PySpark - SparkContext
SparkContext è il punto di ingresso per qualsiasi funzionalità Spark. Quando eseguiamo un'applicazione Spark, viene avviato un programma driver, che ha la funzione principale e il tuo SparkContext viene avviato qui. Il programma driver esegue quindi le operazioni all'interno degli esecutori sui nodi di lavoro.
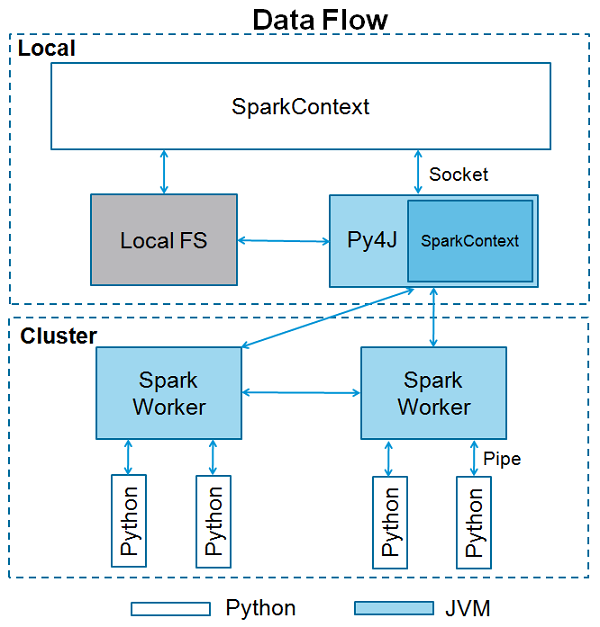
SparkContext usa Py4J per avviare un file JVM e crea un file JavaSparkContext. Per impostazione predefinita, PySpark ha SparkContext disponibile come‘sc’, quindi la creazione di un nuovo SparkContext non funzionerà.
Il blocco di codice seguente contiene i dettagli di una classe PySpark e i parametri che possono essere accettati da SparkContext.
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)Parametri
Di seguito sono riportati i parametri di SparkContext.
Master - È l'URL del cluster a cui si connette.
appName - Nome del tuo lavoro.
sparkHome - Directory di installazione di Spark.
pyFiles - I file .zip o .py da inviare al cluster e da aggiungere a PYTHONPATH.
Environment - Variabili di ambiente dei nodi di lavoro.
batchSize- Il numero di oggetti Python rappresentati come un singolo oggetto Java. Impostare 1 per disabilitare il batch, 0 per scegliere automaticamente la dimensione del batch in base alle dimensioni degli oggetti o -1 per utilizzare una dimensione del batch illimitata.
Serializer - serializzatore RDD.
Conf - Un oggetto di L {SparkConf} per impostare tutte le proprietà di Spark.
Gateway - Utilizza un gateway e una JVM esistenti, altrimenti inizializza una nuova JVM.
JSC - L'istanza JavaSparkContext.
profiler_cls - Una classe di Profiler personalizzato utilizzata per eseguire la profilazione (l'impostazione predefinita è pyspark.profiler.BasicProfiler).
Tra i parametri di cui sopra, master e appnamesono principalmente usati. Le prime due righe di qualsiasi programma PySpark hanno l'aspetto mostrato di seguito:
from pyspark import SparkContext
sc = SparkContext("local", "First App")Esempio di SparkContext - PySpark Shell
Ora che ne sai abbastanza di SparkContext, eseguiamo un semplice esempio sulla shell di PySpark. In questo esempio, conteremo il numero di righe con il carattere "a" o "b" nel fileREADME.mdfile. Quindi, diciamo se ci sono 5 righe in un file e 3 righe hanno il carattere 'a', l'output sarà →Line with a: 3. Lo stesso sarà fatto per il carattere "b".
Note- Non stiamo creando alcun oggetto SparkContext nell'esempio seguente perché, per impostazione predefinita, Spark crea automaticamente l'oggetto SparkContext denominato sc, all'avvio della shell PySpark. Nel caso in cui provi a creare un altro oggetto SparkContext, riceverai il seguente errore:"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30Esempio di SparkContext - Programma Python
Eseguiamo lo stesso esempio usando un programma Python. Crea un file Python chiamatofirstapp.py e inserisci il codice seguente in quel file.
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------Quindi eseguiremo il seguente comando nel terminale per eseguire questo file Python. Otterremo lo stesso output di cui sopra.
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30