システムとメモリのアーキテクチャ
プログラムまたは並行システムを設計する際に考慮する必要のある、さまざまなシステムおよびメモリアーキテクチャスタイルがあります。1つのシステムとメモリスタイルが1つのタスクに適している場合もありますが、他のタスクでエラーが発生しやすい場合があるため、これは非常に必要です。
並行性をサポートするコンピュータシステムアーキテクチャ
Michael Flynnは、1972年に、さまざまなスタイルのコンピュータシステムアーキテクチャを分類するための分類法を示しました。この分類法では、4つの異なるスタイルを次のように定義しています。
- 単一の命令ストリーム、単一のデータストリーム(SISD)
- 単一の命令ストリーム、複数のデータストリーム(SIMD)
- 複数の命令ストリーム、単一のデータストリーム(MISD)
- 複数の命令ストリーム、複数のデータストリーム(MIMD)。
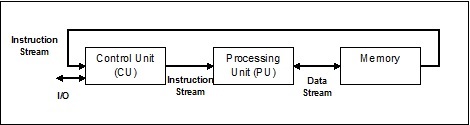
単一の命令ストリーム、単一のデータストリーム(SISD)
名前が示すように、このような種類のシステムには、1つの順次着信データストリームと、データストリームを実行するための1つの単一の処理ユニットがあります。それらは、並列コンピューティングアーキテクチャを備えたユニプロセッサシステムのようなものです。以下はSISDのアーキテクチャです-
SISDの利点
SISDアーキテクチャの利点は次のとおりです-
- 必要な電力が少なくて済みます。
- 複数のコア間の複雑な通信プロトコルの問題はありません。
SISDのデメリット
SISDアーキテクチャの欠点は次のとおりです-
- SISDアーキテクチャの速度は、シングルコアプロセッサと同じように制限されます。
- 大規模なアプリケーションには適していません。
単一の命令ストリーム、複数のデータストリーム(SIMD)
名前が示すように、このような種類のシステムには、複数の着信データストリームと、任意の時点で1つの命令に作用できる多数の処理ユニットがあります。それらは、並列コンピューティングアーキテクチャを備えたマルチプロセッサシステムのようなものです。以下はSIMDのアーキテクチャです-
SIMDの最良の例は、グラフィックカードです。これらのカードには、何百もの個別の処理装置があります。SISDとSIMDの計算上の違いについて話す場合、配列を追加する場合[5, 15, 20] そして [15, 25, 10],SISDアーキテクチャは、3つの異なる追加操作を実行する必要があります。一方、SIMDアーキテクチャでは、1回の追加操作で追加できます。
SIMDの利点
SIMDアーキテクチャの利点は次のとおりです-
複数の要素に対して同じ操作を実行するには、1つの命令のみを使用します。
プロセッサのコア数を増やすことで、システムのスループットを向上させることができます。
処理速度はSISDアーキテクチャよりも高速です。
SIMDのデメリット
SIMDアーキテクチャの欠点は次のとおりです-
- プロセッサのコアの数の間には複雑な通信があります。
- コストはSISDアーキテクチャよりも高くなります。
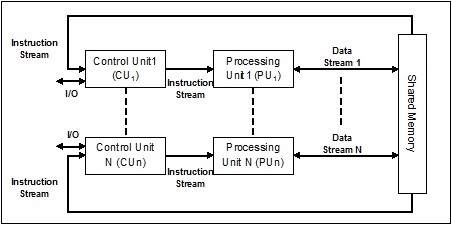
複数命令単一データ(MISD)ストリーム
MISDストリームを備えたシステムには、同じデータセットに対して異なる命令を実行することによって異なる操作を実行する多数の処理装置があります。以下はMISDのアーキテクチャです-
MISDアーキテクチャの代表はまだ商業的に存在していません。
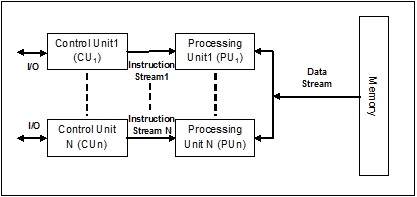
複数命令複数データ(MIMD)ストリーム
MIMDアーキテクチャを使用するシステムでは、マルチプロセッサシステムの各プロセッサは、異なるデータセットのセットに対して独立して異なる命令のセットを並列に実行できます。これは、単一の操作が複数のデータセットに対して実行されるSIMDアーキテクチャとは反対です。以下はMIMDのアーキテクチャです-
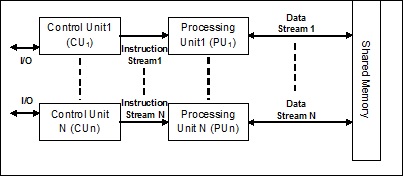
通常のマルチプロセッサはMIMDアーキテクチャを使用します。これらのアーキテクチャは基本的に、コンピュータ支援設計/コンピュータ支援製造、シミュレーション、モデリング、通信スイッチなど、多くのアプリケーション分野で使用されています。
並行性をサポートするメモリアーキテクチャ
並行性や並列性などの概念を使用する場合、プログラムを高速化する必要が常にあります。コンピュータ設計者が見つけた解決策の1つは、共有メモリマルチコンピュータ、つまり、プロセッサが持つすべてのコアからアクセスされる単一の物理アドレス空間を持つコンピュータを作成することです。このシナリオでは、さまざまなスタイルのアーキテクチャが存在する可能性がありますが、次の3つの重要なアーキテクチャスタイルがあります。
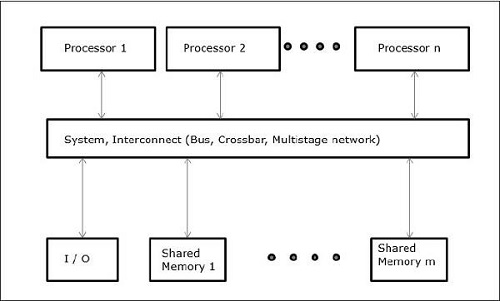
UMA(Uniform Memory Access)
このモデルでは、すべてのプロセッサが物理メモリを均一に共有します。すべてのプロセッサは、すべてのメモリワードへのアクセス時間が等しくなります。各プロセッサには、プライベートキャッシュメモリがあります。周辺機器は一連のルールに従います。
すべてのプロセッサがすべての周辺機器に平等にアクセスできる場合、そのシステムは symmetric multiprocessor。1つまたは少数のプロセッサのみが周辺機器にアクセスできる場合、そのシステムはasymmetric multiprocessor。
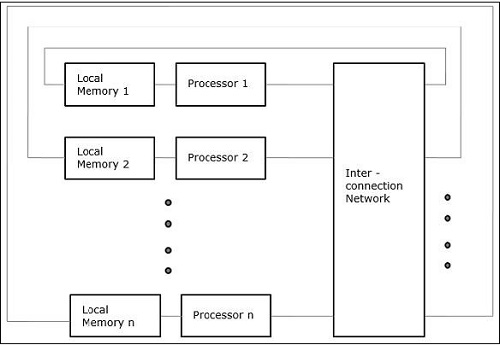
不均一メモリアクセス(NUMA)
NUMAマルチプロセッサモデルでは、アクセス時間はメモリワードの場所によって異なります。ここで、共有メモリは、ローカルメモリと呼ばれるすべてのプロセッサに物理的に分散されています。すべてのローカルメモリのコレクションは、すべてのプロセッサがアクセスできるグローバルアドレス空間を形成します。
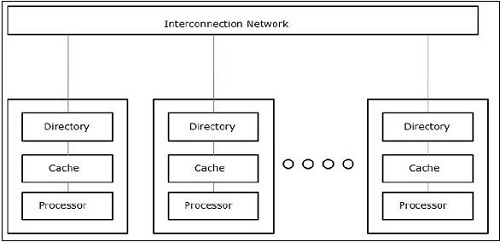
キャッシュオンリーメモリアーキテクチャ(COMA)
COMAモデルは、NUMAモデルの特殊バージョンです。ここでは、すべての分散メインメモリがキャッシュメモリに変換されます。