definita utilizzando l' URL: http://127.0.0.1:8081/addUser e il metodo HTTP: POST sulla macchina locale utilizzando qualsiasi client REST. Questo dovrebbe produrre il seguente risultato:
{
"user1":{"name":"mahesh","password":"password1","profession":"teacher","id":1},
"user2":{"name":"suresh","password":"password2","profession":"librarian","id":2},
"user3":{"name":"ramesh","password":"password3","profession":"clerk","id":3},
"user4":{"name":"mohit","password":"password4","profession":"teacher","id":4}
}Mostra i dettagli
Ora implementeremo un'API che verrà chiamata utilizzando l'ID utente e mostrerà i dettagli dell'utente corrispondente.
server.js
var express = require('express');
var app = express();
var fs = require("fs");
app.get('/:id', function (req, res) {
// First read existing users.
fs.readFile( __dirname + "/" + "users.json", 'utf8', function (err, data) {
var users = JSON.parse( data );
var user = users["user" + req.params.id]
console.log( user );
res.end( JSON.stringify(user));
});
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Ora prova ad accedere all'API definita utilizzando l' URL: http://127.0.0.1:8081/2 e il metodo HTTP: GET sulla macchina locale utilizzando qualsiasi client REST. Questo dovrebbe produrre il seguente risultato:
{"name":"suresh","password":"password2","profession":"librarian","id":2}Elimina utente
Questa API è molto simile all'API addUser in cui riceviamo dati di input tramite req.body e quindi, in base all'ID utente, eliminiamo quell'utente dal database. Per mantenere il nostro programma semplice, supponiamo di eliminare l'utente con ID 2.
server.js
var express = require('express');
var app = express();
var fs = require("fs");
var id = 2;
app.delete('/deleteUser', function (req, res) {
// First read existing users.
fs.readFile( __dirname + "/" + "users.json", 'utf8', function (err, data) {
data = JSON.parse( data );
delete data["user" + 2];
console.log( data );
res.end( JSON.stringify(data));
});
})
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})Ora prova ad accedere all'API definita utilizzando l' URL: http://127.0.0.1:8081/deleteUser e il metodo HTTP: DELETE sulla macchina locale utilizzando qualsiasi client REST. Questo dovrebbe produrre il seguente risultato:
{"user1":{"name":"mahesh","password":"password1","profession":"teacher","id":1},
"user3":{"name":"ramesh","password":"password3","profession":"clerk","id":3}}Node.js viene eseguito in modalità single-thread, ma utilizza un paradigma basato sugli eventi per gestire la concorrenza. Inoltre, facilita la creazione di processi figlio per sfruttare l'elaborazione parallela su sistemi basati su CPU multi-core.
I processi figlio hanno sempre tre flussi child.stdin, child.stdout, e child.stderr che può essere condiviso con i flussi stdio del processo genitore.
Node fornisce child_process modulo che ha i seguenti tre modi principali per creare un processo figlio.
exec - Il metodo child_process.exec esegue un comando in una shell / console e bufferizza l'output.
spawn - child_process.spawn avvia un nuovo processo con un dato comando.
fork - Il metodo child_process.fork è un caso speciale di spawn () per creare processi figli.
Il metodo exec ()
Il metodo child_process.exec esegue un comando in una shell e memorizza l'output nel buffer. Ha la seguente firma:
child_process.exec(command[, options], callback)Parametri
Ecco la descrizione dei parametri utilizzati:
command (String) Il comando da eseguire, con argomenti separati da spazi
options (Oggetto) può comprendere una o più delle seguenti opzioni:
cwd (Stringa) Directory di lavoro corrente del processo figlio
env (Oggetto) Coppie chiave-valore dell'ambiente
encoding (Stringa) (impostazione predefinita: "utf8")
shell (String) Shell per eseguire il comando con (Default: '/ bin / sh' su UNIX, 'cmd.exe' su Windows, La shell dovrebbe comprendere l'opzione -c su UNIX o / s / c su Windows. Su Windows, l'analisi della riga di comando dovrebbe essere compatibile con cmd.exe.)
timeout (Numero) (predefinito: 0)
maxBuffer (Numero) (predefinito: 200 * 1024)
killSignal (Stringa) (impostazione predefinita: "SIGTERM")
uid (Numero) Imposta l'identità dell'utente del processo.
gid (Numero) Imposta l'identità di gruppo del processo.
callback La funzione ottiene tre argomenti error, stdout, e stderr che vengono chiamati con l'output quando il processo termina.
Il metodo exec () restituisce un buffer con una dimensione massima e attende che il processo termini e cerca di restituire tutti i dati memorizzati nel buffer contemporaneamente.
Esempio
Creiamo due file js denominati support.js e master.js -
File: support.js
console.log("Child Process " + process.argv[2] + " executed." );File: master.js
const fs = require('fs');
const child_process = require('child_process');
for(var i=0; i<3; i++) {
var workerProcess = child_process.exec('node support.js '+i,function
(error, stdout, stderr) {
if (error) {
console.log(error.stack);
console.log('Error code: '+error.code);
console.log('Signal received: '+error.signal);
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
});
workerProcess.on('exit', function (code) {
console.log('Child process exited with exit code '+code);
});
}Ora esegui master.js per vedere il risultato -
$ node master.jsVerifica l'output. Il server è stato avviato.
Child process exited with exit code 0
stdout: Child Process 1 executed.
stderr:
Child process exited with exit code 0
stdout: Child Process 0 executed.
stderr:
Child process exited with exit code 0
stdout: Child Process 2 executed.Il metodo spawn ()
Il metodo child_process.spawn avvia un nuovo processo con un dato comando. Ha la seguente firma:
child_process.spawn(command[, args][, options])Parametri
Ecco la descrizione dei parametri utilizzati:
command (String) Il comando da eseguire
args (Array) Elenco di argomenti stringa
options (Oggetto) può comprendere una o più delle seguenti opzioni:
cwd (Stringa) Directory di lavoro corrente del processo figlio.
env (Oggetto) Coppie chiave-valore dell'ambiente.
stdio (Array) String Configurazione stdio del figlio.
customFds (Array) Descrittori di file deprecati per il bambino da utilizzare per stdio.
detached (Booleano) Il bambino sarà un leader del gruppo di processo.
uid (Numero) Imposta l'identità dell'utente del processo.
gid (Numero) Imposta l'identità di gruppo del processo.
Il metodo spawn () restituisce flussi (stdout e stderr) e dovrebbe essere utilizzato quando il processo restituisce una quantità di dati in volume. spawn () inizia a ricevere la risposta non appena il processo inizia l'esecuzione.
Esempio
Crea due file js denominati support.js e master.js -
File: support.js
console.log("Child Process " + process.argv[2] + " executed." );File: master.js
const fs = require('fs');
const child_process = require('child_process');
for(var i = 0; i<3; i++) {
var workerProcess = child_process.spawn('node', ['support.js', i]);
workerProcess.stdout.on('data', function (data) {
console.log('stdout: ' + data);
});
workerProcess.stderr.on('data', function (data) {
console.log('stderr: ' + data);
});
workerProcess.on('close', function (code) {
console.log('child process exited with code ' + code);
});
}Ora esegui master.js per vedere il risultato -
$ node master.jsVerifica l'output. Il server è stato avviato
stdout: Child Process 0 executed.
child process exited with code 0
stdout: Child Process 1 executed.
stdout: Child Process 2 executed.
child process exited with code 0
child process exited with code 0Il metodo fork ()
Il metodo child_process.fork è un caso speciale di spawn () per creare processi Node. Ha la seguente firma:
child_process.fork(modulePath[, args][, options])Parametri
Ecco la descrizione dei parametri utilizzati:
modulePath (String) Il modulo da eseguire nel figlio.
args (Array) Elenco di argomenti stringa
options (Oggetto) può comprendere una o più delle seguenti opzioni:
cwd (Stringa) Directory di lavoro corrente del processo figlio.
env (Oggetto) Coppie chiave-valore dell'ambiente.
execPath (String) Eseguibile utilizzato per creare il processo figlio.
execArgv (Array) Elenco di argomenti stringa passati all'eseguibile (impostazione predefinita: process.execArgv).
silent (Boolean) Se true, stdin, stdout e stderr del figlio verranno reindirizzati al genitore, altrimenti saranno ereditati dal genitore, vedere le opzioni "pipe" e "inherit" per lo stdio di spawn () per ulteriori informazioni dettagli (l'impostazione predefinita è false).
uid (Numero) Imposta l'identità dell'utente del processo.
gid (Numero) Imposta l'identità di gruppo del processo.
Il metodo fork restituisce un oggetto con un canale di comunicazione integrato oltre ad avere tutti i metodi in una normale istanza ChildProcess.
Esempio
Crea due file js denominati support.js e master.js -
File: support.js
console.log("Child Process " + process.argv[2] + " executed." );File: master.js
const fs = require('fs');
const child_process = require('child_process');
for(var i=0; i<3; i++) {
var worker_process = child_process.fork("support.js", [i]);
worker_process.on('close', function (code) {
console.log('child process exited with code ' + code);
});
}Ora esegui master.js per vedere il risultato -
$ node master.jsVerifica l'output. Il server è stato avviato.
Child Process 0 executed.
Child Process 1 executed.
Child Process 2 executed.
child process exited with code 0
child process exited with code 0
child process exited with code 0JXcore, che è un progetto open source, introduce una funzionalità unica per il confezionamento e la crittografia di file sorgente e altre risorse nei pacchetti JX.
Considera di avere un grande progetto composto da molti file. JXcore può comprimerli tutti in un unico file per semplificare la distribuzione. Questo capitolo fornisce una rapida panoramica dell'intero processo a partire dall'installazione di JXcore.
Installazione JXcore
L'installazione di JXcore è abbastanza semplice. Qui abbiamo fornito istruzioni dettagliate su come installare JXcore sul tuo sistema. Segui i passaggi indicati di seguito:
Passo 1
Scarica il pacchetto JXcore da https://github.com/jxcore/jxcore, in base al sistema operativo e all'architettura della macchina. Abbiamo scaricato un pacchetto per Cenots in esecuzione su una macchina a 64 bit.
$ wget https://s3.amazonaws.com/nodejx/jx_rh64.zipPasso 2
Decomprimi il file scaricato jx_rh64.zipe copia il binario jx in / usr / bin o può trovarsi in qualsiasi altra directory in base alla configurazione del tuo sistema.
$ unzip jx_rh64.zip
$ cp jx_rh64/jx /usr/binPassaggio 3
Imposta la tua variabile PATH in modo appropriato per eseguire jx da qualsiasi luogo tu voglia.
$ export PATH=$PATH:/usr/binPassaggio 4
È possibile verificare l'installazione immettendo un semplice comando come mostrato di seguito. Dovresti trovarlo funzionante e stampare il suo numero di versione come segue:
$ jx --version
v0.10.32Imballaggio del codice
Considera di avere un progetto con le seguenti directory in cui hai conservato tutti i tuoi file inclusi Node.js, file principale, index.js e tutti i moduli installati localmente.
drwxr-xr-x 2 root root 4096 Nov 13 12:42 images
-rwxr-xr-x 1 root root 30457 Mar 6 12:19 index.htm
-rwxr-xr-x 1 root root 30452 Mar 1 12:54 index.js
drwxr-xr-x 23 root root 4096 Jan 15 03:48 node_modules
drwxr-xr-x 2 root root 4096 Mar 21 06:10 scripts
drwxr-xr-x 2 root root 4096 Feb 15 11:56 stylePer impacchettare il progetto sopra, devi semplicemente entrare in questa directory ed emettere il seguente comando jx. Supponendo che index.js sia il file di ingresso per il tuo progetto Node.js -
$ jx package index.js indexQui avresti potuto usare qualsiasi altro nome di pacchetto invece di index. Abbiamo usato indexperché volevamo mantenere il nome del nostro file principale come index.jx. Tuttavia, il comando precedente comprimerà tutto e creerà i seguenti due file:
index.jxp Questo è un file intermedio che contiene i dettagli completi del progetto necessari per compilare il progetto.
index.jx Questo è il file binario contenente il pacchetto completo pronto per essere spedito al tuo client o al tuo ambiente di produzione.
Avvio del file JX
Considera che il tuo progetto Node.js originale era in esecuzione come segue:
$ node index.js command_line_argumentsDopo aver compilato il pacchetto utilizzando JXcore, può essere avviato come segue:
$ jx index.jx command_line_argumentsPer saperne di più su JXcore, puoi controllare il suo sito ufficiale.