ApacheFlume-シーケンスジェネレーターソース
前の章では、TwitterソースからHDFSにデータをフェッチする方法を見てきました。この章では、からデータをフェッチする方法について説明しますSequence generator。
前提条件
この章で提供されている例を実行するには、インストールする必要があります HDFS に加えて Flume。したがって、先に進む前に、Hadoopのインストールを確認し、HDFSを開始してください。(HDFSを開始する方法については、前の章を参照してください)。
Flumeの構成
の構成ファイルを使用して、ソース、チャネル、およびシンクを構成する必要があります。 confフォルダ。この章の例では、sequence generator source、 memory channel、 と HDFS sink。
シーケンスジェネレータソース
イベントを継続的に生成するソースです。0から始まり、1ずつ増加するカウンターを維持します。テスト目的で使用されます。このソースを構成するときは、次のプロパティに値を指定する必要があります-
Channels
Source type − seq
チャネル
私たちは使用しています memoryチャネル。メモリチャネルを設定するには、チャネルのタイプに値を指定する必要があります。以下に示すのは、メモリチャネルの構成中に提供する必要のあるプロパティのリストです。
type−チャネルのタイプを保持します。この例では、タイプはMemChannelです。
Capacity−チャネルに保存されているイベントの最大数です。デフォルト値は100です。(オプション)
TransactionCapacity−チャネルが受け入れるまたは送信するイベントの最大数です。デフォルトは100です。(オプション)。
HDFSシンク
このシンクはデータをHDFSに書き込みます。このシンクを構成するには、次の詳細を指定する必要があります。
Channel
type − hdfs
hdfs.path −データが保存されるHDFS内のディレクトリのパス。
また、シナリオに基づいていくつかのオプション値を提供できます。以下に示すのは、アプリケーションで構成しているHDFSシンクのオプションのプロパティです。
fileType −これはHDFSファイルに必要なファイル形式です。 SequenceFile, DataStream そして CompressedStreamこのストリームで使用できる3つのタイプです。この例では、DataStream。
writeFormat −テキストまたは書き込み可能のいずれかです。
batchSize−HDFSにフラッシュされる前にファイルに書き込まれたイベントの数です。デフォルト値は100です。
rollsize−ロールをトリガーするファイルサイズです。デフォルト値は100です。
rollCount−ファイルがロールされる前にファイルに書き込まれたイベントの数です。デフォルト値は10です。
例–構成ファイル
以下に、構成ファイルの例を示します。このコンテンツをコピーして名前を付けて保存seq_gen .conf Flumeのconfフォルダーにあります。
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannel実行
Flumeホームディレクトリを参照し、以下に示すようにアプリケーションを実行します。
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentすべてがうまくいくと、ソースはシーケンス番号の生成を開始し、ログファイルの形式でHDFSにプッシュされます。
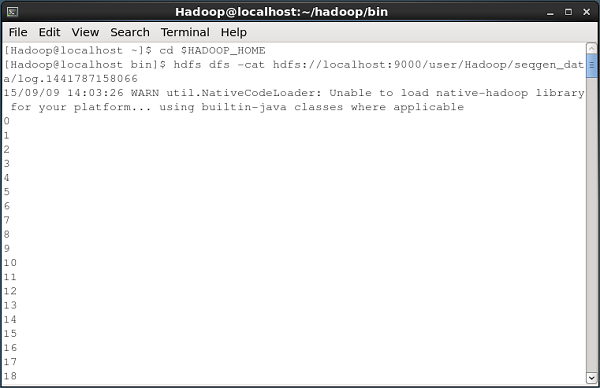
以下に示すのは、シーケンスジェネレーターによって生成されたデータをHDFSにフェッチするコマンドプロンプトウィンドウのスナップショットです。

HDFSの検証
次のURLを使用してHadoop管理WebUIにアクセスできます-
http://localhost:50070/名前の付いたドロップダウンをクリックします Utilitiesページの右側にあります。次の図に示すように、2つのオプションが表示されます。
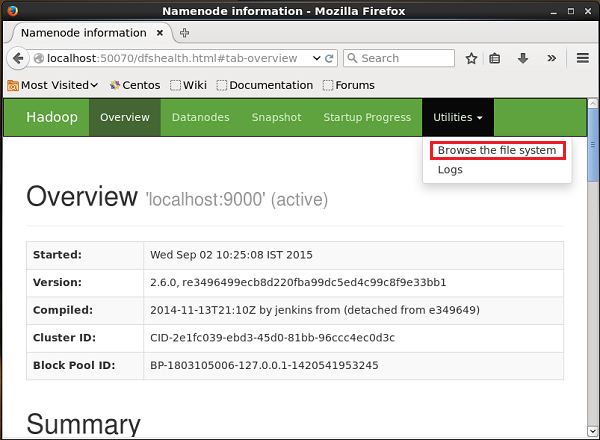
クリック Browse the file system シーケンスジェネレーターによって生成されたデータを保存したHDFSディレクトリのパスを入力します。
この例では、パスは次のようになります /user/Hadoop/ seqgen_data /。次に、シーケンスジェネレーターによって生成され、以下に示すようにHDFSに保存されているログファイルのリストを確認できます。

ファイルの内容を確認する
これらのログファイルにはすべて、連続した形式の番号が含まれています。これらのファイルの内容は、ファイルシステムで次のコマンドを使用して確認できます。cat 以下に示すコマンド。