SAP HANA - Information Modeler
SAP HANA Information Modeler; noto anche come HANA Data Modeler, è il cuore di HANA System. Consente di creare viste di modellazione nella parte superiore delle tabelle del database e implementare la logica di business per creare un report significativo per l'analisi.
Caratteristiche di Information Modeler
Fornisce più viste di dati transazionali archiviati in tabelle fisiche del database HANA per scopi di analisi e logica di business.
Il modellatore informativo funziona solo per le tabelle di archiviazione basate su colonne.
Le viste di modellazione delle informazioni vengono utilizzate da applicazioni basate su Java o HTML o strumenti SAP come SAP Lumira o Analysis Office a scopo di reporting.
È anche possibile utilizzare strumenti di terze parti come MS Excel per connettersi a HANA e creare report.
Le viste di modellazione SAP HANA sfruttano la potenza reale di SAP HANA.
Esistono tre tipi di visualizzazioni delle informazioni, definite come:
- Visualizzazione attributi
- Vista analitica
- Visualizzazione calcolo
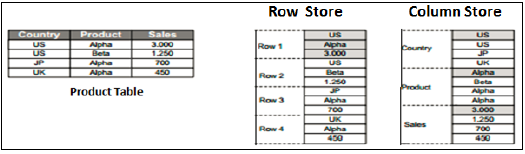
Archivio righe e colonne
Le viste di SAP HANA Modeler possono essere create solo nella parte superiore delle tabelle basate su colonne. La memorizzazione dei dati nelle tabelle delle colonne non è una novità. In precedenza si presumeva che l'archiviazione dei dati in una struttura basata su colonne richiedesse più dimensioni di memoria e non ottimizzata le prestazioni.
Con l'evoluzione di SAP HANA, HANA ha utilizzato l'archiviazione dei dati basata su colonne nelle viste delle informazioni e ha presentato i vantaggi reali delle tabelle a colonne rispetto alle tabelle basate su righe.
Archivio colonne
In una tabella dell'archivio colonne, i dati vengono archiviati verticalmente. Quindi, tipi di dati simili si uniscono come mostrato nell'esempio sopra. Fornisce operazioni di lettura e scrittura della memoria più veloci con l'aiuto di In-Memory Computing Engine.
In un database convenzionale, i dati vengono memorizzati in una struttura basata su righe, cioè orizzontalmente. SAP HANA archivia i dati sia nella struttura basata su righe che in quella basata su colonne. Ciò fornisce l'ottimizzazione delle prestazioni, la flessibilità e la compressione dei dati nel database HANA.
L'archiviazione dei dati nella tabella basata su colonne offre i seguenti vantaggi:
Compressione dati
Accesso in lettura e scrittura alle tabelle più rapido rispetto allo storage convenzionale basato su riga
Flessibilità ed elaborazione parallela
Eseguire aggregazioni e calcoli a una velocità maggiore
Esistono vari metodi e algoritmi per memorizzare i dati nella struttura basata su colonne: Dizionario compresso, Lunghezza di esecuzione compressa e molti altri.
In Dictionary Compressed, le celle vengono memorizzate sotto forma di numeri nelle tabelle e le celle numeriche sono sempre ottimizzate per le prestazioni rispetto ai caratteri.
In Run length compressed, salva il moltiplicatore con il valore della cella in formato numerico e il moltiplicatore mostra il valore ripetitivo nella tabella.

Differenza funzionale - Archivio righe e colonne
È sempre consigliabile utilizzare l'archiviazione basata su colonne, se l'istruzione SQL deve eseguire funzioni e calcoli aggregati. Le tabelle basate su colonne funzionano sempre meglio quando si eseguono funzioni aggregate come Sum, Count, Max, Min.
L'archiviazione basata su riga è preferibile quando l'output deve restituire una riga completa. L'esempio fornito di seguito lo rende facile da capire.

Nell'esempio precedente, durante l'esecuzione di una funzione Aggregate (Sum) nella colonna delle vendite con la clausola Where, utilizzerà solo la colonna Data e Sales durante l'esecuzione della query SQL, quindi se si tratta di una tabella di archiviazione basata su colonne, sarà ottimizzata per le prestazioni, più veloce dei dati è richiesto solo da due colonne.
Durante l'esecuzione di una semplice query di selezione, l'intera riga deve essere stampata nell'output, quindi è consigliabile memorizzare la tabella come Riga basata in questo scenario.
Viste di modellazione delle informazioni
Visualizzazione attributi
Gli attributi sono elementi non misurabili in una tabella di database. Rappresentano dati anagrafici e simili alle caratteristiche di BW. Le viste attributi sono dimensioni in un database o vengono utilizzate per unire dimensioni o altre viste attributi nella modellazione.
Le caratteristiche importanti sono:
- Le viste degli attributi vengono utilizzate nelle viste Analitica e Calcolo.
- La visualizzazione degli attributi rappresenta i dati principali.
- Utilizzato per filtrare le dimensioni delle tabelle delle dimensioni nella vista analitica e di calcolo.
Vista analitica
Le viste analitiche utilizzano la potenza di SAP HANA per eseguire calcoli e funzioni di aggregazione sulle tabelle nel database. Ha almeno una tabella dei fatti con misure e chiavi primarie delle tabelle delle dimensioni e circondata da tabelle delle dimensioni che contengono dati anagrafici.
Le caratteristiche importanti sono:
Le viste analitiche sono progettate per eseguire query con schema Star.
Le viste analitiche contengono almeno una tabella dei fatti e più tabelle delle dimensioni con dati anagrafici ed eseguono calcoli e aggregazioni
Sono simili agli Info Cubes e agli oggetti Info in SAP BW.
Le viste analitiche possono essere create sopra le viste degli attributi e le tabelle dei fatti ed esegue calcoli come il numero di unità vendute, il prezzo totale, ecc.
Viste di calcolo
Le viste di calcolo vengono utilizzate sopra le viste analitiche e Attributo per eseguire calcoli complessi, che non sono possibili con le viste analitiche. La vista Calcolo è una combinazione di tabelle di colonne di base, viste degli attributi e viste analitiche per fornire la logica aziendale.
Le caratteristiche importanti sono:
Le viste di calcolo vengono definite graficamente utilizzando la funzionalità di modellazione HANA o tramite script in SQL.
È stato creato per eseguire calcoli complessi, che non sono possibili con altre viste: viste Attributi e Analitiche del modellatore SAP HANA.
Una o più viste attributi e viste analitiche vengono utilizzate con l'aiuto di funzioni integrate come progetti, unione, unione, classifica in una vista di calcolo.