その他の分類方法
ここでは、遺伝的アルゴリズム、ラフ集合アプローチ、ファジー集合アプローチなどの他の分類方法について説明します。
遺伝的アルゴリズム
遺伝的アルゴリズムのアイデアは、自然の進化に由来しています。遺伝的アルゴリズムでは、まず最初に初期母集団が作成されます。この初期母集団は、ランダムに生成されたルールで構成されています。各ルールはビットの文字列で表すことができます。
たとえば、特定のトレーニングセットでは、サンプルはA1とA2などの2つのブール属性によって記述されます。そして、この特定のトレーニングセットには、C1とC2などの2つのクラスが含まれています。
ルールをエンコードできます IF A1 AND NOT A2 THEN C2 ビット文字列に 100。このビット表現では、左端の2つのビットがそれぞれ属性A1とA2を表します。
同様に、ルール IF NOT A1 AND NOT A2 THEN C1 次のようにエンコードできます 001。
Note−属性にK> 2のK値がある場合、Kビットを使用して属性値をエンコードできます。クラスも同じ方法でエンコードされます。
覚えておくべきポイント-
適者生存の概念に基づいて、現在の母集団の中で最も適者生存のルールと、これらのルールの子孫の値で構成される新しい母集団が形成されます。
ルールの適合性は、一連のトレーニングサンプルでの分類精度によって評価されます。
交叉や突然変異などの遺伝的演算子は、子孫を作成するために適用されます。
クロスオーバーでは、ルールのペアからの部分文字列が交換されて、新しいルールのペアが形成されます。
ミューテーションでは、ルールの文字列内でランダムに選択されたビットが反転されます。
ラフ集合アプローチ
ラフ集合アプローチを使用して、不正確でノイズの多いデータ内の構造的関係を発見できます。
Note−このアプローチは、離散値の属性にのみ適用できます。したがって、連続値の属性は、使用する前に離散化する必要があります。
ラフ集合論は、与えられたトレーニングデータ内の同値類の確立に基づいています。同値類を形成するタプルは識別できません。これは、サンプルがデータを説明する属性に関して同一であることを意味します。
特定の実世界のデータには、使用可能な属性の観点から区別できないクラスがいくつかあります。ラフ集合を使用してroughly そのようなクラスを定義します。
与えられたクラスCについて、ラフ集合の定義は次のように2つの集合で近似されます。
Lower Approximation of C − Cの下位近似は、属性の知識に基づいてクラスCに属することが確実なすべてのデータタプルで構成されます。
Upper Approximation of C − Cの上位近似はすべてのタプルで構成されており、属性の知識に基づいて、Cに属していないとは説明できません。
次の図は、クラスC −の上限と下限の近似を示しています。

ファジィ集合アプローチ
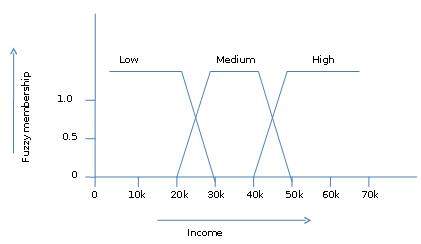
ファジー集合論は、可能性論とも呼ばれます。この理論は、1965年にLotfiZadehによって代替案として提案されました。two-value logic そして probability theory。この理論により、高レベルの抽象化で作業することができます。また、データの不正確な測定に対処するための手段も提供します。
ファジー集合論はまた、曖昧または不正確な事実に対処することを可能にします。たとえば、一連の高収入のメンバーであることは正確です(たとえば、50,000ドルが高い場合、49,000ドルと48,000ドルはどうでしょうか)。要素がSまたはその補集合のいずれかに属する従来のCRISPセットとは異なり、ファジー集合論では、要素は複数のファジーセットに属することができます。
たとえば、収入値$ 49,000は、中程度と高いファジーセットの両方に属しますが、程度は異なります。この収入値のファジー集合表記は次のとおりです。
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96ここで、「m」は、それぞれmedium_incomeとhigh_incomeのファジーセットを操作するメンバーシップ関数です。この表記は、次のように図式的に示すことができます。