DynamoDB-クイックガイド
DynamoDBを使用すると、ユーザーは、任意の量のデータを保存および取得し、任意の量のトラフィックを処理できるデータベースを作成できます。データとトラフィックをサーバーに自動的に分散して、各顧客の要求を動的に管理し、高速なパフォーマンスを維持します。
DynamoDBとRDBMS
DynamoDBはNoSQLモデルを使用します。つまり、非リレーショナルシステムを使用します。次の表は、DynamoDBとRDBMSの違いを示しています-
| 一般的なタスク | RDBMS | DynamoDB |
|---|---|---|
| Connect to the Source | 持続的接続とSQLコマンドを使用します。 | HTTPリクエストとAPI操作を使用します |
| Create a Table | その基本構造はテーブルであり、定義する必要があります。 | 主キーのみを使用し、作成時にスキーマを使用しません。さまざまなデータソースを使用します。 |
| Get Table Info | すべてのテーブル情報は引き続きアクセス可能です | 主キーのみが表示されます。 |
| Load Table Data | 列で構成された行を使用します。 | テーブルでは、属性で作られたアイテムを使用します |
| Read Table Data | SELECTステートメントとフィルタリングステートメントを使用します。 | GetItem、Query、およびScanを使用します。 |
| Manage Indexes | SQLステートメントで作成された標準インデックスを使用します。これに対する変更は、テーブルが変更されると自動的に行われます。 | 同じ機能を実現するためにセカンダリインデックスを使用します。仕様(パーティションキーとソートキー)が必要です。 |
| Modify Table Data | UPDATEステートメントを使用します。 | UpdateItem操作を使用します。 |
| Delete Table Data | DELETEステートメントを使用します。 | DeleteItem操作を使用します。 |
| Delete a Table | DROPTABLEステートメントを使用します。 | DeleteTable操作を使用します。 |
利点
DynamoDBの2つの主な利点は、スケーラビリティと柔軟性です。特定のデータソースと構造の使用を強制することはなく、ユーザーは事実上何でも操作できますが、統一された方法で作業できます。
その設計は、より軽いタスクや操作から要求の厳しいエンタープライズ機能まで、幅広い使用をサポートします。また、Ruby、Java、Python、C#、Erlang、PHP、Perlなどの複数の言語を簡単に使用できます。
制限事項
DynamoDBには特定の制限がありますが、これらの制限が必ずしも大きな問題を引き起こしたり、確実な開発を妨げたりするわけではありません。
以下の点から確認できます−
Capacity Unit Sizes−読み取り容量の単位は、4KB以下のアイテムの1秒あたりの単一の一貫した読み取りです。書き込み容量の単位は、1KB以下のアイテムの1秒あたり1回の書き込みです。
Provisioned Throughput Min/Max−すべてのテーブルとグローバルセカンダリインデックスには、少なくとも1つの読み取りおよび1つの書き込み容量ユニットがあります。最大値は地域によって異なります。米国では、40Kの読み取りと書き込みがテーブルあたりの上限(アカウントあたり80K)のままであり、他の地域ではテーブルあたり10Kの上限があり、アカウントの上限は20Kです。
Provisioned Throughput Increase and Decrease −これは必要に応じて何度でも増やすことができますが、減少はテーブルごとに1日4回以下に制限されたままです。
Table Size and Quantity Per Account −テーブルサイズに制限はありませんが、より高い上限を要求しない限り、アカウントには256テーブルの制限があります。
Secondary Indexes Per Table −ローカル5つとグローバル5つが許可されます。
Projected Secondary Index Attributes Per Table −DynamoDBは20個の属性を許可します。
Partition Key Length and Values −最小長は1バイト、最大長は2048バイトですが、DynamoDBでは値に制限はありません。
Sort Key Length and Values −その最小長は1バイト、最大長は1024バイトであり、テーブルでローカルセカンダリインデックスを使用しない限り、値に制限はありません。
Table and Secondary Index Names −名前は、長さが3文字以上、255文字以内である必要があります。AZ、az、0〜9、「_」、「-」、および「。」の文字を使用します。
Attribute Names −キーと特定の属性を除いて、1文字が最小で、64KBが最大のままです。
Reserved Words − DynamoDBは、名前としての予約語の使用を妨げません。
Expression Length−式の文字列には4KBの制限があります。属性式には255バイトの制限があります。式の置換変数には2MBの制限があります。
DynamoDBを使用する前に、その基本的なコンポーネントとエコシステムについて理解しておく必要があります。DynamoDBエコシステムでは、テーブル、属性、およびアイテムを操作します。テーブルはアイテムのセットを保持し、アイテムは属性のセットを保持します。属性は、それ以上の分解を必要としないデータの基本要素、つまりフィールドです。
主キー
主キーはテーブルアイテムの一意の識別手段として機能し、セカンダリインデックスはクエリの柔軟性を提供します。DynamoDBは、テーブルデータを変更することでレコードイベントをストリーミングします。
テーブルの作成には、名前だけでなく主キーも設定する必要があります。テーブルアイテムを識別します。2つのアイテムがキーを共有することはありません。DynamoDBは2種類の主キーを使用します-
Partition Key−この単純な主キーは、「パーティションキー」と呼ばれる単一の属性で構成されます。内部的には、DynamoDBはキー値をハッシュ関数の入力として使用してストレージを決定します。
Partition Key and Sort Key −「複合主キー」と呼ばれるこのキーは、2つの属性で構成されています。
パーティションキーと
ソートキー。
DynamoDBは最初の属性をハッシュ関数に適用し、同じパーティションキーを持つアイテムを一緒に保存します。並べ替えキーによって順序が決定されます。アイテムはパーティションキーを共有できますが、ソートキーは共有できません。
主キー属性は、スカラー(単一)値のみを許可します。文字列、数値、またはバイナリデータ型。非キー属性には、これらの制約はありません。
二次インデックス
これらのインデックスを使用すると、代替キーを使用してテーブルデータをクエリできます。DynamoDBはそれらの使用を強制しませんが、クエリを最適化します。
DynamoDBは2種類のセカンダリインデックスを使用します-
Global Secondary Index −このインデックスには、テーブルキーとは異なる可能性のあるパーティションキーとソートキーがあります。
Local Secondary Index −このインデックスは、テーブルと同じパーティションキーを持っていますが、ソートキーが異なります。
API
DynamoDBが提供するAPIオペレーションには、コントロールプレーン、データプレーン(作成、読み取り、更新、削除など)、ストリームの操作が含まれます。コントロールプレーン操作では、次のツールを使用してテーブルを作成および管理します-
- CreateTable
- DescribeTable
- ListTables
- UpdateTable
- DeleteTable
データプレーンでは、次のツールを使用してCRUD操作を実行します-
| 作成する | 読んだ | 更新 | 削除 |
|---|---|---|---|
PutItem BatchWriteItem |
GetItem BatchGetItem クエリ スキャン |
UpdateItem | DeleteItem BatchWriteItem |
ストリーム操作はテーブルストリームを制御します。次のストリームツールを確認できます-
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
プロビジョニングされたスループット
テーブルの作成では、プロビジョニングされたスループットを指定します。これにより、読み取りと書き込み用にリソースが予約されます。容量単位を使用して、スループットを測定および設定します。
アプリケーションが設定されたスループットを超えると、要求は失敗します。DynamoDB GUIコンソールでは、設定されたスループットと使用されたスループットを監視して、より適切で動的なプロビジョニングを行うことができます。
一貫性を読む
DynamoDBは eventually consistent そして strongly consistent動的なアプリケーションのニーズをサポートするために読み取ります。結果整合性のある読み取りは、常に現在のデータを提供するとは限りません。
非常に一貫性のある読み取りは、常に現在のデータを配信します(機器の障害やネットワークの問題を除く)。結果整合性のある読み取りがデフォルト設定として機能し、でtrueの設定が必要です。ConsistentRead それを変更するパラメータ。
パーティション
DynamoDBは、データストレージにパーティションを使用します。これらのテーブルのストレージ割り当てにはSSDバッキングがあり、ゾーン間で自動的に複製されます。DynamoDBはすべてのパーティションタスクを管理し、ユーザーの関与を必要としません。
テーブルの作成では、テーブルはCREATING状態になり、パーティションが割り当てられます。アクティブ状態になったら、操作を実行できます。容量が最大に達したとき、またはスループットを変更したときに、システムはパーティションを変更します。
DynamoDB環境は、Amazon WebServicesアカウントを使用してDynamoDBGUIコンソールにアクセスするだけで構成されていますが、ローカルインストールを実行することもできます。
次のWebサイトに移動します- https://aws.amazon.com/dynamodb/
「GetStartedwith Amazon DynamoDB」ボタンをクリックするか、Amazon WebServicesアカウントをお持ちでない場合は「CreateAWSAccount」ボタンをクリックします。シンプルなガイド付きプロセスにより、関連するすべての料金と要件が通知されます。
プロセスに必要なすべてのステップを実行すると、アクセスできるようになります。AWSコンソールにサインインしてから、DynamoDBコンソールに移動するだけです。
関連する料金を回避するために、未使用または不要な資料を必ず削除してください。
ローカルインストール
AWS(Amazon Web Service)は、ローカルインストール用のバージョンのDynamoDBを提供します。Webサービスや接続なしでアプリケーションを作成することをサポートします。また、ローカルデータベースを許可することにより、プロビジョニングされたスループット、データストレージ、および転送料金を削減します。このガイドは、ローカルインストールを前提としています。
デプロイの準備ができたら、アプリケーションにいくつかの小さな調整を加えて、AWSでの使用に変換できます。
インストールファイルは .jar executable。Linux、Unix、Windows、およびJavaをサポートするその他のOSで動作します。次のリンクのいずれかを使用してファイルをダウンロードします-
Tarball − http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
Zip archive − http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip
Note−他のリポジトリがファイルを提供しますが、必ずしも最新バージョンである必要はありません。最新のインストールファイルについては、上記のリンクを使用してください。また、Javaランタイムエンジン(JRE)バージョン6.x以降のバージョンがあることを確認してください。DynamoDBは古いバージョンでは実行できません。
適切なアーカイブをダウンロードした後、そのディレクトリ(DynamoDBLocal.jar)を抽出し、目的の場所に配置します。
次に、コマンドプロンプトを開き、DynamoDBLocal.jarを含むディレクトリに移動し、次のコマンドを入力して、DynamoDBを起動できます。
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDbDynamoDBの起動に使用したコマンドプロンプトを閉じて、DynamoDBを停止することもできます。
作業環境
JavaScriptシェル、GUIコンソール、および複数の言語を使用して、DynamoDBを操作できます。使用可能な言語には、Ruby、Java、Python、C#、Erlang、PHP、およびPerlが含まれます。
このチュートリアルでは、概念とコードを明確にするために、JavaおよびGUIコンソールの例を使用します。Javaを利用するには、Java IDE、AWS SDK for Javaをインストールし、JavaSDKのAWSセキュリティ認証情報を設定します。
ローカルからWebサービスコードへの変換
デプロイの準備ができたら、コードを変更する必要があります。調整は、コード言語およびその他の要因によって異なります。主な変更は、単に変更することで構成されていますendpointローカルポイントからAWSリージョンへ。その他の変更には、アプリケーションのより深い分析が必要です。
ローカルインストールは、次の主な違いを含むがこれらに限定されない多くの点でWebサービスと異なります。
ローカルインストールはすぐにテーブルを作成しますが、サービスにははるかに時間がかかります。
ローカルインストールはスループットを無視します。
削除はローカルインストールですぐに行われます。
ネットワークのオーバーヘッドがないため、ローカルインストールでは読み取り/書き込みがすばやく発生します。
DynamoDBには、操作を実行するための3つのオプションがあります。WebベースのGUIコンソール、JavaScriptシェル、および選択したプログラミング言語です。
このチュートリアルでは、明確さと概念を理解するために、GUIコンソールとJava言語の使用に焦点を当てます。
GUIコンソール
GUIコンソールまたはAmazonDynamoDBのAWSマネジメントコンソールは、次のアドレスにあります- https://console.aws.amazon.com/dynamodb/home
これにより、次のタスクを実行できます-
- CRUD
- テーブルアイテムを表示
- テーブルクエリを実行する
- テーブル容量監視のアラームを設定する
- テーブルメトリックをリアルタイムで表示
- テーブルアラームの表示

DynamoDBアカウントにテーブルがない場合は、アクセス時にテーブルの作成をガイドします。そのメイン画面には、一般的な操作を実行するための3つのショートカットがあります-
- テーブルを作成する
- テーブルの追加とクエリ
- テーブルの監視と管理
JavaScriptシェル
DynamoDBには、インタラクティブなJavaScriptシェルが含まれています。シェルはWebブラウザー内で実行され、推奨されるブラウザーにはFirefoxとChromeが含まれます。

Note −他のブラウザを使用すると、エラーが発生する場合があります。
Webブラウザを開き、次のアドレスを入力してシェルにアクセスします-http://localhost:8000/shell
シェルを使用するには、左側のペインにJavaScriptと入力し、左側のペインの右上隅にある[再生]アイコンボタンをクリックして、コードを実行します。コード結果が右側のペインに表示されます。
DynamoDBとJava
Java開発環境を利用して、DynamoDBでJavaを使用します。操作は、通常のJava構文と構造を確認します。
DynamoDBでサポートされるデータ型には、属性、アクション、および選択したコーディング言語に固有のデータ型が含まれます。
属性データ型
DynamoDBは、テーブル属性のデータ型の大規模なセットをサポートしています。各データ型は、次の3つのカテゴリのいずれかに分類されます-
Scalar −これらのタイプは単一の値を表し、数値、文字列、バイナリ、ブール、およびnullが含まれます。
Document −これらのタイプは、ネストされた属性を持つ複雑な構造を表し、リストとマップが含まれます。
Set −これらのタイプは複数のスカラーを表し、文字列セット、数値セット、およびバイナリセットが含まれます。
DynamoDBは、テーブルの作成時に属性やデータ型の定義を必要としないスキーマレスのNoSQLデータベースであることを忘れないでください。テーブルの作成時に列データ型を必要とするRDBMSとは対照的に、主キー属性のデータ型のみが必要です。
スカラー
Numbers − 38桁に制限されており、正、負、またはゼロのいずれかです。
String −これらはUTF-8を使用するUnicodeであり、最小長は> 0、最大長は400KBです。
Binary−暗号化されたデータ、画像、圧縮されたテキストなどのバイナリデータを保存します。DynamoDBは、そのバイトを符号なしと見なします。
Boolean −trueまたはfalseを格納します。
Null −それらは未知または未定義の状態を表します。
資料
List −順序付けられた値のコレクションを格納し、角かっこ([...])を使用します。
Map −順序付けされていない名前と値のペアのコレクションを格納し、中括弧({...})を使用します。
セットする
セットには、数値、文字列、バイナリのいずれであっても、同じタイプの要素が含まれている必要があります。セットに課せられる唯一の制限は、400KBのアイテムサイズ制限で構成され、各要素は一意です。
アクションデータ型
DynamoDB APIは、アクションで使用されるさまざまなデータ型を保持します。次のキータイプの選択を確認できます-
AttributeDefinition −キーテーブルとインデックススキーマを表します。
Capacity −テーブルまたはインデックスによって消費されるスループットの量を表します。
CreateGlobalSecondaryIndexAction −テーブルに追加された新しいグローバルセカンダリインデックスを表します。
LocalSecondaryIndex −ローカルセカンダリインデックスのプロパティを表します。
ProvisionedThroughput −インデックスまたはテーブルのプロビジョニングされたスループットを表します。
PutRequest −PutItemリクエストを表します。
TableDescription −テーブルのプロパティを表します。
サポートされているJavaデータ型
DynamoDBは、Javaのプリミティブデータ型、Setコレクション、および任意の型のサポートを提供します。
テーブルの作成は、通常、テーブルの生成、名前の付け、主キー属性の確立、および属性データ型の設定で構成されます。
これらのタスクを実行するには、GUIコンソール、Java、または別のオプションを利用します。
GUIコンソールを使用してテーブルを作成する
でコンソールにアクセスしてテーブルを作成します https://console.aws.amazon.com/dynamodb。次に、「テーブルの作成」オプションを選択します。
この例では、ID番号(数値属性)で識別される一意の属性の製品を含む、製品情報が入力されたテーブルを生成します。の中にCreate Table画面で、テーブル名フィールドにテーブル名を入力します。パーティションキーフィールドに主キー(ID)を入力します。データ型に「数値」を入力します。
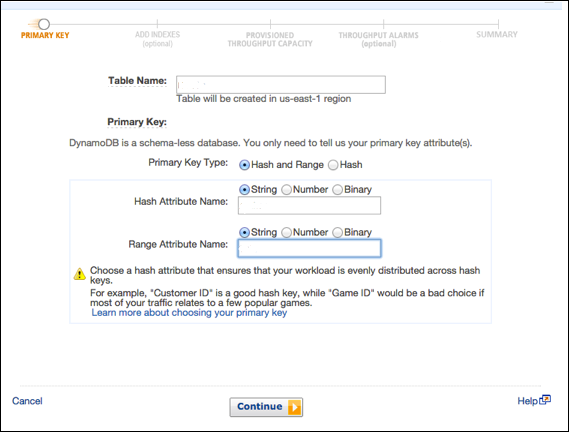
すべての情報を入力したら、 Create。
Javaを使用してテーブルを作成する
Javaを使用して同じテーブルを作成します。その主キーは、次の2つの属性で構成されます-
ID −パーティションキーとScalarAttributeTypeを使用します N、数を意味します。
Nomenclature −ソートキーとScalarAttributeTypeを使用します S、文字列を意味します。
Javaは createTable methodテーブルを生成します。呼び出し内で、テーブル名、主キー属性、および属性データ型が指定されます。
次の例を確認できます-
import java.util.Arrays;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ScalarAttributeType;
public class ProductsCreateTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
String tableName = "Products";
try {
System.out.println("Creating the table, wait...");
Table table = dynamoDB.createTable (tableName,
Arrays.asList (
new KeySchemaElement("ID", KeyType.HASH), // the partition key
// the sort key
new KeySchemaElement("Nomenclature", KeyType.RANGE)
),
Arrays.asList (
new AttributeDefinition("ID", ScalarAttributeType.N),
new AttributeDefinition("Nomenclature", ScalarAttributeType.S)
),
new ProvisionedThroughput(10L, 10L)
);
table.waitForActive();
System.out.println("Table created successfully. Status: " +
table.getDescription().getTableStatus());
} catch (Exception e) {
System.err.println("Cannot create the table: ");
System.err.println(e.getMessage());
}
}
}上記の例では、エンドポイントに注意してください。 .withEndpoint。
ローカルホストを使用したローカルインストールの使用を示します。また、必要なことに注意してくださいProvisionedThroughput parameter、ローカルインストールは無視します。
テーブルのロードは通常、ソースファイルの作成、ソースファイルがDynamoDBと互換性のある構文に準拠していることの確認、ソースファイルの宛先への送信、および正常な設定の確認で構成されます。
GUIコンソール、Java、または別のオプションを使用してタスクを実行します。
GUIコンソールを使用してテーブルをロードする
コマンドラインとコンソールの組み合わせを使用してデータをロードします。データは複数の方法でロードできますが、そのいくつかは次のとおりです。
- コンソール
- コマンドライン
- コードとまた
- データパイプライン(チュートリアルの後半で説明する機能)
ただし、速度を上げるために、この例ではシェルとコンソールの両方を使用しています。まず、次の構文でソースデータを宛先にロードします-
aws dynamodb batch-write-item -–request-items file://[filename]例-
aws dynamodb batch-write-item -–request-items file://MyProductData.json−のコンソールにアクセスして、操作が成功したことを確認します。
https://console.aws.amazon.com/dynamodb
選択 Tables ナビゲーションペインから、テーブルリストから宛先テーブルを選択します。
を選択 Itemsタブを使用して、テーブルへの入力に使用したデータを調べます。選択するCancel テーブルリストに戻ります。
Javaを使用してテーブルをロードする
最初にソースファイルを作成してJavaを採用します。ソースファイルはJSON形式を使用しています。各製品には、2つの主キー属性(IDと命名法)とJSONマップ(統計)があります-
[
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
...
]次の例を確認できます-
{
"ID" : 122,
"Nomenclature" : "Particle Blaster 5000",
"Stat" : {
"Manufacturer" : "XYZ Inc.",
"sales" : "1M+",
"quantity" : 500,
"img_src" : "http://www.xyz.com/manuals/particleblaster5000.jpg",
"description" : "A laser cutter used in plastic manufacturing."
}
}次のステップは、アプリケーションが使用するディレクトリにファイルを配置することです。
Javaは主に putItem そして path methods ロードを実行します。
ファイルを処理してロードするための次のコード例を確認できます-
import java.io.File;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.databind.node.ObjectNode;
public class ProductsLoadData {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
JsonParser parser = new JsonFactory()
.createParser(new File("productinfo.json"));
JsonNode rootNode = new ObjectMapper().readTree(parser);
Iterator<JsonNode> iter = rootNode.iterator();
ObjectNode currentNode;
while (iter.hasNext()) {
currentNode = (ObjectNode) iter.next();
int ID = currentNode.path("ID").asInt();
String Nomenclature = currentNode.path("Nomenclature").asText();
try {
table.putItem(new Item()
.withPrimaryKey("ID", ID, "Nomenclature", Nomenclature)
.withJSON("Stat", currentNode.path("Stat").toString()));
System.out.println("Successful load: " + ID + " " + Nomenclature);
} catch (Exception e) {
System.err.println("Cannot add product: " + ID + " " + Nomenclature);
System.err.println(e.getMessage());
break;
}
}
parser.close();
}
}テーブルのクエリでは、主にテーブルを選択し、パーティションキーを指定して、クエリを実行する必要があります。セカンダリインデックスを使用し、スキャン操作を通じてより詳細なフィルタリングを実行するオプションがあります。
GUIコンソール、Java、または別のオプションを使用してタスクを実行します。
GUIコンソールを使用したテーブルのクエリ
以前に作成したテーブルを使用して、いくつかの簡単なクエリを実行します。まず、コンソールを開きます。https://console.aws.amazon.com/dynamodb
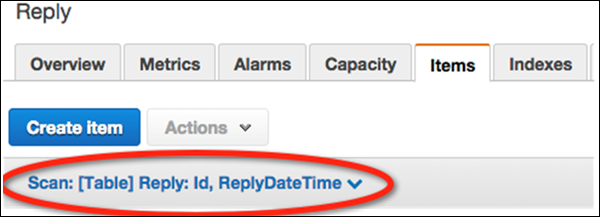
選択 Tables ナビゲーションペインから、 Replyテーブルリストから。次に、Items タブをクリックして、ロードされたデータを表示します。
下のデータフィルタリングリンク(「スキャン:[テーブル]返信」)を選択します Create Item ボタン。
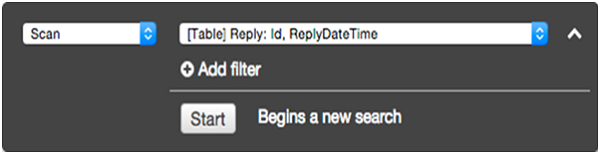
フィルタリング画面で、操作のクエリを選択します。適切なパーティションキー値を入力し、をクリックしますStart。
ザ・ Reply 次に、テーブルは一致するアイテムを返します。
Javaを使用したテーブルのクエリ
Javaのqueryメソッドを使用して、データ取得操作を実行します。オプションとしてソートキーを使用して、パーティションキー値を指定する必要があります。
最初に作成してJavaクエリをコーディングします querySpec objectパラメータの説明。次に、オブジェクトをクエリメソッドに渡します。前の例のパーティションキーを使用します。
次の例を確認できます-
import java.util.HashMap;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
public class ProductsQuery {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
HashMap<String, String> nameMap = new HashMap<String, String>();
nameMap.put("#ID", "ID");
HashMap<String, Object> valueMap = new HashMap<String, Object>();
valueMap.put(":xxx", 122);
QuerySpec querySpec = new QuerySpec()
.withKeyConditionExpression("#ID = :xxx")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(valueMap);
ItemCollection<QueryOutcome> items = null;
Iterator<Item> iterator = null;
Item item = null;
try {
System.out.println("Product with the ID 122");
items = table.query(querySpec);
iterator = items.iterator();
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.getNumber("ID") + ": "
+ item.getString("Nomenclature"));
}
} catch (Exception e) {
System.err.println("Cannot find products with the ID number 122");
System.err.println(e.getMessage());
}
}
}クエリはパーティションキーを使用しますが、セカンダリインデックスはクエリに別のオプションを提供することに注意してください。それらの柔軟性により、キー以外の属性のクエリが可能になります。これについては、このチュートリアルの後半で説明します。
scanメソッドは、すべてのテーブルデータを収集することにより、取得操作もサポートします。ザ・optional .withFilterExpression 指定された基準外のアイテムが結果に表示されないようにします。
このチュートリアルの後半で、 scanning詳細に。ここで、次の例を見てください-
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.ScanSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class ProductsScan {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
ScanSpec scanSpec = new ScanSpec()
.withProjectionExpression("#ID, Nomenclature , stat.sales")
.withFilterExpression("#ID between :start_id and :end_id")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(new ValueMap().withNumber(":start_id", 120)
.withNumber(":end_id", 129));
try {
ItemCollection<ScanOutcome> items = table.scan(scanSpec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
Item item = iter.next();
System.out.println(item.toString());
}
} catch (Exception e) {
System.err.println("Cannot perform a table scan:");
System.err.println(e.getMessage());
}
}
}この章では、テーブルを削除する方法と、テーブルを削除するさまざまな方法について説明します。
テーブルの削除は、テーブル名だけを必要とする単純な操作です。このタスクを実行するには、GUIコンソール、Java、またはその他のオプションを利用します。
GUIコンソールを使用してテーブルを削除する
最初に-でコンソールにアクセスして、削除操作を実行します。
https://console.aws.amazon.com/dynamodb。
選択 Tables ナビゲーションペインから、次の画面に示すように、テーブルリストから削除するテーブルを選択します。
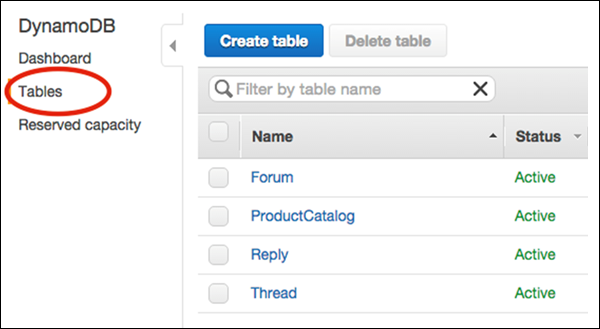
最後に、 Delete Table。[テーブルの削除]を選択すると、確認が表示されます。その後、テーブルが削除されます。
Javaを使用してテーブルを削除する
使用 deleteテーブルを削除する方法。概念をよりよく説明するために、以下に例を示します。
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ProductsDeleteTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
try {
System.out.println("Performing table delete, wait...");
table.delete();
table.waitForDelete();
System.out.print("Table successfully deleted.");
} catch (Exception e) {
System.err.println("Cannot perform table delete: ");
System.err.println(e.getMessage());
}
}
}DynamoDBは、テーブル操作、データ読み取り、およびデータ変更のための強力なAPIツールの幅広いセットを提供します。
Amazonは使用をお勧めします AWS SDKs(たとえば、Java SDK)低レベルのAPIを呼び出すのではなく。ライブラリを使用すると、低レベルのAPIと直接やり取りする必要がなくなります。ライブラリは、認証、シリアル化、接続などの一般的なタスクを簡素化します。
テーブルを操作する
DynamoDBは、テーブル管理のための5つの低レベルアクションを提供します-
CreateTable−これはテーブルを生成し、ユーザーが設定したスループットを含みます。複合か単純かにかかわらず、主キーを設定する必要があります。また、1つまたは複数のセカンダリインデックスを使用できます。
ListTables −これは、現在のAWSユーザーのアカウントにあり、エンドポイントに関連付けられているすべてのテーブルのリストを提供します。
UpdateTable −これにより、スループットとグローバルセカンダリインデックスのスループットが変更されます。
DescribeTable−これはテーブルメタデータを提供します。たとえば、状態、サイズ、インデックスなどです。
DeleteTable −これは単にテーブルとそのインデックスを消去します。
データの読み取り
DynamoDBは、データ読み取りのための4つの低レベルアクションを提供します-
GetItem−主キーを受け入れ、関連するアイテムの属性を返します。デフォルトの結果整合性のある読み取り設定への変更を許可します。
BatchGetItem− 1つまたは複数のテーブルのオプションを使用して、主キーを介して複数のアイテムに対して複数のGetItemリクエストを実行します。返されるアイテムは100個以下で、16MB未満である必要があります。結果整合性と強い整合性のある読み取りが可能になります。
Scan−すべてのテーブル項目を読み取り、結果整合性のある結果セットを生成します。条件で結果をフィルタリングできます。インデックスの使用を回避し、テーブル全体をスキャンするため、予測可能性を必要とするクエリには使用しないでください。
Query−単一または複数のテーブルアイテムまたはセカンダリインデックスアイテムを返します。パーティションキーに指定された値を使用し、比較演算子を使用してスコープを狭めることができます。両方のタイプの整合性のサポートが含まれ、各応答はサイズの1MBの制限に従います。
データの変更
DynamoDBは、データ変更のための4つの低レベルアクションを提供します-
PutItem−これにより、新しいアイテムが生成されるか、既存のアイテムが置き換えられます。同一の主キーが検出されると、デフォルトでアイテムが置き換えられます。条件付き演算子を使用すると、デフォルトを回避し、特定の条件下でのみアイテムを置き換えることができます。
BatchWriteItem−これは、複数のPutItemリクエストとDeleteItemリクエストの両方を、複数のテーブルで実行します。1つの要求が失敗しても、操作全体に影響はありません。キャップは25アイテム、サイズは16MBです。
UpdateItem −既存のアイテム属性を変更し、条件演算子を使用して特定の条件下でのみ更新を実行できるようにします。
DeleteItem −主キーを使用してアイテムを消去し、条件演算子を使用して削除の条件を指定することもできます。
DynamoDBでのアイテムの作成は、主にアイテムと属性の指定、および条件を指定するオプションで構成されます。各アイテムは属性のセットとして存在し、各属性には特定のタイプの値が指定され、割り当てられています。
値のタイプには、スカラー、ドキュメント、またはセットが含まれます。アイテムには400KBのサイズ制限があり、その制限内に収まる属性がいくつでもある可能性があります。名前と値のサイズ(バイナリおよびUTF-8の長さ)によってアイテムのサイズが決まります。短い属性名を使用すると、アイテムのサイズを最小限に抑えることができます。
Note−すべての主キー属性を指定する必要があります。主キーにはパーティションキーのみが必要です。パーティションキーとソートキーの両方を必要とする複合キー。
また、テーブルには事前定義されたスキーマがないことを忘れないでください。劇的に異なるデータセットを1つのテーブルに保存できます。
このタスクを実行するには、GUIコンソール、Java、または別のツールを使用します。
GUIコンソールを使用してアイテムを作成する方法は?
コンソールに移動します。左側のナビゲーションペインで、[Tables。宛先として使用するテーブル名を選択してから、Items 次のスクリーンショットに示すようにタブ。
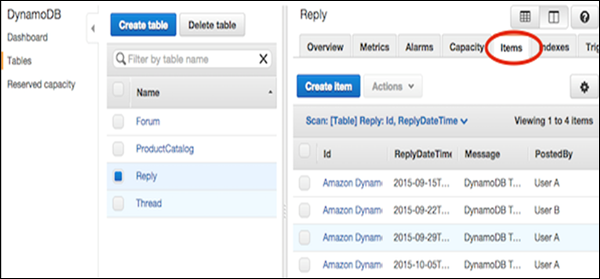
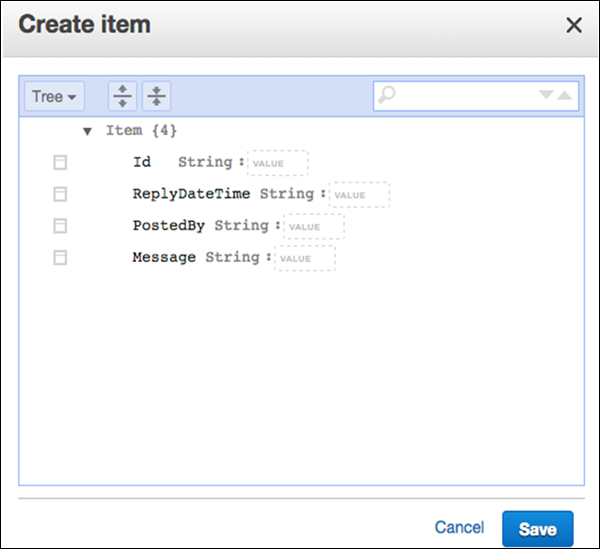
選択する Create Item。[アイテムの作成]画面には、必要な属性値を入力するためのインターフェイスがあります。セカンダリインデックスも入力する必要があります。
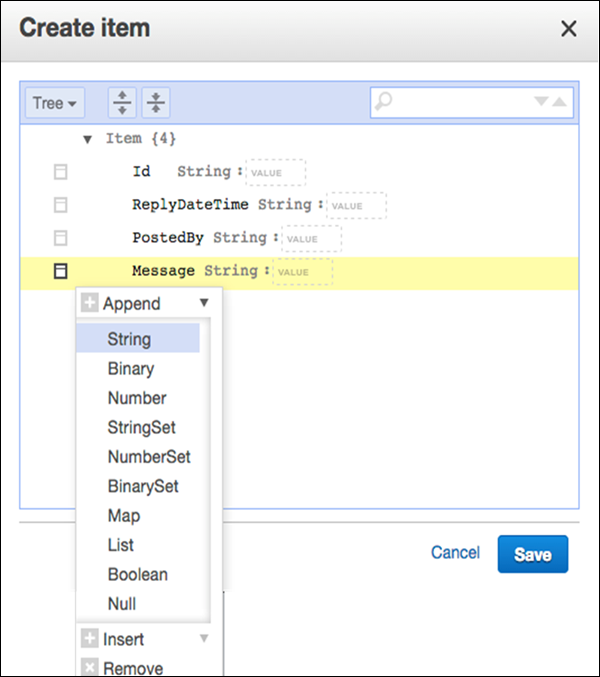
さらに属性が必要な場合は、左側のアクションメニューを選択してください Message。次に、Append、および目的のデータ型。
すべての重要な情報を入力した後、 Save アイテムを追加します。
アイテム作成でJavaを使用する方法は?
アイテム作成操作でJavaを使用することは、DynamoDBクラスインスタンス、テーブルクラスインスタンス、アイテムクラスインスタンスを作成し、作成するアイテムの主キーと属性を指定することで構成されます。次に、putItemメソッドを使用して新しいアイテムを追加します。
例
DynamoDB dynamoDB = new DynamoDB (new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
// Spawn a related items list
List<Number> RELItems = new ArrayList<Number>();
RELItems.add(123);
RELItems.add(456);
RELItems.add(789);
//Spawn a product picture map
Map<String, String> photos = new HashMap<String, String>();
photos.put("Anterior", "http://xyz.com/products/101_front.jpg");
photos.put("Posterior", "http://xyz.com/products/101_back.jpg");
photos.put("Lateral", "http://xyz.com/products/101_LFTside.jpg");
//Spawn a product review map
Map<String, List<String>> prodReviews = new HashMap<String, List<String>>();
List<String> fiveStarRVW = new ArrayList<String>();
fiveStarRVW.add("Shocking high performance.");
fiveStarRVW.add("Unparalleled in its market.");
prodReviews.put("5 Star", fiveStarRVW);
List<String> oneStarRVW = new ArrayList<String>();
oneStarRVW.add("The worst offering in its market.");
prodReviews.put("1 Star", oneStarRVW);
// Generate the item
Item item = new Item()
.withPrimaryKey("Id", 101)
.withString("Nomenclature", "PolyBlaster 101")
.withString("Description", "101 description")
.withString("Category", "Hybrid Power Polymer Cutter")
.withString("Make", "Brand – XYZ")
.withNumber("Price", 50000)
.withString("ProductCategory", "Laser Cutter")
.withBoolean("Availability", true)
.withNull("Qty")
.withList("ItemsRelated", RELItems)
.withMap("Images", photos)
.withMap("Reviews", prodReviews);
// Add item to the table
PutItemOutcome outcome = table.putItem(item);次の大きな例もご覧ください。
Note−次のサンプルは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
次のサンプルでは、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class CreateItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
}DynamoDBでアイテムを取得するには、GetItemを使用し、テーブル名とアイテムの主キーを指定する必要があります。一部を省略するのではなく、必ず完全な主キーを含めてください。
たとえば、複合キーのソートキーを省略します。
GetItemの動作は3つのデフォルトに準拠しています-
- 結果整合性のある読み取りとして実行されます。
- すべての属性を提供します。
- 容量単位の消費量については詳しく説明していません。
これらのパラメーターを使用すると、デフォルトのGetItemの動作をオーバーライドできます。
アイテムを取得する
DynamoDBは、複数のサーバー間でアイテムの複数のコピーを維持することで信頼性を確保します。書き込みが成功するたびにこれらのコピーが作成されますが、実行にはかなりの時間がかかります。結果整合性を意味します。つまり、アイテムを書き込んだ後すぐに読み取りを試みることはできません。
GetItemのデフォルトの結果整合性のある読み取りを変更できますが、より新しいデータのコストは、より多くの容量ユニットの消費のままです。具体的には、2倍です。注DynamoDBは通常、1秒以内にすべてのコピーで一貫性を実現します。
GUIコンソール、Java、または別のツールを使用して、このタスクを実行できます。
Javaを使用したアイテムの取得
アイテム取得操作でJavaを使用するには、DynamoDBクラスインスタンス、テーブルクラスインスタンスを作成し、テーブルインスタンスのgetItemメソッドを呼び出す必要があります。次に、アイテムの主キーを指定します。
次の例を確認できます-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
Item item = table.getItem("IDnum", 109);場合によっては、この操作のパラメーターを指定する必要があります。
次の例では、 .withProjectionExpression そして GetItemSpec 検索仕様用-
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("IDnum", 122)
.withProjectionExpression("IDnum, EmployeeName, Department")
.withConsistentRead(true);
Item item = table.getItem(spec);
System.out.println(item.toJSONPretty());理解を深めるために、次の大きな例を確認することもできます。
Note−次のサンプルは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
このサンプルでは、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
package com.amazonaws.codesamples.document;
import java.io.IOException
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class GetItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void retrieveItem() {
Table table = dynamoDB.getTable(tableName);
try {
Item item = table.getItem("ID", 303, "ID, Nomenclature, Manufacturers", null);
System.out.println("Displaying retrieved items...");
System.out.println(item.toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot retrieve items.");
System.err.println(e.getMessage());
}
}
}DynamoDBでアイテムを更新するには、主にアイテムの完全な主キーとテーブル名を指定します。変更する属性ごとに新しい値が必要です。操作は使用しますUpdateItem、既存のアイテムを変更するか、不足しているアイテムの発見時にそれらを作成します。
更新では、操作の前後に元の値と新しい値を表示して変更を追跡することができます。UpdateItemはReturnValues これを達成するためのパラメータ。
Note −操作は容量単位消費を報告しませんが、使用することができます ReturnConsumedCapacity パラメータ。
このタスクを実行するには、GUIコンソール、Java、またはその他のツールを使用します。
GUIツールを使用してアイテムを更新する方法は?
コンソールに移動します。左側のナビゲーションペインで、[Tables。必要なテーブルを選択してから、Items タブ。
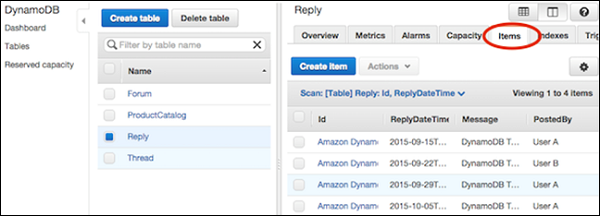
更新したい項目を選択し、 Actions | Edit。
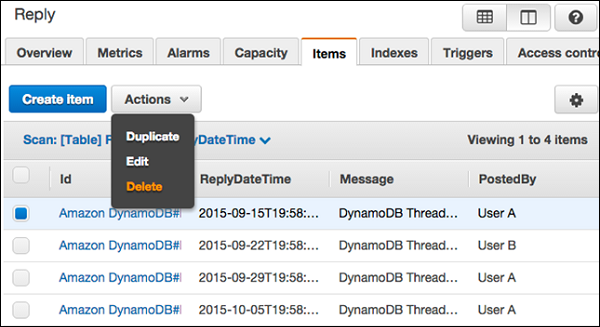
で必要な属性または値を変更します Edit Item 窓。
Javaを使用してアイテムを更新する
アイテムの更新操作でJavaを使用するには、Tableクラスインスタンスを作成し、そのインスタンスを呼び出す必要があります。 updateItem方法。次に、アイテムの主キーを指定し、UpdateExpression 属性の変更の詳細。
以下は同じ例です-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#M", "Make");
expressionAttributeNames.put("#P", "Price
expressionAttributeNames.put("#N", "ID");
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":val1",
new HashSet<String>(Arrays.asList("Make1","Make2")));
expressionAttributeValues.put(":val2", 1); //Price
UpdateItemOutcome outcome = table.updateItem(
"internalID", // key attribute name
111, // key attribute value
"add #M :val1 set #P = #P - :val2 remove #N", // UpdateExpression
expressionAttributeNames,
expressionAttributeValues);ザ・ updateItem メソッドでは、条件を指定することもできます。これは、次の例で確認できます。
Table table = dynamoDB.getTable("ProductList");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#P", "Price");
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":val1", 44); // change Price to 44
expressionAttributeValues.put(":val2", 15); // only if currently 15
UpdateItemOutcome outcome = table.updateItem (new PrimaryKey("internalID",111),
"set #P = :val1", // Update
"#P = :val2", // Condition
expressionAttributeNames,
expressionAttributeValues);カウンターを使用してアイテムを更新する
DynamoDBはアトミックカウンターを許可します。つまり、UpdateItemを使用して、他のリクエストに影響を与えることなく属性値をインクリメント/デクリメントします。さらに、カウンターは常に更新されます。
以下は、それを行う方法を説明する例です。
Note−次のサンプルは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
このサンプルでは、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class UpdateItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void updateAddNewAttribute() {
Table table = dynamoDB.getTable(tableName);
try {
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#na", "NewAttribute");
UpdateItemSpec updateItemSpec = new UpdateItemSpec()
.withPrimaryKey("ID", 303)
.withUpdateExpression("set #na = :val1")
.withNameMap(new NameMap()
.with("#na", "NewAttribute"))
.withValueMap(new ValueMap()
.withString(":val1", "A value"))
.withReturnValues(ReturnValue.ALL_NEW);
UpdateItemOutcome outcome = table.updateItem(updateItemSpec);
// Confirm
System.out.println("Displaying updated item...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot add an attribute in " + tableName);
System.err.println(e.getMessage());
}
}
}DynamoDBでアイテムを削除するには、テーブル名とアイテムキーを指定するだけで済みます。また、間違った項目を削除しないようにするために必要な条件式を使用することを強くお勧めします。
いつものように、GUIコンソール、Java、またはその他の必要なツールを使用して、このタスクを実行できます。
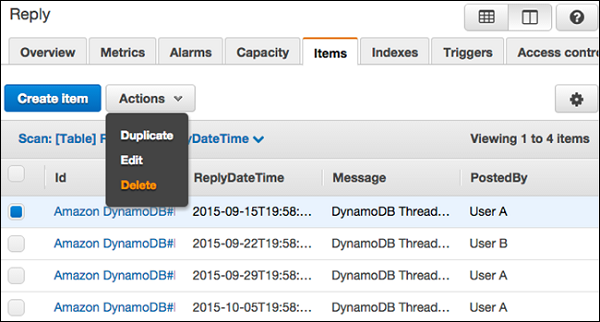
GUIコンソールを使用してアイテムを削除する
コンソールに移動します。左側のナビゲーションペインで、[Tables。次に、テーブル名を選択し、Items タブ。
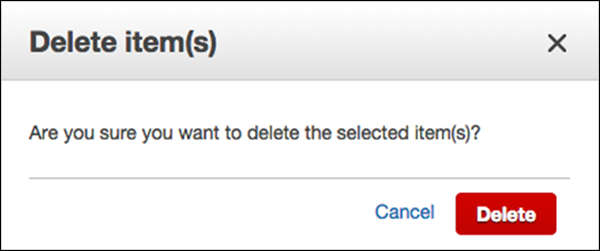
削除したい項目を選択し、 Actions | Delete。
A Delete Item(s)次の画面に示すように、ダイアログボックスが表示されます。「削除」を選択して確認します。
Javaを使用してアイテムを削除する方法は?
アイテムの削除操作でJavaを使用するには、DynamoDBクライアントインスタンスを作成し、 deleteItem アイテムのキーを使用する方法。
あなたはそれが詳細に説明されている次の例を見ることができます。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
DeleteItemOutcome outcome = table.deleteItem("IDnum", 151);誤った削除から保護するためのパラメーターを指定することもできます。単に使用するConditionExpression。
例-
Map<String,Object> expressionAttributeValues = new HashMap<String,Object>();
expressionAttributeValues.put(":val", false);
DeleteItemOutcome outcome = table.deleteItem("IDnum",151,
"Ship = :val",
null, // doesn't use ExpressionAttributeNames
expressionAttributeValues);以下は、理解を深めるためのより大きな例です。
Note−次のサンプルは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
このサンプルでは、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class DeleteItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void deleteItem() {
Table table = dynamoDB.getTable(tableName);
try {
DeleteItemSpec deleteItemSpec = new DeleteItemSpec()
.withPrimaryKey("ID", 303)
.withConditionExpression("#ip = :val")
.withNameMap(new NameMap()
.with("#ip", "InProduction"))
.withValueMap(new ValueMap()
.withBoolean(":val", false))
.withReturnValues(ReturnValue.ALL_OLD);
DeleteItemOutcome outcome = table.deleteItem(deleteItemSpec);
// Confirm
System.out.println("Displaying deleted item...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot delete item in " + tableName);
System.err.println(e.getMessage());
}
}
}バッチ書き込みは、複数のアイテムを作成または削除することにより、複数のアイテムに対して機能します。これらの操作はBatchWriteItem、16MB以下の書き込みと25リクエストの制限があります。各アイテムは400KBのサイズ制限に従います。バッチ書き込みでもアイテムの更新は実行できません。
バッチ書き込みとは何ですか?
バッチ書き込みでは、複数のテーブル間でアイテムを操作できます。操作の呼び出しは個々の要求ごとに発生します。つまり、操作は相互に影響を与えず、異種混合が許可されます。たとえば、1つPutItem と3つ DeleteItemバッチ内のリクエスト。PutItemリクエストの失敗は他のリクエストに影響を与えません。リクエストが失敗すると、操作は失敗した各リクエストに関連する情報(キーとデータ)を返します。
Note− DynamoDBがアイテムを処理せずに返す場合は、それらを再試行します。ただし、オーバーロードに基づく別のリクエストの失敗を回避するには、バックオフ方式を使用してください。
以下のステートメントの1つ以上が真であることが証明された場合、DynamoDBはバッチ書き込み操作を拒否します-
リクエストがプロビジョニングされたスループットを超えています。
リクエストは使用しようとします BatchWriteItems アイテムを更新します。
リクエストは、1つのアイテムに対して複数の操作を実行します。
リクエストテーブルが存在しません。
リクエストのアイテム属性がターゲットと一致しません。
リクエストがサイズ制限を超えています。
バッチ書き込みには特定のものが必要です RequestItem パラメータ-
削除操作が必要 DeleteRequest キー subelements 属性名と値を意味します。
ザ・ PutRequest アイテムには Item subelement 属性と属性値のマップを意味します。
Response −操作が成功すると、HTTP 200応答が生成されます。これは、消費された容量単位、テーブル処理メトリック、および未処理のアイテムなどの特性を示します。
Javaでのバッチ書き込み
DynamoDBクラスインスタンスを作成してバッチ書き込みを実行します。 TableWriteItems すべての操作を記述し、を呼び出すクラスインスタンス batchWriteItem TableWriteItemsオブジェクトを使用するメソッド。
Note−複数のテーブルへのバッチ書き込みでは、すべてのテーブルに対してTableWriteItemsインスタンスを作成する必要があります。また、未処理のリクエストがないかリクエストレスポンスを確認してください。
次のバッチ書き込みの例を確認できます-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
TableWriteItems forumTableWriteItems = new TableWriteItems("Forum")
.withItemsToPut(
new Item()
.withPrimaryKey("Title", "XYZ CRM")
.withNumber("Threads", 0));
TableWriteItems threadTableWriteItems = new TableWriteItems(Thread)
.withItemsToPut(
new Item()
.withPrimaryKey("ForumTitle","XYZ CRM","Topic","Updates")
.withHashAndRangeKeysToDelete("ForumTitle","A partition key value",
"Product Line 1", "A sort key value"));
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem (
forumTableWriteItems, threadTableWriteItems);次のプログラムは、バッチがJavaでどのように書き込むかをよりよく理解するためのもう1つの大きな例です。
Note−次の例では、以前に作成されたデータソースを想定しています。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
この例では、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.BatchWriteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.TableWriteItems;
import com.amazonaws.services.dynamodbv2.model.WriteRequest;
public class BatchWriteOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
batchWriteMultiItems();
}
private static void batchWriteMultiItems() {
try {
// Place new item in Forum
TableWriteItems forumTableWriteItems = new TableWriteItems(forumTableName)
//Forum
.withItemsToPut(new Item()
.withPrimaryKey("Name", "Amazon RDS")
.withNumber("Threads", 0));
// Place one item, delete another in Thread
// Specify partition key and range key
TableWriteItems threadTableWriteItems = new TableWriteItems(threadTableName)
.withItemsToPut(new Item()
.withPrimaryKey("ForumName","Product
Support","Subject","Support Thread 1")
.withString("Message", "New OS Thread 1 message")
.withHashAndRangeKeysToDelete("ForumName","Subject", "Polymer Blaster",
"Support Thread 100"));
System.out.println("Processing request...");
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem (
forumTableWriteItems, threadTableWriteItems);
do {
// Confirm no unprocessed items
Map<String, List<WriteRequest>> unprocessedItems
= outcome.getUnprocessedItems();
if (outcome.getUnprocessedItems().size() == 0) {
System.out.println("All items processed.");
} else {
System.out.println("Gathering unprocessed items...");
outcome = dynamoDB.batchWriteItemUnprocessed(unprocessedItems);
}
} while (outcome.getUnprocessedItems().size() > 0);
} catch (Exception e) {
System.err.println("Could not get items: ");
e.printStackTrace(System.err);
}
}
}バッチ取得操作は、単一または複数のアイテムの属性を返します。これらの操作は通常、主キーを使用して目的のアイテムを識別することで構成されます。ザ・BatchGetItem 操作は、個々の操作の制限と独自の制約の対象となります。
バッチ検索操作での次の要求により、拒否されます-
- 100個以上のアイテムをリクエストしてください。
- スループットを超えるリクエストを行います。
バッチ取得操作は、制限を超える可能性のある要求の部分的な処理を実行します。
For example−制限を超えるのに十分なサイズの複数のアイテムを取得する要求は、要求処理の一部になり、未処理の部分を示すエラーメッセージが表示されます。未処理のアイテムが戻ってきたら、テーブルを調整するのではなく、これを管理するためのバックオフアルゴリズムソリューションを作成します。
ザ・ BatchGet操作は最終的に一貫した読み取りで実行されるため、一貫性の高い読み取りを変更する必要があります。また、並行して検索を実行します。
Note−返品されたアイテムの順序。DynamoDBはアイテムをソートしません。また、要求されたアイテムがないことを示すものでもありません。さらに、これらの要求は容量単位を消費します。
すべてのBatchGet操作には RequestItems 読み取りの一貫性、属性名、主キーなどのパラメーター。
Response −操作が成功すると、HTTP 200応答が生成されます。これは、消費された容量単位、テーブル処理メトリック、および未処理のアイテムなどの特性を示します。
Javaを使用したバッチ取得
BatchGet操作でJavaを使用するには、DynamoDBクラスインスタンスを作成する必要があります。 TableKeysAndAttributes アイテムの主キー値リストを記述し、TableKeysAndAttributesオブジェクトをに渡すクラスインスタンス BatchGetItem 方法。
以下は、BatchGet操作の例です-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
TableKeysAndAttributes forumTableKeysAndAttributes = new TableKeysAndAttributes
(forumTableName);
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys (
"Title",
"Updates",
"Product Line 1"
);
TableKeysAndAttributes threadTableKeysAndAttributes = new TableKeysAndAttributes (
threadTableName);
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys (
"ForumTitle",
"Topic",
"Product Line 1",
"P1 Thread 1",
"Product Line 1",
"P1 Thread 2",
"Product Line 2",
"P2 Thread 1"
);
BatchGetItemOutcome outcome = dynamoDB.batchGetItem (
forumTableKeysAndAttributes, threadTableKeysAndAttributes);
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Table items " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item);
}
}次の大きな例を確認できます。
Note−次のプログラムは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
このプログラムは、Eclipse IDE、AWS認証ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用します。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.BatchGetItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.TableKeysAndAttributes;
import com.amazonaws.services.dynamodbv2.model.KeysAndAttributes;
public class BatchGetOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
retrieveMultipleItemsBatchGet();
}
private static void retrieveMultipleItemsBatchGet() {
try {
TableKeysAndAttributes forumTableKeysAndAttributes =
new TableKeysAndAttributes(forumTableName);
//Create partition key
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys (
"Name",
"XYZ Melt-O-tron",
"High-Performance Processing"
);
TableKeysAndAttributes threadTableKeysAndAttributes =
new TableKeysAndAttributes(threadTableName);
//Create partition key and sort key
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys (
"ForumName",
"Subject",
"High-Performance Processing",
"HP Processing Thread One",
"High-Performance Processing",
"HP Processing Thread Two",
"Melt-O-Tron",
"MeltO Thread One"
);
System.out.println("Processing...");
BatchGetItemOutcome outcome = dynamoDB.batchGetItem(forumTableKeysAndAttributes,
threadTableKeysAndAttributes);
Map<String, KeysAndAttributes> unprocessed = null;
do {
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Table items for " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item.toJSONPretty());
}
}
// Confirm no unprocessed items
unprocessed = outcome.getUnprocessedKeys();
if (unprocessed.isEmpty()) {
System.out.println("All items processed.");
} else {
System.out.println("Gathering unprocessed items...");
outcome = dynamoDB.batchGetItemUnprocessed(unprocessed);
}
} while (!unprocessed.isEmpty());
} catch (Exception e) {
System.err.println("Could not get items.");
System.err.println(e.getMessage());
}
}
}クエリは、主キーを介してアイテムまたはセカンダリインデックスを検索します。クエリを実行するには、パーティションキーと特定の値、または並べ替えキーと値が必要です。比較でフィルタリングするオプションがあります。クエリのデフォルトの動作は、提供された主キーに関連付けられたアイテムのすべての属性を返すことで構成されます。ただし、を使用して目的の属性を指定できます。ProjectionExpression パラメータ。
クエリは KeyConditionExpression項目を選択するためのパラメーター。これには、等式条件の形式でパーティションキーの名前と値を指定する必要があります。存在するソートキーに追加の条件を提供するオプションもあります。
ソートキー条件のいくつかの例は次のとおりです。
| シニア番号 | 状態と説明 |
|---|---|
| 1 | x = y 属性xがyと等しい場合、trueと評価されます。 |
| 2 | x < y xがyより小さい場合、trueと評価されます。 |
| 3 | x <= y xがy以下の場合、trueと評価されます。 |
| 4 | x > y xがyより大きい場合、trueと評価されます。 |
| 5 | x >= y xがy以上の場合、trueと評価されます。 |
| 6 | x BETWEEN y AND z xが> = yであり、<= zである場合、trueと評価されます。 |
DynamoDBは、次の機能もサポートしています。 begins_with (x, substr)
属性xが指定された文字列で始まる場合、trueと評価されます。
以下の条件は、特定の要件に準拠する必要があります-
属性名は、azまたはAZセット内の文字で始まる必要があります。
属性名の2番目の文字は、az、AZ、または0〜9のセットに含まれている必要があります。
属性名は予約語を使用できません。
上記の制約に準拠していない属性名は、プレースホルダーを定義できます。
クエリは、ソートキーの順序で取得を実行し、存在する条件とフィルター式を使用して処理します。クエリは常に結果セットを返し、一致しない場合は空の結果セットを返します。
結果は常にソートキーの順序で返され、データ型ベースの順序で、変更可能なデフォルトが昇順として返されます。
Javaによるクエリ
Javaでのクエリを使用すると、テーブルとセカンダリインデックスをクエリできます。パーティションキーと等式条件を指定する必要があり、ソートキーと条件を指定するオプションもあります。
Javaでのクエリに必要な一般的な手順には、DynamoDBクラスインスタンス、ターゲットテーブルのTableクラスインスタンスの作成、およびテーブルインスタンスのクエリメソッドを呼び出してクエリオブジェクトを受け取ることが含まれます。
クエリへの応答には、 ItemCollection 返されたすべてのアイテムを提供するオブジェクト。
次の例は、詳細なクエリを示しています-
DynamoDB dynamoDB = new DynamoDB (
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1"));
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
Item item = null;
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.toJSONPretty());
}クエリメソッドは、さまざまなオプションのパラメータをサポートしています。次の例は、これらのパラメータを利用する方法を示しています-
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn and ResponseTM > :nn_responseTM")
.withFilterExpression("Author = :nn_author")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1")
.withString(":nn_responseTM", twoWeeksAgoStr)
.withString(":nn_author", "Member 123"))
.withConsistentRead(true);
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}次の大きな例を確認することもできます。
Note−次のプログラムは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
この例では、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
package com.amazonaws.codesamples.document;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.Page;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class QueryOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "Reply";
public static void main(String[] args) throws Exception {
String forumName = "PolyBlaster";
String threadSubject = "PolyBlaster Thread 1";
getThreadReplies(forumName, threadSubject);
}
private static void getThreadReplies(String forumName, String threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", replyId));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\ngetThreadReplies results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}スキャン操作は、すべてのテーブルアイテムまたはセカンダリインデックスを読み取ります。デフォルトの関数では、インデックスまたはテーブル内のすべてのアイテムのすべてのデータ属性が返されます。を採用するProjectionExpression フィルタリング属性のパラメータ。
一致するものが見つからない場合でも、スキャンごとに結果セットが返されるため、セットは空になります。スキャンは1MB以下を取得し、データをフィルタリングするオプションがあります。
Note −スキャンのパラメータとフィルタリングはクエリにも適用されます。
スキャン操作の種類
Filtering−スキャン操作は、スキャンまたはクエリの後にデータを変更するフィルター式による細かいフィルタリングを提供します。結果を返す前に。式は比較演算子を使用します。それらの構文は、フィルター式で許可されていないキー属性を除いて、条件式に似ています。フィルタ式でパーティションまたはソートキーを使用することはできません。
Note − 1MBの制限は、フィルタリングを適用する前に適用されます。
Throughput Specifications−スキャンはスループットを消費しますが、消費は返されたデータではなくアイテムのサイズに焦点を合わせます。すべての属性を要求するか、少数の属性のみを要求するかにかかわらず、消費量は同じままであり、フィルター式を使用するかどうかも消費量に影響しません。
Pagination− DynamoDBは結果をページ分割し、結果を特定のページに分割します。返される結果には1MBの制限が適用され、それを超えると、残りのデータを収集するために別のスキャンが必要になります。ザ・LastEvaluatedKeyvalueを使用すると、この後続のスキャンを実行できます。値をに適用するだけですExclusiveStartkey。いつLastEvaluatedKey値がnullになると、操作はデータのすべてのページを完了します。ただし、null以外の値は、より多くのデータが残っていることを自動的に意味するわけではありません。null値のみがステータスを示します。
The Limit Parameter−制限パラメーターは結果サイズを管理します。DynamoDBはこれを使用して、データを返す前に処理するアイテムの数を確立し、スコープ外では機能しません。xの値を設定すると、DynamoDBは最初のx個の一致するアイテムを返します。
LastEvaluatedKey値は、部分的な結果をもたらす制限パラメーターの場合にも適用されます。スキャンを完了するために使用します。
Result Count −クエリとスキャンへの応答には、に関連する情報も含まれます ScannedCountカウント。スキャン/クエリされたアイテムを定量化し、返されたアイテムを定量化します。フィルタリングしない場合、それらの値は同じです。1MBを超える場合、カウントは処理された部分のみを表します。
Consistency−クエリ結果とスキャン結果は結果整合性のある読み取りですが、強い整合性のある読み取りを設定することもできます。使用ConsistentRead この設定を変更するパラメータ。
Note −一貫性のある読み取り設定は、強く一貫性に設定されている場合、2倍の容量単位を使用することで消費に影響を与えます。
Performance−スキャンはテーブル全体またはセカンダリインデックスをクロールするため、クエリはスキャンよりもパフォーマンスが高く、応答が遅くなり、スループットが大量に消費されます。スキャンは小さなテーブルやフィルターの少ない検索に最適ですが、突然の加速された読み取りアクティビティの回避や並列スキャンの活用など、いくつかのベストプラクティスに従うことで、無駄のないスキャンを設計できます。
クエリは、特定の条件を満たす特定の範囲のキーを検索します。パフォーマンスは、キーの量ではなく、取得するデータの量によって決まります。操作のパラメーターと一致の数は、特にパフォーマンスに影響を与えます。
パラレルスキャン
スキャン操作は、デフォルトで順次処理を実行します。次に、1MBの部分でデータを返します。これにより、アプリケーションは次の部分をフェッチするように求められます。これにより、大きなテーブルとインデックスのスキャンが長くなります。
この特性は、スキャンが常に利用可能なスループットを十分に活用するとは限らないことも意味します。DynamoDBは、テーブルデータを複数のパーティションに分散します。スキャンスループットは、単一パーティション操作のため、単一パーティションに制限されたままです。
この問題の解決策は、テーブルまたはインデックスを論理的にセグメントに分割することです。次に、「ワーカー」がセグメントを並行して(同時に)スキャンします。セグメントとのパラメータを使用しますTotalSegments 特定のワーカーによってスキャンされたセグメントを指定し、処理されたセグメントの合計量を指定します。
労働者番号
最高のアプリケーションパフォーマンスを実現するには、ワーカー値(セグメントパラメーター)を試してみる必要があります。
Note−大量のワーカーを使用した並列スキャンは、すべてのスループットを消費する可能性があるため、スループットに影響を与えます。この問題は、1人のワーカーがすべてのスループットを消費するのを防ぐために使用できるLimitパラメーターを使用して管理します。
以下はディープスキャンの例です。
Note−次のプログラムは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
この例では、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ScanOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "ProductList";
public static void main(String[] args) throws Exception {
findProductsUnderOneHun(); //finds products under 100 dollars
}
private static void findProductsUnderOneHun() {
Table table = dynamoDB.getTable(tableName);
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":pr", 100);
ItemCollection<ScanOutcome> items = table.scan (
"Price < :pr", //FilterExpression
"ID, Nomenclature, ProductCategory, Price", //ProjectionExpression
null, //No ExpressionAttributeNames
expressionAttributeValues);
System.out.println("Scanned " + tableName + " to find items under $100.");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}DynamoDBは、主キー属性のインデックスを使用してアクセスを改善します。これらは、アプリケーションへのアクセスとデータの取得を高速化し、アプリケーションの遅延を減らすことでパフォーマンスの向上をサポートします。
二次インデックス
セカンダリインデックスは、属性サブセットと代替キーを保持します。インデックスを対象とするクエリまたはスキャン操作のいずれかを介して使用します。
その内容には、投影またはコピーする属性が含まれます。作成時に、インデックスの代替キーと、インデックスに投影する属性を定義します。次に、DynamoDBは、テーブルから供給された主キー属性を含む、属性のインデックスへのコピーを実行します。これらのタスクを実行した後は、テーブルで実行するかのようにクエリ/スキャンを使用するだけです。
DynamoDBは、すべてのセカンダリインデックスを自動的に維持します。追加や削除などのアイテム操作では、ターゲットテーブルのインデックスを更新します。
DynamoDBは2種類のセカンダリインデックスを提供します-
Global Secondary Index−このインデックスには、ソーステーブルとは異なる可能性のあるパーティションキーとソートキーが含まれます。インデックスに対するクエリ/スキャンがすべてのテーブルデータとすべてのパーティションにまたがる機能があるため、ラベル「グローバル」を使用します。
Local Secondary Index−このインデックスは、パーティションキーをテーブルと共有しますが、異なるソートキーを使用します。その「ローカル」な性質は、すべてのパーティションが同一のパーティションキー値を持つテーブルパーティションにスコープすることに起因します。
使用するのに最適なインデックスのタイプは、アプリケーションのニーズによって異なります。次の表に示されている2つの違いを考慮してください-
| 品質 | グローバルセカンダリインデックス | ローカルセカンダリインデックス |
|---|---|---|
| キースキーマ | 単純または複合主キーを使用します。 | 常に複合主キーを使用します。 |
| 主な属性 | インデックスパーティションキーとソートキーは、文字列、数値、またはバイナリテーブル属性で構成できます。 | インデックスのパーティションキーは、テーブルパーティションキーと共有される属性です。ソートキーは、文字列、数値、またはバイナリテーブル属性にすることができます。 |
| パーティションごとのサイズ制限キー値 | サイズ制限はありません。 | パーティションキー値に関連付けられたインデックス付きアイテムの合計サイズに10GBの最大制限を課します。 |
| オンラインインデックス操作 | テーブルの作成時にそれらを生成したり、既存のテーブルに追加したり、既存のテーブルを削除したりできます。 | テーブルの作成時に作成する必要がありますが、削除したり、既存のテーブルに追加したりすることはできません。 |
| クエリ | これにより、テーブル全体とすべてのパーティションをカバーするクエリが可能になります。 | これらは、クエリで提供されたパーティションキー値を介して単一のパーティションをアドレス指定します。 |
| 一貫性 | これらのインデックスのクエリは、結果整合性のあるオプションのみを提供します。 | これらのクエリは、結果整合性または強い整合性のオプションを提供します。 |
| スループットコスト | これには、読み取りと書き込みのスループット設定が含まれます。クエリ/スキャンは、テーブルではなくインデックスから容量を消費します。これは、テーブル書き込みの更新にも適用されます。 | クエリ/スキャンはテーブルの読み取り容量を消費します。テーブル書き込みはローカルインデックスを更新し、テーブル容量単位を消費します。 |
| 投影 | クエリ/スキャンは、インデックスに投影された属性のみを要求でき、テーブル属性の取得はできません。 | クエリ/スキャンは、投影されていない属性を要求できます。さらに、それらの自動フェッチが発生します。 |
セカンダリインデックスを使用して複数のテーブルを作成する場合は、順番に作成してください。つまり、テーブルを作成し、それがアクティブ状態に達するのを待ってから、別のテーブルを作成して再度待機します。DynamoDBでは同時作成は許可されていません。
各セカンダリインデックスには特定の仕様が必要です-
Type −ローカルまたはグローバルを指定します。
Name −テーブルと同じ命名規則を使用します。
Key Schema −最上位の文字列、数値、またはバイナリタイプのみが許可され、インデックスタイプが他の要件を決定します。
Attributes for Projection − DynamoDBはそれらを自動的に投影し、任意のデータ型を許可します。
Throughput −グローバルセカンダリインデックスの読み取り/書き込み容量を指定します。
インデックスの制限は、テーブルごとに5つのグローバルと5つのローカルのままです。
インデックスに関する詳細情報には、次のコマンドでアクセスできます。 DescribeTable。名前、サイズ、アイテム数を返します。
Note −これらの値は6時間ごとに更新されます。
インデックスデータへのアクセスに使用されるクエリまたはスキャンで、テーブル名とインデックス名、結果に必要な属性、および条件ステートメントを指定します。DynamoDBには、結果を昇順または降順で返すオプションがあります。
Note −テーブルを削除すると、すべてのインデックスも削除されます。
異なる属性を持つさまざまなクエリタイプを必要とするアプリケーションは、これらの詳細なクエリを実行する際に、単一または複数のグローバルセカンダリインデックスを使用できます。
For example −ユーザー、ユーザーのログインステータス、およびログイン時間を追跡するシステム。前の例の増加により、データに対するクエリが遅くなります。
グローバルセカンダリインデックスは、テーブルからの属性の選択を整理することにより、クエリを高速化します。データの並べ替えに主キーを使用し、キーテーブル属性やテーブルと同一のキースキーマを必要としません。
すべてのグローバルセカンダリインデックスには、ソートキーのオプションを含むパーティションキーが含まれている必要があります。インデックスキースキーマはテーブルとは異なる場合があり、インデックスキー属性は任意の最上位の文字列、数値、またはバイナリテーブル属性を使用できます。
プロジェクションでは、他のテーブル属性を使用できますが、クエリは親テーブルから取得しません。
属性の予測
射影は、テーブルからセカンダリインデックスにコピーされた属性セットで構成されます。射影は常にテーブルパーティションキーとソートキーで発生します。クエリでは、プロジェクションにより、DynamoDBはプロジェクションの任意の属性にアクセスできます。それらは本質的に独自のテーブルとして存在します。
セカンダリインデックスの作成では、プロジェクションの属性を指定する必要があります。DynamoDBは、このタスクを実行する3つの方法を提供します-
KEYS_ONLY−すべてのインデックス項目は、テーブルパーティションとソートキーの値、およびインデックスキーの値で構成されます。これにより、最小のインデックスが作成されます。
INCLUDE −KEYS_ONLY属性と指定された非キー属性が含まれます。
ALL −すべてのソーステーブル属性が含まれ、可能な限り最大のインデックスが作成されます。
属性をグローバルセカンダリインデックスに投影する際のトレードオフに注意してください。これは、スループットとストレージコストに関連しています。
次の点を考慮してください-
待ち時間が短く、いくつかの属性にのみアクセスする必要がある場合は、必要な属性のみを投影します。これにより、ストレージと書き込みのコストが削減されます。
アプリケーションが特定の非キー属性に頻繁にアクセスする場合は、スキャンの消費量と比較してストレージコストが低いため、それらを予測します。
頻繁にアクセスされる属性の大規模なセットを投影できますが、これには高いストレージコストがかかります。
まれなテーブルクエリと頻繁な書き込み/更新にはKEYS_ONLYを使用します。これはサイズを制御しますが、それでもクエリで優れたパフォーマンスを提供します。
グローバルセカンダリインデックスのクエリとスキャン
クエリを利用して、インデックス内の単一または複数のアイテムにアクセスできます。インデックスとテーブル名、必要な属性、および条件を指定する必要があります。結果を昇順または降順で返すオプションがあります。
スキャンを利用して、すべてのインデックスデータを取得することもできます。テーブル名とインデックス名が必要です。フィルタ式を使用して、特定のデータを取得します。
テーブルとインデックスのデータ同期
DynamoDBは、インデックスの親テーブルとの同期を自動的に実行します。アイテムに対する変更操作ごとに非同期更新が発生しますが、アプリケーションはインデックスに直接書き込みません。
DynamoDBのメンテナンスがインデックスに与える影響を理解する必要があります。インデックスの作成時に、キー属性とデータ型を指定します。つまり、書き込み時に、これらのデータ型はキースキーマデータ型と一致する必要があります。
アイテムの作成または削除時に、インデックスは結果整合性のある方法で更新されますが、データの更新はほんの一瞬で伝播します(何らかのタイプのシステム障害が発生しない限り)。アプリケーションのこの遅延を考慮する必要があります。
Throughput Considerations in Global Secondary Indexes−複数のグローバルセカンダリインデックスがスループットに影響を与えます。インデックスの作成には、テーブルとは別に存在する容量ユニットの仕様が必要であるため、操作ではテーブルユニットではなくインデックス容量ユニットが消費されます。
これにより、クエリまたは書き込みがプロビジョニングされたスループットを超えた場合にスロットルが発生する可能性があります。を使用してスループット設定を表示するDescribeTable。
Read Capacity−グローバルセカンダリインデックスは結果整合性を提供します。クエリでは、DynamoDBはテーブルに使用されるものと同じプロビジョニング計算を実行しますが、アイテムサイズではなくインデックスエントリサイズを使用するという唯一の違いがあります。返されるクエリの制限は1MBのままです。これには、返されるすべてのアイテムの属性名のサイズと値が含まれます。
書き込み容量
書き込み操作が発生すると、影響を受けるインデックスは書き込みユニットを消費します。書き込みスループットコストは、テーブルの書き込みで消費される書き込み容量の単位と、インデックスの更新で消費される単位の合計です。書き込み操作を成功させるには、十分な容量が必要です。そうしないと、スロットルが発生します。
書き込みコストも特定の要因に依存し続けますが、その一部は次のとおりです。
インデックス付き属性を定義する新しいアイテムまたは未定義のインデックス付き属性を定義するアイテムの更新は、単一の書き込み操作を使用してアイテムをインデックスに追加します。
インデックス付きキー属性値を変更する更新では、2回の書き込みを使用してアイテムを削除し、新しいアイテムを書き込みます。
インデックス付き属性の削除をトリガーするテーブル書き込みは、1回の書き込みを使用して、インデックス内の古いアイテムの投影を消去します。
更新操作の前後にインデックスに存在しないアイテムは、書き込みを使用しません。
インデックスキー属性値ではなく、インデックスキースキーマの投影属性値のみを変更する更新では、1回の書き込みを使用して、インデックスへの投影属性の値を更新します。
これらの要素はすべて、アイテムサイズが1KB以下であることを前提としています。
グローバルセカンダリインデックスストレージ
アイテムの書き込み時に、DynamoDBは、属性が存在する必要があるすべてのインデックスに正しい属性のセットを自動的にコピーします。これは、テーブルアイテムストレージと属性ストレージの料金を請求することでアカウントに影響を与えます。使用されるスペースは、これらの量の合計から生じます-
- テーブルの主キーのバイトサイズ
- インデックスキー属性のバイトサイズ
- 投影された属性のバイトサイズ
- インデックスアイテムごとに100バイトのオーバーヘッド
平均アイテムサイズを見積もり、グローバルセカンダリインデックスキー属性を持つテーブルアイテムの数量を掛けることで、ストレージのニーズを見積もることができます。
DynamoDBは、インデックスパーティションまたはソートキーとして定義された未定義の属性を持つテーブルアイテムのアイテムデータを書き込みません。
グローバルセカンダリインデックスCrud
を使用して、グローバルセカンダリインデックスを含むテーブルを作成します。 CreateTable とペアになっている操作 GlobalSecondaryIndexesパラメータ。インデックスパーティションキーとして機能する属性を指定するか、インデックスソートキーに別の属性を使用する必要があります。すべてのインデックスキー属性は、文字列、数値、またはバイナリスカラーである必要があります。また、以下で構成されるスループット設定を提供する必要があります。ReadCapacityUnits そして WriteCapacityUnits。
使用する UpdateTable GlobalSecondaryIndexesパラメーターをもう一度使用して、既存のテーブルにグローバルセカンダリインデックスを追加します。
この操作では、次の入力を提供する必要があります-
- インデックス名
- キースキーマ
- 投影された属性
- スループット設定
グローバルセカンダリインデックスを追加することにより、アイテムの量、予測される属性の量、書き込み容量、および書き込みアクティビティのために、大きなテーブルではかなりの時間がかかる場合があります。使用するCloudWatch プロセスを監視するためのメトリック。
使用する DescribeTableグローバルセカンダリインデックスのステータス情報を取得します。4つのうちの1つを返しますIndexStatus GlobalSecondaryIndexesの場合-
CREATING −インデックスの構築段階と、その使用不可を示します。
ACTIVE −インデックスを使用する準備ができていることを示します。
UPDATING −スループット設定の更新状況を示します。
DELETING −インデックスの削除ステータス、およびその永続的な使用不可を示します。
ロード/バックフィル段階でグローバルセカンダリインデックスのプロビジョニングされたスループット設定を更新します(DynamoDBがインデックスに属性を書き込み、追加/削除/更新されたアイテムを追跡します)。使用するUpdateTable この操作を実行します。
バックフィル段階では、他のインデックスを追加/削除できないことを覚えておく必要があります。
UpdateTableを使用して、グローバルセカンダリインデックスを削除します。操作ごとに1つのインデックスのみを削除できますが、最大5つまでの複数の操作を同時に実行できます。削除プロセスは親テーブルの読み取り/書き込みアクティビティには影響しませんが、操作が完了するまで他のインデックスを追加/削除することはできません。
Javaを使用したグローバルセカンダリインデックスの操作
CreateTableを使用して、インデックスを使用してテーブルを作成します。DynamoDBクラスインスタンスを作成するだけです。CreateTableRequest リクエスト情報のクラスインスタンスを作成し、リクエストオブジェクトをCreateTableメソッドに渡します。
次のプログラムは短い例です-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
// Attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("City")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Date")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Wind")
.withAttributeType("N"));
// Key schema of the table
ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("City")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.RANGE)); //Sort key
// Wind index
GlobalSecondaryIndex windIndex = new GlobalSecondaryIndex()
.withIndexName("WindIndex")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 10)
.withWriteCapacityUnits((long) 1))
.withProjection(new Projection().withProjectionType(ProjectionType.ALL));
ArrayList<KeySchemaElement> indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Wind")
.withKeyType(KeyType.RANGE)); //Sort key
windIndex.setKeySchema(indexKeySchema);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName("ClimateInfo")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 5)
.withWriteCapacityUnits((long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(windIndex);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());でインデックス情報を取得します DescribeTable。まず、DynamoDBクラスインスタンスを作成します。次に、インデックスを対象とするTableクラスインスタンスを作成します。最後に、テーブルをdescribeメソッドに渡します。
ここに短い例があります-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ClimateInfo");
TableDescription tableDesc = table.describe();
Iterator<GlobalSecondaryIndexDescription> gsiIter =
tableDesc.getGlobalSecondaryIndexes().iterator();
while (gsiIter.hasNext()) {
GlobalSecondaryIndexDescription gsiDesc = gsiIter.next();
System.out.println("Index data " + gsiDesc.getIndexName() + ":");
Iterator<KeySchemaElement> kse7Iter = gsiDesc.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType());
}
Projection projection = gsiDesc.getProjection();
System.out.println("\tProjection type: " + projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tNon-key projected attributes: "
+ projection.getNonKeyAttributes());
}
}クエリを使用して、テーブルクエリと同様にインデックスクエリを実行します。DynamoDBクラスインスタンス、ターゲットインデックスのテーブルクラスインスタンス、特定のインデックスのインデックスクラスインスタンスを作成し、インデックスとクエリオブジェクトをクエリメソッドに渡すだけです。
よりよく理解するために次のコードを見てください-
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ClimateInfo");
Index index = table.getIndex("WindIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("#d = :v_date and Wind = :v_wind")
.withNameMap(new NameMap()
.with("#d", "Date"))
.withValueMap(new ValueMap()
.withString(":v_date","2016-05-15")
.withNumber(":v_wind",0));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
System.out.println(iter.next().toJSONPretty());
}次のプログラムは、理解を深めるためのより大きな例です。
Note−次のプログラムは、以前に作成されたデータソースを想定している場合があります。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
この例では、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Index;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.GlobalSecondaryIndex;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.Projection;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
public class GlobalSecondaryIndexSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
public static String tableName = "Bugs";
public static void main(String[] args) throws Exception {
createTable();
queryIndex("CreationDateIndex");
queryIndex("NameIndex");
queryIndex("DueDateIndex");
}
public static void createTable() {
// Attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("BugID")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Name")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CreationDate")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("DueDate")
.withAttributeType("S"));
// Table Key schema
ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>();
tableKeySchema.add (new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add (new KeySchemaElement()
.withAttributeName("Name")
.withKeyType(KeyType.RANGE)); //Sort key
// Indexes' initial provisioned throughput
ProvisionedThroughput ptIndex = new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L);
// CreationDateIndex
GlobalSecondaryIndex creationDateIndex = new GlobalSecondaryIndex()
.withIndexName("CreationDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("CreationDate")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("INCLUDE")
.withNonKeyAttributes("Description", "Status"));
// NameIndex
GlobalSecondaryIndex nameIndex = new GlobalSecondaryIndex()
.withIndexName("NameIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("Name")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("KEYS_ONLY"));
// DueDateIndex
GlobalSecondaryIndex dueDateIndex = new GlobalSecondaryIndex()
.withIndexName("DueDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("DueDate")
.withKeyType(KeyType.HASH)) //Partition key
.withProjection(new Projection()
.withProjectionType("ALL"));
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput( new ProvisionedThroughput()
.withReadCapacityUnits( (long) 1)
.withWriteCapacityUnits( (long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(creationDateIndex, nameIndex, dueDateIndex);
System.out.println("Creating " + tableName + "...");
dynamoDB.createTable(createTableRequest);
// Pause for active table state
System.out.println("Waiting for ACTIVE state of " + tableName);
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void queryIndex(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println
("\n*****************************************************\n");
System.out.print("Querying index " + indexName + "...");
Index index = table.getIndex(indexName);
ItemCollection<QueryOutcome> items = null;
QuerySpec querySpec = new QuerySpec();
if (indexName == "CreationDateIndex") {
System.out.println("Issues filed on 2016-05-22");
querySpec.withKeyConditionExpression("CreationDate = :v_date and begins_with
(BugID, :v_bug)")
.withValueMap(new ValueMap()
.withString(":v_date","2016-05-22")
.withString(":v_bug","A-"));
items = index.query(querySpec);
} else if (indexName == "NameIndex") {
System.out.println("Compile error");
querySpec.withKeyConditionExpression("Name = :v_name and begins_with
(BugID, :v_bug)")
.withValueMap(new ValueMap()
.withString(":v_name","Compile error")
.withString(":v_bug","A-"));
items = index.query(querySpec);
} else if (indexName == "DueDateIndex") {
System.out.println("Items due on 2016-10-15");
querySpec.withKeyConditionExpression("DueDate = :v_date")
.withValueMap(new ValueMap()
.withString(":v_date","2016-10-15"));
items = index.query(querySpec);
} else {
System.out.println("\nInvalid index name");
return;
}
Iterator<Item> iterator = items.iterator();
System.out.println("Query: getting result...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}一部のアプリケーションは主キーでのみクエリを実行しますが、状況によっては代替のソートキーの恩恵を受けます。単一または複数のローカルセカンダリインデックスを作成して、アプリケーションに選択を許可します。
数百万のアイテムを組み合わせるなどの複雑なデータアクセス要件により、より効率的なクエリ/スキャンを実行する必要があります。ローカルセカンダリインデックスは、パーティションキー値の代替ソートキーを提供します。また、すべてまたは一部のテーブル属性のコピーも保持します。それらはテーブルパーティションキーによってデータを編成しますが、異なるソートキーを使用します。
ローカルセカンダリインデックスを使用すると、テーブル全体をスキャンする必要がなくなり、ソートキーを使用した簡単で迅速なクエリが可能になります。
すべてのローカルセカンダリインデックスは、特定の条件を満たす必要があります-
- 同一のパーティションキーとソーステーブルパーティションキー。
- 1つのスカラー属性のみのソートキー。
- 非キー属性として機能するソーステーブルソートキーの射影。
すべてのローカルセカンダリインデックスは、親テーブルのパーティションキーとソートキーを自動的に保持します。クエリでは、これは、投影された属性の効率的な収集と、投影されていない属性の取得を意味します。
ローカルセカンダリインデックスのストレージ制限は、すべてのテーブルアイテムとパーティションキー値を共有するインデックスアイテムを含むパーティションキー値ごとに10GBのままです。
属性の投影
一部の操作では、複雑さのために過剰な読み取り/フェッチが必要です。これらの操作は、かなりのスループットを消費する可能性があります。プロジェクションを使用すると、これらの属性を分離することで、コストのかかるフェッチを回避し、豊富なクエリを実行できます。予測は、セカンダリインデックスにコピーされた属性で構成されていることに注意してください。
セカンダリインデックスを作成するときは、投影される属性を指定します。DynamoDBが提供する3つのオプションを思い出してください。KEYS_ONLY, INCLUDE, and ALL。
予測で特定の属性を選択するときは、関連するコストのトレードオフを考慮してください。
必要な属性の小さなセットのみを投影すると、ストレージコストが大幅に削減されます。
頻繁にアクセスされる非キー属性を予測する場合は、スキャンコストをストレージコストで相殺します。
ほとんどまたはすべての非キー属性を投影する場合、これにより柔軟性が最大化され、スループットが低下します(取得なし)。ただし、ストレージコストは上昇します。
頻繁な書き込み/更新とまれなクエリに対してKEYS_ONLYを投影すると、サイズは最小限に抑えられますが、クエリの準備は維持されます。
ローカルセカンダリインデックスの作成
使用 LocalSecondaryIndex単一または複数のローカルセカンダリインデックスを作成するためのCreateTableのパラメータ。ソートキーには、キー以外の属性を1つ指定する必要があります。テーブルの作成時に、ローカルセカンダリインデックスを作成します。削除時に、これらのインデックスを削除します。
ローカルセカンダリインデックスを持つテーブルは、パーティションキー値ごとにサイズが10GBの制限に従う必要がありますが、任意の数のアイテムを格納できます。
ローカルセカンダリインデックスのクエリとスキャン
ローカルセカンダリインデックスに対するクエリ操作は、インデックス内の複数のアイテムがソートキー値を共有している場合、パーティションキー値が一致するすべてのアイテムを返します。一致するアイテムは特定の順序で返されません。ローカルセカンダリインデックスのクエリは、最終的な一貫性または強力な一貫性のいずれかを使用し、強力な一貫性のある読み取りが最新の値を提供します。
スキャン操作は、すべてのローカルセカンダリインデックスデータを返します。スキャンでは、テーブルとインデックス名を指定し、フィルター式を使用してデータを破棄できるようにする必要があります。
アイテムの書き方
ローカルセカンダリインデックスの作成時に、ソートキー属性とそのデータ型を指定します。アイテムを作成するとき、アイテムがインデックスキーの属性を定義している場合、そのタイプはキースキーマのデータ型と一致する必要があります。
DynamoDBは、テーブルアイテムとローカルセカンダリインデックスアイテムに1対1の関係要件を課しません。複数のローカルセカンダリインデックスを持つテーブルは、少ないテーブルよりも書き込みコストが高くなります。
ローカルセカンダリインデックスのスループットに関する考慮事項
クエリの読み取り容量の消費は、データアクセスの性質によって異なります。クエリは結果整合性または強い整合性のいずれかを使用し、結果整合性のある読み取りでは半分のユニットと比較して、1つのユニットを使用する強い整合性のある読み取りが行われます。
結果の制限には、最大1MBのサイズが含まれます。結果のサイズは、一致するインデックスアイテムのサイズの合計から最も近い4KBに切り上げられ、一致するテーブルアイテムのサイズも最も近い4KBに切り上げられます。
書き込み容量の消費量は、プロビジョニングされたユニット内にとどまります。テーブルの書き込みで消費されたユニットとインデックスの更新で消費されたユニットの合計を見つけることにより、プロビジョニングされた合計コストを計算します。
また、コストに影響を与える主な要因を検討することもできます。
インデックス付き属性を定義するアイテムを書き込むか、アイテムを更新して未定義のインデックス付き属性を定義すると、単一の書き込み操作が発生します。
テーブルの更新によってインデックス付きキーの属性値が変更されると、2回の書き込みが発生して削除され、次に–アイテムが追加されます。
書き込みによってインデックス付き属性が削除されると、1回の書き込みが発生して、古いアイテムの投影が削除されます。
更新前または更新後にアイテムがインデックス内に存在しない場合、書き込みは発生しません。
ローカルセカンダリインデックスストレージ
テーブルアイテムの書き込み時に、DynamoDBは適切な属性セットを必要なローカルセカンダリインデックスに自動的にコピーします。これにより、アカウントに課金されます。使用されるスペースは、テーブルの主キーのバイトサイズ、インデックスキーの属性のバイトサイズ、現在予測される属性のバイトサイズ、および各インデックス項目のオーバーヘッドの100バイトの合計から生じます。
推定ストレージは、平均インデックスアイテムサイズを推定し、テーブルアイテムの数量を掛けることによって取得されます。
Javaを使用したローカルセカンダリインデックスの操作
最初にDynamoDBクラスインスタンスを作成して、ローカルセカンダリインデックスを作成します。次に、必要なリクエスト情報を使用してCreateTableRequestクラスインスタンスを作成します。最後に、createTableメソッドを使用します。
例
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
CreateTableRequest createTableRequest = new
CreateTableRequest().withTableName(tableName);
//Provisioned Throughput
createTableRequest.setProvisionedThroughput (
new ProvisionedThroughput()
.withReadCapacityUnits((long)5)
.withWriteCapacityUnits(( long)5));
//Attributes
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Make")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Model")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Line")
.withAttributeType("S"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
//Key Schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Make")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Model")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Make")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Line")
.withKeyType(KeyType.RANGE)); //Sort key
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("Type");
nonKeyAttributes.add("Year");
projection.setNonKeyAttributes(nonKeyAttributes);
LocalSecondaryIndex localSecondaryIndex = new LocalSecondaryIndex()
.withIndexName("ModelIndex")
.withKeySchema(indexKeySchema)
.withProjection(p rojection);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
localSecondaryIndexes.add(localSecondaryIndex);
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());describeメソッドを使用してローカルセカンダリインデックスに関する情報を取得します。DynamoDBクラスインスタンスを作成し、Tableクラスインスタンスを作成して、そのテーブルをdescribeメソッドに渡すだけです。
例
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
Table table = dynamoDB.getTable(tableName);
TableDescription tableDescription = table.describe();
List<LocalSecondaryIndexDescription> localSecondaryIndexes =
tableDescription.getLocalSecondaryIndexes();
Iterator<LocalSecondaryIndexDescription> lsiIter =
localSecondaryIndexes.iterator();
while (lsiIter.hasNext()) {
LocalSecondaryIndexDescription lsiDescription = lsiIter.next();
System.out.println("Index info " + lsiDescription.getIndexName() + ":");
Iterator<KeySchemaElement> kseIter = lsiDescription.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType());
}
Projection projection = lsiDescription.getProjection();
System.out.println("\tProjection type: " + projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tNon-key projected attributes: " +
projection.getNonKeyAttributes());
}
}テーブルクエリと同じ手順を使用してクエリを実行します。DynamoDBクラスインスタンス、テーブルクラスインスタンス、インデックスクラスインスタンス、クエリオブジェクトを作成し、クエリメソッドを利用するだけです。
例
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
Table table = dynamoDB.getTable(tableName);
Index index = table.getIndex("LineIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Make = :v_make and Line = :v_line")
.withValueMap(new ValueMap()
.withString(":v_make", "Depault")
.withString(":v_line", "SuperSawz"));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> itemsIter = items.iterator();
while (itemsIter.hasNext()) {
Item item = itemsIter.next();
System.out.println(item.toJSONPretty());
}次の例を確認することもできます。
Note−次の例では、以前に作成されたデータソースを想定しています。実行を試みる前に、サポートライブラリを取得し、必要なデータソース(必要な特性を持つテーブル、またはその他の参照ソース)を作成します。
次の例では、Eclipse IDE、AWS認証情報ファイル、およびEclipse AWSJavaプロジェクト内のAWSToolkitも使用しています。
例
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Index;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.PutItemOutcome;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.LocalSecondaryIndex;
import com.amazonaws.services.dynamodbv2.model.Projection;
import com.amazonaws.services.dynamodbv2.model.ProjectionType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ReturnConsumedCapacity;
import com.amazonaws.services.dynamodbv2.model.Select;
public class LocalSecondaryIndexSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
public static String tableName = "ProductOrders";
public static void main(String[] args) throws Exception {
createTable();
query(null);
query("IsOpenIndex");
query("OrderCreationDateIndex");
}
public static void createTable() {
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 1)
.withWriteCapacityUnits((long) 1));
// Table partition and sort keys attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CustomerID")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderID")
.withAttributeType("N"));
// Index primary key attributes
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderDate")
.withAttributeType("N"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OpenStatus")
.withAttributeType("N"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
// Table key schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderID")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
// OrderDateIndex
LocalSecondaryIndex orderDateIndex = new LocalSecondaryIndex()
.withIndexName("OrderDateIndex");
// OrderDateIndex key schema
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderDate")
.withKeyType(KeyType.RANGE)); //Sort key
orderDateIndex.setKeySchema(indexKeySchema);
// OrderCreationDateIndex projection w/attributes list
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("ProdCat");
nonKeyAttributes.add("ProdNomenclature");
projection.setNonKeyAttributes(nonKeyAttributes);
orderCreationDateIndex.setProjection(projection);
localSecondaryIndexes.add(orderDateIndex);
// IsOpenIndex
LocalSecondaryIndex isOpenIndex = new LocalSecondaryIndex()
.withIndexName("IsOpenIndex");
// OpenStatusIndex key schema
indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OpenStatus")
.withKeyType(KeyType.RANGE)); //Sort key
// OpenStatusIndex projection
projection = new Projection() .withProjectionType(ProjectionType.ALL);
OpenStatusIndex.setKeySchema(indexKeySchema);
OpenStatusIndex.setProjection(projection);
localSecondaryIndexes.add(OpenStatusIndex);
// Put definitions in CreateTable request
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
System.out.println("Spawning table " + tableName + "...");
System.out.println(dynamoDB.createTable(createTableRequest));
// Pause for ACTIVE status
System.out.println("Waiting for ACTIVE table:" + tableName);
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void query(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println("\n*************************************************\n");
System.out.println("Executing query on" + tableName);
QuerySpec querySpec = new QuerySpec()
.withConsistentRead(true)
.withScanIndexForward(true)
.withReturnConsumedCapacity(ReturnConsumedCapacity.TOTAL);
if (indexName == "OpenStatusIndex") {
System.out.println("\nEmploying index: '" + indexName
+ "' open orders for this customer.");
System.out.println(
"Returns only user-specified attribute list\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerID = :v_custmid and
OpenStatus = :v_openstat")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]")
.withNumber(":v_openstat", 1));
querySpec.withProjectionExpression(
"OrderDate, ProdCat, ProdNomenclature, OrderStatus");
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else if (indexName == "OrderDateIndex") {
System.out.println("\nUsing index: '" + indexName
+ "': this customer's orders placed after 05/22/2016.");
System.out.println("Projected attributes are returned\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerID = :v_custmid and OrderDate
>= :v_ordrdate")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]")
.withNumber(":v_ordrdate", 20160522));
querySpec.withSelect(Select.ALL_PROJECTED_ATTRIBUTES);
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else {
System.out.println("\nNo index: All Jane's orders by OrderID:\n");
querySpec.withKeyConditionExpression("CustomerID = :v_custmid")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]"));
ItemCollection<QueryOutcome> items = table.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
}DynamoDBは集計関数を提供しません。これらのタスクを実行するには、クエリ、スキャン、インデックス、およびさまざまなツールを創造的に使用する必要があります。これらすべてにおいて、これらの操作でのクエリ/スキャンのスループット費用は高額になる可能性があります。
好みのDynamoDBコーディング言語用にライブラリやその他のツールを使用するオプションもあります。使用する前に、DynamoDBとの互換性を確認してください。
最大または最小を計算する
結果のストレージの昇順/降順、Limitパラメーター、および順序を設定するパラメーターを使用して、最高値と最低値を見つけます。
例-
Map<String, AttributeValue> eaval = new HashMap<>();
eaval.put(":v1", new AttributeValue().withS("hashval"));
queryExpression = new DynamoDBQueryExpression<Table>()
.withIndexName("yourindexname")
.withKeyConditionExpression("HK = :v1")
.withExpressionAttributeValues(values)
.withScanIndexForward(false); //descending order
queryExpression.setLimit(1);
QueryResultPage<Lookup> res =
dynamoDBMapper.queryPage(Table.class, queryExpression);カウントを計算する
使用する DescribeTableただし、テーブルアイテムの数を取得するには、古いデータを提供することに注意してください。また、Javaを利用するgetScannedCount method。
活用する LastEvaluatedKey すべての結果を確実に提供するため。
例-
ScanRequest scanRequest = new ScanRequest().withTableName(yourtblName);
ScanResult yourresult = client.scan(scanRequest);
System.out.println("#items:" + yourresult.getScannedCount());平均と合計の計算
インデックスとクエリ/スキャンを利用して、処理前に値を取得およびフィルタリングします。次に、オブジェクトを介してこれらの値を操作するだけです。
DynamoDBは、指定された認証情報を使用してリクエストを認証します。これらの認証情報は必須であり、AWSリソースアクセスの権限が含まれている必要があります。これらのアクセス許可は、DynamoDBのほぼすべての側面から、操作または機能のマイナーな機能にまで及びます。
権限の種類
このセクションでは、DynamoDBのさまざまなパーミッションとリソースアクセスについて説明します。
ユーザーの認証
サインアップ時に、root資格情報として機能するパスワードと電子メールを提供しました。DynamoDBはこのデータをAWSアカウントに関連付け、それを使用してすべてのリソースへの完全なアクセスを提供します。
ルート認証情報は、管理アカウントの作成にのみ使用することをお勧めします。これにより、より少ない権限でIAMアカウント/ユーザーを作成できます。IAMユーザーは、IAMサービスで生成された他のアカウントです。それらのアクセス許可/特権には、安全なページへのアクセスと、テーブルの変更などの特定のカスタム許可が含まれます。
アクセスキーは、追加のアカウントとアクセスのための別のオプションを提供します。これらを使用してアクセスを許可し、特定の状況で手動でアクセスを許可しないようにします。フェデレーションユーザーは、IDプロバイダーを介したアクセスを許可することにより、さらに別のオプションを提供します。
管理
AWSリソースは引き続きアカウントの所有権の下にあります。権限ポリシーは、リソースの生成またはアクセスに付与される権限を管理します。管理者は、権限ポリシーをIAM ID、つまりロール、グループ、ユーザー、およびサービスに関連付けます。また、リソースに権限を付加します。
権限は、ユーザー、リソース、およびアクションを指定します。管理者は、管理者権限を持つアカウントにすぎないことに注意してください。
操作とリソース
テーブルはDynamoDBの主要なリソースのままです。サブリソースは、ストリームやインデックスなどの追加リソースとして機能します。これらのリソースは一意の名前を使用しており、その一部を次の表に示します。
| タイプ | ARN(Amazonリソース名) |
|---|---|
| ストリーム | arn:aws:dynamodb:region:account-id:table / table-name / stream / stream-label |
| インデックス | arn:aws:dynamodb:region:account-id:table / table-name / index / index-name |
| テーブル | arn:aws:dynamodb:region:account-id:table / table-name |
所有
リソース所有者は、リソースを生成したAWSアカウント、またはリソース作成でのリクエスト認証を担当するプリンシパルエンティティアカウントとして定義されます。DynamoDB環境内でこれがどのように機能するかを検討してください-
ルート資格情報を使用してテーブルを作成する場合、アカウントはリソース所有者のままです。
IAMユーザーを作成し、テーブルを作成する権限をユーザーに付与する場合、アカウントはリソース所有者のままです。
IAMユーザーを作成してユーザーに付与する場合、およびテーブルを作成するためのロール、アクセス許可を引き受けることができるすべてのユーザーに、アカウントはリソース所有者のままです。
リソースアクセスの管理
アクセスの管理では、主にユーザーとリソースアクセスを説明するアクセス許可ポリシーに注意を払う必要があります。ポリシーをIAMIDまたはリソースに関連付けます。ただし、DynamoDBはIAM /アイデンティティポリシーのみをサポートします。
IDベース(IAM)ポリシーを使用すると、次の方法で特権を付与できます。
- ユーザーまたはグループにアクセス許可を添付します。
- クロスアカウント権限の役割に権限を添付します。
他のAWSでは、リソースベースのポリシーが許可されています。これらのポリシーは、S3バケットなどへのアクセスを許可します。
ポリシー要素
ポリシーは、アクション、効果、リソース、およびプリンシパルを定義します。これらの操作を実行する権限を付与します。
Note − API操作には、複数のアクションに対する権限が必要な場合があります。
次のポリシー要素を詳しく見てください-
Resource −ARNはこれを識別します。
Action −キーワードは、これらのリソース操作、および許可するか拒否するかを識別します。
Effect −アクションに対するユーザー要求の効果を指定します。つまり、デフォルトとして拒否を使用して許可または拒否します。
Principal −これは、ポリシーに関連付けられているユーザーを識別します。
条件
権限の付与では、特定の日付など、ポリシーがアクティブになる条件を指定できます。AWSシステム全体のキーとDynamoDBキーを含む条件キーで条件を表現します。これらのキーについては、チュートリアルの後半で詳しく説明します。
コンソールのアクセス許可
ユーザーがコンソールを使用するには、特定の基本的な権限が必要です。また、他の標準サービスのコンソールに対するアクセス許可も必要です-
- CloudWatch
- データパイプライン
- IDおよびアクセス管理
- 通知サービス
- Lambda
IAMポリシーが制限されすぎていることが判明した場合、ユーザーはコンソールを効果的に使用できません。また、CLIまたはAPIを呼び出すだけのユーザーのアクセス許可について心配する必要はありません。
一般的なIamポリシー
AWSは、スタンドアロンのIAMマネージドポリシーを使用して、パーミッションの一般的な操作をカバーしています。それらは、付与する必要があるものについての詳細な調査を回避できるようにする主要なアクセス許可を提供します。
それらのいくつかは次のとおりです-
AmazonDynamoDBReadOnlyAccess −コンソールを介した読み取り専用アクセスを提供します。
AmazonDynamoDBFullAccess −コンソールを介したフルアクセスを提供します。
AmazonDynamoDBFullAccesswithDataPipeline −コンソールを介したフルアクセスを提供し、データパイプラインを使用したエクスポート/インポートを許可します。
もちろん、カスタムポリシーを作成することもできます。
特権の付与:シェルの使用
Javascriptシェルを使用して権限を付与できます。次のプログラムは、一般的なアクセス許可ポリシーを示しています-
{
"Version": "2016-05-22",
"Statement": [
{
"Sid": "DescribeQueryScanToolsTable",
"Effect": "Deny",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": "arn:aws:dynamodb:us-west-2:account-id:table/Tools"
}
]
}次の3つの例を確認できます-
Block the user from executing any table action.
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "AllAPIActionsOnTools",
"Effect": "Deny",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:us-west-2:155556789012:table/Tools"
}
]
}Block access to a table and its indices.
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "AccessAllIndexesOnTools",
"Effect": "Deny",
"Action": [
"dynamodb:*"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:155556789012:table/Tools",
"arn:aws:dynamodb:us-west-2:155556789012:table/Tools/index/*"
]
}
]
}Block a user from making a reserved capacity offering purchase.
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "BlockReservedCapacityPurchases",
"Effect": "Deny",
"Action": "dynamodb:PurchaseReservedCapacityOfferings",
"Resource": "arn:aws:dynamodb:us-west-2:155556789012:*"
}
]
}特権の付与:GUIコンソールの使用
GUIコンソールを使用してIAMポリシーを作成することもできます。まず、選択しますTablesナビゲーションペインから。テーブルリストで、ターゲットテーブルを選択し、次の手順に従います。
Step 1 −を選択します Access control タブ。
Step 2− IDプロバイダー、アクション、およびポリシー属性を選択します。選択するCreate policy すべての設定を入力した後。
Step 3 −選択 Attach policy instructions、およびポリシーを適切なIAMロールに関連付けるために必要な各ステップを完了します。
DynamoDB APIは、パーミッションを必要とするアクションの大規模なセットを提供します。権限を設定する際には、許可されるアクション、許可されるリソース、およびそれぞれの条件を確立する必要があります。
ポリシーの「アクション」フィールド内でアクションを指定できます。ポリシーの「リソース」フィールド内でリソース値を指定します。ただし、API操作でDynamodb:プレフィックスを含む正しい構文を使用していることを確認してください。
例- dynamodb:CreateTable
条件キーを使用して権限をフィルタリングすることもできます。
権限とAPIアクション
次の表に示すAPIアクションと関連する権限をよく見てください-
| API操作 | 必要な許可 |
|---|---|
| BatchGetItem | dynamodb:BatchGetItem |
| BatchWriteItem | dynamodb:BatchWriteItem |
| CreateTable | dynamodb:CreateTable |
| DeleteItem | dynamodb:DeleteItem |
| DeleteTable | dynamodb:DeleteTable |
| DescriptionLimits | dynamodb:DescribeLimits |
| DescriptionReservedCapacity | dynamodb:DescribeReservedCapacity |
| DescriptionReservedCapacityOfferings | dynamodb:DescribeReservedCapacityOfferings |
| DescriptionStream | dynamodb:DescribeStream |
| DescriptionTable | dynamodb:DescribeTable |
| GetItem | dynamodb:GetItem |
| GetRecords | dynamodb:GetRecords |
| GetShardIterator | dynamodb:GetShardIterator |
| ListStreams | dynamodb:ListStreams |
| ListTables | dynamodb:ListTables |
| PurchaseReservedCapacityOfferings | dynamodb:PurchaseReservedCapacityOfferings |
| PutItem | dynamodb:PutItem |
| クエリ | dynamodb:クエリ |
| スキャン | dynamodb:スキャン |
| UpdateItem | dynamodb:UpdateItem |
| UpdateTable | dynamodb:UpdateTable |
リソース
次の表で、許可された各APIアクションに関連付けられたリソースを確認できます-
| API操作 | 資源 |
|---|---|
| BatchGetItem | arn:aws:dynamodb:region:account-id:table / table-name |
| BatchWriteItem | arn:aws:dynamodb:region:account-id:table / table-name |
| CreateTable | arn:aws:dynamodb:region:account-id:table / table-name |
| DeleteItem | arn:aws:dynamodb:region:account-id:table / table-name |
| DeleteTable | arn:aws:dynamodb:region:account-id:table / table-name |
| DescriptionLimits | arn:aws:dynamodb:region:account-id:* |
| DescriptionReservedCapacity | arn:aws:dynamodb:region:account-id:* |
| DescriptionReservedCapacityOfferings | arn:aws:dynamodb:region:account-id:* |
| DescriptionStream | arn:aws:dynamodb:region:account-id:table / table-name / stream / stream-label |
| DescriptionTable | arn:aws:dynamodb:region:account-id:table / table-name |
| GetItem | arn:aws:dynamodb:region:account-id:table / table-name |
| GetRecords | arn:aws:dynamodb:region:account-id:table / table-name / stream / stream-label |
| GetShardIterator | arn:aws:dynamodb:region:account-id:table / table-name / stream / stream-label |
| ListStreams | arn:aws:dynamodb:region:account-id:table / table-name / stream / * |
| ListTables | * |
| PurchaseReservedCapacityOfferings | arn:aws:dynamodb:region:account-id:* |
| PutItem | arn:aws:dynamodb:region:account-id:table / table-name |
| クエリ | arn:aws:dynamodb:region:account-id:table / table-name または arn:aws:dynamodb:region:account-id:table / table-name / index / index-name |
| スキャン | arn:aws:dynamodb:region:account-id:table / table-name または arn:aws:dynamodb:region:account-id:table / table-name / index / index-name |
| UpdateItem | arn:aws:dynamodb:region:account-id:table / table-name |
| UpdateTable | arn:aws:dynamodb:region:account-id:table / table-name |
DynamoDBでは、パーミッションを付与する際に、条件キーを使用した詳細なIAMポリシーを通じてパーミッションの条件を指定できます。これは、特定のアイテムや属性へのアクセスなどの設定をサポートします。
Note −DynamoDBはタグをサポートしていません。
詳細な制御
いくつかの条件により、ユーザーアカウントに基づいて特定のアイテムへの読み取り専用アクセスを許可するなど、アイテムや属性に至るまでの特異性が可能になります。セキュリティ資格情報を管理する条件付きIAMポリシーを使用して、このレベルの制御を実装します。次に、ポリシーを目的のユーザー、グループ、およびロールに適用するだけです。後で説明するトピックであるWebIdentity Federationは、Amazon、Facebook、およびGoogleのログインを介したユーザーアクセスを制御する方法も提供します。
IAMポリシーの条件要素は、アクセス制御を実装します。ポリシーに追加するだけです。その使用例は、テーブル項目および属性へのアクセスを拒否または許可することです。条件要素は、条件キーを使用して権限を制限することもできます。
条件キーの次の2つの例を確認できます-
dynamodb:LeadingKeys −パーティションキー値と一致するIDを持たないユーザーによるアイテムアクセスを防止します。
dynamodb:Attributes −ユーザーがリストされている属性以外の属性にアクセスしたり操作したりするのを防ぎます。
評価時に、IAMポリシーは真または偽の値になります。いずれかの部分がfalseと評価された場合、ポリシー全体がfalseと評価され、アクセスが拒否されます。ユーザーが適切にアクセスできるように、必要なすべての情報を条件キーに必ず指定してください。
事前定義された条件キー
AWSは、すべてのサービスに適用される事前定義された条件キーのコレクションを提供します。これらは、ユーザーとアクセスの調査における幅広い使用法と詳細をサポートします。
Note −条件キーには大文字と小文字が区別されます。
次のサービス固有のキーの選択を確認できます-
dynamodb:LeadingKey−テーブルの最初のキー属性を表します。パーティションキー。条件でForAllValues修飾子を使用します。
dynamodb:Select−クエリ/スキャン要求の選択パラメータを表します。値はALL_ATTRIBUTES、ALL_PROJECTED_ATTRIBUTES、SPECIFIC_ATTRIBUTES、またはCOUNTである必要があります。
dynamodb:Attributes−リクエスト内の属性名リスト、またはリクエストから返された属性を表します。その値とその関数はAPIアクションパラメーターに似ています。たとえば、BatchGetItemはAttributesToGetを使用します。
dynamodb:ReturnValues −リクエストのReturnValuesパラメータを表し、ALL_OLD、UPDATED_OLD、ALL_NEW、UPDATED_NEW、およびNONEの値を使用できます。
dynamodb:ReturnConsumedCapacity −リクエストのReturnConsumedCapacityパラメータを表し、TOTALおよびNONEの値を使用できます。
Web Identity Federationを使用すると、大規模なユーザーグループの認証と承認を簡素化できます。個々のアカウントの作成をスキップして、一時的な資格情報またはトークンを取得するためにユーザーにIDプロバイダーへのログインを要求することができます。AWS Security Token Service(STS)を使用して認証情報を管理します。アプリケーションはこれらのトークンを使用してサービスと対話します。
Web Identity Federationは、Amazon、Google、Facebookなどの他のIDプロバイダーもサポートしています。
Function−使用中、Web Identity Federationは最初にユーザーとアプリの認証のためにIDプロバイダーを呼び出し、プロバイダーはトークンを返します。これにより、アプリはAWS STSを呼び出し、入力用のトークンを渡します。STSはアプリを承認し、一時的なアクセス認証情報を付与します。これにより、アプリはIAMロールを使用し、ポリシーに基づいてリソースにアクセスできます。
WebIDフェデレーションの実装
使用する前に、次の3つの手順を実行する必要があります-
サポートされているサードパーティのIDプロバイダーを使用して、開発者として登録します。
アプリケーションをプロバイダーに登録して、アプリIDを取得します。
ポリシーの添付を含め、単一または複数のIAMロールを作成します。アプリごとにプロバイダーごとに役割を使用する必要があります。
Web IdentityFederationを使用するIAMロールの1つを想定します。次に、アプリは3段階のプロセスを実行する必要があります-
- Authentication
- 資格情報の取得
- リソースアクセス
最初のステップでは、アプリは独自のインターフェースを使用してプロバイダーを呼び出し、トークンプロセスを管理します。
次に、ステップ2でトークンを管理し、アプリに AssumeRoleWithWebIdentityAWSSTSへのリクエスト。リクエストには、最初のトークン、プロバイダーアプリID、およびIAMロールのARNが含まれます。STSは、特定の期間が経過すると期限切れになるように設定された資格情報を提供します。
最後のステップで、アプリはDynamoDBリソースのアクセス情報を含む応答をSTSから受信します。これは、アクセス資格情報、有効期限、ロール、およびロールIDで構成されます。
データパイプラインを使用すると、テーブル、ファイル、またはS3バケットとの間でデータをエクスポートおよびインポートできます。もちろん、これはバックアップ、テスト、および同様のニーズやシナリオで役立つことがわかります。
エクスポートでは、データパイプラインコンソールを使用します。これにより、新しいパイプラインが作成され、Amazon EMR(Elastic MapReduce)クラスターが起動されてエクスポートが実行されます。EMRはDynamoDBからデータを読み取り、ターゲットに書き込みます。EMRについては、このチュートリアルの後半で詳しく説明します。
インポート操作では、データパイプラインコンソールを使用します。データパイプラインコンソールは、パイプラインを作成し、EMRを起動してインポートを実行します。ソースからデータを読み取り、宛先に書き込みます。
Note −使用されるサービス、具体的にはEMRとS3を考慮すると、エクスポート/インポート操作にはコストがかかります。
データパイプラインの使用
データパイプラインを使用する場合は、アクションとリソースのアクセス許可を指定する必要があります。IAMロールまたはポリシーを利用してそれらを定義できます。インポート/エクスポートを実行しているユーザーは、アクティブなアクセスキーIDと秘密キーが必要になることに注意する必要があります。
データパイプラインのIAMの役割
データパイプラインを使用するには、2つのIAMロールが必要です-
DataPipelineDefaultRole −これには、パイプラインに実行を許可するすべてのアクションが含まれます。
DataPipelineDefaultResourceRole −これには、パイプラインがプロビジョニングすることを許可するリソースがあります。
データパイプラインを初めて使用する場合は、各ロールを生成する必要があります。以前のすべてのユーザーは、既存の役割のためにこれらの役割を持っています。
IAMコンソールを使用してデータパイプラインのIAMロールを作成し、次の4つの手順を実行します-
Step 1 −次の場所にあるIAMコンソールにログインします。 https://console.aws.amazon.com/iam/
Step 2 −選択 Roles ダッシュボードから。
Step 3 −選択 Create New Role。次に、DataPipelineDefaultRoleをRole Name フィールドを選択し、 Next Step。の中にAWS Service Roles のリスト Role Type パネル、に移動 Data Pipeline、を選択します Select。選択するCreate Role の中に Review パネル。
Step 4 −選択 Create New Role。
DataPipelineのインポート/エクスポート機能を利用してバックアップを実行します。バックアップの実行方法は、GUIコンソールを使用するか、データパイプラインを直接使用するか(API)によって異なります。コンソールを使用する場合はテーブルごとに個別のパイプラインを作成するか、直接オプションを使用する場合は単一のパイプラインで複数のテーブルをインポート/エクスポートします。
データのエクスポートとインポート
エクスポートを実行する前に、AmazonS3バケットを作成する必要があります。1つ以上のテーブルからエクスポートできます。
次の4つのステップのプロセスを実行して、エクスポートを実行します-
Step 1 − AWSマネジメントコンソールにログインし、次の場所にあるデータパイプラインコンソールを開きます。 https://console.aws.amazon.com/datapipeline/
Step 2 − AWSリージョンでパイプラインを使用していない場合は、 Get started now。1つ以上ある場合は、Create new pipeline。
Step 3−作成ページで、パイプラインの名前を入力します。選択Build using a templateSourceパラメーターの場合。選択するExport DynamoDB table to S3リストから。にソーステーブルを入力しますSource DynamoDB table name フィールド。
宛先S3バケットを Output S3 Folder次の形式を使用するテキストボックス:s3:// nameOfBucket / region / nameOfFolder。ログファイルのS3宛先をに入力しますS3 location for logs テキストボックス。
Step 4 −選択 Activate すべての設定を入力した後。
パイプラインは、作成プロセスを完了するのに数分かかる場合があります。コンソールを使用して、そのステータスを監視します。エクスポートされたファイルを表示して、S3コンソールで正常に処理されたことを確認します。
データのインポート
インポートが成功するのは、次の条件が当てはまる場合のみです。宛先テーブルを作成し、宛先とソースが同じ名前を使用し、宛先とソースが同じキースキーマを使用している。
設定された宛先テーブルを使用できますが、インポートにより、キーを共有するデータアイテムがソースアイテムと置き換えられ、余分なアイテムがテーブルに追加されます。宛先は別のリージョンを使用することもできます。
複数のソースをエクスポートできますが、インポートできるのは操作ごとに1つだけです。次の手順に従ってインポートを実行できます-
Step 1 − AWSマネジメントコンソールにログインし、データパイプラインコンソールを開きます。
Step 2 −クロスリージョンインポートを実行する場合は、宛先リージョンを選択する必要があります。
Step 3 −選択 Create new pipeline。
Step 4 −パイプライン名を Nameフィールド。選択Build using a template [ソース]パラメーターとして、テンプレートリストで[ Import DynamoDB backup data from S3。
にソースファイルの場所を入力します Input S3 Folderテキストボックス。に宛先テーブル名を入力しますTarget DynamoDB table nameフィールド。次に、ログファイルの場所をS3 location for logs テキストボックス。
Step 5 −選択 Activate すべての設定を入力した後。
インポートは、パイプラインの作成直後に開始されます。パイプラインが作成プロセスを完了するまでに数分かかる場合があります。
エラー
エラーが発生すると、データパイプラインコンソールにパイプラインステータスとしてERRORが表示されます。エラーのあるパイプラインをクリックすると、詳細ページが表示され、プロセスのすべてのステップと障害が発生したポイントが表示されます。内のログファイルもいくつかの洞察を提供します。
エラーの一般的な原因は次のように確認できます-
インポートの宛先テーブルが存在しないか、ソースと同一のキースキーマを使用していません。
S3バケットが存在しないか、読み取り/書き込み権限がありません。
パイプラインがタイムアウトしました。
必要なエクスポート/インポート権限がありません。
AWSアカウントがリソース制限に達しました。
Amazonは、CloudWatchコンソール、コマンドライン、またはCloudWatchAPIを介してパフォーマンスを集約および分析するためのCloudWatchを提供しています。また、アラームの設定やタスクの実行にも使用できます。特定のイベントに対して指定されたアクションを実行します。
Cloudwatchコンソール
管理コンソールにアクセスし、次の場所でCloudWatchコンソールを開いてCloudWatchを利用します。 https://console.aws.amazon.com/cloudwatch/。
その後、次の手順を実行できます-
選択する Metrics ナビゲーションペインから。
内のDynamoDBメトリックの下 CloudWatch Metrics by Category ペイン、選択 Table Metrics。
上のペインを使用して下にスクロールし、テーブルメトリックのリスト全体を調べます。ザ・Viewing リストはメトリックオプションを提供します。
結果インターフェースでは、リソース名とメトリックの横にあるチェックボックスを選択することで、各メトリックを選択/選択解除できます。次に、各アイテムのグラフを表示できるようになります。
API統合
クエリを使用してCloudWatchにアクセスできます。メトリックス値を使用してCloudWatchアクションを実行します。Note DynamoDBは、値がゼロのメトリックを送信しません。それらのメトリックがその値のままである期間のメトリックを単にスキップします。
以下は、最も一般的に使用されるメトリックの一部です-
ConditionalCheckFailedRequests−条件付きPutItem書き込みなどの条件付き書き込みで失敗した試行の数を追跡します。失敗した書き込みは、評価時にこのメトリックを1つ増やしてfalseにします。また、HTTP400エラーもスローします。
ConsumedReadCapacityUnits−特定の期間に使用された容量単位を定量化します。これを使用して、個々のテーブルとインデックスの消費を調べることができます。
ConsumedWriteCapacityUnits−特定の期間に使用された容量単位を定量化します。これを使用して、個々のテーブルとインデックスの消費を調べることができます。
ReadThrottleEvents−テーブル/インデックスの読み取りでプロビジョニングされた容量単位を超える要求を定量化します。複数のスロットルを使用したバッチ操作を含め、スロットルごとに増分します。
ReturnedBytes −特定の期間内に取得操作で返されたバイトを定量化します。
ReturnedItemCount−特定の期間にクエリおよびスキャン操作で返されたアイテムを定量化します。これは、評価されたものではなく、返されたアイテムのみに対応します。これらは通常、まったく異なる数値です。
Note −存在するメトリックは他にもたくさんあり、これらのほとんどを使用すると、平均、合計、最大、最小、およびカウントを計算できます。
DynamoDBにはCloudTrail統合が含まれています。アカウント内のDynamoDBからのまたはDynamoDBに対する低レベルのAPIリクエストをキャプチャし、指定されたS3バケットにログファイルを送信します。コンソールまたはAPIからの呼び出しを対象としています。このデータを使用して、行われたリクエストとそのソース、ユーザー、タイムスタンプなどを判別できます。
有効にすると、他のサービスレコードを含むログファイルのアクションを追跡します。8つのアクションと2つのストリームをサポートします-
8つのアクションは次のとおりです-
- CreateTable
- DeleteTable
- DescribeTable
- ListTables
- UpdateTable
- DescribeReservedCapacity
- DescribeReservedCapacityOfferings
- PurchaseReservedCapacityOfferings
一方、2つのストリームは-
- DescribeStream
- ListStreams
すべてのログには、リクエストを行っているアカウントに関する情報が含まれています。rootユーザーとIAMユーザーのどちらがリクエストを行ったか、一時的な認証情報を使用しているか、フェデレーションを使用しているかなどの詳細情報を確認できます。
ログファイルは、アーカイブと削除の設定とともに、指定した期間ストレージに残ります。デフォルトでは、暗号化されたログが作成されます。新しいログのアラートを設定できます。リージョンやアカウントにまたがる複数のログを1つのバケットに整理することもできます。
ログファイルの解釈
各ファイルには、単一または複数のエントリが含まれています。各エントリは、複数のJSON形式のイベントで構成されています。エントリはリクエストを表し、関連情報が含まれています。注文の保証はありません。
次のサンプルログファイルを確認できます-
{"Records": [
{
"eventVersion": "5.05",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKTTIOSZODNN8SAMPLE:jane",
"arn": "arn:aws:sts::155522255533:assumed-role/users/jane",
"accountId": "155522255533",
"accessKeyId": "AKTTIOSZODNN8SAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2016-05-11T19:01:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKTTI44ZZ6DHBSAMPLE",
"arn": "arn:aws:iam::499955777666:role/admin-role",
"accountId": "499955777666",
"userName": "jill"
}
}
},
"eventTime": "2016-05-11T14:33:20Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "DeleteTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": {"tableName": "Tools"},
"responseElements": {"tableDescription": {
"tableName": "Tools",
"itemCount": 0,
"provisionedThroughput": {
"writeCapacityUnits": 25,
"numberOfDecreasesToday": 0,
"readCapacityUnits": 25
},
"tableStatus": "DELETING",
"tableSizeBytes": 0
}},
"requestID": "4D89G7D98GF7G8A7DF78FG89AS7GFSO5AEMVJF66Q9ASUAAJG",
"eventID": "a954451c-c2fc-4561-8aea-7a30ba1fdf52",
"eventType": "AwsApiCall",
"apiVersion": "2013-04-22",
"recipientAccountId": "155522255533"
}
]}AmazonのElasticMapReduce(EMR)を使用すると、ビッグデータを迅速かつ効率的に処理できます。EMRはEC2インスタンスでApacheHadoopを実行しますが、プロセスを簡素化します。Apache Hiveを利用して、SQLに似たクエリ言語であるHiveQLを介したクエリマップReduceジョブフローを使用します。Apache Hiveは、クエリとアプリケーションを最適化する方法として機能します。
管理コンソールの[EMR]タブ、EMR CLI、API、またはSDKを使用して、ジョブフローを起動できます。Hiveをインタラクティブに実行するか、スクリプトを利用するオプションもあります。
EMRの読み取り/書き込み操作はスループットの消費に影響を与えますが、大きな要求では、バックオフアルゴリズムの保護を使用して再試行を実行します。また、EMRを他の操作やタスクと同時に実行すると、スロットルが発生する可能性があります。
DynamoDB / EMR統合は、バイナリおよびバイナリセット属性をサポートしていません。
DynamoDB / EMR統合の前提条件
EMRを使用する前に、必要な項目のこのチェックリストを確認してください-
- AWSアカウント
- EMR操作で使用されるのと同じアカウントで入力されたテーブル
- DynamoDB接続を備えたカスタムHiveバージョン
- DynamoDB接続のサポート
- S3バケット(オプション)
- SSHクライアント(オプション)
- EC2キーペア(オプション)
ハイブのセットアップ
EMRを使用する前に、キーペアを作成してHiveをインタラクティブモードで実行します。キーペアにより、ジョブフローのEC2インスタンスとマスターノードへの接続が可能になります。
次の手順に従ってこれを実行できます-
管理コンソールにログインし、次の場所にあるEC2コンソールを開きます。 https://console.aws.amazon.com/ec2/
コンソールの右上部分でリージョンを選択します。リージョンがDynamoDBリージョンと一致することを確認します。
ナビゲーションペインで、 Key Pairs。
選択する Create Key Pair。
の中に Key Pair Name フィールドに名前を入力して選択します Create。
次の形式を使用する結果の秘密鍵ファイルをダウンロードします:filename.pem。
Note −キーペアがないとEC2インスタンスに接続できません。
Hiveクラスター
Hiveを実行するためのHive対応クラスターを作成します。Hive-to-DynamoDB接続に必要なアプリケーションとインフラストラクチャの環境を構築します。
このタスクは、次の手順を使用して実行できます-
EMRコンソールにアクセスします。
選択する Create Cluster。
作成画面で、クラスターのわかりやすい名前でクラスター構成を設定し、[ Yes 終了保護とチェックオン Enabled ロギング用、S3宛先 log folder S3 location、および Enabled デバッグ用。
[ソフトウェア構成]画面で、フィールドが保持されていることを確認します Amazon Hadoopディストリビューションの場合、AMIバージョンの最新バージョン、インストールするアプリケーションのデフォルトのHiveバージョン-Hive、およびインストールするアプリケーションのデフォルトのPigバージョン-Pig。
[ハードウェア構成]画面で、フィールドが保持されていることを確認します Launch into EC2-Classic ネットワークの場合、 No Preference EC2アベイラビリティーゾーンの場合、マスター-Amazon EC2インスタンスタイプのデフォルト、リクエストスポットインスタンスのチェックなし、コア-Amazon EC2インスタンスタイプのデフォルト、 2 カウントの場合、リクエストスポットインスタンスのチェックなし、タスクのデフォルト-Amazon EC2インスタンスタイプ、 0 カウントの場合、リクエストスポットインスタンスのチェックはありません。
クラスターの障害を防ぐために十分な容量を提供する制限を必ず設定してください。
[セキュリティとアクセス]画面で、フィールドがEC2キーペアのキーペアを保持していることを確認します。 No other IAM users IAMユーザーアクセスで、および Proceed without roles IAMの役割で。
[ブートストラップアクション]画面を確認しますが、変更しないでください。
設定を確認し、 Create Cluster 終わった時に。
A Summary クラスターの開始時にペインが表示されます。
SSHセッションをアクティブ化する
マスターノードに接続してCLI操作を実行するには、アクティブなSSHセッションが必要です。EMRコンソールでクラスターを選択して、マスターノードを見つけます。マスターノードを次のようにリストしますMaster Public DNS Name。
PuTTYがない場合は、インストールしてください。次に、PuTTYgenを起動し、Load。PEMファイルを選択して開きます。PuTTYgenは、インポートが成功したことを通知します。選択するSave private key PuTTY秘密鍵形式(PPK)で保存するには、 Yesパスフレーズなしで保存するため。次に、PuTTYキーの名前を入力し、Save、PuTTYgenを閉じます。
最初にPuTTYを起動して、PuTTYを使用してマスターノードと接続します。選択Sessionカテゴリリストから。[ホスト名]フィールドにhadoop @ DNSと入力します。展開Connection > SSH カテゴリリストで、を選択します Auth。制御オプション画面で、Browse認証用の秘密鍵ファイル用。次に、秘密鍵ファイルを選択して開きます。選択するYes セキュリティアラートポップアップ用。
マスターノードに接続すると、Hadoopコマンドプロンプトが表示されます。これは、インタラクティブなHiveセッションを開始できることを意味します。
ハイブテーブル
Hiveは、HiveQLを使用してEMRクラスターでクエリを実行できるデータウェアハウスツールとして機能します。以前の設定では、作業プロンプトが表示されます。「hive」と入力し、必要なコマンドを入力するだけで、Hiveコマンドをインタラクティブに実行できます。詳細については、当社のハイブのチュートリアルを参照してくださいハイブ。
DynamoDBストリームを使用すると、テーブルアイテムの変更を追跡して応答できます。この機能を使用して、ソース間で情報を更新することにより変更に応答するアプリケーションを作成します。大規模なマルチユーザーシステムの数千人のユーザーのデータを同期します。これを使用して、更新に関する通知をユーザーに送信します。そのアプリケーションは多様で実質的であることが証明されています。DynamoDBストリームは、この機能を実現するために使用される主要なツールとして機能します。
ストリームは、テーブル内のアイテムの変更を含む時系列のシーケンスをキャプチャします。彼らはこのデータを最大24時間保持します。アプリケーションはそれらを使用して、元のアイテムと変更されたアイテムをほぼリアルタイムで表示します。
テーブルで有効になっているストリームは、すべての変更をキャプチャします。すべてのCRUD操作で、DynamoDBは変更されたアイテムの主キー属性を使用してストリームレコードを作成します。前後の画像などの追加情報のストリームを構成できます。
ストリームには2つの保証があります-
各レコードはストリームに1回表示され、
各アイテムの変更により、変更と同じ順序のストリームレコードが生成されます。
すべてのストリームはリアルタイムで処理されるため、アプリケーションの関連機能に使用できます。
ストリームの管理
テーブルの作成時に、ストリームを有効にできます。既存のテーブルでは、ストリームの無効化または設定の変更が可能です。ストリームは非同期操作の機能を提供します。つまり、テーブルのパフォーマンスに影響はありません。
シンプルなストリーム管理のためにAWSマネジメントコンソールを利用します。まず、コンソールに移動して、Tables。[概要]タブで、Manage Stream。ウィンドウ内で、テーブルデータの変更に関するストリームに追加された情報を選択します。すべての設定を入力したら、Enable。
既存のストリームを無効にする場合は、 Manage Stream、 その後 Disable。
API CreateTableおよびUpdateTableを利用して、ストリームを有効化または変更することもできます。パラメータStreamSpecificationを使用して、ストリームを構成します。StreamEnabledはステータスを指定します。つまり、有効の場合はtrue、無効の場合はfalseを意味します。
StreamViewTypeは、ストリームに追加される情報(KEYS_ONLY、NEW_IMAGE、OLD_IMAGE、およびNEW_AND_OLD_IMAGES)を指定します。
ストリームリーディング
エンドポイントに接続してAPIリクエストを行うことにより、ストリームを読み取って処理します。各ストリームはストリームレコードで構成され、すべてのレコードはストリームを所有する単一の変更として存在します。ストリームレコードには、発行順序を示すシーケンス番号が含まれています。レコードは、シャードとも呼ばれるグループに属しています。シャードは、いくつかのレコードのコンテナとして機能し、レコードへのアクセスとトラバースに必要な情報も保持します。24時間後、レコードは自動的に削除されます。
これらのシャードは必要に応じて生成および削除され、長続きしません。また、通常は書き込みアクティビティの急増に応じて、複数の新しいシャードに自動的に分割されます。ストリームを無効にすると、開いているシャードが閉じます。シャード間の階層関係は、アプリケーションが正しい処理順序のために親シャードに優先順位を付ける必要があることを意味します。KinesisAdapterを使用してこれを自動的に行うことができます。
Note −変更が発生しない操作では、ストリームレコードは書き込まれません。
レコードにアクセスして処理するには、次のタスクを実行する必要があります-
- ターゲットストリームのARNを決定します。
- ターゲットレコードを保持しているストリームのシャードを決定します。
- シャードにアクセスして、目的のレコードを取得します。
Note−シャードを一度に読み取るプロセスは最大2つ必要です。2プロセスを超えると、ソースを調整できます。
利用可能なストリームAPIアクションには次のものがあります
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
次のストリーム読み取りの例を確認できます-
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClient;
import com.amazonaws.services.dynamodbv2.model.AttributeAction;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.AttributeValue;
import com.amazonaws.services.dynamodbv2.model.AttributeValueUpdate;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeStreamRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeStreamResult;
import com.amazonaws.services.dynamodbv2.model.DescribeTableResult;
import com.amazonaws.services.dynamodbv2.model.GetRecordsRequest;
import com.amazonaws.services.dynamodbv2.model.GetRecordsResult;
import com.amazonaws.services.dynamodbv2.model.GetShardIteratorRequest;
import com.amazonaws.services.dynamodbv2.model.GetShardIteratorResult;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.Record;
import com.amazonaws.services.dynamodbv2.model.Shard;
import com.amazonaws.services.dynamodbv2.model.ShardIteratorType;
import com.amazonaws.services.dynamodbv2.model.StreamSpecification;
import com.amazonaws.services.dynamodbv2.model.StreamViewType;
import com.amazonaws.services.dynamodbv2.util.Tables;
public class StreamsExample {
private static AmazonDynamoDBClient dynamoDBClient =
new AmazonDynamoDBClient(new ProfileCredentialsProvider());
private static AmazonDynamoDBStreamsClient streamsClient =
new AmazonDynamoDBStreamsClient(new ProfileCredentialsProvider());
public static void main(String args[]) {
dynamoDBClient.setEndpoint("InsertDbEndpointHere");
streamsClient.setEndpoint("InsertStreamEndpointHere");
// table creation
String tableName = "MyTestingTable";
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("ID")
.withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName("ID")
.withKeyType(KeyType.HASH)); //Partition key
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_AND_OLD_IMAGES);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L))
.withStreamSpecification(streamSpecification);
System.out.println("Executing CreateTable for " + tableName);
dynamoDBClient.createTable(createTableRequest);
System.out.println("Creating " + tableName);
try {
Tables.awaitTableToBecomeActive(dynamoDBClient, tableName);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Get the table's stream settings
DescribeTableResult describeTableResult =
dynamoDBClient.describeTable(tableName);
String myStreamArn = describeTableResult.getTable().getLatestStreamArn();
StreamSpecification myStreamSpec =
describeTableResult.getTable().getStreamSpecification();
System.out.println("Current stream ARN for " + tableName + ": "+ myStreamArn);
System.out.println("Stream enabled: "+ myStreamSpec.getStreamEnabled());
System.out.println("Update view type: "+ myStreamSpec.getStreamViewType());
// Add an item
int numChanges = 0;
System.out.println("Making some changes to table data");
Map<String, AttributeValue> item = new HashMap<String, AttributeValue>();
item.put("ID", new AttributeValue().withN("222"));
item.put("Alert", new AttributeValue().withS("item!"));
dynamoDBClient.putItem(tableName, item);
numChanges++;
// Update the item
Map<String, AttributeValue> key = new HashMap<String, AttributeValue>();
key.put("ID", new AttributeValue().withN("222"));
Map<String, AttributeValueUpdate> attributeUpdates =
new HashMap<String, AttributeValueUpdate>();
attributeUpdates.put("Alert", new AttributeValueUpdate()
.withAction(AttributeAction.PUT)
.withValue(new AttributeValue().withS("modified item")));
dynamoDBClient.updateItem(tableName, key, attributeUpdates);
numChanges++;
// Delete the item
dynamoDBClient.deleteItem(tableName, key);
numChanges++;
// Get stream shards
DescribeStreamResult describeStreamResult =
streamsClient.describeStream(new DescribeStreamRequest()
.withStreamArn(myStreamArn));
String streamArn =
describeStreamResult.getStreamDescription().getStreamArn();
List<Shard> shards =
describeStreamResult.getStreamDescription().getShards();
// Process shards
for (Shard shard : shards) {
String shardId = shard.getShardId();
System.out.println("Processing " + shardId + " in "+ streamArn);
// Get shard iterator
GetShardIteratorRequest getShardIteratorRequest = new
GetShardIteratorRequest()
.withStreamArn(myStreamArn)
.withShardId(shardId)
.withShardIteratorType(ShardIteratorType.TRIM_HORIZON);
GetShardIteratorResult getShardIteratorResult =
streamsClient.getShardIterator(getShardIteratorRequest);
String nextItr = getShardIteratorResult.getShardIterator();
while (nextItr != null && numChanges > 0) {
// Read data records with iterator
GetRecordsResult getRecordsResult =
streamsClient.getRecords(new GetRecordsRequest().
withShardIterator(nextItr));
List<Record> records = getRecordsResult.getRecords();
System.out.println("Pulling records...");
for (Record record : records) {
System.out.println(record);
numChanges--;
}
nextItr = getRecordsResult.getNextShardIterator();
}
}
}
}リクエストの処理が失敗すると、DynamoDBはエラーをスローします。各エラーは、HTTPステータスコード、例外名、およびメッセージで構成されます。エラー管理は、エラーを伝播するSDKまたは独自のコードに基づいています。
コードとメッセージ
例外は、さまざまなHTTPヘッダーステータスコードに分類されます。4xxと5xxは、リクエストの問題とAWSに関連するエラーを保持します。
HTTP4xxカテゴリの例外の選択は次のとおりです-
AccessDeniedException −クライアントは要求に正しく署名できませんでした。
ConditionalCheckFailedException −falseと評価された条件。
IncompleteSignatureException −リクエストに不完全な署名が含まれていました。
HTTP5xxカテゴリの例外は次のとおりです-
- 内部サーバーエラー
- サービスは利用できません
再試行とバックオフアルゴリズム
エラーは、サーバー、スイッチ、ロードバランサー、その他の構造やシステムなど、さまざまな原因で発生します。一般的なソリューションは、信頼性をサポートする単純な再試行で構成されます。すべてのSDKにはこのロジックが自動的に含まれており、アプリケーションのニーズに合わせて再試行パラメーターを設定できます。
For example − Javaは、再試行を停止するためのmaxErrorRetry値を提供します。
Amazonは、フローを制御するために、再試行に加えてバックオフソリューションを使用することをお勧めします。これは、再試行間の待機期間を徐々に増やし、最終的にはかなり短い期間の後に停止することで構成されます。注SDKは自動再試行を実行しますが、指数バックオフは実行しません。
次のプログラムは、再試行バックオフの例です。
public enum Results {
SUCCESS,
NOT_READY,
THROTTLED,
SERVER_ERROR
}
public static void DoAndWaitExample() {
try {
// asynchronous operation.
long token = asyncOperation();
int retries = 0;
boolean retry = false;
do {
long waitTime = Math.min(getWaitTime(retries), MAX_WAIT_INTERVAL);
System.out.print(waitTime + "\n");
// Pause for result
Thread.sleep(waitTime);
// Get result
Results result = getAsyncOperationResult(token);
if (Results.SUCCESS == result) {
retry = false;
} else if (Results.NOT_READY == result) {
retry = true;
} else if (Results.THROTTLED == result) {
retry = true;
} else if (Results.SERVER_ERROR == result) {
retry = true;
} else {
// stop on other error
retry = false;
}
} while (retry && (retries++ < MAX_RETRIES));
}
catch (Exception ex) {
}
}
public static long getWaitTime(int retryCount) {
long waitTime = ((long) Math.pow(3, retryCount) * 100L);
return waitTime;
}特定のプラクティスでは、さまざまなソースや要素を操作するときに、コードを最適化し、エラーを防ぎ、スループットコストを最小限に抑えます。
以下は、DynamoDBで最も重要で一般的に使用されるベストプラクティスの一部です。
テーブル
テーブルの分散は、最良のアプローチが読み取り/書き込みアクティビティをすべてのテーブルアイテムに均等に分散することを意味します。
テーブルアイテムへの均一なデータアクセスを目指します。最適なスループットの使用は、主キーの選択とアイテムのワークロードパターンに依存します。ワークロードをパーティションキー値全体に均等に分散します。頻繁に使用される少量のパーティションキー値などは避けてください。大量の個別のパーティションキー値など、より適切な選択肢を選択してください。
パーティションの動作を理解します。DynamoDBによって自動的に割り当てられたパーティションを見積もります。
DynamoDBはバーストスループットの使用法を提供し、電力の「バースト」のために未使用のスループットを予約します。バーストは大量のスループットをすばやく消費するため、このオプションを多用しないでください。さらに、それは信頼できるリソースを証明していません。
アップロード時に、パフォーマンスを向上させるためにデータを配布します。割り当てられたすべてのサーバーに同時にアップロードすることにより、これを実装します。
頻繁に使用されるアイテムをキャッシュして、読み取りアクティビティをデータベースではなくキャッシュにオフロードします。
アイテム
スロットリング、パフォーマンス、サイズ、およびアクセスコストは、依然としてアイテムの最大の懸念事項です。1対多のテーブルを選択します。属性を削除し、テーブルを分割してアクセスパターンに一致させます。この単純なアプローチにより、効率を劇的に向上させることができます。
大きな値を保存する前に圧縮します。標準の圧縮ツールを利用します。S3などの大きな属性値には代替ストレージを使用します。オブジェクトをS3に保存し、識別子をアイテムに保存できます。
仮想アイテムピースを介して、複数のアイテムに大きな属性を分散します。これにより、アイテムサイズの制限に対する回避策が提供されます。
クエリとスキャン
クエリとスキャンは、主にスループット消費の課題に悩まされています。バーストは避けてください。バーストは通常、一貫性の高い読み取りに切り替えるなどの結果として発生します。低リソースの方法で並列スキャンを使用します(つまり、スロットルのないバックグラウンド機能)。さらに、それらは大きなテーブルでのみ使用し、スループットまたはスキャン操作を十分に活用していない状況ではパフォーマンスが低下します。
ローカルセカンダリインデックス
インデックスは、スループットとストレージコスト、およびクエリの効率の分野で問題を提示します。属性を頻繁にクエリしない限り、インデックス作成は避けてください。予測では、インデックスが肥大化するため、賢明に選択してください。頻繁に使用するもののみを選択してください。
スパースインデックスを使用します。これは、すべてのテーブルアイテムに並べ替えキーが表示されないインデックスを意味します。これらは、ほとんどのテーブルアイテムに存在しない属性に対するクエリに役立ちます。
アイテムコレクション(すべてのテーブルアイテムとそのインデックス)の拡張に注意してください。追加/更新操作により、テーブルとインデックスの両方が大きくなり、コレクションの制限は10GBのままです。
グローバルセカンダリインデックス
インデックスは、スループットとストレージコスト、およびクエリの効率の分野で問題を提示します。テーブルでの読み取り/書き込みの分散と同様に、ワークロードの均一性を提供する主要な属性の分散を選択します。データを均等に分散する属性を選択します。また、スパースインデックスを利用します。
適度な量のデータを要求するクエリで高速検索を行うために、グローバルセカンダリインデックスを活用します。