XML - Guida rapida
XML sta per Extensible Markup Langoscia. È un linguaggio di markup basato su testo derivato da SGML (Standard Generalized Markup Language).
I tag XML identificano i dati e vengono utilizzati per archiviare e organizzare i dati, invece di specificare come visualizzarli come i tag HTML, che vengono utilizzati per visualizzare i dati. XML non sostituirà l'HTML nel prossimo futuro, ma introduce nuove possibilità adottando molte caratteristiche di successo dell'HTML.
Ci sono tre importanti caratteristiche di XML che lo rendono utile in una varietà di sistemi e soluzioni:
XML is extensible - XML ti consente di creare i tuoi tag auto-descrittivi, o linguaggio, che si adattano alla tua applicazione.
XML carries the data, does not present it - XML consente di memorizzare i dati indipendentemente da come verranno presentati.
XML is a public standard - XML è stato sviluppato da un'organizzazione chiamata World Wide Web Consortium (W3C) ed è disponibile come standard aperto.
Utilizzo XML
Un breve elenco di utilizzo di XML dice tutto:
XML può funzionare dietro le quinte per semplificare la creazione di documenti HTML per siti web di grandi dimensioni.
XML può essere utilizzato per scambiare le informazioni tra organizzazioni e sistemi.
XML può essere utilizzato per l'offload e il ricaricamento dei database.
XML può essere utilizzato per archiviare e organizzare i dati, che possono personalizzare le esigenze di gestione dei dati.
XML può essere facilmente unito ai fogli di stile per creare quasi tutti gli output desiderati.
Praticamente, qualsiasi tipo di dati può essere espresso come documento XML.
Cos'è il markup?
XML è un linguaggio di markup che definisce un insieme di regole per la codifica dei documenti in un formato leggibile sia dall'uomo che dalla macchina. Quindi cos'è esattamente un linguaggio di markup? Il markup è un'informazione aggiunta a un documento che ne esalta il significato in certi modi, in quanto identifica le parti e come si relazionano tra loro. Più specificamente, un linguaggio di markup è un insieme di simboli che possono essere inseriti nel testo di un documento per delimitare ed etichettare le parti di quel documento.
L'esempio seguente mostra come appare il markup XML, quando incorporato in una parte di testo:
<message>
<text>Hello, world!</text>
</message>Questo frammento include i simboli di markup o tag come <message> ... </message> e <text> ... </text>. I tag <message> e </message> contrassegnano l'inizio e la fine del frammento di codice XML. I tag <text> e </text> circondano il testo Hello, world !.
XML è un linguaggio di programmazione?
Un linguaggio di programmazione è costituito da regole grammaticali e da un proprio vocabolario utilizzato per creare programmi per computer. Questi programmi istruiscono il computer a eseguire attività specifiche. XML non si qualifica per essere un linguaggio di programmazione in quanto non esegue calcoli o algoritmi. Di solito è memorizzato in un semplice file di testo e viene elaborato da un software speciale in grado di interpretare XML.
In questo capitolo, discuteremo le semplici regole di sintassi per scrivere un documento XML. Di seguito è riportato un documento XML completo:
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Puoi notare che ci sono due tipi di informazioni nell'esempio sopra:
Markup, come <contact-info>
Il testo o i dati del carattere, Punto tutorial e (040) 123-4567 .
Il diagramma seguente illustra le regole di sintassi per scrivere diversi tipi di markup e testo in un documento XML.
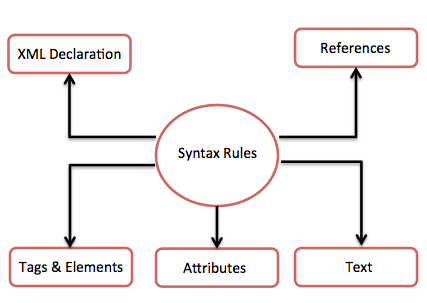
Vediamo in dettaglio ogni componente del diagramma sopra.
Dichiarazione XML
Il documento XML può opzionalmente avere una dichiarazione XML. È scritto come segue:
<?xml version = "1.0" encoding = "UTF-8"?>Dove versione è la versione XML e codifica specifica la codifica dei caratteri utilizzata nel documento.
Regole di sintassi per la dichiarazione XML
La dichiarazione XML fa distinzione tra maiuscole e minuscole e deve iniziare con "<?xml>" dove "xml"è scritto in minuscolo.
Se il documento contiene una dichiarazione XML, deve essere strettamente la prima dichiarazione del documento XML.
La dichiarazione XML deve essere strettamente la prima dichiarazione nel documento XML.
Un protocollo HTTP può sovrascrivere il valore di codifica inserito nella dichiarazione XML.
Tag ed elementi
Un file XML è strutturato da diversi elementi XML, chiamati anche nodi XML o tag XML. I nomi degli elementi XML sono racchiusi tra parentesi triangolari <> come mostrato di seguito -
<element>Regole di sintassi per tag ed elementi
Element Syntax - Ogni elemento XML deve essere chiuso con gli elementi di inizio o di fine come mostrato di seguito -
<element>....</element>o in casi semplici, proprio in questo modo -
<element/>Nesting of Elements- Un elemento XML può contenere più elementi XML come suoi figli, ma gli elementi figli non devono sovrapporsi. cioè, un tag di fine di un elemento deve avere lo stesso nome di quello del tag di inizio senza corrispondenza più recente.
L'esempio seguente mostra tag nidificati non corretti:
<?xml version = "1.0"?>
<contact-info>
<company>TutorialsPoint
</contact-info>
</company>L'esempio seguente mostra i tag nidificati corretti:
<?xml version = "1.0"?>
<contact-info>
<company>TutorialsPoint</company>
<contact-info>Root Element- Un documento XML può avere un solo elemento radice. Ad esempio, quello che segue non è un documento XML corretto, perché sia il filex e y gli elementi si verificano al livello superiore senza un elemento radice -
<x>...</x>
<y>...</y>L'esempio seguente mostra un documento XML formato correttamente:
<root>
<x>...</x>
<y>...</y>
</root>Case Sensitivity- I nomi degli elementi XML fanno distinzione tra maiuscole e minuscole. Ciò significa che il nome dell'elemento iniziale e quello finale devono essere esattamente nello stesso caso.
Per esempio, <contact-info> è diverso da <Contact-Info>
Attributi XML
Un attributespecifica una singola proprietà per l'elemento, utilizzando una coppia nome / valore. Un elemento XML può avere uno o più attributi. Ad esempio:
<a href = "http://www.tutorialspoint.com/">Tutorialspoint!</a>Qui href è il nome dell'attributo e http://www.tutorialspoint.com/ è il valore dell'attributo.
Regole di sintassi per attributi XML
I nomi degli attributi in XML (a differenza dell'HTML) fanno distinzione tra maiuscole e minuscole. Cioè, HREF e href sono considerati due diversi attributi XML.
Lo stesso attributo non può avere due valori in una sintassi. L'esempio seguente mostra una sintassi errata perché l'attributo b è specificato due volte
-
<a b = "x" c = "y" b = "z">....</a>I nomi degli attributi sono definiti senza virgolette, mentre i valori degli attributi devono sempre apparire tra virgolette. L'esempio seguente mostra una sintassi xml errata
-
<a b = x>....</a>Nella sintassi precedente, il valore dell'attributo non è definito tra virgolette.
Riferimenti XML
I riferimenti in genere consentono di aggiungere o includere testo o markup aggiuntivo in un documento XML. I riferimenti iniziano sempre con il simbolo"&" che è un carattere riservato e termina con il simbolo ";". XML ha due tipi di riferimenti:
Entity References- Un riferimento all'entità contiene un nome tra i delimitatori di inizio e di fine. Per esempio&dove amp è il nome . Il nome si riferisce a una stringa di testo e / o markup predefinita.
Character References - Questi contengono riferimenti, come A, contiene un segno cancelletto ("#") seguito da un numero. Il numero si riferisce sempre al codice Unicode di un carattere. In questo caso, 65 si riferisce all'alfabeto "A".
Testo XML
I nomi degli elementi XML e degli attributi XML fanno distinzione tra maiuscole e minuscole, il che significa che il nome degli elementi iniziale e finale devono essere scritti nello stesso caso. Per evitare problemi di codifica dei caratteri, tutti i file XML devono essere salvati come file Unicode UTF-8 o UTF-16.
I caratteri di spazio vuoto come spazi, tabulazioni e interruzioni di riga tra gli elementi XML e tra gli attributi XML verranno ignorati.
Alcuni caratteri sono riservati dalla sintassi XML stessa. Quindi, non possono essere utilizzati direttamente. Per usarli, vengono utilizzate alcune entità di sostituzione, elencate di seguito:
| Carattere non consentito | Entità sostitutiva | Descrizione del personaggio |
|---|---|---|
| < | & lt; | meno di |
| > | & gt; | più grande di |
| & | & amp; | e commerciale |
| ' | & apos; | apostrofo |
| " | & quot; | Virgolette |
Un documento XML è un'unità di base di informazioni XML composta da elementi e altri markup in un pacchetto ordinato. Un documento XML può contenere un'ampia varietà di dati. Ad esempio, database di numeri, numeri che rappresentano la struttura molecolare o un'equazione matematica.
Esempio di documento XML
Un semplice documento è mostrato nel seguente esempio:
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>L'immagine seguente mostra le parti del documento XML.

Sezione prologo del documento
Document Prologsi trova all'inizio del documento, prima dell'elemento radice. Questa sezione contiene:
- Dichiarazione XML
- Dichiarazione del tipo di documento
Puoi saperne di più sulla dichiarazione XML in questo capitolo - Dichiarazione XML
Sezione Elementi del documento
Document Elementssono gli elementi costitutivi di XML. Questi dividono il documento in una gerarchia di sezioni, ognuna con uno scopo specifico. Puoi separare un documento in più sezioni in modo che possano essere renderizzate in modo diverso o utilizzate da un motore di ricerca. Gli elementi possono essere contenitori, con una combinazione di testo e altri elementi.
Puoi saperne di più sugli elementi XML in questo capitolo - Elementi XML
Questo capitolo tratta la dichiarazione XML in dettaglio. XML declarationcontiene dettagli che preparano un processore XML per analizzare il documento XML. È facoltativo, ma quando viene utilizzato deve essere visualizzato nella prima riga del documento XML.
Sintassi
La seguente sintassi mostra la dichiarazione XML:
<?xml
version = "version_number"
encoding = "encoding_declaration"
standalone = "standalone_status"
?>Ogni parametro è costituito da un nome di parametro, un segno di uguale (=) e un valore di parametro all'interno di una citazione. La tabella seguente mostra la sintassi sopra in dettaglio:
| Parametro | Parameter_value | Parameter_description |
|---|---|---|
| Versione | 1.0 | Specifica la versione dello standard XML utilizzato. |
| Codifica | UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, da ISO-8859-1 a ISO-8859-9, ISO-2022-JP, Shift_JIS, EUC-JP | Definisce la codifica dei caratteri utilizzata nel documento. UTF-8 è la codifica predefinita utilizzata. |
| Indipendente, autonomo | si o no | Informa il parser se il documento si basa sulle informazioni da una fonte esterna, come la DTD (External Document Type Definition), per il suo contenuto. Il valore predefinito è impostato su no . Impostandolo su sì si dice al processore che non sono richieste dichiarazioni esterne per l'analisi del documento. |
Regole
Una dichiarazione XML dovrebbe rispettare le seguenti regole:
Se la dichiarazione XML è presente nell'XML, deve essere inserita come prima riga nel documento XML.
Se la dichiarazione XML è inclusa, deve contenere l'attributo del numero di versione.
I nomi e i valori dei parametri fanno distinzione tra maiuscole e minuscole.
I nomi sono sempre in minuscolo.
L'ordine di posizionamento dei parametri è importante. L'ordine corretto è: versione, codifica e standalone.
È possibile utilizzare virgolette singole o doppie.
La dichiarazione XML non ha tag di chiusura, ad es </?xml>
Esempi di dichiarazione XML
Di seguito sono riportati alcuni esempi di dichiarazioni XML:
Dichiarazione XML senza parametri -
<?xml >Dichiarazione XML con definizione della versione -
<?xml version = "1.0">Dichiarazione XML con tutti i parametri definiti -
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>Dichiarazione XML con tutti i parametri definiti tra virgolette singole -
<?xml version = '1.0' encoding = 'iso-8859-1' standalone = 'no' ?>Impariamo a conoscere una delle parti più importanti di XML, i tag XML. XML tagscostituiscono la base di XML. Definiscono l'ambito di un elemento in XML. Possono anche essere usati per inserire commenti, dichiarare le impostazioni necessarie per analizzare l'ambiente e per inserire istruzioni speciali.
Possiamo categorizzare ampiamente i tag XML come segue:
Inizia tag
L'inizio di ogni elemento XML non vuoto è contrassegnato da un tag di inizio. Di seguito è riportato un esempio di tag iniziale:
<address>Fine tag
Ogni elemento che ha un tag di inizio dovrebbe terminare con un tag di fine. Di seguito è riportato un esempio di tag di fine:
</address>Notare che i tag finali includono un solidus ("/") prima del nome di un elemento.
Tag vuoto
Il testo che appare tra il tag iniziale e il tag finale è chiamato contenuto. Un elemento che non ha contenuto è definito vuoto. Un elemento vuoto può essere rappresentato in due modi come segue:
Un tag di inizio seguito immediatamente da un tag di fine come mostrato di seguito:
<hr></hr>Un tag di elementi vuoti completo è come mostrato di seguito:
<hr />I tag di elementi vuoti possono essere utilizzati per qualsiasi elemento che non ha contenuto.
Regole dei tag XML
Di seguito sono riportate le regole da seguire per utilizzare i tag XML:
Regola 1
I tag XML fanno distinzione tra maiuscole e minuscole. La seguente riga di codice è un esempio di sintassi errata </Address>, a causa della differenza tra maiuscole e minuscole in due tag, che viene trattata come sintassi errata in XML.
<address>This is wrong syntax</Address>Il codice seguente mostra un modo corretto, dove usiamo lo stesso caso per nominare il tag di inizio e di fine.
<address>This is correct syntax</address>Regola 2
I tag XML devono essere chiusi in un ordine appropriato, ovvero, un tag XML aperto all'interno di un altro elemento deve essere chiuso prima che l'elemento esterno venga chiuso. Ad esempio:
<outer_element>
<internal_element>
This tag is closed before the outer_element
</internal_element>
</outer_element>XML elementspossono essere definiti come elementi costitutivi di un XML. Gli elementi possono comportarsi come contenitori per contenere testo, elementi, attributi, oggetti multimediali o tutti questi.
Ogni documento XML contiene uno o più elementi, il cui ambito è delimitato da tag di inizio e fine o, per gli elementi vuoti, da un tag di elemento vuoto.
Sintassi
Di seguito è riportata la sintassi per scrivere un elemento XML:
<element-name attribute1 attribute2>
....content
</element-name>dove,
element-nameè il nome dell'elemento. Il nome del suo caso nei tag di inizio e di fine deve corrispondere.
attribute1, attribute2sono attributi dell'elemento separati da spazi bianchi. Un attributo definisce una proprietà dell'elemento. Associa un nome a un valore, che è una stringa di caratteri. Un attributo è scritto come -
name = "value"nome è seguito da un segno = e da un valore stringa tra virgolette doppie ("") o singole ('').
Elemento vuoto
Un elemento vuoto (elemento senza contenuto) ha la seguente sintassi:
<name attribute1 attribute2.../>Di seguito è riportato un esempio di un documento XML che utilizza vari elementi XML:
<?xml version = "1.0"?>
<contact-info>
<address category = "residence">
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>
</contact-info>Regole degli elementi XML
Le seguenti regole devono essere seguite per gli elementi XML:
Il nome di un elemento può contenere qualsiasi carattere alfanumerico. Gli unici segni di punteggiatura consentiti nei nomi sono il trattino (-), il punteggio inferiore (_) e il punto (.).
I nomi fanno distinzione tra maiuscole e minuscole. Ad esempio, Indirizzo, indirizzo e INDIRIZZO sono nomi diversi.
I tag di inizio e fine di un elemento devono essere identici.
Un elemento, che è un contenitore, può contenere testo o elementi come mostrato nell'esempio precedente.
Questo capitolo descrive il XML attributes. Gli attributi fanno parte degli elementi XML. Un elemento può avere più attributi univoci. Attribute fornisce ulteriori informazioni sugli elementi XML. Per essere più precisi, definiscono le proprietà degli elementi. Un attributo XML è sempre una coppia nome-valore.
Sintassi
Un attributo XML ha la seguente sintassi:
<element-name attribute1 attribute2 >
....content..
< /element-name>dove attributo1 e attributo2 hanno la seguente forma:
name = "value"il valore deve essere tra virgolette doppie ("") o singole (''). In questo caso, attributo1 e attributo2 sono etichette di attributi univoche.
Gli attributi vengono utilizzati per aggiungere un'etichetta univoca a un elemento, posizionare l'etichetta in una categoria, aggiungere un flag booleano o associarlo in altro modo a una stringa di dati. L'esempio seguente dimostra l'uso degli attributi:
<?xml version = "1.0" encoding = "UTF-8"?>
<!DOCTYPE garden [
<!ELEMENT garden (plants)*>
<!ELEMENT plants (#PCDATA)>
<!ATTLIST plants category CDATA #REQUIRED>
]>
<garden>
<plants category = "flowers" />
<plants category = "shrubs">
</plants>
</garden>Gli attributi vengono utilizzati per distinguere tra elementi con lo stesso nome, quando non si desidera creare un nuovo elemento per ogni situazione. Quindi, l'uso di un attributo può aggiungere un po 'più di dettaglio nel differenziare due o più elementi simili.
Nell'esempio precedente, abbiamo classificato le piante includendo la categoria di attributi e assegnando valori diversi a ciascuno degli elementi. Quindi, abbiamo due categorie di piante , uno di fiori e altri arbusti . Quindi, abbiamo due elementi vegetali con attributi diversi.
Puoi anche osservare che abbiamo dichiarato questo attributo all'inizio di XML.
Tipi di attributi
La tabella seguente elenca il tipo di attributi:
| Tipo di attributo | Descrizione |
|---|---|
| StringType | Accetta qualsiasi stringa letterale come valore. CDATA è un StringType. CDATA sono dati di caratteri. Ciò significa che qualsiasi stringa di caratteri non di markup è una parte legale dell'attributo. |
| TokenizedType | Questo è un tipo più vincolato. I vincoli di validità annotati nella grammatica vengono applicati dopo che il valore dell'attributo è stato normalizzato. Gli attributi TokenizedType sono forniti come -
|
| EnumeratedType | Questo ha un elenco di valori predefiniti nella sua dichiarazione. di cui deve assegnare un valore. Esistono due tipi di attributi enumerati:
|
Regole degli attributi degli elementi
Di seguito sono riportate le regole che devono essere seguite per gli attributi:
Il nome di un attributo non deve apparire più di una volta nello stesso tag di inizio o tag di elementi vuoti.
Un attributo deve essere dichiarato nella DTD (Document Type Definition) utilizzando una dichiarazione elenco attributi.
I valori degli attributi non devono contenere riferimenti a entità dirette o indirette a entità esterne.
Il testo sostitutivo di qualsiasi entità a cui si fa riferimento direttamente o indirettamente in un valore di attributo non deve contenere un segno minore di (<)
Questo capitolo spiega come funzionano i commenti nei documenti XML. XML commentssono simili ai commenti HTML. I commenti vengono aggiunti come note o righe per comprendere lo scopo di un codice XML.
I commenti possono essere utilizzati per includere collegamenti, informazioni e termini correlati. Sono visibili solo nel codice sorgente; non nel codice XML. I commenti possono apparire ovunque nel codice XML.
Sintassi
Il commento XML ha la seguente sintassi:
<!--Your comment-->Un commento inizia con <!-- e termina con -->. Puoi aggiungere note testuali come commenti tra i personaggi. Non devi annidare un commento dentro l'altro.
Esempio
L'esempio seguente dimostra l'uso dei commenti nel documento XML:
<?xml version = "1.0" encoding = "UTF-8" ?>
<!--Students grades are uploaded by months-->
<class_list>
<student>
<name>Tanmay</name>
<grade>A</grade>
</student>
</class_list>Qualsiasi testo tra <!-- e --> caratteri è considerato come un commento.
Regole per i commenti XML
Le seguenti regole dovrebbero essere seguite per i commenti XML:
- I commenti non possono essere visualizzati prima della dichiarazione XML.
- I commenti possono apparire ovunque in un documento.
- I commenti non devono apparire all'interno dei valori degli attributi.
- I commenti non possono essere nidificati all'interno degli altri commenti.
Questo capitolo descrive l'XML Character Entities. Prima di comprendere le entità carattere, dobbiamo prima capire cos'è un'entità XML.
Come indicato da W3 Consortium, la definizione di entità è la seguente:
"L'entità documento funge da radice dell'albero delle entità e da punto di partenza per un processore XML".
Ciò significa che le entità sono i segnaposto in XML. Questi possono essere dichiarati nel prologo del documento o in un DTD. Esistono diversi tipi di entità e in questo capitolo discuteremo di Character Entity.
Entrambi, HTML e XML, hanno alcuni simboli riservati al loro utilizzo, che non possono essere utilizzati come contenuto nel codice XML. Per esempio,< e >i segni vengono utilizzati per aprire e chiudere i tag XML. Per visualizzare questi caratteri speciali, vengono utilizzate le entità carattere.
Ci sono pochi caratteri speciali o simboli che non possono essere digitati direttamente dalla tastiera. Le entità carattere possono essere utilizzate anche per visualizzare quei simboli / caratteri speciali.
Tipi di entità carattere
Esistono tre tipi di entità carattere:
- Entità carattere predefinite
- Entità di caratteri numerati
- Entità personaggio con nome
Entità carattere predefinite
Vengono introdotti per evitare l'ambiguità durante l'utilizzo di alcuni simboli. Ad esempio, si osserva un'ambiguità quando minore di (< ) o maggiore di ( > ) viene utilizzato con il tag dell'angolo (<>). Le entità carattere sono fondamentalmente utilizzate per delimitare i tag in XML. Di seguito è riportato un elenco di entità carattere predefinite dalla specifica XML. Questi possono essere usati per esprimere caratteri senza ambiguità.
E commerciale - &
Virgoletta singola - '
Maggiore di - >
Meno di - <
Virgolette doppie - "
Entità di caratteri numerici
Il riferimento numerico viene utilizzato per fare riferimento a un'entità carattere. Il riferimento numerico può essere in formato decimale o esadecimale. Poiché sono disponibili migliaia di riferimenti numerici, questi sono un po 'difficili da ricordare. Il riferimento numerico si riferisce al carattere tramite il suo numero nel set di caratteri Unicode.
La sintassi generale per il riferimento numerico decimale è -
&# decimal number ;La sintassi generale per il riferimento numerico esadecimale è -
&#x Hexadecimal number ;La tabella seguente elenca alcune entità carattere predefinite con i loro valori numerici:
| Nome dell'entità | Personaggio | Riferimento decimale | Riferimento esadecimale |
|---|---|---|---|
| quot | " | & # 34; | & # x22; |
| amp | & | & # 38; | & # x26; |
| apos | ' | & # 39; | & # x27; |
| lt | < | & # 60; | & # x3C; |
| gt | > | & # 62; | & # x3E; |
Entità personaggio con nome
Poiché è difficile ricordare i caratteri numerici, il tipo più preferito di entità carattere è l'entità carattere nominata. Qui, ogni entità è identificata con un nome.
Ad esempio:
"Aacute" rappresenta il
carattere maiuscolo con accento acuto.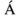
'ugrave' rappresenta il piccolo
con accento grave.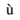
In questo capitolo, discuteremo XML CDATA section. Il termine CDATA significa Dati carattere. CDATA è definito come blocchi di testo che non vengono analizzati dal parser, ma sono altrimenti riconosciuti come markup.
Le entità predefinite come &lt;, &gt;, e &amp;richiedono la digitazione e sono generalmente difficili da leggere nel markup. In questi casi, è possibile utilizzare la sezione CDATA. Utilizzando la sezione CDATA, stai ordinando al parser che la particolare sezione del documento non contiene markup e deve essere trattata come testo normale.
Sintassi
Di seguito è riportata la sintassi per la sezione CDATA:
<![CDATA[
characters with markup
]]>La sintassi sopra è composta da tre sezioni:
CDATA Start section - CDATA inizia con il delimitatore di nove caratteri <![CDATA[
CDATA End section - La sezione CDATA termina con ]]> delimitatore.
CData section- I caratteri tra questi due allegati vengono interpretati come caratteri e non come markup. Questa sezione può contenere caratteri di markup (<,> e &), ma vengono ignorati dal processore XML.
Esempio
Il seguente codice di markup mostra un esempio di CDATA. Qui, ogni carattere scritto all'interno della sezione CDATA viene ignorato dal parser.
<script>
<![CDATA[
<message> Welcome to TutorialsPoint </message>
]] >
</script >Nella sintassi precedente, tutto ciò che si trova tra <message> e </message> viene trattato come dati di caratteri e non come markup.
Regole CDATA
Le regole fornite devono essere seguite per XML CDATA -
- CDATA non può contenere la stringa "]]>" ovunque nel documento XML.
- L'annidamento non è consentito nella sezione CDATA.
In questo capitolo, discuteremo whitespacegestione nei documenti XML. Lo spazio bianco è una raccolta di spazi, tabulazioni e nuove righe. Sono generalmente utilizzati per rendere un documento più leggibile.
Il documento XML contiene due tipi di spazi bianchi: spazio vuoto significativo e spazio vuoto insignificante. Entrambi sono spiegati di seguito con esempi.
Spazio vuoto significativo
Uno spazio vuoto significativo si verifica all'interno dell'elemento che contiene testo e markup presenti insieme. Ad esempio:
<name>TanmayPatil</name>e
<name>Tanmay Patil</name>I due elementi precedenti sono diversi a causa dello spazio tra Tanmay e Patil. Qualsiasi programma che legge questo elemento in un file XML è obbligato a mantenere la distinzione.
Spazio vuoto insignificante
Uno spazio vuoto insignificante indica lo spazio in cui è consentito solo il contenuto dell'elemento. Ad esempio:
<address.category = "residence"><address....category = "..residence">Gli esempi precedenti sono gli stessi. Qui, lo spazio è rappresentato da punti (.). Nell'esempio sopra, lo spazio tra indirizzo e categoria è insignificante.
Un attributo speciale denominato xml:spacepuò essere associato a un elemento. Ciò indica che gli spazi non devono essere rimossi dall'applicazione per quell'elemento. Puoi impostare questo attributo sudefault o preserve come mostrato nell'esempio seguente:
<!ATTLIST address xml:space (default|preserve) 'preserve'>Dove,
Il valore default segnala che le modalità di elaborazione degli spazi vuoti predefinite di un'applicazione sono accettabili per questo elemento.
Il valore preserve indica l'applicazione per conservare tutti gli spazi bianchi.
Questo capitolo descrive il Processing Instructions (PIs). Come definito dalla raccomandazione XML 1.0,
"Le istruzioni di elaborazione (PI) consentono ai documenti di contenere istruzioni per le applicazioni. Le PI non fanno parte dei dati carattere del documento, ma DEVONO essere trasmesse all'applicazione.
Le istruzioni di elaborazione (PI) possono essere utilizzate per passare le informazioni alle applicazioni. I PI possono apparire ovunque nel documento al di fuori del markup. Possono apparire nel prologo, inclusa la definizione del tipo di documento (DTD), nel contenuto testuale o dopo il documento.
Sintassi
La seguente è la sintassi di PI -
<?target instructions?>Dove
target - Identifica l'applicazione a cui è diretta l'istruzione.
instruction - Un carattere che descrive le informazioni che l'applicazione deve elaborare.
Un PI inizia con un tag speciale <? e termina con ?>. L'elaborazione del contenuto termina immediatamente dopo la stringa?> è incontrato.
Esempio
I PI sono usati raramente. Sono usati principalmente per collegare un documento XML a un foglio di stile. Di seguito è riportato un esempio:
<?xml-stylesheet href = "tutorialspointstyle.css" type = "text/css"?>Qui, l' obiettivo è il foglio di stile xml . href = "tutorialspointstyle.css" e type = "text / css" sono dati o istruzioni che l'applicazione di destinazione utilizzerà al momento dell'elaborazione del documento XML specificato.
In questo caso, un browser riconosce il target indicando che l'XML deve essere trasformato prima di essere mostrato; il primo attributo indica che il tipo di trasformazione è XSL e il secondo attributo punta alla sua posizione.
Regole delle istruzioni di elaborazione
Un PI può contenere qualsiasi dato tranne la combinazione ?>, che viene interpretato come delimitatore di chiusura. Ecco due esempi di PI validi:
<?welcome to pg = 10 of tutorials point?>
<?welcome?>Encodingè il processo di conversione dei caratteri Unicode nella loro rappresentazione binaria equivalente. Quando il processore XML legge un documento XML, codifica il documento a seconda del tipo di codifica. Quindi, dobbiamo specificare il tipo di codifica nella dichiarazione XML.
Tipi di codifica
Esistono principalmente due tipi di codifica:
- UTF-8
- UTF-16
UTF sta per UCS Transformation Format e UCS stesso significa Universal Character Set . Il numero 8 o 16 si riferisce al numero di bit utilizzati per rappresentare un carattere. Sono 8 (da 1 a 4 byte) o 16 (2 o 4 byte). Per i documenti senza informazioni sulla codifica, UTF-8 è impostato per impostazione predefinita.
Sintassi
Il tipo di codifica è incluso nella sezione prologo del documento XML. La sintassi per la codifica UTF-8 è la seguente:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>La sintassi per la codifica UTF-16 è la seguente:
<?xml version = "1.0" encoding = "UTF-16" standalone = "no" ?>Esempio
L'esempio seguente mostra la dichiarazione di codifica -
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Nell'esempio sopra encoding="UTF-8", specifica che vengono utilizzati 8 bit per rappresentare i caratteri. Per rappresentare caratteri a 16 bit,UTF-16 può essere utilizzata la codifica.
I file XML codificati con UTF-8 tendono ad essere di dimensioni inferiori rispetto a quelli codificati con il formato UTF-16.
Validationè un processo mediante il quale viene convalidato un documento XML. Un documento XML è considerato valido se il suo contenuto corrisponde agli elementi, attributi e dichiarazione del tipo di documento (DTD) associata e se il documento è conforme ai vincoli espressi in esso. La convalida viene gestita in due modi dal parser XML. Sono -
- Documento XML ben formato
- Documento XML valido
Documento XML ben formato
Si dice che sia un documento XML well-formed se rispetta le seguenti regole:
I file XML non DTD devono utilizzare le entità carattere predefinite per amp(&), apos(single quote), gt(>), lt(<), quot(double quote).
Deve seguire l'ordine del tag. cioè, il tag interno deve essere chiuso prima di chiudere il tag esterno.
Ciascuno dei suoi tag di apertura deve avere un tag di chiusura o deve essere un tag di terminazione automatica (<title> .... </title> o <title />).
Deve avere un solo attributo in un tag di inizio, che deve essere citato.
amp(&), apos(single quote), gt(>), lt(<), quot(double quote) entità diverse da queste devono essere dichiarate.
Esempio
Di seguito è riportato un esempio di un documento XML ben formato:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
<!DOCTYPE address
[
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone (#PCDATA)>
]>
<address>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>Si dice che l'esempio sopra sia ben formato come:
Definisce il tipo di documento. Qui, il tipo di documento èelement genere.
Include un elemento radice denominato come address.
Ciascuno degli elementi figlio tra nome, azienda e telefono è racchiuso nel suo tag autoesplicativo.
L'ordine dei tag viene mantenuto.
Documento XML valido
Se un documento XML è ben formato e ha una dichiarazione del tipo di documento (DTD) associata, si dice che sia un documento XML valido. Studieremo di più sulla DTD nel capitolo XML - DTD .
La dichiarazione del tipo di documento XML, comunemente nota come DTD, è un modo per descrivere con precisione il linguaggio XML. I DTD controllano il vocabolario e la validità della struttura dei documenti XML rispetto alle regole grammaticali del linguaggio XML appropriato.
Un DTD XML può essere specificato all'interno del documento, oppure può essere conservato in un documento separato e quindi apprezzato separatamente.
Sintassi
La sintassi di base di un DTD è la seguente:
<!DOCTYPE element DTD identifier
[
declaration1
declaration2
........
]>Nella sintassi sopra,
Il DTD inizia con <! DOCTYPE delimitatore.
Un element dice al parser di analizzare il documento dall'elemento root specificato.
DTD identifierè un identificatore per la definizione del tipo di documento, che può essere il percorso di un file sul sistema o l'URL di un file su Internet. Se il DTD punta a un percorso esterno, viene chiamatoExternal Subset.
The square brackets [ ]racchiudere un elenco facoltativo di dichiarazioni di entità denominato Internal Subset .
DTD interno
Una DTD viene definita DTD interna se gli elementi vengono dichiarati all'interno dei file XML. Per fare riferimento a un DTD interno, l' attributo standalone nella dichiarazione XML deve essere impostato suyes. Ciò significa che la dichiarazione funziona indipendentemente da una fonte esterna.
Sintassi
Di seguito è riportata la sintassi del DTD interno:
<!DOCTYPE root-element [element-declarations]>dove elemento-radice è il nome dell'elemento radice e dichiarazioni-elementi è dove dichiari gli elementi.
Esempio
Di seguito è riportato un semplice esempio di DTD interna:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
<!DOCTYPE address [
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone (#PCDATA)>
]>
<address>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>Esaminiamo il codice sopra -
Start Declaration - Inizia la dichiarazione XML con la seguente dichiarazione.
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>DTD- Subito dopo l'intestazione XML, segue la dichiarazione del tipo di documento , comunemente indicato come DOCTYPE -
<!DOCTYPE address [La dichiarazione DOCTYPE ha un punto esclamativo (!) All'inizio del nome dell'elemento. Il DOCTYPE informa il parser che un DTD è associato a questo documento XML.
DTD Body - La dichiarazione DOCTYPE è seguita dal corpo della DTD, dove si dichiarano elementi, attributi, entità e notazioni.
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone_no (#PCDATA)>Qui vengono dichiarati diversi elementi che compongono il vocabolario del documento <name>. <! ELEMENT name (#PCDATA)> definisce il nome dell'elemento di tipo "#PCDATA". Qui #PCDATA significa dati di testo analizzabili.
End Declaration - Infine, la sezione di dichiarazione del DTD viene chiusa utilizzando una parentesi di chiusura e una parentesi angolare di chiusura (]>). Ciò termina efficacemente la definizione e, successivamente, il documento XML segue immediatamente.
Regole
La dichiarazione del tipo di documento deve apparire all'inizio del documento (preceduta solo dall'intestazione XML) - non è consentita altrove all'interno del documento.
Analogamente alla dichiarazione DOCTYPE, le dichiarazioni degli elementi devono iniziare con un punto esclamativo.
Il nome nella dichiarazione del tipo di documento deve corrispondere al tipo di elemento dell'elemento radice.
DTD esterno
Nella DTD esterna gli elementi vengono dichiarati al di fuori del file XML. Vi si accede specificando gli attributi di sistema che possono essere il file .dtd legale o un URL valido. Per fare riferimento a un DTD esterno, l' attributo autonomo nella dichiarazione XML deve essere impostato comeno. Ciò significa che la dichiarazione include informazioni dalla fonte esterna.
Sintassi
Di seguito è riportata la sintassi per DTD esterno:
<!DOCTYPE root-element SYSTEM "file-name">dove nome-file è il file con estensione .dtd .
Esempio
L'esempio seguente mostra l'utilizzo della DTD esterna:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<!DOCTYPE address SYSTEM "address.dtd">
<address>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>Il contenuto del file DTD address.dtd è come mostrato -
<!ELEMENT address (name,company,phone)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT phone (#PCDATA)>Tipi
È possibile fare riferimento a un DTD esterno utilizzando entrambi system identifiers o public identifiers.
Identificatori di sistema
Un identificatore di sistema consente di specificare la posizione di un file esterno contenente le dichiarazioni DTD. La sintassi è la seguente:
<!DOCTYPE name SYSTEM "address.dtd" [...]>Come puoi vedere, contiene la parola chiave SYSTEM e un riferimento URI che punta alla posizione del documento.
Identificatori pubblici
Gli identificatori pubblici forniscono un meccanismo per individuare le risorse DTD e sono scritti come segue:
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">Come puoi vedere, inizia con la parola chiave PUBLIC, seguita da un identificatore specializzato. Gli identificatori pubblici vengono utilizzati per identificare una voce in un catalogo. Gli identificatori pubblici possono seguire qualsiasi formato, tuttavia, viene chiamato un formato comunemente usatoFormal Public Identifiers, or FPIs.
XML Schema è comunemente noto come XML Schema Definition (XSD). Viene utilizzato per descrivere e convalidare la struttura e il contenuto dei dati XML. Lo schema XML definisce gli elementi, gli attributi e i tipi di dati. L'elemento dello schema supporta gli spazi dei nomi. È simile a uno schema di database che descrive i dati in un database.
Sintassi
È necessario dichiarare uno schema nel documento XML come segue:
Esempio
L'esempio seguente mostra come utilizzare lo schema:
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:element name = "contact">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>L'idea alla base degli schemi XML è che descrivono il formato legittimo che un documento XML può assumere.
Elementi
Come abbiamo visto nel capitolo XML - Elementi , gli elementi sono i mattoni del documento XML. Un elemento può essere definito all'interno di un XSD come segue:
<xs:element name = "x" type = "y"/>Tipi di definizione
È possibile definire gli elementi dello schema XML nei seguenti modi:
Tipo semplice
L'elemento di tipo semplice viene utilizzato solo nel contesto del testo. Alcuni dei tipi semplici predefiniti sono: xs: integer, xs: boolean, xs: string, xs: date. Ad esempio:
<xs:element name = "phone_number" type = "xs:int" />Tipo complesso
Un tipo complesso è un contenitore per altre definizioni di elementi. Ciò consente di specificare quali elementi figlio un elemento può contenere e di fornire una struttura all'interno dei documenti XML. Ad esempio:
<xs:element name = "Address">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>Nell'esempio precedente, l' elemento Address è costituito da elementi figlio. Questo è un contenitore per altri<xs:element> definizioni, che permette di costruire una semplice gerarchia di elementi nel documento XML.
Tipi globali
Con il tipo globale, puoi definire un singolo tipo nel tuo documento, che può essere utilizzato da tutti gli altri riferimenti. Ad esempio, supponi di voler generalizzare la persona e la società per diversi indirizzi della società. In tal caso, è possibile definire un tipo generale come segue:
<xs:element name = "AddressType">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>Ora usiamo questo tipo nel nostro esempio come segue:
<xs:element name = "Address1">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone1" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name = "Address2">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone2" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>Invece di dover definire il nome e la società per due volte (una volta per Indirizzo1 e una volta per Indirizzo2 ), ora abbiamo una definizione unica. Ciò semplifica la manutenzione, ovvero, se si decide di aggiungere elementi "Codice postale" all'indirizzo, è necessario aggiungerli in un unico punto.
Attributi
Gli attributi in XSD forniscono informazioni aggiuntive all'interno di un elemento. Gli attributi hanno proprietà di nome e tipo come mostrato di seguito:
<xs:attribute name = "x" type = "y"/>Un documento XML è sempre descrittivo. La struttura ad albero è spesso indicata comeXML Tree e svolge un ruolo importante per descrivere facilmente qualsiasi documento XML.
La struttura ad albero contiene elementi radice (genitore), elementi figlio e così via. Utilizzando la struttura ad albero, puoi conoscere tutti i rami e sottorami successivi a partire dalla radice. L'analisi inizia dalla radice, quindi si sposta lungo il primo ramo fino a un elemento, prende il primo ramo da lì e così via ai nodi foglia.
Esempio
L'esempio seguente mostra una semplice struttura ad albero XML:
<?xml version = "1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>La seguente struttura ad albero rappresenta il documento XML di cui sopra -
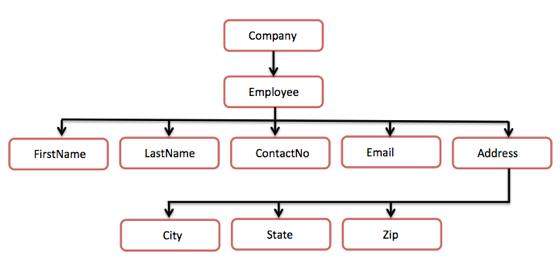
Nel diagramma sopra, c'è un elemento radice denominato <company>. Al suo interno, c'è un altro elemento <Dipendente>. All'interno dell'elemento dipendente, sono presenti cinque rami denominati <FirstName>, <LastName>, <ContactNo>, <Email> e <Address>. All'interno dell'elemento <Address>, ci sono tre rami secondari, denominati <City> <State> e <Zip>.
Il Document Object Model (DOM)è il fondamento di XML. I documenti XML hanno una gerarchia di unità informative chiamate nodi ; DOM è un modo per descrivere quei nodi e le relazioni tra loro.
Un documento DOM è una raccolta di nodi o pezzi di informazioni organizzati in una gerarchia. Questa gerarchia consente a uno sviluppatore di navigare attraverso l'albero alla ricerca di informazioni specifiche. Poiché si basa su una gerarchia di informazioni, si dice che il DOM sia basato su albero .
Il DOM XML, d'altra parte, fornisce anche un'API che consente a uno sviluppatore di aggiungere, modificare, spostare o rimuovere nodi nell'albero in qualsiasi punto per creare un'applicazione.
Esempio
Il seguente esempio (sample.htm) analizza un documento XML ("address.xml") in un oggetto DOM XML e quindi estrae alcune informazioni da esso con JavaScript -
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id = "name"></span><br>
<b>Company:</b> <span id = "company"></span><br>
<b>Phone:</b> <span id = "phone"></span>
</div>
<script>
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body>
</html>Contenuti di address.xml sono i seguenti -
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Ora conserviamo questi due file sample.htm e address.xml nella stessa directory /xml ed eseguire il sample.htmfile aprendolo in qualsiasi browser. Questo dovrebbe produrre il seguente output.

Qui puoi vedere come viene estratto ciascuno dei nodi figlio per visualizzare i loro valori.
UN Namespaceè un insieme di nomi univoci. Lo spazio dei nomi è un meccanismo mediante il quale è possibile assegnare il nome di elemento e attributo a un gruppo. Lo spazio dei nomi è identificato da URI (Uniform Resource Identifiers).
Dichiarazione dello spazio dei nomi
Uno spazio dei nomi viene dichiarato utilizzando attributi riservati. Tale nome di attributo deve esserexmlns o iniziare con xmlns: mostrato come di seguito -
<element xmlns:name = "URL">Sintassi
Lo spazio dei nomi inizia con la parola chiave xmlns.
La parola name è il prefisso dello spazio dei nomi.
Il URL è l'identificatore dello spazio dei nomi.
Esempio
Lo spazio dei nomi influisce solo su un'area limitata del documento. Un elemento contenente la dichiarazione e tutti i suoi discendenti rientrano nell'ambito dello spazio dei nomi. Di seguito è riportato un semplice esempio di spazio dei nomi XML:
<?xml version = "1.0" encoding = "UTF-8"?>
<cont:contact xmlns:cont = "www.tutorialspoint.com/profile">
<cont:name>Tanmay Patil</cont:name>
<cont:company>TutorialsPoint</cont:company>
<cont:phone>(011) 123-4567</cont:phone>
</cont:contact>Qui, il prefisso dello spazio dei nomi è conte l'identificatore dello spazio dei nomi (URI) come www.tutorialspoint.com/profile . Ciò significa che i nomi degli elementi e degli attributi con l'estensionecontprefisso (incluso l'elemento contact), appartengono tutti allo spazio dei nomi www.tutorialspoint.com/profile .
XML Databaseviene utilizzato per archiviare enormi quantità di informazioni nel formato XML. Poiché l'uso di XML è in aumento in ogni campo, è necessario disporre di un luogo sicuro in cui archiviare i documenti XML. I dati memorizzati nel database possono essere interrogati utilizzandoXQuery, serializzato ed esportato nel formato desiderato.
Tipi di database XML
Esistono due tipi principali di database XML:
- Abilitato per XML
- XML nativo (NXD)
XML: database abilitato
Il database abilitato per XML non è altro che l'estensione prevista per la conversione del documento XML. Si tratta di un database relazionale, in cui i dati vengono archiviati in tabelle costituite da righe e colonne. Le tabelle contengono una serie di record, che a loro volta sono costituiti da campi.
Database XML nativo
Il database XML nativo si basa sul contenitore anziché sul formato della tabella. Può memorizzare grandi quantità di documenti e dati XML. Il database XML nativo viene interrogato daXPath-espressioni.
Il database XML nativo presenta un vantaggio rispetto al database abilitato per XML. È altamente in grado di memorizzare, interrogare e mantenere il documento XML rispetto al database abilitato per XML.
Esempio
L'esempio seguente mostra il database XML:
<?xml version = "1.0"?>
<contact-info>
<contact1>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact1>
<contact2>
<name>Manisha Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 789-4567</phone>
</contact2>
</contact-info>Qui, viene creata una tabella dei contatti che contiene i record dei contatti (contact1 e contact2), che a sua volta è composta da tre entità: nome, azienda e telefono .
Questo capitolo descrive i vari methods to view an XML document. Un documento XML può essere visualizzato utilizzando un semplice editor di testo o qualsiasi browser. La maggior parte dei principali browser supporta XML. I file XML possono essere aperti nel browser semplicemente facendo doppio clic sul documento XML (se si tratta di un file locale) o digitando il percorso dell'URL nella barra degli indirizzi (se il file si trova sul server), allo stesso modo di apriamo altri file nel browser. I file XML vengono salvati con estensione".xml" estensione.
Esploriamo vari metodi con cui possiamo visualizzare un file XML. L'esempio seguente (sample.xml) viene utilizzato per visualizzare tutte le sezioni di questo capitolo.
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Editor di testo
Qualsiasi semplice editor di testo come Blocco note, TextPad o TextEdit può essere utilizzato per creare o visualizzare un documento XML come mostrato di seguito:
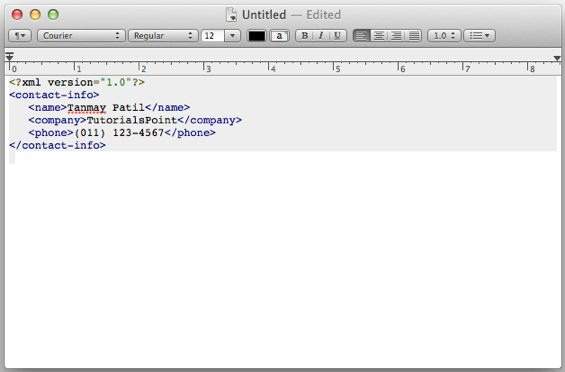
Browser Firefox
Apri il codice XML sopra in Chrome facendo doppio clic sul file. Il codice XML visualizza la codifica con colore, che rende il codice leggibile. Mostra il segno più (+) o meno (-) sul lato sinistro dell'elemento XML. Quando facciamo clic sul segno meno (-), il codice si nasconde. Quando si fa clic sul segno più (+), le righe del codice vengono espanse. L'output in Firefox è come mostrato di seguito:

Browser Chrome
Apri il codice XML sopra nel browser Chrome. Il codice viene visualizzato come mostrato di seguito -

Errori nel documento XML
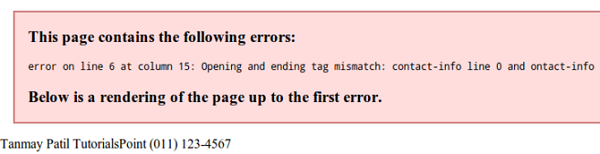
Se nel codice XML mancano alcuni tag, viene visualizzato un messaggio nel browser. Proviamo ad aprire il seguente file XML in Chrome:
<?xml version = "1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>Nel codice sopra, i tag di inizio e di fine non corrispondono (fare riferimento al tag contact_info), quindi un messaggio di errore viene visualizzato dal browser come mostrato di seguito -
XML Editorè un editor di linguaggio di markup. I documenti XML possono essere modificati o creati utilizzando editor esistenti come Blocco note, WordPad o qualsiasi editor di testo simile. Puoi anche trovare un editor XML professionale online o da scaricare, che ha funzionalità di modifica più potenti come:
- Chiude automaticamente i tag che sono rimasti aperti.
- Controlla rigorosamente la sintassi.
- Evidenzia la sintassi XML con il colore per una maggiore leggibilità.
- Ti aiuta a scrivere un codice XML valido.
- Fornisce la verifica automatica dei documenti XML rispetto a DTD e schemi.
Editor XML open source
Di seguito sono riportati alcuni editor XML open source:
Online XML Editor - Questo è un editor XML leggero che puoi usare online.
Xerlin - Xerlin è un editor XML open source per piattaforma Java 2 rilasciato con licenza Apache. È un'applicazione di modellazione XML basata su Java, per creare e modificare facilmente file XML.
CAM - Content Assembly Mechanism - Lo strumento CAM XML Editor viene fornito con XML + JSON + SQL Open-XDX sponsorizzato da Oracle.
XML parserè una libreria software o un pacchetto che fornisce l'interfaccia alle applicazioni client per lavorare con i documenti XML. Verifica il formato corretto del documento XML e può anche convalidare i documenti XML. I browser moderni hanno parser XML incorporati.
Il diagramma seguente mostra come il parser XML interagisce con il documento XML:
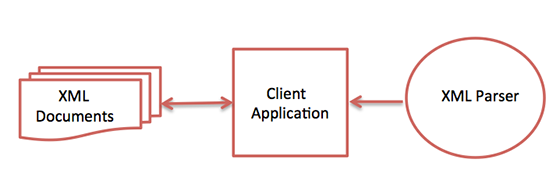
L'obiettivo di un parser è trasformare XML in un codice leggibile.
Per facilitare il processo di analisi, sono disponibili alcuni prodotti commerciali che facilitano la scomposizione del documento XML e producono risultati più affidabili.
Alcuni parser comunemente usati sono elencati di seguito:
MSXML (Microsoft Core XML Services) - Questo è un set standard di strumenti XML di Microsoft che include un parser.
System.Xml.XmlDocument - Questa classe fa parte della libreria .NET, che contiene una serie di classi differenti relative al lavoro con XML.
Java built-in parser- La libreria Java ha il proprio parser. La libreria è progettata in modo tale da poter sostituire il parser integrato con un'implementazione esterna come Xerces di Apache o Saxon.
Saxon - Saxon offre strumenti per analizzare, trasformare e interrogare XML.
Xerces - Xerces è implementato in Java ed è sviluppato dalla famosa Apache Software Foundation open source.
Quando un programma software legge un documento XML e intraprende azioni di conseguenza, si parla di elaborazione dell'XML. Qualsiasi programma in grado di leggere ed elaborare documenti XML è noto come processore XML . Un processore XML legge il file XML e lo trasforma in strutture in memoria a cui può accedere il resto del programma.
Il processore XML più fondamentale legge un documento XML e lo converte in una rappresentazione interna per altri programmi o subroutine da utilizzare. Questo è chiamato parser ed è un componente importante di ogni programma di elaborazione XML.
Il processore implica l'elaborazione delle istruzioni, che possono essere studiate nel capitolo Istruzioni di elaborazione .
Tipi
I processori XML sono classificati come validating o non-validatingtipi, a seconda che controllino o meno la validità dei documenti XML. Un processore che rileva un errore di validità deve essere in grado di segnalarlo, ma può continuare con la normale elaborazione.
A few validating parsers are - xml4c (IBM, in C ++), xml4j (IBM, in Java), MSXML (Microsoft, in Java), TclXML (TCL), xmlproc (Python), XML :: Parser (Perl), Java Project X (Sun, in Giava).
A few non-validating parsers are - OpenXML (Java), Lark (Java), xp (Java), AElfred (Java), expat (C), XParse (JavaScript), xmllib (Python).