Spark - RDD
Set di dati distribuiti resilienti
Resilient Distributed Datasets (RDD) è una struttura dati fondamentale di Spark. È una raccolta distribuita immutabile di oggetti. Ogni set di dati in RDD è suddiviso in partizioni logiche, che possono essere calcolate su diversi nodi del cluster. Gli RDD possono contenere qualsiasi tipo di oggetti Python, Java o Scala, comprese le classi definite dall'utente.
Formalmente, un RDD è una raccolta di record partizionata di sola lettura. Gli RDD possono essere creati tramite operazioni deterministiche sui dati su una memoria stabile o su altri RDD. RDD è una raccolta di elementi a tolleranza d'errore su cui è possibile operare in parallelo.
Esistono due modi per creare RDD: parallelizing una raccolta esistente nel programma del driver o referencing a dataset in un sistema di archiviazione esterno, come un file system condiviso, HDFS, HBase o qualsiasi origine dati che offra un formato di input Hadoop.
Spark fa uso del concetto di RDD per ottenere operazioni MapReduce più veloci ed efficienti. Discutiamo prima di come avvengono le operazioni di MapReduce e perché non sono così efficienti.
La condivisione dei dati è lenta in MapReduce
MapReduce è ampiamente adottato per l'elaborazione e la generazione di set di dati di grandi dimensioni con un algoritmo distribuito parallelo su un cluster. Consente agli utenti di scrivere calcoli paralleli, utilizzando una serie di operatori di alto livello, senza doversi preoccupare della distribuzione del lavoro e della tolleranza ai guasti.
Sfortunatamente, nella maggior parte dei framework attuali, l'unico modo per riutilizzare i dati tra i calcoli (Es: tra due lavori MapReduce) è scriverli su un sistema di archiviazione stabile esterno (Es: HDFS). Sebbene questo framework fornisca numerose astrazioni per accedere alle risorse di calcolo di un cluster, gli utenti vogliono ancora di più.
Tutti e due Iterative e Interactivele applicazioni richiedono una condivisione dei dati più rapida tra lavori paralleli. La condivisione dei dati è lenta in MapReduce a causa direplication, serialization, e disk IO. Per quanto riguarda il sistema di archiviazione, la maggior parte delle applicazioni Hadoop trascorrono più del 90% del tempo in operazioni di lettura-scrittura HDFS.
Operazioni iterative su MapReduce
Riutilizza i risultati intermedi in più calcoli in applicazioni in più fasi. La figura seguente spiega come funziona il framework corrente, mentre si eseguono le operazioni iterative su MapReduce. Ciò comporta notevoli sovraccarichi a causa della replica dei dati, dell'I / O del disco e della serializzazione, che rallentano il sistema.
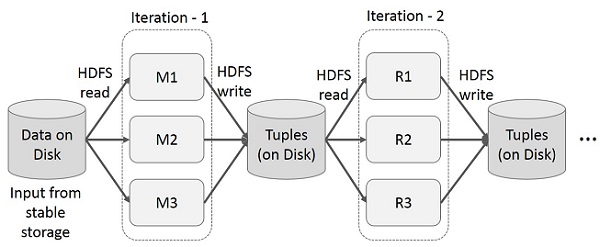
Operazioni interattive su MapReduce
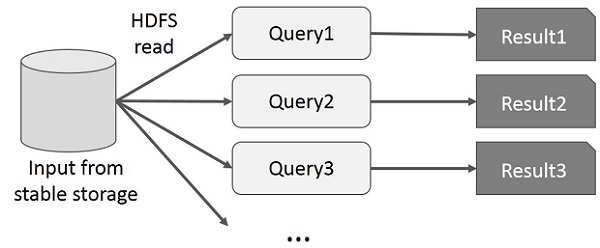
L'utente esegue query ad-hoc sullo stesso sottoinsieme di dati. Ogni query eseguirà l'I / O del disco sulla memoria stabile, che può dominare il tempo di esecuzione dell'applicazione.
La figura seguente spiega come funziona il framework corrente durante l'esecuzione delle query interattive su MapReduce.
Condivisione dei dati utilizzando Spark RDD
La condivisione dei dati è lenta in MapReduce a causa di replication, serialization, e disk IO. Nella maggior parte delle applicazioni Hadoop, trascorrono più del 90% del tempo in operazioni di lettura e scrittura HDFS.
Riconoscendo questo problema, i ricercatori hanno sviluppato un framework specializzato chiamato Apache Spark. L'idea chiave della scintilla èResiliente Ddistribuito Datasets (RDD); supporta il calcolo dell'elaborazione in memoria. Ciò significa che memorizza lo stato della memoria come un oggetto tra i lavori e l'oggetto è condivisibile tra questi lavori. La condivisione dei dati in memoria è da 10 a 100 volte più veloce della rete e del disco.
Proviamo ora a scoprire come avvengono le operazioni iterative e interattive in Spark RDD.
Operazioni iterative su Spark RDD
L'illustrazione riportata di seguito mostra le operazioni iterative su Spark RDD. Memorizzerà i risultati intermedi in una memoria distribuita invece che nell'archiviazione stabile (disco) e renderà il sistema più veloce.
Note - Se la memoria distribuita (RAM) non è sufficiente per memorizzare i risultati intermedi (stato del lavoro), memorizzerà tali risultati sul disco
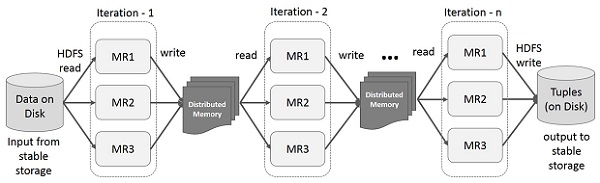
Operazioni interattive su Spark RDD
Questa illustrazione mostra le operazioni interattive su Spark RDD. Se diverse query vengono eseguite ripetutamente sullo stesso set di dati, questi particolari dati possono essere conservati in memoria per tempi di esecuzione migliori.

Per impostazione predefinita, ogni RDD trasformato può essere ricalcolato ogni volta che si esegue un'azione su di esso. Tuttavia, potresti anchepersistun RDD in memoria, nel qual caso Spark manterrà gli elementi nel cluster per un accesso molto più rapido, la prossima volta che lo interrogherai. È inoltre disponibile il supporto per la persistenza di RDD su disco o per la replica su più nodi.