DBMS-インデックス作成
データはレコードの形で保存されていることを私たちは知っています。すべてのレコードにはキーフィールドがあり、一意に認識されるのに役立ちます。
インデックス作成は、インデックス作成が行われたいくつかの属性に基づいてデータベースファイルからレコードを効率的に取得するためのデータ構造手法です。データベースシステムでの索引付けは、本で見られるものと似ています。
インデックス付けは、そのインデックス付け属性に基づいて定義されます。インデックス作成には次のタイプがあります-
Primary Index−プライマリインデックスは、順序付けされたデータファイルで定義されます。データファイルは、key field。キーフィールドは通常、リレーションの主キーです。
Secondary Index −セカンダリインデックスは、候補キーであり、すべてのレコードで一意の値を持つフィールド、または重複する値を持つ非キーから生成できます。
Clustering Index−クラスタリングインデックスは、順序付けられたデータファイルで定義されます。データファイルは、キー以外のフィールドで並べ替えられます。
順序付きインデックスには2つのタイプがあります-
- 高密度インデックス
- スパースインデックス
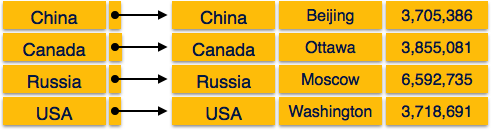
高密度インデックス
高密度インデックスでは、データベース内のすべての検索キー値のインデックスレコードがあります。これにより検索が高速になりますが、インデックスレコード自体を格納するためにより多くのスペースが必要になります。インデックスレコードには、検索キー値とディスク上の実際のレコードへのポインタが含まれています。
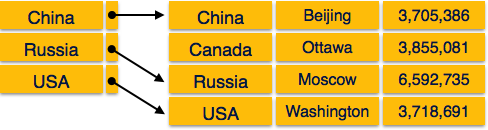
スパースインデックス
スパースインデックスでは、すべての検索キーに対してインデックスレコードが作成されるわけではありません。ここのインデックスレコードには、検索キーとディスク上のデータへの実際のポインタが含まれています。レコードを検索するには、最初にインデックスレコードを続行し、データの実際の場所に到達します。探しているデータがインデックスをたどって直接到達する場所ではない場合、システムは目的のデータが見つかるまで順次検索を開始します。
マルチレベルインデックス
インデックスレコードは、検索キー値とデータポインタで構成されます。マルチレベルインデックスは、実際のデータベースファイルとともにディスクに保存されます。データベースのサイズが大きくなると、インデックスのサイズも大きくなります。検索操作を高速化するために、インデックスレコードをメインメモリに保持する必要性が非常に高くなっています。シングルレベルインデックスが使用されている場合、大きなサイズのインデックスをメモリに保持できず、複数のディスクアクセスが発生します。
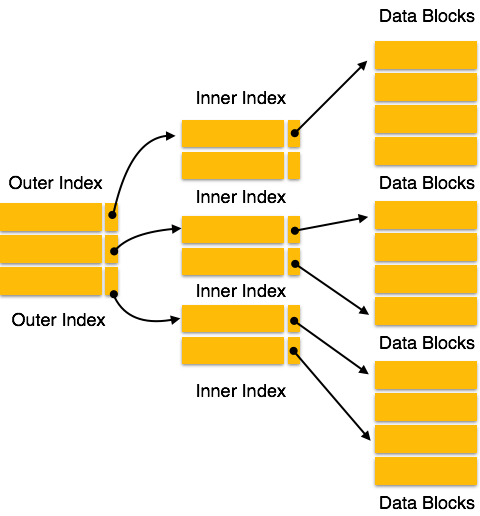
マルチレベルインデックスは、インデックスをいくつかの小さなインデックスに分割して、最も外側のレベルを非常に小さくして、メインメモリのどこにでも簡単に収容できる単一のディスクブロックに保存できるようにするのに役立ちます。
B +ツリー
AB +ツリーは、マルチレベルのインデックス形式に従う平衡二分探索木です。B +ツリーのリーフノードは、実際のデータポインタを示します。B +ツリーにより、すべてのリーフノードが同じ高さに保たれ、バランスが保たれます。さらに、リーフノードはリンクリストを使用してリンクされます。したがって、B +ツリーは、シーケンシャルアクセスだけでなくランダムアクセスもサポートできます。
B +ツリーの構造
すべてのリーフノードは、ルートノードから等距離にあります。AB +ツリーは次の順序ですn どこ nすべてのB +ツリーに対して固定されています。
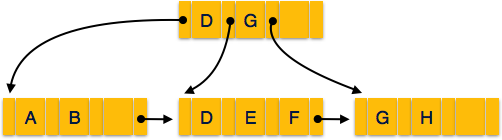
Internal nodes −
- 内部(非リーフ)ノードには、ルートノードを除いて、少なくとも⌈n/2⌉のポインターが含まれています。
- 最大で、内部ノードには次のものを含めることができます n ポインタ。
Leaf nodes −
- リーフノードには、少なくとも⌈n/2⌉レコードポインタと⌈n/2⌉キー値が含まれています。
- リーフノードには最大で n レコードポインタと n キー値。
- すべてのリーフノードには1つのブロックポインタが含まれています P 次のリーフノードをポイントし、リンクリストを形成します。
B +ツリー挿入
B +ツリーは下から埋められ、各エントリはリーフノードで実行されます。
- リーフノードがオーバーフローした場合-
ノードを2つの部分に分割します。
パーティション i = ⌊(m+1)/2⌋.
最初 i エントリは1つのノードに保存されます。
残りのエントリ(i + 1以降)は新しいノードに移動されます。
ith キーはリーフの親で複製されます。
非リーフノードがオーバーフローした場合-
ノードを2つの部分に分割します。
でノードを分割します i = ⌈(m+1)/2⌉。
までのエントリ i 1つのノードに保持されます。
残りのエントリは新しいノードに移動されます。
B +ツリーの削除
B +ツリーエントリはリーフノードで削除されます。
ターゲットエントリが検索され、削除されます。
内部ノードの場合は、削除して左側のエントリに置き換えます。
削除後、アンダーフローがテストされ、
アンダーフローが発生した場合は、左側のノードからエントリを配布します。
左から配布できない場合は
ノードから直接配布します。
左または右からの配布が不可能な場合は、
ノードを左右にマージします。