Architettura di computer paralleli - Guida rapida
Negli ultimi 50 anni, ci sono stati enormi sviluppi nelle prestazioni e nelle capacità di un sistema informatico. Ciò è stato possibile con l'aiuto della tecnologia VLSI (Very Large Scale Integration). La tecnologia VLSI consente di ospitare un gran numero di componenti su un singolo chip e di aumentare le frequenze di clock. Pertanto, più operazioni possono essere eseguite contemporaneamente, in parallelo.
L'elaborazione parallela è anche associata alla località e alla comunicazione dei dati. Parallel Computer Architecture è il metodo di organizzare tutte le risorse per massimizzare le prestazioni e la programmabilità entro i limiti dati dalla tecnologia e dal costo in ogni istante di tempo.
Perché l'architettura parallela?
L'architettura dei computer paralleli aggiunge una nuova dimensione allo sviluppo del sistema informatico utilizzando un numero sempre maggiore di processori. In linea di principio, le prestazioni ottenute utilizzando un gran numero di processori sono superiori alle prestazioni di un singolo processore in un dato momento.
Tendenze applicative
Con l'avanzamento della capacità hardware, è aumentata anche la domanda di un'applicazione ben performante, che a sua volta ha posto una domanda sullo sviluppo dell'architettura del computer.
Prima dell'era dei microprocessori, il sistema informatico ad alte prestazioni era ottenuto dalla tecnologia dei circuiti esotici e dall'organizzazione della macchina, che li rendeva costosi. Ora, il sistema informatico ad alte prestazioni si ottiene utilizzando più processori e le applicazioni più importanti e impegnative vengono scritte come programmi paralleli. Pertanto, per prestazioni più elevate è necessario sviluppare sia architetture parallele che applicazioni parallele.
Per aumentare le prestazioni di un'applicazione Speedup è il fattore chiave da considerare. Speedup su p processori è definito come -
$$Speedup(p \ processors)\equiv\frac{Performance(p \ processors)}{Performance(1 \ processor)}$$Per il singolo problema risolto,
$$performance \ of \ a \ computer \ system = \frac{1}{Time \ needed \ to \ complete \ the \ problem}$$ $$Speedup \ _{fixed \ problem} (p \ processors) =\frac{Time(1 \ processor)}{Time(p \ processor)}$$Informatica scientifica e ingegneristica
L'architettura parallela è diventata indispensabile nell'informatica scientifica (come fisica, chimica, biologia, astronomia, ecc.) E nelle applicazioni di ingegneria (come la modellazione dei giacimenti, l'analisi del flusso d'aria, l'efficienza della combustione, ecc.). In quasi tutte le applicazioni, c'è un'enorme richiesta di visualizzazione dell'output computazionale che porta alla richiesta di sviluppo del calcolo parallelo per aumentare la velocità di calcolo.
Calcolo commerciale
Nell'informatica commerciale (come video, grafica, database, OLTP, ecc.) Sono necessari anche computer ad alta velocità per elaborare enormi quantità di dati entro un tempo specificato. Il desktop utilizza programmi multithread che sono quasi come i programmi paralleli. Ciò a sua volta richiede lo sviluppo di un'architettura parallela.
Tendenze tecnologiche
Con lo sviluppo della tecnologia e dell'architettura, c'è una forte domanda per lo sviluppo di applicazioni ad alte prestazioni. Gli esperimenti dimostrano che i computer paralleli possono funzionare molto più velocemente del massimo processore singolo sviluppato. Inoltre, i computer paralleli possono essere sviluppati entro i limiti della tecnologia e del costo.
La tecnologia principale utilizzata qui è la tecnologia VLSI. Pertanto, oggi sempre più transistor, gate e circuiti possono essere installati nella stessa area. Con la riduzione della dimensione della caratteristica VLSI di base, anche la frequenza di clock migliora in proporzione ad essa, mentre il numero di transistor cresce con il quadrato. Ci si può aspettare che l'uso di molti transistor contemporaneamente (parallelismo) abbia prestazioni molto migliori rispetto all'aumento della frequenza di clock
Le tendenze tecnologiche suggeriscono che il blocco di base a chip singolo darà una capacità sempre maggiore. Pertanto, aumenta la possibilità di posizionare più processori su un singolo chip.
Tendenze architettoniche
Lo sviluppo tecnologico decide cosa è fattibile; l'architettura converte il potenziale della tecnologia in prestazioni e capacità.Parallelism e localitysono due metodi in cui volumi maggiori di risorse e più transistor migliorano le prestazioni. Tuttavia, questi due metodi competono per le stesse risorse. Quando vengono eseguite più operazioni in parallelo, il numero di cicli necessari per eseguire il programma si riduce.
Tuttavia, sono necessarie risorse per supportare ciascuna delle attività concorrenti. Le risorse sono necessarie anche per allocare la memoria locale. Le migliori prestazioni si ottengono con un piano d'azione intermedio che utilizza le risorse per utilizzare un grado di parallelismo e un grado di località.
In generale, la storia dell'architettura dei computer è stata divisa in quattro generazioni che hanno seguito le tecnologie di base:
- Tubi a vuoto
- Transistors
- Circuiti integrati
- VLSI
Fino al 1985, la durata è stata dominata dalla crescita del parallelismo a livello di bit. Microprocessori a 4 bit seguiti da 8 bit, 16 bit e così via. Per ridurre il numero di cicli necessari per eseguire un'operazione completa a 32 bit, la larghezza del percorso dati è stata raddoppiata. Successivamente, sono state introdotte le operazioni a 64 bit.
La crescita in instruction-level-parallelismha dominato dalla metà degli anni '80 alla metà degli anni '90. L'approccio RISC ha mostrato che era semplice pipeline le fasi di elaborazione delle istruzioni in modo che in media un'istruzione venga eseguita in quasi ogni ciclo. La crescita della tecnologia dei compilatori ha reso le pipeline di istruzioni più produttive.
A metà degli anni '80, i computer basati su microprocessore erano costituiti da
- Un'unità di elaborazione intera
- Un'unità in virgola mobile
- Un controller della cache
- SRAM per i dati della cache
- Archiviazione dei tag
Con l'aumento della capacità del chip, tutti questi componenti sono stati fusi in un unico chip. Pertanto, un singolo chip consisteva in hardware separato per operazioni aritmetiche su interi, operazioni in virgola mobile, operazioni di memoria e operazioni di ramo. Oltre al pipeline di singole istruzioni, recupera più istruzioni alla volta e le invia in parallelo a diverse unità funzionali, ove possibile. Questo tipo di parallelismo a livello di istruzione viene chiamatosuperscalar execution.
Le macchine parallele sono state sviluppate con diverse architetture distinte. In questa sezione, discuteremo la diversa architettura di computer paralleli e la natura della loro convergenza.
Architettura della comunicazione
L'architettura parallela migliora i concetti convenzionali dell'architettura del computer con l'architettura della comunicazione. L'architettura del computer definisce le astrazioni critiche (come il confine del sistema utente e il confine hardware-software) e la struttura organizzativa, mentre l'architettura della comunicazione definisce le operazioni di comunicazione e sincronizzazione di base. Affronta anche la struttura organizzativa.
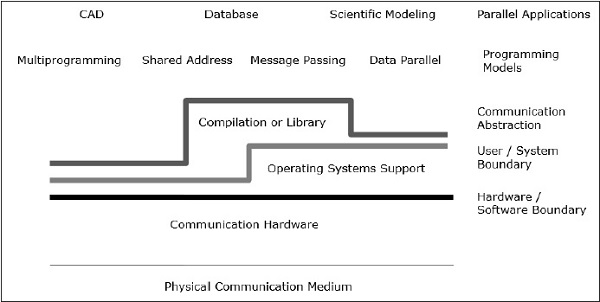
Il modello di programmazione è lo strato superiore. Le applicazioni sono scritte nel modello di programmazione. I modelli di programmazione parallela includono:
- Spazio degli indirizzi condiviso
- Passaggio del messaggio
- Programmazione parallela dei dati
Shared addressprogrammare è proprio come usare una bacheca, dove si può comunicare con una o più persone inserendo informazioni in un luogo particolare, che è condiviso da tutte le altre persone. L'attività individuale è coordinata annotando chi sta facendo quale compito.
Message passing è come una telefonata o una lettera in cui un destinatario specifico riceve informazioni da un mittente specifico.
Data parallella programmazione è una forma organizzata di cooperazione. Qui, diverse persone eseguono un'azione su elementi separati di un set di dati contemporaneamente e condividono le informazioni a livello globale.
Memoria condivisa
I multiprocessori a memoria condivisa sono una delle classi più importanti di macchine parallele. Offre un rendimento migliore sui carichi di lavoro multiprogrammazione e supporta programmi paralleli.
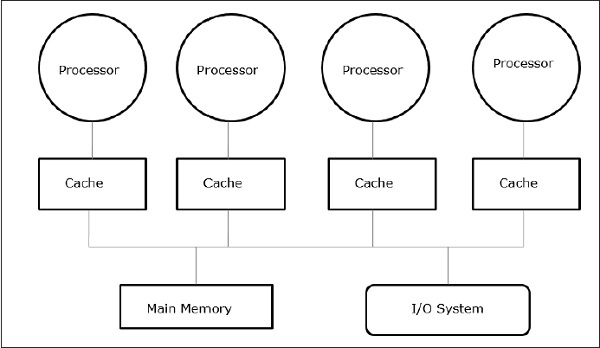
In questo caso, tutti i sistemi informatici consentono a un processore e a un set di controller I / O di accedere a una raccolta di moduli di memoria mediante un'interconnessione hardware. La capacità di memoria viene aumentata aggiungendo moduli di memoria e la capacità di I / O viene aumentata aggiungendo dispositivi al controller I / O o aggiungendo controller I / O aggiuntivo. La capacità di elaborazione può essere aumentata aspettando che sia disponibile un processore più veloce o aggiungendo più processori.
Tutte le risorse sono organizzate attorno a un bus di memoria centrale. Attraverso il meccanismo di accesso al bus, qualsiasi processore può accedere a qualsiasi indirizzo fisico nel sistema. Poiché tutti i processori sono equidistanti da tutte le posizioni di memoria, il tempo di accesso o la latenza di tutti i processori è la stessa su una posizione di memoria. Questo è chiamatosymmetric multiprocessor.
Architettura a passaggio di messaggi
L'architettura di passaggio dei messaggi è anche un'importante classe di macchine parallele. Fornisce la comunicazione tra i processori come operazioni di I / O esplicite. In questo caso, la comunicazione viene combinata a livello di I / O, invece del sistema di memoria.
Nell'architettura di passaggio dei messaggi, la comunicazione utente viene eseguita utilizzando il sistema operativo o le chiamate di libreria che eseguono molte azioni di livello inferiore, inclusa l'effettiva operazione di comunicazione. Di conseguenza, esiste una distanza tra il modello di programmazione e le operazioni di comunicazione a livello di hardware fisico.
Send e receiveè la più comune operazione di comunicazione a livello utente nel sistema di trasmissione dei messaggi. Invia specifica un buffer dati locale (che deve essere trasmesso) e un processore remoto ricevente. Ricevi specifica un processo di invio e un buffer dati locale in cui verranno inseriti i dati trasmessi. Nell'operazione di invio, un fileidentifier o a tag è allegato al messaggio e l'operazione di ricezione specifica la regola di corrispondenza come un tag specifico da un processore specifico o qualsiasi tag da qualsiasi processore.
La combinazione di un invio e di una ricezione corrispondente completa una copia da memoria a memoria. Ciascuna estremità specifica il proprio indirizzo dati locale e un evento di sincronizzazione a coppie.
Convergenza
Lo sviluppo dell'hardware e del software ha sbiadito il confine netto tra la memoria condivisa e i campi di passaggio dei messaggi. Il passaggio dei messaggi e uno spazio di indirizzi condiviso rappresentano due distinti modelli di programmazione; ciascuno fornisce un paradigma trasparente per la condivisione, la sincronizzazione e la comunicazione. Tuttavia, le strutture di base della macchina sono convergenti verso un'organizzazione comune.
Elaborazione parallela dei dati
Un'altra importante classe di macchine parallele è variamente chiamata: array di processori, architettura parallela dei dati e macchine per dati multipli con istruzione singola. La caratteristica principale del modello di programmazione è che le operazioni possono essere eseguite in parallelo su ogni elemento di una grande struttura dati regolare (come array o matrice).
I linguaggi di programmazione parallela ai dati vengono generalmente applicati visualizzando lo spazio degli indirizzi locale di un gruppo di processi, uno per processore, che formano uno spazio globale esplicito. Poiché tutti i processori comunicano insieme e c'è una vista globale di tutte le operazioni, è possibile utilizzare uno spazio di indirizzi condiviso o il passaggio di messaggi.
Problemi di progettazione fondamentali
Lo sviluppo del solo modello di programmazione non può aumentare l'efficienza del computer né lo sviluppo dell'hardware da solo può farlo. Tuttavia, lo sviluppo dell'architettura del computer può fare la differenza nelle prestazioni del computer. Possiamo comprendere il problema di progettazione concentrandoci su come i programmi utilizzano una macchina e su quali tecnologie di base vengono fornite.
In questa sezione, discuteremo dell'astrazione della comunicazione e dei requisiti di base del modello di programmazione.
Astrazione di comunicazione
L'astrazione della comunicazione è l'interfaccia principale tra il modello di programmazione e l'implementazione del sistema. È come il set di istruzioni che fornisce una piattaforma in modo che lo stesso programma possa essere eseguito correttamente su molte implementazioni. Le operazioni a questo livello devono essere semplici.
L'astrazione della comunicazione è come un contratto tra l'hardware e il software, che si concede reciprocamente la flessibilità per migliorare senza influire sul lavoro.
Requisiti del modello di programmazione
Un programma parallelo ha uno o più thread che operano sui dati. Un modello di programmazione parallela definisce quali dati possono essere forniti dai threadname, quale operations può essere eseguito sui dati nominati e quale ordine è seguito dalle operazioni.
Per confermare che le dipendenze tra i programmi vengono applicate, un programma parallelo deve coordinare l'attività dei suoi thread.
L'elaborazione parallela è stata sviluppata come una tecnologia efficace nei computer moderni per soddisfare la domanda di prestazioni più elevate, costi inferiori e risultati accurati nelle applicazioni della vita reale. Gli eventi simultanei sono comuni nei computer odierni a causa della pratica di multiprogrammazione, multiprocessing o multicomputing.
I computer moderni hanno pacchetti software potenti ed estesi. Per analizzare lo sviluppo delle prestazioni dei computer, dobbiamo prima comprendere lo sviluppo di base di hardware e software.
Computer Development Milestones - Ci sono due fasi principali di sviluppo del computer - mechanical o electromechanicalparti. I computer moderni si sono evoluti dopo l'introduzione dei componenti elettronici. Gli elettroni ad alta mobilità nei computer elettronici hanno sostituito le parti operative nei computer meccanici. Per la trasmissione delle informazioni, il segnale elettrico che viaggia quasi alla velocità di una luce ha sostituito gli ingranaggi o le leve meccaniche.
Elements of Modern computers - Un moderno sistema informatico è costituito da hardware, set di istruzioni, programmi applicativi, software di sistema e interfaccia utente.

I problemi di elaborazione sono classificati come calcolo numerico, ragionamento logico ed elaborazione delle transazioni. Alcuni problemi complessi potrebbero richiedere la combinazione di tutte e tre le modalità di elaborazione.
Evolution of Computer Architecture- Negli ultimi quattro decenni, l'architettura dei computer ha subito cambiamenti rivoluzionari. Abbiamo iniziato con l'architettura Von Neumann e ora abbiamo multicomputer e multiprocessori.
Performance of a computer system- Le prestazioni di un sistema informatico dipendono sia dalla capacità della macchina che dal comportamento del programma. La capacità della macchina può essere migliorata con una migliore tecnologia hardware, caratteristiche architettoniche avanzate e una gestione efficiente delle risorse. Il comportamento del programma è imprevedibile poiché dipende dall'applicazione e dalle condizioni di runtime
Multiprocessori e multicomputer
In questa sezione, discuteremo di due tipi di computer paralleli:
- Multiprocessors
- Multicomputers
Multicomputer a memoria condivisa
I tre modelli multiprocessore di memoria condivisa più comuni sono:
Accesso alla memoria uniforme (UMA)
In questo modello, tutti i processori condividono la memoria fisica in modo uniforme. Tutti i processori hanno lo stesso tempo di accesso a tutte le parole di memoria. Ogni processore può avere una memoria cache privata. La stessa regola viene seguita per i dispositivi periferici.
Quando tutti i processori hanno uguale accesso a tutte le periferiche, il sistema viene chiamato a symmetric multiprocessor. Quando solo uno o pochi processori possono accedere ai dispositivi periferici, il sistema viene chiamatoasymmetric multiprocessor.
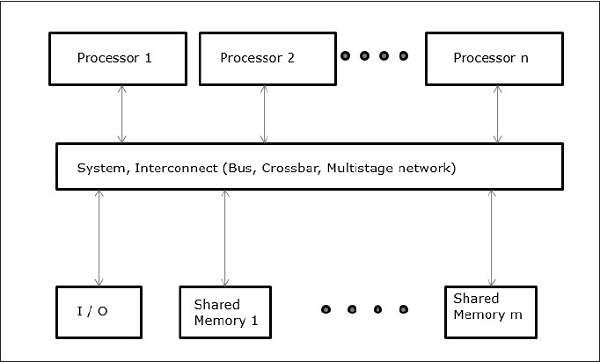
Accesso alla memoria non uniforme (NUMA)
Nel modello multiprocessore NUMA, il tempo di accesso varia con la posizione della parola di memoria. Qui, la memoria condivisa è distribuita fisicamente tra tutti i processori, chiamati memorie locali. La raccolta di tutte le memorie locali forma uno spazio indirizzi globale a cui possono accedere tutti i processori.
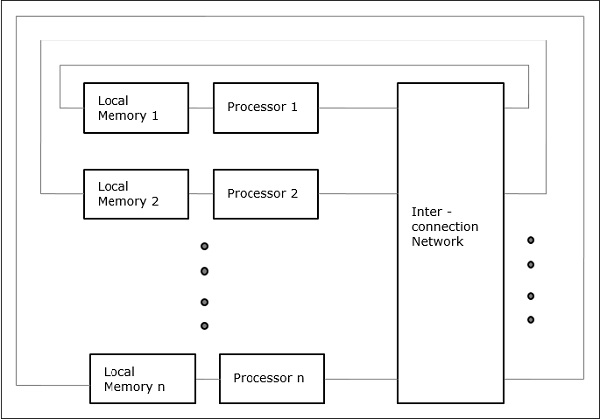
Cache Only Memory Architecture (COMA)
Il modello COMA è un caso speciale del modello NUMA. Qui, tutte le memorie principali distribuite vengono convertite in memorie cache.

Distributed - Memory Multicomputers- Un sistema multicomputer a memoria distribuita è costituito da più computer, noti come nodi, interconnessi da una rete di passaggio di messaggi. Ogni nodo funge da computer autonomo con un processore, una memoria locale e talvolta dispositivi I / O. In questo caso, tutte le memorie locali sono private e sono accessibili solo ai processori locali. Ecco perché si chiamano le macchine tradizionalino-remote-memory-access (NORMA) macchine.

Computer multivettore e SIMD
In questa sezione, discuteremo di supercomputer e processori paralleli per l'elaborazione vettoriale e il parallelismo dei dati.
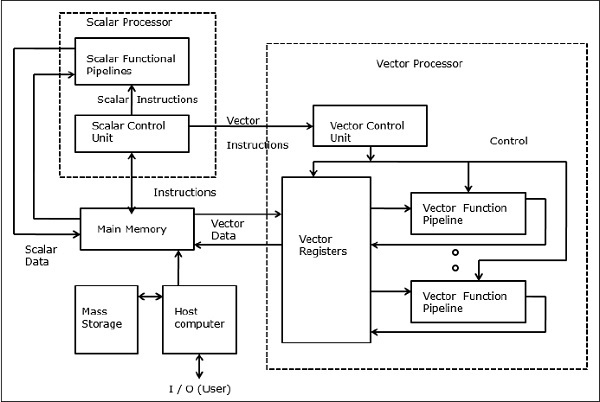
Supercomputer vettoriali
In un computer vettoriale, un processore vettoriale è collegato al processore scalare come funzionalità opzionale. Il computer host carica prima il programma ei dati nella memoria principale. Quindi l'unità di controllo scalare decodifica tutte le istruzioni. Se le istruzioni decodificate sono operazioni scalari o operazioni di programma, il processore scalare esegue tali operazioni utilizzando pipeline funzionali scalari.
Se invece le istruzioni decodificate sono operazioni vettoriali, le istruzioni verranno inviate all'unità di controllo vettoriale.
Supercomputer SIMD
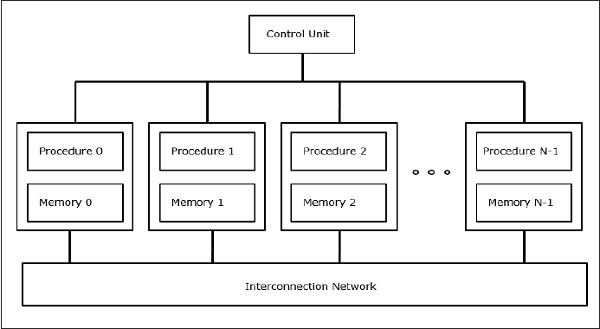
Nei computer SIMD, un numero 'N' di processori è collegato a un'unità di controllo e tutti i processori hanno le loro unità di memoria individuali. Tutti i processori sono collegati da una rete di interconnessione.
Modelli PRAM e VLSI
Il modello ideale fornisce una struttura adeguata per lo sviluppo di algoritmi paralleli senza considerare i vincoli fisici oi dettagli di implementazione.
I modelli possono essere applicati per ottenere limiti teorici delle prestazioni su computer paralleli o per valutare la complessità VLSI sull'area del chip e il tempo operativo prima che il chip venga fabbricato.
Macchine parallele ad accesso casuale
Sheperdson e Sturgis (1963) hanno modellato i computer convenzionali uniprocessore come macchine ad accesso casuale (RAM). Fortune e Wyllie (1978) hanno sviluppato un modello PRAM (parallel random access-machine) per modellare un computer parallelo idealizzato con zero accessi alla memoria e sincronizzazione.

Una PRAM con N processori dispone di un'unità di memoria condivisa. Questa memoria condivisa può essere centralizzata o distribuita tra i processori. Questi processori operano su una memoria di lettura, una memoria di scrittura e un ciclo di calcolo sincronizzati. Quindi, questi modelli specificano come vengono gestite le operazioni di lettura e scrittura simultanee.
Di seguito sono riportate le possibili operazioni di aggiornamento della memoria:
Exclusive read (ER) - In questo metodo, in ogni ciclo un solo processore può leggere da qualsiasi posizione di memoria.
Exclusive write (EW) - In questo metodo, almeno un processore può scrivere in una posizione di memoria alla volta.
Concurrent read (CR) - Consente a più processori di leggere le stesse informazioni dalla stessa posizione di memoria nello stesso ciclo.
Concurrent write (CW)- Consente operazioni di scrittura simultanee nella stessa posizione di memoria. Per evitare conflitti di scrittura vengono impostati alcuni criteri.
Modello di complessità VLSI
I computer paralleli utilizzano chip VLSI per fabbricare array di processori, array di memoria e reti di commutazione su larga scala.
Al giorno d'oggi, le tecnologie VLSI sono bidimensionali. La dimensione di un chip VLSI è proporzionale alla quantità di spazio di archiviazione (memoria) disponibile in quel chip.
Possiamo calcolare la complessità spaziale di un algoritmo dall'area del chip (A) dell'implementazione del chip VLSI di quell'algoritmo. Se T è il tempo (latenza) necessario per eseguire l'algoritmo, AT fornisce un limite superiore al numero totale di bit elaborati attraverso il chip (o I / O). Per alcuni computer, esiste un limite inferiore, f (s), tale che
AT 2 > = O (f (s))
Dove A = area del chip e T = tempo
Tracce di sviluppo architettonico
L'evoluzione dei computer paralleli ho diffuso lungo i seguenti binari:
- Tracce multiple del processore
- Traccia multiprocessore
- Traccia multicomputer
- Traccia dati multipli
- Pista di vettore
- Traccia SIMD
- Traccia di più thread
- Traccia multithread
- Traccia del flusso di dati
In multiple processor track, si presume che diversi thread vengano eseguiti contemporaneamente su processori diversi e comunichino attraverso il sistema di memoria condivisa (traccia multiprocessore) o di passaggio di messaggi (traccia multicomputer).
In multiple data track, si presume che lo stesso codice venga eseguito sull'enorme quantità di dati. Viene fatto eseguendo le stesse istruzioni su una sequenza di elementi di dati (traccia vettoriale) o attraverso l'esecuzione della stessa sequenza di istruzioni su un insieme di dati simile (traccia SIMD).
In multiple threads track, si presume che l'esecuzione interfogliata di vari thread sullo stesso processore nasconda i ritardi di sincronizzazione tra i thread in esecuzione su processori diversi. L'interleaving dei thread può essere grossolano (traccia multithread) o fine (traccia del flusso di dati).
Negli anni '80, un processore per scopi speciali era popolare per chiamare i multicomputer Transputer. Un transputer era costituito da un processore core, una piccola memoria SRAM, un'interfaccia di memoria principale DRAM e quattro canali di comunicazione, tutti su un singolo chip. Per effettuare una comunicazione parallela con il computer, i canali sono stati collegati per formare una rete di Transputers. Ma ha una mancanza di potenza di calcolo e quindi non è in grado di soddisfare la crescente domanda di applicazioni parallele. Questo problema è stato risolto dallo sviluppo dei processori RISC ed era anche economico.
Il moderno computer parallelo utilizza microprocessori che utilizzano il parallelismo a diversi livelli come il parallelismo a livello di istruzione e il parallelismo a livello di dati.
Processori ad alte prestazioni
I processori RISC e RISCy dominano l'attuale mercato dei computer paralleli.
Le caratteristiche del RISC tradizionale sono:
- Ha poche modalità di indirizzamento.
- Ha un formato fisso per le istruzioni, solitamente 32 o 64 bit.
- Ha istruzioni di caricamento / memorizzazione dedicate per caricare i dati dalla memoria per registrare e memorizzare i dati dal registro alla memoria.
- Le operazioni aritmetiche vengono sempre eseguite sui registri.
- Utilizza pipelining.
La maggior parte dei microprocessori oggigiorno sono superscalari, ovvero in un computer parallelo vengono utilizzate più pipeline di istruzioni. Pertanto, i processori superscalari possono eseguire più di un'istruzione allo stesso tempo. L'efficacia dei processori superscalari dipende dalla quantità di parallelismo a livello di istruzione (ILP) disponibile nelle applicazioni. Per mantenere le pipeline piene, le istruzioni a livello di hardware vengono eseguite in un ordine diverso da quello del programma.
Molti microprocessori moderni utilizzano l' approccio del super pipelining . Nel super pipeline , per aumentare la frequenza di clock, il lavoro svolto all'interno di una fase della pipeline viene ridotto e il numero di fasi della pipeline viene aumentato.
Processori VLIW (Very Large Instruction Word)
Questi sono derivati dalla microprogrammazione orizzontale e dall'elaborazione superscalare. Le istruzioni nei processori VLIW sono molto grandi. Le operazioni all'interno di una singola istruzione vengono eseguite in parallelo e vengono inoltrate alle unità funzionali appropriate per l'esecuzione. Quindi, dopo aver recuperato un'istruzione VLIW, le sue operazioni vengono decodificate. Quindi le operazioni vengono inviate alle unità funzionali in cui vengono eseguite in parallelo.
Processori vettoriali
I processori vettoriali sono un coprocessore per un microprocessore generico. I processori vettoriali sono generalmente registro-registro o memoria-memoria. Un'istruzione vettoriale viene recuperata e decodificata e quindi viene eseguita una determinata operazione per ciascun elemento dei vettori operandi, mentre in un normale processore un'operazione vettoriale necessita di una struttura ad anello nel codice. Per renderlo più efficiente, i processori vettoriali concatenano insieme diverse operazioni vettoriali, ovvero il risultato di un'operazione vettoriale viene inoltrato a un'altra come operando.
Caching
Le cache sono un elemento importante dei microprocessori ad alte prestazioni. Dopo ogni 18 mesi, la velocità dei microprocessori diventa il doppio, ma i chip DRAM per la memoria principale non possono competere con questa velocità. Quindi, vengono introdotte cache per colmare il divario di velocità tra il processore e la memoria. Una cache è una memoria SRAM veloce e piccola. Molte più cache vengono applicate nei processori moderni come le cache TLB (Translation Look-Apart Buffers), le cache di istruzioni e di dati, ecc.
Cache mappata diretta
Nelle cache mappate direttamente, una funzione "modulo" viene utilizzata per la mappatura uno a uno degli indirizzi nella memoria principale per le posizioni della cache. Poiché alla stessa voce della cache possono essere associati più blocchi di memoria principale, il processore deve essere in grado di determinare se un blocco di dati nella cache è il blocco di dati effettivamente necessario. Questa identificazione viene eseguita memorizzando un tag insieme a un blocco della cache.
Cache completamente associativa
Una mappatura completamente associativa consente di posizionare un blocco cache ovunque nella cache. Utilizzando alcuni criteri di sostituzione, la cache determina una voce di cache in cui memorizza un blocco di cache. Le cache completamente associative hanno una mappatura flessibile, che riduce al minimo il numero di conflitti di immissione nella cache. Poiché un'implementazione completamente associativa è costosa, non vengono mai utilizzate su larga scala.
Set-associative Cache
Una mappatura insieme-associativa è una combinazione di una mappatura diretta e una mappatura completamente associativa. In questo caso, le voci della cache sono suddivise in set di cache. Come nella mappatura diretta, esiste una mappatura fissa dei blocchi di memoria su un set nella cache. Ma all'interno di un set di cache, un blocco di memoria è mappato in modo completamente associativo.
Strategie di cache
Oltre al meccanismo di mappatura, le cache richiedono anche una serie di strategie che specifichino cosa dovrebbe accadere in caso di determinati eventi. In caso di cache (set-) associative, la cache deve determinare quale blocco della cache deve essere sostituito da un nuovo blocco che entra nella cache.
Alcune strategie di sostituzione ben note sono:
- First-In First Out (FIFO)
- Usato meno di recente (LRU)
In questo capitolo discuteremo di multiprocessori e multicomputer.
Interconnessioni di sistema multiprocessore
L'elaborazione parallela richiede l'uso di interconnessioni di sistema efficienti per una comunicazione veloce tra i dispositivi di input / output e periferici, i multiprocessori e la memoria condivisa.
Sistemi bus gerarchici
Un sistema bus gerarchico è costituito da una gerarchia di bus che collegano vari sistemi e sottosistemi / componenti in un computer. Ogni bus è costituito da una serie di linee di segnale, controllo e alimentazione. Bus diversi come bus locali, bus backplane e bus I / O vengono utilizzati per eseguire diverse funzioni di interconnessione.
I bus locali sono i bus implementati sui circuiti stampati. Un bus backplane è un circuito stampato su cui vengono utilizzati molti connettori per collegare schede funzionali. I bus che collegano i dispositivi di input / output a un sistema informatico sono noti come bus I / O.
Interruttore della barra trasversale e memoria multiporta
Le reti commutate forniscono interconnessioni dinamiche tra gli ingressi e le uscite. I sistemi di piccole o medie dimensioni utilizzano principalmente reti crossbar. Le reti multistadio possono essere estese ai sistemi più grandi, se il problema della maggiore latenza può essere risolto.
Sia lo switch crossbar che l'organizzazione della memoria multiporta sono una rete a stadio singolo. Sebbene una rete a stadio singolo sia più economica da costruire, potrebbero essere necessari più passaggi per stabilire determinate connessioni. Una rete multistadio ha più di uno stadio di quadri elettrici. Queste reti dovrebbero essere in grado di collegare qualsiasi input a qualsiasi output.
Reti multistadio e combinate
Le reti multistadio o le reti di interconnessione multistadio sono una classe di reti di computer ad alta velocità che è composta principalmente da elementi di elaborazione su un'estremità della rete e elementi di memoria sull'altra estremità, collegati da elementi di commutazione.
Queste reti vengono applicate per costruire sistemi multiprocessore più grandi. Questo include Omega Network, Butterfly Network e molti altri.
Multicomputer
I multicomputer sono architetture MIMD a memoria distribuita. Il diagramma seguente mostra un modello concettuale di un multicomputer:
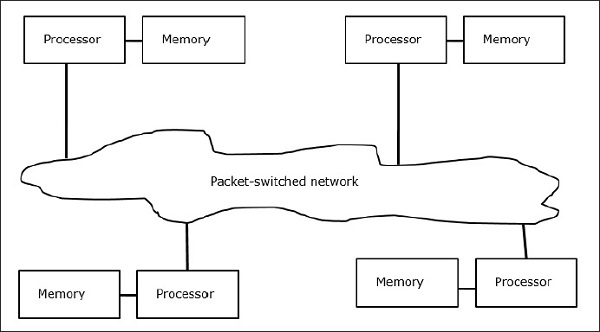
I multicomputer sono macchine che trasmettono messaggi che applicano il metodo di commutazione di pacchetto per lo scambio di dati. In questo caso, ogni processore ha una memoria privata, ma nessuno spazio di indirizzi globale poiché un processore può accedere solo alla propria memoria locale. Quindi, la comunicazione non è trasparente: qui i programmatori devono inserire esplicitamente le primitive di comunicazione nel loro codice.
Non avere una memoria accessibile a livello globale è uno svantaggio dei multicomputer. Questo può essere risolto utilizzando i seguenti due schemi:
- Memoria condivisa virtuale (VSM)
- Memoria virtuale condivisa (SVM)
In questi schemi, il programmatore dell'applicazione presuppone una grande memoria condivisa indirizzabile a livello globale. Se necessario, i riferimenti alla memoria effettuati dalle applicazioni vengono tradotti nel paradigma del passaggio di messaggi.
Memoria condivisa virtuale (VSM)
VSM è un'implementazione hardware. Quindi, il sistema di memoria virtuale del sistema operativo è implementato in modo trasparente su VSM. Quindi, il sistema operativo pensa di essere in esecuzione su una macchina con una memoria condivisa.
Memoria virtuale condivisa (SVM)
SVM è un'implementazione software a livello di sistema operativo con supporto hardware dalla MMU (Memory Management Unit) del processore. Qui, l'unità di condivisione sono le pagine di memoria del sistema operativo.
Se un processore indirizza una particolare posizione di memoria, la MMU determina se la pagina di memoria associata all'accesso alla memoria è nella memoria locale oppure no. Se la pagina non è in memoria, in un normale computer viene sostituita dal disco dal sistema operativo. Ma, in SVM, il sistema operativo recupera la pagina dal nodo remoto che possiede quella particolare pagina.
Tre generazioni di multicomputer
In questa sezione, discuteremo di tre generazioni di multicomputer.
Scelte progettuali in passato
Mentre seleziona una tecnologia di processore, un progettista di multicomputer sceglie processori a grana media a basso costo come elementi costitutivi. La maggior parte dei computer paralleli è costruita con microprocessori standard disponibili in commercio. La memoria distribuita è stata scelta per più computer anziché utilizzare la memoria condivisa, il che limitava la scalabilità. Ogni processore ha la propria unità di memoria locale.
Per lo schema di interconnessione, i multicomputer dispongono di reti dirette punto a punto con passaggio di messaggi anziché reti di commutazione degli indirizzi. Per la strategia di controllo, il progettista di più computer sceglie le operazioni asincrone MIMD, MPMD e SMPD. Il Cosmic Cube di Caltech (Seitz, 1983) è il primo multi-computer di prima generazione.
Sviluppo presente e futuro
I computer di nuova generazione si sono evoluti da multicomputer a grana media e fine utilizzando una memoria virtuale condivisa a livello globale. Attualmente i multi-computer di seconda generazione sono ancora in uso. Ma utilizzando processori migliori come i386, i860, ecc. I computer di seconda generazione si sono sviluppati molto.
I computer di terza generazione sono i computer di prossima generazione in cui verranno utilizzati i nodi implementati VLSI. Ogni nodo può avere un processore da 14 MIPS, canali di routing da 20 Mbyte / se 16 Kbyte di RAM integrati su un singolo chip.
Il sistema Intel Paragon
In precedenza, i nodi omogenei venivano utilizzati per creare multicomputer ipercubo, poiché tutte le funzioni venivano assegnate all'host. Quindi, questo ha limitato la larghezza di banda di I / O. Pertanto, per risolvere problemi su larga scala in modo efficiente o con un throughput elevato, questi computer non potevano essere utilizzati. Il sistema Intel Paragon è stato progettato per superare questa difficoltà. Ha trasformato il multicomputer in un server applicazioni con accesso multiutente in un ambiente di rete.
Meccanismi di passaggio dei messaggi
I meccanismi di passaggio dei messaggi in una rete multicomputer richiedono un supporto hardware e software speciale. In questa sezione, discuteremo alcuni schemi.
Schemi di instradamento dei messaggi
In multicomputer con schema di memorizzazione e instradamento di inoltro, i pacchetti sono la più piccola unità di trasmissione delle informazioni. Nelle reti instradate da wormhole, i pacchetti vengono ulteriormente suddivisi in flit. La lunghezza del pacchetto è determinata dallo schema di routing e dall'implementazione della rete, mentre la lunghezza del flit è influenzata dalla dimensione della rete.
In Store and forward routing, i pacchetti sono l'unità di base della trasmissione delle informazioni. In questo caso, ogni nodo utilizza un buffer di pacchetto. Un pacchetto viene trasmesso da un nodo di origine a un nodo di destinazione attraverso una sequenza di nodi intermedi. La latenza è direttamente proporzionale alla distanza tra la sorgente e la destinazione.
In wormhole routing, la trasmissione dal nodo di origine al nodo di destinazione avviene tramite una sequenza di router. Tutti i flit dello stesso pacchetto vengono trasmessi in una sequenza inseparabile in modo pipeline. In questo caso, solo l'header flit sa dove sta andando il pacchetto.
Deadlock e canali virtuali
Un canale virtuale è un collegamento logico tra due nodi. È formato da un buffer flit nel nodo sorgente e nel nodo ricevitore e un canale fisico tra di loro. Quando un canale fisico viene allocato per una coppia, un buffer sorgente viene accoppiato con un buffer del ricevitore per formare un canale virtuale.
Quando tutti i canali sono occupati da messaggi e nessuno dei canali nel ciclo viene liberato, si verificherà una situazione di deadlock. Per evitare ciò, è necessario seguire uno schema per evitare i deadlock.
In questo capitolo discuteremo i protocolli di coerenza della cache per far fronte ai problemi di incoerenza multicache.
Il problema della coerenza della cache
In un sistema multiprocessore, può verificarsi incoerenza dei dati tra livelli adiacenti o all'interno dello stesso livello della gerarchia di memoria. Ad esempio, la cache e la memoria principale potrebbero avere copie incoerenti dello stesso oggetto.
Poiché più processori operano in parallelo e in modo indipendente più cache possono possedere copie diverse dello stesso blocco di memoria, ciò crea cache coherence problem. Cache coherence schemes aiuta a evitare questo problema mantenendo uno stato uniforme per ogni blocco di dati memorizzato nella cache.
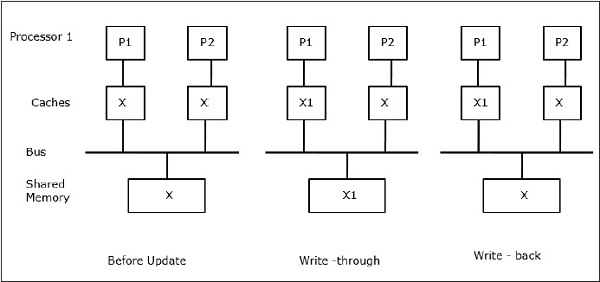
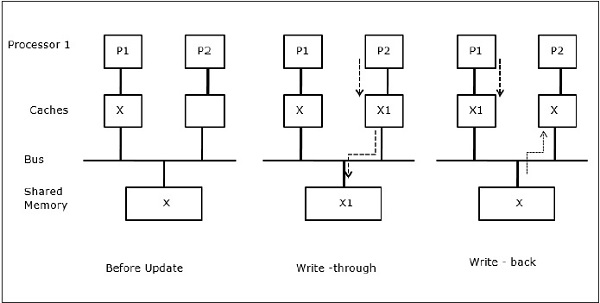
Sia X un elemento di dati condivisi a cui fanno riferimento due processori, P1 e P2. All'inizio, tre copie di X sono coerenti. Se il processore P1 scrive un nuovo dato X1 nella cache, utilizzandowrite-through policy, la stessa copia verrà scritta immediatamente nella memoria condivisa. In questo caso, si verifica un'incoerenza tra la memoria cache e la memoria principale. Quando unwrite-back policy viene utilizzato, la memoria principale verrà aggiornata quando i dati modificati nella cache vengono sostituiti o invalidati.
In generale, ci sono tre fonti di problemi di incoerenza:
- Condivisione di dati scrivibili
- Migrazione dei processi
- Attività di I / O
Protocolli Snoopy Bus
I protocolli Snoopy raggiungono la coerenza dei dati tra la memoria cache e la memoria condivisa attraverso un sistema di memoria basato su bus. Write-invalidate e write-update i criteri vengono utilizzati per mantenere la coerenza della cache.
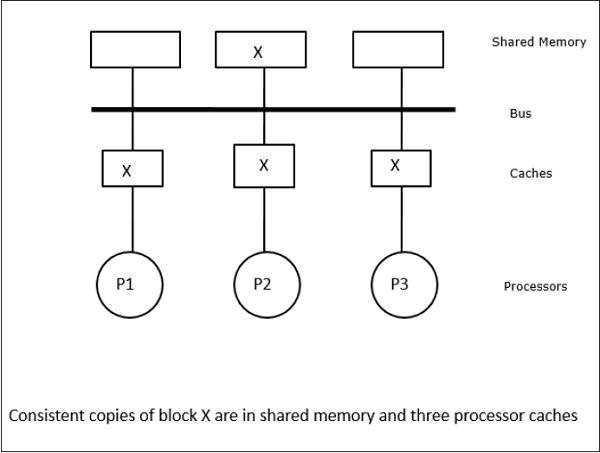
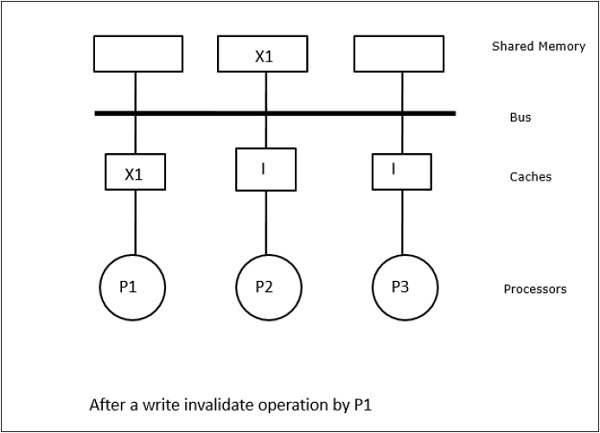
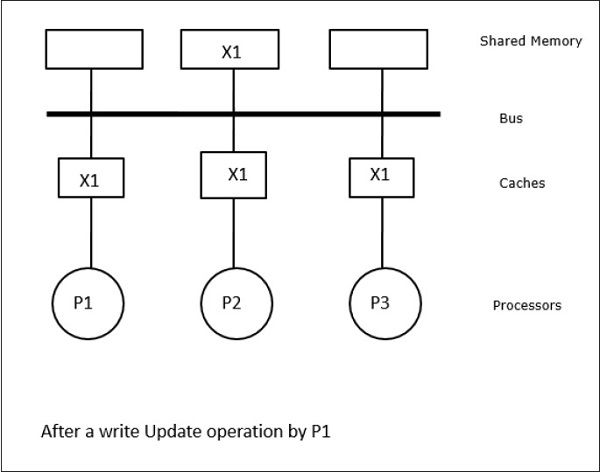
In questo caso, abbiamo tre processori P1, P2 e P3 che hanno una copia coerente dell'elemento di dati "X" nella loro memoria cache locale e nella memoria condivisa (Figura-a). Il processore P1 scrive X1 nella sua memoria cache usandowrite-invalidate protocol. Quindi, tutte le altre copie vengono invalidate tramite il bus. È indicato con "I" (Figura-b). I blocchi non convalidati sono noti anche comedirty, cioè non dovrebbero essere usati. Ilwrite-update protocolaggiorna tutte le copie della cache tramite il bus. Usandowrite back cache, viene aggiornata anche la copia in memoria (Figura-c).
Eventi e azioni nella cache
I seguenti eventi e azioni si verificano sull'esecuzione dei comandi di accesso alla memoria e di invalidamento:
Read-miss- Quando un processore vuole leggere un blocco e non è nella cache, si verifica una lettura mancata. Questo avvia unbus-readoperazione. Se non esiste alcuna copia sporca, la memoria principale che dispone di una copia coerente fornisce una copia alla memoria cache richiedente. Se una copia sporca esiste in una memoria cache remota, tale cache limiterà la memoria principale e invierà una copia alla memoria cache richiedente. In entrambi i casi, la copia cache entrerà nello stato valido dopo una lettura mancata.
Write-hit - Se la copia è sporca o reservedstato, la scrittura viene eseguita localmente e il nuovo stato è sporco. Se il nuovo stato è valido, il comando write-invalidate viene trasmesso a tutte le cache, invalidando le loro copie. Quando la memoria condivisa viene scritta, lo stato risultante viene riservato dopo questa prima scrittura.
Write-miss- Se un processore non riesce a scrivere nella memoria cache locale, la copia deve provenire dalla memoria principale o da una memoria cache remota con un blocco sporco. Questo viene fatto inviando unread-invalidatecomando, che invaliderà tutte le copie della cache. Quindi la copia locale viene aggiornata con uno stato sporco.
Read-hit - Il read-hit viene sempre eseguito nella memoria cache locale senza provocare una transizione di stato o utilizzare il bus snoopy per l'invalidazione.
Block replacement- Quando una copia è sporca, deve essere riscritta nella memoria principale con il metodo di sostituzione dei blocchi. Tuttavia, quando la copia è in uno stato valido, riservato o non valido, non avrà luogo alcuna sostituzione.
Protocolli basati su directory
Utilizzando una rete multistadio per creare un multiprocessore di grandi dimensioni con centinaia di processori, i protocolli della cache snoopy devono essere modificati per adattarsi alle capacità di rete. Essendo la trasmissione molto costosa da eseguire in una rete multistadio, i comandi di coerenza vengono inviati solo a quelle cache che conservano una copia del blocco. Questo è il motivo per lo sviluppo di protocolli basati su directory per multiprocessori connessi alla rete.
In un sistema di protocolli basato su directory, i dati da condividere vengono inseriti in una directory comune che mantiene la coerenza tra le cache. Qui, la directory funge da filtro in cui i processori chiedono il permesso di caricare una voce dalla memoria primaria alla sua memoria cache. Se una voce viene modificata, la directory la aggiorna o invalida le altre cache con quella voce.
Meccanismi di sincronizzazione hardware
La sincronizzazione è una forma speciale di comunicazione in cui invece del controllo dei dati, le informazioni vengono scambiate tra processi di comunicazione che risiedono nello stesso o in diversi processori.
I sistemi multiprocessore utilizzano meccanismi hardware per implementare operazioni di sincronizzazione di basso livello. La maggior parte dei multiprocessori dispone di meccanismi hardware per imporre operazioni atomiche come operazioni di lettura, scrittura o lettura-modifica-scrittura della memoria per implementare alcune primitive di sincronizzazione. Oltre alle operazioni di memoria atomica, alcuni interrupt tra processori vengono utilizzati anche per scopi di sincronizzazione.
Coerenza della cache nelle macchine con memoria condivisa
Il mantenimento della coerenza della cache è un problema nel sistema multiprocessore quando i processori contengono memoria cache locale. L'incongruenza dei dati tra le diverse cache si verifica facilmente in questo sistema.
Le principali aree di preoccupazione sono:
- Condivisione di dati scrivibili
- Migrazione dei processi
- Attività di I / O
Condivisione di dati scrivibili
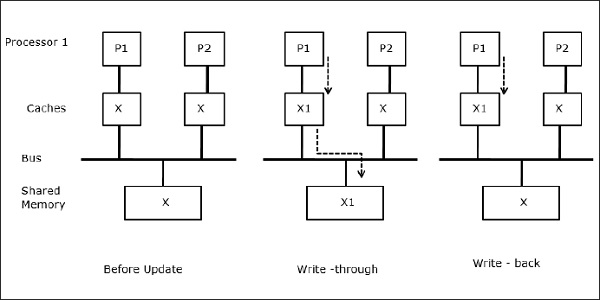
Quando due processori (P1 e P2) hanno lo stesso elemento dati (X) nelle loro cache locali e un processo (P1) scrive nell'elemento dati (X), poiché le cache sono cache locale write-through di P1, la memoria principale è anche aggiornato. Ora, quando P2 cerca di leggere l'elemento dati (X), non trova X perché l'elemento dati nella cache di P2 è diventato obsoleto.
Migrazione dei processi
Nella prima fase, la cache di P1 ha l'elemento dati X, mentre P2 non ha nulla. Un processo su P2 scrive prima su X e poi migra a P1. Ora, il processo inizia a leggere l'elemento di dati X, ma poiché il processore P1 ha dati obsoleti, il processo non può leggerli. Quindi, un processo su P1 scrive nell'elemento dati X e quindi migra su P2. Dopo la migrazione, un processo su P2 inizia a leggere l'elemento di dati X ma trova una versione obsoleta di X nella memoria principale.
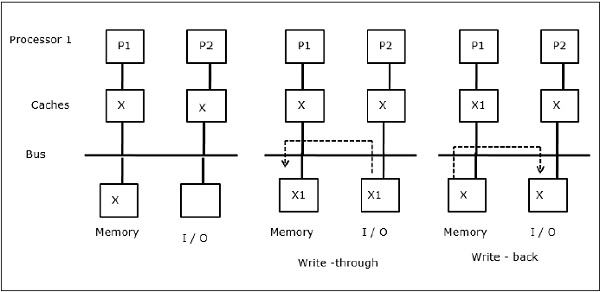
Attività di I / O
Come illustrato nella figura, un dispositivo I / O viene aggiunto al bus in un'architettura multiprocessore a due processori. All'inizio, entrambe le cache contengono l'elemento dati X. Quando il dispositivo I / O riceve un nuovo elemento X, memorizza il nuovo elemento direttamente nella memoria principale. Ora, quando P1 o P2 (supponiamo P1) tentano di leggere l'elemento X, ottiene una copia obsoleta. Quindi, P1 scrive sull'elemento X. Ora, se il dispositivo I / O prova a trasmettere X, ottiene una copia obsoleta.
Accesso alla memoria uniforme (UMA)
L'architettura Uniform Memory Access (UMA) significa che la memoria condivisa è la stessa per tutti i processori nel sistema. Classi popolari di macchine UMA, comunemente utilizzate per (file) server, sono i cosiddetti Symmetric Multiprocessors (SMP). In un SMP, tutte le risorse di sistema come memoria, dischi, altri dispositivi I / O, ecc. Sono accessibili dai processori in modo uniforme.
Accesso alla memoria non uniforme (NUMA)
Nell'architettura NUMA, ci sono più cluster SMP con una rete interna indiretta / condivisa, che sono collegati in una rete di passaggio di messaggi scalabile. Quindi, l'architettura NUMA è un'architettura di memoria distribuita fisicamente condivisa logicamente.
In una macchina NUMA, il controller della cache di un processore determina se un riferimento di memoria è locale alla memoria dell'SMP o è remoto. Per ridurre il numero di accessi alla memoria remota, le architetture NUMA di solito applicano processori di memorizzazione nella cache che possono memorizzare nella cache i dati remoti. Ma quando sono coinvolte le cache, è necessario mantenere la coerenza della cache. Quindi questi sistemi sono noti anche come CC-NUMA (Cache Coherent NUMA).
Cache Only Memory Architecture (COMA)
Le macchine COMA sono simili alle macchine NUMA, con l'unica differenza che le memorie principali delle macchine COMA agiscono come cache a mappatura diretta o set-associative. I blocchi di dati vengono sottoposti ad hashing in una posizione nella cache DRAM in base ai loro indirizzi. I dati che vengono recuperati in remoto vengono effettivamente archiviati nella memoria principale locale. Inoltre, i blocchi di dati non hanno una posizione di casa fissa, possono muoversi liberamente in tutto il sistema.
Le architetture COMA hanno principalmente una rete di passaggio di messaggi gerarchica. Uno switch in un tale albero contiene una directory con elementi di dati come sottoalbero. Poiché i dati non hanno una posizione di casa, devono essere cercati esplicitamente. Ciò significa che un accesso remoto richiede un attraversamento lungo gli switch nell'albero per cercare i dati richiesti nelle loro directory. Quindi, se uno switch nella rete riceve più richieste dalla sua sottostruttura per gli stessi dati, le combina in una singola richiesta che viene inviata al genitore dello switch. Quando i dati richiesti vengono restituiti, lo switch ne invia più copie nella sua sottostruttura.
COMA contro CC-NUMA
Di seguito sono riportate le differenze tra COMA e CC-NUMA.
COMA tende ad essere più flessibile di CC-NUMA perché COMA supporta in modo trasparente la migrazione e la replica dei dati senza la necessità del sistema operativo.
Le macchine COMA sono costose e complesse da costruire perché richiedono hardware di gestione della memoria non standard e il protocollo di coerenza è più difficile da implementare.
Gli accessi remoti in COMA sono spesso più lenti di quelli in CC-NUMA poiché la rete ad albero deve essere attraversata per trovare i dati.
Esistono molti metodi per ridurre il costo dell'hardware. Un metodo consiste nell'integrare l'assistenza alla comunicazione e la rete in modo meno stretto nel nodo di elaborazione e aumentare la latenza e l'occupazione delle comunicazioni.
Un altro metodo consiste nel fornire la replica automatica e la coerenza nel software anziché nell'hardware. Quest'ultimo metodo fornisce replica e coerenza nella memoria principale e può essere eseguito con una varietà di granularità. Consente l'utilizzo di parti di base standard per i nodi e l'interconnessione, riducendo al minimo il costo dell'hardware. Questo mette sotto pressione il programmatore per ottenere buone prestazioni.
Modelli di consistenza della memoria rilassata
Il modello di consistenza della memoria per uno spazio di indirizzi condiviso definisce i vincoli nell'ordine in cui le operazioni di memoria nelle stesse posizioni o in posizioni diverse sembrano essere eseguite l'una rispetto all'altra. In realtà, qualsiasi livello di sistema che supporta un modello di denominazione dello spazio di indirizzi condiviso deve avere un modello di consistenza della memoria che include l'interfaccia del programmatore, l'interfaccia utente-sistema e l'interfaccia hardware-software. Il software che interagisce con quel livello deve essere consapevole del proprio modello di consistenza della memoria.
Specifiche di sistema
La specifica di sistema di un'architettura specifica l'ordinamento e il riordino delle operazioni di memoria e quante prestazioni possono essere effettivamente ottenute da esso.
Di seguito sono riportati i pochi modelli di specifica che utilizzano i rilassamenti nell'ordine del programma:
Relaxing the Write-to-Read Program Order- Questa classe di modelli consente all'hardware di sopprimere la latenza delle operazioni di scrittura che sono state perse nella memoria cache di primo livello. Quando la scrittura mancata è nel buffer di scrittura e non è visibile ad altri processori, il processore può completare le letture che hanno colpito nella sua memoria cache o anche una singola lettura che manca nella sua memoria cache.
Relaxing the Write-to-Read and Write-to-Write Program Orders- Consentendo alle scritture di ignorare le precedenti scritture in sospeso in varie posizioni, è possibile unire più scritture nel buffer di scrittura prima di aggiornare la memoria principale. Pertanto, più scritture mancano da sovrapporre e diventano visibili fuori ordine. La motivazione è di minimizzare ulteriormente l'impatto della latenza di scrittura sul tempo di interruzione del processore e di aumentare l'efficienza della comunicazione tra i processori rendendo i nuovi valori dei dati visibili ad altri processori.
Relaxing All Program Orders- Nessun ordine di programma è garantito per impostazione predefinita, ad eccezione dei dati e delle dipendenze di controllo all'interno di un processo. Pertanto, il vantaggio è che le richieste di lettura multiple possono essere in sospeso allo stesso tempo, e nell'ordine del programma possono essere ignorate da scritture successive e possono esse stesse completate fuori ordine, permettendoci di nascondere la latenza di lettura. Questo tipo di modelli sono particolarmente utili per i processori programmati dinamicamente, che possono continuare le letture perse in passato su altri riferimenti di memoria. Consentono molti dei riordini, anche l'eliminazione degli accessi effettuati dalle ottimizzazioni del compilatore.
L'interfaccia di programmazione
Le interfacce di programmazione presumono che non sia necessario mantenere gli ordini di programma tra le operazioni di sincronizzazione. È garantito che tutte le operazioni di sincronizzazione siano esplicitamente etichettate o identificate come tali. La libreria runtime o il compilatore traduce queste operazioni di sincronizzazione nelle appropriate operazioni di conservazione dell'ordine richieste dalle specifiche del sistema.
Il sistema garantisce quindi esecuzioni coerenti in sequenza anche se può riordinare le operazioni tra le operazioni di sincronizzazione in qualsiasi modo desideri senza interrompere le dipendenze da una posizione all'interno di un processo. Ciò consente al compilatore una flessibilità sufficiente tra i punti di sincronizzazione per i riordini che desidera e garantisce anche al processore di eseguire tutti i riordinamenti consentiti dal suo modello di memoria. All'interfaccia del programmatore, il modello di coerenza dovrebbe essere debole almeno quanto quello dell'interfaccia hardware, ma non è necessario che sia lo stesso.
Meccanismi di traduzione
Nella maggior parte dei microprocessori, tradurre le etichette in meccanismi di mantenimento dell'ordine equivale a inserire un'istruzione di barriera di memoria adatta prima e / o dopo ogni operazione etichettata come sincronizzazione. Consentirebbe di salvare le istruzioni con singoli carichi / negozi indicando quali ordini applicare ed evitare istruzioni aggiuntive. Tuttavia, poiché le operazioni sono generalmente poco frequenti, questo non è il modo in cui la maggior parte dei microprocessori ha preso finora.
Superamento dei limiti di capacità
Abbiamo discusso i sistemi che forniscono replica automatica e coerenza nell'hardware solo nella memoria cache del processore. Una cache del processore, senza prima essere replicata nella memoria principale locale, replica i dati allocati in remoto direttamente su riferimento.
Un problema con questi sistemi è che l'ambito della replica locale è limitato alla cache hardware. Se un blocco viene sostituito dalla memoria cache, deve essere recuperato dalla memoria remota quando è nuovamente necessario. Lo scopo principale dei sistemi discussi in questa sezione è risolvere il problema della capacità di replica, fornendo comunque coerenza nell'hardware e granularità fine dei blocchi della cache per l'efficienza.
Cache terziarie
Per risolvere il problema della capacità di replica, un metodo consiste nell'utilizzare una cache di accesso remoto grande ma più lenta. Ciò è necessario per la funzionalità, quando i nodi della macchina sono essi stessi multiprocessori su piccola scala e possono essere semplicemente ingranditi per le prestazioni. Conterrà anche blocchi remoti replicati che sono stati sostituiti dalla memoria cache del processore locale.
Cache-only Memory Architectures (COMA)
Nelle macchine COMA, ogni blocco di memoria dell'intera memoria principale ha un tag hardware ad esso collegato. Non esiste un nodo fisso in cui è sempre garantito lo spazio allocato per un blocco di memoria. I dati migrano dinamicamente o vengono replicati nelle memorie principali dei nodi che li accedono / attraggono. Quando si accede a un blocco remoto, viene replicato nella memoria dell'attrazione e portato nella cache, ed è mantenuto coerente in entrambi i punti dall'hardware. Un blocco dati può risiedere in qualsiasi memoria di attrazione e può spostarsi facilmente da uno all'altro.
Riduzione dei costi hardware
Ridurre i costi significa spostare alcune funzionalità dell'hardware specializzato nel software in esecuzione sull'hardware esistente. È molto più facile per il software gestire la replica e la coerenza nella memoria principale che nella cache dell'hardware. I metodi a basso costo tendono a fornire replica e coerenza nella memoria principale. Affinché la coerenza sia controllata in modo efficiente, ciascuno degli altri componenti funzionali dell'assistenza può trarre vantaggio dalla specializzazione e dall'integrazione dell'hardware.
Gli sforzi di ricerca mirano a ridurre i costi con approcci diversi, ad esempio eseguendo il controllo degli accessi in hardware specializzato, ma assegnando altre attività a software e hardware di base. Un altro approccio consiste nell'eseguire il controllo degli accessi nel software ed è progettato per assegnare un'astrazione coerente dello spazio degli indirizzi condivisi su nodi e reti commodity senza supporto hardware specializzato.
Implicazioni per il software parallelo
Il modello di consistenza della memoria rilassata richiede che i programmi paralleli etichettino gli accessi in conflitto desiderati come punti di sincronizzazione. Un linguaggio di programmazione fornisce il supporto per etichettare alcune variabili come sincronizzazione, che verrà quindi tradotta dal compilatore nell'istruzione di conservazione dell'ordine adatta. Per limitare il riordino degli accessi alla memoria condivisa da parte dei compilatori, il compilatore può utilizzare le etichette da solo.
Un interconnection networkin una macchina parallela trasferisce le informazioni da qualsiasi nodo di origine a qualsiasi nodo di destinazione desiderato. Questa attività dovrebbe essere completata con la minore latenza possibile. Dovrebbe consentire che un gran numero di tali trasferimenti avvenga contemporaneamente. Inoltre, dovrebbe essere poco costoso rispetto al costo del resto della macchina.
La rete è composta da collegamenti e interruttori, che aiutano a inviare le informazioni dal nodo di origine al nodo di destinazione. Una rete è specificata dalla sua topologia, algoritmo di instradamento, strategia di commutazione e meccanismo di controllo del flusso.
Struttura organizzativa
Le reti di interconnessione sono composte dai seguenti tre componenti di base:
Links- Un collegamento è un cavo di una o più fibre ottiche o fili elettrici con un connettore a ciascuna estremità collegato a uno switch o a una porta di interfaccia di rete. Attraverso questo, un segnale analogico viene trasmesso da un'estremità, ricevuto dall'altra per ottenere il flusso di informazioni digitali originale.
Switches- Un interruttore è composto da una serie di porte di ingresso e uscita, una "barra trasversale" interna che collega tutti gli ingressi a tutte le uscite, buffer interno e logica di controllo per effettuare la connessione ingresso-uscita in ogni momento. In genere, il numero di porte di input è uguale al numero di porte di output.
Network Interfaces- L'interfaccia di rete si comporta in modo molto diverso rispetto ai nodi di commutazione e può essere collegata tramite collegamenti speciali. L'interfaccia di rete formatta i pacchetti e costruisce l'instradamento e le informazioni di controllo. Potrebbe avere un buffer di input e output, rispetto a uno switch. Può eseguire il controllo degli errori end-to-end e il controllo del flusso. Pertanto, il suo costo è influenzato dalla complessità di elaborazione, dalla capacità di archiviazione e dal numero di porte.
Rete di interconnessione
Le reti di interconnessione sono composte da elementi di commutazione. La topologia è il modello per collegare i singoli interruttori ad altri elementi, come processori, memorie e altri interruttori. Una rete consente lo scambio di dati tra processori nel sistema parallelo.
Direct connection networks- Le reti dirette hanno connessioni punto a punto tra i nodi vicini. Queste reti sono statiche, il che significa che le connessioni punto a punto sono fisse. Alcuni esempi di reti dirette sono anelli, maglie e cubi.
Indirect connection networks- Le reti indirette non hanno vicini fissi. La topologia di comunicazione può essere modificata dinamicamente in base alle esigenze dell'applicazione. Le reti indirette possono essere suddivise in tre parti: reti bus, reti multistadio e interruttori crossbar.
Bus networks- Una rete bus è composta da un numero di linee di bit su cui sono collegate più risorse. Quando i bus utilizzano le stesse linee fisiche per i dati e gli indirizzi, i dati e le linee degli indirizzi vengono multiplexati nel tempo. Quando ci sono più bus-master collegati all'autobus, è richiesto un arbitro.
Multistage networks- Una rete multistadio è composta da più fasi di interruttori. È composto da interruttori "axb" collegati mediante un particolare schema di connessione interstadio (ISC). Gli elementi switch piccoli 2x2 sono una scelta comune per molte reti multistadio. Il numero di fasi determina il ritardo della rete. Scegliendo diversi modelli di connessione interstadio, è possibile creare vari tipi di rete multistadio.
Crossbar switches- Un interruttore della barra trasversale contiene una matrice di semplici elementi dell'interruttore che possono essere attivati e disattivati per creare o interrompere una connessione. Attivando un elemento interruttore nella matrice, è possibile stabilire una connessione tra un processore e una memoria. Gli interruttori della barra trasversale non bloccano, ovvero tutte le permutazioni di comunicazione possono essere eseguite senza blocco.
Valutazione dei compromessi di progettazione nella topologia di rete
Se la preoccupazione principale è la distanza di instradamento, la dimensione deve essere massimizzata e deve essere creato un ipercubo. Nell'instradamento store-and-forward, supponendo che il grado di commutazione e il numero di collegamenti non siano stati un fattore di costo significativo e che il numero di collegamenti o il grado di commutazione siano i costi principali, la dimensione deve essere ridotta al minimo e una maglia costruito.
Nel peggiore dei casi, modello di traffico per ciascuna rete, è preferibile avere reti ad alta dimensione in cui tutti i percorsi sono brevi. Nei modelli in cui ogni nodo comunica con solo uno o due vicini vicini, è preferibile avere reti di dimensioni ridotte, poiché vengono effettivamente utilizzate solo alcune dimensioni.
Routing
L'algoritmo di instradamento di una rete determina quale dei possibili percorsi dall'origine alla destinazione viene utilizzato come rotte e come viene determinato il percorso seguito da ogni particolare pacchetto. L'instradamento dell'ordine delle dimensioni limita l'insieme di percorsi legali in modo che esista esattamente un percorso da ciascuna origine a ciascuna destinazione. Quello ottenuto percorrendo prima la distanza corretta nella dimensione di ordine superiore, poi la dimensione successiva e così via.
Meccanismi di instradamento
Aritmetica, selezione della porta basata sulla sorgente e ricerca nella tabella sono tre meccanismi utilizzati dagli switch ad alta velocità per determinare il canale di uscita dalle informazioni nell'intestazione del pacchetto. Tutti questi meccanismi sono più semplici del tipo di calcolo del routing generale implementato nei router LAN e WAN tradizionali. Nelle reti di computer parallele, lo switch deve prendere la decisione di instradamento per tutti i suoi input in ogni ciclo, quindi il meccanismo deve essere semplice e veloce.
Routing deterministico
Un algoritmo di instradamento è deterministico se il percorso intrapreso da un messaggio è determinato esclusivamente dalla sua origine e destinazione e non da altro traffico nella rete. Se un algoritmo di routing seleziona solo i percorsi più brevi verso la destinazione, è minimo, altrimenti non è minimo.
Deadlock Freedom
Il deadlock può verificarsi in varie situazioni. Quando due nodi tentano di inviare dati l'un l'altro e ciascuno inizia a inviare prima di ricevere, può verificarsi un deadlock "frontale". Un altro caso di deadlock si verifica quando più messaggi sono in competizione per le risorse all'interno della rete.
La tecnica di base per dimostrare che una rete è priva di deadlock, consiste nell'eliminare le dipendenze che possono verificarsi tra i canali a seguito di messaggi che si spostano attraverso le reti e nel mostrare che non ci sono cicli nel grafico delle dipendenze del canale complessivo; quindi non ci sono modelli di traffico che possono portare a un deadlock. Il modo comune per farlo è numerare le risorse del canale in modo che tutte le rotte seguano una particolare sequenza crescente o decrescente, in modo che non si verifichino cicli di dipendenza.
Cambia design
La progettazione di una rete dipende dalla progettazione dell'interruttore e dal modo in cui gli interruttori sono cablati insieme. Il grado dello switch, i suoi meccanismi di routing interni e il suo buffer interno decidono quali topologie possono essere supportate e quali algoritmi di routing possono essere implementati. Come qualsiasi altro componente hardware di un sistema informatico, uno switch di rete contiene il percorso dei dati, il controllo e l'archiviazione.
Porti
Il numero totale di pin è in realtà il numero totale di porte di input e output moltiplicato per la larghezza del canale. Poiché il perimetro del chip cresce lentamente rispetto all'area, gli interruttori tendono ad essere limitati dai pin.
Datapath interno
Il datapath è la connettività tra ciascun set di porte di input e ogni porta di output. Viene generalmente definita barra trasversale interna. Una barra trasversale non bloccante è quella in cui ciascuna porta di ingresso può essere collegata a un'uscita distinta in qualsiasi permutazione simultaneamente.
Buffer di canale
L'organizzazione della memoria buffer all'interno dello switch ha un impatto importante sulle prestazioni dello switch. I router e gli switch tradizionali tendono ad avere ampi buffer SRAM o DRAM esterni alla struttura dello switch, mentre negli switch VLSI il buffering è interno allo switch ed esce dallo stesso budget di silicio del percorso dati e della sezione di controllo. Con l'aumentare delle dimensioni e della densità del chip, è disponibile più buffering e il progettista della rete ha più opzioni, ma lo spazio del buffer è comunque una scelta primaria e la sua organizzazione è importante.
Controllo del flusso
Quando più flussi di dati nella rete tentano di utilizzare le stesse risorse di rete condivise contemporaneamente, è necessario intraprendere alcune azioni per controllare questi flussi. Se non vogliamo perdere alcun dato, alcuni flussi devono essere bloccati mentre altri procedono.
Il problema del controllo del flusso si pone in tutte le reti ea molti livelli. Ma è qualitativamente diverso nelle reti di computer parallele rispetto alle reti locali e geografiche. Nei computer paralleli, il traffico di rete deve essere distribuito con la stessa precisione del traffico su un bus e vi è un numero molto elevato di flussi paralleli su scala temporale molto ridotta.
La velocità dei microprocessori è aumentata di oltre un fattore dieci per decennio, ma la velocità delle memorie commodity (DRAM) è solo raddoppiata, ovvero il tempo di accesso è dimezzato. Pertanto, la latenza dell'accesso alla memoria in termini di cicli di clock del processore cresce di sei volte in 10 anni. I multiprocessori hanno intensificato il problema.
Nei sistemi basati su bus, la creazione di un bus a larghezza di banda elevata tra il processore e la memoria tende ad aumentare la latenza nell'ottenere i dati dalla memoria. Quando la memoria è distribuita fisicamente, la latenza della rete e dell'interfaccia di rete si aggiunge a quella dell'accesso alla memoria locale sul nodo.
La latenza di solito cresce con le dimensioni della macchina, poiché più nodi implicano più comunicazione rispetto al calcolo, più salti nella rete per la comunicazione generale e probabilmente più contese. L'obiettivo principale della progettazione hardware è ridurre la latenza dell'accesso ai dati mantenendo una larghezza di banda elevata e scalabile.
Panoramica sulla tolleranza alla latenza
Il modo in cui viene gestita la tolleranza alla latenza si comprende meglio osservando le risorse nella macchina e come vengono utilizzate. Dal punto di vista del processore, l'architettura di comunicazione da un nodo all'altro può essere vista come una pipeline. Le fasi della pipeline includono interfacce di rete all'origine e alla destinazione, nonché nei collegamenti di rete e negli switch lungo il percorso. Esistono anche fasi nell'assistenza alla comunicazione, nel sistema di memoria / cache locale e nel processore principale, a seconda di come l'architettura gestisce la comunicazione.
Il problema di utilizzo nella struttura di comunicazione di base è o il processore o l'architettura di comunicazione è occupata in un dato momento, e nella pipeline di comunicazione solo uno stadio è occupato alla volta mentre la singola parola trasmessa si fa strada dalla sorgente alla destinazione. Lo scopo della tolleranza alla latenza è quello di sovrapporre il più possibile l'uso di queste risorse.
Tolleranza alla latenza nel passaggio di messaggi espliciti
Il trasferimento effettivo dei dati durante il passaggio dei messaggi è in genere avviato dal mittente, utilizzando un'operazione di invio. Un'operazione di ricezione non motiva di per sé la comunicazione dei dati, ma piuttosto copia i dati da un buffer in entrata nello spazio degli indirizzi dell'applicazione. La comunicazione avviata dal destinatario viene eseguita inviando un messaggio di richiesta al processo che è l'origine dei dati. Il processo quindi restituisce i dati tramite un altro invio.
Un'operazione di invio sincrono ha una latenza di comunicazione pari al tempo necessario per comunicare tutti i dati nel messaggio alla destinazione, al tempo per l'elaborazione della ricezione e al tempo per la restituzione di un riconoscimento. La latenza di un'operazione di ricezione sincrona è il suo sovraccarico di elaborazione; che include la copia dei dati nell'applicazione e la latenza aggiuntiva se i dati non sono ancora arrivati. Vorremmo nascondere queste latenze, comprese le spese generali se possibile, ad entrambe le estremità.
Tolleranza alla latenza in uno spazio di indirizzi condiviso
La comunicazione di base avviene tramite letture e scritture in uno spazio di indirizzi condiviso. Per comodità, si chiama comunicazione di lettura-scrittura. La comunicazione avviata dal destinatario viene eseguita con operazioni di lettura che determinano l'accesso ai dati dalla memoria o dalla cache di un altro processore. Se non è presente la memorizzazione nella cache dei dati condivisi, la comunicazione avviata dal mittente può essere eseguita tramite scritture sui dati allocati nelle memorie remote.
Con la coerenza della cache, l'effetto delle scritture è più complesso: le scritture portano alla comunicazione avviata dal mittente o dal destinatario dipende dal protocollo di coerenza della cache. Che sia avviata dal destinatario o avviata dal mittente, la comunicazione in uno spazio di indirizzi condiviso in lettura e scrittura supportato da hardware è naturalmente a grana fine, il che rende la latenza di tolleranza molto importante.
Blocca il trasferimento dei dati in uno spazio di indirizzi condiviso
In uno spazio di indirizzi condiviso, sia mediante hardware che software, la fusione dei dati e l'avvio di trasferimenti a blocchi possono essere effettuati esplicitamente nel programma utente o in modo trasparente dal sistema. I trasferimenti a blocchi espliciti vengono avviati eseguendo un comando simile a un invio nel programma utente. Il comando di invio è spiegato dall'assistenza alla comunicazione, che trasferisce i dati in modo pipeline dal nodo di origine alla destinazione. A destinazione, l'assistente alla comunicazione estrae le parole dati dall'interfaccia di rete e le memorizza nelle posizioni specificate.
Ci sono due differenze principali dal passaggio di messaggi di invio-ricezione, entrambe derivano dal fatto che il processo di invio può specificare direttamente le strutture dati del programma in cui i dati devono essere collocati a destinazione, poiché queste posizioni si trovano nello spazio degli indirizzi condiviso .
Processo di eventi a latenza lunga passati in uno spazio di indirizzi condiviso
Se l'operazione di memoria viene eseguita senza blocco, un processore può procedere oltre un'operazione di memoria ad altre istruzioni. Per le scritture, questo di solito è abbastanza semplice da implementare se la scrittura viene inserita in un buffer di scrittura e il processore va avanti mentre il buffer si occupa di inviare la scrittura al sistema di memoria e monitorarne il completamento come richiesto. La differenza è che, a differenza di una scrittura, una lettura è generalmente seguita molto presto da un'istruzione che necessita del valore restituito dalla lettura.
Pre-comunicazione in uno spazio di indirizzi condiviso
La precomunicazione è una tecnica che è già stata ampiamente adottata nei microprocessori commerciali e la sua importanza è destinata ad aumentare in futuro. Un'istruzione di precaricamento non sostituisce la lettura effettiva dell'elemento dati e l'istruzione di precaricamento stessa deve essere non bloccante, se si vuole raggiungere il suo obiettivo di nascondere la latenza attraverso la sovrapposizione.
In questo caso, poiché i dati condivisi non vengono memorizzati nella cache, i dati precaricati vengono inseriti in una speciale struttura hardware chiamata buffer di precaricamento. Quando la parola viene effettivamente letta in un registro nella successiva iterazione, viene letta dall'intestazione del buffer di prefetch piuttosto che dalla memoria. Se la latenza da nascondere fosse molto maggiore del tempo necessario per calcolare l'iterazione di un singolo ciclo, precaricheremmo diverse iterazioni in anticipo e potenzialmente ci sarebbero diverse parole alla volta nel buffer di precaricamento.
Multithreading in uno spazio di indirizzi condiviso
In termini di nascondere diversi tipi di latenza, il multithreading supportato dall'hardware è forse la tecnica versatile. Presenta i seguenti vantaggi concettuali rispetto ad altri approcci:
Non richiede analisi o supporto software speciali.
Poiché viene invocato dinamicamente, può gestire situazioni imprevedibili, come conflitti di cache, ecc. Così come quelle prevedibili.
Come il precaricamento, non cambia il modello di consistenza della memoria poiché non riordina gli accessi all'interno di un thread.
Mentre le tecniche precedenti mirano a nascondere la latenza di accesso alla memoria, il multithreading può potenzialmente nascondere la latenza di qualsiasi evento a latenza lunga con la stessa facilità, purché l'evento possa essere rilevato in fase di esecuzione. Ciò include anche la sincronizzazione e la latenza delle istruzioni.
Questa tendenza potrebbe cambiare in futuro, poiché le latenze stanno diventando sempre più lunghe rispetto alle velocità del processore. Anche con microprocessori più sofisticati che forniscono già metodi che possono essere estesi per il multithreading e con nuove tecniche di multithreading in fase di sviluppo per combinare il multithreading con il parallelismo a livello di istruzione, questa tendenza sembra certamente subire qualche cambiamento in futuro.