PL / SQL - Guida rapida
Il linguaggio di programmazione PL / SQL è stato sviluppato da Oracle Corporation alla fine degli anni '80 come linguaggio di estensione procedurale per SQL e il database relazionale Oracle. Di seguito sono riportati alcuni fatti importanti su PL / SQL:
PL / SQL è un linguaggio di elaborazione delle transazioni completamente portabile e ad alte prestazioni.
PL / SQL fornisce un ambiente di programmazione integrato, interpretato e indipendente dal sistema operativo.
PL / SQL può anche essere chiamato direttamente dalla riga di comando SQL*Plus interface.
È anche possibile effettuare chiamate dirette da chiamate di linguaggi di programmazione esterni al database.
La sintassi generale di PL / SQL si basa su quella del linguaggio di programmazione ADA e Pascal.
Oltre a Oracle, PL / SQL è disponibile in TimesTen in-memory database e IBM DB2.
Caratteristiche di PL / SQL
PL / SQL ha le seguenti caratteristiche:
- PL / SQL è strettamente integrato con SQL.
- Offre un ampio controllo degli errori.
- Offre numerosi tipi di dati.
- Offre una varietà di strutture di programmazione.
- Supporta la programmazione strutturata tramite funzioni e procedure.
- Supporta la programmazione orientata agli oggetti.
- Supporta lo sviluppo di applicazioni web e pagine server.
Vantaggi di PL / SQL
PL / SQL presenta i seguenti vantaggi:
SQL è il linguaggio di database standard e PL / SQL è fortemente integrato con SQL. PL / SQL supporta SQL statico e dinamico. SQL statico supporta le operazioni DML e il controllo delle transazioni dal blocco PL / SQL. In Dynamic SQL, SQL consente di incorporare istruzioni DDL in blocchi PL / SQL.
PL / SQL consente di inviare un intero blocco di istruzioni al database in una sola volta. Ciò riduce il traffico di rete e fornisce prestazioni elevate per le applicazioni.
PL / SQL offre un'elevata produttività ai programmatori in quanto può eseguire query, trasformare e aggiornare i dati in un database.
PL / SQL consente di risparmiare tempo nella progettazione e nel debug grazie a funzionalità avanzate, come la gestione delle eccezioni, l'incapsulamento, l'occultamento dei dati e i tipi di dati orientati agli oggetti.
Le applicazioni scritte in PL / SQL sono completamente portabili.
PL / SQL fornisce un alto livello di sicurezza.
PL / SQL fornisce l'accesso a pacchetti SQL predefiniti.
PL / SQL fornisce il supporto per la programmazione orientata agli oggetti.
PL / SQL fornisce supporto per lo sviluppo di applicazioni Web e pagine server.
In questo capitolo, discuteremo la configurazione dell'ambiente di PL / SQL. PL / SQL non è un linguaggio di programmazione autonomo; è uno strumento all'interno dell'ambiente di programmazione Oracle.SQL* Plusè uno strumento interattivo che consente di digitare istruzioni SQL e PL / SQL al prompt dei comandi. Questi comandi vengono quindi inviati al database per l'elaborazione. Una volta elaborate le dichiarazioni, i risultati vengono restituiti e visualizzati sullo schermo.
Per eseguire programmi PL / SQL, dovresti avere Oracle RDBMS Server installato sulla tua macchina. Questo si occuperà dell'esecuzione dei comandi SQL. La versione più recente di Oracle RDBMS è 11g. È possibile scaricare una versione di prova di Oracle 11g dal seguente collegamento:
Scarica Oracle 11g Express Edition
Dovrai scaricare la versione a 32 o 64 bit dell'installazione in base al tuo sistema operativo. Di solito ci sono due file. Abbiamo scaricato la versione a 64 bit. Utilizzerai anche passaggi simili sul tuo sistema operativo, non importa se è Linux o Solaris.
win64_11gR2_database_1of2.zip
win64_11gR2_database_2of2.zip
Dopo aver scaricato i due file di cui sopra, dovrai decomprimerli in una singola directory database e sotto troverai le seguenti sottodirectory:
Passo 1
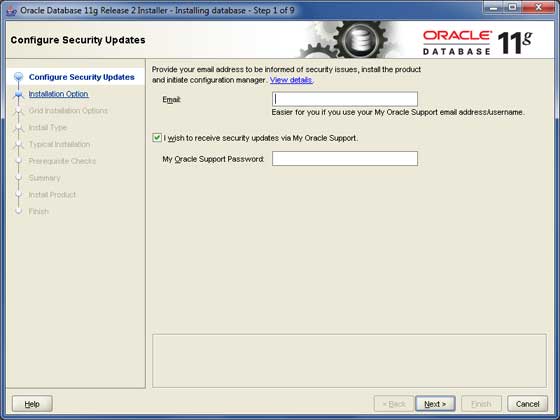
Avviamo ora Oracle Database Installer utilizzando il file di installazione. Di seguito è la prima schermata. Puoi fornire il tuo ID e-mail e selezionare la casella di controllo come mostrato nella seguente schermata. Clicca ilNext pulsante.
Passo 2
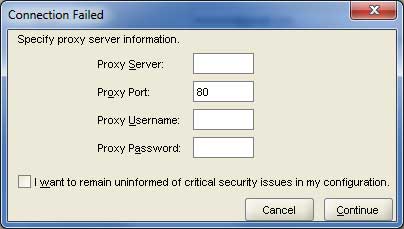
Verrai indirizzato alla seguente schermata; deseleziona la casella di controllo e fai clic suContinue per procedere.
Passaggio 3
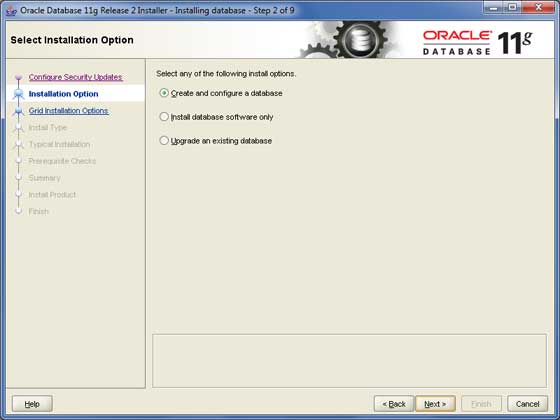
Seleziona la prima opzione Create and Configure Database utilizzando il pulsante di opzione e fare clic su Next per procedere.
Passaggio 4
Partiamo dal presupposto che tu stia installando Oracle per lo scopo di base dell'apprendimento e che lo stia installando sul tuo PC o laptop. Quindi, seleziona il fileDesktop Class opzione e fare clic su Next per procedere.
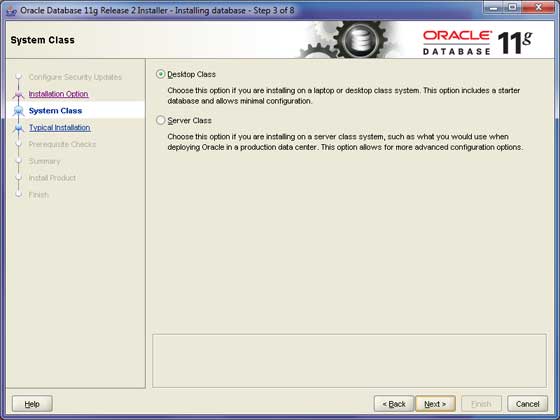
Passaggio 5
Fornisci una posizione in cui installerai Oracle Server. Basta modificare il fileOracle Basee le altre posizioni verranno impostate automaticamente. Dovrai anche fornire una password; questo verrà utilizzato dal DBA di sistema. Dopo aver fornito le informazioni richieste, fare clic suNext per procedere.
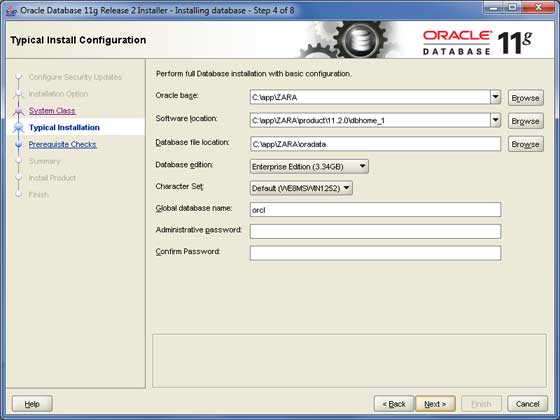
Passaggio 6
Di nuovo, fai clic su Next per procedere.
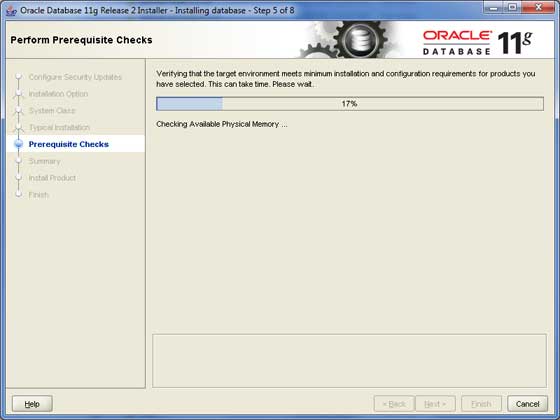
Passaggio 7
Clicca il Finishpulsante per procedere; questo avvierà l'effettiva installazione del server.
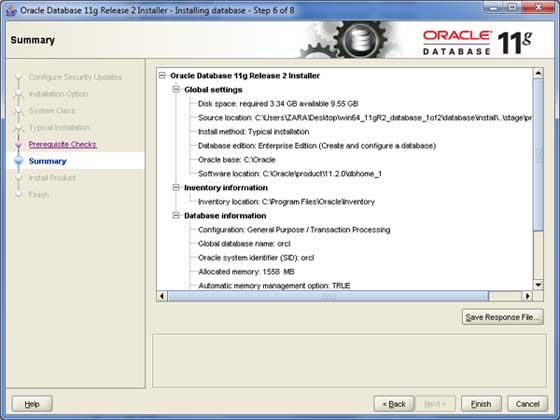
Passaggio 8
Questo richiederà alcuni istanti, finché Oracle non inizierà a eseguire la configurazione richiesta.

Passaggio 9
Qui, l'installazione di Oracle copierà i file di configurazione richiesti. Questo dovrebbe richiedere un momento -
Passaggio 10
Una volta copiati i file del database, apparirà la seguente finestra di dialogo. Basta fare clic suOK pulsante ed esci.
Passaggio 11
Dopo l'installazione, avrai la seguente finestra finale.
Passo finale
È ora il momento di verificare l'installazione. Al prompt dei comandi, usa il seguente comando se stai usando Windows:
sqlplus "/ as sysdba"Dovresti avere il prompt SQL in cui scrivere i tuoi comandi e script PL / SQL -

Editor di testo
L'esecuzione di programmi di grandi dimensioni dal prompt dei comandi potrebbe farti perdere inavvertitamente parte del lavoro. Si consiglia sempre di utilizzare i file di comando. Per utilizzare i file di comando:
Digita il codice in un editor di testo, ad esempio Notepad, Notepad+, o EditPlus, eccetera.
Salva il file con l'estensione .sql estensione nella directory home.
Avvia il file SQL*Plus command prompt dalla directory in cui hai creato il tuo file PL / SQL.
genere @file_name al prompt dei comandi SQL * Plus per eseguire il programma.
Se non stai utilizzando un file per eseguire gli script PL / SQL, copia semplicemente il tuo codice PL / SQL e fai clic con il pulsante destro del mouse sulla finestra nera che visualizza il prompt SQL; utilizzare ilpasteopzione per incollare il codice completo al prompt dei comandi. Infine, basta premereEnter per eseguire il codice, se non è già stato eseguito.
In questo capitolo, discuteremo la sintassi di base di PL / SQL che è un file block-structuredlinguaggio; ciò significa che i programmi PL / SQL sono suddivisi e scritti in blocchi logici di codice. Ogni blocco è composto da tre sottoparti:
| S.No | Sezioni e descrizione |
|---|---|
| 1 | Declarations Questa sezione inizia con la parola chiave DECLARE. È una sezione opzionale e definisce tutte le variabili, i cursori, i sottoprogrammi e gli altri elementi da utilizzare nel programma. |
| 2 | Executable Commands Questa sezione è racchiusa tra le parole chiave BEGIN e ENDed è una sezione obbligatoria. Consiste nelle istruzioni PL / SQL eseguibili del programma. Dovrebbe avere almeno una riga di codice eseguibile, che potrebbe essere solo un fileNULL command per indicare che non deve essere eseguito nulla. |
| 3 | Exception Handling Questa sezione inizia con la parola chiave EXCEPTION. Questa sezione opzionale contieneexception(s) che gestiscono gli errori nel programma. |
Ogni istruzione PL / SQL termina con un punto e virgola (;). I blocchi PL / SQL possono essere nidificati all'interno di altri blocchi PL / SQL utilizzandoBEGIN e END. Di seguito è riportata la struttura di base di un blocco PL / SQL:
DECLARE
<declarations section>
BEGIN
<executable command(s)>
EXCEPTION
<exception handling>
END;L'esempio "Hello World"
DECLARE
message varchar2(20):= 'Hello, World!';
BEGIN
dbms_output.put_line(message);
END;
/Il end;linea segnala la fine del blocco PL / SQL. Per eseguire il codice dalla riga di comando SQL, potrebbe essere necessario digitare / all'inizio della prima riga vuota dopo l'ultima riga del codice. Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Hello World
PL/SQL procedure successfully completed.Gli identificatori PL / SQL
Gli identificatori PL / SQL sono costanti, variabili, eccezioni, procedure, cursori e parole riservate. Gli identificatori sono costituiti da una lettera eventualmente seguita da più lettere, numeri, segni di dollaro, trattini bassi e segni di numero e non devono superare i 30 caratteri.
Per impostazione predefinita, identifiers are not case-sensitive. Quindi puoi usareinteger o INTEGERper rappresentare un valore numerico. Non è possibile utilizzare una parola chiave riservata come identificatore.
I delimitatori PL / SQL
Un delimitatore è un simbolo con un significato speciale. Di seguito è riportato l'elenco dei delimitatori in PL / SQL:
| Delimitatore | Descrizione |
|---|---|
| +, -, *, / | Addizione, sottrazione / negazione, moltiplicazione, divisione |
| % | Indicatore di attributo |
| ' | Delimitatore di stringa di caratteri |
| . | Selettore dei componenti |
| (,) | Delimitatore di espressione o elenco |
| : | Indicatore della variabile host |
| , | Separatore articoli |
| " | Delimitatore identificatore citato |
| = | Operatore relazionale |
| @ | Indicatore di accesso remoto |
| ; | Terminatore di istruzioni |
| := | Operatore di assegnazione |
| => | Operatore di associazione |
| || | Operatore di concatenazione |
| ** | Operatore di esponenziazione |
| <<, >> | Delimitatore etichetta (inizio e fine) |
| /*, */ | Delimitatore di commenti su più righe (inizio e fine) |
| -- | Indicatore di commento a riga singola |
| .. | Operatore di intervallo |
| <, >, <=, >= | Operatori relazionali |
| <>, '=, ~=, ^= | Diverse versioni di NOT EQUAL |
I commenti PL / SQL
I commenti al programma sono dichiarazioni esplicative che possono essere incluse nel codice PL / SQL che scrivi e aiuta chiunque a leggerne il codice sorgente. Tutti i linguaggi di programmazione consentono una qualche forma di commenti.
PL / SQL supporta commenti su una riga e su più righe. Tutti i caratteri disponibili all'interno di qualsiasi commento vengono ignorati dal compilatore PL / SQL. I commenti PL / SQL su una riga iniziano con il delimitatore - (doppio trattino) ei commenti su più righe sono racchiusi da / * e * /.
DECLARE
-- variable declaration
message varchar2(20):= 'Hello, World!';
BEGIN
/*
* PL/SQL executable statement(s)
*/
dbms_output.put_line(message);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Hello World
PL/SQL procedure successfully completed.Unità di programma PL / SQL
Un'unità PL / SQL è una delle seguenti:
- Blocco PL / SQL
- Function
- Package
- Corpo del pacchetto
- Procedure
- Trigger
- Type
- Tipo corpo
Ciascuna di queste unità sarà discussa nei capitoli seguenti.
In questo capitolo, discuteremo i tipi di dati in PL / SQL. Le variabili PL / SQL, le costanti ei parametri devono avere un tipo di dati valido, che specifica un formato di archiviazione, vincoli e un intervallo di valori valido. Ci concentreremo sulSCALAR e il LOBtipi di dati in questo capitolo. Gli altri due tipi di dati verranno trattati in altri capitoli.
| S.No | Categoria e descrizione |
|---|---|
| 1 | Scalar Valori singoli senza componenti interni, come a NUMBER, DATE, o BOOLEAN. |
| 2 | Large Object (LOB) Puntatori a oggetti di grandi dimensioni che vengono memorizzati separatamente da altri elementi di dati, come testo, immagini grafiche, clip video e forme d'onda audio. |
| 3 | Composite Elementi di dati che hanno componenti interni a cui è possibile accedere individualmente. Ad esempio, raccolte e record. |
| 4 | Reference Puntatori ad altri elementi di dati. |
Tipi e sottotipi di dati scalari PL / SQL
I tipi e i sottotipi di dati scalari PL / SQL rientrano nelle seguenti categorie:
| S.No | Tipo di data e descrizione |
|---|---|
| 1 | Numeric Valori numerici su cui vengono eseguite le operazioni aritmetiche. |
| 2 | Character Valori alfanumerici che rappresentano singoli caratteri o stringhe di caratteri. |
| 3 | Boolean Valori logici su cui vengono eseguite le operazioni logiche. |
| 4 | Datetime Date e orari. |
PL / SQL fornisce sottotipi di tipi di dati. Ad esempio, il tipo di dati NUMBER ha un sottotipo chiamato INTEGER. È possibile utilizzare i sottotipi nel programma PL / SQL per rendere i tipi di dati compatibili con i tipi di dati in altri programmi incorporando il codice PL / SQL in un altro programma, come un programma Java.
Tipi di dati numerici PL / SQL e sottotipi
La tabella seguente elenca i tipi di dati numerici predefiniti PL / SQL e i loro sottotipi -
| S.No | Tipo di dati e descrizione |
|---|---|
| 1 | PLS_INTEGER Numero intero con segno compreso tra -2.147.483.648 e 2.147.483.647, rappresentato in 32 bit |
| 2 | BINARY_INTEGER Numero intero con segno compreso tra -2.147.483.648 e 2.147.483.647, rappresentato in 32 bit |
| 3 | BINARY_FLOAT Numero a virgola mobile in formato IEEE 754 a precisione singola |
| 4 | BINARY_DOUBLE Numero a virgola mobile in formato IEEE 754 a precisione doppia |
| 5 | NUMBER(prec, scale) Numero a virgola fissa o virgola mobile con valore assoluto compreso tra 1E-130 e (ma non incluso) 1.0E126. Una variabile NUMBER può anche rappresentare 0 |
| 6 | DEC(prec, scale) Tipo a virgola fissa specifico ANSI con massima precisione di 38 cifre decimali |
| 7 | DECIMAL(prec, scale) Tipo a virgola fissa specifico IBM con massima precisione di 38 cifre decimali |
| 8 | NUMERIC(pre, secale) Tipo mobile con massima precisione di 38 cifre decimali |
| 9 | DOUBLE PRECISION Tipo a virgola mobile specifico ANSI con massima precisione di 126 cifre binarie (circa 38 cifre decimali) |
| 10 | FLOAT Tipo a virgola mobile specifico ANSI e IBM con massima precisione di 126 cifre binarie (circa 38 cifre decimali) |
| 11 | INT Tipo intero specifico ANSI con massima precisione di 38 cifre decimali |
| 12 | INTEGER Tipo intero specifico ANSI e IBM con massima precisione di 38 cifre decimali |
| 13 | SMALLINT Tipo intero specifico ANSI e IBM con massima precisione di 38 cifre decimali |
| 14 | REAL Tipo a virgola mobile con massima precisione di 63 cifre binarie (circa 18 cifre decimali) |
Di seguito una dichiarazione valida:
DECLARE
num1 INTEGER;
num2 REAL;
num3 DOUBLE PRECISION;
BEGIN
null;
END;
/Quando il codice precedente viene compilato ed eseguito, produce il seguente risultato:
PL/SQL procedure successfully completedTipi di dati e sottotipi di caratteri PL / SQL
Di seguito è riportato il dettaglio dei tipi di dati carattere predefiniti PL / SQL e dei loro sottotipi:
| S.No | Tipo di dati e descrizione |
|---|---|
| 1 | CHAR Stringa di caratteri a lunghezza fissa con dimensione massima di 32.767 byte |
| 2 | VARCHAR2 Stringa di caratteri a lunghezza variabile con dimensione massima di 32.767 byte |
| 3 | RAW Stringa binaria o byte a lunghezza variabile con dimensione massima di 32.767 byte, non interpretata da PL / SQL |
| 4 | NCHAR Stringa di caratteri nazionali a lunghezza fissa con dimensione massima di 32.767 byte |
| 5 | NVARCHAR2 Stringa di caratteri nazionali a lunghezza variabile con dimensione massima di 32.767 byte |
| 6 | LONG Stringa di caratteri a lunghezza variabile con dimensione massima di 32.760 byte |
| 7 | LONG RAW Stringa binaria o byte a lunghezza variabile con dimensione massima di 32.760 byte, non interpretata da PL / SQL |
| 8 | ROWID Identificatore di riga fisico, l'indirizzo di una riga in una tabella ordinaria |
| 9 | UROWID Identificatore di riga universale (identificatore di riga fisico, logico o esterno) |
Tipi di dati booleani PL / SQL
Il BOOLEANil tipo di dati memorizza i valori logici utilizzati nelle operazioni logiche. I valori logici sono i valori booleaniTRUE e FALSE e il valore NULL.
Tuttavia, SQL non ha un tipo di dati equivalente a BOOLEAN. Pertanto, i valori booleani non possono essere utilizzati in -
- Dichiarazioni SQL
- Funzioni SQL integrate (come TO_CHAR)
- Funzioni PL / SQL richiamate da istruzioni SQL
Tipi di data / ora e intervallo PL / SQL
Il DATEdatatype viene utilizzato per memorizzare datetimes a lunghezza fissa, che includono l'ora del giorno in secondi dalla mezzanotte. Le date valide vanno dal 1 gennaio 4712 a.C. al 31 dicembre 9999 d.C.
Il formato della data predefinito è impostato dal parametro di inizializzazione Oracle NLS_DATE_FORMAT. Ad esempio, il valore predefinito potrebbe essere "GG-LUN-AA", che include un numero di due cifre per il giorno del mese, un'abbreviazione del nome del mese e le ultime due cifre dell'anno. Ad esempio, 01-OCT-12.
Ogni DATE include il secolo, l'anno, il mese, il giorno, l'ora, i minuti e i secondi. La tabella seguente mostra i valori validi per ogni campo:
| Nome campo | Valori data / ora validi | Valori di intervallo validi |
|---|---|---|
| ANNO | Da -4712 a 9999 (escluso anno 0) | Qualsiasi numero intero diverso da zero |
| MESE | Da 01 a 12 | Da 0 a 11 |
| GIORNO | Da 01 a 31 (limitato dai valori di MONTH e YEAR, secondo le regole del calendario per il locale) | Qualsiasi numero intero diverso da zero |
| ORA | Da 00 a 23 | Da 0 a 23 |
| MINUTO | Da 00 a 59 | Da 0 a 59 |
| SECONDO | Da 00 a 59,9 (n), dove 9 (n) è la precisione del tempo frazionario dei secondi | Da 0 a 59,9 (n), dove 9 (n) è la precisione dei secondi frazionari dell'intervallo |
| TIMEZONE_HOUR | Da -12 a 14 (la gamma si adatta alle modifiche dell'ora legale) | Non applicabile |
| TIMEZONE_MINUTE | Da 00 a 59 | Non applicabile |
| TIMEZONE_REGION | Trovato nella visualizzazione dinamica delle prestazioni V $ TIMEZONE_NAMES | Non applicabile |
| TIMEZONE_ABBR | Trovato nella visualizzazione dinamica delle prestazioni V $ TIMEZONE_NAMES | Non applicabile |
Tipi di dati PL / SQL Large Object (LOB)
I tipi di dati LOB (Large Object) si riferiscono a elementi di dati di grandi dimensioni come testo, immagini grafiche, clip video e forme d'onda del suono. I tipi di dati LOB consentono un accesso efficiente, casuale e a tratti a questi dati. Di seguito sono riportati i tipi di dati LOB PL / SQL predefiniti:
| Tipo di dati | Descrizione | Taglia |
|---|---|---|
| BFILE | Utilizzato per archiviare oggetti binari di grandi dimensioni nei file del sistema operativo all'esterno del database. | Dipendente dal sistema. Non può superare i 4 gigabyte (GB). |
| BLOB | Utilizzato per memorizzare oggetti binari di grandi dimensioni nel database. | Da 8 a 128 terabyte (TB) |
| CLOB | Utilizzato per memorizzare grandi blocchi di dati di caratteri nel database. | Da 8 a 128 TB |
| NCLOB | Utilizzato per memorizzare grandi blocchi di dati NCHAR nel database. | Da 8 a 128 TB |
Sottotipi definiti dall'utente PL / SQL
Un sottotipo è un sottoinsieme di un altro tipo di dati, denominato tipo di base. Un sottotipo ha le stesse operazioni valide del suo tipo di base, ma solo un sottoinsieme dei suoi valori validi.
PL / SQL predefinisce diversi sottotipi nel pacchetto STANDARD. Ad esempio, PL / SQL predefinisce i sottotipiCHARACTER e INTEGER come segue -
SUBTYPE CHARACTER IS CHAR;
SUBTYPE INTEGER IS NUMBER(38,0);Puoi definire e utilizzare i tuoi sottotipi. Il seguente programma illustra la definizione e l'utilizzo di un sottotipo definito dall'utente:
DECLARE
SUBTYPE name IS char(20);
SUBTYPE message IS varchar2(100);
salutation name;
greetings message;
BEGIN
salutation := 'Reader ';
greetings := 'Welcome to the World of PL/SQL';
dbms_output.put_line('Hello ' || salutation || greetings);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Hello Reader Welcome to the World of PL/SQL
PL/SQL procedure successfully completed.NULL in PL / SQL
I valori NULL PL / SQL rappresentano missing o unknown datae non sono un numero intero, un carattere o qualsiasi altro tipo di dati specifico. Nota cheNULL non è la stessa di una stringa di dati vuota o del valore del carattere null '\0'. Un null può essere assegnato ma non può essere equiparato a nulla, incluso se stesso.
In questo capitolo, discuteremo delle variabili in Pl / SQL. Una variabile non è altro che un nome dato a un'area di memoria che i nostri programmi possono manipolare. Ogni variabile in PL / SQL ha un tipo di dati specifico, che determina la dimensione e il layout della memoria della variabile; l'intervallo di valori che possono essere memorizzati all'interno di quella memoria e l'insieme di operazioni che possono essere applicate alla variabile.
Il nome di una variabile PL / SQL è costituito da una lettera eventualmente seguita da più lettere, numeri, segni di dollaro, trattini bassi e segni di numero e non deve superare i 30 caratteri. Per impostazione predefinita, i nomi delle variabili non fanno distinzione tra maiuscole e minuscole. Non è possibile utilizzare una parola chiave PL / SQL riservata come nome di variabile.
Il linguaggio di programmazione PL / SQL consente di definire vari tipi di variabili, come i tipi di dati di data e ora, record, raccolte, ecc. Che tratteremo nei capitoli successivi. Per questo capitolo, studiamo solo i tipi di variabili di base.
Dichiarazione di variabili in PL / SQL
Le variabili PL / SQL devono essere dichiarate nella sezione dichiarazione o in un pacchetto come una variabile globale. Quando si dichiara una variabile, PL / SQL alloca memoria per il valore della variabile e la posizione di archiviazione è identificata dal nome della variabile.
La sintassi per dichiarare una variabile è:
variable_name [CONSTANT] datatype [NOT NULL] [:= | DEFAULT initial_value]Dove, nome_variabile è un identificatore valido in PL / SQL, il tipo di dati deve essere un tipo di dati PL / SQL valido o qualsiasi tipo di dati definito dall'utente che abbiamo già discusso nell'ultimo capitolo. Di seguito sono riportate alcune dichiarazioni di variabili valide insieme alla loro definizione:
sales number(10, 2);
pi CONSTANT double precision := 3.1415;
name varchar2(25);
address varchar2(100);Quando si fornisce una dimensione, una scala o un limite di precisione con il tipo di dati, si parla di constrained declaration. Le dichiarazioni vincolate richiedono meno memoria rispetto alle dichiarazioni non vincolate. Ad esempio:
sales number(10, 2);
name varchar2(25);
address varchar2(100);Inizializzazione delle variabili in PL / SQL
Ogni volta che si dichiara una variabile, PL / SQL le assegna un valore predefinito di NULL. Se vuoi inizializzare una variabile con un valore diverso dal valore NULL, puoi farlo durante la dichiarazione, usando uno dei seguenti -
Il DEFAULT parola chiave
Il assignment operatore
Ad esempio:
counter binary_integer := 0;
greetings varchar2(20) DEFAULT 'Have a Good Day';Puoi anche specificare che una variabile non deve avere un'estensione NULL valore utilizzando il NOT NULLvincolo. Se si utilizza il vincolo NOT NULL, è necessario assegnare esplicitamente un valore iniziale per quella variabile.
È una buona pratica di programmazione inizializzare correttamente le variabili altrimenti, a volte i programmi potrebbero produrre risultati inaspettati. Prova il seguente esempio che utilizza vari tipi di variabili:
DECLARE
a integer := 10;
b integer := 20;
c integer;
f real;
BEGIN
c := a + b;
dbms_output.put_line('Value of c: ' || c);
f := 70.0/3.0;
dbms_output.put_line('Value of f: ' || f);
END;
/Quando il codice sopra viene eseguito, produce il seguente risultato:
Value of c: 30
Value of f: 23.333333333333333333
PL/SQL procedure successfully completed.Ambito variabile in PL / SQL
PL / SQL consente l'annidamento di blocchi, ovvero ogni blocco di programma può contenere un altro blocco interno. Se una variabile è dichiarata all'interno di un blocco interno, non è accessibile al blocco esterno. Tuttavia, se una variabile è dichiarata e accessibile a un blocco esterno, è anche accessibile a tutti i blocchi interni annidati. Esistono due tipi di ambito variabile:
Local variables - Variabili dichiarate in un blocco interno e non accessibili ai blocchi esterni.
Global variables - Variabili dichiarate nel blocco più esterno o in un pacchetto.
L'esempio seguente mostra l'utilizzo di Local e Global variabili nella sua forma semplice -
DECLARE
-- Global variables
num1 number := 95;
num2 number := 85;
BEGIN
dbms_output.put_line('Outer Variable num1: ' || num1);
dbms_output.put_line('Outer Variable num2: ' || num2);
DECLARE
-- Local variables
num1 number := 195;
num2 number := 185;
BEGIN
dbms_output.put_line('Inner Variable num1: ' || num1);
dbms_output.put_line('Inner Variable num2: ' || num2);
END;
END;
/Quando il codice sopra viene eseguito, produce il seguente risultato:
Outer Variable num1: 95
Outer Variable num2: 85
Inner Variable num1: 195
Inner Variable num2: 185
PL/SQL procedure successfully completed.Assegnazione dei risultati della query SQL alle variabili PL / SQL
Puoi usare il file SELECT INTOdichiarazione di SQL per assegnare valori alle variabili PL / SQL. Per ogni articolo inSELECT list, deve essere presente una variabile compatibile con il tipo corrispondente nel file INTO list. L'esempio seguente illustra il concetto. Creiamo una tabella denominata CLIENTI -
(For SQL statements, please refer to the SQL tutorial)
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25),
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
Table CreatedInseriamo ora alcuni valori nella tabella -
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'kaushik', 23, 'Kota', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Komal', 22, 'MP', 4500.00 );Il seguente programma assegna i valori dalla tabella sopra alle variabili PL / SQL utilizzando il SELECT INTO clause di SQL -
DECLARE
c_id customers.id%type := 1;
c_name customers.name%type;
c_addr customers.address%type;
c_sal customers.salary%type;
BEGIN
SELECT name, address, salary INTO c_name, c_addr, c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line
('Customer ' ||c_name || ' from ' || c_addr || ' earns ' || c_sal);
END;
/Quando il codice sopra viene eseguito, produce il seguente risultato:
Customer Ramesh from Ahmedabad earns 2000
PL/SQL procedure completed successfullyIn questo capitolo, discuteremo constants e literalsin PL / SQL. Una costante contiene un valore che, una volta dichiarato, non cambia nel programma. Una dichiarazione di costante ne specifica il nome, il tipo di dati e il valore e alloca lo spazio di archiviazione per esso. La dichiarazione può anche imporre l'estensioneNOT NULL constraint.
Dichiarazione di una costante
Una costante viene dichiarata utilizzando il CONSTANTparola chiave. Richiede un valore iniziale e non consente di modificare tale valore. Ad esempio:
PI CONSTANT NUMBER := 3.141592654;
DECLARE
-- constant declaration
pi constant number := 3.141592654;
-- other declarations
radius number(5,2);
dia number(5,2);
circumference number(7, 2);
area number (10, 2);
BEGIN
-- processing
radius := 9.5;
dia := radius * 2;
circumference := 2.0 * pi * radius;
area := pi * radius * radius;
-- output
dbms_output.put_line('Radius: ' || radius);
dbms_output.put_line('Diameter: ' || dia);
dbms_output.put_line('Circumference: ' || circumference);
dbms_output.put_line('Area: ' || area);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Radius: 9.5
Diameter: 19
Circumference: 59.69
Area: 283.53
Pl/SQL procedure successfully completed.I letterali PL / SQL
Un valore letterale è un valore numerico, carattere, stringa o booleano esplicito non rappresentato da un identificatore. Ad esempio, TRUE, 786, NULL, "tutorialspoint" sono tutti valori letterali di tipo Boolean, numero o stringa. PL / SQL, i letterali fanno distinzione tra maiuscole e minuscole. PL / SQL supporta i seguenti tipi di letterali:
- Letterali numerici
- Letterali carattere
- Valori letterali stringa
- Letterali BOOLEANI
- Valori letterali di data e ora
La tabella seguente fornisce esempi di tutte queste categorie di valori letterali.
| S.No | Tipo letterale ed esempio |
|---|---|
| 1 | Numeric Literals 050 78-14 0 +32767 6.6667 0,0 -12,0 3,14159 +7800,00 6E5 1.0E-8 3.14159e0 -1E38 -9.5e-3 |
| 2 | Character Literals 'A' '%' '9' '' 'z' '(' |
| 3 | String Literals 'Ciao mondo!' "Punto tutorial" '19 -NOV-12 ' |
| 4 | BOOLEAN Literals VERO, FALSO e NULLO. |
| 5 | Date and Time Literals DATA "1978-12-25"; TIMESTAMP "2012-10-29 12:01:01"; |
Per incorporare virgolette singole all'interno di una stringa letterale, posizionare due virgolette singole una accanto all'altra come mostrato nel seguente programma:
DECLARE
message varchar2(30):= 'That''s tutorialspoint.com!';
BEGIN
dbms_output.put_line(message);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
That's tutorialspoint.com!
PL/SQL procedure successfully completed.In questo capitolo, discuteremo gli operatori in PL / SQL. Un operatore è un simbolo che dice al compilatore di eseguire specifiche manipolazioni matematiche o logiche. Il linguaggio PL / SQL è ricco di operatori integrati e fornisce i seguenti tipi di operatori:
- Operatori aritmetici
- Operatori relazionali
- Operatori di confronto
- Operatori logici
- Operatori di stringa
Qui capiremo uno per uno gli operatori aritmetici, relazionali, di confronto e logici. Gli operatori String saranno discussi in un capitolo successivo:PL/SQL - Strings.
Operatori aritmetici
La tabella seguente mostra tutti gli operatori aritmetici supportati da PL / SQL. Supponiamovariable A contiene 10 e variable B tiene 5, quindi -
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| + | Aggiunge due operandi | A + B darà 15 |
| - | Sottrae il secondo operando dal primo | A - B darà 5 |
| * | Moltiplica entrambi gli operandi | A * B darà 50 |
| / | Divide il numeratore per il de-numeratore | A / B darà 2 |
| ** | Operatore di esponenziazione, eleva un operando alla potenza di un altro | A ** B darà 100000 |
Operatori relazionali
Gli operatori relazionali confrontano due espressioni o valori e restituiscono un risultato booleano. La tabella seguente mostra tutti gli operatori relazionali supportati da PL / SQL. Supponiamovariable A contiene 10 e variable B detiene 20, quindi -
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| = | Controlla se i valori di due operandi sono uguali o meno, in caso affermativo la condizione diventa vera. | (A = B) non è vero. |
! = <> ~ = |
Controlla se i valori di due operandi sono uguali o meno, se i valori non sono uguali la condizione diventa vera. | (A! = B) è vero. |
| > | Controlla se il valore dell'operando sinistro è maggiore del valore dell'operando destro, in caso affermativo la condizione diventa vera. | (A> B) non è vero. |
| < | Controlla se il valore dell'operando sinistro è inferiore al valore dell'operando destro, in caso affermativo la condizione diventa vera. | (A <B) è vero. |
| > = | Controlla se il valore dell'operando sinistro è maggiore o uguale al valore dell'operando destro, in caso affermativo la condizione diventa vera. | (A> = B) non è vero. |
| <= | Controlla se il valore dell'operando sinistro è minore o uguale al valore dell'operando destro, in caso affermativo la condizione diventa vera. | (A <= B) è vero |
Operatori di confronto
Gli operatori di confronto vengono utilizzati per confrontare un'espressione con un'altra. Il risultato è sempre l'uno o l'altroTRUE, FALSE o NULL.
Mostra esempi
| Operatore | Descrizione | Esempio |
|---|---|---|
| PIACE | L'operatore LIKE confronta un carattere, una stringa o un valore CLOB con un pattern e restituisce TRUE se il valore corrisponde al pattern e FALSE in caso contrario. | Se "Zara Ali" come "Z% A_i" restituisce un valore booleano vero, mentre "Nuha Ali" come "Z% A_i" restituisce un valore booleano falso. |
| FRA | L'operatore BETWEEN verifica se un valore si trova in un intervallo specificato. x TRA a AND b significa che x> = a e x <= b. | Se x = 10, x compreso tra 5 e 20 restituisce vero, x compreso tra 5 e 10 restituisce vero, ma x compreso tra 11 e 20 restituisce falso. |
| IN | I test dell'operatore IN impostano l'appartenenza. x IN (set) significa che x è uguale a qualsiasi membro di set. | Se x = 'm' allora, x in ('a', 'b', 'c') restituisce booleano false ma x in ('m', 'n', 'o') restituisce booleano true. |
| È ZERO | L'operatore IS NULL restituisce il valore BOOLEANO TRUE se il suo operando è NULL o FALSE se non è NULL. I confronti che coinvolgono valori NULL restituiscono sempre NULL. | Se x = 'm', allora 'x è null' restituisce booleano false. |
Operatori logici
La tabella seguente mostra gli operatori logici supportati da PL / SQL. Tutti questi operatori lavorano su operandi booleani e producono risultati booleani. Supponiamovariable A è vero e variable B è falso, quindi -
Mostra esempi
| Operatore | Descrizione | Esempi |
|---|---|---|
| e | Chiamato l'operatore AND logico. Se entrambi gli operandi sono veri, la condizione diventa vera. | (A e B) è falso. |
| o | Chiamato l'operatore OR logico. Se uno dei due operandi è vero, la condizione diventa vera. | (A o B) è vero. |
| non | Chiamato l'operatore NOT logico. Utilizzato per invertire lo stato logico del suo operando. Se una condizione è vera, l'operatore NOT logico la renderà falsa. | non (A e B) è vero. |
Precedenza degli operatori PL / SQL
La precedenza degli operatori determina il raggruppamento dei termini in un'espressione. Ciò influisce sul modo in cui viene valutata un'espressione. Alcuni operatori hanno la precedenza maggiore di altri; ad esempio, l'operatore di moltiplicazione ha una precedenza maggiore dell'operatore di addizione.
Per esempio, x = 7 + 3 * 2; Qui,x è assegnato 13, non 20 perché l'operatore * ha una precedenza maggiore di +, quindi viene prima moltiplicato con 3*2 e poi aggiunge in 7.
Qui, gli operatori con la precedenza più alta vengono visualizzati nella parte superiore della tabella, quelli con la priorità più bassa in fondo. All'interno di un'espressione, verranno valutati per primi gli operatori con precedenza più alta.
La precedenza degli operatori è la seguente: =, <,>, <=,> =, <>,! =, ~ =, ^ =, IS NULL, LIKE, BETWEEN, IN.
Mostra esempi
| Operatore | Operazione |
|---|---|
| ** | esponenziazione |
| +, - | identità, negazione |
| *, / | moltiplicazione, divisione |
| +, -, || | addizione, sottrazione, concatenazione |
| confronto | |
| NON | negazione logica |
| E | congiunzione |
| O | inclusione |
In questo capitolo, discuteremo le condizioni in PL / SQL. Le strutture decisionali richiedono che il programmatore specifichi una o più condizioni che devono essere valutate o testate dal programma, insieme a una o più istruzioni da eseguire se la condizione è determinata essere vera e, facoltativamente, altre istruzioni da eseguire se condizione è determinata essere falsa.
Di seguito è riportata la forma generale di una tipica struttura condizionale (ovvero, processo decisionale) presente nella maggior parte dei linguaggi di programmazione:
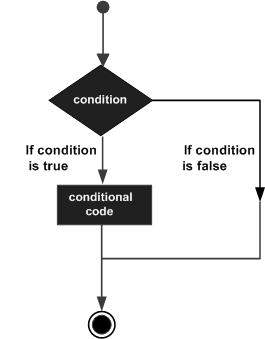
Il linguaggio di programmazione PL / SQL fornisce i seguenti tipi di dichiarazioni decisionali. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| S.No | Dichiarazione e descrizione |
|---|---|
| 1 | IF - ALLORA dichiarazione Il IF statement associa una condizione a una sequenza di istruzioni racchiuse tra le parole chiave THEN e END IF. Se la condizione è vera, le istruzioni vengono eseguite e se la condizione è falsa o NULL, l'istruzione IF non fa nulla. |
| 2 | Istruzione IF-THEN-ELSE IF statement aggiunge la parola chiave ELSEseguito da una sequenza alternativa di affermazioni. Se la condizione è falsa o NULL, viene eseguita solo la sequenza alternativa di istruzioni. Assicura che una delle sequenze di istruzioni venga eseguita. |
| 3 | Istruzione IF-THEN-ELSIF Ti permette di scegliere tra diverse alternative. |
| 4 | Dichiarazione del caso Come l'istruzione IF, il CASE statement seleziona una sequenza di istruzioni da eseguire. Tuttavia, per selezionare la sequenza, l'istruzione CASE utilizza un selettore anziché più espressioni booleane. Un selettore è un'espressione il cui valore viene utilizzato per selezionare una delle diverse alternative. |
| 5 | Istruzione CASE ricercata L'istruzione CASE cercata has no selectored è WHEN le clausole contengono condizioni di ricerca che producono valori booleani. |
| 6 | nidificato IF-THEN-ELSE Puoi usarne uno IF-THEN o IF-THEN-ELSIF dichiarazione dentro un'altra IF-THEN o IF-THEN-ELSIF dichiarazione (i). |
In questo capitolo, discuteremo dei loop in PL / SQL. Potrebbe esserci una situazione in cui è necessario eseguire un blocco di codice più volte. In generale, le istruzioni vengono eseguite in sequenza: la prima istruzione in una funzione viene eseguita per prima, seguita dalla seconda e così via.
I linguaggi di programmazione forniscono varie strutture di controllo che consentono percorsi di esecuzione più complicati.
Un'istruzione loop ci consente di eseguire un'istruzione o un gruppo di istruzioni più volte e la seguente è la forma generale di un'istruzione loop nella maggior parte dei linguaggi di programmazione:
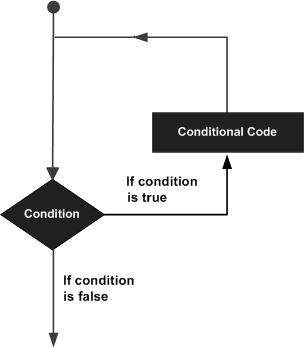
PL / SQL fornisce i seguenti tipi di loop per gestire i requisiti di loop. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| S.No | Tipo e descrizione del loop |
|---|---|
| 1 | PL / SQL Basic LOOP In questa struttura a ciclo, la sequenza di istruzioni è racchiusa tra le istruzioni LOOP e END LOOP. Ad ogni iterazione, la sequenza di istruzioni viene eseguita e quindi il controllo riprende all'inizio del ciclo. |
| 2 | PL / SQL DURANTE LOOP Ripete un'istruzione o un gruppo di istruzioni finché una determinata condizione è vera. Verifica la condizione prima di eseguire il corpo del ciclo. |
| 3 | PL / SQL PER LOOP Esegue più volte una sequenza di istruzioni e abbrevia il codice che gestisce la variabile del ciclo. |
| 4 | Cicli annidati in PL / SQL Puoi usare uno o più loop all'interno di un altro loop di base, while o for. |
Etichettatura di un ciclo PL / SQL
I loop PL / SQL possono essere etichettati. L'etichetta dovrebbe essere racchiusa tra doppie parentesi angolari (<< e >>) e apparire all'inizio dell'istruzione LOOP. Il nome dell'etichetta può anche apparire alla fine dell'istruzione LOOP. È possibile utilizzare l'etichetta nell'istruzione EXIT per uscire dal ciclo.
Il seguente programma illustra il concetto:
DECLARE
i number(1);
j number(1);
BEGIN
<< outer_loop >>
FOR i IN 1..3 LOOP
<< inner_loop >>
FOR j IN 1..3 LOOP
dbms_output.put_line('i is: '|| i || ' and j is: ' || j);
END loop inner_loop;
END loop outer_loop;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
i is: 1 and j is: 1
i is: 1 and j is: 2
i is: 1 and j is: 3
i is: 2 and j is: 1
i is: 2 and j is: 2
i is: 2 and j is: 3
i is: 3 and j is: 1
i is: 3 and j is: 2
i is: 3 and j is: 3
PL/SQL procedure successfully completed.Le dichiarazioni di controllo del loop
Le istruzioni di controllo del ciclo cambiano l'esecuzione dalla sua sequenza normale. Quando l'esecuzione esce da un ambito, tutti gli oggetti automatici creati in tale ambito vengono eliminati.
PL / SQL supporta le seguenti istruzioni di controllo. L'etichettatura dei loop aiuta anche a portare il controllo al di fuori di un loop. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| S.No | Dichiarazione di controllo e descrizione |
|---|---|
| 1 | Dichiarazione EXIT L'istruzione Exit completa il ciclo e il controllo passa all'istruzione immediatamente dopo END LOOP. |
| 2 | Dichiarazione CONTINUA Fa sì che il ciclo salti il resto del suo corpo e ritorni immediatamente le sue condizioni prima di ripetere. |
| 3 | Dichiarazione GOTO Trasferisce il controllo all'istruzione etichettata. Sebbene non sia consigliabile utilizzare l'istruzione GOTO nel programma. |
La stringa in PL / SQL è in realtà una sequenza di caratteri con una specifica di dimensione opzionale. I caratteri possono essere numerici, lettere, spazi vuoti, caratteri speciali o una combinazione di tutti. PL / SQL offre tre tipi di stringhe:
Fixed-length strings- In tali stringhe, i programmatori specificano la lunghezza mentre dichiarano la stringa. La stringa viene riempita a destra con spazi della lunghezza specificata.
Variable-length strings - In tali stringhe, viene specificata una lunghezza massima fino a 32.767, per la stringa e non ha luogo alcun riempimento.
Character large objects (CLOBs) - Si tratta di stringhe di lunghezza variabile che possono essere fino a 128 terabyte.
Le stringhe PL / SQL possono essere variabili o letterali. Un valore letterale stringa è racchiuso tra virgolette. Per esempio,
'This is a string literal.' Or 'hello world'Per includere una virgoletta singola all'interno di una stringa letterale, è necessario digitare due virgolette singole una accanto all'altra. Per esempio,
'this isn''t what it looks like'Dichiarazione di variabili stringa
Il database Oracle fornisce numerosi tipi di dati di stringa, come CHAR, NCHAR, VARCHAR2, NVARCHAR2, CLOB e NCLOB. I tipi di dati preceduti da un'N' siamo 'national character set' datatypes, che memorizzano i dati dei caratteri Unicode.
Se è necessario dichiarare una stringa di lunghezza variabile, è necessario fornire la lunghezza massima di quella stringa. Ad esempio, il tipo di dati VARCHAR2. L'esempio seguente illustra la dichiarazione e l'utilizzo di alcune variabili stringa:
DECLARE
name varchar2(20);
company varchar2(30);
introduction clob;
choice char(1);
BEGIN
name := 'John Smith';
company := 'Infotech';
introduction := ' Hello! I''m John Smith from Infotech.';
choice := 'y';
IF choice = 'y' THEN
dbms_output.put_line(name);
dbms_output.put_line(company);
dbms_output.put_line(introduction);
END IF;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
John Smith
Infotech
Hello! I'm John Smith from Infotech.
PL/SQL procedure successfully completedPer dichiarare una stringa di lunghezza fissa, utilizzare il tipo di dati CHAR. Qui non è necessario specificare una lunghezza massima per una variabile di lunghezza fissa. Se si tralascia il vincolo di lunghezza, Oracle Database utilizza automaticamente una lunghezza massima richiesta. Le due dichiarazioni seguenti sono identiche:
red_flag CHAR(1) := 'Y';
red_flag CHAR := 'Y';Funzioni e operatori di stringa PL / SQL
PL / SQL offre l'operatore di concatenazione (||)per unire due stringhe. La tabella seguente fornisce le funzioni di stringa fornite da PL / SQL:
| S.No | Funzione e scopo |
|---|---|
| 1 | ASCII(x); Restituisce il valore ASCII del carattere x. |
| 2 | CHR(x); Restituisce il carattere con il valore ASCII di x. |
| 3 | CONCAT(x, y); Concatena le stringhe x e y e restituisce la stringa aggiunta. |
| 4 | INITCAP(x); Converte la lettera iniziale di ogni parola in x in maiuscolo e restituisce quella stringa. |
| 5 | INSTR(x, find_string [, start] [, occurrence]); Cerca find_string in x e restituisce la posizione in cui si verifica. |
| 6 | INSTRB(x); Restituisce la posizione di una stringa all'interno di un'altra stringa, ma restituisce il valore in byte. |
| 7 | LENGTH(x); Restituisce il numero di caratteri in x. |
| 8 | LENGTHB(x); Restituisce la lunghezza di una stringa di caratteri in byte per un set di caratteri a byte singolo. |
| 9 | LOWER(x); Converte le lettere in x in minuscolo e restituisce quella stringa. |
| 10 | LPAD(x, width [, pad_string]) ; Pastiglie x con spazi a sinistra, per portare la lunghezza totale della stringa fino a caratteri di larghezza. |
| 11 | LTRIM(x [, trim_string]); Taglia i caratteri da sinistra di x. |
| 12 | NANVL(x, value); Restituisce valore se x corrisponde al valore speciale NaN (non un numero), altrimenti x viene restituito. |
| 13 | NLS_INITCAP(x); Uguale alla funzione INITCAP tranne per il fatto che può utilizzare un metodo di ordinamento diverso come specificato da NLSSORT. |
| 14 | NLS_LOWER(x) ; Uguale alla funzione LOWER tranne per il fatto che può utilizzare un metodo di ordinamento diverso come specificato da NLSSORT. |
| 15 | NLS_UPPER(x); Uguale alla funzione UPPER tranne per il fatto che può utilizzare un metodo di ordinamento diverso come specificato da NLSSORT. |
| 16 | NLSSORT(x); Cambia il metodo di ordinamento dei caratteri. Deve essere specificato prima di qualsiasi funzione NLS; in caso contrario, verrà utilizzato l'ordinamento predefinito. |
| 17 | NVL(x, value); Restituisce il valore se xè zero; in caso contrario, viene restituito x. |
| 18 | NVL2(x, value1, value2); Restituisce valore1 se x non è nullo; se x è nullo, viene restituito valore2. |
| 19 | REPLACE(x, search_string, replace_string); Ricerche x for search_string e lo sostituisce con replace_string. |
| 20 | RPAD(x, width [, pad_string]); Pastiglie x a destra. |
| 21 | RTRIM(x [, trim_string]); Trim x da destra. |
| 22 | SOUNDEX(x) ; Restituisce una stringa contenente la rappresentazione fonetica di x. |
| 23 | SUBSTR(x, start [, length]); Restituisce una sottostringa di xche inizia nella posizione specificata da start. Può essere fornita una lunghezza opzionale per la sottostringa. |
| 24 | SUBSTRB(x); Come SUBSTR tranne per il fatto che i parametri sono espressi in byte invece che in caratteri per i sistemi di caratteri a byte singolo. |
| 25 | TRIM([trim_char FROM) x); Taglia i caratteri da sinistra e destra di x. |
| 26 | UPPER(x); Converte le lettere in x in maiuscolo e restituisce quella stringa. |
Cerchiamo ora di elaborare alcuni esempi per comprendere il concetto:
Esempio 1
DECLARE
greetings varchar2(11) := 'hello world';
BEGIN
dbms_output.put_line(UPPER(greetings));
dbms_output.put_line(LOWER(greetings));
dbms_output.put_line(INITCAP(greetings));
/* retrieve the first character in the string */
dbms_output.put_line ( SUBSTR (greetings, 1, 1));
/* retrieve the last character in the string */
dbms_output.put_line ( SUBSTR (greetings, -1, 1));
/* retrieve five characters,
starting from the seventh position. */
dbms_output.put_line ( SUBSTR (greetings, 7, 5));
/* retrieve the remainder of the string,
starting from the second position. */
dbms_output.put_line ( SUBSTR (greetings, 2));
/* find the location of the first "e" */
dbms_output.put_line ( INSTR (greetings, 'e'));
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
HELLO WORLD
hello world
Hello World
h
d
World
ello World
2
PL/SQL procedure successfully completed.Esempio 2
DECLARE
greetings varchar2(30) := '......Hello World.....';
BEGIN
dbms_output.put_line(RTRIM(greetings,'.'));
dbms_output.put_line(LTRIM(greetings, '.'));
dbms_output.put_line(TRIM( '.' from greetings));
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
......Hello World
Hello World.....
Hello World
PL/SQL procedure successfully completed.In questo capitolo, discuteremo gli array in PL / SQL. Il linguaggio di programmazione PL / SQL fornisce una struttura dati denominataVARRAY, che può memorizzare una raccolta sequenziale di dimensioni fisse di elementi dello stesso tipo. Un varray viene utilizzato per memorizzare una raccolta ordinata di dati, tuttavia è spesso meglio pensare a un array come una raccolta di variabili dello stesso tipo.
Tutti i varray sono costituiti da posizioni di memoria contigue. L'indirizzo più basso corrisponde al primo elemento e l'indirizzo più alto all'ultimo elemento.

Un array fa parte dei dati del tipo di raccolta e sta per array di dimensioni variabili. Studieremo altri tipi di raccolta in un capitolo successivo'PL/SQL Collections'.
Ogni elemento in un file varrayha un indice associato ad esso. Ha anche una dimensione massima che può essere modificata dinamicamente.
Creazione di un tipo di Varray
Un tipo varray viene creato con il CREATE TYPEdichiarazione. È necessario specificare la dimensione massima e il tipo di elementi memorizzati nel varray.
La sintassi di base per la creazione di un tipo VARRAY a livello di schema è:
CREATE OR REPLACE TYPE varray_type_name IS VARRAY(n) of <element_type>Dove,
- varray_type_name è un nome di attributo valido,
- n è il numero di elementi (massimo) nel varray,
- element_type è il tipo di dati degli elementi dell'array.
La dimensione massima di un varray può essere modificata utilizzando il ALTER TYPE dichiarazione.
Per esempio,
CREATE Or REPLACE TYPE namearray AS VARRAY(3) OF VARCHAR2(10);
/
Type created.La sintassi di base per creare un tipo VARRAY all'interno di un blocco PL / SQL è:
TYPE varray_type_name IS VARRAY(n) of <element_type>Ad esempio:
TYPE namearray IS VARRAY(5) OF VARCHAR2(10);
Type grades IS VARRAY(5) OF INTEGER;Cerchiamo ora di elaborare alcuni esempi per comprendere il concetto:
Esempio 1
Il seguente programma illustra l'uso di varrays:
DECLARE
type namesarray IS VARRAY(5) OF VARCHAR2(10);
type grades IS VARRAY(5) OF INTEGER;
names namesarray;
marks grades;
total integer;
BEGIN
names := namesarray('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i in 1 .. total LOOP
dbms_output.put_line('Student: ' || names(i) || '
Marks: ' || marks(i));
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Total 5 Students
Student: Kavita Marks: 98
Student: Pritam Marks: 97
Student: Ayan Marks: 78
Student: Rishav Marks: 87
Student: Aziz Marks: 92
PL/SQL procedure successfully completed.Please note -
In ambiente Oracle, l'indice iniziale per varrays è sempre 1.
È possibile inizializzare gli elementi varray utilizzando il metodo di costruzione del tipo varray, che ha lo stesso nome del varray.
I Varray sono array unidimensionali.
Un varray è automaticamente NULL quando viene dichiarato e deve essere inizializzato prima di poter fare riferimento ai suoi elementi.
Esempio 2
Gli elementi di un varray potrebbero anche essere un% ROWTYPE di qualsiasi tabella di database o% TYPE di qualsiasi campo di tabella di database. L'esempio seguente illustra il concetto.
Useremo la tabella CUSTOMERS memorizzata nel nostro database come -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+L'esempio seguente fa uso di cursor, che studierai in dettaglio in un capitolo a parte.
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
type c_list is varray (6) of customers.name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter + 1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter ||'):'||name_list(counter));
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
PL/SQL procedure successfully completed.In questo capitolo, discuteremo le procedure in PL / SQL. UNsubprogramè un'unità / modulo di programma che esegue un compito particolare. Questi sottoprogrammi vengono combinati per formare programmi più grandi. Questo è fondamentalmente chiamato "design modulare". Un sottoprogramma può essere richiamato da un altro sottoprogramma o programma chiamatocalling program.
È possibile creare un sottoprogramma -
- A livello di schema
- All'interno di un pacchetto
- All'interno di un blocco PL / SQL
A livello di schema, il sottoprogramma è un file standalone subprogram. Viene creato con l'istruzione CREATE PROCEDURE o CREATE FUNCTION. Viene memorizzato nel database e può essere eliminato con l'istruzione DROP PROCEDURE o DROP FUNCTION.
Un sottoprogramma creato all'interno di un pacchetto è un file packaged subprogram. Viene archiviato nel database e può essere eliminato solo quando il pacchetto viene eliminato con l'istruzione DROP PACKAGE. Discuteremo i pacchetti nel capitolo'PL/SQL - Packages'.
I sottoprogrammi PL / SQL sono denominati blocchi PL / SQL che possono essere richiamati con una serie di parametri. PL / SQL fornisce due tipi di sottoprogrammi:
Functions- Questi sottoprogrammi restituiscono un unico valore; utilizzato principalmente per calcolare e restituire un valore.
Procedures- Questi sottoprogrammi non restituiscono direttamente un valore; utilizzato principalmente per eseguire un'azione.
Questo capitolo tratterà aspetti importanti di a PL/SQL procedure. Noi discuteremoPL/SQL function nel prossimo capitolo.
Parti di un sottoprogramma PL / SQL
Ogni sottoprogramma PL / SQL ha un nome e può anche avere un elenco di parametri. Come i blocchi PL / SQL anonimi, i blocchi denominati avranno anche le seguenti tre parti:
| S.No | Parti e descrizione |
|---|---|
| 1 | Declarative Part È una parte facoltativa. Tuttavia, la parte dichiarativa per un sottoprogramma non inizia con la parola chiave DECLARE. Contiene dichiarazioni di tipi, cursori, costanti, variabili, eccezioni e sottoprogrammi annidati. Questi elementi sono locali del sottoprogramma e cessano di esistere quando il sottoprogramma completa l'esecuzione. |
| 2 | Executable Part Questa è una parte obbligatoria e contiene istruzioni che eseguono l'azione designata. |
| 3 | Exception-handling Anche questa è una parte facoltativa. Contiene il codice che gestisce gli errori di runtime. |
Creazione di una procedura
Viene creata una procedura con il CREATE OR REPLACE PROCEDUREdichiarazione. La sintassi semplificata per l'istruzione CREATE OR REPLACE PROCEDURE è la seguente:
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
{IS | AS}
BEGIN
< procedure_body >
END procedure_name;Dove,
nome-procedura specifica il nome della procedura.
L'opzione [OR REPLACE] consente la modifica di una procedura esistente.
L'elenco dei parametri facoltativi contiene nome, modalità e tipi di parametri. IN rappresenta il valore che verrà passato dall'esterno e OUT rappresenta il parametro che verrà utilizzato per restituire un valore al di fuori della procedura.
procedure-body contiene la parte eseguibile.
La parola chiave AS viene utilizzata al posto della parola chiave IS per creare una procedura autonoma.
Esempio
L'esempio seguente crea una semplice procedura che visualizza la stringa "Hello World!" sullo schermo quando viene eseguito.
CREATE OR REPLACE PROCEDURE greetings
AS
BEGIN
dbms_output.put_line('Hello World!');
END;
/Quando il codice sopra viene eseguito utilizzando il prompt SQL, produrrà il seguente risultato:
Procedure created.Esecuzione di una procedura autonoma
Una procedura autonoma può essere chiamata in due modi:
Usando il EXECUTE parola chiave
Chiamare il nome della procedura da un blocco PL / SQL
La procedura sopra denominata 'greetings' può essere chiamato con la parola chiave EXECUTE come -
EXECUTE greetings;La chiamata sopra mostrerà:
Hello World
PL/SQL procedure successfully completed.La procedura può essere richiamata anche da un altro blocco PL / SQL -
BEGIN
greetings;
END;
/La chiamata sopra mostrerà:
Hello World
PL/SQL procedure successfully completed.Eliminazione di una procedura autonoma
Una procedura autonoma viene eliminata con l'estensione DROP PROCEDUREdichiarazione. La sintassi per eliminare una procedura è:
DROP PROCEDURE procedure-name;È possibile eliminare la procedura dei saluti utilizzando la seguente dichiarazione:
DROP PROCEDURE greetings;Modalità dei parametri nei sottoprogrammi PL / SQL
La tabella seguente elenca le modalità dei parametri nei sottoprogrammi PL / SQL:
| S.No | Modalità e descrizione dei parametri |
|---|---|
| 1 | IN Un parametro IN consente di passare un valore al sottoprogramma. It is a read-only parameter. All'interno del sottoprogramma, un parametro IN agisce come una costante. Non può essere assegnato un valore. È possibile passare una costante, una letterale, una variabile inizializzata o un'espressione come parametro IN. Puoi anche inizializzarlo a un valore predefinito; tuttavia, in quel caso, viene omesso dalla chiamata al sottoprogramma.It is the default mode of parameter passing. Parameters are passed by reference. |
| 2 | OUT Un parametro OUT restituisce un valore al programma chiamante. All'interno del sottoprogramma, un parametro OUT agisce come una variabile. È possibile modificarne il valore e fare riferimento al valore dopo averlo assegnato.The actual parameter must be variable and it is passed by value. |
| 3 | IN OUT Un IN OUTil parametro passa un valore iniziale a un sottoprogramma e restituisce un valore aggiornato al chiamante. Può essere assegnato un valore e il valore può essere letto. Il parametro effettivo corrispondente a un parametro formale IN OUT deve essere una variabile, non una costante o un'espressione. Al parametro formale deve essere assegnato un valore.Actual parameter is passed by value. |
Esempio di modalità IN & OUT 1
Questo programma trova il minimo di due valori. Qui, la procedura prende due numeri utilizzando la modalità IN e restituisce il loro minimo utilizzando i parametri OUT.
DECLARE
a number;
b number;
c number;
PROCEDURE findMin(x IN number, y IN number, z OUT number) IS
BEGIN
IF x < y THEN
z:= x;
ELSE
z:= y;
END IF;
END;
BEGIN
a:= 23;
b:= 45;
findMin(a, b, c);
dbms_output.put_line(' Minimum of (23, 45) : ' || c);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Minimum of (23, 45) : 23
PL/SQL procedure successfully completed.Esempio di modalità IN & OUT 2
Questa procedura calcola il quadrato del valore di un valore passato. Questo esempio mostra come possiamo usare lo stesso parametro per accettare un valore e quindi restituire un altro risultato.
DECLARE
a number;
PROCEDURE squareNum(x IN OUT number) IS
BEGIN
x := x * x;
END;
BEGIN
a:= 23;
squareNum(a);
dbms_output.put_line(' Square of (23): ' || a);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Square of (23): 529
PL/SQL procedure successfully completed.Metodi per il passaggio dei parametri
I parametri effettivi possono essere passati in tre modi:
- Notazione di posizione
- Notazione denominata
- Notazione mista
Notazione di posizione
Nella notazione posizionale, puoi chiamare la procedura come -
findMin(a, b, c, d);Nella notazione posizionale, il primo parametro effettivo viene sostituito dal primo parametro formale; il secondo parametro effettivo viene sostituito al secondo parametro formale e così via. Così,a è sostituito da x, b è sostituito da y, c è sostituito da z e d è sostituito da m.
Notazione denominata
Nella notazione denominata, il parametro effettivo è associato al parametro formale utilizzando l'estensione arrow symbol ( => ). La chiamata alla procedura sarà come la seguente:
findMin(x => a, y => b, z => c, m => d);Notazione mista
Nella notazione mista, puoi combinare entrambe le notazioni nella chiamata di procedura; tuttavia, la notazione di posizione dovrebbe precedere la notazione denominata.
La seguente chiamata è legale:
findMin(a, b, c, m => d);Tuttavia, questo non è legale:
findMin(x => a, b, c, d);In questo capitolo, discuteremo le funzioni in PL / SQL. Una funzione è uguale a una procedura tranne per il fatto che restituisce un valore. Pertanto, tutte le discussioni del capitolo precedente valgono anche per le funzioni.
Creazione di una funzione
Una funzione standalone viene creata utilizzando il CREATE FUNCTIONdichiarazione. La sintassi semplificata perCREATE OR REPLACE PROCEDURE l'affermazione è la seguente:
CREATE [OR REPLACE] FUNCTION function_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
RETURN return_datatype
{IS | AS}
BEGIN
< function_body >
END [function_name];Dove,
nome-funzione specifica il nome della funzione.
L'opzione [OR REPLACE] consente la modifica di una funzione esistente.
L'elenco dei parametri facoltativi contiene nome, modalità e tipi di parametri. IN rappresenta il valore che verrà passato dall'esterno e OUT rappresenta il parametro che verrà utilizzato per restituire un valore al di fuori della procedura.
La funzione deve contenere un file return dichiarazione.
La clausola RETURN specifica il tipo di dati che si intende restituire dalla funzione.
function-body contiene la parte eseguibile.
La parola chiave AS viene utilizzata al posto della parola chiave IS per creare una funzione autonoma.
Esempio
L'esempio seguente illustra come creare e chiamare una funzione autonoma. Questa funzione restituisce il numero totale di CLIENTI nella tabella dei clienti.
Useremo la tabella CUSTOMERS, che avevamo creato nel capitolo Variabili PL / SQL -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+CREATE OR REPLACE FUNCTION totalCustomers
RETURN number IS
total number(2) := 0;
BEGIN
SELECT count(*) into total
FROM customers;
RETURN total;
END;
/Quando il codice sopra viene eseguito utilizzando il prompt SQL, produrrà il seguente risultato:
Function created.Chiamare una funzione
Durante la creazione di una funzione, dai una definizione di ciò che la funzione deve fare. Per utilizzare una funzione, dovrai chiamare quella funzione per eseguire l'attività definita. Quando un programma chiama una funzione, il controllo del programma viene trasferito alla funzione chiamata.
Una funzione chiamata esegue l'attività definita e quando viene eseguita la sua istruzione return o quando il file last end statement viene raggiunto, riporta il controllo del programma al programma principale.
Per chiamare una funzione, è sufficiente passare i parametri richiesti insieme al nome della funzione e se la funzione restituisce un valore, è possibile memorizzare il valore restituito. Il programma seguente chiama la funzionetotalCustomers da un blocco anonimo -
DECLARE
c number(2);
BEGIN
c := totalCustomers();
dbms_output.put_line('Total no. of Customers: ' || c);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Total no. of Customers: 6
PL/SQL procedure successfully completed.Esempio
L'esempio seguente mostra la dichiarazione, la definizione e il richiamo di una funzione PL / SQL semplice che calcola e restituisce il massimo di due valori.
DECLARE
a number;
b number;
c number;
FUNCTION findMax(x IN number, y IN number)
RETURN number
IS
z number;
BEGIN
IF x > y THEN
z:= x;
ELSE
Z:= y;
END IF;
RETURN z;
END;
BEGIN
a:= 23;
b:= 45;
c := findMax(a, b);
dbms_output.put_line(' Maximum of (23,45): ' || c);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Maximum of (23,45): 45
PL/SQL procedure successfully completed.Funzioni ricorsive PL / SQL
Abbiamo visto che un programma o un sottoprogramma può chiamare un altro sottoprogramma. Quando un sottoprogramma chiama se stesso, viene indicato come una chiamata ricorsiva e il processo è noto comerecursion.
Per illustrare il concetto, calcoliamo il fattoriale di un numero. Il fattoriale di un numero n è definito come -
n! = n*(n-1)!
= n*(n-1)*(n-2)!
...
= n*(n-1)*(n-2)*(n-3)... 1Il seguente programma calcola il fattoriale di un dato numero chiamando se stesso ricorsivamente:
DECLARE
num number;
factorial number;
FUNCTION fact(x number)
RETURN number
IS
f number;
BEGIN
IF x=0 THEN
f := 1;
ELSE
f := x * fact(x-1);
END IF;
RETURN f;
END;
BEGIN
num:= 6;
factorial := fact(num);
dbms_output.put_line(' Factorial '|| num || ' is ' || factorial);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Factorial 6 is 720
PL/SQL procedure successfully completed.In questo capitolo, discuteremo i cursori in PL / SQL. Oracle crea un'area di memoria, nota come area di contesto, per l'elaborazione di un'istruzione SQL, che contiene tutte le informazioni necessarie per l'elaborazione dell'istruzione; ad esempio, il numero di righe elaborate, ecc.
UN cursorè un puntatore a quest'area di contesto. PL / SQL controlla l'area di contesto tramite un cursore. Un cursore contiene le righe (una o più) restituite da un'istruzione SQL. L'insieme di righe che il cursore tiene è denominatoactive set.
È possibile nominare un cursore in modo che possa essere indicato in un programma per recuperare ed elaborare le righe restituite dall'istruzione SQL, una alla volta. Esistono due tipi di cursori:
- Cursori impliciti
- Cursori espliciti
Cursori impliciti
I cursori impliciti vengono creati automaticamente da Oracle ogni volta che viene eseguita un'istruzione SQL, quando non è presente alcun cursore esplicito per l'istruzione. I programmatori non possono controllare i cursori impliciti e le informazioni in esso contenute.
Ogni volta che viene emessa un'istruzione DML (INSERT, UPDATE e DELETE), un cursore implicito viene associato a questa istruzione. Per le operazioni INSERT, il cursore trattiene i dati che devono essere inseriti. Per le operazioni UPDATE e DELETE, il cursore identifica le righe che sarebbero interessate.
In PL / SQL, puoi fare riferimento al cursore implicito più recente come SQL cursor, che ha sempre attributi come %FOUND, %ISOPEN, %NOTFOUND, e %ROWCOUNT. Il cursore SQL ha attributi aggiuntivi,%BULK_ROWCOUNT e %BULK_EXCEPTIONS, progettato per essere utilizzato con FORALLdichiarazione. La tabella seguente fornisce la descrizione degli attributi più utilizzati:
| S.No | Attributo e descrizione |
|---|---|
| 1 | %FOUND Restituisce TRUE se un'istruzione INSERT, UPDATE o DELETE ha interessato una o più righe o un'istruzione SELECT INTO ha restituito una o più righe. In caso contrario, restituisce FALSE. |
| 2 | %NOTFOUND L'opposto logico di% FOUND. Restituisce TRUE se un'istruzione INSERT, UPDATE o DELETE non ha interessato nessuna riga o un'istruzione SELECT INTO non ha restituito alcuna riga. In caso contrario, restituisce FALSE. |
| 3 | %ISOPEN Restituisce sempre FALSE per i cursori impliciti, poiché Oracle chiude automaticamente il cursore SQL dopo aver eseguito l'istruzione SQL associata. |
| 4 | %ROWCOUNT Restituisce il numero di righe interessate da un'istruzione INSERT, UPDATE o DELETE o restituite da un'istruzione SELECT INTO. |
Si accederà a qualsiasi attributo di cursore SQL come sql%attribute_name come mostrato di seguito nell'esempio.
Esempio
Useremo la tabella CUSTOMERS che abbiamo creato e utilizzato nei capitoli precedenti.
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+Il seguente programma aggiornerà la tabella e aumenterà lo stipendio di ogni cliente di 500 e utilizzerà il SQL%ROWCOUNT attributo per determinare il numero di righe interessate -
DECLARE
total_rows number(2);
BEGIN
UPDATE customers
SET salary = salary + 500;
IF sql%notfound THEN
dbms_output.put_line('no customers selected');
ELSIF sql%found THEN
total_rows := sql%rowcount;
dbms_output.put_line( total_rows || ' customers selected ');
END IF;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
6 customers selected
PL/SQL procedure successfully completed.Se controlli i record nella tabella dei clienti, scoprirai che le righe sono state aggiornate -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2500.00 |
| 2 | Khilan | 25 | Delhi | 2000.00 |
| 3 | kaushik | 23 | Kota | 2500.00 |
| 4 | Chaitali | 25 | Mumbai | 7000.00 |
| 5 | Hardik | 27 | Bhopal | 9000.00 |
| 6 | Komal | 22 | MP | 5000.00 |
+----+----------+-----+-----------+----------+Cursori espliciti
I cursori espliciti sono cursori definiti dal programmatore per ottenere un maggiore controllo su context area. Un cursore esplicito dovrebbe essere definito nella sezione dichiarazione del blocco PL / SQL. Viene creato su un'istruzione SELECT che restituisce più di una riga.
La sintassi per creare un cursore esplicito è:
CURSOR cursor_name IS select_statement;Lavorare con un cursore esplicito include i seguenti passaggi:
- Dichiarazione del cursore per inizializzare la memoria
- Apertura del cursore per allocare la memoria
- Recupero del cursore per recuperare i dati
- Chiudere il cursore per rilasciare la memoria allocata
Dichiarazione del cursore
La dichiarazione del cursore definisce il cursore con un nome e l'istruzione SELECT associata. Ad esempio:
CURSOR c_customers IS
SELECT id, name, address FROM customers;Apertura del cursore
L'apertura del cursore alloca la memoria per il cursore e lo rende pronto per il recupero delle righe restituite dall'istruzione SQL in esso. Ad esempio, apriremo il cursore sopra definito come segue:
OPEN c_customers;Recupero del cursore
Il recupero del cursore implica l'accesso a una riga alla volta. Ad esempio, recupereremo le righe dal cursore sopra aperto come segue:
FETCH c_customers INTO c_id, c_name, c_addr;Chiusura del cursore
Chiudere il cursore significa liberare la memoria allocata. Ad esempio, chiuderemo il cursore sopra aperto come segue:
CLOSE c_customers;Esempio
Di seguito è riportato un esempio completo per illustrare i concetti di cursori espliciti & minua;
DECLARE
c_id customers.id%type;
c_name customer.name%type;
c_addr customers.address%type;
CURSOR c_customers is
SELECT id, name, address FROM customers;
BEGIN
OPEN c_customers;
LOOP
FETCH c_customers into c_id, c_name, c_addr;
EXIT WHEN c_customers%notfound;
dbms_output.put_line(c_id || ' ' || c_name || ' ' || c_addr);
END LOOP;
CLOSE c_customers;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
1 Ramesh Ahmedabad
2 Khilan Delhi
3 kaushik Kota
4 Chaitali Mumbai
5 Hardik Bhopal
6 Komal MP
PL/SQL procedure successfully completed.In questo capitolo, discuteremo dei record in PL / SQL. UNrecordè una struttura dati che può contenere elementi di dati di diverso tipo. I record sono costituiti da campi diversi, simili a una riga di una tabella di database.
Ad esempio, vuoi tenere traccia dei tuoi libri in una biblioteca. Potresti voler tenere traccia dei seguenti attributi di ogni libro, come titolo, autore, oggetto, ID libro. Un record contenente un campo per ciascuno di questi elementi consente di trattare un LIBRO come un'unità logica e consente di organizzare e rappresentare le sue informazioni in un modo migliore.
PL / SQL può gestire i seguenti tipi di record:
- Table-based
- Record basati su cursore
- Record definiti dall'utente
Record basati su tabella
L'attributo% ROWTYPE consente a un programmatore di creare table-based e cursorbased record.
Il seguente esempio illustra il concetto di table-basedrecord. Useremo la tabella CUSTOMERS che avevamo creato e utilizzato nei capitoli precedenti -
DECLARE
customer_rec customers%rowtype;
BEGIN
SELECT * into customer_rec
FROM customers
WHERE id = 5;
dbms_output.put_line('Customer ID: ' || customer_rec.id);
dbms_output.put_line('Customer Name: ' || customer_rec.name);
dbms_output.put_line('Customer Address: ' || customer_rec.address);
dbms_output.put_line('Customer Salary: ' || customer_rec.salary);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Customer ID: 5
Customer Name: Hardik
Customer Address: Bhopal
Customer Salary: 9000
PL/SQL procedure successfully completed.Record basati su cursore
Il seguente esempio illustra il concetto di cursor-basedrecord. Useremo la tabella CUSTOMERS che avevamo creato e utilizzato nei capitoli precedenti -
DECLARE
CURSOR customer_cur is
SELECT id, name, address
FROM customers;
customer_rec customer_cur%rowtype;
BEGIN
OPEN customer_cur;
LOOP
FETCH customer_cur into customer_rec;
EXIT WHEN customer_cur%notfound;
DBMS_OUTPUT.put_line(customer_rec.id || ' ' || customer_rec.name);
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
1 Ramesh
2 Khilan
3 kaushik
4 Chaitali
5 Hardik
6 Komal
PL/SQL procedure successfully completed.Record definiti dall'utente
PL / SQL fornisce un tipo di record definito dall'utente che consente di definire le diverse strutture di record. Questi record sono costituiti da diversi campi. Supponi di voler tenere traccia dei tuoi libri in una biblioteca. Potresti voler monitorare i seguenti attributi di ogni libro:
- Title
- Author
- Subject
- ID libro
Definizione di un record
Il tipo di record è definito come -
TYPE
type_name IS RECORD
( field_name1 datatype1 [NOT NULL] [:= DEFAULT EXPRESSION],
field_name2 datatype2 [NOT NULL] [:= DEFAULT EXPRESSION],
...
field_nameN datatypeN [NOT NULL] [:= DEFAULT EXPRESSION);
record-name type_name;Il record del libro viene dichiarato nel modo seguente:
DECLARE
TYPE books IS RECORD
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;Accesso ai campi
Per accedere a qualsiasi campo di un record, utilizziamo il punto (.)operatore. L'operatore di accesso ai membri è codificato come un periodo tra il nome della variabile del record e il campo a cui si desidera accedere. Di seguito è riportato un esempio per spiegare l'utilizzo del record:
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Print book 1 record
dbms_output.put_line('Book 1 title : '|| book1.title);
dbms_output.put_line('Book 1 author : '|| book1.author);
dbms_output.put_line('Book 1 subject : '|| book1.subject);
dbms_output.put_line('Book 1 book_id : ' || book1.book_id);
-- Print book 2 record
dbms_output.put_line('Book 2 title : '|| book2.title);
dbms_output.put_line('Book 2 author : '|| book2.author);
dbms_output.put_line('Book 2 subject : '|| book2.subject);
dbms_output.put_line('Book 2 book_id : '|| book2.book_id);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Book 1 title : C Programming
Book 1 author : Nuha Ali
Book 1 subject : C Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Zara Ali
Book 2 subject : Telecom Billing Tutorial
Book 2 book_id : 6495700
PL/SQL procedure successfully completed.Registra come parametri di sottoprogramma
È possibile passare un record come parametro di un sottoprogramma proprio come si passa qualsiasi altra variabile. Puoi anche accedere ai campi dei record nello stesso modo in cui hai avuto accesso nell'esempio sopra:
DECLARE
type books is record
(title varchar(50),
author varchar(50),
subject varchar(100),
book_id number);
book1 books;
book2 books;
PROCEDURE printbook (book books) IS
BEGIN
dbms_output.put_line ('Book title : ' || book.title);
dbms_output.put_line('Book author : ' || book.author);
dbms_output.put_line( 'Book subject : ' || book.subject);
dbms_output.put_line( 'Book book_id : ' || book.book_id);
END;
BEGIN
-- Book 1 specification
book1.title := 'C Programming';
book1.author := 'Nuha Ali ';
book1.subject := 'C Programming Tutorial';
book1.book_id := 6495407;
-- Book 2 specification
book2.title := 'Telecom Billing';
book2.author := 'Zara Ali';
book2.subject := 'Telecom Billing Tutorial';
book2.book_id := 6495700;
-- Use procedure to print book info
printbook(book1);
printbook(book2);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Book title : C Programming
Book author : Nuha Ali
Book subject : C Programming Tutorial
Book book_id : 6495407
Book title : Telecom Billing
Book author : Zara Ali
Book subject : Telecom Billing Tutorial
Book book_id : 6495700
PL/SQL procedure successfully completed.In questo capitolo, discuteremo delle eccezioni in PL / SQL. Un'eccezione è una condizione di errore durante l'esecuzione di un programma. PL / SQL supporta i programmatori per rilevare tali condizioni utilizzandoEXCEPTIONblocco nel programma e viene intrapresa un'azione appropriata contro la condizione di errore. Esistono due tipi di eccezioni:
- Eccezioni definite dal sistema
- Eccezioni definite dall'utente
Sintassi per la gestione delle eccezioni
La sintassi generale per la gestione delle eccezioni è la seguente. Qui puoi elencare tutte le eccezioni che puoi gestire. L'eccezione predefinita verrà gestita utilizzandoWHEN others THEN -
DECLARE
<declarations section>
BEGIN
<executable command(s)>
EXCEPTION
<exception handling goes here >
WHEN exception1 THEN
exception1-handling-statements
WHEN exception2 THEN
exception2-handling-statements
WHEN exception3 THEN
exception3-handling-statements
........
WHEN others THEN
exception3-handling-statements
END;Esempio
Scriviamo un codice per illustrare il concetto. Useremo la tabella CUSTOMERS che avevamo creato e utilizzato nei capitoli precedenti -
DECLARE
c_id customers.id%type := 8;
c_name customerS.Name%type;
c_addr customers.address%type;
BEGIN
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
EXCEPTION
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
No such customer!
PL/SQL procedure successfully completed.Il programma sopra mostra il nome e l'indirizzo di un cliente il cui ID è stato fornito. Poiché non vi è alcun cliente con valore ID 8 nel nostro database, il programma genera l'eccezione di runtimeNO_DATA_FOUND, che viene acquisito in EXCEPTION block.
Sollevare eccezioni
Le eccezioni vengono sollevate automaticamente dal server del database ogni volta che si verifica un errore interno al database, ma le eccezioni possono essere sollevate esplicitamente dal programmatore utilizzando il comando RAISE. Di seguito è riportata la semplice sintassi per sollevare un'eccezione:
DECLARE
exception_name EXCEPTION;
BEGIN
IF condition THEN
RAISE exception_name;
END IF;
EXCEPTION
WHEN exception_name THEN
statement;
END;È possibile utilizzare la sintassi precedente per sollevare l'eccezione standard Oracle o qualsiasi eccezione definita dall'utente. Nella sezione successiva, ti forniremo un esempio sulla generazione di un'eccezione definita dall'utente. È possibile aumentare le eccezioni standard Oracle in modo simile.
Eccezioni definite dall'utente
PL / SQL ti consente di definire le tue eccezioni in base alle necessità del tuo programma. Un'eccezione definita dall'utente deve essere dichiarata e quindi sollevata in modo esplicito, utilizzando un'istruzione RAISE o la proceduraDBMS_STANDARD.RAISE_APPLICATION_ERROR.
La sintassi per dichiarare un'eccezione è:
DECLARE
my-exception EXCEPTION;Esempio
L'esempio seguente illustra il concetto. Questo programma richiede un ID cliente, quando l'utente immette un ID non valido, l'eccezioneinvalid_id viene sollevato.
DECLARE
c_id customers.id%type := &cc_id;
c_name customerS.Name%type;
c_addr customers.address%type;
-- user defined exception
ex_invalid_id EXCEPTION;
BEGIN
IF c_id <= 0 THEN
RAISE ex_invalid_id;
ELSE
SELECT name, address INTO c_name, c_addr
FROM customers
WHERE id = c_id;
DBMS_OUTPUT.PUT_LINE ('Name: '|| c_name);
DBMS_OUTPUT.PUT_LINE ('Address: ' || c_addr);
END IF;
EXCEPTION
WHEN ex_invalid_id THEN
dbms_output.put_line('ID must be greater than zero!');
WHEN no_data_found THEN
dbms_output.put_line('No such customer!');
WHEN others THEN
dbms_output.put_line('Error!');
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Enter value for cc_id: -6 (let's enter a value -6)
old 2: c_id customers.id%type := &cc_id;
new 2: c_id customers.id%type := -6;
ID must be greater than zero!
PL/SQL procedure successfully completed.Eccezioni predefinite
PL / SQL fornisce molte eccezioni predefinite, che vengono eseguite quando una regola del database viene violata da un programma. Ad esempio, l'eccezione predefinita NO_DATA_FOUND viene sollevata quando un'istruzione SELECT INTO non restituisce alcuna riga. La tabella seguente elenca alcune delle importanti eccezioni predefinite:
| Eccezione | Errore Oracle | SQLCODE | Descrizione |
|---|---|---|---|
| ACCESS_INTO_NULL | 06530 | -6530 | Viene generato quando a un oggetto nullo viene assegnato automaticamente un valore. |
| CASE_NOT_FOUND | 06592 | -6592 | Viene generato quando nessuna delle scelte nella clausola WHEN di un'istruzione CASE è selezionata e non è presente alcuna clausola ELSE. |
| COLLECTION_IS_NULL | 06531 | -6531 | Viene generato quando un programma tenta di applicare metodi di raccolta diversi da EXISTS a una tabella nidificata o varray non inizializzata o il programma tenta di assegnare valori agli elementi di una tabella nidificata o varray non inizializzata. |
| DUP_VAL_ON_INDEX | 00001 | -1 | Viene generato quando si tenta di memorizzare valori duplicati in una colonna con indice univoco. |
| INVALID_CURSOR | 01001 | -1001 | Viene generato quando si tenta di eseguire un'operazione del cursore non consentita, come la chiusura di un cursore non aperto. |
| NUMERO NON VALIDO | 01722 | -1722 | Viene generato quando la conversione di una stringa di caratteri in un numero fallisce perché la stringa non rappresenta un numero valido. |
| LOGIN_DENIED | 01017 | -1017 | It is raised when a program attempts to log on to the database with an invalid username or password. |
| NO_DATA_FOUND | 01403 | +100 | It is raised when a SELECT INTO statement returns no rows. |
| NOT_LOGGED_ON | 01012 | -1012 | It is raised when a database call is issued without being connected to the database. |
| PROGRAM_ERROR | 06501 | -6501 | It is raised when PL/SQL has an internal problem. |
| ROWTYPE_MISMATCH | 06504 | -6504 | It is raised when a cursor fetches value in a variable having incompatible data type. |
| SELF_IS_NULL | 30625 | -30625 | It is raised when a member method is invoked, but the instance of the object type was not initialized. |
| STORAGE_ERROR | 06500 | -6500 | It is raised when PL/SQL ran out of memory or memory was corrupted. |
| TOO_MANY_ROWS | 01422 | -1422 | It is raised when a SELECT INTO statement returns more than one row. |
| VALUE_ERROR | 06502 | -6502 | It is raised when an arithmetic, conversion, truncation, or sizeconstraint error occurs. |
| ZERO_DIVIDE | 01476 | 1476 | It is raised when an attempt is made to divide a number by zero. |
In this chapter, we will discuss Triggers in PL/SQL. Triggers are stored programs, which are automatically executed or fired when some events occur. Triggers are, in fact, written to be executed in response to any of the following events −
A database manipulation (DML) statement (DELETE, INSERT, or UPDATE)
A database definition (DDL) statement (CREATE, ALTER, or DROP).
A database operation (SERVERERROR, LOGON, LOGOFF, STARTUP, or SHUTDOWN).
Triggers can be defined on the table, view, schema, or database with which the event is associated.
Benefits of Triggers
Triggers can be written for the following purposes −
- Generating some derived column values automatically
- Enforcing referential integrity
- Event logging and storing information on table access
- Auditing
- Synchronous replication of tables
- Imposing security authorizations
- Preventing invalid transactions
Creating Triggers
The syntax for creating a trigger is −
CREATE [OR REPLACE ] TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condition)
DECLARE
Declaration-statements
BEGIN
Executable-statements
EXCEPTION
Exception-handling-statements
END;Where,
CREATE [OR REPLACE] TRIGGER trigger_name − Creates or replaces an existing trigger with the trigger_name.
{BEFORE | AFTER | INSTEAD OF} − This specifies when the trigger will be executed. The INSTEAD OF clause is used for creating trigger on a view.
{INSERT [OR] | UPDATE [OR] | DELETE} − This specifies the DML operation.
[OF col_name] − This specifies the column name that will be updated.
[ON table_name] − This specifies the name of the table associated with the trigger.
[REFERENCING OLD AS o NEW AS n] − This allows you to refer new and old values for various DML statements, such as INSERT, UPDATE, and DELETE.
[FOR EACH ROW] − This specifies a row-level trigger, i.e., the trigger will be executed for each row being affected. Otherwise the trigger will execute just once when the SQL statement is executed, which is called a table level trigger.
WHEN (condition) − This provides a condition for rows for which the trigger would fire. This clause is valid only for row-level triggers.
Esempio
Per cominciare, utilizzeremo la tabella CLIENTI che abbiamo creato e utilizzato nei capitoli precedenti -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+Il seguente programma crea un file row-leveltrigger per la tabella clienti che verrebbe attivato per le operazioni INSERT o UPDATE o DELETE eseguite sulla tabella CUSTOMERS. Questo trigger mostrerà la differenza di stipendio tra i vecchi valori e i nuovi valori -
CREATE OR REPLACE TRIGGER display_salary_changes
BEFORE DELETE OR INSERT OR UPDATE ON customers
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
sal_diff number;
BEGIN
sal_diff := :NEW.salary - :OLD.salary;
dbms_output.put_line('Old salary: ' || :OLD.salary);
dbms_output.put_line('New salary: ' || :NEW.salary);
dbms_output.put_line('Salary difference: ' || sal_diff);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Trigger created.I seguenti punti devono essere considerati qui:
I riferimenti VECCHIO e NUOVO non sono disponibili per i trigger a livello di tabella, ma è possibile utilizzarli per i trigger a livello di record.
Se si desidera eseguire una query sulla tabella nello stesso trigger, è necessario utilizzare la parola chiave AFTER, poiché i trigger possono eseguire query sulla tabella o modificarla di nuovo solo dopo aver applicato le modifiche iniziali e la tabella è tornata in uno stato coerente.
Il trigger sopra è stato scritto in modo tale da attivarsi prima di qualsiasi operazione DELETE o INSERT o UPDATE sulla tabella, ma puoi scrivere il trigger su una o più operazioni, ad esempio BEFORE DELETE, che si attiverà ogni volta che un record verrà cancellato utilizzando l'operazione DELETE sulla tabella.
Attivazione di un trigger
Eseguiamo alcune operazioni DML sulla tabella CUSTOMERS. Ecco un'istruzione INSERT, che creerà un nuovo record nella tabella:
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'Kriti', 22, 'HP', 7500.00 );Quando viene creato un record nella tabella CUSTOMERS, il trigger di creazione precedente, display_salary_changes verrà attivato e visualizzerà il seguente risultato:
Old salary:
New salary: 7500
Salary difference:Poiché si tratta di un nuovo record, il vecchio stipendio non è disponibile e il risultato precedente risulta nullo. Eseguiamo ora un'altra operazione DML sulla tabella CUSTOMERS. L'istruzione UPDATE aggiornerà un record esistente nella tabella -
UPDATE customers
SET salary = salary + 500
WHERE id = 2;Quando un record viene aggiornato nella tabella CUSTOMERS, il precedente crea trigger, display_salary_changes verrà attivato e visualizzerà il seguente risultato:
Old salary: 1500
New salary: 2000
Salary difference: 500In questo capitolo, discuteremo i pacchetti in PL / SQL. I pacchetti sono oggetti schema che raggruppano tipi, variabili e sottoprogrammi PL / SQL correlati logicamente.
Un pacchetto avrà due parti obbligatorie:
- Specifica del pacchetto
- Corpo o definizione del pacchetto
Specifica del pacchetto
La specifica è l'interfaccia del pacchetto. E 'soloDECLARESi tipi, le variabili, le costanti, le eccezioni, i cursori e i sottoprogrammi a cui è possibile fare riferimento dall'esterno del pacchetto. In altre parole, contiene tutte le informazioni sul contenuto del pacchetto, ma esclude il codice per i sottoprogrammi.
Vengono chiamati tutti gli oggetti inseriti nella specifica publicoggetti. Qualsiasi sottoprogramma non nella specifica del pacchetto ma codificato nel corpo del pacchetto è chiamato aprivate oggetto.
Il frammento di codice seguente mostra una specifica del pacchetto con un'unica procedura. È possibile definire molte variabili globali e più procedure o funzioni all'interno di un pacchetto.
CREATE PACKAGE cust_sal AS
PROCEDURE find_sal(c_id customers.id%type);
END cust_sal;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Package created.Corpo del pacchetto
Il corpo del pacchetto ha i codici per vari metodi dichiarati nella specifica del pacchetto e altre dichiarazioni private, che sono nascosti dal codice all'esterno del pacchetto.
Il CREATE PACKAGE BODYL'istruzione viene utilizzata per creare il corpo del pacchetto. Il frammento di codice seguente mostra la dichiarazione del corpo del pacchetto percust_salpacchetto creato sopra. Presumo che abbiamo già la tabella CUSTOMERS creata nel nostro database come menzionato nel capitolo PL / SQL - Variabili .
CREATE OR REPLACE PACKAGE BODY cust_sal AS
PROCEDURE find_sal(c_id customers.id%TYPE) IS
c_sal customers.salary%TYPE;
BEGIN
SELECT salary INTO c_sal
FROM customers
WHERE id = c_id;
dbms_output.put_line('Salary: '|| c_sal);
END find_sal;
END cust_sal;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Package body created.Utilizzo degli elementi del pacchetto
Gli elementi del pacchetto (variabili, procedure o funzioni) sono accessibili con la seguente sintassi:
package_name.element_name;Considera, abbiamo già creato il pacchetto sopra nel nostro schema di database, il seguente programma usa il find_sal metodo del cust_sal pacchetto -
DECLARE
code customers.id%type := &cc_id;
BEGIN
cust_sal.find_sal(code);
END;
/Quando il codice sopra viene eseguito al prompt SQL, richiede di inserire l'ID cliente e quando si inserisce un ID, visualizza lo stipendio corrispondente come segue:
Enter value for cc_id: 1
Salary: 3000
PL/SQL procedure successfully completed.Esempio
Il seguente programma fornisce un pacchetto più completo. Useremo la tabella CLIENTI memorizzata nel nostro database con i seguenti record:
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 3000.00 |
| 2 | Khilan | 25 | Delhi | 3000.00 |
| 3 | kaushik | 23 | Kota | 3000.00 |
| 4 | Chaitali | 25 | Mumbai | 7500.00 |
| 5 | Hardik | 27 | Bhopal | 9500.00 |
| 6 | Komal | 22 | MP | 5500.00 |
+----+----------+-----+-----------+----------+La specifica del pacchetto
CREATE OR REPLACE PACKAGE c_package AS
-- Adds a customer
PROCEDURE addCustomer(c_id customers.id%type,
c_name customerS.No.ame%type,
c_age customers.age%type,
c_addr customers.address%type,
c_sal customers.salary%type);
-- Removes a customer
PROCEDURE delCustomer(c_id customers.id%TYPE);
--Lists all customers
PROCEDURE listCustomer;
END c_package;
/Quando il codice sopra viene eseguito al prompt SQL, crea il pacchetto sopra e visualizza il seguente risultato:
Package created.Creazione del corpo del pacchetto
CREATE OR REPLACE PACKAGE BODY c_package AS
PROCEDURE addCustomer(c_id customers.id%type,
c_name customerS.No.ame%type,
c_age customers.age%type,
c_addr customers.address%type,
c_sal customers.salary%type)
IS
BEGIN
INSERT INTO customers (id,name,age,address,salary)
VALUES(c_id, c_name, c_age, c_addr, c_sal);
END addCustomer;
PROCEDURE delCustomer(c_id customers.id%type) IS
BEGIN
DELETE FROM customers
WHERE id = c_id;
END delCustomer;
PROCEDURE listCustomer IS
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list is TABLE OF customers.Name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer(' ||counter|| ')'||name_list(counter));
END LOOP;
END listCustomer;
END c_package;
/L'esempio sopra fa uso di nested table. Discuteremo il concetto di tabella annidata nel prossimo capitolo.
Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Package body created.Utilizzo del pacchetto
Il seguente programma utilizza i metodi dichiarati e definiti nel pacchetto c_package .
DECLARE
code customers.id%type:= 8;
BEGIN
c_package.addcustomer(7, 'Rajnish', 25, 'Chennai', 3500);
c_package.addcustomer(8, 'Subham', 32, 'Delhi', 7500);
c_package.listcustomer;
c_package.delcustomer(code);
c_package.listcustomer;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
Customer(7): Rajnish
Customer(8): Subham
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
Customer(7): Rajnish
PL/SQL procedure successfully completedIn questo capitolo, discuteremo le collezioni in PL / SQL. Una raccolta è un gruppo ordinato di elementi con lo stesso tipo di dati. Ogni elemento è identificato da un pedice univoco che ne rappresenta la posizione nella raccolta.
PL / SQL fornisce tre tipi di raccolta:
- Tabelle indicizzate o array associativo
- Tabella annidata
- Array di dimensioni variabili o Varray
La documentazione Oracle fornisce le seguenti caratteristiche per ogni tipo di raccolte:
| Tipo di raccolta | Numero di elementi | Tipo pedice | Denso o scarso | Dove creato | Può essere un attributo del tipo di oggetto |
|---|---|---|---|---|---|
| Matrice associativa (o indice per tabella) | Illimitato | Stringa o numero intero | O | Solo nel blocco PL / SQL | No |
| Tabella annidata | Illimitato | Numero intero | Inizia denso, può diventare scarso | O nel blocco PL / SQL oa livello di schema | sì |
| Array di dimensioni variabili (Varray) | Delimitato | Numero intero | Sempre denso | O nel blocco PL / SQL oa livello di schema | sì |
Abbiamo già discusso di varray nel capitolo 'PL/SQL arrays'. In questo capitolo, discuteremo le tabelle PL / SQL.
Entrambi i tipi di tabelle PL / SQL, cioè le tabelle index-by e le tabelle nidificate hanno la stessa struttura e le loro righe sono accessibili utilizzando la notazione del pedice. Tuttavia, questi due tipi di tabelle differiscono in un aspetto; le tabelle nidificate possono essere memorizzate in una colonna del database e le tabelle index-by non possono.
Indice per tabella
Un index-by table (chiamato anche associative array) è un insieme di key-valuecoppie. Ogni chiave è univoca e viene utilizzata per individuare il valore corrispondente. La chiave può essere un numero intero o una stringa.
Una tabella index-by viene creata utilizzando la seguente sintassi. Qui stiamo creando un fileindex-by tabella denominata table_name, le cui chiavi saranno del tipo subscript_type e i valori associati saranno del element_type
TYPE type_name IS TABLE OF element_type [NOT NULL] INDEX BY subscript_type;
table_name type_name;Esempio
L'esempio seguente mostra come creare una tabella per memorizzare valori interi insieme ai nomi e successivamente stampa lo stesso elenco di nomi.
DECLARE
TYPE salary IS TABLE OF NUMBER INDEX BY VARCHAR2(20);
salary_list salary;
name VARCHAR2(20);
BEGIN
-- adding elements to the table
salary_list('Rajnish') := 62000;
salary_list('Minakshi') := 75000;
salary_list('Martin') := 100000;
salary_list('James') := 78000;
-- printing the table
name := salary_list.FIRST;
WHILE name IS NOT null LOOP
dbms_output.put_line
('Salary of ' || name || ' is ' || TO_CHAR(salary_list(name)));
name := salary_list.NEXT(name);
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Salary of James is 78000
Salary of Martin is 100000
Salary of Minakshi is 75000
Salary of Rajnish is 62000
PL/SQL procedure successfully completed.Esempio
Gli elementi di una tabella index-by potrebbero anche essere un file %ROWTYPE di qualsiasi tabella di database o %TYPEdi qualsiasi campo della tabella del database. L'esempio seguente illustra il concetto. Useremo il fileCUSTOMERS tabella memorizzata nel nostro database come -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+DECLARE
CURSOR c_customers is
select name from customers;
TYPE c_list IS TABLE of customers.Name%type INDEX BY binary_integer;
name_list c_list;
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_lis t(counter));
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
PL/SQL procedure successfully completedTabelle annidate
UN nested tableè come un array unidimensionale con un numero arbitrario di elementi. Tuttavia, una tabella nidificata differisce da un array nei seguenti aspetti:
Un array ha un numero dichiarato di elementi, ma una tabella nidificata no. La dimensione di una tabella nidificata può aumentare in modo dinamico.
Un array è sempre denso, cioè ha sempre pedici consecutivi. Un array annidato è inizialmente denso, ma può diventare sparso quando gli elementi vengono eliminati da esso.
Una tabella nidificata viene creata utilizzando la seguente sintassi:
TYPE type_name IS TABLE OF element_type [NOT NULL];
table_name type_name;Questa dichiarazione è simile alla dichiarazione di un file index-by tavolo, ma non c'è INDEX BY clausola.
Una tabella nidificata può essere archiviata in una colonna del database. Può inoltre essere utilizzato per semplificare le operazioni SQL in cui si unisce una tabella a colonna singola con una tabella più grande. Non è possibile memorizzare un array associativo nel database.
Esempio
I seguenti esempi illustrano l'uso della tabella nidificata:
DECLARE
TYPE names_table IS TABLE OF VARCHAR2(10);
TYPE grades IS TABLE OF INTEGER;
names names_table;
marks grades;
total integer;
BEGIN
names := names_table('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i IN 1 .. total LOOP
dbms_output.put_line('Student:'||names(i)||', Marks:' || marks(i));
end loop;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Total 5 Students
Student:Kavita, Marks:98
Student:Pritam, Marks:97
Student:Ayan, Marks:78
Student:Rishav, Marks:87
Student:Aziz, Marks:92
PL/SQL procedure successfully completed.Esempio
Elementi di a nested table può anche essere un file %ROWTYPEdi qualsiasi tabella di database o% TYPE di qualsiasi campo della tabella di database. L'esempio seguente illustra il concetto. Useremo la tabella CUSTOMERS memorizzata nel nostro database come -
Select * from customers;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+DECLARE
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list IS TABLE of customerS.No.ame%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_list(counter));
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Customer(1): Ramesh
Customer(2): Khilan
Customer(3): kaushik
Customer(4): Chaitali
Customer(5): Hardik
Customer(6): Komal
PL/SQL procedure successfully completed.Metodi di raccolta
PL / SQL fornisce i metodi di raccolta incorporati che semplificano l'utilizzo delle raccolte. La tabella seguente elenca i metodi e il loro scopo:
| S.No | Nome metodo e scopo |
|---|---|
| 1 | EXISTS(n) Restituisce TRUE se esiste l'ennesimo elemento in una raccolta; altrimenti restituisce FALSE. |
| 2 | COUNT Restituisce il numero di elementi attualmente contenuti in una raccolta. |
| 3 | LIMIT Controlla la dimensione massima di una raccolta. |
| 4 | FIRST Restituisce i primi numeri di indice (più piccoli) in una raccolta che utilizza gli indici interi. |
| 5 | LAST Restituisce gli ultimi numeri di indice (più grandi) in una raccolta che utilizza gli indici interi. |
| 6 | PRIOR(n) Restituisce il numero di indice che precede l'indice n in una raccolta. |
| 7 | NEXT(n) Restituisce il numero di indice che segue l'indice n. |
| 8 | EXTEND Aggiunge un elemento null a una raccolta. |
| 9 | EXTEND(n) Aggiunge n elementi null a una raccolta. |
| 10 | EXTEND(n,i) Aggiunge ncopie dell'i- esimo elemento in una raccolta. |
| 11 | TRIM Rimuove un elemento dalla fine di una raccolta. |
| 12 | TRIM(n) Rimuove n elementi dalla fine di una raccolta. |
| 13 | DELETE Rimuove tutti gli elementi da una raccolta, impostando COUNT su 0. |
| 14 | DELETE(n) Rimuove il file nthelemento da un array associativo con un tasto numerico o una tabella nidificata. Se l'array associativo ha una chiave stringa, l'elemento corrispondente al valore della chiave viene eliminato. Sen è zero, DELETE(n) non fa nulla. |
| 15 | DELETE(m,n) Rimuove tutti gli elementi nell'intervallo m..nda un array associativo o da una tabella nidificata. Sem è maggiore di n o se m o n è zero, DELETE(m,n) non fa nulla. |
Eccezioni raccolte
La tabella seguente fornisce le eccezioni di raccolta e quando vengono sollevate:
| Eccezione raccolta | Cresciuto in situazioni |
|---|---|
| COLLECTION_IS_NULL | Si tenta di operare su una raccolta atomicamente nulla. |
| NESSUN DATO TROVATO | Un pedice designa un elemento che è stato eliminato o un elemento inesistente di un array associativo. |
| SUBSCRIPT_BEYOND_COUNT | Un pedice supera il numero di elementi in una raccolta. |
| SUBSCRIPT_OUTSIDE_LIMIT | Un pedice è al di fuori dell'intervallo consentito. |
| VALUE_ERROR | Un pedice è nullo o non convertibile nel tipo di chiave. Questa eccezione potrebbe verificarsi se la chiave è definita comePLS_INTEGER intervallo e il pedice è al di fuori di questo intervallo. |
In questo capitolo, discuteremo le transazioni in PL / SQL. Un databasetransactionè un'unità atomica di lavoro che può consistere in una o più istruzioni SQL correlate. È chiamato atomico perché le modifiche al database provocate dalle istruzioni SQL che costituiscono una transazione possono essere collettivamente impegnate, cioè rese permanenti al database o annullate (annullate) dal database.
Un'istruzione SQL eseguita con successo e una transazione confermata non sono la stessa cosa. Anche se un'istruzione SQL viene eseguita correttamente, a meno che non venga eseguito il commit della transazione contenente l'istruzione, è possibile eseguire il rollback e tutte le modifiche apportate dalle istruzioni possono essere annullate.
Avvio e conclusione di una transazione
Una transazione ha un'estensione beginning e un end. Una transazione inizia quando si verifica uno dei seguenti eventi:
La prima istruzione SQL viene eseguita dopo la connessione al database.
Ad ogni nuova istruzione SQL emessa dopo il completamento di una transazione.
Una transazione termina quando si verifica uno dei seguenti eventi:
UN COMMIT o a ROLLBACK viene emessa una dichiarazione.
UN DDL dichiarazione, come CREATE TABLEdichiarazione, viene emessa; perché in quel caso viene eseguito automaticamente un COMMIT.
UN DCL dichiarazione, come un file GRANTdichiarazione, viene emessa; perché in quel caso viene eseguito automaticamente un COMMIT.
L'utente si disconnette dal database.
L'utente esce da SQL*PLUS emettendo il EXIT comando, viene eseguito automaticamente un COMMIT.
SQL * Plus termina in modo anomalo, a ROLLBACK viene eseguito automaticamente.
UN DMLdichiarazione fallisce; in tal caso viene eseguito automaticamente un ROLLBACK per annullare l'istruzione DML.
Commettere una transazione
Una transazione viene resa permanente mediante l'emissione del comando SQL COMMIT. La sintassi generale per il comando COMMIT è:
COMMIT;Per esempio,
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'kaushik', 23, 'Kota', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Komal', 22, 'MP', 4500.00 );
COMMIT;Rollback delle transazioni
Le modifiche apportate al database senza COMMIT potrebbero essere annullate utilizzando il comando ROLLBACK.
La sintassi generale per il comando ROLLBACK è:
ROLLBACK [TO SAVEPOINT < savepoint_name>];Quando una transazione viene interrotta a causa di una situazione senza precedenti, come un errore di sistema, l'intera transazione poiché un commit viene automaticamente annullato. Se non stai usandosavepoint, quindi usa semplicemente la seguente istruzione per ripristinare tutte le modifiche:
ROLLBACK;Punti di salvataggio
I punti di salvataggio sono una sorta di indicatori che aiutano a suddividere una lunga transazione in unità più piccole impostando alcuni punti di controllo. Impostando i punti di salvataggio all'interno di una transazione lunga, è possibile eseguire il rollback a un punto di controllo, se necessario. Questo viene fatto emettendo ilSAVEPOINT comando.
La sintassi generale per il comando SAVEPOINT è:
SAVEPOINT < savepoint_name >;Per esempio
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'Rajnish', 27, 'HP', 9500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (8, 'Riddhi', 21, 'WB', 4500.00 );
SAVEPOINT sav1;
UPDATE CUSTOMERS
SET SALARY = SALARY + 1000;
ROLLBACK TO sav1;
UPDATE CUSTOMERS
SET SALARY = SALARY + 1000
WHERE ID = 7;
UPDATE CUSTOMERS
SET SALARY = SALARY + 1000
WHERE ID = 8;
COMMIT;ROLLBACK TO sav1 - Questa istruzione ripristina tutte le modifiche fino al punto in cui avevi contrassegnato savepoint sav1.
Successivamente, inizieranno le nuove modifiche che apporti.
Controllo automatico delle transazioni
Per eseguire un file COMMIT automaticamente ogni volta che un file INSERT, UPDATE o DELETE comando viene eseguito, è possibile impostare il AUTOCOMMIT variabile d'ambiente come -
SET AUTOCOMMIT ON;È possibile disattivare la modalità di commit automatico utilizzando il seguente comando:
SET AUTOCOMMIT OFF;In questo capitolo, discuteremo la data e l'ora in PL / SQL. Esistono due classi di tipi di dati relativi a data e ora in PL / SQL:
- Tipi di dati datetime
- Tipi di dati di intervallo
I tipi di dati Datetime sono:
- DATE
- TIMESTAMP
- TIMESTAMP CON FUSO ORARIO
- TIMESTAMP CON FUSO ORARIO LOCALE
I tipi di dati Interval sono:
- INTERVALLO DA ANNO A MESE
- INTERVALLO GIORNO AL SECONDO
Valori di campo per i tipi di dati Datetime e Interval
Tutti e due datetime e interval i tipi di dati sono costituiti da fields. I valori di questi campi determinano il valore del tipo di dati. La tabella seguente elenca i campi e i loro possibili valori per datetimes e intervalli.
| Nome campo | Valori data / ora validi | Valori di intervallo validi |
|---|---|---|
| ANNO | Da -4712 a 9999 (escluso anno 0) | Qualsiasi numero intero diverso da zero |
| MESE | Da 01 a 12 | Da 0 a 11 |
| GIORNO | Da 01 a 31 (limitato dai valori di MONTH e YEAR, secondo le regole del calendario per il locale) | Qualsiasi numero intero diverso da zero |
| ORA | Da 00 a 23 | Da 0 a 23 |
| MINUTO | Da 00 a 59 | Da 0 a 59 |
| SECONDO | Da 00 a 59,9 (n), dove 9 (n) è la precisione del tempo frazionario dei secondi La parte 9 (n) non è applicabile per DATE. |
Da 0 a 59,9 (n), dove 9 (n) è la precisione dei secondi frazionari dell'intervallo |
| TIMEZONE_HOUR | Da -12 a 14 (la gamma si adatta alle modifiche dell'ora legale) Non applicabile per DATE o TIMESTAMP. |
Non applicabile |
| TIMEZONE_MINUTE | Da 00 a 59 Non applicabile per DATE o TIMESTAMP. |
Non applicabile |
| TIMEZONE_REGION | Non applicabile per DATE o TIMESTAMP. | Non applicabile |
| TIMEZONE_ABBR | Non applicabile per DATE o TIMESTAMP. | Non applicabile |
I tipi di dati e le funzioni Datetime
Di seguito sono riportati i tipi di dati Datetime:
DATA
Memorizza le informazioni su data e ora sia nei tipi di dati carattere che numerici. È composto da informazioni su secolo, anno, mese, data, ora, minuti e secondi. È specificato come -
TIMESTAMP
È un'estensione del tipo di dati DATE. Memorizza l'anno, il mese e il giorno del tipo di dati DATE, insieme ai valori di ora, minuti e secondi. È utile per memorizzare valori temporali precisi.
TIMESTAMP CON FUSO ORARIO
È una variante di TIMESTAMP che include un nome di regione del fuso orario o una differenza di fuso orario nel suo valore. La differenza di fuso orario è la differenza (in ore e minuti) tra l'ora locale e UTC. Questo tipo di dati è utile per raccogliere e valutare le informazioni sulla data in aree geografiche.
TIMESTAMP CON FUSO ORARIO LOCALE
È un'altra variante di TIMESTAMP che include un offset del fuso orario nel suo valore.
La tabella seguente fornisce le funzioni Datetime (dove x ha il valore datetime) -
| S.No | Nome e descrizione della funzione |
|---|---|
| 1 | ADD_MONTHS(x, y); Aggiunge y mesi a x. |
| 2 | LAST_DAY(x); Restituisce l'ultimo giorno del mese. |
| 3 | MONTHS_BETWEEN(x, y); Restituisce il numero di mesi tra x e y. |
| 4 | NEXT_DAY(x, day); Restituisce la data e l'ora del giorno successivox. |
| 5 | NEW_TIME; Restituisce il valore di ora / giorno da un fuso orario specificato dall'utente. |
| 6 | ROUND(x [, unit]); Round x. |
| 7 | SYSDATE(); Restituisce il datetime corrente. |
| 8 | TRUNC(x [, unit]); Tronca x. |
Funzioni di timestamp (dove, x ha un valore di timestamp) -
| S.No | Nome e descrizione della funzione |
|---|---|
| 1 | CURRENT_TIMESTAMP(); Restituisce un TIMESTAMP WITH TIME ZONE contenente l'ora della sessione corrente insieme al fuso orario della sessione. |
| 2 | EXTRACT({ YEAR | MONTH | DAY | HOUR | MINUTE | SECOND } | { TIMEZONE_HOUR | TIMEZONE_MINUTE } | { TIMEZONE_REGION | } TIMEZONE_ABBR ) FROM x) Estrae e restituisce un anno, mese, giorno, ora, minuto, secondo o fuso orario da x. |
| 3 | FROM_TZ(x, time_zone); Converte TIMESTAMP x e il fuso orario specificato da time_zone in TIMESTAMP WITH TIMEZONE. |
| 4 | LOCALTIMESTAMP(); Restituisce un TIMESTAMP contenente l'ora locale nel fuso orario della sessione. |
| 5 | SYSTIMESTAMP(); Restituisce un TIMESTAMP WITH TIME ZONE contenente l'ora corrente del database insieme al fuso orario del database. |
| 6 | SYS_EXTRACT_UTC(x); Converte TIMESTAMP WITH TIMEZONE x in TIMESTAMP contenente la data e l'ora in UTC. |
| 7 | TO_TIMESTAMP(x, [format]); Converte la stringa x in TIMESTAMP. |
| 8 | TO_TIMESTAMP_TZ(x, [format]); Converte la stringa x in un TIMESTAMP WITH TIMEZONE. |
Esempi
I seguenti frammenti di codice illustrano l'uso delle funzioni precedenti:
Example 1
SELECT SYSDATE FROM DUAL;Output -
08/31/2012 5:25:34 PMExample 2
SELECT TO_CHAR(CURRENT_DATE, 'DD-MM-YYYY HH:MI:SS') FROM DUAL;Output -
31-08-2012 05:26:14Example 3
SELECT ADD_MONTHS(SYSDATE, 5) FROM DUAL;Output -
01/31/2013 5:26:31 PMExample 4
SELECT LOCALTIMESTAMP FROM DUAL;Output -
8/31/2012 5:26:55.347000 PMI tipi di dati e le funzioni dell'intervallo
Di seguito sono riportati i tipi di dati Interval:
IINTERVAL YEAR TO MONTH - Memorizza un periodo di tempo utilizzando i campi data / ora ANNO e MESE.
INTERVALLO DA GIORNO A SECONDO - Memorizza un periodo di tempo in termini di giorni, ore, minuti e secondi.
Funzioni di intervallo
| S.No | Nome e descrizione della funzione |
|---|---|
| 1 | NUMTODSINTERVAL(x, interval_unit); Converte il numero x in un INTERVALLO DA GIORNO A SECONDO. |
| 2 | NUMTOYMINTERVAL(x, interval_unit); Converte il numero x in un INTERVALLO DA ANNO A MESE. |
| 3 | TO_DSINTERVAL(x); Converte la stringa x in un INTERVAL DAY TO SECOND. |
| 4 | TO_YMINTERVAL(x); Converte la stringa x in un INTERVALLO DA ANNO A MESE. |
In questo capitolo, discuteremo l'output DBMS in PL / SQL. IlDBMS_OUTPUTè un pacchetto integrato che consente di visualizzare output, informazioni di debug e inviare messaggi da blocchi PL / SQL, sottoprogrammi, pacchetti e trigger. Abbiamo già utilizzato questo pacchetto durante il nostro tutorial.
Esaminiamo un piccolo frammento di codice che visualizzerà tutte le tabelle utente nel database. Provalo nel tuo database per elencare tutti i nomi delle tabelle -
BEGIN
dbms_output.put_line (user || ' Tables in the database:');
FOR t IN (SELECT table_name FROM user_tables)
LOOP
dbms_output.put_line(t.table_name);
END LOOP;
END;
/DBMS_OUTPUT Sottoprogrammi
Il pacchetto DBMS_OUTPUT ha i seguenti sottoprogrammi:
| S.No | Sottoprogramma e scopo | |
|---|---|---|
| 1 | DBMS_OUTPUT.DISABLE; Disabilita l'output del messaggio. |
|
| 2 | DBMS_OUTPUT.ENABLE(buffer_size IN INTEGER DEFAULT 20000); Abilita l'output del messaggio. Un valore NULL dibuffer_size rappresenta una dimensione del buffer illimitata. |
|
| 3 | DBMS_OUTPUT.GET_LINE (line OUT VARCHAR2, status OUT INTEGER); Recupera una singola riga di informazioni memorizzate nel buffer. |
|
| 4 | DBMS_OUTPUT.GET_LINES (lines OUT CHARARR, numlines IN OUT INTEGER); Recupera una matrice di righe dal buffer. |
|
| 5 | DBMS_OUTPUT.NEW_LINE; Mette un indicatore di fine linea. |
|
| 6 | DBMS_OUTPUT.PUT(item IN VARCHAR2); Inserisce una riga parziale nel buffer. |
|
| 7 | DBMS_OUTPUT.PUT_LINE(item IN VARCHAR2); Inserisce una linea nel buffer. |
Esempio
DECLARE
lines dbms_output.chararr;
num_lines number;
BEGIN
-- enable the buffer with default size 20000
dbms_output.enable;
dbms_output.put_line('Hello Reader!');
dbms_output.put_line('Hope you have enjoyed the tutorials!');
dbms_output.put_line('Have a great time exploring pl/sql!');
num_lines := 3;
dbms_output.get_lines(lines, num_lines);
FOR i IN 1..num_lines LOOP
dbms_output.put_line(lines(i));
END LOOP;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Hello Reader!
Hope you have enjoyed the tutorials!
Have a great time exploring pl/sql!
PL/SQL procedure successfully completed.In questo capitolo, discuteremo di PL / SQL orientato agli oggetti. PL / SQL consente di definire un tipo di oggetto, che aiuta nella progettazione di database orientati agli oggetti in Oracle. Un tipo di oggetto consente di creare tipi compositi. L'utilizzo di oggetti consente di implementare oggetti del mondo reale con una struttura specifica di dati e metodi per il suo funzionamento. Gli oggetti hanno attributi e metodi. Gli attributi sono proprietà di un oggetto e vengono utilizzati per memorizzare lo stato di un oggetto; e metodi sono usati per modellare il suo comportamento.
Gli oggetti vengono creati utilizzando l'istruzione CREATE [OR REPLACE] TYPE. Di seguito è riportato un esempio per creare un semplice fileaddress oggetto costituito da pochi attributi -
CREATE OR REPLACE TYPE address AS OBJECT
(house_no varchar2(10),
street varchar2(30),
city varchar2(20),
state varchar2(10),
pincode varchar2(10)
);
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.Creiamo un altro oggetto customer dove ci avvolgeremo attributes e methods insieme per avere una sensazione orientata agli oggetti -
CREATE OR REPLACE TYPE customer AS OBJECT
(code number(5),
name varchar2(30),
contact_no varchar2(12),
addr address,
member procedure display
);
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.Istanziare un oggetto
La definizione di un tipo di oggetto fornisce un modello per l'oggetto. Per utilizzare questo oggetto, è necessario creare istanze di questo oggetto. È possibile accedere agli attributi e ai metodi dell'oggetto utilizzando il nome dell'istanza ethe access operator (.) come segue -
DECLARE
residence address;
BEGIN
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');
dbms_output.put_line('House No: '|| residence.house_no);
dbms_output.put_line('Street: '|| residence.street);
dbms_output.put_line('City: '|| residence.city);
dbms_output.put_line('State: '|| residence.state);
dbms_output.put_line('Pincode: '|| residence.pincode);
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
House No: 103A
Street: M.G.Road
City: Jaipur
State: Rajasthan
Pincode: 201301
PL/SQL procedure successfully completed.Metodi dei membri
Member methods sono usati per manipolare il file attributesdell'oggetto. Fornisci la dichiarazione di un metodo membro mentre dichiari il tipo di oggetto. Il corpo dell'oggetto definisce il codice per i metodi del membro. Il corpo dell'oggetto viene creato utilizzando l'istruzione CREATE TYPE BODY.
Constructorssono funzioni che restituiscono un nuovo oggetto come valore. Ogni oggetto ha un metodo costruttore definito dal sistema. Il nome del costruttore è lo stesso del tipo di oggetto. Ad esempio:
residence := address('103A', 'M.G.Road', 'Jaipur', 'Rajasthan','201301');Il comparison methodsvengono utilizzati per confrontare gli oggetti. Esistono due modi per confrontare gli oggetti:
Metodo mappa
Il Map methodè una funzione implementata in modo tale che il suo valore dipenda dal valore degli attributi. Ad esempio, per un oggetto cliente, se il codice cliente è lo stesso per due clienti, entrambi i clienti potrebbero essere uguali. Quindi la relazione tra questi due oggetti dipenderà dal valore del codice.
Metodo di ordine
Il Order methodimplementa una logica interna per confrontare due oggetti. Ad esempio, per un oggetto rettangolo, un rettangolo è più grande di un altro rettangolo se entrambi i suoi lati sono più grandi.
Utilizzando il metodo Map
Cerchiamo di comprendere i concetti di cui sopra utilizzando il seguente oggetto rettangolo:
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
member function enlarge( inc number) return rectangle,
member procedure display,
map member function measure return number
);
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.Creazione del corpo del tipo -
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
MAP MEMBER FUNCTION measure return number IS
BEGIN
return (sqrt(length*length + width*width));
END measure;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type body created.Ora usando l'oggetto rettangolo e le sue funzioni membro -
DECLARE
r1 rectangle;
r2 rectangle;
r3 rectangle;
inc_factor number := 5;
BEGIN
r1 := rectangle(3, 4);
r2 := rectangle(5, 7);
r3 := r1.enlarge(inc_factor);
r3.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Length: 8
Width: 9
Length: 5
Width: 7
PL/SQL procedure successfully completed.Utilizzo del metodo Order
Ora il same effect could be achieved using an order method. Ricreamo l'oggetto rettangolo usando un metodo di ordinamento -
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
member procedure display,
order member function measure(r rectangle) return number
);
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.Creazione del corpo del tipo -
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
ORDER MEMBER FUNCTION measure(r rectangle) return number IS
BEGIN
IF(sqrt(self.length*self.length + self.width*self.width)>
sqrt(r.length*r.length + r.width*r.width)) then
return(1);
ELSE
return(-1);
END IF;
END measure;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type body created.Utilizzando l'oggetto rettangolo e le sue funzioni membro -
DECLARE
r1 rectangle;
r2 rectangle;
BEGIN
r1 := rectangle(23, 44);
r2 := rectangle(15, 17);
r1.display;
r2.display;
IF (r1 > r2) THEN -- calling measure function
r1.display;
ELSE
r2.display;
END IF;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Length: 23
Width: 44
Length: 15
Width: 17
Length: 23
Width: 44
PL/SQL procedure successfully completed.Ereditarietà per oggetti PL / SQL
PL / SQL consente di creare oggetti dagli oggetti di base esistenti. Per implementare l'ereditarietà, gli oggetti di base dovrebbero essere dichiarati comeNOT FINAL. L'impostazione predefinita èFINAL.
I seguenti programmi illustrano l'ereditarietà negli oggetti PL / SQL. Creiamo un altro oggetto denominatoTableTop, viene ereditato dall'oggetto Rectangle. Per questo, dobbiamo creare l' oggetto rettangolo di base -
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
member function enlarge( inc number) return rectangle,
NOT FINAL member procedure display) NOT FINAL
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.Creazione del corpo del tipo di base -
CREATE OR REPLACE TYPE BODY rectangle AS
MEMBER FUNCTION enlarge(inc number) return rectangle IS
BEGIN
return rectangle(self.length + inc, self.width + inc);
END enlarge;
MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
END display;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type body created.Creazione del piano del tavolo dell'oggetto figlio -
CREATE OR REPLACE TYPE tabletop UNDER rectangle
(
material varchar2(20),
OVERRIDING member procedure display
)
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.Creazione del corpo del tipo per il piano del tavolo dell'oggetto figlio
CREATE OR REPLACE TYPE BODY tabletop AS
OVERRIDING MEMBER PROCEDURE display IS
BEGIN
dbms_output.put_line('Length: '|| length);
dbms_output.put_line('Width: '|| width);
dbms_output.put_line('Material: '|| material);
END display;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type body created.Utilizzo dell'oggetto da tavolo e delle sue funzioni membro:
DECLARE
t1 tabletop;
t2 tabletop;
BEGIN
t1:= tabletop(20, 10, 'Wood');
t2 := tabletop(50, 30, 'Steel');
t1.display;
t2.display;
END;
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Length: 20
Width: 10
Material: Wood
Length: 50
Width: 30
Material: Steel
PL/SQL procedure successfully completed.Oggetti astratti in PL / SQL
Il NOT INSTANTIABLEla clausola ti consente di dichiarare un oggetto astratto. Non puoi usare un oggetto astratto così com'è; dovrai creare un sottotipo o un tipo figlio di tali oggetti per utilizzarne le funzionalità.
Per esempio,
CREATE OR REPLACE TYPE rectangle AS OBJECT
(length number,
width number,
NOT INSTANTIABLE NOT FINAL MEMBER PROCEDURE display)
NOT INSTANTIABLE NOT FINAL
/Quando il codice precedente viene eseguito al prompt SQL, produce il seguente risultato:
Type created.