Python Data Persistence - Guida rapida
Panoramica di Python - Data Persistence
Nel corso dell'utilizzo di qualsiasi applicazione software, l'utente fornisce alcuni dati da elaborare. I dati possono essere inseriti, utilizzando un dispositivo di input standard (tastiera) o altri dispositivi come file su disco, scanner, fotocamera, cavo di rete, connessione WiFi, ecc.
I dati così ricevuti vengono archiviati nella memoria principale del computer (RAM) sotto forma di varie strutture di dati come variabili e oggetti fino a quando l'applicazione non è in esecuzione. Successivamente, il contenuto della memoria dalla RAM viene cancellato.
Tuttavia, il più delle volte, si desidera che i valori delle variabili e / o degli oggetti siano memorizzati in modo tale da poter essere recuperati ogni volta che è necessario, invece di immettere nuovamente gli stessi dati.
La parola "persistenza" significa "la continuazione di un effetto dopo che la sua causa è stata rimossa". Il termine persistenza dei dati significa che continua a esistere anche dopo che l'applicazione è terminata. Pertanto, i dati memorizzati in un supporto di memorizzazione non volatile come un file su disco sono un archivio di dati persistente.
In questo tutorial, esploreremo vari moduli Python integrati e di terze parti per archiviare e recuperare dati in / da vari formati come file di testo, file CSV, JSON e XML, nonché database relazionali e non relazionali.
Utilizzando l'oggetto File integrato di Python, è possibile scrivere dati di stringa su un file su disco e leggerli da esso. La libreria standard di Python, fornisce moduli per archiviare e recuperare dati serializzati in varie strutture di dati come JSON e XML.
L'API DB di Python fornisce un modo standard di interagire con i database relazionali. Altri pacchetti Python di terze parti, presentano funzionalità di interfacciamento con database NOSQL come MongoDB e Cassandra.
Questo tutorial introduce anche il database ZODB che è un'API di persistenza per oggetti Python. Il formato Microsoft Excel è un formato di file di dati molto popolare. In questo tutorial impareremo come gestire il file .xlsx tramite Python.
Python usa built-in input() e print()funzioni per eseguire operazioni di input / output standard. La funzione input () legge i byte da un dispositivo di flusso di input standard, ad esempio la tastiera.
Il print()la funzione invece, invia i dati verso un dispositivo di flusso di output standard, ovvero il monitor di visualizzazione. Il programma Python interagisce con questi dispositivi IO tramite oggetti stream standardstdin e stdout definito nel modulo sys.
Il input()funzione è in realtà un wrapper intorno al metodo readline () dell'oggetto sys.stdin. Tutte le sequenze di tasti dal flusso di input vengono ricevute fino a quando non viene premuto il tasto "Invio".
>>> import sys
>>> x=sys.stdin.readline()
Welcome to TutorialsPoint
>>> x
'Welcome to TutorialsPoint\n'Nota che, readline()funzione lascia un carattere finale "\ n". Esiste anche un metodo read () che legge i dati dal flusso di input standard fino a quando non viene terminato daCtrl+D personaggio.
>>> x=sys.stdin.read()
Hello
Welcome to TutorialsPoint
>>> x
'Hello\nWelcome to TutorialsPoint\n'Allo stesso modo, print() è una comoda funzione che emula il metodo write () dell'oggetto stdout.
>>> x='Welcome to TutorialsPoint\n'
>>> sys.stdout.write(x)
Welcome to TutorialsPoint
26Proprio come gli oggetti stream predefiniti stdin e stdout, un programma Python può leggere i dati e inviarli a un file su disco oa un socket di rete. Sono anche flussi. Qualsiasi oggetto che ha il metodo read () è un flusso di input. Qualsiasi oggetto che ha il metodo write () è un flusso di output. La comunicazione con lo stream viene stabilita ottenendo il riferimento all'oggetto stream con la funzione open () incorporata.
funzione open ()
Questa funzione incorporata utilizza i seguenti argomenti:
f=open(name, mode, buffering)Il parametro name, è il nome del file su disco o della stringa di byte, la modalità è una stringa di un carattere opzionale per specificare il tipo di operazione da eseguire (lettura, scrittura, aggiunta ecc.) E il parametro di buffering è 0, 1 o -1 che indica il buffering è disattivato, attivato o predefinito di sistema.
La modalità di apertura dei file è enumerata come da tabella sottostante. La modalità predefinita è "r"
| Suor n | Parametri e descrizione |
|---|---|
| 1 | R Aperto per la lettura (impostazione predefinita) |
| 2 | W Aperto per la scrittura, troncando prima il file |
| 3 | X Crea un nuovo file e aprilo per la scrittura |
| 4 | A Aperto in scrittura, da aggiungere alla fine del file se esiste |
| 5 | B Modalità binaria |
| 6 | T Modalità testo (predefinita) |
| 7 | + Apri un file su disco per l'aggiornamento (lettura e scrittura) |
Per salvare i dati su file, è necessario aprirlo con la modalità "w".
f=open('test.txt','w')Questo oggetto file funge da flusso di output e ha accesso al metodo write (). Il metodo write () invia una stringa a questo oggetto e viene memorizzato nel file sottostante.
string="Hello TutorialsPoint\n"
f.write(string)È importante chiudere il flusso, per garantire che tutti i dati rimasti nel buffer siano completamente trasferiti ad esso.
file.close()Prova ad aprire "test.txt" utilizzando qualsiasi editor di test (come il blocco note) per confermare la corretta creazione del file.
Per leggere il contenuto di "test.txt" a livello di codice, è necessario aprirlo in modalità "r".
f=open('test.txt','r')Questo oggetto si comporta come un flusso di input. Python può recuperare i dati dal flusso usandoread() metodo.
string=f.read()
print (string)Il contenuto del file viene visualizzato sulla console Python. L'oggetto File supporta anchereadline() metodo che è in grado di leggere la stringa finché non incontra il carattere EOF.
Tuttavia, se lo stesso file viene aperto in modalità "w" per memorizzare testo aggiuntivo al suo interno, i contenuti precedenti vengono cancellati. Ogni volta che un file viene aperto con il permesso di scrittura, viene trattato come se fosse un nuovo file. Per aggiungere dati a un file esistente, utilizzare "a" per la modalità di aggiunta.
f=open('test.txt','a')
f.write('Python Tutorials\n')Il file ora ha una stringa aggiunta sia precedente che di recente. L'oggetto file supporta anchewritelines() metodo per scrivere ogni stringa in un oggetto elenco nel file.
f=open('test.txt','a')
lines=['Java Tutorials\n', 'DBMS tutorials\n', 'Mobile development tutorials\n']
f.writelines(lines)
f.close()Esempio
Il readlines()restituisce un elenco di stringhe, ciascuna delle quali rappresenta una riga nel file. È anche possibile leggere il file riga per riga fino alla fine del file.
f=open('test.txt','r')
while True:
line=f.readline()
if line=='' : break
print (line, end='')
f.close()Produzione
Hello TutorialsPoint
Python Tutorials
Java Tutorials
DBMS tutorials
Mobile development tutorialsModalità binaria
Per impostazione predefinita, le operazioni di lettura / scrittura su un oggetto file vengono eseguite sui dati della stringa di testo. Se vogliamo gestire file di diversi altri tipi come media (mp3), eseguibili (exe), immagini (jpg) ecc., Dobbiamo aggiungere il prefisso "b" per la modalità di lettura / scrittura.
La seguente istruzione convertirà una stringa in byte e la scriverà in un file.
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()La conversione della stringa di testo in byte è possibile anche utilizzando la funzione encode ().
data="Hello World".encode('utf-8')Dobbiamo usare ‘rb’modalità per leggere il file binario. Il valore restituito del metodo read () viene prima decodificato prima della stampa.
f=open('test.bin', 'rb')
data=f.read()
print (data.decode(encoding='utf-8'))Per scrivere dati interi in un file binario, l'oggetto intero deve essere convertito in byte da to_bytes() metodo.
n=25
n.to_bytes(8,'big')
f=open('test.bin', 'wb')
data=n.to_bytes(8,'big')
f.write(data)Per rileggere da un file binario, converti l'output della funzione read () in intero dalla funzione from_bytes ().
f=open('test.bin', 'rb')
data=f.read()
n=int.from_bytes(data, 'big')
print (n)Per i dati in virgola mobile, dobbiamo usare struct modulo dalla libreria standard di Python.
import struct
x=23.50
data=struct.pack('f',x)
f=open('test.bin', 'wb')
f.write(data)Decomprimere la stringa dalla funzione read (), per recuperare i dati float dal file binario.
f=open('test.bin', 'rb')
data=f.read()
x=struct.unpack('f', data)
print (x)Lettura / scrittura simultanea
Quando un file viene aperto in scrittura (con 'w' o 'a'), non è possibile leggerlo e viceversa. In questo modo viene generato l'errore UnSupportedOperation. Dobbiamo chiudere il file prima di eseguire altre operazioni.
Per eseguire entrambe le operazioni contemporaneamente, dobbiamo aggiungere il carattere '+' nel parametro mode. Quindi, la modalità 'w +' o 'r +' abilita l'uso dei metodi write () e read () senza chiudere un file. L'oggetto File supporta anche la funzione seek () per riavvolgere il flusso in qualsiasi posizione di byte desiderata.
f=open('test.txt','w+')
f.write('Hello world')
f.seek(0,0)
data=f.read()
print (data)
f.close()La tabella seguente riassume tutti i metodi disponibili per un oggetto simile a un file.
| Suor n | Metodo e descrizione |
|---|---|
| 1 | close() Chiude il file. Un file chiuso non può più essere letto o scritto. |
| 2 | flush() Lavare il tampone interno. |
| 3 | fileno() Restituisce il descrittore di file intero. |
| 4 | next() Restituisce la riga successiva dal file ogni volta che viene chiamato. Usa l'iteratore next () in Python 3. |
| 5 | read([size]) Legge al massimo i byte di dimensione dal file (meno se la lettura raggiunge EOF prima di ottenere byte di dimensione). |
| 6 | readline([size]) Legge un'intera riga dal file. Nella stringa viene mantenuto un carattere di nuova riga finale. |
| 7 | readlines([sizehint]) Legge fino a EOF utilizzando readline () e restituisce un elenco contenente le righe. |
| 8 | seek(offset[, whence]) Imposta la posizione corrente del file. 0-inizio 1-corrente 2-fine. |
| 9 | seek(offset[, whence]) Imposta la posizione corrente del file. 0-inizio 1-corrente 2-fine. |
| 10 | tell() Restituisce la posizione corrente del file |
| 11 | truncate([size]) Tronca la dimensione del file. |
| 12 | write(str) Scrive una stringa nel file. Non esiste alcun valore di ritorno. |
Oltre all'oggetto File restituito da open()funzione, le operazioni di I / O sui file possono essere eseguite anche utilizzando la libreria incorporata di Python ha un modulo os che fornisce utili funzioni dipendenti dal sistema operativo. Queste funzioni eseguono operazioni di lettura / scrittura di basso livello sul file.
Il open()la funzione dal modulo os è simile all'open () integrato. Tuttavia, non restituisce un oggetto file ma un descrittore di file, un numero intero univoco corrispondente al file aperto. I valori del descrittore di file 0, 1 e 2 rappresentano i flussi stdin, stdout e stderr. Ad altri file verrà fornito un descrittore di file incrementale da 2 in poi.
Come nel caso di open() funzione incorporata, os.open()la funzione deve anche specificare la modalità di accesso ai file. La tabella seguente elenca le varie modalità definite nel modulo os.
| Sr.No. | Modulo OS e descrizione |
|---|---|
| 1 | os.O_RDONLY Aperto solo in lettura |
| 2 | os.O_WRONLY Aperto solo per la scrittura |
| 3 | os.O_RDWR Aperto per la lettura e la scrittura |
| 4 | os.O_NONBLOCK Non bloccare in apertura |
| 5 | os.O_APPEND Aggiungi a ogni scrittura |
| 6 | os.O_CREAT Crea file se non esiste |
| 7 | os.O_TRUNC Tronca la dimensione a 0 |
| 8 | os.O_EXCL Errore se la creazione e il file esistono |
Per aprire un nuovo file per scrivere dati in esso, specificare O_WRONLY così come O_CREATmodalità inserendo l'operatore pipe (|). La funzione os.open () restituisce un descrittore di file.
f=os.open("test.dat", os.O_WRONLY|os.O_CREAT)Notare che i dati vengono scritti nel file su disco sotto forma di stringa di byte. Quindi, una stringa normale viene convertita in una stringa di byte utilizzando la funzione encode () come in precedenza.
data="Hello World".encode('utf-8')La funzione write () nel modulo os accetta questa stringa di byte e il descrittore di file.
os.write(f,data)Non dimenticare di chiudere il file usando la funzione close ().
os.close(f)Per leggere il contenuto di un file utilizzando la funzione os.read (), utilizzare le seguenti istruzioni:
f=os.open("test.dat", os.O_RDONLY)
data=os.read(f,20)
print (data.decode('utf-8'))Notare che la funzione os.read () necessita di un descrittore di file e del numero di byte da leggere (lunghezza della stringa di byte).
Se si desidera aprire un file per operazioni di lettura / scrittura simultanee, utilizzare la modalità O_RDWR. La tabella seguente mostra importanti funzioni relative al funzionamento dei file nel modulo os.
| Suor n | Funzioni e descrizione |
|---|---|
| 1 | os.close(fd) Chiudi il descrittore di file. |
| 2 | os.open(file, flags[, mode]) Apri il file e imposta vari flag in base ai flag e possibilmente la sua modalità in base alla modalità. |
| 3 | os.read(fd, n) Legge al massimo n byte dal descrittore di file fd. Restituisce una stringa contenente i byte letti. Se è stata raggiunta la fine del file a cui fa riferimento fd, viene restituita una stringa vuota. |
| 4 | os.write(fd, str) Scrivi la stringa str nel descrittore di file fd. Restituisce il numero di byte effettivamente scritti. |
L'oggetto file incorporato di Python restituito dalla funzione open () incorporata di Python ha un importante difetto. Quando viene aperto con la modalità 'w', il metodo write () accetta solo l'oggetto stringa.
Ciò significa che se i dati sono rappresentati in qualsiasi forma non stringa, l'oggetto di una delle classi incorporate (numeri, dizionario, elenchi o tuple) o altre classi definite dall'utente, non può essere scritto direttamente su file. Prima di scrivere, è necessario convertirlo nella sua rappresentazione di stringa.
numbers=[10,20,30,40]
file=open('numbers.txt','w')
file.write(str(numbers))
file.close()Per un file binario, argomento a write()il metodo deve essere un oggetto byte. Ad esempio, l'elenco di numeri interi viene convertito in byte dabytearray() funzione e quindi scritto su file.
numbers=[10,20,30,40]
data=bytearray(numbers)
file.write(data)
file.close()Per rileggere i dati dal file nel rispettivo tipo di dati, è necessario eseguire la conversione inversa.
file=open('numbers.txt','rb')
data=file.read()
print (list(data))Questo tipo di conversione manuale, di un oggetto in formato stringa o byte (e viceversa) è molto macchinoso e noioso. È possibile memorizzare lo stato di un oggetto Python sotto forma di flusso di byte direttamente in un file o flusso di memoria e ripristinarlo al suo stato originale. Questo processo è chiamato serializzazione e deserializzazione.
La libreria incorporata di Python contiene vari moduli per il processo di serializzazione e deserializzazione.
| Sr.No. | Nome e descrizione |
|---|---|
| 1 | pickle Libreria di serializzazione specifica di Python |
| 2 | marshal Libreria utilizzata internamente per la serializzazione |
| 3 | shelve Persistenza dell'oggetto pitonico |
| 4 | dbm libreria che offre interfaccia al database Unix |
| 5 | csv libreria per l'archiviazione e il recupero dei dati Python in formato CSV |
| 6 | json Libreria per la serializzazione nel formato JSON universale |
La terminologia di Python per serializzazione e deserializzazione è rispettivamente pickling e unpickling. Il modulo pickle nella libreria Python, utilizza un formato di dati specifico di Python. Pertanto, le applicazioni non Python potrebbero non essere in grado di deserializzare correttamente i dati selezionati. Si consiglia inoltre di non separare i dati da una fonte non autenticata.
I dati serializzati (decapati) possono essere memorizzati in una stringa di byte o in un file binario. Questo modulo definiscedumps() e loads()funzioni per pickle e unpickle dati usando una stringa di byte. Per il processo basato su file, il modulo hadump() e load() funzione.
I protocolli pickle di Python sono le convenzioni utilizzate nella costruzione e decostruzione di oggetti Python da / a dati binari. Attualmente, il modulo pickle definisce 5 diversi protocolli come elencato di seguito -
| Sr.No. | Nomi e descrizione |
|---|---|
| 1 | Protocol version 0 Protocollo originale "leggibile dall'uomo" compatibile con le versioni precedenti. |
| 2 | Protocol version 1 Vecchio formato binario compatibile anche con le versioni precedenti di Python. |
| 3 | Protocol version 2 Introdotto in Python 2.3 fornisce un efficiente pickling delle classi di nuovo stile. |
| 4 | Protocol version 3 Aggiunto in Python 3.0. consigliato quando è richiesta la compatibilità con altre versioni di Python 3. |
| 5 | Protocol version 4 è stato aggiunto in Python 3.4. Aggiunge il supporto per oggetti molto grandi |
Esempio
Il modulo pickle è costituito dalla funzione dumps () che restituisce una rappresentazione di stringa di dati decapati.
from pickle import dump
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
dctstring=dumps(dct)
print (dctstring)Produzione
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00Raviq\x02X\x03\x00\x00\x00ageq\x03K\x17X\x06\x00\x00\x00Genderq\x04X\x01\x00\x00\x00Mq\x05X\x05\x00\x00\x00marksq\x06KKu.Esempio
Utilizzare la funzione load () per rimuovere il pickle dalla stringa e ottenere l'oggetto dizionario originale.
from pickle import load
dct=loads(dctstring)
print (dct)Produzione
{'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}Gli oggetti decapati possono anche essere memorizzati in modo persistente in un file su disco, utilizzando la funzione dump () e recuperati utilizzando la funzione load ().
import pickle
f=open("data.txt","wb")
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
pickle.dump(dct,f)
f.close()
#to read
import pickle
f=open("data.txt","rb")
d=pickle.load(f)
print (d)
f.close()Il modulo pickle fornisce anche API orientate agli oggetti per il meccanismo di serializzazione sotto forma di Pickler e Unpickler classi.
Come accennato in precedenza, proprio come gli oggetti incorporati in Python, anche gli oggetti delle classi definite dall'utente possono essere serializzati in modo persistente nel file su disco. Nel programma seguente, definiamo una classe utente con nome e numero di cellulare come attributi di istanza. Oltre al costruttore __init __ (), la classe sovrascrive il metodo __str __ () che restituisce una rappresentazione di stringa del suo oggetto.
class User:
def __init__(self,name, mob):
self.name=name
self.mobile=mob
def __str__(self):
return ('Name: {} mobile: {} '. format(self.name, self.mobile))Per decapare l'oggetto della classe precedente in un file usiamo la classe pickler e il suo metodo dump ().
from pickle import Pickler
user1=User('Rajani', '[email protected]', '1234567890')
file=open('userdata','wb')
Pickler(file).dump(user1)
Pickler(file).dump(user2)
file.close()Al contrario, la classe Unpickler ha il metodo load () per recuperare l'oggetto serializzato come segue:
from pickle import Unpickler
file=open('usersdata','rb')
user1=Unpickler(file).load()
print (user1)Le funzionalità di serializzazione degli oggetti del modulo marshal nella libreria standard di Python sono simili al modulo pickle. Tuttavia, questo modulo non viene utilizzato per dati di uso generale. D'altra parte, viene utilizzato da Python stesso per la serializzazione interna degli oggetti di Python per supportare le operazioni di lettura / scrittura sulle versioni compilate dei moduli Python (file .pyc).
Il formato dei dati utilizzato dal modulo marshal non è compatibile con le versioni di Python. Pertanto, uno script Python compilato (file .pyc) di una versione molto probabilmente non verrà eseguito su un'altra.
Proprio come il modulo pickle, il modulo marshal ha anche definito le funzioni load () e dump () per leggere e scrivere oggetti di marshalling da / a file.
dump ()
Questa funzione scrive la rappresentazione in byte dell'oggetto Python supportato in un file. Il file stesso è un file binario con autorizzazione di scrittura
caricare()
Questa funzione legge i dati in byte da un file binario e li converte in un oggetto Python.
L'esempio seguente mostra l'uso delle funzioni dump () e load () per gestire oggetti di codice di Python, che vengono utilizzati per memorizzare moduli Python precompilati.
Il codice utilizza built-in compile() funzione per costruire un oggetto codice da una stringa sorgente che incorpora istruzioni Python.
compile(source, file, mode)Il parametro file dovrebbe essere il file da cui è stato letto il codice. Se non è stato letto da un file, passare una stringa arbitraria.
Il parametro mode è "exec" se la sorgente contiene una sequenza di istruzioni, "eval" se esiste una singola espressione o "single" se contiene una singola istruzione interattiva.
L'oggetto codice di compilazione viene quindi memorizzato in un file .pyc utilizzando la funzione dump ().
import marshal
script = """
a=10
b=20
print ('addition=',a+b)
"""
code = compile(script, "script", "exec")
f=open("a.pyc","wb")
marshal.dump(code, f)
f.close()Per deserializzare, l'oggetto dal file .pyc utilizza la funzione load (). Poiché restituisce un oggetto codice, può essere eseguito utilizzando exec (), un'altra funzione incorporata.
import marshal
f=open("a.pyc","rb")
data=marshal.load(f)
exec (data)Il modulo shelve nella libreria standard di Python fornisce un meccanismo di persistenza degli oggetti semplice ma efficace. L'oggetto scaffale definito in questo modulo è un oggetto simile a un dizionario che viene memorizzato in modo persistente in un file su disco. Questo crea un file simile al database dbm su sistemi simili a UNIX.
Il dizionario scaffale ha alcune limitazioni. Solo il tipo di dati stringa può essere utilizzato come chiave in questo oggetto dizionario speciale, mentre qualsiasi oggetto Python selezionabile può essere utilizzato come valore.
Il modulo shelve definisce tre classi come segue:
| Suor n | Modulo e descrizione di Shelve |
|---|---|
| 1 | Shelf Questa è la classe base per le implementazioni a scaffale. Viene inizializzato con un oggetto tipo dict. |
| 2 | BsdDbShelf Questa è una sottoclasse della classe Shelf. L'oggetto dict passato al suo costruttore deve supportare i metodi first (), next (), previous (), last () e set_location (). |
| 3 | DbfilenameShelf Anche questa è una sottoclasse di Shelf ma accetta un nome di file come parametro per il suo costruttore piuttosto che un oggetto dict. |
La funzione open () definita nel modulo shelve che restituisce un file DbfilenameShelf oggetto.
open(filename, flag='c', protocol=None, writeback=False)Il parametro del nome del file viene assegnato al database creato. Il valore predefinito per il parametro flag è "c" per l'accesso in lettura / scrittura. Altri flag sono "w" (solo scrittura) "r" (sola lettura) e "n" (nuovo con lettura / scrittura).
La serializzazione stessa è governata dal protocollo pickle, l'impostazione predefinita è nessuno. L'ultimo parametro di writeback del parametro per impostazione predefinita è false. Se impostato su true, le voci a cui si accede vengono memorizzate nella cache. Ogni accesso chiama le operazioni sync () e close (), quindi il processo potrebbe essere lento.
Il codice seguente crea un database e memorizza le voci del dizionario in esso.
import shelve
s=shelve.open("test")
s['name']="Ajay"
s['age']=23
s['marks']=75
s.close()Questo creerà il file test.dir nella directory corrente e memorizzerà i dati dei valori-chiave in formato hash. L'oggetto Shelf ha i seguenti metodi disponibili:
| Sr.No. | Metodi e descrizione |
|---|---|
| 1 | close() sincronizzare e chiudere l'oggetto dict persistente. |
| 2 | sync() Riscrivi tutte le voci nella cache se lo scaffale è stato aperto con il writeback impostato su True. |
| 3 | get() restituisce il valore associato alla chiave |
| 4 | items() elenco di tuple: ogni tupla è una coppia chiave-valore |
| 5 | keys() elenco delle chiavi di scaffale |
| 6 | pop() rimuove la chiave specificata e restituisce il valore corrispondente. |
| 7 | update() Aggiorna scaffale da un altro dict / iterabile |
| 8 | values() elenco dei valori di scaffale |
Per accedere al valore di una particolare chiave nello scaffale:
s=shelve.open('test')
print (s['age']) #this will print 23
s['age']=25
print (s.get('age')) #this will print 25
s.pop('marks') #this will remove corresponding k-v pairCome in un oggetto dizionario incorporato, i metodi items (), keys () e values () restituiscono oggetti di visualizzazione.
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('marks', 75)]
print (list(s.keys()))
['name', 'age', 'marks']
print (list(s.values()))
['Ajay', 25, 75]Per unire elementi di un altro dizionario con il metodo shelf usa update ().
d={'salary':10000, 'designation':'manager'}
s.update(d)
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('salary', 10000), ('designation', 'manager')]Il pacchetto dbm presenta un dizionario come i database in stile DBM dell'interfaccia. DBM stands for DataBase Manager. Viene utilizzato dal sistema operativo UNIX (e simile a UNIX). La libreria dbbm è un semplice motore di database scritto da Ken Thompson. Questi database utilizzano oggetti stringa con codifica binaria come chiave e valore.
Il database archivia i dati utilizzando una singola chiave (una chiave primaria) in bucket di dimensioni fisse e utilizza tecniche di hashing per consentire il recupero rapido dei dati tramite chiave.
Il pacchetto dbm contiene i seguenti moduli:
dbm.gnu module è un'interfaccia per la versione della libreria DBM implementata dal progetto GNU.
dbm.ndbm Il modulo fornisce un'interfaccia all'implementazione di UNIX nbdm.
dbm.dumbviene utilizzato come opzione di fallback nel caso in cui non vengano trovate altre implementazioni dbm. Ciò non richiede dipendenze esterne ma è più lento di altri.
>>> dbm.whichdb('mydbm.db')
'dbm.dumb'
>>> import dbm
>>> db=dbm.open('mydbm.db','n')
>>> db['name']=Raj Deshmane'
>>> db['address']='Kirtinagar Pune'
>>> db['PIN']='431101'
>>> db.close()La funzione open () consente la modalità di questi flag:
| Sr.No. | Valore e significato |
|---|---|
| 1 | 'r' Apri database esistente in sola lettura (impostazione predefinita) |
| 2 | 'w' Apri il database esistente per la lettura e la scrittura |
| 3 | 'c' Apri database per la lettura e la scrittura, creandolo se non esiste |
| 4 | 'n' Crea sempre un nuovo database vuoto, aperto per la lettura e la scrittura |
L'oggetto dbm è un oggetto simile a un dizionario, proprio come un oggetto shelf. Quindi, tutte le operazioni del dizionario possono essere eseguite. L'oggetto dbm può richiamare i metodi get (), pop (), append () e update (). Il codice seguente apre "mydbm.db" con il flag "r" e ripete la raccolta di coppie chiave-valore.
>>> db=dbm.open('mydbm.db','r')
>>> for k,v in db.items():
print (k,v)
b'name' : b'Raj Deshmane'
b'address' : b'Kirtinagar Pune'
b'PIN' : b'431101'CSV stands for comma separated values. Questo formato di file è un formato di dati comunemente utilizzato durante l'esportazione / importazione di dati da / verso fogli di calcolo e tabelle di dati nei database. Il modulo csv è stato incorporato nella libreria standard di Python come risultato di PEP 305. Presenta classi e metodi per eseguire operazioni di lettura / scrittura su file CSV secondo le raccomandazioni di PEP 305.
CSV è un formato di dati di esportazione preferito dal software per fogli di calcolo Excel di Microsoft. Tuttavia, il modulo csv può gestire anche dati rappresentati da altri dialetti.
L'interfaccia dell'API CSV è composta dalle seguenti classi di scrittore e lettore:
scrittore()
Questa funzione nel modulo csv restituisce un oggetto writer che converte i dati in una stringa delimitata e li memorizza in un oggetto file. La funzione necessita di un oggetto file con autorizzazione di scrittura come parametro. Ogni riga scritta nel file emette un carattere di nuova riga. Per evitare spazio aggiuntivo tra le righe, il parametro di nuova riga è impostato su "".
La classe writer ha i seguenti metodi:
writerow ()
Questo metodo scrive gli elementi in un iterabile (elenco, tupla o stringa), separandoli dal carattere virgola.
writerows ()
Questo metodo accetta un elenco di iterabili, come parametro e scrive ogni elemento come una riga di elementi separati da virgole nel file.
Example
L'esempio seguente mostra l'uso della funzione writer (). Per prima cosa viene aperto un file in modalità "w". Questo file viene utilizzato per ottenere l'oggetto writer. Ogni tupla nell'elenco di tuple viene quindi scritta su file utilizzando il metodo writerow ().
import csv
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
csvfile=open('persons.csv','w', newline='')
obj=csv.writer(csvfile)
for person in persons:
obj.writerow(person)
csvfile.close()Output
Questo creerà il file "persons.csv" nella directory corrente. Mostrerà i seguenti dati.
Lata,22,45
Anil,21,56
John,20,60Invece di scorrere l'elenco per scrivere ogni riga individualmente, possiamo usare il metodo writerows ().
csvfile=open('persons.csv','w', newline='')
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
obj=csv.writer(csvfile)
obj.writerows(persons)
obj.close()lettore()
Questa funzione restituisce un oggetto lettore che restituisce un iteratore di righe nel file csv file. Utilizzando il normale ciclo for, tutte le righe del file vengono visualizzate nel seguente esempio:
Esempio
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
for row in obj:
print (row)Produzione
['Lata', '22', '45']
['Anil', '21', '56']
['John', '20', '60']L'oggetto lettore è un iteratore. Quindi, supporta la funzione next () che può essere utilizzata anche per visualizzare tutte le righe nel file csv invece di un filefor loop.
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
while True:
try:
row=next(obj)
print (row)
except StopIteration:
breakCome accennato in precedenza, il modulo csv utilizza Excel come dialetto predefinito. Il modulo csv definisce anche una classe dialettale. Il dialetto è un insieme di standard utilizzati per implementare il protocollo CSV. L'elenco dei dialetti disponibili può essere ottenuto dalla funzione list_dialects ().
>>> csv.list_dialects()
['excel', 'excel-tab', 'unix']Oltre agli iterabili, il modulo csv può esportare un oggetto dizionario in un file CSV e leggerlo per popolare l'oggetto dizionario Python. A tale scopo, questo modulo definisce le seguenti classi:
DictWriter ()
Questa funzione restituisce un oggetto DictWriter. È simile all'oggetto writer, ma le righe vengono mappate all'oggetto dizionario. La funzione richiede un oggetto file con autorizzazione di scrittura e un elenco di chiavi utilizzate nel dizionario come parametro dei nomi di campo. Viene utilizzato per scrivere la prima riga del file come intestazione.
writeheader ()
Questo metodo scrive l'elenco delle chiavi nel dizionario come una riga separata da virgole come prima riga del file.
Nell'esempio seguente, viene definito un elenco di elementi del dizionario. Ogni elemento nell'elenco è un dizionario. Utilizzando il metodo writrows (), vengono scritti su file in modo separato da virgole.
persons=[
{'name':'Lata', 'age':22, 'marks':45},
{'name':'Anil', 'age':21, 'marks':56},
{'name':'John', 'age':20, 'marks':60}
]
csvfile=open('persons.csv','w', newline='')
fields=list(persons[0].keys())
obj=csv.DictWriter(csvfile, fieldnames=fields)
obj.writeheader()
obj.writerows(persons)
csvfile.close()Il file persons.csv mostra i seguenti contenuti:
name,age,marks
Lata,22,45
Anil,21,56
John,20,60DictReader ()
Questa funzione restituisce un oggetto DictReader dal file CSV sottostante. Come, nel caso di un oggetto lettore, anche questo è un iteratore, utilizzando il contenuto del file che viene recuperato.
csvfile=open('persons.csv','r', newline='')
obj=csv.DictReader(csvfile)La classe fornisce l'attributo fieldnames, restituendo le chiavi del dizionario utilizzate come intestazione del file.
print (obj.fieldnames)
['name', 'age', 'marks']Usa il ciclo sull'oggetto DictReader per recuperare i singoli oggetti del dizionario.
for row in obj:
print (row)Ciò si traduce nel seguente output:
OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
OrderedDict([('name', 'Anil'), ('age', '21'), ('marks', '56')])
OrderedDict([('name', 'John'), ('age', '20'), ('marks', '60')])Per convertire un oggetto OrderedDict in un dizionario normale, dobbiamo prima importare OrderedDict dal modulo delle collezioni.
from collections import OrderedDict
r=OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
dict(r)
{'name': 'Lata', 'age': '22', 'marks': '45'}JSON sta per JavaScript Object Notation. È un formato di scambio dati leggero. È un formato di testo indipendente dalla lingua e multipiattaforma, supportato da molti linguaggi di programmazione. Questo formato viene utilizzato per lo scambio di dati tra il server Web e i client.
Il formato JSON è simile a pickle. Tuttavia, la serializzazione pickle è specifica di Python mentre il formato JSON è implementato da molti linguaggi, quindi è diventato uno standard universale. La funzionalità e l'interfaccia del modulo json nella libreria standard di Python è simile ai moduli pickle e marshal.
Proprio come nel modulo pickle, anche il modulo json fornisce dumps() e loads() funzione per la serializzazione di oggetti Python in una stringa codificata JSON e dump() e load() le funzioni scrivono e leggono oggetti Python serializzati su / da file.
dumps() - Questa funzione converte l'oggetto in formato JSON.
loads() - Questa funzione converte una stringa JSON in un oggetto Python.
L'esempio seguente mostra l'utilizzo di base di queste funzioni:
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data)
json.loads(s)La funzione dumps () può accettare l'argomento facoltativo sort_keys. Per impostazione predefinita, è False. Se impostato su True, le chiavi del dizionario vengono visualizzate in ordine ordinato nella stringa JSON.
La funzione dumps () ha un altro parametro opzionale chiamato indent che accetta un numero come valore. Decide la lunghezza di ogni segmento della rappresentazione formattata della stringa json, simile all'output di stampa.
Il modulo json ha anche API orientate agli oggetti corrispondenti alle funzioni di cui sopra. Ci sono due classi definite nel modulo: JSONEncoder e JSONDecoder.
Classe JSONEncoder
L'oggetto di questa classe è il codificatore per le strutture dati Python. Ogni tipo di dati Python viene convertito nel tipo JSON corrispondente come mostrato nella tabella seguente:
| Pitone | JSON |
|---|---|
| Dict | oggetto |
| lista, tupla | Vettore |
| Str | corda |
| Enumerazioni int, float, int e float | numero |
| Vero | vero |
| Falso | falso |
| Nessuna | nullo |
La classe JSONEncoder è istanziata dal costruttore JSONEncoder (). I seguenti metodi importanti sono definiti nella classe encoder -
| Sr.No. | Metodi e descrizione |
|---|---|
| 1 | encode() serializza l'oggetto Python in formato JSON |
| 2 | iterencode() Codifica l'oggetto e restituisce un iteratore che fornisce la forma codificata di ogni elemento nell'oggetto. |
| 3 | indent Determina il livello di rientro della stringa codificata |
| 4 | sort_keys è vero o falso per far apparire le chiavi in ordine o meno. |
| 5 | Check_circular se True, controlla il riferimento circolare nell'oggetto di tipo contenitore |
L'esempio seguente codifica l'oggetto elenco Python.
e=json.JSONEncoder()
e.encode(data)Classe JSONDecoder
L'oggetto di questa classe aiuta a decodificare nella stringa json nella struttura dati Python. Il metodo principale in questa classe è decode (). Il codice di esempio seguente recupera l'oggetto elenco Python dalla stringa codificata nel passaggio precedente.
d=json.JSONDecoder()
d.decode(s)Il modulo json definisce load() e dump() funzioni per scrivere dati JSON in un file come un oggetto, che può essere un file su disco o un flusso di byte e leggere i dati da essi.
dump ()
Questa funzione scrive i dati dell'oggetto Python in JSON in un file. Il file deve essere aperto con la modalità "w".
import json
data=['Rakesh', {'marks': (50, 60, 70)}]
fp=open('json.txt','w')
json.dump(data,fp)
fp.close()Questo codice creerà "json.txt" nella directory corrente. Mostra i contenuti come segue:
["Rakesh", {"marks": [50, 60, 70]}]caricare()
Questa funzione carica i dati JSON dal file e restituisce l'oggetto Python da esso. Il file deve essere aperto con il permesso di lettura (dovrebbe avere la modalità "r").
Example
fp=open('json.txt','r')
ret=json.load(fp)
print (ret)
fp.close()Output
['Rakesh', {'marks': [50, 60, 70]}]Il json.tool ha anche un'interfaccia a riga di comando che convalida i dati nel file e stampa l'oggetto JSON in un modo abbastanza formattato.
C:\python37>python -m json.tool json.txt
[
"Rakesh",
{
"marks": [
50,
60,
70
]
}
]XML è l'acronimo di eXtensible Markup Language. È un linguaggio portabile, open source e multipiattaforma molto simile a HTML o SGML e raccomandato dal World Wide Web Consortium.
È un noto formato di scambio di dati, utilizzato da un gran numero di applicazioni come servizi Web, strumenti per ufficio e Service Oriented Architectures(SOA). Il formato XML è leggibile sia dalla macchina che dall'uomo.
Il pacchetto xml della libreria Python standard è costituito dai seguenti moduli per l'elaborazione XML:
| Sr.No. | Moduli e descrizione |
|---|---|
| 1 | xml.etree.ElementTree l'API ElementTree, un processore XML semplice e leggero |
| 2 | xml.dom la definizione dell'API DOM |
| 3 | xml.dom.minidom un'implementazione DOM minima |
| 4 | xml.sax Implementazione dell'interfaccia SAX2 |
| 5 | xml.parsers.expat l'associazione del parser Expat |
I dati nel documento XML sono organizzati in un formato gerarchico ad albero, a partire dalla radice e dagli elementi. Ogni elemento è un singolo nodo dell'albero e ha un attributo racchiuso tra i tag <> e </>. Uno o più sottoelementi possono essere assegnati a ciascun elemento.
Di seguito è riportato un tipico esempio di un documento XML:
<?xml version = "1.0" encoding = "iso-8859-1"?>
<studentlist>
<student>
<name>Ratna</name>
<subject>Physics</subject>
<marks>85</marks>
</student>
<student>
<name>Kiran</name>
<subject>Maths</subject>
<marks>100</marks>
</student>
<student>
<name>Mohit</name>
<subject>Biology</subject>
<marks>92</marks>
</student>
</studentlist>Durante l'utilizzo ElementTreemodulo, il primo passo è impostare l'elemento radice dell'albero. Ogni elemento ha un tag e un attrib che è un oggetto dict. Per l'elemento radice, un attrib è un dizionario vuoto.
import xml.etree.ElementTree as xmlobj
root=xmlobj.Element('studentList')Ora possiamo aggiungere uno o più elementi sotto l'elemento root. Ogni oggetto elemento può avereSubElements. Ogni sottoelemento ha un attributo e una proprietà di testo.
student=xmlobj.Element('student')
nm=xmlobj.SubElement(student, 'name')
nm.text='name'
subject=xmlobj.SubElement(student, 'subject')
nm.text='Ratna'
subject.text='Physics'
marks=xmlobj.SubElement(student, 'marks')
marks.text='85'Questo nuovo elemento viene aggiunto alla radice utilizzando il metodo append ().
root.append(student)Aggiungi tutti gli elementi desiderati usando il metodo sopra. Infine, l'oggetto elemento radice viene scritto in un file.
tree = xmlobj.ElementTree(root)
file = open('studentlist.xml','wb')
tree.write(file)
file.close()Ora vediamo come analizzare il file XML. Per questo, costruisci un albero del documento dando il suo nome come parametro del file nel costruttore ElementTree.
tree = xmlobj.ElementTree(file='studentlist.xml')L'oggetto albero ha getroot() per ottenere l'elemento root e getchildren () restituisce un elenco di elementi sottostanti.
root = tree.getroot()
children = root.getchildren()Un oggetto dizionario corrispondente a ogni sottoelemento viene costruito iterando sulla raccolta di sottoelementi di ogni nodo figlio.
for child in children:
student={}
pairs = child.getchildren()
for pair in pairs:
product[pair.tag]=pair.textOgni dizionario viene quindi aggiunto a un elenco che restituisce l'elenco originale di oggetti dizionario.
SAXè un'interfaccia standard per l'analisi XML guidata dagli eventi. L'analisi di XML con SAX richiede ContentHandler tramite la sottoclasse xml.sax.ContentHandler. Si registrano i callback per gli eventi di interesse e quindi si lascia che il parser proceda attraverso il documento.
SAX è utile quando i tuoi documenti sono di grandi dimensioni o hai limitazioni di memoria in quanto analizza il file mentre lo legge dal disco, di conseguenza l'intero file non viene mai archiviato nella memoria.
Document Object Model
(DOM) API è una raccomandazione del World Wide Web Consortium. In questo caso, l'intero file viene letto in memoria e archiviato in una forma gerarchica (basata su albero) per rappresentare tutte le caratteristiche di un documento XML.
SAX, non veloce come DOM, con file di grandi dimensioni. D'altra parte, DOM può uccidere le risorse, se utilizzato su molti piccoli file. SAX è di sola lettura, mentre DOM consente modifiche al file XML.
Il formato plist è utilizzato principalmente da MAC OS X. Questi file sono fondamentalmente documenti XML. Memorizzano e recuperano le proprietà di un oggetto. La libreria Python contiene il modulo plist, che viene utilizzato per leggere e scrivere file 'elenco delle proprietà' (di solito hanno estensione .plist ').
Il plistlib module è più o meno simile ad altre librerie di serializzazione nel senso, fornisce anche funzioni dumps () e load () per la rappresentazione di stringhe di oggetti Python e funzioni load () e dump () per il funzionamento del disco.
Il seguente oggetto dizionario mantiene la proprietà (chiave) e il valore corrispondente -
proplist = {
"name" : "Ganesh",
"designation":"manager",
"dept":"accts",
"salary" : {"basic":12000, "da":4000, "hra":800}
}Per scrivere queste proprietà in un file su disco, chiamiamo la funzione dump () nel modulo plist.
import plistlib
fileName=open('salary.plist','wb')
plistlib.dump(proplist, fileName)
fileName.close()Al contrario, per rileggere i valori delle proprietà, utilizzare la funzione load () come segue:
fp= open('salary.plist', 'rb')
pl = plistlib.load(fp)
print(pl)Uno dei principali svantaggi dei file CSV, JSON, XML, ecc. È che non sono molto utili per l'accesso casuale e l'elaborazione delle transazioni perché sono in gran parte di natura non strutturata. Quindi, diventa molto difficile modificare i contenuti.
Questi file flat non sono adatti per l'ambiente client-server in quanto mancano di capacità di elaborazione asincrona. L'utilizzo di file di dati non strutturati porta a ridondanza e incoerenza dei dati.
Questi problemi possono essere superati utilizzando un database relazionale. Un database è una raccolta organizzata di dati per rimuovere ridondanza e incoerenza e mantenere l'integrità dei dati. Il modello di database relazionale è molto popolare.
Il suo concetto di base è organizzare i dati in una tabella di entità (chiamata relazione). La struttura della tabella delle entità fornisce un attributo il cui valore è univoco per ogni riga. Tale attributo è chiamato'primary key'.
Quando la chiave primaria di una tabella appare nella struttura di altre tabelle, viene chiamata 'Foreign key'e questo costituisce la base del rapporto tra i due. Sulla base di questo modello, ci sono molti prodotti RDBMS popolari attualmente disponibili -
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
- SQLite
SQLite è un database relazionale leggero utilizzato in un'ampia varietà di applicazioni. È un motore di database SQL autonomo, senza server, a configurazione zero e transazionale. L'intero database è un singolo file, che può essere posizionato ovunque nel file system. È un software open source, con un ingombro molto ridotto e nessuna configurazione. È comunemente utilizzato in dispositivi integrati, IOT e app mobili.
Tutti i database relazionali utilizzano SQL per la gestione dei dati nelle tabelle. Tuttavia, in precedenza, ciascuno di questi database era connesso con l'applicazione Python con l'aiuto del modulo Python specifico per il tipo di database.
Quindi, c'era una mancanza di compatibilità tra di loro. Se un utente volesse passare a un prodotto di database diverso, sarebbe difficile. Questo problema di incompatibilità è stato risolto sollevando la "Proposta di miglioramento di Python (PEP 248)" per consigliare un'interfaccia coerente per i database relazionali noti come DB-API. Vengono chiamate le ultime raccomandazioniDB-APIVersione 2.0. (PEP 249)
La libreria standard di Python è costituita dal modulo sqlite3 che è un modulo compatibile con DB-API per la gestione del database SQLite tramite il programma Python. Questo capitolo spiega la connettività di Python con il database SQLite.
Come accennato in precedenza, Python ha il supporto integrato per il database SQLite sotto forma di modulo sqlite3. Per altri database, il rispettivo modulo Python compatibile con DB-API dovrà essere installato con l'aiuto dell'utilità pip. Ad esempio, per utilizzare il database MySQL è necessario installare il modulo PyMySQL.
pip install pymysqlI seguenti passaggi sono consigliati in DB-API -
Stabilire la connessione con il database utilizzando connect() funzione e ottenere l'oggetto di connessione.
Chiamata cursor() metodo di connessione dell'oggetto per ottenere l'oggetto cursore.
Forma una stringa di query composta da un'istruzione SQL da eseguire.
Eseguire la query desiderata invocando execute() metodo.
Chiudi la connessione.
import sqlite3
db=sqlite3.connect('test.db')Qui, db è l'oggetto di connessione che rappresenta test.db. Nota, quel database verrà creato se non esiste già. L'oggetto di connessione db ha i seguenti metodi:
| Sr.No. | Metodi e descrizione |
|---|---|
| 1 | cursor(): Restituisce un oggetto Cursor che utilizza questa connessione. |
| 2 | commit(): Salva esplicitamente le transazioni in sospeso nel database. |
| 3 | rollback(): Questo metodo facoltativo causa il rollback di una transazione al punto di partenza. |
| 4 | close(): Chiude definitivamente la connessione al database. |
Un cursore funge da handle per una determinata query SQL consentendo il recupero di una o più righe del risultato. L'oggetto Cursor viene ottenuto dalla connessione per eseguire query SQL utilizzando la seguente istruzione:
cur=db.cursor()L'oggetto cursore ha i seguenti metodi definiti:
| Suor n | Metodi e descrizione |
|---|---|
| 1 | execute() Esegue la query SQL in un parametro stringa. |
| 2 | executemany() Esegue la query SQL utilizzando un set di parametri nell'elenco di tuple. |
| 3 | fetchone() Recupera la riga successiva dal set di risultati della query. |
| 4 | fetchall() Recupera tutte le righe rimanenti dal set di risultati della query. |
| 5 | callproc() Chiama una stored procedure. |
| 6 | close() Chiude l'oggetto cursore. |
Il codice seguente crea una tabella in test.db: -
import sqlite3
db=sqlite3.connect('test.db')
cur =db.cursor()
cur.execute('''CREATE TABLE student (
StudentID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT (20) NOT NULL,
age INTEGER,
marks REAL);''')
print ('table created successfully')
db.close()L'integrità dei dati desiderata in un database è ottenuta tramite commit() e rollback()metodi dell'oggetto connessione. La stringa della query SQL potrebbe contenere una query SQL errata che può sollevare un'eccezione, che dovrebbe essere gestita correttamente. Per questo, l'istruzione execute () viene posizionata all'interno del blocco try Se ha successo, il risultato viene salvato in modo persistente utilizzando il metodo commit (). Se la query fallisce, la transazione viene annullata utilizzando il metodo rollback ().
Il codice seguente esegue la query INSERT sulla tabella studenti in test.db.
import sqlite3
db=sqlite3.connect('test.db')
qry="insert into student (name, age, marks) values('Abbas', 20, 80);"
try:
cur=db.cursor()
cur.execute(qry)
db.commit()
print ("record added successfully")
except:
print ("error in query")
db.rollback()
db.close()Se si desidera che i dati nella clausola dei valori della query INSERT vengano forniti dinamicamente dall'input dell'utente, utilizzare la sostituzione dei parametri come consigliato in Python DB-API. Il ? viene utilizzato come segnaposto nella stringa di query e fornisce i valori sotto forma di una tupla nel metodo execute (). L'esempio seguente inserisce un record utilizzando il metodo di sostituzione dei parametri. Nome, età e voti vengono presi come input.
import sqlite3
db=sqlite3.connect('test.db')
nm=input('enter name')
a=int(input('enter age'))
m=int(input('enter marks'))
qry="insert into student (name, age, marks) values(?,?,?);"
try:
cur=db.cursor()
cur.execute(qry, (nm,a,m))
db.commit()
print ("one record added successfully")
except:
print("error in operation")
db.rollback()
db.close()Il modulo sqlite3 definisce The executemany()metodo che è in grado di aggiungere più record contemporaneamente. I dati da aggiungere dovrebbero essere forniti in un elenco di tuple, con ogni tupla contenente un record. L'oggetto elenco è il parametro del metodo executemany (), insieme alla stringa di query. Tuttavia, il metodo executemany () non è supportato da alcuni degli altri moduli.
Il UPDATEquery di solito contiene un'espressione logica specificata dalla clausola WHERE La stringa di query nel metodo execute () dovrebbe contenere una sintassi di query UPDATE. Per aggiornare il valore di "age" a 23 per name = "Anil", definire la stringa come di seguito:
qry="update student set age=23 where name='Anil';"Per rendere il processo di aggiornamento più dinamico, utilizziamo il metodo di sostituzione dei parametri come descritto sopra.
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
a=int(input(‘enter age’))
qry="update student set age=? where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (a, nm))
db.commit()
print("record updated successfully")
except:
print("error in query")
db.rollback()
db.close()Allo stesso modo, l'operazione DELETE viene eseguita chiamando il metodo execute () con una stringa con la sintassi della query DELETE di SQL. Per inciso,DELETE la query di solito contiene anche un file WHERE clausola.
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
qry="DELETE from student where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (nm,))
db.commit()
print("record deleted successfully")
except:
print("error in operation")
db.rollback()
db.close()Una delle operazioni importanti su una tabella di database è il recupero dei record da essa. SQL fornisceSELECTquery per lo scopo. Quando una stringa contenente la sintassi della query SELECT viene fornita al metodo execute (), viene restituito un oggetto set di risultati. Esistono due metodi importanti con un oggetto cursore che utilizzano uno o più record dal set di risultati.
fetchone ()
Recupera il record successivo disponibile dal set di risultati. È una tupla composta dai valori di ogni colonna del record recuperato.
fetchall ()
Recupera tutti i record rimanenti sotto forma di un elenco di tuple. Ogni tupla corrisponde a un record e contiene i valori di ogni colonna nella tabella.
L'esempio seguente elenca tutti i record nella tabella degli studenti
import sqlite3
db=sqlite3.connect('test.db')
37
sql="SELECT * from student;"
cur=db.cursor()
cur.execute(sql)
while True:
record=cur.fetchone()
if record==None:
break
print (record)
db.close()Se prevedi di utilizzare un database MySQL invece di un database SQLite, devi installare PyMySQLmodulo come descritto sopra. Tutti i passaggi nel processo di connettività del database sono gli stessi, poiché il database MySQL è installato su un server, la funzione connect () richiede l'URL e le credenziali di accesso.
import pymysql
con=pymysql.connect('localhost', 'root', '***')L'unica cosa che può differire con SQLite sono i tipi di dati specifici di MySQL. Allo stesso modo, qualsiasi database compatibile con ODBC può essere utilizzato con Python installando il modulo pyodbc.
Qualsiasi database relazionale conserva i dati nelle tabelle. La struttura della tabella definisce il tipo di dati degli attributi che sono fondamentalmente solo dei tipi di dati primari che sono mappati ai corrispondenti tipi di dati incorporati di Python. Tuttavia, gli oggetti definiti dall'utente di Python non possono essere archiviati e recuperati in modo persistente da / a tabelle SQL.
Questa è una disparità tra i tipi SQL e linguaggi di programmazione orientati agli oggetti come Python. SQL non ha un tipo di dati equivalente per altri come dict, tuple, list o qualsiasi classe definita dall'utente.
Se devi memorizzare un oggetto in un database relazionale, i suoi attributi di istanza dovrebbero essere prima decostruiti in tipi di dati SQL, prima di eseguire la query INSERT. D'altra parte, i dati recuperati da una tabella SQL sono in tipi primari. Un oggetto Python del tipo desiderato dovrà essere costruito utilizzando per l'uso nello script Python. È qui che sono utili i mapping relazionali degli oggetti.
Object Relation Mapper (ORM)
Un Object Relation Mapper(ORM) è un'interfaccia tra una classe e una tabella SQL. Una classe Python viene mappata a una determinata tabella nel database, in modo che la conversione tra i tipi di oggetto e SQL venga eseguita automaticamente.
La classe Studenti scritta in codice Python è mappata alla tabella Studenti nel database. Di conseguenza, tutte le operazioni CRUD vengono eseguite chiamando i rispettivi metodi della classe. Ciò elimina la necessità di eseguire query SQL hardcoded nello script Python.
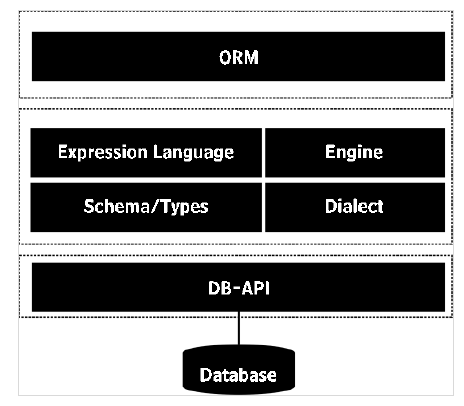
La libreria ORM funge quindi da livello di astrazione sulle query SQL non elaborate e può essere di aiuto nello sviluppo rapido dell'applicazione. SQLAlchemyè un popolare mappatore relazionale di oggetti per Python. Qualsiasi manipolazione dello stato dell'oggetto modello viene sincronizzata con la relativa riga nella tabella del database.
La libreria SQLALchemy include ORM API e linguaggio di espressione SQL (SQLAlchemy Core). Il linguaggio di espressione esegue direttamente i costrutti primitivi del database relazionale.
ORM è un modello di utilizzo astratto e di alto livello costruito sulla base del linguaggio di espressione SQL. Si può dire che ORM è un uso applicato del linguaggio delle espressioni. Discuteremo l'API ORM di SQLAlchemy e utilizzeremo il database SQLite in questo argomento.
SQLAlchemy comunica con vari tipi di database tramite le rispettive implementazioni DBAPI utilizzando un sistema dialettale. Tutti i dialetti richiedono che sia installato un driver DBAPI appropriato. Sono inclusi i dialetti per i seguenti tipi di database:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
L'installazione di SQLAlchemy è facile e diretta, utilizzando l'utilità pip.
pip install sqlalchemyPer verificare se SQLalchemy è installato correttamente e la sua versione, inserisci quanto segue al prompt di Python:
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.3.11'Le interazioni con il database vengono eseguite tramite l'oggetto Engine ottenuto come valore restituito di create_engine() funzione.
engine =create_engine('sqlite:///mydb.sqlite')SQLite consente la creazione di database in memoria. Il motore SQLAlchemy per il database in memoria viene creato come segue:
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')Se invece intendi utilizzare il database MySQL, usa il suo modulo DB-API - pymysql e il rispettivo driver dialetto.
engine = create_engine('mysql+pymydsql://root@localhost/mydb')Il create_engine ha un argomento echo opzionale. Se impostato su true, le query SQL generate dal motore verranno visualizzate sul terminale.
SQLAlchemy contiene declarative baseclasse. Funziona come un catalogo di classi di modelli e tabelle mappate.
from sqlalchemy.ext.declarative import declarative_base
base=declarative_base()Il prossimo passo è definire una classe modello. Deve essere derivato dall'oggetto base della classe dichiarative_base come sopra.
Impostato __tablename__ proprietà al nome della tabella che si desidera creare nel database. Altri attributi corrispondono ai campi. Ognuno è un oggetto Colonna in SQLAlchemy e il suo tipo di dati proviene da uno degli elenchi seguenti:
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
Il codice seguente è la classe modello denominata Student che è mappata alla tabella Studenti.
#myclasses.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Numeric
base=declarative_base()
class Student(base):
__tablename__='Students'
StudentID=Column(Integer, primary_key=True)
name=Column(String)
age=Column(Integer)
marks=Column(Numeric)Per creare una tabella Studenti con una struttura corrispondente, eseguire il metodo create_all () definito per la classe base.
base.metadata.create_all(engine)Ora dobbiamo dichiarare un oggetto della nostra classe Student. Tutte le transazioni del database come l'aggiunta, l'eliminazione o il recupero dei dati dal database, ecc., Vengono gestite da un oggetto Session.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()I dati memorizzati nell'oggetto Student vengono aggiunti fisicamente nella tabella sottostante dal metodo add () della sessione.
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()Ecco l'intero codice per l'aggiunta di record nella tabella degli studenti. Durante l'esecuzione, il registro delle istruzioni SQL corrispondente viene visualizzato sulla console.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()Uscita console
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMITIl session object fornisce anche il metodo add_all () per inserire più di un oggetto in una singola transazione.
sessionobj.add_all([s2,s3,s4,s5])
sessionobj.commit()Ora che i record vengono aggiunti nella tabella, vorremmo recuperarli proprio come fa la query SELECT. L'oggetto sessione dispone del metodo query () per eseguire l'attività. L'oggetto query viene restituito dal metodo query () sul nostro modello Student.
qry=seesionobj.query(Student)Utilizzare il metodo get () di questo oggetto Query recupera l'oggetto corrispondente alla chiave primaria specificata.
S1=qry.get(1)Mentre questa istruzione viene eseguita, la sua istruzione SQL corrispondente echeggiata sulla console sarà la seguente:
BEGIN (implicit)
SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS
"Students_name", "Students".age AS "Students_age",
"Students".marks AS "Students_marks"
FROM "Students"
WHERE "Products"."Students" = ?
sqlalchemy.engine.base.Engine (1,)Il metodo query.all () restituisce un elenco di tutti gli oggetti che possono essere attraversati utilizzando un ciclo.
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)L'aggiornamento di un record nella tabella mappata è molto semplice. Tutto quello che devi fare è recuperare un record utilizzando il metodo get (), assegnare un nuovo valore all'attributo desiderato e quindi eseguire il commit delle modifiche utilizzando l'oggetto sessione. Di seguito cambiamo i voti di Juhi student a 100.
S1=qry.get(1)
S1.marks=100
sessionobj.commit()Eliminare un record è altrettanto facile, eliminando l'oggetto desiderato dalla sessione.
S1=qry.get(1)
Sessionobj.delete(S1)
sessionobj.commit()MongoDB è un documento orientato NoSQLBanca dati. È un database multipiattaforma distribuito con licenza pubblica lato server. Usa JSON come documenti come schema.
Al fine di fornire la capacità di memorizzare dati enormi, più di un server fisico (chiamato frammenti) è interconnessa, in modo da ottenere una scalabilità orizzontale. Il database MongoDB è costituito da documenti.
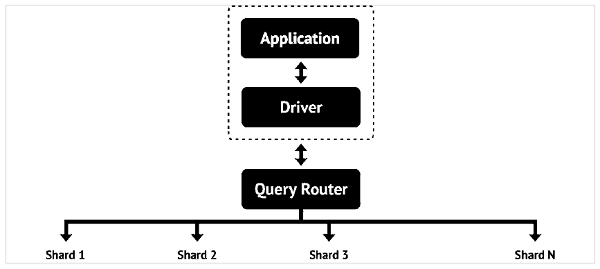
Un documento è analogo a una riga in una tabella di database relazionale. Tuttavia, non ha uno schema particolare. Il documento è una raccolta di coppie chiave-valore, simile al dizionario. Tuttavia, il numero di coppie kv in ogni documento può variare. Proprio come una tabella nel database relazionale ha una chiave primaria, il documento nel database MongoDB ha una chiave speciale chiamata"_id".
Prima di vedere come viene utilizzato il database MongoDB con Python, vediamo brevemente come installare e avviare MongoDB. È disponibile la versione comunitaria e commerciale di MongoDB. La versione comunitaria può essere scaricata da www.mongodb.com/download-center/community .
Supponendo che MongoDB sia installato in c: \ mongodb, il server può essere richiamato utilizzando il seguente comando.
c:\mongodb\bin>mongodIl server MongoDB è attivo alla porta numero 22017 per impostazione predefinita. I database vengono archiviati nella cartella data / bin per impostazione predefinita, sebbene la posizione possa essere modificata tramite l'opzione –dbpath.
MongoDB ha il proprio set di comandi da utilizzare in una shell MongoDB. Per invocare la shell, usaMongo comando.
x:\mongodb\bin>mongoViene visualizzato un prompt della shell simile a MySQL o SQLite prima del quale è possibile eseguire i comandi NoSQL nativi. Tuttavia, siamo interessati a connettere il database MongoDB a Python.
PyMongoIl modulo è stato sviluppato dalla stessa MongoDB Inc per fornire l'interfaccia di programmazione Python. Usa il noto programma di utilità pip per installare PyMongo.
pip3 install pymongoSupponendo che il server MongoDB sia attivo e funzionante (con mongod comando) ed è in ascolto sulla porta 22017, dobbiamo prima dichiarare un file MongoClientoggetto. Controlla tutte le transazioni tra la sessione Python e il database.
from pymongo import MongoClient
client=MongoClient()Usa questo oggetto client per stabilire la connessione con il server MongoDB.
client = MongoClient('localhost', 27017)Viene creato un nuovo database con il seguente comando.
db=client.newdbIl database MongoDB può avere molte raccolte, simili alle tabelle in un database relazionale. Un oggetto Collection viene creato daCreate_collection() funzione.
db.create_collection('students')Ora possiamo aggiungere uno o più documenti nella raccolta come segue:
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
db.create_collection("students")
student=db['students']
studentlist=[{'studentID':1,'Name':'Juhi','age':20, 'marks'=100},
{'studentID':2,'Name':'dilip','age':20, 'marks'=110},
{'studentID':3,'Name':'jeevan','age':24, 'marks'=145}]
student.insert_many(studentlist)
client.close()Per recuperare i documenti (simile alla query SELECT), dovremmo usare find()metodo. Restituisce un cursore con l'aiuto del quale è possibile ottenere tutti i documenti.
students=db['students']
docs=students.find()
for doc in docs:
print (doc['Name'], doc['age'], doc['marks'] )Per trovare un particolare documento invece di tutti in una raccolta, dobbiamo applicare il filtro al metodo find (). Il filtro utilizza operatori logici. MongoDB ha il proprio set di operatori logici come di seguito:
| Suor n | Operatore MongoDB e operatore logico tradizionale |
|---|---|
| 1 | $eq uguale a (==) |
| 2 | $gt maggiore di (>) |
| 3 | $gte maggiore o uguale a (> =) |
| 4 | $in se uguale a qualsiasi valore in array |
| 5 | $lt minore di (<) |
| 6 | $lte minore o uguale a (<=) |
| 7 | $ne diverso da (! =) |
| 8 | $nin se non è uguale a qualsiasi valore in array |
Ad esempio, siamo interessati a ottenere l'elenco degli studenti di età superiore ai 21 anni. Utilizzo dell'operatore $ gt nel filtro perfind() metodo come segue -
students=db['students']
docs=students.find({'age':{'$gt':21}})
for doc in docs:
print (doc.get('Name'), doc.get('age'), doc.get('marks'))Il modulo PyMongo fornisce update_one() e update_many() metodi per modificare uno o più documenti che soddisfano un'espressione di filtro specifica.
Aggiorniamo l'attributo mark di un documento il cui nome è Juhi.
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
doc=db.students.find_one({'Name': 'Juhi'})
db['students'].update_one({'Name': 'Juhi'},{"$set":{'marks':150}})
client.close()Cassandra è un altro popolare database NoSQL. Elevata scalabilità, coerenza e tolleranza agli errori: queste sono alcune delle caratteristiche importanti di Cassandra. Questo èColumn storeBanca dati. I dati vengono archiviati su molti server di prodotti. Di conseguenza, dati altamente disponibili.
Cassandra è un prodotto della fondazione Apache Software. I dati vengono archiviati in modo distribuito su più nodi. Ogni nodo è un singolo server costituito da spazi delle chiavi. Il blocco costitutivo fondamentale del database Cassandra èkeyspace che può essere considerato analogo a un database.
I dati in un nodo di Cassandra vengono replicati in altri nodi su una rete di nodi peer-to-peer. Questo rende Cassandra un database infallibile. La rete è chiamata data center. Più data center possono essere interconnessi per formare un cluster. La natura della replica viene configurata impostando la strategia di replica e il fattore di replica al momento della creazione di uno spazio delle chiavi.
Uno spazio chiavi può avere più di una famiglia di colonne, proprio come un database può contenere più tabelle. Il keyspace di Cassandra non ha uno schema predefinito. È possibile che ogni riga in una tabella Cassandra possa avere colonne con nomi diversi e in numeri variabili.
Il software Cassandra è disponibile anche in due versioni: community e enterprise. L'ultima versione Enterprise di Cassandra è disponibile per il download all'indirizzohttps://cassandra.apache.org/download/. L'edizione comunitaria si trova all'indirizzohttps://academy.datastax.com/planet-cassandra/cassandra.
Cassandra ha il proprio linguaggio di query chiamato Cassandra Query Language (CQL). Le query CQL possono essere eseguite dall'interno di una shell CQLASH, simile alla shell MySQL o SQLite. La sintassi CQL sembra simile a SQL standard.
L'edizione della community di Datastax, inoltre, viene fornita con un IDE Develcenter mostrato nella figura seguente:
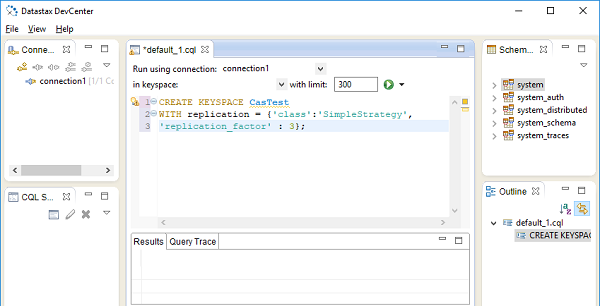
Viene chiamato il modulo Python per lavorare con il database Cassandra Cassandra Driver. È anche sviluppato dalla fondazione Apache. Questo modulo contiene un'API ORM, nonché un'API di base di natura simile a DB-API per database relazionali.
L'installazione del driver Cassandra viene eseguita facilmente utilizzando pip utility.
pip3 install cassandra-driverL'interazione con il database Cassandra, avviene tramite oggetto Cluster. Il modulo Cassandra.cluster definisce la classe Cluster. Dobbiamo prima dichiarare l'oggetto Cluster.
from cassandra.cluster import Cluster
clstr=Cluster()Tutte le transazioni come inserimento / aggiornamento, ecc. Vengono eseguite avviando una sessione con un keyspace.
session=clstr.connect()Per creare un nuovo keyspace, usa execute()metodo dell'oggetto sessione. Il metodo execute () accetta un argomento stringa che deve essere una stringa di query. Il CQL ha l'istruzione CREATE KEYSPACE come segue. Il codice completo è il seguente:
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”Qui, SimpleStrategy è un valore per replication strategy e replication factorè impostato su 3. Come accennato in precedenza, uno spazio delle chiavi contiene una o più tabelle. Ogni tabella è caratterizzata dal tipo di dati. I tipi di dati Python vengono automaticamente analizzati con i tipi di dati CQL corrispondenti in base alla tabella seguente:
| Tipo Python | Tipo CQL |
|---|---|
| Nessuna | NULLO |
| Bool | Booleano |
| Galleggiante | galleggiante, doppio |
| int, lungo | int, bigint, varint, smallint, tinyint, counter |
| decimal.Decimal | Decimale |
| str, Unicode | ascii, varchar, text |
| buffer, bytearray | Blob |
| Data | Data |
| Appuntamento | Timestamp |
| Tempo | Tempo |
| lista, tupla, generatore | Elenco |
| set, frozenset | Impostato |
| dict, OrderedDict | Carta geografica |
| uuid.UUID | timeuuid, uuid |
Per creare una tabella, utilizzare l'oggetto sessione per eseguire la query CQL per la creazione di una tabella.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)Lo spazio delle chiavi così creato può essere ulteriormente utilizzato per inserire righe. La versione CQL della query INSERT è simile all'istruzione SQL Insert. Il codice seguente inserisce una riga nella tabella degli studenti.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"Come ci si aspetterebbe, l'istruzione SELECT viene utilizzata anche con Cassandra. In caso di metodo execute () contenente la stringa di query SELECT, restituisce un oggetto set di risultati che può essere attraversato utilizzando un ciclo.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))La query SELECT di Cassandra supporta l'uso della clausola WHERE per applicare il filtro sul set di risultati da recuperare. Vengono riconosciuti operatori logici tradizionali come <,> == ecc. Per recuperare, solo quelle righe dalla tabella degli studenti per i nomi con età> 20, la stringa di query nel metodo execute () dovrebbe essere la seguente:
rows=session.execute("select * from students WHERE age>20 allow filtering;")Nota, l'uso di ALLOW FILTERING. La parte ALLOW FILTERING di questa istruzione consente di consentire esplicitamente (alcune) query che richiedono il filtraggio.
L'API del driver Cassandra definisce le seguenti classi di tipo Statement nel modulo cassendra.query.
SimpleStatement
Una query CQL semplice e non preparata contenuta in una stringa di query. Tutti gli esempi precedenti sono esempi di SimpleStatement.
BatchStatement
Più query (come INSERT, UPDATE e DELETE) vengono inserite in un batch ed eseguite contemporaneamente. Ogni riga viene prima convertita come SimpleStatement e quindi aggiunta in un batch.
Mettiamo le righe da aggiungere nella tabella Studenti sotto forma di elenco di tuple come segue:
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]Per aggiungere le righe sopra utilizzando BathStatement, eseguire il seguente script:
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)Discorso preparato
L'istruzione preparata è come una query con parametri in DB-API. La sua stringa di query viene salvata da Cassandra per un uso successivo. Il metodo Session.prepare () restituisce un'istanza PreparedStatement.
Per la nostra tabella studenti, una query PreparedStatement per INSERT è la seguente:
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")Successivamente, deve solo inviare i valori dei parametri da associare. Ad esempio:
qry=stmt.bind([1,'Ram', 23,175])Infine, esegui l'istruzione legata sopra.
session.execute(qry)Ciò riduce il traffico di rete e l'utilizzo della CPU perché Cassandra non deve analizzare nuovamente la query ogni volta.
ZODB (Zope object Database) è un database per la memorizzazione di oggetti Python. È compatibile con ACID - caratteristica non trovata nei database NOSQL. Lo ZODB è anche open source, scalabile orizzontalmente e privo di schemi, come molti database NoSQL. Tuttavia, non è distribuito e non offre una facile replica. Fornisce un meccanismo di persistenza per gli oggetti Python. Fa parte del server Zope Application, ma può anche essere utilizzato in modo indipendente.
ZODB è stato creato da Jim Fulton di Zope Corporation. È iniziato come un semplice Persistent Object System. La sua versione attuale è 5.5.0 ed è scritta completamente in Python. utilizzando una versione estesa della persistenza degli oggetti incorporata in Python (pickle).
Alcune delle caratteristiche principali di ZODB sono:
- transactions
- history/undo
- archiviazione collegabile in modo trasparente
- memorizzazione nella cache incorporata
- multiversion concurrency control (MVCC)
- scalabilità su una rete
Lo ZODB è un file hierarchicalBanca dati. C'è un oggetto radice, inizializzato quando viene creato un database. L'oggetto root viene utilizzato come un dizionario Python e può contenere altri oggetti (che possono essere a loro volta simili a un dizionario). Per memorizzare un oggetto nel database è sufficiente assegnarlo a una nuova chiave all'interno del suo contenitore.
ZODB è utile per le applicazioni in cui i dati sono gerarchici ed è probabile che ci siano più letture che scritture. ZODB è un'estensione dell'oggetto pickle. Ecco perché può essere elaborato solo tramite script Python.
Per installare l'ultima versione di ZODB, usa l'utility pip -
pip install zodbVengono installate anche le seguenti dipendenze:
- BTrees==4.6.1
- cffi==1.13.2
- persistent==4.5.1
- pycparser==2.19
- six==1.13.0
- transaction==2.4.0
ZODB fornisce le seguenti opzioni di archiviazione:
FileStorage
Questa è l'impostazione predefinita. Tutto è archiviato in un unico file Data.fs, che è essenzialmente un registro delle transazioni.
DirectoryStorage
Memorizza un file per revisione dell'oggetto. In questo caso, non richiede la ricostruzione di Data.fs.index in caso di arresto non corretto.
RelStorage
Questo memorizza i sottaceti in un database relazionale. PostgreSQL, MySQL e Oracle sono supportati.
Per creare il database ZODB abbiamo bisogno di un archivio, un database e infine una connessione.
Il primo passo è avere un oggetto di archiviazione.
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('mydata.fs')La classe DB utilizza questo oggetto di archiviazione per ottenere l'oggetto database.
db = ZODB.DB(storage)Passare Nessuno al costruttore di DB per creare un database in memoria.
Db=ZODB.DB(None)Infine, stabiliamo la connessione con il database.
conn=db.open()L'oggetto connessione ti dà quindi accesso alla 'root' del database con il metodo 'root ()'. L'oggetto "root" è il dizionario che contiene tutti gli oggetti persistenti.
root = conn.root()Ad esempio, aggiungiamo un elenco di studenti all'oggetto radice come segue:
root['students'] = ['Mary', 'Maya', 'Meet']Questa modifica non viene salvata in modo permanente nel database finché non eseguiamo il commit della transazione.
import transaction
transaction.commit()Per memorizzare l'oggetto di una classe definita dall'utente, la classe deve essere ereditata dalla classe padre persistent.Persistent.
Vantaggi della sottoclasse
Creazione di sottoclassi La classe persistente ha i suoi vantaggi come segue:
Il database terrà automaticamente traccia delle modifiche agli oggetti apportate impostando gli attributi.
I dati verranno salvati nel proprio record di database.
È possibile salvare dati che non sono sottoclasse Persistent, ma verranno archiviati nel record del database di qualsiasi oggetto persistente a cui fa riferimento. Gli oggetti non persistenti sono di proprietà del loro oggetto persistente che li contiene e se più oggetti persistenti fanno riferimento allo stesso oggetto secondario non persistente, otterranno le proprie copie.
Definiamo una classe di studenti sottoclasse Persistent class come sotto -
import persistent
class student(persistent.Persistent):
def __init__(self, name):
self.name = name
def __repr__(self):
return str(self.name)Per aggiungere un oggetto di questa classe, impostiamo prima la connessione come descritto sopra.
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('studentdata.fs')
db = ZODB.DB(storage)
conn=db.open()
root = conn.root()Dichiarare un oggetto aggiunto a root e quindi eseguire il commit della transazione
s1=student("Akash")
root['s1']=s1
import transaction
transaction.commit()
conn.close()L'elenco di tutti gli oggetti aggiunti a root può essere recuperato come un oggetto di visualizzazione con l'aiuto del metodo items () poiché l'oggetto root è simile al dizionario integrato.
print (root.items())
ItemsView({'s1': Akash})Per recuperare l'attributo di un oggetto specifico dalla radice,
print (root['s1'].name)
AkashL'oggetto può essere facilmente aggiornato. Poiché l'API ZODB è un pacchetto Python puro, non richiede l'utilizzo di alcun linguaggio di tipo SQL esterno.
root['s1'].name='Abhishek'
import transaction
transaction.commit()Il database verrà aggiornato immediatamente. Notare che la classe di transazione definisce anche la funzione abort () che è simile al controllo delle transazioni rollback () in SQL.
Microsoft Excel è l'applicazione per fogli di calcolo più popolare. È in uso da oltre 25 anni. Le versioni successive di Excel utilizzanoOffice Open XML Formato di file (OOXML). Quindi, è stato possibile accedere ai file del foglio di calcolo tramite altri ambienti di programmazione.
OOXMLè un formato di file standard ECMA. Python'sopenpyxl pacchetto fornisce funzionalità per leggere / scrivere file Excel con estensione .xlsx.
Il pacchetto openpyxl utilizza una nomenclatura di classe simile alla terminologia di Microsoft Excel. Un documento Excel viene chiamato cartella di lavoro e viene salvato con estensione .xlsx nel file system. Una cartella di lavoro può avere più fogli di lavoro. Un foglio di lavoro presenta una grande griglia di celle, ognuna di esse può memorizzare valore o formula. Le righe e le colonne che formano la griglia sono numerate. Le colonne sono identificate da alfabeti, A, B, C,…., Z, AA, AB e così via. Le righe sono numerate a partire da 1.
Un tipico foglio di lavoro di Excel viene visualizzato come segue:
L'utility pip è abbastanza buona per installare il pacchetto openpyxl.
pip install openpyxlLa classe Workbook rappresenta una cartella di lavoro vuota con un foglio di lavoro vuoto. Dobbiamo attivarlo in modo che alcuni dati possano essere aggiunti al foglio di lavoro.
from openpyxl import Workbook
wb=Workbook()
sheet1=wb.active
sheet1.title='StudentList'Come sappiamo, una cella nel foglio di lavoro è denominata come formato ColumnNameRownumber. Di conseguenza, la cella in alto a sinistra è A1. Assegniamo una stringa a questa cella come -
sheet1['A1']= 'Student List'In alternativa, usa il foglio di lavoro cell()metodo che utilizza il numero di riga e colonna per identificare una cella. Chiama la proprietà value all'oggetto cella per assegnare un valore.
cell1=sheet1.cell(row=1, column=1)
cell1.value='Student List'Dopo aver popolato il foglio di lavoro con i dati, la cartella di lavoro viene salvata chiamando il metodo save () dell'oggetto cartella di lavoro.
wb.save('Student.xlsx')Questo file della cartella di lavoro viene creato nella directory di lavoro corrente.
Il seguente script Python scrive un elenco di tuple in un documento della cartella di lavoro. Ogni tupla memorizza il numero del rotolo, l'età e i voti degli studenti.
from openpyxl import Workbook
wb = Workbook()
sheet1 = wb.active
sheet1.title='Student List'
sheet1.cell(column=1, row=1).value='Student List'
studentlist=[('RollNo','Name', 'age', 'marks'),(1,'Juhi',20,100),
(2,'dilip',20, 110) , (3,'jeevan',24,145)]
for col in range(1,5):
for row in range(1,5):
sheet1.cell(column=col, row=1+row).value=studentlist[row-1][col-1]
wb.save('students.xlsx')La cartella di lavoro students.xlsx viene salvata nella directory di lavoro corrente. Se aperto utilizzando l'applicazione Excel, appare come di seguito:
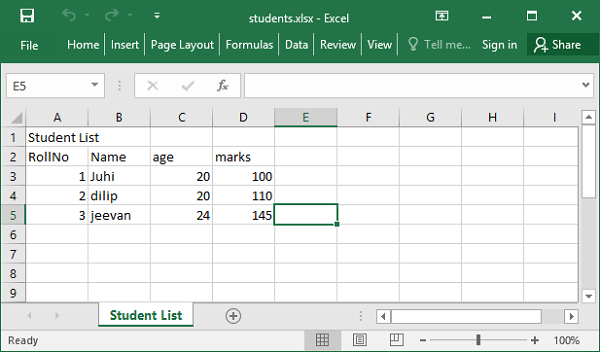
Il modulo openpyxl offre load_workbook() funzione che aiuta a leggere i dati nel documento della cartella di lavoro.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')È ora possibile accedere al valore di qualsiasi cella specificata dal numero di riga e colonna.
cell1=sheet1.cell(row=1, column=1)
print (cell1.value)
Student ListEsempio
Il codice seguente popola un elenco con i dati del foglio di lavoro.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
studentlist=[]
for row in range(1,5):
stud=[]
for col in range(1,5):
val=sheet1.cell(column=col, row=1+row).value
stud.append(val)
studentlist.append(tuple(stud))
print (studentlist)Produzione
[('RollNo', 'Name', 'age', 'marks'), (1, 'Juhi', 20, 100), (2, 'dilip', 20, 110), (3, 'jeevan', 24, 145)]Una caratteristica molto importante dell'applicazione Excel è la formula. Per assegnare una formula a una cella, assegnala a una stringa contenente la sintassi della formula di Excel. Assegna la funzione MEDIA alla cella c6 con età.
sheet1['C6']= 'AVERAGE(C3:C5)'Il modulo Openpyxl ha Translate_formula()funzione per copiare la formula in un intervallo. Il seguente programma definisce la funzione MEDIA in C6 e la copia in C7 che calcola la media dei voti.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
from openpyxl.formula.translate import Translator#copy formula
sheet1['B6']='Average'
sheet1['C6']='=AVERAGE(C3:C5)'
sheet1['D6'] = Translator('=AVERAGE(C3:C5)', origin="C6").translate_formula("D6")
wb.save('students.xlsx')Il foglio di lavoro modificato ora appare come segue: