HCatalog-インストール
Hive、Pig、HBaseなどのすべてのHadoopサブプロジェクトは、Linuxオペレーティングシステムをサポートしています。したがって、システムにLinuxフレーバーをインストールする必要があります。HCatalogは、2013年3月26日にHiveインストールと統合されます。バージョンHive-0.11.0以降、HCatalogにはHiveインストールが付属しています。したがって、以下の手順に従ってHiveをインストールすると、システムにHCatalogが自動的にインストールされます。
ステップ1:JAVAインストールの確認
Hiveをインストールする前に、Javaをシステムにインストールする必要があります。次のコマンドを使用して、システムにJavaがすでにインストールされているかどうかを確認できます。
$ java –versionJavaがすでにシステムにインストールされている場合は、次の応答が表示されます-
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)システムにJavaがインストールされていない場合は、以下の手順に従う必要があります。
ステップ2:Javaをインストールする
次のリンクにアクセスして、Java(JDK <最新バージョン> -X64.tar.gz)をダウンロードします。 http://www.oracle.com/
次に jdk-7u71-linux-x64.tar.gz システムにダウンロードされます。
通常、ダウンロードしたJavaファイルはDownloadsフォルダーにあります。それを確認し、抽出しますjdk-7u71-linux-x64.gz 次のコマンドを使用してファイルします。
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzすべてのユーザーがJavaを使用できるようにするには、Javaを「/ usr / local /」の場所に移動する必要があります。rootを開き、次のコマンドを入力します。
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit設定用 PATH そして JAVA_HOME 変数については、次のコマンドを追加してください ~/.bashrc ファイル。
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/binコマンドを使用してインストールを確認します java -version 上で説明したように端末から。
ステップ3:Hadoopのインストールを確認する
Hiveをインストールする前に、Hadoopをシステムにインストールする必要があります。次のコマンドを使用して、Hadoopのインストールを確認しましょう-
$ hadoop versionHadoopがすでにシステムにインストールされている場合は、次の応答が返されます-
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Hadoopがシステムにインストールされていない場合は、次の手順に進みます-
ステップ4:Hadoopをダウンロードする
次のコマンドを使用して、Apache SoftwareFoundationからHadoop2.4.1をダウンロードして抽出します。
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitステップ5:疑似分散モードでのHadoopのインストール
次の手順を使用してインストールします Hadoop 2.4.1 疑似分散モード。
Hadoopのセットアップ
次のコマンドをに追加することで、Hadoop環境変数を設定できます。 ~/.bashrc ファイル。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin次に、すべての変更を現在実行中のシステムに適用します。
$ source ~/.bashrcHadoop構成
すべてのHadoop構成ファイルは、「$ HADOOP_HOME / etc / hadoop」の場所にあります。Hadoopインフラストラクチャに応じて、これらの構成ファイルに適切な変更を加える必要があります。
$ cd $HADOOP_HOME/etc/hadoopJavaを使用してHadoopプログラムを開発するには、Java環境変数をリセットする必要があります。 hadoop-env.sh 置き換えることによってファイル JAVA_HOME システム内のJavaの場所を含む値。
export JAVA_HOME=/usr/local/jdk1.7.0_71以下に、Hadoopを構成するために編集する必要のあるファイルのリストを示します。
core-site.xml
ザ・ core-site.xml ファイルには、Hadoopインスタンスに使用されるポート番号、ファイルシステムに割り当てられたメモリ、データを格納するためのメモリ制限、読み取り/書き込みバッファのサイズなどの情報が含まれています。
core-site.xmlを開き、<configuration>タグと</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
ザ・ hdfs-site.xmlfileには、レプリケーションデータの値、namenodeパス、ローカルファイルシステムのdatanodeパスなどの情報が含まれています。これは、Hadoopインフラストラクチャを保存する場所を意味します。
以下のデータを想定します。
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeこのファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note −上記のファイルでは、すべてのプロパティ値がユーザー定義であり、Hadoopインフラストラクチャに応じて変更を加えることができます。
糸-site.xml
このファイルは、Hadoopにyarnを構成するために使用されます。ヤーンサイト.xmlファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
このファイルは、使用しているMapReduceフレームワークを指定するために使用されます。デフォルトでは、Hadoopにはyarn-site.xmlのテンプレートが含まれています。まず、ファイルをからコピーする必要がありますmapred-site,xml.template に mapred-site.xml 次のコマンドを使用してファイルします。
$ cp mapred-site.xml.template mapred-site.xmlmapred-site.xmlファイルを開き、このファイルの<configuration>、</ configuration>タグの間に次のプロパティを追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>ステップ6:Hadoopのインストールを確認する
次の手順は、Hadoopのインストールを確認するために使用されます。
Namenodeのセットアップ
次のようにコマンド「hdfsnamenode-format」を使用してnamenodeを設定します-
$ cd ~
$ hdfs namenode -format期待される結果は次のとおりです-
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/HadoopDFSの検証
次のコマンドを使用して、DFSを起動します。このコマンドを実行すると、Hadoopファイルシステムが起動します。
$ start-dfs.sh期待される出力は次のとおりです-
10/24/14 21:37:56 Starting namenodes on [localhost]
localhost: starting namenode, logging to
/home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost:
starting datanode, logging to
/home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]糸スクリプトの検証
次のコマンドを使用して、Yarnスクリプトを開始します。このコマンドを実行すると、Yarnデーモンが起動します。
$ start-yarn.sh期待される出力は次のとおりです-
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/
yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to
/home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.outブラウザでHadoopにアクセスする
Hadoopにアクセスするためのデフォルトのポート番号は50070です。ブラウザーでHadoopサービスを取得するには、次のURLを使用します。
http://localhost:50070/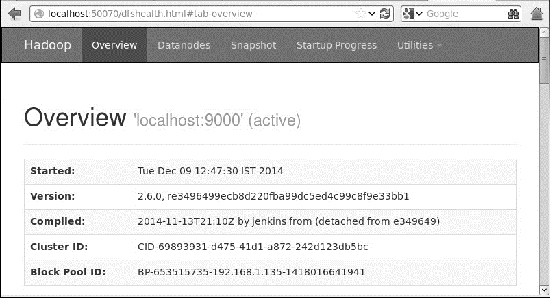
クラスタのすべてのアプリケーションを確認します
クラスタのすべてのアプリケーションにアクセスするためのデフォルトのポート番号は8088です。このサービスにアクセスするには、次のURLを使用してください。
http://localhost:8088/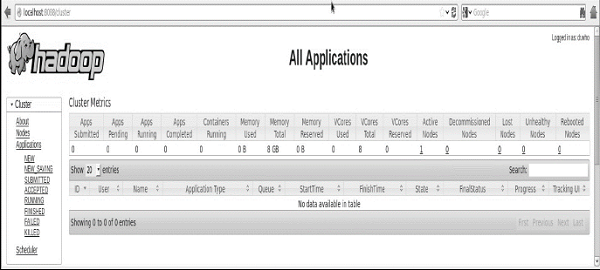
Hadoopのインストールが完了したら、次の手順に進み、システムにHiveをインストールします。
ステップ7:ハイブをダウンロードする
このチュートリアルでは、hive-0.14.0を使用します。次のリンクからダウンロードできますhttp://apache.petsads.us/hive/hive-0.14.0/。それがにダウンロードされると仮定しましょう/Downloadsディレクトリ。ここでは、「」という名前のHiveアーカイブをダウンロードします。apache-hive-0.14.0-bin.tar.gzこのチュートリアルの「」。次のコマンドは、ダウンロードを確認するために使用されます-
$ cd Downloads
$ lsダウンロードが成功すると、次の応答が表示されます-
apache-hive-0.14.0-bin.tar.gz手順8:Hiveをインストールする
システムにHiveをインストールするには、次の手順が必要です。Hiveアーカイブがにダウンロードされていると仮定しましょう/Downloads ディレクトリ。
Hiveアーカイブの抽出と検証
次のコマンドを使用して、ダウンロードを確認し、Hiveアーカイブを抽出します-
$ tar zxvf apache-hive-0.14.0-bin.tar.gz
$ lsダウンロードが成功すると、次の応答が表示されます-
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz/ usr / local / hiveディレクトリへのファイルのコピー
スーパーユーザー「su-」からファイルをコピーする必要があります。次のコマンドは、抽出されたディレクトリからファイルをコピーするために使用されます。/usr/local/hive」ディレクトリ。
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exitHiveの環境をセットアップする
次の行をに追加することで、Hive環境をセットアップできます。 ~/.bashrc ファイル-
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.次のコマンドは、〜/ .bashrcファイルを実行するために使用されます。
$ source ~/.bashrc手順9:Hiveを構成する
HadoopでHiveを構成するには、を編集する必要があります hive-env.sh ファイルは、に配置されます $HIVE_HOME/confディレクトリ。次のコマンドはHiveにリダイレクトしますconfig フォルダを作成し、テンプレートファイルをコピーします-
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh編集する hive-env.sh 次の行を追加してファイル-
export HADOOP_HOME=/usr/local/hadoopこれで、Hiveのインストールが完了しました。ここで、メタストアを構成するために外部データベースサーバーが必要です。ApacheDerbyデータベースを使用します。
ステップ10:ApacheDerbyのダウンロードとインストール
以下の手順に従って、ApacheDerbyをダウンロードしてインストールします-
ApacheDerbyのダウンロード
次のコマンドを使用して、ApacheDerbyをダウンロードします。ダウンロードには時間がかかります。
$ cd ~
$ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz次のコマンドは、ダウンロードを確認するために使用されます-
$ lsダウンロードが成功すると、次の応答が表示されます-
db-derby-10.4.2.0-bin.tar.gzDerbyアーカイブの抽出と検証
次のコマンドは、Derbyアーカイブの抽出と検証に使用されます-
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
$ lsダウンロードが成功すると、次の応答が表示されます-
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz/ usr / local / derbyディレクトリへのファイルのコピー
スーパーユーザー「su-」からコピーする必要があります。次のコマンドは、抽出されたディレクトリからファイルをコピーするために使用されます。/usr/local/derby ディレクトリ-
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exitダービーの環境のセットアップ
次の行をに追加することで、ダービー環境をセットアップできます。 ~/.bashrc ファイル-
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar次のコマンドを使用して実行します ~/.bashrc file −
$ source ~/.bashrcメタストアのディレクトリを作成する
という名前のディレクトリを作成します data $ DERBY_HOMEディレクトリにメタストアデータを保存します。
$ mkdir $DERBY_HOME/dataこれで、Derbyのインストールと環境のセットアップが完了しました。
手順11:Hiveメタストアを構成する
Metastoreの構成とは、データベースが保存されている場所をHiveに指定することを意味します。あなたは編集することによってこれを行うことができますhive-site.xml にあるファイル $HIVE_HOME/confディレクトリ。まず、次のコマンドを使用してテンプレートファイルをコピーします-
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xml編集 hive-site.xml <configuration>タグと</ configuration>タグの間に次の行を追加します-
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create = true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>名前の付いたファイルを作成します jpox.properties そしてそれに次の行を追加します-
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = mine手順12:Hiveのインストールを確認する
Hiveを実行する前に、を作成する必要があります /tmpフォルダーとHDFSの個別のHiveフォルダー。ここでは、/user/hive/warehouseフォルダ。以下に示すように、これらの新しく作成されたフォルダの書き込み権限を設定する必要があります-
chmod g+wHiveを検証する前に、HDFSでそれらを設定します。次のコマンドを使用します-
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse次のコマンドは、Hiveのインストールを確認するために使用されます-
$ cd $HIVE_HOME
$ bin/hiveHiveのインストールが成功すると、次の応答が表示されます-
Logging initialized using configuration in
jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/
hive-log4j.properties Hive history
=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>次のサンプルコマンドを実行して、すべてのテーブルを表示できます-
hive> show tables;
OK Time taken: 2.798 seconds
hive>手順13:HCatalogのインストールを確認する
次のコマンドを使用して、システム変数を設定します HCAT_HOME HCatalogホーム用。
export HCAT_HOME = $HiVE_HOME/HCatalog次のコマンドを使用して、HCatalogのインストールを確認します。
cd $HCAT_HOME/bin
./hcatインストールが成功すると、次の出力が表示されます-
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement