Talend - Guida rapida
Talend è una piattaforma di integrazione software che fornisce soluzioni per l'integrazione dei dati, la qualità dei dati, la gestione dei dati, la preparazione dei dati e i Big Data. La domanda di professionisti ETL con conoscenza di Talend è elevata. Inoltre, è l'unico strumento ETL con tutti i plugin per integrarsi facilmente con l'ecosistema Big Data.
Secondo Gartner, Talend rientra nel quadrante magico dei leader per gli strumenti di integrazione dei dati.
Talend offre vari prodotti commerciali elencati di seguito:
- Talend Data Quality
- Talend Data Integration
- Talend Data Preparation
- Talend Cloud
- Talend Big Data
- Piattaforma Talend MDM (Master Data Management)
- Piattaforma Talend Data Services
- Talend Metadata Manager
- Talend Data Fabric
Talend offre anche Open Studio, uno strumento gratuito open source ampiamente utilizzato per Data Integration e Big Data.
Di seguito sono riportati i requisiti di sistema per scaricare e lavorare su Talend Open Studio:
Sistema operativo consigliato
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
Requisiti di memoria
- Memoria: minimo 4 GB, consigliato 8 GB
- Spazio di archiviazione: 30 GB
Inoltre, è necessario anche un cluster Hadoop attivo e funzionante (preferibilmente Cloudera.
Note - Java 8 deve essere disponibile con le variabili d'ambiente già impostate.
Per scaricare Talend Open Studio for Big Data and Data Integration, segui i passaggi indicati di seguito:
Step 1 - Vai alla pagina: https://www.talend.com/products/big-data/big-data-open-studio/e fare clic sul pulsante di download. Puoi vedere che il file TOS_BD_xxxxxxx.zip inizia a essere scaricato.
Step 2 - Al termine del download, estrai il contenuto del file zip, creerà una cartella con tutti i file Talend al suo interno.
Step 3- Apri la cartella Talend e fai doppio clic sul file eseguibile: TOS_BD-win-x86_64.exe. Accetta il contratto di licenza con l'utente.
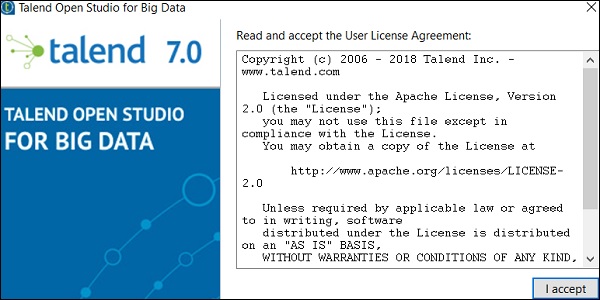
Step 4 - Crea un nuovo progetto e fai clic su Fine.
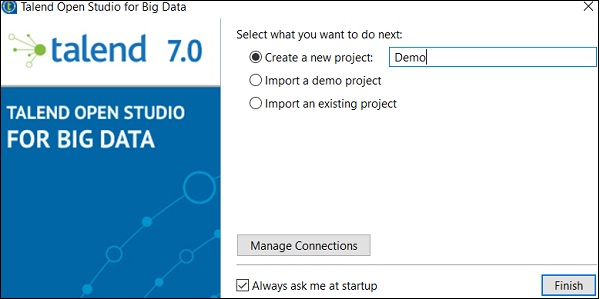
Step 5 - Fai clic su Consenti accesso nel caso in cui ricevi un avviso di sicurezza di Windows.
Step 6 - Ora, si aprirà la pagina di benvenuto di Talend Open Studio.
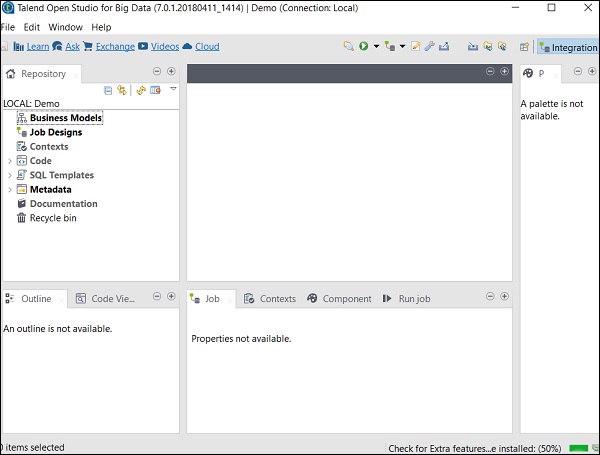
Step 7 - Fare clic su Fine per installare le librerie di terze parti richieste.
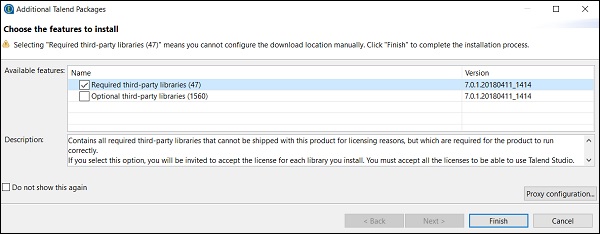
Step 8 - Accetta i termini e fai clic su Fine.
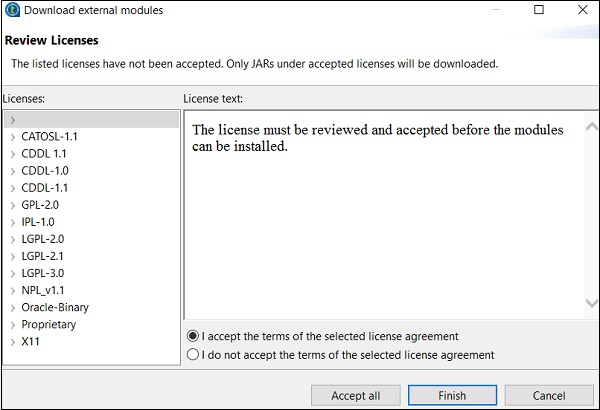
Step 9 - Fare clic su Sì.
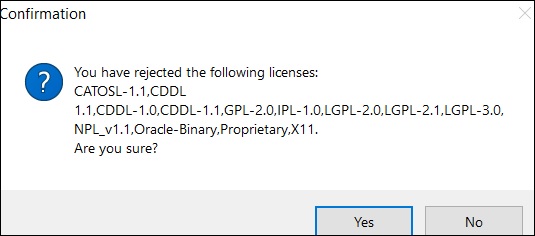
Ora il tuo Talend Open Studio è pronto con le librerie necessarie.
Talend Open Studio è uno strumento ETL open source gratuito per Data Integration e Big Data. È uno strumento di sviluppo basato su Eclipse e un progettista di lavori. È sufficiente trascinare i componenti e collegarli per creare ed eseguire lavori ETL o ETL. Lo strumento creerà automaticamente il codice Java per il lavoro e non è necessario scrivere una singola riga di codice.
Ci sono più opzioni per connettersi con origini dati come RDBMS, Excel, ecosistema SaaS Big Data, nonché app e tecnologie come SAP, CRM, Dropbox e molti altri.
Alcuni importanti vantaggi offerti da Talend Open Studio sono i seguenti:
Fornisce tutte le funzionalità necessarie per l'integrazione e la sincronizzazione dei dati con 900 componenti, connettori incorporati, conversione automatica dei lavori in codice Java e molto altro ancora.
Lo strumento è completamente gratuito, quindi ci sono grandi risparmi sui costi.
Negli ultimi 12 anni, diverse organizzazioni giganti hanno adottato TOS per l'integrazione dei dati, che mostra un fattore di fiducia molto elevato in questo strumento.
La community di Talend per l'integrazione dei dati è molto attiva.
Talend continua ad aggiungere funzionalità a questi strumenti e le documentazioni sono ben strutturate e molto facili da seguire.
La maggior parte delle organizzazioni riceve i dati da più posizioni e li archivia separatamente. Ora, se l'organizzazione deve prendere decisioni, deve prendere dati da diverse fonti, metterli in una vista unificata e quindi analizzarli per ottenere un risultato. Questo processo è chiamato integrazione dei dati.
Benefici
L'integrazione dei dati offre molti vantaggi come descritto di seguito:
Migliora la collaborazione tra i diversi team dell'organizzazione che tentano di accedere ai dati dell'organizzazione.
Risparmia tempo e semplifica l'analisi dei dati, poiché i dati sono integrati in modo efficace.
Il processo automatizzato di integrazione dei dati sincronizza i dati e semplifica il reporting periodico e in tempo reale, che altrimenti richiederebbe molto tempo se eseguito manualmente.
I dati integrati da diverse fonti maturano e migliorano nel tempo, il che alla fine aiuta a migliorare la qualità dei dati.
Lavorare con i progetti
In questa sezione, vediamo come lavorare sui progetti Talend -
Creazione di un progetto
Fare doppio clic sul file eseguibile TOS Big Data, si aprirà la finestra mostrata di seguito.
Seleziona l'opzione Crea un nuovo progetto, menziona il nome del progetto e fai clic su Crea.

Seleziona il progetto che hai creato e fai clic su Fine.

Importazione di un progetto
Fare doppio clic sul file eseguibile TOS Big Data, è possibile visualizzare la finestra come mostrato di seguito. Seleziona l'opzione Importa un progetto demo e fai clic su Seleziona.

Puoi scegliere tra le opzioni mostrate di seguito. Qui stiamo scegliendo Demo di integrazione dei dati. Ora fai clic su Fine.

Ora, dai il nome e la descrizione del progetto. Fare clic su Fine.

Puoi vedere il tuo progetto importato nell'elenco dei progetti esistenti.
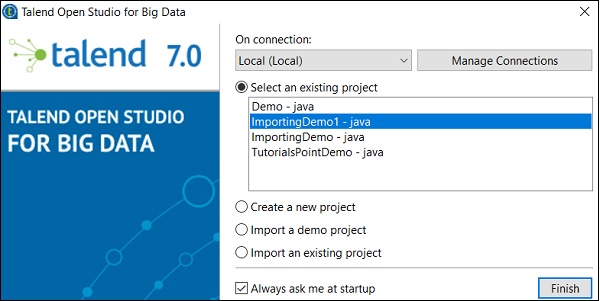
Ora, vediamo come importare un progetto Talend esistente.
Seleziona l'opzione Importa un progetto esistente e fai clic su Seleziona.

Assegnare il nome al progetto e selezionare l'opzione "Seleziona directory principale".

Sfoglia la directory home del tuo progetto Talend esistente e fai clic su Fine.

Il tuo progetto Talend esistente verrà importato.
Apertura di un progetto
Seleziona un progetto dal progetto esistente e fai clic su Fine. Questo aprirà quel progetto Talend.

Eliminazione di un progetto
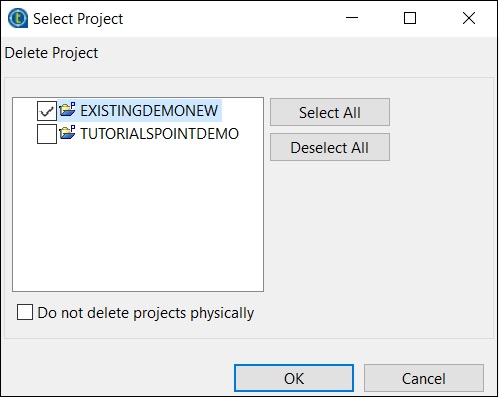
Per eliminare un progetto, fare clic su Gestisci connessioni.

Fare clic su Elimina progetto / i esistente / i

Seleziona il progetto che desideri eliminare e fai clic su Ok.
Fare di nuovo clic su OK.
Esportare un progetto
Fare clic sull'opzione Esporta progetto.

Seleziona il progetto che desideri esportare e dai un percorso a dove dovrebbe essere esportato. Fare clic su Fine.

Business Model è una rappresentazione grafica di un progetto di integrazione dei dati. È una rappresentazione non tecnica del flusso di lavoro dell'azienda.
Perché hai bisogno di un modello di business?
Viene creato un modello di business per mostrare alla dirigenza superiore quello che stai facendo e fa anche capire al tuo team cosa stai cercando di realizzare. La progettazione di un modello di business è considerata una delle migliori pratiche che le organizzazioni adottano all'inizio del loro progetto di integrazione dei dati. Inoltre, aiutando a ridurre i costi, trova e risolve i colli di bottiglia nel tuo progetto. Il modello può essere modificato durante e dopo l'attuazione del progetto, se necessario.
Creazione del modello di business in Talend Open Studio
Talend open studio fornisce molteplici forme e connettori per creare e progettare un modello di business. Ogni modulo in un modello di business può avere una documentazione allegata a se stesso.
Talend Open Studio offre le seguenti forme e opzioni di connettore per la creazione di un modello di business:
Decision - Questa forma viene utilizzata per inserire la condizione if nel modello.
Action - Questa forma viene utilizzata per mostrare qualsiasi trasformazione, traduzione o formattazione.
Terminal - Questa forma mostra il tipo di terminale di uscita.
Data - Questa forma viene utilizzata per mostrare il tipo di dati.
Document - Questa forma viene utilizzata per inserire un oggetto documento che può essere utilizzato per l'input / output dei dati elaborati.
Input - Questa forma viene utilizzata per inserire oggetti di input utilizzando l'utente che può passare i dati manualmente.
List - Questa forma contiene i dati estratti e può essere definita per contenere solo determinati tipi di dati nell'elenco.
Database - Questa forma viene utilizzata per contenere i dati di input / output.
Actor - Questa forma simboleggia le persone coinvolte nel processo decisionale e nei processi tecnici
Ellipse - Inserisce una forma Ellisse.
Gear - Questa forma mostra i programmi manuali che devono essere sostituiti dai lavori Talend.
Tutte le operazioni in Talend vengono eseguite da connettori e componenti. Talend offre oltre 800 connettori e componenti per eseguire diverse operazioni. Questi componenti sono presenti nella tavolozza e ci sono 21 categorie principali a cui appartengono i componenti. Puoi scegliere i connettori e trascinarli nel riquadro di progettazione, creerà automaticamente il codice java che verrà compilato quando salverai il codice Talend.
Le categorie principali che contengono componenti sono mostrate di seguito:
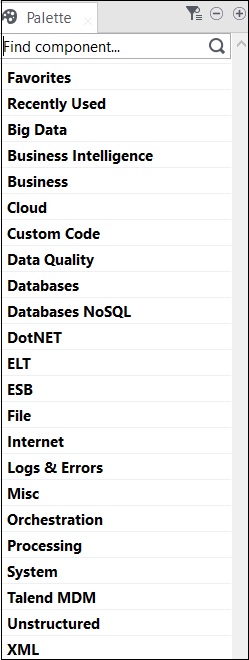
Di seguito è riportato un elenco di connettori e componenti ampiamente utilizzati per l'integrazione dei dati in Talend Open Studio:
tMysqlConnection - Si collega al database MySQL definito nel componente.
tMysqlInput - Esegue una query sul database per leggere un database ed estrarre i campi (tabelle, viste, ecc.) A seconda della query.
tMysqlOutput - Utilizzato per scrivere, aggiornare, modificare i dati in un database MySQL.
tFileInputDelimited - Legge un file delimitato riga per riga e lo divide in campi separati e lo passa al componente successivo.
tFileInputExcel - Legge un file Excel riga per riga e li divide in campi separati e lo passa al componente successivo.
tFileList - Ottiene tutti i file e le directory da un determinato modello di maschera di file.
tFileArchive - Comprime un insieme di file o cartelle in un file di archivio zip, gzip o tar.gz.
tRowGenerator - Fornisce un editor in cui è possibile scrivere funzioni o scegliere espressioni per generare i dati di esempio.
tMsgBox - Restituisce una finestra di dialogo con il messaggio specificato e un pulsante OK.
tLogRow- Monitora i dati che vengono elaborati. Visualizza dati / output nella console di esecuzione.
tPreJob - Definisce i lavori secondari che verranno eseguiti prima dell'inizio del lavoro effettivo.
tMap- Funziona come un plugin in Talend Studio. Prende i dati da una o più origini, li trasforma e quindi invia i dati trasformati a una o più destinazioni.
tJoin - Unisce 2 tabelle eseguendo join interni ed esterni tra il flusso principale e il flusso di ricerca.
tJava - Ti consente di utilizzare codice java personalizzato nel programma Talend.
tRunJob - Gestisce sistemi di lavoro complessi eseguendo un lavoro Talend dopo l'altro.
Questa è l'implementazione tecnica / rappresentazione grafica del modello di business. In questo progetto, uno o più componenti sono collegati tra loro per eseguire un processo di integrazione dei dati. Pertanto, quando si trascinano e rilasciano i componenti nel riquadro di progettazione e ci si connette quindi con i connettori, un progetto di lavoro converte tutto in codice e crea un programma eseguibile completo che forma il flusso di dati.
Creazione di un lavoro
Nella finestra del repository, fare clic con il pulsante destro del mouse su Job Design e fare clic su Create Job.
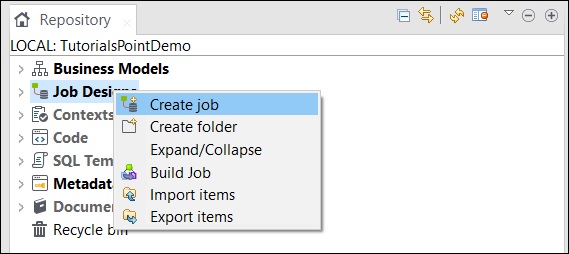
Fornire il nome, lo scopo e la descrizione del lavoro e fare clic su Fine.
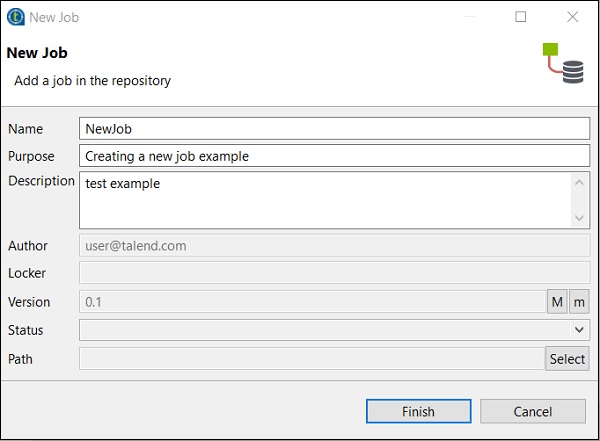
Puoi vedere che il tuo lavoro è stato creato in Job Design.
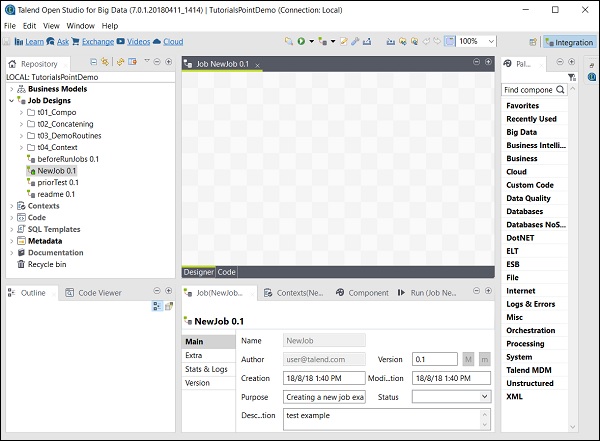
Ora, usiamo questo lavoro per aggiungere componenti, connetterli e configurarli. Qui, prenderemo un file excel come input e produrremo un file excel come output con gli stessi dati.
Aggiunta di componenti a un lavoro
Ci sono diversi componenti nella tavolozza tra cui scegliere. C'è anche un'opzione di ricerca, in cui puoi inserire il nome del componente per selezionarlo.
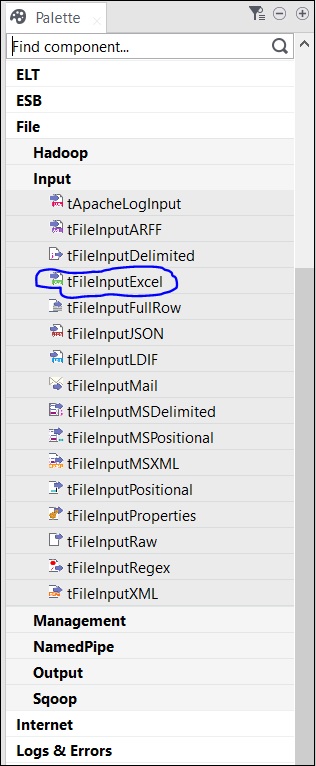
Dal momento che qui stiamo prendendo un file excel come input, trascineremo e rilasciamo il componente tFileInputExcel dalla tavolozza alla finestra Designer.

Ora se fai clic in un punto qualsiasi della finestra di progettazione, verrà visualizzata una casella di ricerca. Trova tLogRow e selezionalo per portarlo nella finestra di progettazione.

Infine, seleziona il componente tFileOutputExcel dalla tavolozza e trascinalo nella finestra di progettazione.
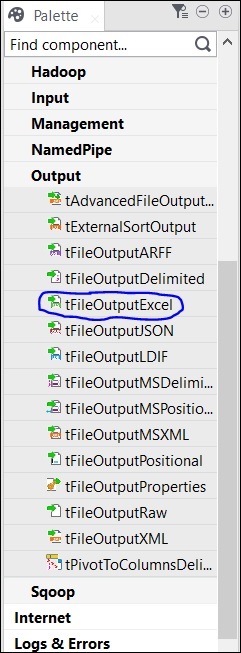
Ora, l'aggiunta dei componenti è terminata.
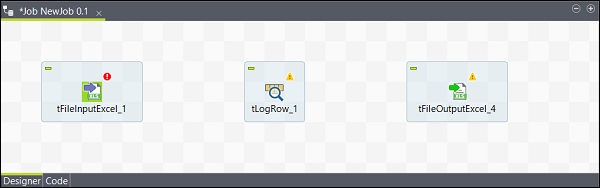
Collegamento dei componenti
Dopo aver aggiunto i componenti, è necessario collegarli. Fare clic con il pulsante destro del mouse sul primo componente tFileInputExcel e disegnare una linea principale su tLogRow come mostrato di seguito.
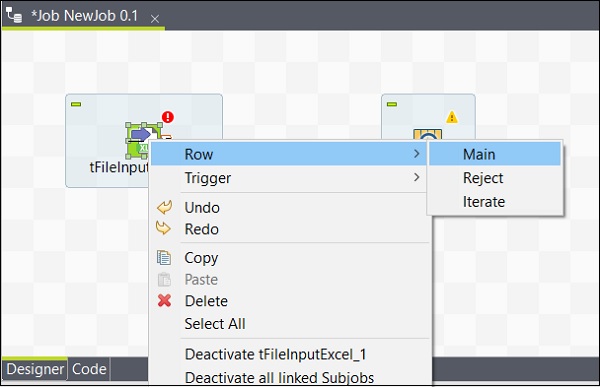
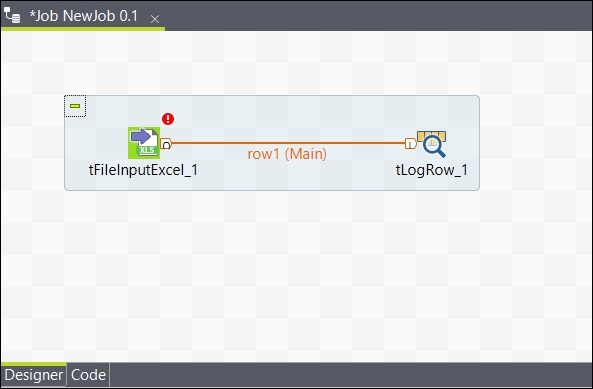
Allo stesso modo, fai clic con il pulsante destro del mouse su tLogRow e traccia una linea principale su tFileOutputExcel. Ora i tuoi componenti sono collegati.
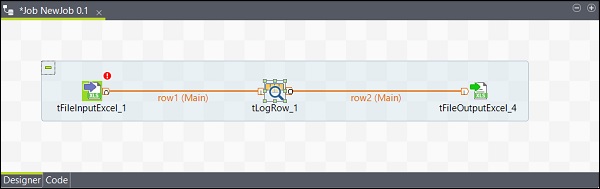
Configurazione dei componenti
Dopo aver aggiunto e collegato i componenti nel lavoro, è necessario configurarli. Per questo, fare doppio clic sul primo componente tFileInputExcel per configurarlo. Fornire il percorso del file di input in Nome file / flusso come mostrato di seguito.
Se il 1 ° riga della excel sta avendo i nomi delle colonne, mettere 1 nell'opzione di intestazione.
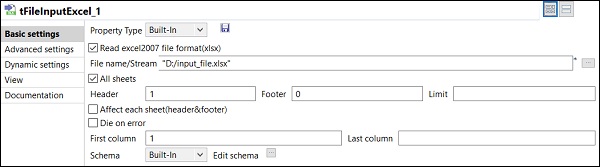
Fare clic su Modifica schema e aggiungere le colonne e il relativo tipo in base al file Excel di input. Fare clic su OK dopo aver aggiunto lo schema.
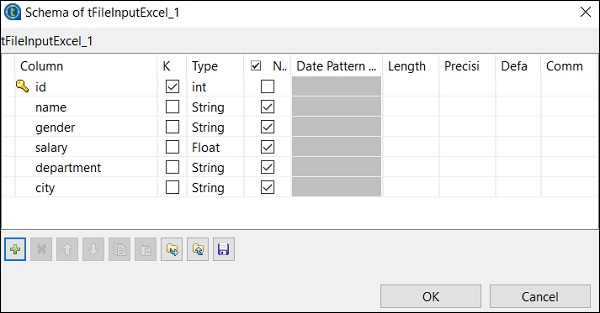
Fare clic su Sì.
Nel componente tLogRow, fai clic sulle colonne di sincronizzazione e seleziona la modalità in cui desideri generare le righe dal tuo input. Qui abbiamo selezionato la modalità Base con "," come separatore di campo.
Infine, nel componente tFileOutputExcel, fornire il percorso del nome del file in cui si desidera archiviare
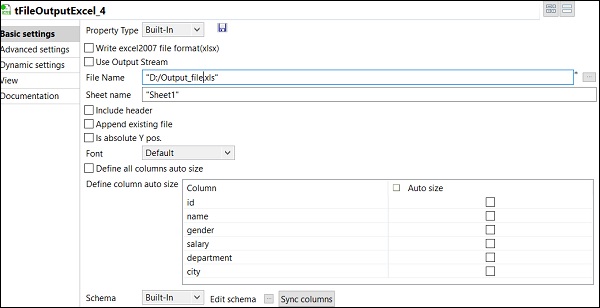
il file Excel di output con il nome del foglio. Click on sync columns.
Esecuzione del lavoro
Una volta terminato di aggiungere, collegare e configurare i componenti, sei pronto per eseguire il tuo lavoro Talend. Fare clic sul pulsante Esegui per iniziare l'esecuzione.

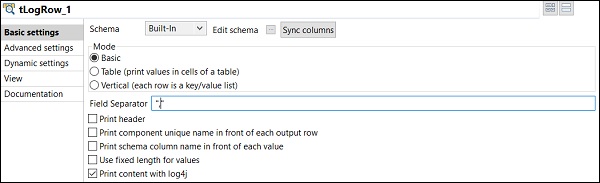
Vedrai l'output nella modalità di base con il separatore ",".
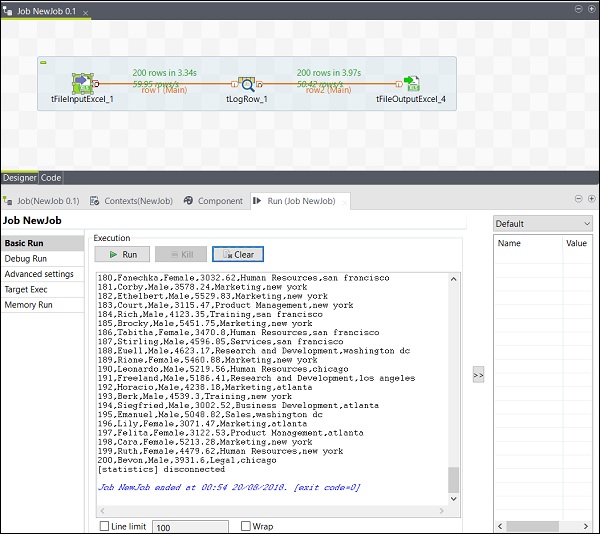
Puoi anche vedere che il tuo output viene salvato come Excel nel percorso di output che hai menzionato.
Metadati significa fondamentalmente dati sui dati. Racconta cosa, quando, perché, chi, dove, quale e come dei dati. In Talend, i metadati contengono tutte le informazioni sui dati presenti in Talend studio. L'opzione dei metadati è presente nel pannello Repository di Talend Open Studio.
Varie fonti come connessioni DB, diversi tipi di file, LDAP, Azure, Salesforce, Web Services FTP, Hadoop Cluster e molte altre opzioni sono presenti in Talend Metadata.
L'utilizzo principale dei metadati in Talend Open Studio è che è possibile utilizzare queste origini dati in diversi lavori semplicemente trascinando e rilasciando dal pannello Metadati nel repository.
Le variabili di contesto sono le variabili che possono avere valori diversi in ambienti diversi. È possibile creare un gruppo di contesto che può contenere più variabili di contesto. Non è necessario aggiungere ciascuna variabile di contesto una alla volta a un lavoro, è sufficiente aggiungere il gruppo di contesto al lavoro.
Queste variabili vengono utilizzate per preparare la produzione del codice. I suoi mezzi utilizzando le variabili di contesto, è possibile spostare il codice in ambienti di sviluppo, test o produzione, verrà eseguito in tutti gli ambienti.
In qualsiasi lavoro, puoi andare alla scheda Contesti come mostrato di seguito e aggiungere variabili di contesto.
In questo capitolo, esaminiamo la gestione dei lavori e le funzionalità corrispondenti incluse in Talend.
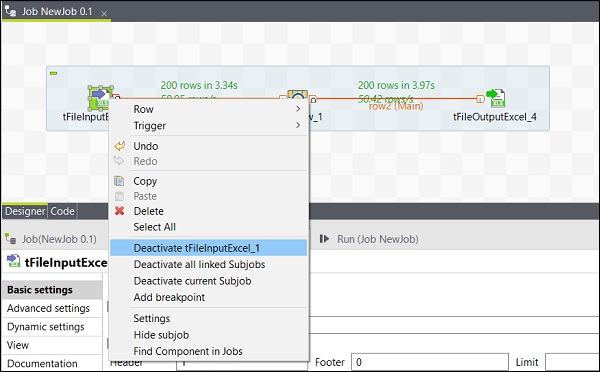
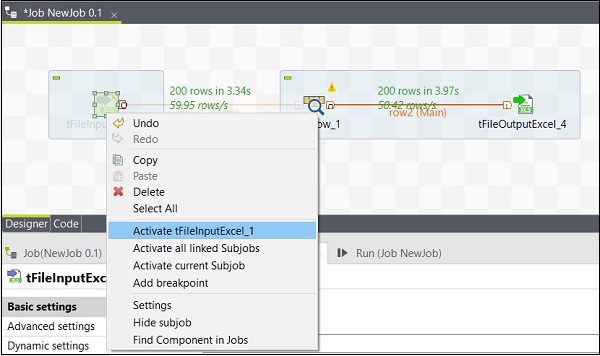
Attivazione / disattivazione di un componente
L'attivazione / disattivazione di un componente è molto semplice. Devi solo selezionare il componente, fare clic destro su di esso e scegliere l'opzione di disattivazione o attivazione di quel componente.
Importazione / esportazione di articoli e lavori di costruzione
Per esportare un elemento dal lavoro, fare clic con il pulsante destro del mouse sul lavoro nei Disegni del lavoro e fare clic su Esporta elementi.
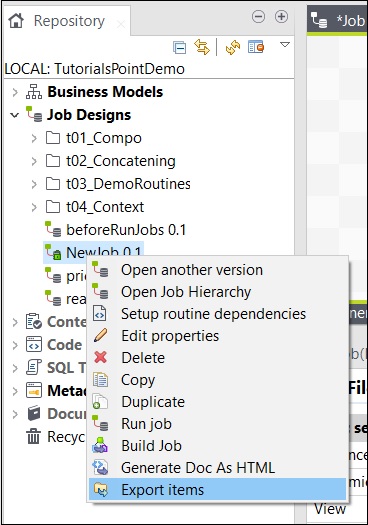
Immettere il percorso in cui si desidera esportare l'elemento e fare clic su Fine.
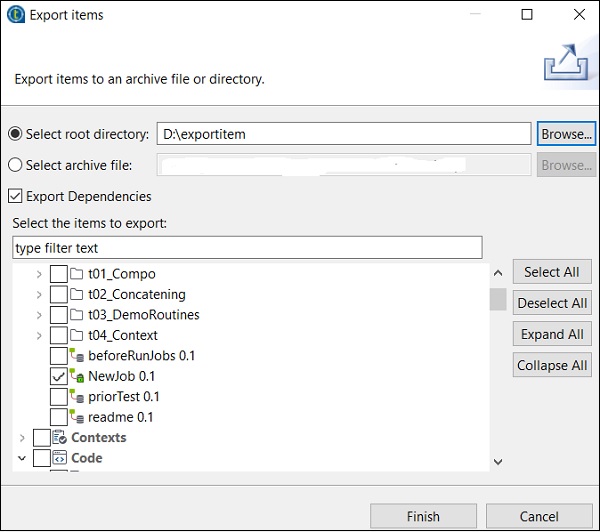
Per importare un elemento dal lavoro, fare clic con il pulsante destro del mouse sul lavoro nei Disegni del lavoro e fare clic su Importa elementi.
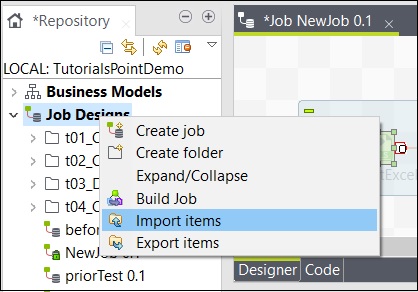
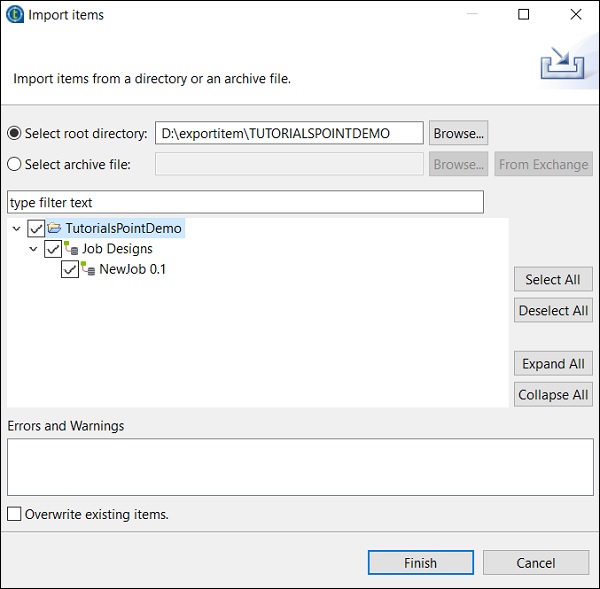
Sfoglia la directory principale da cui desideri importare gli elementi.
Seleziona tutte le caselle di controllo e fai clic su Fine.
In questo capitolo, comprendiamo come gestire l'esecuzione di un lavoro in Talend.
Per creare un lavoro, fare clic con il pulsante destro del mouse sul lavoro e selezionare l'opzione Creazione lavoro.
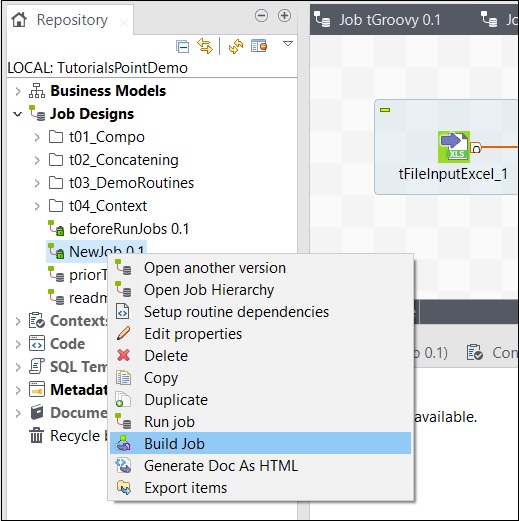
Indicare il percorso in cui si desidera archiviare il lavoro, selezionare la versione del lavoro e il tipo di build, quindi fare clic su Fine.
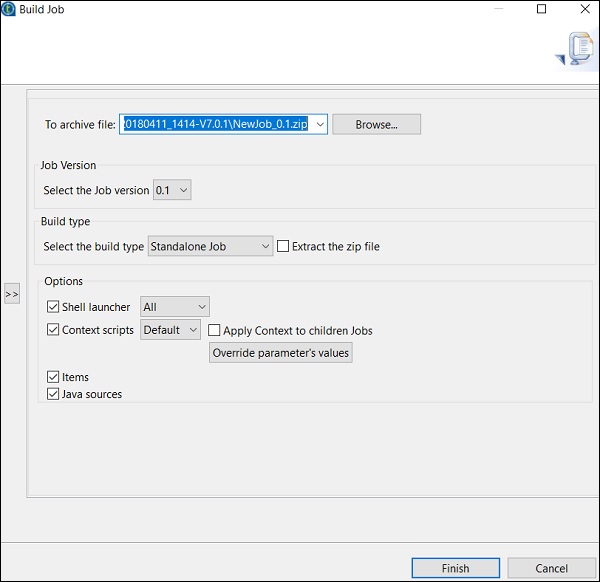
Come eseguire il lavoro in modalità normale
Per eseguire un lavoro in un nodo normale, è necessario selezionare "Esecuzione di base" e fare clic sul pulsante Esegui per avviare l'esecuzione.
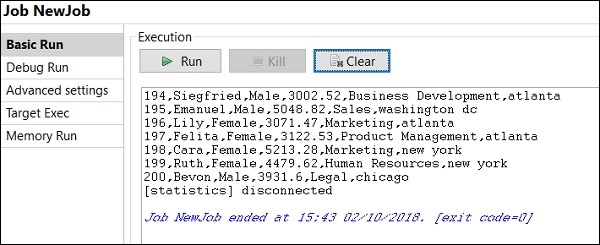
Come eseguire il lavoro in modalità di debug
Per eseguire il lavoro in modalità debug, aggiungi un punto di interruzione ai componenti di cui desideri eseguire il debug.
Quindi, seleziona e fai clic con il pulsante destro del mouse sul componente, fai clic sull'opzione Aggiungi punto di interruzione. Si noti che qui abbiamo aggiunto punti di interruzione ai componenti tFileInputExcel e tLogRow. Quindi, vai a Debug Esegui e fai clic sul pulsante Debug Java.
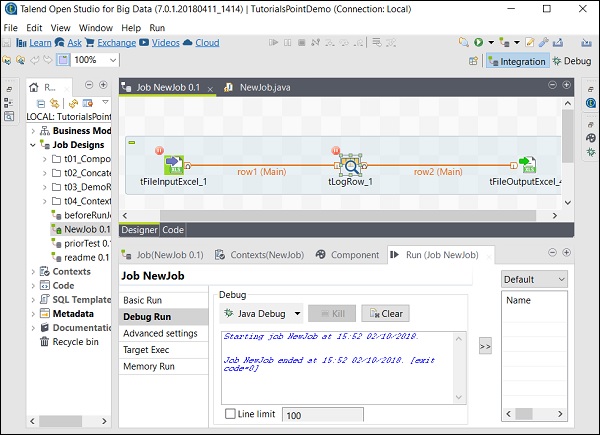
È possibile osservare dallo screenshot seguente che il lavoro verrà ora eseguito in modalità di debug e in base ai punti di interruzione che abbiamo menzionato.
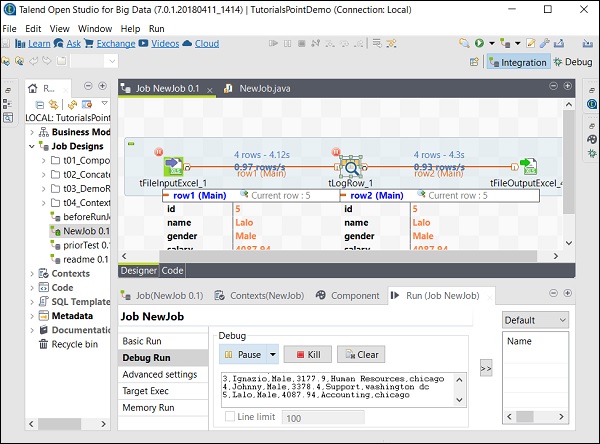
Impostazioni avanzate
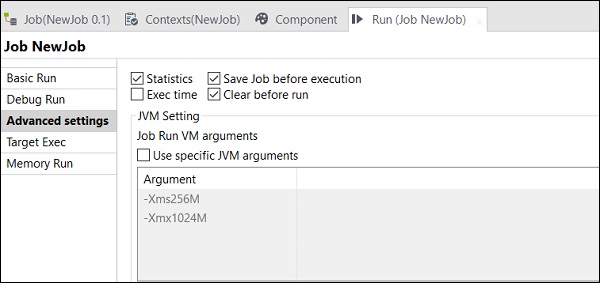
Nelle impostazioni avanzate, è possibile selezionare Statistiche, Tempo di esecuzione, Salva lavoro prima dell'esecuzione, Cancella prima dell'esecuzione e Impostazioni JVM. Ciascuna di questa opzione ha la funzionalità come spiegato qui -
Statistics - Visualizza il tasso di rendimento dell'elaborazione;
Exec Time - Il tempo impiegato per eseguire il lavoro.
Save Job before Execution - Salva automaticamente il lavoro prima che inizi l'esecuzione.
Clear before Run - Rimuove tutto dalla console di output.
JVM Settings - Ci aiuta a configurare i propri argomenti Java.
Lo slogan di Open Studio con Big Data è "Semplifica ETL ed ELT con lo strumento ETL open source gratuito leader per i big data". In questo capitolo, esaminiamo l'utilizzo di Talend come strumento per l'elaborazione dei dati in un ambiente big data.
introduzione
Talend Open Studio - Big Data è uno strumento gratuito e open source per elaborare i tuoi dati molto facilmente in un ambiente di big data. Hai molti componenti Big Data disponibili in Talend Open Studio, che ti consente di creare ed eseguire lavori Hadoop semplicemente trascinando e rilasciando alcuni componenti Hadoop.
Inoltre, non è necessario scrivere grandi righe di codici MapReduce; Talend Open Studio Big Data ti aiuta a farlo con i componenti presenti in esso. Genera automaticamente il codice MapReduce per te, devi solo trascinare e rilasciare i componenti e configurare pochi parametri.
Ti dà anche la possibilità di connetterti a diverse distribuzioni di Big Data come Cloudera, HortonWorks, MapR, Amazon EMR e persino Apache.
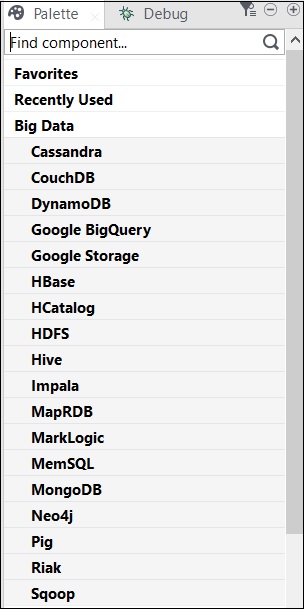
Componenti Talend per Big Data
Di seguito è riportato l'elenco delle categorie con componenti per eseguire un lavoro su un ambiente Big Data incluso in Big Data:
Di seguito è riportato l'elenco dei connettori e dei componenti Big Data in Talend Open Studio:
tHDFSConnection - Utilizzato per la connessione a HDFS (Hadoop Distributed File System).
tHDFSInput - Legge i dati dal percorso hdfs dato, li inserisce nello schema talend e poi li passa al componente successivo del lavoro.
tHDFSList - Recupera tutti i file e le cartelle nel percorso hdfs specificato.
tHDFSPut - Copia il file / cartella dal file system locale (definito dall'utente) a hdfs nel percorso specificato.
tHDFSGet - Copia file / cartella da hdfs al file system locale (definito dall'utente) nel percorso specificato.
tHDFSDelete - Elimina il file da HDFS
tHDFSExist - Controlla se un file è presente su HDFS o meno.
tHDFSOutput - Scrive flussi di dati su HDFS.
tCassandraConnection - Apre la connessione al server Cassandra.
tCassandraRow - Esegue query CQL (Cassandra query language) sul database specificato.
tHBaseConnection - Apre la connessione al database HBase.
tHBaseInput - legge i dati dal database HBase.
tHiveConnection - Apre la connessione al database Hive.
tHiveCreateTable - Crea una tabella all'interno di un database hive.
tHiveInput - Legge i dati dal database dell'hive.
tHiveLoad - Scrive i dati nella tabella hive o in una directory specificata.
tHiveRow - esegue query HiveQL sul database specificato.
tPigLoad - Carica i dati di input nel flusso di output.
tPigMap - Utilizzato per trasformare e instradare i dati in un processo maiale.
tPigJoin - Esegue l'operazione di unione di 2 file in base alle chiavi di unione.
tPigCoGroup - Raggruppa e aggrega i dati provenienti da più input.
tPigSort - Ordina i dati forniti in base a una o più chiavi di ordinamento definite.
tPigStoreResult - Memorizza il risultato dell'operazione suino in uno spazio di archiviazione definito.
tPigFilterRow - Filtra le colonne specificate per suddividere i dati in base alla condizione data.
tPigDistinct - Rimuove le tuple duplicate dalla relazione.
tSqoopImport - Trasferisce i dati da database relazionali come MySQL, Oracle DB a HDFS.
tSqoopExport - Trasferisce i dati da HDFS a database relazionali come MySQL, Oracle DB
In questo capitolo, impariamo in dettaglio come funziona Talend con il file system distribuito Hadoop.
Impostazioni e prerequisiti
Prima di procedere in Talend con HDFS, dovremmo conoscere le impostazioni e i prerequisiti che dovrebbero essere soddisfatti per questo scopo.
Qui stiamo eseguendo Cloudera quickstart 5.10 VM su virtual box. In questa VM deve essere utilizzata una rete solo host.
IP di rete solo host: 192.168.56.101

È necessario che lo stesso host sia in esecuzione anche su cloudera manager.

Ora sul tuo sistema Windows, vai su c: \ Windows \ System32 \ Drivers \ etc \ hosts e modifica questo file utilizzando il Blocco note come mostrato di seguito.

Allo stesso modo, sulla tua VM di avvio rapido cloudera, modifica il tuo file / etc / hosts come mostrato di seguito.
sudo gedit /etc/hosts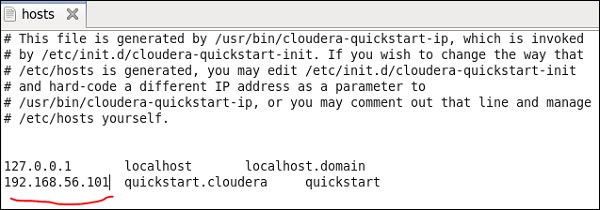
Configurazione della connessione Hadoop
Nel pannello del repository, vai a Metadati. Fare clic con il pulsante destro del mouse su Hadoop Cluster e creare un nuovo cluster. Fornire il nome, lo scopo e la descrizione per questa connessione al cluster Hadoop.
Fare clic su Avanti.

Seleziona la distribuzione come cloudera e scegli la versione che stai utilizzando. Seleziona l'opzione di recupero della configurazione e fai clic su Avanti.

Immettere le credenziali del gestore (URI con porta, nome utente, password) come mostrato di seguito e fare clic su Connetti. Se i dettagli sono corretti, otterrai Cloudera QuickStart nei cluster rilevati.
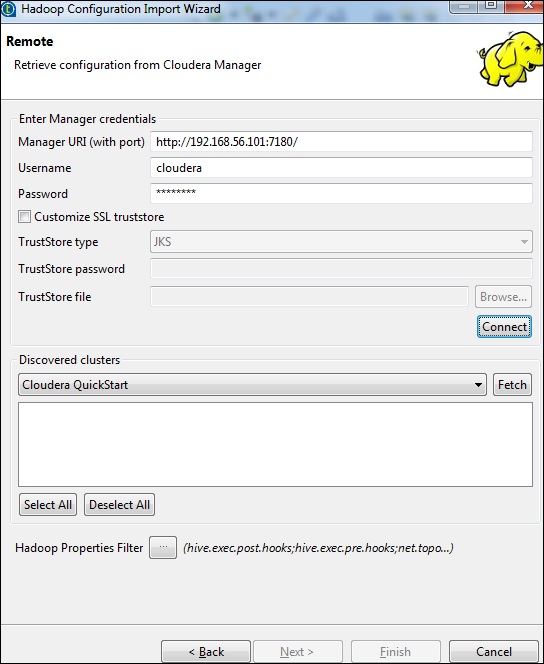
Fare clic su Recupera. Questo recupererà tutte le connessioni e le configurazioni per HDFS, YARN, HBASE, HIVE.
Seleziona tutto e fai clic su Fine.

Notare che tutti i parametri di connessione verranno compilati automaticamente. Menziona cloudera nel nome utente e fai clic su Fine.

Con questo, ti sei connesso con successo a un cluster Hadoop.

Connessione a HDFS
In questo lavoro, elencheremo tutte le directory e i file presenti su HDFS.
In primo luogo, creeremo un lavoro e quindi aggiungeremo componenti HDFS ad esso. Fare clic con il tasto destro su Job Design e creare un nuovo lavoro - hadoopjob.
Ora aggiungi 2 componenti dalla tavolozza: tHDFSConnection e tHDFSList. Fare clic con il tasto destro su tHDFSConnection e collegare questi 2 componenti utilizzando il trigger "OnSubJobOk".
Ora configura entrambi i componenti di talend hdfs.

In tHDFSConnection, scegli Repository come Property Type e seleziona il cluster Hadoop cloudera che hai creato in precedenza. Riempirà automaticamente tutti i dettagli necessari richiesti per questo componente.

In tHDFSList, seleziona "Usa una connessione esistente" e nell'elenco dei componenti scegli la connessione tHDFS che hai configurato.
Assegna il percorso home di HDFS nell'opzione Directory HDFS e fai clic sul pulsante Sfoglia a destra.

Se hai stabilito correttamente la connessione con le suddette configurazioni, vedrai una finestra come mostrato di seguito. Elencherà tutte le directory e i file presenti nella home di HDFS.

Puoi verificarlo controllando il tuo HDFS su cloudera.

Lettura del file da HDFS
In questa sezione, vediamo come leggere un file da HDFS in Talend. È possibile creare un nuovo lavoro per questo scopo, tuttavia qui stiamo usando quello esistente.
Trascina e rilascia 3 componenti: tHDFSConnection, tHDFSInput e tLogRow dalla tavolozza alla finestra di progettazione.
Fare clic con il pulsante destro del mouse su tHDFSConnection e collegare il componente tHDFSInput utilizzando il trigger "OnSubJobOk".
Fare clic con il tasto destro su tHDFSInput e trascinare un collegamento principale su tLogRow.

Nota che tHDFSConnection avrà la configurazione simile a quella precedente. In tHDFSInput, seleziona "Usa una connessione esistente" e dall'elenco dei componenti, scegli tHDFSConnection.
In Nome file, fornire il percorso HDFS del file che si desidera leggere. Qui stiamo leggendo un semplice file di testo, quindi il nostro Tipo di file è File di testo. Allo stesso modo, a seconda dell'input, riempire il separatore di riga, il separatore di campo ei dettagli dell'intestazione come indicato di seguito. Infine, fai clic sul pulsante Modifica schema.

Poiché il nostro file contiene solo testo normale, stiamo aggiungendo solo una colonna di tipo String. Ora fai clic su Ok.
Note - Quando il tuo input ha più colonne di diversi tipi, devi menzionare lo schema qui di conseguenza.

Nel componente tLogRow, fai clic su Sincronizza colonne in modifica schema.
Selezionare la modalità in cui si desidera stampare l'output.

Infine, fare clic su Esegui per eseguire il lavoro.
Una volta che sei riuscito a leggere un file HDFS, puoi vedere il seguente output.

Scrittura di file su HDFS
Vediamo come scrivere un file da HDFS in Talend. Trascina e rilascia 3 componenti: tHDFSConnection, tFileInputDelimited e tHDFSOutput dalla tavolozza alla finestra di progettazione.
Fare clic con il tasto destro su tHDFSConnection e connettere il componente tFileInputDelimited utilizzando il trigger "OnSubJobOk".
Fare clic con il tasto destro su tFileInputDelimited e trascinare un collegamento principale su tHDFSOutput.

Nota che tHDFSConnection avrà la configurazione simile a quella precedente.
Ora, in tFileInputDelimited, fornire il percorso del file di input nell'opzione Nome file / Stream. Qui stiamo usando un file csv come input, quindi il separatore di campo è ",".
Seleziona l'intestazione, il piè di pagina, il limite in base al file di input. Nota che qui la nostra intestazione è 1 perché la riga 1 contiene i nomi delle colonne e il limite è 3 perché stiamo scrivendo solo le prime 3 righe su HDFS.
Ora, fai clic su modifica schema.
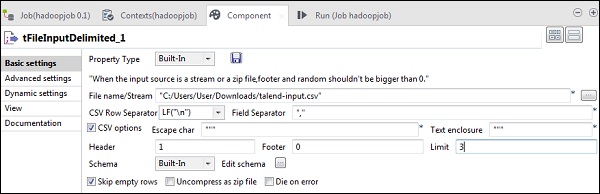
Ora, come da nostro file di input, definisci lo schema. Il nostro file di input ha 3 colonne come indicato di seguito.

Nel componente tHDFSOutput, fai clic su sincronizza colonne. Quindi, seleziona tHDFSConnection in Usa una connessione esistente. Inoltre, in Nome file, fornire un percorso HDFS in cui si desidera scrivere il file.
Nota che il tipo di file sarà un file di testo, l'azione sarà "crea", il separatore di riga sarà "\ n" e il separatore di campo sarà ";"

Infine, fai clic su Esegui per eseguire il tuo lavoro. Una volta che il lavoro è stato eseguito correttamente, controlla se il tuo file è presente su HDFS.

Esegui il seguente comando hdfs con il percorso di output che avevi menzionato nel tuo lavoro.
hdfs dfs -cat /input/talendwriteVedrai il seguente output se riesci a scrivere su HDFS.

Nel capitolo precedente abbiamo visto come Talend lavora con i Big Data. In questo capitolo, vediamo come utilizzare Map Reduce con Talend.
Creazione di un lavoro Talend MapReduce
Impariamo come eseguire un lavoro MapReduce su Talend. Qui eseguiremo un esempio di conteggio parole MapReduce.
A tal fine, fare clic con il pulsante destro del mouse su Job Design e creare un nuovo lavoro - MapreduceJob. Menziona i dettagli del lavoro e fai clic su Fine.
Aggiunta di componenti al lavoro MapReduce
Per aggiungere componenti a un lavoro MapReduce, trascina e rilascia cinque componenti di Talend: tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput dal pallet alla finestra del designer. Fare clic con il tasto destro su tHDFSInput e creare il collegamento principale a tNormalize.
Fare clic con il tasto destro su tNormalize e creare il collegamento principale a tAggregateRow. Quindi, fai clic con il tasto destro su tAggregateRow e crea il collegamento principale a tMap. Ora, fai clic con il tasto destro su tMap e crea il collegamento principale a tHDFSOutput.
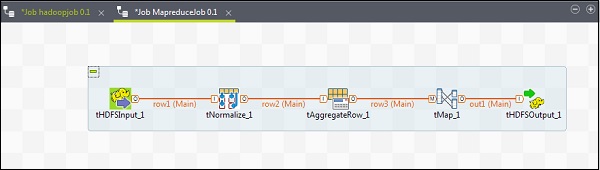
Configurazione di componenti e trasformazioni
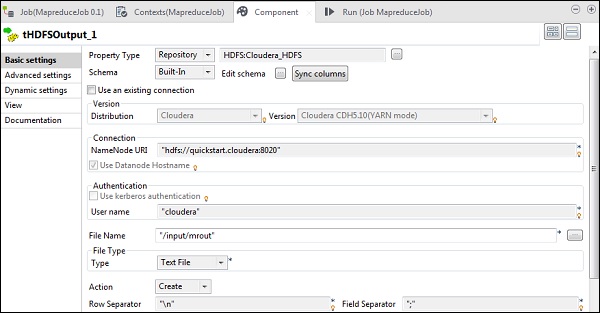
In tHDFSInput, seleziona il cloud di distribuzioneera e la sua versione. Notare che l'URI Namenode deve essere "hdfs: //quickstart.cloudera: 8020" e il nome utente deve essere "cloudera". Nell'opzione del nome file, fornire il percorso del file di input al lavoro MapReduce. Assicurati che questo file di input sia presente su HDFS.
Ora, seleziona il tipo di file, il separatore di riga, il separatore di file e l'intestazione in base al file di input.
Fare clic su modifica schema e aggiungere il campo "riga" come tipo di stringa.
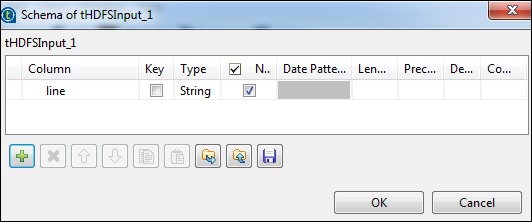
In tNomalize, la colonna da normalizzare sarà riga e il separatore articolo sarà uno spazio bianco -> "". Ora, fai clic su modifica schema. tNormalize avrà una colonna di riga e tAggregateRow avrà 2 colonne di parole e conteggio parole come mostrato di seguito.
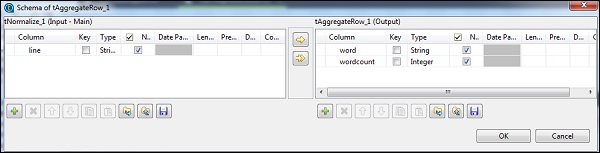
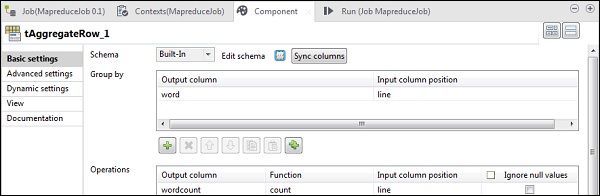
In tAggregateRow, inserisci la parola come colonna di output nell'opzione Raggruppa per. Nelle operazioni, inserisci conteggio parole come colonna di output, funzione come conteggio e posizione della colonna di input come riga.
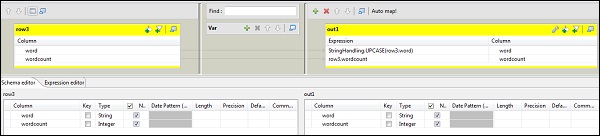
Ora fai doppio clic sul componente tMap per accedere all'editor della mappa e mappare l'input con l'output richiesto. In questo esempio, la parola è mappata con la parola e il conteggio delle parole è mappato con il conteggio delle parole. Nella colonna delle espressioni, fare clic su […] per accedere al generatore di espressioni.
Ora, seleziona StringHandling dall'elenco delle categorie e dalla funzione UPCASE. Modifica l'espressione in "StringHandling.UPCASE (row3.word)" e fai clic su OK. Mantieni row3.wordcount nella colonna dell'espressione corrispondente a wordcount come mostrato di seguito.
In tHDFSOutput, connettiti al cluster Hadoop che abbiamo creato dal tipo di proprietà come repository. Tieni presente che i campi verranno compilati automaticamente. In Nome file, fornire il percorso di output in cui si desidera memorizzare l'output. Mantieni l'azione, il separatore di riga e il separatore di campo come mostrato di seguito.
Esecuzione del lavoro MapReduce
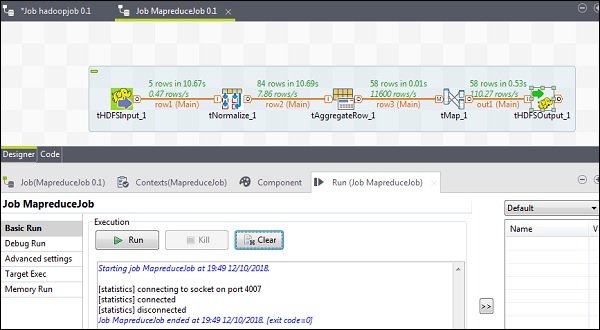
Una volta completata con successo la configurazione, fare clic su Esegui ed eseguire il lavoro MapReduce.
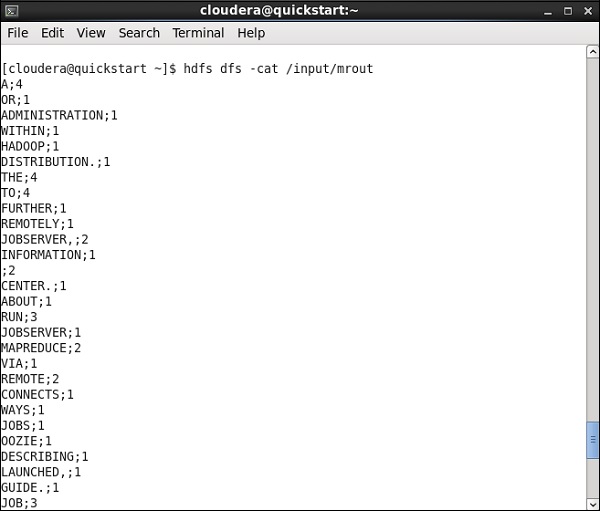
Vai al tuo percorso HDFS e controlla l'output. Nota che tutte le parole saranno in maiuscolo con il loro numero di parole.
In questo capitolo, impariamo come lavorare con un lavoro suino in Talend.
Creazione di un lavoro Talend Pig
In questa sezione, impariamo come eseguire un lavoro Pig su Talend. Qui, elaboreremo i dati del NYSE per scoprire il volume medio delle scorte di IBM.
Per questo, fai clic con il pulsante destro del mouse su Job Design e crea un nuovo lavoro: pigjob. Menziona i dettagli del lavoro e fai clic su Fine.
Aggiunta di componenti a Pig Job
Per aggiungere componenti al lavoro Pig, trascina e rilascia quattro componenti Talend: tPigLoad, tPigFilterRow, tPigAggregate, tPigStoreResult, dal pallet alla finestra del designer.
Quindi, fai clic con il pulsante destro del mouse su tPigLoad e crea la riga Pig Combine su tPigFilterRow. Quindi, fai clic con il pulsante destro del mouse su tPigFilterRow e crea la linea Pig Combine su tPigAggregate. Fare clic con il tasto destro su tPigAggregate e creare la linea di combinazione Pig su tPigStoreResult.
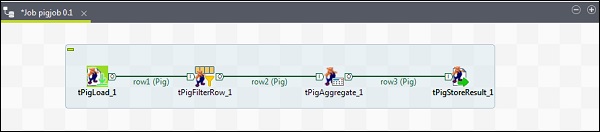
Configurazione di componenti e trasformazioni
In tPigLoad, menziona la distribuzione come cloudera e la versione di cloudera. Notare che l'URI Namenode dovrebbe essere "hdfs: //quickstart.cloudera: 8020" e Resource Manager dovrebbe essere "quickstart.cloudera: 8020". Inoltre, il nome utente dovrebbe essere "cloudera".
Nell'URI del file di input, fornisci il percorso del tuo file di input NYSE al lavoro maiale. Nota che questo file di input dovrebbe essere presente su HDFS.
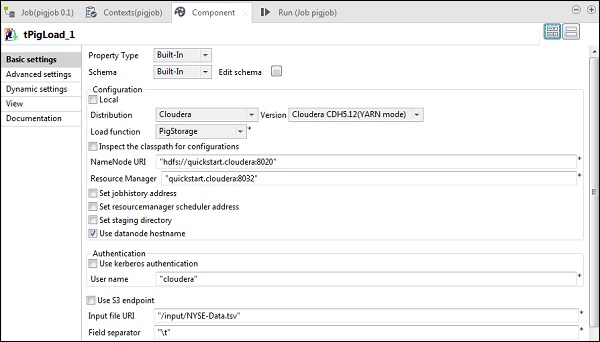
Fai clic su modifica schema, aggiungi le colonne e il relativo tipo come mostrato di seguito.
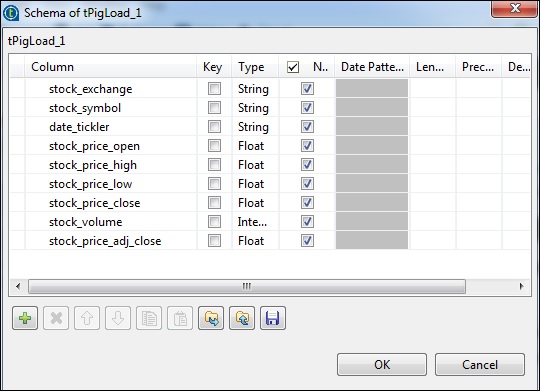
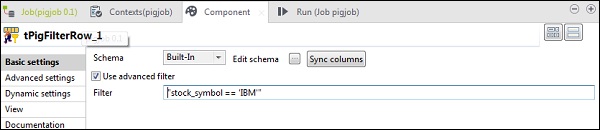
In tPigFilterRow, seleziona l'opzione "Usa filtro avanzato" e inserisci "stock_symbol = = 'IBM'" nell'opzione Filtro.
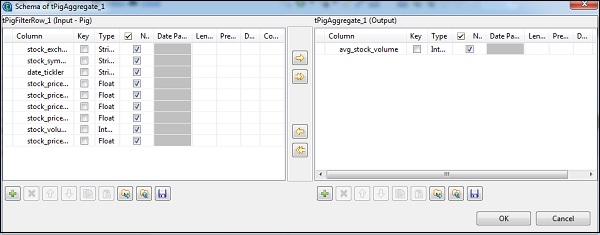
In tAggregateRow, fai clic su modifica schema e aggiungi la colonna avg_stock_volume nell'output come mostrato di seguito.
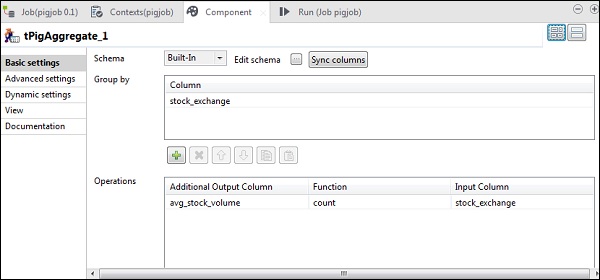
Ora, metti la colonna stock_exchange nell'opzione Group by. Aggiungi la colonna avg_stock_volume nel campo Operations con la funzione count e stock_exchange come colonna di input.
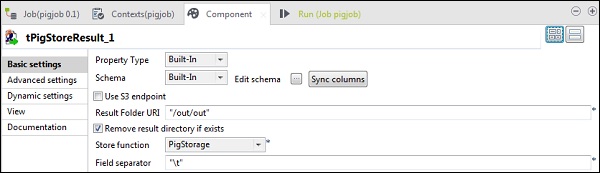
In tPigStoreResult, fornire il percorso di output nell'URI della cartella dei risultati in cui si desidera memorizzare il risultato del lavoro Pig. Seleziona la funzione di archivio come PigStorage e il separatore di campo (non obbligatorio) come "\ t".
Esecuzione del lavoro di maiale
Ora fai clic su Esegui per eseguire il tuo lavoro Pig. (Ignora gli avvertimenti)
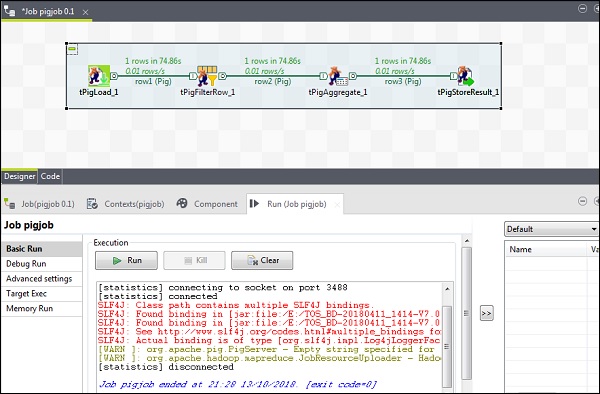
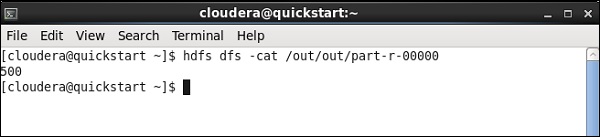
Una volta terminato il lavoro, vai e controlla l'output nel percorso HDFS che hai menzionato per memorizzare il risultato del lavoro maiale. Il volume medio delle scorte di IBM è 500.
In questo capitolo, cerchiamo di capire come lavorare con Hive job su Talend.
Creazione di un lavoro Talend Hive
Ad esempio, caricheremo i dati NYSE in una tabella hive ed eseguiremo una query hive di base. Fare clic con il tasto destro su Job Design e creare un nuovo lavoro: hivejob. Menziona i dettagli del lavoro e clicca su Fine.
Aggiunta di componenti a Hive Job
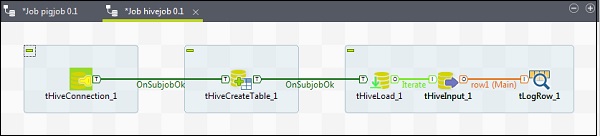
Per assegnare componenti a un lavoro Hive, trascina cinque componenti talend: tHiveConnection, tHiveCreateTable, tHiveLoad, tHiveInput e tLogRow dal pallet alla finestra di progettazione. Quindi, fai clic con il pulsante destro del mouse su tHiveConnection e crea il trigger OnSubjobOk su tHiveCreateTable. Ora, fai clic con il pulsante destro del mouse su tHiveCreateTable e crea il trigger OnSubjobOk su tHiveLoad. Fare clic con il tasto destro su tHiveLoad e creare un trigger di iterazione su tHiveInput. Infine, fai clic con il pulsante destro del mouse su tHiveInput e crea una riga principale su tLogRow.
Configurazione di componenti e trasformazioni
In tHiveConnection, seleziona la distribuzione come cloudera e la sua versione che stai utilizzando. Tieni presente che la modalità di connessione sarà autonoma e il servizio Hive sarà Hive 2. Controlla anche se i seguenti parametri sono impostati di conseguenza:
- Host: "quickstart.cloudera"
- Porta: "10000"
- Database: "predefinito"
- Nome utente: "hive"
Nota che la password verrà compilata automaticamente, non è necessario modificarla. Anche altre proprietà di Hadoop saranno preimpostate e impostate per impostazione predefinita.
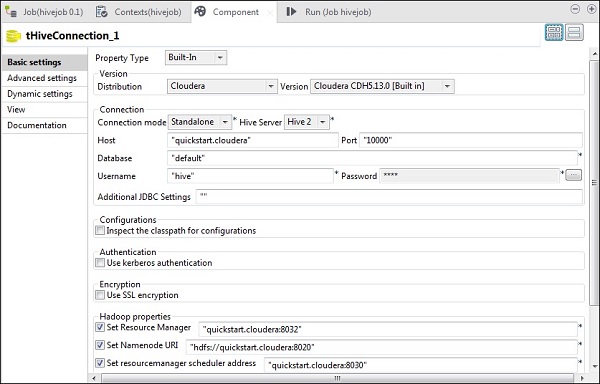
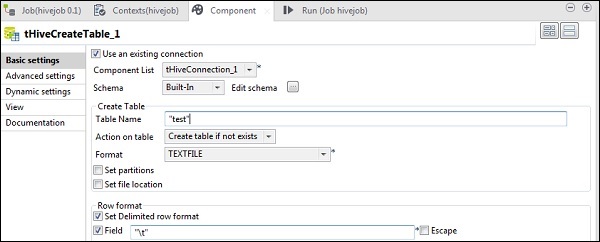
In tHiveCreateTable selezionare Usa una connessione esistente e inserire tHiveConnection nell'elenco dei componenti. Assegna il nome della tabella che desideri creare nel database predefinito. Mantenere gli altri parametri come mostrato di seguito.
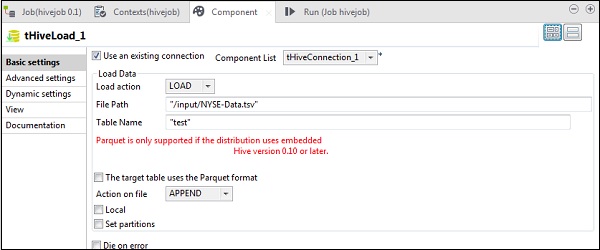
In tHiveLoad, seleziona "Usa una connessione esistente" e inserisci tHiveConnection nell'elenco dei componenti. Selezionare LOAD in Load action. In File Path, fornisci il percorso HDFS del tuo file di input NYSE. Indicare la tabella in Nome tabella, in cui si desidera caricare l'input. Mantenere gli altri parametri come mostrato di seguito.
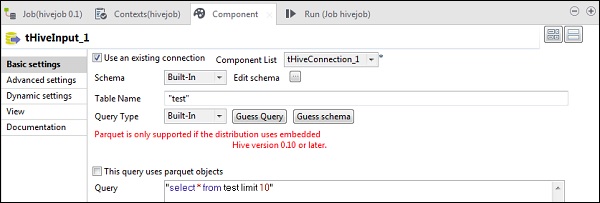
In tHiveInput selezionare Usa una connessione esistente e inserire tHiveConnection nell'elenco dei componenti. Fai clic su modifica schema, aggiungi le colonne e il relativo tipo come mostrato nell'istantanea dello schema di seguito. Ora dai il nome della tabella che hai creato in tHiveCreateTable.
Inserisci la tua query nell'opzione di query che desideri eseguire sulla tabella Hive. Qui stiamo stampando tutte le colonne delle prime 10 righe nella tabella hive di prova.
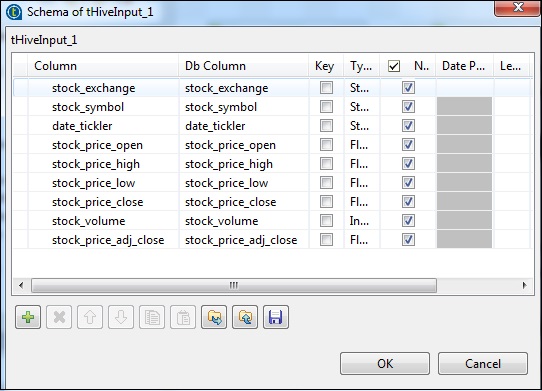
In tLogRow, fai clic su sincronizza colonne e seleziona Modalità tabella per mostrare l'output.
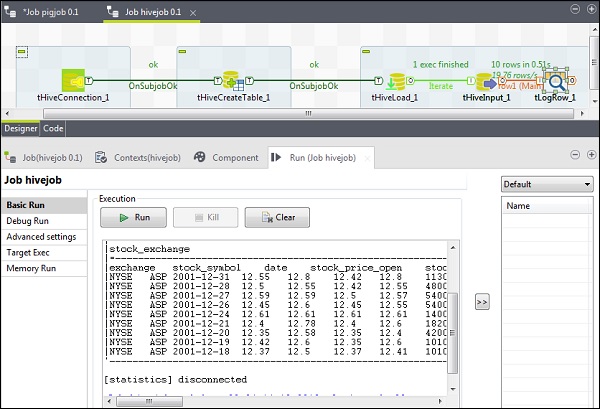
Esecuzione del lavoro dell'alveare
Fare clic su Esegui per iniziare l'esecuzione. Se tutta la connessione ei parametri sono stati impostati correttamente, vedrai l'output della tua query come mostrato di seguito.