Teradata - Guida rapida
Cos'è Teradata?
Teradata è uno dei più diffusi sistemi di gestione di database relazionali. È adatto principalmente per la creazione di applicazioni di data warehousing su larga scala. Teradata ottiene questo risultato dal concetto di parallelismo. È sviluppato dalla società chiamata Teradata.
Storia di Teradata
Di seguito è riportato un breve riassunto della storia di Teradata, elencando le tappe principali.
1979 - Viene incorporata Teradata.
1984 - Rilascio del primo computer database DBC / 1012.
1986- La rivista Fortune nomina Teradata "Prodotto dell'anno".
1999 - Il più grande database al mondo che utilizza Teradata con 130 Terabyte.
2002 - Teradata V2R5 rilasciato con Partition Primary Index e compressione.
2006 - Lancio della soluzione Teradata Master Data Management.
2008 - Teradata 13.0 rilasciato con Active Data Warehousing.
2011 - Acquisisce Teradata Aster ed entra in Advanced Analytics Space.
2012 - Teradata 14.0 introdotto.
2014 - Teradata 15.0 introdotto.
Caratteristiche di Teradata
Di seguito sono riportate alcune delle caratteristiche di Teradata:
Unlimited Parallelism- Il sistema di database Teradata è basato sull'architettura Massively Parallel Processing (MPP). L'architettura MPP divide il carico di lavoro in modo uniforme sull'intero sistema. Il sistema Teradata suddivide l'attività tra i suoi processi e li esegue in parallelo per garantire che l'attività venga completata rapidamente.
Shared Nothing Architecture- L'architettura di Teradata è chiamata Shared Nothing Architecture. I nodi Teradata, i suoi processori del modulo di accesso (AMP) ei dischi associati agli AMP funzionano in modo indipendente. Non sono condivisi con altri.
Linear Scalability- I sistemi Teradata sono altamente scalabili. Possono scalare fino a 2048 nodi. Ad esempio, puoi raddoppiare la capacità del sistema raddoppiando il numero di AMP.
Connectivity - Teradata può connettersi a sistemi collegati al canale come mainframe o sistemi collegati alla rete.
Mature Optimizer- L'ottimizzatore Teradata è uno degli ottimizzatori maturati sul mercato. È stato progettato per essere parallelo sin dal suo inizio. È stato perfezionato per ogni versione.
SQL- Teradata supporta SQL standard del settore per interagire con i dati archiviati nelle tabelle. Oltre a questo, fornisce la propria estensione.
Robust Utilities - Teradata fornisce robuste utilità per importare / esportare dati da / a sistemi Teradata come FastLoad, MultiLoad, FastExport e TPT.
Automatic Distribution - Teradata distribuisce automaticamente i dati in modo uniforme sui dischi senza alcun intervento manuale.
Teradata fornisce Teradata Express per VMWARE, una macchina virtuale Teradata completamente operativa. Fornisce fino a 1 terabyte di spazio di archiviazione. Teradata fornisce sia la versione da 40 GB che da 1 TB di VMware.
Prerequisiti
Poiché la VM è a 64 bit, la CPU deve supportare 64 bit.
Fasi di installazione per Windows
Step 1 - Scarica la versione VM richiesta dal link, https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 - Estrai il file e specifica la cartella di destinazione.
Step 3 - Scarica il lettore VMWare Workstation dal link, https://my.vmware.com/web/vmware/downloads. È disponibile sia per Windows che per Linux. Scarica il lettore di workstation VMWARE per Windows.
Step 4 - Una volta completato il download, installa il software.
Step 5 - Al termine dell'installazione, eseguire il client VMWARE.
Step 6- Seleziona "Apri una macchina virtuale". Naviga nella cartella Teradata VMWare estratta e seleziona il file con estensione .vmdk.
Step 7- Teradata VMWare viene aggiunto al client VMWare. Seleziona il Teradata VMware aggiunto e fai clic su "Riproduci macchina virtuale".

Step 8 - Se viene visualizzato un popup sugli aggiornamenti software, è possibile selezionare "Ricordamelo più tardi".
Step 9 - Immettere il nome utente come root, premere tab e immettere la password come root e premere nuovamente Invio.
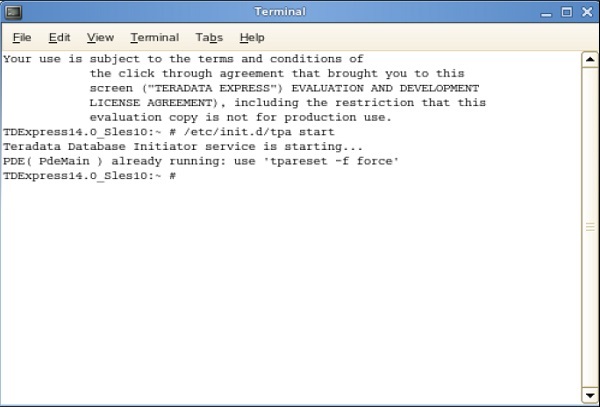
Step 10- Quando viene visualizzata la seguente schermata sul desktop, fare doppio clic su "home di root". Quindi fare doppio clic su "Genome's Terminal". Questo aprirà Shell.

Step 11- Dalla seguente shell, inserisci il comando /etc/init.d/tpa start. Questo avvierà il server Teradata.
Avvio di BTEQ
L'utilità BTEQ viene utilizzata per inviare query SQL in modo interattivo. Di seguito sono riportati i passaggi per avviare l'utilità BTEQ.
Step 1 - Immettere il comando / sbin / ifconfig e annotare l'indirizzo IP di VMWare.
Step 2- Esegui il comando bteq. Al prompt di accesso, inserisci il comando.
Logon <ipaddress> / dbc, dbc; e immettere Alla richiesta della password, immettere la password come dbc;
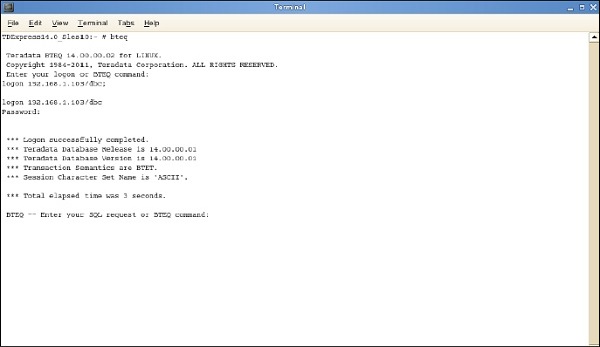
Puoi accedere al sistema Teradata utilizzando BTEQ ed eseguire qualsiasi query SQL.
L'architettura Teradata è basata sull'architettura Massively Parallel Processing (MPP). I componenti principali di Teradata sono Parsing Engine, BYNET e Access Module Processors (AMP). Il diagramma seguente mostra l'architettura di alto livello di un nodo Teradata.
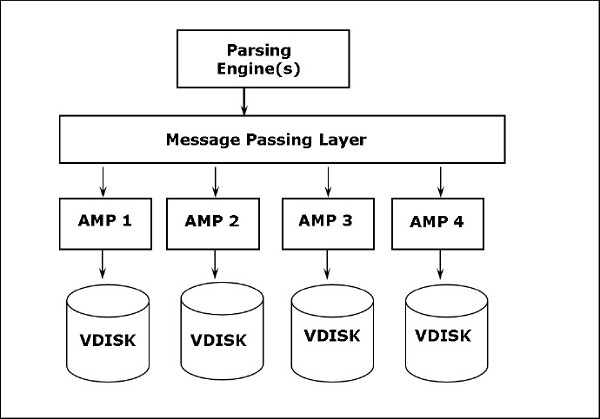
Componenti di Teradata
I componenti chiave di Teradata sono i seguenti:
Node- È l'unità di base nel sistema Teradata. Ogni singolo server in un sistema Teradata è denominato Node. Un nodo è costituito dal proprio sistema operativo, CPU, memoria, copia del software Teradata RDBMS e spazio su disco. Un cabinet è costituito da uno o più nodi.
Parsing Engine- Parsing Engine è responsabile della ricezione delle query dal client e della preparazione di un piano di esecuzione efficiente. Le responsabilità del motore di analisi sono:
Ricevi la query SQL dal client
Analizza il controllo della query SQL per errori di sintassi
Verificare se l'utente ha richiesto il privilegio rispetto agli oggetti utilizzati nella query SQL
Verificare se gli oggetti utilizzati nell'SQL esistono effettivamente
Preparare il piano di esecuzione per eseguire la query SQL e passarlo a BYNET
Riceve i risultati dagli AMP e li invia al client
Message Passing Layer- Message Passing Layer chiamato BYNET, è il livello di rete nel sistema Teradata. Permette la comunicazione tra PE e AMP e anche tra i nodi. Riceve il piano di esecuzione da Parsing Engine e lo invia ad AMP. Allo stesso modo, riceve i risultati dagli AMP e li invia a Parsing Engine.
Access Module Processor (AMP)- Gli AMP, chiamati processori virtuali (vprocs), sono quelli che memorizzano e recuperano effettivamente i dati. Gli AMP ricevono i dati e il piano di esecuzione da Parsing Engine, esegue qualsiasi conversione, aggregazione, filtro, ordinamento del tipo di dati e memorizza i dati nei dischi ad essi associati. I record delle tabelle vengono distribuiti uniformemente tra gli AMP nel sistema. Ogni AMP è associato a un set di dischi su cui sono archiviati i dati. Solo quell'AMP può leggere / scrivere dati dai dischi.
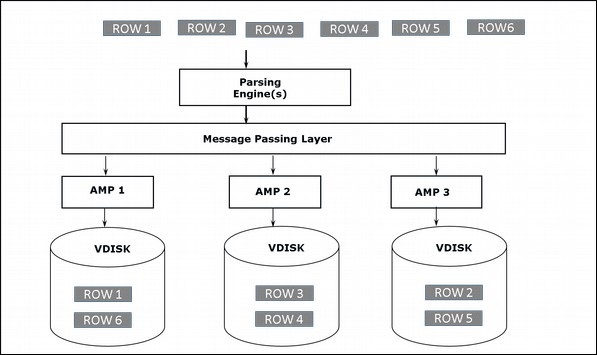
Architettura di archiviazione
Quando il client esegue query per inserire record, il motore di analisi invia i record a BYNET. BYNET recupera i record e invia la riga all'AMP di destinazione. AMP archivia questi record sui propri dischi. Il diagramma seguente mostra l'architettura di archiviazione di Teradata.
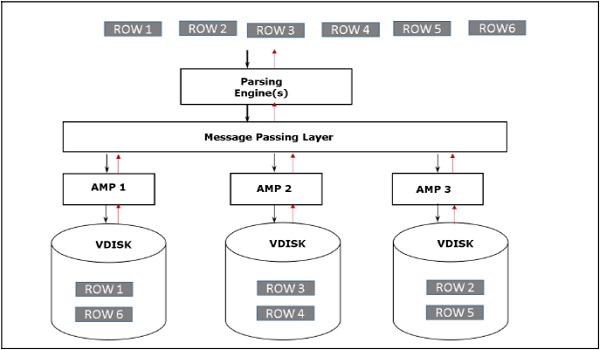
Architettura di recupero
Quando il client esegue query per recuperare i record, il motore di analisi invia una richiesta a BYNET. BYNET invia la richiesta di recupero agli AMP appropriati. Quindi gli AMP cercano i loro dischi in parallelo e identificano i record richiesti e li inviano a BYNET. BYNET invia quindi i record a Parsing Engine che a sua volta li invierà al client. Di seguito è riportata l'architettura di recupero di Teradata.
Relational Database Management System (RDBMS) è un software DBMS che aiuta a interagire con i database. Usano Structured Query Language (SQL) per interagire con i dati archiviati nelle tabelle.
Banca dati
Il database è una raccolta di dati correlati logicamente. Sono accessibili da molti utenti per scopi diversi. Ad esempio, un database delle vendite contiene intere informazioni sulle vendite memorizzate in molte tabelle.
Tabelle
Le tabelle sono l'unità di base in RDBMS in cui vengono memorizzati i dati. Una tabella è una raccolta di righe e colonne. Di seguito è riportato un esempio di tabella dei dipendenti.
| EmployeeNo | Nome di battesimo | Cognome | Data di nascita |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Roberto | Williams | 3/5/1983 |
| 105 | Roberto | James | 12/1/1984 |
| 103 | Peter | Paolo | 4/1/1983 |
Colonne
Una colonna contiene dati simili. Ad esempio, la colonna Data di nascita nella tabella Impiegato contiene le informazioni sulla data di nascita per tutti i dipendenti.
| Data di nascita |
|---|
| 1/5/1980 |
| 11/6/1984 |
| 3/5/1983 |
| 12/1/1984 |
| 4/1/1983 |
Riga
Row è un'istanza di tutte le colonne. Ad esempio, nella tabella dei dipendenti una riga contiene informazioni su un singolo dipendente.
| EmployeeNo | Nome di battesimo | Cognome | Data di nascita |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
Chiave primaria
La chiave primaria viene utilizzata per identificare in modo univoco una riga in una tabella. Non sono consentiti valori duplicati in una colonna di chiave primaria e non possono accettare valori NULL. È un campo obbligatorio in una tabella.
Chiave esterna
Le chiavi esterne vengono utilizzate per creare una relazione tra le tabelle. Una chiave esterna in una tabella figlia è definita come chiave primaria nella tabella padre. Una tabella può avere più di una chiave esterna. Può accettare valori duplicati e anche valori nulli. Le chiavi esterne sono facoltative in una tabella.
Ogni colonna in una tabella è associata a un tipo di dati. I tipi di dati specificano il tipo di valori che verranno archiviati nella colonna. Teradata supporta diversi tipi di dati. Di seguito sono riportati alcuni dei tipi di dati utilizzati di frequente.
| Tipi di dati | Lunghezza (byte) | Gamma di valori |
|---|---|---|
| BYTEINT | 1 | Da -128 a +127 |
| PICCOLO | 2 | Da -32768 a +32767 |
| NUMERO INTERO | 4 | Da -2.147.483.648 a +2147.483.647 |
| BIGINT | 8 | -9.233.372.036.854.775,80 8 a +9.233.372.036.854.775,8 07 |
| DECIMALE | 1-16 | |
| NUMERICO | 1-16 | |
| GALLEGGIANTE | 8 | Formato IEEE |
| CHAR | Formato fisso | 1-64.000 |
| VARCHAR | Variabile | 1-64.000 |
| DATA | 4 | AAAAMMGG |
| TEMPO | 6 o 8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| TIMESTAMP | 10 o 12 | YYMMDDHHMMSS.nnnnnn or YYMMDDHHMMSS.nnnnnn + HHMM |
Le tabelle nel modello relazionale sono definite come raccolta di dati. Sono rappresentati come righe e colonne.
Tipi di tabella
Tipi Teradata supporta diversi tipi di tabelle.
Permanent Table - Questa è la tabella predefinita e contiene i dati inseriti dall'utente e memorizza i dati in modo permanente.
Volatile Table- I dati inseriti in una tabella volatile vengono conservati solo durante la sessione utente. La tabella e i dati vengono eliminati alla fine della sessione. Queste tabelle vengono utilizzate principalmente per contenere i dati intermedi durante la trasformazione dei dati.
Global Temporary Table - La definizione di tabella temporanea globale è persistente ma i dati nella tabella vengono eliminati alla fine della sessione utente.
Derived Table- La tabella derivata contiene i risultati intermedi in una query. La loro durata è all'interno della query in cui vengono creati, utilizzati e rilasciati.
Set contro multiset
Teradata classifica le tabelle come tabelle SET o MULTISET in base a come vengono gestiti i record duplicati. Una tabella definita come tabella SET non archivia i record duplicati, mentre la tabella MULTISET può archiviare record duplicati.
| Suor n | Comandi e descrizione della tabella |
|---|---|
| 1 | Crea tabella Il comando CREATE TABLE viene utilizzato per creare tabelle in Teradata. |
| 2 | Alter Table Il comando ALTER TABLE viene utilizzato per aggiungere o eliminare colonne da una tabella esistente. |
| 3 | Drop Table Il comando DROP TABLE viene utilizzato per eliminare una tabella. |
Questo capitolo introduce i comandi SQL utilizzati per manipolare i dati memorizzati nelle tabelle Teradata.
Inserisci record
L'istruzione INSERT INTO viene utilizzata per inserire record nella tabella.
Sintassi
Di seguito è riportata la sintassi generica per INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);Esempio
Il seguente esempio inserisce i record nella tabella dei dipendenti.
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);Una volta inserita la query precedente, è possibile utilizzare l'istruzione SELECT per visualizzare i record dalla tabella.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentNo | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
Inserisci da un'altra tabella
L'istruzione INSERT SELECT viene utilizzata per inserire record da un'altra tabella.
Sintassi
Di seguito è riportata la sintassi generica per INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;Esempio
Il seguente esempio inserisce i record nella tabella dei dipendenti. Creare una tabella denominata Employee_Bkup con la stessa definizione di colonna della tabella Employee prima di eseguire la seguente query di inserimento.
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;Quando la query precedente viene eseguita, inserirà tutti i record dalla tabella dei dipendenti nella tabella Employee_bkup.
Regole
Il numero di colonne specificato nell'elenco VALUES deve corrispondere alle colonne specificate nella clausola INSERT INTO.
I valori sono obbligatori per le colonne NOT NULL.
Se non viene specificato alcun valore, viene inserito NULL per i campi nullable.
I tipi di dati delle colonne specificati nella clausola VALUES devono essere compatibili con i tipi di dati delle colonne nella clausola INSERT.
Aggiorna record
L'istruzione UPDATE viene utilizzata per aggiornare i record dalla tabella.
Sintassi
Di seguito è riportata la sintassi generica per UPDATE.
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];Esempio
L'esempio seguente aggiorna il reparto dei dipendenti a 03 per il dipendente 101.
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;Nell'output seguente è possibile vedere che DepartmentNo viene aggiornato da 1 a 3 per EmployeeNo 101.
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3Regole
È possibile aggiornare uno o più valori della tabella.
Se la condizione WHERE non è specificata, tutte le righe della tabella sono interessate.
È possibile aggiornare una tabella con i valori di un'altra tabella.
Elimina record
L'istruzione DELETE FROM viene utilizzata per aggiornare i record dalla tabella.
Sintassi
Di seguito è riportata la sintassi generica per DELETE FROM.
DELETE FROM <tablename>
[WHERE condition];Esempio
Il seguente esempio elimina il dipendente 101 dalla tabella Employee.
DELETE FROM Employee
WHERE EmployeeNo = 101;Nell'output seguente, puoi vedere che il dipendente 101 è stato eliminato dalla tabella.
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.Regole
È possibile aggiornare uno o più record della tabella.
Se la condizione WHERE non è specificata, tutte le righe della tabella vengono eliminate.
È possibile aggiornare una tabella con i valori di un'altra tabella.
L'istruzione SELECT viene utilizzata per recuperare i record da una tabella.
Sintassi
Di seguito è riportata la sintassi di base dell'istruzione SELECT.
SELECT
column 1, column 2, .....
FROM
tablename;Esempio
Considera la seguente tabella dei dipendenti.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentNo | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Roberto | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paolo | 21/03/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Roberto | James | 1/4/2008 | 3 | 12/1/1984 |
Di seguito è riportato un esempio di istruzione SELECT.
SELECT EmployeeNo,FirstName,LastName
FROM Employee;Quando questa query viene eseguita, recupera le colonne EmployeeNo, FirstName e LastName dalla tabella dei dipendenti.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulSe vuoi recuperare tutte le colonne da una tabella, puoi usare il seguente comando invece di elencare tutte le colonne.
SELECT * FROM Employee;La query precedente recupererà tutti i record dalla tabella dei dipendenti.
Dove la clausola
La clausola WHERE viene utilizzata per filtrare i record restituiti dall'istruzione SELECT. Una condizione è associata alla clausola WHERE. Solo, vengono restituiti i record che soddisfano la condizione nella clausola WHERE.
Sintassi
Di seguito è riportata la sintassi dell'istruzione SELECT con la clausola WHERE.
SELECT * FROM tablename
WHERE[condition];Esempio
La seguente query recupera i record in cui EmployeeNo è 101.
SELECT * FROM Employee
WHERE EmployeeNo = 101;Quando questa query viene eseguita, restituisce i seguenti record.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike JamesORDINATO DA
Quando viene eseguita l'istruzione SELECT, le righe restituite non sono in un ordine specifico. La clausola ORDER BY viene utilizzata per disporre i record in ordine crescente / decrescente su qualsiasi colonna.
Sintassi
Di seguito è riportata la sintassi dell'istruzione SELECT con la clausola ORDER BY.
SELECT * FROM tablename
ORDER BY column 1, column 2..;Esempio
La query seguente recupera i record dalla tabella dei dipendenti e ordina i risultati in base a FirstName.
SELECT * FROM Employee
ORDER BY FirstName;Quando la query precedente viene eseguita, produce il seguente output.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesRAGGRUPPA PER
La clausola GROUP BY viene utilizzata con l'istruzione SELECT e organizza record simili in gruppi.
Sintassi
Di seguito è riportata la sintassi dell'istruzione SELECT con la clausola GROUP BY.
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;Esempio
L'esempio seguente raggruppa i record per colonna DepartmentNo e identifica il conteggio totale di ogni reparto.
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;Quando la query precedente viene eseguita, produce il seguente output.
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradata supporta i seguenti operatori logici e condizionali. Questi operatori vengono utilizzati per eseguire il confronto e combinare più condizioni.
| Sintassi | Senso |
|---|---|
| > | Più grande di |
| < | Meno di |
| >= | Maggiore o uguale a |
| <= | Minore o uguale a |
| = | Uguale a |
| BETWEEN | Se i valori rientrano nell'intervallo |
| IN | Se i valori in <espressione> |
| NOT IN | Se i valori non sono in <espressione> |
| IS NULL | Se il valore è NULL |
| IS NOT NULL | Se il valore è NON NULL |
| AND | Combina più condizioni. Restituisce true solo se tutte le condizioni sono soddisfatte |
| OR | Combina più condizioni. Restituisce true solo se una delle condizioni è soddisfatta. |
| NOT | Inverte il significato della condizione |
FRA
Il comando BETWEEN viene utilizzato per verificare se un valore rientra in un intervallo di valori.
Esempio
Considera la seguente tabella dei dipendenti.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentNo | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Roberto | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paolo | 21/03/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Roberto | James | 1/4/2008 | 3 | 12/1/1984 |
L'esempio seguente recupera i record con i numeri dei dipendenti compresi nell'intervallo tra 101,102 e 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;Quando la query precedente viene eseguita, restituisce i record dei dipendenti con un numero di dipendenti compreso tra 101 e 103.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterIN
Il comando IN viene utilizzato per verificare il valore rispetto a un determinato elenco di valori.
Esempio
L'esempio seguente recupera i record con i numeri dei dipendenti in 101, 102 e 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);La query precedente restituisce i seguenti record.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterNON IN
Il comando NOT IN inverte il risultato del comando IN. Recupera i record con valori che non corrispondono con l'elenco fornito.
Esempio
L'esempio seguente recupera i record con i numeri dei dipendenti non in 101, 102 e 103.
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);La query precedente restituisce i seguenti record.
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert JamesGli operatori SET combinano i risultati di più istruzioni SELECT. Potrebbe sembrare simile a Join, ma i join combinano colonne di più tabelle mentre gli operatori SET combinano righe di più righe.
Regole
Il numero di colonne di ciascuna istruzione SELECT dovrebbe essere lo stesso.
I tipi di dati di ogni SELECT devono essere compatibili.
ORDER BY dovrebbe essere incluso solo nell'istruzione SELECT finale.
UNIONE
L'istruzione UNION viene utilizzata per combinare i risultati di più istruzioni SELECT. Ignora i duplicati.
Sintassi
Di seguito è riportata la sintassi di base della dichiarazione UNION.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Esempio
Considera la tabella dei dipendenti e la tabella dei salari seguenti.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentNo | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Roberto | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paolo | 21/03/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Roberto | James | 1/4/2008 | 3 | 12/1/1984 |
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
La seguente query UNION combina il valore EmployeeNo dalla tabella Employee e Salary.
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;Quando la query viene eseguita, produce il seguente output.
EmployeeNo
-----------
101
102
103
104
105UNION ALL
L'istruzione UNION ALL è simile a UNION, combina i risultati di più tabelle comprese le righe duplicate.
Sintassi
Di seguito è riportata la sintassi di base dell'istruzione UNION ALL.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Esempio
Di seguito è riportato un esempio per l'istruzione UNION ALL.
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;Quando la query precedente viene eseguita, produce il seguente output. Puoi vedere che restituisce anche i duplicati.
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103INTERSECT
Il comando INTERSECT viene utilizzato anche per combinare i risultati di più istruzioni SELECT. Restituisce le righe dalla prima istruzione SELECT che ha una corrispondenza corrispondente nelle seconde istruzioni SELECT. In altre parole, restituisce le righe che esistono in entrambe le istruzioni SELECT.
Sintassi
Di seguito è la sintassi di base dell'istruzione INTERSECT.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Esempio
Di seguito è riportato un esempio di istruzione INTERSECT. Restituisce i valori EmployeeNo che esistono in entrambe le tabelle.
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;Quando la query precedente viene eseguita, restituisce i seguenti record. EmployeeNo 105 è escluso poiché non esiste nella tabella SALARY.
EmployeeNo
-----------
101
104
102
103MENO / TRANNE
I comandi MINUS / EXCEPT combinano righe di più tabelle e restituiscono le righe che si trovano nella prima SELECT ma non nella seconda SELECT. Entrambi restituiscono gli stessi risultati.
Sintassi
Di seguito è riportata la sintassi di base dell'istruzione MINUS.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Esempio
Di seguito è riportato un esempio di istruzione MINUS.
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;Quando questa query viene eseguita, restituisce il seguente record.
EmployeeNo
-----------
105Teradata fornisce diverse funzioni per manipolare le stringhe. Queste funzioni sono compatibili con lo standard ANSI.
| Suor n | Funzione stringa e descrizione |
|---|---|
| 1 | || Concatena le stringhe insieme |
| 2 | SUBSTR Estrae una parte di una stringa (estensione Teradata) |
| 3 | SUBSTRING Estrae una parte di una stringa (standard ANSI) |
| 4 | INDEX Individua la posizione di un carattere in una stringa (estensione Teradata) |
| 5 | POSITION Individua la posizione di un carattere in una stringa (standard ANSI) |
| 6 | TRIM Taglia gli spazi vuoti da una stringa |
| 7 | UPPER Converte una stringa in maiuscolo |
| 8 | LOWER Converte una stringa in minuscolo |
Esempio
La tabella seguente elenca alcune delle funzioni di stringa con i risultati.
| Funzione stringa | Risultato |
|---|---|
| SELEZIONA SUBSTRING ('magazzino' DA 1 PER 4) | articoli |
| SELEZIONA SUBSTR ('magazzino', 1,4) | articoli |
| SELEZIONA "dati" || '' || 'magazzino' | data warehouse |
| SELEZIONA MAIUSCOLO ('dati') | DATI |
| SELEZIONA INFERIORE ('DATI') | dati |
In questo capitolo vengono descritte le funzioni di data / ora disponibili in Teradata.
Memorizzazione della data
Le date vengono memorizzate come numero intero internamente utilizzando la seguente formula.
((YEAR - 1900) * 10000) + (MONTH * 100) + DAYÈ possibile utilizzare la seguente query per verificare come vengono memorizzate le date.
SELECT CAST(CURRENT_DATE AS INTEGER);Poiché le date vengono memorizzate come numeri interi, è possibile eseguire alcune operazioni aritmetiche su di esse. Teradata fornisce funzioni per eseguire queste operazioni.
ESTRATTO
La funzione EXTRACT estrae parti del giorno, del mese e dell'anno da un valore DATE. Questa funzione viene utilizzata anche per estrarre ore, minuti e secondi dal valore TIME / TIMESTAMP.
Esempio
I seguenti esempi mostrano come estrarre i valori Anno, Mese, Data, Ora, Minuti e secondi dai valori Data e Timestamp.
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000INTERVALLO
Teradata fornisce la funzione INTERVAL per eseguire operazioni aritmetiche sui valori DATE e TIME. Esistono due tipi di funzioni INTERVALLO.
Intervallo anno-mese
- YEAR
- ANNO AL MESE
- MONTH
Intervallo tra giorno e ora
- DAY
- GIORNO IN ORA
- GIORNO IN MINUTO
- GIORNO AL SECONDO
- HOUR
- DA ORA A MINUTO
- ORA AL SECONDO
- MINUTE
- MINUTO A SECONDO
- SECOND
Esempio
L'esempio seguente aggiunge 3 anni alla data corrente.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01L'esempio seguente aggiunge 3 anni e 01 mese alla data corrente.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01L'esempio seguente aggiunge 01 giorno, 05 ore e 10 minuti al timestamp corrente.
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradata fornisce funzioni integrate che sono estensioni di SQL. Di seguito sono riportate le funzioni incorporate comuni.
| Funzione | Risultato |
|---|---|
| SELEZIONA DATA; | Data -------- 16/01/01 |
| SELEZIONA CURRENT_DATE; | Data -------- 16/01/01 |
| SELEZIONA L'ORA; | Ora -------- 04:50:29 |
| SELEZIONA CURRENT_TIME; | Ora -------- 04:50:29 |
| SELEZIONA CURRENT_TIMESTAMP; | Current TimeStamp (6) -------------------------------- 2016-01-01 04: 51: 06.990000 + 00: 00 |
| SELEZIONA DATABASE; | Database ------------------------------ TDUSER |
Teradata supporta funzioni aggregate comuni. Possono essere utilizzati con l'istruzione SELECT.
COUNT - Conta le righe
SUM - Riassume i valori delle colonne specificate
MAX - Restituisce il valore grande della colonna specificata
MIN - Restituisce il valore minimo della colonna specificata
AVG - Restituisce il valore medio della colonna specificata
Esempio
Considera la seguente tabella dei salari.
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 104 | 75.000 | 5.000 | 70.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 105 | 70.000 | 4.000 | 66.000 |
| 103 | 90.000 | 7.000 | 83.000 |
CONTARE
L'esempio seguente conta il numero di record nella tabella Salary.
SELECT count(*) from Salary;
Count(*)
-----------
5MAX
L'esempio seguente restituisce il valore dello stipendio netto massimo del dipendente.
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000MIN
L'esempio seguente restituisce il valore dello stipendio netto minimo del dipendente dalla tabella Salary.
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000AVG
L'esempio seguente restituisce la media del valore salariale netto dei dipendenti dalla tabella.
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800SOMMA
L'esempio seguente calcola la somma dello stipendio netto dei dipendenti da tutti i record della tabella Salary.
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000Questo capitolo spiega le funzioni CASE e COALESCE di Teradata.
CASE Expression
L'espressione CASE valuta ogni riga rispetto a una condizione o alla clausola WHEN e restituisce il risultato della prima corrispondenza. Se non sono presenti corrispondenze, viene restituito il risultato della parte ELSE.
Sintassi
Di seguito è riportata la sintassi dell'espressione CASE.
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
ENDEsempio
Considera la seguente tabella Employee.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentNo | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Roberto | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paolo | 21/03/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Roberto | James | 1/4/2008 | 3 | 12/1/1984 |
L'esempio seguente valuta la colonna DepartmentNo e restituisce il valore 1 se il numero di reparto è 1; restituisce 2 se il numero di reparto è 3; altrimenti restituisce il valore come reparto non valido.
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;Quando la query precedente viene eseguita, produce il seguente output.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 ITL'espressione CASE sopra può anche essere scritta nella seguente forma che produrrà lo stesso risultato di cui sopra.
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;COALESCE
COALESCE è un'istruzione che restituisce il primo valore non nullo dell'espressione. Restituisce NULL se tutti gli argomenti dell'espressione restituiscono NULL. Di seguito è riportata la sintassi.
Sintassi
COALESCE(expression 1, expression 2, ....)Esempio
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
L'istruzione NULLIF restituisce NULL se gli argomenti sono uguali.
Sintassi
Di seguito è riportata la sintassi dell'istruzione NULLIF.
NULLIF(expression 1, expression 2)Esempio
L'esempio seguente restituisce NULL se DepartmentNo è uguale a 3. In caso contrario, restituisce il valore DepartmentNo.
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;La query precedente restituisce i seguenti record. Puoi vedere che il dipendente 105 ha il dipartimento n. come NULL.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2L'indice primario viene utilizzato per specificare dove risiedono i dati in Teradata. Viene utilizzato per specificare quale AMP ottiene la riga di dati. Ogni tabella in Teradata deve avere un indice primario definito. Se l'indice primario non è definito, Teradata assegna automaticamente l'indice primario. L'indice primario fornisce il modo più veloce per accedere ai dati. Una primaria può avere un massimo di 64 colonne.
L'indice primario viene definito durante la creazione di una tabella. Esistono 2 tipi di indici primari.
- Indice primario univoco (UPI)
- Indice primario non univoco (NUPI)
Indice primario univoco (UPI)
Se la tabella è definita per avere UPI, la colonna considerata come UPI non dovrebbe avere valori duplicati. Se vengono inseriti valori duplicati, verranno rifiutati.
Crea indice primario univoco
L'esempio seguente crea la tabella Salary con la colonna EmployeeNo come indice primario univoco.
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Indice primario non univoco (NUPI)
Se la tabella è definita per avere NUPI, la colonna considerata come UPI può accettare valori duplicati.
Crea indice primario non univoco
L'esempio seguente crea la tabella dei conti dei dipendenti con la colonna EmployeeNo come indice primario non univoco. EmployeeNo è definito come Indice primario non univoco poiché un dipendente può avere più account nella tabella; uno per conto stipendio e un altro per conto rimborso.
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);Join viene utilizzato per combinare i record di più di una tabella. Le tabelle vengono unite in base alle colonne / ai valori comuni di queste tabelle.
Sono disponibili diversi tipi di join.
- Inner Join
- Join esterno sinistro
- Right Outer Join
- Join esterno completo
- Self Join
- Cross Join
- Cartesian Production Join
INNER JOIN
Inner Join combina i record di più tabelle e restituisce i valori presenti in entrambe le tabelle.
Sintassi
Di seguito è riportata la sintassi dell'istruzione INNER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Esempio
Considera la tabella dei dipendenti e la tabella dei salari seguenti.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentNo | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Roberto | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paolo | 21/03/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Roberto | James | 1/4/2008 | 3 | 12/1/1984 |
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
La query seguente unisce la tabella Employee e la tabella Salary nella colonna comune EmployeeNo. A ciascuna tabella viene assegnato un alias A e B e alle colonne viene fatto riferimento con l'alias corretto.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);Quando la query precedente viene eseguita, restituisce i seguenti record. L'impiegato 105 non è incluso nel risultato poiché non ha record corrispondenti nella tabella Salario.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000OUTER JOIN
LEFT OUTER JOIN e RIGHT OUTER JOIN combinano anche i risultati di più tabelle.
LEFT OUTER JOIN restituisce tutti i record dalla tabella di sinistra e restituisce solo i record corrispondenti dalla tabella di destra.
RIGHT OUTER JOIN restituisce tutti i record dalla tabella di destra e restituisce solo le righe corrispondenti dalla tabella di sinistra.
FULL OUTER JOINcombina i risultati delle UNITE ESTERNE SINISTRA e ESTERNA DESTRA. Restituisce righe corrispondenti e non corrispondenti dalle tabelle unite.
Sintassi
Di seguito è riportata la sintassi dell'istruzione OUTER JOIN. È necessario utilizzare una delle opzioni da LEFT OUTER JOIN, RIGHT OUTER JOIN o FULL OUTER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Esempio
Considera il seguente esempio della query LEFT OUTER JOIN. Restituisce tutti i record dalla tabella Employee e i record corrispondenti dalla tabella Salary.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;Quando la query precedente viene eseguita, produce il seguente output. Per il dipendente 105, il valore NetPay è NULL, poiché non ha record corrispondenti nella tabella Salary.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?CROSS JOIN
Cross Join unisce ogni riga della tabella di sinistra a ogni riga della tabella di destra.
Sintassi
Di seguito è riportata la sintassi dell'istruzione CROSS JOIN.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;Quando la query precedente viene eseguita, produce il seguente output. L'impiegato n. 101 dalla tabella Impiegato è unito a ogni record dalla tabella Salario.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000Una sottoquery restituisce i record di una tabella in base ai valori di un'altra tabella. È una query SELECT all'interno di un'altra query. La query SELECT chiamata come query interna viene eseguita per prima e il risultato viene utilizzato dalla query esterna. Alcune delle sue caratteristiche salienti sono:
Una query può avere più sottoquery e le sottoquery possono contenere un'altra sottoquery.
Le sottoquery non restituiscono record duplicati.
Se la sottoquery restituisce un solo valore, è possibile utilizzare l'operatore = per utilizzarlo con la query esterna. Se restituisce più valori è possibile utilizzare IN o NOT IN.
Sintassi
Di seguito è riportata la sintassi generica delle sottoquery.
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);Esempio
Considera la seguente tabella degli stipendi.
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
La seguente query identifica il numero del dipendente con lo stipendio più alto. Il SELECT interno esegue la funzione di aggregazione per restituire il valore NetPay massimo e la query SELECT esterna utilizza questo valore per restituire il record del dipendente con questo valore.
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);Quando questa query viene eseguita, produce il seguente output.
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradata supporta i seguenti tipi di tabella per contenere dati temporanei.
- Tabella derivata
- Tabella volatile
- Tabella temporanea globale
Tabella derivata
Le tabelle derivate vengono create, utilizzate e rilasciate all'interno di una query. Questi vengono utilizzati per memorizzare risultati intermedi all'interno di una query.
Esempio
L'esempio seguente crea una tabella derivata EmpSal con record di dipendenti con stipendio maggiore di 75000.
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;Quando viene eseguita la query precedente, restituisce i dipendenti con uno stipendio superiore a 75000.
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000Tabella volatile
Le tabelle volatili vengono create, utilizzate e rilasciate all'interno di una sessione utente. La loro definizione non è memorizzata nel dizionario dei dati. Contengono i dati intermedi della query che viene utilizzata di frequente. Di seguito è riportata la sintassi.
Sintassi
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWSEsempio
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;Quando la query precedente viene eseguita, produce il seguente output.
*** Table has been created.
*** Total elapsed time was 1 second.Tabella temporanea globale
La definizione di tabella temporanea globale è memorizzata nel dizionario dei dati e può essere utilizzata da molti utenti / sessioni. Ma i dati caricati nella tabella temporanea globale vengono conservati solo durante la sessione. È possibile materializzare fino a 2000 tabelle temporanee globali per sessione. Di seguito è riportata la sintassi.
Sintassi
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>Esempio
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);Quando la query precedente viene eseguita, produce il seguente output.
*** Table has been created.
*** Total elapsed time was 1 second.Ci sono tre tipi di spazi disponibili a Teradata.
Spazio permanente
Lo spazio permanente è la quantità massima di spazio disponibile per l'utente / database per contenere le righe di dati. Le tabelle permanenti, i journal, le tabelle di fallback e le sotto-tabelle degli indici secondari utilizzano uno spazio permanente.
Lo spazio permanente non è preallocato per il database / utente. Sono semplicemente definiti come la quantità massima di spazio che il database / utente può utilizzare. La quantità di spazio permanente viene divisa per il numero di AMP. Ogni volta che il limite di AMP viene superato, viene generato un messaggio di errore.
Spazio bobina
Lo spazio di spool è lo spazio permanente inutilizzato che viene utilizzato dal sistema per conservare i risultati intermedi della query SQL. Gli utenti senza spazio di spool non possono eseguire alcuna query.
Simile allo spazio permanente, lo spazio di spool definisce la quantità massima di spazio che l'utente può utilizzare. Lo spazio di spool viene diviso per il numero di AMP. Ogni volta che il limite di AMP viene superato, l'utente riceverà un errore di spazio di spool.
Spazio temporaneo
Lo spazio temporaneo è lo spazio permanente inutilizzato utilizzato dalle tabelle temporanee globali. Lo spazio temporaneo è anche diviso per il numero di AMP.
Una tabella può contenere un solo indice primario. Più spesso, ti imbatterai in scenari in cui la tabella contiene altre colonne, utilizzando le quali si accede frequentemente ai dati. Teradata eseguirà la scansione completa della tabella per tali query. Gli indici secondari risolvono questo problema.
Gli indici secondari sono un percorso alternativo per accedere ai dati. Esistono alcune differenze tra l'indice primario e l'indice secondario.
L'indice secondario non è coinvolto nella distribuzione dei dati.
I valori dell'indice secondario vengono memorizzati in tabelle secondarie. Queste tabelle sono costruite in tutti gli AMP.
Gli indici secondari sono facoltativi.
Possono essere creati durante la creazione della tabella o dopo la creazione di una tabella.
Occupano spazio aggiuntivo poiché creano sotto-tabelle e richiedono anche manutenzione poiché le sotto-tabelle devono essere aggiornate per ogni nuova riga.
Esistono due tipi di indici secondari:
- Indice secondario univoco (USI)
- Indice secondario non univoco (NUSI)
Indice secondario univoco (USI)
Un indice secondario univoco consente solo valori univoci per le colonne definite come USI. L'accesso alla riga dall'USI è un'operazione a due ampere.
Crea un indice secondario univoco
L'esempio seguente crea l'USI nella colonna EmployeeNo della tabella dei dipendenti.
CREATE UNIQUE INDEX(EmployeeNo) on employee;Indice secondario non univoco (NUSI)
Un indice secondario non univoco consente valori duplicati per le colonne definite come NUSI. L'accesso alla riga tramite NUSI è un'operazione su tutti gli amplificatori.
Crea indice secondario non univoco
Il seguente esempio crea NUSI sulla colonna FirstName della tabella dei dipendenti.
CREATE INDEX(FirstName) on Employee;L'ottimizzatore di Teradata presenta una strategia di esecuzione per ogni query SQL. Questa strategia di esecuzione si basa sulle statistiche raccolte sulle tabelle utilizzate all'interno della query SQL. Le statistiche sulla tabella vengono raccolte utilizzando il comando RACCOGLI STATISTICHE. Optimizer richiede informazioni sull'ambiente e dati demografici per elaborare una strategia di esecuzione ottimale.
Informazioni sull'ambiente
- Numero di nodi, AMP e CPU
- Quantità di memoria
Dati demografici
- Numero di righe
- Dimensione riga
- Intervallo di valori nella tabella
- Numero di righe per valore
- Numero di null
Esistono tre approcci per raccogliere statistiche sul tavolo.
- Campionamento AMP casuale
- Raccolta completa delle statistiche
- Utilizzando l'opzione SAMPLE
Raccolta di statistiche
Il comando COLLECT STATISTICS viene utilizzato per raccogliere statistiche su una tabella.
Sintassi
Di seguito è riportata la sintassi di base per raccogliere statistiche su una tabella.
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;Esempio
L'esempio seguente raccoglie le statistiche sulla colonna EmployeeNo della tabella Employee.
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;Quando la query precedente viene eseguita, produce il seguente output.
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.Visualizzazione delle statistiche
È possibile visualizzare le statistiche raccolte utilizzando il comando HELP STATISTICS.
Sintassi
Di seguito è riportata la sintassi per visualizzare le statistiche raccolte.
HELP STATISTICS <tablename>;Esempio
Di seguito è riportato un esempio per visualizzare le statistiche raccolte sulla tabella Employee.
HELP STATISTICS employee;Quando la query precedente viene eseguita, produce il seguente risultato.
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNoLa compressione viene utilizzata per ridurre lo spazio di archiviazione utilizzato dalle tabelle. In Teradata, la compressione può comprimere fino a 255 valori distinti, incluso NULL. Poiché lo spazio di archiviazione è ridotto, Teradata può archiviare più record in un blocco. Ciò si traduce in un tempo di risposta alle query migliorato poiché qualsiasi operazione di I / O può elaborare più righe per blocco. La compressione può essere aggiunta durante la creazione della tabella utilizzando CREATE TABLE o dopo la creazione della tabella utilizzando il comando ALTER TABLE.
Limitazioni
- È possibile comprimere solo 255 valori per colonna.
- La colonna Indice primario non può essere compressa.
- Le tabelle volatili non possono essere compresse.
Compressione multivalore (MVC)
La tabella seguente comprime il campo DepatmentNo per i valori 1, 2 e 3. Quando la compressione viene applicata a una colonna, i valori per questa colonna non vengono memorizzati con la riga. I valori vengono invece memorizzati nell'intestazione della tabella in ogni AMP e solo i bit di presenza vengono aggiunti alla riga per indicare il valore.
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);La compressione multivalore può essere utilizzata quando si dispone di una colonna in una tabella di grandi dimensioni con valori finiti.
Il comando EXPLAIN restituisce il piano di esecuzione del motore di analisi in inglese. Può essere utilizzato con qualsiasi istruzione SQL tranne su un altro comando EXPLAIN. Quando una query è preceduta dal comando EXPLAIN, il piano di esecuzione del Parsing Engine viene restituito all'utente anziché AMP.
Esempi di EXPLAIN
Considera la tabella Employee con la seguente definizione.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );Di seguito vengono forniti alcuni esempi di piano EXPLAIN.
Scansione tabella completa (FTS)
Quando nessuna condizione è specificata nell'istruzione SELECT, l'ottimizzatore può scegliere di utilizzare la scansione completa della tabella in cui si accede a ciascuna riga della tabella.
Esempio
Di seguito è una query di esempio in cui l'ottimizzatore può scegliere FTS.
EXPLAIN SELECT * FROM employee;Quando la query precedente viene eseguita, produce il seguente output. Come si può vedere, l'ottimizzatore sceglie di accedere a tutti gli AMP e a tutte le righe all'interno dell'AMP.
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.Indice primario univoco
Quando si accede alle righe utilizzando l'indice primario univoco, si tratta di un'operazione AMP.
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;Quando la query precedente viene eseguita, produce il seguente output. Come si può vedere, si tratta di un recupero AMP singolo e l'ottimizzatore utilizza l'indice primario univoco per accedere alla riga.
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Indice secondario univoco
Quando si accede alle righe utilizzando l'indice secondario univoco, è un'operazione a due amp.
Esempio
Considera la tabella Salario con la seguente definizione.
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Considera la seguente istruzione SELECT.
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;Quando la query precedente viene eseguita, produce il seguente output. Come si può vedere, l'ottimizzatore recupera la riga in un'operazione a due amplificatori utilizzando un indice secondario univoco.
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Termini aggiuntivi
Di seguito è riportato l'elenco dei termini comunemente visualizzati nel piano EXPLAIN.
... (Last Use) …
Un file di spool non è più necessario e verrà rilasciato al termine di questo passaggio.
... with no residual conditions …
Tutte le condizioni applicabili sono state applicate alle righe.
... END TRANSACTION …
I blocchi delle transazioni vengono rilasciati e le modifiche vengono salvate.
... eliminating duplicate rows ...
Le righe duplicate esistono solo nei file di spool, non nelle tabelle impostate. Esecuzione di un'operazione DISTINCT.
... by way of a traversal of index #n extracting row ids only …
Viene creato un file di spool contenente gli ID riga trovati in un indice secondario (indice #n)
... we do a SMS (set manipulation step) …
Combinazione di righe utilizzando un operatore UNION, MINUS o INTERSECT.
... which is redistributed by hash code to all AMPs.
Ridistribuzione dei dati in preparazione per un join.
... which is duplicated on all AMPs.
Duplicazione dei dati dalla tabella più piccola (in termini di SPOOL) in preparazione per un join.
... (one_AMP) or (group_AMPs)
Indica che verrà utilizzato un AMP o un sottoinsieme di AMP invece di tutti gli AMP.
Una riga viene assegnata a un particolare AMP in base al valore dell'indice primario. Teradata utilizza l'algoritmo di hashing per determinare quale AMP ottiene la riga.
Di seguito è riportato un diagramma di alto livello sull'algoritmo di hashing.

Di seguito sono riportati i passaggi per inserire i dati.
Il cliente invia una richiesta.
Il parser riceve la query e passa il valore PI del record all'algoritmo di hashing.
L'algoritmo di hashing esegue l'hashing del valore dell'indice primario e restituisce un numero a 32 bit, denominato Row Hash.
I bit di ordine superiore della riga hash (i primi 16 bit) vengono utilizzati per identificare la voce della mappa hash. La mappa hash contiene un AMP #. La mappa hash è un array di bucket che contiene AMP # specifici.
BYNET invia i dati all'AMP identificato.
AMP utilizza l'hash della riga a 32 bit per individuare la riga all'interno del proprio disco.
Se è presente un record con lo stesso hash di riga, incrementa l'ID di unicità che è un numero a 32 bit. Per il nuovo hash di riga, l'ID di unicità viene assegnato come 1 e incrementato ogni volta che viene inserito un record con lo stesso hash di riga.
La combinazione di hash di riga e ID di unicità viene chiamata come ID di riga.
L'ID riga è il prefisso di ogni record nel disco.
Ogni riga della tabella nell'AMP è ordinata logicamente in base ai rispettivi ID riga.
Come vengono archiviate le tabelle
Le tabelle vengono ordinate in base al rispettivo ID riga (hash riga + ID univocità) e quindi archiviate all'interno degli AMP. L'ID riga viene memorizzato con ogni riga di dati.
| Row Hash | ID di unicità | EmployeeNo | Nome di battesimo | Cognome |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Roberto | Williams |
| 2A01 2614 | 0000 0001 | 105 | Roberto | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paolo |
JOIN INDEX è una vista materializzata. La sua definizione viene memorizzata in modo permanente ei dati vengono aggiornati ogni volta che vengono aggiornate le tabelle di base a cui fa riferimento l'indice di join. JOIN INDEX può contenere una o più tabelle e contenere anche dati pre-aggregati. Gli indici di join vengono utilizzati principalmente per migliorare le prestazioni.
Sono disponibili diversi tipi di indici di join.
- Indice Single Table Join (STJI)
- Indice di unione di più tabelle (MTJI)
- Indice aggregato di join (AJI)
Indice join tabella singola
L'indice Single Table Join consente di partizionare una tabella di grandi dimensioni in base alle diverse colonne dell'indice primario rispetto a quella della tabella di base.
Sintassi
Di seguito è riportata la sintassi di un JOIN INDEX.
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;Esempio
Considera le seguenti tabelle dei dipendenti e dei salari.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Di seguito è riportato un esempio che crea un indice di join denominato Employee_JI sulla tabella Employee.
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);Se l'utente invia una query con una clausola WHERE su EmployeeNo, il sistema interrogherà la tabella Employee utilizzando l'indice primario univoco. Se l'utente interroga la tabella dei dipendenti utilizzando nome_impiegato, il sistema può accedere all'indice di join Employee_JI utilizzando nome_impiegato. Le righe dell'indice di join vengono sottoposte ad hashing nella colonna dipendente_name. Se l'indice di join non è definito e il nome_impiegato non è definito come indice secondario, il sistema eseguirà la scansione completa della tabella per accedere alle righe che richiede tempo.
È possibile eseguire il seguente piano EXPLAIN e verificare il piano di ottimizzazione. Nell'esempio seguente è possibile vedere che l'ottimizzatore utilizza l'indice di join anziché la tabella Employee di base quando la tabella esegue una query utilizzando la colonna Employee_Name.
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.Indice di unione di più tabelle
Un indice di join multi-tabella viene creato unendo più di una tabella. L'indice di join multi-tabella può essere utilizzato per archiviare il set di risultati delle tabelle unite di frequente per migliorare le prestazioni.
Esempio
Il seguente esempio crea un JOIN INDEX denominato Employee_Salary_JI unendo le tabelle Employee e Salary.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);Ogni volta che le tabelle di base Employee o Salary vengono aggiornate, viene aggiornato automaticamente anche l'indice di join Employee_Salary_JI. Se si esegue una query che unisce le tabelle Employee e Salary, l'ottimizzatore può scegliere di accedere ai dati direttamente da Employee_Salary_JI invece di unirsi alle tabelle. Il piano EXPLAIN sulla query può essere utilizzato per verificare se l'ottimizzatore sceglierà la tabella di base o l'indice di join.
Indice di join aggregato
Se una tabella viene aggregata in modo coerente su determinate colonne, è possibile definire l'indice di join aggregato sulla tabella per migliorare le prestazioni. Una limitazione dell'indice di join aggregato è che supporta solo le funzioni SUM e COUNT.
Esempio
Nell'esempio seguente Employee and Salary viene unito per identificare lo stipendio totale per reparto.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);Le viste sono oggetti di database creati dalla query. Le viste possono essere costruite utilizzando una singola tabella o più tabelle tramite l'unione. La loro definizione è memorizzata in modo permanente nel dizionario dei dati ma non memorizzano la copia dei dati. I dati per la vista vengono creati dinamicamente.
Una vista può contenere un sottoinsieme di righe della tabella o un sottoinsieme di colonne della tabella.
Crea una vista
Le viste vengono create utilizzando l'istruzione CREATE VIEW.
Sintassi
Di seguito è riportata la sintassi per la creazione di una vista.
CREATE/REPLACE VIEW <viewname>
AS
<select query>;Esempio
Considera la seguente tabella Employee.
| EmployeeNo | Nome di battesimo | Cognome | Data di nascita |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Roberto | Williams | 3/5/1983 |
| 105 | Roberto | James | 12/1/1984 |
| 103 | Peter | Paolo | 4/1/1983 |
L'esempio seguente crea una visualizzazione sulla tabella Employee.
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;Usare le viste
È possibile utilizzare la normale istruzione SELECT per recuperare i dati da Views.
Esempio
L'esempio seguente recupera i record da Employee_View;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;Quando la query precedente viene eseguita, produce il seguente output.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulModifica delle viste
Una vista esistente può essere modificata utilizzando l'istruzione REPLACE VIEW.
Di seguito è riportata la sintassi per modificare una visualizzazione.
REPLACE VIEW <viewname>
AS
<select query>;Esempio
L'esempio seguente modifica la visualizzazione Employee_View per l'aggiunta di colonne aggiuntive.
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;Drop View
Una vista esistente può essere eliminata utilizzando l'istruzione DROP VIEW.
Sintassi
Di seguito è riportata la sintassi di DROP VIEW.
DROP VIEW <viewname>;Esempio
Di seguito è riportato un esempio per eliminare la visualizzazione Employee_View.
DROP VIEW Employee_View;Vantaggi delle viste
Le viste forniscono un ulteriore livello di sicurezza limitando le righe o le colonne di una tabella.
Gli utenti possono avere accesso solo alle visualizzazioni invece che alle tabelle di base.
Semplifica l'uso di più tabelle unendole prima utilizzando le viste.
La macro è un insieme di istruzioni SQL che vengono memorizzate ed eseguite chiamando il nome della macro. La definizione di macro è archiviata nel dizionario dei dati. Gli utenti necessitano solo del privilegio EXEC per eseguire la macro. Gli utenti non necessitano di privilegi separati sugli oggetti del database utilizzati all'interno della Macro. Le istruzioni macro vengono eseguite come una singola transazione. Se una delle istruzioni SQL in Macro non riesce, viene eseguito il rollback di tutte le istruzioni. Le macro possono accettare parametri. Le macro possono contenere istruzioni DDL, ma questa dovrebbe essere l'ultima istruzione in Macro.
Crea macro
Le macro vengono create utilizzando l'istruzione CREATE MACRO.
Sintassi
Di seguito è riportata la sintassi generica del comando CREATE MACRO.
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);Esempio
Considera la seguente tabella Employee.
| EmployeeNo | Nome di battesimo | Cognome | Data di nascita |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Roberto | Williams | 3/5/1983 |
| 105 | Roberto | James | 12/1/1984 |
| 103 | Peter | Paolo | 4/1/1983 |
L'esempio seguente crea una macro chiamata Get_Emp. Contiene un'istruzione select per recuperare i record dalla tabella dei dipendenti.
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);Esecuzione di macro
Le macro vengono eseguite utilizzando il comando EXEC.
Sintassi
Di seguito è riportata la sintassi del comando EXECUTE MACRO.
EXEC <macroname>;Esempio
L'esempio seguente esegue i nomi delle macro Get_Emp; Quando viene eseguito il seguente comando, recupera tutti i record dalla tabella dei dipendenti.
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert JamesMacro parametrizzate
Le macro Teradata possono accettare parametri. All'interno di una Macro, questi parametri sono referenziati con; (punto e virgola).
Di seguito è riportato un esempio di una macro che accetta parametri.
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);Esecuzione di macro con parametri
Le macro vengono eseguite utilizzando il comando EXEC. È necessario il privilegio EXEC per eseguire le macro.
Sintassi
Di seguito è riportata la sintassi dell'istruzione EXECUTE MACRO.
EXEC <macroname>(value);Esempio
L'esempio seguente esegue i nomi delle macro Get_Emp; Accetta il dipendente no come parametro ed estrae i record dalla tabella dei dipendenti per quel dipendente.
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000Una procedura memorizzata contiene una serie di istruzioni SQL e istruzioni procedurali. Possono contenere solo dichiarazioni procedurali. La definizione della procedura memorizzata viene memorizzata nel database ei parametri vengono memorizzati nelle tabelle del dizionario dei dati.
Vantaggi
Le stored procedure riducono il carico di rete tra il client e il server.
Fornisce una maggiore sicurezza poiché si accede ai dati tramite stored procedure invece di accedervi direttamente.
Offre una migliore manutenzione poiché la logica aziendale viene testata e archiviata nel server.
Procedura di creazione
Le stored procedure vengono create utilizzando l'istruzione CREATE PROCEDURE.
Sintassi
Di seguito è riportata la sintassi generica dell'istruzione CREATE PROCEDURE.
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;Esempio
Considera la seguente tabella dei salari.
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
L'esempio seguente crea una stored procedure denominata InsertSalary per accettare i valori e inserirli nella tabella Salary.
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;Esecuzione delle procedure
Le stored procedure vengono eseguite utilizzando l'istruzione CALL.
Sintassi
Di seguito è riportata la sintassi generica dell'istruzione CALL.
CALL <procedure name> [(parameter values)];Esempio
L'esempio seguente chiama la stored procedure InsertSalary e inserisce i record nella tabella Salary.
CALL InsertSalary(105,20000,2000,18000);Una volta eseguita la query di cui sopra, produce il seguente output e puoi vedere la riga inserita nella tabella Salary.
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
| 105 | 20.000 | 2.000 | 18.000 |
Questo capitolo discute le varie strategie JOIN disponibili in Teradata.
Metodi di unione
Teradata utilizza diversi metodi di join per eseguire operazioni di join. Alcuni dei metodi Join comunemente usati sono:
- Unisci Unisci
- Join annidato
- Prodotto Join
Unisci Unisci
Il metodo Merge Join viene eseguito quando il join è basato sulla condizione di uguaglianza. Merge Join richiede che le righe di unione si trovino sullo stesso AMP. Le righe vengono unite in base all'hash delle righe. Merge Join utilizza diverse strategie di join per portare le righe nello stesso AMP.
Strategia n. 1
Se le colonne di join sono gli indici primari delle tabelle corrispondenti, le righe di join si trovano già sullo stesso AMP. In questo caso, non è richiesta alcuna distribuzione.
Considera le seguenti tabelle dei dipendenti e dei salari.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Quando queste due tabelle vengono unite nella colonna EmployeeNo, non viene eseguita alcuna ridistribuzione poiché EmployeeNo è l'indice principale di entrambe le tabelle che vengono unite.
Strategia n. 2
Considera le seguenti tabelle Employee e Department.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );Se queste due tabelle vengono unite nella colonna DeparmentNo, le righe devono essere ridistribuite poiché DepartmentNo è un indice primario in una tabella e un indice non primario in un'altra tabella. In questo scenario, l'unione di righe potrebbe non trovarsi sullo stesso AMP. In tal caso, Teradata può ridistribuire la tabella dei dipendenti nella colonna DepartmentNo.
Strategia n. 3
Per le tabelle Employee e Department di cui sopra, Teradata può duplicare la tabella Department su tutti gli AMP, se la dimensione della tabella Department è piccola.
Join annidato
Nested Join non utilizza tutti gli AMP. Affinché il join annidato abbia luogo, una delle condizioni dovrebbe essere l'uguaglianza sull'indice primario univoco di una tabella e quindi l'unione di questa colonna a qualsiasi indice sull'altra tabella.
In questo scenario, il sistema recupererà una riga utilizzando l'indice primario univoco di una tabella e utilizzerà quell'hash di riga per recuperare i record corrispondenti da un'altra tabella. Il join annidato è il più efficiente di tutti i metodi Join.
Prodotto Join
Product Join confronta ogni riga qualificante di una tabella con ogni riga qualificante di un'altra tabella. L'unione del prodotto può avvenire a causa di alcuni dei seguenti fattori:
- Dove manca la condizione.
- La condizione di join non si basa sulla condizione di uguaglianza.
- Gli alias di tabella non sono corretti.
- Condizioni di join multiple.
Partitioned Primary Index (PPI) è un meccanismo di indicizzazione utile per migliorare le prestazioni di determinate query. Quando le righe vengono inserite in una tabella, vengono archiviate in un AMP e disposte in base all'ordine hash delle righe. Quando una tabella viene definita con PPI, le righe vengono ordinate in base al numero di partizione. All'interno di ogni partizione, sono organizzati in base al loro hash di riga. Le righe vengono assegnate a una partizione in base all'espressione di partizione definita.
Vantaggi
Evita la scansione completa della tabella per determinate query.
Evita di utilizzare un indice secondario che richiede una struttura fisica aggiuntiva e una manutenzione I / O aggiuntiva.
Accedi rapidamente a un sottoinsieme di una tabella di grandi dimensioni.
Elimina rapidamente i vecchi dati e aggiungi nuovi dati.
Esempio
Considera la seguente tabella degli ordini con l'indice primario su OrderNo.
| StoreNo | Numero d'ordine | Data dell'ordine | Ordine totale |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1.200 |
| 102 | 7503 | 2015-10-02 | 3.000 |
| 102 | 7504 | 2015-10-03 | 2.454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2.454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
Supponiamo che i record siano distribuiti tra AMP come mostrato nelle tabelle seguenti. Le registrazioni vengono archiviate in AMP, ordinate in base all'hash delle righe.
| RowHash | Numero d'ordine | Data dell'ordine |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | Numero d'ordine | Data dell'ordine |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
Se esegui una query per estrarre gli ordini per una data particolare, l'ottimizzatore può scegliere di utilizzare la scansione completa della tabella, quindi è possibile accedere a tutti i record all'interno dell'AMP. Per evitare ciò, è possibile definire la data dell'ordine come Indice primario partizionato. Quando le righe vengono inserite nella tabella degli ordini, vengono partizionate in base alla data dell'ordine. All'interno di ogni partizione verranno ordinati in base all'hash della riga.
I dati seguenti mostrano come verranno archiviati i record negli AMP, se sono partizionati in base alla data dell'ordine. Se viene eseguita una query per accedere ai record in base alla data dell'ordine, si accederà solo alla partizione che contiene i record per quel particolare ordine.
| Partizione | RowHash | Numero d'ordine | Data dell'ordine |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| Partizione | RowHash | Numero d'ordine | Data dell'ordine |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
Di seguito è riportato un esempio per creare una tabella con l'indice primario della partizione. La clausola PARTITION BY viene utilizzata per definire la partizione.
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);Nell'esempio precedente, la tabella è partizionata in base alla colonna OrderDate. Ci sarà una partizione separata per ogni giorno.
Le funzioni OLAP sono simili alle funzioni aggregate tranne per il fatto che le funzioni aggregate restituiranno solo un valore mentre la funzione OLAP fornirà le singole righe oltre agli aggregati.
Sintassi
Di seguito è riportata la sintassi generale della funzione OLAP.
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)Le funzioni di aggregazione possono essere SUM, COUNT, MAX, MIN, AVG.
Esempio
Considera la seguente tabella degli stipendi.
| EmployeeNo | Schifoso | Deduzione | Retribuzione netta |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Di seguito è riportato un esempio per trovare la somma cumulativa o il totale parziale di NetPay nella tabella Salary. I record vengono ordinati per EmployeeNo e la somma cumulativa viene calcolata nella colonna NetPay.
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;Quando la query precedente viene eseguita, produce il seguente output.
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000RANGO
La funzione RANK ordina i record in base alla colonna fornita. La funzione RANK può anche filtrare il numero di record restituiti in base al rango.
Sintassi
Di seguito è riportata la sintassi generica per utilizzare la funzione RANK.
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])Esempio
Considera la seguente tabella Employee.
| EmployeeNo | Nome di battesimo | Cognome | JoinedDate | DepartmentID | Data di nascita |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/3/2005 | 1 | 1/5/1980 |
| 102 | Roberto | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paolo | 21/03/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Roberto | James | 1/4/2008 | 3 | 12/1/1984 |
La seguente query ordina i record della tabella dei dipendenti in base alla data di iscrizione e assegna la classifica alla data di iscrizione.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;Quando la query precedente viene eseguita, produce il seguente output.
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5La clausola PARTITION BY raggruppa i dati in base alle colonne definite nella clausola PARTITION BY ed esegue la funzione OLAP all'interno di ogni gruppo. Di seguito è riportato un esempio della query che utilizza la clausola PARTITION BY.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;Quando la query precedente viene eseguita, produce il seguente output. Puoi vedere che il grado viene ripristinato per ogni dipartimento.
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1In questo capitolo vengono illustrate le funzionalità disponibili per la protezione dei dati in Teradata.
Giornale transitorio
Teradata utilizza Transient Journal per proteggere i dati da errori di transazione. Ogni volta che viene eseguita una transazione, il giornale di registrazione transitorio conserva una copia delle immagini precedenti delle righe interessate finché la transazione non ha esito positivo o viene annullata correttamente. Quindi, le immagini precedenti vengono eliminate. Il diario transitorio viene mantenuto in ogni AMP. È un processo automatico e non può essere disabilitato.
Ricaderci
Il fallback protegge i dati della tabella archiviando la seconda copia delle righe di una tabella su un altro AMP chiamato come Fallback AMP. Se un AMP non riesce, si accede alle righe di fallback. Con questo, anche se un AMP non riesce, i dati sono ancora disponibili tramite AMP di riserva. L'opzione di fallback può essere utilizzata durante la creazione della tabella o dopo la creazione della tabella. Il fallback garantisce che la seconda copia delle righe della tabella sia sempre archiviata in un altro AMP per proteggere i dati da errori AMP. Tuttavia, il fallback occupa il doppio dello spazio di archiviazione e dell'I / O per inserimento / eliminazione / aggiornamento.
Il diagramma seguente mostra come la copia di riserva delle righe viene archiviata in un altro AMP.
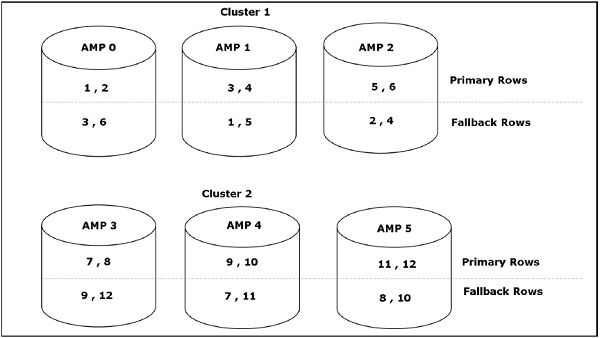
Diario di ripristino AMP giù
Il journal di ripristino di Down AMP viene attivato quando AMP non riesce e la tabella è protetta da fallback. Questo giornale tiene traccia di tutte le modifiche ai dati dell'AMP non riuscito. Il journal viene attivato sugli AMP rimanenti nel cluster. È un processo automatico e non può essere disabilitato. Una volta che l'AMP non riuscito è attivo, i dati dal diario di recupero di Down AMP vengono sincronizzati con l'AMP. Fatto ciò, il giornale viene scartato.
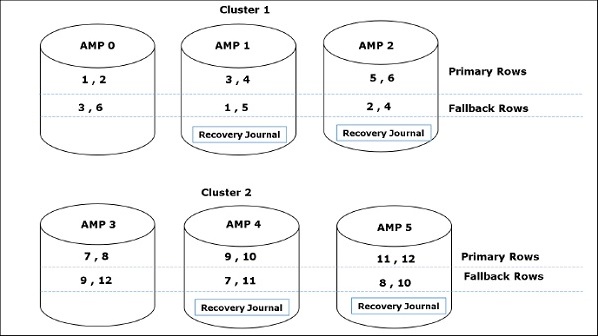
Cliques
Clique è un meccanismo utilizzato da Teradata per proteggere i dati dai guasti dei nodi. Una cricca non è altro che un insieme di nodi Teradata che condividono un insieme comune di array di dischi. Quando un nodo si guasta, i vproc dal nodo guasto migreranno ad altri nodi nella clique e continueranno ad accedere ai loro array di dischi.
Nodo Hot Standby
Hot Standby Node è un nodo che non fa parte dell'ambiente di produzione. Se un nodo si guasta, i vproc dai nodi non riusciti migreranno al nodo hot standby. Una volta ripristinato, il nodo guasto diventa il nodo hot standby. I nodi Hot Standby vengono utilizzati per mantenere le prestazioni in caso di guasti ai nodi.
RAID
Redundant Array of Independent Disks (RAID) è un meccanismo utilizzato per proteggere i dati da errori del disco. L'array di dischi è costituito da un set di dischi raggruppati come unità logica. Questa unità può sembrare una singola unità per l'utente, ma possono essere distribuite su più dischi.
RAID 1 è comunemente usato in Teradata. In RAID 1, ogni disco è associato a un disco mirror. Qualsiasi modifica ai dati nel disco primario si riflette anche nella copia mirror. Se il disco primario si guasta, è possibile accedere ai dati dal disco mirror.

Questo capitolo ha discusso le varie strategie di gestione degli utenti in Teradata.
Utenti
Un utente viene creato utilizzando il comando CREATE USER. In Teradata, un utente è anche simile a un database. Ad entrambi è possibile assegnare spazio e contenere oggetti di database tranne per il fatto che all'utente viene assegnata una password.
Sintassi
Di seguito è riportata la sintassi per CREATE USER.
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;Durante la creazione di un utente, i valori per nome utente, spazio permanente e password sono obbligatori. Altri campi sono facoltativi.
Esempio
Di seguito è riportato un esempio per creare l'utente TD01.
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;Conti
Durante la creazione di un nuovo utente, l'utente può essere assegnato a un account. L'opzione ACCOUNT in CREATE USER viene utilizzata per assegnare l'account. Un utente può essere assegnato a più account.
Sintassi
Di seguito è riportata la sintassi per CREATE USER con l'opzione account.
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountidEsempio
Il seguente esempio crea l'utente TD02 e assegna l'account come IT e Admin.
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);L'utente può specificare l'ID account durante l'accesso al sistema Teradata o dopo aver effettuato l'accesso al sistema utilizzando il comando SET SESSION.
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountidConcedi privilegi
Il comando GRANT viene utilizzato per assegnare uno o più privilegi sugli oggetti del database all'utente o al database.
Sintassi
Di seguito è riportata la sintassi del comando GRANT.
GRANT privileges ON objectname TO username;I privilegi possono essere INSERT, SELECT, UPDATE, REFERENCES.
Esempio
Di seguito è riportato un esempio di dichiarazione GRANT.
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;Revoca privilegi
Il comando REVOKE rimuove i privilegi dagli utenti o dai database. Il comando REVOKE può rimuovere solo privilegi espliciti.
Sintassi
Di seguito è riportata la sintassi di base per il comando REVOKE.
REVOKE [ALL|privileges] ON objectname FROM username;Esempio
Di seguito è riportato un esempio del comando REVOKE.
REVOKE INSERT,SELECT ON Employee FROM TD01;Questo capitolo descrive la procedura di ottimizzazione delle prestazioni in Teradata.
Spiegare
Il primo passaggio nell'ottimizzazione delle prestazioni è l'utilizzo di EXPLAIN sulla query. Il piano EXPLAIN fornisce i dettagli su come l'ottimizzatore eseguirà la query. Nel piano Explain, controlla le parole chiave come livello di confidenza, strategia di join utilizzata, dimensione del file di spool, ridistribuzione, ecc.
Raccogli statistiche
Optimizer utilizza i dati demografici dei dati per elaborare una strategia di esecuzione efficace. Il comando COLLECT STATISTICS viene utilizzato per raccogliere i dati demografici della tabella. Assicurati che le statistiche raccolte sulle colonne siano aggiornate.
Raccogliere statistiche sulle colonne utilizzate nella clausola WHERE e sulle colonne utilizzate nella condizione di unione.
Raccogli statistiche sulle colonne Indice primario univoco.
Raccogli le statistiche sulle colonne dell'indice secondario non univoco. L'ottimizzatore deciderà se può utilizzare NUSI o Full Table Scan.
Raccogli le statistiche sull'indice di join anche se vengono raccolte le statistiche sulla tabella di base.
Raccogli le statistiche sulle colonne di partizionamento.
Tipi di dati
Assicurati che vengano utilizzati i tipi di dati corretti. Ciò eviterà l'uso di uno spazio di archiviazione eccessivo rispetto a quanto richiesto.
Conversione
Assicurati che i tipi di dati delle colonne utilizzate nella condizione di join siano compatibili per evitare conversioni di dati esplicite.
Ordinare
Rimuovere le clausole ORDER BY non necessarie se non richiesto.
Problema di spazio spool
L'errore di spazio di spooling viene generato se la query supera il limite di spazio di spool per AMP per quell'utente. Verificare il piano di spiegazione e identificare il passaggio che consuma più spazio di bobina. Queste query intermedie possono essere suddivise e inserite separatamente per creare tabelle temporanee.
Indice primario
Assicurati che l'indice primario sia definito correttamente per la tabella. La colonna dell'indice principale dovrebbe distribuire uniformemente i dati e dovrebbe essere usata frequentemente per accedere ai dati.
Tavola apparecchiata
Se si definisce una tabella SET, l'ottimizzatore controllerà se il record è duplicato per ogni record inserito. Per rimuovere la condizione di controllo duplicato, è possibile definire l'indice secondario univoco per la tabella.
AGGIORNAMENTO sul tavolo grande
L'aggiornamento della tabella grande richiederà molto tempo. Invece di aggiornare la tabella, puoi eliminare i record e inserire i record con righe modificate.
Eliminazione di tabelle temporanee
Eliminare le tabelle temporanee (tabelle di staging) e i volatili se non sono più necessari. Ciò libererà spazio permanente e spazio sulla bobina.
Tavolo MULTISET
Se si è certi che i record di input non avranno record duplicati, è possibile definire la tabella di destinazione come tabella MULTISET per evitare il controllo delle righe duplicate utilizzato dalla tabella SET.
L'utility FastLoad viene utilizzata per caricare i dati in tabelle vuote. Poiché non utilizza giornali temporanei, i dati possono essere caricati rapidamente. Non carica le righe duplicate anche se la tabella di destinazione è una tabella MULTISET.
Limitazione
La tabella di destinazione non deve avere un indice secondario, un indice di join e un riferimento a chiave esterna.
Come funziona FastLoad
FastLoad viene eseguito in due fasi.
Fase 1
I motori di analisi leggono i record dal file di input e inviano un blocco a ciascun AMP.
Ogni AMP memorizza i blocchi di record.
Quindi gli AMP eseguono l'hashing di ogni record e li ridistribuiscono nell'AMP corretto.
Alla fine della Fase 1, ogni AMP ha le sue righe ma non sono nella sequenza hash delle righe.
Fase 2
La fase 2 inizia quando FastLoad riceve l'istruzione END LOADING.
Ogni AMP ordina i record sull'hash di riga e li scrive sul disco.
I blocchi sulla tabella di destinazione vengono rilasciati e le tabelle di errore vengono eliminate.
Esempio
Crea un file di testo con i seguenti record e denomina il file come dipendente.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Di seguito è riportato uno script FastLoad di esempio per caricare il file precedente nella tabella Employee_Stg.
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;Esecuzione di uno script FastLoad
Dopo aver creato il file di input dipendente.txt e lo script FastLoad è denominato EmployeeLoad.fl, è possibile eseguire lo script FastLoad utilizzando il seguente comando in UNIX e Windows.
FastLoad < EmployeeLoad.fl;Una volta eseguito il comando precedente, lo script FastLoad verrà eseguito e produrrà il registro. Nel registro è possibile visualizzare il numero di record elaborati da FastLoad e il codice di stato.
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsTermini di FastLoad
Di seguito è riportato l'elenco dei termini comuni utilizzati nello script FastLoad.
LOGON - Accede a Teradata e avvia una o più sessioni.
DATABASE - Imposta il database predefinito.
BEGIN LOADING - Identifica la tabella da caricare.
ERRORFILES - Identifica le 2 tabelle di errore che devono essere create / aggiornate.
CHECKPOINT - Definisce quando prendere il checkpoint.
SET RECORD - Specifica se il formato del file di input è formattato, binario, di testo o non formattato.
DEFINE - Definisce il layout del file di input.
FILE - Specifica il nome e il percorso del file di input.
INSERT - Inserisce i record dal file di input nella tabella di destinazione.
END LOADING- Avvia la fase 2 del FastLoad. Distribuisce i record nella tabella di destinazione.
LOGOFF - Termina tutte le sessioni e termina FastLoad.
MultiLoad può caricare più tabelle alla volta e può anche eseguire diversi tipi di attività come INSERT, DELETE, UPDATE e UPSERT. Può caricare fino a 5 tabelle alla volta ed eseguire fino a 20 operazioni DML in uno script. La tabella di destinazione non è richiesta per MultiLoad.
MultiLoad supporta due modalità:
- IMPORT
- DELETE
MultiLoad richiede una tabella di lavoro, una tabella di registro e due tabelle di errori oltre alla tabella di destinazione.
Log Table - Usato per mantenere i checkpoint presi durante il caricamento che verranno usati per il riavvio.
Error Tables- Queste tabelle vengono inserite durante il caricamento quando si verifica un errore. La prima tabella degli errori memorizza gli errori di conversione mentre la seconda tabella degli errori memorizza i record duplicati.
Log Table - Mantiene i risultati di ogni fase di MultiLoad a scopo di riavvio.
Work table- Lo script MultiLoad crea una tabella di lavoro per tabella di destinazione. La tabella di lavoro viene utilizzata per conservare le attività DML e i dati di input.
Limitazione
MultiLoad ha alcune limitazioni.
- Indice secondario univoco non supportato sulla tabella di destinazione.
- Integrità referenziale non supportata.
- Trigger non supportati.
Come funziona MultiLoad
L'importazione di MultiLoad prevede cinque fasi:
Phase 1 - Fase preliminare: esegue le attività di configurazione di base.
Phase 2 - Fase di transazione DML: verifica la sintassi delle istruzioni DML e le porta al sistema Teradata.
Phase 3 - Fase di acquisizione: porta i dati di input nelle tabelle di lavoro e blocca la tabella.
Phase 4 - Fase di applicazione: applica tutte le operazioni DML.
Phase 5 - Fase di pulizia: rilascia il blocco della tabella.
I passaggi coinvolti in uno script MultiLoad sono:
Step 1 - Imposta la tabella di registro.
Step 2 - Accedi a Teradata.
Step 3 - Specificare le tabelle Target, Lavoro ed Errore.
Step 4 - Definisce il layout del file INPUT.
Step 5 - Definisci le query DML.
Step 6 - Assegna un nome al file IMPORT.
Step 7 - Specificare il LAYOUT da utilizzare.
Step 8 - Avvia il caricamento.
Step 9 - Termina il caricamento e termina le sessioni.
Esempio
Crea un file di testo con i seguenti record e denomina il file come dipendente.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3L'esempio seguente è uno script MultiLoad che legge i record dalla tabella Employee e li carica nella tabella Employee_Stg.
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;Esecuzione di uno script MultiLoad
Dopo aver creato il file di input dipendente.txt e lo script multiload è denominato EmployeeLoad.ml, è possibile eseguire lo script Multiload utilizzando il seguente comando in UNIX e Windows.
Multiload < EmployeeLoad.ml;L'utilità FastExport viene utilizzata per esportare i dati dalle tabelle Teradata in file flat. Può anche generare i dati in formato report. I dati possono essere estratti da una o più tabelle utilizzando Join. Poiché FastExport esporta i dati in blocchi da 64 KB, è utile per estrarre grandi volumi di dati.
Esempio
Considera la seguente tabella Employee.
| EmployeeNo | Nome di battesimo | Cognome | Data di nascita |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Roberto | Williams | 3/5/1983 |
| 105 | Roberto | James | 12/1/1984 |
| 103 | Peter | Paolo | 4/1/1983 |
Di seguito è riportato un esempio di uno script FastExport. Esporta i dati dalla tabella dei dipendenti e li scrive in un file Employeedata.txt.
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;Esecuzione di uno script FastExport
Una volta che lo script è stato scritto e denominato come dipendente.fx, è possibile utilizzare il seguente comando per eseguire lo script.
fexp < employee.fxDopo aver eseguito il comando precedente, riceverai il seguente output nel file Employeedata.txt.
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06Termini FastExport
Di seguito è riportato l'elenco dei termini comunemente utilizzati nello script FastExport.
LOGTABLE - Specifica la tabella di registro a scopo di riavvio.
LOGON - Accede a Teradata e avvia una o più sessioni.
DATABASE - Imposta il database predefinito.
BEGIN EXPORT - Indica l'inizio dell'esportazione.
EXPORT - Specifica il file di destinazione e il formato di esportazione.
SELECT - Specifica la query di selezione per esportare i dati.
END EXPORT - Specifica la fine di FastExport.
LOGOFF - Termina tutte le sessioni e termina FastExport.
L'utilità BTEQ è una potente utilità in Teradata che può essere utilizzata sia in modalità batch che interattiva. Può essere utilizzato per eseguire qualsiasi istruzione DDL, istruzione DML, creare macro e stored procedure. BTEQ può essere utilizzato per importare dati in tabelle Teradata da file flat e può anche essere utilizzato per estrarre dati da tabelle in file o report.
Termini BTEQ
Di seguito è riportato l'elenco dei termini comunemente utilizzati negli script BTEQ.
LOGON - Usato per accedere al sistema Teradata.
ACTIVITYCOUNT - Restituisce il numero di righe interessate dalla query precedente.
ERRORCODE - Restituisce il codice di stato della query precedente.
DATABASE - Imposta il database predefinito.
LABEL - Assegna un'etichetta a una serie di comandi SQL.
RUN FILE - Esegue la query contenuta in un file.
GOTO - Trasferisce il controllo a un'etichetta.
LOGOFF - Si disconnette dal database e termina tutte le sessioni.
IMPORT - Specifica il percorso del file di input.
EXPORT - Specifica il percorso del file di output e avvia l'esportazione.
Esempio
Di seguito è riportato uno script BTEQ di esempio.
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;Lo script precedente esegue le seguenti attività.
Accede al sistema Teradata.
Imposta il database predefinito.
Crea una tabella denominata dipendente_bkup.
Seleziona un record dalla tabella Employee per verificare se la tabella ha record.
Elimina la tabella dipendente_bkup, se la tabella è vuota.
Trasferisce il controllo a un'etichetta InsertEmployee che inserisce i record nella tabella employee_bkup
Controlla ERRORCODE per assicurarsi che l'istruzione abbia esito positivo, dopo ogni istruzione SQL.
ACTIVITYCOUNT restituisce il numero di record selezionati / interessati dalla query SQL precedente.