Splunk - Guida rapida
Splunk è un software che elabora e fa emergere informazioni dai dati della macchina e da altre forme di big data. Questi dati macchina sono generati dalla CPU che esegue un server web, dispositivi IOT, registri da app mobili, ecc. Non è necessario fornire questi dati agli utenti finali e non hanno alcun significato commerciale. Tuttavia, sono estremamente importanti per comprendere, monitorare e ottimizzare le prestazioni delle macchine.
Splunk può leggere questi dati non strutturati, semi-strutturati o raramente strutturati. Dopo aver letto i dati, consente di cercare, taggare, creare report e dashboard su questi dati. Con l'avvento dei big data, Splunk è ora in grado di importare big data da varie fonti, che possono o meno essere dati macchina ed eseguire analisi sui big data.
Quindi, da semplice strumento per l'analisi dei log, Splunk ha fatto molta strada per diventare uno strumento analitico generale per dati macchina non strutturati e varie forme di big data.
Categorie di Prodotto
Splunk è disponibile in tre diverse categorie di prodotti come segue:
Splunk Enterprise- Viene utilizzato da aziende che dispongono di grandi infrastrutture IT e attività guidate dall'IT. Aiuta a raccogliere e analizzare i dati da siti Web, applicazioni, dispositivi e sensori, ecc.
Splunk Cloud- È la piattaforma ospitata nel cloud con le stesse funzionalità della versione aziendale. Può essere utilizzato da Splunk stesso o tramite la piattaforma cloud AWS.
Splunk Light- Permette di cercare, segnalare e avvisare su tutti i dati di registro in tempo reale da un unico luogo. Ha funzionalità e caratteristiche limitate rispetto alle altre due versioni.
Caratteristiche di Splunk
In questa sezione, discuteremo le caratteristiche importanti di Enterprise Edition:
Ingestione dei dati
Splunk può importare una varietà di formati di dati come JSON, XML e dati macchina non strutturati come i log web e delle applicazioni. I dati non strutturati possono essere modellati in una struttura dati secondo le necessità dell'utente.
Indicizzazione dei dati
I dati acquisiti vengono indicizzati da Splunk per una ricerca e query più rapide in condizioni diverse.
Ricerca dati
La ricerca in Splunk implica l'utilizzo dei dati indicizzati allo scopo di creare metriche, prevedere tendenze future e identificare modelli nei dati.
Utilizzo degli avvisi
Gli avvisi Splunk possono essere utilizzati per attivare e-mail o feed RSS quando vengono trovati alcuni criteri specifici nei dati analizzati.
Dashboard
Splunk Dashboards può mostrare i risultati della ricerca sotto forma di grafici, report e pivot, ecc.
Modello di dati
I dati indicizzati possono essere modellati in uno o più set di dati basati sulla conoscenza del dominio specializzato. Ciò porta a una navigazione più semplice da parte degli utenti finali che analizzano i casi aziendali senza apprendere i tecnicismi del linguaggio di elaborazione della ricerca utilizzato da Splunk.
In questo tutorial, mireremo a installare la versione enterprise. Questa versione è disponibile per una valutazione gratuita per 60 giorni con tutte le funzionalità abilitate. È possibile scaricare la configurazione utilizzando il collegamento sottostante, disponibile per entrambe le piattaforme Windows e Linux.
https://www.splunk.com/en_us/download/splunk-enterprise.html.
Versione Linux
La versione Linux viene scaricata dal link per il download sopra indicato. Scegliamo il tipo di pacchetto .deb poiché l'installazione verrà eseguita su una piattaforma Ubuntu.
Lo impareremo con un approccio graduale:
Passo 1
Scarica il pacchetto .deb come mostrato nello screenshot qui sotto -
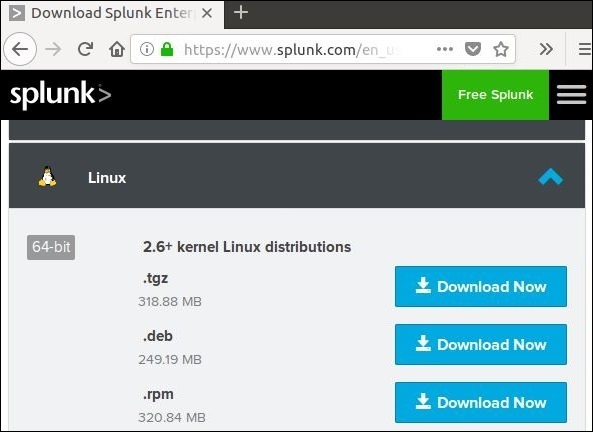
Passo 2
Vai alla directory di download e installa Splunk utilizzando il pacchetto scaricato sopra.
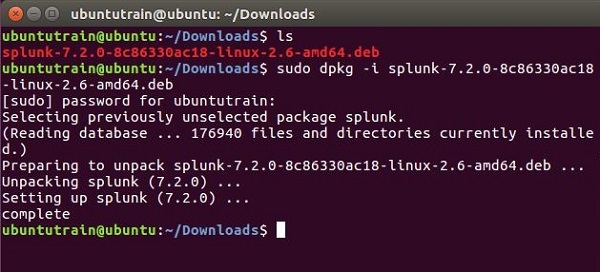
Passaggio 3
Successivamente puoi avviare Splunk usando il seguente comando con l'argomento di accettazione della licenza. Chiederà il nome utente e la password dell'amministratore che dovresti fornire e ricordare.
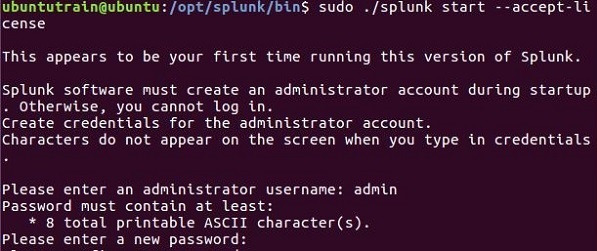
Passaggio 4
Il server Splunk si avvia e menziona l'URL da cui è possibile accedere all'interfaccia Splunk.
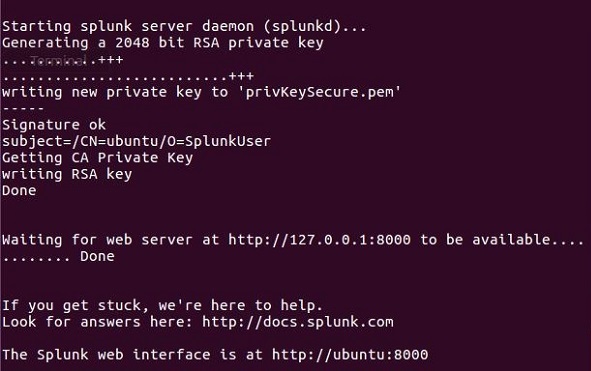
Passaggio 5
Ora puoi accedere all'URL Splunk e inserire l'ID utente e la password dell'amministratore creati nel passaggio 3.

Versione Windows
La versione per Windows è disponibile come programma di installazione msi come mostrato nell'immagine sottostante -
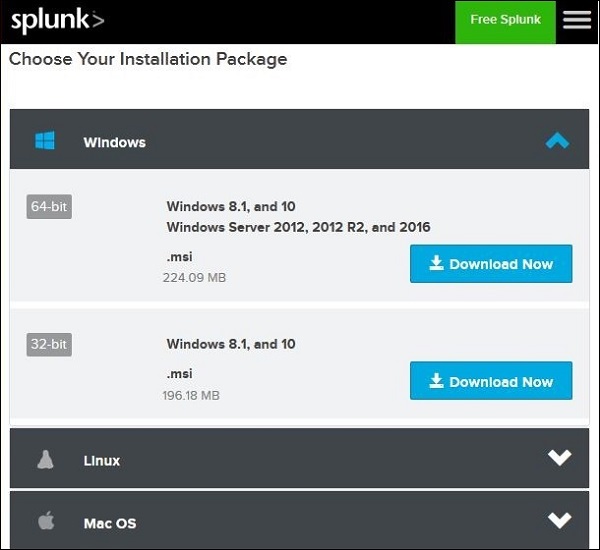
Facendo doppio clic sul programma di installazione msi installa la versione di Windows in un processo semplice. I due passaggi importanti in cui dobbiamo fare la scelta giusta per una corretta installazione sono i seguenti.
Passo 1
Dato che lo stiamo installando su un sistema locale, scegli l'opzione di sistema locale come indicato di seguito:
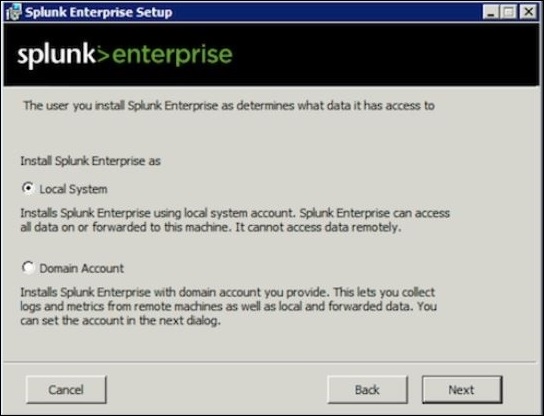
Passo 2
Immettere la password dell'amministratore e ricordarla, poiché verrà utilizzata nelle future configurazioni.
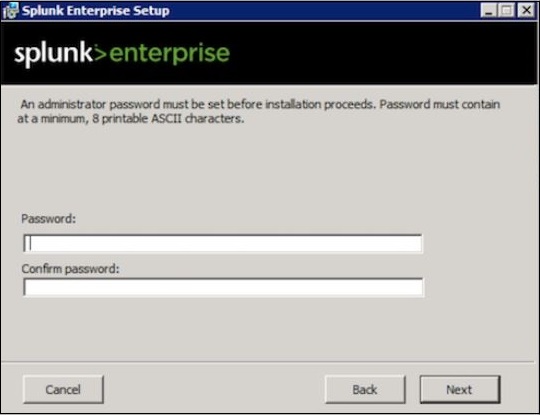
Passaggio 3
Nel passaggio finale, vediamo che Splunk è stato installato con successo e può essere avviato dal browser web.

Passaggio 4
Quindi, apri il browser e inserisci l'URL fornito, http://localhost:8000e accedi a Splunk utilizzando l'ID utente e la password dell'amministratore.

L'interfaccia web di Splunk è costituita da tutti gli strumenti necessari per cercare, segnalare e analizzare i dati ingeriti. La stessa interfaccia web fornisce funzionalità per l'amministrazione degli utenti e dei loro ruoli. Fornisce anche collegamenti per l'importazione dei dati e le app integrate disponibili in Splunk.
L'immagine sotto mostra la schermata iniziale dopo il login a Splunk con le credenziali di amministratore.
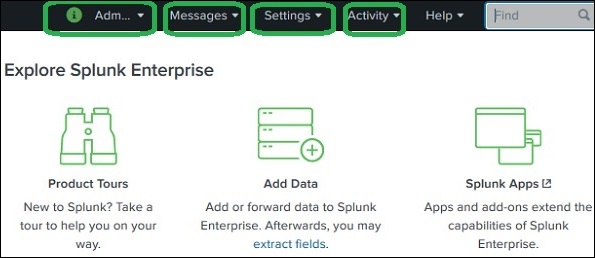
Link amministratore
Il menu a discesa Amministratore offre la possibilità di impostare e modificare i dettagli dell'amministratore. Possiamo reimpostare l'ID e-mail e la password dell'amministratore utilizzando la schermata seguente:
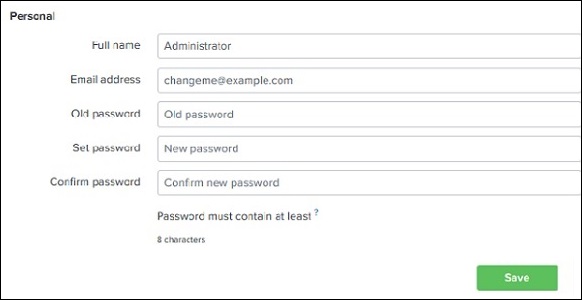
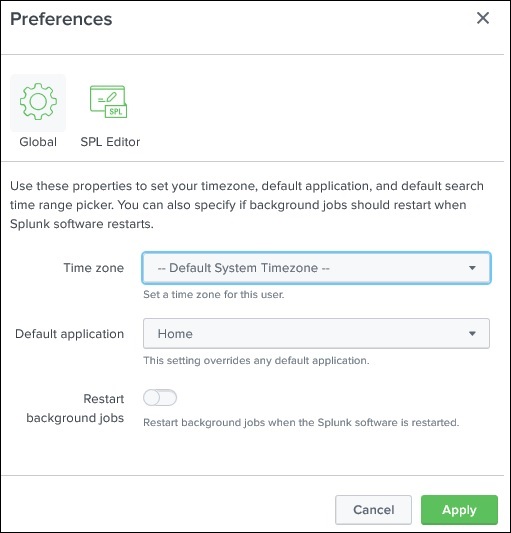
Oltre al collegamento dell'amministratore, possiamo anche navigare nell'opzione delle preferenze in cui possiamo impostare il fuso orario e l'applicazione home su cui si aprirà la pagina di destinazione dopo il tuo login. Attualmente, si è aperto nella home page come mostrato di seguito:
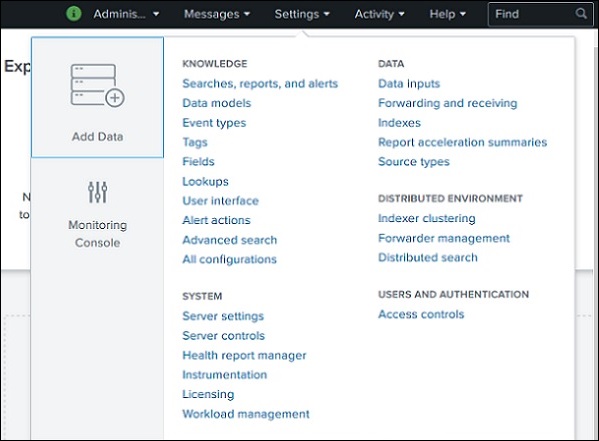
Collegamento alle impostazioni
Questo è un collegamento che mostra tutte le funzionalità principali disponibili in Splunk. Ad esempio, è possibile aggiungere i file di ricerca e le definizioni di ricerca scegliendo il collegamento di ricerca.
Discuteremo le impostazioni importanti di questi collegamenti nei capitoli successivi.
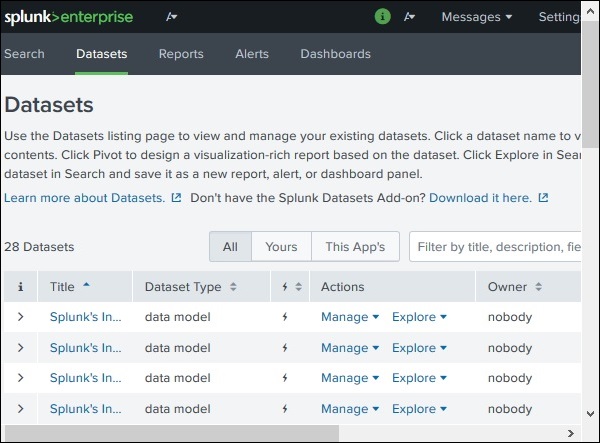
Link di ricerca e reportistica
Il collegamento di ricerca e report ci porta alle funzioni in cui possiamo trovare i set di dati disponibili per la ricerca dei report e degli avvisi creati per queste ricerche. È chiaramente mostrato nello screenshot qui sotto -
L'inserimento dei dati in Splunk avviene tramite Add Datafunzione che fa parte dell'app di ricerca e segnalazione. Dopo aver effettuato l'accesso, la schermata iniziale dell'interfaccia di Splunk mostra il fileAdd Data come mostrato di seguito.
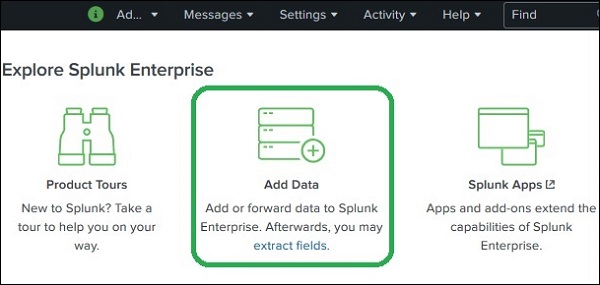
Facendo clic su questo pulsante, ci viene presentata la schermata per selezionare l'origine e il formato dei dati che intendiamo inviare a Splunk per l'analisi.
Raccolta dei dati
Possiamo ottenere i dati per l'analisi dal sito web ufficiale di Splunk. Salva questo file e decomprimilo nell'unità locale. All'apertura della cartella, puoi trovare tre file che hanno formati diversi. Sono i dati di registro generati da alcune app web. Possiamo anche raccogliere un altro set di dati fornito da Splunk, disponibile su dalla pagina web ufficiale di Splunk.
Useremo i dati di entrambi questi set per comprendere il funzionamento delle varie funzionalità di Splunk.
Caricamento dei dati
Successivamente, scegliamo il file, secure.log dalla cartella, mailsvche abbiamo mantenuto nel nostro sistema locale come menzionato nel paragrafo precedente. Dopo aver selezionato il file, passiamo al passaggio successivo utilizzando il pulsante successivo di colore verde nell'angolo in alto a destra.
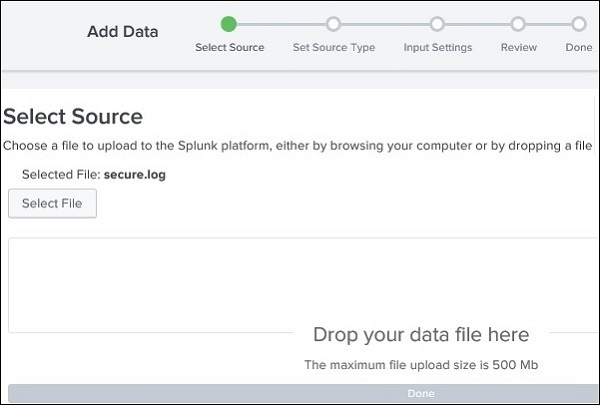
Selezione del tipo di origine
Splunk ha una funzionalità integrata per rilevare il tipo di dati ingeriti. Offre inoltre all'utente la possibilità di scegliere un tipo di dati diverso da quello scelto da Splunk. Facendo clic sul menu a discesa del tipo di origine, possiamo vedere vari tipi di dati che Splunk può importare e abilitare per la ricerca.
Nell'esempio corrente fornito di seguito, scegliamo il tipo di sorgente predefinito.
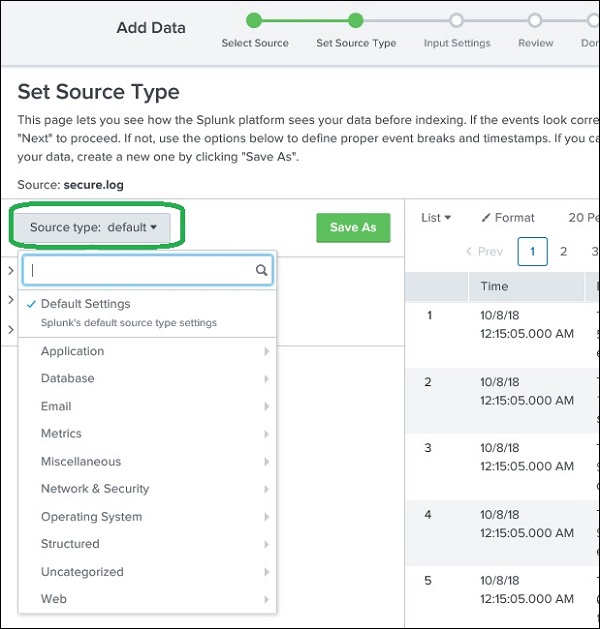
Impostazioni di input
In questa fase di importazione dei dati, configuriamo il nome host da cui vengono importati i dati. Di seguito sono riportate le opzioni tra cui scegliere, per il nome host:
Valore costante
È il nome host completo in cui risiedono i dati di origine.
regex sul percorso
Quando si desidera estrarre il nome host con un'espressione regolare. Quindi inserisci la regex per l'host che desideri estrarre nel campo Espressione regolare.
segmento nel percorso
Quando desideri estrarre il nome host da un segmento nel percorso dell'origine dati, inserisci il numero del segmento nel campo Numero segmento. Ad esempio, se il percorso dell'origine è / var / log / e si desidera che il terzo segmento (il nome del server host) sia il valore dell'host, immettere "3".
Successivamente, scegliamo il tipo di indice da creare sui dati di input per la ricerca. Scegliamo la strategia dell'indice predefinita. L'indice di riepilogo crea solo un riepilogo dei dati tramite l'aggregazione e crea un indice su di esso mentre l'indice di cronologia serve per memorizzare la cronologia di ricerca. È chiaramente rappresentato nell'immagine qui sotto:
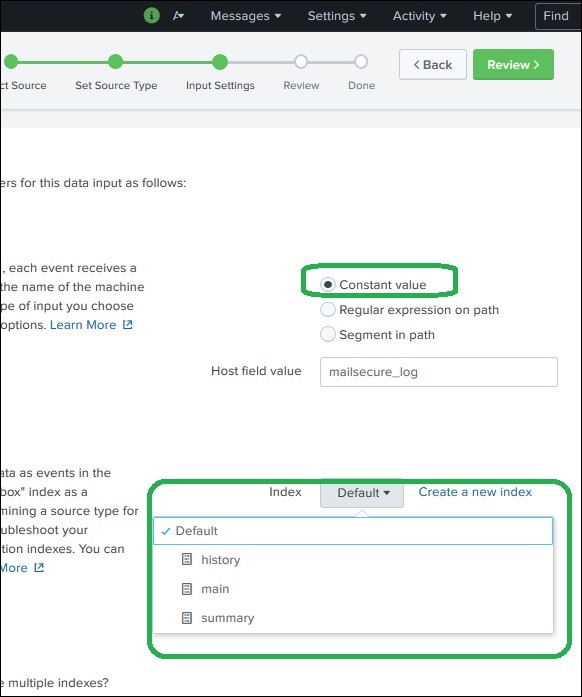
Impostazioni di revisione
Dopo aver fatto clic sul pulsante successivo, vediamo un riepilogo delle impostazioni che abbiamo scelto. Lo esaminiamo e scegliamo Avanti per completare il caricamento dei dati.
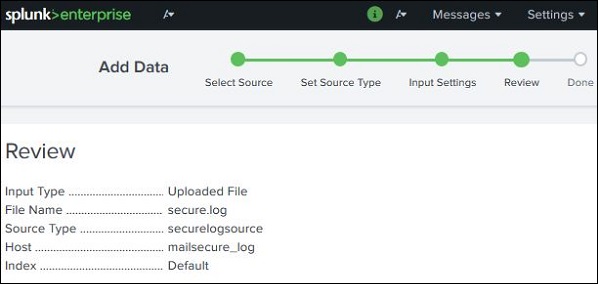
Al termine del caricamento, viene visualizzata la schermata sottostante che mostra l'acquisizione dei dati riuscita e ulteriori possibili azioni che possiamo intraprendere sui dati.

Tutti i dati in arrivo a Splunk vengono prima giudicati dalla sua unità di elaborazione dati incorporata e classificati in determinati tipi e categorie di dati. Ad esempio, se si tratta di un registro dal server Web Apache, Splunk è in grado di riconoscerlo e creare campi appropriati dai dati letti.
Questa funzionalità in Splunk è chiamata rilevamento del tipo di origine e utilizza i suoi tipi di origine incorporati noti come tipi di origine "pre-addestrati" per ottenere questo risultato.
Ciò semplifica le cose per l'analisi poiché l'utente non deve classificare manualmente i dati e assegnare alcun tipo di dati ai campi dei dati in arrivo.
Tipi di sorgenti supportati
I tipi di sorgenti supportati in Splunk possono essere visualizzati caricando un file tramite Add Datae quindi selezionando il menu a discesa per Tipo di origine. Nell'immagine sottostante, abbiamo caricato un file CSV e quindi verificato tutte le opzioni disponibili.
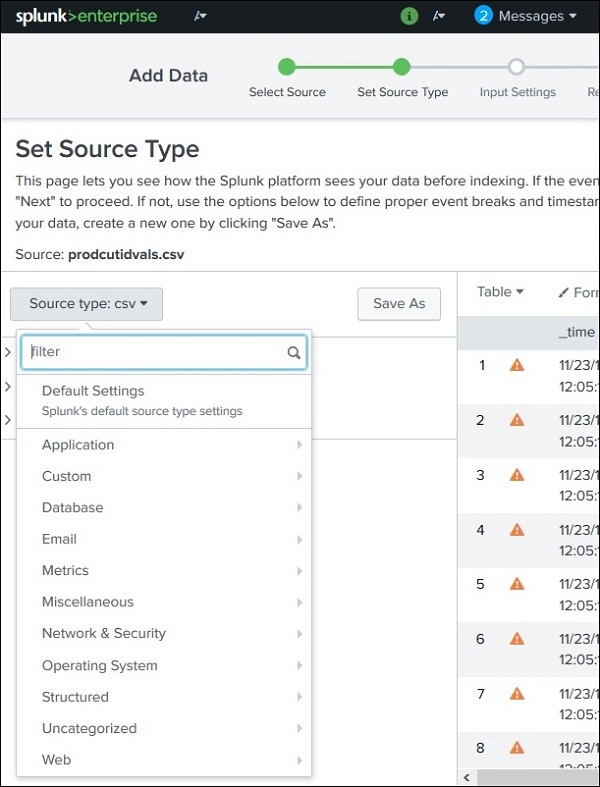
Sottocategoria del tipo di origine
Anche in quelle categorie, possiamo fare ulteriore clic per vedere tutte le sottocategorie supportate. Quindi, quando scegli la categoria di database, puoi trovare i diversi tipi di database e i loro file supportati che Splunk può riconoscere.
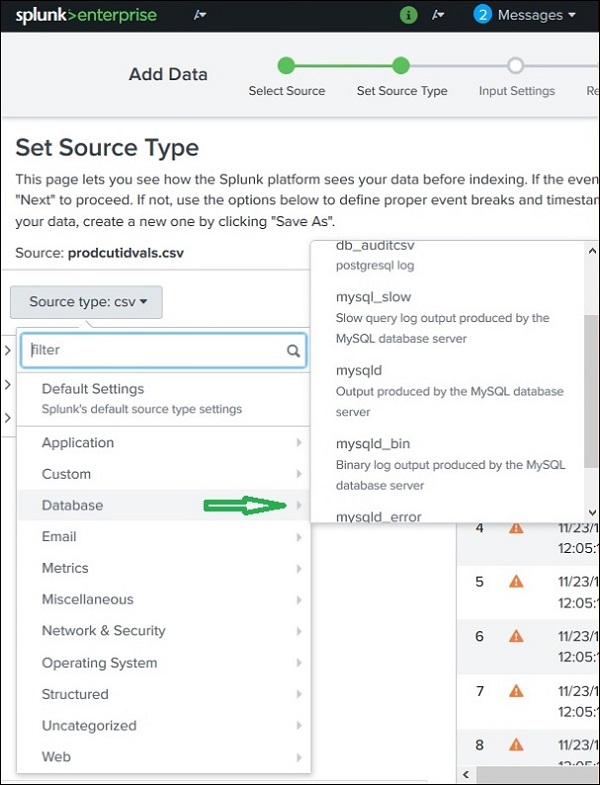
Tipi di sorgenti pre-addestrati
La tabella seguente elenca alcuni degli importanti tipi di sorgenti pre-addestrati che Splunk riconosce:
| Nome del tipo di origine | Natura |
|---|---|
| access_combined | Registri del server Web http in formato combinato NCSA (possono essere generati da Apache o altri server Web) |
| access_combined_wcookie | Log del server Web http in formato combinato NCSA (possono essere generati da Apache o altri server Web), con il campo cookie aggiunto alla fine |
| apache_error | Registro degli errori del server Web Apache standard |
| linux_messages_syslog | Syslog linux standard (/ var / log / messages sulla maggior parte delle piattaforme) |
| log4j | Output standard di Log4j prodotto da qualsiasi server J2EE utilizzando log4j |
| mysqld_error | Registro degli errori mysql standard |
Splunk ha una robusta funzionalità di ricerca che ti consente di cercare nell'intero set di dati che viene importato. Questa funzione è accessibile tramite l'app denominataSearch & Reporting che può essere visualizzato nella barra laterale sinistra dopo aver effettuato l'accesso all'interfaccia web.
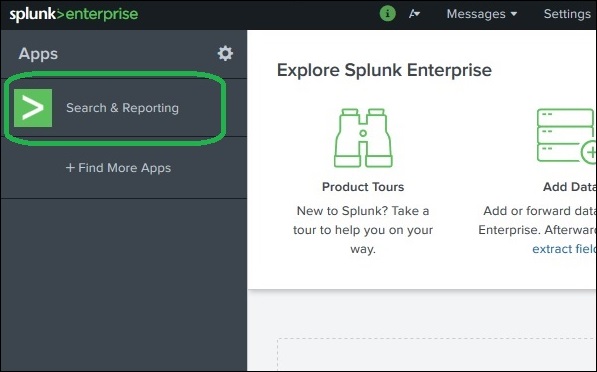
Facendo clic su search & Reporting app, ci viene presentata una casella di ricerca, dove possiamo iniziare la nostra ricerca sui dati di log che abbiamo caricato nel capitolo precedente.
Digitiamo il nome host nel formato mostrato di seguito e facciamo clic sull'icona di ricerca presente nell'angolo più a destra. Questo ci dà il risultato evidenziando il termine di ricerca.

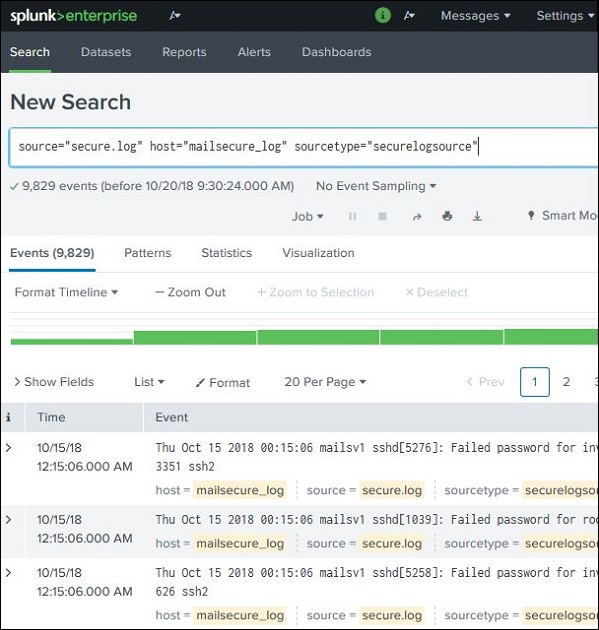
Combinazione di termini di ricerca
Possiamo combinare i termini utilizzati per la ricerca scrivendoli uno dopo l'altro ma inserendo le stringhe di ricerca dell'utente tra virgolette doppie.
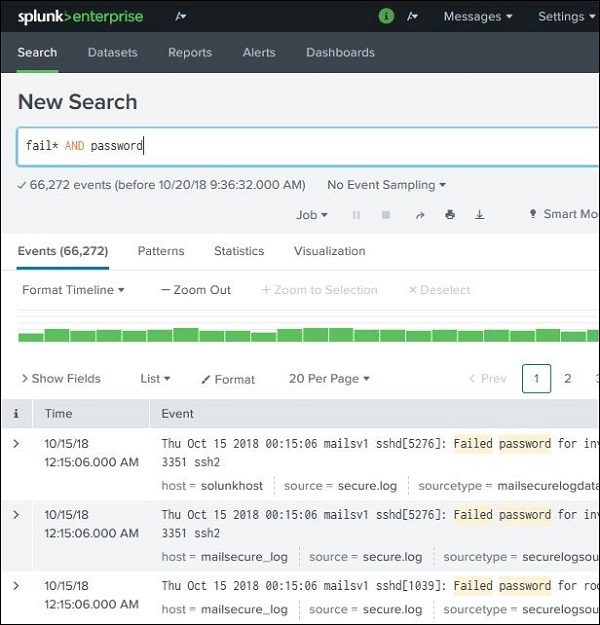
Utilizzando Wild Card
Possiamo utilizzare i caratteri jolly nella nostra opzione di ricerca combinata con il AND/ORoperatori. Nella ricerca di seguito, otteniamo il risultato in cui il file di registro contiene i termini che contengono errore, errore, errore, ecc., Insieme al termine password nella stessa riga.
Affinamento dei risultati di ricerca
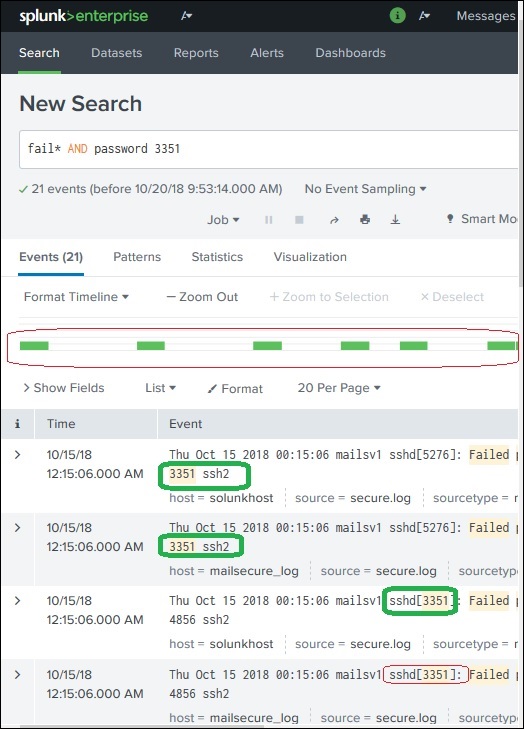
Possiamo ulteriormente perfezionare il risultato della ricerca selezionando una stringa e aggiungendola alla ricerca. Nell'esempio seguente, facciamo clic sulla stringa3351 e seleziona l'opzione Add to Search.
Dopo 3351viene aggiunto al termine di ricerca, otteniamo il risultato seguente che mostra solo quelle righe del registro che contengono 3351 in esse. Contrassegna anche come è cambiata la cronologia del risultato della ricerca man mano che abbiamo perfezionato la ricerca.
Quando Splunk legge i dati macchina caricati, interpreta i dati e li divide in molti campi che rappresentano un singolo fatto logico sull'intero record di dati.
Ad esempio, un singolo record di informazioni può contenere il nome del server, il timestamp dell'evento, il tipo di evento registrato se un tentativo di accesso o una risposta http, ecc. Anche in caso di dati non strutturati, Splunk cerca di dividere i campi in valori chiave accoppia o separali in base ai tipi di dati che hanno, numerico e stringa, ecc.
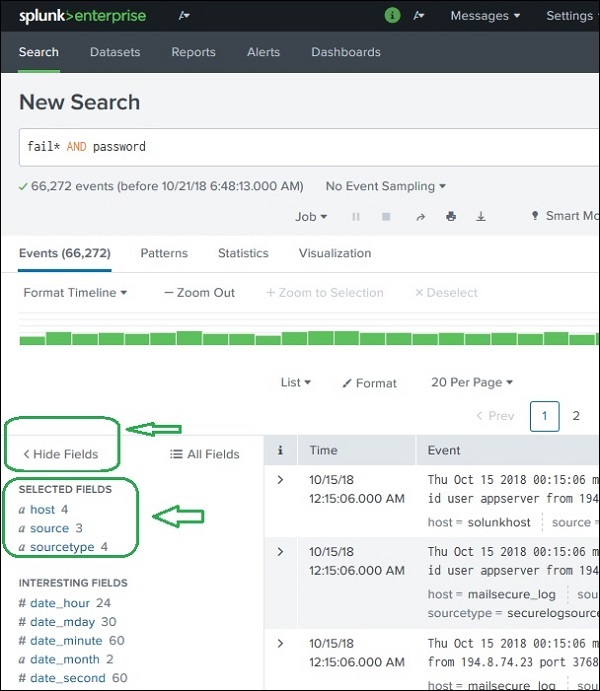
Continuando con i dati caricati nel capitolo precedente, possiamo vedere i campi del file secure.logcliccando sul link mostra campi che aprirà la seguente schermata. Possiamo notare i campi che Splunk ha generato da questo file di registro.
La scelta dei campi
Possiamo scegliere quali campi visualizzare selezionando o deselezionando i campi dall'elenco di tutti i campi. Facendo clic suall fieldsapre una finestra che mostra l'elenco di tutti i campi. Alcuni di questi campi sono contrassegnati da segni di spunta a indicare che sono già selezionati. Possiamo usare le caselle di controllo per scegliere i nostri campi da visualizzare.
Oltre al nome del campo, mostra il numero di valori distinti dei campi, il tipo di dati e la percentuale di eventi in cui è presente questo campo.
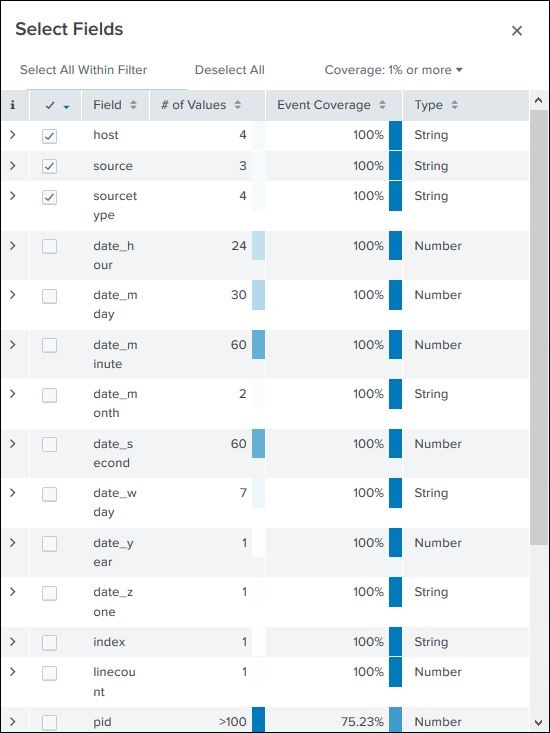
Riepilogo del campo
Statistiche molto dettagliate per ogni campo selezionato diventano disponibili facendo clic sul nome del campo. Mostra tutti i valori distinti per il campo, il loro conteggio e le loro percentuali.
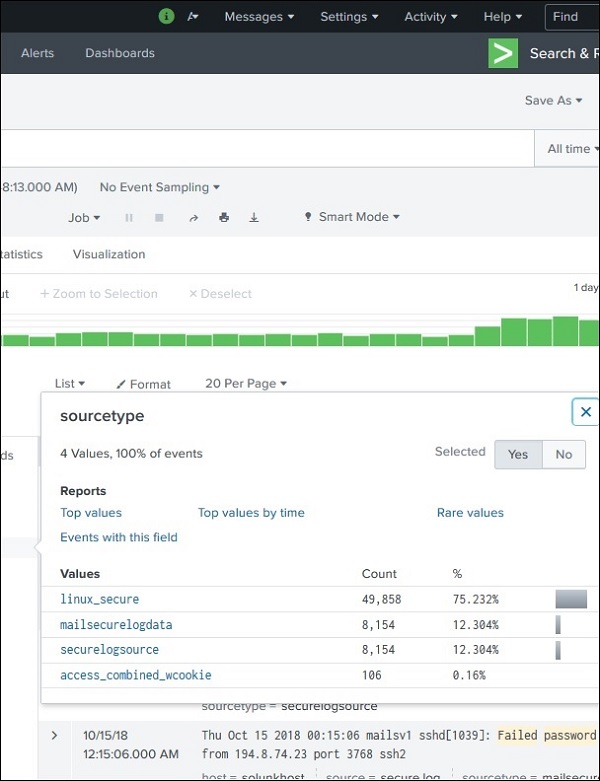
Utilizzo dei campi nella ricerca
I nomi dei campi possono anche essere inseriti nella casella di ricerca insieme ai valori specifici per la ricerca. Nell'esempio seguente, ci proponiamo di trovare tutti i record per la data, 15 ottobre per l'host denominatomailsecure_log. Otteniamo il risultato per questa data specifica.

L'interfaccia web di Splunk mostra la timeline che indica la distribuzione degli eventi in un intervallo di tempo. Sono disponibili intervalli di tempo preimpostati da cui è possibile selezionare un intervallo di tempo specifico oppure è possibile personalizzare l'intervallo di tempo secondo le proprie necessità.
La schermata seguente mostra varie opzioni di timeline preimpostate. La scelta di una di queste opzioni recupererà i dati solo per quel periodo di tempo specifico che puoi anche analizzare ulteriormente, utilizzando le opzioni della sequenza temporale personalizzata disponibili.
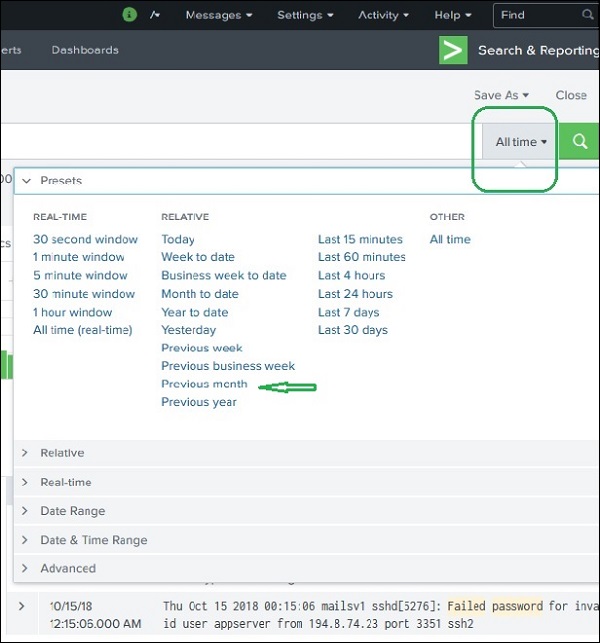
Ad esempio, la scelta dell'opzione mese precedente ci dà il risultato solo per il mese precedente come puoi vedere lo spread del grafico della sequenza temporale qui sotto.
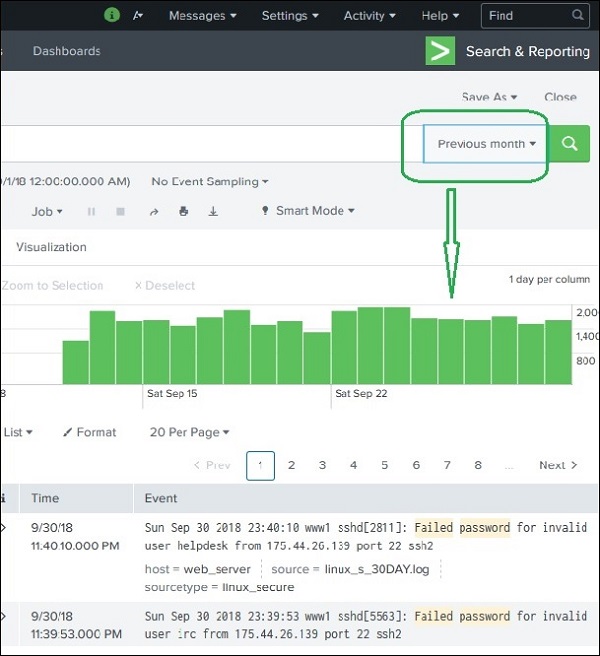
Selezione di un sottoinsieme temporale
Facendo clic e trascinando sulle barre nella timeline, possiamo selezionare un sottoinsieme del risultato già esistente. Ciò non causa la riesecuzione della query. Filtra solo i record dal set di risultati esistente.
L'immagine sotto mostra la selezione di un sottoinsieme dal set di risultati -
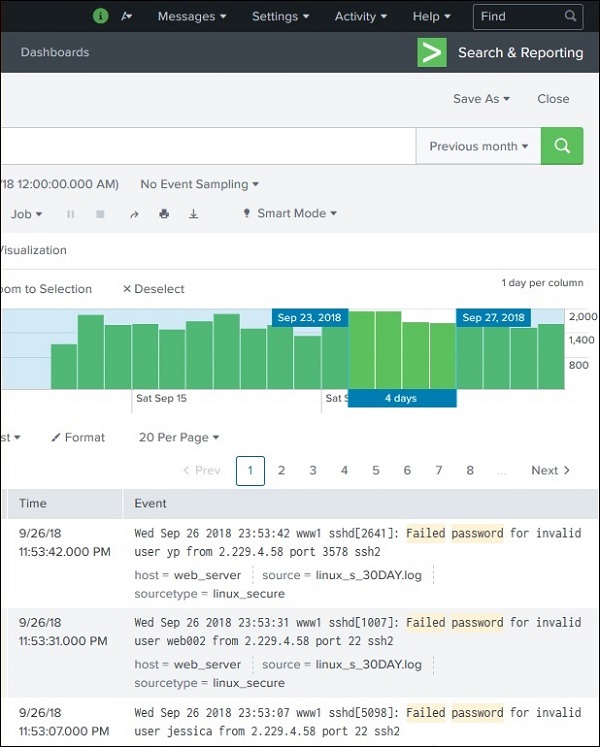
Prima e ultima
I due comandi, il primo e l'ultimo, possono essere utilizzati nella barra di ricerca per indicare l'intervallo di tempo in cui filtrare i risultati. È simile alla selezione del sottoinsieme temporale, ma avviene tramite i comandi piuttosto che tramite l'opzione di fare clic su una barra temporale specifica. Quindi, fornisce un controllo più preciso su quell'intervallo di dati che puoi scegliere per la tua analisi.
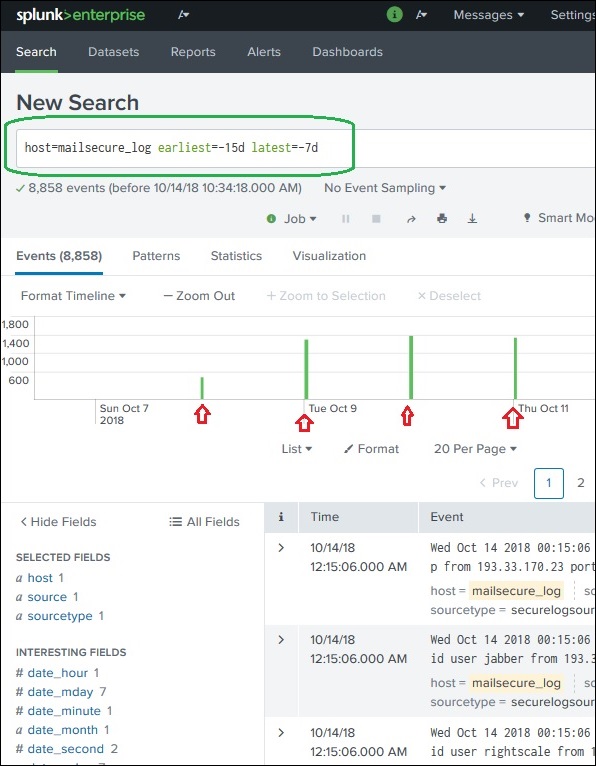
Nell'immagine sopra, diamo un intervallo di tempo compreso tra gli ultimi 7 giorni e gli ultimi 15 giorni. Quindi, vengono visualizzati i dati tra questi due giorni.
Eventi nelle vicinanze
Possiamo anche trovare eventi nelle vicinanze di un momento specifico menzionando quanto vicino vogliamo che gli eventi vengano filtrati. Abbiamo la possibilità di scegliere la scala dell'intervallo, come - secondi, minuti, giorni e settimana ecc.
Quando si esegue una query di ricerca, il risultato viene archiviato come lavoro nel server Splunk. Sebbene questo lavoro sia stato creato da un utente specifico, può essere condiviso con altri utenti in modo che possano iniziare a utilizzare questo set di risultati senza la necessità di creare nuovamente la query per esso. I risultati possono anche essere esportati e salvati come file che possono essere condivisi con utenti che non utilizzano Splunk.
Condivisione del risultato della ricerca
Una volta che una query è stata eseguita con successo, possiamo vedere una piccola freccia verso l'alto in mezzo a destra della pagina web. Facendo clic su questa icona si ottiene un URL in cui è possibile accedere alla query e al risultato. È necessario concedere l'autorizzazione agli utenti che utilizzeranno questo collegamento. L'autorizzazione viene concessa tramite l'interfaccia di amministrazione di Splunk.

Trovare i risultati salvati
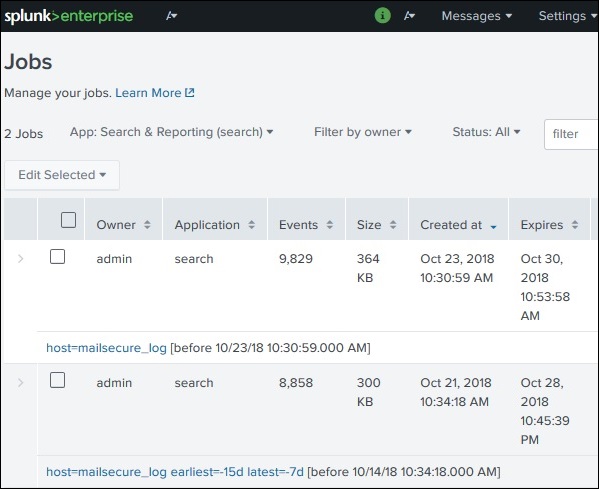
I lavori salvati per essere utilizzati da tutti gli utenti con le autorizzazioni appropriate possono essere individuati cercando il collegamento ai lavori sotto il menu delle attività nella barra in alto a destra dell'interfaccia di Splunk. Nell'immagine sottostante, facciamo clic sul collegamento evidenziato denominato lavori per trovare i lavori salvati.

Dopo aver fatto clic sul collegamento sopra, otteniamo l'elenco di tutti i lavori salvati come mostrato di seguito. Lui, dobbiamo notare che c'è un post con la data di scadenza in cui il lavoro salvato verrà automaticamente rimosso da Splunk. È possibile modificare questa data selezionando il lavoro e facendo clic su Modifica selezionato, quindi scegliendo Estendi scadenza.
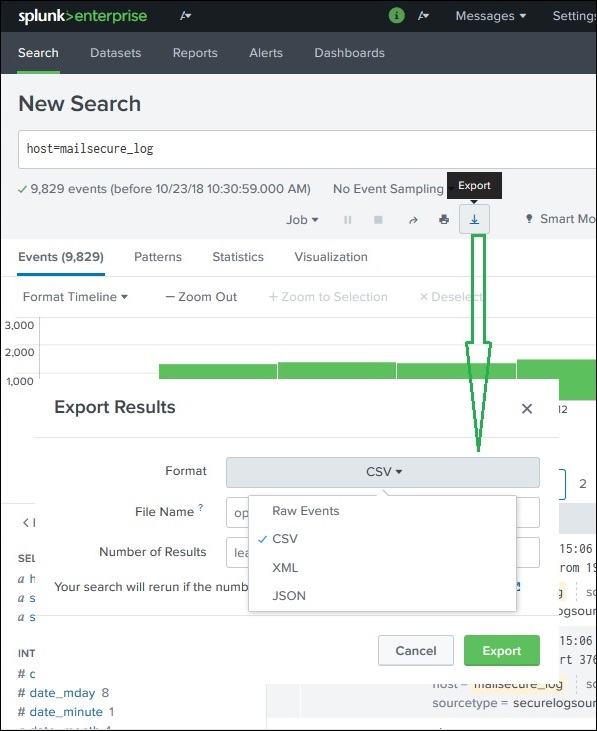
Esportazione del risultato della ricerca
Possiamo anche esportare i risultati di una ricerca in un file. I tre diversi formati disponibili per l'esportazione sono: CSV, XML e JSON. Facendo clic sul pulsante Esporta dopo aver scelto i formati, il file viene scaricato dal browser locale nel sistema locale. Questo è spiegato nell'immagine sottostante -
Splunk Search Processing Language (SPL) è un linguaggio contenente molti comandi, funzioni, argomenti, ecc., Che vengono scritti per ottenere i risultati desiderati dai set di dati. Ad esempio, quando ottieni un set di risultati per un termine di ricerca, potresti voler filtrare ulteriormente alcuni termini più specifici dal set di risultati. Per questo, è necessario aggiungere alcuni comandi aggiuntivi al comando esistente. Ciò si ottiene imparando l'uso di SPL.
Componenti di SPL
L'SPL ha i seguenti componenti.
Search Terms - Queste sono le parole chiave o le frasi che stai cercando.
Commands - L'azione che vuoi intraprendere sul set di risultati come formattare il risultato o contarli.
Functions- Quali sono i calcoli che applicherai ai risultati. Come Sum, Average ecc.
Clauses - Come raggruppare o rinominare i campi nel set di risultati.
Cerchiamo di discutere tutti i componenti con l'aiuto delle immagini nella sezione sottostante -
Termini di ricerca
Questi sono i termini che menzioni nella barra di ricerca per ottenere record specifici dal set di dati che soddisfano i criteri di ricerca. Nell'esempio seguente, stiamo cercando record che contengono due termini evidenziati.
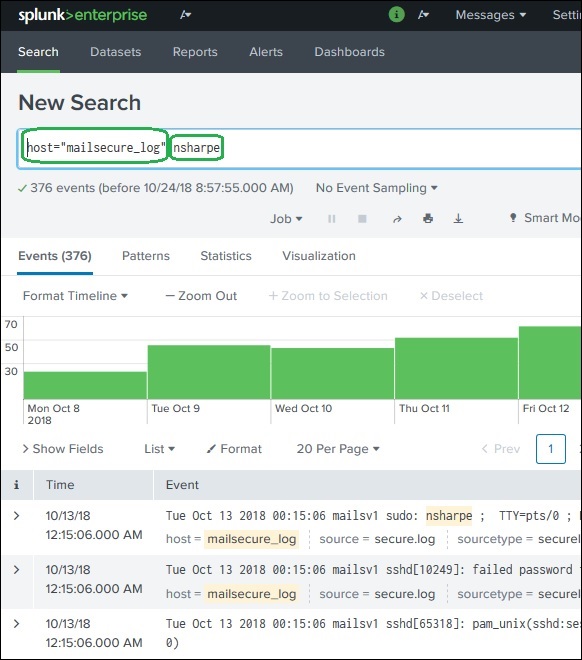
Comandi
È possibile utilizzare molti comandi integrati forniti da SPL per semplificare il processo di analisi dei dati nel set di risultati. Nell'esempio seguente utilizziamo il comando head per filtrare solo i primi 3 risultati di un'operazione di ricerca.

Funzioni
Insieme ai comandi, Splunk fornisce anche molte funzioni integrate che possono ricevere input da un campo analizzato e fornire l'output dopo aver applicato i calcoli su quel campo. Nell'esempio seguente, utilizziamo l'estensioneStats avg() funzione che calcola il valore medio del campo numerico preso come input.

Clausole
Quando vogliamo ottenere risultati raggruppati per qualche campo specifico o vogliamo rinominare un campo nell'output, usiamo il group byrispettivamente la clausola e la clausola as. Nell'esempio seguente, otteniamo la dimensione media dei byte di ogni file presente nel fileweb_applicationlog. Come puoi vedere, il risultato mostra il nome di ogni file così come i byte medi per ogni file.
