ApacheKafka-クイックガイド
ビッグデータでは、膨大な量のデータが使用されます。データに関しては、2つの大きな課題があります。1つ目は大量のデータを収集する方法であり、2つ目は収集したデータを分析することです。これらの課題を克服するには、メッセージングシステムが必要です。
Kafkaは、分散型ハイスループットシステム向けに設計されています。Kafkaは、従来のメッセージブローカーの代わりとして非常にうまく機能する傾向があります。Kafkaは、他のメッセージングシステムと比較して、スループット、組み込みのパーティショニング、レプリケーション、および固有のフォールトトレランスが優れているため、大規模なメッセージ処理アプリケーションに最適です。
メッセージングシステムとは何ですか?
メッセージングシステムは、あるアプリケーションから別のアプリケーションにデータを転送する責任があるため、アプリケーションはデータに集中できますが、データの共有方法について心配する必要はありません。分散メッセージングは、信頼性の高いメッセージキューの概念に基づいています。メッセージは、クライアントアプリケーションとメッセージングシステムの間で非同期にキューに入れられます。2種類のメッセージングパターンを使用できます。1つはポイントツーポイントで、もう1つはパブリッシュ/サブスクライブ(pub-sub)メッセージングシステムです。ほとんどのメッセージングパターンは次のとおりですpub-sub。
ポイントツーポイントメッセージングシステム
ポイントツーポイントシステムでは、メッセージはキューに保持されます。1人以上のコンシューマーがキュー内のメッセージを消費できますが、特定のメッセージは最大1人のコンシューマーのみが消費できます。コンシューマーがキュー内のメッセージを読み取ると、そのメッセージはそのキューから消えます。このシステムの典型的な例は注文処理システムで、各注文は1つの注文処理者によって処理されますが、複数の注文処理者も同時に機能します。次の図は、構造を示しています。

パブリッシュ/サブスクライブメッセージングシステム
パブリッシュ/サブスクライブシステムでは、メッセージはトピックに永続化されます。ポイントツーポイントシステムとは異なり、コンシューマーは1つ以上のトピックをサブスクライブし、そのトピック内のすべてのメッセージを消費できます。パブリッシュ/サブスクライブシステムでは、メッセージプロデューサーはパブリッシャーと呼ばれ、メッセージコンシューマーはサブスクライバーと呼ばれます。実際の例は、スポーツ、映画、音楽などのさまざまなチャンネルを公開しているDish TVです。誰でも自分のチャンネルのセットを購読して、購読しているチャンネルが利用可能になるといつでもそれらを取得できます。

カフカとは何ですか?
Apache Kafkaは、分散パブリッシュ/サブスクライブメッセージングシステムであり、大量のデータを処理でき、あるエンドポイントから別のエンドポイントにメッセージを渡すことができる堅牢なキューです。Kafkaは、オフラインとオンラインの両方のメッセージの消費に適しています。Kafkaメッセージはディスク上に保持され、データ損失を防ぐためにクラスター内で複製されます。Kafkaは、ZooKeeper同期サービスの上に構築されています。リアルタイムのストリーミングデータ分析のために、ApacheStormおよびSparkと非常によく統合されています。
利点
以下はKafkaのいくつかの利点です-
Reliability − Kafkaは、分散、パーティション化、複製、およびフォールトトレランスを備えています。
Scalability − Kafkaメッセージングシステムは、ダウンタイムなしで簡単に拡張できます。
Durability− Kafkaは
分散コミットログ
を使用します。
これは、メッセージができるだけ速くディスクに保持されるため、耐久性があります。Performance− Kafkaは、メッセージの公開とサブスクライブの両方で高いスループットを発揮します。大量のメッセージが保存されても安定したパフォーマンスを維持します。
Kafkaは非常に高速で、ダウンタイムとデータ損失がゼロであることを保証します。
ユースケース
Kafkaは多くのユースケースで使用できます。それらのいくつかを以下に示します-
Metrics− Kafkaは、運用監視データによく使用されます。これには、分散アプリケーションからの統計を集約して、運用データの集中フィードを生成することが含まれます。
Log Aggregation Solution − Kafkaを組織全体で使用して、複数のサービスからログを収集し、それらを標準形式で複数の消費者が利用できるようにすることができます。
Stream Processing−StormやSparkStreamingなどの一般的なフレームワークは、トピックからデータを読み取り、処理し、処理されたデータを新しいトピックに書き込んで、ユーザーとアプリケーションが利用できるようにします。Kafkaの強力な耐久性は、ストリーム処理のコンテキストでも非常に役立ちます。
カフカの必要性
Kafkaは、すべてのリアルタイムデータフィードを処理するための統合プラットフォームです。Kafkaは、低遅延のメッセージ配信をサポートし、マシン障害が発生した場合のフォールトトレランスを保証します。多数の多様な消費者を処理する能力があります。Kafkaは非常に高速で、毎秒200万回の書き込みを実行します。Kafkaはすべてのデータをディスクに保持します。つまり、基本的にすべての書き込みはOS(RAM)のページキャッシュに送られます。これにより、ページキャッシュからネットワークソケットにデータを転送するのが非常に効率的になります。
Kafkaに深く入り込む前に、トピック、ブローカー、プロデューサー、コンシューマーなどの主要な用語を知っておく必要があります。次の図は主な用語を示し、表は図のコンポーネントを詳細に説明しています。
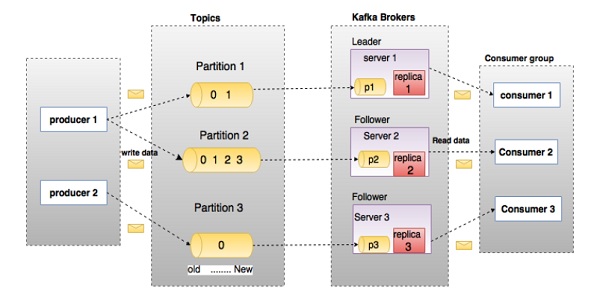
上の図では、トピックは3つのパーティションに構成されています。パーティション1には2つのオフセット係数0と1があります。パーティション2には4つのオフセット係数0、1、2、および3があります。パーティション3には1つのオフセット係数0があります。レプリカのIDは、レプリカをホストするサーバーのIDと同じです。
トピックのレプリケーション係数が3に設定されている場合、Kafkaは各パーティションの3つの同一のレプリカを作成し、それらをクラスターに配置して、すべての操作で使用できるようにします。クラスター内の負荷を分散するために、各ブローカーはそれらのパーティションの1つ以上を保管します。複数のプロデューサーとコンシューマーは、同時にメッセージを公開および取得できます。
| S.No | コンポーネントと説明 |
|---|---|
| 1 | Topics 特定のカテゴリに属するメッセージのストリームは、トピックと呼ばれます。データはトピックに保存されます。 トピックはパーティションに分割されます。Kafkaは、トピックごとに、最小で1つのパーティションを保持します。このような各パーティションには、不変の順序でメッセージが含まれています。パーティションは、同じサイズのセグメントファイルのセットとして実装されます。 |
| 2 | Partition トピックには多くのパーティションがある可能性があるため、任意の量のデータを処理できます。 |
| 3 | Partition offset パーティション化された各メッセージには、 |
| 4 | Replicas of partition レプリカは、パーティションの |
| 5 | Brokers
|
| 6 | Kafka Cluster Kafkaが複数のブローカーを持っていることをKafkaクラスターと呼びます。Kafkaクラスターは、ダウンタイムなしで拡張できます。これらのクラスターは、メッセージデータの永続性とレプリケーションを管理するために使用されます。 |
| 7 | Producers プロデューサーは、1つ以上のKafkaトピックへのメッセージの発行者です。プロデューサーはKafkaブローカーにデータを送信します。プロデューサーがブローカーにメッセージを公開するたびに、ブローカーはメッセージを最後のセグメントファイルに追加するだけです。実際には、メッセージはパーティションに追加されます。プロデューサーは、選択したパーティションにメッセージを送信することもできます。 |
| 8 | Consumers 消費者はブローカーからデータを読み取ります。コンシューマーは、1つ以上のトピックをサブスクライブし、ブローカーからデータをプルすることによって公開されたメッセージを消費します。 |
| 9 | Leader
|
| 10 | Follower リーダーの指示に従うノードは、フォロワーと呼ばれます。リーダーが失敗した場合、フォロワーの1人が自動的に新しいリーダーになります。フォロワーは通常のコンシューマーとして機能し、メッセージをプルして、独自のデータストアを更新します。 |
次の図を見てください。Kafkaのクラスター図を示しています。

次の表で、上の図に示されている各コンポーネントについて説明します。
| S.No | コンポーネントと説明 |
|---|---|
| 1 | Broker Kafkaクラスターは通常、負荷分散を維持するために複数のブローカーで構成されます。Kafkaブローカーはステートレスであるため、クラスターの状態を維持するためにZooKeeperを使用します。1つのKafkaブローカーインスタンスは1秒あたり数十万の読み取りと書き込みを処理でき、各ブローカーはパフォーマンスに影響を与えることなくTBのメッセージを処理できます。Kafkaブローカーリーダーの選出はZooKeeperで行うことができます。 |
| 2 | ZooKeeper ZooKeeperは、Kafkaブローカーの管理と調整に使用されます。ZooKeeperサービスは主に、Kafkaシステムでの新しいブローカーの存在またはKafkaシステムでのブローカーの障害についてプロデューサーとコンシューマーに通知するために使用されます。ブローカーの存在または失敗に関してZookeeperが受け取った通知に従って、プロデューサーとコンシューマーが決定を下し、他のブローカーとのタスクの調整を開始します。 |
| 3 | Producers プロデューサーはデータをブローカーにプッシュします。新しいブローカーが開始されると、すべてのプロデューサーがそれを検索し、その新しいブローカーにメッセージを自動的に送信します。Kafkaプロデューサーはブローカーからの確認応答を待たず、ブローカーが処理できる速度でメッセージを送信します。 |
| 4 | Consumers Kafkaブローカーはステートレスであるため、コンシューマーはパーティションオフセットを使用して消費されたメッセージの数を維持する必要があります。コンシューマーが特定のメッセージオフセットを確認した場合、それはコンシューマーが以前のすべてのメッセージを消費したことを意味します。コンシューマーは、ブローカーに非同期プル要求を発行して、バイトのバッファーを使用できるようにします。コンシューマーは、オフセット値を指定するだけで、パーティション内の任意のポイントに巻き戻しまたはスキップできます。消費者オフセット値はZooKeeperによって通知されます。 |
今のところ、Kafkaのコアコンセプトについて説明しました。ここで、Kafkaのワークフローに光を当てましょう。
Kafkaは、1つ以上のパーティションに分割されたトピックのコレクションです。Kafkaパーティションは、線形に順序付けられたメッセージのシーケンスであり、各メッセージはインデックス(オフセットと呼ばれます)によって識別されます。Kafkaクラスター内のすべてのデータは、パーティションの非交和です。着信メッセージはパーティションの最後に書き込まれ、メッセージはコンシューマーによって順次読み取られます。耐久性は、メッセージをさまざまなブローカーに複製することによって提供されます。
Kafkaは、pub-subベースとキューベースの両方のメッセージングシステムを、高速で信頼性が高く、永続的なフォールトトレランスとゼロダウンタイムの方法で提供します。どちらの場合も、プロデューサーはトピックにメッセージを送信するだけで、コンシューマーは必要に応じて任意の1つのタイプのメッセージングシステムを選択できます。次のセクションの手順に従って、消費者が選択したメッセージングシステムを選択する方法を理解しましょう。
Pub-Subメッセージングのワークフロー
以下は、Pub-Subメッセージングの段階的なワークフローです-
プロデューサーは定期的にトピックにメッセージを送信します。
Kafkaブローカーは、その特定のトピック用に構成されたパーティションにすべてのメッセージを保存します。これにより、メッセージがパーティション間で均等に共有されます。プロデューサーが2つのメッセージを送信し、2つのパーティションがある場合、Kafkaは1つのメッセージを最初のパーティションに保存し、2番目のメッセージを2番目のパーティションに保存します。
消費者は特定のトピックを購読します。
コンシューマーがトピックをサブスクライブすると、Kafkaはトピックの現在のオフセットをコンシューマーに提供し、Zookeeperアンサンブルにオフセットを保存します。
消費者は、新しいメッセージを定期的に(100 Msなど)Kafkaに要求します。
Kafkaは、プロデューサーからメッセージを受信すると、これらのメッセージをコンシューマーに転送します。
消費者はメッセージを受け取り、それを処理します。
メッセージが処理されると、コンシューマーはKafkaブローカーに確認応答を送信します。
Kafkaは確認応答を受信すると、オフセットを新しい値に変更し、Zookeeperで更新します。オフセットはZookeeperで維持されるため、消費者はサーバーの暴動中でも次のメッセージを正しく読み取ることができます。
この上記のフローは、コンシューマーがリクエストを停止するまで繰り返されます。
コンシューマーは、いつでもトピックの目的のオフセットに巻き戻し/スキップして、後続のすべてのメッセージを読むことができます。
キューメッセージング/コンシューマーグループのワークフロー
単一のコンシューマーではなくキューメッセージングシステムでは、同じグループID
を持つコンシューマーのグループがトピックにサブスクライブします。簡単に言うと、同じグループID
を持つトピックにサブスクライブしているコンシューマーは、単一のグループと見なされ、メッセージはそれらの間で共有されます。このシステムの実際のワークフローを確認してみましょう。
プロデューサーは定期的にトピックにメッセージを送信します。
Kafkaは、前のシナリオと同様に、その特定のトピック用に構成されたパーティションにすべてのメッセージを保存します。
単一のコンシューマーが特定のトピックをサブスクライブします。
グループID
がグループ1の
トピック-01
を想定します。パブ-subメッセージングと同じ方法で、消費者とのカフカの相互作用の新しい消費者が同じトピック、サブスクライブするまで
トピック-01を
同じとグループID
としてグループ-1
。新しいコンシューマーが到着すると、Kafkaは操作を共有モードに切り替え、2つのコンシューマー間でデータを共有します。この共有は、消費者の数がその特定のトピック用に構成されたパーティションの数に達するまで続きます。
コンシューマーの数がパーティションの数を超えると、既存のコンシューマーのいずれかがサブスクライブを解除するまで、新しいコンシューマーはそれ以上メッセージを受信しません。このシナリオは、Kafkaの各コンシューマーに少なくとも1つのパーティションが割り当てられ、すべてのパーティションが既存のコンシューマーに割り当てられると、新しいコンシューマーが待機する必要があるために発生します。
この機能は、
コンシューマーグループ
とも呼ばれます。同様に、Kafkaは非常にシンプルで効率的な方法で両方のシステムの長所を提供します。
ZooKeeperの役割
Apache Kafkaの重要な依存関係は、分散構成および同期サービスであるApacheZookeeperです。Zookeeperは、Kafkaブローカーとコンシューマーの間の調整インターフェイスとして機能します。Kafkaサーバーは、Zookeeperクラスターを介して情報を共有します。Kafkaは、トピック、ブローカー、コンシューマーオフセット(キューリーダー)などの情報などの基本的なメタデータをZookeeperに保存します。
すべての重要な情報はZookeeperに保存され、通常はこのデータをアンサンブル全体に複製するため、Kafkaブローカー/ Zookeeperの障害はKafkaクラスターの状態に影響を与えません。Zookeeperが再起動すると、Kafkaは状態を復元します。これにより、Kafkaのダウンタイムはゼロになります。Kafkaブローカー間のリーダー選出も、リーダーが失敗した場合にZookeeperを使用して行われます。
Zookeeperの詳細については、zookeeperを参照してください。
次の章では、Java、ZooKeeper、およびKafkaをマシンにインストールする方法についてさらに詳しく説明します。
以下は、マシンにJavaをインストールするための手順です。
ステップ1-Javaインストールの確認
うまくいけば、あなたはすでにあなたのマシンにjavaをインストールしているので、次のコマンドを使ってそれを確認するだけです。
$ java -versionJavaがマシンに正常にインストールされている場合は、インストールされているJavaのバージョンを確認できます。
ステップ1.1-JDKをダウンロードする
Javaがダウンロードされていない場合は、次のリンクにアクセスして最新バージョンのJDKをダウンロードし、最新バージョンをダウンロードしてください。
http://www.oracle.com/technetwork/java/javase/downloads/index.html現在、最新バージョンはJDK 8u 60で、ファイルは「jdk-8u60-linux-x64.tar.gz」です。お使いのマシンにファイルをダウンロードしてください。
ステップ1.2-ファイルを抽出する
通常、ダウンロードされるファイルはダウンロードフォルダーに保存され、それを確認して、次のコマンドを使用してtarセットアップを抽出します。
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzステップ1.3-OptDirectoryに移動する
すべてのユーザーがJavaを使用できるようにするには、抽出したJavaコンテンツをusr / local / java
/フォルダーに移動します。
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/ステップ1.4-パスを設定する
パス変数とJAVA_HOME変数を設定するには、次のコマンドを〜/ .bashrcファイルに追加します。
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin次に、すべての変更を現在実行中のシステムに適用します。
$ source ~/.bashrcステップ1.5-Javaの代替
次のコマンドを使用して、JavaAlternativesを変更します。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Step 1.6 −ステップ1で説明した検証コマンド(java -version)を使用してjavaを検証します。
ステップ2-ZooKeeperフレームワークのインストール
ステップ2.1-ZooKeeperをダウンロードする
マシンにZooKeeperフレームワークをインストールするには、次のリンクにアクセスして、ZooKeeperの最新バージョンをダウンロードしてください。
http://zookeeper.apache.org/releases.html現在、ZooKeeperの最新バージョンは3.4.6(ZooKeeper-3.4.6.tar.gz)です。
ステップ2.2-tarファイルを抽出する
次のコマンドを使用してtarファイルを抽出します
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataステップ2.3-構成ファイルを作成する
コマンドvi「conf / zoo.cfg」と以下のすべてのパラメーターを使用してconf / zoo.cfg
という名前の構成ファイルを開き、開始点として設定します。
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2設定ファイルが正常に保存され、再びターミナルに戻ったら、zookeeperサーバーを起動できます。
ステップ2.4-ZooKeeperサーバーを起動します
$ bin/zkServer.sh startこのコマンドを実行すると、次のような応答が返されます。
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDステップ2.5-CLIを起動します
$ bin/zkCli.sh上記のコマンドを入力すると、zookeeperサーバーに接続され、以下の応答が返されます。
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]ステップ2.6-Zookeeperサーバーを停止する
サーバーに接続してすべての操作を実行した後、次のコマンドでzookeeperサーバーを停止できます-
$ bin/zkServer.sh stopこれで、JavaとZooKeeperがマシンに正常にインストールされました。ApacheKafkaをインストールする手順を見てみましょう。
ステップ3-ApacheKafkaのインストール
次の手順を続行して、マシンにKafkaをインストールします。
ステップ3.1-Kafkaをダウンロードする
マシンにKafkaをインストールするには、以下のリンクをクリックしてください-
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz現在、最新バージョン、すなわち– kafka_2.11_0.9.0.0.tgz マシンにダウンロードされます。
ステップ3.2-tarファイルを抽出する
次のコマンドを使用してtarファイルを抽出します-
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0これで、最新バージョンのKafkaがマシンにダウンロードされました。
ステップ3.3-サーバーを起動します
次のコマンドを実行してサーバーを起動できます-
$ bin/kafka-server-start.sh config/server.propertiesサーバーが起動すると、画面に次の応答が表示されます-
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….ステップ4-サーバーを停止します
すべての操作を実行した後、次のコマンドを使用してサーバーを停止できます-
$ bin/kafka-server-stop.sh config/server.propertiesKafkaのインストールについてはすでに説明したので、次の章でKafkaの基本的な操作を実行する方法を学ぶことができます。
まず、単一ノード-単一ブローカー
構成の実装を開始し、次にセットアップを単一ノード-複数ブローカー構成に移行します。
うまくいけば、Java、ZooKeeper、Kafkaがマシンにインストールされているはずです。Kafka ClusterはZooKeeperを使用するため、Kafka Cluster Setupに移動する前に、まずZooKeeperを起動する必要があります。
ZooKeeperを起動します
新しいターミナルを開き、次のコマンドを入力します-
bin/zookeeper-server-start.sh config/zookeeper.propertiesKafka Brokerを起動するには、次のコマンドを入力します-
bin/kafka-server-start.sh config/server.propertiesKafka Brokerを起動した後、ZooKeeperターミナルでコマンドjps
を入力すると、次の応答が表示されます。
821 QuorumPeerMain
928 Kafka
931 Jpsこれで、QuorumPeerMainがZooKeeperデーモンで、もう1つがKafkaデーモンである2つのデーモンがターミナルで実行されていることがわかります。
シングルノード-シングルブローカー構成
この構成では、単一のZooKeeperとブローカーIDインスタンスがあります。以下はそれを設定する手順です-
Creating a Kafka Topic− kafka
は、サーバー上にトピックを作成するためのkafka-topics.sh
という名前のコマンドラインユーティリティを提供します。新しいターミナルを開き、以下の例を入力します。
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-Kafka単一のパーティションと1つのレプリカ要素を持つHello-Kafka
という名前のトピックを作成しました。上記で作成された出力は、次の出力のようになります-
Output−作成されたトピックHello-Kafka
トピックが作成されると、Kafkaブローカーのターミナルウィンドウで通知を受け取り、config /server.propertiesファイルの「/ tmp / kafka-logs /」で指定された作成済みトピックのログを取得できます。
トピックのリスト
Kafkaサーバーのトピックのリストを取得するには、次のコマンドを使用できます-
Syntax
bin/kafka-topics.sh --list --zookeeper localhost:2181Output
Hello-Kafkaトピックを作成したので、Hello-Kafka
のみをリストします。複数のトピックを作成する場合、出力にトピック名が表示されるとします。
プロデューサーを起動してメッセージを送信する
Syntax
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name上記の構文から、プロデューサーコマンドラインクライアントには2つの主要なパラメーターが必要です-
Broker-list−メッセージの送信先となるブローカーのリスト。この場合、ブローカーは1つだけです。ブローカーがポート9092でリッスンしていることがわかっているため、Config / server.propertiesファイルにはブローカーのポートIDが含まれているため、直接指定できます。
トピック名-トピック名の例を次に示します。
Example
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafkaプロデューサーはstdinからの入力を待ち、Kafkaクラスターに公開します。デフォルトでは、すべての新しい行が新しいメッセージとして公開され、デフォルトのプロデューサープロパティがconfig /producer.properties
ファイルで指定されます。これで、以下に示すように、ターミナルに数行のメッセージを入力できます。
Output
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first messageMy second messageメッセージを受信するためにコンシューマーを開始する
プロデューサーと同様に、デフォルトのコンシューマープロパティはconfig /consumer.proper-ties
ファイルで指定されます。新しいターミナルを開き、メッセージを消費するために以下の構文を入力します。
Syntax
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginningExample
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginningOutput
Hello
My first message
My second message最後に、プロデューサーの端末からメッセージを入力して、コンシューマーの端末に表示されるのを確認できます。今のところ、単一のブローカーを持つ単一ノードクラスターについて非常によく理解しています。次に、複数のブローカーの構成に移りましょう。
単一ノード-複数のブローカー構成
マルチブローカークラスターのセットアップに進む前に、まずZooKeeperサーバーを起動します。
Create Multiple Kafka Brokers− con-fig /server.propertiesにすでに1つのKafkaブローカーインスタンスがあります。ここで、複数のブローカーインスタンスが必要になるため、既存のserver.prop-ertiesファイルを2つの新しい構成ファイルにコピーし、名前をserver-one.propertiesおよびserver-two.prop-ertiesに変更します。次に、両方の新しいファイルを編集し、次の変更を割り当てます-
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2Start Multiple Brokers− 3つのサーバーですべての変更が行われた後、3つの新しい端末を開いて、各ブローカーを1つずつ起動します。
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.propertiesこれで、マシン上で3つの異なるブローカーが実行されています。自分で試して、次のように入力してすべてのデーモンを確認してくださいjps ZooKeeperターミナルで、応答が表示されます。
トピックの作成
3つの異なるブローカーが実行されているため、このトピックのレプリケーション係数値を3として割り当てましょう。ブローカーが2つある場合、割り当てられるレプリカ値は2になります。
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic MultibrokerapplicationOutput
created topic “Multibrokerapplication”次のように、Describe
コマンドを使用して、現在作成されているトピックをリッスンしているブローカーを確認します。
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cationOutput
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cation
Topic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:
Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1上記の出力から、最初の行はすべてのパーティションの要約を示し、トピック名、パーティション数、およびすでに選択したレプリケーション係数を示していると結論付けることができます。2行目では、各ノードがパーティションのランダムに選択された部分のリーダーになります。
私たちの場合、最初のブローカー(broker.id 0)がリーダーであることがわかります。次に、レプリカ:0,2,1は、すべてのブローカーがトピックを複製することを意味し、最終的にIsr
は同期
レプリカのセットになり
ます。さて、これは現在生きていてリーダーによって追いついているレプリカのサブセットです。
プロデューサーを起動してメッセージを送信する
この手順は、シングルブローカーのセットアップと同じです。
Example
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic MultibrokerapplicationOutput
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second messageメッセージを受信するためにコンシューマーを開始する
この手順は、シングルブローカーのセットアップに示されているものと同じです。
Example
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion --from-beginningOutput
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second message基本的なトピック操作
この章では、さまざまな基本的なトピック操作について説明します。
トピックの変更
Kafkaクラスターでトピックを作成する方法をすでに理解しているように。次のコマンドを使用して、作成したトピックを変更しましょう。
Syntax
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name
--parti-tions countExample
We have already created a topic “Hello-Kafka” with single partition count and one replica factor.
Now using “alter” command we have changed the partition count.
bin/kafka-topics.sh --zookeeper localhost:2181
--alter --topic Hello-kafka --parti-tions 2Output
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!トピックの削除
トピックを削除するには、次の構文を使用できます。
Syntax
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_nameExample
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafkaOutput
> Topic Hello-kafka marked for deletionNote −次の場合、これは影響しません delete.topic.enable trueに設定されていません
Javaクライアントを使用してメッセージを公開および消費するためのアプリケーションを作成しましょう。Kafkaプロデューサークライアントは、次のAPIで構成されています。
KafkaProducer API
このセクションでは、KafkaプロデューサーAPIの最も重要なセットを理解しましょう。KafkaProducer APIの中心的な部分は、KafkaProducer
クラスです。KafkaProducerクラスは、コンストラクター内のKafkaブローカーを次のメソッドに接続するオプションを提供します。
KafkaProducerクラスは、トピックに非同期でメッセージを送信するためのsendメソッドを提供します。send()の署名は次のとおりです
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);ProducerRecord −プロデューサーは、送信を待機しているレコードのバッファーを管理します。
Callback −レコードがサーバーによって確認されたときに実行するユーザー指定のコールバック(nullはコールバックがないことを示します)。
KafkaProducerクラスは、以前に送信されたすべてのメッセージが実際に完了したことを確認するためのフラッシュメソッドを提供します。flushメソッドの構文は次のとおりです-
public void flush()KafkaProducerクラスは、特定のトピックのパーティションメタデータを取得するのに役立つpartitionForメソッドを提供します。これは、カスタムパーティショニングに使用できます。このメソッドのシグネチャは次のとおりです-
public Map metrics()プロデューサーによって維持されている内部メトリックのマップを返します。
public void close()-KafkaProducerクラスは、以前に送信されたすべての要求が完了するまで、closeメソッドブロックを提供します。
プロデューサーAPI
Producer APIの中心的な部分は、Producer
クラスです。プロデューサークラスは、次のメソッドによってコンストラクターでKafkaブローカーに接続するオプションを提供します。
プロデューサークラス
プロデューサークラスはsendメソッドをに提供します send 次の署名を使用して、単一または複数のトピックにメッセージを送信します。
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);プロデューサーには2つのタイプがあります– Sync そして Async。
同じAPI構成が同期
プロデューサーにも適用されます。それらの違いは、同期プロデューサーはメッセージを直接送信しますが、バックグラウンドでメッセージを送信することです。より高いスループットが必要な場合は、非同期プロデューサーをお勧めします。0.8のような以前のリリースでは、非同期プロデューサーには、エラーハンドラーを登録するためのsend()のコールバックがありません。これは、現在のリリース0.9でのみ使用できます。
public void close()
プロデューサークラスは提供します close すべてのKafkaブローカーへのプロデューサープール接続を閉じる方法。
構成設定
わかりやすくするために、ProducerAPIの主な構成設定を次の表に示します。
| S.No | 構成設定と説明 |
|---|---|
| 1 | client.id プロデューサーアプリケーションを識別します |
| 2 | producer.type 同期または非同期のいずれか |
| 3 | acks acks構成は、プロデューサー要求の下での基準を制御し、完全であると見なされます。 |
| 4 | retries プロデューサーリクエストが失敗した場合は、特定の値で自動的に再試行します。 |
| 5 | bootstrap.servers ブローカーのブートストラップリスト。 |
| 6 | linger.ms リクエストの数を減らしたい場合は、linger.msをある値よりも大きい値に設定できます。 |
| 7 | key.serializer シリアライザーインターフェイスのキー。 |
| 8 | value.serializer シリアライザーインターフェイスの値。 |
| 9 | batch.size バッファサイズ。 |
| 10 | buffer.memory バッファリングのためにプロデューサーが使用できるメモリの合計量を制御します。 |
ProducerRecord API
ProducerRecordは、Kafka cluster.ProducerRecordクラスコンストラクターに送信されるキーと値のペアであり、次の署名を使用して、パーティション、キー、および値のペアを持つレコードを作成します。
public ProducerRecord (string topic, int partition, k key, v value)Topic −レコードに追加されるユーザー定義のトピック名。
Partition −パーティション数
Key −レコードに含まれるキー。
- Value −記録内容
public ProducerRecord (string topic, k key, v value)ProducerRecordクラスコンストラクターは、キーと値のペアがあり、パーティションがないレコードを作成するために使用されます。
Topic −レコードを割り当てるトピックを作成します。
Key −レコードのキー。
Value −内容を記録します。
public ProducerRecord (string topic, v value)ProducerRecordクラスは、パーティションとキーなしでレコードを作成します。
Topic −トピックを作成します。
Value −内容を記録します。
ProducerRecordクラスのメソッドを次の表に示します-
| S.No | クラスのメソッドと説明 |
|---|---|
| 1 | public string topic() トピックがレコードに追加されます。 |
| 2 | public K key() レコードに含まれるキー。そのようなキーがない場合、ここでnullが返されます。 |
| 3 | public V value() 内容を記録します。 |
| 4 | partition() レコードのパーティション数 |
SimpleProducerアプリケーション
アプリケーションを作成する前に、まずZooKeeperとKafkaブローカーを起動し、次にcreatetopicコマンドを使用してKafkaブローカーで独自のトピックを作成します。その後、Sim-pleProducer.java
という名前のJavaクラスを作成し、次のコーディングを入力します。
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}Compilation −アプリケーションは、次のコマンドを使用してコンパイルできます。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution −以下のコマンドでアプリケーションを実行できます。
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>Output
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10簡単な消費者の例
現在、Kafkaクラスターにメッセージを送信するプロデューサーを作成しました。次に、Kafkaクラスターからメッセージを消費するコンシューマーを作成しましょう。KafkaConsumer APIは、Kafkaクラスターからのメッセージを消費するために使用されます。KafkaConsumerクラスコンストラクターは以下で定義されています。
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)configs −コンシューマー構成のマップを返します。
KafkaConsumerクラスには、以下の表にリストされている次の重要なメソッドがあります。
| S.No | 方法と説明 |
|---|---|
| 1 | public java.util.Set<TopicPar-tition> assignment() 消費者によって現在割り当てられているパーティションのセットを取得します。 |
| 2 | public string subscription() 指定されたトピックのリストをサブスクライブして、動的に割り当てられたパーティションを取得します。 |
| 3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) 指定されたトピックのリストをサブスクライブして、動的に割り当てられたパーティションを取得します。 |
| 4 | public void unsubscribe() 指定されたパーティションのリストからトピックのサブスクライブを解除します。 |
| 5 | public void sub-scribe(java.util.List<java.lang.String> topics) 指定されたトピックのリストをサブスクライブして、動的に割り当てられたパーティションを取得します。指定されたトピックのリストが空の場合、unsubscribe()と同じように扱われます。 |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) 引数パターンは正規表現の形式でサブスクライブパターンを参照し、リスナー引数はサブスクライブパターンから通知を受け取ります。 |
| 7 | public void as-sign(java.util.List<TopicParti-tion> partitions) パーティションのリストを顧客に手動で割り当てます。 |
| 8 | poll() サブスクライブ/割り当てAPIの1つを使用して指定されたトピックまたはパーティションのデータをフェッチします。データのポーリング前にトピックがサブスクライブされていない場合、これはエラーを返します。 |
| 9 | public void commitSync() トピックとパーティションのすべてのサブスクライブされたリストについて、最後のpoll()で返されたコミットオフセット。同じ操作がcommitAsyn()に適用されます。 |
| 10 | public void seek(TopicPartition partition, long offset) コンシューマーが次のpoll()メソッドで使用する現在のオフセット値を取得します。 |
| 11 | public void resume() 一時停止したパーティションを再開します。 |
| 12 | public void wakeup() 消費者を起こします。 |
ConsumerRecord API
ConsumerRecord APIは、Kafkaクラスターからレコードを受信するために使用されます。このAPIは、トピック名、レコードの受信元のパーティション番号、およびKafkaパーティション内のレコードを指すオフセットで構成されます。ConsumerRecordクラスは、特定のトピック名、パーティション数、および<key、value>のペアを持つコンシューマーレコードを作成するために使用されます。以下の署名があります。
public ConsumerRecord(string topic,int partition, long offset,K key, V value)Topic −Kafkaクラスターから受信したコンシューマーレコードのトピック名。
Partition −トピックのパーティション。
Key −レコードのキー(キーが存在しない場合)はnullが返されます。
Value −内容を記録します。
ConsumerRecords API
ConsumerRecords APIは、ConsumerRecordのコンテナーとして機能します。このAPIは、特定のトピックのパーティションごとのConsumerRecordのリストを保持するために使用されます。そのコンストラクターは以下に定義されています。
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)TopicPartition −特定のトピックのパーティションのマップを返します。
Records −ConsumerRecordのリストを返します。
ConsumerRecordsクラスには、次のメソッドが定義されています。
| S.No | メソッドと説明 |
|---|---|
| 1 | public int count() すべてのトピックのレコード数。 |
| 2 | public Set partitions() このレコードセット内のデータを含むパーティションのセット(データが返されない場合、セットは空です)。 |
| 3 | public Iterator iterator() イテレータを使用すると、コレクションを循環して、要素を取得または削除できます。 |
| 4 | public List records() 指定されたパーティションのレコードのリストを取得します。 |
構成設定
コンシューマクライアントAPIの主な構成設定の構成設定を以下に示します-
| S.No | 設定と説明 |
|---|---|
| 1 | bootstrap.servers ブローカーのブートストラップリスト。 |
| 2 | group.id 個々の消費者をグループに割り当てます。 |
| 3 | enable.auto.commit 値がtrueの場合はオフセットの自動コミットを有効にし、そうでない場合はコミットしません。 |
| 4 | auto.commit.interval.ms 更新された消費オフセットがZooKeeperに書き込まれる頻度を返します。 |
| 5 | session.timeout.ms KafkaがZooKeeperが要求(読み取りまたは書き込み)に応答するのを待ってから、メッセージをあきらめて消費し続けるミリ秒数を示します。 |
SimpleConsumerアプリケーション
プロデューサーの申請手順はここでも同じです。まず、ZooKeeperとKafkaブローカーを起動します。次に、作成SimpleConsumerの
名前のJavaクラスを使用してアプリケーションをSimpleCon-sumer.java
し、次のコードを入力します。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilation −アプリケーションは、次のコマンドを使用してコンパイルできます。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution − アプリケーションは、次のコマンドを使用して実行できます
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>Input−プロデューサーCLIを開き、トピックにいくつかのメッセージを送信します。単純な入力を「HelloConsumer」として入力できます。
Output −以下が出力になります。
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello Consumer消費者グループは、Kafkaトピックからのマルチスレッドまたはマルチマシンの消費です。
消費者グループ
コンシューマーは、同じ
group.id
を使用してグループに参加できます。
グループの最大の並列処理は、グループ内のコンシューマーの数←パーティションの数です。
Kafkaは、トピックのパーティションをグループ内のコンシューマーに割り当て、各パーティションがグループ内の1人のコンシューマーによって消費されるようにします。
Kafkaは、メッセージがグループ内の1人のコンシューマーによってのみ読み取られることを保証します。
消費者は、ログに保存された順序でメッセージを見ることができます。
消費者のリバランス
プロセス/スレッドを追加すると、Kafkaのバランスが再調整されます。コンシューマーまたはブローカーがZooKeeperにハートビートを送信できない場合は、Kafkaクラスターを介して再構成できます。このリバランス中に、Kafkaは使用可能なパーティションを使用可能なスレッドに割り当て、パーティションを別のプロセスに移動する可能性があります。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}コンパイル
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java実行
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupここでは、2つのコンシューマーを持つmy-group
としてサンプルグループ名を作成しました。同様に、グループとそのグループ内のコンシューマーの数を作成できます。
入力
プロデューサーCLIを開き、次のようなメッセージを送信します。
Test consumer group 01
Test consumer group 02最初のプロセスの出力
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 012番目のプロセスの出力
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02これで、Javaクライアントのデモを使用してSimpleConsumerとConsumeGroupを理解できたと思います。これで、Javaクライアントを使用してメッセージを送受信する方法についてのアイデアが得られました。次の章では、Kafkaとビッグデータテクノロジーの統合を続けましょう。
この章では、KafkaをApacheStormと統合する方法を学習します。
ストームについて
Stormは、もともとNathanMarzとBackTypeのチームによって作成されました。短期間で、Apache Stormは、大量のデータを処理できる分散リアルタイム処理システムの標準になりました。Stormは非常に高速であり、ベンチマークでは、ノードごとに1秒あたり100万を超えるタプルが処理されます。Apache Stormは継続的に実行され、構成されたソース(Spouts)からデータを消費し、データを処理パイプライン(Bolts)に渡します。組み合わせて、注ぎ口とボルトがトポロジーを作ります。
ストームとの統合
KafkaとStormは自然に相互に補完し合い、それらの強力な協力により、高速で移動するビッグデータのリアルタイムストリーミング分析が可能になります。KafkaとStormの統合は、開発者がStormトポロジからデータストリームを簡単に取り込んで公開できるようにすることです。
概念の流れ
注ぎ口はストリームのソースです。たとえば、注ぎ口はKafkaトピックからタプルを読み取り、それらをストリームとして出力する場合があります。ボルトは入力ストリームを消費し、処理し、場合によっては新しいストリームを放出します。Boltsは、関数の実行、タプルのフィルタリング、ストリーミング集約、ストリーミング結合、データベースとの通信など、あらゆることを実行できます。Stormトポロジの各ノードは並行して実行されます。トポロジは、終了するまで無期限に実行されます。Stormは、失敗したタスクを自動的に再割り当てします。さらに、Stormは、マシンがダウンしてメッセージがドロップされた場合でも、データが失われないことを保証します。
Kafka-Storm統合APIについて詳しく見ていきましょう。KafkaをStormと統合するための3つの主要なクラスがあります。それらは次のとおりです-
BrokerHosts-ZkHostsとStaticHosts
BrokerHostsはインターフェースであり、ZkHostsとStaticHostsはその2つの主要な実装です。ZkHostsは、ZooKeeperで詳細を維持することにより、Kafkaブローカーを動的に追跡するために使用され、StaticHostsは、Kafkaブローカーとその詳細を手動/静的に設定するために使用されます。ZkHostsは、Kafkaブローカーにアクセスするためのシンプルで高速な方法です。
ZkHostsの署名は次のとおりです-
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)ここで、brokerZkStrはZooKeeperホストであり、brokerZkPathはKafkaブローカーの詳細を維持するためのZooKeeperパスです。
KafkaConfig API
このAPIは、Kafkaクラスターの構成設定を定義するために使用されます。KafkaCon-figの署名は次のように定義されています
public KafkaConfig(BrokerHosts hosts, string topic)Hosts −BrokerHostsはZkHosts / StaticHostsにすることができます。
Topic −トピック名。
SpoutConfig API
Spoutconfigは、追加のZooKeeper情報をサポートするKafkaConfigの拡張です。
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)Hosts − BrokerHostsは、BrokerHostsインターフェースの任意の実装にすることができます
Topic −トピック名。
zkRoot −ZooKeeperルートパス。
id −注ぎ口は、Zookeeperで消費されたオフセットの状態を保存します。IDは、注ぎ口を一意に識別する必要があります。
SchemeAsMultiScheme
SchemeAsMultiSchemeは、Kafkaから消費されたByteBufferがストームタプルに変換される方法を指示するインターフェースです。これはMultiSchemeから派生し、Schemeクラスの実装を受け入れます。Schemeクラスの実装はたくさんあり、そのような実装の1つがStringSchemeです。これは、バイトを単純な文字列として解析します。また、出力フィールドの名前も制御します。署名は次のように定義されます。
public SchemeAsMultiScheme(Scheme scheme)Scheme −kafkaから消費されるバイトバッファ。
KafkaSpout API
KafkaSpoutは、Stormと統合されるスパウトの実装です。kafkaトピックからメッセージをフェッチし、それをタプルとしてStormエコシステムに送信します。KafkaSpoutは、SpoutConfigから構成の詳細を取得します。
以下は、単純なKafkaスパウトを作成するためのサンプルコードです。
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);ボルトの作成
Boltは、タプルを入力として受け取り、タプルを処理し、出力として新しいタプルを生成するコンポーネントです。BoltsはIRichBoltインターフェースを実装します。このプログラムでは、2つのボルトクラスWordSplitter-BoltとWordCounterBoltを使用して操作を実行します。
IRichBoltインターフェースには次のメソッドがあります-
Prepare−ボルトに実行環境を提供します。エグゼキュータはこのメソッドを実行して、注ぎ口を初期化します。
Execute −入力の単一のタプルを処理します。
Cleanup −ボルトがシャットダウンするときに呼び出されます。
declareOutputFields −タプルの出力スキーマを宣言します。
文を単語に分割するロジックを実装するSplitBolt.javaと、一意の単語を分離してその出現回数をカウントするロジックを実装するCountBolt.javaを作成しましょう。
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}トポロジへの送信
ストームトポロジは基本的にスリフト構造です。TopologyBuilderクラスは、複雑なトポロジを作成するためのシンプルで簡単なメソッドを提供します。TopologyBuilderクラスには、注ぎ口を設定するメソッド(setSpout)とボルトを設定するメソッド(setBolt)があります。最後に、TopologyBuilderにはto-pologyを作成するためのcreateTopologyがあります。shuffleGroupingメソッドとfieldsGroupingメソッドは、注ぎ口とボルトのストリームグループ化を設定するのに役立ちます。
Local Cluster−開発目的で、LocalCluster
オブジェクトを使用してローカルクラスターを作成し、LocalCluster
クラスのsubmitTopology
メソッドを使用してトポロジを送信できます。
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}コンパイルを移動する前に、Kakfa-Storm統合にはキュレーターのZooKeeperクライアントJavaライブラリが必要です。Curatorバージョン2.9.1は、Apache Stormバージョン0.9.5(このチュートリアルで使用)をサポートします。以下に指定したjarファイルをダウンロードして、Javaクラスパスに配置します。
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
依存関係ファイルを含めた後、次のコマンドを使用してプログラムをコンパイルします。
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.java実行
Kafka Producer CLI(前の章で説明)を起動し、my-first-topic
という新しいトピックを作成し、以下に示すようにいくつかのサンプルメッセージを提供します-
hello
kafka
storm
spark
test message
another test message次のコマンドを使用してアプリケーションを実行します-
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSampleこのアプリケーションの出力例を以下に示します。
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2この章では、ApacheKafkaをSparkStreamingAPIと統合する方法について説明します。
Sparkについて
Spark Streaming APIは、ライブデータストリームのスケーラブルで高スループットのフォールトトレラントなストリーム処理を可能にします。データは、Kafka、Flume、Twitterなどの多くのソースから取り込むことができ、map、reduce、join、windowなどの高レベル関数などの複雑なアルゴリズムを使用して処理できます。最後に、処理されたデータをファイルシステム、データベース、およびライブダッシュボードにプッシュできます。復元力のある分散データセット(RDD)は、Sparkの基本的なデータ構造です。これは、オブジェクトの不変の分散コレクションです。RDDの各データセットは論理パーティションに分割され、クラスターのさまざまなノードで計算できます。
Sparkとの統合
Kafkaは、Sparkストリーミングの潜在的なメッセージングおよび統合プラットフォームです。Kafkaは、データのリアルタイムストリームの中央ハブとして機能し、SparkStreamingの複雑なアルゴリズムを使用して処理されます。データが処理されると、Spark Streamingは結果をさらに別のKafkaトピックに公開したり、HDFS、データベース、またはダッシュボードに保存したりできます。次の図は、概念的なフローを示しています。

それでは、Kafka-SparkAPIについて詳しく見ていきましょう。
SparkConf API
これは、Sparkアプリケーションの構成を表します。さまざまなSparkパラメーターをキーと値のペアとして設定するために使用されます。
SparkConf
クラスには次のメソッドがあります-
set(string key, string value) −構成変数を設定します。
remove(string key) −構成からキーを削除します。
setAppName(string name) −アプリケーションのアプリケーション名を設定します。
get(string key) −キーを取得
StreamingContext API
これは、Spark機能の主要なエントリポイントです。SparkContextは、Sparkクラスターへの接続を表し、クラスター上にRDD、アキュムレーター、およびブロードキャスト変数を作成するために使用できます。署名は次のように定義されます。
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)master −接続するクラスターURL(例:mesos:// host:port、spark:// host:port、local [4])。
appName −クラスターWebUIに表示するジョブの名前
batchDuration −ストリーミングデータがバッチに分割される時間間隔
public StreamingContext(SparkConf conf, Duration batchDuration)新しいSparkContextに必要な構成を提供して、StreamingContextを作成します。
conf −スパークパラメータ
batchDuration −ストリーミングデータがバッチに分割される時間間隔
KafkaUtils API
KafkaUtils APIは、KafkaクラスターをSparkストリーミングに接続するために使用されます。このAPIには、以下のように定義された重要なメソッドcreateStream
シグネチャがあります。
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)上記のメソッドは、KafkaBrokersからメッセージをプルする入力ストリームを作成するために使用されます。
ssc −StreamingContextオブジェクト。
zkQuorum −Zookeeperクォーラム。
groupId −このコンシューマーのグループID。
topics −消費するトピックのマップを返します。
storageLevel −受信したオブジェクトを保存するために使用するストレージレベル。
KafkaUtils APIには別のメソッドcreateDirectStreamがあります。これは、レシーバーを使用せずにKafkaBrokersからメッセージを直接プルする入力ストリームを作成するために使用されます。このストリームは、Kafkaからの各メッセージが変換に1回だけ含まれることを保証できます。
サンプルアプリケーションはScalaで行われます。アプリケーションをコンパイルするには、sbt
、scalaビルドツール(mavenと同様)をダウンロードしてインストールしてください。主なアプリケーションコードを以下に示します。
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}ビルドスクリプト
spark-kafka統合は、spark、sparkストリーミング、およびsparkKafka統合jarに依存します。新しいファイルbuild.sbt
を作成し、アプリケーションの詳細とその依存関係を指定します。SBTは、
アプリケーションをコンパイルし、梱包しながら、必要なjarファイルをダウンロードします。
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"コンパイル/パッケージング
次のコマンドを実行して、アプリケーションのjarファイルをコンパイルおよびパッケージ化します。アプリケーションを実行するには、jarファイルをsparkコンソールに送信する必要があります。
sbt packageSparkに送信する
Kafka Producer CLI(前の章で説明)を起動し、my-first-topic
という新しいトピックを作成し、以下に示すようにいくつかのサンプルメッセージを提供します。
Another spark test message次のコマンドを実行して、アプリケーションをSparkコンソールに送信します。
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>このアプリケーションの出力例を以下に示します。
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..リアルタイムアプリケーションを分析して、最新のTwitterフィードとそのハッシュタグを取得しましょう。以前、StormとSparkのKafkaとの統合を見てきました。どちらのシナリオでも、Kafkaエコシステムにメッセージを送信するために(cliを使用して)Kafkaプロデューサーを作成しました。次に、ストームとスパークの統合は、Kafkaコンシューマーを使用してメッセージを読み取り、ストームとスパークのエコシステムにそれぞれ注入します。したがって、実際には、Kafkaプロデューサーを作成する必要があります。
- 「TwitterストリーミングAPI」を使用してTwitterフィードを読みます。
- フィードを処理し、
- ハッシュタグを抽出し、
- カフカに送ってください。
いったんハッシュタグは
カフカによって受信され、ストーム/スパーク統合は、インフォア-mationを受け取り、ストーム/スパークエコシステムに送信します。
TwitterストリーミングAPI
「TwitterストリーミングAPI」には、どのプログラミング言語でもアクセスできます。「twitter4j」はオープンソースの非公式Javaライブラリであり、「TwitterストリーミングAPI」に簡単にアクセスするためのJavaベースのモジュールを提供します。「twitter4j」は、ツイートにアクセスするためのリスナーベースのフレームワークを提供します。「TwitterストリーミングAPI」にアクセスするには、Twitter開発者アカウントにサインインする必要があり、次のものを取得する必要がありますOAuth 認証の詳細。
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
開発者アカウントが作成されたら、「twitter4j」jarファイルをダウンロードして、Javaクラスパスに配置します。
完全なTwitterKafkaプロデューサーコーディング(KafkaTwitterProducer.java)を以下に示します-
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}コンパイル
次のコマンドを使用してアプリケーションをコンパイルします-
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.java実行
2つのコンソールを開きます。以下に示すように、上記のコンパイル済みアプリケーションを1つのコンソールで実行します。
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic food前の章で説明したSpark / Stormアプリケーションのいずれかを別のウィンドウで実行します。注意すべき主な点は、使用されるトピックはどちらの場合も同じでなければならないということです。ここでは、トピック名として「my-first-topic」を使用しています。
出力
このアプリケーションの出力は、キーワードとTwitterの現在のフィードによって異なります。サンプル出力を以下に示します(ストーム統合)。
. . .
food : 1
foodie : 2
burger : 1
. . .「org.apache.kafka.tools。*」にパッケージ化されたKafkaツール。ツールは、システムツールとレプリケーションツールに分類されます。
システムツール
システムツールは、runclassスクリプトを使用してコマンドラインから実行できます。構文は次のとおりです-
bin/kafka-run-class.sh package.class - - optionsシステムツールのいくつかを以下に示します-
Kafka Migration Tool −このツールは、ブローカーをあるバージョンから別のバージョンに移行するために使用されます。
Mirror Maker −このツールは、あるKafkaクラスターを別のクラスターにミラーリングするために使用されます。
Consumer Offset Checker −このツールは、指定されたトピックとコンシューマーグループのセットのコンシューマーグループ、トピック、パーティション、オフセット、logSize、所有者を表示します。
レプリケーションツール
Kafkaレプリケーションは高レベルの設計ツールです。レプリケーションツールを追加する目的は、耐久性と可用性を高めることです。レプリケーションツールのいくつかを以下に示します-
Create Topic Tool −これにより、デフォルトのパーティション数、レプリケーションファクターでトピックが作成され、Kafkaのデフォルトスキームを使用してレプリカの割り当てが行われます。
List Topic Tool−このツールは、特定のトピックリストの情報を一覧表示します。コマンドラインにトピックが指定されていない場合、ツールはZookeeperにクエリを実行してすべてのトピックを取得し、それらの情報を一覧表示します。ツールが表示するフィールドは、トピック名、パーティション、リーダー、レプリカ、isrです。
Add Partition Tool−トピックの作成、トピックのパーティション数を指定する必要があります。後で、トピックのボリュームが増えると、トピックにさらに多くのパーティションが必要になる場合があります。このツールは、特定のトピックにパーティションを追加するのに役立ち、追加されたパーティションの手動レプリカ割り当ても可能にします。
Kafkaは、今日の最高の産業用アプリケーションの多くをサポートしています。この章では、Kafkaの最も注目すべきアプリケーションのいくつかの非常に簡単な概要を説明します。
ツイッター
Twitterは、ユーザーのツイートを送受信するためのプラットフォームを提供するオンラインソーシャルネットワーキングサービスです。登録ユーザーはツイートを読んだり投稿したりできますが、未登録ユーザーはツイートを読むことしかできません。Twitterは、ストリーム処理インフラストラクチャの一部としてStorm-Kafkaを使用しています。
Apache Kafkaは、LinkedInでアクティビティストリームデータと運用メトリックに使用されます。Kafkaメッセージングシステムは、LinkedIn Newsfeed、LinkedIn Todayなどのさまざまな製品で、Hadoopなどのオフライン分析システムに加えて、オンラインメッセージの消費を支援します。Kafkaの強力な耐久性は、LinkedInに関連する重要な要素の1つでもあります。
Netflix
Netflixは、オンデマンドインターネットストリーミングメディアのアメリカの多国籍プロバイダーです。Netflixは、リアルタイムの監視とイベント処理にKafkaを使用しています。
Mozilla
Mozillaは、1998年にNetscapeのメンバーによって作成されたフリーソフトウェアコミュニティです。Kafkaはまもなく、Mozillaの現在の本番システムの一部を置き換えて、テレメトリ、テストパイロットなどのプロジェクトのエンドユーザーのブラウザからパフォーマンスと使用状況のデータを収集します。
オラクル
オラクルは、OSB(Oracle Service Bus)と呼ばれるエンタープライズサービスバス製品からKafkaへのネイティブ接続を提供します。これにより、開発者はOSBの組み込みメディエーション機能を活用して段階的なデータパイプラインを実装できます。